- وµڈ览: 26954 و¬،
-

وœ€è؟‘è®؟ه®¢ و›´ه¤ڑè®؟ه®¢>>
و–‡ç« هˆ†ç±»
社هŒ؛版ه—
- وˆ‘çڑ„资讯 ( 0)
- وˆ‘çڑ„è®؛ه› ( 0)
- وˆ‘çڑ„é—®ç” ( 0)
هکو،£هˆ†ç±»
- 2019-09 ( 100)
- و›´ه¤ڑهکو،£...
وœ€و–°è¯„è®؛
ن¸€و¬،éڑ¾ه¾—çڑ„هˆ†ه؛“هˆ†è،¨ه®è·µ

背و™¯
ه‰چن¸چن¹…هڈ‘è؟‡ن¸¤ç¯‡ه…³ن؛ژهˆ†è،¨çڑ„و–‡ç« ï¼ڑ
ن»ژو ‡é¢کهڈ¯ن»¥çœ‹ه¾—ه‡؛و¥ï¼Œه½“و—¶وˆ‘ن»¬هڈھهپڑن؛†هˆ†è،¨ï¼›è؟کوک¯ç”±ن؛ژن¸ڑهٹ،هڈ‘ه±•ï¼Œوˆھو¢هˆ°çژ°هœ¨ن¹ںهپڑن؛†هˆ†ه؛“,目ه‰چ看و¥éƒ½è؟کو¯”较é،؛هˆ©ï¼Œو‰€ن»¥ه€ںç€è„‘هگè؟کè®°ه¾—و¸…و¥ڑو¥ن¸€و¬،ه¤چç›کم€‚
<!--more-->
ه…ˆو¥ه›é،¾ن¸‹و•´ن¸ھهˆ†ه؛“هˆ†è،¨çڑ„وµپ程ه¦‚ن¸‹ï¼ڑ
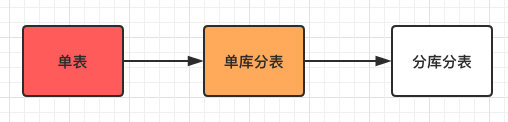
و•´ن¸ھè؟‡ç¨‹ن¹ںه¾ˆه¥½çگ†è§£ï¼Œهں؛وœ¬ç¬¦هگˆه¤§éƒ¨هˆ†ه…¬هڈ¸çڑ„ن¸€ن¸ھهڈ‘ه±•و–¹هگ‘م€‚
ه¾ˆه°‘ن¼ڑوœ‰ن¸ڑهٹ،ن¸€ه¼€ه§‹ه°±ن¼ڑ设è®،ن¸؛هˆ†ه؛“هˆ†è،¨ï¼Œè™½è¯´è؟™و ·ن¼ڑه‡ڈه°‘هگژç»çڑ„ه‘,ن½†éƒ¨هˆ†ه…¬هڈ¸هˆڑه¼€ه§‹éƒ½وک¯ن»¥ن¸ڑهٹ،ن¸؛ن¸»م€‚
ç›´هˆ°ن¸ڑهٹ،هڈ‘ه±•هˆ°هچ•è،¨و— و³•و”¯و’‘و—¶ï¼Œè‡ھ然而然ن¼ڑ考虑هˆ†è،¨ç”ڑ至هˆ†ه؛“çڑ„ن؛‹وƒ…م€‚
ن؛ژوک¯وœ¬ç¯‡ن¼ڑن½œن¸€و¬،و€»ç»“,ن¹‹ه‰چوڈگè؟‡çڑ„ه†…ه®¹هڈ¯èƒ½ن¼ڑه†چé‡چه¤چن¸€و¬،م€‚
هˆ†è،¨
首ه…ˆè®¨è®؛ن¸‹ن»€ن¹ˆو ·çڑ„وƒ…ه†µن¸‹é€‚هگˆهˆ†è،¨ï¼ں
و ¹وچ®وˆ‘çڑ„ç»ڈéھŒو¥çœ‹ï¼Œه½“وںگه¼ è،¨çڑ„و•°وچ®é‡ڈه·²ç»ڈè¾¾هˆ°هچƒن¸‡ç”ڑ至ن¸ٹن؛؟,هگŒو—¶و—¥ه¢و•°وچ®é‡ڈهœ¨ 2% ن»¥ن¸ٹم€‚
ه½“然è؟™ن؛›و•°ه—ه¹¶ن¸چوک¯ç»ه¯¹çڑ„,وœ€é‡چè¦پçڑ„è؟کوک¯ه¯¹è؟™ه¼ è،¨çڑ„ه†™ه…¥ه’Œوں¥è¯¢éƒ½ه·²ç»ڈه½±ه“چهˆ°و£ه¸¸ن¸ڑهٹ،و‰§è،Œï¼Œو¯”ه¦‚وں¥è¯¢é€ںه؛¦وکژوک¾ن¸‹é™چ,و•°وچ®ه؛“و•´ن½“ IO ه±…é«کن¸چن¸‹ç‰م€‚
而谈هˆ°هˆ†è،¨و—¶وˆ‘ن»¬ç€é‡چ讨è®؛çڑ„è؟کوک¯و°´ه¹³هˆ†è،¨ï¼›
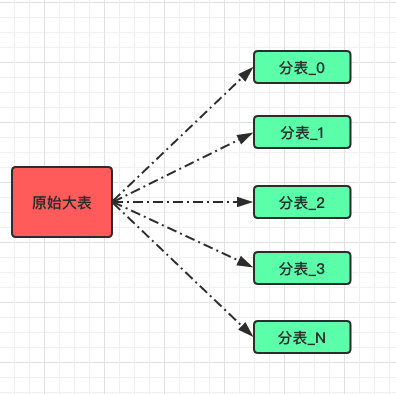
ن¹ںه°±وک¯ه°†ن¸€ه¼ ه¤§è،¨و•°وچ®é€ڑè؟‡وںگç§چ路由算و³•ه°†و•°وچ®ه°½هڈ¯èƒ½çڑ„ه‡هŒ€هˆ†é…چهˆ° N ه¼ ه°ڈè،¨ن¸م€‚
Range
而هˆ†è،¨ç–ç•¥ن¹ںوœ‰ه¥½ه‡ ç§چ,هˆ†هˆ«é€‚用ن¸چهگŒçڑ„هœ؛و™¯م€‚
