- жµПиІИ: 53333 жђ°
- жАІеИЂ:

- жЭ•иЗ™: зП†жµЈ
-

жЦЗзЂ†еИЖз±ї
з§ЊеМЇзЙИеЭЧ
- жИСзЪДиµДиЃѓ ( 0)
- жИСзЪДиЃЇеЭЫ ( 8)
- жИСзЪДйЧЃз≠Ф ( 0)
е≠Шж°£еИЖз±ї
- 2012-12 ( 1)
- 2012-08 ( 4)
- 2012-06 ( 12)
- жЫіе§Ъе≠Шж°£...
жЬАжЦ∞иѓДиЃЇ
еЖЕе≠ШжХ∞жНЃеЇУеЖЕж†ЄеЉАеПС(иљђиљљ)
иљђиљљпЉЪhttp://www.cnblogs.com/konyel/articles/1511133.html
1 еИЭи°Ј
иЃЄе§ЪдЇЇеРђеИ∞еЖЕе≠ШжХ∞жНЃеЇУзђђдЄАеН∞и±°е∞±жШѓе§ІеЮЛзЪДзФµдњ°дЉБдЄЪпЉМйУґи°МзЪДиІ£еЖ≥жЦєж°ИпЉМдљЖеЕґеЃЮеЖЕе≠ШжХ∞жНЃзЪДеЇФзФ®зЫЄељУеєњж≥ЫпЉМдїОдЄ≠еЮЛзљСзЂЩеєґеПСеИ∞жЙєйЗПжЦЗдїґе§ДзРЖйГљеПѓдї•жЬЙеЊИжЬЙжХИзЪДеЇФзФ®гАВ еЬ®еХЖдЄЪйҐЖеЯЯзЪДеЖЕе≠ШжХ∞жНЃеЇУдЄїи¶БALTIBASE,дЄОOracleпЉМTimeSenпЉМдљЖеЕґжШВиіµзЪДжОИжЭГиієпЉИжХ∞еНБдЄЗ$пЉЙдї§иЃЄе§ЪжЩЃйАЪзФ®жИЈжЬЫиАМеНіж≠•гАВ
еЬ®ињЩйЗМеЄМжЬЫиГљжХіеРИеЬ®иЗ™иЇЂеѓєжХ∞жНЃе§ДзРЖдЄЪеК°зЪДпЉМеЉАеПСеєґеХЖдЄЪеМЦдЄАжђЊйЭҐеРСжЩЃйАЪзФ®жИЈзЪДеЖЕе≠ШжХ∞жНЃеЇУпЉМжХіеРИжЦЗдїґжХ∞жНЃе§ДзРЖпЉМеТМжХ∞жНЃеЇУжХ∞жНЃе§ДзРЖпЉМеєґеПСйЂШжХИзОЗе§ДзРЖзЪДеЖЕе≠ШжХ∞жНЃеЇУиІ£еЖ≥жЦєж°ИгАВ
иАМеЉАеПСжИСдїђжХ∞жНЃеЇУзЪДжЦєеРСпЉМељУзДґдЄНеЬ®дЇОдЄОжЬЙеНБе§Ъеєіж†єеЯЇзЪДTimeSenдїђзЂЮдЇЙпЉМеЬ®дЇОеЉАеПСдЄАжђЊжЛ•жЬЙеЯЇжЬђеКЯиГљпЉМеЕЈе§ЗдЇМжђ°еЉАеПСзЪДдїЈеАЉ зЪДеЖЕе≠ШжХ∞жНЃе§ДзРЖиљѓдїґпЉМеєґжПРдЊЫеЬ®жЙєйЗПжХ∞жНЃе§ДзРЖпЉМдЄОеєґеПСжХ∞жНЃе§ДзРЖзЪДиІ£еЖ≥жЦєж°ИпЉМеЇФиѓ•иГљжї°иґ≥е§ІйГ®еИЖеЃҐжИЈзЪДжХ∞жНЃе§ДзРЖйЬАж±ВгАВ
дї•дЄЛжШѓеЖЕе≠ШжХ∞жНЃеЇУзЪДзЃАдїЛдљЬиАЕдЄЇ:жЩЇйЫ®йЭТ
зФ±дЇОжККе§Іе§ЪжХ∞жХ∞жНЃйГљжФЊеЬ®еЖЕе≠ШдЄ≠ињЫи°МжУНдљЬпЉМдљњеЊЧеЖЕе≠ШжХ∞жНЃеЇУжЬЙзЭАжѓФз£БзЫШжХ∞жНЃеЇУйЂШеЊЧе§ЪзЪДжАІиГљи°®зО∞пЉМињЩдЄАзЙєзВєйЭЮеЄЄе•СеРИзФµдњ°дЉБдЄЪињРиР•жФѓжТСз≥їзїЯеѓєеЃЮжЧґжАІзЪДи¶Бж±ВгАВ
зФµдњ°дЄЪзЪДзЂЮдЇЙж≠£еЬ®еЕ®жЦєдљНеЬ∞е±ХеЉАпЉМињЩзІНзЂЮдЇЙењЕзДґеЄ¶жЭ•жЦ∞зЪДдїЈеАЉйУЊж®°еЉПдї•еПКжЦ∞зЪДиЃ°иієжЦєеЉПпЉМињЩдЇЫеПШеМЦеѓєзЫЃеЙНзЪДзФµдњ°ињРиР•жФѓжТС з≥їзїЯжШѓдЄАдЄ™жМСжИШгАВжѓФе¶ВпЉМе§ЪзІНдЄЪеК°зЪДиЃ°иієзОѓиКВе∞ЖдЄНеЖНжШѓеНХдЄАзЪДжМЙзЕІжЧґйХњжИЦйАЪдњ°иЈЭз¶їжФґеПЦиієзФ®пЉМиАМеПѓиГљжШѓж†єжНЃжЧґйХњгАБеЖЕеЃєгАБдљњзФ®йЗПз≠Йе§ЪзІНеПВжХ∞зЪДзїДеРИиЃ°иієгАВдЄЇдЇЖеЇФеѓєињЩ дЇЫжМСжИШпЉМзФµдњ°дЉБдЄЪеЕИеРОеЉХеЕ•дЇЖеЖЕе≠ШжХ∞жНЃеЇУпЉМдї•жПРйЂШеРОеП∞жХ∞жНЃзЃ°зРЖзЪДеЃЮжЧґжАІгАБз≤Њз°ЃжАІеТМзБµжіїжАІгАВ
еЖЕе≠ШжХ∞жНЃеЇУ
еЖЕе≠ШжХ∞жНЃеЇУпЉМй°ЊеРНжАЭдєЙе∞±жШѓе∞ЖжХ∞жНЃжФЊеЬ®еЖЕе≠ШдЄ≠зЫіжО•жУНдљЬзЪДжХ∞жНЃеЇУгАВзЫЄеѓєдЇОз£БзЫШпЉМеЖЕе≠ШзЪДжХ∞жНЃиѓїеЖЩйАЯеЇ¶и¶БйЂШеЗЇеЗ†дЄ™жХ∞йЗПзЇІпЉМ е∞ЖжХ∞жНЃдњЭе≠ШеЬ®еЖЕе≠ШдЄ≠зЫЄжѓФдїОз£БзЫШдЄКиЃњйЧЃиГље§ЯжЮБе§ІеЬ∞жПРйЂШеЇФзФ®зЪДжАІиГљгАВеРМжЧґпЉМеЖЕе≠ШжХ∞жНЃеЇУжКЫеЉГдЇЖз£БзЫШжХ∞жНЃзЃ°зРЖзЪДдЉ†зїЯжЦєеЉПпЉМеЯЇдЇОеЕ®йГ®жХ∞жНЃйГљеЬ®еЖЕе≠ШдЄ≠йЗНжЦ∞иЃЊиЃ°дЇЖдљУз≥їзїУ жЮДпЉМеєґдЄФеЬ®жХ∞жНЃзЉУе≠ШгАБењЂйАЯзЃЧж≥ХгАБеєґи°МжУНдљЬжЦєйЭҐдєЯињЫи°МдЇЖзЫЄеЇФзЪДжФєињЫпЉМжЙАдї•жХ∞жНЃе§ДзРЖйАЯеЇ¶жѓФдЉ†зїЯжХ∞жНЃеЇУзЪДжХ∞жНЃе§ДзРЖйАЯеЇ¶и¶БењЂеЊИе§ЪпЉМдЄАиИђйГљеЬ®10еАНдї•дЄКгАВеЖЕе≠ШжХ∞жНЃеЇУ зЪДжЬАе§ІзЙєзВєжШѓеЕґвАЬдЄїжЛЈиіЭвАЭжИЦвАЬеЈ•дљЬзЙИжЬђвАЭеЄЄй©їеЖЕе≠ШпЉМеН≥жіїеК®дЇЛеК°еП™дЄОеЃЮжЧґеЖЕе≠ШжХ∞жНЃеЇУзЪДеЖЕе≠ШжЛЈиіЭжЙУдЇ§йБУгАВжШЊзДґпЉМеЃГи¶Бж±ВиЊГе§ІзЪДеЖЕе≠ШйЗПпЉМдљЖеєґйЭЮдїїдљХжЧґеИїжХідЄ™жХ∞жНЃеЇУ йГље≠ШжФЊеЬ®еЖЕе≠ШпЉМеН≥еЖЕе≠ШжХ∞жНЃеЇУз≥їзїЯињШжШѓи¶Бе§ДзРЖI/OгАВ
е∞љзЃ°еЖЕе≠ШжХ∞жНЃеЇУеЈ≤дЄНжШѓдЉ†зїЯз£БзЫШжХ∞жНЃеЇУзЪДж¶ВењµпЉМдљЖжШѓеЖЕе≠ШжХ∞жНЃеЇУжЬђиі®дЄКињШжШѓжХ∞жНЃеЇУпЉМеЃГдєЯеЕЈжЬЙдЄАиИђжХ∞жНЃеЇУзЪДеЯЇжЬђеКЯиГљ:
вЦ† ж∞ЄдєЕжХ∞жНЃзЪДзЃ°зРЖпЉМеМЕжЛђжХ∞жНЃеЇУзЪДеЃЪдєЙгАБе≠ШеВ®гАБзїіжК§з≠Й;
вЦ† еЃМжИРеРДзІНжХ∞жНЃжУНдљЬпЉМе¶Вжߕ胥е§ДзРЖгАБе≠ШеПЦгАБеЃМжХіжАІж£АжЯ•;
вЦ† дЇЛеК°зЃ°зРЖпЉМеМЕжЛђи∞ГеЇ¶дЄОеєґеПСжОІеИґз≠Й;
вЦ† еѓєе≠ШеПЦзЪДжОІеИґеТМеЃЙеЕ®жАІж£Ай™М;
вЦ† еЕЈжЬЙжХ∞жНЃеЇУзЪДеПѓйЭ†жАІжБҐе§НжЬЇеИґгАВ
зЫЄеѓєдЇОеИ©зФ®з®ЛеЇПеЉАеПСжЙЛжЃµи∞ГзФ®еЖЕе≠Ше§ДзРЖжЭ•иѓіпЉМеЖЕе≠ШжХ∞жНЃеЇУиЗ™жЬЙеЕґдЉШеКњгАВй¶ЦеЕИпЉМеЖЕе≠ШжХ∞жНЃеЇУжШѓдЇІеУБеМЦзЪДжХ∞жНЃеЇУзЃ°зРЖиљѓдїґпЉМжЮБ е§ІзЉ©зЯ≠дЇЖеЉАеПСеС®жЬЯ; еЕґжђ°пЉМеЖЕе≠ШжХ∞жНЃеЇУжЬЙзЭАеЉАжФЊзЪДеє≥еП∞еТМжО•еП£пЉМз®ЛеЇПеЉАеПСеТМзІїж§НжЫіеК†зБµжіїдЊњжНЈпЉМдєЯдЊњдЇОзїіжК§еТМдЇМжђ°еЉАеПС; зђђдЄЙпЉМеПѓдї•йАЪињЗдљњзФ®зїЯдЄАзЪДSQLиѓ≠и®АжЦєдЊњеЬ∞жߕ胥еЖЕе≠ШдЄ≠зЪДжХ∞жНЃ; жЬАеРОпЉМиГљеЬ®жХ∞жНЃеЇУдЄ≠дњЭйЪЬжХ∞жНЃзЪДеЃЙеЕ®жАІеТМеЃМжХіжАІгАВињЩдЇЫдЉШеКњпЉМеѓєдЇОењЂйАЯйГ®зљ≤еТМзЃАеМЦзїіжК§йГљжШѓжЬЙеИ©зЪДгАВ
