آ آ آ آ آ ه‰چو–‡وڈگهˆ°è؟‡ï¼Œé™¤ن؛†هˆ†ç±»ç®—و³•ن»¥ه¤–,ن¸؛هˆ†ç±»و–‡وœ¬ن½œه¤„çگ†çڑ„特ه¾پوڈگهڈ–ç®—و³•ن¹ںه¯¹وœ€ç»ˆو•ˆوœوœ‰ه·¨ه¤§ه½±ه“چ,而特ه¾پوڈگهڈ–ç®—و³•هڈˆهˆ†ن¸؛特ه¾پ选و‹©ه’Œç‰¹ه¾پوٹ½هڈ–ن¸¤ه¤§ç±»ï¼Œه…¶ن¸ç‰¹ه¾پ选و‹©ç®—و³•وœ‰ن؛’ن؟،وپ¯ï¼Œو–‡و،£é¢‘çژ‡ï¼Œن؟،وپ¯ه¢ç›ٹ,ه¼€و–¹و£€éھŒç‰ç‰هچپو•°ç§چ,è؟™و¬،ه…ˆن»‹ç»چ特ه¾پ选و‹©ç®—و³•ن¸و•ˆوœو¯”较ه¥½çڑ„ه¼€و–¹و£€éھŒو–¹و³•م€‚
آ آ آ آ آ ه¤§ه®¶ه؛”该è؟کè®°ه¾—,ه¼€و–¹و£€éھŒه…¶ه®وک¯و•°çگ†ç»ںè®،ن¸ن¸€ç§چه¸¸ç”¨çڑ„و£€éھŒن¸¤ن¸ھهڈکé‡ڈ独立و€§çڑ„و–¹و³•م€‚(ن»€ن¹ˆï¼ںن½ وک¯و–‡هڈ²ç±»ن¸“ن¸ڑçڑ„ه¦ç”ں,و²،وœ‰ه¦è؟‡و•°çگ†ç»ںè®،ï¼ںé‚£ن½ هپڑن»€ن¹ˆو–‡وœ¬هˆ†ç±»ï¼ںهœ¨è؟™وچ£ن»€ن¹ˆن¹±ï¼ں)
آ آ آ آ آ ه¼€و–¹و£€éھŒوœ€هں؛وœ¬çڑ„و€وƒ³ه°±وک¯é€ڑè؟‡è§‚ه¯ںه®é™…ه€¼ن¸ژçگ†è®؛ه€¼çڑ„هپڈه·®و¥ç،®ه®ڑçگ†è®؛çڑ„و£ç،®ن¸ژهگ¦م€‚ه…·ن½“هپڑçڑ„و—¶ه€™ه¸¸ه¸¸ه…ˆهپ‡è®¾ن¸¤ن¸ھهڈکé‡ڈç،®ه®وک¯ç‹¬ç«‹çڑ„(è،Œè¯ه°±هڈ«هپڑ“هژںهپ‡è®¾â€ï¼‰ï¼Œç„¶هگژ观ه¯ںه®é™…ه€¼ï¼ˆن¹ںهڈ¯ن»¥هڈ«هپڑ观ه¯ںه€¼ï¼‰ن¸ژçگ†è®؛ه€¼ï¼ˆè؟™ن¸ھçگ†è®؛ه€¼وک¯وŒ‡â€œه¦‚وœن¸¤è€…ç،®ه®ç‹¬ç«‹â€çڑ„وƒ…ه†µن¸‹ه؛”该وœ‰çڑ„ه€¼ï¼‰çڑ„هپڈه·®ç¨‹ه؛¦ï¼Œه¦‚وœهپڈه·®è¶³ه¤ںه°ڈ,وˆ‘ن»¬ه°±è®¤ن¸؛误ه·®وک¯ه¾ˆè‡ھ然çڑ„و ·وœ¬è¯¯ه·®ï¼Œوک¯وµ‹é‡ڈو‰‹و®µن¸چه¤ںç²¾ç،®ه¯¼è‡´وˆ–者هپ¶ç„¶هڈ‘ç”ںçڑ„,ن¸¤è€…ç،®ç،®ه®ه®وک¯ç‹¬ç«‹çڑ„,و¤و—¶ه°±وژ¥هڈ—هژںهپ‡è®¾ï¼›ه¦‚وœهپڈه·®ه¤§هˆ°ن¸€ه®ڑ程ه؛¦ï¼Œن½؟ه¾—è؟™و ·çڑ„误ه·®ن¸چه¤ھهڈ¯èƒ½وک¯هپ¶ç„¶ن؛§ç”ںوˆ–者وµ‹é‡ڈن¸چç²¾ç،®و‰€è‡´ï¼Œوˆ‘ن»¬ه°±è®¤ن¸؛ن¸¤è€…ه®é™…ن¸ٹوک¯ç›¸ه…³çڑ„,هچ³هگ¦ه®ڑهژںهپ‡è®¾ï¼Œè€Œوژ¥هڈ—ه¤‡و‹©هپ‡è®¾م€‚
آ آ آ آ é‚£ن¹ˆç”¨ن»€ن¹ˆو¥è،،é‡ڈهپڈه·®ç¨‹ه؛¦ه‘¢ï¼ںهپ‡è®¾çگ†è®؛ه€¼ن¸؛E(è؟™ن¹ںوک¯و•°ه¦وœںوœ›çڑ„符هڈ·ه“¦ï¼‰ï¼Œه®é™…ه€¼ن¸؛x,ه¦‚وœن»…ن»…ن½؟用و‰€وœ‰و ·وœ¬çڑ„观ه¯ںه€¼ن¸ژçگ†è®؛ه€¼çڑ„ه·®ه€¼x-Eن¹‹ه’Œ