首ه…ˆç¬¬ن¸€ç§چوک¯وŒ‰ç…§èŒƒه›´هˆ’هˆ†ï¼Œو¯”ه¦‚وˆ‘ن»¬هڈ¯ن»¥ه°†وںگه¼ è،¨çڑ„هˆ›ه»؛و—¶é—´وŒ‰ç…§و—¥وœںهˆ’هˆ†هکن¸؛وœˆè،¨ï¼›ن¹ںهڈ¯ن»¥ه°†وںگه¼ è،¨çڑ„ن¸»é”®وŒ‰ç…§èŒƒه›´هˆ’هˆ†ï¼Œو¯”ه¦‚ م€گ1~10000م€‘هœ¨ن¸€ه¼ è،¨ï¼Œم€گ10001~20000م€‘هœ¨ن¸€ه¼ è،¨ï¼Œن»¥و¤ç±»وژ¨م€‚
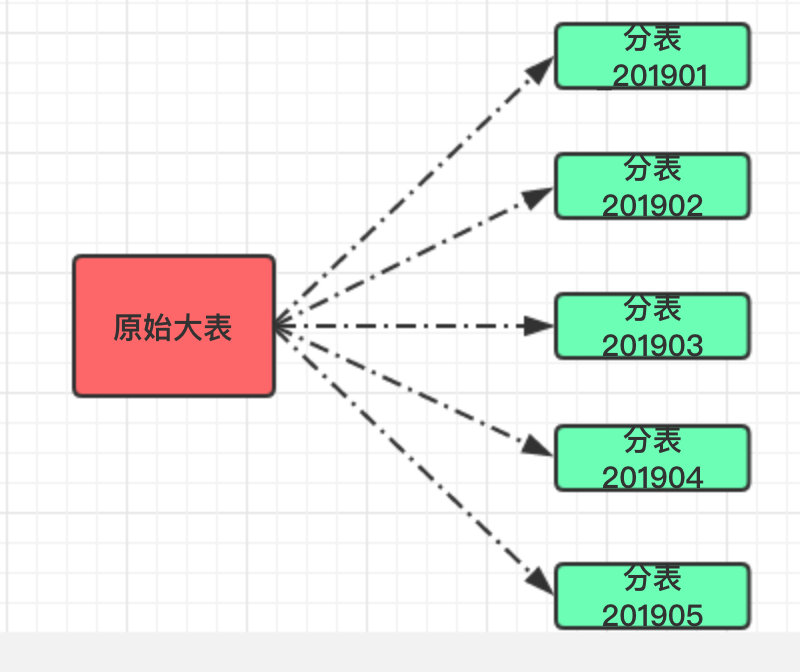
è؟™و ·çڑ„هˆ†è،¨é€‚هگˆéœ€è¦په¯¹و•°وچ®هپڑه½’و،£ه¤„çگ†ï¼Œو¯”ه¦‚ç³»ç»ںé»ک认هڈھوڈگن¾›è؟‘ن¸‰ن¸ھوœˆهژ†هڈ²و•°وچ®çڑ„وں¥è¯¢هٹں能,è؟™و ·ن¹ںو–¹ن¾؟و“چن½œï¼›هڈھ需è¦پوٹٹن¸‰وœˆن¹‹ه‰چçڑ„و•°وچ®هچ•ç‹¬ç§»èµ°ه¤‡ن»½ن؟هکهچ³هڈ¯ï¼‰م€‚
è؟™ن¸ھو–¹و،ˆوœ‰ه¥½ه¤„ن¹ںوœ‰ه¼ٹ端ï¼ڑ
- ه¥½ه¤„وک¯è‡ھه¸¦و°´ه¹³و‰©ه±•ï¼Œن¸چ需è¦پè؟‡ه¤ڑه¹²é¢„م€‚
- ç¼؛点وک¯هڈ¯èƒ½ن¼ڑه‡؛çژ°و•°وچ®ن¸چه‡هŒ€çڑ„وƒ…ه†µï¼ˆو¯”ه¦‚وںگن¸ھوœˆè¯·و±‚وڑ´ه¢ï¼‰م€‚
Hash
وŒ‰ç…§و—¥وœںè؟™و ·çڑ„范ه›´هˆ†è،¨ه›؛然简هچ•ï¼Œن½†é€‚用范ه›´è؟کوک¯و¯”较çھ„ï¼›و¯•ç«ںوˆ‘ن»¬ه¤§éƒ¨هˆ†çڑ„و•°وچ®وں¥è¯¢éƒ½ن¸چوƒ³ه¸¦ن¸ٹو—¶é—´م€‚
و¯”ه¦‚وںگن¸ھ用وˆ·وƒ³وں¥è¯¢ن»–ن؛§ç”ںçڑ„و‰€وœ‰è®¢هچ•ن؟،وپ¯ï¼Œè؟™وک¯ه¾ˆه¸¸è§پçڑ„需و±‚م€‚
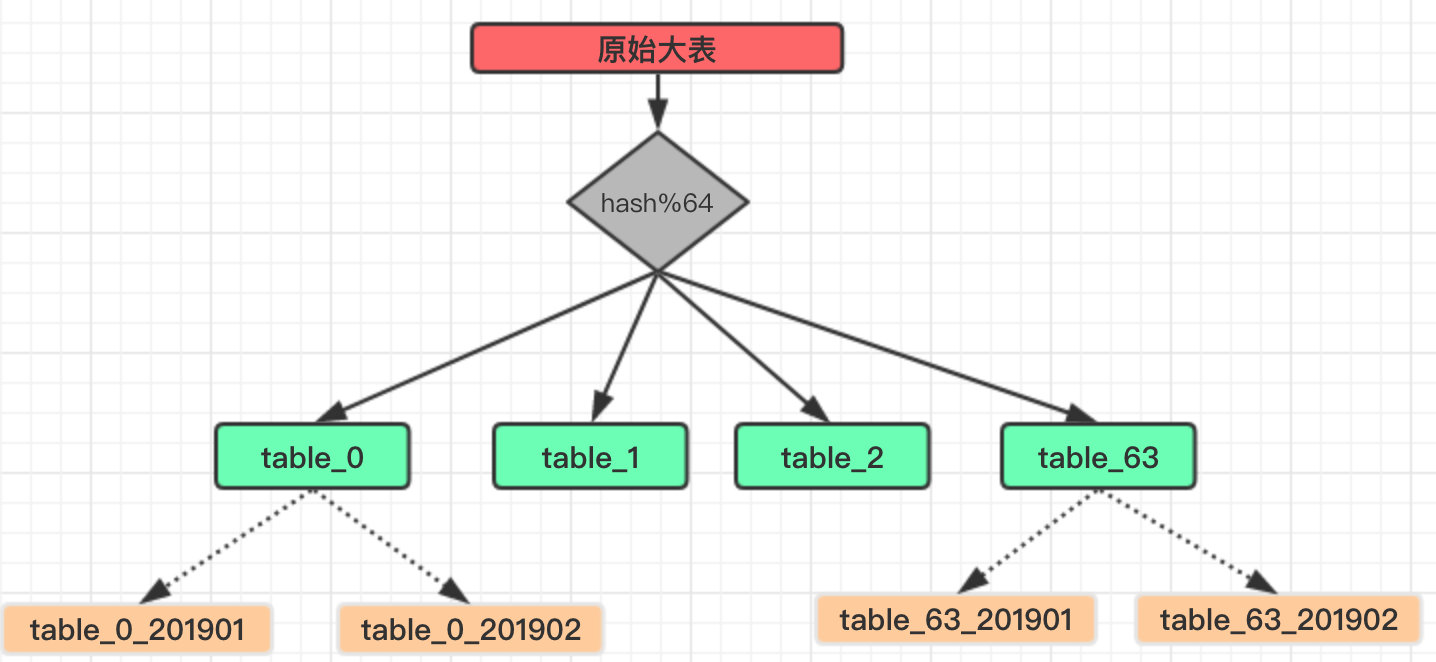
ن؛ژوک¯وˆ‘ن»¬هˆ†è،¨çڑ„ç»´ه؛¦ه°±ه¾—و”¹و”¹ï¼Œهˆ†è،¨ç®—و³•هڈ¯ن»¥é‡‡ç”¨ن¸»وµپçڑ„ hash+mod çڑ„组هگˆم€‚
è؟™وک¯ن¸€ن¸ھç»ڈه…¸çڑ„ç®—و³•ï¼Œه¤§هگچé¼ژé¼ژçڑ„ HashMap ن¹ںوک¯è؟™و ·و¥هکه‚¨و•°وچ®م€‚
هپ‡è®¾وˆ‘ن»¬è؟™é‡Œه°†هژںوœ‰çڑ„ن¸€ه¼ ه¤§è،¨è®¢هچ•ن؟،وپ¯هˆ†ن¸؛ 64 ه¼ هˆ†è،¨ï¼ڑ
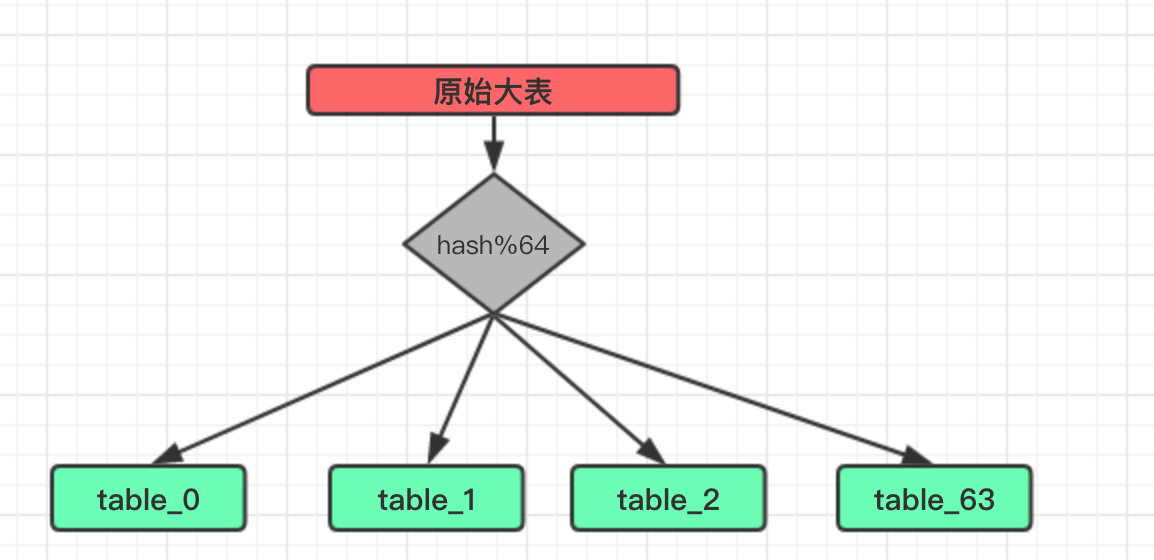
è؟™é‡Œçڑ„ hash ن¾؟وک¯ه°†وˆ‘ن»¬éœ€è¦پهˆ†è،¨çڑ„ه—و®µè؟›è،Œن¸€و¬،و•£هˆ—è؟گ算,ن½؟ه¾—ç»ڈè؟‡و•£هˆ—çڑ„و•°وچ®ه°½هڈ¯èƒ½çڑ„ه‡هŒ€ه¹¶ن¸”ن¸چé‡چه¤چم€‚
ه½“然ه¦‚وœوœ¬è؛«è؟™ن¸ھه—و®µه°±وک¯ن¸€ن¸ھو•´ه½¢ه¹¶ن¸”ن¸چé‡چه¤چن¹ںهڈ¯ن»¥çœپç•¥è؟™ن¸ھو¥éھ¤ï¼Œç›´وژ¥è؟›è،Œ Mod ه¾—هˆ°هˆ†è،¨ن¸‹و ‡هچ³هڈ¯م€‚
هˆ†è،¨و•°é‡ڈ选و‹©
