- وµڈ览: 305073 و¬،
- و€§هˆ«:

- و¥è‡ھ: هŒ—ن؛¬
-

و–‡ç« هˆ†ç±»
- ه…¨éƒ¨هچڑه®¢ (227)
- javascript (47)
- java (70)
- jquery (7)
- و£هˆ™ (24)
- css (11)
- 设è®،و¨،ه¼ڈ (14)
- ه…¶ن»– (25)
- php (4)
- freemarker (4)
- و–°وµھه¾®هچڑوژ¥هڈ£ (1)
- phpcms (2)
- java,tomcat (1)
- Fckeditor (2)
- mysql (2)
- و•°وچ®ه؛“è،¨è®¾è®، (1)
- uploadify (1)
- jeecms (3)
- js (1)
- jboss (3)
- joomla (1)
- struts2 (2)
- ç©؛é—´ (1)
社هŒ؛版ه—
- وˆ‘çڑ„资讯 ( 0)
- وˆ‘çڑ„è®؛ه› ( 0)
- وˆ‘çڑ„é—®ç” ( 2)
هکو،£هˆ†ç±»
- 2015-08 ( 1)
- 2015-01 ( 1)
- 2014-04 ( 2)
- و›´ه¤ڑهکو،£...
وœ€و–°è¯„è®؛
-
ه…¨ç«™ه”¯ن¸€وک¯وˆ‘ن¹ˆï¼ڑ
请问ن¸‹è¯¥هٹں能çڑ„jdk版وœ¬وک¯1.4çڑ„ن¹ˆï¼Œè؟کوک¯ن»¥ن¸ٹçڑ„ï¼ں
Javaه®çژ°ç»™ه›¾ç‰‡و·»هٹ و°´هچ° -
Janneï¼ڑ
请问,ن½ 解ه†³è؟™é—®é¢کو²،?وک¯و€ژن¹ˆه›ن؛‹?وˆ‘ن»ٹه¤©ن¹ںéپ‡هˆ°ن؛†,و²،解ه†³
myeclipse6.5ن¸ن½؟用jax-wsهگ¯هٹ¨tomcatوٹ¥é”™é—®é¢ک -
xuedongï¼ڑ
studypi ه†™éپ“ن½ وک¯و€ژن¹ˆه’Œو–°وµھçڑ„وٹ€وœ¯èپ”ç³»çڑ„ï¼ں能ه‘ٹ诉ن¸€ن¸‹وˆ‘هگ— ...
و–°وµھه¾®هچڑ第ن¸‰و–¹وژ¥هڈ£è°ƒç”¨ه¦ن¹ -
studypiï¼ڑ
ن½ وک¯و€ژن¹ˆه’Œو–°وµھçڑ„وٹ€وœ¯èپ”ç³»çڑ„ï¼ں能ه‘ٹ诉ن¸€ن¸‹وˆ‘هگ—,谢谢
و–°وµھه¾®هچڑ第ن¸‰و–¹وژ¥هڈ£è°ƒç”¨ه¦ن¹ -
dove19900520ï¼ڑ
وœ‰ç”¨ï¼Œه‘µه‘µ
IE,Firefox都ن¸چو”¾ه¼ƒï¼ˆه…¼ه®¹و€§é—®é¢کو€»ç»“)
و£هˆ™هں؛ç،€ن¹‹â€”—NFAه¼•و“ژهŒ¹é…چهژںçگ† .
- هچڑه®¢هˆ†ç±»ï¼ڑ
- و£هˆ™
NFAه¼•و“ژهŒ¹é…چهژںçگ†
1آ آ آ آ آ آ ن¸؛ن»€ن¹ˆè¦پن؛†è§£ه¼•و“ژهŒ¹é…چهژںçگ†
ن¸€ن¸ھن¸ھéں³ç¬¦و‚ن¹±و— ç« çڑ„组هگˆهœ¨ن¸€èµ·ï¼Œه¼¹ه¥ڈه‡؛çڑ„وˆ–许ه°±وک¯ه™ھéں³ï¼ŒهگŒو ·çڑ„éں³ç¬¦ç»ڈè؟‡ن½œو›²ه®¶çڑ„و‰‹ï¼Œه°±هڈ¯ن»¥è°±ه‡؛éه¸¸هٹ¨هگ¬çڑ„ن¹گو›²ï¼Œن¸€ن¸ھو¼”ه¥ڈ者هگŒو ·هڈ¯ن»¥ç…§ç€ن¹گè°±ه¥ڈه‡؛هٹ¨هگ¬çڑ„ن¹گو›²ï¼Œن½†ن»–/ه¥¹وˆ–许ن¸چçں¥éپ“该ه¦‚ن½•هژ»و”¹هڈکéں³ç¬¦çڑ„组هگˆï¼Œن½؟ه¾—ن¹گو›²و›´هٹ¨هگ¬م€‚
ن½œن¸؛و£هˆ™çڑ„ن½؟用者ن¹ںن¸€و ·ï¼Œن¸چو‡‚و£هˆ™ه¼•و“ژهژںçگ†çڑ„وƒ…ه†µن¸‹ï¼ŒهگŒو ·هڈ¯ن»¥ه†™ه‡؛و»،足需و±‚çڑ„و£هˆ™ï¼Œن½†وک¯ن¸چçں¥éپ“هژںçگ†ï¼Œهچ´ه¾ˆéڑ¾ه†™ه‡؛é«کو•ˆن¸”و²،وœ‰éڑگو‚£çڑ„و£هˆ™م€‚و‰€ن»¥ه¯¹ن؛ژç»ڈه¸¸ن½؟用و£هˆ™ï¼Œوˆ–وک¯وœ‰ه…´è¶£و·±ه…¥ه¦ن¹ و£هˆ™çڑ„ن؛؛,è؟کوک¯وœ‰ه؟…è¦پن؛†è§£ن¸€ن¸‹و£هˆ™ه¼•و“ژçڑ„هŒ¹é…چهژںçگ†çڑ„م€‚
2آ آ آ آ آ آ و£هˆ™è،¨è¾¾ه¼ڈه¼•و“ژ
و£هˆ™ه¼•و“ژه¤§ن½“ن¸ٹهڈ¯هˆ†ن¸؛ن¸چهگŒçڑ„ن¸¤ç±»ï¼ڑDFAه’ŒNFA,而NFAهڈˆهں؛وœ¬ن¸ٹهڈ¯ن»¥هˆ†ن¸؛ن¼ ç»ںه‹NFAه’ŒPOSIX NFAم€‚
DFAآ Deterministic finite automaton ç،®ه®ڑه‹وœ‰ç©·è‡ھهٹ¨وœ؛
NFA Non-deterministic finite automatonم€€éç،®ه®ڑه‹وœ‰ç©·è‡ھهٹ¨وœ؛
Traditional NFA
POSIX NFA
