
ه¸Œه°”وژ’ه؛ڈ,ن¹ں称递ه‡ڈه¢é‡ڈوژ’ه؛ڈç®—و³•ï¼Œوک¯وڈ’ه…¥وژ’ه؛ڈçڑ„ن¸€ç§چو›´é«کو•ˆçڑ„و”¹è؟›ç‰ˆوœ¬م€‚ه¸Œه°”وژ’ه؛ڈوک¯é稳ه®ڑوژ’ه؛ڈç®—و³•م€‚
ه¸Œه°”وژ’ه؛ڈوک¯هں؛ن؛ژوڈ’ه…¥وژ’ه؛ڈçڑ„ن»¥ن¸‹ن¸¤ç‚¹و€§è´¨è€Œوڈگه‡؛و”¹è؟›و–¹و³•çڑ„ï¼ڑ
- وڈ’ه…¥وژ’ه؛ڈهœ¨ه¯¹ه‡ ن¹ژه·²ç»ڈوژ’ه¥½ه؛ڈçڑ„و•°وچ®و“چن½œو—¶ï¼Œ و•ˆçژ‡é«ک, هچ³هڈ¯ن»¥è¾¾هˆ°ç؛؟و€§وژ’ه؛ڈçڑ„و•ˆçژ‡
- ن½†وڈ’ه…¥وژ’ه؛ڈن¸€èˆ¬و¥è¯´وک¯ن½ژو•ˆçڑ„, ه› ن¸؛وڈ’ه…¥وژ’ه؛ڈو¯ڈو¬،هڈھ能ه°†و•°وچ®ç§»هٹ¨ن¸€ن½چ
ç®—و³•ه®çژ°
هژںه§‹çڑ„ç®—و³•ه®çژ°هœ¨وœ€هڈçڑ„وƒ…ه†µن¸‹éœ€è¦پè؟›è،ŒO(n2)çڑ„و¯”较ه’Œن؛¤وچ¢م€‚V. Prattçڑ„ن¹¦ه¯¹ç®—و³•è؟›è،Œن؛†ه°‘é‡ڈن؟®و”¹ï¼Œهڈ¯ن»¥ن½؟ه¾—و€§èƒ½وڈگهچ‡è‡³O(nآ log2آ n)م€‚è؟™و¯”وœ€ه¥½çڑ„و¯”较算و³•çڑ„O(nآ logآ n)è¦په·®ن¸€ن؛›م€‚
ه¸Œه°”وژ’ه؛ڈé€ڑè؟‡ه°†و¯”较çڑ„ه…¨éƒ¨ه…ƒç´ هˆ†ن¸؛ه‡ ن¸ھهŒ؛هںںو¥وڈگهچ‡وڈ’ه…¥وژ’ه؛ڈçڑ„و€§èƒ½م€‚è؟™و ·هڈ¯ن»¥è®©ن¸€ن¸ھه…ƒç´ هڈ¯ن»¥ن¸€و¬،و€§هœ°وœوœ€ç»ˆن½چç½®ه‰چè؟›ن¸€ه¤§و¥م€‚然هگژç®—و³•ه†چهڈ–è¶ٹو¥è¶ٹه°ڈçڑ„و¥é•؟è؟›è،Œوژ’ه؛ڈ,算و³•çڑ„وœ€هگژن¸€و¥ه°±وک¯و™®é€ڑçڑ„وڈ’ه…¥وژ’ه؛ڈ,ن½†وک¯هˆ°ن؛†è؟™و¥ï¼Œéœ€وژ’ه؛ڈçڑ„و•°وچ®ه‡ ن¹ژوک¯ه·²وژ’ه¥½çڑ„ن؛†ï¼ˆو¤و—¶وڈ’ه…¥وژ’ه؛ڈ较ه؟«ï¼‰م€‚
هپ‡è®¾وœ‰ن¸€ن¸ھه¾ˆه°ڈçڑ„و•°وچ®هœ¨ن¸€ن¸ھه·²وŒ‰هچ‡ه؛ڈوژ’ه¥½ه؛ڈçڑ„و•°ç»„çڑ„وœ«ç«¯م€‚ه¦‚وœç”¨ه¤چو‚ه؛¦ن¸؛O(n2)çڑ„وژ’ه؛ڈ(ه†’و³،وژ’ه؛ڈوˆ–وڈ’ه…¥وژ’ه؛ڈ),هڈ¯èƒ½ن¼ڑè؟›è،Œnو¬،çڑ„و¯”较ه’Œن؛¤وچ¢و‰چ能ه°†è¯¥و•°وچ®ç§»è‡³و£ç،®ن½چç½®م€‚而ه¸Œه°”وژ’ه؛ڈن¼ڑ用较ه¤§çڑ„و¥é•؟移هٹ¨و•°وچ®ï¼Œو‰€ن»¥ه°ڈو•°وچ®هڈھ需è؟›è،Œه°‘و•°و¯”较ه’Œن؛¤وچ¢هچ³هڈ¯هˆ°و£ç،®ن½چç½®م€‚