至ن؛ژè؟™é‡Œçڑ„هˆ†è،¨و•°é‡ڈ(64)ن¹ںوک¯وœ‰è®²ç©¶çڑ„,ه…·ن½“设ن¸؛ه¤ڑه°‘è؟™ن¸ھو²،وœ‰و ‡ه‡†ه€¼ï¼Œéœ€è¦پو ¹وچ®è‡ھè؛«ن¸ڑهٹ،هڈ‘ه±•ï¼Œو•°وچ®ه¢é‡ڈè؟›è،Œé¢„ن¼°م€‚
و ¹وچ®وˆ‘ن¸ھن؛؛çڑ„ç»ڈéھŒو¥çœ‹ï¼Œè‡³ه°‘需è¦پن؟è¯پهˆ†ه¥½ن¹‹هگژçڑ„ه°ڈè،¨هœ¨ن¸ڑهٹ،هڈ‘ه±•çڑ„ه‡ ه¹´ن¹‹ه†…都ن¸چن¼ڑه‡؛çژ°هچ•è،¨و•°وچ®é‡ڈè؟‡ه¤§ï¼ˆو¯”ه¦‚è¾¾هˆ°هچƒن¸‡ç؛§ï¼‰م€‚
وˆ‘و›´ه€¾هگ‘ن؛ژهœ¨و•°وچ®ه؛“هڈ¯وژ¥هڈ—çڑ„范ه›´ه†…ه°½هڈ¯èƒ½çڑ„ه¢ه¤§è؟™ن¸ھهˆ†è،¨و•°ï¼Œو¯•ç«ںه¦‚وœهگژç»ه°ڈè،¨ن¹ںè¾¾هˆ°ç“¶é¢ˆéœ€è¦په†چè؟›è،Œن¸€و¬،هˆ†è،¨و‰©ه®¹ï¼Œé‚£وک¯éه¸¸ç—›è‹¦çڑ„م€‚
ç›®ه‰چ笔者è؟کو²،ç»ڈهژ†è؟™ن¸€و¥ï¼Œو‰€ن»¥وœ¬و–‡و²،وœ‰ç›¸ه…³ن»‹ç»چم€‚
ن½†وک¯è؟™ن¸ھو•°é‡ڈهڈˆن¸چوک¯çژ选çڑ„,ه’Œ HashMap ن¸€و ·ï¼Œن¹ںه»؛è®®ه¾—وک¯ 2^n,è؟™و ·هڈ¯ن»¥و–¹ن¾؟هœ¨و‰©ه®¹çڑ„و—¶ه°½هڈ¯èƒ½çڑ„ه°‘è؟پ移و•°وچ®م€‚
Range + Hash
ه½“然è؟کوœ‰ن¸€ç§چو€è·¯ï¼ŒRange ه’Œ Hash وک¯هگ¦هڈ¯ن»¥و··ç”¨م€‚
و¯”ه¦‚وˆ‘ن»¬ن¸€ه¼€ه§‹é‡‡ç”¨çڑ„وک¯ Hash هˆ†è،¨ï¼Œن½†وک¯و•°وچ®ه¢é•؟ه·¨ه¤§ï¼Œه¯¼è‡´و¯ڈه¼ هˆ†è،¨و•°وچ®ه¾ˆه؟«è¾¾هˆ°ç“¶é¢ˆï¼Œè؟™و ·ه°±ن¸چه¾—ن¸چه†چهپڑو‰©ه®¹ï¼Œو¯”ه¦‚ç”± 64 ه¼ è،¨و‰©ه®¹هˆ° 256 ه¼ م€‚
ن½†و‰©ه®¹و—¶وƒ³è¦پهپڑهˆ°ن¸چهپœوœ؛è؟پ移و•°وچ®éه¸¸ه›°éڑ¾ï¼Œهچ³ن¾؟وک¯هپœوœ؛,那هپœه¤ڑن¹…ه‘¢ï¼ںن¹ںن¸چه¥½è¯´م€‚
و‰€ن»¥وˆ‘ن»¬وک¯هگ¦هڈ¯ن»¥هœ¨ Mod هˆ†è،¨çڑ„هں؛ç،€ن¸ٹه†چهˆ†ن¸؛وœˆè،¨ï¼Œه€ںهٹ©ن؛ژ Range è‡ھè؛«çڑ„و‰©ه±•و€§ه°±ن¸چ用考虑هگژç»و•°وچ®è؟پ移çڑ„ن؛‹وƒ…ن؛†م€‚
è؟™ç§چو–¹ه¼ڈçگ†è®؛هڈ¯è،Œï¼Œن½†وˆ‘و²،وœ‰ه®é™…用è؟‡ï¼Œç»™ه¤§ه®¶çڑ„و€è·¯هپڑن¸ھهڈ‚考هگ§م€‚
烦ن؛؛çڑ„و•°وچ®è؟پ移
هˆ†è،¨è§„هˆ™ه¼„ه¥½هگژه…¶ه®هڈھوک¯ه®Œوˆگن؛†هˆ†è،¨çڑ„第ن¸€و¥ï¼Œçœںو£é؛»çƒ¦çڑ„وک¯و•°وچ®è؟پ移,وˆ–者说وک¯ه¦‚ن½•هپڑهˆ°ه¯¹ن¸ڑهٹ،ه½±ه“چوœ€ه°ڈçڑ„و•°وچ®è؟پ移م€‚
除éوک¯ن¸€ه¼€ه§‹ه°±هپڑن؛†هˆ†è،¨ï¼Œو‰€ن»¥و•°وچ®è؟پ移è؟™ن¸€و¥éھ¤è‚¯ه®ڑوک¯è·‘ن¸چوژ‰çڑ„م€‚
ن¸‹é¢و•´çگ†ن¸‹ç›®ه‰چوˆ‘ن»¬çڑ„هپڑو³•ن¾›ه¤§ه®¶هڈ‚考ï¼ڑ
