
在前面两篇文章中,我们用一个框架梳理了各大优化算法,并且指出了以Adam为代表的自适应学习率优化算法可能存在的问题。那么,在实践中我们应该如何选择呢?
本文介绍Adam+SGD的组合策略,以及一些比较有用的tricks.
回顾前文:
不同优化算法的核心差异:下降方向
从第一篇的框架中我们看到,不同优化算法最核心的区别,就是第三步所执行的下降方向:
这个式子中,前半部分是实际的学习率(也即下降步长),后半部分是实际的下降方向。SGD算法的下降方向就是该位置的梯度方向的反方向,带一阶动量的SGD的下降方向则是该位置的一阶动量方向。自适应学习率类优化算法为每个参数设定了不同的学习率,在不同维度上设定不同步长,因此其下降方向是缩放过(scaled)的一阶动量方向。
由于下降方向的不同,可能导致不同算法到达完全不同的局部最优点。An empirical analysis of the optimization of deep network loss surfaces 这篇论文中做了一个有趣的实验,他们把目标函数值和相应的参数形成的超平面映射到一个三维空间,这样我们可以直观地看到各个算法是如何寻找超平面上的最低点的。
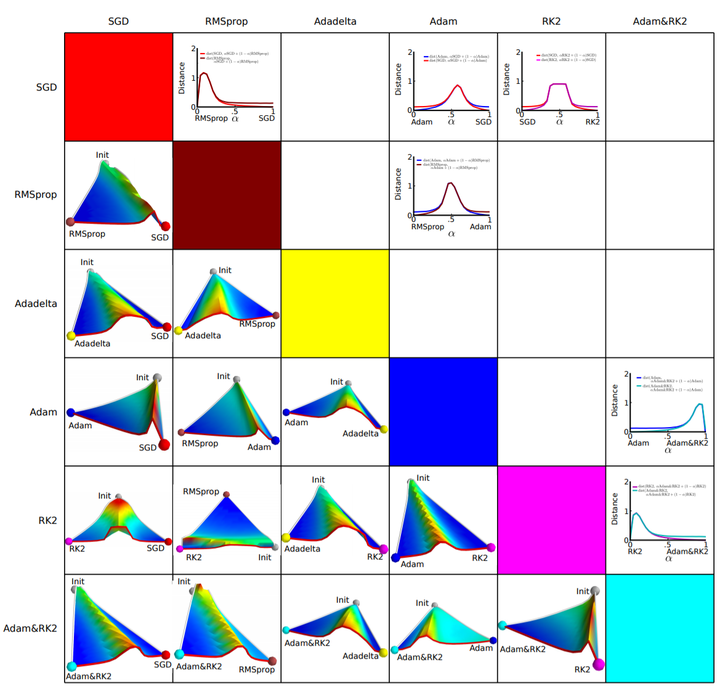
上图是论文的实验结果,横纵坐标表示降维后的特征空间,区域颜色则表示目标函数值的变化,红色是高原,蓝色是洼地。他们做的是配对儿实验,让两个算法从同一个初始化位置开始出发,然后对比优化的结果。可以看到,几乎任何两个算法都走到了不同的洼地,他们中间往往隔了一个很高的高原。这就说明,不同算法在高原的时候,选择了不同的下降方向。
Adam+SGD 组合策略
正是在每一个十字路口的选择,决定了你的归宿。如果上天能够给我一个再来一次的机会,我会对那个女孩子说:SGD!
不同优化算法的优劣依然是未有定论的争议话题。据我在paper和各类社区看到的反馈,主流的观点认为:Adam等自适应学习率算法对于稀疏数据具有优势,且收敛速度很快;但精调参数的SGD(+Momentum)往往能够取得更好的最终结果。
那么我们就会想到,可不可以把这两者结合起来,先用Adam快速下降,再用SGD调优,一举两得?思路简单,但里面有两个技术问题:
- 什么时候切换优化算法?——如果切换太晚,Adam可能已经跑到自己的盆地里去了,SGD再怎么好也跑不出来了。
- 切换算法以后用什么样的学习率?——Adam用的是自适应学习率,依赖的是二阶动量的累积,SGD接着训练的话,用什么样的学习率?
上一篇中提到的论文 Improving Generalization Performance by Switching from Adam to SGD 提出了解决这两个问题的思路。
首先来看第二个问题,切换之后用什么样的学习率。Adam的下降方向是
而SGD的下降方向是
.
