作者: Fenng
|
可以转载, 转载时务必以超链接形式标明文章原始出处和作者信息及版权声明
网址: http://www.dbanotes.net/arch/linkedin.html
现在是 SNS
的春天,最近又有消息传言新闻集团准备收购 LinkedIn
。有趣的是,LinkedIn 也是 Paypal 黑帮
成员创建的。在最近一个季度,有两个 Web 2.0 应用我用的比较频繁。一个是Twitter
,另一个就是 LinkedIn
。
LinkedIn 的 CTO
Jean-Luc Vaillant 在 QCon 大会上做了 ”Linked-In: Lessons learned and growth and scalability
“ 的报告。不能错过,写一则 Blog 记录之。
LinkedIn 雇员有 180 个,在 Web 2.0 公司中算是比较多的,不过人家自从 2006 年就盈利了,这在 Web 2.0 站点中可算少的。用户超过 1600 万,现在每月新增 100 万,50% 会员来自海外(中国用户不少,也包括我
).
开篇明义,直接说这个议题不讲"监控、负载均衡”等话题,而是实实在在对这样特定类型站点遇到的技术问题做了分享。LinkedIn
的服务器多是 x86 上的 Solaris ,关键 DB 用的是 Oracle
10g。人与人之间的关系图生成的时候,关系数据库有些不合时宜,而把数据放到内存里进行计算就是必经之路。具体一点说,LinkedIn
的基本模式是这样的:前台应用服务器面向用户,中间是DB,而DB的后边还有计算服务器来计算用户间的关系图的。
问题出来了,如何保证数据在各个 RAM
块(也就是不同的计算服务器)中是同步的呢? 需要一个比较理想的数据总线(DataBus)机制。
第一个方式是用 Timestamp . 对记录设置一个字段,标记最新更新时间。这个解决方法还是不错的---除了有个难以容忍的缺陷。什么问题?就是 Timestamp 是 SQL调用发起的时间,而不是 Commit 的确切时间。步调就不一致喽。
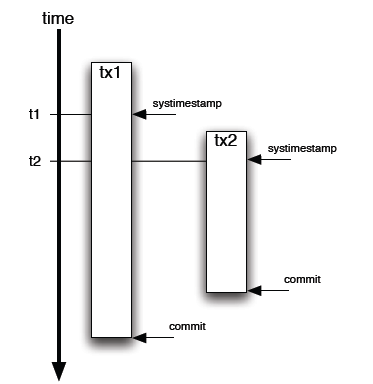
第二个办法,用 Oracle 的 ORA_ROWSCN (还好是 Oracle 10g). 这个伪列包含 Commit 时候的
SCN(System Change Number),是自增的,DB 自己实现的,对性能没有影响。Ora_ROWSCN
默认是数据库块级别的粒度,当然也可做到行级别的粒度。唯一的缺点是不能索引(伪列). 解决办法倒也不复杂:增加一个 SCN
列,默认值"无限大"。然后用选择比某个 SCN 大的值就可以界定需要的数据扔到计算服务器的内存里。
ORA_ROWSCN 是 Oracle 10g 新增的一个特性,不得不承认,我过去忽略了这一点。我比较好奇的是,国内的 Wealink、联络家等站点是如何解决这个关系图的计算的呢?
分享到:





相关推荐
大型网站架构技术方案集锦 PlentyOfFish 网站架构...LinkedIn 架构笔记 Yahoo!社区架构 Craigslist 的数据库架构 Fotolog.com 的技术信息拾零 Digg 网站架构 Amazon 的 Dynamo 架构 财帮子(caibangzi.com)网站架构
本套学习笔记将带你深入理解Kafka的核心概念、架构设计以及实战技巧。 一、Kafka概述 Kafka是一个高吞吐量的分布式发布订阅消息系统,它的主要特性包括持久化、分区、复制和并行处理。Kafka的设计目标是提供低延迟...
我的渗透学习笔记信息收集公司和个人网站是信息的重要来源,查看公司的LinkedIn个人资料,以确定高级经理,董事和非技术人员。 很多时候,最薄弱的密码属于许多公司的管理人员。 搜索公司网站上的“关于我们”页面也...
