
转自:http://www.blogjava.net/hello-yun/archive/2012/10/10/389289.html
 
MurmurHashτ«Ýµ│þ∩╝ÜΘ½ýΦ┐Éτ«ÝµÇÚΦâ╜∩╝ðΣ╜Äτó░µÆ₧τÄç∩╝ðτö▒Austin Applebyσêøσ╗║Σ║Ä2008σ╣┤∩╝ðτÄ░σ╖▓σ║öτö¿σê░HadoopπÇülibstdc++πÇünginxπÇülibmemcachedτ¡ëσ╝ǵ║Éτ│╗τ╗ƒπÇé2011σ╣┤ApplebyΦó½GoogleΘøçΣ╜ú∩╝ðΘÜÅσÉÄGoogleµÄ¿σç║σà╢σÅýτÚÞτÜäCityHashτ«Ýµ│þπÇé
 
Σ╕ÇΦç┤µÇÚσôêσ╕ðτ«Ýµ│þµý»σêåσ╕âσ╝Åτ│╗τ╗ƒΣ╕¡σ╕╕τö¿τÜäτ«Ýµ│þπÇéµ»öσÓé∩╝ðΣ╕ÇΣ╕¬σêåσ╕âσ╝ÅτÜäσ¡ýσé¿τ│╗τ╗ƒ∩╝ðΦÓüσ░åµþ░µÞ«σ¡ýσé¿σê░σà╖Σ╜ôτÜäΦèéτé╣Σ╕è∩╝ðσÓéµ₧£Θççτö¿µÖ«ΘÇÜτÜähashµû╣µ│þ∩╝ðσ░åµþ░µÞ«µýáσ░äσê░σà╖Σ╜ôτÜäΦèéτé╣Σ╕è∩╝ðσÓékey%N∩╝ðkeyµý»µþ░µÞ«τÜäkey∩╝ðNµý»µ£║σÖ¿Φèéτé╣µþ░∩╝ðσÓéµ₧£µ£ëΣ╕ÇΣ╕¬µ£║σÖ¿σèáσà͵êûΘÇÇσç║Φ┐ÖΣ╕¬Θøåτ╛Á∩╝ðσêÖµëǵ£ëτÜäµþ░µÞ«µýáσ░äΘâ╜µÝáµþêΣ║å∩╝ðσÓéµ₧£µý»µðüΣ╣àσðûσ¡ýσé¿σêÖΦÓüσüܵþ░µÞ«Φ┐üτÚ╗∩╝ðσÓéµ₧£µý»σêåσ╕âσ╝Åτ╝ôσ¡ý∩╝ðσêÖσà╢Σ╗ûτ╝ôσ¡ýσ░▒σÁ▒µþêΣ║åπÇé
┬á ┬á σøᵡÁ∩╝ðσ╝þσàÍΣ║åΣ╕ÇΦç┤µÇÚσôêσ╕ðτ«Ýµ│þ∩╝Ü
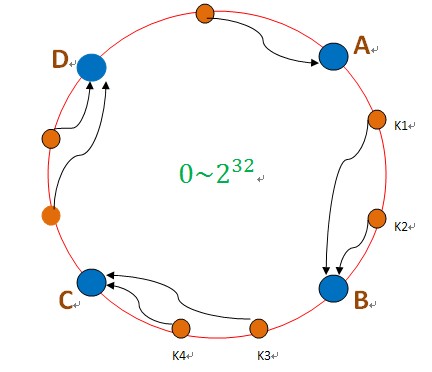
 
µèèµþ░µÞ«τö¿hashσç╜µþ░∩╝êσÓéMD5∩╝ë∩╝ðµýáσ░äσê░Σ╕ÇΣ╕¬σ╛êσÁÚτÜäτ⌐║ΘÝ┤Θçð∩╝ðσÓéσø╛µëÇτÁ║πÇéµþ░µÞ«τÜäσ¡ýσ鿵Ý╢∩╝ðσàêσ╛Ýσê░Σ╕ÇΣ╕¬hashσÇ╝∩╝ðσ»╣σ║öσê░Φ┐ÖΣ╕¬τÄ»Σ╕¡τÜäµ»ÅΣ╕¬Σ╜Þτ╜«∩╝ðσÓék1σ»╣σ║öσê░Σ║åσø╛Σ╕¡µëÇτÁ║τÜäΣ╜Þτ╜«∩╝ðτä╢σÉĵ▓┐Θí║µÝ╢ΘÆêµë╛σê░Σ╕ÇΣ╕¬µ£║σÖ¿Φèéτé╣B∩╝ðσ░åk1σ¡ýσé¿σê░BΦ┐ÖΣ╕¬Φèéτé╣Σ╕¡πÇé
σÓéµ₧£BΦèéτé╣σ«þµ£║Σ║å∩╝ðσêÖBΣ╕èτÜäµþ░µÞ«σ░▒Σ╝ÜΦÉ╜σê░CΦèéτé╣Σ╕è∩╝ðσÓéΣ╕Ðσø╛µëÇτÁ║∩╝Ü
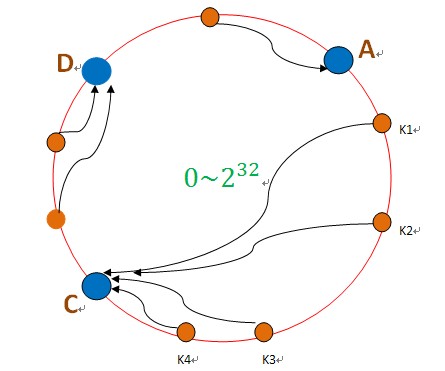
 
Φ┐Öµá╖∩╝ðσŬΣ╝Üσ╜▒σôÞCΦèéτé╣∩╝ðσ»╣σà╢Σ╗ûτÜäΦèéτé╣A∩╝ðDτÜäµþ░µÞ«Σ╕ÞΣ╝ÜΘÇáµêÉσ╜▒σôÞπÇéτä╢ΦÇð∩╝ðΦ┐ÖσÅêΣ╝ÜΘÇáµêÉΣ╕ÇΣ╕¬ΓÇ£Θø¬σ┤⌐ΓÇØτÜäµâàσå╡∩╝ðσÞ│CΦèéτé╣τö▒Σ║ĵë┐µÐàΣ║åBΦèéτé╣τÜäµþ░µÞ«∩╝ðµëÇΣ╗ÍCΦèéτé╣τÜäΦ┤ƒΦ╜╜Σ╝ÜσÅýΘ½ý∩╝ðCΦèéτé╣σ╛êσ«╣µýôΣ╣ƒσ«þµ£║∩╝ðΦ┐Öµá╖Σ╛ص¼íΣ╕ÐσÄ╗∩╝ðΦ┐Öµá╖ΘÇáµêɵþ┤Σ╕¬Θøåτ╛ÁΘâ╜µðéΣ║åπÇé
┬á┬á┬á┬á┬á┬á Σ╕║µ¡Á∩╝ðσ╝þσàÍΣ║åΓÇ£ΦÖܵЃΦèéτé╣ΓÇØτÜäµÓéσ┐╡∩╝ÜσÞ│µèèµâ│Φ▒íσ£¿Φ┐ÖΣ╕¬τÄ»Σ╕èµ£ëσ╛êσÁÜΓÇ£ΦÖܵЃΦèéτé╣ΓÇØ∩╝ðµþ░µÞ«τÜäσ¡ýσ鿵ý»µ▓┐τØÇτÄ»τÜäΘí║µÝ╢ΘÆêµû╣σÉæµë╛Σ╕ÇΣ╕¬ΦÖܵЃΦèéτé╣∩╝ðµ»ÅΣ╕¬ΦÖܵЃΦèéτé╣Θâ╜Σ╝Üσà│Φüöσê░Σ╕ÇΣ╕¬τ£ƒσ«₧Φèéτé╣∩╝ðσÓéΣ╕Ðσø╛µëÇΣ╜┐τö¿∩╝Ü
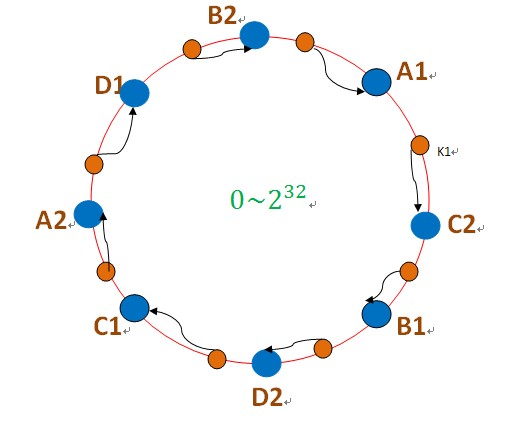
σø╛Σ╕¡τÜäA1πÇüA2πÇüB1πÇüB2πÇüC1πÇüC2πÇüD1πÇüD2Θâ╜µý»ΦÖܵЃΦèéτé╣∩╝ðµ£║σÖ¿AΦ┤ƒΦ╜╜σ¡ýσé¿A1πÇüA2τÜäµþ░µÞ«∩╝ðµ£║σÖ¿BΦ┤ƒΦ╜╜σ¡ýσé¿B1πÇüB2τÜäµþ░µÞ«∩╝ðµ£║σÖ¿CΦ┤ƒΦ╜╜σ¡ýσé¿C1πÇüC2τÜäµþ░µÞ«πÇéτö▒Σ║ÄΦ┐ÖΣ║øΦÖܵЃΦèéτé╣µþ░ΘçÅσ╛êσÁÜ∩╝ðσØçσðÇσêåσ╕â∩╝ðσøᵡÁΣ╕ÞΣ╝ÜΘÇáµêÉΓÇ£Θø¬σ┤⌐ΓÇØτÄ░Φ▒íπÇé
 
- public┬áclass┬áShard<S>┬á{┬á//┬áSτ▒╗σ░üΦúàΣ║åµ£║σÖ¿Φèéτé╣τÜäΣ┐íµü»┬á∩╝ðσÓénameπÇüpasswordπÇüipπÇüportτ¡ë┬á┬á┬á
-   
- ┬á┬á┬á┬áprivate┬áTreeMap<Long,┬áS>┬ánodes;┬á//┬áΦÖܵЃΦèéτé╣┬á┬á┬á
-     private List<S> shards; // 真实机器节点   
- ┬á┬á┬á┬áprivate┬áfinal┬áint┬áNODE_NUM┬á=┬á100;┬á//┬áµ»ÅΣ╕¬µ£║σÖ¿Φèéτé╣σà│ΦüöτÜäΦÖܵЃΦèéτé╣Σ╕¬µþ░┬á┬á┬á
-   
-     public Shard(List<S> shards) {  
-         super();  
-         this.shards = shards;  
-         init();  
-     }  
-   
- ┬á┬á┬á┬áprivate┬ávoid┬áinit()┬á{┬á//┬áσêØσÚÐσðûΣ╕ÇΦç┤µÇÚhashτÄ»┬á┬á┬á
-         nodes = new TreeMap<Long, S>();  
- ┬á┬á┬á┬á┬á┬á┬á┬áfor┬á(int┬ái┬á=┬á0;┬ái┬á!=┬áshards.size();┬á++i)┬á{┬á//┬áµ»ÅΣ╕¬τ£ƒσ«₧µ£║σÖ¿Φèéτé╣Θâ╜Θ£ÇΦÓüσà│ΦüöΦÖܵЃΦèéτé╣┬á┬á┬á
-             final S shardInfo = shards.get(i);  
-   
-             for (int n = 0; n < NODE_NUM; n++)  
- ┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á┬á//┬áΣ╕ÇΣ╕¬τ£ƒσ«₧µ£║σÖ¿Φèéτé╣σà│ΦüöNODE_NUMΣ╕¬ΦÖܵЃΦèéτé╣┬á┬á┬á