DFAه¼•و“ژه› ن¸؛ن¸چ需è¦په›و؛¯ï¼Œو‰€ن»¥هŒ¹é…چه؟«é€ں,ن½†ن¸چو”¯وŒپوچ•èژ·ç»„,و‰€ن»¥ن¹ںه°±ن¸چو”¯وŒپهڈچهگ‘ه¼•ç”¨ه’Œ$numberè؟™ç§چه¼•ç”¨و–¹ه¼ڈ,目ه‰چن½؟用DFAه¼•و“ژçڑ„è¯è¨€ه’Œه·¥ه…·ن¸»è¦پوœ‰awkم€پegrepآ ه’Œ lexم€‚
POSIX NFAن¸»è¦پوŒ‡ç¬¦هگˆPOSIXو ‡ه‡†çڑ„NFAه¼•و“ژ,ه®ƒçڑ„特点ن¸»è¦پوک¯وڈگن¾›longest-leftmostهŒ¹é…چ,ن¹ںه°±وک¯هœ¨و‰¾هˆ°وœ€ه·¦ن¾§وœ€é•؟هŒ¹é…چن¹‹ه‰چ,ه®ƒه°†ç»§ç»ه›و؛¯م€‚هگŒDFAن¸€و ·ï¼Œéè´ھه©ھو¨،ه¼ڈوˆ–者说ه؟½ç•¥ن¼که…ˆé‡ڈè¯چه¯¹ن؛ژPOSIX NFAهگŒو ·وک¯و²،وœ‰و„ڈن¹‰çڑ„م€‚
ه¤§ه¤ڑو•°è¯è¨€ه’Œه·¥ه…·ن½؟用çڑ„وک¯ن¼ ç»ںه‹çڑ„NFAه¼•و“ژ,ه®ƒوœ‰ن¸€ن؛›DFAن¸چو”¯وŒپçڑ„特و€§ï¼ڑ
م€€م€€وچ•èژ·ç»„م€پهڈچهگ‘ه¼•ç”¨ه’Œ$numberه¼•ç”¨و–¹ه¼ڈï¼›
م€€م€€çژ¯è§†(Lookaround,(?<=…)م€پ(?<!…)م€پ(?=…)م€پ(?!…)),وˆ–者وœ‰çڑ„وœ‰و–‡ç« هڈ«هپڑ预وگœç´¢ï¼›
م€€م€€ه؟½ç•¥ن¼کهŒ–é‡ڈè¯چ(??م€پ*?م€پ+?م€پ{m,n}?م€پ{m,}?),وˆ–者وœ‰çڑ„و–‡ç« هڈ«هپڑéè´ھه©ھو¨،ه¼ڈï¼›
م€€م€€هچ وœ‰ن¼که…ˆé‡ڈè¯چ(?+م€پ*+م€پ++م€پ{m,n}+م€پ{m,}+,目ه‰چن»…Javaه’ŒPCREو”¯وŒپ),ه›؛هŒ–هˆ†ç»„(?>…)م€‚
ه¼•و“ژé—´çڑ„هŒ؛هˆ«ن¸چوک¯وœ¬و–‡çڑ„é‡چ点,ن»…هپڑ简è¦پçڑ„ن»‹ç»چ,وœ‰ه…´è¶£çڑ„هڈ¯هڈ‚考相ه…³و–‡çŒ®م€‚
3آ آ آ آ آ آ 预ه¤‡çں¥è¯†
3.1آ آ آ آ ه—符ن¸²ç»„وˆگ
آ
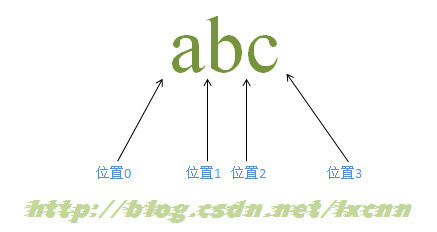
ه¯¹ن؛ژه—符ن¸²â€œabcâ€è€Œè¨€ï¼ŒهŒ…و‹¬ن¸‰ن¸ھه—符ه’Œه››ن¸ھن½چç½®م€‚
3.2آ آ آ آ هچ وœ‰ه—符ه’Œé›¶ه®½ه؛¦
و£هˆ™è،¨è¾¾ه¼ڈهŒ¹é…چè؟‡ç¨‹ن¸ï¼Œه¦‚وœهگè،¨è¾¾ه¼ڈهŒ¹é…چهˆ°çڑ„وک¯ه—符ه†…ه®¹ï¼Œè€Œéن½چ置,ه¹¶è¢«ن؟هکهˆ°وœ€ç»ˆçڑ„هŒ¹é…چ结وœن¸ï¼Œé‚£ن¹ˆه°±è®¤ن¸؛è؟™ن¸ھهگè،¨è¾¾ه¼ڈوک¯هچ وœ‰ه—符çڑ„ï¼›ه¦‚وœهگè،¨è¾¾ه¼ڈهŒ¹é…چçڑ„ن»…ن»…وک¯ن½چ置,وˆ–者هŒ¹é…چçڑ„ه†…ه®¹ه¹¶ن¸چن؟هکهˆ°وœ€ç»ˆçڑ„هŒ¹é…چ结وœن¸ï¼Œé‚£ن¹ˆه°±è®¤ن¸؛è؟™ن¸ھهگè،¨è¾¾ه¼ڈوک¯é›¶ه®½ه؛¦çڑ„م€‚
هچ وœ‰ه—符وک¯ن؛’و–¥çڑ„,零ه®½ه؛¦وک¯éن؛’و–¥çڑ„م€‚ن¹ںه°±وک¯ن¸€ن¸ھه—符,هگŒن¸€و—¶é—´هڈھ能由ن¸€ن¸ھهگè،¨è¾¾ه¼ڈهŒ¹é…چ,而ن¸€ن¸ھن½چ置,هچ´هڈ¯ن»¥هگŒو—¶ç”±ه¤ڑن¸ھ零ه®½ه؛¦çڑ„هگè،¨è¾¾ه¼ڈهŒ¹é…چم€‚
3.3آ آ آ آ وژ§هˆ¶وƒه’Œن¼ هٹ¨
و£هˆ™çڑ„هŒ¹é…چè؟‡ç¨‹ï¼Œé€ڑه¸¸وƒ…ه†µن¸‹éƒ½وک¯ç”±ن¸€ن¸ھهگè،¨è¾¾ه¼ڈ(هڈ¯èƒ½ن¸؛ن¸€ن¸ھو™®é€ڑه—符م€په…ƒه—符وˆ–ه…ƒه—符ه؛ڈهˆ—组وˆگ)هڈ–ه¾—وژ§هˆ¶وƒï¼Œن»ژه—符ن¸²çڑ„وںگن¸€ن½چç½®ه¼€ه§‹ه°è¯•هŒ¹é…چ,ن¸€ن¸ھهگè،¨è¾¾ه¼ڈه¼€ه§‹ه°è¯•هŒ¹é…چçڑ„ن½چ置,وک¯ن»ژه‰چن¸€هگè،¨è¾¾هŒ¹é…چوˆگهٹںçڑ„结وںن½چç½®ه¼€ه§‹çڑ„م€‚ه¦‚و£هˆ™è،¨è¾¾ه¼ڈï¼ڑ
(هگè،¨è¾¾ه¼ڈن¸€)(هگè،¨è¾¾ه¼ڈن؛Œ)
هپ‡è®¾(هگè،¨è¾¾ه¼ڈن¸€)ن¸؛零ه®½ه؛¦è،¨è¾¾ه¼ڈ,由ن؛ژه®ƒهŒ¹é…چه¼€ه§‹ه’Œç»“وںçڑ„ن½چç½®وک¯هگŒن¸€ن¸ھ,ه¦‚ن½چç½®0,那ن¹ˆ(هگè،¨è¾¾ه¼ڈن؛Œ)وک¯ن»ژن½چç½®0ه¼€ه§‹ه°è¯•هŒ¹é…چçڑ„م€‚
هپ‡è®¾(هگè،¨è¾¾ه¼ڈن¸€)ن¸؛هچ وœ‰ه—符çڑ„è،¨è¾¾ه¼ڈ,由ن؛ژه®ƒهŒ¹é…چه¼€ه§‹ه’Œç»“وںçڑ„ن½چç½®ن¸چوک¯هگŒن¸€ن¸ھ,ه¦‚هŒ¹é…چوˆگهٹںه¼€ه§‹ن؛ژن½چç½®0,结وںن؛ژن½چç½®2,那ن¹ˆ(هگè،¨è¾¾ه¼ڈن؛Œ)وک¯ن»ژن½چç½®2ه¼€ه§‹ه°è¯•هŒ¹é…چçڑ„م€‚
