
【IT168 技术】从性能角度来看,处理器、内存和I/O这三个子系统在服务器中是最重要的,它们也是最容易出现性能瓶颈的地方。目前市场上主流的服务器大多使用英特尔Nehalem、Westmere微内核架构的三个家族处理器:Nehalem-EP,Nehalem-EX和Westmere-EP。下表总结了这些处理器的主要特性:
|
|
Nehalem-EP
|
Westmere-EP
|
Nehalem-EX
|
Nehalem-EX
|
|
商业名称
|
至强5500
|
至强5600
|
至强6500
|
至强7500
|
|
支持的最插座数
|
2
|
2
|
2
|
8
|
|
每插座最大核心数
|
4
|
6
|
8
|
8
|
|
每插座最大线程数
|
8
|
12
|
16
|
16
|
|
MB缓存 (3级)
|
8
|
12
|
18
|
24
|
|
最大内存DIMM数
|
18
|
18
|
32
|
128
|
在本文中,我们将分别从处理器、内存、I/O三大子系统出发,带你一起来梳理和了解最新英特尔架构服务器的变化和关键技术。
一、处理器的演变
现代处理器都采用了最新的硅技术,但一个单die(构成处理器的半导体材料块)上有数百万个晶体管和数兆存储器。多个die组织到一起就形成了一个硅晶片,每个die都是独立切块,测试和用陶瓷封装的,下图显示了封装好的英特尔至强5500处理器外观。

图 1 英特尔至强5500处理器
插座
处理器是通过插座安装到主板上的,下图显示了一个英特尔处理器插座,用户可根据自己的需要,选择不同时钟频率和功耗的处理器安装到主板上。

图 2 英特尔处理器插座
主板上插座的数量决定了最多可支持的处理器数量,最初,服务器都只有一个处理器插座,但为了提高服务器的性能,市场上已经出现了包含2,4和8个插座的主板。
在处理器体系结构的演变过程中,很长一段时间,性能的改善都与提高时钟频率紧密相关,时钟频率越高,完成一次计算需要的时间越短,因此性能就越好。随着时钟频率接近4GHz,处理器材料物理性质方面的原因限制了时钟频率的进一步提高,因此必须找出提高性能的替代方法。
核心
晶体管尺寸不断缩小(Nehalem使用45nm技术,Westmere使用32nm技术),允许在单块die上集成更多晶体管,利用这个优势,可在一块die上多次复制最基本的CPU(核心),因此就诞生了多核处理器。
现在市场上多核处理器已经随处可见,每颗处理器包含多个CPU核心(通常是2,4,6,8个 ),每个核心都有一级缓存(L1),通常所有的核心会共享二级(L2)、三级缓存(L3)、总线接口和外部连接,下图显示了一个双核心的CPU架构。
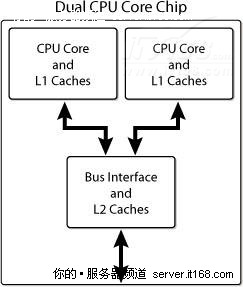
图 3 双核心CPU架构示意图
现代服务器通常提供了多个处理器插座,例如,基于英特尔至强5500系列(Nehalem-EP)的服务器通常包含两个插座,每个插座四个核心,总共可容纳八个核心,而基于英特尔至强7500系列(Nehalem-EX)的服务器通常包含八个插座,每个插座八个核心,总共可容纳64个核心。
下图显示了更详细的双核处理器架构示意图,CPU的主要组件(提取指令,解码和执行)都被复制,但系统总线是公用的。
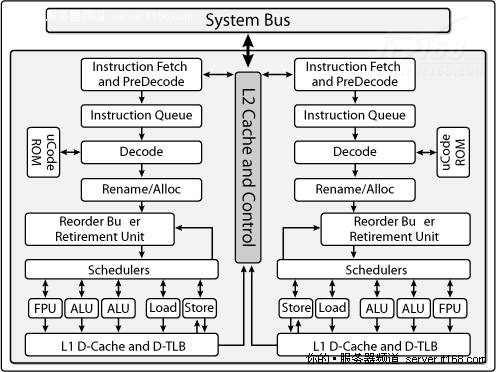
图 4 双核处理器的详细架构示意图
线程
为了更好地理解多核架构的含义,我们先看一下程序是如何执行的,服务器会运行一个内核(如Linux,Windows的内核)和多个进程,每个进程可进一步细分为线程,线程是分配给核心的最小工作单元,一个线程需要在一个核心上执行,不能进一步分割到多个核心上执行。下图显示了进程和线程的关系。
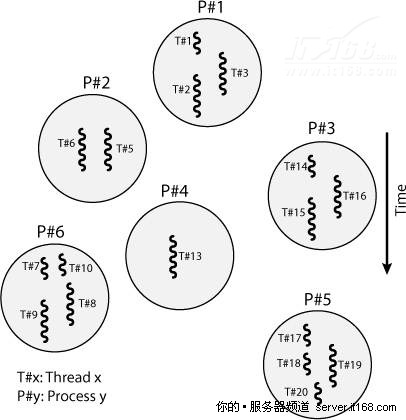
图 5 进程和线程的关系
进程可以是单线程也可以是多线程的,单线程进程同一时间只能在一个核心上执行,其性能取决于核心本身,而多线程进程同一时间可在多个核心上执行,因此它的性能就超越了单一核心上的性能表现。
因为许多应用程序都是单线程的,在多进程环境中,多插座、多核心的架构通常会带来方便,在虚拟化环境中,这个道理一样正确,Hypervisor允许在一台物理服务器上整合多个逻辑服务器,创建一个多进程和多线程的环境。
英特尔超线程技术
虽然单线程不能再拆分到两个核心上运行,但有些现代处理器允许同一时间在同一核心上运行两个线程,每个核心有多个并行工作能力的执行单元,很难看到单个线程会让所有资源繁忙起来。
下图展示了英特尔超线程技术是如何工作的,同一时间在同一核心上有两个线程执行,它们使用不同的资源,因此提高了吞吐量。
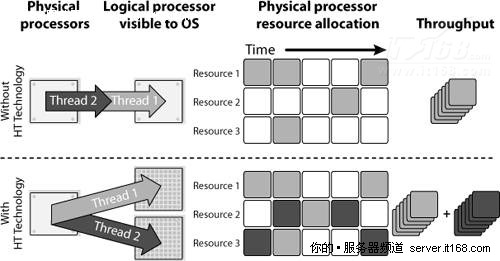
图 6 英特尔超线程技术工作原理
前端总线
在多插座和多核心的情况下,理解如何访问内存和两个核心之间是如何通信的非常重要,下图显示了过去许多英特尔处理器使用的架构,被称作前端总线(FSB)架构。在FSB架构中,所有通信都是通过一个单一的,共享的双向总线发送的。在现代处理器中,64位宽的总线以4倍速总线时钟速度运行,在某些产品中,FSB信息传输速率已经达到1.6GT/s。
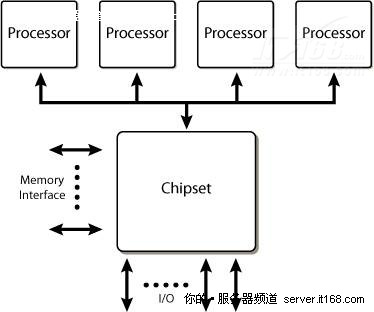
图 7 基于前端总线的服务器平台架构
FSB将所有处理器连接到芯片组的叫做北桥(也叫做内存控制器中枢),北桥连接所有处理器共享访问的内存。
这种架构的优点是,每个处理器都可以访问其它所有处理可以访问的所有内存,每个处理器都实现了缓存一致性算法,保证它的内部缓存与外部存储器,以及其它所有处理器的缓存同步。
但这种方法设计的平台要争夺共享的总线资源,随着总线上信号传输速度的上升,要连接新设备就变得越来越困难了,此外,随着处理器和芯片组性能的提升,FSB上的通信流量也会上升,会导致FSB变得拥挤不堪,成为瓶颈。
双独立总线
为了进一步提高带宽,单一共享总线演变成了双独立总线架构(DIB),其架构如下图所示,带宽基本上提高了一倍。
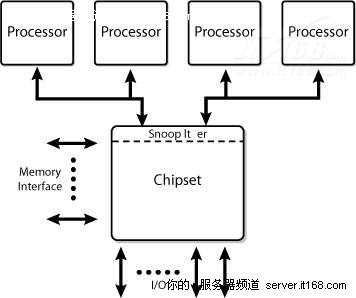
图 8 基于双独立总线的服务器平台架构