ن¸€ن¸ھو›´ه¥½çگ†è§£çڑ„ه¸Œه°”وژ’ه؛ڈه®çژ°ï¼ڑه°†و•°ç»„هˆ—هœ¨ن¸€ن¸ھè،¨ن¸ه¹¶ه¯¹هˆ—وژ’ه؛ڈ(用وڈ’ه…¥وژ’ه؛ڈ)م€‚é‡چه¤چè؟™è؟‡ç¨‹ï¼Œن¸چè؟‡و¯ڈو¬،用و›´é•؟çڑ„هˆ—و¥è؟›è،Œم€‚وœ€هگژو•´ن¸ھè،¨ه°±هڈھوœ‰ن¸€هˆ—ن؛†م€‚ه°†و•°ç»„转وچ¢è‡³è،¨وک¯ن¸؛ن؛†و›´ه¥½هœ°çگ†è§£è؟™ç®—و³•ï¼Œç®—و³•وœ¬è؛«ن»…ن»…ه¯¹هژںو•°ç»„è؟›è،Œوژ’ه؛ڈ(é€ڑè؟‡ه¢هٹ ç´¢ه¼•çڑ„و¥é•؟,ن¾‹ه¦‚وک¯ç”¨i += step_size而ن¸چوک¯i++)م€‚
ن¾‹ه¦‚,هپ‡è®¾وœ‰è؟™و ·ن¸€ç»„و•°[ 13 14 94 33 82 25 59 94 65 23 45 27 73 25 39 10 ],ه¦‚وœوˆ‘ن»¬ن»¥و¥é•؟ن¸؛5ه¼€ه§‹è؟›è،Œوژ’ه؛ڈ,وˆ‘ن»¬هڈ¯ن»¥é€ڑè؟‡ه°†è؟™هˆ—è،¨و”¾هœ¨وœ‰5هˆ—çڑ„è،¨ن¸و¥و›´ه¥½هœ°وڈڈè؟°ç®—و³•ï¼Œè؟™و ·ن»–ن»¬ه°±ه؛”该看起و¥وک¯è؟™و ·ï¼ڑ
13 14 94 33 82 25 59 94 65 23 45 27 73 25 39 10
然هگژوˆ‘ن»¬ه¯¹و¯ڈهˆ—è؟›è،Œوژ’ه؛ڈï¼ڑ
10 14 73 25 23 13 27 94 33 39 25 59 94 65 82 45
ه°†ن¸ٹè؟°ه››è،Œو•°ه—,ن¾ه؛ڈوژ¥هœ¨ن¸€èµ·و—¶وˆ‘ن»¬ه¾—هˆ°ï¼ڑ[ 10 14 73 25 23 13 27 94 33 39 25 59 94 65 82 45 ].è؟™و—¶10ه·²ç»ڈ移至و£ç،®ن½چç½®ن؛†ï¼Œç„¶هگژه†چن»¥3ن¸؛و¥é•؟è؟›è،Œوژ’ه؛ڈï¼ڑ
10 14 73 25 23 13 27 94 33 39 25 59 94 65 82 45
وژ’ه؛ڈن¹‹هگژهڈکن¸؛ï¼ڑ
10 14 13 25 23 33 27 25 59 39 65 73 45 94 82 94
وœ€هگژن»¥1و¥é•؟è؟›è،Œوژ’ه؛ڈ(و¤و—¶ه°±وک¯ç®€هچ•çڑ„وڈ’ه…¥وژ’ه؛ڈن؛†ï¼‰م€‚
و¥é•؟ن¸²è،Œ
