
ŃĆÉÕēŹķØóķā©ÕłåõĖ║ĶĮ¼ĶĮĮ--beginŃĆæ
ķĆÜĶ┐ć┬Āķććķøåń│╗ń╗¤┬Āµłæõ╗¼ķćć ķøåõ║åÕż¦ķćŵ¢ćµ£¼µĢ░µŹ«’╝īõĮåµś»µ¢ćµ£¼õĖŁµ£ēÕŠłÕżÜķćŹÕżŹµĢ░µŹ«ÕĮ▒ÕōŹµłæõ╗¼Õ»╣õ║Äń╗ōµ×£ńÜäÕłåµ×ÉŃĆéÕłåµ×ÉÕēŹµłæõ╗¼ķ£ĆĶ”üÕ»╣Ķ┐Öõ║øµĢ░µŹ«ÕÄ╗ķÖżķćŹÕżŹ’╝īÕ”éõĮĢķĆēµŗ®ÕÆīĶ«ŠĶ«Īµ¢ćµ£¼ńÜäÕÄ╗ķćŹń«Śµ│Ģ’╝¤ÕĖĖĶ¦üńÜäµ£ēõĮÖÕ╝”Õż╣ Ķ¦Æń«Śµ│ĢŃĆüµ¼¦Õ╝ÅĶĘØń”╗ŃĆüJaccardńøĖõ╝╝Õ║”ŃĆüµ£ĆķĢ┐Õģ¼Õģ▒ÕŁÉõĖ▓ŃĆüń╝¢ĶŠæĶĘØń”╗ńŁēŃĆéĶ┐Öõ║øń«Śµ│ĢÕ»╣õ║ÄÕŠģµ»öĶŠāńÜäµ¢ćµ£¼µĢ░µŹ«õĖŹÕżÜµŚČĶ┐śµ»öĶŠāÕźĮńö©’╝īÕ”éµ×£µłæõ╗¼ńÜäńł¼ĶÖ½µ»ÅÕż®ķććķøåńÜäµĢ░µŹ«õ╗źÕŹāõĖćĶ«Īń«Ś’╝īµłæõ╗¼Õ”éõĮĢÕ»╣õ║ÄĶ┐Öõ║øµĄĘķćÅÕŹāõĖćń║¦ńÜäµĢ░µŹ«Ķ┐øĶĪīķ½śµĢłńÜäÕÉłÕ╣ČÕÄ╗ķćŹŃĆéµ£Ćń«ĆÕŹĢńÜäÕüܵ│Ģµś»µŗ┐ńØĆÕŠģµ»öĶŠāńÜäµ¢ćµ£¼ÕÆīµĢ░µŹ«Õ║ōõĖŁµēƵ£ēńÜäµ¢ćµ£¼µ»öĶŠāõĖĆķüŹÕ”éµ×£µś»ķćŹÕżŹńÜäµĢ░µŹ«Õ░▒µĀćńż║õĖ║ķćŹÕżŹŃĆéń£ŗĶĄĘµØźÕŠłń«ĆÕŹĢ’╝īµłæõ╗¼µØźÕüÜõĖ¬µĄŗĶ»Ģ’╝īÕ░▒µŗ┐µ£Ćń«ĆÕŹĢńÜäõĖżõĖ¬µĢ░µŹ«õĮ┐ńö©ApacheµÅÉõŠøńÜä Levenshtein for ÕŠ¬ńÄ»100wµ¼ĪĶ«Īń«ŚĶ┐ÖõĖżõĖ¬µĢ░µŹ«ńÜäńøĖõ╝╝Õ║”ŃĆéõ╗ŻńĀüń╗ōµ×£Õ”éõĖŗ’╝Ü
- String┬Ās1┬Ā=┬Ā"õĮĀÕ”łÕ”łÕ¢ŖõĮĀÕø×Õ«ČÕÉāķźŁÕō”’╝īÕø×Õ«ČńĮŚÕø×Õ«ČńĮŚ"┬Ā;┬Ā
- ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀString┬Ās2┬Ā=┬Ā"õĮĀÕ”łÕ”łÕŽõĮĀÕø×Õ«ČÕÉāķźŁÕĢ”’╝īÕø×Õ«ČńĮŚÕø×Õ«ČńĮŚ"┬Ā;┬Ā
- ┬Ā┬Ā
- ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ālong┬Āt1┬Ā=┬ĀSystem.currentTimeMillis();┬Ā
- ┬Ā┬Ā
- ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āfor┬Ā(int┬Āi┬Ā=┬Ā0;┬Āi┬Ā<┬Ā1000000;┬Āi++)┬Ā{┬Ā
- ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āint┬Ādis┬Ā=┬ĀStringUtils┬Ā.getLevenshteinDistance(s1,┬Ās2);┬Ā
- ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā}┬Ā
- ┬Ā┬Ā
- ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ālong┬Āt2┬Ā=┬ĀSystem.currentTimeMillis();┬Ā
- ┬Ā┬Ā
- ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀSystem.┬Āout┬Ā.println("┬ĀĶĆŚĶ┤╣µŚČķŚ┤’╝Ü┬Ā"┬Ā+┬Ā(t2┬Ā-┬Āt1)┬Ā+┬Ā"┬Ā┬Āms┬Ā");┬Ā
ĶĆŚĶ┤╣µŚČķŚ┤’╝Ü 4266 ms
