TensorMask: A Foundation for Dense Object Segmentation
一种密集实例分割的基本方法
原文链接:https://arxiv.org/pdf/1903.12174.pdf
建议对照原文阅读,内部公式显示不出来,所以用了简单文本/截图的表示方式。文中一些翻译用词为个人观点,如果偏差请谅解指出
摘要
在密集规则的网格上生成边界框物体预测的滑窗目标检测器非常流行。对比而言,现代的实例分割方法一般先检测物体的边界框,然后裁剪分割出对应的预测区域,比如Mask R-CNN。本文我们调查了密集滑窗实例分割(dense sliding-window instance segmentation)的范式,而这个目前还未被研究。我们研究发现,这个方法从根本上不同于其他的密集预测任务,如语义分割或边界框目标检测,因为每个空间位置的输出是空间维度的几何结构。为了公式化说明这个问题,我们将密集实例分割看作是一种4D张量的预测任务,并且提出了一种叫做TensorMask的通用框架,来显式地捕捉到几何信息并且能够在4D张量上使用新的运算。我们证明这种张量的视角可以在baseline上获得巨大的提升,并且能够和Mask R-CNN不相上下。这些结果显示了,在密集掩膜预测上,TensorMask可以作为新方法的基础模型和对这项任务的更完整的理解。
序言
滑窗范式(sliding-window paradigm)(通过在考察图像位置对应的密集集合上的窗口来寻找目标)是一种计算机视觉领域最早的也最成功的概念,很自然地和卷积神经网络联系在一起。然而,尽管目前依靠滑窗预测来生成初始候选区域并微调候选区域以获得更准确的预测的方法表现的非常出色,比如目标检测的Faster R-CNN和实例分割的Mask R-CNN。这类方法霸占了COCO检测挑战的排行榜。
最近,有一些回避了微调阶段,着眼于直接通过滑窗预测的边界框目标检测器再起,并且表现出了不错的结果,比如SSD和RetinaNet。对比而言,密集滑窗的实例分割一直没有动静,没有这样一种和SSD/RetinaNet可比拟的直接的、密集的方法用在分割掩膜预测上。为什么密集方法在检测上用到却没有出现在实例分割中呢?这是一个很有趣的基本学术问题。我们的目标就是构建这样一座桥梁来为密集实例分割搭建基础,弥补断层。
我们发现,目前不存在一种定义密集掩膜表征方法的核心概念以及在神经网络有效实现这些概念的方法。不像尺度无关的固定的、低维表征的边界框,分割掩膜需要更丰富、结构信息更多的表征。举例来说,掩膜本身是一个2D的空间图,更大物体的掩膜会得益于更大的空间图。研究密集掩膜有效的表征是使能密集实例分割的关键一步。
为了解决这个问题,我们定义了一系列核心概念来表征高维张量的掩膜,并且允许密集掩膜预测的新型网络结构的探索。我们提出并实验了几种网络来验证所提出的表征方法的优越性。我们的框架叫做TensorMask,是第一个采用密集滑窗方式的实例分割模型,效果可以与Mask R-CNN相提并论。
TensroMask表征的中心观点是使用结构化的4D张量来表征空间范围的掩膜。这个观点和先前的类别无关的、使用非结构化的3D张量的模型如DeepMask和InstanceFCN相比,后者掩膜被包在第三个通道维上。通道维度不像表征物体位置的维度,它没有明确的几何意义因此很难处理。通过使用基本的通道表征,模型就会失去从2D实体中使用结构化信息的机会,就好像MLPs和ConvNets在表征2D图像上的差异一样。
