
дёҖпјҺВ зҙўеј•д»Ӣз»Қ
В 1.1В В зҙўеј•зҡ„еҲӣе»әВ иҜӯжі•В пјҡВ В
CREATEВ UNIUQEВ |В BITMAPВ INDEXВ <schema>.<index_name>
В В В В В В В ONВ <schema>.<table_name>
В В В В В В В В В В В В (<column_name>В |В <expression>В ASCВ |В DESC,В
В В В В В В В В В В В В В В <column_name>В |В <expression>В ASCВ |В DESC,...)В
В В В В В TABLESPACEВ <tablespace_name>В
В В В В В STORAGEВ <storage_settings>В
В В В В В LOGGINGВ |В NOLOGGINGВ
В В В В COMPUTEВ STATISTICSВ
В В В В В NOCOMPRESSВ |В COMPRESS<nn>В
В В В В В NOSORTВ |В REVERSEВ
В В В В В PARTITIONВ |В GLOBALВ PARTITION<partition_setting>
В
зӣёе…іиҜҙжҳҺ
1пјүВ В UNIQUEВ |В BITMAPВ пјҡжҢҮе®ҡUNIQUEВ дёәе”ҜдёҖеҖјзҙўеј•пјҢВ BITMAPВ дёәдҪҚеӣҫзҙўеј•пјҢВ зңҒз•ҘдёәB-TreeВ зҙўеј•гҖӮВ
2пјүВ <column_name>В |В <expression>В ASCВ |В DESCВ пјҡеҸҜд»ҘеҜ№еӨҡеҲ—иҝӣиЎҢиҒ”еҗҲзҙўеј•пјҢеҪ“дёәexpressionВ ж—¶еҚіВ вҖңВ еҹәдәҺеҮҪж•°зҡ„зҙўеј•В вҖқВ
3пјүВ TABLESPACEВ пјҡжҢҮе®ҡеӯҳж”ҫзҙўеј•зҡ„иЎЁз©әй—ҙВ (зҙўеј•е’ҢеҺҹиЎЁдёҚеңЁдёҖдёӘиЎЁз©әй—ҙж—¶ж•ҲзҺҮжӣҙй«ҳВ )В
4пјүВ STORAGEВ пјҡеҸҜиҝӣдёҖжӯҘи®ҫзҪ®иЎЁз©әй—ҙзҡ„еӯҳеӮЁеҸӮж•°В
5пјүВ LOGGINGВ |В NOLOGGINGВ пјҡжҳҜеҗҰеҜ№зҙўеј•дә§з”ҹйҮҚеҒҡж—Ҙеҝ—(В еҜ№еӨ§иЎЁе°ҪйҮҸдҪҝз”ЁВ NOLOGGINGВ жқҘеҮҸе°‘еҚ з”Ёз©әй—ҙ并жҸҗй«ҳж•ҲзҺҮВ )В
6пјүВ COMPUTEВ STATISTICSВ пјҡеҲӣе»әж–°зҙўеј•ж—¶ж”¶йӣҶз»ҹи®ЎдҝЎжҒҜВ
7пјүВ NOCOMPRESSВ |В COMPRESS<nn>В пјҡжҳҜеҗҰдҪҝз”ЁвҖңВ й”®еҺӢзј©В вҖқ(В дҪҝз”Ёй”®еҺӢзј©еҸҜд»ҘеҲ йҷӨдёҖдёӘй”®еҲ—дёӯеҮәзҺ°зҡ„йҮҚеӨҚеҖјВ )В
8пјүВ NOSORTВ |В REVERSEВ пјҡNOSORTВ иЎЁзӨәдёҺиЎЁдёӯзӣёеҗҢзҡ„йЎәеәҸеҲӣе»әзҙўеј•пјҢВ REVERSEВ иЎЁзӨәзӣёеҸҚйЎәеәҸеӯҳеӮЁзҙўеј•еҖјВ
9пјүВ PARTITIONВ |В NOPARTITIONВ пјҡеҸҜд»ҘеңЁВ еҲҶеҢәиЎЁВ е’ҢжңӘеҲҶеҢәиЎЁдёҠеҜ№еҲӣе»әзҡ„зҙўеј•иҝӣиЎҢеҲҶеҢә
В
В
1.В 2В В зҙўеј•зү№зӮ№пјҡВ В
第дёҖВ пјҢйҖҡиҝҮеҲӣе»әе”ҜдёҖжҖ§зҙўеј•пјҢеҸҜд»ҘдҝқиҜҒж•°жҚ®еә“иЎЁдёӯжҜҸдёҖиЎҢж•°жҚ®зҡ„е”ҜдёҖжҖ§гҖӮВ
第дәҢВ пјҢеҸҜд»ҘеӨ§еӨ§еҠ еҝ«ж•°жҚ®зҡ„жЈҖзҙўйҖҹеәҰпјҢиҝҷд№ҹжҳҜеҲӣе»әзҙўеј•зҡ„жңҖдё»иҰҒзҡ„еҺҹеӣ гҖӮВ
第дёүВ пјҢеҸҜд»ҘеҠ йҖҹиЎЁе’ҢиЎЁд№Ӣй—ҙзҡ„иҝһжҺҘпјҢзү№еҲ«жҳҜеңЁе®һзҺ°ж•°жҚ®зҡ„еҸӮиҖғе®Ңж•ҙжҖ§ж–№йқўзү№еҲ«жңүж„Ҹд№үгҖӮВ
第еӣӣВ пјҢеңЁдҪҝз”ЁеҲҶз»„е’ҢжҺ’еәҸеӯҗеҸҘиҝӣиЎҢж•°жҚ®жЈҖзҙўж—¶пјҢеҗҢж ·еҸҜд»Ҙжҳҫи‘—еҮҸе°‘жҹҘиҜўдёӯеҲҶз»„е’ҢжҺ’еәҸзҡ„ж—¶й—ҙгҖӮВ
第дә”В пјҢйҖҡиҝҮдҪҝз”Ёзҙўеј•пјҢеҸҜд»ҘеңЁжҹҘиҜўзҡ„иҝҮзЁӢдёӯпјҢдҪҝз”ЁдјҳеҢ–йҡҗи—ҸеҷЁпјҢжҸҗй«ҳзі»з»ҹзҡ„жҖ§иғҪгҖӮВ
В
В
1.В 3В В зҙўеј•дёҚи¶іпјҡ
第дёҖВ пјҢеҲӣе»әзҙўеј•е’Ңз»ҙжҠӨзҙўеј•иҰҒиҖ—иҙ№ж—¶й—ҙпјҢиҝҷз§Қж—¶й—ҙйҡҸзқҖж•°жҚ®йҮҸзҡ„еўһеҠ иҖҢеўһеҠ гҖӮВ
第дәҢВ пјҢзҙўеј•йңҖиҰҒеҚ зү©зҗҶз©әй—ҙпјҢйҷӨдәҶж•°жҚ®иЎЁеҚ ж•°жҚ®з©әй—ҙд№ӢеӨ–пјҢжҜҸдёҖдёӘзҙўеј•иҝҳиҰҒеҚ дёҖе®ҡзҡ„зү©зҗҶз©әй—ҙпјҢеҰӮжһңиҰҒе»әз«ӢиҒҡз°Үзҙўеј•пјҢйӮЈд№ҲйңҖиҰҒзҡ„з©әй—ҙе°ұдјҡжӣҙеӨ§гҖӮВ
第дёүВ пјҢеҪ“еҜ№иЎЁдёӯзҡ„ж•°жҚ®иҝӣиЎҢеўһеҠ гҖҒеҲ йҷӨе’Ңдҝ®ж”№зҡ„ж—¶еҖҷпјҢзҙўеј•д№ҹиҰҒеҠЁжҖҒзҡ„з»ҙжҠӨпјҢиҝҷж ·е°ұйҷҚдҪҺдәҶж•°жҚ®зҡ„з»ҙжҠӨйҖҹеәҰгҖӮВ
В
В
1.В 4В В еә”иҜҘе»әзҙўеј•еҲ—зҡ„зү№зӮ№пјҡ
1пјүВ еңЁз»ҸеёёйңҖиҰҒжҗңзҙўзҡ„еҲ—дёҠпјҢеҸҜд»ҘеҠ еҝ«жҗңзҙўзҡ„йҖҹеәҰпјӣВ
2пјүВ еңЁдҪңдёәдё»й”®зҡ„еҲ—дёҠпјҢејәеҲ¶иҜҘеҲ—зҡ„е”ҜдёҖжҖ§е’Ңз»„з»ҮиЎЁдёӯж•°жҚ®зҡ„жҺ’еҲ—з»“жһ„пјӣВ
3пјүВ еңЁз»Ҹеёёз”ЁеңЁиҝһжҺҘзҡ„еҲ—дёҠпјҢиҝҷдәӣеҲ—дё»иҰҒжҳҜдёҖдәӣеӨ–й”®пјҢеҸҜд»ҘеҠ еҝ«иҝһжҺҘзҡ„йҖҹеәҰпјӣВ
4пјүВ еңЁз»ҸеёёйңҖиҰҒж №жҚ®иҢғеӣҙиҝӣиЎҢжҗңзҙўзҡ„еҲ—дёҠеҲӣе»әзҙўеј•пјҢеӣ дёәзҙўеј•е·Із»ҸжҺ’еәҸпјҢе…¶жҢҮе®ҡзҡ„иҢғеӣҙжҳҜиҝһз»ӯзҡ„пјӣВ
5пјүВ еңЁз»ҸеёёйңҖиҰҒжҺ’еәҸзҡ„еҲ—дёҠеҲӣе»әзҙўеј•пјҢеӣ дёәзҙўеј•е·Із»ҸжҺ’еәҸпјҢиҝҷж ·жҹҘиҜўеҸҜд»ҘеҲ©з”Ёзҙўеј•зҡ„жҺ’еәҸпјҢеҠ еҝ«жҺ’еәҸжҹҘиҜўж—¶й—ҙпјӣВ
6пјүВ еңЁз»ҸеёёдҪҝз”ЁеңЁWHEREВ еӯҗеҸҘдёӯзҡ„еҲ—дёҠйқўеҲӣе»әзҙўеј•пјҢеҠ еҝ«жқЎд»¶зҡ„еҲӨж–ӯйҖҹеәҰгҖӮВ
В
В
1.В 5В В дёҚеә”иҜҘе»әзҙўеј•еҲ—зҡ„зү№зӮ№пјҡ
第дёҖВ пјҢеҜ№дәҺйӮЈдәӣеңЁжҹҘиҜўдёӯеҫҲе°‘дҪҝз”ЁжҲ–иҖ…еҸӮиҖғзҡ„еҲ—дёҚеә”иҜҘеҲӣе»әзҙўеј•гҖӮиҝҷжҳҜеӣ дёәпјҢ既然иҝҷдәӣеҲ—еҫҲе°‘дҪҝз”ЁеҲ°пјҢеӣ жӯӨжңүзҙўеј•жҲ–иҖ…ж— зҙўеј•пјҢ并дёҚиғҪжҸҗй«ҳжҹҘиҜўйҖҹеәҰгҖӮзӣёеҸҚпјҢз”ұдәҺеўһеҠ дәҶзҙўеј•пјҢеҸҚиҖҢйҷҚдҪҺдәҶзі»з»ҹзҡ„з»ҙжҠӨйҖҹеәҰе’ҢеўһеӨ§дәҶз©әй—ҙйңҖжұӮгҖӮВ
第дәҢВ пјҢеҜ№дәҺйӮЈдәӣеҸӘжңүеҫҲе°‘ж•°жҚ®еҖјзҡ„еҲ—д№ҹдёҚеә”иҜҘеўһеҠ зҙўеј•гҖӮиҝҷжҳҜеӣ дёәпјҢз”ұдәҺиҝҷдәӣеҲ—зҡ„еҸ–еҖјеҫҲе°‘пјҢдҫӢеҰӮдәәдәӢиЎЁзҡ„жҖ§еҲ«еҲ—пјҢеңЁжҹҘиҜўзҡ„з»“жһңдёӯпјҢз»“жһңйӣҶзҡ„ж•°жҚ®иЎҢеҚ дәҶиЎЁдёӯж•°жҚ®иЎҢзҡ„еҫҲеӨ§жҜ”дҫӢпјҢеҚійңҖиҰҒеңЁиЎЁдёӯжҗңзҙўзҡ„ж•°жҚ®иЎҢзҡ„жҜ”дҫӢеҫҲеӨ§гҖӮеўһеҠ зҙўеј•пјҢ并дёҚиғҪжҳҺжҳҫеҠ еҝ«жЈҖзҙўйҖҹеәҰгҖӮВ
第дёүВ пјҢеҜ№дәҺйӮЈдәӣе®ҡд№үдёәВ blobВ ж•°жҚ®зұ»еһӢзҡ„еҲ—дёҚеә”иҜҘеўһеҠ зҙўеј•гҖӮиҝҷжҳҜеӣ дёәпјҢиҝҷдәӣеҲ—зҡ„ж•°жҚ®йҮҸиҰҒд№ҲзӣёеҪ“еӨ§пјҢиҰҒд№ҲеҸ–еҖјеҫҲе°‘гҖӮВ
第еӣӣВ пјҢеҪ“дҝ®ж”№жҖ§иғҪиҝңиҝңеӨ§дәҺжЈҖзҙўжҖ§иғҪж—¶пјҢдёҚеә”иҜҘеҲӣе»әзҙўеј•гҖӮиҝҷжҳҜеӣ дёәпјҢдҝ®ж”№жҖ§иғҪе’ҢжЈҖзҙўжҖ§иғҪжҳҜдә’зӣёзҹӣзӣҫзҡ„гҖӮеҪ“еўһеҠ зҙўеј•ж—¶пјҢдјҡжҸҗй«ҳжЈҖзҙўжҖ§иғҪпјҢдҪҶжҳҜдјҡйҷҚдҪҺдҝ®ж”№жҖ§иғҪгҖӮеҪ“еҮҸе°‘зҙўеј•ж—¶пјҢдјҡжҸҗй«ҳдҝ®ж”№жҖ§иғҪпјҢйҷҚдҪҺжЈҖзҙўжҖ§иғҪгҖӮеӣ жӯӨпјҢеҪ“дҝ®ж”№жҖ§иғҪиҝңиҝңеӨ§дәҺжЈҖзҙўжҖ§иғҪж—¶пјҢдёҚеә”иҜҘеҲӣе»әзҙўеј•гҖӮВ