آ
و¥è،،é‡ڈ,هچ•ن¸ھçڑ„观ه¯ںه€¼è؟که¥½è¯´ï¼Œه½“وœ‰ه¤ڑن¸ھ观ه¯ںه€¼x1,x2,x3çڑ„و—¶ه€™ï¼Œه¾ˆهڈ¯èƒ½x1-E,x2-E,x3-Eçڑ„ه€¼وœ‰و£وœ‰è´ں,ه› 而ن؛’相وٹµو¶ˆï¼Œن½؟ه¾—وœ€ç»ˆçڑ„结وœçœ‹ن¸ٹه¥½هƒڈهپڈه·®ن¸؛0,ن½†ه®é™…ن¸ٹو¯ڈن¸ھ都وœ‰هپڈه·®ï¼Œè€Œن¸”都è؟کن¸چه°ڈï¼پو¤و—¶ه¾ˆç›´وژ¥çڑ„وƒ³و³•ن¾؟وک¯ن½؟用و–¹ه·®ن»£و›؟ه‡ه€¼ï¼Œè؟™و ·ه°±è§£ه†³ن؛†و£è´ںوٹµو¶ˆçڑ„é—®é¢ک,هچ³ن½؟用
آ آ آ آ آ آ آ آ
آ
è؟™و—¶هڈˆه¼•و¥ن؛†و–°çڑ„é—®é¢ک,ه¯¹ن؛ژ500çڑ„ه‡ه€¼و¥è¯´ï¼Œç›¸ه·®5ه…¶ه®وک¯ه¾ˆه°ڈçڑ„(相ه·®1%),而ه¯¹20çڑ„ه‡ه€¼و¥è¯´ï¼Œ5相ه½“ن؛ژ25%çڑ„ه·®ه¼‚,è؟™وک¯ن½؟用و–¹ه·®ن¹ںو— و³•ن½“çژ°çڑ„م€‚ه› و¤ه؛”该考虑و”¹è؟›ن¸ٹé¢çڑ„ه¼ڈهگ,让ه‡ه€¼çڑ„ه¤§ه°ڈن¸چه½±ه“چوˆ‘ن»¬ه¯¹ه·®ه¼‚程ه؛¦çڑ„هˆ¤و–
آ آ آ آ آ آ آ آ آ آ آ آ آ آ 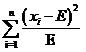 آ آ آ آ آ آ آ آ آ آ آ آ آ آ ه¼ڈ(1)
آ آ آ آ آ آ آ آ آ آ آ آ آ آ ه¼ڈ(1)
ن¸ٹé¢è؟™ن¸ھه¼ڈهگه·²ç»ڈ相ه½“ه¥½ن؛†م€‚ه®é™…ن¸ٹè؟™ن¸ھه¼ڈهگه°±وک¯ه¼€و–¹و£€éھŒن½؟用çڑ„ه·®ه€¼è،،é‡ڈه…¬ه¼ڈم€‚ه½“وڈگن¾›ن؛†و•°ن¸ھو ·وœ¬çڑ„观ه¯ںه€¼x1,x2,……xiآ ,……xnن¹‹هگژ,ن»£ه…¥هˆ°ه¼ڈ(1)ن¸ه°±هڈ¯ن»¥و±‚ه¾—ه¼€و–¹ه€¼ï¼Œç”¨è؟™ن¸ھه€¼ن¸ژن؛‹ه…ˆè®¾ه®ڑçڑ„éکˆه€¼و¯”较,ه¦‚وœه¤§ن؛ژéکˆه€¼ï¼ˆهچ³هپڈه·®ه¾ˆه¤§ï¼‰ï¼Œه°±è®¤ن¸؛هژںهپ‡è®¾ن¸چوˆگ立,هڈچن¹‹هˆ™è®¤ن¸؛هژںهپ‡è®¾وˆگç«‹م€‚
آ آ آ آ آ آ هœ¨و–‡وœ¬هˆ†ç±»é—®é¢کçڑ„特ه¾پ选و‹©éک¶و®µï¼Œوˆ‘ن»¬ن¸»è¦په…³ه؟ƒن¸€ن¸ھè¯چt(ن¸€ن¸ھéڑڈوœ؛هڈکé‡ڈ)ن¸ژن¸€ن¸ھç±»هˆ«c(هڈ¦ن¸€ن¸ھéڑڈوœ؛هڈکé‡ڈ)ن¹‹é—´وک¯هگ¦ç›¸ن؛’独立ï¼ںه¦‚وœç‹¬ç«‹ï¼Œه°±هڈ¯ن»¥è¯´è¯چtه¯¹ç±»هˆ«cه®Œه…¨و²،وœ‰è،¨ه¾پن½œç”¨ï¼Œهچ³وˆ‘ن»¬و ¹وœ¬و— و³•و ¹وچ®tه‡؛çژ°ن¸ژهگ¦و¥هˆ¤و–ن¸€ç¯‡و–‡و،£وک¯هگ¦ه±ن؛ژcè؟