Õż¦ĶĘīń£╝ķĢ£’╝īÕ▒ģńäČĶ«Īń«ŚĶĆŚĶ┤╣4ń¦ÆŃĆéÕüćĶ«Šµłæõ╗¼õĖĆÕż®ķ£ĆĶ”üµ»öĶŠā100wµ¼Ī’╝īÕģēµś»µ»öĶŠā100wµ¼ĪńÜäµĢ░µŹ«µś»ÕÉ”ķćŹÕżŹÕ░▒ķ£ĆĶ”ü4s’╝īÕ░▒ń«Ś4sõĖĆõĖ¬µ¢ćµĪŻ’╝īÕŹĢń║┐ń©ŗõĖĆÕłåķƤµēŹÕżä ńÉå15õĖ¬µ¢ćµĪŻ’╝īõĖĆõĖ¬Õ░ŵŚČµēŹ900õĖ¬’╝īõĖĆÕż®õ╣¤µēŹ21600õĖ¬µ¢ćµĪŻ’╝īĶ┐ÖõĖ¬µĢ░ÕŁŚÕÆīõĖĆÕż®100wńøĖÕĘ«ńöÜĶ┐£’╝īķ£ĆĶ”üÕżÜÕ░æµ£║ÕÖ©ÕÆīĶĄäµ║ɵēŹĶāĮĶ¦ŻÕå│ŃĆé
õĖ║µŁżµłæõ╗¼ķ£ĆĶ”üõĖĆń¦ŹÕ║öÕ»╣õ║ĵĄĘķćŵĢ░µŹ«Õ£║µÖ»ńÜäÕÄ╗ķ揵¢╣µĪł’╝īń╗ÅĶ┐ćńĀöń®ČÕÅæńÄ░µ£ēń¦ŹÕŽ local sensitive hash Õ▒Ćķā©µĢŵä¤ÕōłÕĖī ńÜäõĖ£Ķź┐’╝īµŹ«Ķ»┤Ķ┐ÖńÄ®µäÅÕÅ»õ╗źµŖŖµ¢ćµĪŻķÖŹń╗┤Õł░hashµĢ░ÕŁŚ’╝īµĢ░ÕŁŚõĖżõĖżĶ«Īń«ŚĶ┐Éń«ŚķćÅĶ”üÕ░ÅÕŠłÕżÜŃĆ鵤źµēŠÕŠłÕżÜµ¢ćµĪŻÕÉÄń£ŗÕł░googleÕ»╣õ║ÄńĮæķĪĄÕÄ╗ķćŹõĮ┐ńö©ńÜ䵜»simhash’╝īõ╗¢ õ╗¼µ»ÅÕż®ķ£ĆĶ”üÕżäńÉåńÜäµ¢ćµĪŻÕ£©õ║┐ń║¦Õł½’╝īÕż¦Õż¦ĶČģĶ┐ćõ║åµłæõ╗¼ńÄ░Õ£©µ¢ćµĪŻńÜäµ░┤Õ╣│ŃĆ鵌óńäČĶĆüÕż¦Õōźõ╣¤µ£ēń▒╗õ╝╝ńÜäÕ║öńö©’╝īµłæõ╗¼õ╣¤ĶĄČń┤¦Õ░ØĶ»ĢõĖŗŃĆésimhashµś»ńö▒ Charikar Õ£©2002Õ╣┤µÅÉÕć║µØźńÜä’╝īÕÅéĶĆā┬ĀŃĆŖSimilarity estimation techniques from rounding algorithmsŃĆŗ┬ĀŃĆé õ╗ŗń╗ŹõĖŗĶ┐ÖõĖ¬ń«Śµ│ĢõĖ╗Ķ”üÕĤńÉå’╝īõĖ║õ║åõŠ┐õ║ÄńÉåĶ¦ŻÕ░ĮķćÅõĖŹõĮ┐ńö©µĢ░ÕŁ”Õģ¼Õ╝Å’╝īÕłåõĖ║Ķ┐ÖÕćĀµŁź’╝Ü
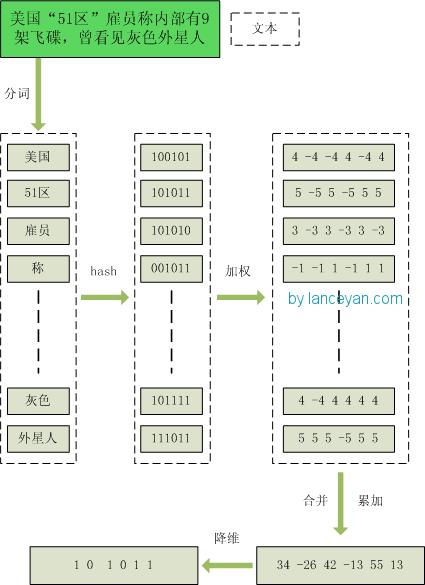
- 1ŃĆüÕłåĶ»Ź’╝īµŖŖķ£ĆĶ”üÕłżµ¢Łµ¢ćµ£¼ÕłåĶ»ŹÕĮóµłÉĶ┐ÖõĖ¬µ¢ćń½ĀńÜäńē╣ÕŠüÕŹĢĶ»ŹŃĆéµ£ĆÕÉÄÕĮóµłÉÕÄ╗µÄēÕÖ¬ķ¤│Ķ»ŹńÜäÕŹĢĶ»ŹÕ║ÅÕłŚÕ╣ČõĖ║µ»ÅõĖ¬Ķ»ŹÕŖĀõĖŖµØāķ插╝īµłæ õ╗¼ÕüćĶ«ŠµØāķćŹÕłåõĖ║5õĖ¬ń║¦Õł½’╝ł1~5’╝ēŃĆéµ»öÕ”é’╝ÜŌĆ£ ńŠÄÕøĮŌĆ£51Õī║ŌĆØķøćÕæśń¦░Õåģķā©µ£ē9µ×ČķŻ×ńó¤’╝īµøŠń£ŗĶ¦üńü░Ķē▓Õż¢µś¤õ║║ ŌĆØ ==> ÕłåĶ»ŹÕÉÄõĖ║ ŌĆ£ ńŠÄÕøĮ’╝ł4’╝ē 51Õī║’╝ł5’╝ē ķøćÕæś’╝ł3’╝ē ń¦░’╝ł1’╝ē Õåģķā©’╝ł2’╝ē µ£ē’╝ł1’╝ē 9µ×Č’╝ł3’╝ē ķŻ×ńó¤’╝ł5’╝ē µøŠ’╝ł1’╝ē ń£ŗĶ¦ü’╝ł3’╝ē ńü░Ķē▓’╝ł4’╝ē Õż¢µś¤õ║║’╝ł5’╝ēŌĆØ’╝īµŗ¼ÕÅĘķćīµś»õ╗ŻĶĪ©ÕŹĢĶ»ŹÕ£©µĢ┤õĖ¬ÕÅźÕŁÉķćīķćŹĶ”üń©ŗÕ║”’╝īµĢ░ÕŁŚĶČŖÕż¦ĶČŖķćŹĶ”üŃĆé
- 2ŃĆühash’╝īķĆÜĶ┐ćhashń«Śµ│ĢµŖŖµ»ÅõĖ¬Ķ»ŹÕÅśµłÉhashÕĆ╝’╝īµ»öÕ”éŌĆ£ńŠÄÕøĮŌĆØķĆÜĶ┐ćhashń«Śµ│ĢĶ«Īń«ŚõĖ║ 100101,ŌĆ£51Õī║ŌĆØķĆÜĶ┐ćhashń«Śµ│ĢĶ«Īń«ŚõĖ║ 101011ŃĆéĶ┐ÖµĀʵłæõ╗¼ńÜäÕŁŚń¼”õĖ▓Õ░▒ÕÅśµłÉõ║åõĖĆõĖ▓õĖ▓µĢ░ÕŁŚ’╝īĶ┐śĶ«░ÕŠŚµ¢ćń½ĀÕ╝ĆÕż┤Ķ»┤Ķ┐ćńÜäÕÉŚ’╝īĶ”üµŖŖµ¢ćń½ĀÕÅśõĖ║µĢ░ÕŁŚĶ«Īń«ŚµēŹĶāĮµÅÉķ½śńøĖõ╝╝Õ║”Ķ«Īń«ŚµĆ¦ĶāĮ’╝īńÄ░Õ£©µś»ķÖŹń╗┤Ķ┐ćń©ŗĶ┐øĶĪīµŚČŃĆé
