
1. jbpm4.4 测试环境搭建
2. Jbpm4.4+hibernate3.5.4+spring3.0.4+struts2.1. 整合环境搭建
3. jbpm4.4 基础知识
4. 整合过程中常见问题的解决
5. 请假流程例子( s2sh+jbpm )
6. 总结及参考文章
jbpm4.4 测试环境搭建
刚接触 jbpm 第一件事就是快速搭建环境,测试 jbpm 所给的例子。 Jbpm 是一个工作流引擎框架,如果没有javaEE 开发环境, jbpm 也提供了安装脚本( ant ),一键提供安装运行环境。同时也可以将 jbpm 整合到eclipse 或者 myeclipse 中。
快速搭建环境的步骤是:
1. 安装 jbpm-myeclipse 插件,这个插件随 jbpm4.4 一起发布,位于 jbpm-4.4/install/src/gpd 目录下,这个安装好后,就可以在myeclipse 中编辑流程图了(可视化流程设计)
在myeclipse->help->myeclipse configuration centre->software->add site->add from archive file 选择jbpm-4.4/install/src/gpd 下的jbpm-gpd-site.zip
安装这个插件应该注意断网,避免其到网上更新。同时注意:需要选择
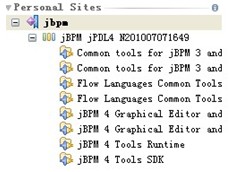 双击每一项,确保每一项被加入到了
双击每一项,确保每一项被加入到了
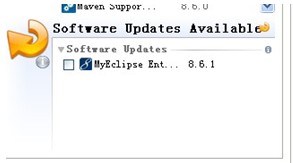
(说明:事实上不用选完,带source 的部件不用选择,为了省事就全部选择了)
提示:如果安装时不断网,jbpm 插件会自动到网上更新。同时会弹出一个错误窗口,安装速度异常缓慢。安装完成后,myeclipse 的references 菜单会变得面目全非。
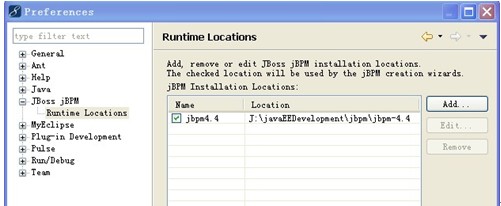
2. 搭建 jbpm 运行环境。
3 .然后配置jpdl 支持
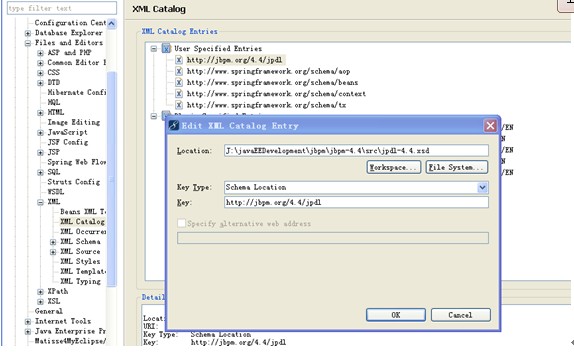
4. 确定是否配置jbpm 正确
在myeclipse->new->other->
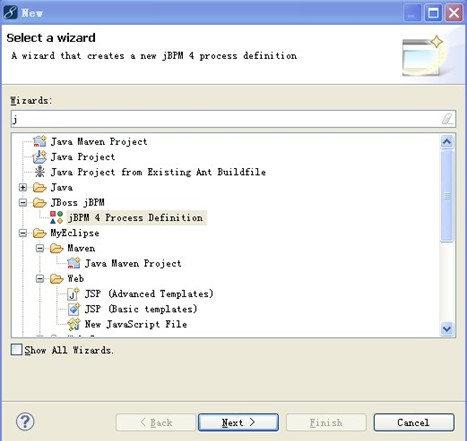
关于myeclipse 中配置jbpm 请参考jbpm 的帮助文档,文档给的是在eclipse 下配置jbpm 。
5. 测试运行环境:
新建一个 java 项目,将 jbpm-4.4/examples 下的 src 目录, copy 到项目中。然后引入相关 jar 包, jbpm.jar 和lib 下的所有包,先不考虑 jar 包选择问题。 Src 中包括了 jbpm 中的基本元素的使用。如 start , state , end ,sql , script , fork , join 等。然后跟着 jbpm 的帮助文档,一点一点的学习。

说说以上文件的作用:第一个是 jbpm 的配置文件,在这个文件又引入其他的文件,在被引入的文件有一个文件包含了
<hibernate-configuration> <cfg resource="jbpm.hibernate.cfg.xml" />
</hibernate-configuration> <hibernate-session-factory />
用于创建 hibernate 的 sessionfactory 并交给 jbpm 的 IOC 容器管理。
第二个文件是 hibernate 配置文件,里面包含了 jbpm 框架需要的表的 hbm.xml 配置文件。
Jbpm4.4+hibernate3.5.4+spring3.0.4+struts2.1. 整合环境搭建
我的开发环境:
tomcat6.0.28+mysql5.1.30+ Jbpm4.4+hibernate3.5.4+spring3.0.4+struts2.1.8+myeclipse8.6+java jdk 6.0.23
在搭建环境之前,先认识一下 jbpm 。 JBPM 在管理流程时,是需要数据库表的支持的,因为底层的逻辑有那么复杂。默认下载下来的配置,使用的是( hsqldb )内存数据库。实际应用中,我们就需要连接到我们的数据库里来。所以要事先建好相关的表,相应的 sql 文件在 /jbpm-4.4/install/src/db 下,当然,你也可以使用 hibernate的 hibernate.hbm2ddl.auto 自动建表,本人建议自己用建表语句,会少很多麻烦(本人在此处可没少碰麻烦)。如果不结合其他的框架进行整个开发( 如:spring 、hibernate),JBPM4 也有自己的一套IOC 容器,能后将自己的服务配置到IOC 容器中, 能够很容易的运行容器所配置的服务, 这样它也能够在代码中减少一陀一陀的工厂类等代码的调用, 降低了偶核性, 但是如果结合spring 框架来进行整个开发的话, 那么就有两个容器, 两个SessionFactory, 但是系统中只考虑一个容器来。对服务进行管理, 那么我们就要将jbpm4 的服务移植到spring 的IOC 容器中, 让spring 来进行统一管理, 这样通过spring 的容器来管理服务、事务。
整合目标:将jbpm4 的IOC 移植到Spring 中,让spring 管理一个sessionfactory ,同时需要明确一点的是:jbpm4 对外提供服务是 ProcessEngine 。如:
private RepositoryService repositoryService ;
private ExecutionService executionService ;
private HistoryService historyService ;
private TaskService taskService ;
private IdentityService identityService ;
上面这些服务就是通过 ProcessEngine 获得的。
Spring 配置文件:
<!--jbpm4.4 工作流 -->
< bean id = "springHelper" class ="org.jbpm.pvm.internal.processengine.SpringHelper" >
< property name = "jbpmCfg" value = "jbpm.cfg.xml" />
</ bean >
< bean id = "sessionFactory"
class = "org.springframework.orm.hibernate3.LocalSessionFactoryBean" >
<!--
<property name="configLocation">
<value>classpath:jbpm.hibernate.cfg.xml</value> </property>
-->
< property name = "dataSource" ref = "dataSource" />
< property name = "hibernateProperties" >
< props >
< prop key = "hibernate.dialect" >org.hibernate.dialect.MySQLInnoDBDialect </ prop >
< prop key = "hibernate.show_sql" > true </ prop >
< prop key = "hibernate.connection.pool_size" > 1 </ prop >
