
https://zhuanlan.zhihu.com/p/46997268
NLPзӘҒз ҙжҖ§жҲҗжһң BERT жЁЎеһӢиҜҰз»Ҷи§ЈиҜ»
![]()
дёҚжҮӮз®—жі•зҡ„дә§е“Ғз»ҸзҗҶдёҚжҳҜеҘҪзҡ„зЁӢеәҸе‘ҳ
вҖӢе…іжіЁеҘ№
82 дәәиөһдәҶиҜҘж–Үз«
GoogleеҸ‘еёғзҡ„и®әж–ҮгҖҠPre-training of Deep Bidirectional Transformers for Language UnderstandingгҖӢпјҢжҸҗеҲ°зҡ„BERTжЁЎеһӢеҲ·ж–°дәҶиҮӘ然иҜӯиЁҖеӨ„зҗҶзҡ„11йЎ№и®°еҪ•гҖӮжңҖиҝ‘еңЁеҒҡNLPдёӯй—®зӯ”зӣёе…ізҡ„еҶ…е®№пјҢжҠҪз©әеҶҷдәҶзҜҮи®әж–ҮиҜҰз»Ҷи§ЈиҜ»гҖӮжҲ‘еҸ‘зҺ°еӨ§йғЁеҲҶе…іжіЁдәәе·ҘжҷәиғҪйўҶеҹҹзҡ„жңӢеҸӢзңӢдёҚжҮӮйҮҢйқўзҡ„дё»иҰҒз»“и®әпјҢдёәдәҶи®©дҪ еҝ«йҖҹдәҶи§Ји®әж–ҮзІҫй«“пјҢиҝҷйҮҢзү№ең°дёәеҲқеӯҰиҖ…е’ҢеҲҡжҺҘи§Ұж·ұеәҰеӯҰд№ зҡ„жңӢеҸӢ们еҘүдёҠжҠҖиғҪзӮ№зӘҒз ҙroadmapгҖӮеҰӮжһңеҲ«дәәеҶҷзҡ„и®әж–Үи§ЈиҜ»дҪ зңӢдёҚжҮӮпјҢд»ЈиЎЁдҪ йңҖиҰҒиЎҘе……еҹәзЎҖзҹҘиҜҶе•ҰгҖӮеҸҰеӨ–з»ҷдәҶдё»иҰҒи®әж–ҮеҸӮиҖғпјҢеңЁз¬¬дә”йғЁеҲҶпјҢеёҢжңӣеҜ№дҪ еңЁNLPйўҶеҹҹе…Ёйқўзҡ„дәҶи§ЈжңүжүҖеё®еҠ©гҖӮ
В
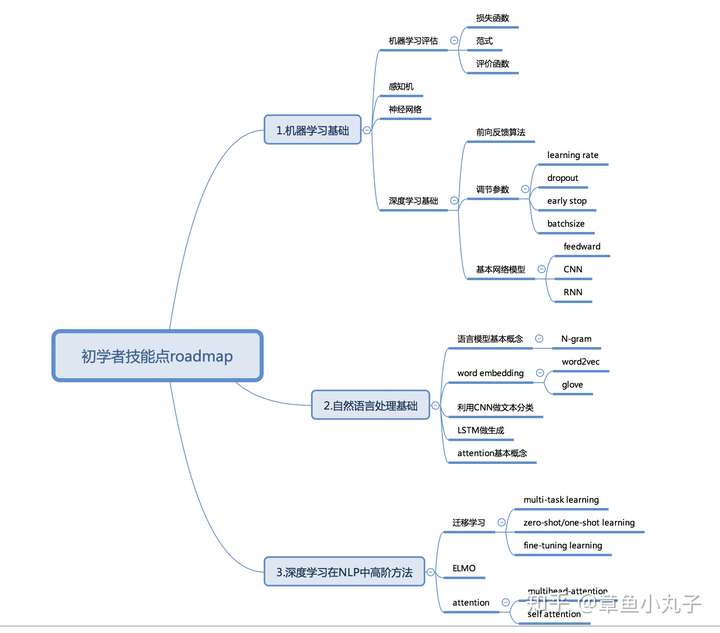
дёҖгҖҒ жҖ»дҪ“д»Ӣз»Қ
BERTжЁЎеһӢе®һйҷ…дёҠжҳҜдёҖдёӘиҜӯиЁҖзј–з ҒеҷЁпјҢжҠҠиҫ“е…Ҙзҡ„еҸҘеӯҗжҲ–иҖ…ж®өиҗҪиҪ¬еҢ–жҲҗзү№еҫҒеҗ‘йҮҸпјҲembeddingпјүгҖӮи®әж–ҮдёӯжңүдёӨеӨ§дә®зӮ№пјҡ1.еҸҢеҗ‘зј–з ҒеҷЁгҖӮдҪңиҖ…жІҝз”ЁдәҶгҖҠattention is all you needгҖӢйҮҢжҸҗеҲ°зҡ„иҜӯиЁҖзј–з ҒеҷЁпјҢ并жҸҗеҮәеҸҢеҗ‘зҡ„жҰӮеҝөпјҢеҲ©з”ЁmaskedиҜӯиЁҖжЁЎеһӢе®һзҺ°еҸҢеҗ‘гҖӮ2.дҪңиҖ…жҸҗеҮәдәҶдёӨз§Қйў„и®ӯз»ғзҡ„ж–№жі•MaskedиҜӯиЁҖжЁЎеһӢе’ҢдёӢдёҖдёӘеҸҘеӯҗзҡ„йў„жөӢж–№жі•гҖӮдҪңиҖ…и®ӨдёәзҺ°еңЁеҫҲеӨҡиҜӯиЁҖжЁЎеһӢдҪҺдј°дәҶйў„и®ӯз»ғзҡ„еҠӣйҮҸгҖӮMaskedиҜӯиЁҖжЁЎеһӢжҜ”иө·йў„жөӢдёӢдёҖдёӘеҸҘеӯҗзҡ„иҜӯиЁҖжЁЎеһӢпјҢеӨҡдәҶеҸҢеҗ‘зҡ„жҰӮеҝөгҖӮ
дәҢгҖҒ жЁЎеһӢжЎҶжһ¶