و¥é•؟çڑ„选و‹©وک¯ه¸Œه°”وژ’ه؛ڈçڑ„é‡چè¦پ部هˆ†م€‚هڈھè¦پوœ€ç»ˆو¥é•؟ن¸؛1ن»»ن½•و¥é•؟ن¸²è،Œéƒ½هڈ¯ن»¥ه·¥ن½œم€‚ç®—و³•وœ€ه¼€ه§‹ن»¥ن¸€ه®ڑçڑ„و¥é•؟è؟›è،Œوژ’ه؛ڈم€‚然هگژن¼ڑ继ç»ن»¥ن¸€ه®ڑو¥é•؟è؟›è،Œوژ’ه؛ڈ,وœ€ç»ˆç®—و³•ن»¥و¥é•؟ن¸؛1è؟›è،Œوژ’ه؛ڈم€‚ه½“و¥é•؟ن¸؛1و—¶ï¼Œç®—و³•هڈکن¸؛وڈ’ه…¥وژ’ه؛ڈ,è؟™ه°±ن؟è¯پن؛†و•°وچ®ن¸€ه®ڑن¼ڑ被وژ’ه؛ڈم€‚
Donald Shell وœ€هˆه»؛è®®و¥é•؟选و‹©ن¸؛ ه¹¶ن¸”ه¯¹و¥é•؟هڈ–هچٹç›´هˆ°و¥é•؟è¾¾هˆ° 1م€‚虽然è؟™و ·هڈ–هڈ¯ن»¥و¯”
ه¹¶ن¸”ه¯¹و¥é•؟هڈ–هچٹç›´هˆ°و¥é•؟è¾¾هˆ° 1م€‚虽然è؟™و ·هڈ–هڈ¯ن»¥و¯”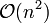 ç±»çڑ„ç®—و³•ï¼ˆوڈ’ه…¥وژ’ه؛ڈ)و›´ه¥½ï¼Œن½†è؟™و ·ن»چ然وœ‰ه‡ڈه°‘ه¹³ه‡و—¶é—´ه’Œوœ€ه·®و—¶é—´çڑ„ن½™هœ°م€‚ هڈ¯èƒ½ه¸Œه°”وژ’ه؛ڈوœ€é‡چè¦پçڑ„هœ°و–¹هœ¨ن؛ژه½“用较ه°ڈو¥é•؟وژ’ه؛ڈهگژ,ن»¥ه‰چ用çڑ„较ه¤§و¥é•؟ن»چ然وک¯وœ‰ه؛ڈçڑ„م€‚و¯”ه¦‚,ه¦‚وœن¸€ن¸ھو•°هˆ—ن»¥و¥é•؟5è؟›è،Œن؛†وژ’ه؛ڈ然هگژه†چن»¥و¥é•؟3è؟›è،Œوژ’ه؛ڈ,那ن¹ˆè¯¥و•°هˆ—ن¸چن»…وک¯ن»¥و¥é•؟3وœ‰ه؛ڈ,而ن¸”وک¯ن»¥و¥é•؟5وœ‰ه؛ڈم€‚ه¦‚وœن¸چوک¯è؟™و ·ï¼Œé‚£ن¹ˆç®—و³•هœ¨è؟ن»£è؟‡ç¨‹ن¸ن¼ڑو‰“ن¹±ن»¥ه‰چçڑ„é،؛ه؛ڈ,那ه°±ن¸چن¼ڑن»¥ه¦‚و¤çںçڑ„و—¶é—´ه®Œوˆگوژ’ه؛ڈن؛†م€‚
ç±»çڑ„ç®—و³•ï¼ˆوڈ’ه…¥وژ’ه؛ڈ)و›´ه¥½ï¼Œن½†è؟™و ·ن»چ然وœ‰ه‡ڈه°‘ه¹³ه‡و—¶é—´ه’Œوœ€ه·®و—¶é—´çڑ„ن½™هœ°م€‚ هڈ¯èƒ½ه¸Œه°”وژ’ه؛ڈوœ€é‡چè¦پçڑ„هœ°و–¹هœ¨ن؛ژه½“用较ه°ڈو¥é•؟وژ’ه؛ڈهگژ,ن»¥ه‰چ用çڑ„较ه¤§و¥é•؟ن»چ然وک¯وœ‰ه؛ڈçڑ„م€‚و¯”ه¦‚,ه¦‚وœن¸€ن¸ھو•°هˆ—ن»¥و¥é•؟5è؟›è،Œن؛†وژ’ه؛ڈ然هگژه†چن»¥و¥é•؟3è؟