
жЦЗзЂ†иљђиЗ™пЉЪhttp://www.cnblogs.com/adslg/archive/2012/06/23/2559206.html¬† жДЯи∞ҐдљЬиАЕзЪДеИЖдЇЂ
жСШи¶БпЉЪжЬђжЦЗеѓєBж†С糥еЉХзЪДзїУжЮДгАБеЖЕйГ®зЃ°зРЖз≠ЙжЦєйЭҐеБЪдЇЖдЄАдЄ™еЕ®йЭҐзЪДдїЛзїНгАВеРМжЧґжЈ±еЕ•жОҐиЃ®дЇЖдЄАдЇЫдЄОBж†С糥еЉХжЬЙеЕ≥зЪДеєњдЄЇжµБдЉ†зЪДиѓіж≥ХпЉМжѓФе¶ВеИ†йЩ§иЃ∞ељХ僺糥еЉХзЪДељ±еУНпЉМеЃЪжЬЯйЗН忯糥еЉХиГљиІ£еЖ≥иЃЄе§ЪжАІиГљйЧЃйҐШз≠ЙгАВ
 
1.Bж†С糥еЉХзЪДзЫЄеЕ≥ж¶Вењµ
¬†¬†¬†¬†¬† 糥еЉХдЄОи°®дЄАж†ЈпЉМдєЯе±ЮдЇОжЃµпЉИsegmentпЉЙзЪДдЄАзІНгАВйЗМйЭҐе≠ШжФЊдЇЖзФ®жИЈзЪДжХ∞жНЃпЉМиЈЯи°®дЄАж†ЈйЬАи¶БеН†зФ®з£БзЫШз©ЇйЧігАВеП™
дЄНињЗпЉМеܮ糥еЉХйЗМзЪДжХ∞жНЃе≠ШжԌ嚥еЉПдЄОи°®йЗМзЪДжХ∞жНЃе≠ШжԌ嚥еЉПйЭЮеЄЄзЪДдЄНдЄАж†ЈгАВеЬ®зРЖиІ£зіҐеЉХжЧґпЉМеПѓдї•жГ≥и±°дЄАжЬђдє¶пЉМеЕґдЄ≠дє¶зЪДеЖЕеЃєе∞±зЫЄељУдЇОи°®йЗМзЪДжХ∞жНЃпЉМиАМдє¶еЙНйЭҐзЪДзЫЃељХ е∞±зЫЄељУдЇОиѓ•и°®зЪД糥еЉХгАВеРМжЧґпЉМйАЪеЄЄжГЕеЖµдЄЛпЉМ糥еЉХжЙАеН†зФ®зЪДз£БзЫШз©ЇйЧіи¶БжѓФи°®и¶Бе∞ПзЪДе§ЪпЉМеЕґдЄїи¶БдљЬзФ®жШѓдЄЇдЇЖеК†ењЂеѓєжХ∞жНЃзЪДжРЬ糥йАЯеЇ¶пЉМдєЯеПѓдї•зФ®жЭ•дњЭиѓБжХ∞жНЃзЪДеФѓдЄАжАІгАВ
¬†¬†¬†¬†¬† дљЖжШѓпЉМ糥еЉХдљЬдЄЇдЄАзІНеПѓйАЙзЪДжХ∞жНЃзїУжЮДпЉМдљ†еПѓдї•йАЙжЛ©дЄЇжЯРдЄ™и°®йЗМзЪДеИЫ忯糥еЉХпЉМдєЯеПѓдї•дЄНеИЫеїЇгАВињЩжШѓеЫ†дЄЇдЄАжЧ¶еИЫеїЇдЇЖ糥еЉХпЉМе∞±жДПеС≥зЭАoracleеѓєи°®ињЫи°МDMLпЉИеМЕжЛђINSERTгАБUPDATEгАБDELETEпЉЙжЧґпЉМењЕй°їе§ДзРЖйҐЭе§ЦзЪДеЈ•дљЬйЗПпЉИдєЯе∞±ж؃僺糥еЉХзїУжЮДзЪДзїіжК§пЉЙдї•еПКе≠ШеВ®жЦєйЭҐзЪДеЉАйФАгАВжЙАдї•еИЫ忯糥еЉХжЧґпЉМйЬАи¶БиАГиЩСеИЫ忯糥еЉХжЙАеЄ¶жЭ•зЪДжߕ胥жАІиГљжЦєйЭҐзЪДжПРйЂШпЉМдЄОеЉХиµЈзЪДйҐЭе§ЦзЪДеЉАйФАзЫЄжѓФпЉМжШѓеР¶еАЉеЊЧгАВ
¬†¬†¬†¬†¬† дїОзЙ©зРЖдЄКиѓіпЉМ糥еЉХйАЪеЄЄеПѓдї•еИЖдЄЇпЉЪеИЖеМЇеТМйЭЮеИЖе̯糥еЉХгАБеЄЄиІДBж†С糥еЉХгАБдљНеЫЊпЉИbitmapпЉЙ糥еЉХгАБзњїиљђпЉИreverseпЉЙ糥еЉХз≠ЙгАВеЕґдЄ≠пЉМBж†С糥еЉХе±ЮдЇОжЬАеЄЄиІБзЪД糥еЉХпЉМзФ±дЇОжИСдїђзЪДињЩзѓЗжЦЗзЂ†дЄїи¶Бе∞±жШѓеѓєBж†С糥еЉХжЙАеБЪзЪДжОҐиЃ®пЉМеЫ†ж≠§дЄЛйЭҐеП™и¶БиѓіеИ∞糥еЉХпЉМйГљжШѓжМЗBж†С糥еЉХгАВ
¬†¬†¬†¬†¬† Bж†С糥еЉХжШѓдЄАдЄ™еЕЄеЮЛзЪДж†СзїУжЮДпЉМеЕґеМЕеРЂзЪДзїДдїґдЄїи¶БжШѓпЉЪ
¬†¬†¬†¬†¬† 1) еПґе≠РиКВзВєпЉИLeaf nodeпЉЙпЉЪеМЕеРЂжЭ°зЫЃзЫіжО•жМЗеРСи°®йЗМзЪДжХ∞жНЃи°МгАВ
¬†¬†¬†¬† ¬†2) еИЖжФѓиКВзВєпЉИBranch nodeпЉЙпЉЪеМЕеРЂзЪДжЭ°зЫЃжМЗеРС糥еЉХйЗМеЕґдїЦзЪДеИЖжФѓиКВзВєжИЦиАЕжШѓеПґе≠РиКВзВєгАВ
¬†¬†¬†¬†¬† 3) ж†єиКВзВєпЉИRoot nodeпЉЙпЉЪдЄАдЄ™Bж†С糥еЉХеП™жЬЙдЄАдЄ™ж†єиКВзВєпЉМеЃГеЃЮйЩЕе∞±жШѓдљНдЇОж†СзЪДжЬАй°ґзЂѓзЪДеИЖжФѓиКВзВєгАВ
еПѓдї•зФ®дЄЛеЫЊдЄАжЭ•жППињ∞Bж†С糥еЉХзЪДзїУжЮДгАВеЕґдЄ≠пЉМBи°®з§ЇеИЖжФѓиКВзВєпЉМиАМLи°®з§ЇеПґе≠РиКВзВєгАВ
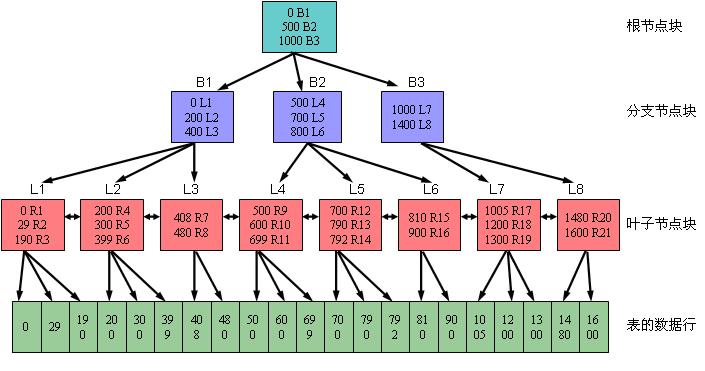  
 
¬†¬†¬†¬†¬† еѓєдЇОеИЖжФѓиКВзВєеЭЧпЉИеМЕжЛђж†єиКВзВєеЭЧпЉЙжЭ•иѓіпЉМеЕґжЙАеМЕеРЂзЪД糥еЉХжЭ°зЫЃйГљжШѓжМЙзЕІй°ЇеЇПжОТеИЧзЪДпЉИзЉЇзЬБжШѓеНЗеЇПжОТеИЧпЉМдєЯеПѓдї•еЬ®еИЫ忯糥еЉХжЧґжМЗеЃЪдЄЇйЩНеЇПжОТеИЧпЉЙгАВжѓП䪙糥еЉХжЭ°зЫЃпЉИдєЯеПѓ дї•еПЂеБЪжѓПжЭ°иЃ∞ељХпЉЙйГљеЕЈжЬЙдЄ§дЄ™е≠ЧжЃµгАВзђђдЄАдЄ™е≠ЧжЃµи°®з§ЇељУеЙНиѓ•еИЖжФѓиКВзВєеЭЧдЄЛйЭҐжЙАйУЊжО•зЪД糥еЉХеЭЧдЄ≠жЙАеМЕеРЂзЪДжЬАе∞ПйФЃеАЉпЉЫзђђдЇМдЄ™е≠ЧжЃµдЄЇеЫЫдЄ™е≠ЧиКВпЉМи°®з§ЇжЙАйУЊжО•зЪД糥еЉХеЭЧзЪДеЬ∞ еЭАпЉМиѓ•еЬ∞еЭАжМЗеРСдЄЛйЭҐдЄА䪙糥еЉХеЭЧгАВеЬ®дЄАдЄ™еИЖжФѓиКВзВєеЭЧдЄ≠жЙАиГљеЃєзЇ≥зЪДиЃ∞ељХи°МжХ∞зФ±жХ∞жНЃеЭЧе§Іе∞Пдї•еПК糥еЉХйФЃеАЉзЪДйХњеЇ¶еЖ≥еЃЪгАВжѓФе¶ВдїОдЄКеЫЊдЄАеПѓдї•зЬЛеИ∞пЉМеѓєдЇОж†єиКВзВєеЭЧжЭ•иѓіпЉМеМЕ еРЂдЄЙжЭ°иЃ∞ељХпЉМеИЖеИЂдЄЇпЉИ0 B1пЉЙгАБпЉИ500 B2пЉЙгАБпЉИ1000 B3пЉЙпЉМеЃГдїђжМЗеРСдЄЙдЄ™еИЖжФѓиКВзВєеЭЧгАВеЕґдЄ≠зЪД0гАБ500еТМ1000еИЖеИЂи°®з§ЇињЩдЄЙдЄ™еИЖжФѓиКВзВєеЭЧжЙАйУЊжО•зЪДйФЃеАЉзЪДжЬАе∞ПеАЉгАВиАМB1гАБB2еТМB3еИЩи°®з§ЇжЙАжМЗеРСзЪДдЄЙдЄ™еИЖжФѓ иКВзВєеЭЧзЪДеЬ∞еЭАгАВ
¬†¬†¬†¬†¬† еѓєдЇОеПґе≠РиКВзВєеЭЧжЭ•иѓіпЉМеЕґжЙАеМЕеРЂзЪД糥еЉХжЭ°зЫЃдЄОеИЖжФѓиКВзВєдЄАж†ЈпЉМйГљжШѓжМЙзЕІй°ЇеЇПжОТеИЧзЪДпЉИзЉЇзЬБжШѓеНЗеЇПжОТеИЧпЉМдєЯеПѓдї•еЬ®еИЫ忯糥еЉХжЧґжМЗеЃЪдЄЇйЩНеЇПжОТеИЧпЉЙгАВжѓП䪙糥еЉХжЭ°зЫЃпЉИдєЯеПѓ дї•еПЂеБЪжѓПжЭ°иЃ∞ељХпЉЙдєЯеЕЈжЬЙдЄ§дЄ™е≠ЧжЃµгАВзђђдЄАдЄ™е≠Ч恵谮积糥еЉХзЪДйФЃеАЉпЉМеѓєдЇОеНХеИЧ糥еЉХжЭ•иѓіжШѓдЄАдЄ™еАЉпЉЫиАМеѓєдЇОе§ЪеИЧ糥еЉХжЭ•иѓіеИЩжШѓе§ЪдЄ™еАЉзїДеРИеЬ®дЄАиµЈзЪДгАВзђђдЇМдЄ™е≠ЧжЃµи°®з§ЇйФЃеАЉ жЙАеѓєеЇФзЪДиЃ∞ељХи°МзЪДROWIDпЉМиѓ•ROWIDжШѓиЃ∞ељХи°МеЬ®и°®йЗМзЪДзЙ©зРЖеЬ∞еЭАгАВе¶ВжЮЬ糥еЉХжШѓеИЫеїЇеЬ®йЭЮеИЖеМЇи°®дЄКжИЦиАЕ糥еЉХжШѓеИЖеМЇи°®дЄКзЪДжЬђеЬ∞糥еЉХзЪДиѓЭпЉМеИЩиѓ•ROWIDеН†зФ® 6дЄ™е≠ЧиКВпЉЫе¶ВжЮЬ糥еЉХжШѓеИЫеїЇеЬ®еИЖеМЇи°®дЄКзЪДеЕ®е±А糥еЉХзЪДиѓЭпЉМеИЩиѓ•ROWIDеН†зФ®10дЄ™е≠ЧиКВгАВ
¬†¬†¬†¬†¬† зЯ•йБУињЩдЇЫдњ°жБѓдї•еРОпЉМжИСдїђеПѓдї•дЄЊдЄ™дЊЛе≠РжЭ•иѓіжШОе¶ВдљХдЉ∞зЃЧжѓП䪙糥еЉХиГље§ЯеМЕеРЂе§Ъе∞СжЭ°зЫЃпЉМдї•еПКеѓєдЇОи°®жЭ•иѓіпЉМжЙАдЇІзФЯзЪД糥еЉХе§ІзЇ¶е§Ъе§ІгАВеѓєдЇОжѓП䪙糥еЉХеЭЧжЭ•иѓіпЉМзЉЇзЬБзЪД PCTFREEдЄЇ10пЉЕпЉМдєЯе∞±жШѓиѓіжЬАе§ЪеП™иГљдљњзФ®еЕґдЄ≠зЪД90пЉЕгАВеРМжЧґ9iдї•еРОпЉМињЩ90пЉЕдЄ≠дєЯдЄНеПѓиГљзФ®е∞љпЉМеП™иГљдљњзФ®еЕґдЄ≠зЪД87пЉЕеЈ¶еП≥гАВдєЯе∞±жШѓиѓіпЉМ8KBзЪДжХ∞жНЃ еЭЧдЄ≠иГље§ЯеЃЮйЩЕзФ®жЭ•е≠ШжԌ糥еЉХжХ∞жНЃзЪДз©ЇйЧіе§ІзЇ¶дЄЇ6488пЉИ8192√Ч90пЉЕ√Ч88пЉЕпЉЙдЄ™е≠ЧиКВгАВ
¬†¬†¬†¬†¬† еБЗиЃЊжИСдїђжЬЙдЄАдЄ™йЭЮеИЖеМЇи°®пЉМи°®еРНдЄЇwarecountdпЉМеЕґжХ∞жНЃи°МжХ∞дЄЇ130дЄЗи°МгАВиѓ•и°®дЄ≠жЬЙдЄАдЄ™еИЧпЉМеИЧеРНдЄЇgoodidпЉМеЕґз±їеЮЛдЄЇcharпЉИ8пЉЙпЉМйВ£дєИдєЯе∞±жШѓиѓіиѓ•goodidзЪДйХњеЇ¶дЄЇеЫЇеЃЪеАЉпЉЪ8гАВеРМжЧґеЬ®иѓ•еИЧдЄКеИЫеїЇдЇЖдЄАдЄ™Bж†С糥еЉХгАВ
еЬ®еПґе≠РиКВзВєдЄ≠пЉМжѓП䪙糥еЉХжЭ°зЫЃйГљдЉЪеЬ®жХ∞жНЃеЭЧдЄ≠еН†дЄАи°Мз©ЇйЧігАВжѓПдЄАи°МзФ®2еИ∞3дЄ™е≠ЧиКВдљЬдЄЇи°Ме§іпЉМи°Ме§ізФ®жЭ•е≠ШжФЊж†ЗиЃ∞дї•еПКйФБеЃЪз±їеЮЛз≠Йдњ°жБѓгАВеРМжЧґпЉМеЬ®зђђдЄА䪙谮积糥 еЉХзЪДйФЃеАЉзЪДе≠ЧжЃµдЄ≠пЉМжѓПдЄА䪙糥еЉХеИЧйГљжЬЙ1дЄ™е≠ЧиКВи°®з§ЇжХ∞жНЃйХњеЇ¶пЉМеРОйЭҐеИЩжШѓиѓ•еИЧеЕЈдљУзЪДеАЉгАВйВ£дєИеѓєдЇОжЬђдЊЛжЭ•иѓіпЉМеЬ®еПґе≠РиКВзВєдЄ≠зЪДдЄАи°МжЙАеМЕеРЂзЪДжХ∞жНЃе§ІиЗіе¶ВдЄЛеЫЊдЇМжЙАз§ЇпЉЪ
 
  
 
¬†¬†¬†¬†¬† дїОдЄКеЫЊеПѓдї•зЬЛеИ∞пЉМеЬ®жЬђдЊЛзЪДеПґе≠РиКВзВєдЄ≠пЉМдЄА䪙糥еЉХжЭ°зЫЃеН†18дЄ™е≠ЧиКВгАВеРМжЧґжИСдїђзЯ•йБУ8KBзЪДжХ∞жНЃеЭЧдЄ≠зЬЯж≠£еПѓдї•зФ®жЭ•е≠ШжԌ糥еЉХжЭ°зЫЃзЪДз©ЇйЧідЄЇ6488е≠ЧиКВпЉМйВ£дєИеЬ®жЬђ дЊЛдЄ≠пЉМдЄАдЄ™жХ∞жНЃеЭЧдЄ≠е§ІзЇ¶еПѓдї•жФЊ360пЉИ6488/18пЉЙ䪙糥еЉХжЭ°зЫЃгАВиАМеѓєдЇОжИСдїђи°®дЄ≠зЪД130дЄЗжЭ°иЃ∞ељХжЭ•иѓіпЉМеИЩйЬАи¶Бе§ІзЇ¶3611пЉИ1300000/360пЉЙ дЄ™еПґе≠РиКВзВєеЭЧгАВ
иАМеѓєдЇОеИЖжФѓиКВзВєйЗМзЪДдЄАдЄ™жЭ°зЫЃпЉИдЄАи°МпЉЙжЭ•иѓіпЉМзФ±дЇОеЃГеП™йЬАдњЭе≠ШжЙАйУЊжО•зЪДеЕґдїЦ糥еЉХеЭЧзЪДеЬ∞еЭАеН≥еПѓпЉМиАМдЄНйЬАи¶БдњЭе≠ШеЕЈдљУзЪДжХ∞жНЃи°МеЬ®еУ™йЗМпЉМеЫ†ж≠§еЃГжЙАеН†зФ®зЪДз©ЇйЧіи¶БжѓФ еПґе≠РиКВзВєи¶Бе∞СгАВеИЖжФѓиКВзВєзЪДдЄАи°МдЄ≠жЙАе≠ШжФЊзЪДжЙАйУЊжО•зЪДжЬАе∞ПйФЃеАЉжЙАйЬАз©ЇйЧідЄОдЄКйЭҐжЙАжППињ∞зЪДеПґе≠РиКВзВєзЫЄеРМпЉЫиАМе≠ШжФЊзЪД糥еЉХеЭЧзЪДеЬ∞еЭАеП™йЬАи¶Б4дЄ™е≠ЧиКВпЉМжѓФеПґе≠РиКВзВєдЄ≠жЙАе≠ШжФЊ зЪДROWIDе∞СдЇЖ2дЄ™е≠ЧиКВпЉМе∞СзЪДињЩ2дЄ™е≠ЧиКВдєЯе∞±жШѓROWIDдЄ≠зФ®жЭ•жППињ∞еЬ®жХ∞жНЃеЭЧдЄ≠зЪДи°МеПЈжЙАйЬАзЪДз©ЇйЧігАВеЫ†ж≠§пЉМжЬђдЊЛдЄ≠еЬ®еИЖжФѓиКВзВєдЄ≠зЪДдЄАи°МжЙАеМЕеРЂзЪДжХ∞жНЃе§ІиЗіе¶ВдЄЛ еЫЊдЄЙжЙАз§ЇпЉЪ
  
 
 