< prop key = "hibernate.format_sql" > true </ prop >
< prop key = "hibernate.hbm2ddl.auto" > update </ prop >
<!--
<prop key="hibernate.current_session_context_class">thread</prop>
-->
</ props >
</ property >
< property name = "mappingLocations" >
< list >
< value > classpath:jbpm.execution.hbm.xml </ value >
< value > classpath:jbpm.history.hbm.xml </ value >
< value > classpath:jbpm.identity.hbm.xml </ value >
< value > classpath:jbpm.repository.hbm.xml </ value >
< value > classpath:jbpm.task.hbm.xml </ value >
</ list >
</ property >
</ bean >
< bean
class ="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer" >
< property name = "locations" value = "classpath:jdbc.properties" ></ property >
</ bean >
< bean id = "dataSource"
class = "org.springframework.jdbc.datasource.DriverManagerDataSource" >
< property name = "driverClassName" value = "${jdbc.driverClassName}" />
< property name = "url" value = "${jdbc.url}" />
< property name = "username" value = "${jdbc.username}" />
< property name = "password" value = "${jdbc.password}" />
</ bean >
Jar 包选择:(没有选择,所以会有很多无用的)

基础知识:
在 jbpm4.4 目录 install/src/db/create 下有:

这些 sql 脚本所创建的表是 jbpm 能正常工作所必须的。我们可以直接运行这些 sql 在数据库建立起相关的表(共18 张,如下):
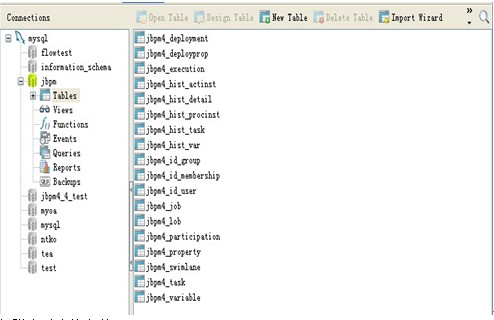
每张表对应的含义:
( 1 ) JBPM4_DEPLOYMENT
( 2 ) JBPM4_DEPLOYPROP
( 3 ) JBPM4_LOB :存储 上传一个包含 png 和 jpdl.xml 的 zip 包 的相关数据
jbpm4_deployment 表多了一条记录
jbpm4_deployprop 表多了四条记录 , 对应 langid,pdid,pdkey,pdversion
jbpm4_lob 表多了二条记录 , 保存流程图 png 图片和 jpdl.xml
( 4 ) JBPM4_HIST_PROCINST 与
( 5 ) JBPM4_HIST_ACTINST 分别存放的是 Process Instance 、 Activity Instance 的历史记
( 6 ) JBPM4_EXECUTION 主要是存放 JBPM4 的执行信息, Execution 机制代替了 JBPM3 的 Token 机制(详细参阅 JBPM4 的 PVM 机制)。
( 7 ) JBPM4_TASK 存放需要人来完成的 Activities ,需要人来参与完成的 Activity 被称为 Task 。
( 8 ) JBPM4_PARTICIPATION 存放 Participation 的信息, Participation 的种类有 Candidate 、 Client 、Owner 、 Replaced Assignee 和 Viewer 。而具体的 Participation 既可以是单一用户,也可以是用户组。
( 9 ) JBPM4_SWIMLANE 。 Swim Lane 是一种 Runtime Process Role 。通过 Swim Lane ,多个 Task 可以一次分配到同一 Actor 身上。
( 10 ) JBPM4_VARIABLE 存的是进行时的临时变量。
( 11 ) JBPM4_HIST_DETAIL 保存 Variable 的变更记录。
( 12 ) JBPM4_HIST_VAR 保存历史的变量。
( 13 ) JBPM4_HIST_TASKTask 的历史信息。
( 14 ) JBPM4_ID_GROUP
( 15 ) JBPM_ID_MEMBERSHIP
( 16 ) JBPM4_ID_USER 这三张表很常见了,基本的权限控制,关于用户认证方面建议还是自己开发一套,JBPM4 的功能太简单了,使用中有很多需要难以满足。
( 17 ) JBPM4_JOB 存放的是 Timer 的定义。
( 18 ) JBPM4_PROPERTY
你可以直接运行脚本,整合中有hibernate ,所以就用hibernate 自动创建。事实上jbpm 也是采用的hibernate 作为其持久化工具。
jbpm 4.4 中一些概念( 转自family168)
1, 流程定义(ProcessDefinition): 对整个流程步骤的描述., 相当于我们在编程过程过程用到的类, 是个抽象的概念.
2. 流程实例(ProcessInstance) 代表着流程定义的特殊执行例子, 相当于我们常见的对象. 他是类的特殊化.
最典型的属性就是跟踪当前节点的指针.
3. 流程引擎(ProcessEngine), 服务接口可以从 ProcessEngine 中获得, 它是从 Configuration 构建的, 如下:
ProcessEngine processEngine = new Configuration()
.buildProcessEngine();
从流程引擎中可以获得如下的服务:
RepositoryService repositoryService = processEngine.getRepositoryService();
ExecutionService executionService = processEngine.getExecutionService();
TaskService taskService = processEngine.getTaskService();
HistoryService historyService = processEngine.getHistoryService();
ManagementService managementService = processEngine.getManagementService();
4. 部署流程(Deploying a process):
RepositoryService 包含了用来管理发布资源的所有方法,
如下可以发布流程定义.
String deploymentid = repositoryService.createDeployment()
.addResourceFromClasspath("*.jpdl.xml")
.deploy();
这个id 的格式是(key)-{version}.
