
原文:http://langyu.iteye.com/blog/909170
可参考:
http://younglibin.iteye.com/blog/1930169
MapReduce依赖Hadoop FileSystem存储job执行过程中需要的所有资源文件。这些文件有job的jar文件、job的配置文件、job的mapper需要处理的目标文件(输入文件)以及job的输出结果。MapReduce可以根据配置文件中File System的URI判断当前是使用哪种Hadoop支持的File System,默认是local system。我更关注job在TT上的表现,而TT又是依赖于DN,所以之后所说的File System都是指HDFS。
运行在Cluster上的MapReduce job需要关注的配置文件有:mapred-default.xml与mapred-site.xml,它们之间没有太大的区别,从名称上分,site文件中应当配置与Cluster有关的内容,default就可以随便配置了。与它们有关的引文有:How To Configure 和 Cluster setup。
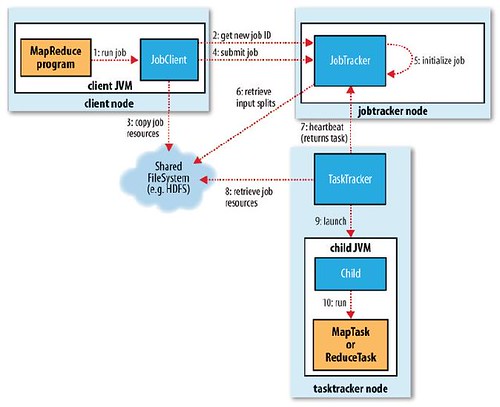
上图表示job的完整执行流程。本篇blog只关注从第一步到第四步的具体实现,当然也会从模拟的例子按步就班叙述。下面开始我们的进程。。。
MapReduce自带WordCount的例子,如流程第一步,在设置基本的参数后,启动job
- Cluster cluster = new Cluster(config);
- Job job = Job.getInstance(cluster);
- job.setMapperClass(WordMapper.class);
- job.setReducerClass(WordReducer.class);
- job.setJarByClass(WordCount.class);
- job.setCombinerClass(WordReducer.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(IntWritable.class);
- FileInputFormat.addInputPath(job, new Path(args[0]));
- FileOutputFormat.setOutputPath(job, new Path(args[1]));
- job.submit();
注意这里的FileInputFormat.addInputPath(job, path),首先得确定MapReduce的输入文件或目录应该在File system上存在,如果MapReduce依赖于HDFS,就得先将本地的文件上传到HDFS上。MapReduce为了防止一个job的输出结果覆盖之前job的输出结果,要求每个job的输出目录都必须独立与其它job,且这个目录在job初始化时不应该存在,只有job需要时才去创建,否则就会报错。我以为MapReduce会在用户第一次设置输出目录时去检查这个目录的有效性,但事实上它是等做了一大堆事情后才去检查,这点让我很困惑。
在job提交初期,也如流程中的第二步,client会向JT申请一个jobID来作为job的标识符。jobID的格式如job_201101281410_0001,中间的字符串为JT的标识符,后面是job的序号,从1开始一直递增。
在得到jobID后,MapReduce就需要将job执行必要的资源文件copy到File system上去。在copy之前,我们得先确定这些资源文件存放在File system的什么地方。JT设置有一个工作目录(Staging area, 也称数据中转站),用来存储与每个job相关的数据。这个目录的前缀由mapreduce.jobtracker.staging.root.dir 参数来指定,默认是/tmp/hadoop/mapred/staging,每个client user可以提交多个job,在这个目录后就得附加user name的信息。所以这个工作目录(Staging area)类似于:/tmp/hadoop/mapred/staging/denny/.staging/。与job相关的资源文件存储的目录是工作目录+jobID:${Staging area}/job_201101281410_0001。
这些资源文件存储的情况如下:
- stagingArea/job_yyyyMMddHHmm_tttt/job.jar 执行job任务的那个jar文件
- stagingArea/job_yyyyMMddHHmm_tttt/files 存储job的输入文件
- stagingArea/job_yyyyMMddHHmm_tttt/libjars 与job相关的其它jar文件
- stagingArea/job_yyyyMMddHHmm_tttt/archives job的archives文件
如果当前的File system是HDFS,那么对于上面的每个文件,我们会设置它在HDFS的replication,这个值由mapreduce.client.submit.file.replication参数指定,默认是10,比普通HDFS文件的默认幅本数大很多,可能也是考虑到把输入数据放到更多的DT上,尽可能实现本地数据计算。
把资源文件上传到File system之后,负责job提交的程序会检查job设置的输出目录(output dir)。如果这个目录没有指定或是目录在File system上存在,就会抛出异常。为啥非要在上传那么多文件后才做这项关键检查呢?
