- 浏览: 2124362 次
- 性别:

- 来自: 广州
-

文章分类
最新评论
-
ratlsun:
想请教下uc最新版本在android4.2和4.3版本上是不是 ...
UC浏览器8.3 (for iPhone)设计理念.“無”为而设 -
gly0920sky520123:
很有用哦,谢谢
DOS命令大全(经典收藏) -
chenyu0748:
UC加油,花哥加油~
UC浏览器8.3 (for iPhone)设计理念.“無”为而设 -
cnliuyix:
LZ搞点更有层次的吧,介个一般工程里根本用不到这么简单的。Si ...
Android 设计一个可单选,多选的Demo -
gang4415:
rgz03407@163.com
JSR规范,系统参数测试大全
转一篇好文章,
原文地址:http://www.cnblogs.com/jillzhang/archive/2006/11/06/551298.html
1.LZW的全称是什么?
Lempel-Ziv-Welch (LZW).
2. LZW的简介和压缩原理是什么?
LZW压缩算法是一种新颖的压缩方法,由Lemple-Ziv-Welch 三人共同创造,用他们的名字命名。它采用了一种先进的串表压缩,将每个第一次出现的串放在一个串表中,用一个数字来表示串,压缩文件只存贮数字,则不存贮串,从而使图象文件的压缩效率得到较大的提高。奇妙的是,不管是在压缩还是在解压缩的过程中都能正确的建立这个串表,压缩或解压缩完成后,这个串表又被丢弃。
LZW算法中,首先建立一个字符串表,把每一个第一次出现的字符串放入串表中,并用一个数字来表示,这个数字与此字符串在串表中的位置有关,并将这个数字存入压缩文件中,如果这个字符串再次出现时,即可用表示它的数字来代替,并将这个数字存入文件中。压缩完成后将串表丢弃。如"print" 字符串,如果在压缩时用266表示,只要再次出现,均用266表示,并将"print"字符串存入串表中,在图象解码时遇到数字266,即可从串表中查出266所代表的字符串"print",在解压缩时,串表可以根据压缩数据重新生成。
3.在详细介绍算法之前,先列出一些与该算法相关的概念和词汇
1)'Character': 字符,一种基础数据元素,在普通文本文件中,它占用1个单独的byte,而在图像中,它却是 一种代表给定像素颜色的索引值。
2)'CharStream':数据文件中的字符流。
3)'Prefix':前缀。如这个单词的含义一样,代表着在一个字符最直接的前一个字符。一个前缀字符长度可以为0,一个prefix和一个character可以组成一个字符串(string),
4)'Suffix': 后缀,是一个字符,一个字符串可以由(A,B)来组成,A是前缀,B是后缀,当A长度为0的时候,代表Root,根
5)'Code:码,用于代表一个字符串的位置编码
6)'Entry',一个Code和它所代表的字符串(string)
4.压缩算法的简单示例,不是完全实现LZW算法,只是从最直观的角度看lzw算法的思想
对原始数据ABCCAABCDDAACCDB进行LZW压缩
原始数据中,只包括4个字符(Character),A,B,C,D,四个字符可以用一个2bit的数表示,0-A,1-B,2-C,3-D,从最直观的角度看,原始字符串存在重复字符:ABCCAABCDDAACCDB,用4代表AB,5代表CC,上面的字符串可以替代表示为:45A4CDDAA5DB,这样是不是就比原数据短了一些呢!
