概念
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜寻引擎还会使用基于连结分析的评级方法,以确定文件在搜寻结果中出现的顺序。
原理
在一份给定的文件里,词频 (term frequency, TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(分子一般小于分母 区别于IDF),以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)
逆向文件频率 (inverse document frequency, IDF) 是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TFIDF实际上是:TF * IDF,TF词频(Term Frequency),IDF反文档频率(Inverse Document Frequency)。TF表示词条在文档d中出现的频率(另一说:TF词频(Term Frequency)指的是某一个给定的词语在该文件中出现的次数)。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m+k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。(另一说:IDF反文档频率(Inverse Document Frequency)是指果包含词条的文档越少,IDF越大,则说明词条具有很好的类别区分能力。)但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。这就是IDF的不足之处.
在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)对于在某一特定文件里的词语 来说,它的重要性可表示为:
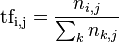
以上式子中 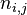 是该词在文件
是该词在文件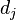 中的出现次数,而分母则是在文件中所有字词的出现次数之和。
中的出现次数,而分母则是在文件中所有字词的出现次数之和。
逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:
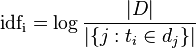
其中
- |D|:语料库中的文件总数
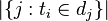 :包含词语的文件数目(即
:包含词语的文件数目(即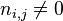 的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用
的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用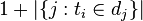
然后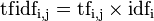
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
示例
一:有很多不同的数学公式可以用来计算TF-IDF。这边的例子以上述的数学公式来计算。词频 (TF) 是一词语出现的次数除以该文件的总词语数。假如一篇文件的总词语数是100个,而词语“母牛”出现了3次,那么“母牛”一词在该文件中的词频就是3/100=0.03。一个计算文件频率 (DF) 的方法是测定有多少份文件出现过“母牛”一词,然后除以文件集里包含的文件总数。所以,如果“母牛”一词在1,000份文件出现过,而文件总数是10,000,000份的话,其逆向文件频率就是 log(10,000,000 / 1,000)=4。最后的TF-IDF的分数为0.03 * 4=0.12。
二:根据关键字k1,k2,k3进行搜索结果的相关性就变成TF1*IDF1 + TF2*IDF2 + TF3*IDF3。比如document1的term总量为1000,k1,k2,k3在document1出现的次数是100,200,50。包含了 k1, k2, k3的docuement总量分别是 1000, 10000,5000。document set的总量为10000。 TF1 = 100/1000 = 0.1 TF2 = 200/1000 = 0.2 TF3 = 50/1000 = 0.05 IDF1 = log(10000/1000) = log(10) = 2.3 IDF2 = log(10000/100000) = log(1) = 0; IDF3 = log(10000/5000) = log(2) = 0.69 这样关键字k1,k2,k3与docuement1的相关性= 0.1*2.3 + 0.2*0 + 0.05*0.69 = 0.2645 其中k1比k3的比重在document1要大,k2的比重是0.
三:在某个一共有一千词的网页中“原子能”、“的”和“应用”分别出现了 2 次、35 次 和 5 次,那么它们的词频就分别是 0.002、0.035 和 0.005。 我们将这三个数相加,其和 0.042 就是相应网页和查询“原子能的应用” 相关性的一个简单的度量。概括地讲,如果一个查询包含关键词 w1,w2,...,wN, 它们在一篇特定网页中的词频分别是: TF1, TF2, ..., TFN。 (TF: term frequency)。 那么,这个查询和该网页的相关性就是:TF1 + TF2 + ... + TFN。
读者可能已经发现了又一个漏洞。在上面的例子中,词“的”站了总词频的 80% 以上,而它对确定网页的主题几乎没有用。我们称这种词叫“应删除词”(Stopwords),也就是说在度量相关性是不应考虑它们的频率。在汉语中,应删除词还有“是”、“和”、“中”、“地”、“得”等等几十个。忽略这些应删除词后,上述网页的相似度就变成了0.007,其中“原子能”贡献了 0.002,“应用”贡献了 0.005。细心的读者可能还会发现另一个小的漏洞。在汉语中,“应用”是个很通用的词,而“原子能”是个很专业的词,后者在相关性排名中比前者重要。因此我们需要给汉语中的每一个词给一个权重,这个权重的设定必须满足下面两个条件:
1. 一个词预测主题能力越强,权重就越大,反之,权重就越小。我们在网页中看到“原子能”这个词,或多或少地能了解网页的主题。我们看到“应用”一次,对主题基本上还是一无所知。因此,“原子能“的权重就应该比应用大。
2. 应删除词的权重应该是零。
我们很容易发现,如果一个关键词只在很少的网页中出现,我们通过它就容易锁定搜索目标,它的权重也就应该大。反之如果一个词在大量网页中出现,我们看到它仍然不很清楚要找什么内容,因此它应该小。概括地讲,假定一个关键词 w 在 Dw 个网页中出现过,那么 Dw 越大,w的权重越小,反之亦然。在信息检索中,使用最多的权重是“逆文本频率指数” (Inverse document frequency 缩写为IDF),它的公式为log(D/Dw)其中D是全部网页数。比如,我们假定中文网页数是D=10亿,应删除词“的”在所有的网页中都出现,即Dw=10亿,那么它的IDF=log(10亿/10亿)= log (1) = 0。假如专用词“原子能”在两百万个网页中出现,即Dw=200万,则它的权重IDF=log(500) =6.2。又假定通用词“应用”,出现在五亿个网页中,它的权重IDF = log(2)则只有 0.7。也就只说,在网页中找到一个“原子能”的比配相当于找到九个“应用”的匹配。利用 IDF,上述相关性计算个公式就由词频的简单求和变成了加权求和,即 TF1*IDF1 + TF2*IDF2 +... + TFN*IDFN。在上面的例子中,该网页和“原子能的应用”的相关性为 0.0161,其中“原子能”贡献了 0.0126,而“应用”只贡献了0.0035。这个比例和我们的直觉比较一致了。




相关推荐
《LDA与TF-IDF算法:深度探讨与应用》 在信息检索和自然语言处理领域,LDA(Latent Dirichlet Allocation)和TF-IDF(Term Frequency-Inverse Document Frequency)是两种至关重要的算法,它们在文本分析、文档分类...