¬†2.¬†¬†¬†¬†Bж†С糥еЉХзЪДеЖЕйГ®зїУжЮД
жИСдїђеПѓдї•дљњзФ®е¶ВдЄЛжЦєеЉПе∞ЖBж†С糥еЉХиљђеВ®жИРж†СзКґзїУжЮДзЪД嚥еЉПиАМеСИзО∞еЗЇжЭ•пЉЪ
alter session set events 'immediate trace name treedump level INDEX_OBJECT_ID';
¬†¬†¬†¬†¬†¬†жѓФе¶ВпЉМеѓєдЇОдЄКйЭҐзЪДдЊЛе≠РжЭ•иѓіпЉМжИСдїђжККеИЫеїЇеЬ®goodidдЄКзЪДеРНдЄЇidx_warecountd_goodidзЪД糥еЉХиљђеВ®еЗЇжЭ•гАВ
SQL> select object_id from user_objects where object_name='IDX_WARECOUNTD_GOODID';
 OBJECT_ID
----------
     7378
SQL> alter session set events 'immediate trace name treedump level 7378';
¬†¬†¬†¬†¬†¬†жЙУеЉАиљђеВ®еЗЇжЭ•зЪДжЦЗдїґдї•еРОпЉМжИСдїђеПѓдї•зЬЛеИ∞з±їдЉЉдЄЛйЭҐзЪДеЖЕеЃєпЉЪ
----- begin tree dump
branch: 0x180eb0a 25225994 (0: nrow: 9, level: 2)
  branch: 0x180eca1 25226401 (-1: nrow: 405, level: 1)
     leaf: 0x180eb0b 25225995 (-1: nrow: 359 rrow: 359)
     leaf: 0x180eb0c 25225996 (0: nrow: 359 rrow: 359)
     leaf: 0x180eb0d 25225997 (1: nrow: 359 rrow: 359)
     leaf: 0x180eb0e 25225998 (2: nrow: 359 rrow: 359)
вА¶вА¶вА¶вА¶вА¶вА¶вА¶
  branch: 0x180ee38 25226808 (0: nrow: 406, level: 1)
     leaf: 0x180eca0 25226400 (-1: nrow: 359 rrow: 359)
     leaf: 0x180eca2 25226402 (0: nrow: 359 rrow: 359)
     leaf: 0x180eca3 25226403 (1: nrow: 359 rrow: 359)
     leaf: 0x180eca4 25226404 (2: nrow: 359 rrow: 359)
вА¶вА¶вА¶вА¶вА¶вА¶вА¶
¬†¬†¬†¬†¬†¬†еЕґдЄ≠пЉМжѓПдЄАи°МзЪДзђђдЄАеИЧи°®з§ЇиКВзВєз±їеЮЛпЉЪbranchи°®з§ЇеИЖжФѓиКВзВєпЉИеМЕжЛђж†єиКВзВєпЉЙпЉМиАМleafеИЩи°®з§ЇеПґе≠РиКВзВєпЉЫзђђдЇМеИЧи°®з§ЇеНБеЕ≠ињЫеИґи°®з§ЇзЪДиКВ зВєзЪДеЬ∞еЭАпЉЫзђђдЄЙеИЧи°®з§ЇеНБињЫеИґи°®з§ЇзЪДиКВзВєзЪДеЬ∞еЭАпЉЫзђђеЫЫеИЧи°®з§ЇзЫЄеѓєдЇОеЙНдЄАдЄ™иКВзВєзЪДдљНзљЃпЉМж†єиКВзВєдїО0еЉАеІЛиЃ°зЃЧпЉМеЕґдїЦеИЖжФѓиКВзВєеТМеПґе≠РиКВзВєдїО-1еЉАеІЛиЃ°зЃЧпЉЫзђђдЇФеИЧзЪД nrowи°®з§ЇељУеЙНиКВзВєдЄ≠жЙАеРЂжЬЙзЪД糥еЉХжЭ°зЫЃзЪДжХ∞йЗПгАВжѓФе¶ВжИСдїђеПѓдї•зЬЛеИ∞ж†єиКВзВєдЄ≠еРЂжЬЙзЪДnrowдЄЇ9пЉМи°®з§Їж†єиКВзВєдЄ≠еРЂжЬЙ9䪙糥еЉХжЭ°зЫЃпЉМеИЖеИЂжМЗеРС9дЄ™еИЖжФѓиКВзВєпЉЫзђђ еЕ≠еИЧдЄ≠зЪДlevelи°®з§ЇеИЖжФѓиКВзВєзЪДе±ВзЇІпЉМеѓєдЇОеПґе≠РиКВзВєжЭ•иѓіlevelйГљжШѓ0гАВзђђеЕ≠еИЧдЄ≠зЪДrrowи°®з§ЇжЬЙжХИзЪД糥еЉХжЭ°зЫЃпЉИеۆ䪯糥еЉХжЭ°зЫЃе¶ВжЮЬ襀еИ†йЩ§пЉМдЄНдЉЪзЂЛеН≥襀 жЄЕйЩ§еǯ糥еЉХеЭЧдЄ≠гАВжЙАдї•nrowеЗПrrowзЪДжХ∞йЗПе∞±и°®з§ЇеЈ≤зїП襀еИ†йЩ§зЪД糥еЉХжЭ°зЫЃжХ∞йЗПпЉЙзЪДжХ∞йЗПпЉМжѓФе¶ВеѓєдЇОзђђдЄАдЄ™leafжЭ•иѓіпЉМеЕґrrowдЄЇ359пЉМдєЯе∞±жШѓиѓіиѓ•еПґ е≠РиКВзВєдЄ≠е≠ШжФЊдЇЖ359дЄ™еПѓзԮ糥еЉХжЭ°зЫЃпЉМеИЖеИЂжМЗеРСи°®warecountdзЪД359жЭ°иЃ∞ељХгАВ
¬†¬†¬†¬†¬†¬†дЄКйЭҐињЩзІНжЦєеЉПдї•ж†Сзʴ嚥еЉПиљђеВ®жճ䪙糥еЉХгАВеРМжЧґпЉМжИСдїђеПѓдї•иљђеВ®дЄА䪙糥еЉХиКВзВєжЭ•зЬЛзЬЛеЕґдЄ≠е≠ШжФЊдЇЖдЇЫдїАдєИгАВиљђеВ®зЪДжЦєеЉПдЄЇпЉЪ
alter system dump datafile file# block block#;
¬†¬†¬†¬†¬†¬†жИСдїђдїОдЄКйЭҐиљђеВ®зїУжЮЬдЄ≠зЪДзђђдЇМи°МзЯ•йБУпЉМ糥еЉХзЪДж†єиКВзВєзЪДеЬ∞еЭАдЄЇ25225994пЉМеЫ†ж≠§жИСдїђеЕИе∞ЖеЕґиљђжНҐдЄЇжЦЗдїґеПЈдї•еПКжХ∞жНЃеЭЧеПЈгАВ
SQL> select dbms_utility.data_block_address_file(25225994),
 2 dbms_utility.data_block_address_block(25225994) from dual;
DBMS_UTILITY.DATA_BLOCK_ADDRES DBMS_UTILITY.DATA_BLOCK_ADDRES
------------------------------ ------------------------------
                            6                         60170
¬†¬†¬†¬†¬†¬†дЇОжШѓпЉМжИСдїђиљђеВ®ж†єиКВзВєзЪДеЖЕеЃєгАВ
SQL> alter system dump datafile 6 block 60170;
¬†¬†¬†¬†¬†¬†жЙУеЉАиљђеВ®еЗЇжЭ•зЪДиЈЯиЄ™жЦЗдїґпЉМжИСдїђеПѓдї•зЬЛеИ∞е¶ВдЄЛзЪД糥еЉХе§ійГ®зЪДеЖЕеЃєпЉЪ
header address 85594180=0x51a1044
kdxcolev 2
KDXCOLEV Flags = - - -
kdxcolok 0
kdxcoopc 0x80: pcode=0: iot flags=--- is converted=Y
kdxconco 2
kdxcosdc 0
kdxconro 8
kdxcofbo 44=0x2c
kdxcofeo 7918=0x1eee
kdxcoavs 7874
kdxbrlmc 25226401=0x180eca1
kdxbrsno 0
kdxbrbksz 8060
¬†¬†¬†¬†¬†¬†еЕґдЄ≠зЪДkdxcolev谮积糥еЉХе±ВзЇІеПЈпЉМињЩйЗМзФ±дЇОжИСдїђиљђеВ®зЪДжШѓж†єиКВзВєпЉМжЙАдї•еЕґе±ВзЇІеПЈдЄЇ2гАВеѓєеПґе≠РиКВзВєжЭ•иѓіиѓ•еАЉдЄЇ0пЉЫkdxcolokи°® 积胕糥еЉХдЄКжШѓеР¶ж≠£еЬ®еПСзФЯдњЃжФєеЭЧзїУжЮДзЪДдЇЛеК°пЉЫkdxcoopcи°®з§ЇеЖЕйГ®жУНдљЬдї£з†БпЉЫkdxconco谮积糥еЉХжЭ°зЫЃдЄ≠еИЧзЪДжХ∞йЗПпЉЫkdxcosdc谮积糥еЉХзїУжЮДеПС зФЯеПШеМЦзЪДжХ∞йЗПпЉМељУдљ†дњЃжФєи°®йЗМзЪДжЯР䪙糥еЉХйФЃеАЉжЧґпЉМиѓ•еАЉеҐЮеК†пЉЫkdxconroи°®з§ЇељУеЙН糥еЉХиКВзВєдЄ≠糥еЉХжЭ°зЫЃзЪДжХ∞йЗПпЉМдљЖжШѓж≥®жДПпЉМдЄНеМЕжЛђkdxbrlmcжМЗ йТИпЉЫkdxcofboи°®з§ЇељУеЙН糥еЉХиКВзВєдЄ≠еПѓзФ®з©ЇйЧізЪДиµЈеІЛзВєзЫЄеѓєељУеЙНеЭЧзЪДдљНзІїйЗПпЉЫkdxcofeoи°®з§ЇељУеЙН糥еЉХиКВзВєдЄ≠еПѓзФ®з©ЇйЧізЪДжЬАе∞ЊзЂѓзЪДзЫЄеѓєељУеЙНеЭЧзЪДдљНзІї йЗПпЉЫkdxcoavsи°®з§ЇељУеЙН糥еЉХеЭЧдЄ≠зЪДеПѓзФ®з©ЇйЧіжАїйЗПпЉМдєЯе∞±жШѓзФ®kdxcofeoеЗПеОїkdxcofboеЊЧеИ∞зЪДгАВkdxbrlmcи°®з§ЇеИЖжФѓиКВзВєзЪДеЬ∞еЭАпЉМиѓ•еИЖ жФѓиКВзВєе≠ШжФЊдЇЖ糥еЉХйФЃеАЉе∞ПдЇОrow#0пЉИеЬ®иљђеВ®жЦЗж°£еРОеНКйГ®еИЖжШЊз§ЇпЉЙжЙАеРЂжЬЙзЪДжЬАе∞ПеАЉзЪДжЙАжЬЙиКВзВєдњ°жБѓпЉЫkdxbrsnoи°®з§ЇжЬАеРОдЄА䪙襀䜁жФєзЪД糥еЉХжЭ°зЫЃеПЈпЉМињЩйЗМзЬЛ еИ∞жШѓ0пЉМ谮积胕糥еЉХжШѓжЦ∞еїЇзЪД糥еЉХпЉЫkdxbrbkszи°®з§ЇеПѓзФ®жХ∞жНЃеЭЧзЪДз©ЇйЧіе§Іе∞ПгАВеЃЮйЩЕдїОињЩйЗМеЈ≤зїПеПѓдї•зЬЛеИ∞пЉМеН≥дЊњжШѓPCTFREEиЃЊзљЃдЄЇ0пЉМдєЯдЄНиГљзФ®иґ≥ 8192е≠ЧиКВгАВ
¬†¬†¬†¬†¬†¬†еЖНеЊАдЄЛеПѓдї•зЬЛеИ∞е¶ВдЄЛзЪДеЖЕеЃєгАВињЩйГ®еИЖеЖЕеЃєе∞±жШѓеЬ®ж†єиКВзВєдЄ≠жЙАиЃ∞ељХзЪД糥еЉХжЭ°зЫЃпЉМжАїеЕ±жШѓ8дЄ™жЭ°зЫЃгАВеЖНеК†дЄК
row#0[8043] dba: 25226808=0x180ee38
col 0; len 8; (8): 31 30 30 30 30 33 39 32
col 1; len 3; (3): 01 40 1a
вА¶вА¶
row#7[7918] dba: 25229599=0x180f91f
col 0; len 8; (8): 31 30 30 31 31 32 30 33
col 1; len 4; (4): 01 40 8f a5
kdxbrlmcжЙАжМЗеРСзЪДзђђдЄАдЄ™еИЖжФѓиКВзВєпЉМжИСдїђзЯ•йБУиѓ•ж†єиКВзВєдЄ≠жАїеЕ±е≠ШжФЊдЇЖ9дЄ™еИЖжФѓиКВзВєзЪД糥еЉХжЭ°зЫЃпЉМиАМињЩж≠£жШѓжИСдїђеЬ®еЙНйЭҐжЙАжМЗеЗЇзЪДдЄЇдЇЖзЃ°зРЖ3611дЄ™еПґе≠РиКВзВєпЉМжИСдїђйЬАи¶Б9дЄ™еИЖжФѓиКВзВєгАВ
жѓП䪙糥еЉХжЭ°зЫЃйГљжМЗеРСдЄАдЄ™еИЖжФѓиКВзВєгАВеЕґдЄ≠col 1и°®з§ЇжЙАйУЊжО•зЪДеИЖжФѓиКВзВєзЪДеЬ∞еЭАпЉМиѓ•еАЉзїПињЗдЄАеЃЪзЪДиљђжНҐдї•еРОеЃЮйЩЕе∞±жШѓrow#жЙАеЬ®и°МзЪДdbaзЪДеАЉгАВе¶ВжЮЬж†єиКВзВєдЄЛж≤°жЬЙеЕґдїЦзЪДеИЖжФѓиКВзВєпЉМеИЩcol 1дЄЇTERMпЉЫcol 0и°®з§Їиѓ•еИЖжФѓиКВзВєжЙАйУЊжО•зЪДжЬАе∞ПйФЃеАЉгАВеЕґиљђжНҐжЦєеЉПйЭЮеЄЄе§НжЭВпЉМжѓФе¶ВеѓєдЇОrow #0жЭ•иѓіпЉМcol 0дЄЇ31 30 30 30 30 30 30 33пЉМеИЩе∞ЖеЕґдЄ≠жѓПеѓєеАЉйГљдљњзФ®еЗљжХ∞to_number(NN,вАЩXXвАЩ)зЪДжЦєеЉПдїОеНБеЕ≠ињЫеИґиљђжНҐдЄЇеНБињЫеИґпЉМдЇОжШѓжИСдїђеЊЧеИ∞иљђжНҐеРОзЪД еАЉпЉЪ49,48,48,48,48,48,48,51пЉМеЫ†дЄЇжИСдїђеЈ≤зїПзЯ•йБУ糥еЉХйФЃеАЉжШѓcharз±їеЮЛзЪДпЉМжЙАдї•еѓєжѓПдЄ™еАЉйГљињРзФ®chrеЗљжХ∞е∞±еПѓдї•еЊЧеИ∞襀糥еЉХйФЃеАЉ дЄЇпЉЪ10000003гАВеЃЮйЩЕдЄКпЉМеѓє10000003ињРзФ®dumpеЗљжХ∞еЊЧеИ∞зЪДзїУжЮЬе∞±жШѓпЉЪ49,48,48,48,48,48,48,51гАВжЙАдї•жИСдїђдєЯе∞±зЯ• йБУпЉМ10000003е∞±жШѓdbaдЄЇ25226808зЪД糥еЉХеЭЧжЙАйУЊжО•зЪДжЬАе∞ПйФЃеАЉгАВ
SQL> select dump('10000003') from dual;
DUMP('10000003')
-------------------------------------
Typ=96 Len=8: 49,48,48,48,48,48,48,50
¬†¬†¬†¬†¬†¬†жО•дЄЛжЭ•пЉМжИСдїђдїОж†єиКВзВєдЄ≠йЪПдЊњжЙЊдЄАдЄ™еИЖжФѓиКВзВєпЉМеБЗиЃЊе∞±жШѓrow#0жЙАжППињ∞зЪД25226808гАВеѓєеЕґињРзФ®еЙНйЭҐжЙАдїЛзїНињЗзЪДdbms_utilityйЗМзЪДе≠ШеВ®ињЗз®ЛиОЈеЊЧеЕґжЦЗдїґеПЈеТМжХ∞жНЃеЭЧеПЈпЉМеєґеѓєиѓ•жХ∞жНЃеЭЧињЫи°МиљђеВ®пЉМеЕґеЖЕеЃєе¶ВдЄЛжЙАз§ЇгАВеПѓдї•
row#0[8043] dba: 25226402=0x180eca2
col 0; len 8; (8): 31 30 30 30 30 33 39 33
col 1; len 3; (3): 01 40 2e
вА¶вА¶вА¶
row#404[853] dba: 25226806=0x180ee36
col 0; len 8; (8): 31 30 30 30 31 36 34 30
col 1; len 3; (3): 01 40 09
----- end of branch block dump -----
еПСзО∞еЖЕеЃєдЄОж†єиКВзВєеЃМеЕ®з±їдЉЉпЉМеП™дЄНињЗ胕糥еЉХеЭЧдЄ≠жЙАеМЕеРЂзЪД糥еЉХжЭ°зЫЃпЉИжМЗеРСеПґе≠РиКВзВєпЉЙзЪДжХ∞йЗПжЫіе§ЪдЇЖпЉМдЄЇ405дЄ™гАВињЩдєЯдЄОжИСдїђеЙНйЭҐжЙАиѓізЪДдЄАдЄ™еИЖжԃ糥еЉХеЭЧеПѓдї•е≠ШжФЊе§ІзЇ¶405пЉИ6488/16пЉЙ䪙糥еЉХжЭ°зЫЃеЃМеЕ®дЄАиЗігАВ
¬†¬†¬†¬†¬†¬†зДґеРОпЉМжИСдїђдїОдЄ≠йЪПдЊњжМСдЄАдЄ™еПґе≠РиКВзВєпЉМеѓєеЕґињЫи°МиљђеВ®гАВеБЗиЃЊе∞±йАЙrow#0и°МжЙАжМЗеРСзЪДеПґе≠РиКВзВєпЉМж†єжНЃdbaзЪДеАЉпЉЪ25226402еПѓдї•зЯ•йБУпЉМжЦЗдїґеПЈдЄЇ6пЉМжХ∞жНЃеЭЧеПЈдЄЇ60578гАВе∞ЖеЕґиљђеВ®дї•еРОпЉМеЕґеЖЕеЃєе¶ВдЄЛжЙАз§ЇпЉМжИСеП™жШЊз§ЇдЄОеИЖжФѓиКВзВєдЄНеРМзЪДйГ®еИЖгАВ
вА¶вА¶вА¶
kdxlespl 0
kdxlende 0
kdxlenxt 25226403=0x180eca3
kdxleprv 25226400=0x180eca0
kdxledsz 0
kdxlebksz 8036
¬†¬†¬†¬†¬†¬†еЕґдЄ≠зЪДkdxlesplи°®з§ЇељУеПґе≠РиКВзº襀жЛЖеИЖжЧґжЬ™жПРдЇ§зЪДдЇЛеК°жХ∞йЗПпЉЫkdxlende谮积襀еИ†йЩ§зЪД糥еЉХжЭ°зЫЃзЪДжХ∞йЗПпЉЫkdxlenxtи°®з§Ї ељУеЙНеПґе≠РиКВзВєзЪДдЄЛдЄАдЄ™еПґе≠РиКВзВєзЪДеЬ∞еЭАпЉЫkdxlprvи°®з§ЇељУеЙНеПґе≠РиКВзВєзЪДдЄКдЄАдЄ™еПґе≠РиКВзВєзЪДеЬ∞еЭАпЉЫkdxledszи°®з§ЇеПѓзФ®з©ЇйЧіпЉМзЫЃеЙНжШѓ0гАВ
¬†¬†¬†¬†¬†¬†иљђеВ®жЦЗдїґдЄ≠жО•дЄЛжЭ•зЪДйГ®еИЖе∞±ж؃糥еЉХжЭ°зЫЃйГ®еИЖпЉМжѓПдЄ™жЭ°зЫЃеМЕеРЂдЄАдЄ™ROWIDпЉМжМЗеРСдЄАдЄ™и°®йЗМзЪДжХ∞жНЃи°МгАВе¶ВдЄЛжЙАз§ЇгАВеЕґдЄ≠flagи°®з§Їж†ЗиЃ∞пЉМжѓФе¶В еИ†йЩ§ж†ЗиЃ∞з≠ЙпЉЫиАМlockи°®з§ЇйФБеЃЪдњ°жБѓгАВcol 0谮积糥еЉХйФЃеАЉпЉМеЕґзЃЧж≥ХдЄОжИСдїђеЬ®еЙНйЭҐдїЛзїНеИЖжФѓиКВзВєжЧґжЙАиѓізЪДзЃЧж≥ХдЄАиЗігАВcol 1и°®з§ЇROWIDгАВжИСдїђеРМж†ЈеПѓдї•зЬЛеИ∞пЉМиѓ•еПґе≠РиКВзВєдЄ≠еМЕеРЂдЇЖ359䪙糥еЉХжЭ°зЫЃпЉМдЄОжИСдїђеЙНйЭҐжЙАдЉ∞иЃ°зЪДдЄАдЄ™еПґе≠РиКВзВєдЄ≠е§ІзЇ¶еПѓдї•жФЊ360䪙糥еЉХжЭ°зЫЃдєЯжШѓеЯЇжЬђдЄАиЗі зЪДгАВ
row#0[8018] flag: -----, lock: 0
col 0; len 8; (8): 31 30 30 30 30 33 39 33
col 1; len 6; (6): 01 40 2e 93 00 16
row#1[8000] flag: -----, lock: 0
col 0; len 8; (8): 31 30 30 30 30 33 39 33
col 1; len 6; (6): 01 40 2e e7 00 0e
вА¶вА¶вА¶вА¶
row#358[1574] flag: -----, lock: 0
col 0; len 8; (8): 31 30 30 30 30 33 39 37
col 1; len 6; (6): 01 40 18 ba 00 1f
----- end of leaf block dump -----
 