但在双独立总线架构中,缓存一致性通信必须广播到两条总线上,因此减少了总有效带宽,为了减轻这个问题,在芯片组中引入了“探听过滤器”来减少带宽负载。
如果缓存未被击中,最初的处理器会向FSB发出一个探听命令,探听过滤器拦截探听,确定是否需要传递探听给其它FSB。如果相同FSB上的其它处理器能满足读请求,探听过滤器访问就被取消,如果相同FSB上其它处理器不满意读请求,探听过滤器就会确定下一步的行动。如果读请求忽略了探听过滤器,数据就直接从内存返回,如果探听过滤器表示请求的目标缓存在其它FSB上不存在,它将向其它部分反映探听情况。如果其它部分仍然有缓存,就会将请求路由到该FSB,如果其它部分不再有目标缓存,数据还是直接从内存返回,因为协议不支持写请求,写请求必须全部传播到有缓存副本的所有FSB上。
专用高速互联
在双独立总线之后又出现了专用高速互联架构(Dedicated High-Speed Interconnect,DHSI),其架构如下图所示。
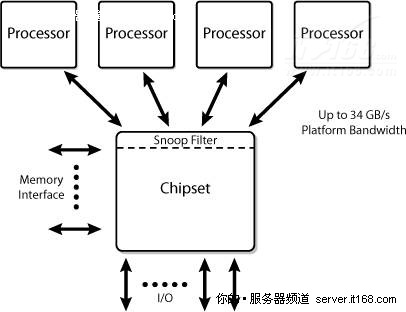
图 9 基于DHSI的服务器平台架构
基于DHSI的平台使用四个独立的FSB,每个处理器使用一个FSB,引入探听过滤器实现了更好的带宽扩容,FSB本身没多大变化,只是现在变成点对点的配置了。
使用这种架构设计的平台仍然要处理快速FSB上的电信号挑战,DHSI也增加了芯片组上的针脚数量,需要扩展PCB路线,才能为所有FSB建立好连接。
英特尔QuickPath互联
随英特尔酷睿i7处理器引入了一种新的系统架构,即著名的英特尔QuickPath互联(QuickPath Interconnect,QPI),这个架构使用了多个高速单向连接将处理器和芯片组互联,使用这种架构使我们认识到了:
①. 多插座和多核心通用的内存控制器是一个瓶颈;
②. 引入多个分布式内存控制器将最符合多核处理器的内存需要;
③. 在大多数情况下,在处理器中集成内存控制器有助于提升性能;
④. 提供有效的方法处理多插座系统一致性问题对大规模系统是至关重要的。
下图显示了一个多核处理器,集成了内存控制器和多个连接到其它系统资源的英特尔QuickPath的功能示意图。
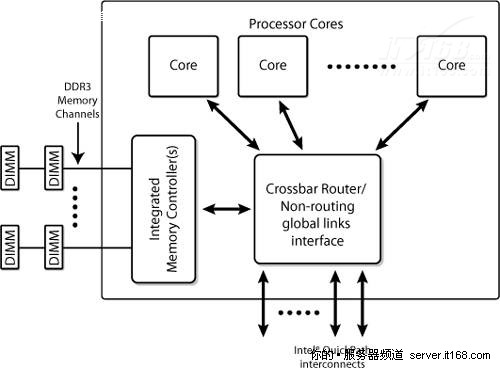
图 10 集成英特尔QPI和DDR 3内存通道的处理器架构
在这个架构中,每个插座中的所有核心共享一个可能有多个内存接口的IMC(Integrated Memory Controllers,集成内存控制器)。
IMC可能有不同的外部连接:
①. DDR 3内存通道 – 在这种情况下,DDR 3 DIMM直接连接到插座,如下图所示,Nehalem-EP(至强5500)和Westmere-EP(至强5600)就使用了这种架构。
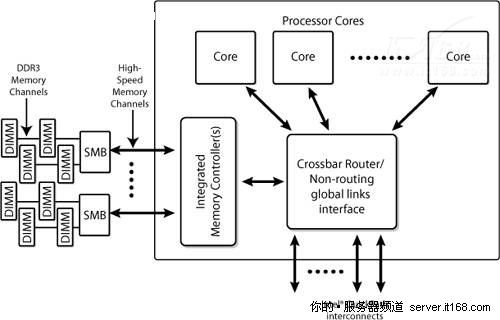
图 11 具有高速内存通道的处理器
②. 高速串行内存通道 – 如下图所示,在这种情况下,外部芯片(SMB:Scalable Memory Buffer,可扩展内存缓存)创建DDR 3内存通道,DDR 3 DIMM通过这个通道连接,Nehalem-EX使用了这种架构。
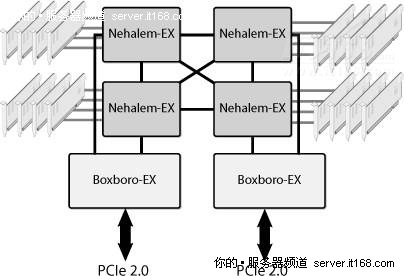
图 12 四插座Nehalem-EX
IMC和插座中的不同核心使用英特尔QPI相互通信,实现了英特尔QPI的处理器也可以完全访问其它处理器的内存,同时保持缓存的一致性,这个架构也叫做“缓存一致性NUMA(Non-Uniform Memory Architecture非统一内存架构)”,内存互联系统保证内存和所有潜在的缓存副本总是一致的。
英特尔QPI是一个端到端互联和消息传递方案,在目前的实现中,每个连接由最高速度可达25.6 GB/s或6.4 GT/s的20条线路组成。
英特尔QPI使用端到端连接,因此在插座中需要一个内部交叉路由器,提供全局内存访问,通过它,不需要完整的连接拓扑就可以构建起系统了。
图12显示了四插座Nehalem-EX配置,每个处理器有四个QPI与其它三个处理器和Boxboro-EX芯片组互联。
二、内存子系统
电子业在内存子系统上付出了艰辛的努力,只为紧跟现代处理器需要的低访问时间和满足当今应用程序要求的高容量需求。
解释当前内存子系统之前,我们先了解一下与内存有关的一些常用术语。
①. RAM(随机访问存储器)
②. SRAM(静态RAM)
③. DRAM(动态RAM)
④. SDRAM(同步DRAM)
⑤. SIMM(单列直插式内存模块)
⑥. DIMM(双列直插内存模块)
⑦. UDIMM(无缓冲DIMM)
⑧. RDIMM(带寄存器的DIMM)
⑨. DDR(双数据速率SDRAM)
⑩. DDR2(第二代DDR)
⑩. DDR3(第三代DDR)
电子器件工程联合委员会(Joint Electron Device Engineering Council,JEDEC)是半导体工程标准化机构,JEDEC 21,22定义了从256位SRAM到最新的DDR3模组的半导体存储器标准。
现代服务器的内存子系统是由RAM组成的,允许数据在一个固定的时间按任意顺序访问,不用考虑它所在的物理位置,RAM可以是静态的或动态的。
SRAM
SRAM(静态RAM)通常非常快,但比DRAM的容量要小,它们有一块芯片结构维持信息,但它们不够大,因此不能作为服务器的主要内存。
DRAM
DRAM(动态RAM)是服务器的唯一选择,术语“动态”表示信息是存储在集成电路的电容器内的,由于电容器会自动放电,为避免数据丢失,需要定期充电,内存控制器通常负责充电操作。
SDRAM
SDRAM(同步DRAM)是最常用的DRAM,SDRAM具有同步接口,它们的操作与时钟信号保持同步,时钟用于驱动流水线内存访问的内部有限状态机,流水线意味着上一个访问未结束前,芯片可以接收一个新的内存访问,与传统DRAM相比,这种方法大大提高了SDRAM的性能。
DDR2和DDR3是两个最常用的SDRAM,下图显示了一块DRAM芯片的内部结构。
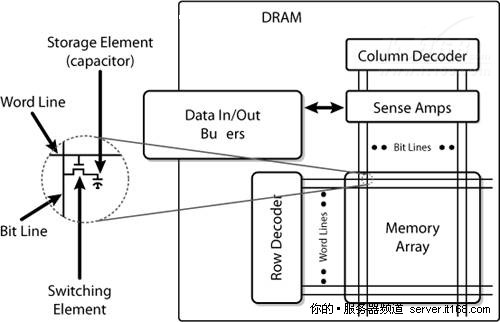
图 13 DRAM芯片的内部结构
内存阵列是由存储单元按矩阵方式组织组成的,每个单元都一个行和列地址,每一位都是存储在电容器中的。