BERTжЁЎеһӢеӨҚз”ЁOpenAIеҸ‘еёғзҡ„гҖҠImproving Language Understanding with Unsupervised LearningгҖӢйҮҢзҡ„жЎҶжһ¶пјҢBERTж•ҙдҪ“жЁЎеһӢз»“жһ„дёҺеҸӮж•°и®ҫзҪ®йғҪе°ҪйҮҸеҒҡеҲ°OpenAI GPTдёҖж ·пјҢеҸӘеңЁйў„и®ӯз»ғж–№жі•еҒҡдәҶж”№йҖ гҖӮиҖҢGPTи®©зј–з ҒеҷЁеҸӘеӯҰд№ жҜҸдёҖдёӘtoken(еҚ•иҜҚпјүдёҺд№ӢеүҚзҡ„зӣёе…іеҶ…е®№гҖӮ
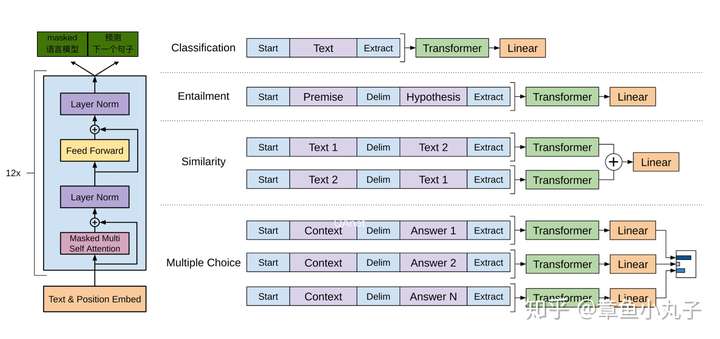
дёҠеӣҫжҳҜж №жҚ®OpenAI GPTзҡ„жһ¶жһ„еӣҫеҒҡзҡ„ж”№еҠЁпјҢд»ҘдҫҝиҜ»иҖ…жӣҙжё…жҘҡзҡ„дәҶи§Јж•ҙдёӘиҝҮзЁӢгҖӮ
ж•ҙдҪ“еҲҶдёәдёӨдёӘиҝҮзЁӢпјҡ1.йў„и®ӯз»ғиҝҮзЁӢпјҲе·Ұиҫ№еӣҫпјүйў„и®ӯз»ғиҝҮзЁӢжҳҜдёҖдёӘmulti-task learningпјҢиҝҒ移еӯҰд№ зҡ„д»»еҠЎпјҢзӣ®зҡ„жҳҜеӯҰд№ иҫ“е…ҘеҸҘеӯҗзҡ„еҗ‘йҮҸгҖӮ2еҫ®и°ғиҝҮзЁӢпјҲеҸіиҫ№еӣҫпјүеҸҜеҹәдәҺе°‘йҮҸзӣ‘зқЈеӯҰд№ ж ·жң¬пјҢеҠ е…ҘFeedwordзҘһз»ҸзҪ‘з»ңпјҢе®һзҺ°зӣ®ж ҮгҖӮеӣ дёәеҫ®и°ғйҳ¶ж®өеӯҰд№ зӣ®ж Үз”ұз®ҖеҚ•зҡ„feedwardзҘһз»ҸзҪ‘з»ңжһ„жҲҗпјҢдё”з”Ёе°‘йҮҸж ҮжіЁж ·жң¬пјҢжүҖд»Ҙи®ӯз»ғж—¶й—ҙзҹӯгҖӮ
1.иҫ“е…ҘиЎЁзӨә
еҜ№жҜ”е…¶д»–иҜӯиЁҖжЁЎеһӢиҫ“е…ҘжҳҜдёҖдёӘеҸҘеӯҗжҲ–иҖ…ж–ҮжЎЈпјҢBertжЁЎеһӢеҜ№иҫ“е…ҘеҒҡдәҶжӣҙе®Ҫжіӣзҡ„е®ҡд№үпјҢиҫ“е…ҘиЎЁзӨәеҚіеҸҜд»ҘжҳҜдёҖдёӘеҸҘеӯҗд№ҹеҸҜд»ҘдёҖеҜ№еҸҘеӯҗпјҲжҜ”еҰӮй—®зӯ”е’Ңзӯ”жЎҲз»„жҲҗзҡ„й—®зӯ”еҜ№пјүгҖӮ
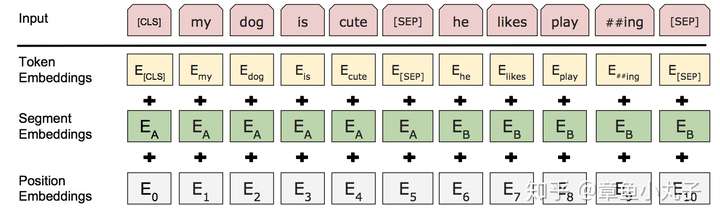
иҫ“е…ҘиЎЁзӨәдёәжҜҸдёӘиҜҚеҜ№еә”зҡ„иҜҚеҗ‘йҮҸпјҢsegmentеҗ‘йҮҸпјҢдҪҚзҪ®еҗ‘йҮҸзӣёеҠ иҖҢжҲҗгҖӮпјҲдҪҚзҪ®еҗ‘йҮҸеҸӮиҖғгҖҠattention is all you needгҖӢпјү
2.йў„и®ӯз»ғиҝҮзЁӢ-MaskedиҜӯиЁҖжЁЎеһӢ
MaskedиҜӯиЁҖжЁЎеһӢжҳҜдёәдәҶи®ӯз»ғж·ұеәҰеҸҢеҗ‘иҜӯиЁҖиЎЁзӨәеҗ‘йҮҸпјҢдҪңиҖ…з”ЁдәҶдёҖдёӘйқһеёёзӣҙжҺҘзҡ„ж–№ејҸпјҢйҒ®дҪҸеҸҘеӯҗйҮҢжҹҗдәӣеҚ•иҜҚпјҢи®©зј–з ҒеҷЁйў„жөӢиҝҷдёӘеҚ•иҜҚжҳҜд»Җд№ҲгҖӮ
и®ӯз»ғж–№жі•дёәпјҡдҪңиҖ…йҡҸжңәйҒ®дҪҸ15%зҡ„еҚ•иҜҚдҪңдёәи®ӯз»ғж ·жң¬гҖӮ
пјҲ1пјүе…¶дёӯ80%з”Ёmasked tokenжқҘд»ЈжӣҝгҖӮ
пјҲ2пјү10%з”ЁйҡҸжңәзҡ„дёҖдёӘиҜҚжқҘжӣҝжҚўгҖӮ
пјҲ3пјү10%дҝқжҢҒиҝҷдёӘиҜҚдёҚеҸҳгҖӮ