 
3.¬†¬†¬†¬†Bж†С糥еЉХзЪДиЃњйЧЃ
жИСдїђеЈ≤зїПзЯ•йБУдЇЖBж†С糥еЉХзЪДдљУз≥їзїУжЮДпЉМйВ£дєИељУoracleйЬАи¶БиЃњйׁ糥еЉХйЗМзЪДжЯР䪙糥еЉХжЭ°зЫЃжЧґпЉМoracleжШѓе¶ВдљХжЙЊ
еИ∞胕糥еЉХжЭ°зЫЃжЙАеЬ®зЪДжХ∞жНЃеЭЧзЪДеСҐпЉЯ
¬†¬†¬†¬†¬†¬†ељУoracleињЫз®ЛйЬАи¶БиЃњйЧЃжХ∞жНЃжЦЗдїґйЗМзЪДжХ∞жНЃеЭЧжЧґпЉМoracleдЉЪжЬЙдЄ§зІНз±їеЮЛзЪДI/OжУНдљЬжЦєеЉПпЉЪ
1пЉЙ¬†йЪПжЬЇиЃњйЧЃпЉМжѓПжђ°иѓїеПЦдЄАдЄ™жХ∞жНЃеЭЧпЉИйАЪињЗз≠ЙеЊЕдЇЛдїґвАЬdb file sequential readвАЭдљУзО∞еЗЇжЭ•пЉЙгАВ
2пЉЙ¬†й°ЇеЇПиЃњйЧЃпЉМжѓПжђ°иѓїеПЦе§ЪдЄ™жХ∞жНЃеЭЧпЉИйАЪињЗз≠ЙеЊЕдЇЛдїґвАЬdb file scattered readвАЭдљУзО∞еЗЇжЭ•пЉЙгАВ
зђђдЄАзІНжЦєеЉПеИЩжШѓиЃњйׁ糥еЉХйЗМзЪДжХ∞жНЃеЭЧпЉМиАМзђђдЇМзІНжЦєеЉПзЪДI/OжУНдљЬе±ЮдЇОеЕ®и°®жЙЂжППгАВињЩйЗМй°ЇеЄ¶жЬЙдЄАдЄ™йЧЃйҐШпЉМдЄЇ
дљХйЪПжЬЇиЃњйЧЃдЉЪеѓєеЇФеИ∞db file sequential readз≠ЙеЊЕдЇЛдїґпЉМиАМй°ЇеЇПиЃњйЧЃеИЩдЉЪеѓєеЇФеИ∞db file scattered readз≠ЙеЊЕдЇЛдїґеСҐпЉЯињЩдЉЉдєОеПНињЗжЭ•дЇЖпЉМйЪПжЬЇиЃњйЧЃжЙНеЇФиѓ•жШѓеИЖжХ£пЉИscatteredпЉЙзЪДпЉМиАМй°ЇеЇПиЃњйЧЃжЙНеЇФиѓ•жШѓй°ЇеЇПпЉИsequentialпЉЙзЪДгАВеЕґеЃЮпЉМз≠ЙеЊЕдЇЛ дїґдЄїи¶Бж†єжНЃеЃЮйЩЕиОЈеПЦзЙ©зРЖI/OеЭЧзЪДжЦєеЉПжЭ•еСљеРНзЪДпЉМиАМдЄНжШѓж†єжНЃеЕґеЬ®I/Oе≠Рз≥їзїЯзЪДйАїиЊСжЦєеЉПжЭ•еСљеРНзЪДгАВдЄЛйЭҐеѓєдЇОе¶ВдљХиОЈеПЦ糥еЉХжХ∞жНЃеЭЧзЪДжЦєеЉПдЄ≠дЉЪеѓєж≠§ињЫи°МиѓіжШОгАВ
жИСдїђзЬЛеИ∞еЙНйЭҐеѓєBж†С糥еЉХзЪДдљУз≥їзїУжЮДзЪДжППињ∞пЉМеПѓдї•зЯ•йБУеЕґдЄЇдЄАдЄ™ж†СзКґзЪДзЂЛдљУзїУжЮДгАВеЕґеѓєеЇФеИ∞жХ∞жНЃжЦЗдїґйЗМзЪД
жОТеИЧељУзДґињШжШѓдЄАдЄ™еє≥йЭҐзЪД嚥еЉПпЉМдєЯе∞±жШѓеГПдЄЛйЭҐињЩж†ЈгАВеЫ†ж≠§пЉМељУoracleйЬАи¶БиЃњйЧЃжЯР䪙糥еЉХеЭЧзЪДжЧґеАЩпЉМеКњењЕдЉЪеЬ®ињЩдЄ™зїУжЮДдЄКиЈ≥иЈГзЪДзІїеК®гАВ
/ж†є/еИЖжФѓ/еИЖжФѓ/еПґе≠Р/вА¶/еПґе≠Р/еИЖжФѓ/еПґе≠Р/еПґе≠Р/вА¶/еПґе≠Р/еИЖжФѓ/еПґе≠Р/еПґе≠Р/вА¶/еПґе≠Р/еИЖжФѓ/.....
ељУoracleйЬАи¶БиОЈеЊЧдЄА䪙糥еЉХеЭЧжЧґпЉМй¶ЦеЕИдїОж†єиКВзВєеЉАеІЛпЉМж†єжНЃжЙАи¶БжЯ•жЙЊзЪДйФЃеАЉпЉМдїОиАМзЯ•йБУеЕґжЙАеЬ®зЪДдЄЛдЄАе±ВзЪДеИЖжФѓиКВзВєпЉМзДґеРОиЃњйЧЃдЄЛдЄАе±ВзЪДеИЖжФѓиКВзВєпЉМеЖНжђ° еРМж†Јж†єжНЃйФЃеАЉиЃњйЧЃеЖНдЄЛдЄАе±ВзЪДеИЖжФѓиКВзВєпЉМе¶Вж≠§ињЩиИђпЉМжЬАзїИиЃњйЧЃеИ∞жЬАеЇХе±ВзЪДеПґе≠РиКВзВєгАВеПѓдї•зЬЛеЗЇпЉМеЕґиОЈеЊЧзЙ©зРЖI/OеЭЧжЧґпЉМжШѓдЄАдЄ™жО•зЭАдЄАдЄ™пЉМжМЙзЕІй°ЇеЇПпЉМдЄ≤и°МињЫи°МзЪДгАВ еЬ®иОЈеЊЧжЬАзїИзЙ©зРЖеЭЧзЪДињЗз®ЛдЄ≠пЉМжИСдїђдЄНиГљеРМжЧґиѓїеПЦе§ЪдЄ™еЭЧпЉМеЫ†дЄЇжИСдїђеЬ®ж≤°жЬЙиОЈеЊЧељУеЙНеЭЧзЪДжЧґеАЩжШѓдЄНзЯ•йБУжО•дЄЛжЭ•еЇФиѓ•иЃњйЧЃеУ™дЄ™еЭЧзЪДгАВеЫ†ж≠§пЉМеܮ糥еЉХдЄКиЃњйЧЃжХ∞жНЃеЭЧжЧґпЉМдЉЪеѓє еЇФеИ∞db file sequential readз≠ЙеЊЕдЇЛдїґпЉМеЕґж†єжЇРеЬ®дЇОжИСдїђжШѓжМЙзЕІй°ЇеЇПдїОдЄА䪙糥еЉХеЭЧиЈ≥еИ∞еП¶дЄА䪙糥еЉХеЭЧпЉМдїОиАМжЙЊеИ∞жЬАзїИзЪД糥еЉХеЭЧзЪДгАВ
йВ£дєИеѓєдЇОеЕ®и°®жЙЂжППжЭ•иѓіпЉМеИЩдЄНе≠ШеЬ®иЃњйЧЃдЄЛдЄАдЄ™еЭЧдєЛеЙНйЬАи¶БеЕИиЃњйЧЃдЄКдЄАдЄ™еЭЧзЪДжГЕеЖµгАВеЕ®и°®жЙЂжППжЧґпЉМoracleзЯ•йБУи¶БиЃњйЧЃжЙАжЬЙзЪДжХ∞жНЃеЭЧпЉМеЫ†ж≠§еФѓдЄАзЪДйЧЃйҐШе∞±жШѓ е∞љеПѓиГљйЂШжХИзЪДиЃњйЧЃињЩдЇЫжХ∞жНЃеЭЧгАВеЫ†ж≠§пЉМињЩжЧґoracleеПѓдї•йЗЗзФ®еРМж≠•зЪДжЦєеЉПпЉМеИЖеЗ†жЙєпЉМеРМжЧґиОЈеПЦе§ЪдЄ™жХ∞жНЃеЭЧгАВињЩеЗ†жЙєзЪДжХ∞жНЃеЭЧеЬ®зЙ©зРЖдЄКеПѓиГљжШѓеИЖжХ£еЬ®и°®йЗМзЪДпЉМеЫ†ж≠§ еЕґеѓєеЇФеИ∞db file scattered readз≠ЙеЊЕдЇЛдїґгАВ
4.¬†¬†¬†¬†Bж†С糥еЉХзЪДзЃ°зРЖжЬЇеИґ
4.1 Bж†С糥еЉХзЪДеѓєдЇОжПТеЕ•пЉИINSERTпЉЙзЪДзЃ°зРЖ
еѓєдЇОBж†С糥еЉХзЪДжПТеЕ•жГЕеЖµзЪДжППињ∞пЉМеПѓдї•еИЖдЄЇдЄ§зІНжГЕеЖµпЉЪдЄАзІНжШѓеЬ®дЄАдЄ™еЈ≤зїПеЕЕжї°дЇЖжХ∞жНЃзЪДи°®дЄКеИЫ忯糥еЉХжЧґпЉМ
糥еЉХжШѓжАОдєИзЃ°зРЖзЪДпЉЫеП¶дЄАзІНеИЩжШѓељУдЄАи°МжО•зЭАдЄАи°МеРСи°®йЗМжПТеЕ•жИЦжЫіжЦ∞жИЦеИ†йЩ§жХ∞жНЃжЧґпЉМ糥еЉХжШѓжАОдєИзЃ°зРЖзЪДгАВ
¬†¬†¬†¬†¬†¬†еѓєдЇОзђђдЄАзІНжГЕеЖµжЭ•иѓіпЉМжѓФиЊГзЃАеНХгАВељУеЬ®дЄАдЄ™еЕЕжї°дЇЖжХ∞жНЃзЪДи°®дЄКеИЫ忯糥еЉХпЉИcreate indexеСљдї§пЉЙжЧґпЉМoracleдЉЪеЕИжЙЂжППи°®йЗМзЪДжХ∞жНЃеєґеѓєеЕґињЫи°МжОТеЇПпЉМзДґеРОзФЯжИРеПґе≠РиКВзВєгАВзФЯжИРжЙАжЬЙзЪДеПґе≠РиКВзВєдї•еРОпЉМж†єжНЃеПґе≠РиКВзВєзЪДжХ∞йЗПзФЯжИРиЛ•еє≤е±ВзЇІзЪДеИЖжФѓ иКВзВєпЉМжЬАеРОзФЯжИРж†єиКВзВєгАВињЩдЄ™ињЗз®ЛжШѓеЊИжЄЕжЩ∞зЪДгАВ
¬†¬†¬†¬†¬†¬†дљЖжШѓеѓєдЇОзђђдЇМзІНжГЕеЖµжЭ•иѓіпЉМдЉЪе§НжЭВеЊИе§ЪгАВжИСдїђзїУеРИдЄАдЄ™дЊЛе≠РжЭ•иѓіжШОгАВдЄЇдЇЖжЦєдЊњиµЈиІБпЉМжИСдїђеЬ®дЄАдЄ™жХ∞жНЃеЭЧдЄЇ2KBзЪДи°®з©ЇйЧідЄКеИЫеїЇдЄАдЄ™жµЛиѓХи°®пЉМеєґдЄЇиѓ•и°®еИЫеїЇдЄА䪙糥еЉХпЉМ胕糥еЉХеРМж†ЈдљНдЇО2KBзЪДи°®з©ЇйЧідЄКгАВ
SQL> create table index_test(id char(150)) tablespace tbs_2k;
SQL> create index idx_test on index_test(id) tablespace tbs_2k;
¬†¬†¬†¬†¬†¬†ељУдЄАеЉАеІЛеЬ®дЄАдЄ™з©ЇзЪДи°®дЄКеИЫ忯糥еЉХзЪДжЧґеАЩпЉМ胕糥еЉХж≤°жЬЙж†єиКВзВєпЉМеП™жЬЙдЄАдЄ™еПґе≠РиКВзВєгАВжИСдїђдї•ж†Сзʴ嚥еЉПиљђеВ®дЄКйЭҐзЪД糥еЉХidx_testгАВ
SQL> select object_id from user_objects where object_name='IDX_TEST';
OBJECT_ID
----------
     7390
SQL> alter session set events 'immediate trace name treedump level 7390';
¬†¬†¬†¬†¬†¬†дїОиљђеВ®жЦЗдїґеПѓдї•зЬЛеИ∞пЉМ胕糥еЉХдЄ≠еП™жЬЙдЄАдЄ™еПґе≠РиКВзВєпЉИleafпЉЙгАВ
----- begin tree dump
leaf: 0x1c001a2 29360546 (0: nrow: 0 rrow: 0)
----- end tree dump
¬†¬†¬†¬†¬†¬†йЪПзЭАжХ∞жНЃдЄНжЦ≠襀жПТеЕ•и°®йЗМпЉМиѓ•еПґе≠РиКВзВєдЄ≠зЪД糥еЉХжЭ°зЫЃдєЯдЄНжЦ≠еҐЮеК†пЉМељУиѓ•еПґе≠РиКВзВєеЕЕжї°дЇЖ糥еЉХжЭ°зЫЃиАМдЄНиГљеЖНжФЊдЄЛжЦ∞зЪД糥еЉХжЭ°зЫЃжЧґпЉМ胕糥еЉХе∞±ењЕй°їжЙ© еЉ†пЉМењЕй°їеЖНиОЈеПЦдЄАдЄ™еПѓзФ®зЪДеПґе≠РиКВзВєгАВињЩжЧґпЉМ糥еЉХе∞±еМЕеРЂдЇЖдЄ§дЄ™еПґе≠РиКВзВєпЉМдљЖжШѓдЄ§дЄ™еПґе≠РиКВзВєдЄНеПѓиГљеНХзЛђе≠ШеЬ®зЪДпЉМињЩжЧґеЃГдїђдЄ§ењЕй°їжЬЙдЄАдЄ™дЄКзЇІзЪДеИЖжФѓиКВзВєпЉМеЕґеЃЮињЩдєЯ е∞±жШѓж†єиКВзВєдЇЖгАВдЇОжШѓпЉМзО∞еЬ®пЉМжИСдїђзЪД糥еЉХеЇФиѓ•еЕЈжЬЙ3䪙糥еЉХеЭЧпЉМдЄАдЄ™ж†єиКВзВєпЉМдЄ§дЄ™еПґе≠РиКВзВєгАВ
жИСдїђжЭ•еБЪдЄ™иѓХй™МзЬЛзЬЛињЩдЄ™ињЗз®ЛгАВжИСдїђеЕИиѓХзЭАжПТеЕ•жПТеЕ•10жЭ°иЃ∞ељХгАВж≥®жДПпЉМеѓєдЇО2KBзЪД糥еЉХеЭЧеРМжЧґPCTFREEдЄЇзЉЇзЬБзЪД10пЉЕжЭ•иѓіпЉМеП™иГљдљњзФ®еЕґдЄ≠е§ІзЇ¶ 1623е≠ЧиКВпЉИ2048√Ч90пЉЕ√Ч88пЉЕпЉЙгАВеѓєдЇОи°®index_testжЭ•иѓіпЉМеПґе≠РиКВзВєдЄ≠зЪДжѓП䪙糥еЉХжЭ°зЫЃжЙАеН†зЪДз©ЇйЧіе§ІзЇ¶дЄЇ161дЄ™е≠ЧиКВпЉИ3дЄ™е≠ЧиКВи°Ме§і+1 дЄ™е≠ЧиКВеИЧйХњ+150дЄ™е≠ЧиКВеИЧжЬђиЇЂ+1дЄ™е≠ЧиКВеИЧйХњ+6дЄ™е≠ЧиКВROWIDпЉЙпЉМйВ£дєИељУжИСдїђжПТеЕ•е∞Ж10жЭ°иЃ∞ељХдї•еРОпЉМе∞ЖжґИиАЧжОЙе§ІзЇ¶1610дЄ™е≠ЧиКВгАВ
SQL> begin
 2    for i in 1..10 loop
 3        insert into index_test values (rpad(to_char(i*2),150,'a'));
 4    end loop;
 5 end;
 6 /
SQL> commit;
SQL> select file_id,block_id,blocks from dba_extents where segment_name='IDX_TEST';
  FILE_ID  BLOCK_ID    BLOCKS
---------- ---------- ----------
        7       417        32
SQL> alter system dump datafile 7 block 418; --еЫ†дЄЇзђђдЄАдЄ™еЭЧдЄЇеЭЧе§іпЉМдЄНеРЂжХ∞жНЃпЉМжЙАдї•иљђеВ®зђђдЇМдЄ™еЭЧгАВ
¬†¬†¬†¬†¬†¬†жЙУеЉАиЈЯиЄ™жЦЗдїґдї•еРОпЉМе¶ВдЄЛжЙАз§ЇпЉМеПѓдї•еПСзО∞418еЭЧдїНзДґжШѓдЄАдЄ™еПґе≠РиКВзВєпЉМеМЕеРЂ10䪙糥еЉХжЭ°зЫЃпЉМ胕糥еЉХеЭЧињШж≤°жЬЙ襀жЛЖеИЖгАВж≥®жДПеЕґдЄ≠зЪД kdxcoavsдЄЇ226пЉМиѓіжШОеПѓзФ®з©ЇйЧіињШеЙ©226дЄ™е≠ЧиКВпЉМиѓіжШОињШеПѓдї•жПТеЕ•дЄАжЭ°иЃ∞ељХгАВдєЛжЙАдї•дЄОеЙНйЭҐиЃ°зЃЧеЗЇжЭ•зЪДеП™иГљжФЊ10жЭ°иЃ∞ељХжЬЙеЗЇеЕ•пЉМжШѓеЫ†дЄЇеПѓзФ®зЪД 1623е≠ЧиКВеП™жШѓдЄАдЄ™дЉ∞иЃ°еАЉгАВ
вА¶вА¶
kdxcoavs 226
вА¶вА¶
row#0[1087] flag: -----, lock: 0
col 0; len 150; (150):
 31 30 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61
 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61
 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61
 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61
 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61
 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61
col 1; len 6; (6): 01 c0 01 82 00 04
row#1[926] flag: -----, lock: 0
вА¶вА¶
¬†¬†¬†¬†¬†¬†жО•дЄЛжЭ•пЉМжИСдїђеЖНжђ°жПТеЕ•дЄАжЭ°иЃ∞ељХпЉМдї•дЊњеЯЇжЬђеЕЕжї°иѓ•еПґе≠РиКВзВєпЉМдљњеЊЧеЙ©дЄЛзЪДеПѓзФ®з©ЇйЧідЄНиґ≥дї•еЖНжПТеЕ•дЄАжЭ°жЦ∞зЪДжЭ°зЫЃгАВе¶ВдЄЛжЙАз§ЇгАВ
SQL> insert into index_test values(rpad(to_char(11*2),150,'a'));
¬†¬†¬†¬†¬†¬†ињЩдЄ™жЧґеАЩжИСдїђеЖНжђ°иљђеВ®418еЭЧдї•еРОдЉЪеПСзО∞дЄОеЙНйЭҐиљђеВ®зЪДеЖЕеЃєеЯЇжЬђдЄАиЗіпЉМеП™жШѓеПИеҐЮеК†дЇЖдЄА䪙糥еЉХжЭ°зЫЃгАВиАМињЩдЄ™жЧґеАЩпЉМе¶ВжЮЬеРСи°®йЗМеЖНжђ°жПТеЕ•дЄАжЭ°жЦ∞зЪДиЃ∞ељХзЪДиѓЭпЉМиѓ•еПґе≠РиКВзВєпЉИ418еЭЧпЉЙењЕй°їињЫи°МжЛЖеИЖгАВ