不像那些通道有向的方法,我们提出的4D张量(V, U, H, W),其中几何子张量(H, W)代表了目标的位置,几何子张量(V, U)代表了表征对应掩膜的位置。换句话说,4D张量包含了关于图像的几何含义和定义明确的单元。从在非结构维上编码掩膜到使用结构化的集合子张量的观点转变,帮助我们定义新的运算和新的网络结构。这些网络可以直接用有几何含义的方法操作子张量(V, U),包括坐标变换、尺度缩放、尺度金字塔等等。
在TensorMask模型的基础上,我们在4D张量的尺度索引表上发展了一种金字塔结构,叫做双向张量金字塔(tensor bipyramid)。相比于抽取多尺度的特征图的特征金字塔,双向张量金字塔包含了形状为(2^k*V,2^k*U,1/2^k*H,1/2^k*W)的4D张量组,其中k是尺度因子。这个结构在(H, W)和(V, U)几何子张量上都有金字塔形状,但是方向相反。这个自然的设计捕获了想要获得的属性**:大的物体需要高分辨率的掩膜和相对粗糙的空间定位(k大),小的物体需要低分辨率的掩膜和精确的空间定位(k小)**。
我们在网络主干上结合了这些模块,训练阶段参照RetinaNet,而将其密集边界框预测器扩展为了我们的密集掩膜预测器。通过详细的消融实验,我们验证了TensorMask的有效性,并且展示了显式捕获几何结构的重要性。最后,TensorMask和Mask R-CNN效果上持平。这些结果意味着我们提出的框架可以为密集滑窗实例分割的未来研究铺路。
相关工作
分类掩膜提议
先检测后分割
先像素级分类后聚类
密集滑窗方法:no prior methods exist for dense sliding-window instance segmentation
掩膜张量表征方式
TensorMask的中心思想是使用结构化的高维张量来表征图像信息(e.g. 掩膜),放在一系列密集滑窗中。
考虑在WxH的特征图上用一个VxU窗口滑动,我们可以通过张量CxHxW表征所有滑窗的位置上的掩膜,每个掩膜可以被参数化为C=V*U个像素,这个思想是DeepMask提出的。
这个表征的潜在精神实际上是一个(V, U, H, W)的4D张量,子张量代表了一个2D空间实体的掩膜。不同于将通道C看做是一个内部安排了VxU掩膜的黑箱,这个张量的观点会使能很多表征密集掩膜重要概念。


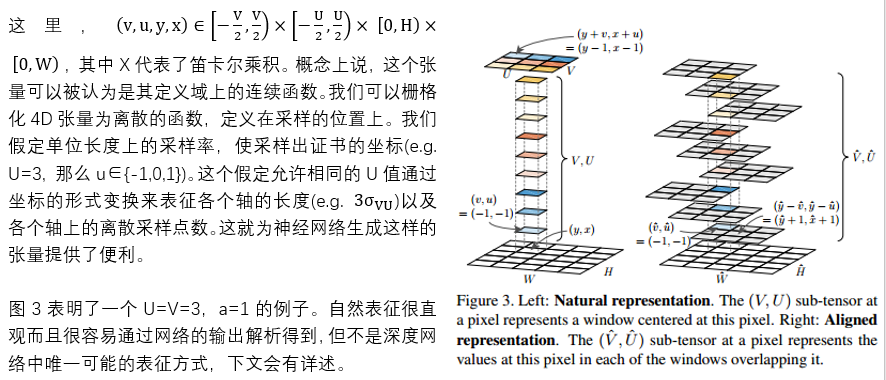




3.6 双向张量金字塔(Tensor bipyramid)
在多尺度目标检测中,使用低分辨率的特征图来抽取大尺度的目标是一种常见的做法。这是因为固定尺寸的滑窗在低分辨率特征图上对应的是输入图像上大尺度的区域。道理在多尺度实例分割中也同样。但是,不同于预测框总是由四个尺度无关的数字表征,一个掩膜的像素尺寸一定和物体尺寸有关,为了保持恒定的分辨率密度。因此,我们采用基于尺度的掩膜像素数量,而不是总是使用VxU来表征不同尺度的掩膜。
考虑到在最精细特征图上的自然表征(V, U, H, W),这里(H, W)有最高的分辨率(最小的单位),我们期望用这个来处理最小的目标,进而(V, U)应该有最低的分辨率。以此为依据,我们构建了一个金字塔模型,逐步降低(H,W),逐步提高(V,U)。严格上说,我们定义双向张量金字塔如下:


TensorMask结构