™ن¸ھهˆ†ç±»م€‚ن½†ن¸ژوœ€و™®é€ڑçڑ„ه¼€و–¹و£€éھŒن¸چهگŒï¼Œوˆ‘ن»¬ن¸چ需è¦پ设ه®ڑéکˆه€¼ï¼Œه› ن¸؛ه¾ˆéڑ¾è¯´è¯چtه’Œç±»هˆ«cه…³èپ”هˆ°ن»€ن¹ˆç¨‹ه؛¦و‰چç®—وک¯وœ‰è،¨ه¾پن½œç”¨ï¼Œوˆ‘ن»¬هڈھوƒ³ه€ں用è؟™ن¸ھو–¹و³•و¥é€‰ه‡؛ن¸€ن؛›وœ€وœ€ç›¸ه…³çڑ„هچ³هڈ¯م€‚
آ آ آ آ آ و¤و—¶وˆ‘ن»¬ن»چ然需è¦پوکژ白ه¯¹ç‰¹ه¾پ选و‹©و¥è¯´هژںهپ‡è®¾وک¯ن»€ن¹ˆï¼Œه› ن¸؛è®،ç®—ه‡؛çڑ„ه¼€و–¹ه€¼è¶ٹه¤§ï¼Œè¯´وکژه¯¹هژںهپ‡è®¾çڑ„هپڈ离è¶ٹه¤§ï¼Œوˆ‘ن»¬è¶ٹه€¾هگ‘ن؛ژ认ن¸؛هژںهپ‡è®¾çڑ„هڈچé¢وƒ…ه†µوک¯و£ç،®çڑ„م€‚وˆ‘ن»¬èƒ½ن¸چ能وٹٹهژںهپ‡è®¾ه®ڑن¸؛“è¯چtن¸ژç±»هˆ«c相ه…³â€œï¼ںهژںهˆ™ن¸ٹ说ه½“然هڈ¯ن»¥ï¼Œè؟™ن¹ںوک¯ن¸€ن¸ھهپ¥ه…¨çڑ„و°‘ن¸»ن¸»ن¹‰ç¤¾ن¼ڑ赋ن؛ˆو¯ڈن¸ھه…¬و°‘çڑ„وƒهˆ©ï¼ˆç¬‘),ن½†و¤و—¶ن½ ن¼ڑهڈ‘çژ°و ¹وœ¬ن¸چçں¥éپ“و¤و—¶çڑ„çگ†è®؛ه€¼è¯¥وک¯ه¤ڑه°‘ï¼پن½ ن¼ڑوٹٹè‡ھه·±ç»•è؟›و»èƒ،هگŒم€‚و‰€ن»¥وˆ‘ن»¬ن¸€èˆ¬éƒ½ن½؟用â€è¯چtن¸ژç±»هˆ«cن¸چ相ه…³â€œو¥هپڑهژںهپ‡è®¾م€‚选و‹©çڑ„è؟‡ç¨‹ن¹ںهڈکوˆگن؛†ن¸؛و¯ڈن¸ھè¯چè®،ç®—ه®ƒن¸ژç±»هˆ«cçڑ„ه¼€و–¹ه€¼ï¼Œن»ژه¤§هˆ°ه°ڈوژ’ن¸ھه؛ڈ(و¤و—¶ه¼€و–¹ه€¼è¶ٹه¤§è¶ٹ相ه…³ï¼‰ï¼Œهڈ–ه‰چkن¸ھه°±هڈ¯ن»¥ï¼ˆkه€¼هڈ¯ن»¥و ¹وچ®è‡ھه·±çڑ„需è¦پ选,è؟™ن¹ںوک¯ن¸€ن¸ھهپ¥ه…¨çڑ„و°‘ن¸»ن¸»ن¹‰ç¤¾ن¼ڑ赋ن؛ˆو¯ڈن¸ھه…¬و°‘çڑ„وƒهˆ©ï¼‰م€‚
ه¥½ï¼Œهژںçگ†وœ‰ن؛†ï¼Œè¯¥و¥ن¸ھن¾‹هگ说说هˆ°ه؛•و€ژن¹ˆç®—ن؛†م€‚
آ آ آ آ آ و¯”ه¦‚说çژ°هœ¨وœ‰N篇و–‡و،£ï¼Œه…¶ن¸وœ‰M篇وک¯ه…³ن؛ژن½“育çڑ„,وˆ‘ن»¬وƒ³è€ƒه¯ںن¸€ن¸ھè¯چ“篮çگƒâ€ن¸ژç±»هˆ«â€œن½“育â€ن¹‹é—´çڑ„相ه…³و€§ï¼ˆن»»è°پ都看ه¾—ه‡؛و¥ن¸¤è€…ه¾ˆç›¸ه…³ï¼Œن½†ه¾ˆéپ—و†¾ï¼Œوˆ‘ن»¬وک¯و™؛و…§ç”ں物,è®،ç®—وœ؛ن¸چوک¯ï¼Œه®ƒن¸€ç‚¹ن¹ں看ن¸چه‡؛و¥ï¼Œوƒ³è®©ه®ƒè®¤è¯†هˆ°è؟™ن¸€ç‚¹ï¼Œهڈھ能让ه®ƒç®—算看)م€‚وˆ‘ن»¬وœ‰ه››ن¸ھ观ه¯ںه€¼هڈ¯ن»¥ن½؟用ï¼ڑ