5.LZW算法的适用范围
为了区别代表串的值(Code)和原来的单个的数据值(String),需要使它们的数值域不重合,上面用0-3来代表A-D,那么AB就必须用大于3的数值来代替,再举另外一个例子,原来的数值范围可以用8bit来表示,那么就认为原始的数的范围是0~255,压缩程序生成的标号的范围就不能为0~255(如果是0-255,就重复了)。只能从256开始,但是这样一来就超过了8位的表示范围了,所以必须要扩展数据的位数,至少扩展一位,但是这样不是增加了1个字符占用的空间了么?但是却可以用一个字符代表几个字符,比如原来255是8bit,但是现在用256来表示254,255两个数,还是划得来的。从这个原理可以看出LZW算法的适用范围是原始数据串最好是有大量的子串多次重复出现,重复的越多,压缩效果越好。反之则越差,可能真的不减反增了。
6.LZW算法中特殊标记
随着新的串(string)不断被发现,标号也会不断地增长,如果原数据过大,生成的标号集(string table)会越来越大,这时候操作这个集合就会产生效率问题。如何避免这个问题呢?Gif在采用lzw算法的做法是当标号集足够大的时候,就不能增大了,干脆从头开始再来,在这个位置要插入一个标号,就是清除标志CLEAR,表示从这里我重新开始构造字典,以前的所有标记作废,开始使用新的标记。
这时候又有一个问题出现,足够大是多大?这个标号集的大小为比较合适呢?理论上是标号集大小越大,则压缩比率就越高,但开销也越高。 一般根据处理速度和内存空间连个因素来选定。GIF规范规定的是12位,超过12位的表达范围就推倒重来,并且GIF为了提高压缩率,采用的是变长的字长。比如说原始数据是8位,那么一开始,先加上一位再说,开始的字长就成了9位,然后开始加标号,当标号加到512时,也就是超过9为所能表达的最大数据时,也就意味着后面的标号要用10位字长才能表示了,那么从这里开始,后面的字长就是10位了。依此类推,到了2^12也就是4096时,在这里插一个清除标志,从后面开始,从9位再来。
GIF规定的清除标志CLEAR的数值是原始数据字长表示的最大值加1,如果原始数据字长是8,那么清除标志就是256,如果原始数据字长为4那么就是16。另外GIF还规定了一个结束标志END,它的值是清除标志CLEAR再加1。由于GIF规定的位数有1位(单色图),4位(16色)和8位(256色),而1位的情况下如果只扩展1位,只能表示4种状态,那么加上一个清除标志和结束标志就用完了,所以1位的情况下就必须扩充到3位。其它两种情况初始的字长就为5位和9位。此处参照了http://blog.csdn.net/whycadi/
7.用lzw算法压缩原始数据的示例分析
输入流,也就是原始的数据为:255,24,54,255,24,255,255,24,5,123,45,255,24,5,24,54..................
这个正好可以看到是gif文件中像素数组的一部分,如何对它进行压缩
因为原始数据可以用8bit来表示,故清除标志Clear=255+1 =256,结束标志为End=256+1=257,目前标号集为
0 1 2 3 .................................................................................255 CLEAR END
第一步,读取第一个字符为255,在标记表里面查找,255已经存在,我们已经认识255了,不做处理
第二步,取第二个字符,此时前缀为A,形成当前的Entry为(255,24),在标记集合不存在,我们并不认识255,24好,这次你小子来了,我就记住你,把它在标记集合中标记为258,然后输出前缀A,保留后缀24,并作为下一次的前缀(后缀变前缀)
第三步,取第三个字符为54,当前Entry(24,54),不认识,记录(24,54)为标号259,并输出24,后缀变前缀
第四部:取第四个字符255,Entry=(54,255),不认识,记录(54,255)为标号260,输出54,后缀变前缀
第五步 取第5个字符24,entry=(255,24),啊,认识你,这不是老258么,于是把字符串规约为258,并作为前缀
第六步 取第六个字符255,entry=(258,255),不认识,记录(258,255)为261,输出258,后缀变前缀
.......
一直处理到最后一个字符,
用一个表记录处理过程
CLEAR=256,END=257
| 第几步 | 前缀 | 后缀 | Entry | 认识(Y/N) | 输出 | 标号 |
| 1 | 255 | (,255) | ||||
| 2 | 255 | 24 | (255,24) | N | 255 | 258 |
| 3 | 24 | 54 | (24,54) | N | 24 | 259 |
| 4 | 54 | 255 | (54,255) | N | 54 | 260 |
| 5 | 255 | 24 | (255,24) | Y | ||
| 6 | 258 | 255 | (258,255) | N | 258 | 261 |
| 7 | 255 | 255 | (255,255) | N | 255 | 262 |
.....
上面这个示例有些不能完整体现,另外一个例子是
原输入数据为:A B A B A B A B B B A B A B A A C D A C D A D C A B A A A B A B .....
采用LZW算法对其进行压缩,压缩过程用一个表来表述为:
注意原数据中只包含4个character,A,B,C,D
用两bit即可表述,根据lzw算法,首先扩展一位变为3为,Clear=2的2次方+1=4; End=4+1=5;
初始标号集因该为
| 0 | 1 | 2 | 3 | 4 | 5 |
| A | B | C | D | Clear | End |
而压缩过程为:
| 第几步 | 前缀 | 后缀 | Entry | 认识(Y/N) | 输出 | 标号 |
| 1 | A | (,A) | ||||
| 2 | A | B | (A,B) | N | A | 6 |
| 3 | B | A | (B,A) | N | B | 7 |
| 4 | A | B | (A,B) | Y | ||
| 5 | 6 | A | (6,A) | N | 6 | 8 |
| 6 | A | B | (A,B) | Y | ||
| 7 | 6 | A | (6,A) | Y | ||
| 8 | 8 | B | (8,B) | N | 8 | 9 |
| 9 | B | B | (B,B) | N | B | 10 |
| 10 | B | B | (B,B) | Y | ||
| 11 | 10 | A | (10,A) | N | 10 | 11 |
| 12 | A | B | (A,B) | Y |
.....