дҪңиҖ…еңЁи®әж–ҮдёӯжҸҗеҲ°иҝҷж ·еҒҡзҡ„еҘҪеӨ„жҳҜпјҢзј–з ҒеҷЁдёҚзҹҘйҒ“е“ӘдәӣиҜҚйңҖиҰҒйў„жөӢзҡ„пјҢе“ӘдәӣиҜҚжҳҜй”ҷиҜҜзҡ„пјҢеӣ жӯӨиў«иҝ«йңҖиҰҒеӯҰд№ жҜҸдёҖдёӘtokenзҡ„иЎЁзӨәеҗ‘йҮҸгҖӮеҸҰеӨ–дҪңиҖ…иЎЁзӨәпјҢжҜҸдёӘbatchsizeеҸӘжңү15%зҡ„иҜҚиў«йҒ®зӣ–зҡ„еҺҹеӣ пјҢжҳҜжҖ§иғҪејҖй”ҖгҖӮеҸҢеҗ‘зј–з ҒеҷЁжҜ”еҚ•йЎ№зј–з ҒеҷЁи®ӯз»ғиҰҒж…ўгҖӮ
3.йў„жөӢдёӢдёҖдёӘеҸҘеӯҗгҖӮ
йў„и®ӯз»ғдёҖдёӘдәҢеҲҶзұ»зҡ„жЁЎеһӢпјҢжқҘеӯҰд№ еҸҘеӯҗд№Ӣй—ҙзҡ„е…ізі»гҖӮйў„жөӢдёӢдёҖдёӘеҸҘеӯҗзҡ„ж–№жі•еҜ№еӯҰд№ еҸҘеӯҗд№Ӣй—ҙе…ізі»еҫҲжңүеё®еҠ©гҖӮ
и®ӯз»ғж–№жі•пјҡжӯЈж ·жң¬е’Ңиҙҹж ·жң¬жҜ”дҫӢжҳҜ1пјҡ1пјҢ50%зҡ„еҸҘеӯҗжҳҜжӯЈж ·жң¬пјҢйҡҸжңәйҖүжӢ©50%зҡ„еҸҘеӯҗдҪңдёәиҙҹж ·жң¬гҖӮ

[CLS]дёәеҸҘеӯҗиө·е§Ӣз¬ҰпјҢ[MASK]дёәйҒ®и”Ҫз ҒпјҢ[SEP]дёәеҲҶйҡ”з¬Ұе’ҢжҲӘжӯўз¬Ұ
В
4.йў„и®ӯз»ғйҳ¶ж®өеҸӮж•°
пјҲ1пјү256дёӘеҸҘеӯҗдҪңдёәдёҖдёӘbatch,жҜҸдёӘеҸҘеӯҗжңҖеӨҡ512дёӘtokenгҖӮ
пјҲ2пјүиҝӯд»Ј100дёҮжӯҘгҖӮ
пјҲ3пјүжҖ»е…ұи®ӯз»ғж ·жң¬и¶…иҝҮ33дәҝгҖӮ
пјҲ4пјүиҝӯд»Ј40дёӘepochsгҖӮ
пјҲ5пјүз”ЁadamеӯҰд№ зҺҮпјҢ 1 = 0.9, 2 = 0.999гҖӮ
пјҲ6пјүеӯҰд№ зҺҮеӨҙдёҖдёҮжӯҘдҝқжҢҒеӣәе®ҡеҖјпјҢд№ӢеҗҺзәҝжҖ§иЎ°еҮҸгҖӮ
пјҲ7пјүL2иЎ°еҮҸпјҢиЎ°еҮҸеҸӮж•°дёә0.01гҖӮ
пјҲ8пјүdrop outи®ҫзҪ®дёә0.1гҖӮ
пјҲ9пјүжҝҖжҙ»еҮҪж•°з”ЁGELUд»ЈжӣҝRELUгҖӮ
пјҲ10пјүBert baseзүҲжң¬з”ЁдәҶ16дёӘTPUпјҢBert largeзүҲжң¬з”ЁдәҶ64дёӘTPUпјҢи®ӯз»ғж—¶й—ҙ4еӨ©е®ҢжҲҗгҖӮ
пјҲи®әж–Үе®ҡд№үдәҶдёӨдёӘзүҲжң¬пјҢдёҖдёӘжҳҜbaseзүҲжң¬пјҢдёҖдёӘжҳҜlargeзүҲжң¬гҖӮLargeзүҲжң¬пјҲL=24, H=1024, A=16, Total Parameters=340MпјүгҖӮbaseзүҲжң¬пјҲ L=12, H=768, A=12, Total Pa- rameters=110MпјүгҖӮLд»ЈиЎЁзҪ‘з»ңеұӮж•°пјҢHд»ЈиЎЁйҡҗи—ҸеұӮж•°пјҢAд»ЈиЎЁself attention headзҡ„ж•°йҮҸгҖӮпјү
5.еҫ®и°ғйҳ¶ж®ө
еҫ®и°ғйҳ¶ж®өж №жҚ®дёҚеҗҢд»»еҠЎдҪҝз”ЁдёҚеҗҢзҪ‘з»ңжЁЎеһӢгҖӮеңЁеҫ®и°ғйҳ¶ж®өпјҢеӨ§йғЁеҲҶжЁЎеһӢзҡ„и¶…еҸӮж•°и·ҹйў„и®ӯз»ғж—¶е·®дёҚеӨҡпјҢйҷӨдәҶbatchsizeпјҢеӯҰд№ зҺҮпјҢepochsгҖӮ