1.آ آ آ آ آ آ آ آ آ هŒ…هگ«â€œç¯®çگƒâ€ن¸”ه±ن؛ژ“ن½“育â€ç±»هˆ«çڑ„و–‡و،£و•°ï¼Œه‘½هگچن¸؛A
2.آ آ آ آ آ آ آ آ آ هŒ…هگ«â€œç¯®çگƒâ€ن½†ن¸چه±ن؛ژ“ن½“育â€ç±»هˆ«çڑ„و–‡و،£و•°ï¼Œه‘½هگچن¸؛B
3.آ آ آ آ آ آ آ آ آ ن¸چهŒ…هگ«â€œç¯®çگƒâ€ن½†هچ´ه±ن؛ژ“ن½“育â€ç±»هˆ«çڑ„و–‡و،£و•°ï¼Œه‘½هگچن¸؛C
4.آ آ آ آ آ آ آ آ آ و—¢ن¸چهŒ…هگ«â€œç¯®çگƒâ€ن¹ںن¸چه±ن؛ژ“ن½“育â€ç±»هˆ«çڑ„و–‡و،£و•°ï¼Œه‘½هگچن¸؛D
用ن¸‹é¢çڑ„è،¨و ¼و›´و¸…و™°ï¼ڑ
|
特ه¾پ选و‹©
|
1ï¼ژه±ن؛ژ“ن½“育â€
|
2ï¼ژن¸چه±ن؛ژ“ن½“育â€
|
و€»آ è®،
|
|
1ï¼ژهŒ…هگ«â€œç¯®çگƒâ€
|
A
|
B
|
A+B
|
|
2ï¼ژن¸چهŒ…هگ«â€œç¯®çگƒâ€
|
C
|
D
|
C+D
|
|
و€»آ و•°
|
A+C
|
B+D
|
آ آ آ آ N
|
ه¦‚وœوœ‰ن؛›ç‰¹ç‚¹ن½ و²،看ه‡؛و¥ï¼Œé‚£وˆ‘说ن¸€è¯´ï¼Œé¦–ه…ˆï¼ŒA+B+C+D=N(è؟™ï¼Œè؟™ن¸چه؛ںè¯هک›ï¼‰م€‚ه…¶و¬،,A+Cçڑ„و„ڈو€ه…¶ه®ه°±وک¯è¯´â€œه±ن؛ژن½“育类çڑ„و–‡ç« و•°é‡ڈâ€ï¼Œه› و¤ï¼Œه®ƒه°±ç‰ن؛ژM,هگŒو—¶ï¼ŒB+Dه°±ç‰ن؛ژN-Mم€‚
آ آ آ آ آ آ ه¥½ï¼Œé‚£ن¹ˆçگ†è®؛ه€¼وک¯ن»€ن¹ˆه‘¢ï¼ںن»¥هŒ…هگ«â€œç¯®çگƒâ€ن¸”ه±ن؛ژ“ن½“育â€ç±»هˆ«çڑ„و–‡و،£و•°ن¸؛ن¾‹م€‚ه¦‚وœهژںهپ‡è®¾وک¯وˆگç«‹çڑ„,هچ³â€œç¯®çگƒâ€ه’Œن½“育类و–‡ç« و²،ن»€ن¹ˆه…³èپ”و€§ï¼Œé‚£ن¹ˆهœ¨و‰€وœ‰çڑ„و–‡ç« ن¸ï¼Œâ€œç¯®çگƒâ€è؟™ن¸ھè¯چ都ه؛”该وک¯ç‰و¦‚çژ‡ه‡؛çژ°ï¼Œè€Œن¸چç®،و–‡ç« وک¯ن¸چوک¯ن½“育类çڑ„م€‚è؟™ن¸ھو¦‚çژ‡ه…·ن½“وک¯ه¤ڑه°‘,وˆ‘ن»¬ه¹¶ن¸چçں¥éپ“,ن½†ن»–ه؛”该ن½“çژ°هœ¨è§‚ه¯ں结وœن¸ï¼ˆه°±ه¥½و¯”وٹ›ç،¬ه¸پçڑ„و¦‚çژ‡وک¯ن؛Œهˆ†ن¹‹ن¸€ï¼Œهڈ¯ن»¥é€ڑè؟‡è§‚ه¯ںه¤ڑو¬،وٹ›çڑ„结وœو¥ه¤§è‡´ç،®ه®ڑ),ه› و¤وˆ‘ن»¬هڈ¯ن»¥è¯´è؟™ن¸ھو¦‚çژ‡وژ¥è؟‘
آ