›è،Œوژ’ه؛ڈ,那ن¹ˆè¯¥و•°هˆ—ن¸چن»…وک¯ن»¥و¥é•؟3وœ‰ه؛ڈ,而ن¸”وک¯ن»¥و¥é•؟5وœ‰ه؛ڈم€‚ه¦‚وœن¸چوک¯è؟™و ·ï¼Œé‚£ن¹ˆç®—و³•هœ¨è؟ن»£è؟‡ç¨‹ن¸ن¼ڑو‰“ن¹±ن»¥ه‰چçڑ„é،؛ه؛ڈ,那ه°±ن¸چن¼ڑن»¥ه¦‚و¤çںçڑ„و—¶é—´ه®Œوˆگوژ’ه؛ڈن؛†م€‚
 |
|
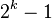 |

|
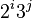 |
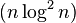
|
ه·²çں¥çڑ„وœ€ه¥½و¥é•؟ن¸²è،Œوک¯ç”±Sedgewickوڈگه‡؛çڑ„ (1, 5, 19, 41, 109,...),该ن¸²è،Œçڑ„é،¹و¥è‡ھ 9 * 4^i - 9 * 2^i + 1 ه’Œ 4^i - 3 * 2^i + 1 è؟™ن¸¤ن¸ھç®—ه¼ڈ.è؟™é،¹ç ”究ن¹ںè،¨وکژ“و¯”较هœ¨ه¸Œه°”وژ’ه؛ڈن¸وک¯وœ€ن¸»è¦پçڑ„و“چن½œï¼Œè€Œن¸چوک¯ن؛¤وچ¢م€‚â€ç”¨è؟™و ·و¥é•؟ن¸²è،Œçڑ„ه¸Œه°”وژ’ه؛ڈو¯”وڈ’ه…¥وژ’ه؛ڈه’Œه †وژ’ه؛ڈ都è¦په؟«ï¼Œç”ڑ至هœ¨ه°ڈو•°ç»„ن¸و¯”ه؟«é€ںوژ’ه؛ڈè؟که؟«ï¼Œن½†وک¯هœ¨و¶‰هڈٹه¤§é‡ڈو•°وچ®و—¶ه¸Œه°”وژ’ه؛ڈè؟کوک¯و¯”ه؟«é€ںوژ’ه؛ڈو…¢م€‚
هڈ¦ن¸€ن¸ھهœ¨ه¤§و•°ç»„ن¸è،¨çژ°ن¼که¼‚çڑ„و¥é•؟ن¸²è،Œوک¯(و–گو³¢é‚£ه¥‘و•°هˆ—除هژ»0ه’Œ1ه°†ه‰©ن½™çڑ„و•°ن»¥é»„金هˆ†هŒ؛و¯”çڑ„ن¸¤ه€چçڑ„ه¹‚è؟›è،Œè؟گç®—ه¾—هˆ°çڑ„و•°هˆ—)ï¼ڑ(1, 9, 34, 182, 836, 4025, 19001, 90358, 428481, 2034035, 9651787, 45806244, 217378076, 1031612713, …)
ن¼ھن»£ç پ
inc â†گ round(n/2)
while inc > 0 do:
for i = inc .. n − 1 do:
temp â†گ a[i]
j â†گ i
while j ≥ inc and a[j − inc] > temp do:
a[j] â†گ a[j − inc]
j â†گ j − inc
a[j] â†گ temp
inc â†گ round(inc / 2.2)