дљЖеЖЕе≠ШжХ∞жНЃеЇУдєЯжЬЙеЕґдЄНеПѓйБњеЕНзЪДзЉЇзВєпЉМжѓФе¶В: дЄНеЃєжШУжБҐе§НпЉМеЖЕе≠ШжХ∞жНЃеЇУдЄ≠зЪДжХ∞жНЃдЄНжАїжШѓж∞ЄдєЕзЪДпЉМдЄЇдЇЖдњЭиѓБеЃЮжЧґпЉМдєЯдЄНдЄАеЃЪжШѓдЄАиЗіеТМзїЭеѓєж≠£з°ЃзЪДпЉМжЬЙзЪДжШѓзЯ≠жЪВзЪДпЉМжЬЙзЪДжШѓжЪВжЧґдЄНдЄАиЗіжИЦйЭЮзїЭеѓєж≠£з°ЃзЪДгАВ
зФµдњ°дЉБдЄЪдЄАзЫіжШѓеЖЕе≠ШжХ∞жНЃеЇУзЪДдЄїи¶БзФ®жИЈпЉМињСеЗ†еєіжЭ•пЉМйЪПзЭАиЃ°зЃЧжЬЇз°ђдїґжКАжЬѓзЪДй£ЮйАЯеПСе±ХгАБеЖЕе≠ШеЃєйЗПзЪДжПРйЂШгАБдїЈж†ЉдЄЛиЈМдї•еПКиЃ° зЃЧжЬЇињЫеЕ•64дљНжЧґдї£жУНдљЬз≥їзїЯеРОеПѓдї•жФѓжМБжЫіе§ІзЪДеЬ∞еЭАпЉМдЄЇеЖЕе≠ШжХ∞жНЃеЇУзЪДеЃЮзО∞жПРдЊЫдЇЖеПѓиГљгАВзЫЃеЙНеЖЕе≠ШжХ∞жНЃеЇУеЬ®зФµдњ°и°МдЄЪзЪДеЇФзФ®дєЯжЧ•иґЛжИРзЖЯпЉМеЈ≤жЬЙиґЕињЗ90GзЪДзФµдњ°з≥їзїЯ ж°ИдЊЛпЉМиГљиЗ™еК®жЙ©е±ХеЖЕе≠Шз©ЇйЧіпЉМдЄНйЬАи¶БйЗНеРѓжХ∞жНЃеЇУпЉМжПРдЊЫESOLиЗ™еЃЪдєЙе≠ШеВ®ињЗз®ЛпЉМжФѓжМБе§ЪзЇњз®ЛпЉМеЉАеПСжХИзОЗйЂШпЉМз®ЛеЇПзІїж§НеЃєжШУз≠Йз≠ЙгАВдЄЛйЭҐдї•дЄ§дЄ™дЊЛе≠РжЭ•дїЛзїНеЖЕе≠ШжХ∞жНЃеЇУ зЪДеЇФзФ®гАВ
зФµдњ°иЃ°иієжХ∞жНЃзЪДеК†иљљ
зФµдњ°зЪДдЇМжђ°жЙєдїЈеТМеЃЮжЧґзіѓиі¶жШѓиЃ°иієз≥їзїЯдЄ≠зЪДдЄ§дЄ™ењЕе§ЗеКЯиГљгАВжЙАи∞УдЇМжђ°жЙєдїЈжШѓзЫЄеѓєдЇОдЄАжђ°жЙєдїЈжЭ•иѓізЪДгАВдЄАжђ°жЙєдїЈжШѓжМЙзЕІеЫљеЃґ ж†ЗеЗЖиµДиієжЭ•ињЫи°МдїЈж†ЉиЃ°зЃЧпЉМжѓФе¶В: еЕ®зРГйАЪжѓПеИЖйТЯжЬђеЬ∞йАЪиѓЭдЄЇ0.4еЕГпЉМеЬ®дЄАжђ°жЙєдїЈеЃМжИРеРОпЉМдЉЪж†єжНЃињЩдЄ™зФ®жИЈзЪДе•Чй§РињЫи°МеЖНдЄАжђ°зЪДиЃ°зЃЧгАВдї•еМЧдЇђеЕ®зРГйАЪзФ®жИЈжО•еРђ4еИЖйТЯзЪДзФµиѓЭдЄЇдЊЛпЉМдЄАжђ°жЙєдїЈеЃМжИРеРОпЉМињЩ жЭ°иѓЭеНХзЪДдїЈж†ЉжШѓ1.6еЕГпЉМе¶ВжЮЬињЩдЄ™зФ®жИЈеПВеК†дЇЖ10еЕГеМЕжЬИжО•еРђе•Чй§РпЉМйВ£дєИеЬ®дЇМжђ°жЙєдїЈеРОпЉМињЩжђ°йАЪиѓЭзЪДиієзФ®е∞±дЄЇ0еЕГгАВдЄАжђ°жЙєдїЈжШѓзФ®дЇОеРДе§ІињРиР•еХЖдєЛйЧізїУзЃЧзЪДпЉМиАМдЇМ жђ°жЙєдїЈжШѓйТИеѓєзФ®жИЈдЄ™дЇЇзЪДгАВ
еЃЮжЧґзіѓиі¶жШѓе∞ЖзФ®жИЈдїОжѓПжЬИ1еПЈеИ∞зЫЃеЙНдЄЇж≠ҐзЪДжЙАжЬЙиієзФ®зіѓеК†иµЈжЭ•пЉМдєЯе∞±жШѓзФ®жИЈзЫЃеЙНеПѓдї•йАЪињЗ10086жЯ•еИ∞жИ™ж≠ҐеИ∞еЙНдЄА姩зЪДеЃЮжЧґиѓЭиієгАВзіѓиі¶еАЉеПѓдї•еЄЃеК©зФ®жИЈжОІеИґйЂШйҐЭиѓЭиієжИЦжШѓдЊЫзФ®жИЈеН≥жЧґжߕ胥жґИиієдњ°жБѓгАВ
дЇМжђ°жЙєдїЈеТМеЃЮжЧґзіѓиі¶ињЗз®ЛжґЙеПКзФ®жИЈиµДжЦЩгАБзФ®жИЈе•Чй§Рз≠ЙдЄОзФ®жИЈзЫЄеЕ≥зЪДдњ°жБѓпЉМзФµдњ°жФѓжТСз≥їзїЯеЬ®еЉАеІЛжЙєдїЈжЧґењЕй°їеК†иљљињЩдЇЫжХ∞жНЃгАВ з®Не§ІдЄАзВєзЪДзЬБзЇІињРиР•еХЖзЪДињЩдЇЫжХ∞жНЃе∞±дЉЪиґЕињЗ1000дЄЗжЭ°пЉМиЃ°иієе§ДзРЖж®°еЮЛдєЯзФ±дЇОе•Чй§РзЪДзїДеРИгАБдЇІеУБзЪДзїДеРИдї•еПКдЄНеРМзЪДдЉШжГ†иІДеИЩеПШеЊЧзЫЄељУе§НжЭВпЉМеК†иљљињЩйГ®еИЖжХ∞жНЃеѓєз≥їзїЯ иАМи®АжШѓдЄАзђФдЄНе∞ПзЪДеЉАйФАпЉМињЩе∞±дљњеЊЧзО∞еЬ®зЪДиЃ°иієе§ДзРЖйАЯеЇ¶жѓФиЊГжЕҐпЉМиАМдЄФеЊИйЪЊеБЪеИ∞еѓєжХ∞жНЃзЪДеЃЮжЧґжЫіжЦ∞гАВеЖЕе≠ШжХ∞жНЃеЇУзЪДеЉХеЕ•еЬ®дЄАеЃЪз®ЛеЇ¶дЄКиІ£еЖ≥дЇЖињЩдЄ™йЧЃйҐШгАВ
еЬ®иЃ°иієдЇМжђ°жЙєдїЈињЗз®ЛдЄ≠жХ∞жНЃйЗПжЬАе§ІзЪДжШѓиѓ¶еНХжХ∞жНЃпЉМињЩйГ®еИЖжХ∞жНЃдЄНзФ®жФЊеЬ®еЖЕе≠ШжХ∞жНЃеЇУдЄ≠пЉМжѓПе§ДзРЖеЃМдЄАдЄ™иѓЭеНХжЦЗдїґжИЦиЊЊеИ∞иЃЊ еЃЪзЪДжПРдЇ§иЃ∞ељХжХ∞жЧґзЫіжО•жУНдљЬз£БзЫШжХ∞жНЃеЇУпЉМдЄНдЉЪељ±еУНз≥їзїЯжАІиГљгАВжЬАжА•еИЗзЪДжШѓе∞ЖзФ®жИЈиµДжЦЩгАБе•Чй§РгАБиР•дЄЪе•Чй§РеТМиЃ°иієе•Чй§РеѓєеЇФеЕ≥з≥їжХ∞жНЃгАБиЃ°иієе•Чй§Рж®°еЮЛжХ∞жНЃеПКзФ®жИЈзіѓиЃ°жХ∞жНЃ жФЊеИ∞еЖЕе≠ШжХ∞жНЃеЇУдЄ≠пЉМињЩйГ®еИЖжХ∞жНЃжߕ胥жУНдљЬињЬжѓФжХ∞жНЃжЦ∞еҐЮеТМжЫіжЦ∞жУНдљЬи¶БйҐСзєБгАВйЩ§дЇЖињЩдЇЫжХ∞жНЃе§ЦпЉМељУзДґињШжЬЙеЇФзФ®йЬАи¶БзЪДеЕґдїЦжХ∞жНЃдєЯйГљеПѓдї•еК†иљљеИ∞еЖЕе≠ШжХ∞жНЃеЇУгАВ
еЬ®йЗЗзФ®еЖЕе≠ШжХ∞жНЃеЇУеРОпЉМзФ®жИЈйАЪињЗиР•дЄЪйГ®жИЦеЃҐжИЈжߕ胥еЃЮжЧґиѓЭиієзЪДжЧґеАЩеЃМеЕ®еПѓдї•еБЪеИ∞еЃЮжЧґпЉМжѓФзЫЃеЙНеП™иГљжПРдЊЫжߕ胥еИ∞еЙНдЄА姩зЪД еЃЮжЧґиѓЭиієеЬ®дЄЪеК°дЄКжЬЙдЇЖиі®зЪДй£ЮиЈГгАВеЫ†дЄЇз≥їзїЯеЬ®е§ДзРЖињЩйГ®еИЖжХ∞жНЃжЧґжߕ胥жµБз®ЛеТМдї•еЙНзЪДеЃМеЕ®дЄАж†ЈпЉМдљЖз≥їзїЯзЬБеОїдЇЖдї•еЊАеЖЕе≠ШдЄ≠зЪДжХ∞жНЃеТМз£БзЫШжХ∞жНЃеЇУжХ∞жНЃеРМж≠•зЪДзОѓиКВпЉМжЙАдї•е∞± иГљеБЪеИ∞дЇЖеЃЮжЧґжߕ胥гАВеѓєдЇОдњ°жОІжЭ•иѓідєЯеРМж†ЈпЉМдї•еЊАз≥їзїЯеЬ®зіѓеЃМиі¶еРОи¶БжМЙзЕІдЄАеЃЪеС®жЬЯеИЈжЦ∞дњ°жОІжХ∞жНЃпЉМињЩе∞±е≠ШеЬ®дЄАдЄ™жЧґйЧіеЈЃпЉМдЄНиГље§ЯеЃМеЕ®еБЪеИ∞еЃЮжЧґгАВ
иАМйЗЗзФ®еЖЕе≠ШжХ∞жНЃеЇУеРОпЉМдњ°жОІеПѓдї•зЫіжО•еПЦеЊЧеЖЕе≠ШжХ∞жНЃеЇУдЄ≠зЪДеЃЮжЧґиѓЭиієзіѓиЃ°и°®дЄ≠зЪДжХ∞жНЃпЉМеЃМеЕ®еЃЮзО∞еЃЮжЧґйҐДи≠¶гАБеБЬжЬЇгАВдЇМжђ°жЙєдїЈеТМзіѓиі¶дЄ≠йЗЗзФ®еЖЕе≠ШжХ∞жНЃеЇУеРОпЉМеѓєйШ≤жђЇиѓИгАБжФґеЕ•дњЭйЪЬз≥їзїЯдєЯжЬЙзЫЄељУе§ІзЪДе•ље§ДпЉМињЩж†ЈиГље§ЯеЕЕеИЖдњЭиѓБињРиР•еХЖзЪДеИЗиЇЂеИ©зЫКгАВ