В
В
1.6В В йҷҗеҲ¶зҙўеј•В
йҷҗеҲ¶зҙўеј•жҳҜдёҖдәӣжІЎжңүз»ҸйӘҢзҡ„ејҖеҸ‘дәәе‘ҳз»ҸеёёзҠҜзҡ„й”ҷиҜҜд№ӢдёҖгҖӮеңЁSQLВ дёӯжңүеҫҲеӨҡйҷ·йҳұдјҡдҪҝдёҖдәӣзҙўеј•ж— жі•дҪҝз”ЁгҖӮдёӢйқўи®Ёи®әдёҖдәӣеёёи§Ғзҡ„й—®йўҳпјҡВ
В В В В В 1.6.1В В В дҪҝз”ЁдёҚзӯүдәҺж“ҚдҪңз¬ҰпјҲ<>В гҖҒВ !=В пјүВ В В В В В В В
В В В В В дёӢйқўзҡ„жҹҘиҜўеҚідҪҝеңЁcust_ratingВ еҲ—жңүдёҖдёӘзҙўеј•пјҢжҹҘиҜўиҜӯеҸҘд»Қ然жү§иЎҢдёҖж¬Ўе…ЁиЎЁжү«жҸҸгҖӮВ В В В В В В
В В В selectВ cust_Id,cust_nameВ fromВ customersВ whereВ В cust_ratingВ <>В 'aa';В В В В В В В В В
жҠҠдёҠйқўзҡ„иҜӯеҸҘж”№жҲҗеҰӮдёӢзҡ„жҹҘиҜўиҜӯеҸҘпјҢиҝҷж ·пјҢеңЁйҮҮз”ЁеҹәдәҺ规еҲҷзҡ„дјҳеҢ–еҷЁиҖҢдёҚжҳҜеҹәдәҺд»Јд»·зҡ„дјҳеҢ–еҷЁпјҲжӣҙжҷәиғҪпјүж—¶пјҢе°ҶдјҡдҪҝз”Ёзҙўеј•гҖӮВ В В В В В В В В
В В selectВ cust_Id,cust_nameВ fromВ customersВ whereВ cust_ratingВ <В 'aa'В orВ cust_ratingВ >В 'aa';В
В В зү№еҲ«жіЁж„ҸпјҡйҖҡиҝҮжҠҠдёҚзӯүдәҺж“ҚдҪңз¬Ұж”№жҲҗВ ORВ жқЎд»¶пјҢе°ұеҸҜд»ҘдҪҝз”Ёзҙўеј•пјҢд»ҘйҒҝе…Қе…ЁиЎЁжү«жҸҸгҖӮВ
В В В В В 1.6.В 2В дҪҝз”ЁВ ISВ NULLВ В жҲ–В ISВ NOTВ NULLВ
В В В дҪҝз”ЁВ ISВ NULLВ В жҲ–В ISВ NOTВ NULLВ еҗҢж ·дјҡйҷҗеҲ¶зҙўеј•зҡ„дҪҝз”ЁВ гҖӮеӣ дёәВ NULLВ еҖје№¶жІЎжңүиў«е®ҡд№үгҖӮеңЁВ SQLВ иҜӯеҸҘдёӯдҪҝз”ЁNULLВ дјҡжңүеҫҲеӨҡзҡ„йә»зғҰгҖӮеӣ жӯӨе»әи®®ејҖеҸ‘дәәе‘ҳеңЁе»әиЎЁж—¶пјҢжҠҠйңҖиҰҒзҙўеј•зҡ„еҲ—и®ҫжҲҗВ В NOTВ NULLВ гҖӮеҰӮжһңиў«зҙўеј•зҡ„еҲ—еңЁжҹҗдәӣиЎҢдёӯеӯҳеңЁВ NULLВ еҖјпјҢе°ұдёҚдјҡдҪҝз”ЁиҝҷдёӘзҙўеј•пјҲйҷӨйқһзҙўеј•жҳҜдёҖдёӘдҪҚеӣҫзҙўеј•пјҢе…ідәҺдҪҚеӣҫзҙўеј•еңЁзЁҚеҗҺеңЁиҜҰз»Ҷи®Ёи®әпјүгҖӮВ
В В В В 1.6В .3В дҪҝз”ЁеҮҪж•°В
В В В еҰӮжһңдёҚдҪҝз”ЁеҹәдәҺеҮҪж•°зҡ„зҙўеј•пјҢйӮЈд№ҲеңЁSQLВ иҜӯеҸҘзҡ„В WHEREВ еӯҗеҸҘдёӯеҜ№еӯҳеңЁзҙўеј•зҡ„еҲ—дҪҝз”ЁеҮҪж•°ж—¶пјҢдјҡдҪҝдјҳеҢ–еҷЁеҝҪз•ҘжҺүиҝҷдәӣзҙўеј•гҖӮВ
В В дёӢйқўзҡ„жҹҘиҜўдёҚдјҡдҪҝз”Ёзҙўеј•пјҲеҸӘиҰҒе®ғдёҚжҳҜеҹәдәҺеҮҪж•°зҡ„зҙўеј•пјүВ
В selectВ empno,ename,deptnoВ fromВ empВ В whereВ В trunc(hiredate)='01-MAY-81';В
В В В жҠҠдёҠйқўзҡ„иҜӯеҸҘж”№жҲҗдёӢйқўзҡ„иҜӯеҸҘпјҢиҝҷж ·е°ұеҸҜд»ҘйҖҡиҝҮзҙўеј•иҝӣиЎҢжҹҘжүҫгҖӮВ
selectВ empno,ename,deptnoВ fromВ empВ whereВ В hiredate<(to_date('01-MAY-81')+0.9999);
В В В 1.6В .4В жҜ”иҫғдёҚеҢ№й…Қзҡ„ж•°жҚ®зұ»еһӢВ В В В В В В В
д№ҹжҳҜжҜ”иҫғйҡҫдәҺеҸ‘зҺ°зҡ„жҖ§иғҪй—®йўҳд№ӢдёҖгҖӮВ жіЁж„ҸдёӢйқўжҹҘиҜўзҡ„дҫӢеӯҗпјҢaccount_numberВ жҳҜдёҖдёӘВ VARCHAR2В зұ»еһӢВ ,В еңЁaccount_numberВ еӯ—ж®өдёҠжңүзҙўеј•гҖӮ
дёӢйқўзҡ„иҜӯеҸҘе°Ҷжү§иЎҢе…ЁиЎЁжү«жҸҸВ пјҡ
В В selectВ bank_name,address,city,state,zipВ fromВ banksВ whereВ account_numberВ =В 990354;В
В В OracleеҸҜд»ҘиҮӘеҠЁжҠҠВ whereВ еӯҗеҸҘеҸҳжҲҗВ to_number(account_number)=990354В пјҢиҝҷж ·е°ұйҷҗеҲ¶дәҶзҙўеј•В зҡ„дҪҝз”ЁВ ,В ж”№жҲҗдёӢйқўзҡ„жҹҘиҜўе°ұеҸҜд»ҘдҪҝз”Ёзҙўеј•пјҡВ
В selectВ bank_name,address,city,state,zipВ fromВ banksВ whereВ account_numberВ ='990354';
зү№еҲ«жіЁж„ҸпјҡВ дёҚеҢ№й…Қзҡ„ж•°жҚ®зұ»еһӢд№Ӣй—ҙжҜ”иҫғдјҡи®©OracleВ иҮӘеҠЁйҷҗеҲ¶зҙўеј•зҡ„дҪҝз”ЁВ ,В еҚідҫҝеҜ№иҝҷдёӘжҹҘиҜўжү§иЎҢВ ExplainВ Planд№ҹдёҚиғҪи®©жӮЁжҳҺзҷҪдёәд»Җд№ҲеҒҡдәҶдёҖж¬ЎВ вҖңВ е…ЁиЎЁжү«жҸҸВ вҖқВ гҖӮ
В
В
1.В 7В В жҹҘиҜўВ зҙўеј•В
жҹҘиҜўDBA_INDEXESВ и§ҶеӣҫеҸҜеҫ—еҲ°иЎЁдёӯжүҖжңүзҙўеј•зҡ„еҲ—иЎЁпјҢжіЁж„ҸеҸӘиғҪйҖҡиҝҮВ USER_INDEXESВ зҡ„ж–№жі•жқҘжЈҖзҙўжЁЎејҸ(schema)В зҡ„зҙўеј•гҖӮи®ҝй—®В USER_IND_COLUMNSВ и§ҶеӣҫеҸҜеҫ—еҲ°дёҖдёӘз»ҷе®ҡиЎЁдёӯиў«зҙўеј•зҡ„зү№е®ҡеҲ—гҖӮ
1.В 8В В В з»„еҗҲзҙўеј•В
еҪ“жҹҗдёӘзҙўеј•еҢ…еҗ«жңүеӨҡдёӘе·Ізҙўеј•зҡ„еҲ—ж—¶пјҢз§°иҝҷдёӘзҙўеј•дёәВ з»„еҗҲпјҲconcatentedВ пјүзҙўеј•В гҖӮеңЁВ Oracle9iВ еј•е…Ҙи·іи·ғејҸжү«жҸҸзҡ„зҙўеј•и®ҝй—®ж–№жі•д№ӢеүҚпјҢжҹҘиҜўеҸӘиғҪеңЁжңүйҷҗжқЎд»¶дёӢдҪҝз”ЁиҜҘзҙўеј•гҖӮжҜ”еҰӮпјҡиЎЁВ empВ жңүдёҖдёӘз»„еҗҲзҙўеј•й”®пјҢиҜҘзҙўеј•еҢ…еҗ«дәҶВ empnoгҖҒВ В enameВ е’ҢВ deptnoВ гҖӮеңЁВ Oracle9iВ д№ӢеүҚйҷӨйқһеңЁВ whereВ д№ӢеҸҘдёӯеҜ№з¬¬дёҖеҲ—пјҲВ empnoВ пјүжҢҮе®ҡдёҖдёӘеҖјпјҢеҗҰеҲҷе°ұдёҚиғҪдҪҝз”ЁиҝҷдёӘзҙўеј•й”®иҝӣиЎҢдёҖж¬ЎиҢғеӣҙжү«жҸҸгҖӮВ
В В В В зү№еҲ«жіЁж„ҸпјҡеңЁOracle9iВ д№ӢеүҚпјҢеҸӘжңүеңЁдҪҝз”ЁеҲ°зҙўеј•зҡ„еүҚеҜјзҙўеј•ж—¶жүҚеҸҜд»ҘдҪҝз”Ёз»„еҗҲзҙўеј•пјҒВ
В
1.В 9В В ORACLEВ ROWIDВ
йҖҡиҝҮжҜҸдёӘиЎҢзҡ„ROWIDВ пјҢзҙўеј•В OracleВ жҸҗдҫӣдәҶи®ҝй—®еҚ•иЎҢж•°жҚ®зҡ„иғҪеҠӣгҖӮВ ROWIDВ е…¶е®һе°ұжҳҜзӣҙжҺҘжҢҮеҗ‘еҚ•зӢ¬иЎҢзҡ„зәҝи·ҜеӣҫгҖӮеҰӮжһңжғіжЈҖжҹҘйҮҚеӨҚеҖјжҲ–жҳҜе…¶д»–еҜ№В ROWIDВ жң¬иә«зҡ„еј•з”ЁпјҢеҸҜд»ҘеңЁд»»дҪ•иЎЁдёӯдҪҝз”Ёе’ҢжҢҮе®ҡВ rowidВ еҲ—гҖӮ
В
1.10В В йҖүжӢ©жҖ§В
В В В дҪҝз”ЁUSER_INDEXESВ и§ҶеӣҫпјҢиҜҘи§ҶеӣҫдёӯжҳҫзӨәдәҶдёҖдёӘВ distinct_keysВ еҲ—гҖӮжҜ”иҫғдёҖдёӢе”ҜдёҖй”®зҡ„ж•°йҮҸе’ҢиЎЁдёӯзҡ„иЎҢж•°пјҢе°ұеҸҜд»ҘеҲӨж–ӯзҙўеј•зҡ„йҖүжӢ©жҖ§гҖӮйҖүжӢ©жҖ§и¶Ҡй«ҳпјҢзҙўеј•иҝ”еӣһзҡ„ж•°жҚ®е°ұи¶Ҡе°‘гҖӮ
1.11В В зҫӨйӣҶеӣ еӯҗ(ClusteringВ Factor)В