必定可以分解为
所在方向及其正交方向上的两个方向之和,那么其在
方向上的投影就意味着SGD在Adam算法决定的下降方向上前进的距离,而在
的正交方向上的投影是 SGD 在自己选择的修正方向上前进的距离。
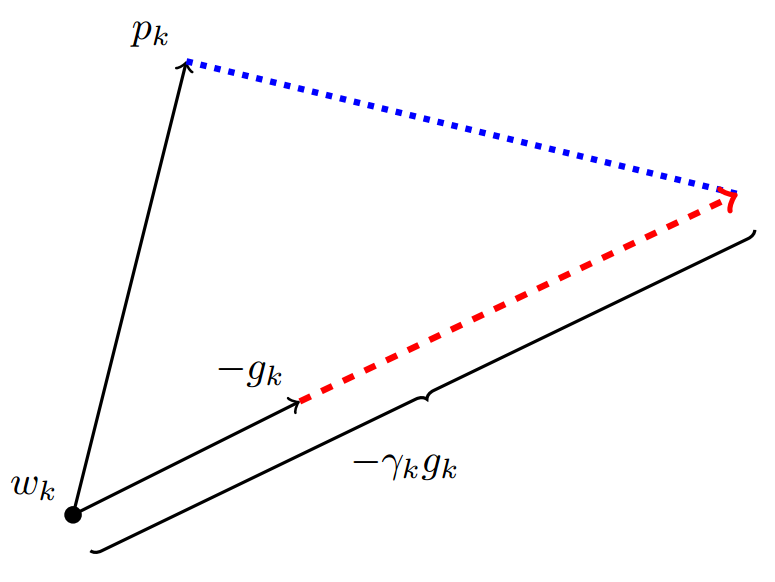 图片来自原文,这里p为Adam下降方向,g为梯度方向,r为SGD的学习率。
图片来自原文,这里p为Adam下降方向,g为梯度方向,r为SGD的学习率。
如果SGD要走完Adam未走完的路,那就首先要接过Adam的大旗——沿着 方向走一步,而后在沿着其正交方向走相应的一步。
这样我们就知道该如何确定SGD的步长(学习率)了——SGD在Adam下降方向上的正交投影,应该正好等于Adam的下降方向(含步长)。也即:
解这个方程,我们就可以得到接续进行SGD的学习率:
为了减少噪声影响,作者使用移动平均值来修正对学习率的估计:
这里直接复用了Adam的 参数。
然后来看第一个问题,何时进行算法的切换。
作者的回答也很简单,那就是当 SGD的相应学习率的移动平均值基本不变的时候,即:
. 每次迭代玩都计算一下SGD接班人的相应学习率,如果发现基本稳定了,那就SGD以
为学习率接班前进。
优化算法的常用tricks
最后,分享一些在优化算法的选择和使用方面的一些tricks。
- 首先,各大算法孰优孰劣并无定论。如果是刚入门,优先考虑SGD+Nesterov Momentum或者Adam.(Standford 231n : The two recommended updates to use are either SGD+Nesterov Momentum or Adam)
- 选择你熟悉的算法——这样你可以更加熟练地利用你的经验进行调参。
- 充分了解你的数据——如果模型是非常稀疏的,那么优先考虑自适应学习率的算法。
- 根据你的需求来选择——在模型设计实验过程中,要快速验证新模型的效果,可以先用Adam进行快速实验优化;在模型上线或者结果发布前,可以用精调的SGD进行模型的极致优化。
- 先用小数据集进行实验。有论文研究指出,随机梯度下降算法的收敛速度和数据集的大小的关系不大。(The mathematics of stochastic gradient descent are amazingly independent of the training set size. In particular, the asymptotic SGD convergence rates are independent from the sample size. [2])因此可以先用一个具有代表性的小数据集进行实验,测试一下最好的优化算法,并通过参数搜索来寻找最优的训练参数。
- 考虑不同算法的组合。先用Adam进行快速下降,而后再换到SGD进行充分的调优。切换策略可以参考本文介绍的方法。
- 数据集一定要充分的打散(shuffle)。这样在使用自适应学习率算法的时候,可以避免某些特征集中出现,而导致的有时学习过度、有时学习不足,使得下降方向出现偏差的问题。
- 训练过程中持续监控训练数据和验证数据上的目标函数值以及精度或者AUC等指标的变化情况。对训练数据的监控是要保证模型进行了充分的训练——下降方向正确,且学习率足够高;对验证数据的监控是为了避免出现过拟合。
- 制定一个合适的学习率衰减策略。可以使用定期衰减策略,比如每过多少个epoch就衰减一次;或者利用精度或者AUC等性能指标来监控,当测试集上的指标不变或者下跌时,就降低学习率。
这里只列举出一些在优化算法方面的trick,如有遗漏,欢迎各位知友在评论中补充,我将持续更新此文。提前致谢!
神经网络模型的设计和训练要复杂得多,initialization, activation, normalization 等等无不是四两拨千斤,这些方面的技巧我再慢慢写,欢迎关注我的知乎专栏和微信公众号(Julius-AI),一起交流学习。
参考文献:
[1] CS231n Convolutional Neural Networks for Visual Recognition
[2] Stochastic Gradient Descent Tricks.
本系列目录:
Adam那么棒,为什么还对SGD念念不忘 (1) —— 一个框架看懂优化算法



相关推荐
SGD、SGDM、Adagrad、AdaDelta 和 Adam 的简介: SGD(Stochastic Gradient Descent,随机梯度下降)是神经网络中最基本的优化算法之一。它通过随机选择一小部分样本进行训练,并基于这些样本的梯度来更新模型参数...