- 3ŃĆüÕŖĀµØā’╝īķĆÜĶ┐ć 2µŁźķ¬żńÜähashńö¤µłÉń╗ōµ×£’╝īķ£ĆĶ”üµīēńģ¦ÕŹĢĶ»ŹńÜäµØāķćŹÕĮóµłÉÕŖĀµØāµĢ░ÕŁŚõĖ▓’╝īµ»öÕ”éŌĆ£ńŠÄÕøĮŌĆØńÜähashÕĆ╝õĖ║ŌĆ£100101ŌĆØ’╝īķĆÜĶ┐ćÕŖĀµØāĶ«Īń«ŚõĖ║ŌĆ£4 -4 -4 4 -4 4ŌĆØ’╝øŌĆ£51Õī║ŌĆØńÜähashÕĆ╝õĖ║ŌĆ£101011ŌĆØ’╝īķĆÜĶ┐ćÕŖĀµØāĶ«Īń«ŚõĖ║ ŌĆ£ 5 -5 5 -5 5 5ŌĆØŃĆé
- 4ŃĆüÕÉłÕ╣Č’╝īµŖŖõĖŖķØóÕÉäõĖ¬ÕŹĢĶ»Źń«ŚÕć║µØźńÜäÕ║ÅÕłŚÕĆ╝ń┤»ÕŖĀ’╝īÕÅśµłÉÕŬµ£ēõĖĆõĖ¬Õ║ÅÕłŚõĖ▓ŃĆéµ»öÕ”é ŌĆ£ńŠÄÕøĮŌĆØńÜä ŌĆ£4 -4 -4 4 -4 4ŌĆØ’╝īŌĆ£51Õī║ŌĆØńÜä ŌĆ£ 5 -5 5 -5 5 5ŌĆØ’╝ī µŖŖµ»ÅõĖĆõĮŹĶ┐øĶĪīń┤»ÕŖĀ’╝ī ŌĆ£4+5 -4+-5 -4+5 4+-5 -4+5 4+5ŌĆØ ==ŃĆŗ ŌĆ£9 -9 1 -1 1 9ŌĆØŃĆéĶ┐ÖķćīõĮ£õĖ║ńż║õŠŗÕŬń«Śõ║åõĖżõĖ¬ÕŹĢĶ»ŹńÜä’╝īń£¤Õ«×Ķ«Īń«Śķ£ĆĶ”üµŖŖµēƵ£ēÕŹĢĶ»ŹńÜäÕ║ÅÕłŚõĖ▓ń┤»ÕŖĀŃĆé
- 5ŃĆüķÖŹń╗┤’╝īµŖŖ4µŁźń«ŚÕć║µØźńÜä ŌĆ£9 -9 1 -1 1 9ŌĆØ ÕÅśµłÉ 0 1 õĖ▓’╝īÕĮóµłÉµłæõ╗¼µ£Ćń╗łńÜäsimhashńŁŠÕÉŹŃĆé Õ”éµ×£µ»ÅõĖĆõĮŹÕż¦õ║Ä0 Ķ«░õĖ║ 1’╝īÕ░Åõ║Ä0 Ķ«░õĖ║ 0ŃĆéµ£ĆÕÉÄń«ŚÕć║ń╗ōµ×£õĖ║’╝ÜŌĆ£1 0 1 0 1 1ŌĆØŃĆé
µĢ┤õĖ¬Ķ┐ćń©ŗÕøŠõĖ║’╝Ü
Õż¦Õ«ČÕÅ»ĶāĮõ╝ܵ£ēń¢æķŚ«’╝īń╗ÅĶ┐ćĶ┐Öõ╣łÕżÜµŁźķ¬żµÉ×Ķ┐Öõ╣łķ║╗ńā”’╝īõĖŹÕ░▒µś»õĖ║õ║åÕŠŚÕł░õĖ¬ 0 1 ÕŁŚń¼”õĖ▓ÕÉŚ’╝¤µłæńø┤µÄźµŖŖĶ┐ÖõĖ¬µ¢ćµ£¼õĮ£õĖ║ÕŁŚń¼”õĖ▓ĶŠōÕģź’╝īńö©hashÕćĮµĢ░ńö¤µłÉ 0 1 ÕĆ╝µø┤ń«ĆÕŹĢŃĆéÕģČÕ«×õĖŹµś»Ķ┐ÖµĀĘńÜä’╝īõ╝Āń╗¤hashÕćĮµĢ░Ķ¦ŻÕå│ńÜ䵜»ńö¤µłÉÕö»õĖĆÕĆ╝’╝īµ»öÕ”é md5ŃĆühashmapńŁēŃĆémd5µś»ńö©õ║Äńö¤µłÉÕö»õĖĆńŁŠÕÉŹõĖ▓’╝īÕŬĶ”üń©ŹÕŠ«ÕżÜÕŖĀõĖĆõĖ¬ÕŁŚń¼”md5ńÜäõĖżõĖ¬µĢ░ÕŁŚń£ŗĶĄĘµØźńøĖÕĘ«ńöÜĶ┐£’╝øhashmapõ╣¤µś»ńö©õ║Äķö«ÕĆ╝Õ»╣µ¤źµēŠ’╝īõŠ┐õ║Ä Õ┐½ķƤµÅÆÕģźÕÆīµ¤źµēŠńÜäµĢ░µŹ«ń╗ōµ×äŃĆéõĖŹĶ┐浳æõ╗¼õĖ╗Ķ”üĶ¦ŻÕå│ńÜ䵜»µ¢ćµ£¼ńøĖõ╝╝Õ║”Ķ«Īń«Ś’╝īĶ”üµ»öĶŠāńÜ䵜»õĖżõĖ¬µ¢ćń½Āµś»ÕÉ”ńøĖĶ»å’╝īÕĮōńäȵłæõ╗¼ķÖŹń╗┤ńö¤µłÉõ║åhashcodeõ╣¤µś»ńö©õ║ÄĶ┐ÖõĖ¬ńø«ńÜäŃĆéń£ŗ Õł░Ķ┐Öķćīõ╝░Ķ«ĪÕż¦Õ«ČÕ░▒µśÄńÖĮõ║å’╝īµłæõ╗¼õĮ┐ńö©ńÜäsimhashÕ░▒ń«ŚµŖŖµ¢ćń½ĀõĖŁńÜäÕŁŚń¼”õĖ▓ÕÅśµłÉ 01 õĖ▓õ╣¤Ķ┐śµś»ÕÅ»õ╗źńö©õ║ÄĶ«Īń«ŚńøĖõ╝╝Õ║”ńÜä’╝īĶĆīõ╝Āń╗¤ńÜähashcodeÕŹ┤õĖŹĶĪīŃĆ鵳æõ╗¼ÕÅ»õ╗źµØźÕüÜõĖ¬µĄŗĶ»Ģ’╝īõĖżõĖ¬ńøĖÕĘ«ÕŬµ£ēõĖĆõĖ¬ÕŁŚń¼”ńÜäµ¢ćµ£¼õĖ▓’╝īŌĆ£õĮĀÕ”łÕ”łÕ¢ŖõĮĀÕø×Õ«ČÕÉāķźŁÕō”’╝īÕø×Õ«ČńĮŚÕø× Õ«ČńĮŚŌĆØ ÕÆī ŌĆ£õĮĀÕ”łÕ”łÕŽõĮĀÕø×Õ«ČÕÉāķźŁÕĢ”’╝īÕø×Õ«ČńĮŚÕø×Õ«ČńĮŚŌĆØŃĆé