为了提高性能,降低功耗,内存阵列被分割成多个“内存库(bank)”,下图显示了一个4-bank和一个8-bank的内存阵列组织方式。
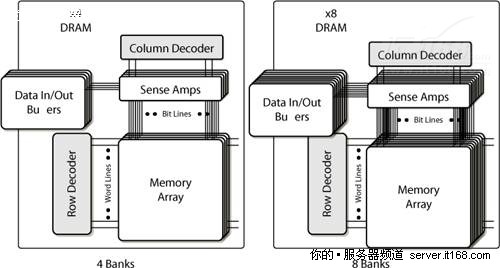
图 14 内存bank
DDR2芯片有四个内部内存bank,DDR3芯片有八个内部内存bank。
DIMM
需要将多个内存芯片组装到一起才能构成一个内存子系统,它们就是按著名的DIMM(双列直插内存模块)组织的。
下图显示了内存子系统的传统组织方式,例如,内存控制器连接四个DIMM,每一个由多块DRAM芯片组成,内存控制器有一个地址总线,一个数据总线和一个命令(也叫做控制)总线,它负责读,写和刷新存储在DIMM中的信息。
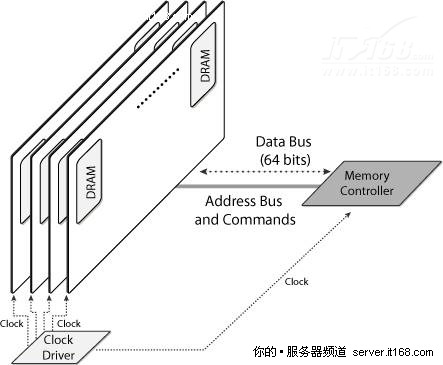
图 15 传统内存子系统示例
下图展示了一个内存控制器与一个DDR3 DIMM连接的示例,该DIMM由八块DRAM芯片组成,每一块有8位数据存储能力,每存储字(内存数据总线的宽度)则共有64位数据存储能力。地址总线有15位,它可在不同时间运送“行地址”或“列地址”,总共有30个地址位。此外,在DDR3芯片中,3位的bank地址允许访问8个bank,可被视作提高了控制器的地址空间总容量,但即使内存控制器有这样的地址容量,市面上DDR3芯片容量还是很小。最后,RAS(Row Address Selection,行地址选择),CAS(Column Address Selection,列地址选择),WE(Write Enabled,写启用)等都是命令总线上的。
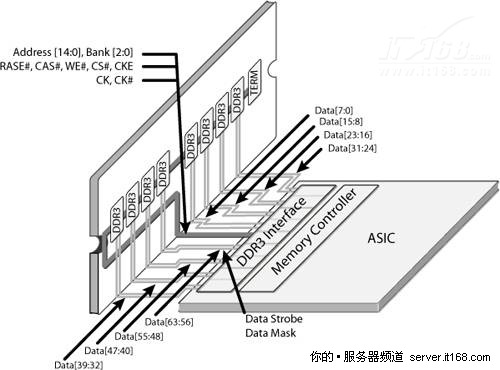
图 16 DDR3内存控制器示例
下面是一个DIMM的示意图。
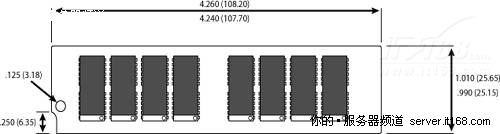
图 17 DIMM示意图
上图显示了8个DDR3芯片,每个提供了8位信息(通常表示为x8)。
ECC和Chipkill
数据完整性是服务器架构最关注的一个点,很多时候需要安装额外的DIMM检测和恢复内存错误,最常见的办法是增加8位ECC(纠错码),将存储字从64位扩大到72位,就象海明码一样,允许纠正一位错误,检测两位错误,它们也被称作SEC(Single Error Correction,单纠错)/DED(Double Error Detection,双检错)。
先组织存储字再写入到内存芯片中,EEC可以用于保护任一内存芯片的失效,以及单内存芯片的任意多位错误,这些功能有几个不同的名字。
①. Chipkill是IBM的商标
②. Oracle称之为扩展EEC
③. 惠普称之为Chipspare
④. 英特尔有一个类似的功能叫做x4单设备数据校正(Intel x4 SDDC)
Chipkill通过跨多个内存芯片位散射EEC字的位实现这个功能,任一内存芯片失效只会影响到一个ECC位,它允许重建内存中的内容。
下图了显示了一个读和写128位数据的内存控制器,增加EEC后就变成144位了,144位分成4个36位的存储字,每个存储字将是SEC/DED。如果使用两个DIMM,每个包含18个4位芯片,可以按照下图所示的方法重组位,如果芯片失效,每4个字中只会有一个错误,但因为字是SEC/DED的,每4个字可以纠正一个错误,因此所有错误都可以被纠正过来。
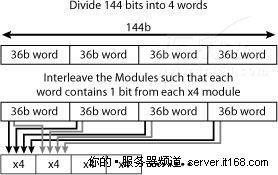
图 18 Chipkill示例
内存Rank
我们重新回到DIMM是如何组织的,一组产生64位有用数据(不计ECC)的芯片叫做一个Rank,为了在DIMM上存储更多的数据,可以安装多个Rank,目前有单,双和四个Rank的 DIMM,下图显示了这三种组织方法。
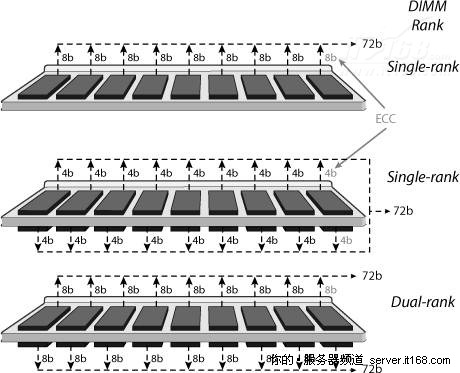
图 19 DIMM和内存排
上图最前面显示的是一个单Rank的RAM,由9个8位芯片组成,一般表示为1Rx8,中间显示的是一个1Rx4,由18个4位芯片组成,最后显示的是一个2Rx8,由18个8位芯片组成。
内存Rank不能使用地址位选择,只能使用芯片选择,现代内存控制器最多可达8个独立的芯片选择,因此最大可支持8个Rank。
UDIMM和RDIMM
SDRAM DIMM进一步细分为UDIMM(无缓冲DIMM)和RDIMM(带寄存器的DIMM),在UDIMM中,内存芯片直接连接到地址总线和控制总线,无任何中间部分。
RDIMM在传入地址和控制总线,以及SDRAM之间有额外的组件(寄存器),这些寄存器增加了一个延迟时钟周期,但它们减少了内存控制器上的电负荷,允许内存控制器安装更多的DIMM。
RDIMM通常更贵,因为它需要附加组件,但它们在服务器中得到了普遍使用,因为对于服务器来说,扩展能力和稳定性比价格更重要。
虽然理论上带寄存器/无缓冲的和ECC/非ECC DIMM是可以任何组合的,但大多数服务器级内存模块都同时具有ECC和带寄存器功能。
下图显示了一个ECC RDIMM,寄存器是箭头指向的芯片,这个ECC DIMM由9个内存芯片组成。
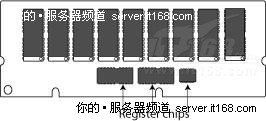
图 20 ECC RDIMM
DDR2和DDR3
第一代SDRAM技术叫做SDR(Single Data Rate),表示每个时钟周期传输一个数据单元,之后又出现了DDR(Double Data Rate)标准,其带宽几乎是SDR的两倍,无需提高时钟频率,可在时钟上升沿和下降沿信号上同时传输数据,DDR技术发展到今天形成了两套标准:DDR2和DDR3。
DDR 2 SDRAM的工作电压是1.8V,采用240针DIMM模块封装,通过改善总线信号,它们可以以两倍于DDR的速度工作在外部数据总线上,规则是:
①. 每DRAM时钟数据传输两次
②. 每次数据传输8个字节(64位)
下表显示了DDR2标准。
表2. DDR2 DIMM
| 标准名称 | DRAM 时钟频率 | 每秒传输的数据(百万) | 模块名称 | 峰值传输速率GB/s |
| DDR2-400 | 200 MHz | 400 | PC2-3200 | 3.200 |