В В ClusteringВ FactorдҪҚдәҺВ USER_INDEXESВ и§ҶеӣҫдёӯгҖӮиҜҘеҲ—еҸҚжҳ дәҶж•°жҚ®зӣёеҜ№дәҺе·ІВ е»әВ зҙўеј•зҡ„еҲ—жҳҜеҗҰжҳҫеҫ—жңүеәҸгҖӮеҰӮжһңClusteringВ FactorВ еҲ—зҡ„еҖјжҺҘиҝ‘дәҺзҙўеј•дёӯзҡ„ж ‘еҸ¶еқ—В (leafВ block)В зҡ„ж•°зӣ®пјҢиЎЁдёӯзҡ„ж•°жҚ®е°ұи¶ҠжңүеәҸгҖӮеҰӮжһңе®ғзҡ„еҖјжҺҘиҝ‘дәҺиЎЁдёӯзҡ„иЎҢж•°пјҢеҲҷиЎЁдёӯзҡ„ж•°жҚ®е°ұдёҚжҳҜеҫҲжңүеәҸгҖӮ
1.12В В дәҢе…ғй«ҳеәҰ(BinaryВ height)В
В В зҙўеј•зҡ„дәҢе…ғй«ҳеәҰеҜ№жҠҠROWIDВ иҝ”еӣһз»ҷз”ЁжҲ·иҝӣзЁӢж—¶жүҖиҰҒжұӮзҡ„В I/OВ йҮҸиө·еҲ°е…ій”®дҪңз”ЁгҖӮеңЁеҜ№дёҖдёӘзҙўеј•иҝӣиЎҢеҲҶжһҗеҗҺпјҢеҸҜд»ҘйҖҡиҝҮжҹҘиҜўВ DBA_INDEXESВ зҡ„В B-В levelВ еҲ—жҹҘзңӢе®ғзҡ„дәҢе…ғй«ҳеәҰВ гҖӮдәҢе…ғй«ҳеәҰдё»иҰҒйҡҸзқҖиЎЁзҡ„еӨ§е°Ҹд»ҘеҸҠиў«зҙўеј•зҡ„еҲ—дёӯеҖјзҡ„иҢғеӣҙзҡ„зӢӯзӘ„зЁӢеәҰиҖҢеҸҳеҢ–гҖӮзҙўеј•дёҠеҰӮжһңжңүеӨ§йҮҸиў«еҲ йҷӨзҡ„иЎҢпјҢе®ғзҡ„дәҢе…ғй«ҳеәҰд№ҹдјҡеўһеҠ гҖӮжӣҙж–°зҙўеј•еҲ—д№ҹзұ»дјјдәҺеҲ йҷӨж“ҚдҪңпјҢеӣ дёәе®ғеўһеҠ дәҶе·ІеҲ йҷӨй”®зҡ„ж•°зӣ®гҖӮВ йҮҚе»әзҙўеј•еҸҜиғҪдјҡйҷҚдҪҺдәҢе…ғй«ҳеәҰВ гҖӮ
1.13В В еҝ«йҖҹе…ЁеұҖжү«жҸҸВ
В В В д»ҺВ Oracle7.3еҗҺе°ұеҸҜд»ҘдҪҝз”Ёеҝ«йҖҹе…ЁеұҖжү«жҸҸВ (FastВ FullВ Scan)В иҝҷдёӘйҖүйЎ№гҖӮиҝҷдёӘйҖүйЎ№е…Ғи®ёВ OracleВ жү§иЎҢдёҖдёӘе…ЁеұҖзҙўеј•жү«жҸҸж“ҚдҪңгҖӮеҝ«йҖҹе…ЁеұҖжү«жҸҸиҜ»еҸ–В B-В ж ‘зҙўеј•дёҠжүҖжңүж ‘еҸ¶еқ—гҖӮеҲқе§ӢеҢ–ж–Ү件дёӯзҡ„В В DB_FILE_MULTIBLOCK_READ_COUNTеҸӮж•°еҸҜд»ҘжҺ§еҲ¶еҗҢж—¶иў«иҜ»еҸ–зҡ„еқ—зҡ„ж•°зӣ®гҖӮ
1.14В В и·іи·ғејҸжү«жҸҸВ
В В д»ҺOracle9iВ ејҖе§ӢпјҢзҙўеј•и·іи·ғејҸжү«жҸҸзү№жҖ§еҸҜд»Ҙе…Ғи®ёдјҳеҢ–еҷЁдҪҝз”Ёз»„еҗҲзҙўеј•пјҢеҚідҫҝзҙўеј•зҡ„еүҚеҜјеҲ—жІЎжңүеҮәзҺ°еңЁВ WHEREВ еӯҗеҸҘдёӯгҖӮзҙўеј•и·іи·ғејҸжү«жҸҸжҜ”е…Ёзҙўеј•жү«жҸҸВ иҰҒеҝ«зҡ„еӨҡгҖӮ
дёӢйқўзҡ„В жҜ”иҫғ他们зҡ„еҢәеҲ«В пјҡВ
SQL>В setВ timingВ on
SQL>В createВ indexВ TT_indexВ onВ TT(teamid,areacode);
зҙўеј•е·ІеҲӣе»әгҖӮ
е·Із”Ёж—¶й—ҙ:В В 00:В 02:В 03.93
SQL>В selectВ count(areacode)В fromВ tt;
COUNT(AREACODE)
---------------
В 7230369
е·Із”Ёж—¶й—ҙ:В В 00:В 00:В 08.31
SQL>В selectВ В /*+В index(ttВ TT_indexВ )*/В В count(areacode)В fromВ tt;
COUNT(AREACODE)
---------------
7230369
е·Із”Ёж—¶й—ҙ:В В 00:В 00:В 07.37
1.15В В зҙўеј•зҡ„зұ»еһӢВ
- B-ж ‘зҙўеј•В В В В В
- дҪҚеӣҫзҙўеј•В В В
- HASHзҙўеј•В В В В
- зҙўеј•зј–жҺ’иЎЁВ В
- еҸҚиҪ¬й”®зҙўеј•
- еҹәдәҺеҮҪж•°зҡ„зҙўеј•
- еҲҶеҢәзҙўеј•
- жң¬ең°е’Ңе…ЁеұҖзҙўеј•
В
В
В
В
В
дәҢпјҺВ зҙўеј•еҲҶзұ»
OracleжҸҗдҫӣдәҶеӨ§йҮҸзҙўеј•йҖүйЎ№гҖӮзҹҘйҒ“еңЁз»ҷе®ҡжқЎд»¶дёӢдҪҝз”Ёе“ӘдёӘйҖүйЎ№еҜ№дәҺдёҖдёӘеә”з”ЁзЁӢеәҸзҡ„жҖ§иғҪжқҘиҜҙйқһеёёйҮҚиҰҒгҖӮдёҖдёӘй”ҷиҜҜзҡ„йҖүжӢ©еҸҜиғҪдјҡеј•еҸ‘жӯ»й”ҒпјҢ并еҜјиҮҙж•°жҚ®еә“жҖ§иғҪжҖҘеү§дёӢйҷҚжҲ–иҝӣзЁӢз»ҲжӯўгҖӮиҖҢеҰӮжһңеҒҡеҮәжӯЈзЎ®зҡ„йҖүжӢ©пјҢеҲҷеҸҜд»ҘеҗҲзҗҶдҪҝз”Ёиө„жәҗпјҢдҪҝйӮЈдәӣе·Із»ҸиҝҗиЎҢдәҶеҮ дёӘе°Ҹж—¶з”ҡиҮіеҮ еӨ©зҡ„иҝӣзЁӢеңЁеҮ еҲҶй’ҹеҫ—д»Ҙе®ҢжҲҗпјҢиҝҷж ·дјҡдҪҝжӮЁз«ӢеҲ»жҲҗдёәдёҖдҪҚиӢұйӣ„гҖӮВ дёӢйқўВ е°ұе°Ҷз®ҖеҚ•зҡ„и®Ёи®әжҜҸдёӘзҙўеј•йҖүйЎ№гҖӮВ
дёӢйқўи®Ёи®әзҡ„зҙўеј•зұ»еһӢпјҡВ
Bж ‘зҙўеј•В (й»ҳи®Өзұ»еһӢВ )В
дҪҚеӣҫзҙўеј•В
HASHзҙўеј•В
зҙўеј•з»„з»ҮиЎЁзҙўеј•В
еҸҚиҪ¬й”®(reverseВ key)В зҙўеј•В
еҹәдәҺеҮҪж•°зҡ„зҙўеј•В
еҲҶеҢәзҙўеј•(В жң¬ең°е’Ңе…ЁеұҖзҙўеј•В )В
дҪҚеӣҫиҝһжҺҘзҙўеј•В
2.1В В Bж ‘зҙўеј•В В В (й»ҳи®Өзұ»еһӢВ )В
В В Bж ‘зҙўеј•еңЁВ OracleВ дёӯжҳҜдёҖдёӘйҖҡз”Ёзҙўеј•гҖӮеңЁеҲӣе»әзҙўеј•ж—¶е®ғе°ұжҳҜй»ҳи®Өзҡ„зҙўеј•зұ»еһӢВ гҖӮВ BВ ж ‘зҙўеј•еҸҜд»ҘжҳҜдёҖдёӘеҲ—зҡ„В (В з®ҖеҚ•)В зҙўеј•пјҢд№ҹеҸҜд»ҘжҳҜз»„еҗҲВ /В еӨҚеҗҲВ (В еӨҡдёӘеҲ—В )В зҡ„зҙўеј•гҖӮВ BВ ж ‘зҙўеј•жңҖеӨҡеҸҜд»ҘеҢ…жӢ¬В 32В еҲ—В гҖӮВ
еңЁВ дёӢеӣҫВ зҡ„дҫӢеӯҗдёӯпјҢBВ ж ‘зҙўеј•дҪҚдәҺйӣҮе‘ҳиЎЁзҡ„В last_nameВ еҲ—дёҠгҖӮиҝҷдёӘзҙўеј•зҡ„дәҢе…ғй«ҳеәҰдёәВ 3В пјӣжҺҘдёӢжқҘпјҢВ OracleВ дјҡз©ҝиҝҮдёӨдёӘж ‘жһқеқ—В (branchВ block)В пјҢеҲ°иҫҫеҢ…еҗ«жңүВ ROWIDВ зҡ„ж ‘еҸ¶еқ—гҖӮеңЁжҜҸдёӘж ‘жһқеқ—дёӯпјҢж ‘жһқиЎҢеҢ…еҗ«й“ҫдёӯдёӢдёҖдёӘеқ—зҡ„В IDеҸ·гҖӮВ
ж ‘еҸ¶еқ—еҢ…еҗ«В дәҶВ зҙўеј•еҖјВ гҖҒВ ROWIDВ пјҢд»ҘеҸҠжҢҮеҗ‘еүҚдёҖдёӘе’ҢеҗҺдёҖдёӘж ‘еҸ¶еқ—зҡ„В жҢҮй’ҲВ гҖӮOracleВ еҸҜд»Ҙд»ҺдёӨдёӘж–№еҗ‘йҒҚеҺҶиҝҷдёӘдәҢеҸүж ‘гҖӮВ BВ ж ‘зҙўеј•дҝқеӯҳдәҶеңЁзҙўеј•еҲ—дёҠжңүеҖјзҡ„жҜҸдёӘж•°жҚ®иЎҢзҡ„В ROWIDВ еҖјгҖӮВ OracleдёҚдјҡеҜ№зҙўеј•еҲ—дёҠеҢ…еҗ«В NULLВ еҖјзҡ„иЎҢиҝӣиЎҢзҙўеј•В гҖӮеҰӮжһңзҙўеј•жҳҜеӨҡдёӘеҲ—зҡ„з»„еҗҲзҙўеј•пјҢиҖҢе…¶дёӯеҲ—дёҠеҢ…еҗ«NULLВ еҖјпјҢиҝҷдёҖиЎҢе°ұдјҡеӨ„дәҺеҢ…еҗ«В NULLВ еҖјзҡ„зҙўеј•еҲ—дёӯпјҢдё”е°Ҷиў«еӨ„зҗҶдёәз©әВ (В и§ҶдёәВ NULL)В гҖӮВ
В В В В В В В В В В В В В В В В В В В В В В В В В 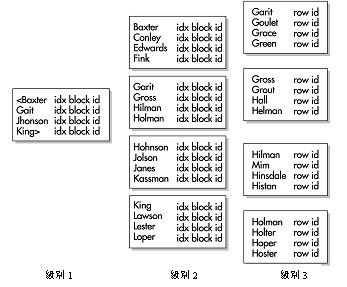 В
В
жҠҖе·§В пјҡВ зҙўеј•еҲ—зҡ„еҖјйғҪеӯҳеӮЁеңЁзҙўеј•дёӯгҖӮеӣ жӯӨпјҢеҸҜд»Ҙе»әз«ӢдёҖдёӘз»„еҗҲВ (В еӨҚеҗҲВ )В зҙўеј•пјҢиҝҷдәӣзҙўеј•еҸҜд»ҘзӣҙжҺҘж»Ўи¶іжҹҘиҜўпјҢиҖҢдёҚз”Ёи®ҝй—®иЎЁгҖӮиҝҷе°ұдёҚз”Ёд»ҺиЎЁдёӯжЈҖзҙўж•°жҚ®пјҢд»ҺиҖҢеҮҸе°‘дәҶВ I/OВ йҮҸгҖӮ
B-treeВ В зү№зӮ№В пјҡВ
- йҖӮеҗҲдёҺеӨ§йҮҸзҡ„еўһгҖҒеҲ гҖҒж”№пјҲOLTPВ пјү
- дёҚиғҪз”ЁеҢ…еҗ«ORВ ж“ҚдҪңз¬Ұзҡ„жҹҘиҜўпјӣ
- йҖӮеҗҲй«ҳеҹәж•°зҡ„еҲ—пјҲе”ҜдёҖеҖјеӨҡпјү
- е…ёеһӢзҡ„ж ‘зҠ¶з»“жһ„пјӣ
- жҜҸдёӘз»“зӮ№йғҪжҳҜж•°жҚ®еқ—пјӣ
- еӨ§еӨҡйғҪжҳҜзү©зҗҶдёҠдёҖеұӮгҖҒдёӨеұӮжҲ–дёүеұӮдёҚе®ҡпјҢйҖ»иҫ‘дёҠдёүеұӮпјӣ