и®ӯз»ғеҸӮж•°пјҡ
Batch size: 16, 32
Learning rate (Adam): 5e-5, 3e-5, 2e-5
Number of epochs: 3, 4
дёүгҖҒе®һйӘҢж•Ҳжһң
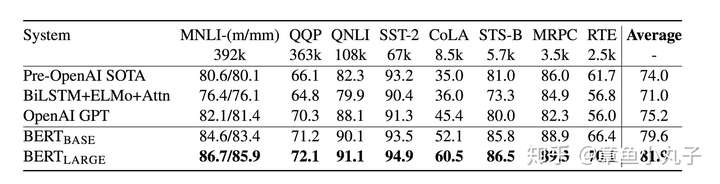
1.еҲҶзұ»ж•°жҚ®йӣҶдёҠзҡ„иЎЁзҺ°
2.й—®зӯ”ж•°жҚ®йӣҶдёҠзҡ„иЎЁзҺ°
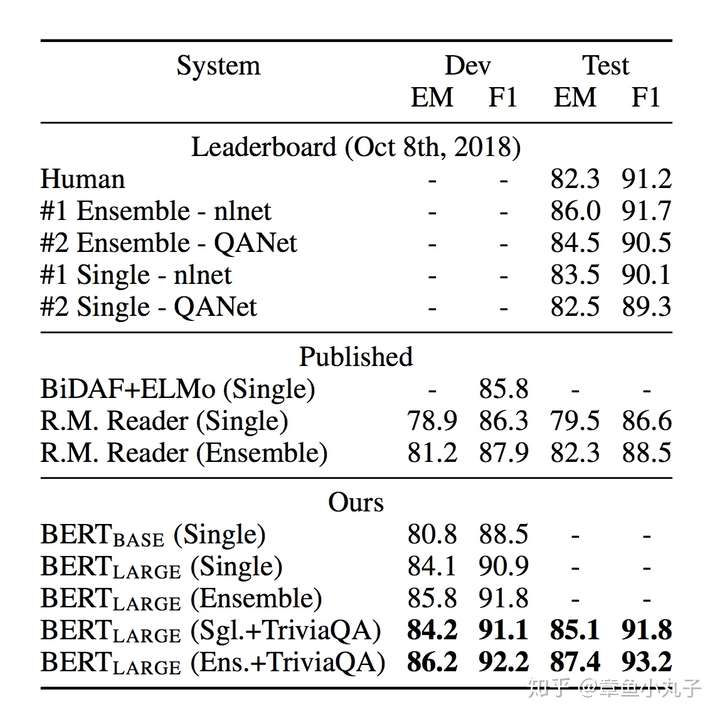
еңЁй—®зӯ”ж•°жҚ®йӣҶSQuAD v1.1дёҠзҡ„иЎЁзҺ°пјҢTriviaQAжҳҜдёҖдёӘй—®зӯ”ж•°жҚ®йӣҶгҖӮEMзҡ„еҹәжң¬з®—жі•жҳҜжҜ”иҫғдёӨдёӘеӯ—з¬ҰдёІзҡ„йҮҚеҗҲзҺҮгҖӮF1жҳҜз»јеҗҲиЎЎйҮҸеҮҶзЎ®зҺҮе’ҢеҸ¬еӣһзҺҮзҡ„дёҖдёӘжҢҮж ҮгҖӮ
3.е‘ҪеҗҚе®һдҪ“иҜҶеҲ«дёҠзҡ„иЎЁзҺ°
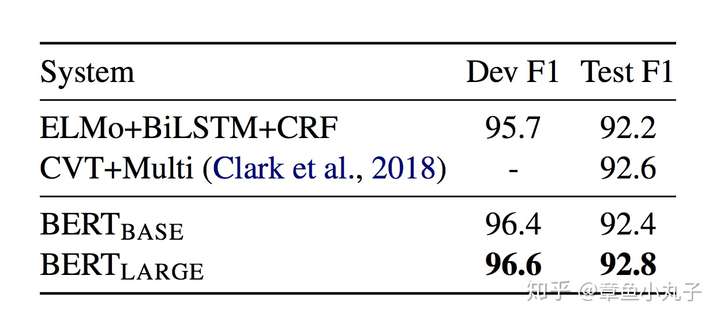
4.еёёиҜҶжҺЁзҗҶдёҠзҡ„иЎЁзҺ°

еӣӣгҖҒжЁЎеһӢз®ҖеҢ–жөӢиҜ•
Blation studyе°ұжҳҜдёәдәҶз ”з©¶жЁЎеһӢдёӯжүҖжҸҗеҮәзҡ„дёҖдәӣз»“жһ„жҳҜеҗҰжңүж•ҲиҖҢи®ҫи®Ўзҡ„е®һйӘҢгҖӮеҜ№иҜҘжЁЎеһӢжҺЁе№ҝе’Ңе·ҘзЁӢеҢ–йғЁзҪІжңүжһҒеӨ§дҪңз”ЁгҖӮ
1.йў„и®ӯз»ғж•ҲжһңжөӢиҜ•
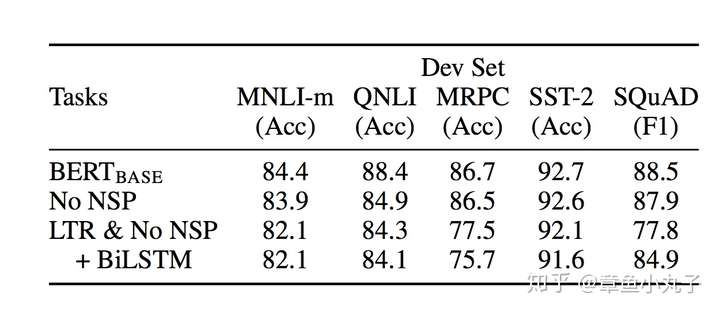
NO NSP:В з”ЁmaskedиҜӯиЁҖжЁЎеһӢпјҢжІЎз”ЁдёӢдёҖдёӘеҸҘеӯҗйў„жөӢж–№жі•пјҲnext sentence predictionпјү
LTR&NO NSP:В з”Ёд»Һе·ҰеҲ°еҸіпјҲLTRпјүиҜӯиЁҖжЁЎеһӢпјҢжІЎжңүmaskedиҜӯиЁҖжЁЎеһӢпјҢжІЎз”ЁдёӢдёҖдёӘеҸҘеӯҗйў„жөӢж–№жі•
+BiLSTM:В еҠ е…ҘеҸҢеҗ‘LSTMжЁЎеһӢеҒҡйў„и®ӯз»ғгҖӮ
В
2.жЁЎеһӢз»“жһ„зҡ„еӨҚжқӮеәҰеҜ№з»“жһңзҡ„еҪұе“Қ
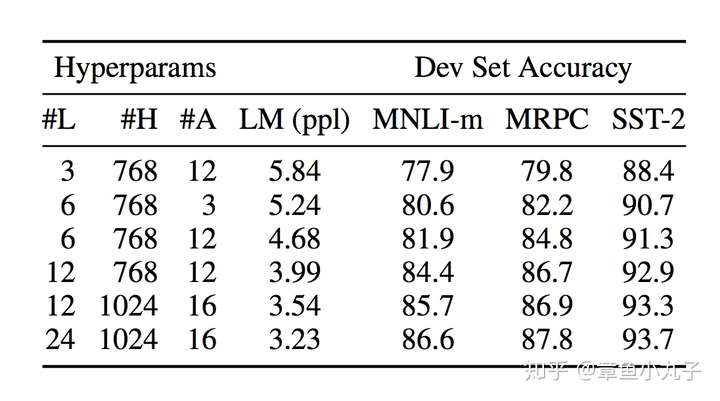
Lд»ЈиЎЁзҪ‘з»ңеұӮж•°пјҢHд»ЈиЎЁйҡҗи—ҸеұӮж•°пјҢAд»ЈиЎЁself attention headзҡ„ж•°йҮҸгҖӮ
3.йў„и®ӯз»ғдёӯtraining stepеҜ№з»“жһңзҡ„еҪұе“Қ

4.еҹәдәҺзү№еҫҒзҡ„ж–№жі•еҜ№з»“жһңзҡ„еҪұе“Қ

В
дә”гҖҒйҮҚиҰҒеҸӮиҖғи®әж–Ү
еҰӮдҪ•дҪ жғідәҶи§Ј2017е№ҙеҲ°2018е№ҙNLPйўҶеҹҹйҮҚиҰҒеҸ‘еұ•и¶ӢеҠҝпјҢдҪ еҸҜд»ҘеҸӮиҖғд»ҘдёӢеҮ зҜҮи®әж–ҮгҖӮgoogleзӣҙжҺҘе°ұеҸҜд»ҘдёӢиҪҪгҖӮ
гҖҠAttention is all you needгҖӢ2017е№ҙNLPйўҶеҹҹжңҖйҮҚиҰҒзӘҒз ҙжҖ§и®әж–Үд№ӢдёҖгҖӮ