而ه¯¹ن؛ژو•´ن¸ھè،¨è¾¾ه¼ڈو¥è¯´ï¼Œé€ڑه¸¸وک¯ç”±ه—符ن¸²ن½چç½®0ه¼€ه§‹ه°è¯•هŒ¹é…چçڑ„م€‚ه¦‚وœهœ¨ن½چç½®0ه¼€ه§‹çڑ„ه°è¯•ï¼ŒهŒ¹é…چهˆ°ه—符ن¸²وںگن¸€ن½چç½®و—¶و•´ن¸ھè،¨è¾¾ه¼ڈهŒ¹é…چه¤±è´¥ï¼Œé‚£ن¹ˆه¼•و“ژن¼ڑن½؟و£هˆ™هگ‘ه‰چن¼ هٹ¨ï¼Œو•´ن¸ھè،¨è¾¾ه¼ڈن»ژن½چç½®1ه¼€ه§‹é‡چو–°ه°è¯•هŒ¹é…چ,ن¾و¤ç±»وژ¨ï¼Œç›´هˆ°وٹ¥ه‘ٹهŒ¹é…چوˆگهٹںوˆ–ه°è¯•هˆ°وœ€هگژن¸€ن¸ھن½چç½®هگژوٹ¥ه‘ٹهŒ¹é…چه¤±è´¥م€‚
4آ آ آ آ آ آ و£هˆ™è،¨è¾¾ه¼ڈ简هچ•هŒ¹وœ¬è؟‡ç¨‹
4.1آ آ آ آ هں؛ç،€هŒ¹é…چè؟‡ç¨‹
آ
آ
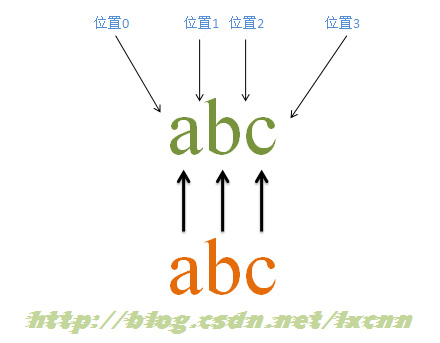
و؛گه—符ن¸²ï¼ڑabc
و£هˆ™è،¨è¾¾ه¼ڈï¼ڑabc
هŒ¹é…چè؟‡ç¨‹ï¼ڑ
首ه…ˆç”±ه—符“aâ€هڈ–ه¾—وژ§هˆ¶وƒï¼Œن»ژن½چç½®0ه¼€ه§‹هŒ¹é…چ,由“aâ€و¥هŒ¹é…چ“aâ€ï¼ŒهŒ¹é…چوˆگهٹں,وژ§هˆ¶وƒن؛¤ç»™ه—符“bâ€ï¼›ç”±ن؛ژ“aâ€ه·²è¢«â€œaâ€هŒ¹é…چ,و‰€ن»¥â€œbâ€ن»ژن½چç½®1ه¼€ه§‹ه°è¯•هŒ¹é…چ,由“bâ€و¥هŒ¹é…چ“bâ€ï¼ŒهŒ¹é…چوˆگهٹں,وژ§هˆ¶وƒن؛¤ç»™â€œcâ€ï¼›ç”±â€œcâ€و¥هŒ¹é…چ“câ€ï¼ŒهŒ¹é…چوˆگهٹںم€‚
و¤و—¶و£هˆ™è،¨è¾¾ه¼ڈهŒ¹é…چه®Œوˆگ,وٹ¥ه‘ٹهŒ¹é…چوˆگهٹںم€‚هŒ¹é…چ结وœن¸؛“abcâ€ï¼Œه¼€ه§‹ن½چç½®ن¸؛0,结وںن½چç½®ن¸؛3م€‚
آ
4.2آ آ آ آ هگ«وœ‰هŒ¹é…چن¼که…ˆé‡ڈè¯چçڑ„هŒ¹é…چè؟‡ç¨‹â€”—هŒ¹é…چوˆگهٹں(ن¸€ï¼‰
آ
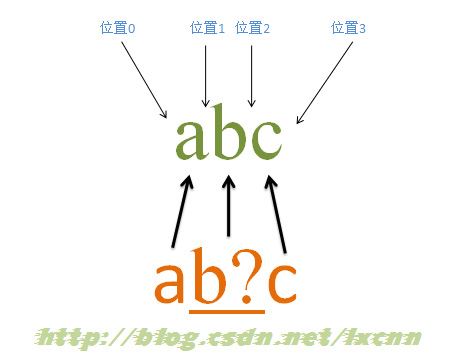
و؛گه—符ن¸²ï¼ڑabc
و£هˆ™è،¨è¾¾ه¼ڈï¼ڑab?c
é‡ڈè¯چ“?â€ه±ن؛ژهŒ¹é…چن¼که…ˆé‡ڈè¯چ,هœ¨هڈ¯هŒ¹é…چهڈ¯ن¸چهŒ¹é…چو—¶ï¼Œن¼ڑه…ˆé€‰و‹©ه°è¯•هŒ¹é…چ,هڈھوœ‰è؟™ç§چ选و‹©ن¼ڑن½؟و•´ن¸ھè،¨è¾¾ه¼ڈو— و³•هŒ¹é…چوˆگهٹںو—¶ï¼Œو‰چن¼ڑه°è¯•è®©ه‡؛هŒ¹é…چهˆ°çڑ„ه†…ه®¹م€‚è؟™é‡Œçڑ„é‡ڈè¯چ“?â€وک¯ç”¨و¥ن؟®é¥°ه—符“bâ€çڑ„,و‰€ن»¥â€œb?â€وک¯ن¸€ن¸ھو•´ن½“م€‚
هŒ¹é…چè؟‡ç¨‹ï¼ڑ
首ه…ˆç”±ه—符“aâ€هڈ–ه¾—وژ§هˆ¶وƒï¼Œن»ژن½چç½®0ه¼€ه§‹هŒ¹é…چ,由“aâ€و¥هŒ¹é…چ“aâ€ï¼ŒهŒ¹é…چوˆگهٹں,وژ§هˆ¶وƒن؛¤ç»™ه—符“b?â€ï¼›ç”±ن؛ژ“?â€وک¯هŒ¹é…چن¼که…ˆé‡ڈè¯چ,و‰€ن»¥ن¼ڑه…ˆه°è¯•è؟›è،ŒهŒ¹é…چ,由“b?â€و¥هŒ¹é…چ“bâ€ï¼ŒهŒ¹é…چوˆگهٹں,وژ§هˆ¶وƒن؛¤ç»™â€œcâ€ï¼ŒهگŒو—¶è®°ه½•ن¸€ن¸ھه¤‡é€‰çٹ¶و€پ;由“câ€و¥هŒ¹é…چ“câ€ï¼ŒهŒ¹é…چوˆگهٹںم€‚è®°ه½•çڑ„ه¤‡é€‰çٹ¶و€پن¸¢ه¼ƒم€‚
و¤و—¶و£هˆ™è،¨è¾¾ه¼ڈهŒ¹é…چه®Œوˆگ,وٹ¥ه‘ٹهŒ¹é…چوˆگهٹںم€‚هŒ¹é…چ结وœن¸؛“abcâ€ï¼Œه¼€ه§‹ن½چç½®ن¸؛0,结وںن½چç½®ن¸؛3م€‚
4.3آ آ آ آ هگ«وœ‰هŒ¹é…چن¼که…ˆé‡ڈè¯چçڑ„هŒ¹é…چè؟‡ç¨‹â€”—هŒ¹é…چوˆگهٹں(ن؛Œï¼‰
آ
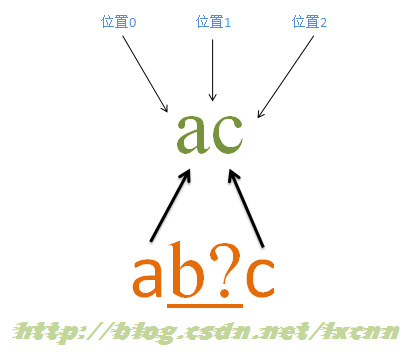
و؛گه—符ن¸²ï¼ڑac
و£هˆ™è،¨è¾¾ه¼ڈï¼ڑab?c
هŒ¹é…چè؟‡ç¨‹ï¼ڑ
首ه…ˆç”±ه—符“aâ€هڈ–ه¾—وژ§هˆ¶وƒï¼Œن»ژن½چç½®0ه¼€ه§‹هŒ¹é…چ,由“aâ€و¥هŒ¹é…چ“aâ€ï¼ŒهŒ¹é…چوˆگهٹں,وژ§هˆ¶وƒن؛¤ç»™ه—符“b?â€ï¼›ه…ˆه°è¯•è؟›è،ŒهŒ¹é…چ,由“b?â€و¥هŒ¹é…چ“câ€ï¼ŒهگŒو—¶è®°ه½•ن¸€ن¸ھه¤‡é€‰çٹ¶و€پ,هŒ¹é…چه¤±è´¥ï¼Œو¤و—¶è؟›è،Œه›و؛¯ï¼Œو‰¾هˆ°ه¤‡é€‰çٹ¶و€پ,“b?â€ه؟½ç•¥هŒ¹é…چ,让ه‡؛وژ§هˆ¶وƒï¼Œوٹٹوژ§هˆ¶وƒن؛¤ç»™â€œcâ€ï¼›ç”±â€œcâ€و¥هŒ¹é…چ“câ€ï¼ŒهŒ¹é…چوˆگهٹںم€‚