- еҸ¶еӯҗеқ—ж•°жҚ®жҳҜжҺ’еәҸзҡ„пјҢд»Һе·Ұеҗ‘еҸійҖ’еўһпјӣ
- еңЁеҲҶж”Ҝеқ—е’Ңж №еқ—дёӯж”ҫзҡ„жҳҜзҙўеј•зҡ„иҢғеӣҙпјӣ
В
2.2В В дҪҚеӣҫзҙўеј•В
дҪҚеӣҫзҙўеј•йқһеёёйҖӮеҗҲдәҺеҶізӯ–ж”ҜжҢҒзі»з»ҹ(DecisionВ SupportВ SystemВ пјҢВ DSS)В е’Ңж•°жҚ®д»“еә“В пјҢе®ғ们дёҚеә”иҜҘз”ЁдәҺйҖҡиҝҮдәӢеҠЎеӨ„зҗҶеә”з”ЁзЁӢеәҸи®ҝй—®зҡ„иЎЁгҖӮе®ғ们еҸҜд»ҘдҪҝз”Ёиҫғе°‘еҲ°дёӯзӯүеҹәж•°(В дёҚеҗҢеҖјзҡ„ж•°йҮҸВ )В зҡ„еҲ—и®ҝй—®йқһеёёеӨ§зҡ„иЎЁгҖӮе°Ҫз®ЎдҪҚеӣҫзҙўеј•жңҖеӨҡеҸҜиҫҫВ 30В дёӘеҲ—пјҢдҪҶйҖҡеёёе®ғ们йғҪеҸӘз”ЁдәҺе°‘йҮҸзҡ„еҲ—гҖӮВ
дҫӢеҰӮпјҢжӮЁзҡ„иЎЁеҸҜиғҪеҢ…еҗ«дёҖдёӘз§°дёәSexВ зҡ„еҲ—пјҢе®ғжңүдёӨдёӘеҸҜиғҪеҖјпјҡз”·е’ҢеҘігҖӮиҝҷдёӘеҹәж•°еҸӘдёәВ 2В пјҢеҰӮжһңз”ЁжҲ·йў‘з№Ғең°ж №жҚ®В SexеҲ—зҡ„еҖјжҹҘиҜўиҜҘиЎЁпјҢиҝҷе°ұжҳҜдҪҚеӣҫзҙўеј•зҡ„еҹәеҲ—гҖӮеҪ“дёҖдёӘиЎЁеҶ…еҢ…еҗ«дәҶеӨҡдёӘдҪҚеӣҫзҙўеј•ж—¶пјҢжӮЁеҸҜд»ҘдҪ“дјҡеҲ°дҪҚеӣҫзҙўеј•зҡ„зңҹжӯЈеЁҒеҠӣгҖӮеҰӮжһңжңүеӨҡдёӘеҸҜз”Ёзҡ„дҪҚеӣҫзҙўеј•пјҢВ OracleВ е°ұеҸҜд»ҘеҗҲ并д»ҺжҜҸдёӘдҪҚеӣҫзҙўеј•еҫ—еҲ°зҡ„з»“жһңйӣҶпјҢеҝ«йҖҹеҲ йҷӨдёҚеҝ…иҰҒзҡ„ж•°жҚ®гҖӮ
BitmapВ tВ зү№зӮ№В пјҡВ
- йҖӮеҗҲдёҺеҶізӯ–ж”ҜжҢҒзі»з»ҹпјӣ
- еҒҡUPDATEВ д»Јд»·йқһеёёй«ҳпјӣ
- йқһеёёйҖӮеҗҲORВ ж“ҚдҪңз¬Ұзҡ„жҹҘиҜўпјӣ
- еҹәж•°жҜ”иҫғе°‘зҡ„ж—¶еҖҷжүҚиғҪе»әдҪҚеӣҫзҙўеј•пјӣ
жҠҖе·§пјҡВ еҜ№дәҺжңүиҫғдҪҺеҹәж•°зҡ„еҲ—йңҖиҰҒдҪҝз”ЁдҪҚеӣҫзҙўеј•гҖӮжҖ§еҲ«еҲ—е°ұжҳҜиҝҷж ·дёҖдёӘдҫӢеӯҗпјҢе®ғжңүдёӨдёӘеҸҜиғҪеҖјпјҡз”·жҲ–еҘі(В еҹәж•°д»…дёә2)В гҖӮВ дҪҚеӣҫеҜ№дәҺдҪҺеҹәж•°(В е°‘йҮҸзҡ„дёҚеҗҢеҖјВ )В еҲ—жқҘиҜҙйқһеёёеҝ«В пјҢиҝҷжҳҜеӣ дёәзҙўеј•зҡ„е°әеҜёзӣёеҜ№дәҺBВ ж ‘зҙўеј•жқҘиҜҙе°ҸдәҶеҫҲеӨҡгҖӮеӣ дёәиҝҷдәӣзҙўеј•жҳҜдҪҺеҹәж•°зҡ„В BВ ж ‘зҙўеј•пјҢжүҖд»Ҙйқһеёёе°ҸпјҢеӣ жӯӨжӮЁеҸҜд»Ҙз»ҸеёёжЈҖзҙўиЎЁдёӯи¶…иҝҮеҚҠж•°зҡ„иЎҢпјҢ并且д»ҚдҪҝз”ЁдҪҚеӣҫзҙўеј•гҖӮВ
еҪ“еӨ§еӨҡж•°жқЎзӣ®дёҚдјҡеҗ‘дҪҚеӣҫж·»еҠ ж–°зҡ„еҖјж—¶пјҢдҪҚеӣҫзҙўеј•еңЁжү№еӨ„зҗҶ(В еҚ•з”ЁжҲ·В )В ж“ҚдҪңдёӯеҠ иҪҪиЎЁВ (В жҸ’е…Ҙж“ҚдҪңВ )В ж–№йқўйҖҡеёёиҰҒжҜ”В Bж ‘еҒҡеҫ—еҘҪгҖӮеҪ“еӨҡдёӘдјҡиҜқеҗҢж—¶еҗ‘иЎЁдёӯжҸ’е…ҘиЎҢж—¶дёҚеә”иҜҘдҪҝз”ЁдҪҚеӣҫзҙўеј•пјҢеңЁеӨ§еӨҡж•°дәӢеҠЎеӨ„зҗҶеә”з”ЁзЁӢеәҸдёӯйғҪдјҡеҸ‘з”ҹиҝҷз§Қжғ…еҶөгҖӮВ
зӨәдҫӢВ
дёӢйқўжқҘзңӢдёҖдёӘзӨәдҫӢиЎЁPARTICIPANTВ пјҢиҜҘиЎЁеҢ…еҗ«дәҶжқҘиҮӘдёӘдәәзҡ„и°ғжҹҘж•°жҚ®гҖӮеҲ—В Age_CodeВ гҖҒВ Income_LevelВ гҖҒEducation_LevelВ е’ҢВ Marital_StatusВ йғҪеҢ…жӢ¬дәҶеҗ„иҮӘзҡ„дҪҚеӣҫзҙўеј•гҖӮВ дёӢеӣҫВ жҳҫзӨәдәҶжҜҸдёӘзӣҙж–№еӣҫдёӯзҡ„ж•°жҚ®е№іиЎЎжғ…еҶөпјҢд»ҘеҸҠеҜ№и®ҝй—®жҜҸдёӘдҪҚеӣҫзҙўеј•зҡ„жҹҘиҜўзҡ„жү§иЎҢи·Ҝеҫ„гҖӮеӣҫдёӯзҡ„жү§иЎҢи·Ҝеҫ„жҳҫзӨәдәҶжңүеӨҡе°‘дёӘдҪҚеӣҫзҙўеј•иў«еҗҲ并пјҢеҸҜд»ҘзңӢеҮәжҖ§иғҪеҫ—еҲ°дәҶжҳҫи‘—зҡ„жҸҗй«ҳгҖӮВ 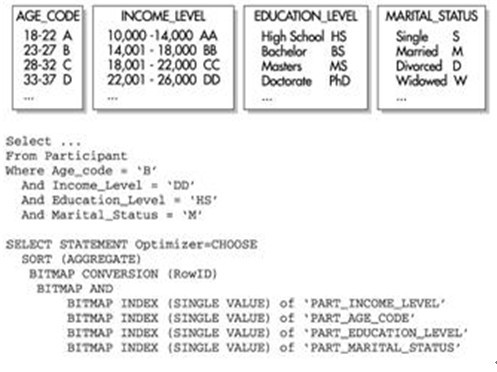
еҰӮВ дёҠеӣҫВ еӣҫжүҖзӨәпјҢдјҳеҢ–еҷЁдҫқж¬ЎдҪҝз”Ё4В дёӘеҚ•зӢ¬зҡ„дҪҚеӣҫзҙўеј•пјҢиҝҷдәӣзҙўеј•зҡ„еҲ—еңЁВ WHEREВ еӯҗеҸҘдёӯиў«еј•з”ЁгҖӮжҜҸдёӘдҪҚеӣҫи®°еҪ•жҢҮй’ҲВ (В дҫӢеҰӮВ 0В жҲ–В 1)В пјҢз”ЁдәҺжҢҮзӨәиЎЁдёӯзҡ„е“ӘдәӣиЎҢеҢ…еҗ«дҪҚеӣҫдёӯзҡ„е·ІзҹҘеҖјгҖӮжңүдәҶиҝҷдәӣдҝЎжҒҜеҗҺпјҢВ OracleВ е°ұжү§иЎҢВ BITMAPВ ANDж“ҚдҪңд»ҘжҹҘжүҫе°Ҷд»ҺжүҖжңүВ 4В дёӘдҪҚеӣҫдёӯиҝ”еӣһе“ӘдәӣиЎҢгҖӮиҜҘеҖјз„¶еҗҺиў«иҪ¬жҚўдёәВ ROWIDВ еҖјпјҢ并且жҹҘиҜўз»§з»ӯе®ҢжҲҗеү©дҪҷзҡ„еӨ„зҗҶе·ҘдҪңгҖӮВ жіЁж„ҸпјҢжүҖжңү4В дёӘеҲ—йғҪжңүйқһеёёдҪҺзҡ„еҹәж•°пјҢдҪҝз”Ёзҙўеј•еҸҜд»Ҙйқһеёёеҝ«йҖҹең°иҝ”еӣһеҢ№й…Қзҡ„иЎҢгҖӮВ
жҠҖе·§пјҡВ еңЁдёҖдёӘжҹҘиҜўдёӯеҗҲ并еӨҡдёӘдҪҚеӣҫзҙўеј•еҗҺпјҢеҸҜд»ҘдҪҝжҖ§иғҪжҳҫи‘—жҸҗй«ҳгҖӮдҪҚеӣҫзҙўеј•дҪҝз”Ёеӣәе®ҡй•ҝеәҰзҡ„ж•°жҚ®зұ»еһӢиҰҒжҜ”еҸҜеҸҳй•ҝеәҰзҡ„ж•°жҚ®зұ»еһӢеҘҪгҖӮиҫғеӨ§е°әеҜёзҡ„еқ—д№ҹдјҡжҸҗй«ҳеҜ№дҪҚеӣҫзҙўеј•зҡ„еӯҳеӮЁе’ҢиҜ»еҸ–жҖ§иғҪгҖӮВ
дёӢйқўзҡ„жҹҘиҜўеҸҜжҳҫзӨәзҙўеј•зұ»еһӢгҖӮВ
SQL>В selectВ index_name,В index_typeВ fromВ user_indexes;
INDEX_NAMEВ В В В В В В В В INDEX_TYPE
------------------------------В ----------------------
TT_INDEXВ В В В В В В В В В В В NORMAL
IX_CUSTADDR_TPВ В В В NORMAL
Bж ‘зҙўеј•В дҪңдёәNORMALВ еҲ—еҮәпјӣиҖҢВ дҪҚеӣҫзҙўеј•В зҡ„зұ»еһӢеҖјдёәВ BITMAPВ гҖӮВ
жҠҖе·§пјҡВ еҰӮжһңиҰҒжҹҘиҜўдҪҚеӣҫзҙўеј•еҲ—иЎЁпјҢеҸҜд»ҘеңЁUSERВ _INDEXESВ и§ҶеӣҫдёӯжҹҘиҜўВ index_typeВ еҲ—гҖӮВ
е»әи®®дёҚиҰҒеңЁдёҖдәӣиҒ”жңәдәӢеҠЎеӨ„зҗҶ(OLTP)В еә”з”ЁзЁӢеәҸдёӯдҪҝз”ЁдҪҚеӣҫзҙўеј•В гҖӮBВ ж ‘зҙўеј•зҡ„зҙўеј•еҖјдёӯеҢ…еҗ«В ROWIDВ пјҢиҝҷж ·OracleВ е°ұеҸҜд»ҘеңЁиЎҢзә§еҲ«дёҠй”Ғе®ҡзҙўеј•гҖӮдҪҚеӣҫзҙўеј•еӯҳеӮЁдёәеҺӢзј©зҡ„зҙўеј•еҖјпјҢе…¶дёӯеҢ…еҗ«дәҶдёҖе®ҡиҢғеӣҙзҡ„В ROWIDВ пјҢеӣ жӯӨOracleВ еҝ…йЎ»й’ҲеҜ№дёҖдёӘз»ҷе®ҡеҖјй”Ғе®ҡжүҖжңүиҢғеӣҙеҶ…зҡ„В ROWIDВ гҖӮиҝҷз§Қй”Ғе®ҡзұ»еһӢеҸҜиғҪеңЁжҹҗдәӣВ DMLВ иҜӯеҸҘдёӯйҖ жҲҗжӯ»й”ҒгҖӮSELECTВ иҜӯеҸҘдёҚдјҡеҸ—еҲ°иҝҷз§Қй”Ғе®ҡй—®йўҳзҡ„еҪұе“ҚгҖӮВ
дҪҚеӣҫзҙўеј•В зҡ„дҪҝз”ЁВ йҷҗеҲ¶В пјҡ
- еҹәдәҺ规еҲҷзҡ„дјҳеҢ–еҷЁдёҚдјҡиҖғиҷ‘дҪҚеӣҫзҙўеј•гҖӮ
- еҪ“жү§иЎҢALTERВ TABLEВ иҜӯеҸҘ并дҝ®ж”№еҢ…еҗ«жңүдҪҚеӣҫзҙўеј•зҡ„еҲ—ж—¶пјҢдјҡдҪҝдҪҚеӣҫзҙўеј•еӨұж•ҲгҖӮ
- дҪҚеӣҫзҙўеј•дёҚеҢ…еҗ«д»»дҪ•еҲ—ж•°жҚ®пјҢ并且дёҚиғҪз”ЁдәҺд»»дҪ•зұ»еһӢзҡ„е®Ңж•ҙжҖ§жЈҖжҹҘгҖӮ
- дҪҚеӣҫзҙўеј•дёҚиғҪиў«еЈ°жҳҺдёәе”ҜдёҖзҙўеј•гҖӮ
- дҪҚеӣҫзҙўеј•зҡ„жңҖеӨ§й•ҝеәҰдёә30В гҖӮ
жҠҖе·§пјҡВ дёҚиҰҒеңЁз№ҒйҮҚзҡ„OLTPВ зҺҜеўғдёӯдҪҝз”ЁдҪҚеӣҫзҙўеј•В