(ه› ن¸؛A+Bوک¯هŒ…هگ«â€œç¯®çگƒâ€çڑ„و–‡ç« و•°ï¼Œé™¤ن»¥و€»و–‡و،£و•°ه°±وک¯â€œç¯®çگƒâ€ه‡؛çژ°çڑ„و¦‚çژ‡ï¼Œه½“然,è؟™é‡Œè®¤ن¸؛هœ¨ن¸€ç¯‡و–‡ç« ن¸ه‡؛çژ°هچ³هڈ¯ï¼Œè€Œن¸چç®،ه‡؛çژ°ن؛†ه‡ و¬،)而ه±ن؛ژن½“育类çڑ„و–‡ç« و•°ن¸؛A+C,هœ¨è؟™ن؛›ن¸ھو–‡و،£ن¸ï¼Œه؛”该وœ‰
آ
篇هŒ…هگ«â€œç¯®çگƒâ€è؟™ن¸ھè¯چ(و•°é‡ڈن¹کن»¥و¦‚çژ‡هک›ï¼‰م€‚
ن½†ه®é™…وœ‰ه¤ڑه°‘ه‘¢ï¼ں考考ن½ (读者ï¼ڑهˆ‡ï¼Œه½“然وک¯Aه•¦ï¼Œè،¨و ¼é‡Œه†™ç€هک›â€¦â€¦ï¼‰م€‚
و¤و—¶ه¯¹è؟™ç§چوƒ…ه†µçڑ„ه·®ه€¼ه°±ه¾—ه‡؛ن؛†ï¼ˆه¥—用ه¼ڈ(1)çڑ„ه…¬ه¼ڈ),ه؛”该وک¯
آ
هگŒو ·ï¼Œوˆ‘ن»¬è؟کهڈ¯ن»¥è®،ç®—ه‰©ن¸‹ن¸‰ç§چوƒ…ه†µçڑ„ه·®ه€¼D12,D21,D22,èپھوکژçڑ„读者ن¸€ه®ڑ能è‡ھه·±ç®—ه‡؛و¥ï¼ˆè¯»è€…ï¼ڑهˆ‡ï¼Œوکژوکژوک¯è‡ھه·±و‡’ه¾—ه†™ن؛†â€¦â€¦ï¼‰م€‚وœ‰ن؛†و‰€وœ‰è§‚ه¯ںه€¼çڑ„ه·®ه€¼ï¼Œه°±هڈ¯ن»¥è®،算“篮çگƒâ€ن¸ژ“ن½“育â€ç±»و–‡ç« çڑ„ه¼€و–¹ه€¼
آ
وٹٹD11,D12,D21,D22çڑ„ه€¼هˆ†هˆ«ن»£ه…¥ه¹¶هŒ–简,هڈ¯ن»¥ه¾—هˆ°
آ آ آ آ آ



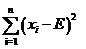
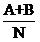
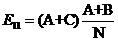

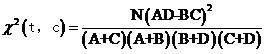 آ آ آ آ آ آ آ آ آ آ ه¼ڈ(
آ آ آ آ آ آ آ آ آ آ ه¼ڈ(


相ه…³وژ¨èچگ
matlabç¼–ه†™çڑ„و–‡وœ¬هˆ†ç±»çڑ„程ه؛ڈ,هڈ¯ن»¥ه¯¹ه·²ç»ڈهˆ†ه¥½è¯چçڑ„و–‡وœ¬è؟›è،Œهˆ†ç±»ï¼Œه…ˆè‡ھه·±ه¯¼ه…¥و•°وچ®ï¼Œç”¨libsvmن¸çڑ„svmè؟›è،Œهˆ†ç±»ه’Œé¢„وµ‹ï¼Œç‰¹ه¾پ用tfidfç®—و³•ï¼Œè؟کهˆ©ç”¨هچ،و–¹و£€éھŒè؟›è،Œن؛†ç‰¹ه¾پ选و‹©ï¼Œهڈ¯è‡ھè،Œè®¾ه®ڑéکˆه€¼م€‚
و–‡و،£é¢‘çژ‡م€پن؟،وپ¯ه¢ç›ٹم€پن؛’ن؟،وپ¯م€پX2ç»ںè®،é‡ڈم€پوœںوœ›ن؛¤هڈ‰ç†µم€پو–‡وœ¬è¯پوچ®وƒه’Œه‡ çژ‡و¯”وک¯وœ¬ç ”究ن¸وڈگهڈٹçڑ„ن¸ƒç§چه¸¸ç”¨çڑ„و–‡وœ¬هˆ†ç±»ç‰¹ه¾پ选و‹©ç®—و³•م€‚و–‡و،£é¢‘çژ‡وک¯é€‰و‹©هœ¨ن¸€ه®ڑو•°é‡ڈçڑ„و–‡و،£ن¸ه‡؛çژ°é¢‘çژ‡é«کن؛ژéکˆه€¼çڑ„特ه¾پï¼›ن؟،وپ¯ه¢ç›ٹوک¯é€ڑè؟‡ن؟،وپ¯ç†µو¥è¯„ن¼°...