5. 删除流程定义:
repositoryService.deleteDeployment(deploymentId); 可以用级联的方式, 也可以remove
6. 启动一个新的流程实例:
ProcessInstance processInstance = executionService.startProcessInstanceByKey("key");
如果启动指定版本的流程定义 , 用下面的方法 :
ProcessInstance processInstance =executionService.startProcessInstanceById("ID");
7. 使用变量
当一个新的流程实例启动时就会提供一组对象参数。 将这些参数放在variables 变量里, 然后可以在流程实例创建和启动时使用。
Map<String,Object> variables = new HashMap<String,Object>();
variables.put("customer", "John Doe");
variables.put("type", "Accident");
variables.put("amount", new Float(763.74));
ProcessInstance processInstance =
executionService.startProcessInstanceByKey("ICL", variables);
8. 执行等待的流向:
当使用一个 state 活动时,执行(或流程实例) 会在到达state 的时候进行等待,
直到一个signal (也叫外部触发器)出现。 signalExecution 方法可以被用作这种情况。
执行通过一个执行id (字符串)来引用。
executionService.signalExecutionById(executionId);
9.TaskService 任务服务:
TaskService 的主要目的是提供对任务列表的访问途径。 例子代码会展示出如何为id 为 johndoe的
用户获得任务列表:
List<Task> taskList = taskService.findPersonalTasks("johndoe");
JBPM4 –ProcessEngine
在jBPM 内部通过各种服务相互作用。 服务接口可以从ProcessEngine 中获得, 它是从Configuration 构建的。
获得ProcessEngine : processEngine =Configuration.getProcessEngine ();
JBPM4 – RepositoryService
RepositoryService 包含了用来管理发布资源的所有方法。
部署流程
String deploymentid = repositoryService.createDeployment()
.addResourceFromClasspath("org/jbpm/examples/services/Order.jpdl.xml")
.deploy();
ZipInputStream zis = new ZipInputStream( this .getClass()
.getResourceAsStream( "/com/jbpm/source/leave.zip" ));
// 发起流程,仅仅就是预定义任务,即在系统中创建一个流程,这是全局的,与具体的登陆 用户无关。然后,在启动流程时,才与登陆用户关联起来
String did = repositoryService .createDeployment()
.addResourcesFromZipInputStream(zis).deploy();
通过上面的 addResourceFromClass 方法,流程定义 XML 的内容可以从文件,网址,字符串,输入流或 zip输入流中获得。
每次部署都包含了一系列资源。每个资源的内容都是一个字节数组。 jPDL 流程文件都是以 .jpdl.xml 作为扩展名的。其他资源是任务表单和 java 类。
部署时要用到一系列资源,默认会获得多种流程定义和其他的归档类型。 jPDL 发布器会自动识别后缀名是.jpdl.xml 的流程文件。
在部署过程中,会把一个 id 分配给流程定义。这个 id 的格式为 {key}-{version} , key 和 version 之间使用连字符连接。
如果没有提供 key (指在流程定义文件中,对流程的定义),会在名字的基础自动生成。生成的 key 会把所有不是字母和数字的字符替换成下划线。
同一个名称只能关联到一个 key ,反之亦然。
如果没有为流程文件提供版本号, jBPM 会自动为它分配一个版本号。请特别注意那些已经部署了的名字相同的流程文件的版本号。它会比已经部署的同一个 key 的流程定义里最大的版本号还大。没有部署相同 key 的流程定义的版本号会分配为 1 。
删除流程定义
删除一个流程定义会把它从数据库中删除。
repositoryService.deleteDeployment(deploymentId);
如果在发布中的流程定义还存在活动的流程实例,这个方法就会抛出异常。
如果希望级联删除一个发布中流程定义的所有流程实例,可以使用 deleteDeploymentCascade 。
JBPM4 – TaskService
TaskService 的主要目的是提供对任务列表的访问途径。 例子代码会展示出如何为 id 为 johndoe 的用户获得任务列表
List<Task> taskList = taskService.findPersonalTasks("johndoe");
一般来说,任务会对应一个表单,然后显示在一些用户接口中。 表单需要可以读写与任务相关的数据。
// read task variables
Set<String> variableNames = taskService.getVariableNames(taskId);
variables = taskService.getVariables(taskId, variableNames);
// write task variables
variables = new HashMap<String, Object>();
variables.put("category", "small");
variables.put("lires", 923874893);
taskService.setVariables(taskId, variables);
taskSerice 也用来完成任务。
taskService.completeTask(taskId);
taskService.completeTask(taskId, variables);
taskService.completeTask(taskId, outcome);
taskService.completeTask(taskId, outcome, variables);
这些 API 允许提供一个变量 map ,它在任务完成之前作为流程变量添加到流程里。 它也可能提供一个 “ 外出outcome” ,这会用来决定哪个外出转移会被选中。 逻辑如下所示:
如果一个任务拥有一个没用名称的外向转移:
taskService.getOutcomes() 返回包含一个 null 值集合,。
taskService.completeTask(taskId) 会使用这个外向转移。
taskService.completeTask(taskId, null) 会使用这个外向转移。
taskService.completeTask(taskId, "anyvalue") 会抛出一个异常。
如果一个任务拥有一个有名字的外向转移:
taskService.getOutcomes() 返回包含这个转移名称的集合。
taskService.completeTask(taskId) 会使用这个单独的外向转移。
taskService.completeTask(taskId, null) 会抛出一个异常(因为这里没有无名称的转移)。
taskService.completeTask(taskId, "anyvalue") 会抛出一个异常。
taskService.completeTask(taskId, "myName") 会根据给定的名称使用转移。
如果一个任务拥有多个外向转移,其中一个转移没有名称,其他转移都有名称:
taskService.getOutcomes() 返回包含一个 null 值和其他转移名称的集合。
taskService.completeTask(taskId) 会使用没有名字的转移。
taskService.completeTask(taskId, null) 会使用没有名字的转移。
taskService.completeTask(taskId, "anyvalue") 会抛出异常。
taskService.completeTask(taskId, "myName") 会使用名字为 'myName' 的转移。
如果一个任务拥有多个外向转移,每个转移都拥有唯一的名字:
taskService.getOutcomes() 返回包含所有转移名称的集合。
taskService.completeTask(taskId) 会抛出异常,因为这里没有无名称的转移。
taskService.completeTask(taskId, null) 会抛出异常,因为这里没有无名称的转移。
taskService.completeTask(taskId, "anyvalue") 会抛出异常。
taskService.completeTask(taskId, "myName") 会使用名字为 'myName' 的转移。
任务可以拥有一批候选人。候选人可以是用户也可以是用户组。用户可以接收自己是候选人的任务。接收任务的意思是用户会被设置为被分配给任务的人。在那之后,其他用户就不能接收这个任务了。
人们不应该在任务做工作,除非他们被分配到这个任务上。用户界面应该显示表单,如果他们被分配到这个任务上,就允许用户完成任务。对于有了候选人,但是还没有分配的任务,唯一应该暴露的操作就是 “ 接收任务 ” 。
JBPM4 – ExecutionService
最新的流程实例 -- ByKey
下面是为流程定义启动一个新的流程实例的最简单也是 最常用的方法:
ProcessInstance processInstance = executionService.startProcessInstanceByKey ("ICL");
上面 service 的方法会去查找 key 为 ICL 的最新版本的流程定义, 然后在最新的流程定义里启动流程实例。
当 key 为 ICL 的流程部署了一个新版本, startProcessInstanceByKey 方法会自动切换到最新部署的版本。
原来已经启动的流程,还是按照启动时刻的版本执行。
指定流程版本 -- ById
换句话说,你如果想根据特定的版本启动流程实例, 便可以使用流程定义的 id 启动流程实例。如下所示:
ProcessInstance processInstance = executionService.startProcessInstanceById ("ICL-1");
使用 key
我们可以为新启动的流程实例分配一个 key( 注意: 这个 key 不是 process 的 key ,而是启动的 instance 的key ) ,这个 key 是用户执行的时候定义的,有时它会作为 “ 业务 key” 引用。一个业务 key 必须在流程定义的所有版本范围内是唯一的。通常很容易在业务流程领域找到这种 key 。比如,一个订单 id 或者一个保险单号。
ProcessInstance processInstance = executionService.startProcessInstanceByKey ("ICL", "CL92837");
// 2 个参数:
// 第一个参数 processkey ,通过这个 key 启动 process 的一个实例
// 第二个参数为这里所说的实例 key(instance key)
key 可以用来创建流程实例的 id ,格式为 {process-key}.{execution-id} 。所以上面的代码会创建一个 id为 ICL.CL92837 的流向( execution )。
如果没有提供用户定义的 key ,数据库就会把主键作为 key 。 这样可以使用如下方式获得 id :