2.3В В HASHзҙўеј•В
дҪҝз”ЁHASHВ зҙўеј•еҝ…йЎ»иҰҒдҪҝз”ЁВ HASHВ йӣҶзҫӨВ гҖӮе»әз«ӢдёҖдёӘйӣҶзҫӨжҲ–HASHВ йӣҶзҫӨзҡ„еҗҢж—¶пјҢд№ҹе°ұе®ҡд№үдәҶдёҖдёӘйӣҶзҫӨй”®гҖӮиҝҷдёӘй”®е‘ҠиҜүВ OracleВ еҰӮдҪ•еңЁйӣҶзҫӨдёҠеӯҳеӮЁиЎЁгҖӮеңЁеӯҳеӮЁж•°жҚ®ж—¶пјҢжүҖжңүдёҺиҝҷдёӘйӣҶзҫӨй”®зӣёе…ізҡ„иЎҢйғҪиў«еӯҳеӮЁеңЁдёҖдёӘж•°жҚ®еә“еқ—дёҠгҖӮеҰӮжһңж•°жҚ®йғҪеӯҳеӮЁеңЁеҗҢдёҖдёӘж•°жҚ®еә“еқ—дёҠпјҢ并且е°ҶВ HASHВ зҙўеј•дҪңдёәВ WHEREВ еӯҗеҸҘдёӯзҡ„зЎ®еҲҮеҢ№й…ҚпјҢВ OracleВ е°ұеҸҜд»ҘйҖҡиҝҮжү§иЎҢдёҖдёӘHASHВ еҮҪж•°е’ҢВ I/OВ жқҘи®ҝй—®ж•°жҚ®В вҖ”вҖ”В иҖҢйҖҡиҝҮдҪҝз”ЁдёҖдёӘдәҢе…ғй«ҳеәҰдёәВ 4В зҡ„В BВ ж ‘зҙўеј•жқҘи®ҝй—®ж•°жҚ®пјҢеҲҷйңҖиҰҒеңЁжЈҖзҙўж•°жҚ®ж—¶дҪҝз”ЁВ 4В дёӘВ I/OВ гҖӮеҰӮВ дёӢеӣҫВ жүҖзӨәпјҢе…¶дёӯзҡ„жҹҘиҜўжҳҜдёҖдёӘзӯүд»·жҹҘиҜўпјҢз”ЁдәҺеҢ№й…ҚHASHВ еҲ—е’ҢзЎ®еҲҮзҡ„еҖјгҖӮВ OracleВ еҸҜд»Ҙеҝ«йҖҹдҪҝз”ЁиҜҘеҖјпјҢеҹәдәҺВ HASHВ еҮҪж•°зЎ®е®ҡиЎҢзҡ„зү©зҗҶеӯҳеӮЁдҪҚзҪ®гҖӮВ
HASHзҙўеј•еҸҜиғҪжҳҜи®ҝй—®ж•°жҚ®еә“дёӯж•°жҚ®зҡ„жңҖеҝ«ж–№жі•пјҢдҪҶе®ғд№ҹжңүиҮӘиә«зҡ„зјәзӮ№В гҖӮйӣҶзҫӨй”®дёҠдёҚеҗҢеҖјзҡ„ж•°зӣ®еҝ…йЎ»еңЁеҲӣе»әHASHйӣҶзҫӨд№ӢеүҚе°ұиҰҒзҹҘйҒ“гҖӮйңҖиҰҒеңЁеҲӣе»әВ HASHВ йӣҶзҫӨзҡ„ж—¶еҖҷжҢҮе®ҡиҝҷдёӘеҖјгҖӮдҪҺдј°дәҶйӣҶзҫӨй”®зҡ„дёҚеҗҢеҖјзҡ„ж•°еӯ—еҸҜиғҪдјҡйҖ жҲҗйӣҶзҫӨзҡ„еҶІзӘҒВ (В дёӨдёӘйӣҶзҫӨзҡ„й”®еҖјжӢҘжңүзӣёеҗҢзҡ„В HASHВ еҖјВ )В гҖӮиҝҷз§ҚеҶІзӘҒжҳҜйқһеёёж¶ҲиҖ—иө„жәҗзҡ„гҖӮеҶІзӘҒдјҡйҖ жҲҗз”ЁжқҘеӯҳеӮЁйўқеӨ–иЎҢзҡ„зј“еҶІжәўеҮәпјҢ然еҗҺйҖ жҲҗйўқеӨ–зҡ„В I/OВ гҖӮеҰӮжһңдёҚеҗҢВ HASHВ еҖјзҡ„ж•°зӣ®е·Із»Ҹиў«дҪҺдј°пјҢжӮЁе°ұеҝ…йЎ»еңЁйҮҚе»әиҝҷдёӘйӣҶзҫӨд№ӢеҗҺж”№еҸҳиҝҷдёӘеҖјгҖӮ
ALTERВ CLUSTERе‘Ҫд»ӨдёҚиғҪж”№еҸҳВ HASHВ й”®зҡ„ж•°зӣ®гҖӮВ HASHВ йӣҶзҫӨиҝҳеҸҜиғҪжөӘиҙ№з©әй—ҙВ гҖӮеҰӮжһңж— жі•зЎ®е®ҡйңҖиҰҒеӨҡе°‘з©әй—ҙжқҘз»ҙжҠӨжҹҗдёӘйӣҶзҫӨй”®дёҠзҡ„жүҖжңүиЎҢпјҢе°ұеҸҜиғҪйҖ жҲҗз©әй—ҙзҡ„жөӘиҙ№гҖӮеҰӮжһңВ дёҚиғҪдёәйӣҶзҫӨзҡ„жңӘжқҘеўһй•ҝеҲҶй…ҚеҘҪйҷ„еҠ зҡ„з©әй—ҙВ пјҢHASHйӣҶзҫӨеҸҜиғҪе°ұВ дёҚжҳҜжңҖеҘҪзҡ„йҖүжӢ©В гҖӮВ еҰӮжһңеә”з”ЁзЁӢеәҸз»ҸеёёеңЁйӣҶзҫӨиЎЁдёҠиҝӣиЎҢе…ЁиЎЁжү«жҸҸВ пјҢHASHВ йӣҶзҫӨеҸҜиғҪд№ҹВ дёҚжҳҜжңҖеҘҪзҡ„йҖүжӢ©гҖӮз”ұдәҺйңҖиҰҒдёәжңӘжқҘзҡ„еўһй•ҝеҲҶй…ҚеҘҪйӣҶзҫӨзҡ„еү©дҪҷз©әй—ҙйҮҸпјҢе…ЁиЎЁжү«жҸҸеҸҜиғҪйқһеёёж¶ҲиҖ—иө„жәҗгҖӮВ
еңЁе®һзҺ°HASHВ йӣҶзҫӨд№ӢеүҚдёҖе®ҡиҰҒе°ҸеҝғгҖӮжӮЁйңҖиҰҒе…Ёйқўең°и§ӮеҜҹеә”з”ЁзЁӢеәҸпјҢдҝқиҜҒеңЁе®һзҺ°иҝҷдёӘйҖүйЎ№д№ӢеүҚе·Із»ҸдәҶи§Је…ідәҺиЎЁе’Ңж•°жҚ®зҡ„еӨ§йҮҸдҝЎжҒҜгҖӮВ йҖҡеёёпјҢHASHВ еҜ№дәҺдёҖдәӣеҢ…еҗ«жңүеәҸеҖјзҡ„йқҷжҖҒж•°жҚ®йқһеёёжңүж•ҲгҖӮВ
жҠҖе·§пјҡВ HASHзҙўеј•еңЁжңүйҷҗеҲ¶жқЎд»¶В (В йңҖиҰҒжҢҮе®ҡдёҖдёӘзЎ®е®ҡзҡ„еҖјиҖҢдёҚжҳҜдёҖдёӘеҖјиҢғеӣҙВ )В зҡ„жғ…еҶөдёӢйқһеёёжңүз”ЁгҖӮВ
В В В В В В В В В В В В В В В В В В В В В В В В В 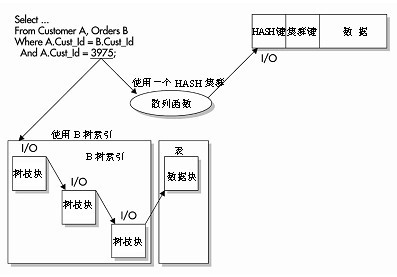 В
В
2.4В В зҙўеј•з»„з»ҮиЎЁВ
зҙўеј•з»„з»ҮиЎЁдјҡжҠҠиЎЁзҡ„еӯҳеӮЁз»“жһ„ж”№жҲҗBВ ж ‘з»“жһ„пјҢд»ҘиЎЁзҡ„дё»й”®иҝӣиЎҢжҺ’еәҸгҖӮиҝҷз§Қзү№ж®Ҡзҡ„иЎЁе’Ңе…¶д»–зұ»еһӢзҡ„иЎЁдёҖж ·пјҢеҸҜд»ҘеңЁиЎЁдёҠжү§иЎҢжүҖжңүзҡ„В DMLВ е’ҢВ DDLВ иҜӯеҸҘгҖӮВ з”ұдәҺиЎЁзҡ„зү№ж®Ҡз»“жһ„пјҢROWID 并没жңүиў«е…іиҒ”еҲ°иЎЁзҡ„иЎҢдёҠгҖӮВ
еҜ№дәҺдёҖдәӣж¶үеҸҠзІҫзЎ®еҢ№й…Қе’ҢиҢғеӣҙжҗңзҙўзҡ„иҜӯеҸҘпјҢзҙўеј•з»„з»ҮиЎЁжҸҗдҫӣдәҶдёҖз§ҚеҹәдәҺй”®зҡ„еҝ«йҖҹж•°жҚ®и®ҝй—®жңәеҲ¶гҖӮВ еҹәдәҺдё»й”®еҖјзҡ„UPDATEВ е’ҢВ DELETEВ иҜӯеҸҘзҡ„жҖ§иғҪд№ҹеҗҢж ·еҫ—д»ҘжҸҗй«ҳпјҢВ иҝҷжҳҜеӣ дёәиЎҢеңЁзү©зҗҶдёҠжңүеәҸгҖӮз”ұдәҺй”®еҲ—зҡ„еҖјеңЁиЎЁе’Ңзҙўеј•дёӯйғҪжІЎжңүйҮҚеӨҚпјҢВ еӯҳеӮЁжүҖйңҖиҰҒзҡ„з©әй—ҙд№ҹйҡҸд№ӢеҮҸе°‘гҖӮВ
еҰӮжһңдёҚдјҡйў‘з№Ғең°ж №жҚ®дё»й”®еҲ—жҹҘиҜўж•°жҚ®пјҢеҲҷйңҖиҰҒеңЁзҙўеј•з»„з»ҮиЎЁдёӯзҡ„е…¶д»–еҲ—дёҠеҲӣе»әдәҢзә§зҙўеј•гҖӮдёҚдјҡйў‘з№Ғж №жҚ®дё»й”®жҹҘиҜўиЎЁзҡ„еә”з”ЁзЁӢеәҸдёҚдјҡдәҶи§ЈеҲ°дҪҝз”Ёзҙўеј•з»„з»ҮиЎЁзҡ„е…ЁйғЁдјҳзӮ№гҖӮВ еҜ№дәҺжҖ»жҳҜйҖҡиҝҮеҜ№дё»й”®зҡ„зІҫзЎ®еҢ№й…ҚжҲ–иҢғеӣҙжү«жҸҸиҝӣиЎҢи®ҝй—®зҡ„иЎЁпјҢе°ұйңҖиҰҒиҖғиҷ‘дҪҝз”Ёзҙўеј•з»„з»ҮиЎЁгҖӮВ
жҠҖе·§пјҡВ еҸҜд»ҘеңЁзҙўеј•з»„з»ҮиЎЁдёҠе»әз«ӢдәҢзә§зҙўеј•гҖӮВ
2.5В В еҸҚиҪ¬й”®зҙўеј•В
еҪ“иҪҪе…ҘдёҖдәӣжңүеәҸж•°жҚ®ж—¶пјҢзҙўеј•иӮҜе®ҡдјҡзў°еҲ°дёҺI/OВ зӣёе…ізҡ„дёҖдәӣ瓶йўҲгҖӮеңЁж•°жҚ®иҪҪе…Ҙжңҹй—ҙпјҢжҹҗйғЁеҲҶзҙўеј•е’ҢзЈҒзӣҳиӮҜе®ҡдјҡжҜ”е…¶д»–йғЁеҲҶдҪҝз”Ёйў‘з№Ғеҫ—еӨҡгҖӮдёәдәҶи§ЈеҶіиҝҷдёӘй—®йўҳпјҢеҸҜд»ҘжҠҠзҙўеј•иЎЁз©әй—ҙеӯҳж”ҫеңЁиғҪеӨҹжҠҠВ ж–Ү件зү©зҗҶеҲҶеүІеңЁеӨҡдёӘзЈҒзӣҳдёҠзҡ„зЈҒзӣҳдҪ“зі»з»“жһ„дёҠВ гҖӮВ
дёәдәҶи§ЈеҶіиҝҷдёӘй—®йўҳпјҢOracleВ иҝҳжҸҗдҫӣдәҶдёҖз§ҚеҸҚиҪ¬й”®зҙўеј•зҡ„ж–№жі•гҖӮеҰӮжһңж•°жҚ®д»ҘеҸҚиҪ¬й”®зҙўеј•еӯҳеӮЁпјҢиҝҷдәӣж•°жҚ®зҡ„еҖје°ұдјҡдёҺеҺҹе…ҲеӯҳеӮЁзҡ„ж•°еҖјзӣёеҸҚгҖӮиҝҷж ·пјҢж•°жҚ®В 1234В гҖҒВ 1235В е’ҢВ 1236В е°ұиў«еӯҳеӮЁжҲҗВ 4321В гҖҒВ 5321В е’ҢВ 6321В гҖӮВ з»“жһңе°ұжҳҜзҙўеј•дјҡдёәжҜҸж¬Ўж–°жҸ’е…Ҙзҡ„иЎҢжӣҙж–°дёҚеҗҢзҡ„зҙўеј•еқ—гҖӮВ
жҠҖе·§пјҡВ еҰӮжһңжӮЁзҡ„зЈҒзӣҳе®№йҮҸжңүйҷҗпјҢеҗҢж—¶иҝҳиҰҒжү§иЎҢеӨ§йҮҸзҡ„жңүеәҸиҪҪе…ҘпјҢе°ұеҸҜд»ҘдҪҝз”ЁеҸҚиҪ¬й”®зҙўеј•гҖӮВ
дёҚеҸҜд»Ҙе°ҶеҸҚиҪ¬й”®зҙўеј•дёҺдҪҚеӣҫзҙўеј•жҲ–зҙўеј•з»„з»ҮиЎЁз»“еҗҲдҪҝз”ЁгҖӮВ еӣ дёәВ дёҚиғҪеҜ№дҪҚеӣҫзҙўеј•е’Ңзҙўеј•з»„з»ҮиЎЁиҝӣиЎҢеҸҚиҪ¬й”®еӨ„зҗҶгҖӮВ
2.6В В еҹәдәҺеҮҪж•°зҡ„зҙўеј•В