ķĆÜĶ┐ćsimhashĶ«Īń«Śń╗ōµ×£õĖ║’╝Ü
1000010010101101111111100000101011010001001111100001001011001011
1000010010101101011111100000101011010001001111100001101010001011
ķĆÜĶ┐ć hashcodeĶ«Īń«ŚõĖ║’╝Ü
1111111111111111111111111111111110001000001100110100111011011110
1010010001111111110010110011101
Õż¦Õ«ČÕÅ»õ╗źń£ŗÕŠŚÕć║µØź’╝īńøĖõ╝╝ńÜäµ¢ćµ£¼ÕŬµ£ēķā©Õłå 01 õĖ▓ÕÅśÕī¢õ║å’╝īĶĆīµÖ«ķĆÜńÜähashcodeÕŹ┤õĖŹĶāĮÕüÜÕł░’╝īĶ┐ÖõĖ¬Õ░▒µś»Õ▒Ćķā©µĢŵä¤ÕōłÕĖīńÜäķŁģÕŖøŃĆéńø«ÕēŹBroderµÅÉÕć║ńÜäshinglingń«Śµ│ĢÕÆīCharikarńÜä simhashń«Śµ│ĢÕ║öĶ»źń«Śµś»õĖÜńĢīÕģ¼Ķ«żµ»öĶŠāÕźĮńÜäń«Śµ│ĢŃĆéÕ£©simhashńÜäÕÅæµśÄõ║║CharikarńÜäĶ«║µ¢ćõĖŁÕ╣ȵ▓Īµ£ēń╗ÖÕć║ÕģĘõĮōńÜäsimhashń«Śµ│ĢÕÆīĶ»üµśÄ’╝īŌĆ£ķćÅÕŁÉÕøŠńüĄŌĆØÕŠŚÕć║ńÜäĶ»üµśÄsimhashµś»ńö▒ķÜŵ£║ĶČģÕ╣│ķØóhashń«Śµ│Ģµ╝öÕÅśĶĆīµØźńÜäŃĆé
ńÄ░Õ£©ķĆÜĶ┐ćĶ┐ÖµĀĘńÜäĶĮ¼µŹó’╝īµłæõ╗¼µŖŖÕ║ōķćīńÜäµ¢ćµ£¼ķāĮĶĮ¼µŹóõĖ║simhash õ╗ŻńĀü’╝īÕ╣ČĶĮ¼µŹóõĖ║longń▒╗Õ×ŗÕŁśÕé©’╝īń®║ķŚ┤Õż¦Õż¦ÕćÅÕ░æŃĆéńÄ░Õ£©µłæõ╗¼ĶÖĮńäČĶ¦ŻÕå│õ║åń®║ķŚ┤’╝īõĮåµś»Õ”éõĮĢĶ«Īń«ŚõĖżõĖ¬simhashńÜäńøĖõ╝╝Õ║”Õæó’╝¤ķÜŠķüōµś»µ»öĶŠāõĖżõĖ¬simhashńÜä 01µ£ēÕżÜÕ░æõĖ¬õĖŹÕÉīÕÉŚ’╝¤Õ»╣ńÜä’╝īÕģČÕ«×õ╣¤Õ░▒µś»Ķ┐ÖµĀĘ’╝īµłæõ╗¼ķĆÜĶ┐浥ʵśÄĶĘØń”╗’╝łHamming distance’╝ēÕ░▒ÕÅ»õ╗źĶ«Īń«ŚÕć║õĖżõĖ¬simhashÕł░Õ║ĢńøĖõ╝╝õĖŹńøĖõ╝╝ŃĆéõĖżõĖ¬simhashÕ»╣Õ║öõ║īĶ┐øÕłČ’╝ł01õĖ▓’╝ēÕÅ¢ÕĆ╝õĖŹÕÉīńÜäµĢ░ķćÅń¦░õĖ║Ķ┐ÖõĖżõĖ¬simhashńÜäµĄĘ µśÄĶĘØń”╗ŃĆéõĖŠõŠŗÕ”éõĖŗ’╝Ü┬Ā10101┬ĀÕÆī┬Ā00110┬Āõ╗Äń¼¼õĖĆõĮŹÕ╝ĆÕ¦ŗõŠØµ¼Īµ£ēń¼¼õĖĆõĮŹŃĆüń¼¼ÕøøŃĆüń¼¼õ║öõĮŹõĖŹÕÉī’╝īÕłÖµĄĘµśÄĶĘØń”╗õĖ║3ŃĆéÕ»╣õ║Äõ║īĶ┐øÕłČÕŁŚń¼”õĖ▓ńÜäaÕÆīb’╝īµĄĘµśÄĶĘØń”╗õĖ║ńŁēõ║ÄÕ£©a XOR bĶ┐Éń«Śń╗ōµ×£õĖŁ1ńÜäõĖ¬µĢ░’╝łµÖ«ķüŹń«Śµ│Ģ’╝ēŃĆé
õĖ║õ║åķ½śµĢłµ»öĶŠā’╝īµłæõ╗¼ķóäÕģłÕŖĀĶĮĮõ║åÕ║ōķćīÕŁśÕ£©µ¢ćµ£¼Õ╣ČĶĮ¼µŹóõĖ║simhash code ÕŁśÕé©Õ£©ÕåģÕŁśń®║ķŚ┤ŃĆéµØźõĖƵØĪµ¢ćµ£¼ÕģłĶĮ¼µŹóõĖ║ simhash code’╝īńäČÕÉÄÕÆīÕåģÕŁśķćīńÜäsimhash code Ķ┐øĶĪīµ»öĶŠā’╝īµĄŗĶ»Ģ100wµ¼ĪĶ«Īń«ŚÕ£©100msŃĆéķƤÕ║”Õż¦Õż¦µÅÉÕŹćŃĆé