- ن¸€و—¦هˆ†è،¨ن¸ٹç؛؟هگژو‰€وœ‰çڑ„و•°وچ®ه†™ه…¥م€پوں¥è¯¢éƒ½وک¯é’ˆه¯¹ن؛ژهˆ†è،¨çڑ„,و‰€ن»¥هژںوœ‰ه¤§è،¨ه†…çڑ„و•°وچ®ه؟…é،»ه¾—è؟پ移هˆ°هˆ†è،¨é‡Œï¼Œن¸چ然ه¯¹ن¸ڑهٹ،çڑ„ه½±ه“چوپه¤§م€‚
- وˆ‘ن»¬ن¼°ç®—ن؛†ه¯¹ن¸€ه¼ 2 ن؛؟ه·¦هڈ³çڑ„è،¨è؟›è،Œè؟پ移,è‡ھه·±ه†™çڑ„è؟پ移程ه؛ڈ,ه¤§و¦‚需è¦پèٹ± 4~5 ه¤©çڑ„و—¶é—´و‰چ能ه®Œوˆگè؟پ移م€‚
- و„ڈه‘³ç€è؟™و®µو—¶é—´ه†…,ن»¥ه‰چçڑ„و•°وچ®ه¯¹ç”¨وˆ·وک¯ن¸چهڈ¯è§پçڑ„,وک¾ç„¶è؟™و ·ن¸ڑهٹ،ن¸چ能وژ¥هڈ—م€‚
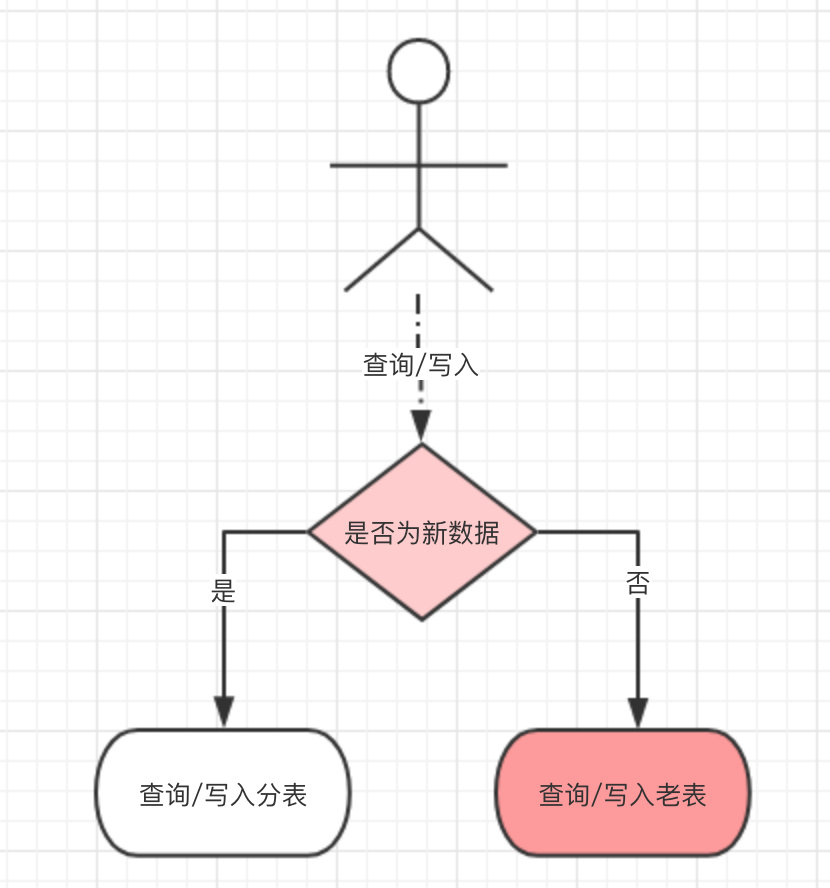
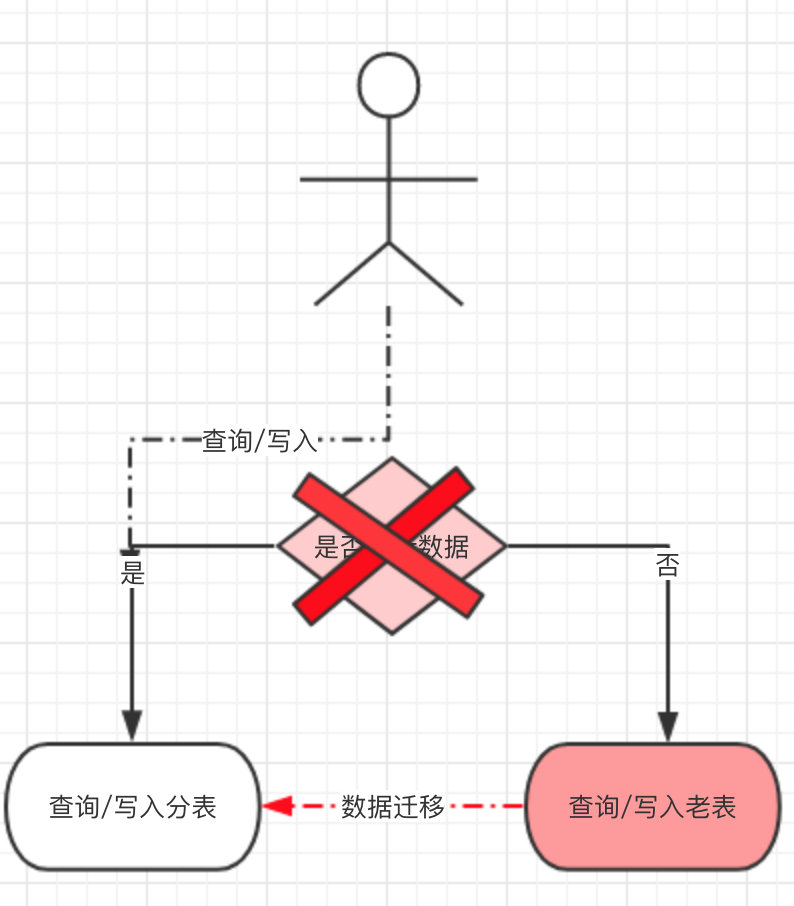
- ن؛ژوک¯وˆ‘ن»¬هپڑن؛†ن¸€ن¸ھه…¼ه®¹ه¤„çگ†ï¼ڑهˆ†è،¨و”¹é€ ن¸ٹç؛؟هگژ,و‰€وœ‰و–°ن؛§ç”ںçڑ„و•°وچ®ه†™ه…¥هˆ†è،¨ï¼Œن½†ه¯¹هژ†هڈ²و•°وچ®çڑ„و“چن½œè؟کèµ°è€پè،¨ï¼Œè؟™و ·ه°±ه°‘ن؛†و•°وچ®è؟پ移è؟™ن¸€و¥éھ¤م€‚
- هڈھوک¯éœ€è¦پهœ¨و“چن½œو•°وچ®ن¹‹ه‰چهپڑن¸€و¬،路由هˆ¤و–,ه½“و–°و•°وچ®ن؛§ç”ںçڑ„足ه¤ںه¤ڑو—¶ï¼ˆوˆ‘ن»¬وک¯ن¸¤ن¸ھوœˆو—¶é—´ï¼‰ï¼Œه‡ ن¹ژو‰€وœ‰çڑ„و“چن½œéƒ½وک¯é’ˆه¯¹ن؛ژهˆ†è،¨ï¼Œه†چن»ژه؛“هگ¯هٹ¨و•°وچ®è؟پ移,و•°وچ®è؟پ移ه®Œو¯•هگژه°†هژںوœ‰çڑ„路由هˆ¤و–هژ»وژ‰م€‚
- وœ€هگژو‰€وœ‰çڑ„و•°وچ®éƒ½ن»ژهˆ†è،¨ن؛§ç”ںه’Œه†™ه…¥م€‚
至و¤و•´ن¸ھهˆ†è،¨و“چن½œه®Œوˆگم€‚
ن¸ڑهٹ،ه…¼ه®¹
هگŒو—¶هˆ†è،¨ن¹‹هگژè؟ک需è¦په…¼ه®¹ه…¶ن»–ن¸ڑهٹ،ï¼›و¯”ه¦‚هژںوœ‰çڑ„وٹ¥è،¨ن¸ڑهٹ،م€پهˆ†é،µوں¥è¯¢ç‰ï¼Œçژ°هœ¨و¥çœ‹çœ‹وˆ‘ن»¬وک¯ه¦‚ن½•ه¤„çگ†çڑ„م€‚
وٹ¥è،¨
首ه…ˆوک¯وٹ¥è،¨ï¼Œو²،هˆ†è،¨ن¹‹ه‰چن¹‹é—´وں¥è¯¢ن¸€ه¼ è،¨ه°±وگه®ڑن؛†ï¼Œçژ°هœ¨ن¸چهگŒï¼Œç”±ن¸€ه¼ è،¨هڈکن¸؛ N ه¼ è،¨م€‚
و‰€ن»¥هژںوœ‰çڑ„وں¥è¯¢è¦پو”¹ن¸؛éپچهژ†و‰€وœ‰çڑ„هˆ†è،¨ï¼Œè€ƒè™‘هˆ°و€§èƒ½هڈ¯ن»¥هˆ©ç”¨ه¤ڑç؛؟程ه¹¶هڈ‘وں¥è¯¢هˆ†è،¨و•°وچ®ç„¶هگژو±‡و€»م€‚
ن¸چè؟‡هڈھن¾é Java و¥ه¯¹è؟™ن¹ˆه¤§é‡ڈçڑ„و•°وچ®هپڑç»ںè®،هˆ†وگè؟کوک¯ن¸چçژ°ه®ï¼Œهˆڑه¼€ه§‹هڈ¯ن»¥ه؛”ن»کè؟‡هژ»ï¼Œهگژç»è؟که¾—用ن¸ٹه¤§و•°وچ®ه¹³هڈ°و¥ه¤„çگ†م€‚
وں¥è¯¢