本篇文章将从一个通用的框架出发,探讨不同优化算法的异同,包括SGD(随机梯度下降)、SGD with Momentum、Nesterov Accelerated Gradient(NAG)以及AdaGrad等。 首先,我们设定基本的优化问题:目标函数是 ,参数...
本文将探讨十种常见的优化算法,包括随机梯度下降(SGD)、动量优化(Momentum)、Nesterov动量优化(Nesterov Momentum)、AdaGrad、RMSProp、AdaDelta、Adam、AdaMax、Nadam以及NadaMax。这些算法的核心区别在于...
本文将探讨一系列从简单到复杂的优化算法,包括SGD(随机梯度下降)、SGD with Momentum(动量SGD)、Nesterov Accelerated Gradient(NAG)以及基于二阶矩估计的算法如AdaGrad、AdaDelta、Adam和AdamW。 **1. SGD...
- 在机器学习中,训练模型的过程本质上就是优化问题,比如最小化损失函数,常用的优化算法有SGD(随机梯度下降)、Adam等。 - 在金融工程中,资产组合优化是一个典型的数值最优化问题,通过调整投资组合中不同资产...
模型的训练过程往往涉及到优化算法的选择,TensorFlow 2 是一个广泛使用的深度学习框架,其中包含了多种优化器,如 SGD (Stochastic Gradient Descent),SGDM (Stochastic Gradient Descent with Momentum),ADAGRAD...
### Keras SGD 随机梯度下降优化器参数设置详解 #### 一、引言 在深度学习领域,优化算法对于模型的训练至关重要。Keras作为一种流行的深度学习框架,提供了多种优化器来帮助用户训练神经网络。其中,**随机梯度...
综合所述,这篇论文通过提出带有延迟更新的在线学习算法,不仅解决了SGD算法的顺序性问题,还揭示了在多核架构和现代存储技术环境下如何有效地进行并行学习,从而为并行算法的发展铺平了道路,并对机器学习领域产生...
包含Adam、SGD(随机梯度下降)、RMSprop等常用优化器的Matlab实现,这些优化算法在深度学习模型的训练中至关重要。 这些源码不仅有助于理解和实践各种优化算法,还便于进一步的定制和扩展,以适应特定问题的需求...
本文将对深度学习中常用的优化算法进行深入的研究,并探讨在不同应用场景下的算法选择与优化技巧。 首先,梯度下降(GD)算法是深度学习中最基础的优化方法之一。通过计算损失函数关于模型参数的梯度,然后沿着梯度...
3. **批量梯度下降法(Batch Gradient Descent,BGD)**:与SGD相反,BGD使用整个数据集来计算梯度,确保每次更新都是全局最优,但计算成本较高。 4. **小批量梯度下降法(Mini-Batch Gradient Descent)**:介于SGD...
1. **为什么要使用SGD** - **一阶方法优于二阶方法**:由于高维非凸函数中鞍点的存在,二阶方法如牛顿法容易陷入鞍点,而一阶方法如SGD则相对能够较好地避开。在高维空间,鞍点比局部极小值更为常见,这使得一阶...
# SGD和Adam优化器在卷积神经网络上的结果对比实验 文档+代码整理 1. 使用ResNet18进行实验,研究了batch size、学习率和权重初始化对图像分类任务的影响; 2. 针对LeNet、AlexNet、ResNet18三种卷积神经网络,比较...
在本主题中,我们将探讨三种基本的梯度下降方法以及多种现代优化算法,包括动量法、Nesterov、Adagrad、Adadelta、RMSprop和Adam等。这些算法在提升模型训练效率和性能方面起着重要作用。 首先,梯度下降是最基本的...
还可以使用随机梯度下降(SGD)或其变种,如Adam、RMSprop等,这些算法动态调整学习率,有助于避开局部最小值。 3. **样本输入顺序的影响**:在线学习过程中,样本输入顺序可能导致训练结果不稳定。批处理学习方式...
这个资源包“常见优化算法的matlab实现”提供了对优化算法的MATLAB代码实现,对于学习和应用这些算法非常有帮助。 首先,我们要理解什么是优化算法。优化算法是一种寻找问题最优解的方法,通常涉及在给定约束条件下...
- Ftrl:适用于稀疏数据的优化算法,它在损失函数中引入了正则化项,并在每次迭代中对权重向量的非零元素和零元素使用不同的学习率。 - Proximal Gradient Descent:用于求解带有正则项的优化问题,该方法通过引入...
常见的优化算法有SGD、Momentum、Adam等。本文对不同的优化算法进行了分析和比较。 六、实验结果 本文以 Cifar10数据集作为输入数据,在卷积神经网络中比较分析了不同训练和优化算法对网络的正确率和收敛性的...
**Python-AdaBound:一种融合Adam与SGD优势的优化器** 在深度学习领域,优化器的选择对于模型的训练效率和性能至关重要。Adam(Adaptive Moment Estimation)和SGD(Stochastic Gradient Descent)是两种广泛使用的...
串行的SGD矩阵分解算法会遇到可扩展性问题,为了减少运算时间可以进行并行化处理。