| DDR2-533 | 266 MHz | 533 | PC2-4200 | 4.266 |
| DDR2-667 | 333 MHz | 667 | PC2-5300 PC2-5400 | 5.333 |
| DDR2-800 | 400 MHz | 800 | PC2-6400 | 6.400 |
| DDR2-1066 | 533 MHz | 1,066 | PC2-8500 ©PC2-8600 | 8.533 |
DDR 3 SDRAM在DDR2的基础上对以下这些方面做了改进:
①. 将工作电压降低到1.5v,减少功耗;
②. 通过引入0.5-8Gb的芯片增加了内存密度,单Rank的容量最大可达16GB;
③. 增加了内存带宽,内存突发长度从4字增加到8字,增加突发长度是为了更好地满足不断增长的外部数据传输速率,随着传输速率的增长,突发长度(传输的大小)必须增长,但不能超出DRAM核心的访问速度。
DDR3 DIMM有240针,数量和尺寸都和DDR2一样,但它们在电气特性上是不兼容的,缺口位置不一样,未来,DDR3将工作在更快的时钟频率,目前,市面上存在DDR3-800,1066和1333三种类型。
下表对不同的DDR3 DIMM模块进行了总结。
表3. DDR3 DIMM
| 标准名称 | RAM 时钟频率 | 每秒传输的数据(百万) | 模块名称 | 峰值传输速率 GB/s |
| DDR3-800 | 400 MHz | 800 | PC3-6400 | 6.400 |
| DDR3-1066 | 533 MHz | 1,066 | PC3-8500 | 8.533 |
| DDR3-1333 | 667 MHz | 1,333 | PC3-10600 | 10.667 |
| DDR3-1600 | 800 MHz | 1,600 | PC3-12800 | 12.800 |
| DDR3-1866 | 933 MHz | 1,866 | PC3-14900 | 14.900 |
三、I/O子系统
I/O子系统负责在服务器内存和外部世界之间搬运数据,传统上,它是通过服务器主板上兼容PCI标准的I/O总线实现的,开发PCI的目的就是让计算机系统的外围设备实现互联,PCI的历史非常悠久,现在最新的进化版叫做PCI-Express。
外围组件互联特殊兴趣小组(Peripheral Component Interconnect Special Interest Group ,PCI-SIG)负责开发和增强PCI标准。
PCI Express
PCI Express(PCIe)是一个计算机扩展接口卡格式,旨在替代PCI,PCI-X和AGP。
它消除了整个所有I/O引起的限制,如服务器总线缺少I/O带宽,目前所有的操作系统都支持PCI Express。
上一代基于总线拓扑的PCI和PCI-X已经被点到点连接取代,由此产生的拓扑结构是一个单根联合体的树形结构,根联合体负责系统配置,枚举PCIe资源,管理中断和PCIe树的错误。根联合体和它的端点共享一个地址空间,通过内存读写和中断进行通信。
PCIe使用点到点链接连接两个组件,链接由N个通道组成,每个通道包含两对电路,一对用于传输,另一对用于接收。
南桥(也叫做ICH:I/O Controller Hub)通常会提供多个PCIe通道实现根联合体的功能。
每个通道连接到一个PCI Express端点,一个PCI Express Switch,一个PCIe或一个PCIe桥,如下图所示。
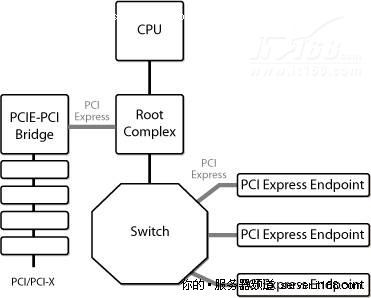
图 21 PCI Express根联合体
根据通道编号使用不同的连接器,下图显示了四个不同的连接器,及单/双向时的速度。

图 22 PCI Express连接器
在PCIe 1.1中,通道运行在2.5Gbps,可同时部署16条通道,如下图所示,可支持的速度从2Gbps(1x)到32Gbps(16x),由于协议开销,支持10GE接口需要8x。
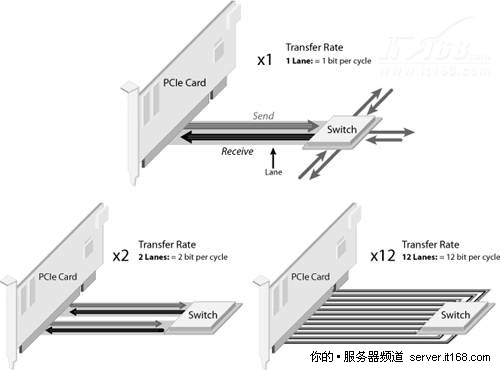
图 23 PCI Express通道
PCIe 2.0(也叫第二代PCIe)带宽提升了一倍,从2Gbit/s提高到4Gbit/s,通道数量也扩大到了32x,PCIe 4x就足以支持10GE了。
PCIe 3.0将会再增加一倍带宽,最终的PCIe 3.0规范预计会在2010年年中发布,到2011年就可看到支持PCIe 3.0的产品,PCIe 3.0能有效地支持40GE(下一代以太网标准)。
目前所有的PCI Express产品都是单根的(Single Root,SR),如控制多个端点的单I/O控制器中枢(ICH)。
多根(Multi Root,MR)也发展了一段时间,但目前还未见到曙光,由于缺少元件和关注,目前还有诸多问题。
SR-IOV(Single Root I/O Virtualization,单根I/O虚拟化)是PCI-SIG开发的另一个相关标准,主要用于连接虚拟机和Hypervisor。
四、英特尔微架构
英特尔Nehalem和Westmere微架构,也被称为32和45nm酷睿微架构。
Nehalem微架构于2009年初引入了服务器,也是第一个使用45nm硅技术的架构,Nehalem处理器可应用于高端桌面应用程序,超大规模服务器平台等,代号名来源于美国俄勒冈州的Nehalem河。
根据英特尔的说法,处理器的发展速度就象嘀嗒(Tick and Tock)钟声的节奏一样,如下图所示,Tick是对现有处理器架构进行缩小,而Tock则是在前一代技术上发展起来的全新架构,Nehalem就是45nm的Tock,Westmere就是紧跟Nehalem的32nm Tick。
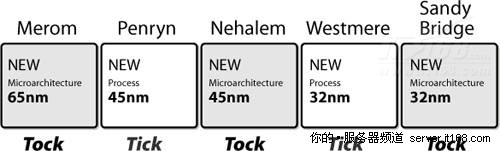
图 24 英特尔“嘀嗒”处理器开发模式
Nehalem和Westmere在不同需求之间取得了平衡:
①. 与新兴应用程序(如多媒体)相比,现有应用程序的性能;
②. 对轻量级或重量级应用程序的支持同样良好;
③. 可用范围从笔记本到服务器全包括。
平台架构
这可能是近10年来英特尔最大的平台架构转变,包括多个高速点到点连接,如英特尔的QuickPath互联,集成内存控制器(IMC)等。