еП¶е§ЦпЉМеЬ®йЗЗзФ®еЖЕе≠ШжХ∞жНЃеЇУеРОпЉМжХідљУжПРйЂШдЇЖз≥їзїЯжЙєдїЈгАБзіѓиі¶зЪДе§ДзРЖйАЯеЇ¶пЉМе§Іе§ІзЉУиІ£иЃњйЧЃз£БзЫШжХ∞жНЃеЇУзЪДеОЛеКЫпЉМжПРйЂШжХ∞жНЃжߕ胥гАБдњЃжФєгАБеИ†йЩ§зЪДжХИзОЗпЉМдєЯдЄЇеРОдїШиієеТМйҐДдїШиієзЪДиЮНеРИжПРдЊЫдЇЖеПѓиГљгАВ
зФµдњ°иЃ°иієжХ∞жНЃзЪДеРМж≠•
зФµдњ°иР•дЄЪжХ∞жНЃеТМиЃ°иієз≥їзїЯдЄ≠зЪДжХ∞жНЃжАїжШѓеЬ®дЄНжЦ≠зЪДеПШеМЦдЄ≠пЉМињЩе∞±жґЙеПКеЖЕе≠ШжХ∞жНЃеЇУдЄ≠зЪДжХ∞жНЃеТМз£БзЫШжХ∞жНЃеЇУжХ∞жНЃзЪДеРМж≠•йЧЃйҐШпЉИдЄЇ дЇЖжППињ∞жЄЕж•ЪпЉМињЩйЗМзЪДз£БзЫШжХ∞жНЃеЇУдї•Oracle DBдЄЇдЊЛжЭ•иѓіжШОпЉЙгАВжХ∞жНЃеРМж≠•еМЕжЛђдЄ§йГ®еИЖ: дїОеЖЕе≠ШжХ∞жНЃеЇУеИ∞Oracle DBжХ∞жНЃеРМж≠•еТМдїОOracle DBеИ∞еЖЕе≠ШжХ∞жНЃеЇУзЪДеРМж≠•гАВ
1. Oracle DBеИ∞еЖЕе≠ШжХ∞жНЃеЇУеРМж≠•
ињЩйГ®еИЖжХ∞жНЃеРМж≠•йЗЗзФ®еҐЮйЗПи°®зЪДжЦєеЉПпЉМиР•дЄЪз≥їзїЯжИЦCRMжЦ∞еҐЮжИЦжЫіжЦ∞зЪДжХ∞жНЃе∞ЖзФЯжИРеИ∞OracleзЪДеҐЮйЗПи°®дЄ≠пЉМиЃ°иієеРОеП∞з®Л еЇПеЕИеИ∞ињЩдЇЫеҐЮйЗПи°®дЄ≠жߕ胥жХ∞жНЃгАВе¶ВжЮЬиГљеЬ®ињЩдЇЫеҐЮйЗПи°®дЄ≠жЯ•еИ∞жХ∞жНЃе∞±жККињЩдЇЫжХ∞жНЃжЫіжЦ∞еИ∞еЖЕе≠ШжХ∞жНЃеЇУеѓєеЇФи°®дЄ≠пЉМе¶ВжЮЬжЯ•дЄНеИ∞пЉМе∞±зЫіжО•дїОеЖЕе≠ШжХ∞жНЃеЇУдЄ≠зЫіжО•жߕ胥пЉМдїОиАМдњЭиѓБ дЇЖжХ∞жНЃзЪДеЃМжХіжАІеТМеЃЮжЧґжАІгАВзФ±дЇОеҐЮйЗПи°®зЪДжХ∞жНЃйЗПдЄАиИђдЉЪеЊИе∞ПпЉМжЙАдї•ињЩйГ®еИЖжУНдљЬдЄНдЉЪељ±еУНз≥їзїЯзЪДжАІиГљгАВ
2. еЖЕе≠ШжХ∞жНЃеЇУеИ∞Oracle DBеРМж≠•
зФ±дЇОOracleзЪДиЃ°иієеРОеП∞жЙєдїЈгАБзіѓиі¶жХ∞жНЃеЗ†дєОйГљеК†иљљеИ∞дЇЖеЖЕе≠ШжХ∞жНЃеЇУдЄ≠пЉМжЙАдї•OracleжХ∞жНЃеЇУеѓєеЇФзЪДжХ∞жНЃи°®е∞ЖдЄїи¶БзФ®дЇОеѓєеЖЕе≠ШжХ∞жНЃеЇУзЪДжХ∞жНЃе§ЗдїљгАВ
зФ®жИЈжЬАжЦ∞зЪДеЃЮжЧґиѓЭиієз≠Йдњ°жБѓйГљдњЭе≠ШеЬ®еЖЕе≠ШжХ∞жНЃеЇУдЄ≠пЉМеЃЮжЧґиѓЭиієжߕ胥е∞ЖзЫіжО•ињЮжО•еИ∞еЖЕе≠ШжХ∞жНЃеЇУдЄ≠жߕ胥пЉМдњЭиѓБзФ®жИЈеЊЧеИ∞жЬАжЦ∞зЪД иієзФ®дњ°жБѓгАВдњ°жОІдєЯзЫіжО•дїОеЖЕе≠ШжХ∞жНЃеЇУжߕ胥жХ∞жНЃпЉМеЫ†ж≠§еѓєOracleдЄ≠зЪДињЩйГ®еИЖжХ∞жНЃеЈ≤зїПж≤°жЬЙеЃЮжЧґжАІзЪДи¶Бж±ВгАВињЩжЧґеЖЕе≠ШжХ∞жНЃеЇУеИ∞OracleзЪДеРМж≠•еПѓдї•зФ±еЇФзФ®з®ЛеЇП зФЯжИРжЦЗдїґпЉМеЃЪжЧґеЬ∞еЊАOracleжХ∞жНЃеЇУдЄ≠еРМж≠•е§ЗдїљпЉМжИЦиАЕйЗЗзФ®Oracle е≠ШеВ®ињЗз®ЛеЬ®з≥їзїЯзЫЄеѓєз©ЇйЧ≤жЧґйЧіжЃµињЫи°МжХ∞жНЃеѓЉеЕ•е∞±еПѓдї•дЇЖгАВ
жАїдљУиАМи®АпЉМзФ±дЇОеЄВеЬЇдЄОжКАжЬѓзЪДењЂйАЯеПСе±ХпЉМзФµдњ°дЄЪеК°еЬ®дЄНжЦ≠жЙ©еЕЕпЉМеЕґињРиР•еТМзЃ°зРЖдЄНжЦ≠дЉШеМЦпЉМдЉ†зїЯзЪДдЄАдЇЫжФѓжТСз≥їзїЯзЪДжЮґжЮДеЈ≤ зїПйАРжЄРдЄНиГљжї°иґ≥жЧ•зЫКеҐЮйХњзЪДдЄЪеК°и¶Бж±ВеТМеЃҐжИЈйЬАж±ВпЉМеЉХеЕ•дЄАдЇЫжЦ∞зЪДжКАжЬѓжЭ•иІ£еЖ≥жИСдїђзФЯдЇІдЄ≠йБЗеИ∞зЪДйЧЃйҐШжШѓењЕзДґзЪДгАВжѓФе¶ВйЗЗзФ®еЖЕе≠ШжХ∞жНЃеЇУжЭ•дї£жЫњдї•еЙНзЪДеЕ±дЇЂеЖЕе≠ШжКАжЬѓпЉМдљњеЊЧ еОЯжЭ•еЬ®еЖЕе≠ШдЄ≠дЄНж†ЗеЗЖзЪДдЄЬи•њпЉМеМЕжЛђжО•еП£гАБж†ЉеЉПеТМзЃ°зРЖйГљж†ЗеЗЖеМЦдЇЖгАВ
еЖЕе≠ШжХ∞жНЃеЇУеП™жШѓе§ЪзІНжЦ∞жКАжЬѓдЄ≠жЬЙдї£и°®жАІзЪДдЄАзІНиАМеЈ≤пЉМеП™и¶БиІ£жФЊжАЭжГ≥гАБйАЙзФ®еЊЧељУпЉМеЃМеЕ®еПѓдї•еЬ®жКХеЕ•дЄНе§ІзЪДжГЕеЖµдЄЛеЕЛжЬНз≥їзїЯдЄ≠зЪДзУґйҐИпЉМдї•жЬАе∞ПзЪДдї£дїЈиОЈеЊЧжЬАе§ІеЫЮжК•гАВ
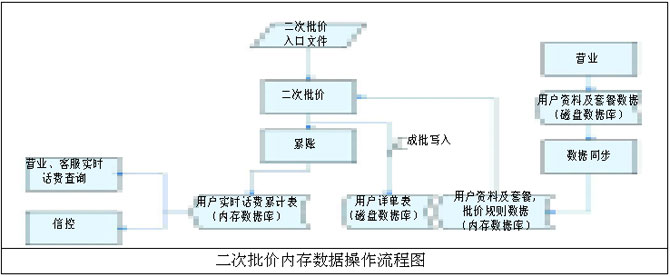
дЇМжђ°жЙєдїЈеЖЕе≠ШжХ∞жНЃжУНдљЬжµБз®ЛеЫЊ
йУЊжО•дЄА:еЖЕе≠ШжХ∞жНЃеЇУдЄОдЉ†зїЯжХ∞жНЃеЇУзЪДеЉВеРМ
дЉ†зїЯзЪДжХ∞жНЃеЇУз≥їзїЯжШѓеЕ≥з≥їеЮЛжХ∞жНЃеЇУпЉМеЉАеПСињЩзІНжХ∞жНЃеЇУзЪДзЫЃзЪДпЉМжШѓе§ДзРЖж∞ЄдєЕгАБз®≥еЃЪзЪДжХ∞жНЃгАВеЕ≥з≥їжХ∞жНЃеЇУеЉЇи∞ГзїіжК§жХ∞жНЃзЪДеЃМжХіжАІгАБдЄАиЗіжАІпЉМдљЖеЊИйЪЊй°ЊеПКжЬЙеЕ≥жХ∞жНЃеПКеЕґе§ДзРЖзЪДеЃЪжЧґйЩРеИґпЉМдЄНиГљжї°иґ≥еЈ•дЄЪзФЯдЇІзЃ°зРЖеЃЮжЧґеЇФзФ®зЪДйЬАи¶БпЉМеЫ†дЄЇеЃЮжЧґдЇЛеК°и¶Бж±Вз≥їзїЯиГљиЊГеЗЖз°ЃеЬ∞йҐДжК•дЇЛеК°зЪДињРи°МжЧґйЧігАВ
еѓєз£БзЫШжХ∞жНЃеЇУиАМи®АпЉМзФ±дЇОз£БзЫШе≠ШеПЦгАБеЖЕе§Це≠ШзЪДжХ∞жНЃдЉ†йАТгАБзЉУеЖ≤еМЇзЃ°зРЖгАБжОТйШЯз≠ЙеЊЕеПКйФБзЪДеїґињЯз≠ЙдљњеЊЧдЇЛеК°еЃЮйЩЕеє≥еЭЗжЙІи°МжЧґйЧі дЄОдЉ∞зЃЧзЪДжЬАеЭПжГЕеЖµжЙІи°МжЧґйЧізЫЄеЈЃеЊИе§ІпЉМе¶ВжЮЬе∞ЖжХідЄ™жХ∞жНЃеЇУжИЦеЕґдЄїи¶БзЪДвАЬеЈ•дљЬвАЭйГ®еИЖжФЊеЕ•еЖЕе≠ШпЉМдљњжѓПдЄ™дЇЛеК°еЬ®жЙІи°МињЗз®ЛдЄ≠ж≤°жЬЙI/OпЉМеИЩдЄЇз≥їзїЯиЊГеЗЖз°ЃдЉ∞зЃЧеТМеЃЙжОТдЇЛеК° зЪДињРи°МжЧґйЧіпЉМдљњдєЛеЕЈжЬЙиЊГе•љзЪДеК®жАБеПѓйҐДжК•жАІжПРдЊЫдЇЖжЬЙеКЫзЪДжФѓжМБпЉМеРМжЧґдєЯдЄЇеЃЮзО∞дЇЛеК°зЪДеЃЪжЧґйЩРеИґжЙУдЄЛдЇЖеЯЇз°АгАВињЩе∞±жШѓеЖЕе≠ШжХ∞жНЃеЇУеЗЇзО∞зЪДдЄїи¶БеОЯеЫ†гАВ