当进行到第12步的时候,标号集应该为
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| A | B | C | D | Clear | End | AB | BA | 6A | 8B | BB | 10A |
8.LZW算法的伪代码实现
 STRING = get input character
STRING = get input character2
WHILE there are still input characters DO3
CHARACTER = get input character4
IF STRING+CHARACTER is in the string table then5
STRING = STRING+character6
ELSE7
output the code for STRING8
add STRING+CHARACTER to the string table9
STRING = CHARACTER10
END of IF11
END of WHILE12
output the code for STRING 13
9.LZW算法的流程图
没有安visio,画了一个,比较难看,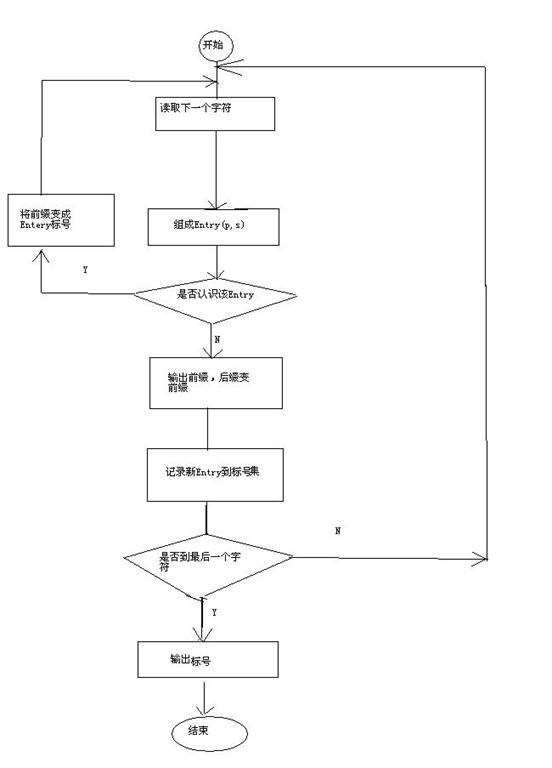


发表评论

-
汉字点阵字库原理
2011-01-28 10:09 3409一、 汉字编码 1. ... -
如何通过改jad和Manifest把其它手机的java游戏改成N830的
2011-01-25 10:21 1381首先要明确一点,不是所有的游戏都能改的。 <200 ... -
索爱手机IMSI序列号获取
2011-01-20 11:29 1992国际移动用户识别码(I ... -
J2ME数组的复制及连接操作
2010-11-19 10:47 1295public class Arrays { /** ... -
手机 J2ME MIDP 性能测试工具(MIDP BenchMark)
2010-11-19 10:35 1480JavaME Test Suitehttp://www.dog ... -
SocketConnection 参数详细介绍
2010-03-23 11:34 2152请大家看下面的代码: len = is.read(gDat ... -
J2ME使用Socket通过cmwap接入点访问安全HTTPS
2010-03-17 16:36 484这个问题是在我升级J2ME版XHTML浏览器的时候被引入的 ... -
一些很特别的J2ME开源项目(转
2010-03-11 09:43 2387StrutsME 一个轻量级的序列化协议,使J2ME客户端能调 ... -
WMLC 检查charset编码
2009-12-16 15:27 180http://www.iana.org/assignments ... -
Eclipse快捷键
2009-12-01 10:38 1434编辑相关快捷键 Eclipse的编辑功能非常强大,掌 ... -
改善你的J2ME程序界面-使用开源UI库
2009-09-03 16:45 3728J2ME自带UI不是太美观,使用起来也不太方面,为了解决这 ... -
<a> 标签,target="blank",target="_blank" 的区别。
2009-05-27 13:00 11610在编写html代码的时候。 target="bla ... -
贡献 高效的MIDlet 编程
2009-05-23 15:32 1917从网上找到这本资料。 是E文版的。 大家顺便锻炼下E文 -
How to use pop-up TextBox in Java ME
2009-05-23 13:44 1792Overview One of the Displayabl ... -
How to use freely resizable font in in Java ME
2009-05-23 13:41 1353Contents [hide] 1 Overview 2 ... -
A Simple Ordered Hashtable
2009-05-23 12:08 1600This article illustrates how to ... -
开发NokiaS40系列应用程序初级篇
2009-05-22 18:56 1739本文讲述如何搭建Nokia S40系列手机应用程序的开发环境 ... -
索尼爱立信手机在 J2ME 程序中的字体大小
2009-05-18 16:25 1377之前有朋友问到索尼爱立信手机在 J2me 程序中的字体大小,请 ... -
If-Modified-Since & If-None-Match
2009-05-13 11:01 14593google告诉网站站长:您� ... -
WAP 2.0介绍和使用规范
2009-05-08 16:09 11477—— XHTML MP and WCSS一、WAP的常识(省略 ...