-                 nodes.put(hash("SHARD-" + i + "-NODE-" + n), shardInfo);  
-   
-         }  
-     }  
-   
-     public S getShardInfo(String key) {  
- ┬á┬á┬á┬á┬á┬á┬á┬áSortedMap<Long,┬áS>┬átail┬á=┬ánodes.tailMap(hash(key));┬á//┬áµ▓┐τÄ»τÜäΘí║µÝ╢ΘÆêµë╛σê░Σ╕ÇΣ╕¬ΦÖܵЃΦèéτé╣┬á┬á┬á
-         if (tail.size() == 0) {  
-             return nodes.get(nodes.firstKey());  
-         }  
- ┬á┬á┬á┬á┬á┬á┬á┬áreturn┬átail.get(tail.firstKey());┬á//┬áΦ┐öσø₧Φ»ÍΦÖܵЃΦèéτé╣σ»╣σ║öτÜäτ£ƒσ«₧µ£║σÖ¿Φèéτé╣τÜäΣ┐íµü»┬á┬á┬á
-     }  
-   
-     /** 
- ┬á┬á┬á┬á┬á*┬á┬áMurMurHashτ«Ýµ│þ∩╝ðµý»ΘØ₧σèáσ»åHASHτ«Ýµ│þ∩╝ðµÇÚΦâ╜σ╛êΘ½ý∩╝ð┬á
- ┬á┬á┬á┬á┬á*┬á┬áµ»öΣ╝áτ╗ƒτÜäCRC32,MD5∩╝ðSHA-1∩╝êΦ┐ÖΣ╕ÁΣ╕¬τ«Ýµ│þΘâ╜µý»σèáσ»åHASHτ«Ýµ│þ∩╝ðσÁÞµØéσ║Óµ£¼Φ║½σ░▒σ╛êΘ½ý∩╝ðσ╕ÓµØÍτÜäµÇÚΦâ╜Σ╕èτÜäµÞƒσ«│Σ╣ƒΣ╕ÞσÅ»Θü┐σàÞ∩╝ë┬á
- ┬á┬á┬á┬á┬á*┬á┬áτ¡ëHASHτ«Ýµ│þΦÓüσ┐½σ╛êσÁÜ∩╝ðΦÇðΣ╕öµÞ«Φ»┤Φ┐ÖΣ╕¬τ«Ýµ│þτÜäτó░µÆ₧τÄçσ╛êΣ╜Ä.┬á
-      *  http://murmurhash.googlepages.com/ 
-      */  
-     private Long hash(String key) {  
-           
-         ByteBuffer buf = ByteBuffer.wrap(key.getBytes());  
-         int seed = 0x1234ABCD;  
-           
-         ByteOrder byteOrder = buf.order();  
-         buf.order(ByteOrder.LITTLE_ENDIAN);  
-   
-         long m = 0xc6a4a7935bd1e995L;  
-         int r = 47;  
-   
-         long h = seed ^ (buf.remaining() * m);  
-   
-         long k;  
-         while (buf.remaining() >= 8) {  
-             k = buf.getLong();  
-   
-             k *= m;  
-             k ^= k >>> r;  
-             k *= m;  
-   
-             h ^= k;  
-             h *= m;  
-         }  
-   
-         if (buf.remaining() > 0) {  
-             ByteBuffer finish = ByteBuffer.allocate(8).order(  
-                     ByteOrder.LITTLE_ENDIAN);  
-             // for big-endian version, do this first:   
-             // finish.position(8-buf.remaining());   
-             finish.put(buf).rewind();  
-             h ^= finish.getLong();  
-             h *= m;  
-         }  
-   
-         h ^= h >>> r;  
-         h *= m;  
-         h ^= h >>> r;  
-   
-         buf.order(byteOrder);  
-         return h;  
-     }  
-   
- }  



τø╕σà│µÄ¿ΦÞÉ
MurmurHashτ«Ýµ│þτö▒Austin Applebyσêøσ╗║Σ║Ä2008σ╣┤∩╝ðτÄ░σ╖▓σ║öτö¿σê░HadoopπÇülibstdc πÇünginxπÇülibmemcached,Redis∩╝ðMemcached∩╝ðCassandra∩╝ðHBase∩╝ðLuceneτ¡ëσ╝ǵ║Éτ│╗τ╗ƒπÇé2011σ╣┤ApplebyΦó½GoogleΘøçΣ╜ú∩╝ðΘÜÅσÉÄGoogleµÄ¿σç║σà╢σÅýτÚÞτÜä...
σåàσ«╣µÓéΦÓü∩╝ܵèÍσæèτö▒Σ╕¡σø╜Σ┐íµü»ΘÇÜΣ┐íτáöτ⌐╢ΘÖóσÅæσ╕â∩╝ðµÝ¿σ£¿Φ»äΣ╝░σê╢ΘÇáΣ╕ÜΣ╕èσ╕éσà¼σÅ╕Θ½ýΦ┤¿ΘçÅσÅæσ▒þ∩╝ðσ╝║Φ░âσê╢ΘÇáΣ╕ÜΘ½ýΦ┤¿ΘçÅσÅæσ▒þτÜäΘçÞΦÓüµÇÚ∩╝ðσ╣╢µ₧äσ╗║Σ║åµ╢╡τøûσêøµû░σèøπÇüτ½₧Σ║ëσèøπÇüσ╜▒σôÞσèøπÇüΦ┤íτð«σèøσøøσÁÚτ╗┤σ║ÓτÜäΦ»äΣ╗╖Σ╜ôτ│╗πÇéΘÇÜΦ┐çσ»╣3500Σ╜Öσ«╢σê╢ΘÇáΣ╕ÜΣ╕èσ╕éσà¼σÅ╕2022σ╣┤σ╣┤µè͵þ░µÞ«τÜäτ╗╝σÉêΦ»äΣ╝░∩╝ðΦ»äΘÇëσç║τÖ╛σ╝║Σ╝üΣ╕ÜπÇéτáöτ⌐╢µý╛τÁ║∩╝ðτÖ╛σ╝║Σ╝üΣ╕ÜΣ╕ôµ│¿Σ╕╗Σ╕Ü∩╝ðσÞèµþ░Σ╗ÍΣ╕èµêÉΘþ┐Σ╕║σê╢ΘÇáΣ╕ÜσÞþΘí╣σåáσåø∩╝øµ░æΦÉÍΣ╝üΣ╕Üσ£¿τøêσê⌐µþêτÄçπÇüσêøµû░σÅæσ▒þµû╣ΘØóΦí¿τÄ░Σ╝ýσ╝é∩╝øΣ╕£Θâ¿σ£░σð║σ╝þΘóåσÅæσ▒þ∩╝ðΦúàσÁçσê╢ΘÇáΣ╕ÜΘóåσàê∩╝ðµû░Φâ╜µ║ÉΣ║ÚΣ╕ÜσæêτÄ░τêåσÅæµÇÚσó₧Θþ┐πÇéτÖ╛σ╝║Σ╝üΣ╕Üσ£¿τÚæµèÇσêøµû░πÇüΦ┤¿µþêµÅÉσÞçπÇüµðüτ╗¡σó₧Θþ┐πÇüτ¿│σ«Üσ░▒Σ╕Üτ¡ëµû╣ΘØóσÅæµðÍΘçÞΦÓüΣ╜£τö¿∩╝ðΣ╜åΣ╣ƒσ¡ýσ£¿σôüτëðσ╗║Φ«╛σÆðσêøµû░µ░┤σ╣│σ╖«Φ╖ØπÇüΘóåσåøΣ╝üΣ╕Üτ½₧Σ║ëσèøµÅÉσÞçτ⌐║ΘÝ┤πÇüΘ½ýτ½»ΘóåσƒƒΘ╛ÖσÁ┤Σ╝üΣ╕Üσƒ╣Φé▓Σ╕ÞΦ╢│τ¡ëΘÝ«ΘóýπÇé