еЖЕе≠ШжХ∞жНЃеЇУжЙАе§ДзРЖзЪДжХ∞жНЃйАЪеЄЄжШѓвАЬзЯ≠жЪВвАЭзЪДпЉМеН≥жЬЙдЄАеЃЪзЪДжЬЙжХИжЧґйЧіпЉМињЗжЧґеИЩжЬЙжЦ∞зЪДжХ∞жНЃдЇІзФЯпЉМиАМељУеЙНзЪДеЖ≥з≠ЦжО®еѓЉеПШжИРжЧ† жХИгАВжЙАдї•пЉМеЃЮйЩЕеЇФзФ®дЄ≠йЗЗзФ®еЖЕе≠ШжХ∞жНЃеЇУжЭ•е§ДзРЖеЃЮжЧґжАІеЉЇзЪДдЄЪеК°йАїиЊСе§ДзРЖжХ∞жНЃгАВиАМдЉ†зїЯжХ∞жНЃеЇУжЧ®еЬ®е§ДзРЖж∞ЄдєЕгАБз®≥еЃЪзЪДжХ∞жНЃпЉМеЕґжАІиГљзЫЃж†ЗжШѓйЂШзЪДз≥їзїЯеРЮеРРйЗПеТМдљОзЪДдї£дїЈпЉМ е§ДзРЖжХ∞жНЃзЪДеЃЮжЧґжАІе∞±и¶БиАГиЩСзЪДзЫЄеѓєе∞СдЄАдЇЫгАВеЃЮйЩЕеЇФзФ®дЄ≠еИ©зФ®дЉ†зїЯжХ∞жНЃеЇУињЩдЄАзЙєжАІе≠ШжФЊзЫЄеѓєеЃЮжЧґжАІи¶Бж±ВдЄНйЂШзЪДжХ∞жНЃгАВ
еЬ®еЃЮйЩЕеЇФзФ®дЄ≠ињЩдЄ§зІНжХ∞жНЃеЇУеЄЄеЄЄзїУеРИдљњзФ®пЉМиАМдЄНжШѓдї•еЖЕе≠ШжХ∞жНЃеЇУжЫњдї£дЉ†зїЯжХ∞жНЃеЇУгАВ
йУЊжО•дЇМ:еЗ†жђЊеЖЕе≠ШжХ∞жНЃеЇУдЇІеУБ
вЦ† Oracle TimesTen
Oracle TimesTenжШѓOracleдїОTimesTenеЕђеПЄжФґиі≠зЪДдЄАдЄ™еЖЕе≠ШдЉШеМЦзЪДеЕ≥з≥їжХ∞жНЃеЇУпЉМеЃГдЄЇеЇФзФ®з®ЛеЇПжПРдЊЫдЇЖеЃЮжЧґдЉБдЄЪеТМи°МдЄЪпЉИдЊЛе¶ВзФµдњ°гАБиµДжЬђеЄВеЬЇеТМеЫљйШ≤пЉЙ жЙАйЬАзЪДеН≥жЧґеУНеЇФжАІеТМйЭЮеЄЄйЂШзЪДеРЮеРРйЗПгАВOracle TimesTenеПѓдљЬдЄЇйЂШйАЯзЉУе≠ШжИЦеµМеЕ•еЉПжХ∞жНЃеЇУ襀йГ®зљ≤еЬ®еЇФзФ®з®ЛеЇПе±ВдЄ≠пЉМеЃГеИ©зФ®ж†ЗеЗЖзЪД SQL жО•еП£еѓєеЃМеЕ®дљНдЇОзЙ©зРЖеЖЕе≠ШдЄ≠зЪДжХ∞жНЃе≠ШеВ®еМЇињЫи°МжУНдљЬгАВ
вЦ† Altibase
AltibaseжШѓдЄАдЄ™еЬ®дЇЛеК°дЉШеЕИзЪДзОѓеҐГдЄ≠жПРдЊЫйЂШжАІиГљеТМйЂШеПѓзФ®жАІзЪДиљѓдїґиІ£еЖ≥жЦєж°ИгАВеЃГжПРдЊЫйЂШжАІиГљгАБеЃєйФЩиГљеКЫеТМдЇЛеК°зЃ° зРЖиГљеКЫпЉМзЙєеИЂйАВеРИйАЪдњ°гАБзљСдЄКйУґи°МгАБиѓБеИЄдЇ§жШУгАБеЃЮжЧґеЇФзФ®еТМеµМеЕ•еЉПз≥їзїЯйҐЖеЯЯгАВAltibaseиГље§ЯжЬАе§ІйЩРеЇ¶еЬ∞еПСжМ•жХ∞жНЃеЇУжЬНеК°з≥їзїЯзЪДжљЬеКЫпЉМеҐЮеЉЇжХ∞жНЃжЬНеК°еЩ®зЪДе§ДзРЖ иГљеКЫгАВAltibaseжФѓжМБеЃҐжИЈзЂѓ/жЬНеК°еЩ®жЮґжЮДжИЦеµМеЕ•еЉПжЮґжЮДгАВеЕґдЄ≠еЃҐжИЈзЂѓ/жЬНеК°еЩ®жЮґжЮДйЭЮеЄЄйАВеРИдЄАиИђзЪДеЇФзФ®гАВиАМеµМеЕ•еЉПжЮґжЮДе∞ЖеЇФзФ®з®ЛеЇПеµМеЕ•еИ∞жХ∞жНЃеЇУжЬНеК°еЩ®пЉМйАВ еРИдЇОжЬЙйЂШжЧґжХИи¶Бж±ВзЪДеЃЮжЧґз≥їзїЯгАВ
вЦ† eXtremeDB
eXtremeDBеЃЮжЧґжХ∞жНЃеЇУжШѓMcObjectеЕђеПЄзЪДдЄАжђЊзЙєеИЂдЄЇеЃЮжЧґдЄОеµМеЕ•еЉПз≥їзїЯжХ∞жНЃзЃ°зРЖиАМиЃЊиЃ°зЪДжХ∞жНЃеЇУпЉМеП™жЬЙ 50KеИ∞130KзЪДеЉАйФАпЉМйАЯеЇ¶иЊЊеИ∞еЊЃзІТзЇІгАВeXtremeDBеЃМеЕ®й©їзХЩеЬ®дЄїеЖЕе≠ШдЄ≠пЉМдЄНдљњзФ®жЦЗдїґз≥їзїЯпЉИеМЕжЛђеЖЕе≠ШзЫШпЉЙгАВeXtremeDBйЗЗзФ®дЇЖжЦ∞зЪДз£БзЫШиЮНеРИ жКАжЬѓпЉМе∞ЖеЖЕе≠ШжЛУе±ХеИ∞з£БзЫШпЉМе∞Жз£БзЫШељУеБЪиЩЪжЛЯеЖЕе≠ШжЭ•зФ®пЉМеЃЮжЧґжАІиГљдњЭжМБеЊЃзІТзЇІзЪДеРМжЧґпЉМжХ∞жНЃзЃ°зРЖйЗПеЬ®32BITдЄЛиГљиЊЊеИ∞20GгАВ
2пЉМзФ±еЉАжЇРиљѓдїґеЕ•жЙЛ
зФ±дЇОжИСдїђељУзДґеЊЧдЄНеИ∞жЬЙеЕ≥еЖЕе≠ШжХ∞жНЃеЇУе§ДзРЖжХ∞жНЃзЪДж†ЄењГжКАжЬѓпЉМжЙАдї•жИСдїђеП™иГљеЗЇеЉАжЇРеЖЕе≠ШжХ∞жНЃеЇУеЕ•жЙЛпЉМз†Фз©ґеЖЕе≠ШжХ∞жНЃзЪДеЉАеПСпЉМ
еЄВйЭҐдЄКжЬЙдЄ§жђЊиСЧеРНзЪДеЉАжЇРеЖЕе≠ШжХ∞жНЃеЇУ Oracle Berkeley DB дЄО SQLite
дљЖдљњзФ®ињЗзЪДдЇЇдЉЪеПСзО∞дї•дЄКдЄ§жђЊжХ∞жНЃеЇУжЬЙдї•дЄКзЪДзЉЇзВєеТМдЉШзВє
Oracle Berkeley DB еКЯиГљзЫЄељУжИРзЖЯпЉМжФѓжМБйЂШеєґеПСпЉМе§ЪзІНиѓїеЖЩйФБпЉМе±АйГ®йФБпЉМдЄФеЕЈжЬЙжХ∞жНЃеОЯе≠РзЪДеЃМжХіжАІдњЭжК§гАВ
дљЖзЉЇзВєзЪДдЄНжФѓжМБsqlиІ£жЮРпЉМOracle е∞ЖеЕґеЃЪдљНдЄЇеЉЇе§ІзЪДдЄНеЕЈжЬЙDBMSзЪДжЦЗдїґжХ∞жНЃе§ДзРЖиљѓдїґгАВеОЯеЫ†зРЖжЙАељУзДґпЉИдЄНиГљдЄОиЗ™еЈ±зЪДTimesenжЙУеѓєеП∞пЉЙ
SQLite жЬЙиЊГжИРзЖЯDBMS,ељУзДґжФѓжМБSQLиІ£жЮР пЉМдљЖдЄНжФѓжМБе±АйГ®йФБ,иѓїеЖЩйФБдЄЇжХідЄ™жХ∞жНЃеЇУйФБеЃЪпЉМељУзДґдЄНжФѓжМБйЂШеєґеПСжУНдљЬз≠ЙзЙєзВє,пЉИж†єжНЃеѓєSQLiteзЪДжЬАжЦ∞жЦЗж°£пЉМSQLite 3.6зЙИжЬђеПѓдї•жФѓжТСжХ∞жНЃй°µзЇІзЪД(page)жХ∞жНЃйФБпЉМеЬ®дї•еРОжЦЗж°£дЄ≠дЉЪжЈїеК†жФєжЬЇеИґзЪДиѓ¶зїЖеЙЦжЮРпЉЙ
йВ£дєИжИСдїђдЉЪжГ≥еИ∞пЉМе¶ВжЮЬе∞ЖдЄ§жђЊеЉАжЇРиљѓдїґзЪДдЉШзЉЇзВєзїУеРИпЉМйВ£дєИжИСдїђеПѓдї•жХіеРИеЗЇжИСдїђзЪДеЖЕе≠ШжХ∞жНЃеЇУзЪДеИЭж≠•ељҐжАБгАВ
ињЩдЄ§дЄ™еЖЕе≠ШжХ∞жНЃеЇУйГљжЬЙеЉЇе§ІеЃМеЦДзЪДжЦЗж°£пЉМеЄЃеК©жИСдїђдЇЖиІ£еЗЇеЕґдЄ≠зЪДжЬЇеИґеТМжО•еП£пЉМињЫдЄАж≠•еК†е§ІзЪДжХіеРИзЪДеПѓиГљжАІгАВ
3,жХ∞жНЃеЇУж†ЄењГ VDBE пЉИVirtual Database EngineпЉЙ
еЬ®ж≠§еЕИжДЯи∞ҐеЉАжЇРз§ЊеМЇзЪДдЉЩиЃ°дїђдЄЇжИСжПРдЊЫйЭЮеЄЄдЉШзІАзЪДзРЖиЃЇжЦЗж°£пЉМдљЖеЬ®ж≠§жЈ±и°®жДЯи∞ҐпЉМ
ж≠£жШѓжЬЙдљ†дїђзЪДжЧ†зІБеТМеНЪе≠¶пЉМдЇЇз±їжЙНиГљеЬ®зІСе≠¶зЊОдЄљзЪДйБУиЈѓдЄКдЄНжЦ≠еЙНињЫгАВ
Eric NieblerпЉМ Kevlin HenneyпЉМChris KohlhoffпЉМJohn Maddock, Howard Hinnant пЉМJeff Garland
First of all,thanks to the open source community guys
to provide the excellent documentation of the database theory for me,
For your selfless and erudite, human can promote himself persistently in the beautiful
road of science.