µ£¬Õ«īÕŠģń╗Ł’╝Ü
1ŃĆüńø«ÕēŹķƤÕ║”µÅÉÕŹćõ║åõĮåµś»µĢ░µŹ«µś»õĖŹµ¢ŁÕó×ķćÅńÜä’╝īÕ”éµ×£µ£¬µØźµĢ░µŹ«ÕÅæÕ▒ĢÕł░õĖĆõĖ¬Õ░ŵŚČ100w’╝īµīēńÄ░Õ£©õĖƵ¼Ī100ms’╝īõĖĆõĖ¬ń║┐ń©ŗÕżäńÉåõĖĆń¦ÆķƤ 10µ¼Ī’╝īõĖĆÕłåķƤ 60 * 10 µ¼Ī’╝īõĖĆõĖ¬Õ░ŵŚČ 60*10 *60 µ¼Ī = 36000µ¼Ī’╝īõĖĆÕż® 60*10*60*24 = 864000µ¼ĪŃĆé µłæõ╗¼ńø«µĀ浜»õĖĆÕż®100wµ¼Ī’╝īķĆÜĶ┐ćÕó×ÕŖĀõĖżõĖ¬ń║┐ń©ŗÕ░▒ÕÅ»õ╗źÕ«īµłÉŃĆéõĮåµś»Õ”éµ×£Ķ”üõĖĆõĖ¬Õ░ŵŚČ100wµ¼ĪÕæó’╝¤ÕłÖķ£ĆĶ”üÕó×ÕŖĀ30õĖ¬ń║┐ń©ŗÕÆīńøĖÕ║öńÜäńĪ¼õ╗ČĶĄäµ║Éõ┐ØĶ»üķƤÕ║”ĶāĮÕż¤ĶŠŠÕł░’╝īĶ┐ÖµĀĘ µłÉµ£¼õ╣¤õĖŖÕÄ╗õ║åŃĆéĶāĮÕÉ”µ£ēµø┤ÕźĮńÜäÕŖ×µ│Ģ’╝īµÅÉķ½śµłæõ╗¼µ»öĶŠāńÜäµĢłńÄć’╝¤
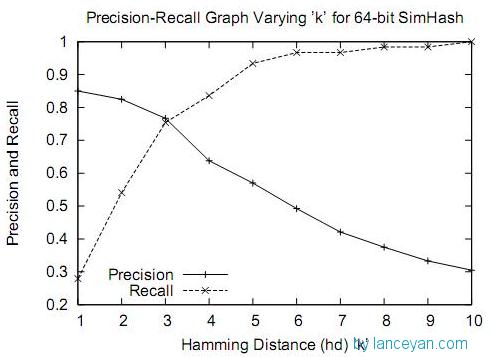
2ŃĆüķĆÜĶ┐ćÕż¦ķćŵĄŗĶ»Ģ’╝īsimhashńö©õ║ĵ»öĶŠāÕż¦µ¢ćµ£¼’╝īµ»öÕ”é500ÕŁŚõ╗źõĖŖµĢłµ×£ķāĮĶ┐śĶø«ÕźĮ’╝īĶĘØń”╗Õ░Åõ║Ä3ńÜäÕ¤║µ£¼ķāĮµś»ńøĖõ╝╝’╝īĶ»»ÕłżńÄćõ╣¤µ»öĶŠāõĮÄŃĆéõĮåµś»Õ”éµ×£µłæõ╗¼ÕżäńÉåńÜä µś»ÕŠ«ÕŹÜõ┐Īµü»’╝īµ£ĆÕżÜõ╣¤Õ░▒140õĖ¬ÕŁŚ’╝īõĮ┐ńö©simhashńÜäµĢłµ×£Õ╣ČõĖŹķéŻõ╣łńÉåµā│ŃĆéń£ŗÕ”éõĖŗÕøŠ’╝īÕ£©ĶĘØń”╗õĖ║3µŚČµś»õĖĆõĖ¬µ»öĶŠāµŖśõĖŁńÜäńé╣’╝īÕ£©ĶĘØń”╗õĖ║10µŚČµĢłµ×£ÕĘ▓ń╗ÅÕŠłÕĘ«õ║å’╝īõĖŹ Ķ┐浳æõ╗¼µĄŗĶ»Ģń¤Łµ¢ćµ£¼ÕŠłÕżÜń£ŗĶĄĘµØźńøĖõ╝╝ńÜäĶĘØń”╗ńĪ«Õ«×õĖ║10ŃĆéÕ”éµ×£õĮ┐ńö©ĶĘØń”╗õĖ║3’╝īń¤Łµ¢ćµ£¼Õż¦ķćÅķćŹÕżŹõ┐Īµü»õĖŹõ╝ÜĶó½Ķ┐ćµ╗ż’╝īÕ”éµ×£õĮ┐ńö©ĶĘØń”╗õĖ║10’╝īķĢ┐µ¢ćµ£¼ńÜäķöÖĶ»»ńÄćõ╣¤ķØ×ÕĖĖķ½ś’╝īÕ”éõĮĢ Ķ¦ŻÕå│’╝¤
ŃĆÉÕÉÄķØóÕŖĀĶć¬ÕĘ▒ńÜä-ÕÉÄń╗ŁĶĪźŃĆæ



ńøĖÕģ│µÄ©ĶŹÉ
µ£¼µ¢ćÕ░åµĘ▒ÕģźµÄóĶ«©Õ”éõĮĢÕł®ńö©Pythonń╝¢ń©ŗĶ»ŁĶ©ĆÕÆīÕōłÕĖīń«Śµ│ĢµØźµ£ēµĢłÕ£░Õ«×ńÄ░ÕøŠÕāÅÕÄ╗ķćŹŃĆé ķ”¢Õģł’╝īµłæõ╗¼Ķ”üńÉåĶ¦ŻÕōłÕĖīń«Śµ│ĢńÜäÕ¤║µ£¼ÕĤńÉåŃĆéÕōłÕĖī’╝łHash’╝ēń«Śµ│Ģµś»õĖĆń¦ŹÕ░åõ╗╗µäÅķĢ┐Õ║”ńÜäĶŠōÕģź’╝łõ╣¤ÕŽÕüÜķó䵜ĀÕ░ä’╝ēķĆÜĶ┐ćõĖĆõĖ¬ń«Śµ│Ģ’╝īÕÅśµŹóµłÉÕø║Õ«ÜķĢ┐Õ║”ńÜäĶŠōÕć║’╝īĶ┐ÖõĖ¬...
simhashµś»õĖĆń¦ŹÕ▒Ćķā©µĢŵä¤ÕōłÕĖīń«Śµ│Ģ’╝īÕ«āĶāĮÕż¤Õ░åķ½śń╗┤µ¢ćµ£¼µĢ░µŹ«µśĀÕ░äÕł░õĮÄń╗┤ń®║ķŚ┤’╝īÕÉīµŚČõ┐ØńĢÖÕĤµĢ░µŹ«ńÜäńøĖõ╝╝µĆ¦ŃĆéķĆÜĶ┐ćĶ«Īń«ŚõĖŹÕÉīµ¢ćµ£¼µīćń║╣õ╣ŗķŚ┤ńÜäµ▒ēµśÄĶĘØń”╗’╝łHamming Distance’╝ē’╝īÕÅ»õ╗źÕŠŚÕł░õĖżõĖ¬µ¢ćµ£¼µīćń║╣ńÜäńøĖõ╝╝Õ║”ŃĆéµ▒ēµśÄĶĘØń”╗µś»µīćõĖżõĖ¬ÕŁŚń¼”õĖ▓...
