
GECCO(易用的轻量化的网络爬虫)
初衷
现在开发应用已经离不开爬虫,网络信息浩如烟海,对互联网的信息加以利用是如今所有应用程序都必须要掌握的技术。了解过现在的一些爬虫软件,python语言编写的爬虫框架scrapy得到了较为广泛的应用。gecco的设计和架构受到了scrapy一些启发,结合java语言的特点,形成了如下软件框架。易用是gecco框架首要目标,只要有一些java开发基础,会写jquery的选择器,就能轻松配置爬虫。
结构图
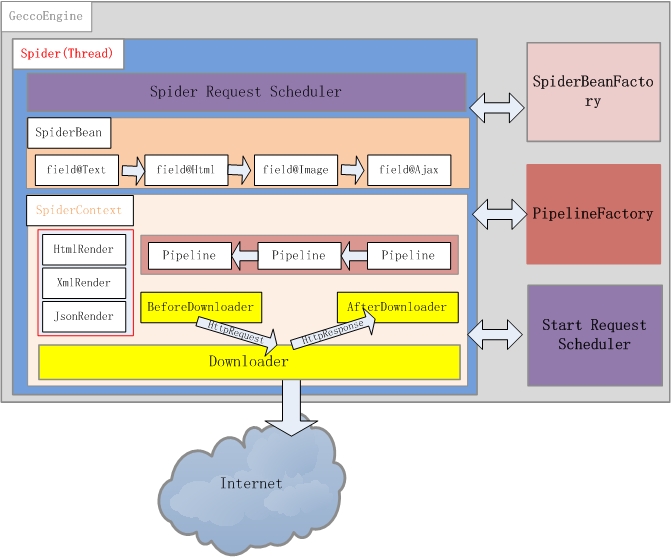
基本构件介绍
GeccoEngine
是爬虫引擎,每个爬虫引擎最好独立进程,在分布式爬虫场景下,可以单独分配一台爬虫服务器。引擎包括Scheduler、Downloader、Spider、SpiderBeanFactory4个主要模块
Scheduler
需要下载的请求都放在这里管理,可以认为这里是一个队列,保存了所有待抓取的请求。系统默认采用FIFO的方式管理请求。
Downloader
下载器,负责将Scheduler里的请求下载下来,系统默认采用Unirest作为下载引擎。
Spider
一个爬虫引擎可以包含多个爬虫,每个爬虫可以认为是一个单独线程,爬虫会从Scheduler中获取需要待抓取的请求。爬虫的任务就是下载网页并渲染相应的JavaBean。
SpiderBeanFactory
SpiderBean是爬虫渲染的JavaBean的统一接口类,所有Bean均继承该接口。SpiderBeanFactroy会根据请求的url地址,匹配相应的SpiderBean,同时生成该SpiderBean的上下文SpiderBeanContext. SpiderBeanContext包括需要该SpiderBean的渲染类(目前支持HTML、JSON两种Bean的渲染方式)、下载前处理类、下载后处理类以及渲染完成后对SpiderBean的后续处理Pipeline。
Download
<dependency>
<groupId>com.geccocrawler</groupId>
<artifactId>gecco</artifactId>
<version>1.0.1</version>
</dependency>
QuikStart
配置需要渲染的SpiderBean
@Gecco(matchUrl="https://github.com/{user}/{project}", pipelines="consolePipeline")
public class MyGithub implements HtmlBean {
private static final long serialVersionUID = -7127412585200687225L;
@RequestParameter("user")
private String user;
@RequestParameter("project")
private String project;
@HtmlField(cssPath=".repository-meta-content")
private String title;
@Text
@HtmlField(cssPath=".pagehead-actions li:nth-child(2) .social-count")
private int star;
@Text
@HtmlField(cssPath=".pagehead-actions li:nth-child(3) .social-count")
private int fork;
@HtmlField(cssPath=".entry-content")
private String readme;
public String getReadme() {
return readme;
}
public void setReadme(String readme) {
this.readme = readme;
}
public String getUser() {
return user;
}
public void setUser(String user) {
this.user = user;
}
public String getProject() {
return project;
}
public void setProject(String project) {
this.project = project;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public int getStar() {
return star;
}
public void setStar(int star) {
this.star = star;
}
public int getFork() {
return fork;
}
public void setFork(int fork) {
this.fork = fork;
}
}
启动爬虫引擎
public static void main(String[] args) {
GeccoEngine.create()
.classpath("com.geccocrawler.gecco.demo")
//爬虫userAgent设置
.userAgent("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.85 Safari/537.36")
//开始抓取的页面地址
.start("https://github.com/xtuhcy/gecco")
//开启几个爬虫线程
.thread(1)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(2000)
.run();
}
公共注解说明
@Gecco
定义一个SpiderBean必须有的注解,告诉爬虫引擎什么样的url转换成该java bean,使用什么渲染器渲染,java bean渲染完成后传递给哪些管道过滤器继续处理
- matchUrl:摒弃正则表达式的匹配方式,采用更容易理解的{value}方式,如:https://github.com/{user}/{project}。user和project变量将会在request中获取。