Eric NieblerпЉМ Kevlin HenneyпЉМChris KohlhoffпЉМJohn Maddock, Howard Hinnant пЉМ
Jeff Garland
иѓіжШОпЉЪдї•дЄЛжЦЗж°£йЭЮдЄУдЄЪжЦЗж°£пЉМдєЯйЭЮдЄ•и∞®е≠¶жЬѓиЃЇжЦЗпЉМеП™жШѓжИСеЬ®иІ£иѓїжХ∞жНЃеЇУжКАжЬѓиµДжЦЩжЧґзЪДиЗ™иЇЂзРЖиІ£пЉМеПѓиГљжЬЙдЄНе∞СзЪДйФЩиѓѓпЉМеЄМжЬЫеРДдљНйЂШжЙЛе§ІдЊ†жМЗж≠£пЉМ
й¶ЦеЕИпЉМжИСдїђеЕИжШОз°ЃдЄЛVDBEзЪДж¶ВењµпЉМеЕґеЃЮжИСдїђеЬ®жЙІи°МsqlзЪДињЗз®ЛдЄ≠пЉМжѓФе¶ВInsertзЪДиѓ≠еП•жЧґпЉМжШѓзФ±VDBEе∞ЖеСљдї§еИЖжЛЖжИРжХ∞жНЃжУНдљЬзЪДеОЯе≠РжМЗдї§пЉИinstructionпЉЙпЉМVDBEе∞ЖеЕґиІ£жЮРпЉМжЛЖеИЖпЉМжОТеЇПпЉМжЙНжЙІи°МеЗЇжИСдїђжЬАеРОзЪДзїУжЮЬгАВиАМVDBEеПѓдї•зРЖиІ£дЄЇиІ£жЮРињЩдЇЫиЩЪжЛЯжЬЇеЩ®жМЗдї§пЉМеєґжЙІи°МжЬЇеЩ®жУНдљЬзЪДиЩЪжЛЯжЬЇгАВVDBEеПѓдї•иѓіжШѓжХ∞жНЃеЇУжКАжЬѓдЄ≠жЬАж†ЄењГзЪДжКАжЬѓпЉМжИСдїђеЃМеЦДдЇЖдЄАдЄ™жХ∞жНЃеЇУзЪДVDBEпЉМйВ£дєИжИСзЪДеЊБйАФе∞±иГЬеИ©дЇЖдЄАеНКдЇЖгАВ
дљЖдї§жИСжГКе•ЗзЪДжШѓVDBEж≤°дїАдєИйЪЊдї•зРЖиІ£зЪДйЂШжЈ±зЯ•иѓЖпЉМеЕИдЇЇе∞ЖдЄАдЄ™е§НжЭВзЪДз≥їзїЯзФ®зЃАеНХзЪДжЦєж≥ХеЈІе¶ЩзЪДеЃЮзО∞дЇЖгАВ
еЬ®ињЩдЄ™жХ∞жНЃеЇУиЩЪжЛЯжЬЇдЄ≠пЉМжѓПдЄАзІНжМЗдї§пЉИinstructionпЉЙйГљиЩЪжЛЯжЬЇдЄ≠йГљжШѓеЫЇеМЦзЪДпЉМе∞±жШѓиѓіжѓПдЄАзІНдЄАжЙІи°МйГљжШѓжМЙзЕІеЫЇеЃЪзЪДйАїиЊСеОїжУНдљЬпЉМиАМжѓПдЄАзІНжМЗдї§пЉИinstructionпЉЙйГљжЬЙдЇФзІНжИЦжХ∞зІНжХ∞жНЃжУНдљЬпЉИoperandпЉЙдљЬдЄЇжУНдљЬзЪДеПВжХ∞пЉИжИСзЪДзРЖиІ£пЉЙгАВиАМињЩжХ∞зІНжХ∞жНЃжУНдљЬйГљжШѓиЈЯиЩЪжЛЯжЬЇдЄ≠зЪДж≥®еЖМжЬЇпЉИregisterпЉЙ*ж≥®1*зЫЄеЕ≥иБФзЪДгАВ
дї•дЄЛжШѓsqliteжЦЗж°£дЄ≠жПРдЊЫзЪДжХ∞жНЃеЇУжМЗдї§жУНдљЬзЪДеЃЮдЊЛ
жѓФе¶В delete from tbl1 where two<20;
жИСдїђжЙІи°Мдї•дЄКињЩжЭ°зЃАеНХзЪДиѓ≠еП•гАВ
addr opcode p1 p2 p3 p4 p5 comment
---- ------------- ---- ---- ---- --------- -- -------
1 Goto 0 20 0 00
2 OpenRead 0 2 0 00 tbl
3 SetNumColumns 0 2 0 00
4 Rewind 0 11 0 00
5 Column 0 1 2 00 tbl.two
6 Integer 20 3 0 00
7 Ge 3 10 2 cs(BINARY) 6a
8 Rowid 0 1 0 00
9 FifoWrite 1 0 0 00
10 Next 0 5 0 00
11 Close 0 0 0 00
12 OpenWrite 0 2 0 00 tbl
13 SetNumColumns 0 2 0 00
14 FifoRead 1 18 0 00
15 NotExists 0 17 1 00
16 Delete 0 1 0 tbl 00
17 Goto 0 14 0 00
18 Close 0 0 0 00
19 Halt 0 0 0 00
20 Transaction 0 1 0 00
21 VerifyCookie 0 1 0 00
22 TableLock -1 2 0 tbl 00
23 Goto 0 2 0 00
жХ∞жНЃеЇУдЄ≠жЙІи°Мдї•дЄКжЬЇеЩ®жМЗдї§еИЧи°®
еЕґдЄ≠зЪДopcodeе∞±жШѓе¶ВдЄКиѓізЪДжЬЇеЩ®жМЗдї§пЉМиАМ p1,p2,p3,p4,p5 е∞±жШѓжХ∞жНЃжУНдљЬпЉМжИСе∞ЖеЕґзРЖиІ£дЄЇжИСдїђз®ЛеЇПдЄ≠еЗљжХ∞зЪДеПВжХ∞гАВ
жИСеЕИйАРдЄ™дїЛзїНдЄЛжМЗдї§зЪДеКЯиГљ
GotoпЉЪиЈ≥иљђиЗ≥p2жЙАжМЗзЪДжМЗдї§еЬ∞еЭАпЉИAddrпЉЙ
TransactionпЉЪињЩдЄ™жИСдїђеЊИзЬЉзЖЯпЉМеЉАеРѓдЄАдЄ™дЇЛеК°пЉМP1жШѓжХ∞жНЃеЇУзЪДId,0дЄЇдЄїжХ∞жНЃеЇУпЉМ1пЉМ2дЄЇйЩДеК†еЕ≥иБФзЪДжХ∞жНЃеЇУпЉМе¶ВжЮЬ
P2дЄЇйЭЮ0еАЉпЉМдї£и°®дЄАдЄ™еЖЩдЇЛеК°еЉАеІЛжЙІи°МпЉМињЩжЧґжУНдљЬдЉЪжПРдЇ§дЄАдЄ™пЉИRESERVED lockпЉЙдєРиІВйФБпЉМж≤°жЬЙдЄАдЄ™ињЫз®ЛеПѓдї•жЙІи°МеЖЩ
дЇЛеК°гАВе¶ВжЮЬP2е§ІдЇОз≠ЙдЇО2пЉМйВ£дєИдЇЛеК°дЉЪжПРдЇ§дЄАдЄ™пЉИEXCLUSIVE lockпЉЙжВ≤иІВйФБпЉМеН≥еЕґдїЦињЫз®ЛдЄНиГљиѓїдєЯдЄНиГљеЖЩгАВ
OpenRead:дЄЇдЄАдЄ™жХ∞жНЃи°®жЙУеЉАдЄАдЄ™еП™иѓїзЪДжХ∞жНЃеЇУжЄЄж†ЗпЉМж†єжХ∞жНЃеПґпЉИroot pageпЉЙжШѓжХ∞жНЃжУНдљЬP2гАВ
RewindпЉЪиѓїеПЦжХ∞жНЃи°®жИЦ糥еЉХзЪДзђђP1дЄ™еЃЮдљУпЉМе¶ВжХ∞жНЃи°®жИЦ糥еЉХдЄЇз©ЇпЉМдЄФP2е§ІдЇО0пЉМжМЗдї§еЬ∞еЭАиЈ≥иљђиЗ≥p2,е¶ВжЮЬP2дЄЇ0еєґжХ∞жНЃи°®
жИЦ糥еЉХдЄЇз©ЇиЈ≥иљђиЗ≥дЄЛдЄАдЄ™еЬ∞еЭАзЪДжМЗдї§гАВ
SetNumColumnsпЉЪж†єжНЃP2иЃЊеЃЪжЄЄж†ЗзЪДеИЧжХ∞
з≠Йз≠ЙпЉМжМЗдї§зЪДжДПжАЭе∞±дЄНдЄАдЄАиІ£йЗКдЇЖпЉМжЬЙеЕіиґ£зЪДеРМе≠¶еПѓдї•еПВзЬЛsqliteжЦЗж°£,
иѓ•еЖЕеЃєдєЯзЫЄељУйЗНи¶БпЉМдєЯиЃЄеЬ®еРОйЭҐзЪДзЙИжЬђжИСдЉЪе∞ЖжМЗдї§зЪДеЖЕеЃєи°•еЕ®
VDBEж≠£жШѓе∞ЖдЄАдЄ™дЄ™зЃАеНХзЪДжХ∞жНЃжУНдљЬпЉМжЙІи°МеЗЇdelete from tbl1 where two<20;зЪДеК®дљЬгАВ
йВ£дєИжИСдїђеПѓдї•зЯ•йБУдЇЖVDBEз©ґзЂЯеБЪдЇЖдїАдєИдЄЬи•њ

дїОеЫЊдЄКжИСдїђеПѓдї•зЬЛеИ∞пЉМжИСдїђжХ∞жНЃеЇУзЪДеЖЕж†ЄжШѓзФ±дЄЙйГ®еИЖжЮДжИРпЉМ
1пЉМеЃЮзО∞жИСдїђзЖЯжВЙеµМеЕ•sqlиѓ≠еП•зЪДc\c++жО•еП£гАВ
2пЉМе∞Жsqlиѓ≠еП•иІ£жЮРжИРеРДдЄ™иЩЪжЛЯжЬЇжМЗдї§пЉИinstructionпЉЙпЉМе§ЪдЇПдЇЖSQLiteжИСдїђжЬЙдЄАдЄ™дЉШзІАзЪДиІ£жЮРеЩ®еПѓдї•еАЯйЙігАВ
3пЉМзФ±VDBEеОїеЃЮзО∞еРДдЄ™жЬЇеЩ®жМЗдї§зЪДзЃЧж≥ХгАВиѓізЩљдЇЖе∞±жШѓдЄАдЄ™еПИдЄАдЄ™зЪДCеЗљжХ∞гАВ
ж≥®1пЉЪеПИдЄАдЄ™йЗНи¶БзЪДжЬЇеИґпЉМжИСз®НеРОи°•еЕЕжЦЗж°£гАВ
4пЉМsqlиІ£жЮРеЩ®еИЭж≠•иЃЊиЃ°жЦЗж°£
еЬ®жЮДжАЭsql иІ£жЮРеЩ®дєЛеЙНпЉМеПВзЬЛдЇЖsqliteзЪДзЫЄеЕ≥жЦЗж°£пЉМsqlиІ£жЮРеЩ®зЪДйЪЊеЇ¶еЬ®дЇОиДЪжЬђдЄОCйАїиЊСзЪДе§НжЭВжШ†е∞ДеЕ≥з≥їпЉМеЬ®ињЩйЗМsqliteдЄЇжИСдїђжПРдЊЫдЇЖдЄАдЄ™еПѓеАЯйЙізЪДиІ£еЖ≥жЦєж°ИпЉМе∞±жШѓCдї£з†БзЪДиДЪжЬђзФЯжИРеЩ®пЉМдї•дЄЛзїЩеЗЇжИСе§ІиЗіжЮДжАЭзЪДжµБз®ЛеЫЊ
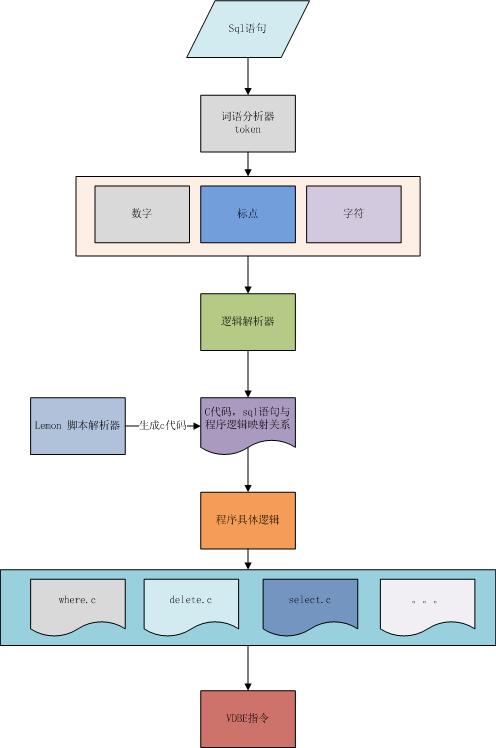
1пЉМй¶ЦеЕИзФ®йАїиЊСеИЖжФѓпЉМе∞Жиѓ≠еП•дЄ≠зЪДзђ¶еПЈељТз±їпЉМжЮДеїЇиѓ≠ж≥Хж†С гАВ
2пЉМе∞ЖйАїиЊСиДЪжЬђзФЯжИРCиѓ≠и®АпЉМиЃ©з®ЛеЇПиОЈеПЦиІ£жЮРsqlиДЪжЬђзЪДиГљеКЫгАВ
3пЉМиІ£жЮРеЩ®и∞ГзФ®з®ЛеЇПйАїиЊСпЉМжЙІи°МVDBEжМЗдї§гАВ
еЙНйЭҐиѓідЇЖпЉМиѓНж≥ХзЪДиІ£жЮРеЩ®жЬАе§ІзЪДйЪЊзВєеЬ®дЄОе∞Жиѓ≠еП•дЄ≠еЕ≥йФЃиѓНдЄОеПВжХ∞е§Ъж†ЈзїДеРИпЉМдЄОз®ЛеЇПеЕЈдљУзЪДе§ДзРЖйАїиЊСдЄАдЄАеѓєеЇФгАВињЩжШѓдЄАдЄ™еЕЙжГ≥жГ≥е∞±е§іе§ІзЪДдЇЛжГЕпЉМдЄЇж≠§пЉМжИСдїђжЙЊеИ∞дЇЖдЄАдЄ™иГљеЊИе•љзЪДиІ£еЖ≥ињЩдЄ™йЪЊйҐШзЪДжЦєж°ИпЉМдї£з†БзФЯжИРеЩ®гАВ
lemonдї£з†БзФЯжИРеЩ®пЉМзЃАеНХзЪДиѓіе∞±жШѓе∞ЖжИСдїђеЖЩе•љзЪДcontext-free grammar (CFG) иѓ≠ж≥ХиДЪжЬђпЉМзФ®жЭ•зФЯдЇІеЕЈдљУзЪДcдї£з†БзЪДйАїиЊСпЉМињЩдЄЬи•њжШѓзЉЦеЖЩиѓНж≥ХиІ£жЮРеЩ®дЄОзЉЦиѓСеЈ•еЕЈзЪДеИ©еЩ®гАВ
дї•дЄЛжЭ•еЙЦжЮРдЄЛињЩзІНCFGиѓ≠ж≥ХиДЪжЬђпЉМжАОдєИйЕНзљЃдЄОlemonдї£з†БзФЯжИРеЩ®дЄ≠гАВ
lemonиѓ≠ж≥ХжЦЗдїґжШѓжЬЙдЄАжЃµдЄАжЃµзЪДиѓ≠ж≥ХиІДеИЩжЃµжЮДжИРзЪДпЉМжѓПдЄ™иѓ≠ж≥ХиІДеИЩжЃµйГљжШѓйАЪињЗ"::="зїДеРИиµЈжЭ•зЪДпЉМеРОйЭҐиЈЯand/orз≠ЙйАїиЊСи°®иЊЊеЉПпЉМжѓПдЄ™иѓ≠ж≥ХиІДеИЩжЃµйГљжШѓдї•еП•еПЈзїУе∞ЊзЪДгАВиѓ≠ж≥ХжЃµзЪДеП≥иЊєеПѓдї•дЄЇз©ЇгАВиІДеИЩеПѓдї•еЈ≤дїїжДПзЪДй°ЇеЇПеЗЇзО∞еЬ®жЦЗдїґдЄ≠пЉМйЩ§дЇЖ%startзЪДеЕ≥йФЃиѓНдЊЛе§ЦпЉМињЩдЄ™дЄЛйЭҐдЉЪжПРеИ∞пЉМиѓ≠ж≥ХжЃµе§Іж¶ВеГПињЩж†ЈпЉЪ
expr ::= expr PLUS expr.