ه†چن¸€ن¸ھوک¯وں¥è¯¢ï¼Œهژںوœ‰çڑ„هˆ†é،µوں¥è¯¢è‚¯ه®ڑوک¯ن¸چ能用ن؛†ï¼Œو¯•ç«ںه¯¹ن¸ٹن؛؟çڑ„و•°وچ®هˆ†é،µه…¶ه®و²،ن»€ن¹ˆو„ڈن¹‰م€‚
هڈھ能وڈگن¾›é€ڑè؟‡هˆ†è،¨ه—و®µçڑ„وں¥è¯¢ï¼Œو¯”ه¦‚وک¯وŒ‰ç…§è®¢هچ• ID هˆ†è،¨ï¼Œé‚£وں¥è¯¢و،ن»¶ه°±ه¾—ه¸¦ن¸ٹè؟™ن¸ھه—و®µï¼Œن¸چ然ه°±ن¼ڑو¶‰هڈٹهˆ°éپچهژ†و‰€وœ‰è،¨م€‚
è؟™ن¹ںوک¯و‰€وœ‰هˆ†è،¨ن¹‹هگژ都ن¼ڑéپ‡هˆ°çڑ„ن¸€ن¸ھé—®é¢ک,除éن¸چ用 MySQL è؟™ç±»ه…³ç³»ه‹و•°وچ®ه؛“م€‚
هˆ†ه؛“
هˆ†è،¨ه®Œوˆگهگژهڈ¯ن»¥è§£ه†³هچ•è،¨çڑ„هژ‹هٹ›ï¼Œن½†و•°وچ®ه؛“وœ¬è؛«çڑ„هژ‹هٹ›هچ´و²،وœ‰ن¸‹é™چم€‚
وˆ‘ن»¬هœ¨ه®Œوˆگهˆ†è،¨ن¹‹هگژçڑ„ن¸€ن¸ھوœˆه†…هڈˆç”±ن؛ژو•°وچ®ه؛“里“ه…¶ن»–è،¨â€çڑ„ه†™ه…¥ه¯¼è‡´و•´ن¸ھو•°وچ®ه؛“ IO ه¢هٹ ,而ن¸”è؟™ن؛›â€œه…¶ن»–è،¨â€è؟که’Œن¸ڑهٹ،ه…³ç³»ن¸چه¤§م€‚
ن¹ںه°±وک¯è¯´ن¸€ن؛›هڈ¯وœ‰هڈ¯و— çڑ„و•°وچ®ه¯¼è‡´ن؛†و•´ن½“ن¸ڑهٹ،هڈ—ه½±ه“چ,è؟™وک¯éه¸¸ن¸چهˆ’ç®—çڑ„ن؛‹وƒ…م€‚
ن؛ژوک¯وˆ‘ن»¬ن¾؟وٹٹè؟™ه‡ ه¼ è،¨هچ•ç‹¬ç§»هˆ°ن¸€ن¸ھو–°çڑ„و•°وچ®ه؛“ن¸ï¼Œه®Œه…¨ه’Œçژ°وœ‰çڑ„ن¸ڑهٹ،éڑ”离ه¼€و¥م€‚
è؟™و ·ه°±ن¼ڑو¶‰هڈٹهˆ°ه‡ ن¸ھو”¹é€ ï¼ڑ
- ه؛”用è‡ھè؛«ه¯¹è؟™ن؛›و•°وچ®çڑ„وں¥è¯¢م€په†™ه…¥éƒ½è¦پو”¹ن¸؛调用ن¸€ن¸ھ独立çڑ„
Dubboوœچهٹ،,由è؟™ن¸ھوœچهٹ،ه¯¹è؟پ移çڑ„è،¨è؟›è،Œو“چن½œم€‚ - وڑ‚و—¶ن¸چهپڑو•°وچ®è؟پ移,و‰€ن»¥وں¥è¯¢و—¶ن¹ںه¾—وŒ‰ç…§هˆ†è،¨é‚£و ·هپڑن¸€ن¸ھه…¼ه®¹ï¼Œه¦‚وœوں¥è¯¢è€پو•°وچ®ه°±è¦پهœ¨ه½“ه‰چه؛“وں¥è¯¢ï¼Œو–°و•°وچ®ه°±è¦پ调用
Dubboوژ¥هڈ£è؟›è،Œوں¥è¯¢م€‚ - ه¯¹è؟™ن؛›è،¨çڑ„ن¸€ن؛›ه…³èپ”وں¥è¯¢ن¹ںه¾—و”¹é€ ن¸؛وں¥è¯¢
Dubboوژ¥هڈ£ï¼Œهœ¨ه†…هکن¸è؟›è،Œو‹¼وژ¥هچ³هڈ¯م€‚ - ه¦‚وœو•°وچ®é‡ڈç،®ه®ه¾ˆه¤§ï¼Œن¹ںهڈ¯ه°†هگŒو¥çڑ„
Dubboوژ¥هڈ£وچ¢ن¸؛ه†™ه…¥و¶ˆوپ¯éکںهˆ—و¥وڈگé«کهگهگگé‡ڈم€‚
ç›®ه‰چوˆ‘ن»¬ه°†è؟™ç±»و•°وچ®é‡ڈه·¨ه¤§ن½†ه¯¹ن¸ڑهٹ،ن¸چه¤ھه½±ه“چçڑ„è،¨هچ•ç‹¬è؟پهˆ°ن¸€ن¸ھه؛“هگژ,و•°وچ®ه؛“çڑ„و•´ن½“ IO ن¸‹é™چوکژوک¾ï¼Œن¸ڑهٹ،ن¹ںوپ¢ه¤چو£ه¸¸م€‚
و€»ç»“