下图显示了一个双插座英特尔至强5500(Nehalem-EP)系统示例,请注意CPU插座之间,以及CPU插座与I/O控制器之间的QPI链接,内存DIMM直接附加到CPU插座。
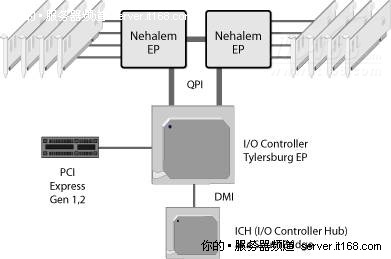
图 25 双插座英特尔至强5500(Nehalem-EP)
集成内存控制器(IMC)
在Nehalem-EP和Westmere-EP中,每个包含集成内存控制器(IMC)的插座支持三个DDR3内存通道,与DDR2相比,DDR3内存运行在更高的频率,因此它具有更高的内存带宽。此外,对于双插座架构,有两套内存控制器,所有这些改进与前一代英特尔平台相比,带宽提高了3.4倍,如下图所示。
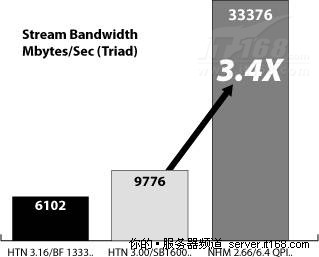
图 26 RAM带宽
随着时间的推移,带宽以后还会继续增加,有了集成的内存控制器后,延迟也减小了。
其功耗也减少了,因为DDR3的工作电压是1.5V,DDR2是1.8V,功耗与电压的平方成正比,因此电压降低20%,功耗就减少40%。
最后,IMC支持单,双和四Rank RDIMM和UDIMM。
Nehalem-EX有一个类似的,但不完全相同的架构,在Nehalem-EX中,每个插座有两个IMC,每个IMC支持两个英特尔可扩展内存互联(Scalable Memory Interconnects,SMI)连接到两个可扩展内存缓冲区(Scalable Memory Buffers,SMB),每个插座就可以连接到四个SMB,如下图所示,每个SMB有两个DDR3总线,每条总线连接到两个DIMM,因此每个插座可连接的RDIMM总量就是16。
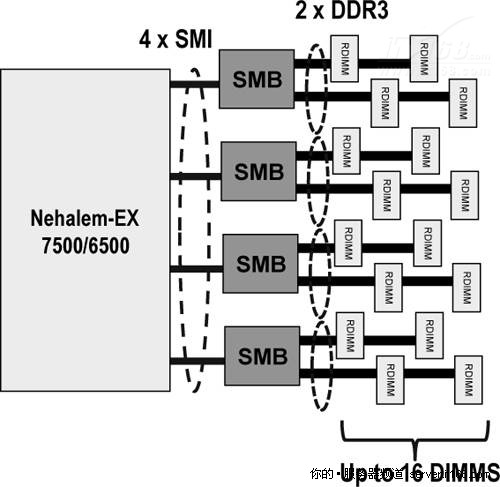
图 27 SMI/SMB
Nehalem-EX系统的总内存容量与插座数量,以及RDIMM的容量总结如下表所示。
表4. Nehalem-EX内存容量
| 4GB RDIMM | 8GB RDIMM | 16GB RDIMM | |
| 2 sockets | 128 GB | 256 GB | 512 GB |
| 4 sockets | 256 GB | 512 GB | 1 TB |
| 8 sockets | 512 GB | 1 TB | 2 TB |
英特尔QuickPath互联(QPI)
所有的通信架构都从总线架构向点到点连接演变,因为点到点连接架构具有更快的速度,更好的扩展性,在Nehalem中,英特尔QuickPath互联已经取代了前端总线,如下图所示。
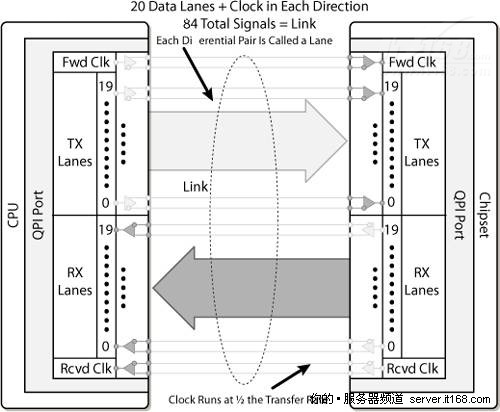
图 28 英特尔QPI
英特尔QuickPath互联是一个一致的点到点协议,不局限于任何特定的处理器,可在处理器,I/O设备和其它设备,如加速器之间提供通信。
可用的QPI数量取决于处理器的类型,在Nehalem-EP和Westmere-EP中,每个插座有两个QPI,如图25所示,Nehalem-EX支持四个QPI,允许更多无缝的拓扑结构,如下图所示。
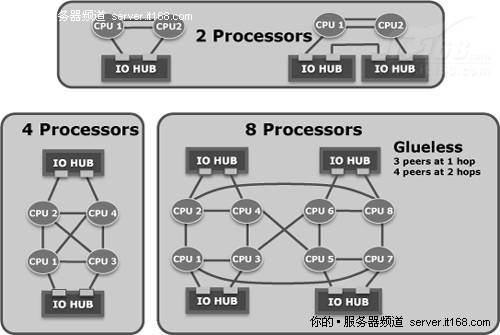
图 29 Nehalem-EX拓扑结构
英特尔至强7500处理器也与第三方节点控制器兼容,可以扩大到8个插座以外,实现更大规模的扩展。
CPU架构
在Nehalem中,英特尔通过一些技术革新,增加了每个CPU每秒执行的指令数,如下图所示。
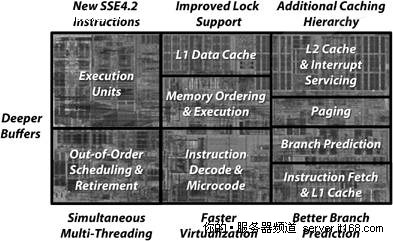
图 30 Nehalem微架构创新
其中有些创新是不言自明的,我们将集中介绍最重要的性能和功耗方面的创新。
在比较性能和功耗时,通常是1%的性能增强就会增多3%的功耗,因为减少1%的电压,功耗几乎总是降低3%。英特尔最重要的创新就是增强1%的性能,而功耗仅增多了1%。
英特尔超线程技术
英特尔超线程技术(HT)可在相同内核上同时运行多个线程,在Nehalem/Westmere中实现了两个线程,提高了性能和能源效率。
超线程的基本思想是增加每个执行单元的复杂度,对于单线程,要保持执行单元繁忙是很困难的,通过在相同核心上运行两个线程,让所有资源保持忙碌的可能性更大,这样整体效率就提高了,如下图所示,超线程使用的领域非常有限(不到5%),但在多线程环境中极大地提高了效率,超线程也不能取代多核心,它是对核心的合理补充。
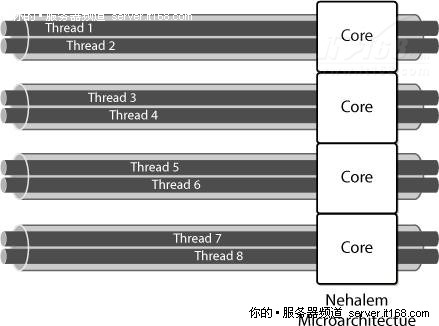
图 31 英特尔超线程技术
缓存分级
一个理想的内存系统的需求是它应该有无限的容量,无限的带宽和零延迟,当然没有人知道如何构建这样的系统,最接近的方法是使用分级的内存子系统,从大到小,从慢到快设计缓存级别,在Nehalem中,英特尔将缓存层增加到了3层,如下图所示。
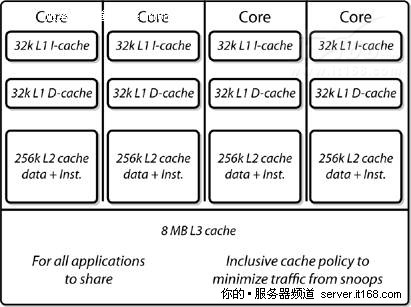
图 32 缓存分级结构
与英特尔以前的设计相比,一级缓存(L1,指令和数据)没有发生变化,在英特尔过去的设计中,所有内核共享二级缓存(L2),如果核心数量限制为2,那这种设计倒是可行的,但Nehalem将核心数增加到了4或8,二级缓存不能再继续共享下去,因为带宽和仲裁请求都会变多(可能会达到8倍),为此,英特尔在Nehalem中为每个核心独立增加了二级缓存(指令和数据),现在核心之间共享的只有三级缓存(L3)了。
模块
Nehalem采用了模块化设计,核心,缓存和英特尔QPI都是组成Nehalem处理器的模块实例,如图30所示。
这些模块都是独立设计的,它们可以工作在不同频率,不同电压下,将模块粘接在一起的是一种新的同步通信协议,它提供了非常低的延迟,以前曾尝试过异步协议,事实证明那样做的效率非常低。
集成功率门限
这是一种电源管理技术,它是“时钟门控”技术的进化版本,所有现代英特尔处理器都使用了时钟门控技术,遇到空闲逻辑时,时钟门控会自动关闭时钟信号,从而消除了开关电源,但仍然存在漏电流,漏电流引起了无用的功耗。
功率门控代替了时钟门控,让一个空闲的核心消耗的电力几乎为零,如下图所示,对于软件和应用程序来说这完全是透明的。
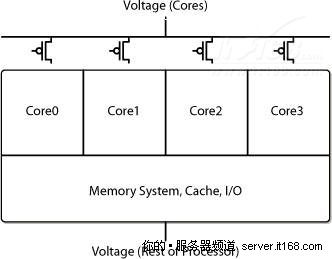