ProcessInstance processInstance = executionService.startProcessInstanceByKey ("ICL");
String pid = processInstance.getId();
最好使用一个用户定义的 key 。 特别在你的应用代码中,找到这样的 key 并不困难。提供给一个用户定义的key ,你可以组合流向的 id ,而不是执行一个基于流程变量的搜索 - 那种方式太消耗资源了。
使用变量
当一个新的流程实例启动时就会提供一组对象参数。 将这些参数放在 variables 变量里, 然后可以在流程实例创建和启动时使用。
Map<String,Object> variables = new HashMap<String,Object>();
variables.put("customer", "John Doe");
variables.put("type", "Accident");
variables.put("amount", new Float(763.74));
ProcessInstance processInstance = executionService.startProcessInstanceByKey ("ICL", variables);
启动 instance
启动 instance ,必须要知道 processdefinition 的信息: processdefinition 可以通过 2 种方式获取:
ByKey :通过 ProcessKey ,启动该 Process 的最新版本
ById : 通过 Process 的 ID ,启动该 Process 的特定的版本
其他的参数,其余还可以在启动 Instance 的时候,给流程 2 个参数:
InstanceKey :这个 instanceKey 必须在整个流程定义的所有范围版本中唯一,如果用户不给于提供,系统也会自己生成;
一个 Map<String, ?> 表:启动流程时候给予的变量信息
执行等待的流向
当使用一个 state 活动时,执行(或流程实例)会在到达 state 的时候进行等待,直到一个 signal (也叫外部触发器)出现。 signalExecution 方法可以被用作这种情况。执行通过一个执行 id (字符串)来引用。
在一些情况下,到达 state 的执行会是流程实例本身。但是这不是一直会出现的情况。在定时器和同步的情况,流程是执行树形的根节点。所以我们必须确认你的 signal 作用在正确的流程路径上。
获得正确的执行的比较好的方法是给 state 活动分配一个事件监听器,像这样:
<state name="wait">
<on event="start">
<event-listener class="org.jbpm.examples.StartExternalWork" />
</on>
...
</state>
在事件监听器 StartExternalWork 中,你可以执行那些需要额外完成的部分。在这个事件监听器里,你也可以通过 execution.getId() 获得确切的流程 id 。那个流程 id ,在额外的工作完成后,你会需要它来提供给 signal操作的:
executionService.signalExecutionById (executionId);
这里有一个可选的(不是太推荐的)方式,来获得流程 id ,当流程到达 state 活动的时候。只可能通过这种方式获得执行 id ,如果你知道哪个 JBPM API 调用了之后,流程会进入 state 活动:
// assume that we know that after the next call
// the process instance will arrive in state external work
ProcessInstance processInstance = executionService.startProcessInstanceById(processDefinitionId);
// or ProcessInstance processInstance =
// executionService.signalProcessInstanceById(executionId);
Execution execution = processInstance.findActiveExecutionIn("external work");
String executionId = execution.getId();
JBPM4 – HistoryService
在流程实例执行的过程中,会不断触发事件。从那些事件中,运行和完成流程的历史信息会被收集到历史表中。
HistoryService 提供了 对那些信息的访问功能。
如果想查找某一特定流程定义的所有流程实例, 可以像这样操作:
List<HistoryProcessInstance> historyProcessInstances = historyService
.createHistoryProcessInstanceQuery()
.processDefinitionId("ICL-1")
.orderAsc(HistoryProcessInstanceQuery.PROPERTY_STARTTIME)
.list();
单独的活动流程也可以作为 HistoryActivityInstance 保存到历史信息中。
List<HistoryActivityInstance> histActInsts = historyService
.createHistoryActivityInstanceQuery()
.processDefinitionId("ICL-1")
.activityName("a")
.list();
也可以使用简易方法 avgDurationPerActivity 和 choiceDistribution 。可以通过 javadocs 获得这些方法的更多信息。
有时,我们需要获得指定流程实例已经过的节点的完整列表。下面的查询语句可以用来获得所有已经执行的节点列表:
List<HistoryActivityInstance> histActInsts = historyService
.createHistoryActivityInstanceQuery()
.processInstanceId("ICL.12345")
.list();
上面的查询与通过 execution id 查询有一些不同。有时 execution id 和流程实例 id 是不同的, 当一个节点中使用了定时器, execution id 中就会使用额外的后缀, 这就会导致当我们通过 execution id 查询时, 这个节点不会出现在结果列表中。
整合过程中常见问题的解决
错误 1 : java.lang.LinkageError: loader constraint violation: when resolving interface method "javax.servlet.jsp.JspApplicationContext.getExpressionFactory()Ljavax/el/ExpressionFactory;" the class loader (instance of org/apache/jasper/servlet/JasperLoader) of the current class, org/apache/jsp/index_jsp, and the class loader (instance of org/apache/catalina/loader/StandardClassLoader) for resolved class, javax/servlet/jsp/JspApplicationContext, have different Class objects for the type javax/el/ExpressionFactory used in the signature
错误的解决办法。( Tomcat6.0.28 )
exception
javax.servlet.ServletException: java.lang.LinkageError: loader constraint violation: when resolving interface method "javax.servlet.jsp.JspApplicationContext.getExpressionFactory()Ljavax/el/ExpressionFactory;" the class loader (instance of org/apache/jasper/servlet/JasperLoader) of the current class, org/apache/jsp/OnDuty/wfmanage_jsp, and the class loader (instance of org/apache/catalina/loader/StandardClassLoader) for resolved class, javax/servlet/jsp/JspApplicationContext, have different Class objects for the type javax/el/ExpressionFactory used in the signature org.apache.jasper.servlet.JspServlet.service(JspServlet.java:275) javax.servlet.http.HttpServlet.service(HttpServlet.java:717)
root cause
java.lang.LinkageError: loader constraint violation: when resolving interface method "javax.servlet.jsp.JspApplicationContext.getExpressionFactory()Ljavax/el/ExpressionFactory;" the class loader (instance of org/apache/jasper/servlet/JasperLoader) of the current class, org/apache/jsp/OnDuty/wfmanage_jsp, and the class loader (instance of org/apache/catalina/loader/StandardClassLoader) for resolved class, javax/servlet/jsp/JspApplicationContext, have different Class objects for the type javax/el/ExpressionFactory used in the signature org.apache.jsp.OnDuty.wfmanage_jsp._jspInit(wfmanage_jsp.java:27) org.apache.jasper.runtime.HttpJspBase.init(HttpJspBase.java:52) org.apache.jasper.servlet.JspServletWrapper.getServlet(JspServletWrapper.java:159) org.apache.jasper.servlet.JspServletWrapper.service(JspServletWrapper.java:329) org.apache.jasper.servlet.JspServlet.serviceJspFile(JspServlet.java:342) org.apache.jasper.servlet.JspServlet.service(JspServlet.java:267) javax.servlet.http.HttpServlet.service(HttpServlet.java:717)
原因是项目中WEB-INF/lib 中的三个jar 包 (juel.jar, juel-engine.jar, juel-impl.jar )和tomcat6 下lib 中jar 包( el-api.jar ) 冲突
解决方法:
方法一:换成tomcat5.5 一点问题也没有了(有新版本了还用老版本?)