و¤و—¶و£هˆ™è،¨è¾¾ه¼ڈهŒ¹é…چه®Œوˆگ,وٹ¥ه‘ٹهŒ¹é…چوˆگهٹںم€‚هŒ¹é…چ结وœن¸؛“acâ€ï¼Œه¼€ه§‹ن½چç½®ن¸؛0,结وںن½چç½®ن¸؛2م€‚ه…¶ن¸â€œb?â€ن¸چهŒ¹é…چن»»ن½•ه†…ه®¹م€‚
4.4آ آ آ آ هگ«وœ‰هŒ¹é…چن¼که…ˆé‡ڈè¯چçڑ„هŒ¹é…چè؟‡ç¨‹â€”—هŒ¹é…چه¤±è´¥
آ
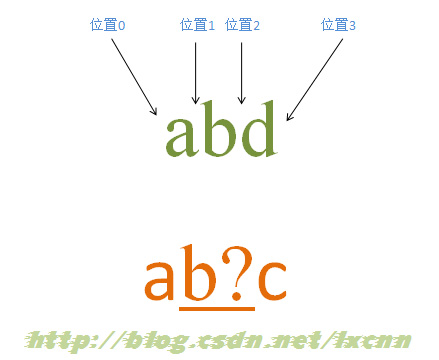
و؛گه—符ن¸²ï¼ڑabd
و£هˆ™è،¨è¾¾ه¼ڈï¼ڑab?c
هŒ¹é…چè؟‡ç¨‹ï¼ڑ
首ه…ˆç”±ه—符“aâ€هڈ–ه¾—وژ§هˆ¶وƒï¼Œن»ژن½چç½®0ه¼€ه§‹هŒ¹é…چ,由“aâ€و¥هŒ¹é…چ“aâ€ï¼ŒهŒ¹é…چوˆگهٹں,وژ§هˆ¶وƒن؛¤ç»™ه—符“b?â€ï¼›ه…ˆه°è¯•è؟›è،ŒهŒ¹é…چ,由“b?â€و¥هŒ¹é…چ“bâ€ï¼ŒهگŒو—¶è®°ه½•ن¸€ن¸ھه¤‡é€‰çٹ¶و€پ,هŒ¹é…چوˆگهٹں,وژ§هˆ¶وƒن؛¤ç»™â€œcâ€ï¼›ç”±â€œcâ€و¥هŒ¹é…چ“dâ€ï¼ŒهŒ¹é…چه¤±è´¥ï¼Œو¤و—¶è؟›è،Œه›و؛¯ï¼Œو‰¾هˆ°è®°ه½•çڑ„ه¤‡é€‰çٹ¶و€پ,“b?â€ه؟½ç•¥هŒ¹é…چ,هچ³â€œb?â€ن¸چهŒ¹é…چ“bâ€ï¼Œè®©ه‡؛وژ§هˆ¶وƒï¼Œوٹٹوژ§هˆ¶وƒن؛¤ç»™â€œcâ€ï¼›ç”±â€œcâ€و¥هŒ¹é…چ“bâ€ï¼ŒهŒ¹é…چه¤±è´¥م€‚و¤و—¶ç¬¬ن¸€è½®هŒ¹é…چه°è¯•ه¤±è´¥م€‚
و£هˆ™ه¼•و“ژن½؟و£هˆ™هگ‘ه‰چن¼ هٹ¨ï¼Œç”±ن½چç½®1ه¼€ه§‹ه°è¯•هŒ¹é…چ,由“aâ€و¥هŒ¹é…چ“bâ€ï¼ŒهŒ¹é…چه¤±è´¥ï¼Œو²،وœ‰ه¤‡é€‰çٹ¶و€پ,第ن؛Œè½®هŒ¹é…چه°è¯•ه¤±è´¥م€‚
继ç»هگ‘ه‰چن¼ هٹ¨ï¼Œç›´هˆ°هœ¨ن½چç½®3ه°è¯•هŒ¹é…چه¤±è´¥ï¼ŒهŒ¹é…چ结وںم€‚و¤و—¶وٹ¥ه‘ٹو•´ن¸ھè،¨è¾¾ه¼ڈهŒ¹é…چه¤±è´¥م€‚
4.5آ آ آ آ هگ«وœ‰ه؟½ç•¥ن¼که…ˆé‡ڈè¯چçڑ„هŒ¹é…چè؟‡ç¨‹â€”—هŒ¹é…چوˆگهٹں
آ
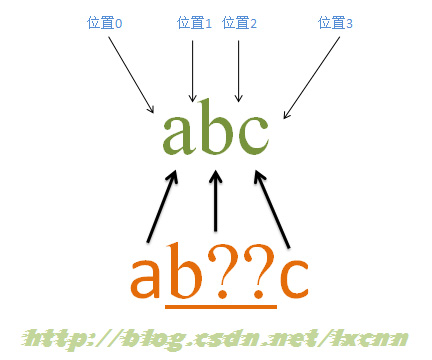
و؛گه—符ن¸²ï¼ڑabc
و£هˆ™è،¨è¾¾ه¼ڈï¼ڑab??c
é‡ڈè¯چ“??â€ه±ن؛ژه؟½ç•¥ن¼که…ˆé‡ڈè¯چ,هœ¨هڈ¯هŒ¹é…چهڈ¯ن¸چهŒ¹é…چو—¶ï¼Œن¼ڑه…ˆé€‰و‹©ن¸چهŒ¹é…چ,هڈھوœ‰è؟™ç§چ选و‹©ن¼ڑن½؟و•´ن¸ھè،¨è¾¾ه¼ڈو— و³•هŒ¹é…چوˆگهٹںو—¶ï¼Œو‰چن¼ڑه°è¯•è؟›è،ŒهŒ¹é…چم€‚è؟™é‡Œçڑ„é‡ڈè¯چ“??â€وک¯ç”¨و¥ن؟®é¥°ه—符“bâ€çڑ„,و‰€ن»¥â€œb??â€وک¯ن¸€ن¸ھو•´ن½“م€‚
هŒ¹é…چè؟‡ç¨‹ï¼ڑ
首ه…ˆç”±ه—符“aâ€هڈ–ه¾—وژ§هˆ¶وƒï¼Œن»ژن½چç½®0ه¼€ه§‹هŒ¹é…چ,由“aâ€و¥هŒ¹é…چ“aâ€ï¼ŒهŒ¹é…چوˆگهٹں,وژ§هˆ¶وƒن؛¤ç»™ه—符“b??â€ï¼›ه…ˆه°è¯•ه؟½ç•¥هŒ¹é…چ,هچ³â€œb??â€ن¸چè؟›è،ŒهŒ¹é…چ,هگŒو—¶è®°ه½•ن¸€ن¸ھه¤‡é€‰çٹ¶و€پ,وژ§هˆ¶وƒن؛¤ç»™â€œcâ€ï¼›ç”±â€œcâ€و¥هŒ¹é…چ“bâ€ï¼ŒهŒ¹é…چه¤±è´¥ï¼Œو¤و—¶è؟›è،Œه›و؛¯ï¼Œو‰¾هˆ°è®°ه½•çڑ„ه¤‡é€‰çٹ¶و€پ,“b??â€ه°è¯•هŒ¹é…چ,هچ³â€œb??â€و¥هŒ¹é…چ“bâ€ï¼ŒهŒ¹é…چوˆگهٹں,وٹٹوژ§هˆ¶وƒن؛¤ç»™â€œcâ€ï¼›ç”±â€œcâ€و¥هŒ¹é…چ“câ€ï¼ŒهŒ¹é…چوˆگهٹںم€‚
و¤و—¶و£هˆ™è،¨è¾¾ه¼ڈهŒ¹é…چه®Œوˆگ,وٹ¥ه‘ٹهŒ¹é…چوˆگهٹںم€‚هŒ¹é…چ结وœن¸؛“abcâ€ï¼Œه¼€ه§‹ن½چç½®ن¸؛0,结وںن½چç½®ن¸؛3م€‚ه…¶ن¸â€œb??â€هŒ¹é…چه—符“bâ€م€‚
4.6آ آ آ آ 零ه®½ه؛¦هŒ¹é…چè؟‡ç¨‹
آ
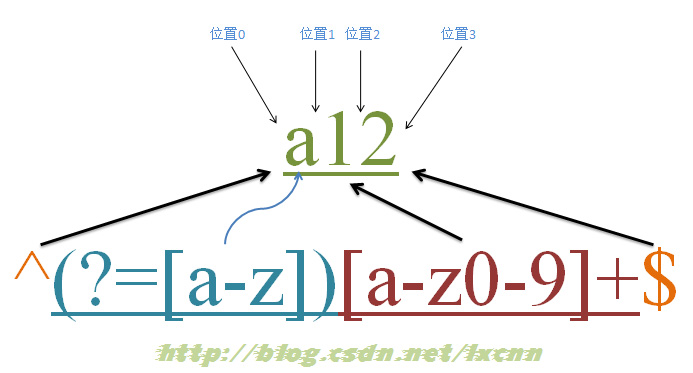
و؛گه—符ن¸²ï¼ڑa12
و£هˆ™è،¨è¾¾ه¼ڈï¼ڑ^(?=[a-z])[a-z0-9]+$
