对着眼前黑色支撑的天空 / 我突然只有沉默了
我驾着最后一班船离开 / 才发现所有的灯塔都消失了
这是如此触目惊心的 / 因为失去了方向我已停止了
就象一个半山腰的攀登者 / 凭着那一点勇气和激情来到这儿
如此上下都不着地地喘息着 / 闭上眼睛疼痛的感觉溶化了
--达达乐队《黄金时代》
好几个地方看到这个 Facebook - Needle in a Haystack: Efficient Storage of Billions of Photos
,是 Facebook 的 Jason Sobel 做的一个 PPT,揭示了不少比较有参考价值的信息。【也别错过我过去的这篇Facebook 的PHP性能与扩展性
】
图片规模
作为世界上最大的 SNS
站点之一,Facebook 图片有多少? 65 亿张原始图片,每张图片存为 4-5 个不同尺寸,这样总计图片文件有 300 亿左右,总容量 540T,天! 峰值的时候每秒钟请求 47.5 万个图片 (当然多数通过 CDN
) ,每周上传 1 亿张图片。
图片存储
前一段时间说 Facebook 服务器超过 10000 台,现在打开不止了吧,Facebook 融到的大把银子都用来买硬件
了。图片是存储在 Netapp NAS上的,采用 NFS
方式。
图片写入
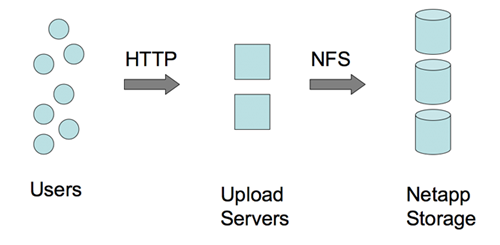
尽管这么大的量,似乎图片写入并不是问题。如上图,是直接通过 NFS
写的。
图片读取
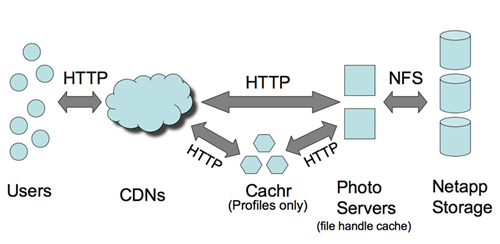
CDN
和 Cachr 承担了大部分访问压力。尽管 Netapp 设备不便宜,但基本上不承担多大的访问压力,否则吃不消。CDN 针对 Profile 图象的命中率有 99.8%,普通图片也有 92% 的命中率。命中丢失的部分采由 Netapp 承担。
图中的 Cachr 这个组件,应该是用来消息通知(基于调整过的 evhttp的嘛),Memcached 作为后端存储。Web
图片服务器是 Lighttpd,用于 FHC (文件处理 Cache),后端也是 Memcached。Facebook 的 Memcached
服务器数量差不多世界上最大了,人家连 MYSQL 服务器还有两千台呢。
Haystacks --大海捞针
这么大的数据量如何进行索引? 如何快速定位文件? 这是通过 Haystacks 来做到的。Haystacks
是用户层抽象机制,简单的说就是把图片元数据的进行有效的存储管理。传统的方式可能是通过 DB 来做,Facebook
是通过文件系统来完成的。通过 GET / POST 进行读/写操作,应该说,这倒也是个比较有趣的思路,如果感兴趣的话,看一下 GET /
POST 请求的方法或许能给我们点启发。
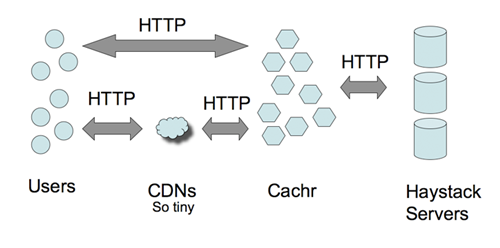
总体来看,Facebook 的图片处理还是采用成本偏高的方法来做的。技术含量貌似并不大。不清楚是否对图片作 Tweak,比如不影响图片质量的情况下减小图片尺寸。
分享到:





相关推荐
在大数据领域,Facebook作为全球最大的社交网络之一,面临着海量数据的收集、存储和处理挑战。为了有效应对这些挑战,Facebook开发了名为Scribe的系统,它是一个集中式的日志聚合服务,专门用于处理大规模分布式系统...