expr ::= expr TIMES expr.
expr ::= LPAREN expr RPAREN.
expr ::= VALUE.
lemonиѓ≠ж≥ХжЦЗдїґеП¶дЄАдЄ™йЗНи¶БзЪДеКЯиГљпЉМе∞±жШѓеµМеЕ•Cиѓ≠еП•пЉМељУжї°иґ≥ељУеЙНзЪДиѓ≠ж≥ХиІДеИЩжЧґжЙІи°М{}еЖЕзЪДCиѓ≠еП•гАВ
е¶ВдЄЛпЉЪ
expr ::= expr PLUS expr. { printf("Doing an addition...\n"); }
еП¶е§ЦпЉМжЯ†ж™ђзЙМдї£з†БзФЯжИРеЩ®ињШжФѓжМБдЄАдЄЛеЕ≥йФЃе≠ЧпЉМ
* %destructor
* %extra_argument
* %include
* %left
* %name
* %nonassoc
* %parse_accept
* %parse_failure
* %right
* %stack_overflow
* %stack_size
* %start_symbol
* %syntax_error
* %token_destructor
* %token_prefix
* %token_type
* %type
* %left * %right еЃЪдєЙињРзЃЧзђ¶еЕ≥йФЃе≠Ч
дЊЛе≠РпЉМ
%left OR.
%left AND.
%right NOT.
%left IS MATCH LIKE_KW BETWEEN IN ISNULL NOTNULL NE EQ.
%left GT LE LT GE.
%right ESCAPE.
%left BITAND BITOR LSHIFT RSHIFT.
%left PLUS MINUS.
%left STAR SLASH REM.
%left CONCAT.
%left COLLATE.
%right UMINUS UPLUS BITNOT
жШѓзЪДпЉМдЄКйЭҐзЪДе∞±жШѓеЃЪдєЙsqlињРзЃЧзђ¶зЪДдЊЛе≠РпЉМleftдЄЇеЈ¶ињРзЃЧзђ¶пЉМrightдЄЇеП≥ињРзЃЧзђ¶.
%type еЃЪдєЙеЗљжХ∞зЪДз±їеЮЛ е¶Вvoid int з≠Й
%token_type {Token} еЃЪдєЙиѓ≠еП•е≠Чзђ¶зЪДз±їеЮЛ
%default_type {Token} йїШиЃ§иѓ≠еП•е≠Чзђ¶зЪДз±їеЮЛ
%destructor жЮДжЮРж†ЗиѓЖ
%type nt {void*}
%destructor nt { free($$); }
nt(A) ::= ID NUM. { A = malloc( 100 ); }
ињЩйЗМ%typeеЃЪдєЙдЇЖз±їеЮЛдЄЇvoidзЪДеЗљжХ∞пЉМ%destructorеЃЪдєЙдЇЖељУеЗљжХ∞ntеЗЇе†ЖжЧґпЉМз®ЛеЇПењЕй°їжЙІи°МзЪДеК®дљЬгАВ
еЕґдїЦеЕ≥йФЃе≠ЧдЄНдЄАдЄАдїЛзїНпЉМжЬЙеЕіиґ£зЪДеРМе≠¶иѓЈеПВзЕІжЦЗж°£ http://www.hwaci.com/sw/lemon/lemon.html
йВ£дєИеИ∞ињЩйЗМпЉМжИСдїђе∞ЖйЕНзљЃе•љзЪДиѓ≠ж≥ХиІДеИЩеѓЉеЕ•lemonдЄ≠пЉМlemonдЉЪдЄЇжИСдїђзФЯжИРдЄ§дЄ™CжЦЗдїґпЉМдЄАдЄ™е§іжЦЗдїґпЉМдЄОдЄАдЄ™.cжЦЗдїґпЉМе§іжЦЗдїґдЄ≠еМЕжЛђжИСдїђеЃЪдєЙзЪДеЕ≥йФЃе≠ЧпЉМ.cе∞±жШѓиѓ≠ж≥ХдЄОйАїиЊСжШ†е∞ДзЪДдї£з†БпЉМиАМlemonдЄЇжИСдїђдїАдєИдЇЖеЗ†дЄ™жЦєдЊњзЪДжО•еП£пЉМиЃ©жИСдїђи∞ГзФ®иІ£жЮРеЩ®
01 ParseTree *ParseFile(const char *zFilename){
02 Tokenizer *pTokenizer;
03 void *pParser;
04 Token sToken;
05 int hTokenId;
06 ParserState sState;
07
08 pTokenizer = TokenizerCreate(zFilename); ---иІ£жЮРиѓНзїД
09 pParser = ParseAlloc( malloc ); ---еЉАиЊЯеЖЕе≠Ш
10 InitParserState(&sState); ---еИЭеІЛеМЦ
11 while( GetNextToken(pTokenizer, &hTokenId, &sToken) ){
12 Parse(pParser, hTokenId, sToken, &sState); ---иІ£жЮР
13 }
14 Parse(pParser, 0, sToken, &sState);
15 ParseFree(pParser, free ); ---йЗКжФЊеЖЕе≠Ш
16 TokenizerFree(pTokenizer);
17 return sState.treeRoot; ----ињФеЫЮиѓ≠ж≥Хж†С
18 }
жШѓзЪДпЉМйЕНе•љйАїиЊСпЉМжИСдїђдЄНзФ®еЖЩдЄАеП•дї£з†БпЉМжИСдїђеЃМжИРдЇЖиѓ≠ж≥ХиІ£жЮРжЬАе§НжЭВзЪДйГ®еИЖпЉМзЫЃж†ЗиґКжЭ•иґКињСдЇЖгАВ
Times TenдљУз≥їзїУжЮД
еєґеПСзЃ°зРЖпЉЪ
жФѓжМБе§ЪзЇњз®ЛиЃњйЧЃгАВ
жФѓжМБдЄНеРМзЪДдЇЛеК°йЪФз¶їзЇІеИЂпЉЪRead committed Serializable
жФѓжМБдЄНеРМзЇІеИЂзЪДйФБжОІеИґпЉЪеЇУзЇІпЉМи°®зЇІпЉМи°МзЇІ
жФѓжМБжЛіпЉЪзФ®дЇОдњЭжК§еЖЕйГ®жХ∞жНЃзїУжЮД
иЗ™еК®ж≠їйФБж£АжµЛеТМиІ£йЩ§
еЃМжХізЪДдЇЛеК°жОІеИґжЬЇеИґпЉМеМЕжЛђcommit/rollback
жХ∞жНЃдЄАиЗіжАІпЉЪжХ∞жНЃеЇУжАїжШѓдњЭжМБжХ∞жНЃдЄАиЗізКґжАБпЉМеєґдЄФеЬ®жОЙзФµз≠ЙжГЕеЖµдЄЛиГље§ЯеЯЇдЇОз£БзЫШпЉИжЧ•ењЧз≠ЙпЉЙжБҐе§НдЄАиЗіжАІгАВ
еПѓйЭ†жАІпЉЪйАЪињЗlogеТМCheckpoint fileдњЭиѓБеПѓйЭ†жАІ
жЧ•ењЧпЉЪ
жФѓжМБиЗ™еК®ж£АжЯ•зВє
жФѓжМБдЇЇеЈ•еЉЇеИґж£АжЯ•зВє
жФѓжМБеЃМжХіжЧ•ењЧжЬЇеИґгАВ
жФѓжМБжЧ•ењЧеЖЩеЕ•з°ђзЫШпЉМеЖЩеЕ•еЖЕе≠ШпЉМжФѓжМБдЄНеЖЩжЧ•ењЧдї•жПРйЂШжХИзОЗгАВ
йХЬеГПе§НеИґпЉЪ
зБµжіїзЪДйЕНзљЃпЉЪжФѓжМБе§ЪзІН嚥еЉП
ењЂйАЯеПѓйЭ†пЉЪдЄНжШѓеЯЇдЇОжХ∞жНЃе§НеИґпЉМиАМжШѓеЯЇдЇОжЧ•ењЧгАВ
жФѓжМБеРМж≠•жИЦеЉВж≠•ж®°еЉП
жФѓжМБйХЬеГПдєЛйЧізЪДиЗ™жБҐе§Н
жФѓжМБжХЕйЪЬжЧґпЉМеЇФзФ®иЃњйЧЃиЗ™еК®ењЂйАЯеЃЙеЕ®еИЗжНҐеИ∞е§ЗзФ®
oracleжХ∞жНЃеЇУзЉУе≠ШпЉЪ
TimesTen CacheдЄ≠и°®зђ¶еРИеЕ≥з≥їж®°еЮЛ
Cache жПРдЊЫеП™иѓїпЉМиЗ™еК®еИЈжЦ∞жХ∞жНЃеЇУжХ∞жНЃпЉМиЗ™еК®еИЈеЕ•жХ∞жНЃеЇУпЉМжЙЛеЈ•еИЈеЕ•жХ∞жНЃеЇУз≠Йе§ЪзІНжХ∞жНЃеРМж≠•жЬЇеИґгАВ