我们由TensorMask的表征方式构建了整个模型。这些模型中有在滑动窗口中生成掩膜的掩膜预测头部网络,和预测目标分类的分类头部网络,后者和滑窗目标检测器中的框回归和分类头部类似。框预测在TensorMask中是不必要的,但是可以被很简单的加入进来。
4.1 掩膜预测头
我们的掩膜预测分支和FPN的卷积主干相连,FPN会生成尺寸为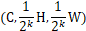 的特征金字塔,其中对于每个k,通道C都是固定的。这些特征图会被用来当做各个预测头部的输入:掩膜预测、类别预测、框预测。对于不同层次会有权重,但是不同任务之间没有权重。
的特征金字塔,其中对于每个k,通道C都是固定的。这些特征图会被用来当做各个预测头部的输入:掩膜预测、类别预测、框预测。对于不同层次会有权重,但是不同任务之间没有权重。
输出表征。 自然表征永远是网络的输出格式。任何表征(自然、对齐等等)可以被用在中间层中,但是都在最后会被转换成自然表征格式的输出。这个标准化解耦了来自网络设计的损失函数定义,简化不同表征的的使用。另外,我们的掩膜输出是类无关的,也就是说,滑窗总是会预测单个无关类别的掩膜,掩膜的类别会交由分类头来预测。类无关的掩膜预测避免了将输出尺寸和类别数量相乘。
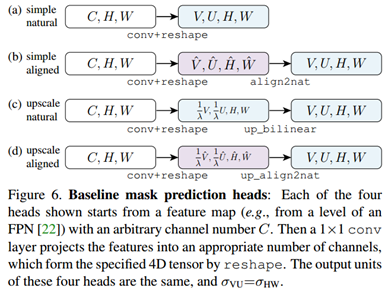
baseline头部。我们设计了四种baseline头部,见图6,每种头部接受一个(C, H, W)作为输入特征图。然后通过合适输出通道数对1x1卷积核加ReLU来将特征图变为下一层所需要的4D张量,我们令这步操作为conv+reshape。图6a和6b是使用了自然表征和对齐表征的简单头部。在两种例子中,我们使用V*U作为1x1卷积的输出通道数,紧接着做align2nat操作。图6c和6d是使用了自然表征和对齐表征的放大头部,其1x1卷积输出通道数比简单头部少λ倍。
在baseline的TensorMask模型中,四个头部之一被选中并且和所有FPN层连接,输出形式是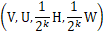 ,如图7a,对于每个头部,输出滑窗总是和特征图有相同的单位,也就是对于每一层:
,如图7a,对于每个头部,输出滑窗总是和特征图有相同的单位,也就是对于每一层: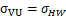 。
。
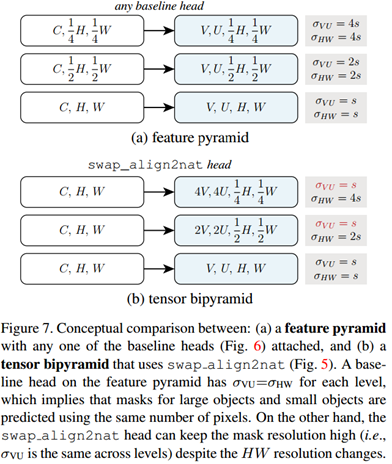
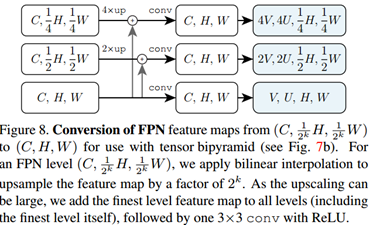
**双向张量金字塔头。**不同于baseline头部,双向张量金字塔头部每层都接受高分辨率(H,W)特征图作为输入。图8展示了一种对FPN的小改动来获得这些特征图,对于每个结果层,都为(C, H, W),我们首先使用conv+reshape来产生合适的4D张量,接着用swap_align2nat运行掩膜预测头部,见图7b。这个双向张量金字塔模型在TensorMask中是最有效。
训练
标签分配。我们使用了DeepMask的标签分配规则来给每个窗分配标签。满足关于ground-truth掩膜m的三个条件的窗就认为是正例:
i) 包含度 Containment: 窗口完全包含m并且m的长边至少是窗长边的1/2,也就是: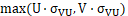 .