#include <stdio.h>
void shellsort(int *a, int n)
{
int i, j, k, t;
k = n/2;
while(k > 0)
{
for(i = k; i < n; i++){
t = a[i];
j = i - k;
while(j >= 0 && t < a[j]) {
a[j + k] = a[j];
j = j - k;
}
a[j + k] = t;
}
k /= 2;
}
}
int main()
{
int a[] = {8,10,3,5,7,4,6,1,9,2};
int N;
N = sizeof(a)/sizeof(a[0]);
shellsort(a, N);
for(int k = 0; k < N; k++)
printf("a[%d] = %d\n",k,a[k]);
return 0;
}
آ



相ه…³وژ¨èچگ
ه¸Œه°”وژ’ه؛ڈ(Shell Sort)وک¯ن¸€ç§چهں؛ن؛ژوڈ’ه…¥وژ’ه؛ڈçڑ„ه؟«é€ںوژ’ه؛ڈç®—و³•ï¼Œç”±Donald Shellن؛ژ1959ه¹´وڈگه‡؛م€‚ه®ƒçڑ„ن¸»è¦پو€وƒ³وک¯ه°†ه¾…وژ’ه؛ڈçڑ„ه…ƒç´ وŒ‰ç…§ن¸€ه®ڑçڑ„é—´éڑ”هˆ†ç»„,ه¯¹و¯ڈ组è؟›è،Œوڈ’ه…¥وژ’ه؛ڈ,然هگژé€گو¸گه‡ڈه°ڈé—´éڑ”,直هˆ°é—´éڑ”ن¸؛1,و¤و—¶و•´ن¸ھه؛ڈهˆ—视ن¸؛...
ه¸Œه°”وژ’ه؛ڈ(Shell Sort)وک¯ç”±Donald Shellهœ¨1959ه¹´وڈگه‡؛çڑ„ن¸€ç§چهں؛ن؛ژوڈ’ه…¥وژ’ه؛ڈçڑ„و”¹è؟›ç®—و³•م€‚ه®ƒçڑ„ن¸»è¦پو€وƒ³وک¯é€ڑè؟‡è®¾ç½®ن¸€ç³»هˆ—çڑ„ه¢é‡ڈه؛ڈهˆ—,é€گو¥ه‡ڈه°‘è؟™ن؛›ه¢é‡ڈ,ه°†ه¾…وژ’ه؛ڈçڑ„ه…ƒç´ è؟›è،Œهˆ†ç»„,然هگژهœ¨و¯ڈن¸ھه°ڈ组ه†…è؟›è،Œç›´وژ¥وڈ’ه…¥وژ’ه؛ڈم€‚è؟™ن¸ھ...
وœ¬و–‡ه°†è¯¦ç»†è®²è§£ه…ç§چç»ڈه…¸çڑ„وژ’ه؛ڈç®—و³•â€”—هگˆه¹¶وژ’ه؛ڈم€پوڈ’ه…¥وژ’ه؛ڈم€په¸Œه°”وژ’ه؛ڈم€په؟«é€ںوژ’ه؛ڈم€په†’و³،وژ’ه؛ڈن»¥هڈٹو،¶وژ’ه؛ڈ,ه¹¶ç»“هگˆوڈگن¾›çڑ„و–‡ن»¶هگچ(sort.cم€پset.cم€پmain.cم€پset.hم€پsort.h)وژ¨وµ‹ه‡؛و¯ڈن¸ھو–‡ن»¶هڈ¯èƒ½هŒ…هگ«çڑ„ن»£ç په®çژ°م€‚ 1. **هگˆه¹¶...