еҸҜд»ҘеңЁиЎЁдёӯеҲӣе»әеҹәдәҺеҮҪж•°зҡ„зҙўеј•гҖӮеҰӮжһңжІЎжңүеҹәдәҺеҮҪж•°зҡ„зҙўеј•пјҢд»»дҪ•еңЁеҲ—дёҠжү§иЎҢдәҶеҮҪж•°зҡ„жҹҘиҜўйғҪдёҚиғҪдҪҝз”ЁиҝҷдёӘеҲ—зҡ„зҙўеј•гҖӮдҫӢеҰӮпјҢдёӢйқўзҡ„жҹҘиҜўе°ұдёҚиғҪдҪҝз”ЁJOBВ еҲ—дёҠзҡ„зҙўеј•пјҢйҷӨйқһе®ғжҳҜеҹәдәҺеҮҪж•°зҡ„зҙўеј•пјҡВ
selectВ *В В В fromВ empВ В В whereВ UPPER(job)В =В 'MGR';В
дёӢйқўзҡ„жҹҘиҜўдҪҝз”ЁJOBВ еҲ—дёҠзҡ„зҙўеј•пјҢдҪҶжҳҜе®ғе°ҶдёҚдјҡиҝ”еӣһВ JOBВ еҲ—е…·жңүВ MgrВ жҲ–В mgrВ еҖјзҡ„иЎҢпјҡВ
selectВ *В В В fromВ empВ В В whereВ jobВ =В 'MGR';
еҸҜд»ҘеҲӣе»әиҝҷж ·зҡ„зҙўеј•пјҢе…Ғи®ёзҙўеј•и®ҝй—®ж”ҜжҢҒеҹәдәҺеҮҪж•°зҡ„еҲ—жҲ–ж•°жҚ®гҖӮеҸҜд»ҘеҜ№еҲ—иЎЁиҫҫејҸUPPER(job)В еҲӣе»әзҙўеј•пјҢиҖҢдёҚжҳҜзӣҙжҺҘеңЁВ JOBВ еҲ—дёҠе»әз«Ӣзҙўеј•В пјҢеҰӮВ пјҡВ
createВ indexВ EMP$UPPER_JOBВ onВ В В emp(UPPER(job));
е°Ҫз®ЎеҹәдәҺеҮҪж•°зҡ„зҙўеј•йқһеёёжңүз”ЁпјҢдҪҶеңЁе»әз«Ӣе®ғ们д№ӢеүҚеҝ…йЎ»е…ҲиҖғиҷ‘дёӢйқўдёҖдәӣй—®йўҳпјҡВ
иғҪйҷҗеҲ¶еңЁиҝҷдёӘеҲ—дёҠдҪҝз”Ёзҡ„еҮҪж•°еҗ—пјҹеҰӮжһңиғҪпјҢиғҪйҷҗеҲ¶жүҖжңүеңЁиҝҷдёӘеҲ—дёҠжү§иЎҢзҡ„жүҖжңүеҮҪж•°еҗ—В
жҳҜеҗҰжңүи¶іеӨҹеә”д»ҳйўқеӨ–зҙўеј•зҡ„еӯҳеӮЁз©әй—ҙпјҹВ
еңЁжҜҸеҲ—дёҠеўһеҠ зҡ„зҙўеј•ж•°йҮҸдјҡеҜ№й’ҲеҜ№иҜҘиЎЁжү§иЎҢзҡ„DMLВ иҜӯеҸҘзҡ„жҖ§иғҪеёҰжқҘдҪ•з§ҚеҪұе“ҚпјҹВ
еҹәдәҺеҮҪж•°зҡ„зҙўеј•йқһеёёжңүз”ЁпјҢдҪҶеңЁе®һзҺ°ж—¶еҝ…йЎ»е°ҸеҝғгҖӮеңЁиЎЁдёҠеҲӣе»әзҡ„зҙўеј•и¶ҠеӨҡпјҢINSERTВ гҖҒВ UPDATEВ е’ҢВ DELETEиҜӯеҸҘзҡ„жү§иЎҢе°ұдјҡиҠұиҙ№и¶ҠеӨҡзҡ„ж—¶й—ҙгҖӮВ
жіЁж„ҸпјҡВ еҜ№дәҺдјҳеҢ–еҷЁжүҖдҪҝз”Ёзҡ„еҹәдәҺеҮҪж•°зҡ„зҙўеј•жқҘиҜҙпјҢВ еҝ…йЎ»жҠҠеҲқе§ӢеҸӮж•°QUERYВ _REWRITEВ _В ENABLEDВ и®ҫе®ҡдёәTRUEВ гҖӮВ
зӨәдҫӢпјҡВ
selectВ В В В count(*)В В В fromВ В В В sampleВ В В whereВ ratio(balance,limit)В >.5;В
ElapsedВ time:В 20.1В minutes
createВ indexВ ratio_idx1В onВ В В sampleВ (ratio(balance,В limit));
selectВ В count(*)В В В fromВ В sampleВ В В whereВ ratio(balance,limit)В >.5;В
ElapsedВ time:В 7В seconds!!!В
2.7В В еҲҶеҢәзҙўеј•В
еҲҶеҢәзҙўеј•е°ұжҳҜз®ҖеҚ•ең°жҠҠдёҖдёӘзҙўеј•еҲҶжҲҗеӨҡдёӘзүҮж–ӯгҖӮйҖҡиҝҮжҠҠдёҖдёӘзҙўеј•еҲҶжҲҗеӨҡдёӘзүҮж–ӯпјҢеҸҜд»Ҙи®ҝй—®жӣҙе°Ҹзҡ„зүҮж–ӯ(В д№ҹжӣҙеҝ«В )В пјҢ并且еҸҜд»ҘжҠҠиҝҷдәӣзүҮж–ӯеҲҶеҲ«еӯҳж”ҫеңЁдёҚеҗҢзҡ„зЈҒзӣҳй©ұеҠЁеҷЁдёҠВ (В йҒҝе…ҚВ I/OВ й—®йўҳВ )В гҖӮВ Bж ‘е’ҢдҪҚеӣҫзҙўеј•йғҪеҸҜд»Ҙиў«еҲҶеҢәпјҢиҖҢВ HASHзҙўеј•дёҚеҸҜд»Ҙиў«еҲҶеҢәВ гҖӮеҸҜд»ҘжңүеҘҪеҮ з§ҚеҲҶеҢәж–№жі•пјҡВ иЎЁиў«еҲҶеҢәиҖҢзҙўеј•жңӘиў«еҲҶеҢәВ пјӣВ иЎЁжңӘиў«еҲҶеҢәиҖҢзҙўеј•иў«еҲҶеҢәВ пјӣВ иЎЁе’Ңзҙўеј•йғҪиў«еҲҶеҢәВ гҖӮдёҚз®ЎйҮҮз”Ёе“Әз§Қж–№жі•пјҢВ йғҪеҝ…йЎ»дҪҝз”ЁеҹәдәҺжҲҗжң¬зҡ„дјҳеҢ–еҷЁВ гҖӮеҲҶеҢәиғҪеӨҹжҸҗдҫӣжӣҙеӨҡеҸҜд»ҘжҸҗй«ҳжҖ§иғҪе’ҢеҸҜз»ҙжҠӨжҖ§зҡ„еҸҜиғҪжҖ§В
жңүдёӨз§Қзұ»еһӢзҡ„еҲҶеҢәзҙўеј•пјҡВ жң¬ең°еҲҶеҢәзҙўеј•В е’ҢВ е…ЁеұҖеҲҶеҢәзҙўеј•В гҖӮжҜҸдёӘзұ»еһӢйғҪжңүдёӨдёӘеӯҗзұ»еһӢпјҢжңүеүҚзјҖзҙўеј•е’Ңж— еүҚзјҖзҙўеј•гҖӮиЎЁеҗ„еҲ—дёҠзҡ„зҙўеј•еҸҜд»Ҙжңүеҗ„з§Қзұ»еһӢзҙўеј•зҡ„з»„еҗҲгҖӮВ еҰӮжһңдҪҝз”ЁдәҶдҪҚеӣҫзҙўеј•пјҢе°ұеҝ…йЎ»жҳҜжң¬ең°зҙўеј•В гҖӮжҠҠзҙўеј•еҲҶеҢәжңҖдё»иҰҒзҡ„еҺҹеӣ жҳҜеҸҜд»ҘеҮҸе°‘жүҖйңҖиҜ»еҸ–зҡ„зҙўеј•зҡ„еӨ§е°ҸпјҢеҸҰеӨ–жҠҠеҲҶеҢәж”ҫеңЁдёҚеҗҢзҡ„иЎЁз©әй—ҙдёӯеҸҜд»ҘжҸҗй«ҳеҲҶеҢәзҡ„еҸҜз”ЁжҖ§е’ҢеҸҜйқ жҖ§гҖӮВ
еңЁдҪҝз”ЁеҲҶеҢәеҗҺзҡ„иЎЁе’Ңзҙўеј•ж—¶пјҢOracleВ иҝҳж”ҜжҢҒ并иЎҢжҹҘиҜўе’Ң并иЎҢВ DMLВ гҖӮиҝҷж ·е°ұеҸҜд»ҘеҗҢж—¶жү§иЎҢеӨҡдёӘиҝӣзЁӢпјҢд»ҺиҖҢеҠ еҝ«еӨ„зҗҶиҝҷжқЎиҜӯеҸҘгҖӮВ
2.7.В 1.жң¬ең°еҲҶеҢәзҙўеј•В (В йҖҡеёёдҪҝз”Ёзҡ„зҙўеј•В )В
еҸҜд»ҘдҪҝз”ЁдёҺиЎЁзӣёеҗҢзҡ„еҲҶеҢәй”®е’ҢиҢғеӣҙз•ҢйҷҗжқҘеҜ№жң¬ең°зҙўеј•еҲҶеҢәгҖӮжҜҸдёӘжң¬ең°зҙўеј•зҡ„еҲҶеҢәеҸӘеҢ…еҗ«дәҶе®ғжүҖе…іиҒ”зҡ„иЎЁеҲҶеҢәзҡ„й”®е’ҢROWIDВ гҖӮжң¬ең°зҙўеј•еҸҜд»ҘжҳҜВ BВ ж ‘жҲ–дҪҚеӣҫзҙўеј•гҖӮеҰӮжһңжҳҜВ BВ ж ‘зҙўеј•пјҢе®ғеҸҜд»ҘжҳҜе”ҜдёҖжҲ–дёҚе”ҜдёҖзҡ„зҙўеј•гҖӮВ
иҝҷз§Қзұ»еһӢзҡ„зҙўеј•ж”ҜжҢҒеҲҶеҢәзӢ¬з«ӢжҖ§пјҢиҝҷе°ұж„Ҹе‘ізқҖеҜ№дәҺеҚ•зӢ¬зҡ„еҲҶеҢәпјҢеҸҜд»ҘиҝӣиЎҢеўһеҠ гҖҒжҲӘеҸ–гҖҒеҲ йҷӨгҖҒеҲҶеүІгҖҒи„ұжңәзӯүеӨ„зҗҶпјҢиҖҢдёҚз”ЁеҗҢж—¶еҲ йҷӨжҲ–йҮҚе»әзҙўеј•гҖӮВ OracleиҮӘеҠЁз»ҙжҠӨиҝҷдәӣжң¬ең°зҙўеј•гҖӮВ жң¬ең°зҙўеј•еҲҶеҢәиҝҳеҸҜд»Ҙиў«еҚ•зӢ¬йҮҚе»әпјҢиҖҢе…¶д»–еҲҶеҢәдёҚдјҡеҸ—еҲ°еҪұе“ҚгҖӮ
2.7.1.1В В жңүеүҚзјҖзҡ„зҙўеј•В
жңүеүҚзјҖзҡ„зҙўеј•еҢ…еҗ«дәҶжқҘиҮӘеҲҶеҢәй”®зҡ„й”®пјҢ并жҠҠе®ғ们дҪңдёәзҙўеј•зҡ„еүҚеҜјгҖӮдҫӢеҰӮпјҢи®©жҲ‘们еҶҚж¬ЎеӣһйЎҫparticipantВ иЎЁгҖӮеңЁеҲӣе»әиҜҘиЎЁеҗҺпјҢдҪҝз”ЁВ survey_idВ е’ҢВ survey_dateВ иҝҷдёӨдёӘеҲ—иҝӣиЎҢиҢғеӣҙеҲҶеҢәпјҢ然еҗҺеңЁВ survey_idВ еҲ—дёҠе»әз«ӢдёҖдёӘжңүеүҚзјҖзҡ„жң¬ең°зҙўеј•пјҢеҰӮВ дёӢеӣҫВ жүҖзӨәгҖӮиҝҷдёӘзҙўеј•зҡ„жүҖжңүеҲҶеҢәйғҪиў«зӯүд»·еҲ’еҲҶпјҢе°ұжҳҜиҜҙзҙўеј•зҡ„еҲҶеҢәйғҪдҪҝз”ЁиЎЁзҡ„зӣёеҗҢиҢғеӣҙз•ҢйҷҗжқҘеҲӣе»әгҖӮВ
В В В В В В В В В В В В В В В В В 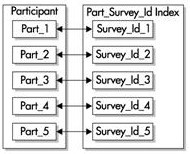
жҠҖе·§пјҡВ жң¬ең°зҡ„жңүеүҚзјҖзҙўеј•еҸҜд»Ҙи®©OracleВ еҝ«йҖҹеү”йҷӨдёҖдәӣдёҚеҝ…иҰҒзҡ„еҲҶеҢәгҖӮд№ҹе°ұжҳҜиҜҙжІЎжңүеҢ…еҗ«В WHEREВ жқЎд»¶еӯҗеҸҘдёӯд»»дҪ•еҖјзҡ„еҲҶеҢәе°ҶдёҚдјҡиў«и®ҝй—®пјҢиҝҷж ·д№ҹжҸҗй«ҳдәҶиҜӯеҸҘзҡ„жҖ§иғҪгҖӮВ
2.7.1.2В В ж— еүҚзјҖзҡ„зҙўеј•В