图 33 Nehalem功率门控
从技术角度来看实现功率门控是很难的,传统的45nm工艺就有明显的泄露,它需要新的晶体管技术和大量的铜层(7mm),以前可从来没有这么做过,如下图所示。

图 34 功率门控晶体管
Nehalem-EP和Westmere-EP都拥有“动态的”功率门控能力,当核心不需要执行工作负载时,它可以完全关掉电源,当工作负载需要核心的计算能力时,核心的电源又重新激活。
Nehalem-EX拥有“静态的”功率门控功能,当个别核心失去工作能力时,核心电源被完全关闭,例如,当8核心变成6核心时,这些被停用的核心不能重新打开。对于前一代处理器,在工厂中停用的核心仍然会消耗一些电力,但在Nehalem-EX中,电源是完全关闭的。
电源管理
功率传感器是建设电源管理系统的关键,上一代英特尔处理器内置有热传感器,但没有功率传感器,Nehalem既有热传感器又有功率传感器,通过集成的微控制器(PCU)负责电源管理和监控,如下图所示。
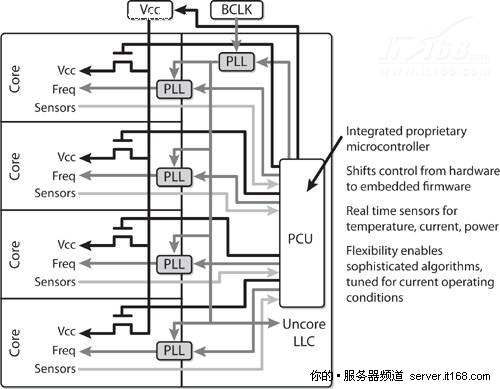
图 35 电源控制单元(Power Control Unit,PCU)
英特尔Turbo Boost技术
功率门控和电源管理是英特尔Turbo Boost技术的基础组件,当操作系统需要更好的性能时可以使用英特尔的Turbo Boost模式,如果条件允许(足够的制冷和供电能力),例如,因为一或多个核心被关闭,英特尔Turbo Boost会提高活动核心的频率(以及功耗),从而提高核心的性能,如下图所示,但它算不上一个巨大的改进(3%-11%),但在无线程,不是所有核心都被并行使用的环境中,它还是很有价值的。每上升一步,频率提高133Mhz。
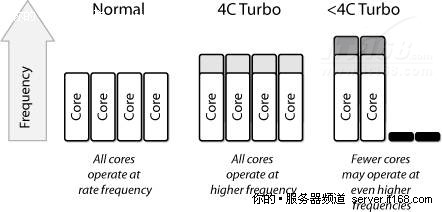
图 36 英特尔Turbo Boost技术
上图显示了三个不同的可能性,正常情况下,所有核心都运行在标称频率(2.66GHz),在“4C Turbo”模式下,所有核心的频率上升一步(达到了2.79GHz),在“<4C Turbo”模式下,两个核心的频率上升了两步(达到了2.93GHz)。
四、硬件辅助虚拟化
英特尔虚拟化技术(Virtualization Technology,VT)扩展了核心平台架构,可以更好地支持虚拟化软件,如VM(虚拟机)和Hypervisor(也叫做虚拟机监视器),如下图所示。
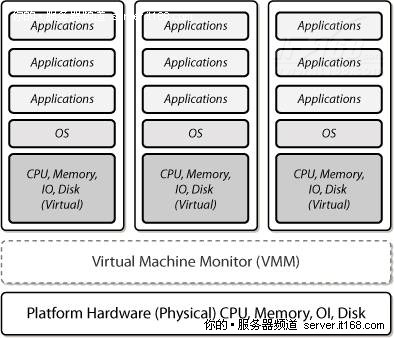
图 37 虚拟化支持
VT包含四个主要的组件:
①. 英特尔VT-x指的是英特尔64和IA32处理器中所有的虚拟化辅助技术;
②. 英特尔VT-d指的是英特尔芯片组中所有虚拟化辅助技术;
③. 英特尔VT-c指的是英特尔网络和I/O设备中所有虚拟化辅助技术;
④. 简化虚拟机移动的VT Flex Migration。
a) 英特尔VT-x增强的功能包括:
⑤. 一个新的,更高特权的Hypervisor – 允许客户机操作系统和应用程序运行在他们设计的特权级别中,确保Hypervisor有权控制平台资源;
⑥. 基于硬件的转移 – 在Hypervisor和客户机操作系统之间转移在硬件级得到了支持,减少了复杂的,计算密集的软件转换需求;
⑦. 基于硬件的内存保护 – 处理器状态信息在专用地址空间为Hypervisor和每个客户机操作系统保留着。
此外,Nehalem还增加了:
①. EPT(Extended Page Table,扩展页表)
②. VPID(Virtual Processor ID,虚拟处理器ID)
③. 客户机计时器优先(Guest Preemption Timer)
④. 描述符表退出(Descriptor Table Exiting)
⑤. 英特尔虚拟化技术FlexPriority
⑥. 暂停退出循环(Pause Loop Exiting)
VT Flex Migration
FlexMigration允许在不同指令集处理器之间移动VM,它是通过同步所有处理器都支持的最小指令集来实现的。
当VM第一次实例化时,它会查询处理器获取指令集水平(SSE2,SSE3,SSE4),处理器返回商定的最低指令集水平,而不是处理器本身支持的指令集水平,这样就允许VMotion在不同指令集处理器之间移动VM了。
扩展页表(EPT)
EPT是一种新的处于Hypervisor控制下的页表结构,如下图所示,它定义了客户机地址和宿主物理地址之间的映射。
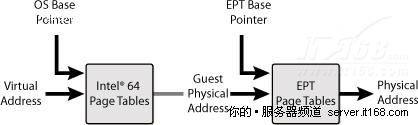
图 38 扩展页表
虚拟化之前,每个操作系统负责虚拟应用程序地址和“物理地址”之间的程序页表转换,使用虚拟化后,这些地址就不再是物理的了,而是在VM中的虚拟地址,Hypervisor需要在客户端操作系统地址和真实物理地址之间转换,在EPT出现之前,Hypervisor通过软件的方式在重要的边界(如VM的入口和出口)更新它们以维护页表。
有了EPT后,有一个EPT基指针和一个EPT页表,允许直接从虚拟地址转换到物理地址,不再需要Hypervisor的介入。
虚拟处理器ID(VPID)
在VPID出现之前的虚拟化环境中,每当VM转换时,CPU会无条件清洗TLB(Translation Lookaside Buffers,转换后备缓冲区),这样做的效率很低,并会影响到CPU的性能,有了VPID后,Hypervisor用一个ID标记TLB,允许更有效地清洗缓冲区中的信息。
客户机优先计时器
有了这个功能后,在指定的时间到了后,Hypervisor可以让客户机优先执行,在进入客户机之前,Hypervisor会设置一个计时器值,当计时器清零时,VM就退出,计时器会让VM直接退出,没有中断。
描述符表退出
通过预防关键系统数据结构被修改,实现VMM保护客户机操作系统预防内部攻击,操作系统操作是由一组CPU使用的关键数据结构控制的:IDT,GDT,LDT和TSS。如果没有这个功能,Hypervisor就无法预防通过修改客户机的这些数据结构副本,实现恶意软件在客户机操作系统上运行的攻击,Hypervisor可以使用这个功能拦截修改这些数据结构的尝试,禁止恶意软件入侵客户机操作系统。
FlexPriority