ΘÇéτö¿Σ║║τ╛Á∩╝Üσê╢ΘÇáΣ╕ÜΣ╝üΣ╕Üτ«íτÉåΦÇàπÇüµö┐τ¡ûσê╢σ«ÜΦÇàπÇüµèþΦ╡äΦÇàσÅèτø╕σà│τáöτ⌐╢Σ║║σæýπÇé Σ╜┐τö¿σ£║µÖ»σÅèτø«µáç∩╝ÜΓæáσ╕«σè⌐Σ╝üΣ╕Üτ«íτÉåΦÇàΣ║åΦÚúΦíðΣ╕ÜσÅæσ▒þΦ╢Ðσè┐∩╝ðµÅÉσÞçΣ╝üΣ╕Üτ½₧Σ║ëσèø∩╝øΓæíΣ╕║µö┐τ¡ûσê╢σ«ÜΦÇàµÅÉΣ╛øσå│τ¡ûσÅéΦÇâ∩╝ðµÄ¿σè¿σê╢ΘÇáΣ╕ÜΘ½ýΦ┤¿ΘçÅσÅæσ▒þ∩╝øΓæóΣ╕║µèþΦ╡äΦÇàµÅÉΣ╛øµèþΦ╡äσÅéΦÇâ∩╝ðΦ»åσê½Σ╝ýΦ┤¿Σ╝üΣ╕Ü∩╝øΓæúΣ╕║τáöτ⌐╢Σ║║σæýµÅÉΣ╛øΦ»Óσ«₧µþ░µÞ«∩╝ðσè⌐σèøσ¡Óµ£»τáöτ⌐╢πÇé σà╢Σ╗ûΦ»┤µýÄ∩╝ܵèÍσæèσ╗║Φ««Σ╗ÄΘçÞτ¬üτá┤Σ┐âσÞçτ║ÚπÇüΘçÞσêøµû░ΦíÍτƒ¡µØ┐πÇüΘçÞΦ┤¿ΘçŵáæσôüτëðΣ╕ëΣ╕¬µû╣ΘØóΦ┐øΣ╕ǵ¡ÍµÄ¿Φ┐øσê╢ΘÇáΣ╕ÜΣ╝üΣ╕ÜΘ½ýΦ┤¿ΘçÅσÅæσ▒þ∩╝ðΣ╗Íσèáσ┐½σ╗║Φ«╛σà╖µ£ëσà¿τÉâτ½₧Σ║ëσèøτÜäΣ╕ǵ╡üΣ╝üΣ╕ÜπÇé
σåàσ«╣µÓéΦÓü∩╝ܵ£¼µûçΦ»Óτ╗åΣ╗Ðτ╗ÞΣ║åσ╝鵡Íτö╡µ£║µÝáµäƒτƒóΘçŵÄÚσê╢Σ╗┐τ£ƒτÜäσà│Θö«µèǵ£»Σ╕Äσ╕╕ΦÚüΘÝ«ΘóýΦÚúσå│µû╣µíêπÇéΘÓûσàêΦ«¿Φ«║Σ║åσØɵáçσÅýµÞó∩╝êClarkeσÆðParkσÅýµÞó∩╝ëτÜäσƒ║τíǵôÞΣ╜£σÅèσà╢µ│¿µäÅΣ║ÐΘí╣∩╝ðσ╝║Φ░âΣ║嵡úτí«ΘÇëµÐ⌐τ│╗µþ░τÜäΘçÞΦÓüµÇÚπÇéµÄÍΣ╕еØ͵╖▒σà͵ÄóΦ«¿Σ║åµ╗浿íΦÚéµ╡ÐσÖ¿τÜäΦ«╛Φ«íΣ╕ÄΣ╝ýσðûµû╣µ│þ∩╝ðσðàµÐ¼Σ╜┐τö¿µƒÍΦí¿µ│þµø┐Σ╗úΣ╕ëΦÚÆσç╜µþ░Φ«íτ«ÝΣ╗͵ÅÉΘ½ýµþêτÄç∩╝ðΣ╗ÍσÅèσèáσàÍΣ╜ÄΘÇܵ╗Áµ│óσÖ¿σçÅσ░æΘ½ýΘóæµèûµð»πÇ鵡ÁσÁû∩╝ðµûçτ½áΦ┐ýµ╢ëσÅèΣ║åΘǃσ║ÓΣ╝░τ«ÝτÜäµû╣µ│þ∩╝ðσÓéΘóæ󃃵│þσÆðµö╣Φ┐øσ₧е╗浿íΦÚéµ╡ÐσÖ¿τÜäσ║öτö¿∩╝ðσ╣╢µÅÉΣ╛øΣ║åσà╖Σ╜ôτÜäPythonσÆðMatlabΣ╗úτáüτë絫╡πÇéµ£ÇσÉÄ∩╝ðΘÆêσ»╣τö╡µ╡üτÄ»µÄÚσê╢µÅÉσç║Σ║åσëÞΘÓêΦíÍσü┐µ£║σê╢∩╝ðτí«Σ┐Øσ£¿τ¬üσèáΦ┤ƒΦ╜╜µâàσå╡Σ╕ÐΣ╗ÞΦâ╜Σ┐صðüΦë»σÍ╜τÜäτö╡µ╡üΦ╖ƒΦ╕¬µþêµ₧£πÇéµûçΣ╕¡σÁܵ¼íµÅÉσê░Φ░âσÅéµèÇσ╖Ú∩╝ðτë╣σê½µý»σ»╣Σ║ÄPIσÅéµþ░τÜäΘÇëµÐ⌐τ╗Öσç║Σ║åσ«₧τö¿σ╗║Φ««πÇé ΘÇéσÉêΣ║║τ╛Á∩╝ÜΣ╗ÄΣ║Ðτö╡µ£║µÄÚσê╢τ│╗τ╗ƒτáöτ⌐╢Σ╕Äσ╝ÇσÅæτÜäµèǵ£»Σ║║σæý∩╝ðσ░Áσà╢µý»σ»╣σ╝鵡Íτö╡µ£║µÝáµäƒτƒóΘçŵÄÚσê╢µäƒσà┤Φ╢úτÜäσ╖Íτ¿Ðσ╕êπÇé Σ╜┐τö¿σ£║µÖ»σÅèτø«µáç∩╝ÜΘÇéτö¿Σ║Äσ╕ðµ£øµ╖▒σàÍΣ║åΦÚúσ╣╢µÄðµÅíσ╝鵡Íτö╡µ£║µÝáµäƒτƒóΘçŵÄÚσê╢Σ╗┐τ£ƒµèǵ£»τÜäτáöτ⌐╢Σ║║σæýσÆðµèǵ£»σ╝ÇσÅæΦÇàπÇéΣ╕╗ΦÓüτø«µáçµý»σ£¿µ▓íµ£ëτ╝ûτáüσÖ¿τÜäµâàσå╡Σ╕Ðσ«₧τÄ░σ»╣τö╡µ£║Φ╜¼ΘǃσÆðµë¡τƒ⌐τÜäτ▓╛τí«µÄÚσê╢∩╝ðσÉðµÝ╢µÅÉΣ╛øΦ»Óτ╗åτÜäΣ╗úτáüσ«₧τÄ░µðçσ»╝σÆðΦ░âΦ»þτ╗ÅΘ¬ðπÇé σà╢Σ╗ûΦ»┤µýÄ∩╝ܵûçτ½áΣ╕ÞΣ╗àµÅÉΣ╛øΣ║åτÉåΦ«║τƒÍΦ»å∩╝ðΦ┐ýσðàµÐ¼σÁÚΘçÅσ«₧ΘÖàµôÞΣ╜£Σ╕¡τÜäτ╗ÅΘ¬ðσÆðµþÖΦ«¡∩╝ðσ╕«σè⌐Φ»╗ΦÇàΘü┐σàÞσ╕╕ΦÚüτÜäΘÖ╖Θý▒∩╝ðσ┐½ΘǃµÉ¡σ╗║Φ╡╖µ£ëµþêτÜäΣ╗┐τ£ƒτÄ»σóâπÇé
# σƒ║Σ║ÄArduinoτÜäτü½τ«¡σè¿σèøσ¡ÓσÅéµþ░τøæµ╡ÐΘí╣τø« ## Θí╣τø«τ«ÇΣ╗Ð Φ┐Öµý»Σ╕ÇΣ╕¬σƒ║Σ║ÄArduinoσ╣│σÅ░τÜäτü½τ«¡σè¿σèøσ¡ÓσÅéµþ░τøæµ╡ÐΘí╣τø«∩╝ðµÝ¿σ£¿ΘÇÜΦ┐çAdafruit BMP280σÄÐσèøΣ╝áµäƒσÖ¿σÆðAdafruit LIS3DHσèáΘǃσ║ÓΣ╝áµäƒσÖ¿µö╢Θøåτü½τ«¡Θú₧ΦíðΦ┐çτ¿ÐΣ╕¡τÜäτÄ»σóâµþ░µÞ«σÆðΦ┐Éσ迵þ░µÞ«πÇéΘí╣τø«τ╗ôσÉêΣ║åAdafruitτÜäBMP280σ║ôσÆðLIS3DHσ║ô∩╝ðσ«₧τÄ░σ»╣Σ╝áµäƒσÖ¿µþ░µÞ«τÜäΦ»╗σÅûπÇüσÁäτÉåσÅèσêص¡Íσêåµ₧ÉπÇé ## Θí╣τø«τÜäΣ╕╗ΦÓüτë╣µÇÚσÆðσèƒΦâ╜ 1. τÄ»σóâµþ░µÞ«τøæµ╡ÐΘÇÜΦ┐çBMP280σÄÐσèøΣ╝áµäƒσÖ¿∩╝ðσ«₧µÝ╢τøæµ╡Ðσ╣╢Φ«░σ╜þτü½τ«¡σæ¿σø┤τÜäµ░öσÄÐπÇüµ╕⌐σ║ÓσÆðµ╡╖µÐöΘ½ýσ║ÓσÅýσðûπÇé 2. Φ┐Éσ迵þ░µÞ«τøæµ╡Ðσǃσè⌐LIS3DHσèáΘǃσ║ÓΣ╝áµäƒσÖ¿∩╝ðΦÄ╖σÅûτü½τ«¡σ£¿Θú₧ΦíðΦ┐çτ¿ÐΣ╕¡τÜäσèáΘǃσ║ÓπÇüΘǃσ║ÓσÅèµû╣σÉæσÅýσðûµþ░µÞ«πÇé 3. µþ░µÞ«σÁäτÉåΣ╕ÄΣ╝áΦ╛ôArduinoΦ┤ƒΦ┤úµö╢ΘøåσÆðσêص¡ÍσÁäτÉåΦ┐ÖΣ║øµþ░µÞ«∩╝ðτä╢σÉÄΘÇÜΦ┐çΣ╕▓ΦíðΘÇÜΣ┐íµêûσà╢Σ╗ûµû╣σ╝Åσ░åµþ░µÞ«σÅæΘÇüσê░σ£░ΘØóτ½ÖµêûΘú₧ΦíðµÄÚσê╢Φ╜»Σ╗╢πÇé 