相关推荐
LZW(Lempel-Ziv-Welch)数据压缩算法是一种广泛应用的无损压缩方法,由Abraham Lempel、Jacob Ziv和W. Terry Welch三位科学家在1977年提出。它主要通过构建一个动态编码表来实现对输入数据的高效压缩,尤其适合文本...
### LZW数据压缩算法的原理分析 #### 一、LZW算法概述 LZW(Lempel-Ziv-Welch)算法是由Jacob Ziv、Abraham Lempel和Terry Welch三位学者共同提出的,这是一种非常高效的数据压缩算法,广泛应用于各种场景中,特别...
采用VHDL语言进行硬件描述语言编程可以详细定义硬件的功能和行为,这为实现复杂的数据压缩算法提供了便利。VHDL不仅能够精确地描述算法的逻辑功能,而且还可以通过仿真和综合工具来验证和优化硬件设计。通过将软件...
lzw压缩算法原理分析借鉴 lzw压缩算法是一种新颖的压缩方法,由Lemple-Ziv-Welch三人共同创造,用他们的名字命名。该算法采用了一种先进的串表压缩,将每个第一次出现的串放在一个串表中,用一个数字来表示串,压缩...
LZW(Lempel-Ziv-Welch)数据压缩算法是一种广泛应用的无损压缩方法,由Abraham Lempel、Jacob Ziv和Walter Welch在1970年代提出。这个算法主要基于查找和合并重复的数据模式来实现数据的压缩。在VC++环境下,我们...
LZW算法是一种广泛应用于无损数据压缩的算法,它的核心原理是用较短的编码代替较长的字符串序列,从而达到压缩数据的目的。该算法不会对输入数据进行复杂的分析,而是通过建立和使用一个动态生成的字典(或称为字符...
LZW(Lempel-Ziv-Welch)压缩算法是一种数据压缩方法,广泛应用于文本、图像和其他二进制数据的压缩。它通过构建一个动态的字典来编码数据,允许新出现的模式被编码为较短的代码,从而实现数据的高效压缩。以下是...
LZW(Lempel-Ziv-Welch)压缩算法是一种数据压缩方法,广泛应用于文本、图像和其他类型的数据。它由Abraham Lempel、Jacob Ziv和William A. Welch在1970年代提出,是LZW算法的一种具体实现。LZW算法的主要特点是通过...
LZW(Lempel-Ziv-Welch)压缩算法是一种常用的无损数据压缩方法,尤其在文本和图像数据中表现出色。它基于字典编码,通过查找和组合已出现过的模式来减少数据中的冗余,从而实现压缩。在这个多媒体技术教程中,我们...
了解并掌握LZW和RLE压缩算法,对于理解数据压缩原理,以及在实际项目中选择合适的压缩方法,都是非常有帮助的。这些算法不仅用于文件压缩,还被应用在图形图像处理、网络传输等领域。同时,它们也是许多高级压缩算法...
本文将详细介绍LZW压缩算法的原理,并通过对比分析其与其他LZ系列算法的区别,进一步探讨其实现方法。 #### 二、LZW压缩算法概述 LZW压缩算法是由Jacob Ziv和Abraham Lempel于1978年提出的一种基于字典的压缩算法...
LZW(Lempel-Ziv-Welch)压缩算法是一种数据压缩方法,广泛应用于文本、图像和其他类型的数据。它的核心思想是通过构建一个字典来查找重复的模式,并用更短的编码来表示这些模式,从而实现数据压缩。在本文中,我们...
在这个压缩包中,"LZW数据压缩"很可能是包含C语言源代码的文件,你可以通过阅读和分析这些源代码来了解LZW算法的具体实现细节,包括如何构建字典,如何编码和解码,以及如何处理字典重置等步骤。这对于深入理解数据...
以下是对"常用数据无损压缩算法分析"这一主题的详细探讨。 一、无损压缩的基本原理 无损压缩算法的核心思想是通过查找数据中的冗余和规律,将其编码为更紧凑的形式,而解压时能完全恢复原始数据。无损压缩的关键...
LZW(Lempel-Ziv-Welch)压缩算法是一种常用的无损数据压缩方法,由Abraham Lempel、Jacob Ziv和Welch在1970年代提出。这种算法主要应用于文本压缩,如在GIF图像格式中就采用了LZW压缩。LZW的核心思想是通过构建一个...
LZW压缩算法,即Lempel-Ziv-Welch压缩算法,是一种广泛应用于数据压缩领域的技术,特别是在文本和图像文件的压缩中表现出色。LZW算法的压缩原理基于构建一个动态词典,将输入数据中的重复模式替换为较短的编码,从而...