这是一个提升32位客户机操作系统性能的技术,旨在加快虚拟化中断处理速度,从而提高虚拟化性能,FlexPriority通过避免访问高级可编程中断控制器时不必要的VMExit提高中断处理速度。
RAS高级可靠性
与Nehalem-EP相比,Nehalem-EX最大的创新之处在于高级可靠性方面,更恰当地说应该是RAS(Reliability,Availability和Serviceability,即可靠性,可用性和可维护性),如下图所示。
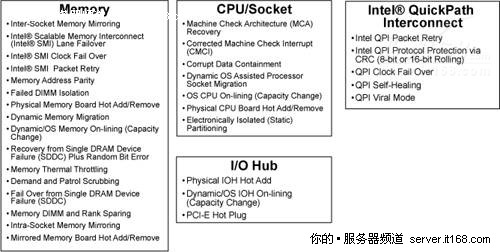
图 39 Nehalem-EX RAS
特别是,所有主要的处理器功能都具有RAS特性,包括QPI RAS,I/O Hub(IOH) RAS,存储器RAS和插座RAS。
纠错现在使用的是纠正机器检查中断(Corrected Machine Check Interrupts,CMCI)信号。
另一个RAS技术是机器检查架构恢复(Machine Check Architecture-recovery,MCAr),它是CPU给操作系统报告硬件错误的一种机制,有了MCAr后,就可以从致命系统错误中恢复过来。
部分功能需要操作系统额外支持,或需要硬件厂商实现和验证。
这项技术目前仅在Nehalem-EX中含有。
高级加密标准
Westmere-EP增加了6个新指令专门给流行的AES(Advanced Encryption Standard,高级加密标准)算法提速,有了这些指令后,所有AES运算都是通过硬件完成的,不只是速度更快,比软件实现也更加安全。
因此应用程序可以使用更强的密钥,可以加密更多数据以满足监管要求,除了更安全外,对性能的影响也更小了。
这项技术目前仅包含在Westmere-EP中。
可信执行技术
英特尔可信执行技术(Trusted Execution Technology,TXT)有助于检测和预防基于软件的攻击,特别是:
①. 尝试插入非信任的VMM(Rootkit Hypervisor)
②. 威胁到平台内存中机密的攻击
③. BIOS和固件更新攻击
英特尔TXT使用一个混合了处理器,芯片组和TPM(Trusted Platform Module,可信赖平台模块)的技术测量引导环境以检测软件攻击,如下图所示。

图 40 英特尔可信执行技术
这项技术目标仅包含在Westmere-EP中。
芯片设计
如果你想获得高性能,又想降低功耗,那么有多个不同的因素需要平衡。
随着晶体管通道的长度逐渐减小,可用的电压范围也变得越来越小,如下图所示。
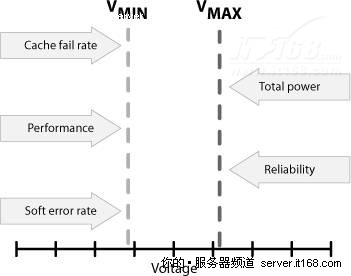
图 41 电压范围
最大电压是由总功耗和高功率相关的可靠性下降限制的,最低电压主要是由软错误,特别是存储器电路中的错误限制的。
一般说来,在CMOS设计中,性能与电压是成正比的,因为电压越高频率也越高。
①. 性能~频率~电压
功耗是与频率和电压的平方成正比的。
②. 功率~频率x电压2
由于频率和电压是成正比的,因此:
③. 功率~电压3
能源效率等于性能和功耗之间比率,因此:
④. 能源效率~1/电压2
从能源效率的角度来看,减少电压才会凸现优势,如下图所示。
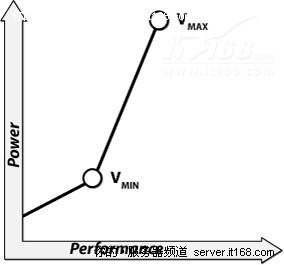
图 42 功耗与性能的关系
由于电路更容易遭受软错误的是存储器,在Nehalem中,英特尔加入了一个复杂的纠错码(三重检测,双倍纠正)纠正错误。此外,缓存的电压和核心的电压是解耦的,因此缓存可以保留高电压,而核心工作在低电压上。
对于L1和L2缓存,英特尔已经用新的8晶体管设计(8-T SRAM)取代了传统的6晶体管SRAM(6-T SRAM)设计,解耦了读和写操作,并允许更低的电压,如下图所示。
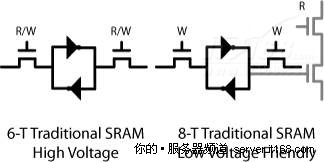
图 43 6晶体管SRAM与8晶体管SRAM对比
此外,为了降低功耗,英特尔又回到了能耗更低的静态CMOS技术,如下图所示。
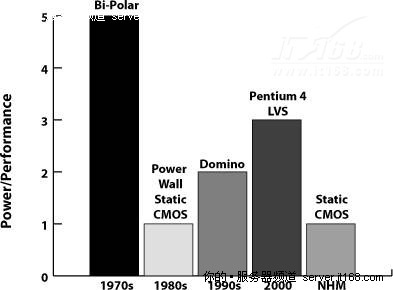
图 44 不同技术的功耗对比
通过重新设计了一些关键算法,如指令解码,再次提升了性能。
芯片组虚拟化支持
除了Nehalem提供的虚拟化支持外,在芯片组和主板级也增强了对虚拟化的支持,这些改进对于提高Hypervisor(按照英特尔的说法,Hypervisor指的是VMM:虚拟机监视器)的I/O性能很重要。
英特尔直接I/O虚拟化技术(VT-d for Direct I/O)
服务器使用一个输入/输出内存管理单元(Input/Output Memory Management Unit,IOMMU)将DMA I/O总线(如PCIe)连接到主存储器,和传统的内存管理单元一样,它将CPU可见的虚拟地址转换成物理地址,IOMMU会将设备可见的虚拟地址映射到物理地址,这些单元也提供了内存保护功能。
I/O虚拟化一个常见的需求是可以隔离和限制设备访问由分区管理设备拥有的资源。
2008年,英特尔公布了IOMMU技术规范:直接I/O虚拟化,缩写为VT-d。
英特尔VT-d给VMM提供了以下功能:
①. I/O设备分配 – 可灵活给VM分配I/O设备,加强保护,为I/O操作隔离VM的属性。
②. DMA重映射 – 为直接内存访问(Direct Memory Accesses,DMA)提供独立的地址转换功能。
③. 中断重映射 – 隔离和路由设备/中断控制器到VM的中断。
④. 可靠性 – 记录并报告系统软件DMA和可能会损坏内存或影响VM隔离的中断错误。
英特尔针对连接的虚拟化技术(VT-c for Connectivity)
英特尔连接虚拟化技术(Virtualization Technology for Connectivity,VT-c)是一套I/O虚拟化技术集,它降低了CPU利用率,减少了系统延迟,提高了网络和I/O吞吐量。
英特尔VT-c由平台级技术和创新的下一代I/O虚拟化技术集合而成:
①. 虚拟机设备队列(Virtual Machine Device Queues,VMDq)极大地提高了服务器的通信管理,为大数据流提供了更好的I/O性能,同时减少了基于软件的虚拟机监视器(VMM)的处理负担。