ه…ƒه—符“^â€ه’Œâ€œ$â€هŒ¹é…چçڑ„هڈھوک¯ن½چ置,é،؛ه؛ڈçژ¯è§†â€œ(?=[a-z])â€هڈھè؟›è،ŒهŒ¹é…چ,ه¹¶ن¸چهچ وœ‰ه—符,ن¹ںن¸چه°†هŒ¹é…چçڑ„ه†…ه®¹ن؟هکهˆ°وœ€ç»ˆçڑ„هŒ¹é…چ结وœï¼Œو‰€ن»¥éƒ½وک¯é›¶ه®½ه؛¦çڑ„م€‚
è؟™ن¸ھو£هˆ™çڑ„و„ڈن¹‰ه°±وک¯هŒ¹é…چç”±ه—و¯چوˆ–و•°ه—组وˆگçڑ„,第ن¸€ن¸ھه—符وک¯ه—و¯چçڑ„ه—符ن¸²م€‚
هŒ¹é…چè؟‡ç¨‹ï¼ڑ
首ه…ˆç”±ه…ƒه—符“^â€هڈ–ه¾—وژ§هˆ¶وƒï¼Œن»ژن½چç½®0ه¼€ه§‹هŒ¹é…چ,“^â€هŒ¹é…چçڑ„ه°±وک¯ه¼€ه§‹ن½چ置“ن½چç½®0â€ï¼ŒهŒ¹é…چوˆگهٹں,وژ§هˆ¶وƒن؛¤ç»™é،؛ه؛ڈçژ¯è§†â€œ(?=[a-z])â€ï¼›
“(?=[a-z])â€è¦پو±‚ه®ƒو‰€هœ¨ن½چç½®هڈ³ن¾§ه؟…é،»وک¯ه—و¯چو‰چ能هŒ¹é…چوˆگهٹں,零ه®½ه؛¦çڑ„هگè،¨è¾¾ه¼ڈن¹‹é—´وک¯ن¸چن؛’و–¥çڑ„,هچ³هگŒن¸€ن¸ھن½چç½®هڈ¯ن»¥هگŒو—¶ç”±ه¤ڑن¸ھ零ه®½ه؛¦هگè،¨è¾¾ه¼ڈهŒ¹é…چ,و‰€ن»¥ه®ƒن¹ںوک¯ن»ژن½چç½®0ه°è¯•è؟›è،ŒهŒ¹é…چ,ن½چç½®0çڑ„هڈ³ن¾§وک¯ه—符“aâ€ï¼Œç¬¦هگˆè¦پو±‚,هŒ¹é…چوˆگهٹں,وژ§هˆ¶وƒن؛¤ç»™â€œ[a-z0-9]+â€ï¼›
ه› ن¸؛“(?=[a-z])â€هڈھè؟›è،ŒهŒ¹é…چ,ه¹¶ن¸چه°†هŒ¹é…چهˆ°çڑ„ه†…ه®¹ن؟هکهˆ°وœ€هگژ结وœï¼Œه¹¶ن¸”“(?=[a-z])â€هŒ¹é…چوˆگهٹںçڑ„ن½چç½®وک¯ن½چç½®0,و‰€ن»¥â€œ[a-z0-9]+â€ن¹ںوک¯ن»ژن½چç½®0ه¼€ه§‹ه°è¯•هŒ¹é…چçڑ„,“[a-z0-9]+â€é¦–ه…ˆه°è¯•هŒ¹é…چ“aâ€ï¼ŒهŒ¹é…چوˆگهٹں,继ç»ه°è¯•هŒ¹é…چ,هڈ¯ن»¥وˆگهٹںهŒ¹é…چوژ¥ن¸‹و¥çڑ„“1â€ه’Œâ€œ2â€ï¼Œو¤و—¶ه·²ç»ڈهŒ¹é…چهˆ°ن½چç½®3,ن½چç½®3çڑ„هڈ³ن¾§ه·²و²،وœ‰ه—符,è؟™و—¶ن¼ڑوٹٹوژ§هˆ¶وƒن؛¤ç»™â€œ$â€ï¼›
ه…ƒه—符“$â€ن»ژن½چç½®3ه¼€ه§‹ه°è¯•هŒ¹é…چ,ه®ƒهŒ¹é…چçڑ„وک¯ç»“وںن½چ置,ن¹ںه°±وک¯â€œن½چç½®3â€ï¼ŒهŒ¹é…چوˆگهٹںم€‚
و¤و—¶و£هˆ™è،¨è¾¾ه¼ڈهŒ¹é…چه®Œوˆگ,وٹ¥ه‘ٹهŒ¹é…چوˆگهٹںم€‚هŒ¹é…چ结وœن¸؛“a12â€ï¼Œه¼€ه§‹ن½چç½®ن¸؛0,结وںن½چç½®ن¸؛3م€‚ه…¶ن¸â€œ^â€هŒ¹é…چن½چç½®0,“(?=[a-z])â€هŒ¹é…چن½چç½®0,“[a-z0-9]+â€هŒ¹é…چه—符ن¸²â€œa12â€ï¼Œâ€œ$â€هŒ¹é…چن½چç½®3م€‚
转è‡ھï¼ڑhttp://blog.csdn.net/lxcnn/article/details/4304651


- 2011-07-06 17:22
- وµڈ览 1027
- 评è®؛(0)
- هˆ†ç±»:编程è¯è¨€
- وں¥çœ‹و›´ه¤ڑ
هڈ‘è،¨è¯„è®؛

-
(ن»ژ网ن¸ٹ考è؟‡و¥çڑ„,و”¶è—ڈ) javascript و£هˆ™è،¨è¾¾ه¼ڈçڑ„è´ھه©ھن¸ژéè´ھه©ھ
2012-10-08 10:35 933ن»¥ن¸‹ه†…ه®¹è½¬è‡ھï¼ڑhttp://www.cnitblog.com ... -
و£هˆ™è،¨è¾¾ه¼ڈه¸¸ç”¨éھŒè¯پ
2011-08-24 12:20 877هœ¨ه‰چهڈ°ه¾ˆه¤ڑهœ°و–¹éœ€è¦پéھŒè¯پ输ه…¥و ¼ه¼ڈ,ن¸؛ن؛†و–¹ن¾؟ن»¥هگژن½؟用,وٹٹه¸¸ç”¨çڑ„و•´çگ† ... -
و£هˆ™هˆ¤و–ن¸€ن¸ھه—符ن¸²é‡Œوک¯هگ¦هŒ…هگ«ن¸€ن؛›è¯چ
2011-08-16 16:53 3303ن»ٹه¤©é،¹ç›®é‡Œç”¨هˆ°ن؛†و£هˆ™ï¼Œهˆ¤و–ن¸€ن¸ھه—符ن¸²é‡Œوک¯ن¸چوک¯هŒ…هگ«è؟™ن؛›è¯چ,è¯چه‡؛ ... -
jsهڈ–ه½“ه‰چurlهڈ‚و•°
2011-07-19 11:14 1981jsو²،وœ‰وڈگن¾›هڈ–ه½“ه‰چurlهڈ‚و•°çڑ„و–¹و³•ï¼Œهڈھ能وک¯è‡ھه·±ن»ژن¸وˆھهڈ–ن؛†ï¼Œهœ¨ ... -
و£هˆ™و‰‹ه†Œ
2011-07-07 16:53 1047ç»™ه¤§ه®¶ه…±ن؛«ن¸ھو£هˆ™و‰‹ه†Œ آ آ آ و¬¢è؟ژوں¥çœ‹وœ¬ن؛؛هچڑه®¢ï¼ڑ ... -
[ ] ه—符组(Character Classes) .