ÕøĀµŁż’╝īK8ÕĘźÕģĘÕÅ»ĶāĮń╗ōÕÉłõ║åÕģČõ╗¢ńÜäńøĖõ╝╝µĆ¦µ»öĶŠāń«Śµ│Ģ’╝īÕ”éJaccardńøĖõ╝╝Õ║”µł¢õĮÖÕ╝”ńøĖõ╝╝Õ║”’╝īõ╗źµø┤ń▓ŠńĪ«Õ£░Õłżµ¢Łµ¢ćµ£¼ńÜäńøĖõ╝╝ń©ŗÕ║”ŃĆé µŁżÕż¢’╝īK8µ¢ćµ£¼ÕÄ╗ķćŹÕĘźÕģĘĶ┐śÕÅ»ĶāĮµö»µīüÕłåÕØŚÕżäńÉåÕÆīÕ╣ČĶĪīĶ«Īń«Ś’╝īõ╗źµÅÉķ½śÕżäńÉåķƤÕ║”ŃĆéÕłåÕØŚÕżäńÉåµś»µīćÕ░åÕż¦µ¢ćõ╗ȵŗåÕłåµłÉ...
4. ÕōłÕĖīń«Śµ│Ģ’╝ܵ¢ćõ╗ČÕÄ╗ķćŹńÜäõĖĆõĖ¬ÕĖĖĶ¦üµ¢╣µ│Ģµś»õĮ┐ńö©ÕōłÕĖīń«Śµ│Ģ’╝łÕ”éMD5ŃĆüSHA-1µł¢SHA-256’╝ē’╝īĶ«Īń«Śµ»ÅõĖ¬µ¢ćõ╗ČńÜäÕö»õĖƵĀćĶ»åń¼”’╝łÕōłÕĖīÕĆ╝’╝ēŃĆéÕ”éµ×£õĖżõĖ¬µ¢ćõ╗ČńÜäÕōłÕĖīÕĆ╝ńøĖÕÉī’╝īķéŻõ╣łÕ«āõ╗¼ńÜäÕåģÕ«╣ÕŠłÕÅ»ĶāĮõĖƵĀĘŃĆéĶ┐Öń¦Źµ¢╣µ│Ģķ½śµĢłõĖöÕćåńĪ«’╝īõĮåÕÅ»ĶāĮõ╝ÜķüćÕł░ÕōłÕĖī...
Õ£©ITķóåÕ¤¤’╝īÕøŠńēćÕÄ╗ķ揵ś»õĖĆķĪ╣ķćŹĶ”üńÜäõ╗╗ÕŖĪ’╝īÕ░żÕģČÕ£©Õż¦Ķ¦äµ©ĪµĢ░µŹ«ÕżäńÉåÕÆīÕŁśÕ驵ŚČ’╝īõŠŗÕ”éńĮæń╗£ńł¼ĶÖ½µŖōÕÅ¢ÕøŠńē浳¢Õ¬ÆõĮōÕ║ōń«ĪńÉåŃĆé"Deduplication_ÕøŠńēćÕÄ╗ķćŹ_"Ķ┐ÖõĖ¬µĀćķóśµēƵīćńÜäÕ░▒µś»õĖĆń¦ŹķÆłÕ»╣ÕøŠÕāÅĶ┐øĶĪīķćŹÕżŹµŻĆµ¤źńÜäµŖƵ£»’╝īńø«ńÜ䵜»µ£ēµĢłÕ£░Ķ»åÕł½Õ╣ČÕÄ╗ķÖż...
- ÕåģÕ«╣µ»öĶŠā’╝ÜÕ»╣õ║Äķā©ÕłåÕōłÕĖīÕĆ╝õĖŹÕÉīõĮåÕåģÕ«╣ńøĖõ╝╝ńÜäµ¢ćõ╗Č’╝īÕÅ»õ╗źĶ┐øĶĪīķĆÉĶĪīµł¢Õģ│ķö«Ķ»Źµ»öĶŠāµØźńĪ«Õ«Üµś»ÕÉ”ķćŹÕżŹŃĆé - ķóäÕżäńÉåµŖƵ£»’╝ÜÕ”éÕÄ╗ķÖżń®║µĀ╝ŃĆüµŹóĶĪīń¼”’╝īń╗¤õĖĆÕż¦Õ░ÅÕåÖńŁē’╝īõ╗źµÅÉķ½śÕÄ╗ķ揵Ģłµ×£ŃĆé 4. **"ń▓ŠĶŗ▒txtµ¢ćµ£¼µĢ┤ńÉåÕĘźÕģĘń«▒v3.5"ńÜäÕŖ¤ĶāĮńē╣µĆ¦*...
ĶĮ»õ╗Čõ╝ÜķüŹÕÄåµĢ┤õĖ¬µēŗµ£║ÕÅĘńĀüÕłŚĶĪ©’╝īķĆÜĶ┐ćµ»öĶŠāµ»ÅõĖ¬ÕÅĘńĀüõĖÄÕģČõ╗¢ÕÅĘńĀüńÜäńøĖõ╝╝µĆ¦µØźĶ»åÕł½Õ╣ČÕÄ╗ķÖżķćŹÕżŹķĪ╣ŃĆéĶ┐Öõ║øń«Śµ│ĢÕÅ»ĶāĮÕīģµŗ¼ÕōłÕĖīńó░µÆ×µŻĆµĄŗŃĆüµÄÆÕ║ÅÕÉĵ¤źµēŠķćŹÕżŹķĪ╣µł¢Õł®ńö©µĢ░µŹ«Õ║ōń┤óÕ╝ĢµŖƵ£»ńŁēŃĆéÕ£©ÕżäńÉåÕż¦ķćŵĢ░µŹ«µŚČ’╝īķ½śµĢłńÜäÕÄ╗ķćŹń«Śµ│ĢÕÅ»õ╗źµśŠĶæŚµÅÉķ½śÕżäńÉå...