- render:bean渲染类型,计划支持html、json、xml、rss
- pipelines:bean渲染完成后,后续的管道过滤器
@Request
将请求的request注入到属性中,属性必须是HttpRequest类型。
@RequestParameter
将url中使用{}包围起来的变量注入到属性中,属性支持java基本类型的自动转换。
- value:url中的变量名
@FieldRenderName
属性的渲染有时会较复杂,不能用已有的注解描述,gecco爬虫支持属性渲染的自定义方式,自定义渲染器实现CustomFieldRender接口,并定义属性渲染器名称。
- value:使用的自定义属性渲染器的名称
HTML渲染器注解说明
@HtmlField
html属性定义,表示该属性是通过html查找解析,在html的渲染器下使用
- cssPath:jquery风格的元素选择器,使用jsoup实现。jsoup在分析html方面提供了极大的便利。计划实现xpath风格的元素选择器。
@Href
表示该字段是一个链接类型的元素,jsoup会默认获取元素的href属性值。属性必须是String类型。
- value:默认获取href属性值,可以多选,按顺序查找
- click:表示是否点击打开,继续让爬虫抓取
@Image
表示该字段是一个图片类型的元素,jsoup会默认获取元素的src属性值。属性必须是String类型。
- value:默认获取src属性值,可以多选,按顺序查找
- download:表示是否需要将图片下载到本地(暂未实现)
@Attr
获取html元素的attribute。属性支持java基本类型的自动转换。
- value:表示属性名称
@Text
获取元素的text或者owntext。属性支持java基本类型的自动转换。
- own:是否获取owntext,默认为是
@Html
默认类型,可以不写,获取html元素的整个节点内容。属性必须是String类型。
@Ajax
html页面上很多元素是通过ajax请求获取,gecco爬虫支持ajax请求。ajax请求会在html的基本元素渲染完成后调用,可以通过[value]获取当前已经渲染完成的属性值,通过{value}方式获取request的属性值。
- url:ajax请求地址,如:http://p.3.cn/prices/mgets?skuIds=J[code]或者http://p.3.cn/prices/mgets?skuIds=J{code}
JSON渲染器注解说明
json渲染器采用的fastjson。
@JSONPath
使用fastjson的jsonpath,jsonpath类似是一种对象查询语言,能方便的查询json中个字段的值,详情请查看fastjson-jsonpath
@JSONPath("$.p[0]")
private float price;
Ajax例子
ajax例子请查看源码中的com.geccocrawler.gecco.demo.ajax。
可扩展特性
一、Spider支持下载前后的自定义,实现接口BeforeDownload自定义下载前操作,实现接口AfterDownload自定义下载后操作,通过注解@SpiderName("com.geccocrawler.gecco.demo.MyGithub")关联到某个SpiderBean
二、SpiderBean的属性渲染有时通过注解无法获取需要的数据,比如十分复杂的ajax请求,可以采用自定义属性渲染器的方式,实现接口CustomFieldRender,属性增加注解:@FieldRenderName("CustomFieldRenderName")
三、结合spring开发pipeline
-
实现SpringPipeLineFactory,例如:
@Service public class SpringPipelineFactory implements PipelineFactory, ApplicationContextAware { private ApplicationContext applicationContext; @Override public void setApplicationContext(ApplicationContext applicationContext) throws BeansException { this.applicationContext = applicationContext; } @Override public Pipeline<? extends SpiderBean> getPipeline(String name) { try { Object bean = applicationContext.getBean(name); if(bean instanceof Pipeline) { return (Pipeline<? extends SpiderBean>)bean; } } catch(NoSuchBeanDefinitionException ex) { System.out.println("no such pipeline : " + name); } return null; } } -
并在GeccoEngine中设置
@Resource(name="springPipelineFactory") private PipelineFactory springPipelineFactory; GeccoEngine.create().pipelineFactory(springPipelineFactory)... -
在SpiderBean中引起SpringBean的pipeline的方式和之前没有区别
@Service SpringPipeline impelments Pipeline... @Gecco(matchUrl="...", pipelines="springPipeline") TestSpiderBean implemnets HtmlBean...



相关推荐
《深入理解gecco:易用轻量级网络爬虫的奥秘》 在当今的互联网时代,数据挖掘和信息分析的重要性日益凸显,而网络爬虫作为获取这些数据的关键工具,其重要性不言而喻。这里我们要探讨的是“gecco”,一个被标记为...