### 海量数据处理平台体系架构分析 #### 一、引言 随着互联网技术的飞速发展,人类社会正经历着前所未有的数据爆炸时代。这些数据不仅数量巨大,而且种类繁多,包括文本、图像、视频等多种形式。如何有效地管理和...
3. 海量数据处理技术 对于海量数据的处理,文章提到了日志分析和搜索引擎应用。例如,Google的搜索引擎每天需要处理大量网页更新,这就需要高效的索引和更新机制。而数据分析系统如Hadoop的MapReduce框架,则为大...
Hadoop框架之所以受到各大网站和公司的青睐,如Yahoo、Amazon EC2、Facebook等,是因为它在处理海量数据方面表现出色。它不仅能够有效处理大规模数据集,而且具有良好的容错机制和自我管理能力。此外,Hadoop生态...
RCFile最初是由Facebook工程师为了解决数据仓库在处理海量数据时面临的挑战而提出的。传统的数据存储格式,如TextFile和SequenceFile,主要采用行存储方式,但在面对大规模数据分析时存在诸多不足。Facebook工程师在...
Facebook数据中心是全球互联网巨头Facebook为支撑其海量用户需求和数据处理能力的重要基础设施。Facebook的数据中心设计和运营在行业内具有显著的创新性和效率性,尤其是在节能和成本控制方面。以下是关于Facebook...
总结而言,互联网海量数据存储及处理的技术发展趋势主要包括分布式存储、NoSQL数据库、大数据处理框架和实时数据处理技术。随着互联网应用的持续创新和数据量的进一步增长,这些领域的研究和实践将继续深入,以应对...
它依赖于高效的数据处理技术,传统的商业智能系统无法应对海量非结构化数据。因此,针对大数据的分析需求,Google开发了GFS(Google File System)用于存储大量数据,并提出了MapReduce模型用于并行处理数据。后来,...
3. **分布式存储**: Facebook可能会采用Hadoop或Spark这样的大数据处理框架,对海量数据进行分布式存储和处理。这些系统能处理PB级别的数据,并支持离线批处理和实时分析。 4. **数据库集群**: 为了提高可用性和...
在Google、Facebook、淘宝等大互联网公司出现之后,这些公司注册和在线用户数量都非常大,因此该公司交易系统需要解决“海量数据+高并发+数据一致性+高可用性”的问题。为了解决该问题,从目前资料来看,其实没有一...
【Hadoop与海量数据处理】 Hadoop是基于分布式计算的开源框架,特别适合处理大规模数据。在电信企业中,Hadoop集群可以用来处理用户清单、信令和日志等海量数据,提供可动态扩展的数据库。利用Hadoop的MapReduce模型...
数据处理方面,如Hadoop框架的出现,支持了海量数据的分布式处理,提升了数据处理的可靠性、效率和可伸缩性。大数据分析技术在图书馆用户关系管理中的应用,可以为用户推荐阅读资料、提供个性化服务,进行网络舆情...
这篇论文聚焦于Facebook如何利用云计算技术来支持其庞大的用户基础、处理海量数据以及优化服务性能。 首先,论文可能会探讨Facebook的基础设施,包括数据中心的设计和布局。Facebook的数据中心是云计算的核心,它们...
大数据处理指的是对海量数据进行存储、计算和分析的过程。数据中心节能调度则涉及使用有效的技术手段来降低数据中心运行时的能耗。异构存储系统指的数据中心内采用不同存储设备和存储技术的存储系统,其特点是在性能...
Facebook的数据仓库在处理海量数据方面面临着巨大挑战。为了优化数据处理效率,Facebook引入了一种名为RCFile(Record Columnar File)的数据存储结构。RCFile结合了行存储和列存储的优势,旨在解决大数据处理中的...
Facebook作为全球领先的社交网络平台,面临着海量数据处理的挑战。为了更好地管理和利用这些数据,Facebook引入了Apache Hadoop系统,并对其进行了大量的定制化开发,尤其是在提升系统的实时处理能力方面取得了显著...
除了GFS,还有Facebook的Haystac和淘宝的TFS等分布式文件系统,它们的设计都旨在满足海量数据存储和快速处理的需求。 四、MapReduce模型 MapReduce是大数据处理中的核心计算模型,由Google提出,旨在简化大规模...