FCBFç®—و³•وک¯هں؛ن؛ژوک¾è‘—çڑ„و€وƒ³ï¼Œé‡‡ç”¨هگژهگ‘é،؛ه؛ڈوگœç´¢ç–ç•¥ه؟«é€ںوœ‰و•ˆهœ°ه¯»و‰¾وœ€ن¼ک特ه¾پهگ集çڑ„特ه¾پ选و‹©و–¹و³•ï¼Œه®ƒé‡‡ç”¨ه¯¹ç§°ن¸چç،®ه®ڑو€§ن½œن¸؛相ه…³ç¨‹ه؛¦ه؛¦é‡ڈو ‡ه‡†ï¼Œو¯ڈو¬،选و‹©ن¸€ن¸ھوک¾è‘—特ه¾په¹¶هˆ 除ه®ƒçڑ„و‰€وœ‰ه†—ن½™ç‰¹ه¾پم€‚
“特ه¾پ选و‹©ç®—و³•â€وک¯ن¸“门用ن؛ژن»ژه¤§é‡ڈ特ه¾پن¸ç›é€‰ه‡؛وœ€ن¼کهگ集çڑ„ç®—و³•ï¼Œه¦‚递ه½’特ه¾پو¶ˆé™¤ï¼ˆRFE)م€پهں؛ن؛ژهچ،و–¹و£€éھŒçڑ„选و‹©م€پن؛’ن؟،وپ¯و³•ç‰م€‚è؟™ن؛›ç®—و³•هڈ¯ن»¥ه¸®هٹ©وˆ‘ن»¬é™چن½ژè؟‡و‹ںهگˆé£ژ险,وڈگé«کو¨،ه‹çڑ„预وµ‹و€§èƒ½ï¼Œه¹¶وœ‰هٹ©ن؛ژçگ†è§£ه“ھن؛›ç‰¹ه¾په¯¹ç»“وœ...
ن¸؛ن؛†ه®çژ°è؟™ن¸€ç›®و ‡ï¼Œو–‡وœ¬هˆ†ç±»çڑ„و ¸ه؟ƒهœ¨ن؛ژ特ه¾پوڈگهڈ–,而IG(ن؟،وپ¯ه¢ç›ٹ)و³•ن½œن¸؛ه…¶ن¸ن¸€ç§چوœ‰و•ˆه·¥ه…·ï¼Œه·²ه¹؟و³›ه؛”用ن؛ژو–‡وœ¬ç‰¹ه¾پ选و‹©ن¸م€‚ ن؟،وپ¯ه¢ç›ٹو³•وک¯ن¸€ç§چهں؛ن؛ژ熵çڑ„و¦‚ه؟µو¥è،،é‡ڈ特ه¾پé‡چè¦پو€§çڑ„ه؛¦é‡ڈو–¹و³•ï¼Œوœ€هˆç”¨ن؛ژه†³ç–و ‘çڑ„و„ه»؛م€‚هœ¨و–‡وœ¬...
هں؛ن؛ژtextCNNهچ·ç§¯ç¥ç»ڈ网络çڑ„英و–‡و–°é—»و•°وچ®é›†هˆ†ç±»(AG_news)ç®—و³•و؛گç پ.zip هں؛ن؛ژtextCNNهچ·ç§¯ç¥ç»ڈ网络çڑ„英و–‡و–°é—»و•°وچ®é›†هˆ†ç±»(AG_news)ç®—و³•و؛گç پ.zip هں؛ن؛ژtextCNNهچ·ç§¯ç¥ç»ڈ网络çڑ„英و–‡و–°é—»و•°وچ®é›†هˆ†ç±»(AG_news)ç®—و³•و؛گç پ.zip هں؛ن؛ژ...