随着深度学习技术的不断进步和应用场景的不断拓展,轻量级神经网络的设计和优化仍然是一个活跃的研究领域。未来的研究方向可能会集中在如何在保证性能的同时进一步降低模型的复杂度,以及如何在不同的硬件平台上实现...
Python Web轻量级框架,如Web.py,是用于构建高效、简洁且易于维护的Web应用程序的工具。在Python的世界里,有许多这样的框架可供选择,但Web.py因其小巧、灵活和强大的特性而备受开发者喜爱。本教程将深入探讨Web....
本文将深入探讨基于分布式配置中心配置限流参数的Redis轻量级分布式限流组件——lightweight-rate-limiter。该组件旨在帮助开发者实现高效、灵活的限流策略,确保服务的稳定性和性能。 一、限流概念与重要性 限流...
轻量级贪婪分层训练神经网络的这些特性使其成为解决资源受限环境下的深度学习问题的一个有力工具,也使得它在学术研究和工业应用中具有潜在的广泛适用性。随着深度学习技术的不断进步和应用领域的不断拓展,这种神经...
KeePass Password Safe is a free, open source, lightweight, and easy-to-use password manager for Windows, Linux and Mac OS X, with ports for Android, iPhone/iPad and other mobile devices. With so many ...
《轻量级人体姿态估计:深度学习在骨骼点检测中的应用》 在现代科技领域,人工智能(AI)的发展正以前所未有的速度推动着各个行业的变革。其中,深度学习作为AI的重要分支,已经在图像处理、自然语言处理以及计算机...
《Java Web轻量级开发面试教程》是一本专注于Java Web轻量级开发面试知识的书籍,其源代码资料通常包含了用于演示和学习的Java Web项目。这些代码项目往往采用了轻量级的框架和技术,例如Spring框架中的Spring MVC和...
该压缩包文件包含了一个基于深度学习的无场景约束全自动车牌识别系统,主要采用了4种轻量级深度卷积网络(Lightweight Deep Convolutional Neural Networks, 简称LCNNs)来实现高效的车牌检测与识别。源码的实现语言...
ALIKE 是一种高效的关键点检测和描述符提取算法,其特点是具有高准确性和轻量级网络架构。下面是对 ALIKE 的详细介绍: 关键点检测 传统的 Non-Maximum-Suppression (NMS) 算法通过选择局部分数最高的像素作为关键...
针对这两个问题,现代UNIX变体系统引入了一系列改进措施,其中最重要的是**线程**和**轻量级进程**(Lightweight Process, LWP)的概念和技术。本篇将深入探讨这两种机制的基本原理、实现细节及其优势与不足。 ####...
文件名为"LSR.ORM"可能是一个具体的ORM框架或者库,其名称暗示了它可能是"Lightweight Simple ORM"的缩写,设计目标是提供一个简单、轻量级的.NET ORM解决方案。关于LSR.ORM,我们可以推测它可能包含以下组件或特性...
轻量级卷积神经网络(Lightweight Convolutional Neural Network)是一种特殊的CNN结构,旨在减少计算复杂度和存储空间的占用。轻量级CNN 通常使用 depthwise separable convolution、channel shuffle 和 group ...
Java轻量级ORM框架是Java开发中的一个重要工具,它简化了数据库操作,使得开发者可以更加专注于业务逻辑,而不是繁琐的数据访问代码。ORM(Object-Relational Mapping)框架将对象模型与关系数据库模型进行映射,...
总结:基于μC/OS-II的轻量级嵌入式WEB服务器设计结合了嵌入式操作系统、轻量级网络协议栈和文件系统,通过CGI实现了动态页面服务,为工业测控领域的低成本远程监控提供了有效解决方案。该技术的发展预示着未来远程...
该系统通过一系列关键技术实现了一个高效、轻量级的3D模型展示方案。 1. **模型后端预处理**: - 为了减轻前端负担,系统首先在后端对大模型进行聚类和分割。这一过程是基于层次包围盒(Hierarchy Bounding Box)...
GenHTTP Web服务器GenHTTP是用纯C#编写的轻量级Web服务器,对第三方库的依赖性很小。 该项目的主要目的是为.NET编写的小型Web应用程序和Web服务提供服务,使开发人员可以专注于功能而不是处理基础结构。 例如,该...
针对这一问题,作者提出了一种名为LPM(Lightweight Prediction Mechanism)的轻量级预测机制,该机制利用卡尔曼滤波算法来建立QoS状态转换模型,从而实现对QoS的高效预测。 卡尔曼滤波是一种在存在噪声情况下进行...
这两个路径的输出随后被融合,从而在保持网络轻量化的同时增强语义分割的性能。 在Python环境中,LEDNet的实现通常依赖于深度学习框架,如TensorFlow或PyTorch。开发人员可以利用这些框架提供的工具,如数据预处理...