ж— еүҚзјҖзҡ„зҙўеј•е№¶жІЎжңүжҠҠеҲҶеҢәй”®зҡ„еүҚеҜјеҲ—дҪңдёәзҙўеј•зҡ„еүҚеҜјеҲ—гҖӮиӢҘдҪҝз”ЁжңүеҗҢж ·еҲҶеҢәй”®(survey_idВ е’ҢВ survey_date)В зҡ„зӣёеҗҢеҲҶеҢәиЎЁпјҢе»әз«ӢеңЁВ survey_dateВ еҲ—дёҠзҡ„зҙўеј•е°ұжҳҜдёҖдёӘжң¬ең°зҡ„ж— еүҚзјҖзҙўеј•пјҢеҰӮВ дёӢеӣҫВ жүҖзӨәгҖӮеҸҜд»ҘеңЁиЎЁзҡ„д»»дёҖеҲ—дёҠеҲӣе»әжң¬ең°ж— еүҚзјҖзҙўеј•пјҢдҪҶзҙўеј•зҡ„жҜҸдёӘеҲҶеҢәеҸӘеҢ…еҗ«иЎЁзҡ„зӣёеә”еҲҶеҢәзҡ„й”®еҖјгҖӮВ
В В В В В В В В В В В В В В В В В В В В В В В В В В 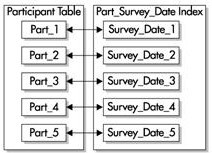
В
еҰӮжһңиҰҒжҠҠж— еүҚзјҖзҡ„зҙўеј•и®ҫдёәе”ҜдёҖзҙўеј•пјҢиҝҷдёӘзҙўеј•е°ұеҝ…йЎ»еҢ…еҗ«еҲҶеҢәй”®зҡ„еӯҗйӣҶгҖӮеңЁиҝҷдёӘдҫӢеӯҗдёӯпјҢжҲ‘们еҝ…йЎ»жҠҠеҢ…еҗ«surveyе’ҢВ (В жҲ–В )survey_idВ зҡ„еҲ—иҝӣиЎҢз»„еҗҲВ (В еҸӘиҰҒВ survey_idВ дёҚжҳҜзҙўеј•зҡ„第дёҖеҲ—пјҢе®ғе°ұжҳҜдёҖдёӘжңүеүҚзјҖзҡ„зҙўеј•В )В гҖӮВ
жҠҖе·§пјҡВ еҜ№дәҺдёҖдёӘе”ҜдёҖзҡ„ж— еүҚзјҖзҙўеј•пјҢе®ғеҝ…йЎ»еҢ…еҗ«еҲҶеҢәй”®зҡ„еӯҗйӣҶгҖӮВ
2.7.В 2.В В В е…ЁеұҖеҲҶеҢәзҙўеј•В
е…ЁеұҖеҲҶеҢәзҙўеј•еңЁдёҖдёӘзҙўеј•еҲҶеҢәдёӯеҢ…еҗ«жқҘиҮӘеӨҡдёӘиЎЁеҲҶеҢәзҡ„й”®гҖӮдёҖдёӘе…ЁеұҖеҲҶеҢәзҙўеј•зҡ„еҲҶеҢәй”®жҳҜеҲҶеҢәиЎЁдёӯдёҚеҗҢзҡ„жҲ–жҢҮе®ҡдёҖдёӘиҢғеӣҙзҡ„еҖјгҖӮеңЁеҲӣе»әе…ЁеұҖеҲҶеҢәзҙўеј•ж—¶пјҢеҝ…йЎ»е®ҡд№үеҲҶеҢәй”®зҡ„иҢғеӣҙе’ҢеҖјгҖӮВ е…ЁеұҖзҙўеј•еҸӘиғҪжҳҜBВ ж ‘зҙўеј•В гҖӮВ OracleеңЁй»ҳи®Өжғ…еҶөдёӢдёҚдјҡз»ҙжҠӨе…ЁеұҖеҲҶеҢәзҙўеј•гҖӮеҰӮжһңдёҖдёӘеҲҶеҢәиў«жҲӘеҸ–гҖҒеўһеҠ гҖҒеҲҶеүІгҖҒеҲ йҷӨзӯүпјҢе°ұеҝ…йЎ»йҮҚе»әе…ЁеұҖеҲҶеҢәзҙўеј•В пјҢйҷӨйқһеңЁдҝ®ж”№иЎЁж—¶жҢҮе®ҡALTERВ TABLEВ е‘Ҫд»Өзҡ„В UPDATEВ GLOBALВ INDEXESВ еӯҗеҸҘгҖӮ
2.7.2.1В В жңүеүҚзјҖзҡ„зҙўеј•В
йҖҡеёёпјҢе…ЁеұҖжңүеүҚзјҖзҙўеј•еңЁеә•еұӮиЎЁдёӯжІЎжңүз»ҸиҝҮеҜ№зӯүеҲҶеҢәгҖӮжІЎжңүд»Җд№Ҳеӣ зҙ иғҪйҷҗеҲ¶зҙўеј•зҡ„еҜ№зӯүеҲҶеҢәпјҢдҪҶOracleВ еңЁз”ҹжҲҗжҹҘиҜўи®ЎеҲ’жҲ–жү§иЎҢеҲҶеҢәз»ҙжҠӨж“ҚдҪңж—¶пјҢ并дёҚдјҡе……еҲҶеҲ©з”ЁеҜ№зӯүеҲҶеҢәгҖӮеҰӮжһңзҙўеј•иў«еҜ№зӯүеҲҶеҢәпјҢе°ұеҝ…йЎ»жҠҠе®ғеҲӣе»әдёәдёҖдёӘжң¬ең°зҙўеј•пјҢиҝҷж ·В OracleВ еҸҜд»Ҙз»ҙжҠӨиҝҷдёӘзҙўеј•пјҢ并дҪҝз”Ёе®ғжқҘеҲ йҷӨдёҚеҝ…иҰҒзҡ„еҲҶеҢәпјҢеҰӮВ дёӢеӣҫВ жүҖзӨәгҖӮеңЁиҜҘеӣҫзҡ„3В дёӘзҙўеј•еҲҶеҢәдёӯпјҢжҜҸдёӘеҲҶеҢәйғҪеҢ…еҗ«жҢҮеҗ‘еӨҡдёӘиЎЁеҲҶеҢәдёӯиЎҢзҡ„зҙўеј•жқЎзӣ®гҖӮВ
В В В В В В В В В 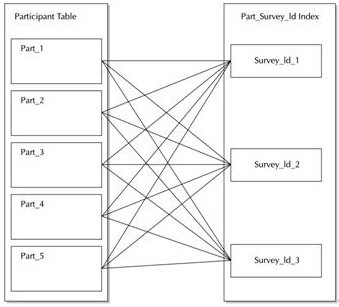
В В В В В В В В В В В В В В В В В В В В В В В В
В В В В В В В В В В еҲҶеҢәзҡ„гҖҒе…ЁеұҖжңүеүҚзјҖзҙўеј•В
жҠҖе·§В пјҡВ еҰӮжһңдёҖдёӘе…ЁеұҖзҙўеј•е°Ҷиў«еҜ№зӯүеҲҶеҢәпјҢе°ұеҝ…йЎ»жҠҠе®ғеҲӣе»әдёәдёҖдёӘжң¬ең°зҙўеј•пјҢиҝҷж ·OracleВ еҸҜд»Ҙз»ҙжҠӨиҝҷдёӘзҙўеј•пјҢ并дҪҝз”Ёе®ғжқҘеҲ йҷӨдёҚеҝ…иҰҒзҡ„еҲҶеҢәгҖӮ
2.7.2.2В В ж— еүҚзјҖзҡ„зҙўеј•В
OracleдёҚж”ҜжҢҒж— еүҚзјҖзҡ„е…ЁеұҖзҙўеј•гҖӮВ
2.8В В дҪҚеӣҫиҝһжҺҘзҙўеј•В
дҪҚеӣҫиҝһжҺҘзҙўеј•жҳҜеҹәдәҺдёӨдёӘиЎЁзҡ„иҝһжҺҘзҡ„дҪҚеӣҫзҙўеј•пјҢеңЁж•°жҚ®д»“еә“зҺҜеўғдёӯдҪҝз”Ёиҝҷз§Қзҙўеј•ж”№иҝӣиҝһжҺҘз»ҙеәҰиЎЁе’ҢдәӢе®һиЎЁзҡ„жҹҘиҜўзҡ„жҖ§иғҪгҖӮеҲӣе»әдҪҚеӣҫиҝһжҺҘзҙўеј•ж—¶пјҢж ҮеҮҶж–№жі•жҳҜиҝһжҺҘзҙўеј•дёӯеёёз”Ёзҡ„з»ҙеәҰиЎЁе’ҢдәӢе®һиЎЁгҖӮеҪ“з”ЁжҲ·еңЁдёҖж¬ЎжҹҘиҜўдёӯз»“еҗҲжҹҘиҜўдәӢе®һиЎЁе’Ңз»ҙеәҰиЎЁж—¶пјҢе°ұдёҚйңҖиҰҒжү§иЎҢиҝһжҺҘпјҢеӣ дёәеңЁдҪҚеӣҫиҝһжҺҘзҙўеј•дёӯе·Із»ҸжңүеҸҜз”Ёзҡ„иҝһжҺҘз»“жһңгҖӮйҖҡиҝҮеҺӢзј©дҪҚеӣҫиҝһжҺҘзҙўеј•дёӯзҡ„ROWIDВ иҝӣдёҖжӯҘж”№иҝӣжҖ§иғҪпјҢ并且еҮҸе°‘и®ҝй—®ж•°жҚ®жүҖйңҖзҡ„В I/OВ ж•°йҮҸгҖӮ
еҲӣе»әдҪҚеӣҫиҝһжҺҘзҙўеј•ж—¶пјҢжҢҮе®ҡж¶үеҸҠзҡ„дёӨдёӘиЎЁгҖӮзӣёеә”зҡ„иҜӯжі•еә”иҜҘйҒөеҫӘеҰӮдёӢжЁЎејҸпјҡВ
createВ bitmapВ indexВ FACT_DIM_COL_IDXВ В В onВ FACT(DIM.Descr_Col)В В В fromВ FACT,В DIMВ
whereВ FACT.JoinColВ =В DIM.JoinCol;
дҪҚеӣҫиҝһжҺҘзҡ„иҜӯжі•жҜ”иҫғзү№еҲ«пјҢе…¶дёӯеҢ…еҗ«FROMВ еӯҗеҸҘе’ҢВ WHEREВ еӯҗеҸҘпјҢ并且引用дёӨдёӘеҚ•зӢ¬зҡ„иЎЁгҖӮзҙўеј•еҲ—йҖҡеёёжҳҜз»ҙеәҰиЎЁдёӯзҡ„жҸҸиҝ°еҲ—В вҖ”вҖ”В е°ұжҳҜиҜҙпјҢеҰӮжһңз»ҙеәҰжҳҜВ CUSTOMERВ пјҢ并且е®ғзҡ„дё»й”®жҳҜВ CUSTOMER_IDВ пјҢеҲҷйҖҡеёёзҙўеј•Customer_NameВ иҝҷж ·зҡ„еҲ—гҖӮеҰӮжһңдәӢе®һиЎЁеҗҚдёәВ SALESВ пјҢеҸҜд»ҘдҪҝз”ЁеҰӮдёӢзҡ„е‘Ҫд»ӨеҲӣе»әзҙўеј•пјҡВ
createВ В В bitmapВ В В indexВ В В SALES_CUST_NAME_IDX
onВ В SALES(CUSTOMER.Customer_Name)В В В В fromВ SALES,В CUSTOMERВ
whereВ В SALES.Customer_ID=CUSTOMER.Customer_ID;
еҰӮжһңз”ЁжҲ·жҺҘдёӢжқҘдҪҝз”ЁжҢҮе®ҡCustomer_NameВ еҲ—еҖјзҡ„В WHEREВ еӯҗеҸҘжҹҘиҜўВ SALESВ е’ҢВ CUSTOMERВ иЎЁпјҢдјҳеҢ–еҷЁе°ұеҸҜд»ҘдҪҝз”ЁдҪҚеӣҫиҝһжҺҘзҙўеј•еҝ«йҖҹиҝ”еӣһеҢ№й…ҚиҝһжҺҘжқЎд»¶е’ҢВ Customer_NameВ жқЎд»¶зҡ„иЎҢгҖӮ
дҪҚеӣҫиҝһжҺҘзҙўеј•зҡ„дҪҝз”ЁдёҖиҲ¬дјҡеҸ—еҲ°йҷҗеҲ¶В пјҡ
1пјүВ еҸӘеҸҜд»Ҙзҙўеј•з»ҙеәҰиЎЁдёӯзҡ„еҲ—гҖӮ
2пјүВ з”ЁдәҺиҝһжҺҘзҡ„еҲ—еҝ…йЎ»жҳҜз»ҙеәҰиЎЁдёӯзҡ„дё»й”®жҲ–е”ҜдёҖзәҰжқҹпјӣеҰӮжһңжҳҜеӨҚеҗҲдё»й”®пјҢеҲҷеҝ…йЎ»дҪҝз”ЁиҝһжҺҘдёӯзҡ„жҜҸдёҖеҲ—гҖӮ
3пјүВ дёҚеҸҜд»ҘеҜ№зҙўеј•з»„з»ҮиЎЁеҲӣе»әдҪҚеӣҫиҝһжҺҘзҙўеј•пјҢ并且йҖӮз”ЁдәҺ常规дҪҚеӣҫзҙўеј•зҡ„йҷҗеҲ¶д№ҹйҖӮз”ЁдәҺдҪҚеӣҫиҝһжҺҘзҙўеј•гҖӮВ
В



зӣёе…іжҺЁиҚҗ
жҖ»зҡ„жқҘиҜҙпјҢOracleзҙўеј•иҜҰи§ЈеҸҠSQLдјҳеҢ–жҳҜдёҖдёӘж·ұеәҰе№ҝеәҰе…је…·зҡ„дё»йўҳпјҢйңҖиҰҒз»“еҗҲе®һйҷ…ж•°жҚ®еә“з»“жһ„е’ҢдёҡеҠЎйңҖжұӮпјҢзҒөжҙ»еә”з”Ёеҗ„з§Қзҙўеј•зұ»еһӢе’ҢдјҳеҢ–зӯ–з•ҘпјҢд»Ҙе®һзҺ°ж•°жҚ®еә“жҖ§иғҪзҡ„жңҖеӨ§еҢ–гҖӮйҖҡиҝҮж·ұе…ҘеӯҰд№ е’Ңе®һи·өпјҢдҪ еҸҜд»ҘжӣҙеҘҪең°й©ҫй©ӯOracleж•°жҚ®еә“...