.
ii) 中心度 Centrality: m对应边界框的中心与窗的中心距离小于l2距离下的一个单位(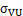 ).
).
iii) 唯一性 Uniqueness: 没有其他的掩膜m’≠m,满足以上两个条件。
如果m满足以上三个条件,那么这个窗会被标记为对应gt给出的掩膜、物体类别、框所对应的正例。否则,这个窗会被标记为负例。
对比基于IoU的框分配规则(RPN, SSD, RetinaNet),我们的规则是**掩膜驱动(mask-driven)**的。实验显示,相比于RetinaNet的9个多尺度锚点(anchor)使用一个或两个固定长宽比的窗尺寸我们的规则效果更好,
损失。对于掩膜预测头,我们采用了每像素二值分类损失。在我们的设置中,gt掩膜在滑窗中占比较大的区域,导致前景和背景像素失衡。因此我们使用focal loss而不是二值交叉熵来解决样本不平衡问题,尤其是当我们使用γ=2,α=1.5的FL*时效果尤为显著。单一窗的掩膜损失为窗中所有像素的平均(注意到tensor bipyramid中窗尺寸在不同层次中是变化的),总掩膜损失为所有正例窗的损失的平均(负例窗不贡献掩膜损失)。
对于分类头,我们采用γ=3,α=0.3的FL*,对于框回归,我们采用无参数的l1损失,总损失为各个任务损失的加权和。
实现细节。每个FPN层经过四个Cx3x3卷积+relu输出(而不是FPN原始的只有一个卷积)。对于各个头部,权重在各个层次中被共享,而不是在各个任务中。另外,我们发现FPN中平均(而不是加和)自顶向下和横向连接能够提高训练稳定性。我们使用FPN的第2-7层经过四个C=128的卷积来做掩膜和框的头部。分类头部的C=256。除非额外说明,我们都使用ResNet50。
训练中,所有模型都用ImageNet初始化权重,我们使用尺度抖动(scale jitter),将图像短边随机从[640, 800]像素中采样。参考SSD和YOLO,训练时间更长(~65-160epoch),我们使用6倍规则(6x schedule, rethinking imagenet pre-training)(~72epoch)提高效果。batchsize=16*8,基本学习率为0.02,1k次迭代的线性warm-up,其他超参数参考[13](//github.com/facebookresearch/detectron)。
预测
预测和密集滑窗目标检测器相似。我们使用单尺度的800像素作为图像短边。我们的模型为每个窗输出一个掩膜预测,一个类别分数和一个预测框。NMS根据框的IoU筛选最高分数的预测。为了将预测的soft掩膜转换为原图分辨率的二值掩膜,我们使用和Mask R-CNN同样的方法和超参数。
实验
我们提供了COCO实例分割数据集上的结果。所有模型在train2017的118k张图片上训练,在val2017的5k张图片上上测试。最终结果在test-dev集上测试。我们使用COCO掩膜平均精度(AP),当我们具体指代框的AP时,我们会用AP^bb。
5.1 TensorMask表征
首先我们研究了在ResNet-50-FPN主干上V=U=15的不同张量表征。我们提供了定量的结果在表2上,并且提供了定量的比较在图2和9.