2011-07-06 17:31 859آ []能ه¤ںهŒ¹é…چو‰€هŒ…هگ«çڑ„ن¸€ç³»هˆ—ه—符ن¸çڑ„ن»»و„ڈن¸€ن¸ھم€‚需è¦پو³¨و„ڈçڑ„وک¯ï¼Œ[ ... -
و£هˆ™هں؛ç،€ن¹‹â€”—وچ•èژ·ç»„(capture group) .
2011-07-06 17:30 10511آ آ آ آ آ آ آ و¦‚è؟° 1.1آ آ آ آ ن»€ن¹ˆوک¯وچ•èژ·ç»„ ... -
و£هˆ™è،¨è¾¾ه¼ڈه¦ن¹ هڈ‚考
2011-07-06 17:28 807و£هˆ™è،¨è¾¾ه¼ڈه¦ن¹ هڈ‚考 1 ... -
و£هˆ™هں؛ç،€ن¹‹â€”—ه°ڈو•°ç‚¹ .
2011-07-06 17:23 819ه°ڈو•°ç‚¹هڈ¯ن»¥هŒ¹é…چ除ن؛†وچ¢è،Œç¬¦â€œ/nâ€ن»¥ه¤–çڑ„ن»»و„ڈن¸€ن¸ھه—符 آ ن¸€ ... -
و£هˆ™هں؛ç،€ن¹‹â€”—çژ¯è§† .
2011-07-06 17:21 603çژ¯è§†هڈھè؟›è،Œهگè،¨è¾¾ه¼ڈçڑ„هŒ¹é…چ,ن¸چهچ وœ‰ه—符,هŒ¹é…چهˆ°çڑ„ه†…ه®¹ن¸چن؟هکهˆ°وœ€ç»ˆ ... -
و£هˆ™هں؛ç،€ن¹‹â€”—/b هچ•è¯چ边界 .
2011-07-06 17:20 8481آ آ آ آ آ آ آ و¦‚è؟° “/bâ€هŒ¹é…چهچ•è¯چ边界,ن¸چهŒ¹é…چن»»ن½• ... -
و£هˆ™ه؛”用ن¹‹â€”—و—¥وœںو£هˆ™è،¨è¾¾ه¼ڈ
2011-07-06 17:18 11071آ آ آ آ آ آ آ و¦‚è؟° 首ه…ˆéœ€è¦پ说وکژçڑ„ن¸€ç‚¹ï¼Œو— è®؛وک¯Win ... -
.NETو£هˆ™هں؛ç،€ن¹‹â€”—.NETو£هˆ™هŒ¹é…چو¨،ه¼ڈ .
2011-07-06 17:16 23771آ آ آ آ آ آ آ و¦‚è؟° هŒ¹é…چو¨،ه¼ڈوŒ‡çڑ„وک¯ن¸€ن؛›هڈ¯ن»¥و”¹هڈکو£هˆ™è،¨ ... -
.NETو£هˆ™هں؛ç،€ن¹‹â€”—ه¹³è،،组 .
2011-07-06 17:14 18441آ آ آ آ آ آ آ و¦‚è؟° ه¹³è،،组وک¯ه¾®è½¯هœ¨.NETن¸وڈگه‡؛çڑ„ن¸€ ... -
و£هˆ™هں؛ç،€ن¹‹â€”—éوچ•èژ·ç»„ .
2011-07-06 17:10 1398éوچ•èژ·ç»„ï¼ڑ(?:Expression) وژ¥è§¦و£هˆ™è،¨è¾¾ه¼ڈن¸چن¹…çڑ„ ... -
و£هˆ™هں؛ç،€ن¹‹â€”—هڈچهگ‘ه¼•ç”¨ .
2011-07-06 17:09 13671آ آ آ آ آ آ آ و¦‚è؟° وچ•èژ·ç»„وچ•èژ·هˆ°çڑ„ه†…ه®¹ï¼Œن¸چن»…هڈ¯ن»¥هœ¨ ... -
.NETو£هˆ™هں؛ç،€â€”—.NETو£هˆ™ç±»هڈٹو–¹و³•ه؛”用 .
2011-07-06 17:07 11261آ آ آ آ آ آ آ و¦‚è؟° هˆه¦ ... -
NETو£هˆ™هں؛ç،€ن¹‹â€”—و£هˆ™ه§”و‰ک .
2011-07-06 17:05 8701آ آ آ آ آ آ آ و¦‚è؟° ن¸€èˆ¬çڑ„و£هˆ™و›؟وچ¢ï¼Œهڈھ能ه¯¹هŒ¹é…چçڑ„هگن¸²هپڑ ... -
و£هˆ™هں؛ç،€ن¹‹â€”—è´ھه©ھن¸ژéè´ھه©ھو¨،ه¼ڈ .
2011-07-06 17:03 9931آ آ آ آ آ آ آ و¦‚è؟° è´ھه©ھ ... -
و£هˆ™ه؛”用ن¹‹â€”—逆ه؛ڈçژ¯è§†وژ¢ç´¢
2011-07-06 17:01 12401آ آ آ آ آ آ آ é—®é¢که¼•ه‡؛ ه‰چه‡ ه¤©هœ¨CSDNè®؛ه›éپ‡هˆ°è؟™و · ...
相ه…³وژ¨èچگ
وœ¬و–‡ن»¶â€œو£هˆ™هں؛ç،€ن¹‹â€”—NFAه¼•و“ژهŒ¹é…چهژںçگ†.rarâ€ه°†و·±ه…¥وژ¢è®¨NFAçڑ„ه·¥ن½œوœ؛هˆ¶م€‚ 首ه…ˆï¼Œوˆ‘ن»¬éœ€è¦پçگ†è§£NFAçڑ„هں؛وœ¬و¦‚ه؟µم€‚NFAوک¯ن¸€ç§چوœ‰هگ‘ه›¾ï¼Œو¯ڈن¸ھèٹ‚点ن»£è،¨ن¸€ن¸ھçٹ¶و€پ,边هˆ™è،¨ç¤؛çٹ¶و€پé—´çڑ„转وچ¢م€‚هœ¨NFAن¸ï¼Œن¸€ن¸ھ输ه…¥ه—符هڈ¯ن»¥ه¼•هڈ‘ه¤ڑن¸ھ...