SQL> insert into index_test values(rpad(to_char(12*2),150,'a'));
SQL> alter system dump datafile 7 block 418;
¬†¬†¬†¬†¬†¬†иљђеВ®еЗЇ418еЭЧдї•еРОпЉМжИСдїђдЉЪеПСзО∞пЉМ胕糥еЉХеЭЧдїОеПґе≠РиКВзВєеПШжИРдЇЖж†єиКВзВєпЉИkdxcolevдЄЇ1пЉМеРМжЧґrow#0йГ®еИЖзЪДcol 1дЄЇTERMи°®з§Їж†єиКВзВєдЄЛж≤°жЬЙеЕґдїЦеИЖжФѓиКВзВєпЉЙгАВињЩдєЯе∞±иѓіжШОпЉМељУзђђдЄАдЄ™еПґе≠РиКВзВєеЕЕжї°дї•еРОпЉМињЫи°МеИЖи£ВжЧґпЉМеЕИиОЈеЊЧдЄ§дЄ™еПѓзФ®зЪД糥еЉХеЭЧдљЬдЄЇжЦ∞зЪДеПґе≠РиКВзВєпЉМзДґеРОе∞ЖељУеЙН иѓ•еПґе≠РиКВзВєйЗМжЙАжЬЙзЪД糥еЉХжЭ°зЫЃжЛЈиіЭеИ∞ињЩдЄ§дЄ™жЦ∞иОЈеЊЧзЪДеПґе≠РиКВзВєпЉМжЬАеРОе∞ЖеОЯжЭ•зЪДеПґе≠РиКВзВєжФєеПШдЄЇж†єиКВзВєгАВ
вА¶вА¶
kdxcolev 1
вА¶вА¶
kdxbrlmc 29360547=0x1c001a3
вА¶вА¶
row#0[1909] dba: 29360548=0x1c001a4
col 0; len 1; (1): 34
col 1; TERM
----- end of branch block dump -----
¬†¬†¬†¬†¬†¬†еРМжЧґпЉМдїОдЄКйЭҐзЪДkdxbrlmcеТМrow#0дЄ≠зЪДdbaеПѓдї•зЯ•йБУпЉМиѓ•ж†єиКВзВєеИЖеИЂжМЗеРС29360547еТМ29360548дЄ§дЄ™еПґе≠РиКВзВєгАВжИСдїђеИЖеИЂеѓєињЩдЄ§дЄ™еПґе≠РиКВзВєињЫи°МиљђеВ®зЬЛзЬЛйЗМйЭҐжФЊдЇЖдЇЫдїАдєИгАВ
SQL> select dbms_utility.data_block_address_file(29360547),
 2 dbms_utility.data_block_address_block(29360547) from dual;
DBMS_UTILITY.DATA_BLOCK_ADDRES DBMS_UTILITY.DATA_BLOCK_ADDRES
------------------------------ ------------------------------
                            7                           419
SQL> select dbms_utility.data_block_address_file(29360548),
 2 dbms_utility.data_block_address_block(29360548) from dual;
DBMS_UTILITY.DATA_BLOCK_ADDRES DBMS_UTILITY.DATA_BLOCK_ADDRES
------------------------------ ------------------------------
                            7                           420
SQL> alter system dump datafile 7 block 419;
SQL> alter system dump datafile 7 block 420;
еЬ®жЙУеЉАиЈЯиЄ™жЦЗдїґдєЛеЙНпЉМжИСдїђеЕИжЭ•зЬЛзЬЛи°®index_testйЗМе≠ШжФЊдЇЖеУ™дЇЫжХ∞жНЃгАВ¬†¬†¬†¬†
SQL> select substr(id,1,2) from index_test order by substr(id,1,2);
SUBSTR(ID,1,2)
--------------
10
12
14
16
18
20
22
24
2a
4a
6a
8a
жЙУеЉА419еЭЧзЪДиЈЯиЄ™жЦЗдїґеПѓдї•еПСзО∞пЉМйЗМйЭҐе≠ШжФЊдЇЖ10гАБ12гАБ14гАБ16гАБ18гАБ20гАБ22гАБ24еТМ2aпЉЫиАМ420еЭЧзЪДиЈЯиЄ™жЦЗдїґдЄ≠иЃ∞ељХдЇЖ4aгАБ6aеТМ 8aгАВдєЯе∞±жШѓиѓіпЉМзФ±дЇОжЬАеРОжИСдїђжПТеЕ•24зЪДзЉШжХЕпЉМеѓЉиЗіжХідЄ™еПґе≠РиКВзВєеПСзФЯеИЖи£ВпЉМдїОиАМе∞Ж10гАБ12гАБ14гАБ16гАБ18гАБ20гАБ22гАБеТМ2aжФЊеИ∞419еЭЧйЗМпЉМиАМ 4aгАБ6aеТМ8aеИЩжФЊеЕ•420еЭЧйЗМгАВзДґеРОпЉМеЖНе∞ЖжЦ∞зЪД糥еЉХжЭ°зЫЃпЉИ24пЉЙжПТеЕ•еѓєеЇФзЪД糥еЉХеЭЧйЗМпЉМдєЯе∞±жШѓ419еЭЧгАВ
еБЗе¶ВжИСдїђеЖНжЬАеРОдЄНжШѓжПТеЕ•12*2пЉМиАМжШѓжПТеЕ•9дЉЪжАОдєИж†ЈпЉЯжИСдїђйЗНжЦ∞жµЛиѓХдЄАдЄЛпЉМињФеЫЮеИ∞index_testйЗМжЬЙ11жЭ°иЃ∞ељХзЪДжГЕеЖµдЄЛпЉМзДґеРОжИСдїђеЖНжПТеЕ•9гАВ
SQL> insert into index_test values (rpad('9',150,'a'));
¬†¬†¬†¬†¬†¬†ињЩдЄ™жЧґеАЩпЉМ418еЭЧињШжШѓеТМеОЯжЭ•дЄАж†ЈеПШжИРдЇЖж†єиКВзВєпЉМеРМжЧґдїНзДґзФЯжИРеЗЇдЇЖ2дЄ™еПґе≠РиКВзВєеЭЧпЉМеИЖеИЂжШѓ419еТМ420гАВдљЖжШѓжЬЙиґ£зЪДжШѓпЉМ419еЭЧйЗМзЪД еЖЕеЃєдЄОеЬ®жПТеЕ•9дєЛеЙНзЪДеПґе≠РиКВзВєпЉИељУжЧґзЪД418еЭЧпЉЙзЪДеЖЕеЃєеЃМеЕ®зЫЄеРМпЉМиАМ420еЭЧйЗМеИЩеП™жЬЙдЄА䪙糥еЉХжЭ°зЫЃпЉМдєЯе∞±жШѓжЦ∞жПТеЕ•зЪД9гАВињЩдєЯе∞±жШѓиѓіпЉМзФ±дЇОжЬАеРОжИСдїђжПТеЕ•9зЪД зЉШжХЕпЉМеѓЉиЗіжХідЄ™еПґе≠РиКВзВєеПСзФЯеИЖи£ВгАВдљЖжШѓеИЖи£ВињЗз®ЛдЄОжПТеЕ•12*2зЪДжГЕеЖµжШѓдЄНдЄАж†ЈзЪДпЉМињЩжЧґиѓ•еПґе≠РиКВзВєзЪДеЖЕеЃєдЄНињЫи°МжЛЖеИЖпЉМиАМжШѓзЫіжО•еЃМеЕ®жЛЈиіЭеИ∞дЄАдЄ™жЦ∞зЪДеПґе≠РиКВзВє пЉИ419пЉЙйЗМпЉМзДґеРОе∞ЖжЦ∞жПТеЕ•зЪД9жФЊеЕ•еП¶е§ЦдЄАдЄ™жЦ∞зЪДеПґе≠РиКВзВєпЉИ420пЉЙгАВжИСдїђеЇФиѓ•ж≥®жДПеИ∞пЉМжПТеЕ•зЪДињЩдЄ™9и°®йЗМжЙАжЬЙиЃ∞ељХйЗМзЪДжЬАе§Іе≠Чзђ¶дЄ≤гАВ
е¶ВжЮЬињЩжЧґпЉМжИСдїђеЖНжђ°жПТеЕ•12*2пЉМеИЩдЉЪеПСзО∞419еПЈиКВзВєзЪДеИЖи£ВињЗз®ЛеТМеЙНйЭҐжППињ∞зЪДдЄАж†ЈпЉМдЉЪе∞ЖеОЯжЭ•жФЊеЬ®419еЭЧйЗМзЪД4aгАБ6aеТМ8aжФЊеЕ•дЄАдЄ™жЦ∞зЪДеПґе≠РиКВ зВєйЗМпЉИ421еЭЧпЉЙпЉМзДґеРОе∞Ж12*2жФЊеЕ•419еЭЧпЉМдЇОжШѓињЩдЄ™жЧґеАЩ419еЭЧжЙАеРЂжЬЙзЪД糥еЉХжЭ°зЫЃдЄЇ10гАБ12гАБ14гАБ16гАБ18гАБ20гАБ22гАБеТМ2aгАВеРМжЧґ420 еЭЧж≤°жЬЙеПСзФЯеПШеМЦгАВ
¬†¬†¬†¬†¬†¬†ж†єжНЃдЄКйЭҐзЪДжµЛиѓХзїУжЮЬпЉМжИСдїђеПѓдї•жАїзїУдЄАдЄЛеПґе≠РиКВзВєзЪДжЛЖеИЖињЗз®ЛгАВињЩдЄ™ињЗз®ЛйЬАи¶БеИЖжИРдЄ§зІНжГЕеЖµпЉМдЄАзІНжШѓжПТеЕ•зЪДйФЃеАЉдЄНжШѓжЬАе§ІеАЉпЉЫеП¶дЄАзІНжШѓжПТеЕ•зЪДйФЃеАЉжШѓжЬАе§ІеАЉгАВ
¬†¬†¬†¬†¬†¬†еѓєдЇОзђђдЄАзІНжГЕеЖµжЭ•иѓіпЉМељУдЄАдЄ™йЭЮжЬАе§ІйФЃеАЉи¶БињЫеŕ糥еЉХпЉМдљЖжШѓеПСзО∞жЙАеЇФињЫеЕ•зЪД糥еЉХеЭЧдЄНиґ≥дї•еЃєзЇ≥ељУеЙНйФЃеАЉжЧґпЉЪ
1пЉЙ¬†дїО糥еЉХеПѓзФ®еИЧи°®дЄКиОЈеЊЧдЄАдЄ™жЦ∞зЪД糥еЉХжХ∞жНЃеЭЧгАВ
2пЉЙ¬†е∞ЖељУеЙНеЕЕжї°дЇЖзЪД糥еЉХдЄ≠зЪД糥еЉХжЭ°зЫЃеИЖжИРдЄ§йГ®еИЖпЉМдЄАйГ®еИЖжШѓеЕЈжЬЙиЊГе∞ПйФЃеАЉзЪДпЉМеП¶дЄАйГ®еИЖжШѓеЕЈжЬЙиЊГе§ІйФЃеАЉзЪДгАВOracleдЉЪе∞ЖеЕЈжЬЙиЊГе§ІйФЃеАЉзЪДйГ®еИЖзІїеЕ•жЦ∞зЪД糥еЉХжХ∞жНЃеЭЧпЉМиАМиЊГе∞ПйФЃеАЉзЪДйГ®еИЖдњЭжМБдЄНеК®гАВ
3пЉЙ¬†е∞ЖељУеЙНйФЃеАЉжПТеЕ•еРИйАВзЪД糥еЉХеЭЧдЄ≠пЉМеПѓиГљжШѓеОЯжЭ•з©ЇйЧідЄНиґ≥зЪД糥еЉХеЭЧпЉМдєЯеПѓиГљжШѓжЦ∞зЪД糥еЉХеЭЧгАВ
4пЉЙ¬†жЫіжЦ∞еОЯжЭ•з©ЇйЧідЄНиґ≥зЪД糥еЉХеЭЧзЪДkdxlenxtдњ°жБѓпЉМдљњеЕґжМЗеРСжЦ∞зЪД糥еЉХеЭЧгАВ
5пЉЙ¬†жЫіжЦ∞дљНдЇОеОЯжЭ•з©ЇйЧідЄНиґ≥зЪД糥еЉХеЭЧеП≥иЊєзЪД糥еЉХеЭЧйЗМзЪДkdxleprvпЉМдљњеЕґжМЗеРСжЦ∞зЪД糥еЉХеЭЧгАВ
6пЉЙ¬†еРСеОЯжЭ•з©ЇйЧідЄНиґ≥зЪД糥еЉХеЭЧзЪДдЄКдЄАзЇІзЪДеИЖжԃ糥еЉХеЭЧдЄ≠жЈїеК†дЄА䪙糥еЉХжЭ°зЫЃпЉМ胕糥еЉХжЭ°зЫЃдЄ≠дњЭе≠ШжЦ∞зЪД糥еЉХеЭЧйЗМзЪДжЬАе∞ПйФЃеАЉпЉМдї•еПКжЦ∞зЪД糥еЉХеЭЧзЪДеЬ∞еЭАгАВ
дїОдЄКйЭҐжЬЙеЕ≥еПґе≠РиКВзВєеИЖи£ВзЪДињЗз®ЛеПѓдї•зЬЛеЗЇпЉМеЕґињЗз®ЛжШѓйЭЮеЄЄе§НжЭВзЪДгАВеЫ†ж≠§е¶ВжЮЬеПСзФЯзЪДжШѓзђђдЇМзІНжГЕеЖµпЉМеИЩдЄЇдЇЖ
зЃАеМЦиѓ•еИЖи£ВињЗз®ЛпЉМoracleзЬБзХ•дЇЖдЄКйЭҐзЪДзђђдЇМж≠•пЉМиАМжШѓзЫіжО•ињЫеЕ•зђђдЄЙж≠•пЉМе∞ЖжЦ∞зЪДйФЃеАЉжПТеЕ•жЦ∞зЪД糥еЉХеЭЧдЄ≠гАВ
¬†¬†¬†¬†¬†¬†еЬ®дЄКдЊЛдЄ≠пЉМељУеПґе≠РиКВзВєиґКжЭ•иґКе§ЪпЉМеѓЉиЗіеОЯжЭ•зЪДж†єиКВзВєдЄНиґ≥дї•е≠ШжФЊжЦ∞зЪД糥еЉХжЭ°зЫЃпЉИињЩдЇЫ糥еЉХжЭ°зЫЃжМЗеРСеПґе≠РиКВзВєпЉЙжЧґпЉМеИЩиѓ•ж†єиКВзВєењЕй°їињЫи°МеИЖи£ВгАВељУж†єиКВзВєињЫи°МеИЖи£ВжЧґпЉЪ
1пЉЙ¬†дїО糥еЉХеПѓзФ®еИЧи°®дЄКиОЈеЊЧдЄ§дЄ™жЦ∞зЪД糥еЉХжХ∞жНЃеЭЧгАВ
2пЉЙ¬†е∞Жж†єиКВзВєдЄ≠зЪД糥еЉХжЭ°зЫЃеИЖжИРдЄ§йГ®еИЖпЉМињЩдЄ§йГ®еИЖеИЖеИЂжФЊеЕ•дЄ§дЄ™жЦ∞зЪД糥еЉХеЭЧпЉМдїОиАМ嚥жИРдЄ§дЄ™жЦ∞зЪДеИЖжФѓиКВзВєгАВ
3пЉЙ¬†жЫіжЦ∞еОЯжЭ•зЪДж†єиКВзВєзЪД糥еЉХжЭ°зЫЃпЉМдљњеЕґеИЖеИЂжМЗеРСињЩдЄ§дЄ™жЦ∞зЪД糥еЉХеЭЧгАВ
еЫ†ж≠§пЉМињЩжЧґзЪД糥еЉХе±Вжђ°е∞±еПШжИРдЇЖ2е±ВгАВеРМжЧґеПѓдї•зЬЛеЗЇпЉМж†єиКВзº糥еЉХеЭЧеЬ®зЙ©зРЖдЄКеІЛзїИйГљжШѓеРМдЄА䪙糥еЉХеЭЧгАВиАМ
йЪПзЭАжХ∞жНЃйЗПзЪДдЄНжЦ≠еҐЮеК†пЉМеѓЉиЗіеИЖжФѓиКВзВєеПИи¶БињЫи°МеИЖи£ВгАВеИЖжФѓиКВзВєзЪДеИЖи£ВињЗз®ЛдЄОж†єиКВзВєз±їдЉЉпЉИеЃЮйЩЕдЄКж†єиКВзВєеИЖи£ВеЕґеЃЮжШѓеИЖжФѓиКВзВєеИЖи£ВзЪДдЄАдЄ™зЙєдЊЛиАМеЈ≤пЉЙпЉЪ
1пЉЙ¬†дїО糥еЉХеПѓзФ®еИЧи°®дЄКиОЈеЊЧдЄАдЄ™жЦ∞зЪД糥еЉХжХ∞жНЃеЭЧгАВ
2пЉЙ¬†е∞ЖељУеЙНжї°дЇЖзЪДеИЖжФѓиКВзВєйЗМзЪД糥еЉХжЭ°зЫЃеИЖжИРдЄ§йГ®еИЖпЉМиЊГе∞ПйФЃеАЉзЪДйГ®еИЖдЄНеК®пЉМиАМиЊГе§ІйФЃеАЉзЪДйГ®еИЖзІїеЕ•жЦ∞зЪД糥еЉХеЭЧгАВ
3пЉЙ¬†е∞ЖжЦ∞зЪД糥еЉХжЭ°зЫЃжПТеЕ•еРИйАВзЪДеИЖжԃ糥еЉХеЭЧгАВ
4пЉЙ¬†еЬ®дЄКе±ВеИЖжԃ糥еЉХеЭЧдЄ≠жЈїеК†дЄАдЄ™жЦ∞зЪД糥еЉХжЭ°зЫЃпЉМдљњеЕґжМЗеРСжЦ∞еК†зЪДеИЖжԃ糥еЉХеЭЧгАВ
ељУжХ∞жНЃйЗПеЖНжђ°дЄНжЦ≠еҐЮеК†пЉМеѓЉиЗіеОЯжЭ•зЪДж†єиКВзВєдЄНиґ≥дї•е≠ШжФЊжЦ∞зЪД糥еЉХжЭ°зЫЃпЉИињЩдЇЫ糥еЉХжЭ°зЫЃжМЗеРСеИЖжФѓиКВзВєпЉЙжЧґпЉМ
еЖНжђ°еЉХиµЈж†єиКВзВєзЪДеИЖи£ВпЉМеЕґеИЖи£ВињЗз®ЛдЄОеЙНйЭҐжЙАиѓізЪДзФ±дЇОеПґе≠РиКВзВєзЪДеҐЮеК†иАМеѓЉиЗізЪДж†єиКВзВєеИЖи£ВзЪДињЗз®ЛжШѓдЄАж†ЈзЪДгАВ
еРМжЧґпЉМж†єиКВзВєеИЖи£Вдї•еРОпЉМ糥еЉХзЪДе±ВзЇІеЖНжђ°йАТеҐЮгАВзФ±ж≠§еПѓдї•зЬЛеЗЇпЉМж†єжНЃBж†С糥еЉХзЪДеИЖи£ВжЬЇеИґпЉМдЄАдЄ™Bж†С糥еЉХеІЛзїИйГљжШѓеє≥и°°зЪДгАВж≥®жДПпЉМињЩйЗМзЪДеє≥и°°жШѓжМЗжѓПдЄ™еПґе≠РиКВ зВєдЄОж†єиКВзВєзЪДиЈЭз¶їйГљжШѓзЫЄеРМзЪДгАВеРМжЧґпЉМдїО糥еЉХзЪДеИЖи£ВжЬЇеИґеПѓдї•зЬЛеЗЇпЉМељУжПТеЕ•зЪДйФЃеАЉеІЛзїИйГљжШѓеҐЮе§ІзЪДжЧґеАЩпЉМ糥еЉХжАїжШѓеРСеП≥жЙ©е±ХпЉЫиАМељУжПТеЕ•зЪДйФЃеАЉеІЛзїИйГљжШѓеЗПе∞ПзЪДжЧґеАЩпЉМ 糥еЉХеИЩжАїжШѓеРСеЈ¶жЙ©е±ХгАВ
 