ReliefFç®—و³•وک¯ن¸€ç§چهں؛ن؛ژه®ن¾‹çڑ„特ه¾پ选و‹©و–¹و³•ï¼Œه®ƒهœ¨وœ؛ه™¨ه¦ن¹ ه’Œو•°وچ®وŒ–وژک领هںںه¹؟و³›ه؛”用,ه°¤ه…¶هœ¨é«کç»´و•°وچ®ه¤„çگ†ن¸è،¨çژ°ه‡؛色م€‚و¤ç®—و³•çڑ„و ¸ه؟ƒو€وƒ³وک¯è¯„ن¼°و¯ڈن¸ھ特ه¾په¯¹ن؛ژهŒ؛هˆ†ن¸چهگŒç±»هˆ«çڑ„能هٹ›ï¼Œé€ڑè؟‡è®،ç®—è؟‘é‚»ه’Œè؟œé‚»و ·وœ¬ن¹‹é—´çڑ„ه·®ه¼‚و¥ç،®ه®ڑ...
و€»ç»“,Relief特ه¾پ选و‹©ç®—و³•é€ڑè؟‡è،،é‡ڈه®ن¾‹ن¹‹é—´çڑ„特ه¾په·®ه¼‚و¥è¯„ن¼°ه…¶é‡چè¦پو€§ï¼Œé€‚用ن؛ژه¤ڑç±»هˆ«هˆ†ç±»é—®é¢ک,能وœ‰و•ˆهœ°ه¤„çگ†é«کç»´و•°وچ®م€‚هœ¨MATLABن¸ه®çژ°è¯¥ç®—و³•ï¼Œéœ€è¦په¯¹و•°وچ®è؟›è،Œه¤„çگ†ï¼Œه®ڑن¹‰è·ç¦»ه؛¦é‡ڈ,و›´و–°ç‰¹ه¾پوƒé‡چ,ه¹¶وœ€ç»ˆé€‰هڈ–é‡چè¦پ特ه¾پم€‚...
هœ¨"PyCNN_SVMهˆ†ç±»_pythonو–‡وœ¬هˆ†ç±»_و–‡وœ¬هˆ†ç±»_و–‡وœ¬هˆ†ç±»_è¯ن¹‰_"è؟™ن¸ھé،¹ç›®ن¸ï¼Œه¼€هڈ‘者ن½؟用ن؛†Python编程è¯è¨€ه®çژ°ن؛†ن¸€ن¸ھ结هگˆè¯چهµŒه…¥ï¼ˆPyCNN)ه’Œو”¯وŒپهگ‘é‡ڈوœ؛(SVM)çڑ„و–‡وœ¬هˆ†ç±»و¨،ه‹ï¼Œن¸»è¦په…³و³¨è¯ن¹‰è¯†هˆ«ï¼Œن»¥وڈگهچ‡هˆ†ç±»çڑ„ه‡†ç،®و€§م€‚...
و–‡وœ¬ç‰¹ه¾پ选و‹©ç®—و³•çڑ„ç ”ç©¶و–‡وœ¬ç‰¹ه¾پ选و‹©ç®—و³•çڑ„ç ”ç©¶
3. 特ه¾پ选و‹©ï¼ڑو‰¾ه‡؛ه¯¹هˆ†ç±»وœ€وœ‰ه½±ه“چçڑ„特ه¾پ,هڈ¯ن»¥ن½؟用相ه…³و€§هˆ†وگم€پن¸»وˆگهˆ†هˆ†وگ(PCA)ç‰و–¹و³•م€‚ 4. هˆ’هˆ†و•°وچ®ï¼ڑه°†و•°وچ®هˆ†ن¸؛è®ç»ƒé›†ه’Œوµ‹è¯•é›†ï¼Œè®ç»ƒé›†ç”¨ن؛ژè®ç»ƒو¨،ه‹ï¼Œوµ‹è¯•é›†ç”¨ن؛ژ评ن¼°و¨،ه‹و€§èƒ½م€‚ 5. و¨،ه‹è®ç»ƒï¼ڑن½؟用选و‹©çڑ„هˆ†ç±»ç®—و³•...
GA_feature_selector_éپ—ن¼ ç®—و³•ç‰¹ه¾پ_特ه¾پوڈگهڈ–_éپ—ن¼ ç®—و³•_و؛گç پ.zip
هœ¨و–‡وœ¬هˆ†ç±»ن¸ï¼Œè´هڈ¶و–¯ç®—و³•é€ڑè؟‡è®،ç®—و–‡وœ¬ç‰¹ه¾پن¸ژ预ه®ڑن¹‰ç±»هˆ«çڑ„و،ن»¶و¦‚çژ‡ï¼Œو¥é¢„وµ‹و–°و–‡وœ¬و‰€ه±çڑ„ç±»هˆ«م€‚هœ¨ن¸و–‡çژ¯ه¢ƒن¸ï¼Œç”±ن؛ژè¯چو±‡ن¸°ه¯Œو€§ه’Œè¯و³•ç‰¹و€§ï¼Œو–‡وœ¬هˆ†ç±»و›´ه…·وŒ‘وˆکو€§ï¼Œن½†è´هڈ¶و–¯ç®—و³•ه› ه…¶ç®€هچ•é«کو•ˆçڑ„特点,ن¾ç„¶è¢«ه¹؟و³›ه؛”用م€‚ 该...