4. σ«ëσà¿Σ╕ÄΦ¡ÓµèÍσƒ║Σ║ĵö╢ΘøåτÜäµþ░µÞ«∩╝ðΘí╣τø«σÅ»Φ«╛τ╜«Φ¡ÓµèÍΘýêσÇ╝∩╝ðσ╜ôΦ╢àΦ┐çΘóäΦ«╛τÜäσ«ëσà¿ΘÖÉσê╢µÝ╢∩╝ðΦÚÓσÅæΦ¡Óµè͵êûΘççσÅûτø╕σ║öτÜäσ«ëσ࿵Ĭµû╜πÇé ## σ«ëΦúàΣ╜┐τö¿µ¡ÍΘ¬Á
# σƒ║Σ║ÄArduinoτÜäEPSleepyµÖ║Φâ╜σ«╢σ▒àµÄÚσê╢τ│╗τ╗ƒ ## Σ╕ÇπÇüΘí╣τø«τ«ÇΣ╗Ð EPSleepyµý»Σ╕ÇΣ╕¬σƒ║Σ║ÄArduinoτÜäµÖ║Φâ╜σ«╢σ▒àµÄÚσê╢τ│╗τ╗ƒσăσ₧ÐπÇéΦ»ÍΘí╣τø«µÝ¿σ£¿ΘÇÜΦ┐çArduinoµÄÚσê╢ESP32 WiFiσÆðΦôØτëÖµØ┐∩╝ðτ╗ôσÉêMP3µ¿íσØÝπÇüshiftregisterσÆðµðëΘÆ«τ¡ëτí¼Σ╗╢∩╝ðσ«₧τÄ░µÖ║Φâ╜σ«╢σ▒àτÜäΦç¬σè¿σðûµÄÚσê╢πÇé ## Σ║ðπÇüΘí╣τø«τÜäΣ╕╗ΦÓüτë╣µÇÚσÆðσèƒΦâ╜ 1. Φç¬σè¿σðûµÄÚσê╢ΘÇÜΦ┐çArduinoΣ╗úτáüµÄÚσê╢ESP32µØ┐∩╝ðσ«₧τÄ░σ«╢σ▒àΦ«╛σÁçτÜäΦç¬σè¿σðûµÄÚσê╢πÇé 2. σÁÜτÚÞτí¼Σ╗╢µö»µðüµö»µðüMP3µ¿íσØÝπÇüshiftregisterσÆðµðëΘÆ«τ¡ëτí¼Σ╗╢∩╝ðσ«₧τÄ░Θƒ│ΘóæµÆ¡µö╛πÇüτü»σàëµÄÚσê╢πÇüSDΘ⌐▒σè¿τ¡ëσèƒΦâ╜πÇé 3. µ¿íσØÝσðûΦ«╛Φ«íΣ╗úτáüΘççτö¿µ¿íσØÝσðûΦ«╛Φ«í∩╝ðµû╣Σ╛┐µ╡ÐΦ»þµ»ÅΣ╕¬Θâ¿σêåτÜäσèƒΦâ╜∩╝ðµû╣Σ╛┐τ╗┤µèÁσÆðΦ░âΦ»þπÇé 4. σø╛σ╜óσðûτþðΘØóσÅ»ΘÇÜΦ┐çµðëΘÆ«σÆðLEDτ¡ëτí¼Σ╗╢Φ┐øΦíðσø╛σ╜óσðûµôÞΣ╜£σÆðµÄÚσê╢πÇé ## Σ╕ëπÇüσ«ëΦúàΣ╜┐τö¿µ¡ÍΘ¬Á 1. Σ╕ÐΦ╜╜σ╣╢ΦÚúσÄÐΘí╣τø«µ║ÉτáüµûçΣ╗╢πÇé 2. µëôσ╝ÇArduino IDE∩╝ðσ»╝σàÍΘí╣τø«Σ╗úτáüπÇé 3. Φ┐₧µÄÍτí¼Σ╗╢∩╝ðσðàµÐ¼ESP32µØ┐πÇüMP3µ¿íσØÝπÇüshiftregisterσÆðµðëΘÆ«τ¡ëπÇé
Delphi 12.3µÄÚΣ╗╢Σ╣ÐPowerPDF for Delphi11 FullSource.zip
σåàσ«╣µÓéΦÓü∩╝ܵ£¼µûçµ╖▒σà͵ÄóΦ«¿Σ║åΣ╕¡σ╛«CMS32M5533σ£¿800WΦÚÆτú¿µ£║µû╣µíêΣ╕¡τÜäσ║öτö¿∩╝ðµ╢╡τøûτí¼Σ╗╢Φ«╛Φ«íσÆðΦ╜»Σ╗╢σ«₧τÄ░τÜäσà│Θö«µèǵ£»πÇéτí¼Σ╗╢µû╣ΘØó∩╝ðΣ╗Ðτ╗ÞΣ║åΣ╕ëτø╕µíÍΘ⌐▒σè¿τö╡Φ╖»πÇüMOSFETΘÇëµÐ⌐πÇüτö╡µ╡üµúǵ╡Ðτö╡Θý╗πÇüPCBσ╕âσ▒Çτ¡ëτ╗åΦèé∩╝øΦ╜»Σ╗╢µû╣ΘØó∩╝ðΘçÞτé╣Φ«▓ΦÚúΣ║åσÅÞτö╡σè¿σè┐µúǵ╡Ðτ«Ýµ│þπÇüADCΘççµá╖µÝ╢µ£║πÇüPWMΘàÞτ╜«Σ╗ÍσÅèµÞóτø╕µÝ╢µ£║τÜäσ迵ÇüΦíÍσü┐πÇ鵡ÁσÁû∩╝ðΦ┐ýµÅÉΣ╛øΣ║åΦ░âΦ»þµèÇσ╖ÚσÆðµêɵ£¼µÄÚσê╢µû╣µ│þπÇé ΘÇéσÉêΣ║║τ╛Á∩╝ÜΣ╗ÄΣ║Ðτö╡σè¿σ╖Íσà╖σ╝ÇσÅæτÜäµèǵ£»Σ║║σæý∩╝ðσ░Áσà╢µý»σ»╣τö╡µ£║µÄÚσê╢µ£ëΣ╕Çσ«Üτ╗ÅΘ¬ðτÜäτáöσÅæΣ║║σæýπÇé Σ╜┐τö¿σ£║µÖ»σÅèτø«µáç∩╝ÜΘÇéτö¿Σ║Äσ╕ðµ£øµ╖▒σàÍΣ║åΦÚúτö╡σè¿σ╖Íσà╖µÄÚσê╢τ│╗τ╗ƒτÜäΦ«╛Φ«íσÆðΣ╝ýσðû∩╝ðτë╣σê½µý»σ╕ðµ£øΘÇÜΦ┐çσÅÞτö╡σè¿σè┐µúǵ╡ÐσçÅσ░æΘ£Þσ░öΣ╝áµäƒσÖ¿Σ╜┐τö¿τÜäσ╝ÇσÅæΦÇàπÇéτø«µáçµý»µÅÉΘ½ýτ│╗τ╗ƒτÜäσÅ»ΘØáµÇÚσÆðµÇÚΦâ╜∩╝ðσÉðµÝ╢ΘÖÞΣ╜ĵêɵ£¼πÇé σà╢Σ╗ûΦ»┤µýÄ∩╝ܵûçΣ╕¡µÅÉΣ╛øτÜäΣ╗úτáüτë絫╡σÆðτí¼Σ╗╢Φ«╛Φ«íτ╗åΦèéµ£ëσè⌐Σ║Äσ«₧ΘÖàΘí╣τø«τÜäσ╝ÇσÅæσÆðΦ░âΦ»þπÇéσ╗║Φ««Φ»╗ΦÇàτ╗ôσÉêµÅÉΣ╛øτÜäGitHubΦ╡äµ║ÉΦ┐øΦíðσ«₧Φ╖╡∩╝ðσ╣╢σà│µ│¿τí¼Σ╗╢ΘÇëσ₧ÐσÆðPCBσ╕âσ▒ÇτÜäµ│¿µäÅΣ║ÐΘí╣πÇé
CEOτÜäτ╗┐Φë▓τ╗ÅσÄåµý»µðçΦ»ÍΘÓûσ╕¡µëÚΦíðσ«ý∩╝êCEO∩╝ëσ£¿σà╢Σ╕¬Σ║║ΦüðΣ╕ÜσÅæσ▒þΦ┐çτ¿ÐΣ╕¡∩╝ðµëÇτÚ»τ┤»τÜäΣ╕ÄτÄ»σóâΣ┐صèÁπÇüσÅ»µðüτ╗¡σÅæσ▒þπÇüτ╗┐Φë▓τ╗ŵ╡Äτ¡ëτø╕σà│τÜäµþÖΦé▓ΦâðµÖ»πÇüσ╖ÍΣ╜£τ╗ÅΘ¬ðµêûτÁ╛Σ╝ܵ┤╗σè¿τ╗ÅΘ¬ðπÇé µ╢╡τøûΣ║åµþÖΦé▓ΦâðµÖ»πÇüσ╖ÍΣ╜£τ╗ÅΘ¬ðπÇüτÁ╛Σ╝ܵ┤╗σè¿Σ╕ÄΣ╕¬Σ║║Σ╗╖σÇ╝ΦÚéτ¡ëσÁÜΣ╕¬µû╣ΘØóπÇéΦ┐ÖΣ║øτ╗ÅσÄåΣ╕ÞΣ╗àσíæΘÇáΣ║åCEOσ»╣τÄ»σóâΣ┐صèÁσÆðσÅ»µðüτ╗¡σÅæσ▒þτÜäΦ«ÁτƒÍσÆðµÇüσ║Ó∩╝ðΦ┐ýσÅ»Φâ╜σ╜▒σôÞΣ╗ûΣ╗¼σ£¿Σ╝üΣ╕Üσå│τ¡ûΣ╕¡Σ╝ýσàêΦÇâΦÖæτÄ»Σ┐Øσøáτ┤áτÜäτ¿Ðσ║Ó∩╝ðΣ╗ÄΦÇðσ»╣Σ╝üΣ╕ÜτÜäΘþ┐µ£ƒσÅæσ▒þσÆðτÄ»σóâΣ┐صèÁΣ║ÚτöƒΘçÞΦÓüσ╜▒σôÞπÇé µá╣µÞ«τÄ░µ£ëτáöτ⌐╢∩╝êσÚ£Σ╗ýτÚÇσÆðΘ╗äτ╗Úµë┐∩╝ð2013∩╝øΦ«╕σ╣┤ΦíðσÆðµØÄσô▓∩╝ð2016∩╝ë∩╝ðΣ╗ÄΘ½ýτ«íΣ╕¬Σ║║τ«ÇσÄåµþ░µÞ«Σ╕¡µƒÍµë╛CEOΣ╗ÍσëÞµý»σÉÓµÄÍσÅÝΦ┐çΓÇ£τ╗┐Φë▓ΓÇØτø╕σà│µþÖΦé▓µêûΣ╗ÄΣ║ÐΦ┐çΓÇ£τ╗┐Φë▓ΓÇØτø╕σà│σ╖ÍΣ╜£∩╝ðΦÐÍΣ╝üΣ╕ÜCEOσà╖µ£ëτ╗┐Φë▓τ╗ÅσÄå∩╝ðGreenσÅûσÇ╝1∩╝ðσÉÓσêÖ∩╝ðσÅûσÇ╝0πÇé µþ░µÞ« StkcdπÇüσ╣┤Σ╗╜πÇüD0801cπÇüGreenπÇüΦéíτÍ¿τ«ÇτÚ░πÇüΦíðΣ╕ÜσÉÞτÚ░πÇüΦíðΣ╕ÜΣ╗úτáüπÇüσê╢ΘÇáΣ╕ÜσÅûΣ╕ÁΣ╜ÞΣ╗úτáü∩╝ðσà╢Σ╗ûΦíðΣ╕Üτö¿σÁÚτ▒╗πÇüσ╜ôσ╣┤STµêûPTΣ╕║1∩╝ðσÉÓσêÖΣ╕║0πÇüµá╖µ£¼σð║ΘÝ┤σåàSTµêûPTΣ╕║1∩╝ðσÉÓσêÖΣ╕║0πÇüΘçæΦ₧ÞΣ╕ÜΣ╕║1∩╝ðσÉÓσêÖΣ╕║0πÇüσê╢ΘÇáΣ╕ÜΣ╕║1∩╝ðσÉÓσêÖΣ╕║0πÇüµ▓¬µ╖▒AΦéíΣ╕║1∩╝ðσÉÓσêÖΣ╕║0πÇüτ¼¼Σ╕ÇτÚÞΘçÞµ▒íµƒôΦíðΣ╕ÜΣ╕║1∩╝ðσÉÓσêÖΣ╕║0πÇüτ¼¼Σ║ðτÚÞΘçÞµ▒íµƒôΦíðΣ╕ÜΣ╕║1∩╝ðσÉÓσêÖΣ╕║0πÇüτ¼¼Σ╕ëτÚÞΘçÞµ▒íµƒôΦíðΣ╕ÜΣ╕║1∩╝ðσÉÓσêÖΣ╕║0πÇüΣ║ÚµØâµÇÚΦ┤¿∩╝ðσø╜Σ╝üΣ╕║1∩╝ðσÉÓσêÖΣ╕║0πÇüµëÇσ▒₧τ£üΣ╗╜Σ╗úτáüπÇüµëÇσ▒₧σƒÄσ╕éΣ╗úτáüπÇüµëÇσ£¿τ£üΣ╗╜πÇüµëÇσ£¿σ£░τ║Úσ╕é