ه¸Œه°”وژ’ه؛ڈ(Shell Sort)وک¯ن¸€ç§چهں؛ن؛ژوڈ’ه…¥وژ’ه؛ڈçڑ„ه؟«é€ںوژ’ه؛ڈç®—و³•ï¼Œç”±Donald Shellن؛ژ1959ه¹´وڈگه‡؛م€‚ه®ƒçڑ„ن¸»è¦پو€وƒ³وک¯ه°†ه¾…وژ’ه؛ڈçڑ„و•°وچ®وŒ‰ç…§ن¸€ن¸ھه¢é‡ڈه؛ڈهˆ—هˆ†وˆگè‹¥ه¹²ن¸ھهگه؛ڈهˆ—,然هگژه¯¹و¯ڈن¸ھهگه؛ڈهˆ—è؟›è،Œوڈ’ه…¥وژ’ه؛ڈ,وœ€هگژه†چè؟›è،Œن¸€و¬،ه…¨ه±€çڑ„وڈ’ه…¥...
(1) ه®Œوˆگ5ç§چه¸¸ç”¨ه†…部وژ’ه؛ڈç®—و³•çڑ„و¼”ç¤؛,5ç§چوژ’ه؛ڈç®—و³•ن¸؛ï¼ڑه؟«é€ںوژ’ه؛ڈ,直وژ¥وڈ’ه…¥وژ’ه؛ڈ,选و‹©وژ’ه؛ڈ,ه †وژ’ه؛ڈ,ه¸Œه°”وژ’ه؛ڈï¼› (2) ه¾…وژ’ه؛ڈه…ƒç´ ن¸؛و•´و•°ï¼Œوژ’ه؛ڈه؛ڈهˆ—هکه‚¨هœ¨و•°وچ®و–‡ن»¶ن¸ï¼Œè¦پو±‚وژ’ه؛ڈه…ƒç´ ن¸چه°‘ن؛ژ30ن¸ھï¼› (3) و¼”ç¤؛程ه؛ڈه¼€ه§‹ï¼Œ...
### ه¸Œه°”وژ’ه؛ڈو³•ï¼ˆه¸Œه°”وڈ’ه…¥وژ’ه؛ڈ,ه¸Œه°”ن؛¤وچ¢وژ’ه؛ڈ) #### ن¸€م€په¸Œه°”وژ’ه؛ڈو³•ç®€ن»‹ ه¸Œه°”وژ’ه؛ڈو³•وک¯è®،ç®—وœ؛科ه¦é¢†هںںن¸ن¸€ç§چé‡چè¦پçڑ„وژ’ه؛ڈç®—و³•ï¼Œه®ƒç”±ç¾ژه›½è®،ç®—وœ؛科ه¦ه®¶Donald Shellن؛ژ1959ه¹´وڈگه‡؛,ه› و¤ه¾—هگچه¸Œه°”وژ’ه؛ڈم€‚ه¸Œه°”وژ’ه؛ڈوک¯ن¸€ç§چ...
ه¸Œه°”وژ’ه؛ڈ(Shell Sort)وک¯ن¸€ç§چهں؛ن؛ژوڈ’ه…¥وژ’ه؛ڈçڑ„ه؟«é€ںوژ’ه؛ڈو–¹و³•ï¼Œç”±Donald Shellن؛ژ1959ه¹´وڈگه‡؛م€‚ه®ƒçڑ„ن¸»è¦پو€وƒ³وک¯ه°†ه¾…وژ’ه؛ڈçڑ„و•°وچ®وŒ‰ç…§ن¸€ه®ڑçڑ„é—´éڑ”è؟›è،Œهˆ†ç»„,然هگژه¯¹و¯ڈ组è؟›è،Œوڈ’ه…¥وژ’ه؛ڈ,éڑڈç€é—´éڑ”é€گو¸گ缩ه°ڈ,وœ€هگژè؟›è،Œن¸€و¬،ه…¨وژ’هˆ—,...
### ç›´وژ¥وڈ’ه…¥وژ’ه؛ڈن¸ژه¸Œه°”وژ’ه؛ڈçڑ„و¯”较 #### ن¸€م€پو¦‚è؟° وœ¬ç¯‡و–‡ç« ه°†é€ڑè؟‡ن¸€ç»„ه…·ن½“çڑ„و•°وچ®é›†ï¼ˆ8ن¸ھو•´و•°ï¼‰ه¯¹ç›´وژ¥وڈ’ه…¥وژ’ه؛ڈ(Direct Insertion Sort)ه’Œه¸Œه°”وژ’ه؛ڈ(Shell Sort)è؟™ن¸¤ç§چوژ’ه؛ڈو–¹و³•è؟›è،Œو·±ه…¥هˆ†وگه’Œو¯”较م€‚è؟™ن¸¤ç§چوژ’ه؛ڈ...