жң¬зҜҮеҶ…е®№е°Ҷж·ұе…Ҙи§ЈжһҗOracleзҙўеј•зҡ„еҹәжң¬жҰӮеҝөгҖҒеҺҹзҗҶд»ҘеҸҠзұ»еһӢгҖӮ йҰ–е…ҲпјҢзҙўеј•жҳҜеҸҜйҖүзҡ„иЎЁеҜ№иұЎпјҢе…¶дё»иҰҒзӣ®зҡ„жҳҜжҸҗеҚҮжҹҘиҜўйҖҹеәҰгҖӮе°Ҫз®Ўзҙўеј•еҸҜд»Ҙжҳҫи‘—жҸҗй«ҳж•°жҚ®жЈҖзҙўзҡ„ж•ҲзҺҮпјҢдҪҶеҗҢж—¶д№ҹеҚ з”ЁйўқеӨ–зҡ„еӯҳеӮЁз©әй—ҙпјҢ并еҸҜиғҪеҪұе“Қж•°жҚ®жҸ’е…ҘгҖҒжӣҙж–°е’Ң...
Oracleзҙўеј•жҳҜж•°жҚ®еә“з®ЎзҗҶзі»з»ҹдёӯз”ЁдәҺеҠ йҖҹж•°жҚ®жЈҖзҙўзҡ„е…ій”®ж•°жҚ®з»“жһ„пјҢе°Өе…¶еңЁеӨ„зҗҶеӨ§йҮҸж•°жҚ®жҹҘиҜўж—¶пјҢе…¶ж•ҲзҺҮиҮіе…ійҮҚиҰҒгҖӮжң¬ж–Үе°Ҷж·ұе…ҘжҺўи®ЁOracleдёӯзҡ„Bж ‘зҙўеј•пјҢеҢ…жӢ¬е®ғзҡ„жҰӮеҝөгҖҒеҲӣе»әгҖҒеҲ йҷӨе’Ңдҝ®ж”№пјҢд»ҘеҸҠеҰӮдҪ•зҗҶи§Је…¶е·ҘдҪңеҺҹзҗҶгҖӮ йҰ–е…ҲпјҢ...
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮиҜҰз»Ҷд»Ӣз»ҚдәҶ Oracleдёӯзҡ„еҗ„з§Қзҙўеј•зұ»еһӢеҸҠе…¶дҪҝз”ЁеңәжҷҜпјҢеҢ…жӢ¬ B*Treeзҙўеј•гҖҒдҪҚеӣҫзҙўеј•гҖҒзҙўеј•з»„з»ҮиЎЁгҖҒйҷҚеәҸзҙўеј•гҖҒеҸҚеҗ‘й”®зҙўеј•е’ҢеҹәдәҺеҮҪж•°зҡ„зҙўеј•гҖӮжҜҸз§Қзҙўеј•зҡ„дјҳзјәзӮ№гҖҒйҖӮз”ЁеңәеҗҲе’ҢеҲӣе»әж–№жі•еқҮжңүиҜҰз»Ҷд»Ӣз»ҚгҖӮж–Үз« иҝҳи®Ёи®әдәҶ...
oracleж•°жҚ®еә“дёӯеҰӮдҪ•е»әз«Ӣзҙўеј•пјҢе»әз«Ӣзҙўеј•жңүд»Җд№ҲдјҳеҠҝпјҢзҙўеј•иҜҘеҰӮдҪ•дҪҝз”Ё
Oracleзҙўеј•жҳҜж•°жҚ®еә“з®ЎзҗҶзі»з»ҹOracleдёӯз”ЁдәҺеҠ йҖҹж•°жҚ®жЈҖзҙўзҡ„йҮҚиҰҒе·Ҙе…·гҖӮзҙўеј•зҡ„жҰӮеҝөзұ»дјјдәҺд№ҰзұҚзҡ„зӣ®еҪ•пјҢе®ғзҡ„дё»иҰҒдҪңз”ЁжҳҜжҸҗй«ҳжҹҘиҜўйҖҹеәҰпјҢзү№еҲ«жҳҜеңЁеӨ„зҗҶеӨ§йҮҸж•°жҚ®зҡ„иЎЁж—¶гҖӮOracleзҙўеј•еҲҶдёәйҖ»иҫ‘дёҠе’Ңзү©зҗҶдёҠзӢ¬з«Ӣзҡ„еҜ№иұЎпјҢеҲӣе»әжҲ–еҲ йҷӨзҙўеј•...
**Oracleзҙўеј•иҜҰи§Ј** Oracleзҙўеј•жҳҜж•°жҚ®еә“з®ЎзҗҶзі»з»ҹдёӯз”ЁдәҺжҸҗй«ҳжҹҘиҜўж•ҲзҺҮзҡ„йҮҚиҰҒж•°жҚ®з»“жһ„гҖӮе®ғзҡ„е·ҘдҪңеҺҹзҗҶзұ»дјјдәҺд№ҰзұҚзҡ„зӣ®еҪ•пјҢе…Ғи®ёж•°жҚ®еә“зі»з»ҹеҝ«йҖҹе®ҡдҪҚеҲ°жүҖйңҖзҡ„ж•°жҚ®иЎҢпјҢиҖҢж— йңҖжү«жҸҸж•ҙдёӘиЎЁгҖӮзҙўеј•зҡ„еӯҳеңЁдҪҝеҫ—еҜ№еӨ§йҮҸж•°жҚ®зҡ„жҹҘжүҫгҖҒ...
иҝҷд»Ҫ"Oracle笔记иҜҰи§Јиө„ж–ҷз”ЁдҫӢ"ж¶өзӣ–дәҶOracleж•°жҚ®еә“зҡ„ж ёеҝғжҰӮеҝөгҖҒе®үиЈ…й…ҚзҪ®гҖҒSQLиҜӯиЁҖгҖҒиЎЁе’Ңзҙўеј•гҖҒеӯҳеӮЁз»“жһ„гҖҒеӨҮд»ҪжҒўеӨҚгҖҒжҖ§иғҪдјҳеҢ–зӯүеӨҡдёӘж–№йқўпјҢжҳҜеӯҰд№ е’ҢжҺҢжҸЎOracleж•°жҚ®еә“зҡ„е®қиҙөиө„жәҗгҖӮ йҰ–е…ҲпјҢOracleж•°жҚ®еә“зҡ„еҹәзЎҖйғЁеҲҶеҢ…жӢ¬...
### Oracleзҙўеј•дјҳеҢ–зӣёе…ізҹҘиҜҶзӮ№иҜҰи§Ј #### дёҖгҖҒеҹәжң¬зҙўеј•жҰӮеҝө еңЁOracleж•°жҚ®еә“дёӯпјҢзҙўеј•жҳҜжҸҗй«ҳж•°жҚ®жЈҖзҙўйҖҹеәҰзҡ„йҮҚиҰҒе·Ҙе…·гҖӮйҖҡиҝҮжҹҘиҜў`DBA_INDEXES`и§ҶеӣҫпјҢеҸҜд»ҘиҺ·еҸ–еҲ°еҪ“еүҚж•°жҚ®еә“дёӯжүҖжңүиЎЁзҡ„жүҖжңүзҙўеј•дҝЎжҒҜгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢеҰӮжһң...
### Oracleзҙўеј•зұ»еһӢиҜҰи§Ј #### дёҖгҖҒB\*Treeзҙўеј•пјҡж•°жҚ®жЈҖзҙўзҡ„еҹәзҹі еңЁOracleж•°жҚ®еә“дёӯпјҢB\*Treeзҙўеј•жҳҜжңҖеёёи§Ғзҡ„зҙўеј•з»“жһ„пјҢд№ҹжҳҜй»ҳи®ӨеҲӣе»әзҡ„зҙўеј•зұ»еһӢгҖӮе®ғеҹәдәҺдәҢеҸүж ‘еҺҹзҗҶпјҢз”ұеҲҶж”Ҝеқ—(branch block)е’ҢеҸ¶еқ—(leaf block)жһ„жҲҗпјҢ...
### Oracleзҙўеј•иҜҰи§Ј #### дёҖгҖҒзҙўеј•жҰӮеҝөдёҺдҪңз”Ё **зҙўеј•е®ҡд№ү**пјҡзҙўеј•жҳҜеңЁиЎЁзҡ„дёҖдёӘжҲ–еӨҡдёӘеҲ—дёҠеҲӣе»әзҡ„дёҖз§Қж•°жҚ®з»“жһ„пјҢе®ғзҡ„дё»иҰҒзӣ®зҡ„жҳҜдёәдәҶжҸҗй«ҳж•°жҚ®и®ҝй—®зҡ„йҖҹеәҰгҖӮзҙўеј•е°ұеғҸжҳҜеӣҫд№Ұзҡ„зӣ®еҪ•пјҢеҸҜд»Ҙеё®еҠ©з”ЁжҲ·еҝ«йҖҹе®ҡдҪҚеҲ°жүҖйңҖзҡ„ж•°жҚ®гҖӮ ...
### Oracleзҙўеј•иҜҰи§Ј еңЁOracleж•°жҚ®еә“з®ЎзҗҶдёӯпјҢзҙўеј•жҳҜдёҖз§ҚйҮҚиҰҒзҡ„ж•°жҚ®з»“жһ„пјҢе®ғиғҪжҳҫи‘—жҸҗеҚҮж•°жҚ®жЈҖзҙўзҡ„йҖҹеәҰгҖӮжң¬ж–Үе°Ҷд»ҺB-treeзҙўеј•е…ҘжүӢпјҢиҜҰз»Ҷи§Јжһҗе…¶з»“жһ„дёҺзү№жҖ§пјҢ并结еҗҲе…·дҪ“зҡ„еӣҫи§ЈдёҺе®һдҫӢжқҘеё®еҠ©иҜ»иҖ…жӣҙеҘҪең°зҗҶи§Је’ҢжҺҢжҸЎOracleзҙўеј•...
### Oracleдёӯзҡ„зҙўеј•иҜҰи§Ј #### дёҖгҖҒROWIDзҡ„жҰӮеҝө ROWIDжҳҜдёҖз§Қзү№ж®Ҡзҡ„ж•°жҚ®зұ»еһӢпјҢз”ЁдәҺеӯҳеӮЁиЎҢеңЁж•°жҚ®ж–Ү件дёӯзҡ„е…·дҪ“дҪҚзҪ®гҖӮе®ғжҳҜдёҖдёӘ64дҪҚзј–з Ғзҡ„ж•°жҚ®пјҢз”ұеӯ—з¬Ұ`A-Z`гҖҒ`a-z`гҖҒ`0-9`гҖҒ`+`е’Ң`/`з»„жҲҗгҖӮеңЁOracleж•°жҚ®еә“дёӯпјҢROWIDз”ЁдәҺ...
### Oracleзҙўеј•дҪҝз”Ёж ·дҫӢиҜҰи§Ј #### дёҖгҖҒзҙўеј•е№¶иЎҢеҲӣе»ә еңЁOracleж•°жҚ®еә“дёӯпјҢ并иЎҢеҲӣе»әзҙўеј•еҸҜд»Ҙжҳҫи‘—жҸҗй«ҳеҲӣе»әзҙўеј•зҡ„йҖҹеәҰпјҢе°Өе…¶жҳҜеңЁеӨ„зҗҶеӨ§йҮҸж•°жҚ®ж—¶гҖӮдёӢйқўзҡ„SQLиҜӯеҸҘеұ•зӨәдәҶеҰӮдҪ•е№¶иЎҢеҲӣе»әдёҖдёӘзҙўеј•пјҡ ```sql CREATE INDEX IDX_GD...
#### дёҖгҖҒOracleзҙўеј•жҰӮиҝ° зҙўеј•еңЁж•°жҚ®еә“з®ЎзҗҶзі»з»ҹдёӯжү®жј”зқҖжһҒе…¶йҮҚиҰҒзҡ„и§’иүІпјҢе®ғиғҪжҳҫи‘—жҸҗй«ҳжҹҘиҜўжҖ§иғҪгҖӮеңЁOracleж•°жҚ®еә“дёӯпјҢзҙўеј•жҳҜдёҖз§Қзү№ж®Ҡзҡ„ж•°жҚ®з»“жһ„пјҢз”ЁдәҺеҝ«йҖҹжҹҘжүҫж•°жҚ®еә“иЎЁдёӯзҡ„и®°еҪ•гҖӮзҙўеј•еҸҜд»Ҙе»әз«ӢеңЁиЎЁзҡ„дёҖдёӘеҲ—жҲ–еӨҡдёӘеҲ—дёҠ...
### Oracle еҲӣе»әе’ҢеҲ йҷӨзҙўеј•иҜҰи§Ј #### дёҖгҖҒOracleзҙўеј•жҰӮиҝ° еңЁOracleж•°жҚ®еә“дёӯпјҢзҙўеј•жҳҜдёҖз§ҚйҮҚиҰҒзҡ„ж•°жҚ®з»“жһ„пјҢз”ЁдәҺжҸҗй«ҳж•°жҚ®жЈҖзҙўйҖҹеәҰгҖӮйҖҡиҝҮеҲӣе»әзҙўеј•пјҢеҸҜд»Ҙжҳҫи‘—жҸҗеҚҮжҹҘиҜўжҖ§иғҪпјҢе°Өе…¶жҳҜеңЁеӨ„зҗҶеӨ§еһӢж•°жҚ®иЎЁж—¶жӣҙдёәжҳҺжҳҫгҖӮзҙўеј•зұ»дјј...