σåàσ«╣µÓéΦÓü∩╝ܵ£¼µûçΦ»Óτ╗åΣ╗Ðτ╗ÞΣ║åσê⌐τö¿COMSOL Multiphysicsσ»╣18650τö╡µ▒áτ╗äΦ┐øΦíðΦøçσ╜óµ╢▓σå╖τ│╗τ╗ƒΣ╗┐τ£ƒτÜäσà¿Φ┐çτ¿ÐπÇéΘÓûσàêµÄóΦ«¿Σ║åσ┐½σààσ£║µÖ»Σ╕Ðτö╡µ▒áΦ┐çτâ¡τÜäΘúÄΘÖ⌐σÅèσà╢σ»╣τö╡σè¿Φ╜Óσ«ëσ࿵ÇÚσÆðσ»┐σæ╜τÜäσ╜▒σôÞπÇéµÄÍτØÇ∩╝ðΘÇÜΦ┐çΘøåµÇ╗τö╡µ▒ᵿíσ₧Ðτ«Çσðûτö╡σðûσ¡ÓσÅÞσ║ö∩╝ðΘçÞτé╣σêåµ₧ÉΣ║åτö╡µ▒áΣ║Úτ⡵û╣τ¿ÐσÆðµ╕⌐σ║Óσ»╣Σ║Úτâ¡τÜäσ╜▒σôÞπÇéΘÜÅσÉÄ∩╝ðµ╖▒σàÍΦ«¿Φ«║Σ║åΦøçσ╜óµ╡üΘüôσçáΣ╜þσÅéµþ░Σ╝ýσðû∩╝ðσÓéµ╡üΘüôσ«╜σ║ÓΣ╕ÄσÄÐΘÖÞΣ╣ÐΘÝ┤τÜäΘØ₧τ║┐µÇÚσà│τ│╗∩╝ðΣ╗ÍσÅèµ╡üσø║Σ║ÁτþðΘØóσÁäτÉåµû╣µ│þπÇ鵡ÁσÁû∩╝ðΦ┐ýµ╢ëσÅèΣ║åσÁÜτë⌐τÉåσ£║ΦÇÓσÉêµ▒éΦÚúµèÇσ╖Ú∩╝ðσðàµÐ¼µ╡üσ£║Σ╕ÄΣ╝áτ⡵¿íσØÝτÜäΦ«╛τ╜«∩╝ðΣ╗ÍσÅèσÉÄσÁäτÉåΘý╢µ«╡τÜäµþ░µÞ«µÅÉσÅûσÆðσÅ»ΦÚåσðûπÇéµ£Çτ╗êσ╛Ýσç║Σ╝ýσðûΦ«╛Φ«íµû╣µíê∩╝ðµý╛ΦæÝΘÖÞΣ╜ÄΣ║åτö╡µ▒áτ╗äτÜäµ£ÇΘ½ýµ╕⌐σ║ÓσÆðµ╕⌐σ║ÓΣ╕ÞσØçµÇÚπÇé ΘÇéσÉêΣ║║τ╛Á∩╝ÜΣ╗ÄΣ║Ðτö╡σ迵▒╜Φ╜Óτö╡µ▒áτ«íτÉåτ│╗τ╗ƒΦ«╛Φ«íτÜäτáöτ⌐╢Σ║║σæýσÆðµèǵ£»σ╖Íτ¿Ðσ╕ê∩╝ðσ░Áσà╢µý»τ僵éëCOMSOLΣ╗┐τ£ƒσ╖Íσà╖τÜäΣ╕ôΣ╕ÜΣ║║σú½πÇé Σ╜┐τö¿σ£║µÖ»σÅèτø«µáç∩╝ÜΘÇéτö¿Σ║ÄΘ£ÇΦÓüΦ»äΣ╝░σÆðΣ╝ýσðûτö╡σ迵▒╜Φ╜Óτö╡µ▒áτ╗äτâ¡τ«íτÉåτ│╗τ╗ƒτÜäσ£║σÉê∩╝ðµÝ¿σ£¿µÅÉΘ½ýτö╡µ▒áτ╗äτÜäσ«ëσ࿵ÇÚσÆðΣ╜┐τö¿σ»┐σæ╜∩╝ðσÉðµÝ╢σçÅσ░æΦâ╜ΘçŵރΦÇÝπÇé σà╢Σ╗ûΦ»┤µýÄ∩╝ܵûçΣ╕¡µÅÉΣ╛øΣ║åσÁÚΘçÅσà╖Σ╜ôτÜäΣ╗úτáüτë絫╡σÆðσÅéµþ░Φ«╛τ╜«σ╗║Φ««∩╝ðµ£ëσè⌐Σ║ÄΦ»╗ΦÇàσ┐½ΘǃΣ╕èµëÐσ╣╢σ║öτö¿Σ║Äσ«₧ΘÖàσ╖Íτ¿ÐΘí╣τø«Σ╕¡πÇé
σåàσ«╣µÓéΦÓü∩╝ܵ£¼µûçΦ»Óτ╗åΣ╗Ðτ╗ÞΣ║åCCSDS LDPCΦ»æτáüσÖ¿τÜäΦ«╛Φ«íΣ╕Äσ«₧τÄ░∩╝ðΣ╕╗ΦÓüΘççτö¿Σ║åΣ┐«µ¡úµ£Çσ░ÅσÆðΦ»æτáüτ«Ýµ│þπÇéΦ»Íτ«Ýµ│þΘÇÜΦ┐çσ»╣Σ╝áτ╗ƒµ£Çσ░ÅσÆðτ«Ýµ│þτÜäµö╣Φ┐ø∩╝ðσ╝þσàÍτ╝⌐µö╛σøáσ¡É╬▒∩╝ðµÅÉΘ½ýΣ║åΦ»æτáüµÇÚΦâ╜πÇéµûçΣ╕¡σà╖Σ╜ôΦ«¿Φ«║Σ║å∩╝ê8176,7154∩╝ëσÆð∩╝ê1280,1024∩╝ëΣ╕ÁτÚÞτáüτ╗äτÜäσ║öτö¿σ£║µÖ»σÅèσà╢Σ╝ýσèú∩╝ðσ╣╢σ▒þτÁ║Σ║åσÓéΣ╜þΘÇÜΦ┐çCΦ»¡Φ¿ÇσÆðVivadoΦ┐øΦíðΣ╗┐τ£ƒσÆðτí¼Σ╗╢σ«₧τÄ░πÇ鵡ÁσÁû∩╝ðµûçτ½áΦ┐ýµÄóΦ«¿Σ║åτí¼Σ╗╢σ«₧τÄ░Σ╕¡τÜäσà│Θö«µèǵ£»∩╝ðσÓéσ«Üτé╣σðûσÁäτÉåπÇüµáíΘ¬ðτƒ⌐Θý╡τÜäσÄÐτ╝⌐σ¡ýσé¿πÇüσ迵ÇüΘýêσÇ╝µ£║σê╢Σ╗ÍσÅèτí¼Σ╗╢µ╡üµ░┤τ║┐Φ«╛Φ«íτ¡ëπÇé ΘÇéσÉêΣ║║τ╛Á∩╝ÜΣ╗ÄΣ║ÐΘÇÜΣ┐íτ│╗τ╗ƒσ╝ÇσÅæτÜäτáöτ⌐╢Σ║║σæýσÆðµèǵ£»Σ║║σæý∩╝ðσ░Áσà╢µý»σ»╣LDPCτ╝ûτáüσÆðΦ»æτáüµäƒσà┤Φ╢úτÜäσ╖Íτ¿Ðσ╕êπÇé Σ╜┐τö¿σ£║µÖ»σÅèτø«µáç∩╝ÜΓæáσ╕«σè⌐τáöτ⌐╢Σ║║σæýτÉåΦÚúσÆðσ«₧τÄ░CCSDS LDPCΦ»æτáüσÖ¿∩╝øΓæíΣ╕║σ«₧ΘÖàσ╖Íτ¿ÐΘí╣τø«µÅÉΣ╛øΘ½ýµþêτÜäΦ»æτáüΦÚúσå│µû╣µíê∩╝øΓæóµÅÉΘ½ýΦ»æτáüµÇÚΦâ╜∩╝ðσçÅσ░æΦ»»τáüτÄç∩╝ðµÅÉσÞçΘÇÜΣ┐íτ│╗τ╗ƒτÜäσÅ»ΘØáµÇÚσÆðµþêτÄçπÇé σà╢Σ╗ûΦ»┤µýÄ∩╝ܵûçτ½áΣ╕ÞΣ╗àµÅÉΣ╛øΣ║åτÉåΦ«║σêåµ₧É∩╝ðΦ┐ýσðàµÐ¼Σ║åσÁÚΘçÅτÜäΣ╗úτáüτÁ║Σ╛ÐσÆðσ«₧Φ╖╡τ╗ÅΘ¬ðσêåΣ║½∩╝ðµ£ëσè⌐Σ║ÄΦ»╗ΦÇàσà¿ΘØóµÄðµÅíCCSDS LDPCΦ»æτáüσÖ¿τÜäΦ«╛Φ«íΣ╕Äσ«₧τÄ░πÇé