SQLиѓ≠еП•дЉ†йАТеКЯиГљпЉЪеѓєдЇОдЄНеЬ®еЖЕе≠ШжХ∞жНЃеЇУдЄ≠и°®зЪДиЃњйЧЃпЉМtimestenдЉ†йАТеИ∞жХ∞жНЃеЇУжЙІи°М
SQLеЉАеПС
жФѓжМБSQL92зЪДеЗљжХ∞
еЯЇдЇОдї£дїЈзЪДжߕ胥дЉШеМЦжЬЇеИґ
еЃМеЦДзЪД糥еЉХжЦєеЉП
жФѓжМБеИЖеЄГеЉПдЇЛеК°е§ДзРЖ
жФѓжМБODBC2.5 JDBC3.0
жФѓжМБcеТМc++еЇУ
жФѓжМБеСљдї§дЇ§дЇТжЦєеЉПttlsql
жФѓжМБдЇЛдїґиІ¶еПСеПѓдї•йГ®еИЖжЫњдї£иІ¶еПСеЩ®
еЃЙеЕ®жОІеИґ
еПѓдї•еЉАеРѓеТМеЕ≥йЧ≠еЃЙеЕ®иЃњйЧЃжОІеИґ
7зІНиЃњйЧЃжЭГйЩРжОІеИґпЉЪInstance AdministratorпЉМ ConnectпЉМ CreateDatastoreпЉМ SelectпЉМ WriteпЉМ DDLпЉМ and Admin
жФѓжМБSQL GRANT/REVOKEжЦєеЉПжОИжЭГ
======================================================
еЬ®жИСдїђйЬАи¶БзЪДйЬАж±ВдЄ≠пЉМеЕ®йЭҐеЃЮзО∞жЙАжЬЙзЪДж°ЖжЮґжШѓдЄНзО∞еЃЮзЪДгАВдЄЇж≠§жИСдїђе∞ЖеКЯиГљеИЖдЄЇеЗ†жЬЯеЃЮзО∞
еЈ•з®ЛдЄАжЬЯпЉЪ
йЬАж±ВзЫЃзЪДпЉЪеЃЮзО∞еЖЕе≠ШжХ∞жНЃеЇУеЯЇжЬђеКЯиГље±ЮжАІпЉМдЄЇдї•еРОйЗНи¶БеКЯиГљзЪДжЙ©е±ХйҐДзХЩдљЩеЬ∞гАВ
еєґеПСзЃ°зРЖпЉЪ
жФѓжМБе§ЪзЇњз®ЛиЃњйЧЃгАВ(еЈ≤иГљеЃЮзО∞пЉЙ
жФѓжМБеЫЫзІНеЫЫдЄ™дЇЛеК°йЪФз¶їзЇІеИЂгАВ(иЊГйЪЊеЃЮзО∞пЉЙ
жФѓжМБдЄНеРМзЇІеИЂзЪДйФБжОІеИґпЉЪеЇУзЇІпЉМи°®зЇІпЉМи°МзЇІгАВ(йЪЊеЃЮзО∞пЉЙ
еЃМжХізЪДдЇЛеК°жОІеИґжЬЇеИґпЉМеМЕжЛђcommit/rollbackгАВ(еЈ≤иГљеЃЮзО∞пЉЙ
еЃМеЦДзЪД糥еЉХжЦєеЉП(еЈ≤иГљеЃЮзО∞)
жХ∞жНЃдЄАиЗіжАІпЉЪжХ∞жНЃеЇУжАїжШѓдњЭжМБжХ∞жНЃдЄАиЗізКґжАБпЉМеєґдЄФеЬ®жОЙзФµз≠ЙжГЕеЖµдЄЛиГље§ЯеЯЇдЇОз£БзЫШпЉИжЧ•ењЧз≠ЙпЉЙжБҐе§НдЄАиЗіжАІгАВ(иЊГеЃєжШУеЃЮзО∞пЉЙ
еЈ•з®ЛдЇМжЬЯпЉЪ
жФѓжМБSQL92зЪДеЗљжХ∞(еЈ≤иГљеЃЮзО∞пЉЙ
SQLеЉАеПС(еЈ≤иГљеЃЮзО∞пЉЙ
жФѓжМБcеТМc++еЇУпЉИиЊГжШУеЃЮзО∞пЉЙ
еЃЪжЧґOracleдЄОMysqlз£БзЫШжХ∞жНЃеЇУзГ≠е§ЗдїљпЉИеЊИйЪЊеЃЮзО∞пЉЙ
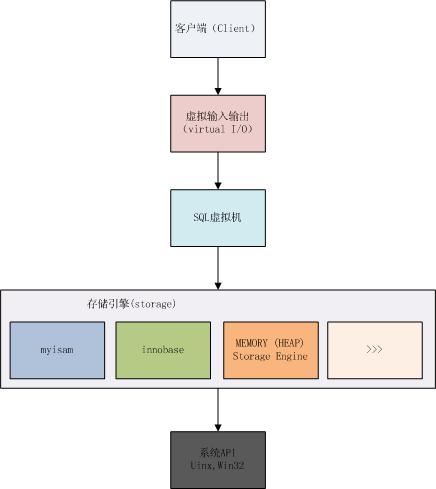
зїПињЗеdž姩啚啚еЬ∞жЯ•зЬЛзЪДMysqlзЪДжЇРз†БеПКжЦЗж°£пЉМдї•дЄКжШѓMysqlе§ІиЗізЪДзїУжЮДеЫЊпЉМжИСдїђеЙЦжЮРmysqlзЪДзЫЃзЪДжШѓдїОдЄ≠жИСдїђеОїеАЯйЙідїЦжХ∞жНЃе§ДзРЖзЪДдЄАдЇЫжЦєж≥ХпЉМеѓєдЇОsqlиЩЪжЛЯжЬЇжИСдїђеЙНйЭҐеЈ≤зїПиІ£жЮРињЗSQLiteжЮДеїЇSQLиЩЪжЛЯжЬЇзЪДеБЪж≥ХпЉМеЬ®жИСдїђжЯ•зЬЛMysqlеЖЕйГ®жЬЇеИґ,зЪДжЧґеАЩпЉМжИСдїђеПСзО∞MysqlзЪДеБЪж≥ХиЈЯSQLiteжШѓдЄАж†ЈзЪДеП™дЄНињЗе∞ЖLemenдї£з†БзФЯжИРеЩ®жНҐжИРyacc.
йВ£жИСдїђзЪДеЈ•дљЬе∞±жФЊеИ∞е≠ШеВ®еЉХжУОдЄ≠пЉМйЗНзВєеОїдЇЖиІ£,
1,MysqlдЄ≠зЪДеєґеПСйФБжЬЇеИґ
The MyISAM Storage Engine,The MEMORY (HEAP) Storage EngineжПРдЊЫзЪДйГљжШѓTableзЇІзЪДжХ∞жНЃйФБпЉМеЖЕе≠ШжХ∞жНЃеЇУзЪДеєґеПСйФБжЬЇеИґгАВ
2пЉМ The InnoDB Storage Engine
The InnoDB Storage EngineжШѓMysqlдЄ≠жКАжЬѓеПВжХ∞жЬАеЕ®йЭҐзЪДжХ∞жНЃеЉХжУОпЉМйЗНзВєдЇЖиІ£Data cachesдЄОз£БзЫШзЪДдЇ§жНҐжУНдљЬпЉМеѓєдЇОжИСдїђжФєињЫжХ∞жНЃеЉХжУОжШѓжЬАйЗНи¶БзЪДжКАжЬѓгАВ
The InnoDB Storage EngineжПРдЊЫRowзЇІзЪДеєґеПСйФБпЉМињЩеѓєжИСдїђиѓ•жЬЇеЖЕе≠ШжХ∞жНЃеЇУдєЯжШѓжЬАйЗНи¶БзЪДдЄАж≠•.
3 пЉМеПВиАГInnoDBпЉМMEMORY (HEAP)дЄОsqliteдЄЙиАЕжѓФиЊГпЉМBtreeеТМheapз≠Йе§ДзРЖжЦєеЉПжЭ•жХ≤еЃЪжХ∞жНЃзїУжЮДжУНдљЬзЪДиЃЊиЃ°гАВ
еЖЕе≠ШжХ∞жНЃеЇУеЖЕж†ЄеЉАеПС еЈ•дљЬжЧ•ењЧпЉИinnodbзЪДеОЯзРЖпЉМзЃЧж≥Хиѓ¶зїЖеЙЦжЮРпЉЙ(дєЭ)
еЗ†дЄ™жШЯжЬЯжЭ•дЄАзЫіеЬ®жХ∞жНЃеЇУжЦЗж°£зЪДе§ІжµЈдЄ≠жµЄж≥°пЉМз™БзДґеПСзО∞жИСињШжШѓж≤°иГљжЈ±еЕ•еИ∞жХ∞жНЃеЇУеЖЕж†ЄеЉАеПСзЪДзЬЯж≠£ж†ЄењГпЉМеІЛзїИеБЬзХЩеЬ®sqliteињЩдЄ™зЃАеНХзЪДж°ЖжЮґжЧ†ж≥Хз™Бз†і,жИСйЬАи¶БйЗНжЦ∞жАЭиАГдЄАдЄ™жЦ∞зЪДеИЗеЕ•зВєпЉМжЬАеЉАеІЛз†Фз©ґSQLiteжХ∞жНЃеЇУпЉМжФґиОЈжШѓжХ∞жНЃеЇУеЉХжУОеЉАеПСзЪДеЯЇжЬђеОЯзРЖпЉМиЩЪжЛЯжЬЇпЉМдї£з†БзФЯжИРпЉМB-treeзЪДеРДзІНзЃЧж≥ХпЉМдљЖељУжИСиАГиЩСжЛУе±ХеЕґеКЯиГљжЧґжИСеВїзЬЉдЇЖпЉМжИСж≤°жЬЙдЄАзІНдЄУдЄЪзЪДжЙЛж≥ХеОїжЙ©е±ХеЕґдЄ≠дЄАзІНеКЯиГљпЉМжѓФе¶ВпЉМељУжИСжГ≥жККеєґеПСжОІеИґзФ±жХідЄ™жХ∞жНЃзЪДжХ∞жНЃйФБжЛУе±ХеИ∞и°®зЇІзФЪиЗ≥и°МзЇІжЧґпЉМе∞±жЭЯжЙЛжЧ†з≠ЦдЇЖгАВ
жИСдїђењЕй°їдїОдЄУдЄЪжХ∞жНЃеЇУеОїдЇЖиІ£жХ∞жНЃеЇУзЪДжѓПдЄ™жЦєйЭҐпЉМжЙНиГљдїОжХідљУжККжП°гАВ
жХ∞жНЃеЇУеЖЕж†ЄеЉАеПСзЪДжЬАиЙ∞йЪЊзЪДдЄАж≠•е∞±жШѓдїОеАЯйЙіеИ∞еИЫжЦ∞пЉМеѓєдЇОжЙУзЃЧеХЖдЄЪзЪДжХ∞жНЃеЇУпЉМдї•sqliteдЄЇж®°зЙИињШж؃姙дЄЪдљЩдЇЖпЉМжЬАеРОењЕй°їдїОеХЖдЄЪзЪДжХ∞жНЃеЇУеЕ•жЙЛжЭ•жФєйА†.