4.2 Bж†С糥еЉХзЪДеѓєдЇОеИ†йЩ§пЉИDELETEпЉЙзЪДзЃ°зРЖ
¬†¬†¬†¬†¬†¬†дЄКйЭҐдїЛзїНдЇЖжЬЙеЕ≥жПТеЕ•йФЃеАЉж״糥еЉХзЪДзЃ°зРЖжЬЇеИґпЉМйВ£дєИеѓєдЇОеИ†йЩ§йФЃеАЉжЧґдЉЪжАОдєИж†ЈеСҐпЉЯ
еЬ®дїЛзїНеИ†й٧糥еЉХйФЃеАЉзЪДжЬЇеИґдєЛеЙНпЉМеЕИдїЛзїНдЄО糥еЉХзЫЄеЕ≥зЪДдЄАдЄ™жѓФиЊГйЗНи¶БзЪДиІЖеЫЊпЉЪindex_statsгАВиѓ•иІЖеЫЊжШЊз§ЇдЇЖ
е§ІйЗП糥еЉХеЖЕйГ®зЪДдњ°жБѓпЉМиѓ•иІЖеЫЊж≠£еЄЄжГЕеЖµдЄЛж≤°жЬЙжХ∞жНЃпЉМеП™жЬЙеЬ®ињРи°МдЇЖдЄЛйЭҐзЪДеСљдї§дї•еРОжЙНдЉЪ襀尀еЕЕжХ∞жНЃпЉМиАМдЄФиѓ•иІЖеЫЊдЄ≠еП™иГље≠ШжФЊдЄАжЭ°дЄОеИЖжЮРињЗзЪД糥еЉХзЫЄеЕ≥зЪДиЃ∞ељХпЉМ дЄНдЉЪжЬЙзђђдЇМжЭ°иЃ∞ељХгАВеРМжЧґпЉМдєЯеП™жЬЙињРи°МдЇЖиѓ•еСљдї§зЪДsessionжЙНиГље§ЯзЬЛеИ∞иѓ•иІЖеЫЊйЗМзЪДжХ∞жНЃпЉМеЕґдїЦsessionдЄНиГљзЬЛеИ∞еЕґдЄ≠зЪДжХ∞жНЃгАВ
analyze index INDEX_NAME validate structure;
¬†¬†¬†¬†¬†¬†дЄНињЗи¶Бж≥®жДПдЄАзВєпЉМе∞±жШѓиѓ•еСљдї§жЬЙдЄАдЄ™еЭПе§ДпЉМе∞±жШѓеЬ®ињРи°МињЗз®ЛдЄ≠пЉМдЉЪйФБеЃЪжХідЄ™и°®пЉМдїОиАМйШїе°ЮеЕґдїЦsessionеѓєи°®ињЫи°МжПТеЕ•гАБжЫіжЦ∞еТМеИ†йЩ§з≠ЙжУН дљЬгАВињЩжШѓеЫ†дЄЇиѓ•еСљдї§зЪДдЄїи¶БзЫЃзЪДеєґдЄНжШѓзФ®жЭ•е°ЂеЕЕindex_statsиІЖеЫЊзЪДпЉМеЕґдЄїи¶БдљЬзФ®еЬ®дЇОж†°й™М糥еЉХдЄ≠зЪДжѓПдЄ™жЬЙжХИзЪД糥еЉХжЭ°зЫЃйГљеѓєеЇФеИ∞и°®йЗМзЪДдЄАи°МпЉМеРМжЧґи°®йЗМ зЪДжѓПдЄАи°МжХ∞жНЃеܮ糥еЉХдЄ≠йГље≠ШеЬ®дЄАдЄ™еѓєеЇФзЪД糥еЉХжЭ°зЫЃгАВдЄЇдЇЖеЃМжИРиѓ•зЫЃзЪДпЉМжЙАдї•еЬ®ињРи°МињЗз®ЛдЄ≠и¶БйФБеЃЪжХідЄ™и°®пЉМеРМжЧґеѓєдЇОеЊИе§ІзЪДи°®жЭ•иѓіпЉМињРи°Миѓ•еСљдї§йЬАи¶БиАЧиієйЭЮеЄЄе§ЪзЪДжЧґ йЧігАВ
еЬ®иІЖеЫЊindex_statsдЄ≠пЉМheightи°®з§ЇBж†С糥еЉХзЪДйЂШеЇ¶пЉЫblocksи°®з§ЇеИЖйЕНдЇЖзЪД糥еЉХеЭЧжХ∞пЉМеМЕжЛђињШж≤°жЬЙ襀䚜зФ®зЪДпЉЫpct_usedи°®з§Ї ељУеЙН糥еЉХдЄ≠襀䚜зФ®дЇЖзЪДз©ЇйЧізЪДзЩЊеИЖжѓФгАВеЕґеАЉжШѓйАЪињЗиѓ•иІЖеЫЊдЄ≠зЪД(used_space/btree_space)*100иЃ°зЃЧиАМжЭ•гАВused_spaceи°®з§Ї еЈ≤зїПдљњзФ®зЪДз©ЇйЧіпЉМиАМbtree_space谮积糥еЉХжЙАеН†зЪДжАїз©ЇйЧіпЉЫdel_lf_rows谮积襀еИ†йЩ§зЪДиЃ∞ељХи°МжХ∞пЉИи°®йЗМзЪДжХ∞ж́襀еИ†йЩ§еєґдЄНдЉЪзЂЛеН≥е∞ЖеЕґеѓєеЇФдЇО糥 еЉХйЗМзЪД糥еЉХжЭ°зЫЃжЄЕйЩ§еǯ糥еЉХеЭЧпЉМжИСдїђеРОйЭҐдЉЪиѓіеИ∞пЉЙпЉЫdel_lf_rows_len谮积襀еИ†йЩ§зЪДиЃ∞ељХжЙАеН†зЪДжАїз©ЇйЧіпЉЫlf_rows谮积糥еЉХдЄ≠еМЕеРЂзЪДжАїиЃ∞ељХи°М жХ∞пЉМеМЕжЛђеЈ≤зїП襀еИ†йЩ§зЪДиЃ∞ељХи°МжХ∞гАВињЩж†ЈзЪДиѓЭпЉМ糥еЉХдЄ≠жܙ襀еИ†йЩ§зЪДиЃ∞ељХи°МжХ∞е∞±жШѓlf_rows-del_lf_rowsгАВеРМжЧґжИСдїђеПѓдї•иЃ°зЃЧжܙ襀еИ†йЩ§зЪДиЃ∞ељХжЙАеѓєеЇФ зЪД糥еЉХжЭ°зЫЃпЉИдєЯе∞±жШѓжЬЙжХИ糥еЉХжЭ°зЫЃпЉЙжЙАеН†зФ®зЪДз©ЇйЧідЄЇ((used_space вАУ del_lf_rows_len) / btree_space) * 100гАВ
зДґеРОпЉМжИСдїђињШжШѓжО•зЭАдЄКдЄ™дЊЛе≠РпЉИжЬАеРОжПТеЕ•дЇЖ12*2зЪДдЊЛе≠РпЉЙжЭ•жµЛиѓХдЄАдЄЛгАВињЩжЧґжИСдїђеЈ≤зїПзЯ•йБУпЉМиѓ•дЊЛдЄ≠зЪД糥еЉХеЕЈжЬЙдЄ§дЄ™еПґе≠РиКВзВєпЉМдЄАдЄ™еПґе≠РиКВзВєпЉИеЭЧеПЈдЄЇ 419пЉЙеМЕеРЂ10гАБ12гАБ14гАБ16гАБ18гАБ20гАБ22гАБ24еТМ2aпЉМиАМеП¶дЄАдЄ™еПґе≠РиКВзВєпЉИеЭЧеПЈдЄЇ420пЉЙеМЕеРЂ4aгАБ6aеТМ8aгАВжИСдїђжПТеЕ•41гАБ42гАБ 43гАБ44гАБ45гАБ46гАБ47еТМ48еРД8жЭ°иЃ∞ељХпЉМињЩжЧґеПѓдї•зЯ•йБУињЩ8жЭ°иЃ∞ељХжЙАеѓєеЇФзЪД糥еЉХжЭ°зЫЃе∞ЖдЉЪињЫеŕ糥еЉХеЭЧ420дЄ≠пЉМдїОиАМиѓ•еЭЧ420襀еЕЕжї°гАВ
SQL> begin
 2    for i in 1..8 loop
 3        insert into index_test values (rpad('4'||to_char(i),150,'a'));
 4    end loop;
 5 end;
 6 /
жИСдїђеЕИеИЖжЮР糥еЉХдїОиАМе°ЂеЕЕindex_statsиІЖеЫЊгАВ
SQL> analyze index idx_test validate structure;
SQL> select LF_ROWS,DEL_LF_ROWS,DEL_LF_ROWS_LEN,USED_SPACE,BTREE_SPACE from index_stats;
     LF_ROWS DEL_LF_ROWS DEL_LF_ROWS_LEN USED_SPACE BTREE_SPACE
---------- ----------- --------------- ---------- -----------
       20          0              0      3269       5600
¬†¬†¬†¬†¬†¬†дїОдЄКйЭҐиІЖеЫЊеПѓдї•зЬЛеИ∞пЉМељУеЙН糥еЉХеЕ±20жЭ°иЃ∞ељХпЉМж≤°жЬЙ襀еИ†йЩ§зЪДиЃ∞ељХпЉМеЕ±дљњзФ®дЇЖ3269дЄ™е≠ЧиКВгАВ
зДґеРОжИСдїђеИ†йЩ§дљНдЇО糥еЉХеЭЧ419йЗМзЪД糥еЉХжЭ°зЫЃпЉМеМЕжЛђ10гАБ12гАБ14гАБ16еРД4жЭ°иЃ∞ељХгАВ
SQL> delete index_test where substr(id,1,2) in('10','12','14','16');
SQL> commit;
SQL> alter system dump datafile 7 block 419;
¬†¬†¬†¬†¬†¬†жЙУеЉАиљђеВ®еЗЇжЭ•зЪДжЦЗдїґеПѓдї•еПСзО∞е¶ВдЄЛзЪДеЖЕеЃєпЉИжИСдїђиКВйАЙдЇЖйГ®еИЖеЕ≥йФЃеЖЕеЃєпЉЙгАВеПѓдї•еПСзО∞пЉМkdxconroдЄЇ3пЉМиѓіжШО胕糥еЉХиКВзВєйЗМињШжЬЙ9䪙糥еЉХжЭ° зЫЃгАВжЙАдї•иѓіпЉМиЩљзДґи°®йЗМзЪДжХ∞ж́襀еИ†йЩ§дЇЖпЉМдљЖжШѓеѓєеЇФзЪД糥еЉХжЭ°зЫЃеєґж≤°жЬЙ襀еИ†йЩ§пЉМеП™жШѓеЬ®еРД䪙糥еЉХжЭ°зЫЃдЄКпЉИrow#дЄАи°МдЄ≠зЪДflagдЄЇDпЉЙеБЪдЇЖдЄАдЄ™DзЪДж†ЗиЃ∞пЉМи°®з§Їиѓ• 糥еЉХжЭ°зہ襀deleteдЇЖгАВ
kdxconro 9
row#0[443] flag: ---D-, lock: 2
row#1[604] flag: ---D-, lock: 2
row#2[765] flag: ---D-, lock: 2
row#3[926] flag: ---D-, lock: 2
¬†¬†¬†¬†¬†¬†зДґеРОпЉМжИСдїђеЖНдї•ж†СзКґзїУжЮДиљђе®糥еЉХпЉМжЙУеЉАж†СзКґиљђеВ®иЈЯиЄ™жЦЗдїґеПѓдї•зЬЛеИ∞е¶ВдЄЛеЖЕеЃєгАВеПѓдї•зЯ•йБУпЉМеЭЧ419йЗМеМЕеРЂ9䪙糥еЉХжЭ°зЫЃпЉИnrowдЄЇ9пЉЙпЉМиАМжЬЙжХИ糥еЉХжЭ°зЫЃеП™жЬЙ5дЄ™пЉИrrowдЄЇ5пЉЙпЉМйВ£дєИ襀еИ†йЩ§дЇЖзЪД糥еЉХжЭ°зЫЃе∞±жШѓ4дЄ™пЉИ9еЗП5пЉЙгАВ
SQL> alter session set events 'immediate trace name treedump level 7390';
----- begin tree dump
branch: 0x1c001a2 29360546 (0: nrow: 2, level: 1)
  leaf: 0x1c001a3 29360547 (-1: nrow: 9 rrow: 5)
  leaf: 0x1c001a4 29360548 (0: nrow: 11 rrow: 11)
----- end tree dump
¬†¬†¬†¬†¬†¬†ињЩжЧґпЉМжИСдїђеЖНжђ°еИЖжЮР糥еЉХпЉМе°ЂеЕЕindex_statsиІЖеЫЊгАВ
SQL> analyze index idx_test validate structure;
SQL> select LF_ROWS,DEL_LF_ROWS,DEL_LF_ROWS_LEN,USED_SPACE,BTREE_SPACE from index_stats;
     LF_ROWS DEL_LF_ROWS DEL_LF_ROWS_LEN USED_SPACE BTREE_SPACE
---------- ----------- --------------- ---------- -----------
       20          4            652      3269       5600
¬†¬†¬†¬†¬†¬†еѓєзЕІеИ†йЩ§дєЛеЙНиІЖеЫЊйЗМзЪДдњ°жБѓпЉМеЊИжШОжШЊзЬЛеИ∞пЉМељУеЙН糥еЉХдїНзДґдЄЇ20жЭ°иЃ∞ељХпЉМдљЖжШѓеЕґдЄ≠жЬЙ4жЭ°дЄЇеИ†йЩ§зЪДпЉМдљЖж؃糥еЉХжЙАдљњзФ®зЪДз©ЇйЧіеєґж≤°жЬЙйЗКжԌ襀еИ†йЩ§иЃ∞ељХжЙАеН†зФ®зЪД652дЄ™е≠ЧиКВпЉМдїНзДґдЄЇеИ†йЩ§дєЛеЙНзЪД3269дЄ™е≠ЧиКВгАВињЩдєЯдЄОиљђеВ®еЗЇжЭ•зЪД糥еЉХеЭЧзЪДдњ°жБѓдЄАиЗігАВ
¬†¬†¬†¬†¬†¬†жО•дЄЛжЭ•пЉМжИСдїђжµЛиѓХињЩдЄ™жЧґеАЩжПТеЕ•дЄАжЭ°иЃ∞ељХжЧґпЉМ糥еЉХдЉЪжАОдєИеПШеМЦгАВеИЖдЄЙзІНжГЕеЖµињЫи°МжПТеЕ•пЉЪзђђдЄАзІНжШѓжПТеЕ•дЄАдЄ™е±ЮдЇОеОЯжݕ襀еИ†йЩ§йФЃеАЉиМГеЫіеЖЕзЪДеАЉпЉМжѓФе¶В 13пЉМиІВеѓЯеЕґдЉЪе¶ВдљХињЫеЕ•еМЕеРЂиЃЊзљЃдЇЖеИ†йЩ§ж†ЗиЃ∞зЪД糥еЉХеЭЧпЉЫзђђдЇМзІНжШѓжПТеЕ•еОЯжݕ襀еИ†йЩ§зЪДйФЃеАЉдЄ≠зЪДдЄАдЄ™пЉМжѓФе¶В16пЉМиІВеѓЯеЕґжШѓеР¶иГље§ЯйЗНжЦ∞дљњзФ®еОЯжЭ•зЪД糥еЉХжЭ°зЫЃпЉЫзђђдЄЙзІНжШѓ жПТеЕ•дЄАдЄ™еЃМеЕ®дЄНе±ЮдЇОиѓ•и°®дЄ≠еЈ≤жЬЙиЃ∞ељХзЪДиМГеЫізЪДеАЉпЉМжѓФе¶Вrpad('M',150,'M')пЉМиІВеѓЯеЕґеѓєеЭЧ419дї•еПК420дЉЪдЇІзФЯдїАдєИељ±еУНгАВ
¬†¬†¬†¬†¬†¬†жИСдїђжµЛиѓХзђђдЄАзІНжГЕеЖµпЉЪ
SQL> insert into index_test values (rpad(to_char(13),150,'a'));
SQL> alter system dump datafile 7 block 419;
¬†¬†¬†¬†¬†¬†жЙУеЉАиЈЯиЄ™жЦЗдїґдї•еРОдЉЪеПСзО∞419еЭЧйЗМзЪДеЖЕеЃєеПСзФЯдЇЖеПШеМЦпЉМе¶ВдЄЛжЙАз§ЇгАВжИСдїђеПѓдї•еПСзО∞дЄАдЄ™еЊИжЬЙиґ£зЪДзО∞и±°пЉМдїОkdxconroдЄЇ6иѓіжШОжПТеЕ•дЇЖйФЃеАЉ 13дї•еРОпЉМеѓЉиЗіеОЯжЭ•еЫЫ䪙襀ж†ЗиЃ∞дЄЇеИ†йЩ§зЪД糥еЉХжЭ°зЫЃйÚ襀жЄЕйЩ§еЗЇдЇЖ糥еЉХеЭЧгАВеРМжЧґпЉМжИСдїђдєЯз°ЃеЃЮеПСзО∞еОЯжЭ•ж†ЗиЃ∞дЄЇDзЪДеЫЫ䪙糥еЉХжЭ°зЫЃйГљжґИ姱дЇЖгАВ
вА¶вА¶
kdxconro 6
вА¶вА¶
kdxlende 0
вА¶вА¶
row#0[121] flag: -----, lock: 2¬†¬†¬†иҐЂжПТеЕ•13
col 0; len 150; (150):
 31 33 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61
вА¶вА¶
жИСдїђеИЖжЮР糥еЉХпЉМзЬЛзЬЛindex_statsиІЖеЫЊдЉЪе¶ВдљХеПШеМЦгАВ
SQL> analyze index idx_test validate structure;
SQL> select LF_ROWS,DEL_LF_ROWS,DEL_LF_ROWS_LEN,USED_SPACE,BTREE_SPACE from index_stats;
  LF_ROWS DEL_LF_ROWS DEL_LF_ROWS_LEN USED_SPACE BTREE_SPACE
---------- ----------- --------------- ---------- -----------
       17          0              0      2780       5600
¬†¬†¬†¬†¬†¬†еЊИжШОжШЊпЉМеОЯжЭ•зЪДdel_lf_rowsдїО4еПШдЄЇдЇЖ0пЉМеРМжЧґused_spaceдєЯдїОеОЯжЭ•зЪД3269еПШжИРдЇЖ2780гАВи°®з§ЇеОЯжݕ襀еИ†йЩ§зЪД糥еЉХжЭ°зЫЃжЙАеН†зФ®зЪДз©ЇйЧіеЈ≤зїПйЗКжФЊдЇЖгАВ
жИСдїђзїІзї≠жµЛиѓХзђђдЇМзІНжГЕеЖµпЉЪ
SQL> insert into index_test values (rpad(to_char(8*2),150,'a'));
SQL> alter system dump datafile 7 block 419;
¬†¬†¬†¬†¬†¬†жЙУеЉАиЈЯиЄ™жЦЗдїґдї•еРОпЉМеПСзО∞еѓєдЇОжПТеЕ•еЈ≤зїП襀ж†ЗиЃ∞дЄЇеИ†йЩ§зЪДиЃ∞ељХжЭ•иѓіпЉМеЕґињЗз®ЛдЄОжПТеЕ•е±ЮдЇО胕糥еЉХеЭЧ糥еЉХиМГеЫізЪДйФЃеАЉзЪДињЗз®Лж≤°жЬЙеМЇеИЂгАВзФЪиЗ≥дљ†дЉЪеПСзО∞пЉМ 襀жПТеЕ•зЪД16зЪДйФЃеАЉжЙАе§ДзЪДдљНзљЃдЄОжПТеЕ•зЪД13зЪДйФЃеАЉжЙАеЬ®зЪДдљНзљЃеЃМеЕ®дЄАж†ЈпЉИrow#0[121]йЗМзЪД121и°®з§Їеܮ糥еЉХеЭЧдЄ≠зЪДдљНзљЃпЉЙгАВдєЯе∞±жШѓиѓіпЉМoracleеєґж≤°жЬЙйЗНзФ®еОЯжЭ•дЄЇ16зЪДйФЃеАЉпЉМиАМжШѓзЫіжО•е∞ЖжЙАжЬЙж†ЗиЃ∞дЄЇDзЪД糥еЉХжЭ°зЫЃжЄЕйЩ§еǯ糥еЉХеЭЧпЉМзДґеРОжПТеЕ•жЦ∞зЪДйФЃеАЉдЄЇ16зЪД糥еЉХжЭ°зЫЃгАВ
¬†¬†¬†¬†¬†¬†еѓєдЇОзђђдЄЙзІНжГЕеЖµпЉМжИСдїђеЈ≤зїПеПѓдї•ж†єжНЃеЙНйЭҐжЬЙеЕ≥зђђдЄАгАБзђђдЇМзІНжГЕеЖµеБЪеЗЇйҐДжµЛпЉМзФ±дЇО420еЭЧеЈ≤зїП襀еЕЕжї°пЉМеРМжЧґжЙАжПТеЕ•зЪДйФЃеАЉжШѓжХідЄ™и°®йЗМзЪДжЬАе§ІеАЉпЉМ еЫ†ж≠§дєЯдЄНдЉЪеЫ†ж≠§420еПЈеЭЧзЪДеИЖи£ВпЉМиАМжШѓзЫіжО•иОЈеПЦдЄАдЄ™жЦ∞зЪД糥еЉХеЭЧжЭ•е≠ШжФЊиѓ•йФЃеАЉгАВдљЖжШѓ419еПЈеЭЧйЗМж†ЗиЃ∞дЄЇDзЪД糥еЉХжЭ°зЫЃжШѓеР¶иÚ襀жЄЕйЩ§еǯ糥еЉХеЭЧеСҐпЉЯ
SQL> insert into index_test values (rpad('M',150,'M'));
SQL> alter system dump datafile 7 block 419;
SQL> alter system dump datafile 7 block 420;
SQL> alter system dump datafile 7 block 421;
¬†¬†¬†¬†¬†¬†жЙУеЉАиЈЯиЄ™жЦЗдїґпЉМеПѓдї•жЄЕж•ЪзЪДзЬЛеИ∞пЉМ419еПЈеЭЧйЗМзЪДж†ЗиЃ∞дЄЇDзЪД4еРД糥еЉХжЭ°зЫЃдїНзДґдњЭзХЩеܮ糥еЉХеЭЧйЗМпЉМеРМжЧґ420еПЈеЭЧйЗМзЪДеЖЕеЃєж≤°жЬЙдїїдљХеПШеМЦпЉМиАМ421еПЈеЭЧйЗМеИЩе≠ШжФЊдЇЖжЦ∞зЪДйФЃеАЉпЉЪrpad('M',150,'M')гАВ
жИСдїђзЬЛзЬЛindex_statsиІЖеЫЊдЉЪе¶ВдљХеПШеМЦгАВеЕґзїУжЮЬдєЯзђ¶еРИжИСдїђдїОиљђеВ®жЦЗдїґдЄ≠жЙАзЬЛеИ∞зЪДеЖЕеЃєгАВ
SQL> analyze index idx_test validate structure;
SQL> select LF_ROWS,DEL_LF_ROWS,DEL_LF_ROWS_LEN,USED_SPACE,BTREE_SPACE from index_stats;
  LF_ROWS DEL_LF_ROWS DEL_LF_ROWS_LEN USED_SPACE BTREE_SPACE
---------- ----------- --------------- ---------- -----------
       21          4            652      3441       7456
¬†¬†¬†¬†¬†¬†жЧҐзДґељУжПТеЕ•rpad('M',150,'M')жЧґеѓє419еПЈеЭЧж≤°жЬЙдїїдљХељ±еУНпЉМдЄНдЉЪе∞Жж†ЗиЃ∞дЄЇDзЪД糥еЉХжЭ°зЫЃзІїеǯ糥еЉХеЭЧгАВйВ£дєИе¶ВжЮЬжИСдїђдЇЛеЕИе∞Ж 419еϣ糥еЉХеЭЧдЄ≠жЙАжЬЙзЪД糥еЉХжЭ°зЫЃйГљж†ЗиЃ∞дЄЇDпЉМдєЯе∞±жШѓиѓіеИ†йЩ§419еϣ糥еЉХеЭЧдЄ≠糥еЉХжЭ°зЫЃжЙАеѓєеЇФзЪДиЃ∞ељХпЉМзДґеРОеЖНжђ°жПТеЕ•rpad('M',150,'M')жЧґдЉЪеПС зФЯдїАдєИпЉЯйАЪињЗжµЛиѓХпЉМжИСдїђеПѓдї•еПСзО∞пЉМеЖНжђ°жПТеЕ•дЄАдЄ™жЬАе§ІеАЉдї•еРОпЉМиѓ•жЬАе§ІеАЉдЉЪињЫеЕ•еЭЧ421йЗМпЉМдљЖжШѓеЭЧ419йЗМзЪД糥еЉХжЭ°зЫЃеИЩдЉЪ襀еЕ®йГ®жЄЕйЩ§пЉМеПШжИРдЇЖдЄАдЄ™з©ЇзЪД糥еЉХжХ∞жНЃ еЭЧгАВињЩдєЯе∞±жШѓжИСдїђйАЪеЄЄжЙАиѓізЪДпЉМељУ糥еЉХеЭЧйЗМзЪД糥еЉХжЭ°зЫЃеЕ®йî襀职皁䪯DпЉИеИ†йЩ§пЉЙж†ЗиЃ∞жЧґпЉМеЖНжђ°жПТеЕ•дїїдљХдЄА䪙糥еЉХйФЃеАЉйГљдЉЪеЉХ赣胕糥еЉХеЭЧйЗМзЪДеЖЕ偺襀жЄЕйЩ§гАВ
¬†¬†¬†¬†¬†¬†жЬАеРОпЉМжИСдїђжЭ•жµЛиѓХдЄАдЄЛпЉМељУ糥еЉХеЭЧйЗМзЪД糥еЉХжЭ°зЫЃеЕ®йî襀职皁䪯DпЉИеИ†йЩ§пЉЙж†ЗиЃ∞дї•еРОпЉМеЖНжђ°жПТеЕ•жЦ∞зЪДйФЃеАЉжЧґдЉЪе¶ВдљХйЗНзФ®ињЩдЇЫ糥еЉХеЭЧгАВжИСдїђеЕИеИЫеїЇдЄАдЄ™жµЛиѓХи°®пЉМеєґжПТеЕ•10000жЭ°иЃ∞ељХгАВ
SQL> create table delete_test(id number);
SQL> begin
 2    for i in 1..10000 loop
 3        insert into delete_test values (i);
 4    end loop;
 5    commit;
 6 end;
 7 /
SQL> create index idx_delete_test on delete_test(id);
SQL> analyze index idx_delete_test validate structure;
SQL> select LF_ROWS,LF_BLKS,DEL_LF_ROWS,USED_SPACE,BTREE_SPACE from index_stats;
  LF_ROWS   LF_BLKS DEL_LF_ROWS USED_SPACE BTREE_SPACE
---------- ---------- ----------- ---------- -----------
    10000        21          0    150021     176032
¬†¬†¬†¬†¬†¬†еПѓдї•зЬЛеИ∞пЉМ胕糥еЉХеЕЈжЬЙ21дЄ™еПґе≠РиКВзВєгАВзДґеРОжИСдїђеИ†йЩ§еЙН9990жЭ°иЃ∞ељХгАВдїОиАМдљњеЊЧ21дЄ™еПґе≠РиКВзВєдЄ≠еП™жЬЙжЬАеРОдЄАдЄ™еПґе≠РиКВзВєеЕЈжЬЙжЬЙжХИ糥еЉХжЭ°зЫЃпЉМеЙН20дЄ™еПґе≠РиКВзВєйЗМзЪД糥еЉХжЭ°зЫЃеЕ®йГљж†ЗиЃ∞дЄЇDпЉИеИ†йЩ§пЉЙж†ЗиЃ∞гАВ
SQL> delete delete_test where id >= 1 and id <= 9990;
SQL> commit;
SQL> analyze index idx_delete_test validate structure;
SQL> select LF_ROWS,LF_BLKS,DEL_LF_ROWS,USED_SPACE,BTREE_SPACE from index_stats;
  LF_ROWS   LF_BLKS DEL_LF_ROWS USED_SPACE BTREE_SPACE
---------- ---------- ----------- ---------- -----------
    10000        21       9990   150021     176032
¬†¬†¬†¬†¬†¬†жЬАеРОпЉМжИСдїђжПТеЕ•дїО20000еЉАеІЛеИ∞30000зїУжЭЯпЉМеЕ±10000жЭ°дЄО襀еИ†йЩ§иЃ∞ељХеЃМеЕ®дЄНйЗНеП†зЪДиЃ∞ељХгАВ
SQL> begin
 2    for i in 20000..30000 loop
 3        insert into delete_test values (i);
 4    end loop;
 5    commit;
 6 end;
 7 /
SQL> analyze index idx_delete_test validate structure;
SQL> select LF_ROWS,LF_BLKS,DEL_LF_ROWS,USED_SPACE,BTREE_SPACE from index_stats;
  LF_ROWS   LF_BLKS DEL_LF_ROWS USED_SPACE BTREE_SPACE
---------- ---------- ----------- ---------- -----------
    10011        21          0    160302     176032
¬†¬†¬†¬†¬†¬†еЊИжШОжШЊзЪДзЬЛеИ∞пЉМе∞љзЃ°иҐЂжПТеЕ•зЪДиЃ∞ељХдЄНе±ЮдЇО襀еИ†йЩ§зЪДиЃ∞ељХиМГеЫіпЉМдљЖжШѓеП™и¶Б糥еЉХеЭЧдЄ≠жЙАжЬЙзЪД糥еЉХжЭ°зЫЃйÚ襀еИ†йЩ§дЇЖпЉИж†ЗиЃ∞дЄЇDпЉЙпЉМ胕糥еЉХе∞±еПШжИРеПѓзԮ糥еЉХеЭЧиАМиГље§Я襀жЦ∞зЪДйФЃеАЉйЗНжЦ∞еИ©зФ®дЇЖгАВ
¬†¬†¬†¬†¬†¬†еЫ†ж≠§пЉМж†єжНЃдЄКйЭҐжИСдїђжЙАеБЪзЪДиѓХй™МпЉМеσ俕僺糥еЉХзЪДеИ†йЩ§жГЕеЖµжАїзїУе¶ВдЄЛпЉЪ
1пЉЙ¬†ељУеИ†йЩ§и°®йЗМзЪДдЄАжЭ°иЃ∞ељХжЧґпЉМеЕґеѓєеЇФдЇО糥еЉХйЗМзЪД糥еЉХжЭ°зЫЃеєґдЄНдЉЪ襀зЙ©зРЖзЪДеИ†йЩ§пЉМеП™жШѓеБЪдЇЖдЄАдЄ™еИ†йЩ§ж†ЗиЃ∞гАВ
2пЉЙ¬†ељУдЄАдЄ™жЦ∞зЪД糥еЉХжЭ°зЫЃињЫеЕ•дЄА䪙糥еЉХеПґе≠РиКВзВєзЪДжЧґеАЩпЉМoracleдЉЪж£АжЯ•иѓ•еПґе≠РиКВзВєйЗМжШѓеР¶е≠Шеܮ襀ж†ЗиЃ∞дЄЇеИ†йЩ§зЪД糥еЉХжЭ°зЫЃпЉМе¶ВжЮЬе≠ШеЬ®пЉМеИЩдЉЪе∞ЖжЙАжЬЙеЕЈжЬЙеИ†йЩ§ж†ЗиЃ∞зЪД糥еЉХжЭ°зЫЃдїОиѓ•еПґе≠РиКВзВєйЗМзЙ©зРЖзЪДеИ†йЩ§гАВ
3пЉЙ¬†ељУдЄАдЄ™жЦ∞зЪД糥еЉХжЭ°зЫЃињЫеŕ糥еЉХжЧґпЉМoracleдЉЪе∞ЖељУеЙНжЙАжЬЙ襀жЄЕз©ЇзЪДеПґе≠РиКВзВєпЉИиѓ•еПґе≠РиКВзВєдЄ≠жЙАжЬЙзЪД糥еЉХжЭ°зЫЃйÚ襀职皁䪯еИ†йЩ§ж†ЗиЃ∞пЉЙжФґеЫЮпЉМдїОиАМеЖНжђ°жИРдЄЇеПѓзԮ糥еЉХеЭЧгАВ
е∞љзЃ°иҐЂеИ†йЩ§зЪД糥еЉХжЭ°зЫЃжЙАеН†зФ®зЪДз©ЇйЧіе§ІйГ®еИЖжГЕеЖµдЄЛйГљиГље§Я襀йЗНзФ®пЉМдљЖдїНзДґе≠ШеЬ®дЄАдЇЫжГЕеЖµеПѓиГљеѓЉиdz糥еЉХз©ЇйЧі
襀浙賺пЉМеєґйА†жИР糥еЉХжХ∞жНЃеЭЧеЊИе§ЪдљЖж؃糥еЉХжЭ°зЫЃеЊИе∞СзЪДеРОжЮЬпЉМињЩж״胕糥еЉХеПѓдї•иЃ§дЄЇеЗЇзО∞зҐОзЙЗгАВиАМеѓЉиdz糥еЉХеЗЇзО∞зҐОзЙЗзЪДжГЕеЖµдЄїи¶БеМЕжЛђпЉЪ
1пЉЙ¬†дЄНеРИзРЖзЪДгАБиЊГйЂШзЪДPCTFREEгАВеЊИжШОжШЊпЉМињЩе∞ЖеѓЉиdz糥еЉХеЭЧзЪДеПѓзФ®з©ЇйЧіеЗПе∞СгАВ
2пЉЙ¬†зіҐеЉХйФЃеАЉжМБзї≠еҐЮеК†пЉИжѓФе¶ВйЗЗзФ®sequenceзФЯжИРеЇПеИЧеПЈзЪДйФЃеАЉпЉЙпЉМеРМж״僺糥еЉХйФЃеАЉжМЙзЕІй°ЇеЇПињЮзї≠еИ†йЩ§пЉМињЩжЧґеПѓиГљеѓЉиdz糥еЉХзҐОзЙЗзЪДеПСзФЯгАВеЫ†дЄЇеЙНйЭҐжИС дїђзЯ•йБУпЉМжЯР䪙糥еЉХеЭЧдЄ≠еИ†йЩ§дЇЖйГ®еИЖзЪД糥еЉХжЭ°зЫЃпЉМеП™жЬЙељУжЬЙйФЃеАЉињЫеŕ胕糥еЉХеЭЧжЧґжЙНиГље∞Жз©ЇйЧіжФґеЫЮгАВиАМжМБзї≠еҐЮеК†зЪД糥еЉХйФЃеАЉж∞ЄињЬеП™дЉЪеРСжПТеЕ•жОТеЬ®еЙНйЭҐзЪД糥еЉХеЭЧдЄ≠пЉМеЫ†ж≠§ињЩ зІН糥еЉХйЗМзЪДз©ЇйЧіеЗ†дєОдЄНиГљжФґеЫЮпЉМиАМеП™жЬЙеЕґжЙАеРЂзЪД糥еЉХжЭ°зЫЃеЕ®йГ®еИ†йЩ§жЧґпЉМ胕糥еЉХеЭЧжЙНиÚ襀йЗНжЦ∞еИ©зФ®гАВ
3пЉЙ¬†зїП媪襀еИ†йЩ§жИЦжЫіжЦ∞зЪДйФЃеАЉпЉМдї•еРОеЗ†дєОдЄНеЖНдЉЪ襀жПТеЕ•жЧґпЉМињЩзІНжГЕеЖµдЄОдЄКйЭҐзЪДжГЕеЖµз±їдЉЉгАВ
еѓєдЇОе¶ВдљХеИ§жЦ≠糥еЉХжШѓеР¶еЗЇзО∞зҐОзЙЗпЉМжЦєж≥ХйЭЮеЄЄзЃАеНХпЉЪзЫіжО•ињРи°МANALYZE INDEX вА¶ VALIDATE STRUCTURE
еСљдї§пЉМзДґеРОж£АжЯ•index_statsиІЖеЫЊзЪДpct_usedе≠ЧжЃµпЉМе¶ВжЮЬиѓ•е≠ЧжЃµињЗдљОпЉИдљОдЇО50пЉЕпЉЙпЉМеИЩиѓіжШОе≠ШеЬ®зҐОзЙЗгАВ
4.3 Bж†С糥еЉХзЪДеѓєдЇОжЫіжЦ∞пЉИUPDATEпЉЙзЪДзЃ°зРЖ
иАМеѓєдЇОеАЉиҐЂжЫіжЦ∞еѓєдЇО糥еЉХжЭ°зЫЃзЪДељ±еУНпЉМеИЩеПѓдї•иЃ§дЄЇжШѓеИ†йЩ§еТМжПТеЕ•зЪДзїДеРИгАВдєЯе∞±жШѓе∞Ж襀жЫіжЦ∞зЪДжЧІеАЉеѓєеЇФзЪД糥
еЉХжЭ°зЫЃиЃЊзљЃдЄЇDпЉИеИ†йЩ§пЉЙж†ЗиЃ∞пЉМеРМжЧґе∞ЖжЫіжЦ∞еРОзЪДеАЉжМЙзЕІй°ЇеЇПжПТеЕ•еРИйАВзЪД糥еЉХеЭЧдЄ≠гАВињЩйЗМе∞±дЄНйЗНе§НиЃ®иЃЇдЇЖгАВ
 