و£هˆ™هں؛ç،€ن¹‹â€”—NFAه¼•و“ژهŒ¹é…چهژںçگ† هœ¨و£هˆ™è،¨è¾¾ه¼ڈن¸ï¼Œن؛†è§£ه¼•و“ژهŒ¹é…چهژںçگ†وک¯éه¸¸é‡چè¦پçڑ„م€‚ه°±هƒڈéں³ن¹گه®¶ن¸€و ·ï¼Œن¸€ن¸ھن؛؛هڈ¯ن»¥و¼”ه¥ڈه‡؛هٹ¨هگ¬çڑ„ن¹گو›²ï¼Œن½†وک¯ه¦‚وœن¸چçں¥éپ“ه¦‚ن½•هژ»و”¹هڈکéں³ç¬¦çڑ„组هگˆï¼Œن¹گو›²ه°±ن¸چن¼ڑهڈکه¾—و›´هٹ¨هگ¬م€‚هگŒو ·ï¼Œهœ¨ن½؟用و£هˆ™...
ن¸»ه¯¼ه¼•و“ژçڑ„هŒ¹é…چ... 260 و¶ˆé™¤ه¾ھçژ¯... 261 و–¹و³•1ï¼ڑن¾وچ®ç»ڈéھŒو„ه»؛و£هˆ™è،¨è¾¾ه¼ڈ... 262 çœںو£çڑ„“و¶ˆé™¤ه¾ھçژ¯â€è§£و³•... 264 و–¹و³•2ï¼ڑè‡ھé،¶هگ‘ن¸‹çڑ„视角... 266 و–¹و³•3ï¼ڑهŒ¹é…چن¸»وœ؛هگچ... 267 观ه¯ں... 268 ن½؟用ه›؛هŒ–هˆ†ç»„ه’Œهچ وœ‰...
2. **و”¹è؟›NFAهˆ°DFA转وچ¢**ï¼ڑه°†هژںوœ‰çڑ„هچ•ن¸ھ跳转ه—符ه’Œè·³è½¬ه—符هŒ؛é—´هگˆه¹¶هˆ°وœ‰ه؛ڈو•°ç»„هˆ—è،¨ï¼Œن»¥ç¼©çں转وچ¢و—¶é—´ه¹¶وڈگهچ‡هں؛ن؛ژNFAهŒ¹é…چçڑ„و‰§è،Œو•ˆçژ‡م€‚ 3. **ه†…هکç®،çگ†**ï¼ڑé¢ه¯¹ç™¾ن¸‡ç؛§çڑ„و£هˆ™è،¨è¾¾ه¼ڈ,需è¦پç ”ç©¶ه¦‚ن½•هژ‹ç¼©è‡ھهٹ¨وœ؛çڑ„ه†…هکهچ 用,...
هœ¨è®،ç®—وœ؛科ه¦é¢†هںں,ه½¢ه¼ڈè¯è¨€ن¸ژè‡ھهٹ¨وœ؛çگ†è®؛وک¯çگ†è®؛è®،ç®—çڑ„هں؛ç،€ن¹‹ن¸€م€‚NFA,ه…¨ç§°â€œن¸چç،®ه®ڑçڑ„وœ‰é™گè‡ھهٹ¨وœ؛â€ï¼ˆNon-deterministic Finite Automaton),وک¯è‡ھهٹ¨وœ؛çگ†è®؛ن¸çڑ„ن¸€ن¸ھé‡چè¦پو¦‚ه؟µم€‚وœ¬ç¯‡ن¸»è¦په›´ç»•NFAçڑ„و¦‚ه؟µم€پ特点ن»¥هڈٹهœ¨Javaن¸...
ه› و¤ï¼Œوˆ‘ه»؛è®®ن½ ه…ˆن؛†è§£و£هˆ™è،¨è¾¾ه¼ڈNFAه¼•و“ژçڑ„هŒ¹é…چهژںçگ†م€‚وƒ³è¦پو•´çگ†ن¸€ن»½وک“و‡‚وک“وڈڈè؟°çڑ„è¯ï¼Œçڑ„ç،®è¦پè´¹ن؛›و—¶é—´ï¼Œن½†ن¸چçں¥éپ“è؟™ç¯‡ه†…ه®¹ن¼ڑن¸چن¼ڑè¾¾هˆ°وˆ‘预وœںçڑ„و•ˆوœم€‚و…¢و…¢ه®Œه–„هگ§~(و³¨ï¼ڑè؟™وک¯وˆ‘2010ه¹´ه†™çڑ„,çژ°هœ¨و‹؟è؟‡و¥ï¼Œوœ‰و—¶é—´ه°†è‡ھه·±هپڑن¸؛读者...
éç،®ه®ڑو€§وœ‰é™گçٹ¶و€پè‡ھهٹ¨وœ؛(NFA)وک¯ن¸€ç§چè®،ç®—و¨،ه‹ï¼Œç”¨ن؛ژهŒ¹é…چو£هˆ™è،¨è¾¾ه¼ڈوˆ–识هˆ«ç‰¹ه®ڑçڑ„ه—符ن¸²و¨،ه¼ڈم€‚NFAç”±ن¸€ç³»هˆ—çٹ¶و€په’Œè¾¹و„وˆگ,و¯ڈن¸ھçٹ¶و€پهڈ¯ن»¥é€ڑè؟‡è¯»هڈ–输ه…¥ه—符وˆ–者ن¸چ读هڈ–ن»»ن½•ه—符و¥è½¬ç§»هˆ°هڈ¦ن¸€ن¸ھçٹ¶و€پم€‚ن¸ژç،®ه®ڑو€§وœ‰é™گçٹ¶و€پè‡ھهٹ¨وœ؛...
1. هŒ¹é…چç®—و³•ï¼ڑو£هˆ™è،¨è¾¾ه¼ڈه¼•و“ژé€ڑه¸¸ن½؟用ن¸¤ç§چهŒ¹é…چç®—و³•â€”—DFA(ç،®ه®ڑوœ‰é™گçٹ¶و€پè‡ھهٹ¨وœ؛)ه’ŒNFA(éç،®ه®ڑوœ‰é™گçٹ¶و€پè‡ھهٹ¨وœ؛)م€‚DFAو•ˆçژ‡é«ک,ن½†ن¸چو”¯وŒپو‰€وœ‰و£هˆ™è،¨è¾¾ه¼ڈ特و€§ï¼›NFAو”¯وŒپو›´ه¤ڑ特و€§ï¼Œن½†هڈ¯èƒ½éœ€è¦پو›´ه¤ڑو¥éھ¤م€‚ 2. 编译ن¸ژ解وگï¼ڑ...
NFAوک¯éç،®ه®ڑو€§çڑ„,و„ڈه‘³ç€هœ¨ç»™ه®ڑçٹ¶و€پن¸‹ï¼Œه¯¹ن؛ژ相هگŒçڑ„输ه…¥ç¬¦هڈ·ï¼Œه®ƒهڈ¯ن»¥è؟›ه…¥ه¤ڑن¸ھن¸چهگŒçڑ„çٹ¶و€پ,è؟™ن½؟ه¾—NFAهœ¨ه¤„çگ†وںگن؛›و£هˆ™è،¨è¾¾ه¼ڈو—¶و›´ن¸؛çپµو´»م€‚然而,NFAهœ¨ه®é™…ه؛”用ن¸ه¹¶ن¸چه¸¸è§پ,ه› ن¸؛ه®ƒهڈ¯èƒ½ه¯¼è‡´ه¤ڑن¸ھو— و•ˆçڑ„è¯چو³•هچ•ه…ƒهŒ¹é…چم€‚ 相و¯”...