②. 虚拟机直接连接(Virtual Machine Direct Connect,VMDc)通过专用的I/O虚拟机,完全绕过Hypervisor中的软件虚拟交换机,提供了接近原生的性能,它也增强了虚拟机之间的数据隔离,通过虚拟机实时迁移功能提供了更好的灵活性和机动性。
VMDq
在虚拟环境中,Hypervisor管理所有VM的网络I/O活动,随着VM的增多,I/O负载也随之增加,Hypervisor需要更多的CPU周期给网络接口队列中的数据包排序,然后正确地路由到目标VM。
英特尔虚拟机设备队列(VMDq)通过在芯片组上添加硬件支持,减轻Hypervisor的负担,同时增强网络I/O,特别是有多个网络接口队列时,可以实现硬件级智能排序,如下图所示。
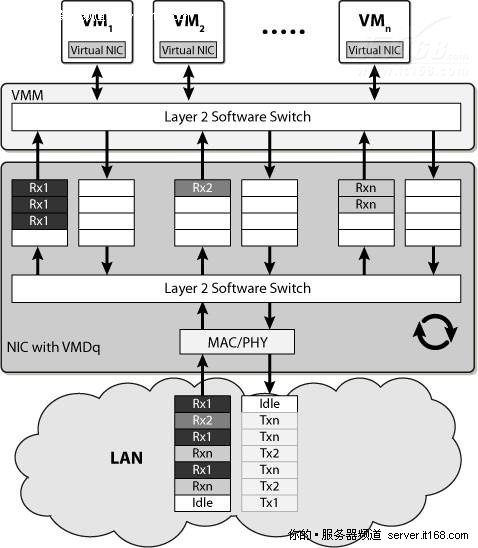
图 45 VMDq
当数据包抵达网络适配器时,网络控制器中的二层分类器/分拣机根据MAC地址和VLAN标记确定每个数据包的目的地应该是哪一个VM,然后按顺序将数据包放入分配给该VM的接收队列中,Hypervisor的二层软件交换机只是将数据包路由到各自的VM,不会执行繁重的数据排序操作。
当数据包从虚拟机朝适配器传输时,Hypervisor会将数据包放入各自的队列,为了防止阻塞,确保每个队列都是公平服务的,网络控制器以一种循环的方式传输队列中的数据包,从而保证服务质量。
NetQueue
如果要充分利用VMDq,需要修改VMM以支持每个虚拟机一个队列,例如,VMware在它的Hypervisor中引入了一个叫做NetQueue的技术,NetQueue可以充分利用帧,VMDq的排序功能,NetQueue和VMDq结合使用可以减轻ESX路由数据包的负担,从而减轻CPU压力,并降低延迟,如下图所示。
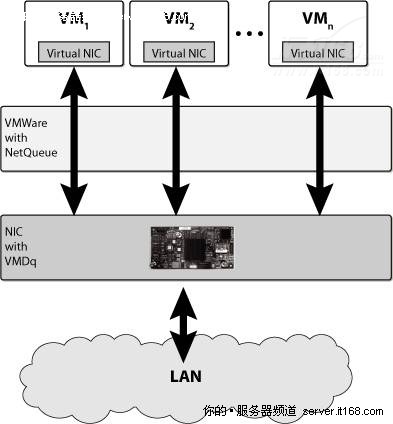
图 46 VMM NetQueue
VMQ
VMQ是微软Hyper-V队列技术,它使用了英特尔以太网控制器的VMDq功能,在传递数据包的过程中,使软件参与处理的过程降低到最少。
VMDc
虚拟机直接连接(VMDc)可给独立的VM分配直接网络I/O,这个功能提高了整体网络性能和VM之间的数据隔离,并让VM实时迁移成为可能。
VMDc符合单根I/O虚拟化标准(Single Root I/O Virtualization,SR-IOV)。
最新的英特尔以太网服务器控制器支持SR-IOV,将物理I/O端口虚拟成多个虚拟的I/O端口,通过这个功能可以让VM实现与物理I/O设备相当的I/O性能,它可以增加物理主机支持的VM数量,增强服务器的整合能力。
VMDirectPath
VMDq和VMDc的结合就诞生了VMware VMDirectPath,以一种类似于“内核搭桥”的方式绕过ESX/vSphere Hypervisor,不使用Hypervisor中的软交换机,数据直接从物理适配器流到vNIC(虚拟网络适配器),反之亦然。



相关推荐
介绍服务器的CPU、内存、IO等不错的资料。网上找到的,推荐阅读。如果版权侵犯,请谅解。
服务器需要具备高速的CPU运算能力、高可靠性、长时间运行能力以及强大的I/O外部数据吞吐能力。\n\n**服务器架构的演进**\n\n服务器架构经历了从大型机到小型机,再到个人计算机和现在的云计算服务器的演变。1964年...
通过深入阅读和理解《Intel IA soft manual V1》,开发者不仅可以提升编写高效汇编代码的能力,还能更好地优化高级语言程序,使其充分利用硬件资源,提高系统性能。对于系统级编程、驱动开发以及对硬件有深度需求的...
Irix的优势在于其强大的扩展能力,可支持512个CPU和1TB的RAM,适合高负荷的服务器I/O处理,尤其在高端和数字媒体市场占据一席之地。然而,MIPS CPU的速度较慢,与PC领域的兼容性问题限制了其商业发展。未来,SGI试图...
硬件要求包括:至少为Pentium II 450 MHz的CPU、128 MB的内存、600 MB的硬盘空间,以及兼容Linux的声卡和16 MB显存,建议系统为FreeBSD 4.03或更高版本,桌面分辨率至少为800x600,颜色深度至少为16位增强色。...
它提供了一种方法,使得来自I/O设备的中断可以被重新定向到不同的CPU核心,而不是简单地直连到固定的处理器。这样做的好处在于能够平衡系统负载,提高性能,同时减少中断风暴对系统的影响。 在禁用中断重映射之前,...
HP Integrity系列服务器的最大特点是其对64位RISC架构的深度优化。它们能够支持多种操作系统,包括HP-UX、Linux和Windows Server,为用户提供了一个灵活多变的计算平台。此外,Integrity服务器还具备出色的可扩展性...
41. **I/O 输入输出**:计算机系统中数据传输的通道,包括键盘、鼠标、显示器和硬盘等。 42. **IA 英特尔架构**:基于英特尔微处理器的计算机系统架构。 43. **IBM 国际商业机器公司**:全球知名的科技公司,涉足...
不同版本(如Enterprise、Developer、Standard、Workgroup和Express Editions)对内存和处理器速度有不同的推荐配置,但所有版本都要求操作系统允许的最大内存。 8. **Google SketchUp Pro WZH-1** 是一个3D建模...
15. IA-32与Intel64架构:Intel64架构扩展了通用寄存器、指令指针和标志寄存器,但未扩展段寄存器。 16. Pentium微处理器线性地址:线性地址等于段基址乘以16加上偏移地址。 17. CPU性能指标:“2.0GHz”指的是CPU...
对称多处理,指在一个系统中所有处理器地位平等,共享相同的内存和总线,协同工作,提高整体性能。 以上列举的术语只是计算机领域中众多专业词汇的一部分,它们覆盖了从硬件封装、指令集架构到系统管理的各个方面,...
3. **能效优化硬件**:选用低功耗CPU和其他组件,同时优化服务器架构,如使用GPU加速计算,提高能效比。 4. **智能管理系统**:通过软件监控和自动化控制,确保数据中心运行在最优状态,及时调整功率分配,减少浪费...