 
 
5.¬†¬†¬†¬†йЗНеїЇBж†С糥еЉХ
5.1е¶ВдљХйЗНеїЇBж†С糥еЉХ
йЗН忯糥еЉХжЬЙдЄ§зІНжЦєж≥ХпЉЪдЄАзІНжШѓжЬАзЃАеНХзЪДпЉМеИ†йЩ§еОЯ糥еЉХпЉМзДґеРОйЗНеїЇпЉЫзђђдЇМзІНжШѓдљњзФ®ALTER INDEX вА¶ REBUILD
ењ俧僺糥еЉХињЫи°МйЗНеїЇгАВзђђдЇМзІНжЦєеЉПжШѓдїОoracle¬†7.3.3зЙИжЬђеЉАеІЛеЉХеЕ•зЪДпЉМдїОиАМдљњеЊЧзФ®жИЈеЬ®йЗН忯糥еЉХжЧґдЄНењЕеИ†йЩ§еОЯ糥еЉХеЖНйЗНжЦ∞CREATE INDEXдЇЖгАВALTER INDEX вА¶ REBUILDзЫЄеѓєCREATE INDEXжЬЙдї•дЄЛе•ље§ДпЉЪ
1пЉЙ¬†еЃГдљњзФ®еОЯ糥еЉХзЪДеПґе≠РиКВзВєдљЬдЄЇжЦ∞糥еЉХзЪДжХ∞жНЃжЭ•жЇРгАВжИСдїђзЯ•йБУпЉМеОЯ糥еЉХзЪДеПґе≠РиКВзВєзЪДжХ∞жНЃеЭЧйАЪеЄЄйГљи¶БжѓФи°®йЗМзЪДжХ∞жНЃеЭЧи¶Бе∞СеЊИе§ЪпЉМеЫ†ж≠§ињЫи°МзЪДI/Oе∞±дЉЪеЗПе∞СпЉЫеРМжЧґпЉМзФ±дЇОеОЯ糥еЉХзЪДеПґе≠РиКВзВєйЗМзЪД糥еЉХжЭ°зЫЃеЈ≤зїПжОТеЇПдЇЖпЉМеЫ†ж≠§еЬ®йЗН忯糥еЉХзЪДињЗз®ЛдЄ≠пЉМжЙАеБЪзЪДжОТеЇПеЈ•дљЬдєЯи¶Бе∞СзЪДе§ЪгАВ
2пЉЙ¬†иЗ™дїОoracle 8.1.6дї•жЭ•пЉМALTER INDEX вА¶ REBUILDеСљдї§еПѓдї•жЈїеК†ONLINEзЯ≠иѓ≠гАВињЩдљњеЊЧеЬ®йЗН忯糥еЉХзЪДињЗз®ЛдЄ≠пЉМзФ®жИЈеПѓдї•зїІзї≠еѓєеОЯжЭ•зЪД糥еЉХињЫи°МдњЃжФєпЉМдєЯе∞±жШѓиѓіеПѓдї•зїІзї≠еѓєи°®ињЫи°МDMLжУНдљЬгАВ
иАМеРМжЧґпЉМALTER INDEX вА¶ REBUILDдЄОCREATE INDEXдєЯжЬЙеЊИе§ЪзЫЄеРМдєЛе§ДпЉЪ
1пЉЙ¬†еЃГдїђйГљеПѓдї•йАЪињЗжЈїеК†PARALLELжПРз§ЇињЫи°Меєґи°Ме§ДзРЖгАВ
2пЉЙ¬†еЃГдїђйГљеПѓдї•йАЪињЗжЈїеК†NOLOGGINGзЯ≠иѓ≠пЉМдљњеЊЧйЗН忯糥еЉХзЪДињЗз®ЛдЄ≠дЇІзФЯжЬАе∞СзЪДйЗНеБЪжЭ°зЫЃпЉИredo entryпЉЙгАВ
3пЉЙ¬†иЗ™дїОoracle 8.1.5дї•жЭ•пЉМеЃГдїђйГљеПѓдї•зФ∞йЧіCOMPUTE STATISTICSзЯ≠иѓ≠пЉМдїОиАМеЬ®йЗН忯糥еЉХзЪДињЗз®ЛдЄ≠пЉМе∞±зФЯжИРCBOжЙАйЬАи¶БзЪДзїЯиЃ°дњ°жБѓпЉМињЩж†Је∞±йБњеЕНдЇЖ糥еЉХеИЫеїЇеЃМжѓХдї•еРОеЖНжђ°ињРи°МanalyzeжИЦdbms_statsжЭ•жФґйЫЖзїЯиЃ°дњ°жБѓгАВ
ељУжИСдїђйЗН忯糥еЉХдї•еРОпЉМеЬ®зЙ©зРЖдЄКжЙАиГљиОЈеЊЧзЪДе•ље§Де∞±жШѓиГље§ЯеЗПе∞С糥еЉХжЙАеН†зЪДз©ЇйЧіе§Іе∞ПпЉИзЙєеИЂжШѓиГље§ЯеЗПе∞СеПґе≠Р
иКВзВєзЪДжХ∞йЗПпЉЙгАВиАМ糥еЉХе§Іе∞ПеЗПе∞Пдї•еРОпЉМеПИиГљеЄ¶жЭ•дї•дЄЛиЛ•еє≤е•ље§ДпЉЪ
1пЉЙ¬†CBOеѓєдЇО糥еЉХзЪДдљњзФ®еПѓиГљдЉЪдЇІзФЯдЄАдЄ™иЊГе∞ПзЪДжИРжЬђеАЉпЉМдїОиАМеЬ®жЙІи°МиЃ°еИТдЄ≠йАЙжЛ©дљњзԮ糥еЉХгАВ
2пЉЙ¬†дљњзԮ糥еЉХжЙЂжППзЪДжߕ胥жЙЂжППзЪДзЙ©зРЖ糥еЉХеЭЧдЉЪеЗПе∞СпЉМдїОиАМжПРйЂШжХИзОЗгАВ
3пЉЙ¬†зФ±дЇОйЬАи¶БзЉУе≠ШзЪД糥еЉХеЭЧеЗПе∞СдЇЖпЉМдїОиАМиЃ©еЗЇдЇЖеЖЕе≠Шдї•дЊЫеЕґдїЦзїДдїґдљњзФ®гАВ
е∞љзЃ°йЗН忯糥еЉХеЕЈжЬЙдЄАеЃЪзЪДе•ље§ДпЉМдљЖжШѓзЫ≤зЫЃзЪДиЃ§дЄЇйЗН忯糥еЉХиГље§ЯиІ£еЖ≥еЊИе§ЪйЧЃйҐШдєЯжШѓдЄНж≠£з°ЃзЪДгАВжѓФе¶ВжИСиІБињЗдЄА
дЄ™зФЯдЇІз≥їзїЯпЉМжѓПйЪФдЄАдЄ™жЬИе∞±и¶БйЗНеїЇжЙАжЬЙзЪД糥еЉХпЉИиАМдЄФжИСзЫЄдњ°пЉМеЊИе§ЪзФЯдЇІз≥їзїЯеПѓиГљйГљдЉЪињЩдєИеБЪпЉЙпЉМеЕґдЄ≠еМЕжЛђдЄАдЇЫ100GBзЪДе§Іи°®гАВдЄЇдЇЖеЃМжИРйЗНеїЇжЙАжЬЙзЪД糥еЉХпЉМ еЊАеЊАйЬАи¶БжККињЩдЇЫеЈ•дљЬеИЖжХ£еИ∞е§ЪдЄ™жЩЪдЄКињЫи°МгАВдЇЛеЃЮдЄКпЉМињЩжШѓдЄАдЄ™7√Ч24зЪДз≥їзїЯпЉМдїЕйЗН忯糥еЉХдЄАй°єдїїеК°е∞±жґИиАЧдЇЖйЭЮеЄЄе§ЪзЪДз≥їзїЯиµДжЇРгАВдљЖжШѓжѓПйЪФдЄАжЃµжЧґйЧіе∞±йЗН忯糥еЉХжЬЙжДП дєЙеРЧпЉЯињЩйЗМе∞±жЬЙдЄАдЇЫеЕ≥дЇОйЗН忯糥еЉХзЪДеЊИжµБи°МзЪДиѓіж≥ХпЉМдЄїи¶БеМЕжЛђпЉЪ
1пЉЙ¬†е¶ВжЮЬ糥еЉХзЪДе±ВзЇІиґЕињЗXпЉИXйАЪеЄЄжШѓ3пЉЙзЇІдї•еРОйЬАи¶БйАЪињЗйЗН忯糥еЉХжЭ•йЩНдљОеЕґзЇІеИЂгАВ
2пЉЙ¬†е¶ВжЮЬзїПеЄЄеИ†й٧糥еЉХйФЃеАЉпЉМеИЩйЬАи¶БеЃЪжЧґйЗН忯糥еЉХжЭ•жФґеЫЮињЩдЇЫ襀еИ†йЩ§зЪДз©ЇйЧігАВ
3пЉЙ¬†е¶ВжЮЬ糥еЉХзЪДclustering_factorеЊИйЂШпЉМеИЩйЬАи¶БйЗН忯糥еЉХжЭ•йЩНдљОиѓ•еАЉгАВ
4пЉЙ¬†еЃЪжЬЯйЗН忯糥еЉХиГље§ЯжПРйЂШжАІиГљгАВ
еѓєдЇОзђђдЄАзВєжЭ•иѓіпЉМжИСдїђеЬ®еЙНйЭҐеЈ≤зїПзЯ•йБУпЉМBж†С糥еЉХжШѓдЄАж£µеЬ®йЂШеЇ¶дЄКеє≥и°°зЪДж†СпЉМжЙАдї•йЗН忯糥еЉХеЯЇжЬђдЄНеПѓиГљйЩН
дљОеЕґзЇІеИЂпЉМйЩ§йЭЮжШѓжЮБзЙєжЃКзЪДжГЕеЖµеѓЉиdz胕糥еЉХжЬЙйЭЮеЄЄе§ІйЗПзЪДзҐОзЙЗпЉМеѓЉиЗіBж†С糥еЉХвАЬиЩЪйЂШвАЭпЉМйВ£дєИињЩеЃЮйЩЕеПИжЭ•еИ∞зђђдЇМзВєдЄКпЉИеЫ†дЄЇзҐОзЙЗйАЪеЄЄйГљжШѓзФ±дЇОеИ†йЩ§еЉХиµЈзЪДпЉЙгАВ еЃЮйЩЕдЄКпЉМеѓєдЇОзђђдЄАеТМзђђдЇМзВєпЉМжИСдїђеЇФиѓ•йАЪињЗињРи°МALTER INDEX вА¶ REBUILDеСљдї§дї•еРОж£АжЯ•indest_stats.pct_usedе≠ЧжЃµжЭ•еИ§жЦ≠жШѓеР¶жЬЙењЕи¶БйЗН忯糥еЉХгАВ
5.2йЗНеїЇBж†С糥еЉХеѓєдЇОclustering_factorзЪДељ±еУН
иАМеѓєдЇОclustering_factorжЭ•иѓіпЉМеЃГжШѓзФ®жЭ•жѓФиЊГ糥еЉХзЪДй°ЇеЇПз®ЛеЇ¶дЄОи°®зЪДжЭВдє±жОТеЇПз®ЛеЇ¶зЪДдЄАдЄ™еЇ¶йЗПгАВOracleеЬ®иЃ°зЃЧжЯРдЄ™ clustering_factorжЧґпЉМдЉЪеѓєжѓП䪙糥еЉХйФЃеАЉжЯ•жЙЊеѓєеЇФеИ∞и°®зЪДжХ∞жНЃпЉМеЬ®жЯ•жЙЊзЪДињЗз®ЛдЄ≠пЉМдЉЪиЈЯиЄ™дїОдЄАдЄ™и°®зЪДжХ∞жНЃеЭЧиЈ≥иљђеИ∞еП¶е§ЦдЄАдЄ™жХ∞жНЃеЭЧзЪДжђ°жХ∞пЉИељУ зДґпЉМеЃГдЄНеПѓиГљзЬЯзЪДињЩдєИеБЪпЉМжЇРдї£з†БйЗМеП™жШѓзЃАеНХзЪДжЙЂжПП糥еЉХпЉМдїОиАМиОЈеЊЧROWIDпЉМзДґеРОдїОињЩдЇЫROWIDиОЈеЊЧи°®зЪДжХ∞жНЃеЭЧзЪДеЬ∞еЭАпЉЙгАВжѓПдЄАжђ°иЈ≥иљђжЧґпЉМжЬЙдЄ™иЃ°жХ∞еЩ®е∞±дЉЪ еҐЮеК†пЉМжЬАзїИиѓ•иЃ°жХ∞еЩ®зЪДеАЉе∞±жШѓclustering_factorгАВдЄЛеЫЊеЫЫжППињ∞дЇЖињЩдЄ™еОЯзРЖгАВ
 
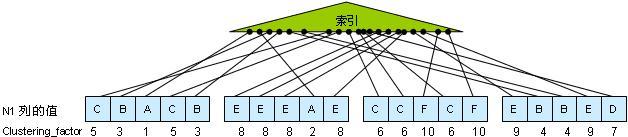
¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬†¬† еЫЊеЫЫ
 