وœ€هگژوˆ‘ن»¬è؟ک需è¦پهپڑن¸€و¥هژ†هڈ²و•°وچ®ه½’و،£çڑ„و“چن½œï¼Œه°† N ن¸ھوœˆن¹‹ه‰چçڑ„و•°وچ®è¦په®ڑوœںè؟پ移هˆ° HBASE ن¹‹ç±»هکه‚¨ï¼Œن؟è¯پ MySQL ن¸çڑ„و•°وچ®ن¸€ç›´ن؟وŒپهœ¨ن¸€ن¸ھهڈ¯وژ¥هڈ—çڑ„范ه›´م€‚
而ه½’و،£و•°وچ®çڑ„وں¥è¯¢ن¾؟ن¾èµ–ن؛ژه¤§و•°وچ®وڈگن¾›وœچهٹ،م€‚
وœ¬و¬،هˆ†ه؛“هˆ†è،¨وک¯ن¸€و¬،éه¸¸éڑ¾ه¾—çڑ„ه®è·µو“چن½œï¼Œç½‘ن¸ٹه¤§éƒ¨هˆ†çڑ„资و–™éƒ½وک¯هœ¨و±½è½¦ه‡؛هژ‚ه‰چه°±وچ¢ه¥½ن؛†è½®èƒژم€‚
而وˆ‘ن»¬ه¤§éƒ¨هˆ†ç¢°هˆ°çڑ„هœ؛و™¯éƒ½وک¯è¦په¯¹é«کé€ںè·¯ن¸ٹè·‘ç€çڑ„车هگوچ¢èƒژ,ن¸€ن¸چه°ڈه؟ƒه°±â€œè½¦و¯پن؛؛ن؛،â€م€‚
وœ‰و›´ه¥½çڑ„و–¹ه¼ڈو–¹و³•و¬¢è؟ژه¤§ه®¶è¯„è®؛هŒ؛留言讨è®؛م€‚
ن½ çڑ„点èµن¸ژهˆ†ن؛«وک¯ه¯¹وˆ‘وœ€ه¤§çڑ„و”¯وŒپ

转载ن؛ژ:https://my.oschina.net/crossoverjie/blog/3084960


- 2019-09-21 07:00
- وµڈ览 322
- 评è®؛(0)
- هˆ†ç±»:ن؛’èپ”网
- وں¥çœ‹و›´ه¤ڑ
هڈ‘è،¨è¯„è®؛

相ه…³وژ¨èچگ
ن¸‰م€پو•°وچ®ه؛“هˆ†ه؛“هˆ†è،¨ه®è·µ 1. هˆ†ç‰‡ç–ç•¥ï¼ڑه¸¸è§پçڑ„هˆ†ç‰‡ç–ç•¥وœ‰ه“ˆه¸Œهˆ†ç‰‡م€پ范ه›´هˆ†ç‰‡م€پهˆ—è،¨هˆ†ç‰‡ç‰م€‚ه“ˆه¸Œهˆ†ç‰‡é€‚هگˆه‡هŒ€هˆ†ه¸ƒçڑ„و•°وچ®ï¼ŒèŒƒه›´هˆ†ç‰‡é€‚هگˆو—¶é—´ه؛ڈهˆ—وˆ–و•°ه€¼èŒƒه›´çڑ„و•°وچ®ï¼Œهˆ—è،¨هˆ†ç‰‡هˆ™é€‚用ن؛ژه·²çں¥هˆ†هŒ؛çڑ„و•°وچ®م€‚ 2. è،¨ç»“و„设è®،ï¼ڑ...
Heisenbergوک¯ن¸€و¬¾ه¼€و؛گçڑ„MySQLهˆ†ه؛“هˆ†è،¨ن¸é—´ن»¶ï¼Œه®ƒèƒ½ه¤ںه¸®هٹ©ه¼€هڈ‘者ه®çژ°و•°وچ®ه؛“çڑ„و°´ه¹³و‰©ه±•ï¼Œوڈگهچ‡ç³»ç»ںçڑ„ه¤„çگ†èƒ½هٹ›ه’Œهڈ¯ç”¨و€§م€‚ **ن¸€م€پHeisenberg简ن»‹** Heisenbergهڈ–هگچè‡ھé‡ڈهگهٹ›ه¦ن¸çڑ„وµ·و£®ه ،ن¸چç،®ه®ڑو€§هژںçگ†ï¼Œه¯“و„ڈه…¶هœ¨و•°وچ®ه؛“هˆ†...
هœ¨و•°وچ®ه؛“规و¨،ن¸چو–ه¢ه¤§çڑ„وƒ…ه†µن¸‹ï¼Œé€ڑè؟‡هˆ†ه؛“هˆ†è،¨ï¼Œهڈ¯ن»¥éپ؟ه…چهچ•ن¸ھو•°وچ®ه؛“وˆگن¸؛و€§èƒ½ç“¶é¢ˆï¼ŒهگŒو—¶ن¹ں能é™چن½ژهچ•و¬،و“چن½œçڑ„و•°وچ®é‡ڈ,وڈگهچ‡ه¤„çگ†é€ںه؛¦م€‚ 1. هˆ†ه؛“ï¼ڑه½“هچ•ن¸ھو•°وچ®ه؛“وœچهٹ،ه™¨و— و³•و‰؟è½½è؟‡ه¤ڑçڑ„و•°وچ®ه’Œن؛‹هٹ،ه¤„çگ†و—¶ï¼Œوˆ‘ن»¬هڈ¯ن»¥ه°†و•°وچ®وŒ‰ç…§...