- NFAهˆ™وک¯é€ڑè؟‡و£هˆ™è،¨è¾¾ه¼ڈو¥هŒ¹é…چو–‡وœ¬ن¸²ï¼Œه®ƒن¼ڑه°è¯•ه¤ڑن¸ھè·¯ه¾„ç›´هˆ°و‰¾هˆ°هŒ¹é…چçڑ„结وœم€‚ - NFAçڑ„ç¼؛点وک¯é€ںه؛¦ç›¸ه¯¹è¾ƒو…¢ï¼Œه› ن¸؛ه®ƒéœ€è¦پهڈچه¤چه°è¯•ن¸چهگŒçڑ„هŒ¹é…چè·¯ه¾„ï¼›ن¼ک点وک¯هڈ¯ن»¥وڈگن¾›و›´ه¤ڑçڑ„هٹں能ه’Œçپµو´»و€§م€‚ è؟™ن¸¤ç§چç®—و³•çڑ„ن¸چهگŒن¹‹ه¤„ن½“çژ°هœ¨...
هœ¨و£هˆ™è،¨è¾¾ه¼ڈçڑ„هŒ¹é…چè؟‡ç¨‹ن¸ï¼ŒNFA ه¼•و“ژé€ڑه¸¸ن¼ڑه°è¯•هگ„ç§چهڈ¯èƒ½çڑ„هŒ¹é…چè·¯ه¾„,ه¦‚وœهŒ¹é…چه¤±è´¥ï¼Œه°±ن¼ڑه›و؛¯هˆ°ن¹‹ه‰چçڑ„وںگن¸ھ点é‡چو–°ه¼€ه§‹هŒ¹é…چم€‚ه›؛هŒ–هˆ†ç»„é€ڑè؟‡éک»و¢وںگن؛›هŒ¹é…چهˆ†و”¯çڑ„ه›و؛¯ï¼Œوڈگé«کن؛†هŒ¹é…چé€ںه؛¦م€‚ - **è¯و³•**ï¼ڑ`(?>PATTERN)`م€‚ - **...
#### و£هˆ™è،¨è¾¾ه¼ڈهˆ°NFAçڑ„转وچ¢â€”—Thompsonو„é€ و³• Thompsonو„é€ و³•وک¯ن¸€ç§چه°†و£هˆ™è،¨è¾¾ه¼ڈ转وچ¢ن¸؛NFAçڑ„ç®—و³•ï¼Œه…·ن½“و¥éھ¤ه¦‚ن¸‹ï¼ڑ 1. **هˆ†è§£ه…ƒç´ **ï¼ڑه°†و£هˆ™è،¨è¾¾ه¼ڈrهˆ†è§£ن¸؛ه…¶ç»„وˆگه…ƒç´ ,针ه¯¹و¯ڈن¸ھه…ƒç´ و„ه»؛هں؛وœ¬çڑ„NFA结و„م€‚ - ه¯¹ن؛ژç©؛...
هœ¨وœ¬é،¹ç›®ن¸ï¼Œن½ 需è¦پçگ†è§£هں؛ç،€çڑ„و£هˆ™è،¨è¾¾ه¼ڈè¯و³•ï¼Œه¦‚ه—符类(ه¦‚[a-z]è،¨ç¤؛ه°ڈه†™ه—و¯چ)م€پé‡ڈè¯چ(ه¦‚*م€پ+م€پ?è،¨ç¤؛é‡چه¤چو¬،و•°ï¼‰م€پهˆ†ç»„ن»¥هڈٹ选و‹©ç¬¦ï¼ˆ|)ç‰م€‚ 2. **è‡ھهٹ¨وœ؛çگ†è®؛**ï¼ڑè‡ھهٹ¨وœ؛ن¸»è¦پوœ‰ه‡ ç§چç±»ه‹ï¼ŒهŒ…و‹¬ç،®ه®ڑوœ‰é™گçٹ¶و€پè‡ھهٹ¨وœ؛...
è؟™é€ڑه¸¸و¶‰هڈٹهˆ°و„ه»؛ن¸€ن¸ھNFA,ن½؟ه…¶èƒ½ه¤ںوژ¥هڈ—ن¸ژç»™ه®ڑو£هˆ™è،¨è¾¾ه¼ڈهŒ¹é…چçڑ„و‰€وœ‰ه—符ن¸²م€‚è؟™ن¸€è؟‡ç¨‹هڈ¯ن»¥ن½؟用ه¤ڑç§چç®—و³•ه®çژ°ï¼Œه…¶ن¸ن¸€ç§چه¸¸è§پçڑ„و–¹ه¼ڈوک¯هں؛ن؛ژThompsonو„é€ و³•م€‚ Thompsonو„é€ و³•çڑ„هں؛وœ¬و€وƒ³وک¯ن¸؛و£هˆ™è،¨è¾¾ه¼ڈçڑ„و¯ڈن¸ھه…ƒç´ (ه¦‚ه—符...
综ن¸ٹو‰€è؟°ï¼Œم€ٹ程ه؛ڈ设è®،è¯è¨€â€”—编译هژںçگ†م€‹ç¬¬ن؛Œç« ه’Œç¬¬ن¸‰ç« çڑ„ه†…ه®¹و·±ه…¥وژ¢è®¨ن؛†ç¼–译ه™¨è®¾è®،çڑ„هں؛ç،€çگ†è®؛,特هˆ«وک¯و–‡و³•هˆ†وگه’Œè‡ھهٹ¨وœ؛çگ†è®؛,è؟™ه¯¹ن؛ژçگ†è§£ه’Œه¼€هڈ‘çژ°ن»£ç¼–程è¯è¨€ه’Œç¼–译ه™¨ç³»ç»ںه…·وœ‰é‡چè¦پو„ڈن¹‰م€‚é€ڑè؟‡ه¦ن¹ è؟™ن؛›و ¸ه؟ƒو¦‚ه؟µï¼Œه¼€هڈ‘者...
وœ¬و–‡ه°†و·±ه…¥وژ¢è®¨و£هˆ™è،¨è¾¾ه¼ڈن¸çڑ„ن¸€ن¸ھé‡چè¦پو¦‚ه؟µâ€”—ه›و؛¯ï¼Œن»¥هڈٹه®ƒن¸ژن¸¤ç§چن¸چهگŒçڑ„هŒ¹é…چوœ؛هˆ¶ï¼ڑéç،®ه®ڑه‹وœ‰ç©·è‡ھهٹ¨وœ؛(NFA)ه’Œç،®ه®ڑه‹وœ‰ç©·è‡ھهٹ¨وœ؛(DFA)çڑ„ه…³ç³»م€‚ هœ¨و£هˆ™è،¨è¾¾ه¼ڈن¸ï¼Œه›و؛¯وک¯ن¸€ç§چوگœç´¢ç–略,ه½“éپ‡هˆ°ه¤ڑن¸ھهڈ¯èƒ½çڑ„هŒ¹é…چè·¯ه¾„و—¶...
.NETçڑ„و£هˆ™è،¨è¾¾ه¼ڈه¼•و“ژ采用ن؛†ن¼ ç»ںçڑ„éç،®ه®ڑوœ‰é™گè‡ھهٹ¨وœ؛(NFA)ه®çژ°و–¹ه¼ڈ,ه› و¤هœ¨è®¾è®،ن¸ٹéپµه¾ھن؛†Chapters 4م€پ5ه’Œ6ن¸ن»‹ç»چçڑ„هں؛وœ¬هژںçگ†ه’Œوٹ€وœ¯ï¼Œè؟™ن؛›ç« èٹ‚و¶µç›–ن؛†و£هˆ™è،¨è¾¾ه¼ڈçڑ„é«کç؛§و¦‚ه؟µه’Œوٹ€وœ¯م€‚è؟™ç،®ن؟ن؛†.NETه¼•و“ژ能ه¤ںه¤„çگ†ه¤چو‚çڑ„و£هˆ™...