гҖҠConvolutional Sequence to Sequence LearningгҖӢ2017е№ҙNLPйўҶеҹҹжңҖйҮҚиҰҒзӘҒз ҙжҖ§и®әж–Үд№ӢдёҖгҖӮ
гҖҠDeep contextualized word representationsгҖӢ2018е№ҙNAACLжңҖдҪіи®әж–ҮпјҢеӨ§еҗҚйјҺйјҺзҡ„ELMOгҖӮ
гҖҠImproving Language Understanding by Generative PreTrainingгҖӢпјҢOpenAI GPTпјҢBertжЁЎеһӢдё»иҰҒеҖҹйүҙе’ҢжҜ”иҫғеҜ№иұЎгҖӮ
гҖҠAn efficient framework for learning sentence representationsгҖӢеҸҘеӯҗеҗ‘йҮҸиЎЁзӨәж–№жі•гҖӮ
гҖҠSemi-supervised sequence tagging with bidirectional language modelsгҖӢжҸҗеҮәеҸҢеҗ‘иҜӯиЁҖжЁЎеһӢгҖӮ
е…ӯгҖҒдёӘдәәи§ӮзӮ№
дёӘдәәи§үеҫ—еҰӮжһңдҪ еӨ§жҰӮдәҶи§Јиҝ‘дёӨе№ҙNLPзҡ„еҸ‘еұ•зҡ„иҜқпјҢBERTжЁЎеһӢзҡ„зӘҒз ҙеңЁжғ…зҗҶд№ӢдёӯпјҢеӨ§еӨҡжҖқжғіжҳҜеҖҹз”ЁеүҚдәәзҡ„зӘҒз ҙпјҢжҜ”еҰӮеҸҢеҗ‘зј–з ҒеҷЁжғіжі•жҳҜеҖҹеҠ©иҝҷзҜҮи®әж–ҮгҖҠSemi-supervised sequence tagging with bidirectional language modelsгҖӢгҖӮ并且пјҢд»–жҸҗеҮәзҡ„дёҖдәӣж–°зҡ„жҖқжғіпјҢжҳҜжҲ‘们иҮӘ然иҖҢ然е°ұдјҡжғіеҲ°зҡ„гҖӮпјҲеҚҒдёҖеңЁе®¶зҡ„ж—¶еҖҷпјҢеңЁеҒҡй—®зӯ”жЁЎеһӢзҡ„ж—¶еҖҷпјҢжҲ‘е°ұеңЁжғіпјҢдёәд»Җд№ҲдёҚиғҪжҠҠеүҚдёҖдёӘеҸҘеӯҗе’ҢеҗҺдёҖдёӘеҸҘеӯҗдҪңдёәж ҮжіЁж•°жҚ®пјҢз»„жҲҗдёҖдёӘдәҢеҲҶзұ»жЁЎеһӢжқҘи®ӯз»ғе‘ўгҖӮпјү
ж•ҙзүҮи®әж–ҮжңҖжңүд»·еҖјзҡ„йғЁеҲҶпјҢжҲ‘и®ӨдёәжҳҜйў„и®ӯз»ғзҡ„дёӨз§Қж–№жі•пјҢдёҚйңҖиҰҒеӨ§йҮҸж ҮжіЁж•°жҚ®пјҢеңЁе·ҘзЁӢе®һи·өе’ҢдёҖдәӣNLPеҹәзЎҖи®ӯз»ғдёӯе…·жңүеҫҲеӨ§еҖҹйүҙж„Ҹд№үгҖӮ
иҮӘ然иҜӯиЁҖеӨ„зҗҶйўҶеҹҹ2017е№ҙе’Ң2018е№ҙзҡ„дёӨдёӘеӨ§и¶ӢеҠҝпјҡдёҖж–№йқўпјҢжЁЎеһӢд»ҺеӨҚжқӮеӣһеҪ’еҲ°з®ҖеҚ•гҖӮеҸҰдёҖж–№йқўпјҢиҝҒ移еӯҰд№ е’ҢеҚҠзӣ‘зқЈеӯҰд№ еӨ§зғӯгҖӮиҝҷдёӨдёӘи¶ӢеҠҝжҳҜNLPд»ҺеӯҰжңҜз•Ңеҗ‘дә§дёҡз•ҢиҝҮжёЎзҡ„иӢ—еӨҙпјҢеӣ дёәзҺ°е®һжғ…еҶөеҫҖеҫҖжҳҜпјҢжӢҝдёҚеҲ°еӨ§йҮҸй«ҳиҙЁйҮҸж ҮжіЁж•°жҚ®пјҢиө„жәҗи®ҫеӨҮжҳӮиҙөи§ЈеҶідёҚдәҶж•ҲзҺҮй—®йўҳгҖӮ



зӣёе…іжҺЁиҚҗ