innodbзЪДзЃАеНХдїЛзїНиѓЈеПВзЕІ(еЖЕе≠ШжХ∞жНЃеЇУеЖЕж†ЄеЉАеПС еЈ•дљЬжЧ•ењЧпЉИMysqlзЪДжЮґжЮДдљУз≥їеИЭиѓїпЉЙ(еЕЂ))
innodbзЪДеОЯзРЖпЉМзЃЧж≥Хиѓ¶зїЖеЙЦжЮРе§ІиЗіеЖЕеЃєе¶ВдЄЛпЉМinnodbдї£з†БеЊИжЬЙжЭ•е§іпЉМжШѓзО∞oracleеЙѓжАїи£БHeikki TuuriеЖЩзЪД,еШњеШњ
йЗНи¶БзЪДжКАжЬѓйГ®еИЖеМЕжЛђдї•дЄЛеЗ†дЄ™и¶БзВєпЉМи¶БеБЪеЗЇеЗЇиЙ≤дЄУдЄЪзЪДеЖЕе≠ШжХ∞жНЃеЇУпЉМеНХеНХи¶БжФєйА†sqliteе∞±жИРеКЯжШѓдЄНеѓєзЪДпЉМдЄАеЃЪи¶БжККжѓПдЄАйГ®еИЖжСЄжЄЕжСЄйАПгАВ
зО∞еЬ®ињЫеЇ¶зЫЃеЙНжШѓеБЬзХЩеЬ®дї•дЄЛжХ∞жНЃеЇУеРДж®°еЭЧзЪДжУНдљЬеЕ≥иБФпЉМжЙАеєЄдї£з†БеєґдЄНйЪЊиѓїпЉМеЊИењЂзЪДињЩж†Јж†ЗйҐШдЉЪйАРдЄ™еК†дЄКйУЊжО•жЭ•еИЖжЮРеЕЈдљУзЪДеЃЮзО∞гАВ
1пЉМеЖЕе≠ШзЃ°зРЖ
2, зЉУе≠Ш汆
3пЉМB-treeжУНдљЬ
4пЉМжХ∞жНЃй°µ
5пЉМдЇЛеК°
6, жЧ•ењЧ
7, з≥їзїЯIO пЉИз£БзЫШжУНдљЬпЉЙ
8, жХ∞жНЃе≠ЧеЕЄ
9пЉМиІ£жЮРеЩ® пЉИиДЪжЬђиѓ¶зїЖпЉЙ
10пЉМжХ∞жНЃйФБ
11, жХ∞жНЃеЇУжХ∞жНЃз±їеЮЛеЃЪдєЙ
ps:еЊИе§ЪдЇЇе§ЪиІЙеЊЧиЗ™еЈ±еБЪжХ∞жНЃеЇУжШѓеєЉз®ЪзЪД,е±±еѓ®зЪДпЉМдЄНеИЗеЃЮйЩЕзЪДпЉМдЇЛеЃЮдЄКдєЯжШѓеЫ∞йЪЊйЗНйЗНпЉМдљЖдљ†и¶БзЯ•йБУinnodbдєЯе∞±Heikki TuuriдЄАдЄ™дЇЇе∞±еХГеЗЇжЭ•зЪД,дЄЇдЇЖжИСжЬАзИ±зЪДжХ∞е≠¶пЉМжИСдЊЭзДґжГ≥еЖНеЭЪжМБдЄАдЄЛпЉМиЩљзДґжЬЙзВєе≠§еНХ,дљЖеЕЕжї°ж±ВзЯ•зЪДењЂдєРгАВ
дєЛеЙНзФ±дЇОиАГиЩСеИ∞дљњзФ®PageзЪДеЖЕе≠ШеТМз£БзЫШдЇТжНҐзЪДжЬЇеИґеЃЮзО∞дЇЖB-treeеБЪдЄЇжХ∞жНЃеЇУзЪДйФЃеАЉзіҐеЉХпЉМеЬ®зЬЯеЃЮзЪДзФЯдЇІзОѓеҐГдЄЛ2000дЄЗдї•дЄКзЪДжХ∞жНЃеїЇзЂЛ糥еЉХдЉЪдљњеИ∞B-treeе±ВжХ∞еҐЮе§ЪпЉМжХИзОЗжШОжШЊдЄЛйЩНпЉМеЬ®ињРзЃЧеЈ•з®ЛдЄ≠дљњзФ®AIXе§ІеЮЛжЬЇйГљзФ®дЇЖжХ∞姩жЙНе∞Ж2000е§ЪдЄЗзЪДжХ∞жНЃзФЯжИРеЗЇжЭ•пЉМжХИжЮЬйЭЮеЄЄдЄНзРЖжГ≥гАВ
еЕ®жЦ∞зЪДж°ЖжЮґйЗЗзФ®дЇЖзЇѓеЖЕе≠ШзЪДзЇҐйїСж†СдљЬдЄЇжХ∞жНЃзЪД糥еЉХпЉМжХИжЮЬеЊИе•љпЉМжАІиГљжµЛиѓХдЄ≠пЉМзФ®thinkpad 201i зФµиДСеїЇзЂЛ1000дЄЗзЪДзЇҐйїСж†СеП™зФ®дЇЖ3еИЖйТЯпЉМжґИиАЧеЖЕе≠Ш270MињЩеЬ®зФµдњ°й°єзЫЃзЪДзФЯдЇІзОѓеҐГжШѓеЃМеЕ®еПѓдї•жО•еПЧзЪДгАВ
иѓ•дї£з†БдљњзФ®еЖЕе≠Ш汆еТМзЇҐйїСж†СзЪДжКАжЬѓпЉМеПВиАГдЄїи¶БжЦЗзМЃеМЕжЛђпЉЪ
http://zh.wikipedia.org/zh/%E7%BA%A2%E9%BB%91%E6%A0%91 зїіеЯЇзЩЊзІС
IBMжЦЗзЂ†пЉМhttp://www.ibm.com/developerworks/cn/linux/l-cn-ppp/index6.html
ељУзДґзљСдЄКиЃЄе§ЪдЇЇзЪДеЃЮзО∞дєЯзїЩдЇЖжИСеЊИе•љзЪДеРѓз§ЇпЉМжБХеЬ®дЄЛдЄНиГљдЄАдЄАеИЧеЗЇгАВ
дєЯиЃЄдљ†дЉЪиѓіпЉМдЄНе∞±еЃЮзО∞дЇЖSTL MAPзЪДеКЯиГљеРЧпЉЯеПѓдї•ињЩдєИиѓіпЉМеЫ†дЄЇеЖЕе≠ШдЄ≠еїЇзЂЛжХ∞жНЃзїУжЮДпЉМзЇҐйїСж†СжШѓжЬАдЉШзЪДжЦєж°ИпЉМжИСеП™иГљдљњзФ®ињЩж†ЈзЪД---еГПmapдЄАж†ЈзЪДдЄЬи•њгАВ
дї•дЄЛжШѓе§ІиЗіеЃЮзО∞дї£з†БзЪДжАЭиЈѓпЉМдљњзФ®еЖЕе≠Ш汆жЭ•е≠ШжФЊдЄ§з±їжХ∞жНЃпЉМдЄАз±їжШѓе≠ШжФЊзЇҐйїСж†СиКВзВєзЪДеЖЕе≠Ш汆пЉМдЄАз±їжШѓе≠ШжФЊйФЃеАЉиКВзВєзЪДеЖЕе≠Ш汆гАВ
еЊИе§ЪжЬЛеПЛеѓєдЇОеЖЕе≠ШжХ∞жНЃеЇУеЉАеПСEmailзїЩжИСдЄНиГљдЄАдЄАеЫЮе§НеЊИжК±ж≠ЙпЉМеЄМжЬЫдї£з†БеѓєеРДдљНжЬЙеЄЃеК©гАВ
еП¶е§ЦеЖЕе≠Ш汆зЪДдї£з†БиѓЈеПВиАГжИСзЪДеП¶дЄАзѓЗжЦЗзЂ†пЉМеЖЕе≠Ш汆зЪДеЃЮзО∞ еЖЕе≠Ш汆еЃМжХіеЃЮзО∞дї£з†БеПКдЄАдЇЫжАЭиАГ


- 2012-01-29 16:26
- жµПиІИ 684
- иѓДиЃЇ(0)
- жЯ•зЬЛжЫіе§Ъ
еПСи°®иѓДиЃЇ

зЫЄеЕ≥жО®иНР
PostgreSQLжХ∞жНЃеЇУеЖЕж†ЄеИЖжЮРPostgreSQLжХ∞жНЃеЇУеЖЕж†ЄеИЖжЮРPostgreSQLжХ∞жНЃеЇУеЖЕж†ЄеИЖжЮРPostgreSQLжХ∞жНЃеЇУеЖЕж†ЄеИЖжЮРPostgreSQLжХ∞жНЃеЇУеЖЕж†ЄеИЖжЮРPostgreSQLжХ∞жНЃеЇУеЖЕж†ЄеИЖжЮРPostgreSQLжХ∞жНЃеЇУеЖЕж†ЄеИЖжЮРPostgreSQLжХ∞жНЃеЇУеЖЕж†ЄеИЖжЮР...
PostgreSQLжХ∞жНЃеЇУеЖЕж†ЄеИЖжЮР.pdf
PostgreSQLжХ∞жНЃеЇУеЖЕж†ЄеИЖжЮР жЄЕжЩ∞зЙИпЉМеЃМжХі415й°µ
гАКPostgreSQLжХ∞жНЃеЇУеЖЕж†ЄеИЖжЮРгАЛељ≠жЩЇеЛЗ еЃМжХізЙИ44M
йАЪињЗеЉАеПСжХ∞жНЃеЇУеЖЕж†ЄпЉМеПѓдї•еЃЪеИґеМЦеЬ∞иІ£еЖ≥ињЩдЇЫйЧЃйҐШпЉМжПРйЂШжХ∞жНЃеЇУеЬ®зЙєеЃЪзОѓеҐГдЄЛзЪДи°®зО∞гАВ жХ∞жНЃеЇУеЖЕж†ЄеЉАеПСжґЙеПКеИ∞жЦЗдїґз≥їзїЯе±ВйЭҐзЪДзЯ•иѓЖгАВжЦЗдїґз≥їзїЯжШѓжХ∞жНЃеЇУе≠ШеВ®жХ∞жНЃзЪДеЯЇз°АпЉМеЃГеЖ≥еЃЪдЇЖжХ∞жНЃзЪДзЙ©зРЖзїДзїЗжЦєеЉПеТМиЃњйЧЃжХИзОЗгАВеЬ®жХ∞жНЃеЇУеЖЕж†Є...
PostgreSQLжХ∞жНЃеЇУеЖЕж†ЄеИЖжЮР.pdPostgreSQLжХ∞жНЃеЇУеЖЕж†ЄеИЖжЮР.pdPostgreSQLжХ∞жНЃеЇУеЖЕж†ЄеИЖжЮР.pdPostgreSQLжХ∞жНЃеЇУеЖЕж†ЄеИЖжЮР.pdPostgreSQLжХ∞жНЃеЇУеЖЕж†ЄеИЖжЮР.pdPostgreSQLжХ∞жНЃеЇУеЖЕж†ЄеИЖжЮР.pdPostgreSQLжХ∞жНЃеЇУеЖЕж†ЄеИЖжЮР.pd
жХ∞жНЃеЇУеЖЕж†ЄеЉАеПСжМЗеНЧ.txt
иЕЊиЃѓе§ІиЃ≤е†В42-жХ∞жНЃеЇУеЖЕж†ЄиЃЊиЃ°жАЭиЈѓжµЕжЮР
еЬ®linuxеє≥еП∞дЄЛжЙЛеЖЩжХ∞жНЃеЇУеЖЕж†ЄпЉМйАЪињЗеѓєжХ∞жНЃеЇУеЖЕж†ЄзЪДеЉАеПСпЉМдЇЖиІ£жХ∞жНЃеЇУињРи°МжЬЇеИґдЄОеОЯзРЖпЉЫ
е¶ВNoSQLжХ∞жНЃеЇУгАБNewSQLгАБеЖЕе≠ШжХ∞жНЃеЇУдї•еПКдЇСеОЯзФЯжХ∞жНЃеЇУз≠ЙжЦ∞еЕіжКАжЬѓпЉМеЃГдїђеѓєдЉ†зїЯжХ∞жНЃеЇУеЖЕж†ЄжПРеЗЇдЇЖжЦ∞зЪДи¶Бж±ВеТМеИЫжЦ∞жАЭиЈѓгАВ йАЪињЗжЈ±еЕ•е≠¶дє†еТМзРЖиІ£дЄКињ∞еЖЕеЃєпЉМжЧ†иЃЇжШѓжХ∞жНЃеЇУзЃ°зРЖеСШгАБеЉАеПСиАЕињШжШѓз≥їзїЯжЮґжЮДеЄИпЉМйГљиГљжЫіе•љеЬ∞зРЖиІ£еТМеЇФзФ®...
PostgreSQLжХ∞жНЃеЇУеЖЕж†ЄеИЖжЮР.part1 еЫ†дЄЇеѓєдЄКдЉ†еЖЕеЃєжЬЙйЩРеИґпЉМжЙАдї•еИЖеЉАдЉ†пЉМиЈЯpart2жФЊеЬ®еРМдЄАжЦЗдїґе§єдЄЛиІ£еОЛе∞±иГљеЊЧеИ∞еЃМжХізЪДpdfпЉМдЇ≤жµЛеПѓзФ®~
PostgreSQLжХ∞жНЃеЇУеЖЕж†ЄеИЖжЮРpart2йГ®еИЖпЉМеЫ†дЄЇеѓєдЄКдЉ†жЦЗдїґе§Іе∞ПжЬЙи¶Бж±ВпЉМжЙАдї•еИЖжИРдЄ§йГ®еИЖеОЛзЉ©пЉМеП™и¶БдЄ§йГ®еИЖеОЛзЉ©еМЕеЬ®еРМдЄАдЄ™жЦЗдїґе§єдЄЛе∞±иГљжИРеКЯеЃМжХіиІ£еОЛ
LinuxеЖЕж†ЄдЄ≠зЪДеУИеЄМи°®еЃЮзО∞еМЕжЛђдЇЖеУИеЄМеЗљжХ∞зЪДйАЙжЛ©гАБзҐ∞жТЮе§ДзРЖз≠ЦзХ•дї•еПКеЖЕе≠ШзЃ°зРЖжЬЇеИґпЉМињЩдЇЫйГљжШѓзРЖиІ£еТМдЉШеМЦеЖЕе≠ШжХ∞жНЃеЇУжАІиГљзЪДйЗНи¶БжЦєйЭҐгАВйАЪињЗеНХеЕГжµЛиѓХеТМжАІиГљжµЛиѓХпЉМжИСдїђеПѓдї•з°ЃдњЭеУИеЄМи°®зЪДж≠£з°ЃжАІеТМдЉШеМЦз®ЛеЇ¶пЉМдїОиАМдЄЇеЇФзФ®з®ЛеЇПжПРдЊЫ...