1. **Õ¤║õ║ÄÕōłÕĖīńÜäµ¢╣µ│Ģ**’╝ÜĶ┐Öµś»µ£ĆÕĖĖĶ¦üńÜäÕÄ╗ķćŹńŁ¢ńĢź’╝īķĆÜĶ┐ćĶ«Īń«Śµ»ÅõĖ¬ń┤óÕ╝ĢµØĪńø«ńÜäÕōłÕĖīÕĆ╝µØźĶ»åÕł½ķćŹÕżŹķĪ╣ŃĆéńøĖÕÉīńÜäÕōłÕĖīÕĆ╝ĶĪ©µśÄÕÅ»ĶāĮÕŁśÕ£©ķćŹÕżŹŃĆéĶ┐Öń¦Źµ¢╣µ│Ģń«ĆÕŹĢÕ┐½ķƤ’╝īõĮåÕÅ»ĶāĮÕŁśÕ£©ÕōłÕĖīÕå▓ń¬üńÜäķŚ«ķóśŃĆé 2. **µīćń║╣µ│Ģ**’╝ÜÕ»╣õ║ĵ¢ćµ£¼µĢ░µŹ«’╝īÕÅ»õ╗źõĮ┐ńö©...
ŃĆÉńģ¦ńēćÕÄ╗ķćŹÕĘźÕģĘŃĆæµś»õĖĆń¦ŹõĖōõĖ║ńö©µłĘĶ¦ŻÕå│ÕŁśÕé©ń®║ķŚ┤Ķó½Õż¦ķćÅķćŹÕżŹńģ¦ńēćÕŹĀńö©ķŚ«ķóśńÜäĶĮ»õ╗ČŃĆéÕ«āķĆÜĶ┐ćÕģłĶ┐øńÜäÕøŠÕāÅĶ»åÕł½µŖƵ£»’╝īĶāĮÕż¤µÖ║ĶāĮÕ£░Õłåµ×ÉÕ╣ȵ»öĶŠāÕøŠńēćńÜäńøĖõ╝╝Õ║”’╝īÕĖ«ÕŖ®ńö©µłĘÕ┐½ķƤµēŠÕł░Õ╣ČÕłĀķÖżķćŹÕżŹµł¢ńøĖõ╝╝ńÜäńģ¦ńēć’╝īõ╗źµŁżµØźõ╝śÕī¢ńĪ¼ńøśń®║ķŚ┤’╝īµÅÉķ½śń«ĪńÉå...
2. **ÕŁŚń¼”õĖ▓Õī╣ķģŹ**’╝ÜķÖżõ║åÕōłÕĖīÕż¢’╝īµ║ÉńĀüÕÅ»ĶāĮõ╣¤ÕīģÕɽõ║åń▓ŠńĪ«µł¢Ķ┐æõ╝╝ńÜäÕŁŚń¼”õĖ▓Õī╣ķģŹń«Śµ│Ģ’╝īÕ”éRabin-KarpŃĆüKMPŃĆüBoyer-Mooreµł¢Sundayń«Śµ│Ģ’╝īĶ┐Öõ║øń«Śµ│ĢÕÅ»õ╗źÕ┐½ķƤµ¤źµēŠµ¢ćµ£¼õĖŁńÜäńøĖÕÉīµł¢ńøĖõ╝╝ńē浫ĄŃĆé 3. **µĢ░µŹ«ń╗ōµ×äõ╝śÕī¢**’╝ÜõĖ║õ║åķ½śµĢłÕŁśÕé©ÕÆī...
ÕÉīµ║ÉńĮæķĪĄÕÄ╗ķćŹõĖ╗Ķ”üķĆÜĶ┐ćÕōłÕĖīÕćĮµĢ░µØźÕ«×ńÄ░’╝īÕ»╣ńĮæķĪĄńÜäURLĶ┐øĶĪīµĢŻÕłŚÕżäńÉåŃĆéÕōłÕĖīÕćĮµĢ░ÕÅ»õ╗źÕ░åURLĶĮ¼Õī¢õĖ║õĖĆõĖ¬Õö»õĖĆńÜäÕōłÕĖīÕĆ╝’╝īÕ”éµ×£õĖżõĖ¬URLń╗ÅĶ┐ćÕōłÕĖīÕÉÄÕŠŚÕł░ńøĖÕÉīńÜäÕĆ╝’╝īķéŻõ╣łÕ«āõ╗¼ÕŠłÕÅ»ĶāĮµīćÕÉæÕÉīõĖĆõĖ¬ńĮæķĪĄŃĆéÕ£©Õ«×ķÖģµōŹõĮ£õĖŁ’╝īķ”¢ÕģłÕ»╣URLĶ┐øĶĪī...
3. **ńøĖõ╝╝Õ║”Ķ«Īń«Ś**’╝ÜÕøŠÕāÅńøĖõ╝╝Õ║”ńÜäĶĪĪķćŵ£ēÕŠłÕżÜń¦Źµ¢╣µ│Ģ’╝īÕ”éÕāÅń┤Āń║¦Õł½ńÜäÕĘ«Õ╝é’╝łÕØćµ¢╣Ķ»»ÕĘ«’╝ēŃĆüń╗ōµ×äńøĖõ╝╝Õ║”µīćµĢ░(SSIM)ŃĆüÕĮÆõĖĆÕī¢õ║Æõ┐Īµü»(NMI)µł¢ĶĆģÕōłÕĖīń«Śµ│Ģ’╝łÕ”éPCA-SIFTŃĆüBRIEFńŁē’╝ēŃĆéOpenCVµÅÉõŠøõ║åķā©ÕłåÕŖ¤ĶāĮµØźÕ«×ńÄ░Ķ┐Öõ║øń«Śµ│Ģ’╝īõŠŗÕ”é`cv2....
õ╝Āń╗¤ńÜäńĮæķĪĄÕÄ╗ķćŹń«Śµ│ĢķĆÜÕĖĖķĆÜĶ┐ćÕōłÕĖī’╝łHashing’╝ēµ¢╣µ│ĢµØźĶ»åÕł½ńĮæķĪĄńÜäńøĖõ╝╝µĆ¦’╝īõĮåĶ┐Öń¦Źµ¢╣µ│ĢÕ£©ÕżäńÉåõĖŁµ¢ćµ¢ćµ£¼µŚČÕÅ»ĶāĮÕŁśÕ£©Õ▒ĆķÖɵƦ’╝īÕøĀõĖ║õĖŁµ¢ćÕŁŚń¼”ńÜäń╝¢ńĀüÕżŹµØéÕ║”ÕÆīĶ»ŁĶ©ĆńÜäĶ»Łõ╣ēĶĪ©ĶŠŠµ¢╣Õ╝ÅõĮ┐ÕŠŚń«ĆÕŹĢÕ£░Ķ┐øĶĪīÕōłÕĖīµ»öĶŠāÕŠĆÕŠĆõĖŹÕż¤ÕćåńĪ«ŃĆé µö╣Ķ┐øńÜäDSC...