еңЁжҺўи®Ёд»ҺWord EmbeddingеҲ°BertжЁЎеһӢзҡ„еҸ‘еұ•еҸІж—¶пјҢйҰ–е…ҲиҰҒдәҶи§ЈиҮӘ然иҜӯиЁҖеӨ„зҗҶ(NLP)йўҶеҹҹйў„и®ӯз»ғжҠҖжңҜзҡ„еҸ‘еұ•и„үз»ңгҖӮйў„и®ӯз»ғжҠҖжңҜжҳҜжҢҮйҖҡиҝҮеңЁеӨ§и§„жЁЎж•°жҚ®йӣҶдёҠи®ӯз»ғжЁЎеһӢпјҢеӯҰд№ иҜӯиЁҖзҡ„йҖҡз”Ёзү№еҫҒпјҢ并е°ҶеӯҰд№ еҲ°зҡ„еҸӮж•°иҝҒ移еҲ°ж–°зҡ„д»»еҠЎдёҠпјҢд»Ҙ...
вҖңnlpвҖқжҳҜвҖңиҮӘ然иҜӯиЁҖеӨ„зҗҶвҖқзҡ„иӢұж–Үзј©еҶҷпјҢBERTеңЁNLPйўҶеҹҹзҡ„жҲҗеҠҹиЎЁжҳҺйў„и®ӯз»ғжЁЎеһӢеҜ№дәҺи§ЈеҶіNLPй—®йўҳзҡ„жңүж•ҲжҖ§гҖӮ еҺӢзј©еҢ…еҶ…зҡ„вҖңchinese-bert_chinese_wwm_pytorchвҖқеҫҲеҸҜиғҪжҳҜдёҖдёӘй’ҲеҜ№дёӯж–Үзҡ„BERTжЁЎеһӢе®һзҺ°пјҢдҪҝз”ЁдәҶPythonзҡ„PyTorch...
еңЁиҮӘ然иҜӯиЁҖеӨ„зҗҶпјҲNLPпјүйўҶеҹҹпјҢBERTпјҲBidirectional Encoder Representations from TransformersпјүжЁЎеһӢжҳҜз”ұGoogleеңЁ2018е№ҙжҸҗеҮәзҡ„дёҖз§Қйў„и®ӯз»ғжЁЎеһӢпјҢе®ғеңЁеӨҡйЎ№NLPд»»еҠЎдёӯеҸ–еҫ—дәҶзӘҒз ҙжҖ§зҡ„жҲҗз»©гҖӮжң¬ж•ҷзЁӢе°Ҷж·ұе…ҘжҺўи®ЁеҰӮдҪ•дҪҝз”Ё...
BERTпјҢе…Ёз§°Bidirectional Encoder Representations from TransformersпјҢжҳҜз”ұGoogleеңЁ2018е№ҙеә•жҺЁеҮәзҡ„дёҖз§Қйў„и®ӯз»ғиҜӯиЁҖжЁЎеһӢпјҢе®ғеңЁиҮӘ然иҜӯиЁҖеӨ„зҗҶпјҲNLPпјүйўҶеҹҹеҸ–еҫ—дәҶйҮҚеӨ§зӘҒз ҙпјҢжү“з ҙдәҶ11йЎ№NLPд»»еҠЎзҡ„и®°еҪ•гҖӮBERTжЁЎеһӢзҡ„еҮәзҺ°еҜ№дәҺ...
еңЁиҮӘ然иҜӯиЁҖеӨ„зҗҶпјҲNLPпјүйўҶеҹҹпјҢе‘ҪеҗҚе®һдҪ“иҜҶеҲ«пјҲNERпјүжҳҜдёҖйЎ№йҮҚиҰҒзҡ„д»»еҠЎпјҢе®ғж¶үеҸҠеҲ°д»Һж–Үжң¬дёӯиҜҶеҲ«еҮәе…·жңүзү№е®ҡж„Ҹд№үзҡ„е®һдҪ“пјҢеҰӮдәәеҗҚгҖҒең°еҗҚгҖҒз»„з»ҮеҗҚзӯүгҖӮPyTorchжҳҜдёҖдёӘжөҒиЎҢзҡ„ж·ұеәҰеӯҰд№ жЎҶжһ¶пјҢиҖҢBERTпјҲBidirectional Encoder ...
BERTжҳҜиҮӘ然иҜӯиЁҖеӨ„зҗҶйўҶеҹҹзҡ„дёҖдёӘйҮҚиҰҒзӘҒз ҙпјҢе®ғйҖҡиҝҮйў„и®ӯз»ғе’Ңеҫ®и°ғзҡ„ж–№ејҸпјҢжҸҗй«ҳдәҶеӨҡз§ҚиҮӘ然иҜӯиЁҖеӨ„зҗҶд»»еҠЎзҡ„жҖ§иғҪпјҢеҰӮй—®зӯ”гҖҒжғ…ж„ҹеҲҶжһҗгҖҒж–Үжң¬еҲҶзұ»зӯүгҖӮ BERTзҡ„ж ёеҝғеҲӣж–°еңЁдәҺе…¶еҸҢеҗ‘зҡ„и®ӯз»ғж–№ејҸпјҢе®ғжү“з ҙдәҶдј з»ҹж–№жі•дёӯд»Һе·ҰеҲ°еҸіжҲ–д»ҺеҸіеҲ°...