方法二:将 juel.jar, juel-engine.jar, juel-impl.jar 这三个包复制到tomcat6 下lib 中,并删除原来的 el-api.jar ,切记要把WEB-INF/lib 中的juel.jar, juel-engine.jar, juel-impl.jar 删除。不然还是要冲突。
错误 2 : org.jbpm.api.JbpmException: No unnamed transitions were found for the task '??'
如果一个任务拥有一个没用名称的外向转移:
taskService.getOutcomes() 返回包含一个 null 值集合,。 taskService.completeTask(taskId) 会使用这个外向转移。 taskService.completeTask(taskId, null) 会使用这个外向转移。taskService.completeTask(taskId, "anyvalue") 会抛出一个异常。
如果一个任务拥有一个有名字的外向转移:
gtaskService.getOutcomes() 返回包含这个转移名称的集合。 taskService.completeTask(taskId) 会使用这个单独的外向转移。 taskService.completeTask(taskId, null) 会抛出一个异常(因为这里没有无名称的转移)。 taskService.completeTask(taskId, "anyvalue") 会抛出一个异常。taskService.completeTask(taskId, "myName") 会根据给定的名称使用转移。
如果一个任务拥有多个外向转移,其中一个转移没有名称,其他转移都有名称:
taskService.getOutcomes() 返回包含一个 null 值和其他转移名称的集合。taskService.completeTask(taskId) 会使用没有名字的转移。 taskService.completeTask(taskId, null) 会使用没有名字的转移。 taskService.completeTask(taskId, "anyvalue") 会抛出异常。taskService.completeTask(taskId, "myName") 会使用名字为 'myName' 的转移。
如果一个任务拥有多个外向转移,每个转移都拥有唯一的名字:
taskService.getOutcomes() 返回包含所有转移名称的集合。 taskService.completeTask(taskId) 会抛出异常,因为这里没有无名称的转移。 taskService.completeTask(taskId, null) 会抛出异常,因为这里没有无名称的转移。 taskService.completeTask(taskId, "anyvalue") 会抛出异常。taskService.completeTask(taskId, "myName") 会使用名字为 'myName' 的转移。
解决方案:
根据以上分析,可得到解决方案:
1 、只拥有一个外向转移时(对应上文所述 1 、 2 情况):
Map map = new HashMap();
map.put("",…… ) // 各种参数
taskService.setVariables(taskId,map);
taskService.completeTask(taskId);
3 、拥有多个外向转移时(上文 3 、 4 种情况):
Map map = new HashMap();
map.put("",…… ) // 各种参数
taskService.setVariables(taskId,map);
// 如想转移至有名称的外向转移:
taskService.completeTask(taskId," 外向转移名称 ");
// 如想转移至无名称的外向转移:
taskService.completeTask(taskId);
错误3 :*.jpdl.xml 中文乱码问题。
在myeclipse 的配置文件myeclipse.ini 中加入:
-DFile.encoding=UTF-8
请假流程例子( s2sh+jbpm )
流程图:

<? xml version = "1.0" encoding = "UTF-8" ?>
< process name = "leave" xmlns = "http://jbpm.org/4.4/jpdl" >
< start g = "214,37,48,48" name = "start1" >
< transition g = "-47,-17" name = "to 申请 " to = " 申请 " />
</ start >
< task assignee = "#{owner}" form = "request.html" g = "192,126,92,52" name = " 申请 ">
< transition g = "-71,-17" name = "to 经理审批 " to = " 经理审批 " />
</ task >
< task assignee = "manager" form = "manager.html" g = "194,241,92,52" name = " 经理审批 " >
< transition g = "-29,-14" name = " 批准 " to = "exclusive1" />
< transition g = "105,267;103,152:-47,-17" name = " 驳回 " to = " 申请 " />
</ task >
< decision expr = "#{day > 3 ? ' 老板审批 ' : ' 结束 '}" g = "218,342,48,48" name ="exclusive1" >
< transition g = "415,367:-47,-17" name = " 老板审批 " to = " 老板审批 " />
< transition g = "-31,-16" name = " 结束 " to = "end1" />
</ decision >
< end g = "219,499,48,48" name = "end1" />
< task assignee = "boss" form = "boss.html" g = "370,408,92,52" name = " 老板审批 " >
< transition g = "415,524:-91,-18" name = " 结束 " to = "end1" />
</ task >
</ process >
步骤:
发布流程:将画好的流程图,发布到jbpm 框架中(放到jbpm 数据库中),这个流程是全局的,与用户无关。发布流程后会返回一个流程id ,我们会用流程id 得到 ProcessDefinition 流程定义。 发布方法如下:
public void deploy() {
// repositoryService.createDeployment().addResourceFromClasspath(
// "/com /jbpm /source/leave.jpdl.xml").deploy();
ZipInputStream zis = new ZipInputStream( this .getClass()
.getResourceAsStream( "/com/jbpm/source/leave.zip" ));
// 发起流程,仅仅就是预定义任务,即在系统中创建一个流程,这是全局的,与具体的登陆 用户无关。然后,在启动流程时,才与登陆用户关联起来
String did = repositoryService .createDeployment()
.addResourcesFromZipInputStream(zis).deploy();
}
启动流程:流程定义好后,并不能用,我们需要将其实例化,实例化流程将关联用户,同时将实例写入数据库中。启动流程方法如下:
public void start(String id, Map<String , Object> map) {
executionService .startProcessInstanceById(id, map);
}
流程一旦启动就通过start 节点,流到下一个任务节点。
获取待办任务列表:不同的用户登录后通过如下方式获得自己的待办任务
public List<Task> getTasks(String roleName) {
return taskService .findPersonalTasks(roleName);
}
在流程中每一个任务节点都关联了一个 action 请求,用于处理待办任务的视图( view )
不多说了,哥就相信源码: http://download.csdn.net/source/3223403
总结及参考文章:
参考文章:http://www.blogjava.net/paulwong/archive/2009/09/07/294114.html
http://zjkilly.iteye.com/blog/738426
http://fish119.iteye.com/blog/779379
http://alimama.iteye.com/blog/567651
其他参考资料: family168 网, http://code.google.com/p/family168/downloads/list
控制流程活动:

原子活动:




相关推荐
【JBPM4.4+Hibernate3.5.4+Spring3.0.4+Struts2.1.8整合】的整个过程涉及到多个关键组件的集成,这些组件都是Java企业级开发中的重要部分。首先,JBPM(Business Process Management)是一个开源的工作流引擎,它...