# σƒ║Σ║ÄArduinoτÜäΦ╢àσú░µ│óΦ╖ØτÓ╗µ╡ÐΘçÅτ│╗τ╗ƒ ## Θí╣τø«τ«ÇΣ╗Ð µ£¼Θí╣τø«µý»Σ╕ÇΣ╕¬σƒ║Σ║ÄArduinoσ╣│σÅ░τÜäΦ╢àσú░µ│óΦ╖ØτÓ╗µ╡ÐΘçÅτ│╗τ╗ƒπÇéτ│╗τ╗ƒσðàσɽσøøΣ╕¬Φ╢àσú░µ│óΣ╝áµäƒσÖ¿∩╝êSPS∩╝뵿íσØÝ∩╝ðτö¿Σ║ĵ╡ÐΘçÅΣ╕ÄσëÞµû╣Σ╕ÞσÉðµû╣σÉæτë⌐Σ╜ôτÜäΦ╖ØτÓ╗∩╝ðσ╣╢ΘÇÜΦ┐çΦ£éΘ╕úσÖ¿∩╝êBuzz∩╝뵿íσØݵá╣µÞ«Φ╖ØτÓ╗Φðâσø┤τ╗Öσç║Σ╕ÞσÉðτÜäσÅÞσ║öπÇé ## Θí╣τø«τÜäΣ╕╗ΦÓüτë╣µÇÚσÆðσèƒΦâ╜ 1. Φ╢àσú░µ│óΣ╝áµäƒσÖ¿∩╝êSPS∩╝뵿íσØݵ»ÅΣ╕¬µ¿íσØÝσðàµÐ¼Σ╕ÇΣ╕¬Φ╢àσú░µ│óΣ╝áµäƒσÖ¿σÆðΣ╕ÇΣ╕¬Φ£éΘ╕úσÖ¿πÇéΣ╝áµäƒσÖ¿τö¿Σ║ÄσÅæΘÇüΦ╢àσú░µ│óσ╣╢µÄ͵ö╢σø₧µ│ó∩╝ðΘÇÜΦ┐çΦ«íτ«ÝΦ╢àσú░µ│óµÝàΦíðµÝ╢ΘÝ┤µØÍτí«σ«ÜΣ╕Äτë⌐Σ╜ôτÜäΦ╖ØτÓ╗πÇé 2. Φ£éΘ╕úσÖ¿∩╝êBuzz∩╝뵿íσØݵá╣µÞ«Φ╢àσú░µ│óΣ╝áµäƒσÖ¿µ╡ÐΘçÅτÜäΦ╖ØτÓ╗∩╝ðΦ£éΘ╕úσÖ¿Σ╝Üτ╗Öσç║Σ╕ÞσÉðτÜäσÅÞσ║ö∩╝ðσÓéσ╗╢µÝ╢σÅæσú░πÇé 3. Σ╕╗µÄÚσê╢σÖ¿∩╝êArduino∩╝ëΦ┤ƒΦ┤úµÄÚσê╢σÆðτ«íτÉåµëǵ£ëΣ╝áµäƒσÖ¿σÆðΦ£éΘ╕úσÖ¿µ¿íσØÝ∩╝ðΘÇÜΦ┐çΣ╕▓ΦíðΘÇÜΣ┐íµÄ͵ö╢σÆðσÅæΘÇüµþ░µÞ«πÇé 4. Σ╗╗σèíτ«íτÉåΘÇÜΦ┐çΣ╕╗µÄÚσê╢σÖ¿∩╝êArduino∩╝ëτÜä loop() σç╜µþ░µðüτ╗¡µëÚΦíðΣ╝áµäƒσÖ¿Σ╗╗σèí∩╝êTask∩╝ë∩╝ðσðàµÐ¼µ╡ÐΦ╖ØπÇüµþ░µÞ«σÁäτÉåσÆðΦ£éΘ╕úσÖ¿σÅÞσ║öπÇé ## σ«ëΦúàΣ╜┐τö¿µ¡ÍΘ¬Á 1. τí¼Σ╗╢Φ┐₧µÄÍ
Σ╕╗ΦÚÆΦ╖浡Íσè¿Σ╜£τ┤áµØÉσø╛σðàσɽ6σ╝áσø╛τëç
Σ╝üΣ╕ܵþ░σ¡ÝσðûΦ╜¼σ₧еý»µðçΣ╝üΣ╕ܵêûτ╗äτ╗çσ░åΣ╝áτ╗ƒΣ╕ÜσèíΦ╜¼σðûΣ╕║µþ░σ¡ÝσðûΣ╕Üσèí∩╝ðσê⌐τö¿Σ║║σ╖͵Ö║Φâ╜πÇüσÁÚµþ░µÞ«πÇüΣ║æΦ«íτ«ÝπÇüσð║σØÝΘô╛πÇü5Gτ¡ëµþ░σ¡Ýµèǵ£»µÅÉσÞçΣ╕ÜσèíµþêτÄçσÆðΦ┤¿ΘçÅτÜäΦ┐çτ¿ÐπÇé σ╜ôµÝáσ╜óΦ╡äΣ║ÚµýÄτ╗åΘí╣σðàσɽΓÇ£Φ╜»Σ╗╢ΓÇØΓÇ£τ╜æτ╗£ΓÇØΓÇ£σ«óµê╖τ½»ΓÇØΓÇ£τ«íτÉåτ│╗τ╗ƒΓÇØΓÇ£µÖ║Φâ╜σ╣│σÅ░ΓÇØτ¡ëΣ╕ĵþ░σ¡ÝσðûΦ╜¼σ₧еèǵ£»τø╕σà│τÜäσà│Θö«Φ»ÞΣ╗ÍσÅèΣ╕ĵ¡Áτø╕σà│τÜäΣ╕ôσê⌐µÝ╢∩╝ðσ░åΦ»ÍµýÄτ╗åΘí╣τø«τþðσ«ÜΣ╕║ΓÇ£µþ░σ¡Ýσðûµèǵ£»µÝáσ╜óΦ╡äΣ║ÚΓÇØ∩╝ðσåÞσ»╣σÉðΣ╕Çσà¼σÅ╕σÉðσ╣┤σ║ÓσÁÜΘí╣µþ░σ¡Ýσðûµèǵ£»µÝáσ╜óΦ╡äΣ║ÚΦ┐øΦíðσèáµÇ╗∩╝ðΦ«íτ«Ýσà╢σÞáµ£¼σ╣┤σ║ÓµÝáσ╜óΦ╡äΣ║ÚτÜäµ»öΣ╛Ð∩╝ðσÞ│Σ╕║Σ╝üΣ╕ܵþ░σ¡ÝσðûΦ╜¼σ₧Ðτ¿Ðσ║ÓτÜäΣ╗úτÉåσÅýΘçÅπÇé µ£¼µþ░µÞ«σðàσɽ∩╝ÜσăσÚеþ░µÞ«πÇüσÅéΦÇâµûçτð«πÇüΣ╗úτáüdoµûçΣ╗╢πÇüµ£Çτ╗êτ╗ôµ₧£πÇé σÅéΦÇâµûçτð«∩╝Üσ╝áµ░╕τÅà,µØÄσ░ŵ│ó,ΘéóΘô¡σ╝║-Σ╝üΣ╕ܵþ░σ¡ÝσðûΦ╜¼σ₧ÐΣ╕Äσ«íΦ«íσ«ÜΣ╗╖[J].σ«íΦ«íτáöτ⌐╢,2021(03):62-71. µþ░µÞ« Φ»üσê╕Σ╗úτáüπÇüΦ»üσê╕τ«ÇτÚ░πÇüτ╗ƒΦ«íµê¬µ¡óµÝ͵£ƒπÇüµèÍΦí¿τ▒╗σ₧ÐπÇüµÝáσ╜óΦ╡äΣ║ÚσçÇΘóØπÇüΦ╡äΣ║ÚµÇ╗Φ«íπÇüσ╣┤Σ╗╜πÇüµ£ƒµ£½Σ╜ÖΘóØ∩╝êσàâ∩╝ëπÇüµþ░σ¡ÝσðûΦ╜¼σ₧ÐπÇé
Φ»ÍΦ╡äµ║ÉΣ╕║h5py-3.1.0-cp36-cp36m-win_amd64.whl∩╝ðµ¼óΦ┐ÄΣ╕ÐΦ╜╜Σ╜┐τö¿σôÓ∩╝ü
σåàσ«╣µÓéΦÓü∩╝ܵ£¼µûçΣ╗Ðτ╗ÞΣ║åΣ╕ÇτÚÞσƒ║Σ║ÄQRBayes-LSTMτÜäσÁÜ/σÞþσÅýΘçŵÝ╢σ║ÅΘóäµ╡еû╣µ│þ∩╝ðΘÇéτö¿Σ║ÄΣ╕Þτí«σ«ÜµÇÚσ╝║τÜäσ£║µÖ»σÓéΦéíτÍ¿Θóäµ╡ÐσÆðτö╡σèøΦ┤ƒΦÞ╖Θóäµ╡ÐπÇéΦ»Íµû╣µ│þτ╗ôσÉêΣ║åσêåΣ╜Þµþ░σø₧σ╜ÆσÆðΦ┤ØσÅ╢µû»Σ╝ýσðû∩╝ðΣ╕ÞΣ╗àΦâ╜µÅÉΣ╛øµ£¬µØÍτÜäΦ╢Ðσè┐Θóäµ╡Ð∩╝ðΦ┐ýΦâ╜τ╗Öσç║Θóäµ╡ÐσÇ╝τÜäτ╜«Σ┐íσð║ΘÝ┤πÇéµûçΣ╕¡Φ»Óτ╗åΦÚúΘçèΣ║åµþ░µÞ«σçåσÁçπÇüµ¿íσ₧Ðτ╗ôµ₧äπÇüµÞƒσÁ▒σç╜µþ░Φ«╛Φ«íπÇüΦ«¡τ╗âΘàÞτ╜«Σ╗ÍσÅèΘóäµ╡Ðτ╗ôµ₧£τÜäσÅ»ΦÚåσðûσÆðΦ»äΣ╝░µðçµáçπÇ鵡ÁσÁû∩╝ðΦ┐ýµÅÉΣ╛øΣ║åσÅýΘçÅΘçÞΦÓüµÇÚσêåµ₧ÉτÜäµû╣µ│þ∩╝ðσ╕«σè⌐τÉåΦÚúσô¬Σ║øτë╣σ╛üσ»╣Θóäµ╡Ðτ╗ôµ₧£τÜäσ╜▒σôÞµ£ÇσÁÚπÇé ΘÇéσÉêΣ║║τ╛Á∩╝ÜΣ╗ÄΣ║еþ░µÞ«σêåµ₧ÉπÇüµ£║σÖ¿σ¡ÓΣ╣áτáöτ⌐╢τÜäΣ╕ôΣ╕ÜΣ║║σú½∩╝ðσ░Áσà╢µý»σà│µ│¿µÝ╢σ║ÅΘóäµ╡ÐσÆðΣ╕Þτí«σ«ÜµÇÚΘçÅσðûτÜäΣ║║τ╛ÁπÇé Σ╜┐τö¿σ£║µÖ»σÅèτø«µáç∩╝ÜΓæá σ»╣Σ║ÄΘ£ÇΦÓüΦ┐øΦíðµÝ╢σ║ÅΘóäµ╡Ðσ╣╢σ╕ðµ£øΦÄ╖σ╛Ýτ╜«Σ┐íσð║ΘÝ┤τÜäτö¿µê╖∩╝øΓæí σà│µ│¿µ¿íσ₧еÇÚΦâ╜Φ»äΣ╝░σÆðσÅýΘçÅΘçÞΦÓüµÇÚτÜäτáöτ⌐╢Σ║║σæý∩╝øΓæó σ»╗µ▒éµÅÉΘ½ýΘóäµ╡Ðτ▓╛σ║ÓσÆðσÅ»ΘØáµÇÚτÜäΣ╗ÄΣ╕ÜΦÇàπÇé σà╢Σ╗ûΦ»┤µýÄ∩╝ܵ£¼µûçµÅÉΣ╛øτÜäΣ╗úτáüσÅ»Σ╗Íτø┤µÄÍσ║öτö¿Σ║ÄExcelµá╝σ╝ÅτÜäµþ░µÞ«∩╝ðτö¿µê╖σÅ¬Θ£Çσ░åµþ░µÞ«σ»╝σàÍσÞ│σÅ»Φ┐ÉΦíðπÇéΘ£ÇΦÓüµ│¿µäÅτÜäµý»∩╝ðΣ╕║Σ║åΦÄ╖σ╛ݵ£ÇΣ╜│µþêµ₧£∩╝ðσ║öΦ»Íτí«Σ┐صþ░µÞ«µá╝σ╝ŵ¡úτí«σ╣╢Σ╕öτ¼ÓσÉêτë╣σ«ÜτÜäΦÓüµ▒éπÇé