简单头部。表1比较了简单头部的自然表征和对齐表征(图6a和6b)两个表征的表现是相似的,有0.2AP的波动范围。自然表征的简单头部可以被看做是特定类别的FPN骨架加focal loss的DeepMask。
放大头部。表2a对比了自然表征和对齐表征在放大头部上的不同。输出尺寸固定在VxU=15x15。对于一个放大系数λ,图6的conv有VU/λ^2个通道,比如9个通道,λ=5(等价于没有放大的225个通道)。对于大的λ准确率上的不同是非常大的:λ=5时对齐比自然头部AP好了15.6个点。
从图9a和9c上就能看出明显的区别。放大对齐头部在λ比较大的时候仍然有较精细的掩膜,这也是归功于tensor bipyramid,输出是(2^k)Vx(2^k)U, λ=2^k。
插值。子张量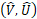 是一个可以被操作的2D空间实体,表2b对比了放大对齐头部用双线性插值和最近邻插值的不同。We refer to this latter variant as unaligned since quantization breaks pixel-to-pixel alignment. 未对齐变量参考InstanceFCN.
是一个可以被操作的2D空间实体,表2b对比了放大对齐头部用双线性插值和最近邻插值的不同。We refer to this latter variant as unaligned since quantization breaks pixel-to-pixel alignment. 未对齐变量参考InstanceFCN.
我们观察到表2b,双线性插值相比最近邻有明显的提升,尤其是λ比较大的情况下(ΔAP=3.2)。这些插值方法从直观上也能从物体间的空隙中看出来,图9b和9c。
Tensor bipyramid。用双向张量金字塔代替最好的特征网络模型,取得了4.1个点的提升。这里掩膜尺寸是VxU=15x15,k=0,对应32Vx32U=480x480,k=5,见图7b。更高的分辨率掩膜预测更大的物体(比如k=5),APL提升了7个点。这个提升不是由于(H/32, W/32)分辨率的输出滑窗带来的。
而且,我们注意到一个4802个通道的卷积很难实现,而采用双线性插值的放大对齐头部使双向张量金字塔成为可能。
滑窗多尺寸。在此之前,我们在每一层用的是单一的滑窗尺寸,也就是VxU=15x15。和当前用在RPN的anchors概念类似,我们也把我们的方法扩展为多个滑窗尺寸。我们设置VxU∈{15x15, 11x11},使每层有了两个头部。表2d展示了两个滑窗尺寸带来的效果,提升了1.6个点。更多的窗尺寸和长宽比仍有探索提升的空间。
5.2 和Mask R-CNN对比
精度上。在test-dev上接近Mask R-CNN,意味着dense sliding-sindow方法效果基本达到了“detect-then-segment”方法。
速度上。最好的R-101-FPN TensorMask模型,包含所有后处理过程,在V100上每图0.38s。对应Mask R-CNN为每图0.09s。这是因为密集滑窗>100k个,而Mask R-CNN<=100个。速度本文不做考虑但有更多研究的空间。




相关推荐
实例分割在计算机视觉领域是一项重要的技术,它涉及到识别并精确分割出图像中每个对象的边界,从而实现对图像内容的精细化理解。在这个“81类实例分割的win程序”中,我们聚焦的是一个专为Windows操作系统设计的工具...
在这个项目中,我们关注的是基于Pytorch实现的Mask R-CNN算法,这是一种强大的实例分割框架,由Facebook AI Research(FAIR)团队在2017年提出。Mask R-CNN不仅能够进行对象检测(像传统的R-CNN和Fast R-CNN),还能...
《PyTorch版Mask R-CNN图像实例分割实战:训练自己的数据集》 在计算机视觉领域,实例分割是一项重要的任务,它旨在识别图像中的每个对象并精确地分割出其边界,而不仅仅是分类。PyTorch作为一款灵活且强大的深度...
Mask R-CNN是一种用于实例分割的深度学习模型,由Facebook AI Research(FAIR)的何凯明等人提出。本文将详细介绍如何在Keras中实现Mask R-CNN。 **一、Mask R-CNN结构** Mask R-CNN是在 Faster R-CNN基础上扩展的...