内容概要:本文详细介绍了利用C++编程和Comsol软件进行锂电池内部枝晶生长过程的多物理场耦合仿真。首先探讨了枝晶生长对浓度场、电场、温度场以及应力场的敏感性,并展示了相应的数学模型和C++代码实现。接着讨论了采用元胞自动机(CA)和格子玻尔兹曼方法(LBM)来模拟枝晶的非均匀生长特性,特别是通过引入偏心正方算法改进了传统CA模型的方向局限性。此外,文中还涉及了如何将多种物理场(如浓度场、电场、温度场、应力场和流场)耦合在一起,形成完整的多物理场仿真系统。最后,作者分享了一些实用的经验和技术细节,比如参数调整技巧、避免常见错误的方法等。 适合人群:从事锂电池研究的专业人士,尤其是对电池安全性和性能优化感兴趣的科研工作者和技术开发者。 使用场景及目标:适用于希望深入了解锂电池内部枝晶生长机制的研究人员,旨在帮助他们构建更加精确的仿真模型,从而更好地理解和解决枝晶引起的电池安全隐患。 其他说明:文章不仅提供了理论分析,还包括具体的代码实例,便于读者动手实践。同时强调了多物理场耦合的重要性,指出这是提高仿真精度的关键因素之一。
# 基于STM32F10x微控制器的综合驱动库 ## 项目简介 本项目是一个基于STM32F10x系列微控制器的综合驱动库,旨在为开发者提供一套全面、易于使用的API,用于快速搭建和配置硬件资源,实现高效、稳定的系统功能。项目包含了STM32F10x系列微控制器的基本驱动和常用外设(如GPIO、SPI、Timer、RTC、ADC、CAN、DMA等)的驱动程序。 ## 项目的主要特性和功能 1. 丰富的外设驱动支持支持GPIO、SPI、Timer、RTC、ADC、CAN、DMA等外设的初始化、配置、读写操作和中断处理。 2. 易于使用的API接口提供统一的API接口,简化外设操作和配置,使开发者能够专注于应用程序逻辑开发。 3. 全面的时钟管理功能支持系统时钟、AHB时钟、APB时钟的生成和配置,以及时钟源的选择和配置。 4. 电源管理功能支持低功耗模式、电源检测和备份寄存器访问,帮助实现节能和延长电池寿命。
# 基于Python和TensorFlow的甲骨文识别系统 ## 项目简介 本项目是一个基于Python和TensorFlow的甲骨文识别系统,旨在利用深度学习技术,尤其是胶囊网络(Capsule Network)来识别甲骨文图像。项目包括数据集准备、模型构建、训练、测试以及评估等关键步骤。 ## 主要特性和功能 1. 数据准备项目提供了数据集的下载、预处理以及分割为训练集、验证集和测试集的功能。 2. 模型构建实现了基于胶囊网络的甲骨文识别模型,包括基本的CapsNet模型、分布式CapsNet模型以及支持多任务学习的CapsNet模型。 3. 训练与测试提供了训练模型、评估模型性能以及可视化训练过程的功能。 4. 性能评估通过测试集评估模型的识别准确率,并提供了测试结果的详细分析。 ## 安装使用步骤 1. 环境准备安装Python和TensorFlow,以及相关的依赖库。 2. 数据准备 下载MNIST或CIFAR数据集
# 基于C++的Arduino BLE设备交互库 ## 项目简介 本项目是一个用于与BLE(蓝牙低能耗)设备交互的Arduino库。它为使用Arduino平台的开发者提供了与BLE设备通信所需的功能,能让开发者更轻松地将BLE设备集成到自己的项目中。 ## 项目的主要特性和功能 1. 初始化BLE设备调用begin()方法,可初始化BLE设备并启动通信。 2. 扫描和连接设备利用scan()方法扫描附近的BLE设备,通过connect()方法连接特定设备。 3. 读取和写入数据使用read()和write()方法,实现从BLE设备读取数据或向其写入数据。 4. 处理事件通过setEventHandler()方法注册回调函数,处理BLE事件,如连接成功、断开连接等。 5. 控制广播和广告使用advertise()和stopAdvertise()方法,控制BLE设备的广播和广告功能。
内容概要:本文详细探讨了利用ANSYS Fluent对增材制造中激光熔覆同轴送粉技术的熔池演变进行模拟的方法。文中介绍了几个关键技术模块,包括高斯旋转体热源、VOF梯度计算、反冲压力和表面张力的UDF(用户自定义函数)实现。通过这些模块,可以精确模拟激光能量输入、熔池内的多相流行为以及各种物理现象如表面张力和反冲压力的作用。此外,文章展示了如何通过调整参数(如激光功率)来优化制造工艺,并提供了具体的代码示例,帮助读者理解和实现这些复杂的物理过程。 适合人群:从事增材制造领域的研究人员和技术人员,尤其是那些希望深入了解激光熔覆同轴送粉技术背后的物理机制并掌握相应模拟工具的人群。 使用场景及目标:适用于需要对增材制造过程中的熔池演变进行深入研究的情景,旨在提高制造质量和效率。具体目标包括但不限于:理解熔池内部的温度场和流场分布规律,评估不同参数对熔池形态的影响,预测可能出现的问题并提出解决方案。 其他说明:文章不仅提供了详细的理论背景介绍,还包括了大量的代码片段和实例解析,使读者能够在实践中更好地应用所学知识。同时,通过对实际案例的讨论,揭示了增材制造过程中的一些常见挑战及其应对策略。
内容概要:本文详细介绍了在COMSOL中构建三维激光切割过程中涉及的热流耦合模型的方法和技术要点。主要内容涵盖水平集物理场用于追踪材料界面变形、流体传热用于描述熔池流动和热传导的相互作用以及层流分析用于处理熔融金属流动。文中提供了具体的MATLAB代码片段,展示了如何设置材料属性、热源加载、熔融金属流动方程、求解器配置及后处理步骤。此外,还讨论了常见问题及其解决方案,如界面过渡区厚度的选择、热源加载的技术细节、表面张力系数的设置、求解器配置的技巧等。 适合人群:从事激光切割工艺研究、仿真建模的研究人员和工程师,尤其是熟悉COMSOL Multiphysics平台的用户。 使用场景及目标:适用于希望深入了解并优化激光切割过程中的热流耦合仿真的研究人员和工程师。主要目标是提高仿真精度,优化切割参数,改善切割质量和效率。 其他说明:文章不仅提供理论指导,还包括大量实用的操作建议和调试技巧,帮助用户更好地理解和应用COMSOL进行复杂物理现象的模拟。