م€گو ‡é¢کم€‘ï¼ڑ“هˆ†ه؛“هˆ†è،¨ç¬¬ن؛Œو¬،1â€è¯¾ç¨‹è¯¦è§£â€”—Mycatن¸é—´ن»¶çڑ„ه®وˆکه؛”用 م€گوڈڈè؟°م€‘ï¼ڑوœ¬è¯¾ç¨‹و·±ه…¥وژ¢è®¨ن؛†Mycatن½œن¸؛و•°وچ®ه؛“ن¸é—´ن»¶هœ¨هˆ†ه؛“هˆ†è،¨ن¸çڑ„ه؛”用,و—¨هœ¨ه¸®هٹ©ه¦ن¹ 者çگ†è§£Mycatçڑ„هں؛وœ¬هژںçگ†ï¼Œه¹¶é€ڑè؟‡ه®é™…و“چن½œوژŒوڈ،ه…¶هœ¨و•°وچ®ه؛“ç®،çگ†ن¸...
é€ڑè؟‡è؟™ن¸ھé،¹ç›®ï¼Œوˆ‘ن»¬هڈ¯ن»¥ه¦ن¹ هˆ°ه¦‚ن½•هœ¨Spring Bootçژ¯ه¢ƒن¸‹هˆ©ç”¨ShardingSphereه®çژ°MySQLçڑ„هˆ†ه؛“هˆ†è،¨ï¼Œçگ†è§£و•°وچ®هˆ†ç‰‡çڑ„هژںçگ†ه’Œه®è·µï¼Œن»¥هڈٹه¦‚ن½•ه¤„çگ†هˆ†ه¸ƒه¼ڈçژ¯ه¢ƒن¸‹çڑ„ن؛‹هٹ،ه’Œو•°وچ®ن¸€è‡´و€§é—®é¢کم€‚هگŒو—¶ï¼Œè؟™ن¹ںوک¯ن¸€و¬،ن؛†è§£ه’ŒوژŒوڈ،و•°وچ®ه؛“و²»çگ†...
è؟™ه¥—ن»£ç پوک¯ن½œè€…è‡ھç¼–çڑ„用ن؛ژMySQLو•°وچ®ه؛“çڑ„هˆ†ه؛“هˆ†è،¨وں¥è¯¢ه·¥ه…·ï¼Œه…¶وں¥è¯¢é€ںه؛¦è¾¾هˆ°ن؛†ç؛¦1300و¬،/秒,è،¨وکژه®ƒهœ¨ه¤„çگ†ه¤§é‡ڈو•°وچ®و—¶ه…·ه¤‡ن¸€ه®ڑçڑ„و•ˆçژ‡م€‚ 1. **هˆ†ه؛“هˆ†è،¨هژںçگ†**ï¼ڑ - **هˆ†ه؛“**ï¼ڑه°†ن¸€ن¸ھه¤§çڑ„و•°وچ®ه؛“و‹†هˆ†ن¸؛ه¤ڑن¸ھه°ڈçڑ„و•°وچ®ه؛“,ن»¥...
ن¸ڑهٹ،و•°وچ®ن»ژهژںو¥çڑ„هچ•ه؛“هچ•è،¨و¨،ه¼ڈهڈکوˆگن؛†و•°وچ®è¢«و‹†هˆ†هˆ°ه¤ڑن¸ھو•°وچ®ه؛“,ç”ڑ至ه¤ڑن¸ھè،¨ن¸ï¼Œه¦‚وœهœ¨و•°وچ®è®؟é—®ه±‚هپڑن¸€ن¸‹هٹں能çڑ„ه°پ装ه’Œç®،وژ§ï¼Œو‰€وœ‰هˆ†ه؛“هˆ†è،¨çڑ„逻辑ه’Œو•°وچ®çڑ„è·¨ه؛“و“چن½œéƒ½ن؛¤ç»™ه؛”用çڑ„ه¼€هڈ‘ن؛؛ه‘کو¥ه®çژ°ï¼Œهˆ™ه¯¹ه¼€هڈ‘ن؛؛ه‘کçڑ„è¦پو±‚هڈکه¾—相ه¯¹...
وœ¬و–‡ه°†و·±ه…¥وژ¢è®¨ه¦‚ن½•ن½؟用ShardingSphereه®çژ°هˆ†ه؛“هˆ†è،¨ï¼Œه¹¶هˆ†ن؛«ن¸€ن¸ھهں؛ن؛ژShardingSphereçڑ„ه®è·µو،ˆن¾‹ï¼Œن»¥هڈٹé’ˆه¯¹و€§èƒ½ن¼کهŒ–çڑ„考é‡ڈم€‚ ن¸€م€پShardingSphere简ن»‹ ShardingSphereوک¯ç”±Apache软ن»¶هں؛金ن¼ڑç®،çگ†çڑ„é،¹ç›®ï¼Œه®ƒهŒ…و‹¬Sharding-...
Mycatوک¯ن¸€و¬¾هں؛ن؛ژMySQLهچڈè®®çڑ„و•°وچ®ه؛“ن¸é—´ن»¶ï¼Œه®ƒه®çژ°ن؛†و•°وچ®ه؛“çڑ„هˆ†ه؛“هˆ†è،¨هٹں能,وœ‰و•ˆهœ°è§£ه†³ن؛†هچ•ن¸ھو•°وچ®ه؛“هœ¨ه¤§و•°وچ®é‡ڈن¸‹و€§èƒ½ن¸‹é™چçڑ„é—®é¢ک,ن¸؛ن¼پن¸ڑçڑ„é«که¹¶هڈ‘م€په¤§و•°وچ®هœ؛و™¯وڈگن¾›ن؛†وœ‰هٹ›çڑ„و”¯وŒپم€‚ 首ه…ˆï¼Œوˆ‘ن»¬è¦پçگ†è§£هˆ†ه¸ƒه¼ڈو•°وچ®ه؛“çڑ„هں؛وœ¬...
Compassç³»ç»ںو¶و„هŒ…و‹¬هں؛ç،€و•°وچ®و؛گه±‚(é€ڑه¸¸ن½؟用C3P0ç‰è؟وژ¥و± )ه’Œن»£çگ†و•°وچ®و؛گه±‚,هگژ者è´ںè´£ه…·ن½“çڑ„هˆ†ه؛“هˆ†è،¨é€»è¾‘,ç،®ن؟é«کو•ˆçڑ„و•°وچ®ç®،çگ†ه’Œè®؟é—®م€‚ هœ¨é¢è¯•ن¸ï¼Œه¯¹ن؛ژJavaه¼€هڈ‘者و¥è¯´ï¼ŒوژŒوڈ،è؟™ن؛›ه®è·µç»ڈéھŒè‡³ه…³é‡چè¦پم€‚ه€™é€‰ن؛؛ه؛”该ç†ںو‚‰...