еңЁеҪ“еүҚзҡ„ITйўҶеҹҹпјҢйў„и®ӯз»ғжЁЎеһӢе·Із»ҸжҲҗдёәиҮӘ然иҜӯиЁҖеӨ„зҗҶпјҲNLPпјүзҡ„ж ёеҝғжҠҖжңҜд№ӢдёҖгҖӮжң¬ж–Үе°Ҷж·ұе…ҘжҺўи®ЁеҹәдәҺйў„и®ӯз»ғBertжЁЎеһӢзҡ„иҜ„иҜӯеӨҡд»»еҠЎж•°жҚ®жҢ–жҺҳеҠҹиғҪе®һзҺ°пјҢиҝҷжҳҜдёҖйЎ№ж—ЁеңЁд»ҺеӨ§йҮҸиҜ„иҜӯж•°жҚ®дёӯжҸҗеҸ–жңүд»·еҖјдҝЎжҒҜзҡ„жҠҖжңҜгҖӮBertпјҢе…Ёз§°дёә...
BERTпјҲBidirectional Encoder Representations from TransformersпјүжҳҜз”ұGoogleеңЁ2018е№ҙжҸҗеҮәзҡ„йў„и®ӯз»ғиҜӯиЁҖжЁЎеһӢпјҢе®ғеңЁеӨҡйЎ№иҮӘ然иҜӯиЁҖеӨ„зҗҶд»»еҠЎдёӯеҸ–еҫ—дәҶзӘҒз ҙжҖ§зҡ„жҲҗз»©гҖӮPyTorchжҳҜFacebookејҖжәҗзҡ„дёҖдёӘж·ұеәҰеӯҰд№ жЎҶжһ¶пјҢд»Ҙе…¶зҒөжҙ»жҖ§...
иҮӘ然иҜӯиЁҖеӨ„зҗҶпјҲNatural Language Processing, NLPпјүжҳҜи®Ўз®—жңә科еӯҰйўҶеҹҹзҡ„дёҖдёӘе…ій”®еҲҶж”ҜпјҢдё“жіЁдәҺз ”з©¶еҰӮдҪ•и®©и®Ўз®—жңәзҗҶи§ЈгҖҒз”ҹжҲҗе’ҢеӨ„зҗҶдәәзұ»зҡ„иҮӘ然иҜӯиЁҖгҖӮиҝ‘е№ҙжқҘпјҢйў„и®ӯз»ғжЁЎеһӢеңЁNLPйўҶеҹҹеҸ–еҫ—дәҶйҮҚеӨ§зӘҒз ҙпјҢжһҒеӨ§ең°жҺЁеҠЁдәҶиҮӘ然иҜӯиЁҖ...
BERTпјҲBidirectional Encoder Representations from TransformersпјүжЁЎеһӢиҮӘд»Һ2018е№ҙ10жңҲз”ұGoogleе…¬еёғе…¶еңЁ11йЎ№иҮӘ然иҜӯиЁҖеӨ„зҗҶпјҲNLPпјүд»»еҠЎдёӯзҡ„еҚ“и¶ҠиЎЁзҺ°еҗҺпјҢдҫҝиҝ…йҖҹжҲҗдёәNLPйўҶеҹҹзҡ„зғӯзӮ№гҖӮBERTжЁЎеһӢжҳҜдёҖз§Қйў„и®ӯз»ғиҜӯиЁҖиЎЁзӨәзҡ„ж–№жі•...
иҮӘ然иҜӯиЁҖеӨ„зҗҶпјҲNLPпјүжҳҜи®Ўз®—жңә科еӯҰйўҶеҹҹзҡ„дёҖдёӘйҮҚиҰҒеҲҶж”ҜпјҢдё»иҰҒе…іжіЁеҰӮдҪ•дҪҝи®Ўз®—жңәзҗҶи§ЈгҖҒи§ЈжһҗгҖҒз”ҹжҲҗе’Ңж“ҚдҪңдәәзұ»иҜӯиЁҖгҖӮBERTпјҲBidirectional Encoder Representations from TransformersпјүжҳҜиҝ‘е№ҙжқҘеңЁNLPйўҶеҹҹзҡ„дёҖйЎ№зӘҒз ҙжҖ§жҠҖжңҜ...
BERTпјҢе…Ёз§°дёәBidirectional Encoder Representations from TransformersпјҢжҳҜGoogleеңЁ2018е№ҙжҸҗеҮәзҡ„дёҖз§ҚTransformerжһ¶жһ„зҡ„ж·ұеәҰеӯҰд№ жЁЎеһӢпјҢе®ғеңЁиҮӘ然иҜӯиЁҖеӨ„зҗҶпјҲNLPпјүд»»еҠЎдёӯеҸ–еҫ—дәҶйҮҚеӨ§зӘҒз ҙпјҢзү№еҲ«жҳҜеңЁиҜӯд№үзҗҶи§Јж–№йқўгҖӮ...
BERTзҡ„еҮәзҺ°ж Үеҝ—зқҖиҮӘ然иҜӯиЁҖеӨ„зҗҶйўҶеҹҹзҡ„йҮҚеӨ§зӘҒз ҙпјҢдёәеҗҺз»ӯз ”з©¶жҸҗдҫӣдәҶејәеӨ§зҡ„еҹәзЎҖжЁЎеһӢе’ҢжҠҖжңҜжЎҶжһ¶гҖӮе®ғдёҚд»…еңЁзҗҶи®әеұӮйқўжҺЁеҠЁдәҶNLPзҡ„еҸ‘еұ•пјҢиҖҢдё”еңЁе®һйҷ…еә”з”Ёдёӯд№ҹеұ•зҺ°еҮәдәҶжһҒй«ҳзҡ„д»·еҖјпјҢжҲҗдёәдәҶдј—еӨҡдјҒдёҡе’Ңз ”з©¶жңәжһ„з«һзӣёйҮҮз”Ёзҡ„жҠҖжңҜж–№жЎҲ...