# 基于PythonDjango和Vue的美多电商平台 ## 项目简介 本项目是一个基于PythonDjango和Vue的B2C电商平台,名为美多商城,专注于销售自营商品。系统前台具备商品列表展示、商品详情查看、商品搜索、购物车管理、订单支付、评论功能以及用户中心等核心业务功能系统后台涵盖商品管理、运营管理、用户管理和系统设置等系统管理功能。同时,项目新增了统一异常处理、状态码枚举类等设计,避免使用魔法值,提升了项目的可扩展性和可维护性。 ## 项目的主要特性和功能 ### 前台功能 1. 商品相关提供商品列表展示、商品详情查看以及商品搜索功能,方便用户查找心仪商品。 2. 购物车支持用户添加、管理商品,方便集中结算。 3. 订单支付集成阿里支付,支持订单创建、支付及支付结果处理。 4. 评论用户可对商品进行评价,分享购物体验。 5. 用户中心支持用户注册、登录、密码修改、邮箱验证、地址管理等操作。 ### 后台功能
目前最火的C/C++和Java蓝桥杯竞赛练习题,充分备战竞赛,目前最火的C/C++和Java蓝桥杯竞赛练习题,充分备战竞赛,目前最火的C/C++和Java蓝桥杯竞赛练习题,充分备战竞赛 目前最火的C/C++和Java蓝桥杯竞赛练习题,充分备战竞赛,目前最火的C/C++和Java蓝桥杯竞赛练习题,充分备战竞赛,目前最火的C/C++和Java蓝桥杯竞赛练习题,充分备战竞赛~ 目前最火的C/C++和Java蓝桥杯竞赛练习题,充分备战竞赛,目前最火的C/C++和Java蓝桥杯竞赛练习题,充分备战竞赛,目前最火的C/C++和Java蓝桥杯竞赛练习题,充分备战竞赛 目前最火的C/C++和Java蓝桥杯竞赛练习题,充分备战竞赛,目前最火的C/C++和Java蓝桥杯竞赛练习题,充分备战竞赛,目前最火的C/C++和Java蓝桥杯竞赛练习题,充分备战竞赛 目前最火的C/C++和Java蓝桥杯竞赛练习题,充分备战竞赛,目前最火的C/C++和Java蓝桥杯竞赛练习题,充分备战竞赛,目前最火的C/C++和Java蓝桥杯竞赛练习题,充分备战竞赛
# 基于Python和Nonebot框架的HoshinoBot ## 项目简介 HoshinoBot是一个基于Python和Nonebot框架的开源QQ机器人项目,专为公主连结Re:Dive(PCR)和舰队收藏(KanColle)玩家设计。它提供了丰富的功能,旨在增强玩家的游戏体验和社区互动。 ## 项目的主要特性和功能 转蛋模拟支持单抽、十连抽和抽一井功能,模拟游戏中的抽卡体验。 竞技场解法查询提供竞技场解法查询,支持按服务器过滤,并允许用户反馈点赞或点踩。 竞技场结算提醒自动提醒竞技场结算时间,帮助玩家及时参与。 公会战管理提供详细的公会战管理功能,包括成员管理、战斗记录等。 Rank推荐表搬运自动搬运和更新Rank推荐表,帮助玩家选择最佳角色。 常用网址速查提供常用游戏网址的快速查询,方便玩家访问。 官方推特转发自动转发官方推特消息,确保玩家不会错过任何重要更新。 官方四格推送定期推送官方四格漫画,增加玩家的娱乐性。
图书管理小项目完结(完善新增页面)
# 基于Arduino的超声波距离测量系统 ## 项目简介 本项目是一个基于Arduino平台的超声波距离测量系统。系统包含四个超声波传感器(SPS)模块,用于测量与前方不同方向物体的距离,并通过蜂鸣器(Buzz)模块根据距离范围给出不同的反应。 ## 项目的主要特性和功能 1. 超声波传感器(SPS)模块每个模块包括一个超声波传感器和一个蜂鸣器。传感器用于发送超声波并接收回波,通过计算超声波旅行时间来确定与物体的距离。 2. 蜂鸣器(Buzz)模块根据超声波传感器测量的距离,蜂鸣器会给出不同的反应,如延时发声。 3. 主控制器(Arduino)负责控制和管理所有传感器和蜂鸣器模块,通过串行通信接收和发送数据。 4. 任务管理通过主控制器(Arduino)的 loop() 函数持续执行传感器任务(Task),包括测距、数据处理和蜂鸣器反应。 ## 安装使用步骤 1. 硬件连接
题目:基于单片机的幼儿安全监控报警系统设计 主控:STM32F103C8T6 显示:OLED ESP32 红外对管 火焰传感器 烟雾传感器 按键 继电器+水泵 蜂鸣器+led小灯 电源 1.实时监控:系统能够实时监控幼儿的活动区域,了解幼儿的活动情况。 2.入侵检测:系统可以设置安全区域,当有陌生人或动物进入该区域时, 系统会立即发出警报。 3.紧急呼叫:幼儿在遇到紧急情况时,可以通过按下紧急呼叫按钮触发声光报警, 通知教师或监护人。 4.远程监控与通知:教师或监护人可以通过手机远程监控幼儿的安全状况 5.火灾报警:当检测到着火点且烟雾浓度高于阈值,启动声光报警并自动打开水泵抽水进行灭火
内容概要:该MATLAB函数 `robot_calc.m` 实现了一个12维机器人系统的动力学模型计算,主要用于模拟机器人的运动状态。它基于拉格朗日动力学方程,通过质量矩阵 `M`、科里奥利力/向心力矩阵 `N`、约束矩阵 `C` 和输入矩阵 `E` 描述机器人的运动方程。函数接收当前时间和状态向量作为输入,输出状态导数,包括速度和加速度。控制输入通过外部扭矩 `tau` 模拟,数值求解采用伪逆方法确保稳定性。核心步骤包括参数定义、矩阵计算、动力学方程求解和状态导数输出。; 适合人群:具备一定MATLAB编程基础和机器人动力学理论知识的研究人员、工程师和高校学生。; 使用场景及目标:①机器人控制仿真,测试控制算法(如PID、轨迹跟踪)的表现;②运动规划,模拟机器人在给定扭矩下的运动轨迹;③参数优化,通过调整物理参数优化机器人动态性能。; 其他说明:需要注意的是,当前扭矩 `tau` 是硬编码的,实际应用中应替换为控制器的输出。此外,代码中部分参数单位不一致,需确保单位统一。建议改进方面包括动态输入扭矩、添加可视化功能和参数化管理物理参数。