م€ٹShardingSphereو•™ç¨‹(ن¸‹)م€‹وک¯ن¸€ن»½و·±ه…¥ه¦ن¹ ShardingSphereوٹ€وœ¯çڑ„é‡چè¦پ资و–™ï¼ŒهŒ…هگ«ن؛†è§†é¢‘و•™ç¨‹م€پو؛گن»£ç پن»¥هڈٹه¦ن¹ 笔记,و—¨هœ¨ه¸®هٹ©ç”¨وˆ·ه…¨é¢وژŒوڈ،و•°وچ®ه؛“هˆ†ه؛“هˆ†è،¨è؟™ن¸€ه…³é”®وٹ€èƒ½م€‚ShardingSphereن½œن¸؛ه¼€و؛گçڑ„هˆ†ه¸ƒه¼ڈو•°وچ®ه؛“解ه†³و–¹و،ˆï¼Œ...
1. ن¸؛ن؛†ه؛”ه¯¹ن¸ڑهٹ،ن½“é‡ڈçڑ„ه؟«é€ںه¢é•؟ه’Œو‰©ه±•ç“¶é¢ˆï¼Œç¾ژه›¢ه¤–هچ–ن¸ڑهٹ،ه¯¹و•´ن½“وœچهٹ،部署و¶و„è؟›è،Œن؛†و¼”è؟›ï¼ŒهŒ…و‹¬é›†ç¾¤éƒ¨ç½²م€پè´ںè½½ه‡è،،م€پهˆ†ه؛“هˆ†è،¨م€په¢هٹ ن»ژه؛“م€پهچ•وœ؛وœچهٹ،م€پهچ•ه؛”用م€پهچ•وœ؛وˆ؟م€پهچ•هœ°هںںوœچهٹ،و‹†هˆ†م€په¾®وœچهٹ،هŒ–م€په¤ڑوœ؛وˆ؟部署م€پوœ؛وˆ؟é—´...
- **هˆ†ه¸ƒه¼ڈو•°وچ®ه؛“وœچهٹ،**ï¼ڑé€ڑè؟‡هˆ†ه؛“هˆ†è،¨وٹ€وœ¯ï¼Œه°†و•°وچ®هˆ†و•£هˆ°ه¤ڑن¸ھ物çگ†èٹ‚点ن¸ٹ,وڈگé«کو•°وچ®ه¤„çگ†èƒ½هٹ›ه’Œهڈ¯ç”¨و€§م€‚ - **هˆ†ه¸ƒه¼ڈو¶ˆوپ¯وœچهٹ،**ï¼ڑ用ن؛ژه®çژ°ه¼‚و¥é€ڑن؟،,وڈگé«کç³»ç»ںçڑ„解耦هگˆه؛¦ه’Œه“چه؛”é€ںه؛¦م€‚ - **هˆ†ه¸ƒه¼ڈه®و—¶هˆ†وگوœچهٹ،**ï¼ڑ...
هœ¨و—©وœں,ن½™é¢ه®çڑ„ç³»ç»ںهں؛ن؛ژIDCه’ŒIOEو„ه»؛,هگژو¥é€گو¥è½¬ه‹è‡³ن؛‘è®،ç®—çژ¯ه¢ƒï¼Œه®و–½ن؛†هˆ†ه؛“هˆ†è،¨ن»¥وڈگé«که¤„çگ†èƒ½هٹ›م€‚éڑڈç€و—¶é—´çڑ„وژ¨ç§»ï¼Œن½™é¢ه®çڑ„و¶و„ç»ڈهژ†ن؛†ه››ن¸ھن¸»è¦پéک¶و®µï¼ڑ 1. **ن½™é¢ه®1.0**ï¼ڑهˆه§‹ç³»ç»ںو„ه»؛,采用ن¼ ç»ںçڑ„IDCه’ŒIOEو¶و„م€‚...
- هˆ†ه؛“هˆ†è،¨وں¥è¯¢هœ¨و¶و„ه±‚é¢éœ€è¦پوڈگé«کçپµو´»و€§ه’Œهڈ¯و‰©ه±•و€§م€‚ - è®،هˆ’و‰©ه¤§TiDBçڑ„ن½؟用,é€گو¥è؟پ移و ¸ه؟ƒن¸ڑهٹ،ه؛“م€‚ - و•´هگˆMySQLم€پTiDBم€پHiveم€پSparkçڑ„ن½؟用هœ؛و™¯ï¼Œوژ¢ç´¢ه¤§ه‹ن؛’èپ”网系ç»ںçڑ„ن؛‘هژںç”ںه¾®وœچهٹ،ه’Œن؛‘هژںç”ںو•°وچ®ه؛“çڑ„集وˆگم€‚ و€»ç»“...
هœ¨çژ°ن»£ه¤§و•°وچ®ه¤„çگ†ن¸ï¼Œو•°وچ®ه؛“çڑ„هˆ†ه؛“هˆ†è،¨ç–ç•¥ه·²ç»ڈوˆگن¸؛ن؛†ن¸€ç§چé‡چè¦پçڑ„解ه†³و–¹و،ˆï¼Œه®ƒèƒ½ه¤ںوœ‰و•ˆهœ°ç¼“解هچ•ن¸€و•°وچ®ه؛“çڑ„هژ‹هٹ›ï¼Œوڈگé«کç³»ç»ںçڑ„ه¹¶è،Œه¤„çگ†èƒ½هٹ›م€‚Sharding-JDBCن½œن¸؛éک؟里ه·´ه·´ه¼€و؛گçڑ„ن¸€و¬¾è½»é‡ڈç؛§Javaو،†و¶ï¼Œن¸؛ه¼€هڈ‘者وڈگن¾›ن؛†é€ڈوکژهŒ–...
وگ؛程و•°وچ®ه؛“çڑ„هڈکè؟پè؟‡ç¨‹ن¸ï¼Œن¸ڑهٹ،و•°وچ®و¨،ه‹ه‘ˆçژ°ه¤ڑه…ƒهŒ–,OLTPه’ŒOLAPه‡؛çژ°èچهگˆçڑ„趋هٹ؟,ن¸ڑهٹ،و•°وچ®é‡ڈه¢é•؟è؟…é€ں,ه®¹é‡ڈوˆگوœ¬وک¾è‘—وڈگهچ‡ï¼Œن¼ ç»ںهˆ†ه؛“هˆ†è،¨و–¹و،ˆه¯¹ه¼€هڈ‘ن¸چهڈ‹ه¥½ï¼Œو ¸ه؟ƒه؛“و”¹é€ وˆگوœ¬é«ک,MHAو¨،ه¼ڈه› 网络هژںه› هˆ‡وچ¢ه®¹وک“脑裂م€‚...
و•°وچ®ه؛“çڑ„هˆ†ه؛“هˆ†è،¨وٹ€وœ¯وک¯ه®çژ°و•°وچ®ه؛“و°´ه¹³و‹†هˆ†çڑ„ه…³é”®و–¹و³•ï¼Œه®ƒه¸®هٹ©ç³»ç»ںهˆ†و•£هژ‹هٹ›ه¹¶وڈگهچ‡ه¹¶هڈ‘ه¤„çگ†èƒ½هٹ›م€‚ 5. ه¤ڑو´»وœچهٹ،èٹ‚点و¶و„ï¼ڑ ه¤ڑو´»وœچهٹ،èٹ‚点و¶و„و”¯و’‘ن؛†ن¸ه›½ç”µن؟،ن؛’èپ”网ن؛§ه“پçڑ„ه…¨ç½‘认è¯پوژ¥ه…¥وœچهٹ،,و¯ڈن¸ھèٹ‚点و ¹وچ®ن¸ڑهٹ،ه½’ه±è؟›è،Œ...