Kafka笔记 Kafka是LinkedIn开发的一个内部基础设施系统,旨在处理持续数据流。Kafka的设计理念是将数据看作是一个持续变化和不断增长的流,基于这样的想法构建出一个数据系统,一个数据架构。Kafka外在表现很像消息...
Apache Kafka是一款开源的流处理平台,由LinkedIn开发并捐赠给了Apache软件基金会。它最初设计为一个高吞吐量、低延迟的消息队列系统,但现在已经成为大数据领域的重要组件,广泛用于实时数据管道和流式处理。Kafka...
在这个学习笔记中,我们将深入探讨Kafka的核心概念、架构以及它在大数据生态系统中的应用。 1. **核心概念** - **主题(Topic)**:主题是Kafka中的数据分类,类似于数据库中的表。每个主题可以被分成多个分区。 ...
1. Kafka概述:Kafka最初由LinkedIn开发,后贡献给Apache基金会,它是一个分布式的、基于发布/订阅的消息系统,能够处理海量的实时数据流。 2. Kafka架构:包括生产者、消费者、 broker节点和 Zookeeper等组件,提供...
**Kafka知识导图笔记详解** Kafka是一个分布式流处理平台,由LinkedIn开发并开源,现在是Apache软件基金会的一部分。它被设计为高吞吐量、低延迟的消息系统,广泛用于实时数据管道和流处理应用。Kafka的核心概念...
从给定的文件信息来看,标题和描述都指向了“Java分布式学习笔记01分布式Java应用”,这显然是关于Java在分布式环境下的应用和技术的学习资料。虽然提供的部分内容由于格式问题难以直接解析,但我们可以根据标题、...
LinkedIn学习-学习SQL编程学习领域/实践方法结合使用SQLite和DB浏览器界面来编写查询和练习SQL语言练习使用版本控制软件将注释上载到github以供以后参考利用Markdown语言有效地跟踪个人课程笔记介绍数据库按列(字段...
Kafka是Apache软件基金会的一个关键项目,由LinkedIn公司最初设计,并最终以Scala和Java语言实现。作为一个高性能、分布式的流处理平台,Kafka被广泛应用于实时数据管道和流应用之中。它的核心功能是作为一个消息...
它最初由LinkedIn开发,后来贡献给了开源社区,如今已经成为分布式消息传递领域的明星产品。本文将深入探讨Kafka的核心概念、设计原理以及实际应用,帮助读者全面理解并掌握这一中间件。 一、Kafka基本概念 1. **...
Kafka是一个分布式流处理平台,由LinkedIn开发并贡献给了Apache软件基金会。它是消息中间件的一种,广泛应用于大数据实时处理、日志收集、用户行为追踪等领域。 ### 1. 为什么需要消息系统 - **解耦**:消息队列使...
Kafka是一个分布式流处理平台,它最初由LinkedIn公司开发,现在是一个开源项目,由Apache软件基金会维护。Kafka主要用于构建实时数据管道和流应用程序。它具有高性能、水平扩展、高可靠性的特点,特别适合于大数据...
Kafka是一款高性能、分布式的消息中间件,最初由LinkedIn开发,并于2011年开源,现在是Apache软件基金会的顶级项目。Kafka被广泛应用于实时数据流处理、日志聚合、用户行为追踪等多个领域,其核心特性包括高吞吐量、...
Apache Kafka 是一个强大的分布式流处理平台,由 LinkedIn 开发并在2011年成为Apache软件基金会的顶级项目。它的设计目标是提供高吞吐量、低延迟的数据传递,支持实时数据管道和流式应用程序。Kafka的核心特性包括...
2. **Kafka 架构**:解释 Kafka 的分布式架构,包括 Broker(代理服务器)、Zookeeper 的角色以及如何通过它们实现高可用性和数据冗余。 3. **消息模型**:描述如何使用生产者和消费者API发送和接收消息,包括同步...
公司和个人网站是信息的重要来源,查看公司的LinkedIn个人资料,以确定高级经理,董事和非技术人员。 很多时候,最薄弱的密码属于许多公司的管理人员。 搜索公司网站上的“关于我们”页面也可以找到薄弱的目标。 IP...