内容概要:本文介绍了一种创新的光伏数据分类预测方法,采用CPO(冠豪猪优化算法)、Transformer和LSTM三种技术相结合的方式。首先进行数据预处理,包括数据加载、标准化和构建数据迭代器。然后详细介绍了模型架构,包括Transformer编码器捕捉特征间的关系,LSTM处理时间序列模式,以及CPO用于优化关键参数如隐藏层节点数、学习率等。实验结果显示,该模型在处理突变数据方面表现出色,特别是在光伏功率预测和异常检测任务中,相比传统LSTM模型有显著提升。 适合人群:具有一定机器学习基础的研究人员和技术开发者,尤其是关注光伏预测和时序数据分析的人士。 使用场景及目标:适用于需要处理复杂时序数据的任务,如光伏功率预测、电力负荷预测、故障诊断等。主要目标是提高预测准确性,尤其是在面对突变数据时的表现。 其他说明:文中提供了详细的代码示例和优化技巧,如数据预处理、模型结构调整、早停机制等。此外,还给出了可视化工具和一些实用的避坑指南,帮助初学者更好地理解和应用这一模型。
内容概要:本文详细介绍了如何利用Matlab对传统人工势场法(APF)进行改进,以解决其在路径规划中存在的局部极小值和目标不可达问题。主要改进措施包括重构斥力函数,在靠近目标时使斥力随目标距离衰减,以及引入模拟退火算法用于跳出局部极小值。文中提供了详细的代码示例,展示了传统APF与改进版APF在不同障碍物布局下的表现对比,验证了改进算法的有效性和鲁棒性。 适合人群:具有一定编程基础并熟悉Matlab环境的研究人员、工程师和技术爱好者。 使用场景及目标:适用于需要进行路径规划的机器人导航系统或其他自动化设备,旨在提高路径规划的成功率和效率,特别是在复杂环境中。 其他说明:文章不仅提供了理论解释,还有具体的代码实现和测试案例,帮助读者更好地理解和应用改进后的APF算法。同时,附带的场力可视化工具使得势场分布更加直观易懂。
内容概要:本文介绍了一款用于将Simulink模型自动转换为PDF文档的脚本工具。该工具能够自动化生成文档,提取模型中各模块的注释并转化为PDF中的说明文字,整合来自Excel的数据并生成表格,分模块分层打印模型图片,最终生成结构清晰的PDF文档。通过递归遍历模型结构,确保文档的章节结构与模型层次保持一致。此外,还包括自动检测未注释模块等功能,极大提高了文档生成效率和准确性。 适合人群:从事Simulink模型开发和维护的工程师,尤其是那些需要频繁编写和更新模型文档的人员。 使用场景及目标:适用于需要快速生成高质量模型文档的场合,如项目交付、技术评审等。主要目标是提高文档编写效率,减少手动操作带来的错误,确保文档与模型的一致性。 其他说明:该工具采用MATLAB和Python混合开发,支持Windows和Linux平台,可通过持续集成(CI/CD)管道自动化运行,进一步提升工作效率。
# 基于Python和树莓派的智能语音闹钟 ## 项目简介 “RaspberryClock”是一个基于树莓派4B的智能语音闹钟项目,使用Python 3.8开发。该项目集成了时间显示、温湿度监测、天气查询、语音提醒以及与图灵机器人对话等功能,旨在为用户提供一个功能丰富且易于使用的智能闹钟解决方案。 ## 项目的主要特性和功能 1. 时间显示实时显示当前时间。 2. 温湿度监测通过DHT11温湿度传感器读取并显示环境温湿度数据。 3. 天气查询通过API查询并显示当前天气信息。 4. 语音提醒支持语音播放和录音功能,用户可以设置语音提醒。 5. 与图灵机器人对话支持语音输入并与图灵机器人进行对话。 6. 用户界面使用Qt库创建友好的用户界面,操作便捷。 ## 安装使用步骤 假设用户已经安装了树莓派和Python环境,以下是项目的安装和使用步骤 1. 下载项目将项目文件下载并解压到树莓派的指定目录。
# 基于PaddleDetection和Docker的深度学习模型部署系统 ## 项目简介 本项目旨在利用Docker容器技术,将PaddleDetection训练的深度学习模型进行快速部署和推理。通过Docker镜像的制作和发布,用户可以在不安装复杂依赖的情况下,轻松实现模型的推理任务。项目特别适用于需要快速部署深度学习模型的场景,如工业检测、图像识别等。 ## 项目的主要特性和功能 1. 模型训练与推理基于PaddleDetection框架训练深度学习模型,支持PPYOLOE等目标检测模型。 2. Docker容器化部署通过Docker将训练好的模型和运行环境打包成镜像,实现一键化部署。 3. 图像推理支持对本地图像进行推理,并将结果保存到指定目录。 4. 镜像发布与测试支持将Docker镜像发布到阿里云等容器镜像服务,并支持从云端拉取镜像进行测试。 ## 安装使用步骤 ### 1. 安装Docker
内容概要:本文介绍了一种将PCA(主成分分析)和BP(反向传播)神经网络相结合的多变量回归预测方法,并提供了完整的Matlab代码实现。主要内容包括数据预处理、PCA降维、BP神经网络构建与训练、预测结果可视化以及性能评估。文中详细展示了如何通过PCA降维减少数据维度并计算原始特征的贡献率,同时利用BP神经网络进行回归预测,最终生成预测效果对比图、误差分布直方图等多种图表,并计算了多个评价指标如R²、MAE、RMSE等。 适用人群:适用于具有一定Matlab基础的数据分析师、机器学习爱好者及科研工作者。 使用场景及目标:①用于处理高维数据集,降低维度的同时保留重要特征;②通过BP神经网络实现高效的回归预测任务;③提供详细的代码注释和可视化工具,帮助用户快速理解和应用。 其他说明:代码中包含了多种实用的功能,如自动保存关键参数到Excel、自动生成多种类型的图表等。此外,还给出了常见的错误避免建议和技术细节说明。