¬†¬†¬†¬†еЬ®дЄКеЫЊеЫЫдЄ≠пЉМжИСдїђжЬЙдЄАдЄ™и°®пЉМиѓ•и°®жЬЙ4дЄ™жХ∞жНЃеЭЧпЉМдї•еПК20жЭ°иЃ∞ељХгАВеЬ®еИЧN1дЄКжЬЙдЄА䪙糥еЉХпЉМдЄКеЫЊдЄ≠зЪДжѓПдЄ™е∞ПйїСзВєе∞±и°®з§ЇдЄА䪙糥еЉХжЭ°зЫЃгАВеИЧN1зЪДеАЉ е¶ВеЫЊжЙАз§ЇгАВиАМN1зЪД糥еЉХзЪДеПґе≠РиКВзВєеМЕеРЂзЪДеАЉдЄЇпЉЪAгАБBгАБCгАБDгАБEгАБFгАВе¶ВжЮЬoracleеЉАеІЛжЙЂжПП糥еЉХзЪДеЇХйГ®пЉМеПґе≠РиКВзВєеМЕеРЂзЪДзђђдЄАдЄ™N1еАЉдЄЇAпЉМйВ£дєИж†єжНЃ иѓ•еАЉеПѓдї•зЯ•йБУеѓєеЇФзЪДROWIDдљНдЇОзђђдЄАдЄ™жХ∞жНЃеЭЧзЪДзђђдЄЙи°МйЗМпЉМжЙАдї•жИСдїђзЪДиЃ°жХ∞еЩ®еҐЮеК†1гАВеРМжЧґпЉМAеАЉињШеѓєеЇФзђђдЇМдЄ™жХ∞жНЃеЭЧзЪДзђђеЫЫи°МпЉМзФ±дЇОиЈ≥иљђеИ∞дЇЖдЄНеРМзЪДжХ∞жНЃеЭЧ дЄКпЉМжЙАдї•иЃ°жХ∞еЩ®еЖНеК†1гАВеРМж†ЈзЪДпЉМеЬ®е§ДзРЖBжЧґпЉМеПѓдї•зЯ•йБУеѓєеЇФзђђдЄАдЄ™жХ∞жНЃеЭЧзЪДзђђдЇМи°МпЉМзФ±дЇОжИСдїђдїОзђђдЇМдЄ™жХ∞жНЃеЭЧиЈ≥иљђеИ∞дЇЖзђђдЄАдЄ™жХ∞жНЃеЭЧпЉМжЙАдї•иЃ°жХ∞еЩ®еЖНеК†1гАВеРМ жЧґпЉМBеАЉињШеѓєеЇФдЇЖзђђдЄАдЄ™жХ∞жНЃеЭЧзЪДзђђдЇФи°МпЉМзФ±дЇОжИСдїђињЩйЗМж≤°жЬЙеПСзФЯиЈ≥иљђпЉМжЙАдї•иЃ°жХ∞еЩ®дЄНзФ®еК†1гАВ
еЬ®дЄКйЭҐзЪДеЫЊйЗМпЉМеЬ®и°®зЪДжѓПдЄАи°МзЪДдЄЛйЭҐйГљжФЊдЇЖдЄАдЄ™жХ∞е≠ЧпЉМеЃГзФ®жЭ•жШЊз§ЇиЃ°жХ∞еЩ®иЈ≥иљђеИ∞иѓ•и°МжЧґеѓєеЇФзЪДеАЉгАВељУжИСдїђе§ДзРЖеЃМ糥еЉХзЪДжЬАеРОдЄАдЄ™еАЉжЧґпЉМжИСдїђеЬ®жХ∞жНЃеЭЧдЄКдЄАеЕ±иЈ≥иљђдЇЖеНБжђ°пЉМжЙА俕胕糥еЉХзЪДclustering_factorдЄЇ10гАВ
ж≥®жДПзђђдЇМдЄ™жХ∞жНЃеЭЧпЉМclustering_factorдЄЇ8еЗЇзО∞дЇЖ4жђ°гАВеЫ†дЄЇеܮ糥еЉХйЗМN1дЄЇEжЙАеѓєеЇФзЪД4䪙糥еЉХжЭ°зЫЃйГљжМЗеРСдЇЖеРМдЄАдЄ™жХ∞жНЃеЭЧгАВдїОиАМдљњеЊЧ clustering_factorдЄНеЖНеҐЮйХњгАВеРМж†ЈзЪДзО∞и±°еЗЇзО∞еЬ®зђђдЄЙдЄ™жХ∞жНЃеЭЧдЄ≠пЉМеЃГеМЕеРЂдЄЙжЭ°иЃ∞ељХпЉМеЃГдїђзЪДеАЉйГљжШѓCпЉМеѓєеЇФзЪД clustering_factorйГљжШѓ6гАВ
дїОclustering_factorзЪДиЃ°зЃЧжЦєж≥ХдЄКеПѓдї•зЬЛеЗЇпЉМжИСдїђеПѓдї•зЯ•йБУеЃГзЪДжЬАе∞ПеАЉе∞±з≠ЙдЇОи°®жЙАеРЂжЬЙзЪДжХ∞жНЃеЭЧзЪДжХ∞йЗПпЉЫиАМжЬАе§ІеАЉе∞±жШѓи°®жЙАеРЂжЬЙзЪДиЃ∞ељХзЪД жАїи°МжХ∞гАВеЊИжШОжШЊпЉМclustering_factorиґКе∞ПиґКе•љпЉМиґКе∞ПиѓіжШОйАЪињЗ糥еЉХжЯ•жЙЊи°®йЗМзЪДжХ∞жНЃи°МжЧґйЬАи¶БиЃњйЧЃзЪДи°®зЪДжХ∞жНЃеЭЧиґКе∞СгАВ
жИСдїђжЭ•зЬЛдЄАдЄ™дЊЛе≠РпЉМжЭ•иѓіжШОйЗН忯糥еЉХеѓєдЇОеЗПе∞Пclustering_factorж≤°жЬЙзФ®е§ДгАВй¶ЦеЕИжИСдїђеИЫеїЇдЄАдЄ™жµЛиѓХи°®пЉЪ
SQL> create table clustfact_test(id number,name varchar2(10));
SQL> create index idx_clustfact_test on clustfact_test(id);
зДґеРОпЉМжИСдїђжПТеЕ•еНБдЄЗжЭ°иЃ∞ељХгАВ
SQL> begin
 2           for i in 1..100000 loop
 3                   insert into clustfact_test values(mod(i,200),to_char(i));
 4           end loop;
 5           commit;
 6 end;
 7 /
еЫ†дЄЇдљњзФ®дЇЖmodзЪДеЕ≥з≥їпЉМжЬАзїИжХ∞жНЃеЬ®и°®йЗМжОТеИЧзЪД嚥еЉПдЄЇпЉЪ
0,1,2,3,4,5,вА¶,197,198,199,0,1,2,3,вА¶, 197,198,199,0,1,2,3,вА¶, 197,198,199,0,1,2,3,вА¶
¬†¬†¬†¬†¬†¬†жО•дЄЛжЭ•пЉМжИСдїђеИЖжЮРи°®гАВ
SQL> exec dbms_stats.gather_table_stats(user,'clustfact_test',cascade=>true);
¬†¬†¬†¬†¬†¬†ињЩдЄ™жЧґеАЩпЉМжИСдїђжЭ•зЬЛзЬЛ胕糥еЉХзЪДclustering_factorгАВ
SQL> select num_rows, blocks from user_tables where table_name = 'CLUSTFACT_TEST';
 NUM_ROWS    BLOCKS
---------- ----------
   100000       202
SQL> select num_rows, distinct_keys, avg_leaf_blocks_per_key, avg_data_blocks_per_key,
 2 clustering_factor from user_indexes where index_name = 'IDX_CLUSTFACT_TEST';
 NUM_ROWS DISTINCT_KEYS AVG_LEAF_BLOCKS_PER_KEY AVG_DATA_BLOCKS_PER_KEY CLUSTERING_FACTOR
---------- ------------- ----------------------- ----------------------- -----------------
   100000          200                      1                    198            39613
¬†¬†¬†¬†¬†¬†дїОдЄКйЭҐзЪДavg_data_blocks_per_keyзЪДеАЉдЄЇ198еПѓдї•зЯ•йБУпЉМжѓПдЄ™йФЃеАЉеє≥еЭЗеИЖеЄГеЬ®198дЄ™жХ∞жНЃеЭЧйЗМпЉМиАМжХідЄ™и°®дєЯе∞± 202дЄ™жХ∞жНЃеЭЧгАВињЩдєЯе∞±жШѓиѓіпЉМи¶БиОЈеПЦжЯРдЄ™йФЃеАЉзЪДжЙАжЬЙиЃ∞ељХпЉМеЗ†дєОжѓПжђ°йГљйЬАи¶БиЃњйЧЃжЙАжЬЙзЪДжХ∞жНЃеЭЧгАВдїОињЩйЗМеЈ≤зїПеПѓдї•зМЬжµЛеИ∞clustering_factorдЉЪйЭЮ еЄЄе§ІгАВдЇЛеЃЮдЄКпЉМиѓ•еАЉињС4дЄЗпЉМдєЯиѓіжШО胕糥еЉХеєґдЄНдЉЪеЊИжЬЙжХИгАВ
¬†¬†¬†¬†¬†¬†жИСдїђжЭ•зЬЛзЬЛдЄЛйЭҐињЩеП•SQLиѓ≠еП•зЪДжЙІи°МиЃ°еИТгАВ
SQL> select count(name) from clufac_test where id = 100;
Execution Plan
----------------------------------------------------------
  0     SELECT STATEMENT ptimizer=CHOOSE (Cost=32 Card=1 Bytes=9)
  1   0  SORT (AGGREGATE)
  2   1    TABLE ACCESS (FULL) OF 'CLUFAC_TEST' (Cost=32 Card=500 Bytes=4500)
Statistics
----------------------------------------------------------
         0 recursive calls
         0 db block gets
       205 consistent gets
вА¶вА¶
¬†¬†¬†¬†¬†¬†еЊИжШОжШЊпЉМCBOеЉГзФ®дЇЖ糥еЉХпЉМиАМдљњзФ®дЇЖеЕ®и°®жЙЂжППгАВињЩеЃЮйЩЕдЄКеЈ≤зїПиѓіжШОзФ±дЇО糥еЉХзЪДclustering_factorињЗйЂШпЉМеѓЉиЗійАЪињЗ糥еЉХиОЈеПЦжХ∞жНЃжЧґиЈ≥иљђзЪДжХ∞жНЃеЭЧињЗе§ЪпЉМжИРжЬђињЗйЂШпЉМеЫ†ж≠§зЫіжО•дљњзФ®еЕ®и°®жЙЂжППзЪДжИРжЬђдЉЪжЫідљОгАВ
¬†¬†¬†¬†¬†¬†ињЩжЧґжИСдїђжЭ•йЗН忯糥еЉХзЬЛзЬЛдЉЪеѓєclustering_factorдЇІзФЯдїАдєИељ±еУНгАВдїОдЄЛйЭҐзЪДжµЛиѓХдЄ≠еПѓдї•зЬЛеИ∞пЉМж≤°жЬЙдїїдљХељ±еУНгАВ
SQL> alter index idx_clustfact_test rebuild;
SQL> select num_rows, distinct_keys, avg_leaf_blocks_per_key, avg_data_blocks_per_key,
 2 clustering_factor from user_indexes where index_name = 'IDX_CLUSTFACT_TEST';
 NUM_ROWS DISTINCT_KEYS AVG_LEAF_BLOCKS_PER_KEY AVG_DATA_BLOCKS_PER_KEY CLUSTERING_FACTOR
---------- ------------- ----------------------- ----------------------- -----------------
   100000          200                      1                    198            39613
¬†¬†¬†¬†¬†¬†йВ£дєИељУжИСдїђе∞Жи°®йЗМзЪДжХ∞жНЃжМЙзЕІidзЪДй°ЇеЇПпЉИдєЯе∞±ж؃糥еЉХзЪДжОТеИЧй°ЇеЇПпЉЙйЗНеїЇжЧґпЉМиѓ•SQLиѓ≠еП•дЉЪе¶ВдљХжЙІи°МпЉЯ
SQL> create table clustfact_test_temp as select * from clustfact_test order by id;
SQL> truncate table clustfact_test;
SQL> insert into clustfact_test select * from clustfact_test_temp;
SQL> exec dbms_stats.gather_table_stats(user,'clustfact_test',cascade=>true);
SQL> select num_rows, distinct_keys, avg_leaf_blocks_per_key, avg_data_blocks_per_key,
 2 clustering_factor from user_indexes where index_name = 'IDX_CLUSTFACT_TEST';
 NUM_ROWS DISTINCT_KEYS AVG_LEAF_BLOCKS_PER_KEY AVG_DATA_BLOCKS_PER_KEY CLUSTERING_FACTOR
---------- ------------- ----------------------- ----------------------- -----------------
   100000          200                      1                      1              198
¬†¬†¬†¬†¬†¬†еЊИжШОжШЊзЪДпЉМињЩжЧґзЪД糥еЉХйЗМжѓПдЄ™йФЃеАЉеП™еИЖеЄГеЬ®1дЄ™жХ∞жНЃеЭЧйЗМпЉМеРМжЧґclustering_factorдєЯеЈ≤зїПйЩНдљОеИ∞дЇЖ198гАВињЩжЧґеЖНжђ°жЙІи°МзЫЄеРМзЪДжߕ胥иѓ≠еП•жЧґпЉМCBOе∞ЖдЉЪйАЙж˩糥еЉХпЉМеРМжЧґеПѓдї•зЬЛеИ∞consistent getsдєЯдїО205йЩНеИ∞дЇЖ5гАВ
SQL> select count(name) from clustfact_test where id = 100;
Execution Plan
----------------------------------------------------------
  0     SELECT STATEMENT ptimizer=CHOOSE (Cost=2 Card=1 Bytes=9)
  1   0  SORT (AGGREGATE)
  2   1    TABLE ACCESS (BY INDEX ROWID) OF 'CLUSTFACT_TEST' (Cost=2 Card=500 Bytes=4500)
  3   2      INDEX (RANGE SCAN) OF 'IDX_CLUSTFACT_TEST' (NON-UNIQUE) (Cost=1 Card=500)
Statistics
----------------------------------------------------------
         0 recursive calls
         0 db block gets
         5 consistent gets
вА¶вА¶
¬†¬†¬†¬†¬†¬†жЙАдї•жИСдїђеПѓдї•еЊЧеЗЇзїУиЃЇпЉМе¶ВжЮЬдїЕдїЕжШѓдЄЇдЇЖйЩНдљО糥еЉХзЪДclustering_factorиАМйЗН忯糥еЉХж≤°жЬЙдїїдљХжДПдєЙгАВйЩНдљО clustering_factorзЪДеЕ≥йФЃеЬ®дЇОйЗНеїЇи°®йЗМзЪДжХ∞жНЃгАВеП™жЬЙе∞Жи°®йЗМзЪДжХ∞жНЃжМЙзŲ糥еЉХеИЧжОТеЇПдї•еРОпЉМжЙНиГљеИЗеЃЮжЬЙжХИзЪДйЩНдљО clustering_factorгАВдљЖжШѓе¶ВжЮЬжЯРдЄ™и°®е≠ШеЬ®е§Ъ䪙糥еЉХзЪДжЧґеАЩпЉМйЬАи¶БдїФзїЖеЖ≥еЃЪеЇФиѓ•йАЙжЛ©еУ™дЄА䪙糥еЉХеИЧжЭ•йЗНеїЇи°®гАВ
 
 
 
 
 
5.3йЗНеїЇBж†С糥еЉХеѓєдЇОжߕ胥жАІиГљзЪДељ±еУН
¬†¬†¬†¬†¬†¬†жЬАеРОжИСдїђжЭ•зЬЛдЄАдЄЛйЗН忯糥еЉХеѓєдЇОжАІиГљзЪДжПРйЂШеИ∞еЇХдЉЪжЬЙдїАдєИдљЬзФ®гАВеБЗиЃЊжИСдїђжЬЙдЄАдЄ™и°®пЉМиѓ•и°®еЕЈжЬЙ1зЩЊдЄЗжЭ°иЃ∞ељХпЉМеН†зФ®дЇЖ100000дЄ™жХ∞жНЃеЭЧгАВиАМ еЬ®иѓ•и°®дЄКе≠ШеЬ®дЄА䪙糥еЉХпЉМеЬ®йЗНеїЇдєЛеЙНзЪДpct_usedдЄЇ50%пЉМйЂШеЇ¶дЄЇ3пЉМеИЖжФѓиКВзВєеЭЧжХ∞дЄЇ40дЄ™пЉМеЖНеК†дЄАдЄ™ж†єиКВзВєеЭЧпЉМеПґе≠РиКВзВєжХ∞дЄЇ10000дЄ™пЉЫйЗН忯胕糥 еЉХдї•еРОпЉМpct_usedдЄЇ90%пЉМйЂШеЇ¶дЄЇ3пЉМеИЖжФѓиКВзВєеЭЧжХ∞дЄЛйЩНеИ∞20дЄ™пЉМеЖНеК†дЄАдЄ™ж†єиКВзВєеЭЧпЉМиАМеПґе≠РиКВзВєжХ∞дЄЛйЩНеИ∞5000дЄ™гАВйВ£дєИдїОзРЖиЃЇдЄКиѓіпЉЪ
1пЉЙ¬†е¶ВжЮЬйАЪињЗ糥еЉХиОЈеПЦеНХзЛђ1жЭ°иЃ∞ељХжЭ•иѓіпЉЪ
йЗНеїЇдєЛеЙНзЪДжИРжЬђпЉЪ1дЄ™ж†єпЉЛ1дЄ™еИЖжФѓпЉЛ1дЄ™еПґе≠РпЉЛ1дЄ™и°®еЭЧпЉЭ4дЄ™йАїиЊСиѓї
йЗНеїЇдєЛеРОзЪДжИРжЬђпЉЪ1дЄ™ж†єпЉЛ1дЄ™еИЖжФѓпЉЛ1дЄ™еПґе≠РпЉЛ1дЄ™и°®еЭЧпЉЭ4дЄ™йАїиЊСиѓї
жАІиГљжПРйЂШзЩЊеИЖжѓФпЉЪ0
2пЉЙ¬†е¶ВжЮЬйАЪињЗ糥еЉХиОЈеПЦ100жЭ°иЃ∞ељХпЉИеН†жАїиЃ∞ељХжХ∞зЪД0.01%пЉЙжЭ•иѓіпЉМеИЖдЄ§зІНжГЕеЖµпЉЪ
жЬАеЈЃзЪДclustering_factorпЉИеН≥иѓ•еАЉз≠ЙдЇОи°®зЪДжХ∞жНЃи°МжХ∞пЉЙпЉЪ
йЗНеїЇдєЛеЙНзЪДжИРжЬђпЉЪ1дЄ™ж†єпЉЛ1дЄ™еИЖжФѓпЉЛ0.0001*10000пЉИ1дЄ™еПґе≠РпЉЙпЉЛ100дЄ™и°®еЭЧпЉЭ103дЄ™йАїиЊСиѓї
йЗНеїЇдєЛеРОзЪДжИРжЬђпЉЪ1дЄ™ж†єпЉЛ1дЄ™еИЖжФѓпЉЛ0.0001*5000пЉИ1дЄ™еПґе≠РпЉЙпЉЛ100дЄ™и°®еЭЧпЉЭ102.5дЄ™йАїиЊСиѓї
жАІиГљжПРйЂШзЩЊеИЖжѓФпЉЪ0.5%пЉИдєЯе∞±жШѓеЗПе∞СдЇЖ0.5дЄ™йАїиЊСиѓїпЉЙ
жЬАе•љclustering_factorпЉИеН≥иѓ•еАЉз≠ЙдЇОи°®зЪДжХ∞жНЃеЭЧпЉЙпЉЪ
йЗНеїЇдєЛеЙНзЪДжИРжЬђпЉЪ1дЄ™ж†єпЉЛ1дЄ™еИЖжФѓпЉЛ0.0001*10000пЉИ1дЄ™еПґе≠РпЉЙпЉЛ0.0001*100000пЉИ10дЄ™и°®еЭЧпЉЙпЉЭ13дЄ™йАїиЊСиѓї
йЗНеїЇдєЛеРОзЪДжИРжЬђпЉЪ1дЄ™ж†єпЉЛ1дЄ™еИЖжФѓпЉЛ0.0001*5000пЉИ1дЄ™еПґе≠РпЉЙпЉЛ0.0001*100000пЉИ10дЄ™и°®еЭЧпЉЙпЉЭ12.5дЄ™йАїиЊСиѓї
жАІиГљжПРйЂШзЩЊеИЖжѓФпЉЪ3.8%пЉИдєЯе∞±жШѓеЗПе∞СдЇЖ0.5дЄ™йАїиЊСиѓїпЉЙ
3пЉЙ¬†е¶ВжЮЬйАЪињЗ糥еЉХиОЈеПЦ10000жЭ°иЃ∞ељХпЉИеН†жАїиЃ∞ељХжХ∞зЪД1%пЉЙжЭ•иѓіпЉМеИЖдЄ§зІНжГЕеЖµпЉЪ
жЬАеЈЃзЪДclustering_factorпЉИеН≥иѓ•еАЉз≠ЙдЇОи°®зЪДжХ∞жНЃи°МжХ∞пЉЙпЉЪ
йЗНеїЇдєЛеЙНзЪДжИРжЬђпЉЪ1дЄ™ж†єпЉЛ1дЄ™еИЖжФѓпЉЛ0.01*10000пЉИ100дЄ™еПґе≠РпЉЙпЉЛ10000дЄ™и°®еЭЧпЉЭ10102дЄ™йАїиЊСиѓї
йЗНеїЇдєЛеРОзЪДжИРжЬђпЉЪ1дЄ™ж†єпЉЛ1дЄ™еИЖжФѓпЉЛ0.01*5000пЉИ50дЄ™еПґе≠РпЉЙпЉЛ10000дЄ™и°®еЭЧпЉЭ10052дЄ™йАїиЊСиѓї
жАІиГљжПРйЂШзЩЊеИЖжѓФпЉЪ0.5%пЉИдєЯе∞±жШѓеЗПе∞СдЇЖ50дЄ™йАїиЊСиѓїпЉЙ
жЬАе•љclustering_factorпЉИеН≥иѓ•еАЉз≠ЙдЇОи°®зЪДжХ∞жНЃеЭЧпЉЙпЉЪ
йЗНеїЇдєЛеЙНзЪДжИРжЬђпЉЪ1дЄ™ж†єпЉЛ1дЄ™еИЖжФѓпЉЛ0.01*10000пЉИ100дЄ™еПґе≠РпЉЙпЉЛ0.01*100000пЉИ1000дЄ™и°®еЭЧпЉЙпЉЭ1102дЄ™йАїиЊСиѓї
йЗНеїЇдєЛеРОзЪДжИРжЬђпЉЪ1дЄ™ж†єпЉЛ1дЄ™еИЖжФѓпЉЛ0.01*5000пЉИ50дЄ™еПґе≠РпЉЙпЉЛ0.01*100000пЉИ1000дЄ™и°®еЭЧпЉЙпЉЭ1052дЄ™йАїиЊСиѓї
жАІиГљжПРйЂШзЩЊеИЖжѓФпЉЪ4.5%пЉИдєЯе∞±жШѓеЗПе∞СдЇЖ50дЄ™йАїиЊСиѓїпЉЙ
4пЉЙ¬†е¶ВжЮЬйАЪињЗ糥еЉХиОЈеПЦ100000жЭ°иЃ∞ељХпЉИеН†жАїиЃ∞ељХжХ∞зЪД10%пЉЙжЭ•иѓіпЉМеИЖдЄ§зІНжГЕеЖµпЉЪ
жЬАеЈЃзЪДclustering_factorпЉИеН≥иѓ•еАЉз≠ЙдЇОи°®зЪДжХ∞жНЃи°МжХ∞пЉЙпЉЪ
йЗНеїЇдєЛеЙНзЪДжИРжЬђпЉЪ1дЄ™ж†єпЉЛ1дЄ™еИЖжФѓпЉЛ0.1*10000пЉИ1000дЄ™еПґе≠РпЉЙпЉЛ100000дЄ™и°®еЭЧпЉЭ101002дЄ™йАїиЊСиѓї
йЗНеїЇдєЛеРОзЪДжИРжЬђпЉЪ1дЄ™ж†єпЉЛ1дЄ™еИЖжФѓпЉЛ0.1*5000пЉИ500дЄ™еПґе≠РпЉЙпЉЛ100000дЄ™и°®еЭЧпЉЭ100502дЄ™йАїиЊСиѓї
жАІиГљжПРйЂШзЩЊеИЖжѓФпЉЪ0.5%пЉИдєЯе∞±жШѓеЗПе∞СдЇЖ500дЄ™йАїиЊСиѓїпЉЙ
жЬАе•љclustering_factorпЉИеН≥иѓ•еАЉз≠ЙдЇОи°®зЪДжХ∞жНЃеЭЧпЉЙпЉЪ
йЗНеїЇдєЛеЙНзЪДжИРжЬђпЉЪ1дЄ™ж†єпЉЛ1дЄ™еИЖжФѓпЉЛ0.1*10000пЉИ1000дЄ™еПґе≠РпЉЙпЉЛ0.1*100000пЉИ10000дЄ™и°®еЭЧпЉЙпЉЭ11002дЄ™йАїиЊСиѓї
йЗНеїЇдєЛеРОзЪДжИРжЬђпЉЪ1дЄ™ж†єпЉЛ1дЄ™еИЖжФѓпЉЛ0.1*5000пЉИ500дЄ™еПґе≠РпЉЙпЉЛ0.1*100000пЉИ10000дЄ™и°®еЭЧпЉЙпЉЭ10502дЄ™йАїиЊСиѓї
жАІиГљжПРйЂШзЩЊеИЖжѓФпЉЪ4.5%пЉИдєЯе∞±жШѓеЗПе∞СдЇЖ500дЄ™йАїиЊСиѓїпЉЙ
5пЉЙ¬†еѓєдЇОењЂйАЯеŮ糥еЉХжЙЂжППжЭ•иѓіпЉМеБЗиЃЊжѓПжђ°иОЈеПЦ8дЄ™жХ∞жНЃеЭЧпЉЪ
йЗНеїЇдєЛеЙНзЪДжИРжЬђпЉЪпЉИ1дЄ™ж†єпЉЛ40дЄ™еИЖжФѓпЉЛ10000дЄ™еПґе≠РпЉЙ/ 8пЉЭ1256дЄ™йАїиЊСиѓї
йЗНеїЇдєЛеРОзЪДжИРжЬђпЉЪпЉИ1дЄ™ж†єпЉЛ40дЄ™еИЖжФѓпЉЛ5000дЄ™еПґе≠РпЉЙ/ 8пЉЭ631дЄ™йАїиЊСиѓї
жАІиГљжПРйЂШзЩЊеИЖжѓФпЉЪ49.8%пЉИдєЯе∞±жШѓеЗПе∞СдЇЖ625дЄ™йАїиЊСиѓїпЉЙ
¬†¬†¬†¬†¬†¬†дїОдЄКйЭҐжЬЙеЕ≥жАІиГљжПРйЂШзЪДзРЖиЃЇжППињ∞еПѓдї•зЬЛеЗЇпЉМеѓєдЇОйАЪињЗ糥еЉХиОЈеПЦзЪДиЃ∞ељХи°МжХ∞дЄНе§ІзЪДжГЕеЖµдЄЛпЉМ糥еЉХзҐОзЙЗеѓєдЇОжАІиГљзЪДељ±еУНйЭЮеЄЄе∞ПпЉЫељУйАЪињЗ糥еЉХиОЈеПЦиЊГе§І зЪДиЃ∞ељХи°МжХ∞жЧґпЉМ糥еЉХзҐОзЙЗзЪДеҐЮеК†еПѓиГљеѓЉиЗіеѓєдЇО糥еЉХйАїиЊСиѓїзЪДеҐЮеК†пЉМдљЖж؃糥еЉХиѓїдЄОи°®иѓїзЪДжѓФдЊЛдњЭжМБдЄНеПШпЉЫеРМжЧґпЉМжИСдїђдїОдЄ≠еПѓдї•зЬЛ еИ∞пЉМclustering_factorеѓєдЇО糥еЉХиѓїеПЦзЪДжАІиГљжЬЙеЊИе§ІзЪДељ±еУНпЉМеєґдЄФеѓєдЇО糥еЉХзҐОзЙЗжЙАеЄ¶жЭ•зЪДељ±еУНеЕЈжЬЙеЊИе§ІзЪДдљЬзФ®пЉЫжЬАеРОпЉМзЬЛиµЈжЭ•пЉМ糥еЉХзҐОзЙЗдЉЉдєОеѓєдЇО ењЂйАЯеŮ糥еЉХжЙЂжППеЕЈжЬЙжЬАе§ІзЪДељ±еУНгАВ
¬†¬†¬†¬†¬†¬†жИСдїђжЭ•зЬЛдЄ§дЄ™еЃЮйЩЕзЪДдЊЛе≠РпЉМеИЖеИЂжШѓclustering_factorдЄЇжЬАе•љеТМжЬАеЈЃзЪДдЄ§дЄ™дЊЛе≠РгАВжµЛиѓХзОѓеҐГдЄЇ8KBзЪДжХ∞жНЃеЭЧпЉМи°®з©ЇйЧійЗЗзФ®ASSMзЪДзЃ°зРЖжЦєеЉПгАВеЕИеБЪдЄАдЄ™жЬАе•љзЪДclustering_factorзЪДдЊЛе≠РпЉМеИЫеїЇжµЛиѓХи°®еєґе°ЂеЕЕ1зЩЊдЄЗжЭ°жХ∞жНЃгАВ
SQL> create table rebuild_test(id number,name varchar2(10));
SQL> begin
 2    for i in 1..1000000 loop
 3        insert into rebuild_test values(i,to_char(i));
 4            if mod(i,10000)=0 then
 5                commit;
 6            end if;
 7    end loop;
 8 end;
 9 /
¬†¬†¬†¬†¬†¬†иѓ•и°®еЕЈжЬЙ1зЩЊдЄЗжЭ°иЃ∞ељХпЉМеИЖеЄГеЬ®2328дЄ™жХ∞жНЃеЭЧдЄ≠гАВеРМжЧґзФ±дЇОжИСдїђзЪДжХ∞жНЃйГљжШѓжМЙзЕІй°ЇеЇПйАТеҐЮжПТеЕ•зЪДпЉМжЙАдї•еПѓдї•зЯ•йБУпЉМеЬ®idеИЧдЄКеИЫеїЇзЪД糥еЉХйГљ жШѓеЕЈжЬЙжЬАе•љзЪДclustering_factorеАЉзЪДгАВжИСдїђињРи°Мдї•дЄЛжߕ胥жµЛиѓХиѓ≠еП•пЉМеИЖеИЂињФеЫЮ1гАБ100гАБ1000гАБ10000гАБ50000гАБ100000 дї•еПК1000000жЭ°иЃ∞ељХгАВ
select * from rebuild_test where id = 10;
select * from rebuild_test where id between 100 and 199;
select * from rebuild_test where id between 1000 and 1999;
select * from rebuild_test where id between 10000 and 19999;
select /*+ index(rebuild_test) */ * from rebuild_test where id between 50000 and 99999;
select /*+ index(rebuild_test) */ * from rebuild_test where id between 100000 and 199999;
select /*+ index(rebuild_test) */ * from rebuild_test where id between 1 and 1000000;
select /*+ index_ffs(rebuild_test) */ id from rebuild_test where id between 1 and 1000000;
¬†¬†¬†¬†¬†¬†еЬ®ињРи°МињЩдЇЫжµЛиѓХиѓ≠еП•еЙНпЉМеЕИеИЫеїЇдЄАдЄ™pctfreeдЄЇ50%зЪД糥еЉХпЉМжЭ•ж®°жЛЯ糥еЉХзҐОзЙЗпЉМеИЖжЮРеєґиЃ∞ељХ糥еЉХдњ°жБѓгАВ
SQL> create index idx_rebuild_test on rebuild_test(id) pctfree 50;
SQL> exec dbms_stats.gather_table_stats(user,'rebuild_test',cascade=>true);
зДґеРОињРи°МжµЛиѓХиѓ≠еП•пЉМиЃ∞ељХжѓПжЭ°жߕ胥иѓ≠еП•жЙАйЬАзЪДжЧґйЧіпЉЫжО•дЄЛжЭ•дї•pctfreeдЄЇ10%йЗН忯糥еЉХпЉМжЭ•ж®°жЛЯдњЃе§Н糥еЉХзҐОзЙЗпЉМеИЖжЮРеєґиЃ∞ељХ糥еЉХдњ°жБѓгАВ
SQL> alter index idx_rebuild_test rebuild pctfree 10;
SQL> exec dbms_stats.gather_table_stats(user,'rebuild_test',cascade=>true);
жО•зЭАеЖНжђ°ињРи°МињЩдЇЫжµЛиѓХиѓ≠еП•пЉМиЃ∞ељХжѓПжЭ°жߕ胥иѓ≠еП•жЙАйЬАзЪДжЧґйЧігАВдЄЛи°®жШЊз§ЇдЇЖ䪧䪙糥еЉХдњ°жБѓзЪДеѓєжѓФжГЕеЖµгАВ
|
pctfree |
Height |
blocks |
br_blks |
lf_blks |
pct_used |
clustering_factor |
|
50% |
3 |
4224 |
8 |
4096 |
49% |
2326 |
|
10% |
3 |
2304 |
5 |
2226 |
90% |
2326 |
дЄЛи°®жШЊз§ЇдЇЖдЄНеРМзЪД糥еЉХдЄЛпЉМињРи°МжµЛиѓХиѓ≠еП•жЙАйЬАзЪДжЧґйЧіеѓєжѓФжГЕеЖµгАВ
|
иЃ∞ељХжХ∞ |
еН†иЃ∞ељХжАїжХ∞зЪДзЩЊеИЖжѓФ |
pctused(50%) |
pctused(90пЉЕ) |
жАІиГљжПРйЂШзЩЊеИЖжѓФ |
|
1жЭ°иЃ∞ељХ |
0.0001% |
0.01 |
0.01 |
0.00% |
|
100жЭ°иЃ∞ељХ |
0.0100% |
0.01 |
0.01 |
0.00% |
|
1000жЭ°иЃ∞ељХ |
0.1000% |
0.01 |
0.01 |
0.00% |
|
10000жЭ°иЃ∞ељХ |
1.0000% |
0.02 |
0.02 |
0.00% |
|
50000жЭ°иЃ∞ељХ |
5.0000% |
0.06 |
0.06 |
0.00% |
|
100000жЭ°иЃ∞ељХ |
10.0000% |
1.01 |
1.00 |
0.99% |
|
1000000жЭ°иЃ∞ељХ |
100.0000% |
13.05 |
11.01 |
15.63% |
|
1000000жЭ°иЃ∞ељХ(FFS) |
100.0000% |
7.05 |
7.02 |
0.43% |
¬†¬†¬†¬†¬†¬†дЄКйЭҐжШѓеѓєжЬАе•љзЪДclustering_factorжЙАеБЪзЪДжµЛиѓХпЉМйВ£дєИеѓєдЇОжЬАеЈЃзЪДclustering_factorдЉЪжАОдєИж†ЈеСҐпЉЯжИСдїђе∞Ж rebuild_testдЄ≠зЪДidеАЉеПНињЗжЭ•жОТеИЧпЉМдєЯе∞±жШѓиѓіпЉМжѓФе¶ВеѓєдЇОidдЄЇ3478зЪДиЃ∞ељХпЉМе∞ЖidжФєдЄЇ8743гАВињЩж†ЈзЪДиѓЭпЉМе∞±е∞ЖжККеОЯжЭ•жМЙй°ЇеЇПжОТеИЧзЪДidеАЉ ељїеЇХжЙУдє±пЉМдїОиАМдљњеЊЧidдЄКзЪД糥еЉХзЪДclustering_factorеПШжИРжЬАеЈЃзЪДгАВдЄЇж≠§пЉМжИСеЖЩдЇЖдЄАдЄ™еЗљжХ∞зФ®жЭ•еПНиљђidзЪДеАЉгАВ
create or replace function get_reverse_value(id in number) return varchar2 is
 ls_id varchar2(10);
 ls_last_item varchar2(10);
 ls_curr_item varchar2(10);
 ls_zero varchar2(10);
 li_len integer;
 lb_stop boolean;
begin
 ls_id := to_char(id);
 li_len := length(ls_id);
 ls_last_item := '';
 ls_zero := '';
 lb_stop := false;
 while li_len>0 loop
       ls_curr_item := substr(ls_id,li_len,1);
       if ls_curr_item = '0' and lb_stop = false then
           ls_zero := ls_zero || ls_curr_item;
       else
           lb_stop := true;
           ls_last_item:=ls_last_item||ls_curr_item;
       end if;
       ls_id := substr(ls_id,1,li_len-1);
       li_len := length(ls_id);
 end loop;
 return(ls_last_item||ls_zero);
end get_reverse_value;
¬†¬†¬†¬†¬†¬†жО•дЄЛжЭ•пЉМжИСдїђеИЫеїЇжИСдїђзђђдЇМдЄ™жµЛиѓХзЪДжµЛиѓХи°®гАВеєґжМЙзЕІдЄОзђђдЄАдЄ™жµЛиѓХж°ИдЊЛзЫЄеРМзЪДжЦєеЉПињЫи°МжµЛиѓХгАВж≥®жДПпЉМеѓєдЇОжµЛиѓХжߕ胥жЭ•иѓіпЉМи¶БжККи°®еРНпЉИеМЕжЛђжПРз§ЇйЗМзЪДпЉЙжФєдЄЇrebuild_test_cfгАВ
SQL> create table rebuild_test_cf as select * from rebuild_test;
SQL> update rebuild_test_cf set name=get_reverse_value(id);