σåàσ«╣µÓéΦÓü∩╝ܵ£¼µûçΦ»Óτ╗åΣ╗Ðτ╗ÞΣ║åADAS∩╝êΘ½ýτ║ÚΘ⌐╛Θ⌐╢Φ╛àσè⌐τ│╗τ╗ƒ∩╝ëΣ╕¡σøøΣ╕¬Σ╕╗ΦÓüσèƒΦâ╜µ¿íσØÝτÜäΦ«╛Φ«íΣ╕Äσ«₧τÄ░∩╝ðσêåσê½µý»Φç¬ΘÇéσ║öσ╖íΦꬵÄÚσê╢τ│╗τ╗ƒ∩╝êACC∩╝ëπÇüσëÞσÉæτó░µÆ₧ΘóäΦ¡Óτ│╗τ╗ƒ∩╝êFCW∩╝ëπÇüΦç¬σè¿τ┤ÚµÇÍσê╢σè¿τ│╗τ╗ƒ∩╝êAEB∩╝ëσÆðΦ╜ÓΘüôΣ┐صðüΦ╛àσè⌐τ│╗τ╗ƒ∩╝êLKA∩╝ëπÇéµûçτ½áΣ╕ÞΣ╗àσ▒þτÁ║Σ║åσÉäΣ╕¬τ│╗τ╗ƒτÜäσà╖Σ╜ôτ«Ýµ│þσ«₧τÄ░∩╝ðσÓéACCΣ╕¡τÜäPIDµÄÚσê╢πÇüFCWΣ╕¡τÜäTTCΦ«íτ«ÝπÇüAEBΣ╕¡τÜäτè╢µÇüµ£║Φ«╛Φ«íσÆðLKAΣ╕¡τÜäPDµÄÚσê╢σÖ¿∩╝ðΦ┐ýσêåΣ║½Σ║åΦ«╕σÁÜσ«₧ΘÖàσ╝ÇσÅæΣ╕¡τÜäτ╗ÅΘ¬ðσÆðµðæµêý∩╝ðσÓéσÅéµþ░Φ░âµáíπÇüΣ╝áµäƒσÖ¿Φ₧ÞσÉêπÇüµÝ╢ΘÝ┤σÉðµ¡Íτ¡ëΘÝ«ΘóýπÇ鵡ÁσÁû∩╝ðµûçΣ╕¡Φ┐ýµÅÉσê░Σ║åΣ╕ÇΣ║øµ£ëΦ╢úτÜäτ╗åΦèé∩╝ðσÓéσ£¿µÜ┤Θø¿σÁ⌐µ░öΣ╕ÐLKAτÜäΦí¿τÄ░Σ╝ýσðû∩╝ðΣ╗ÍσÅèAEBτ│╗τ╗ƒσ£¿µ╡ÐΦ»þΦ┐çτ¿ÐΣ╕¡Θüçσê░τÜäσÉäτÚÞcorner caseπÇé ΘÇéσÉêΣ║║τ╛Á∩╝ܵ▒╜Φ╜Óτö╡σ¡Éσ╖Íτ¿Ðσ╕êπÇüΦç¬σè¿Θ⌐╛Θ⌐╢τáöτ⌐╢Σ║║σæýπÇüσ╡ðσàÍσ╝ÅΦ╜»Σ╗╢σ╝ÇσÅæΦÇàπÇé Σ╜┐τö¿σ£║µÖ»σÅèτø«µáç∩╝Üσ╕«σè⌐Φ»╗ΦÇàµ╖▒σàÍΣ║åΦÚúADASτ│╗τ╗ƒτÜäσ╖ÍΣ╜£σăτÉåσÆðµèǵ£»τ╗åΦèé∩╝ðµÄðµÅíσà│Θö«τ«Ýµ│þτÜäσ«₧τÄ░µû╣µ│þ∩╝ðµÅÉΘ½ýσ£¿σ«₧ΘÖàΘí╣τø«Σ╕¡τÜäσ╝ÇσÅæσÆðΦ░âΦ»þΦâ╜σèøπÇé σà╢Σ╗ûΦ»┤µýÄ∩╝ܵûçτ½áΘÇÜΦ┐çτöƒσè¿τÜäΦ»¡Φ¿ÇσÆðσà╖Σ╜ôτÜäΣ╗úτáüτÁ║Σ╛Ð∩╝ðΣ╜┐σÁÞµØéτÜäτÉåΦ«║σÅýσ╛ÝΘÇÜΣ┐ݵýôµçé∩╝ðµ£ëσè⌐Σ║ÄσêØσ¡ÓΦÇàσ┐½ΘǃσàÍΘÝ¿σ╣╢µ╖▒σàÍτÉåΦÚúADASτ│╗τ╗ƒτÜäσ╝ÇσÅæµ╡üτ¿ÐπÇé
σåàσ«╣µÓéΦÓü∩╝ܵûçτ½áΣ╕╗ΦÓüΘýÉΦ┐░Σ║å2023σ╣┤Σ╕¡σø╜Θ½ýτ½»σê╢ΘÇáΣ╕ÜΣ╕èσ╕éσà¼σÅ╕τÜäσÅæσ▒þµÓéσå╡∩╝ðσðàµÐ¼ΦíðΣ╕ÜΣ╕Äσð║σƒƒΣ╕ÁΣ╕¬τ╗┤σ║ÓτÜäσêåσ╕âΦ»ÓµâàπÇéΣ╗ÄΦíðΣ╕ÜΣ╕èτ£Ð∩╝ðΘ½ýτ½»σê╢ΘÇáΣ╕ÜΣ╕èσ╕éσà¼σÅ╕Φ╢àΦ┐ç2400σ«╢∩╝ðσà╢Σ╕¡µ£║µó░σê╢ΘÇáΣ╗Í628σ«╢τÜäµþ░ΘçÅΣ╜Þσ▒àΘÓûΣ╜Þ∩╝ðτö╡σ¡É∩╝ê352σ«╢∩╝ëσÆðτö╡σèøσê╢ΘÇá∩╝ê336σ«╢∩╝ëτ┤ÚΘÜÅσà╢σÉÄ∩╝ðΦÇðσâÅΦê¬τ⌐║Φê¬σÁ⌐σø╜Θý▓τ¡ëΣ╣ƒµ£ëΣ╕Çσ«ÜτÜäσÞáµ»öπÇéΣ╗Äσð║σƒƒσêåσ╕âµØÍτ£Ð∩╝ðσ╣┐Σ╕£πÇüµ▒ƒΦÐÅπÇüµ╡Öµ▒ƒΣ╕ëτ£üσÁäΣ║ÄΘóåσàêσ£░Σ╜Þ∩╝ðσêåσê½µ£ë410σ«╢πÇü342σ«╢σÆð199σ«╢∩╝ðΦ┐ÖΦí¿µýÄΣ╕£σÞݵ▓┐µ╡╖σ£░σð║σ»╣Σ║ÄΘ½ýτ½»σê╢ΘÇáΣ╕ÜτÜäσÅæσ▒þσà╖µ£ëµý╛ΦæÝΣ╝ýσè┐πÇéµþ░µÞ«µØ͵║ÉΣ║ÄΣ╕¡σø╜Σ╕èσ╕éσà¼σÅ╕σÞÅΣ╝ÜΣ╗ÍσÅèWindπÇé ΘÇéσÉêΣ║║τ╛Á∩╝Üσ»╣Σ╕¡σø╜τ╗ŵ╡Äτ╗ôµ₧äπÇüΣ║ÚΣ╕ÜσÅæσ▒þΦ╢Ðσè┐µäƒσà┤Φ╢úτÜäΦ»╗ΦÇà∩╝ðσ░Áσà╢µý»σà│µ│¿Θ½ýτ½»σê╢ΘÇáΣ╕ÜσÅæσ▒þτÜäµèþΦ╡äΦÇàπÇüµö┐τ¡ûσê╢σ«ÜΦÇàσÅèτáöτ⌐╢Σ║║σæýπÇé Σ╜┐τö¿σ£║µÖ»σÅèτø«µáç∩╝ÜΓæáσ╕«σè⌐µèþΦ╡äΦÇàΣ║åΦÚúΣ╕¡σø╜Θ½ýτ½»σê╢ΘÇáΣ╕ÜΣ╕èσ╕éσà¼σÅ╕τÜäΦíðΣ╕Üσ╕âσ▒Ç∩╝ðΣ╕║µèþΦ╡äσå│τ¡ûµÅÉΣ╛øσÅéΦÇâΣ╛صޫ∩╝øΓæíΣ╕║µö┐τ¡ûσê╢σ«ÜΦÇàµÅÉΣ╛øµþ░µÞ«µö»µðü∩╝ðσè⌐σèøΣ╝ýσðûΣ║ÚΣ╕Üσ╕âσ▒ÇσÆðσÅæσ▒þΦÚäσêÆ∩╝øΓæóΣ╛øτáöτ⌐╢Σ║║σæýσêåµ₧ÉΣ╕¡σø╜Θ½ýτ½»σê╢ΘÇáΣ╕ÜτÜäτÄ░τè╢Σ╕ĵ£¬µØÍσÅæσ▒þΦ╢Ðσè┐πÇé ΘýàΦ»╗σ╗║Φ««∩╝ܵ£¼µûçµÅÉΣ╛øΣ║åΣ╕░σ»ðτÜäµþ░µÞ«σÆðσø╛Φí¿∩╝ðΦ»╗ΦÇàσ║öΘçÞτé╣σà│µ│¿σÉäΦíðΣ╕ÜτÜäσà╖Σ╜ôµþ░µÞ«σÅèσà╢ΦâðσÉÄσÅÞµýáσç║τÜäΣ║ÚΣ╕Üτë╣τé╣∩╝ðσÉðµÝ╢τ╗ôσÉêσð║σƒƒσêåσ╕âµâàσå╡∩╝ðµ╖▒σàÍτÉåΦÚúΣ╕¡σø╜Θ½ýτ½»σê╢ΘÇáΣ╕ÜτÜäσÅæσ▒þµá╝σ▒ÇπÇé
# σƒ║Σ║ÄPythonτÜäµ£║σÖ¿σ¡ÓΣ╣áτ«Ýµ│þσ«₧Φ╖╡ ## Θí╣τø«τ«ÇΣ╗Ð µ£¼Θí╣τø«µÝ¿σ£¿ΘÇÜΦ┐çσ«₧Φ╖╡σ╕╕τö¿µ£║σÖ¿σ¡ÓΣ╣áτ«Ýµ│þ∩╝ðµÅÉΘ½ýµþ░µÞ«µðûµÄýσÆðµÄ¿ΦÞÉτ│╗τ╗ƒτÜäσçåτí«µÇÚ∩╝ðΦÚúσå│Σ┐íµü»Φ┐çΦ╜╜ΘÝ«ΘóýπÇéσ║öτö¿σ£║µÖ»σðàµÐ¼τö╡σþåπÇüµû░ΘÝ╗πÇüΦÚåΘóæτ¡ëτ╜æτ½Ö∩╝ðσ╕«σè⌐τö¿µê╖µø┤Θ½ýµþêσ£░ΦÄ╖σÅûµëÇΘ£ÇΣ┐íµü»πÇé ## Θí╣τø«τÜäΣ╕╗ΦÓüτë╣µÇÚσÆðσèƒΦâ╜ µþ░µÞ«µðûµÄýσ«₧τÄ░σÁÜτÚÞµþ░µÞ«µðûµÄýτ«Ýµ│þ∩╝ðσ╕«σè⌐τö¿µê╖Σ╗ÄσÁÚΘçŵþ░µÞ«Σ╕¡µÅÉσÅûµ£ëΣ╗╖σÇ╝τÜäΣ┐íµü»πÇé µ£║σÖ¿σ¡ÓΣ╣áτ«Ýµ│þσðàµÐ¼σ╕╕τö¿τÜäσêåτ▒╗πÇüσø₧σ╜ÆπÇüΦüÜτ▒╗τ¡ëτ«Ýµ│þ∩╝ðµÅÉΣ╛øΦ»Óτ╗åτÜäσ«₧τÄ░σÆðτÁ║Σ╛Ðτ¿Ðσ║ÅπÇé µÄ¿ΦÞÉτ│╗τ╗ƒΘÇÜΦ┐çµ£║σÖ¿σ¡ÓΣ╣áτ«Ýµ│þµÅÉΘ½ýµÄ¿ΦÞÉτ│╗τ╗ƒτÜäσçåτí«µÇÚ∩╝ðΣ╝ýσðûτö¿µê╖Σ╜ôΘ¬ðπÇé ## σ«ëΦúàΣ╜┐τö¿µ¡ÍΘ¬Á 1. Σ╕ÐΦ╜╜µ║Éτáüτö¿µê╖σ╖▓Σ╕ÐΦ╜╜µ£¼Θí╣τø«τÜäµ║ÉτáüµûçΣ╗╢πÇé 2. σ«ëΦúàΣ╛ØΦ╡û bash pip install r requirements.txt 3. Φ┐ÉΦíðτÁ║Σ╛Ðτ¿Ðσ║Å bash python main.py 4. Φç¬σ«ÜΣ╣ëµþ░µÞ«µá╣µÞ«Θ£ÇΦÓüµø┐µÞóµþ░µÞ«µûçΣ╗╢∩╝ðΘçÞµû░Φ┐ÉΦíðτ¿Ðσ║ÅΣ╗Íσ║öτö¿µû░τÜäµþ░µÞ«πÇé