Õ«āķĆÜĶ┐ćÕ░åµĢ░µŹ«ĶĮ¼µŹóõĖ║õĖĆõĖ¬Õø║Õ«ÜķĢ┐Õ║”ńÜäÕōłÕĖīÕĆ╝’╝īõĮ┐ÕŠŚńøĖõ╝╝ńÜäµ¢ćµĪŻõ╝ܵ£ēµø┤Õ░æńÜäÕōłÕĖīÕå▓ń¬üŃĆéSimHashńÜäÕģ│ķö«Õ£©õ║ÄõĮ┐ńö©ÕżÜõĖ¬õĖŹÕÉīńÜäÕōłÕĖīÕćĮµĢ░’╝īÕ╣ČÕ»╣ń╗ōµ×£Ķ┐øĶĪīÕŖĀµØāµ▒éÕÆī’╝īńäČÕÉÄÕÅ¢µ©ĪÕŠŚÕł░µ£Ćń╗łńÜäÕōłÕĖīÕĆ╝ŃĆéÕĮōõĖżõĖ¬µ¢ćµĪŻńÜäSimHashÕĆ╝õ╣ŗķŚ┤ńÜäHamming...
õĖ╗Ķ”üńö©õ║ĵĢ░µŹ«Õłåµ×ÉŃĆüÕÄ╗ķćŹńŁēÕ£║µÖ»’╝īÕł®ńö©ÕōłÕĖīĶĪ©ķ½śµĢłÕżäńÉåÕż¦Ķ¦äµ©ĪµĢ░µŹ«ńÜäńøĖõ╝╝µĆ¦Ķ«Īń«ŚŃĆé õĖ╗Ķ”üÕŖ¤ĶāĮ’╝Ü ÕōłÕĖīĶĪ©ńÜäµ×äÕ╗║õĖÄń«ĪńÉå’╝ܵö»µīüµÅÆÕģźŃĆüÕłĀķÖżŃĆüµ¤źµēŠµōŹõĮ£ŃĆé ńøĖõ╝╝Õ║”Õłżµ¢Ł’╝ÜÕ¤║õ║ÄÕōłÕĖīÕćĮµĢ░Ķ«Īń«ŚĶŠōÕģźµĢ░µŹ«õ╣ŗķŚ┤ńÜäńøĖõ╝╝µĆ¦ŃĆé µĄŗĶ»ĢÕŖ¤ĶāĮ’╝ܵÅÉõŠø...
Õ£©Õż¦µĢ░µŹ«Õ£║µÖ»õĖŗ’╝īÕōłÕĖīµŖƵ£»ÕĖĖńö©õ║ÄÕ┐½ķƤµ¤źµēŠŃĆüÕÄ╗ķćŹÕÆīÕłåÕĖāÕ╝ÅÕŁśÕé©ŃĆéÕōłÕĖīńó░µÆ×’╝łõĖżõĖ¬õĖŹÕÉīńÜäĶŠōÕģźÕŠŚÕł░ńøĖÕÉīńÜäÕōłÕĖīÕĆ╝’╝ēµś»ÕōłÕĖīĶĪ©ńÜäõĖ╗Ķ”üķŚ«ķóś’╝īĶ¦ŻÕå│µ¢╣µ│ĢÕīģµŗ¼Õ╝ƵöŠÕ»╗ÕØƵ│ĢŃĆüķōŠÕ£░ÕØƵ│ĢÕÆīÕåŹÕōłÕĖīµ│ĢńŁēŃĆéÕ£©KNNń«Śµ│ĢõĖŁ’╝īÕōłÕĖīÕÅ»õ╗źńö©µØźÕ┐½ķĆ¤Õ«ÜõĮŹ...
ÕōłÕĖīµŖƵ£»Õ£©Õż¦µĢ░µŹ«ÕżäńÉåõĖŁńÜäõĮ£ńö©õĖ╗Ķ”üõĮōńÄ░Õ£©Õ┐½ķƤµ¤źµēŠÕÆīµĢ░µŹ«ÕÄ╗ķćŹõĖŖŃĆéÕōłÕĖīÕćĮµĢ░ĶāĮÕż¤Õ░åõ╗╗µäÅÕż¦Õ░ÅńÜäµĢ░µŹ«µśĀÕ░äõĖ║Õø║Õ«ÜķĢ┐Õ║”ńÜäÕōłÕĖīÕĆ╝’╝īķĆÜĶ┐ćÕōłÕĖīÕĆ╝ńÜäµ»öĶŠāÕÅ»õ╗źķ½śµĢłÕ£░Õłżµ¢ŁõĖżõĖ¬µĢ░µŹ«µś»ÕÉ”ńøĖÕÉīŃĆéÕ£©KNNń«Śµ│ĢõĖŁ’╝īÕōłÕĖīµŖƵ£»ÕÅ»õ╗źÕĖ«ÕŖ®µłæõ╗¼Õ┐½ķƤ...
Ķ┐Öõ║øń«Śµ│ĢńÜäńē╣ńé╣µś»Õ£©µ¢ćµ£¼ńøĖõ╝╝Õ║”ĶŠāķ½śµŚČ’╝īõ║¦ńö¤ńÜäÕōłÕĖīÕĆ╝õ╣¤õ╝ÜĶŠāõĖ║ńøĖõ╝╝ŃĆé **minHashÕĤńÉå**’╝ÜminHashµś»õĖĆń¦ŹÕ▒Ćķā©µĢŵä¤ÕōłÕĖīń«Śµ│Ģ’╝īÕ«āķĆÜĶ┐ćÕ»╣ķøåÕÉłõĖŁńÜäÕģāń┤ĀÕ║öńö©ńē╣Õ«ÜńÜäÕōłÕĖīÕćĮµĢ░’╝īµŖĮÕÅ¢Õ░æķćÅÕģāń┤ĀµØźõ╗ŻĶĪ©µĢ┤õĖ¬ķøåÕÉłŃĆéÕ”éµ×£Ķ┐Öõ║øõ╗ŻĶĪ©Õģāń┤ĀńÜä...
ŃĆÉĶĄäµ║ÉĶ»”µāģĶ»┤µśÄŃĆæ ŃĆÉ1ŃĆæĶ»źķĪ╣ńø«õĖ║Ķ┐æµ£¤ń▓ŠÕ┐āµēōķĆĀÕ╝ĆÕÅæ’╝īÕ«īµĢ┤õ╗ŻńĀüŃĆéÕÉīµŚČ’╝īķģŹÕźŚĶĄäµ¢ÖõĖĆÕ║öõ┐▒Õģ©’╝īµČĄńø¢Ķ»”ń╗åńÜäĶ«ŠĶ«Īµ¢ćµĪŻ ŃĆÉ2ŃĆæķĪ╣ńø«õĖŖõ╝ĀÕēŹµ║ÉńĀüń╗ÅĶ┐ćõĖźµĀ╝µĄŗĶ»Ģ’╝īÕ£©ÕżÜń¦ŹńÄ»ÕóāõĖŗÕØćĶāĮń©│Õ«ÜĶ┐ÉĶĪī’╝īÕŖ¤ĶāĮÕ«īÕ¢äõĖöń©│Õ«ÜĶ┐ÉĶĪī’╝īµŖƵ£»ńĀöń®ČŃĆüµĢÖÕŁ”µ╝öńż║...