TF-IDF 算法的核心思想是将词频(Term Frequency)和逆文档频率(Inverse Document Frequency)相乘,得到一个词的 TF-IDF 值,然后按降序排列,取排在最前面的几个词作为关键词。 词频(Term Frequency)是指一个...
### 基于TF-IDF算法抽取文章关键词 #### 一、引言 TF-IDF(Term Frequency-Inverse Document Frequency)是一种广泛应用于信息检索与文本挖掘领域的统计方法,用于评估单词对于一个文档集或者语料库中单个文档的...
4. **TF-IDF的应用**:TF-IDF广泛应用于搜索引擎的排名算法和文本分类任务中。在搜索结果相关性计算时,会比较搜索关键词在每个文档中的TF-IDF值,高TF-IDF值的文档被认为更相关,因此会出现在搜索结果的前面。 5. ...
在这个主题中,"NLP:基于TF-IDF的中文关键词提取"是一个项目,它利用TF-IDF算法来从中文文本中提取具有代表性的关键词。TF-IDF是一种经典的文本特征权重计算方法,广泛应用于信息检索、文档分类和关键词提取等领域...
"基于改进TF-IDF算法的牛疾病智能诊断系统" 本文介绍了一种基于改进TF-IDF算法的牛疾病智能诊断系统。传统的TF-IDF算法存在一些缺陷,例如无法合理地代表某疾病的症状,降低智能诊断系统的性能。为了解决这个问题,...
TF-IDF算法,即词频-逆文档频率(Term Frequency-Inverse Document Frequency)算法,是关键词提取中最常用的方法之一。该算法综合了词频(TF)和逆文档频率(IDF)两个因子来评估词汇在文档集合中的重要性。 在...
在C语言和Python中实现TF-IDF算法,可以为文本分类提供有效的特征权重抽取手段。 首先,我们来详细解释TF-IDF的计算过程: 1. **词频(Term Frequency, TF)**:TF表示一个词在文档中出现的次数。一般而言,一个词在...
下面我们将详细探讨TF-IDF算法及其在分析多个PDF文件关键词中的应用。 1. **词频(Term Frequency, TF)**: 词频是指一个词在文档中出现的次数。通常,一个词在文档中出现的次数越多,它可能越能反映文档的主题。然而...
TF-IDF是一种简单而有效的算法,用于衡量单词在特定文档中的重要性,它基于两个关键概念:词频(Term Frequency,TF)和逆文档频率(Inverse Document Frequency,IDF)。 #### TF-IDF简介 TF-IDF是一种广泛使用的...
TF-IDF算法由两个部分组成:TF(词频,Term Frequency)和IDF(逆文档频率,Inverse Document Frequency)。TF表示一个词在文档中出现的次数,而IDF则是用来抑制常见词汇的重要性,计算一个词的IDF值通常用以下公式...
本研究论文主要探讨了基于Word2vec和改进TF-IDF算法的深度学习模型,以及它们在物流评价分类预测中的应用。研究背景是随着电子商务的兴起,网上购物变得普及,伴随着的是大量的评价信息产生,这些信息对商家来说是...
TF-IDF(Term Frequency-Inverse Document Frequency)是一种在信息...对于提供的文件"TF-IDF.zip",可能包含的就是一个Java实现TF-IDF算法的代码示例或者相关项目,可以进一步研究学习如何在实际项目中应用TF-IDF。
TF-IDF(Term Frequency-Inverse Document Frequency)是一种在信息检索和文本挖掘领域广泛使用的统计方法,用于评估一个词在文档中的重要性。它基于两个概念:词频(Term Frequency, TF)和逆文档频率(Inverse ...
本文将通过梳理文本挖掘技术,并采用TF-IDF算法处理词频信息,运用LDA主题模型进行有效的文本分类,旨在得到有意义的结果。 TF-IDF(Term Frequency-Inverse Document Frequency)算法是文本挖掘中常用的一种统计...
在中文关键词提取的场景中,TF-IDF算法同样具有广泛的适用性。 关键词提取是信息抽取的一个关键步骤,旨在从文本中自动识别出最具代表性和概括性的词语或短语,以便快速理解文本主题。对于特定语料库的中文关键词...
例如,如果用户查询"Python IF-IDF算法",搜索引擎会计算这个查询的每个词在每个文档中的TF-IDF值,然后根据这些值的综合评估来排序文档,返回最相关的那些。 在实际项目中,可能会涉及更复杂的步骤,如停用词过滤...
TF-IDF算法的核心思想是:如果一个词在文档中频繁出现但在整个文集(或语料库)中并不常见,那么这个词对于该文档具有较高的重要性。TF反映了词在文档内的频率,IDF则衡量词的普遍性。 1. **词频(TF)**:TF = (词...
TF-IDF算法,计算较快,但是存在着缺点,由于它只考虑词频的因素,没有体现出词汇在文中上下文的地位,因此不能够很好的突出语义信息。 import numpy as np class TF_IDF_Model(object): def __init__(self, ...