接下来才是整个job提交过程中最重要的一步:对输入文件做数据分片(input split)。MapReduce过程中每个mapper怎样知道处理输入文件的哪部分内容呢?理应在mapper执行之前就确定它处理数据的范围吧,那现在的数据分片工作就是干这种事的。更主要的是分片的数量决定map task的数量,它们之间一一对应。这种数据分片(split)只是逻辑分片,记录它应当访问哪个block,及在这个block上的起始index及数据长度的信息。
下面我们细说怎样划分数据分片。job可能会有多个输入文件,或许分布在不同的目录下。我们获取输入目录的设置,然后识别得到我们需要处理的那些文件。这里我们可以设置一个PathFilter来过滤那些目录中的文件是否符合我们的要求,自定义的PathFilter类可由mapreduce.input.pathFilter.class属性来设置。对于我们获取的每一个输入文件,根据它的block信息产生数据分片,文件之间不能产生分片。我们可以设置数据分片的数据大小,最小字节数由mapreduce.input.fileinputformat.split.minsize设置,默认是1,最大字节数由mapreduce.input.fileinputformat.split.maxsize设置,默认是Long.MAX_VALUE。由用户定义的分片大小的设置及每个文件block大小的设置,可以计算得分片的大小。计算分片大小的公式是
- splitSize = Math.max(minSize, Math.min(maxSize, blockSize))
从公式可以看出,如果maxSize设置大于blockSize,那么每个block就是一个分片,否则就会将一个block文件分隔为多个分片,如果block中剩下的一小段数据量小于splitSize,还是认为它是独立的分片。
产生分片后我们要把这些数据保存起来,序列化到stagingArea/job_yyyyMMddHHmm_tttt/job.split文件中,之后在map task运行时才可以访问到。同时为每个分片分成一个MetaData信息,这个MetaData信息包含每个分片是放在哪台slave server上,它是由JT访问,且作为有效分发map task到拥有物理文件的那台slave server的依据。MetaData信息保存于stagingArea/job_yyyyMMddHHmm_tttt/job.splitmetainfo文件中。
至此,job提交所需要准备的数据大都已经就绪,前面一步的分片任务也确定了需要多少个map task,与job相关的配置都已确定。把job的配置文件上传到stagingArea/job_yyyyMMddHHmm_tttt/job.xml文件中,在client端做的任务就完成了。Client尝试与JT通信,然后把job提交到JT。



相关推荐
1. **初始化Job**:在`Job`类的构造函数中,会创建一个`JobContext`对象,该对象包含了作业配置信息。然后,`submit()`方法会设置作业的输入输出路径、设置Mapper和Reducer等信息。 2. **验证Job**:在提交之前,...
【Debug跟踪Hadoop3.0.0源码之MapReduce Job提交流程】第一节 Configuration和Job对象的初始化前言Configuration和Job对象的初始化后记跳转 前言 不得不说,在此前我对阅读源码这件事是拒绝的,一方面也知道自己非读...
首先,当用户编写好MapReduce程序并调用Job的submit()方法时,客户端会进行一系列的初始化工作。这包括将程序的JAR包、配置信息以及输入输出路径等打包成一个JobConf对象,然后通过JobClient发送到JobTracker。 1. ...
这个过程包括初始化中心点、分配数据点到最近的中心点以及更新中心点等步骤,直到满足停止条件(如中心点不再改变或达到预设迭代次数)。 接下来,我们探讨如何在MapReduce中实现这一过程。Map阶段,每个Mapper接收...