Mask R-CNN是一个非常流行的深度学习模型,由Facebook AI Research(FAIR)开发,用于执行实例分割和对象检测。这个模型基于 Faster R-CNN 架构,并引入了一个额外的分支来预测每个检测框的像素级掩模,从而实现对...
全景分割是一种计算机视觉技术,它旨在对图像中的每一个像素进行分类,从而识别出图像中的所有对象及其轮廓。这种技术在自动驾驶、无人机航拍、虚拟现实等领域有着广泛的应用。本项目专注于利用FAIR-DETR这一深度...
豆芽发根检测数据集是计算机视觉领域的一个重要资源,主要设计用于训练Mask R-CNN这一先进的实例分割模型。在深度学习中,实例分割是一项关键任务,它要求模型不仅能够识别出图像中的物体,还要精确地分割出每个物体...
### Nginx Fair 负载均衡模块详解与配置 #### 概述 Nginx 是一款广泛使用的高性能 HTTP 和反向代理 Web 服务器。它以其稳定、丰富的特性及低资源消耗而闻名。Nginx 支持多种负载均衡算法,其中之一就是 **Fair**...
fair exchange课件fair exchange课件fair exchange课件fair exchange课件
**Nginx Upstream Fair算法详解** Nginx是一款高性能的HTTP和反向代理服务器,广泛应用于网站负载均衡和静态内容处理。在处理后端服务器的负载均衡时,Nginx提供了多种策略,其中之一就是"Fair"(公平)算法。Fair...
在研究生实验室中,这门学科的重要性不言而喻,因为它能够帮助科学家们理解和解释复杂的生物现象。 【基因组学分析】 在研究生实验室会议记录中,可能涉及到基因组学分析的内容。这包括全基因组测序(Whole Genome...
3.刀片服务器技术:HP 刀片服务器技术可以提供高性能和高可靠性的服务器解决方案,Fair Isaac 使用基于 Intel 处理器的 HP 刀片服务器实现了数据中心整合和虚拟化。 4. 虚拟化技术:虚拟化技术可以提高服务器的使用...
标题中的"FAIR"可能指的是“公平”这个概念在信息技术领域的应用,特别是在数据处理和人工智能(AI)领域。"FAIR"原则是“Findable, Accessible, Interoperable, and Reusable”的缩写,这四个词分别代表可发现、可...
3. **抢占机制**:如果一个作业已经获得了过多的资源但未充分利用,Fair Scheduler会抢占这些资源并分配给其他等待的作业。 4. **最小和最大公平性**:每个作业都有一个最小资源配额,以保证其基本运行,同时也有一...
本项目基于PyTorch框架,特别是其强大的图像处理库TorchVision,实现了一个Mask R-CNN模型,用于同时执行目标检测和实例分割。Mask R-CNN是一种流行的深度学习模型,由Facebook AI Research(FAIR)团队开发,它在...
Mask R-CNN是FAIR团队于2017年提出的一种深度学习模型,它是 Faster R-CNN 的扩展,旨在同时实现对象检测和像素级别的语义分割。该模型的核心创新在于引入了一个“分支”结构,这个分支可以在检测到的对象实例上直接...
"nginx-upstream-fair-master.zip"是一个包含Nginx公平负载均衡(fair)第三方模块的压缩包,该模块使得Nginx可以根据服务器的实际响应时间来分配请求,从而实现更公平的负载均衡策略。 公平负载均衡(fair)模块...
《Python-Detectron:探索FAIR的目标检测利器》 在当今人工智能领域,目标检测技术扮演着至关重要的角色,它能够帮助计算机识别图像中的物体并定位它们的位置。Facebook AI Research(FAIR)为这个领域贡献了一个...
"FAIR.m-master.zip" 是一个压缩包,包含了FAIR(Fast Automatic Image Registration)快速图像配准算法的源代码和相关文档。FAIR算法是一种在MATLAB环境中实现的高效图像配准工具,它旨在提高图像处理中的配准速度...
FairUse4WM_CN,用来破解WMV证书的软件