http://usenix.org/events/fast04/tech/full_papers/radkov/radkov_html/node14.html
Impact of Sequential and Random I/O
Two key factors impact the network message overheads of data operations--the size of read and write requests and the access characteristics of the requests (sequential or random). The previous section studied the impact of request sizes on the network message overhead. In this section, we study the effect of sequential and random access patterns on network message overheads.
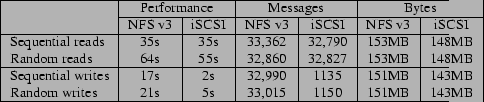
To measure the impact of reads, we create a 128MB file. We then empty the cache and read the file sequentially in 4KB chunks. For random reads, we create a random permutation of the 32K blocks in the file and read the blocks in that order. We perform this experiment first for NFS v3 and then for iSCSI. Table 4 depicts the completion times, network message overheads and bytes transferred in the two systems. As can be seen, for sequential reads, both NFS and iSCSI yield comparable performance. For random reads, NFS is slightly worse (by about 15%). The network message overheads and the bytes transfered are also comparable for iSCSI and NFS.
Next, we repeat the above experiment for writes. We create an empty file and write 4KB data chunks sequentially to a file until the file size grows to 128MB. For random writes, we generate a random permutation of the 32K blocks in the file and write these blocks to newly created file in that order. Table 4 depicts our results. Unlike reads, where NFS and iSCSI are comparable, we find that iSCSI is significantly faster than NFS for both sequential and random writes. The lower completion time of iSCSI is due to the asynchronous writes in the ext3 file system. Since NFS version 3 also supports asynchronous writes, we expected the NFS performance to be similar to iSCSI. However, it appears that the Linux NFS v3 implementation can not take full advantage of asynchronous writes, since it specifies a limit on the number of pending writes in the cache. Once this limit is exceeded, the write-back caches degenerates to a write-through cache and application writes see a pseudo-synchronous behavior. Consequently, the NFS write performance is significantly worse than iSCSI. Note also, while the byte overhead is comparable in the two systems, the number of messages in iSCSI is significantly smaller than NFS. This is because iSCSI appears to issue very large write requests to the server (mean request size is 128KB as opposed to 4.7KB in NFS).
分享到:





相关推荐
此文件创建 100 个大小为 2K 的文件和 100 个大小为 64K 的文件 大小为 2K 的文件表示随机 I/O 访问。 大小为 64K 的文件表示顺序 I/O 访问。 $ ./generateFiles.sh 读取.js 从提供的目录中读取随机文件。 $ node...
再者,顺序与随机读写比例(Random/Sequential)是决定存储性能的重要维度。顺序读写发生在连续的磁盘空间上,效率较高;而随机读写则涉及大量分散的磁盘位置,效率较低。传统机械硬盘在处理随机I/O时性能尤为受限,...
1,methods for accessing file, text data, object ...Sequential and Random access 2,Reading and writing of primitive values 3,Applications and applets are provided with three streams automatically
用法iops [-n|--num-threads threads] [-t|--time time] [-m|--machine-readable] [-b|--block-size size] [-p|--pattern random|sequential] <device>num-threads := number of concurrent io threads, default 32...
"Random Read/Write"则关注硬盘处理随机小文件的能力,这对于数据库和虚拟化环境尤为重要。此外,"File creation/deletion rates"部分揭示了文件系统处理创建和删除操作的速度,这对文件服务器来说十分关键。 除了...
plotly.io re wordcloud.WordCloud pickle.dump random.randint keras_preprocessing.sequence.pad_sequences random seaborn warnings sklearn.feature_extraction.text.CountVectorizer sklearn.metrics.pairwise....
fileio= random 或 sequential,表示文件 I/O 将执行的方式。 fileselect= random 或 sequential,标识选择文件或目录的方式。 xfersizes= 数据传输(读取和写入操作)处理的数据大小。 operation= mkdir、...
至于随机图片的显示,可以利用C#的`System.IO`和`System.Drawing`命名空间。首先,你需要获取本地图片文件夹路径,并从中随机选择一张图片: ```csharp string imageDirectory = @"C:\path\to\image\folder"; ...
- **类和方法**: `System.IO`命名空间包含了多种类,如`FileStream`, `StreamReader`, `StreamWriter`, `Directory`, `FileInfo`, `DirectoryInfo`等,以及用于文件操作的方法,如`Create()`, `Delete()`, `Exists()...
Iometer是对存储子系统的读写性能进行测试的软件。...用户可以通过设置不同的测试的参数,有存取类型(如sequential ,random)、读写块大小(如64K、256K),队列深度等,来模拟实际应用的读写环境进行测试。
tensorflow.keras.models.Sequential tensorflow.keras.layers.Dense tensorflow.keras.optimizers.Adam tensorflow.keras.metrics.Accuracy sklearn.preprocessing.LabelEncoder scipy.stats.chi2_contingency ...
tensorflow.keras.models.Sequential tensorflow.keras.layers.Dense plotly.graph_objects plotly.io.write_image sklearn.preprocessing.StandardScaler sklearn.preprocessing.MultiLabelBinarizer pyspark.sql....
在自然语言处理(NLP)任务中,词嵌入是一种将词汇转化为连续向量表示的技术,使得计算机可以理解和处理文本数据。Keras 是一个高级神经网络 API,它提供了丰富的工具来构建和训练深度学习模型,其中包括 `Embedding...
TensorFlow作为一款强大的开源机器学习框架,为开发者提供了灵活多样的工具来构建和管理数据集。本篇文章将详细介绍如何利用TensorFlow 2.x来创建基于图像的数据集,并通过具体的实例代码展示整个过程。 #### 二、...
Table of Contents Section 1 Introduction to SystemVerilog ...................................................................................................... 1 Section 2 Literal Values................