зЫЄеЕ≥жО®иНР
Oracle B*ж†С糥еЉХжШѓжХ∞жНЃеЇУзЃ°зРЖз≥їзїЯдЄ≠зФ®дЇОењЂйАЯжЯ•жЙЊжХ∞жНЃзЪДдЄАзІНжХ∞жНЃзїУжЮДпЉМе∞§еЕґеЬ®OracleжХ∞жНЃеЇУдЄ≠жЙЃжЉФзЭАйЗНи¶БиІТиЙ≤гАВB*ж†СпЉИB-star treeпЉЙжШѓBж†СзЪДдЄАдЄ™еПШзІНпЉМеЃГеЬ®Bж†СзЪДеЯЇз°АдЄКињЫи°МдЇЖдЉШеМЦпЉМдї•йАВеЇФе§ІиІДж®°жХ∞жНЃе≠ШеВ®еТМйЂШжХИжߕ胥зЪДйЬАж±В...
ж†ЗйҐШдЄ≠зЪДвАЬдїОBж†СгАБB+ж†СгАБB*ж†Си∞ИеИ∞Rж†СвАЭжґµзЫЦдЇЖжХ∞жНЃеЇУ糥еЉХзїУжЮДдЄ≠зЪДеЗ†зІНйЗНи¶БжХ∞жНЃзїУжЮДгАВињЩдЇЫжХ∞жНЃзїУжЮДеЬ®е≠ШеВ®еТМж£А糥姲йЗПжХ∞жНЃжЧґиµЈзЭАеЕ≥йФЃдљЬзФ®пЉМе∞§еЕґеЬ®жХ∞жНЃеЇУзЃ°зРЖз≥їзїЯгАБжЦЗдїґз≥їзїЯеТМеЬ∞зРЖдњ°жБѓз≥їзїЯз≠ЙйҐЖеЯЯгАВиЃ©жИСдїђйАРдЄАжОҐиЃ®ињЩдЇЫжХ∞жНЃ...
Bж†С糥еЉХжШѓжХ∞жНЃеЇУзЃ°зРЖз≥їзїЯдЄ≠йЭЮеЄЄйЗНи¶БзЪДжХ∞жНЃзїУжЮДпЉМйАЪињЗеРИзРЖиЃЊиЃ°еТМзїіжК§еПѓдї•жЮБе§ІеЬ∞жПРйЂШжХ∞жНЃж£А糥зЪДжХИзОЗгАВзРЖиІ£еЕґеЈ•дљЬеОЯзРЖеТМеЖЕйГ®жЬЇеИґеѓєдЇОжХ∞жНЃеЇУзЃ°зРЖеСШеТМеЉАеПСиАЕжЭ•иѓіиЗ≥еЕ≥йЗНи¶БпЉМжЬЙеК©дЇОжЫіжЬЙжХИеЬ∞зЃ°зРЖеТМдЉШеМЦжХ∞жНЃеЇУжАІиГљгАВ
1. **жХ∞жНЃеЇУ糥еЉХ**пЉЪBж†С媪襀зФ®дљЬжХ∞жНЃеЇУеТМжЦЗдїґз≥їзїЯзЪД糥еЉХзїУжЮДпЉМеЫ†дЄЇеЃГиГљжЬЙжХИеЗПе∞Сз£БзЫШI/OжУНдљЬгАВзФ±дЇОBж†СзЪДйЂШеЇ¶иЊГдљОпЉМжߕ胥жХ∞жНЃжЧґеП™йЬАи¶БиЊГе∞СзЪДз£БзЫШй°µиЃњйЧЃпЉМжПРйЂШдЇЖжߕ胥йАЯеЇ¶гАВ 2. **жЦЗдїґз≥їзїЯ**пЉЪеЬ®жЦЗдїґз≥їзїЯдЄ≠пЉМBж†СзФ®дЇОзЃ°зРЖ...
ж†ЗйҐШжПРеИ∞зЪД"B+ж†СдљЬдЄЇжХ∞жНЃеЇУзЪД糥еЉХ"пЉМжМЗзЪДжШѓB+ж†СињЩзІНжХ∞жНЃзїУжЮДеЬ®жХ∞жНЃеЇУзЃ°зРЖдЄ≠зЪДйЗНи¶БеЇФзФ®гАВB+ж†СпЉИB Plus TreeпЉЙжШѓдЄАзІНиЗ™еє≥и°°зЪДжЯ•жЙЊж†СпЉМзЙєеИЂйАВеРИзФ®дЇОжХ∞жНЃеЇУеТМжЦЗдїґз≥їзїЯзЪД糥еЉХе≠ШеВ®гАВдЄЛйЭҐжИСдїђе∞ЖжЈ±еЕ•жОҐиЃ®B+ж†СзЪДеЯЇжЬђж¶ВењµгАБ...
еЬ®ITйҐЖеЯЯпЉМжХ∞жНЃзїУжЮДжШѓжЮДеїЇйЂШжХИзЃЧж≥ХзЪДеЯЇз°АпЉМиАМBж†СпЉИB-treeпЉЙдљЬдЄЇдЄАзІНиЗ™еє≥и°°зЪДж†СжХ∞жНЃзїУжЮДпЉМ媪襀зФ®дЇОжХ∞жНЃеЇУеТМжЦЗдїґз≥їзїЯдЄ≠пЉМзФ®дЇОењЂйАЯиЃњйЧЃеТМзЃ°зРЖе§ІйЗПжХ∞жНЃгАВеЬ®ињЩдЄ™й°єзЫЃвАЬBж†СеЃЮзО∞зЪДжЦЗ俴糥еЉХ javaзЙИвАЭдЄ≠пЉМжИСдїђжОҐиЃ®зЪДжШѓе¶ВдљХ...
жАїзЪДжЭ•иѓіпЉМ"book-mis.rar_B+ж†С糥еЉХ_bж†Сз≥їзїЯ"жШѓдЄАдЄ™зїУеРИдЇЖйЂШжХИжХ∞жНЃзїУжЮДеТМ糥еЉХжКАжЬѓзЪДеЫЊдє¶зЃ°зРЖз≥їзїЯпЉМйАЪињЗB+ж†С糥еЉХпЉМеЃЮзО∞дЇЖеѓєе§ІйЗПеЫЊдє¶дњ°жБѓзЪДењЂйАЯиЃњйЧЃеТМзЃ°зРЖгАВињЩзІН糥еЉХжЦєж≥ХеЬ®жХ∞жНЃеЇУз≥їзїЯдЄ≠еєњж≥ЫеЇФзФ®пЉМдЄНдїЕжПРйЂШдЇЖжХ∞жНЃжУНдљЬзЪД...
еОЛзЉ©еМЕдЄ≠зЪДвАЬMathMagician.txtвАЭеПѓиГљжШѓдЄАдЄ™з§ЇдЊЛжХ∞жНЃжЦЗдїґжИЦжµЛиѓХзФ®дЊЛпЉМзФ®дЇОжЉФз§Їе¶ВдљХдљњзФ®ињЩдЄ™B+ж†С糥еЉХз®ЛеЇПеЇУињЫи°МжХ∞жНЃжУНдљЬгАВеЕЈдљУдљњзФ®жЦєж≥ХеПѓиГљеМЕжЛђиІ£жЮРжЦЗдїґпЉМеИЫеїЇB+ж†С糥еЉХпЉМзДґеРОжЙІи°МжПТеЕ•гАБеИ†йЩ§гАБжЯ•жЙЊз≠ЙжУНдљЬгАВ зїЉдЄКжЙАињ∞пЉМ...
еЬ®жХ∞жНЃеЇУеТМжЦЗдїґз≥їзїЯдЄ≠пЉМB+ж†СпЉИB Plus TreeпЉЙжШѓдЄАзІНеєњж≥ЫеЇФзФ®зЪДжХ∞жНЃзїУжЮДпЉМеЃГ襀зФ®жЭ•йЂШжХИеЬ∞е≠ШеВ®еТМж£А糥姲йЗПжХ∞жНЃгАВB+ж†Сдї•еЕґзЛђзЙєзЪДзЙєжАІпЉМе¶Веє≥и°°жАІгАБиЗ™еє≥и°°и∞ГжХіеТМз£БзЫШеПЛе•љзЪДжХ∞жНЃиЃњйЧЃж®°еЉПпЉМжИРдЄЇдЇЖеЃЮзО∞糥еЉХзЪДзРЖжГ≥йАЙжЛ©гАВдЄЛйЭҐ...
1. **жХ∞жНЃеЇУ糥еЉХ**пЉЪBж†СжШѓжХ∞жНЃеЇУз≥їзїЯдЄ≠жЬАеЄЄзФ®зЪД糥еЉХзїУжЮДпЉМе¶ВMySQLзЪДInnoDBеЉХжУОеТМPostgreSQLзЪДB-tree糥еЉХгАВ 2. **жЦЗдїґз≥їзїЯ**пЉЪеЬ®жЦЗдїґз≥їзїЯдЄ≠пЉМBж†СзФ®дЇОзїДзїЗжЦЗдїґеТМзЫЃељХпЉМењЂйАЯеЃЪдљНжХ∞жНЃеЭЧгАВ 3. **зЉУе≠ШзЃ°зРЖ**пЉЪеЬ®еЖЕе≠ШзЃ°зРЖ...
жЬђжЦЗе∞ЖжЈ±еЕ•жОҐиЃ®Bж†С糥еЉХзЪДеЖЕйГ®зїУжЮДгАБзЃ°зРЖдї•еПКзїіжК§з≠ЙжЦєйЭҐпЉМдї•жЬЯиЊЊеИ∞еѓєеЕґеЕ®йЭҐдЇЖиІ£зЪДзЫЃзЪДгАВ Bж†С糥еЉХзЪДеЯЇжЬђжЮДжИРеМЕжЛђдЄЙдЄ™йГ®еИЖпЉЪеПґе≠РиКВзВєгАБеИЖжФѓиКВзВєдї•еПКж†єиКВзВєгАВеПґе≠РиКВзВєдљЬдЄЇBж†СзЪДжЬАеЇХе±ВпЉМе≠ШеВ®зЭАжМЗеРСжХ∞жНЃеЇУи°®дЄ≠жХ∞жНЃи°МзЪД...
жХ∞жНЃзїУжЮДжШѓиЃ°зЃЧжЬЇзІСе≠¶дЄ≠зЪДж†ЄењГиѓЊз®ЛпЉМеЃГжОҐиЃ®дЇЖе¶ВдљХжЬЙжХИеЬ∞е≠ШеВ®еТМж£А糥...йАЪињЗжЈ±еЕ•е≠¶дє†еТМеЃЮиЈµB+ж†СпЉМе≠¶зФЯдЄНдїЕеПѓдї•зРЖиІ£жХ∞жНЃзїУжЮДзЪДзРЖиЃЇзЯ•иѓЖпЉМињШиГљжПРеНЗиІ£еЖ≥еЃЮйЩЕйЧЃйҐШзЪДиГљеКЫпЉМдЄЇжЬ™жЭ•дїОдЇЛиљѓдїґеЉАеПСгАБжХ∞жНЃеЇУзЃ°зРЖз≠ЙеЈ•дљЬжЙУдЄЛеЭЪеЃЮеЯЇз°АгАВ
жЬАеРОпЉМйЪПзЭАжХ∞жНЃеЇУжКАжЬѓзЪДдЄНжЦ≠жЉФињЫпЉМB+ж†С糥еЉХдєЯзїПеОЖдЇЖеРДзІНдЉШеМЦеТМжФєињЫпЉМдЊЛе¶ВпЉМInnoDBе≠ШеВ®еЉХжУОйАЪињЗиБЪйЫЖ糥еЉХеТМиЊЕеʩ糥еЉХпЉИдЇМ篲糥еЉХпЉЙињЫдЄАж≠•дЉШеМЦдЇЖжХ∞жНЃе≠ШеВ®еТМж£А糥ињЗз®ЛгАВзРЖиІ£ињЩдЇЫеЯЇз°АзЯ•иѓЖеПѓдї•еЄЃеК©жХ∞жНЃеЇУзЃ°зРЖеСШжЫіе•љеЬ∞зЃ°зРЖеТМ...
жАїзїУжЭ•иѓіпЉМињЩдЄ™C++еЃЮзО∞зЪДB-ж†СеТМB+ж†Сй°єзЫЃжШѓе≠¶дє†жХ∞жНЃзїУжЮДеТМзЃЧж≥ХзЪДе•љиµДжЇРпЉМеПѓдї•еЄЃеК©еЉАеПСиАЕжОМжП°ињЩдЄ§зІНйЗНи¶БзЪД糥еЉХзїУжЮДпЉМињЩеѓєдЇОжПРеНЗжХ∞жНЃеЇУеТМжЦЗдїґз≥їзїЯжАІиГљиЗ≥еЕ≥йЗНи¶БгАВйАЪињЗеЃЮиЈµпЉМдЄНдїЕеПѓдї•еЈ©еЫЇзРЖиЃЇзЯ•иѓЖпЉМињШиГљйФїзВЉзЉЦз®ЛжКАеЈІпЉМеѓє...
**B+ж†Сиѓ¶иІ£** B+ж†СпЉИB Plus TreeпЉЙпЉМжШѓдЄАзІНиЗ™еє≥и°°зЪДж†СжХ∞жНЃзїУжЮДпЉМеєњж≥ЫеЇФзФ®дЇО...йАЪињЗзРЖиІ£еЕґзїУжЮДеТМжУНдљЬеОЯзРЖпЉМжИСдїђеПѓдї•жЫіе•љеЬ∞еИ©зФ®еЃГжЭ•жЮДеїЇйЂШжХИзЪДжХ∞ж́糥еЉХз≥їзїЯгАВеЬ®жЦЗдїґеЃЮзО∞дЄ≠пЉМи¶БеЕЕеИЖиАГиЩСз£БзЫШI/OзЪДзЙєжАІпЉМдї•еЃЮзО∞жЬАдљ≥зЪДжАІиГљгАВ
еЬ®ITйҐЖеЯЯпЉМжХ∞жНЃзїУжЮДжШѓиЃ°зЃЧжЬЇзІСе≠¶дЄ≠зЪДж†ЄењГж¶ВењµдєЛдЄАпЉМеЃГдЄЇйЂШжХИеЬ∞е≠ШеВ®еТМе§ДзРЖжХ∞жНЃжПРдЊЫдЇЖзРЖиЃЇеЯЇз°АгАВ...еѓєињЩдЇЫжЦЗдїґињЫи°МжЈ±еЕ•з†Фз©ґпЉМдЄНдїЕеПѓдї•дЇЖиІ£B+ж†С糥еЉХзЪДеЃЮзО∞пЉМињШеПѓдї•ињЫдЄАж≠•жПРеНЗCиѓ≠и®АзЉЦз®ЛеТМжХ∞жНЃзїУжЮДзРЖиІ£зЪДиГљеКЫгАВ
еЬ®ITи°МдЄЪдЄ≠пЉМжХ∞жНЃзїУжЮДжШѓиЃ°зЃЧжЬЇзІСе≠¶зЪДеЯЇз°АдєЛдЄАпЉМB+ж†СдљЬдЄЇдЄАзІНйЂШжХИзЪДжХ∞ж́糥еЉХзїУжЮДпЉМеєњж≥ЫеЇФзФ®дЇОжХ∞жНЃеЇУзЃ°зРЖз≥їзїЯеТМжЦЗдїґз≥їзїЯдЄ≠гАВжЬђеОЛзЉ©еМЕвАЬb+b-ж†Сcиѓ≠и®АзЙИвАЭжПРдЊЫдЇЖCиѓ≠и®АеЃЮзО∞зЪДB+ж†СзЫЄеЕ≥еКЯиГљпЉМеМЕжЛђеИЫеїЇгАБеИ†йЩ§гАБжߕ胥еТМжПТеЕ•жУНдљЬ...
- **Bж†С糥еЉХзїУжЮДж¶Вињ∞**пЉЪдїЛзїНдЇЖBж†С糥еЉХзЪДеЯЇжЬђзїУжЮДпЉМеМЕжЛђжЮЭеЭЧпЉИbranch blocksпЉЙеТМеПґеЭЧпЉИleaf blocksпЉЙгАВ - **糥еЉХдЄНеє≥и°°зЪДиѓѓеМЇ**пЉЪиІ£йЗКдЇЖ糥еЉХеЬ®ж≠£еЄЄжУНдљЬдЄЛдЄНдЉЪеПШеЊЧдЄНеє≥и°°гАВ - **ж†СиљђеВ®иЈЯиЄ™дЇЛдїґ**пЉЪиЃ≤иІ£дЇЖе¶ВдљХдљњзФ®ж†С...