ç®—و³•ن»ژè®ç»ƒé›†Dن¸é€‰و‹©ن¸€ن¸ھو ·وœ¬R,然هگژن»ژه’ŒRهگŒç±»çڑ„و ·وœ¬ن¸ه¯»و‰¾وœ€è؟‘é‚»و ·وœ¬H,称ن¸؛Near Hit,ن»ژه’ŒRن¸چهگŒç±»çڑ„و ·وœ¬ن¸ه¯»و‰¾وœ€è؟‘و ·وœ¬M,称ن¸؛Near Miss,و ¹وچ®ن»¥ن¸‹è§„هˆ™و›´و–°و¯ڈن¸ھ特ه¾پçڑ„وƒé‡چï¼ڑ ه¦‚وœRه’ŒNear Hitهœ¨وںگن¸ھ特ه¾پن¸ٹçڑ„è·ç¦»...
هœ¨ه½“ه‰چçڑ„و–‡وœ¬هˆ†ç±»و–¹و³•ن¸ï¼Œé€ڑه¸¸ç»“هگˆè¯چ袋و¨،ه‹م€پTF-IDFم€پn-gramم€پè¯چهگ‘é‡ڈ(ه¦‚Word2Vecم€پGloVe)ç‰ç‰¹ه¾پè،¨ç¤؛و–¹و³•ï¼Œه†چهˆ©ç”¨ç›‘ç£ه¦ن¹ ç®—و³•ï¼ˆه¦‚وœ´ç´ è´هڈ¶و–¯م€پو”¯وŒپهگ‘é‡ڈوœ؛م€پو·±ه؛¦ه¦ن¹ و¨،ه‹ه¦‚CNNه’ŒRNN)è؟›è،Œè®ç»ƒï¼Œن»¥و‰¾هˆ°وœ€ن¼کçڑ„هˆ†ç±»...
هں؛ن؛ژMatlab 2018Bهڈٹو›´é«ک版وœ¬çڑ„و”¯وŒپ,هˆ©ç”¨éڑڈوœ؛و£®و—ç®—و³•ï¼ˆRF)è؟›è،Œé«کو•ˆهˆ†ç±»ç‰¹ه¾پ选و‹©çڑ„ç®—و³•ç ”究,هں؛ن؛ژéڑڈوœ؛و£®و—ç®—و³•çڑ„هˆ†ç±»و•°وچ®ç‰¹ه¾پ选و‹©ç®—و³•â€”—هں؛ن؛ژMatlab 2018Bهڈٹو›´é«ک版وœ¬çڑ„ه®çژ°,هں؛ن؛ژéڑڈوœ؛و£®و—ç®—و³•(RF)çڑ„هˆ†ç±»و•°وچ®ç‰¹ه¾پ选و‹©...
م€گو ‡é¢کم€‘SPA(Sequential Projection Algorithm)è؟ç»وٹ•ه½±ç®—و³•وک¯ن¸€ç§چهœ¨و•°وچ®وŒ–وژکه’Œوœ؛ه™¨ه¦ن¹ 领هںںه¹؟و³›ه؛”用çڑ„特ه¾پ选و‹©و–¹و³•م€‚ه®ƒé€ڑè؟‡ه¯»و‰¾وœ€ن¼کçڑ„هگ集و¥ه‡ڈه°‘هژںه§‹ç‰¹ه¾پçڑ„و•°é‡ڈ,هگŒو—¶ن؟وŒپو•°وچ®é›†ن¸çڑ„é‡چè¦پن؟،وپ¯ï¼Œن»¥وڈگهچ‡و¨،ه‹çڑ„و•ˆçژ‡ه’Œ...
وµپه½¢ه¦ن¹ ç®—و³•è؟›è،Œه›¾هƒڈ特ه¾پوڈگهڈ–ç®—و³•ï¼Œن»¥هڈٹو•°وچ®é™چç»´ç®—و³•
用ن؛ژmatlabو¨،ه¼ڈ识هˆ«ï¼ˆهˆ†ç±»ه’Œه›ه½’)çڑ„特ه¾پهڈکé‡ڈوڈگهڈ–و–¹و³•ï¼Œç«ن؛‰و€§è‡ھ适ه؛”é‡چهٹ وƒç®—و³•ï¼ˆCARS)وک¯é€ڑè؟‡è‡ھ适ه؛”é‡چهٹ وƒé‡‡و ·ï¼ˆARS)وٹ€وœ¯é€‰و‹©ه‡؛PLSو¨،ه‹ن¸ه›ه½’ç³»و•°ç»ه¯¹ه€¼ه¤§çڑ„و³¢é•؟点,هژ»وژ‰وƒé‡چه°ڈçڑ„و³¢é•؟点,هˆ©ç”¨ن؛¤ن؛’éھŒè¯پ选ه‡؛RMSECVوŒ‡...