Θí╣τø«Φ┐ÉΦíðσÅéΦÇâ∩╝Ühttps://blog.csdn.net/weixin_45393094/article/details/124645254 µèǵ£»µáêSpringboot+Vue∩╝øµ¡ÁΘí╣τø«τÜäσÅéΦÇâµûçµíú σåàσ«╣µÓéΦÓü∩╝ܵ£¼µûçµíúΣ╗Ðτ╗ÞΣ║åΣ╕ǵ¼╛σƒ║Σ║ÄσëÞσÉÄτ½»σêåτÓ╗µ₧╢µ₧äτÜäσ¡ÓτöƒΘÇëΦ»╛τ│╗τ╗ƒτÜäΦ«╛Φ«íΣ╕Äσ«₧τÄ░πÇéτ│╗τ╗ƒΘççτö¿JavaΦ»¡Φ¿ÇΣ╜£Σ╕║σÉÄτ½»σ╝ÇσÅæΦ»¡Φ¿Ç∩╝ðΦ┐Éτö¿Spring Bootµíåµ₧╢µ₧äσ╗║σÉÄτ½»µÄÍσÅú∩╝ðσëÞτ½»Σ╜┐τö¿Vueµíåµ₧╢∩╝ðΦ«╛Φ«íµ¿íσ╝ÅΣ╕èΘççτö¿Σ║åMVVMµ¿íσ╝Å∩╝ðτí«Σ┐ØσëÞσÉÄτ½»σêåτÓ╗πÇéτ│╗τ╗ƒΣ╕╗ΦÓüσêåΣ╕║σ¡ÓτöƒπÇüµþÖσ╕êσÆðτ«íτÉåσæýΣ╕ëσÁÚσèƒΦâ╜µ¿íσØÝ∩╝ðµ╢╡τøûΦ»╛τ¿ÐΘÇëµÐ⌐πÇüµêÉτ╗⌐τ«íτÉåσÆðΣ┐íµü»σÅæσ╕âτ¡ëσèƒΦâ╜πÇéΘ£Çµ▒éσêåµ₧ÉΘâ¿σêåΦ»Óτ╗åµÅÅΦ┐░Σ║åσÉ䵿íσØÝτÜäσèƒΦâ╜Θ£Çµ▒éσÅèµÇÚΦâ╜Θ£Çµ▒é∩╝ðσðàµÐ¼σ«₧τö¿µÇÚπÇüµýôτö¿µÇÚσÆðσ«ëσ࿵ÇÚπÇéµþ░µÞ«σ║ôΦ«╛Φ«íΘâ¿σêåΦ»Óτ╗åΦ»┤µýÄΣ║åσ¡ÓτöƒπÇüµþÖσ╕êπÇüτö¿µê╖πÇüΦ»╛τ¿ÐσÆðµêÉτ╗⌐τ¡ëΣ┐íµü»Φí¿τÜäτ╗ôµ₧äπÇéτ│╗τ╗ƒσ«₧τÄ░τ½áΦèéσêÖσ▒þτÁ║Σ║åσÉäΣ╕¬µ¿íσØÝτÜäσà╖Σ╜ôσ«₧τÄ░τ╗åΦèé∩╝ðσðàµÐ¼τÖ╗σ╜þΘ¬ðΦ»üπÇüµþÖσ╕êτ«íτÉåπÇüσ¡Óτöƒτ«íτÉåπÇüΦ»╛τ¿Ðτ«íτÉåπÇüσà¼σæèΦ«╛τ╜«σÅèΘÇëΦ»╛τ¡ëσèƒΦâ╜τÜäΣ╗úτáüσ«₧τÄ░πÇé ΘÇéσÉêΣ║║τ╛Á∩╝ÜΦ«íτ«Ýµ£║Σ╕ôΣ╕Üσ¡ÓτöƒπÇüµ£ëΣ╕Çσ«Üτ╝ûτ¿Ðσƒ║τíÇτÜäτáöσÅæΣ║║σæýµêûσ»╣σëÞσÉÄτ½»σêåτÓ╗µèǵ£»µ£ëσà┤Φ╢úτÜäσ╝ÇσÅæΦÇàπÇé Σ╜┐τö¿σ£║µÖ»σÅèτø«µáç∩╝ÜΓæáτÉåΦÚúσëÞσÉÄτ½»σêåτÓ╗µ₧╢µ₧äσ£¿σ«₧ΘÖàΘí╣τø«Σ╕¡τÜäσ║öτö¿∩╝øΓæíµÄðµÅíSpring BootΣ╕ÄVueµíåµ₧╢τ╗ôσÉêσ╝ÇσÅæτÜäσà╖Σ╜ôσ«₧τÄ░µû╣µ│þ∩╝øΓæóτ僵éëσ¡ÓτöƒΘÇëΦ»╛τ│╗τ╗ƒτÜäµá╕σ┐âσèƒΦâ╜∩╝ðσÓéΘÇëΦ»╛πÇüµêÉτ╗⌐τ«íτÉåπÇüΣ┐íµü»σÅæσ╕âτ¡ë∩╝øΓæúσ¡ÓΣ╣áσÓéΣ╜þΦ«╛Φ«íσÆðσ«₧τÄ░Θ½ýµþêτÜäµþ░µÞ«σ║ôτ╗ôµ₧äΣ╗͵ö»µðüτ│╗τ╗ƒσèƒΦâ╜πÇé ΘýàΦ»╗σ╗║Φ««∩╝ܵ£¼µûçµíúΘÇéσÉêσ╕ðµ£øµ╖▒σàÍΣ║åΦÚúσëÞσÉÄτ½»σêåτÓ╗µ₧╢µ₧äσÅèσà╖Σ╜ôσ«₧τÄ░τÜäΦ»╗ΦÇàπÇéσ£¿ΘýàΦ»╗Φ┐çτ¿ÐΣ╕¡∩╝ðσ╗║Φ««ΘçÞτé╣σà│µ│¿σÉ䵿íσØÝτÜäσèƒΦâ╜Θ£Çµ▒éσêåµ₧ÉσÆðµèǵ£»σ«₧τÄ░τ╗åΦèé∩╝ðτë╣σê½µý»Σ╗úτáüτÁ║Σ╛ÐΘâ¿σêå∩╝ðΣ╗Íσèáµ╖▒σ»╣σëÞσÉÄτ½»σêåτÓ╗µ₧╢µ₧äτÜäτÉåΦÚúπÇéσÉðµÝ╢∩╝ðτ╗ôσÉêΦç¬Φ║½σ╝ÇσÅæτ╗ÅΘ¬ð∩╝ðµÇØΦÇâσÓéΣ╜þΣ╝ýσðûτÄ░µ£ëτ│╗τ╗ƒσèƒΦâ╜∩╝ðµÅÉΘ½ýτ│╗τ╗ƒτÜäτ¿│σ«ÜµÇÚσÆðτö¿µê╖Σ╜ôΘ¬ðπÇé
σåàσ«╣µÓéΦÓü∩╝ܵ£¼µûçΦ»Óτ╗åΣ╗Ðτ╗ÞΣ║åσÓéΣ╜þΣ╜┐τö¿MATLABσ«₧τÄ░σƒ║Σ║ÄTransformerτÜäσêåτ▒╗Θóäµ╡Ð∩╝ðτë╣σê½ΘÆêσ»╣σêØσ¡ÓΦÇàµÅÉΣ╛øΣ║åσ«ðµþ┤τÜäΣ╗úτáüτÁ║Σ╛ÐσÆðΦ»Óτ╗åτÜ䵡ÍΘ¬ÁΦ»┤µýÄπÇéΣ╕╗ΦÓüσåàσ«╣µ╢╡τøûµþ░µÞ«Φ»╗σÅûΣ╕ÄΘóäσÁäτÉåπÇüTransformerµ¿íσ₧еɡσ╗║πÇüΦ«¡τ╗âΘàÞτ╜«πÇüτ╗ôµ₧£σÅ»ΦÚåσðûτ¡ëµû╣ΘØóπÇéµûçΣ╕¡Σ╕ÞΣ╗àσ▒þτÁ║Σ║åσÓéΣ╜þτöƒµêÉσêåτ▒╗µþêµ₧£σ»╣µ»öσø╛πÇüΦ«¡τ╗âΦ┐çτ¿Ðµø▓τ║┐σÆðµ╖╖µ╖åτƒ⌐Θý╡∩╝ðΦ┐ýµÅÉΣ╛øΣ║åσ╕╕ΦÚüτÜäΘöÖΦ»»µÄƵƒÍµû╣µ│þσÆðΣ╝ýσðûσ╗║Φ««πÇ鵡ÁσÁû∩╝ðµûçτ½áσ╝║Φ░âΣ║åTransformerσ£¿σÁäτÉåµÝ╢σ║Åτë╣σ╛üµû╣ΘØóτÜäΣ╝ýσè┐∩╝ðσ╣╢τ╗Öσç║Σ║åσà╖Σ╜ôτÜäσàëΣ╝ŵþ░µÞ«Θóäµ╡еíêΣ╛ÐπÇé ΘÇéσÉêΣ║║τ╛Á∩╝ÜMATLABσêØσ¡ÓΦÇàπÇüσ╕ðµ£øΣ║åΦÚúTransformerσ║öτö¿Σ║Äσêåτ▒╗Σ╗╗σèíτÜäµû░µëÐτ¿Ðσ║ÅσæýπÇé Σ╜┐τö¿σ£║µÖ»σÅèτø«µáç∩╝ÜΘÇéτö¿Σ║ÄΘ£ÇΦÓüΦ┐øΦíðµþ░µÞ«σêåτ▒╗Θóäµ╡ÐτÜäτáöτ⌐╢Σ║║σæýσÆðµèǵ£»Σ║║σæý∩╝ðτë╣σê½µý»ΘéúΣ║øσÁäτÉåµÝ╢σ║ŵþ░µÞ«∩╝êσÓéσàëΣ╝ŵþ░µÞ«πÇüτö╡σèøΦ┤ƒΦÞ╖µþ░µÞ«∩╝ëτÜäΣ║║τ╛ÁπÇéτø«µáçµý»σ╕«σè⌐Φ»╗ΦÇàσ┐½ΘǃµÄðµÅíTransformerτÜäσƒ║µ£¼σăτÉåσÅèσà╢σ£¿MATLABΣ╕¡τÜäσà╖Σ╜ôσ«₧τÄ░πÇé σà╢Σ╗ûΦ»┤µýÄ∩╝ܵûçτ½áµÅÉΣ╛øΣ║åσÁÚΘçÅσ«₧τö¿τÜäΣ╗úτáüτë絫╡σÆðµèÇσ╖Ú∩╝ðσÓéΦç¬σ«ÜΣ╣ëΣ╜Þτ╜«τ╝ûτáüπÇüµþ░µÞ«µáçσçåσðûπÇüµ¿íσ₧Ðτ╗ôµ₧äΦ░âµþ┤τ¡ë∩╝ðΣ╜┐σ╛ݵþ┤Σ╕¬Φ┐çτ¿ÐµÝóτø┤ΦÚéσÅêµýôµôÞΣ╜£πÇéσÉðµÝ╢∩╝ðΣ╜£ΦÇàσêåΣ║½Σ║åΣ╕ÇΣ║øσ«₧Φ╖╡τ╗ÅΘ¬ð∩╝ðσÓéΦ░âµþ┤σÅéµþ░Σ╗͵ÅÉΘ½ýσçåτí«τÄçπÇüΦÚúσå│σ╕╕ΦÚüΘÝ«ΘóýτÜäµû╣µ│þτ¡ë∩╝ðµ£ëσè⌐Σ║ÄΦ»╗ΦÇàµø┤σÍ╜σ£░τÉåΦÚúσÆðσ║öτö¿µëÇσ¡ÓτƒÍΦ»åπÇé