йў„и®ӯз»ғжЁЎеһӢдҪңдёәиҮӘ然иҜӯиЁҖеӨ„зҗҶпјҲNLPпјүйўҶеҹҹзҡ„йҮҚиҰҒзӘҒз ҙд№ӢдёҖпјҢдёәи§ЈеҶіиҜӯиЁҖзҗҶи§ЈдёҺз”ҹжҲҗзҡ„й—®йўҳжҸҗдҫӣдәҶе…Ёж–°зҡ„и§Ҷи§’е’Ңж–№жі•гҖӮдј з»ҹзҡ„NLPж–№жі•еҫҖеҫҖеҸ—йҷҗдәҺж•°жҚ®йҮҸгҖҒзү№еҫҒе·ҘзЁӢзӯүй—®йўҳпјҢиҖҢйў„и®ӯз»ғжЁЎеһӢеҲҷйҖҡиҝҮеңЁеӨ§и§„жЁЎж— ж ҮжіЁж•°жҚ®дёҠиҝӣиЎҢиҮӘжҲ‘еӯҰд№ ...
BERTпјҲBidirectional Encoder Representations from TransformersпјүжҳҜGoogleеңЁ2018е№ҙжҸҗеҮәзҡ„дёҖз§Қйў„и®ӯз»ғиҜӯиЁҖжЁЎеһӢпјҢе®ғеңЁиҮӘ然иҜӯиЁҖеӨ„зҗҶпјҲNLPпјүйўҶеҹҹеҸ–еҫ—дәҶйҮҚеӨ§зӘҒз ҙгҖӮMXNetжҳҜдёҖдёӘејҖжәҗзҡ„ж·ұеәҰеӯҰд№ жЎҶжһ¶пјҢд»Ҙе…¶й«ҳж•ҲгҖҒзҒөжҙ»е’ҢеҸҜ...
BERTжЁЎеһӢеңЁиҮӘ然иҜӯиЁҖеӨ„зҗҶпјҲNLPпјүйўҶеҹҹеҸ–еҫ—дәҶйқ©е‘ҪжҖ§зҡ„зӘҒз ҙпјҢе°Өе…¶жҳҜеңЁзҗҶи§Је’Ңз”ҹжҲҗдәәзұ»иҜӯиЁҖж–№йқўеұ•зҺ°дәҶеҚ“и¶Ҡзҡ„иғҪеҠӣгҖӮе®ғдё»иҰҒеә”з”ЁдәҺж–Үжң¬еҲҶзұ»гҖҒй—®зӯ”зі»з»ҹгҖҒжңәеҷЁзҝ»иҜ‘гҖҒжғ…ж„ҹеҲҶжһҗзӯүеӨҡдёӘеңәжҷҜгҖӮ BERTзҡ„ж ёеҝғжҖқжғіжҳҜеј•е…ҘдәҶеҸҢеҗ‘...
еңЁиҮӘ然иҜӯиЁҖеӨ„зҗҶпјҲNLPпјүйўҶеҹҹпјҢBERTпјҲBidirectional Encoder Representations from TransformersпјүжҳҜдёҖз§ҚйқһеёёжөҒиЎҢзҡ„йў„и®ӯз»ғжЁЎеһӢпјҢз”ұGoogleеңЁ2018е№ҙжҸҗеҮәгҖӮе®ғйҖҡиҝҮеҲ©з”ЁTransformerжһ¶жһ„е®һзҺ°дәҶеҜ№иҫ“е…ҘеәҸеҲ—зҡ„дёҠдёӢж–ҮзҗҶи§ЈпјҢд»ҺиҖҢ...
BERTпјҲBidirectional Encoder Representations from TransformersпјүжҳҜGoogleдәҺ2018е№ҙжҸҗеҮәзҡ„йў„и®ӯз»ғиҜӯиЁҖжЁЎеһӢпјҢе®ғеңЁеӨҡз§ҚиҮӘ然иҜӯиЁҖеӨ„зҗҶд»»еҠЎдёӯеҸ–еҫ—дәҶзӘҒз ҙжҖ§жҲҗжһңгҖӮеңЁиҷҡеҒҮж–°й—»жЈҖжөӢдёӯпјҢBERTзҡ„дҪҝз”ЁеҸҜиғҪеҢ…жӢ¬пјҡ 1. йў„и®ӯз»ғдёҺеҫ®и°ғ...
иҮӘ然иҜӯиЁҖеӨ„зҗҶпјҲNLPпјүжҳҜи®Ўз®—жңә科еӯҰйўҶеҹҹзҡ„дёҖдёӘйҮҚиҰҒеҲҶж”ҜпјҢдё»иҰҒе…іжіЁеҰӮдҪ•дҪҝи®Ўз®—жңәзҗҶи§ЈгҖҒз”ҹжҲҗе’ҢеӨ„зҗҶдәәзұ»иҮӘ然иҜӯиЁҖгҖӮеңЁNLPдёӯпјҢйў„и®ӯз»ғиҜӯиЁҖжЁЎеһӢжҳҜиҝ‘е№ҙжқҘз ”з©¶зҡ„зғӯзӮ№пјҢе®ғ们еңЁи®ёеӨҡд»»еҠЎдёҠеҸ–еҫ—дәҶжҳҫи‘—зҡ„зӘҒз ҙпјҢеҰӮж–Үжң¬з”ҹжҲҗгҖҒй—®зӯ”зі»з»ҹгҖҒ...
BERTжҳҜз”ұGoogleеңЁ2018е№ҙжҸҗеҮәзҡ„дёҖз§Қйў„и®ӯз»ғиҜӯиЁҖжЁЎеһӢпјҢе®ғеңЁиҮӘ然иҜӯиЁҖеӨ„зҗҶпјҲNLPпјүйўҶеҹҹеҸ–еҫ—дәҶйқ©е‘ҪжҖ§зҡ„зӘҒз ҙгҖӮBERTжЁЎеһӢзҡ„ж ёеҝғи®ҫи®ЎзҗҶеҝөжҳҜйҖҡиҝҮTransformerжһ¶жһ„жҚ•жҚүж–Үжң¬дёӯзҡ„дёҠдёӢж–Үе…ізі»пјҢе®һзҺ°иҜҚд№үзҡ„ж·ұеәҰзҗҶи§ЈгҖӮ жҸҸиҝ°дёӯзҡ„вҖңз”ЁдәҺ...