- **运行说明**:此主函数首先初始化一个Job对象,并对其进行一系列配置,包括指定Mapper、Reducer类等。最后通过调用`job.waitForCompletion(true)`来启动MapReduce任务。 #### 六、总结 通过上述代码和解析,...
1. **设置输入和输出路径**:在MapReduce程序的初始化阶段,需要指定输入数据文件的路径(通常是HDFS中的一个目录)以及预期输出结果的路径。 2. **编写Mapper**:Mapper类包含map()方法,这是处理输入数据的地方。...
1. `configure()`: 这个方法用于初始化Mapper或Reducer类,设置如输入输出格式、分区器、比较器等配置。 2. `map()` 和 `reduce()`: 这两个方法分别是Mapper和Reducer的核心,用户需要根据业务需求实现它们。`map()...
- 作业初始化阶段:jobtracker将作业分解为多个任务,并分配给相应的tasktracker执行。这一阶段还会计算输入数据的分片,以便Map阶段的处理。 - 任务调度阶段:jobtracker向tasktracker分配任务,并监控任务的执行...
- 将节点颜色初始化为白色,距离初始化为无穷大。 - 遍历状态列表,根据颜色和距离更新节点k2的状态。 - 如果列表中的某个状态的边权重更优,则更新k2的边信息。 - 输出更新后的k2和状态。 通过多轮MapReduce...
5. **配置和使用自定义InputFormat**:在你的MapReduce作业中,通过设置`job.setInputFormatClass()`方法指定你的自定义InputFormat类。同时,如果需要,你还可以在JobConf中添加额外的配置参数来指导InputFormat和...
- 这个包中包含了启动MapReduce作业的主要逻辑,通常包括初始化输入输出路径、配置job参数等。 3. **com.ouyang.graph**:这部分负责图的基本建模。 - 定义了图的基本元素如节点(Node)和边(Edge),以及节点的状态...
1. JobClient:提交作业的客户端,负责与ResourceManager通信,初始化ApplicationMaster。 2. ResourceManager:全局资源调度中心,负责分配集群中的资源。 3. NodeManager:运行在每个节点上,管理该节点上的容器,...
// 配置和初始化Job // 添加输入输出路径,设置Mapper和Reducer类 // 设置输出键值类型,运行Job并等待完成 } public static class TokenizerMapper extends Mapper, Text, Text, IntWritable> { // 实现...
文件分发过程涉及RecordReader的初始化和数据读取。 7. **Shuffle与Reduce阶段**: - Mapper的输出会被排序和分区,然后通过网络传输到Reducer。在这个过程中,数据分发和合并再次发生,保证了数据的正确聚合。 8...
2. **作业初始化**:JobTracker解析JobConf(配置信息),计算输入数据的切片(split)信息,根据配置决定map任务的数量。 3. **任务分配**:JobTracker将map任务分配给TaskTracker(YARN中的NodeManager)。 4. **...
在作业初始化过程中,Hadoop将每个作业分解为四种类型的任务:SetupTask(作业初始化任务)、MapTask(Map阶段任务)、ReduceTask(Reduce阶段任务)和CleanupTask(作业结束清理任务)。这四种任务共同构成了作业的...
- **作业初始化**: JobTracker 负责初始化作业,并进行调度。 - **任务分配**: TaskTracker 定期向 JobTracker 请求任务,并执行分配的任务。 - **任务执行**: TaskTracker 启动 Map 或 Reduce 任务,执行具体的计算...
- **任务初始化**:JobTracker从HDFS读取Job.split,分配任务给TaskTracker。 - **任务本地化**:TaskTracker将任务所需资源从HDFS复制到本地,包括job.split、job.jar、配置文件等,解压并启动任务。 4. **错误...
Driver类负责初始化`Job`对象,并设置其属性(如输入路径、输出路径、映射器和化简器类等),然后提交作业进行执行。 #### 四、WordCount实例详解 - **WordCount**:这是一个经典的MapReduce示例程序,用于统计文本...