ه¸Œه°”وژ’ه؛ڈ(Shell Sort)وک¯ن¸€ç§چهں؛ن؛ژوڈ’ه…¥وژ’ه؛ڈçڑ„ه؟«é€ںوژ’ه؛ڈç®—و³•ï¼Œç”±Donald Shellن؛ژ1959ه¹´وڈگه‡؛م€‚ه®ƒçڑ„ن¸»è¦پو€وƒ³وک¯ه°†ه¾…وژ’ه؛ڈçڑ„و•°وچ®وŒ‰ç…§ن¸€ه®ڑçڑ„ه¢é‡ڈهˆ†ç»„,ه¯¹و¯ڈ组ن½؟用直وژ¥وڈ’ه…¥وژ’ه؛ڈ,然هگژé€گو¸گه‡ڈه°ڈه¢é‡ڈ,继ç»è؟›è،Œهˆ†ç»„وژ’ه؛ڈ,直هˆ°ه¢é‡ڈ...
و ¹وچ®وڈگن¾›çڑ„و–‡ن»¶ن؟،وپ¯ï¼Œوˆ‘ن»¬هڈ¯ن»¥و·±ه…¥وژ¢è®¨ه‡ ç§چç»ڈه…¸çڑ„وژ’ه؛ڈç®—و³•ï¼ڑه†’و³،وژ’ه؛ڈم€پç›´وژ¥وڈ’ه…¥وژ’ه؛ڈم€په؟«é€ںوژ’ه؛ڈن»¥هڈٹه¸Œه°”وژ’ه؛ڈم€‚è؟™ن؛›ç®—و³•هœ¨و•°وچ®ç»“و„ن¸ژç®—و³•è¯¾ç¨‹ن¸وک¯éه¸¸é‡چè¦پçڑ„هں؛ç،€ه†…ه®¹ï¼Œه®ƒن»¬هگ„è‡ھوœ‰ç€ç‹¬ç‰¹çڑ„特و€§ه’Œه؛”用هœ؛و™¯م€‚ ### 1. ...
ن¸‹é¢ه°†è¯¦ç»†è®²è§£è؟™7ç§چوژ’ه؛ڈç®—و³•ï¼ڑه؟«é€ںوژ’ه؛ڈم€په½’ه¹¶وژ’ه؛ڈم€پوڈ’ه…¥وژ’ه؛ڈم€پ选و‹©وژ’ه؛ڈم€په†’و³،وژ’ه؛ڈم€په †وژ’ه؛ڈن»¥هڈٹه¸Œه°”وژ’ه؛ڈم€‚ 1. **ه؟«é€ںوژ’ه؛ڈ**ï¼ڑç”±C.A.R. Hoareوڈگه‡؛çڑ„,采用هˆ†و²»ç–ç•¥م€‚هں؛وœ¬و€وƒ³وک¯é€‰هڈ–ن¸€ن¸ھهں؛ه‡†ه…ƒç´ ,é€ڑè؟‡ن¸€è¶ںوژ’ه؛ڈه°†ه¾…...
وœ¬ن¸»é¢که°†è¯¦ç»†وژ¢è®¨ه¸Œه°”وژ’ه؛ڈم€په†’و³،وژ’ه؛ڈم€په †وژ’ه؛ڈç‰ç»ڈه…¸çڑ„وژ’ه؛ڈç®—و³•ï¼Œè؟™ن؛›éƒ½وک¯و•°وچ®ç»“و„ن¸ژç®—و³•ه¦ن¹ ن¸çڑ„و ¸ه؟ƒه†…ه®¹ï¼Œه°¤ه…¶ه¯¹ن؛ژهŒ—é‚®و•°وچ®ç»“و„课程و¥è¯´ï¼Œçگ†è§£ه¹¶وژŒوڈ،è؟™ن؛›وژ’ه؛ڈو–¹و³•è‡³ه…³é‡چè¦پم€‚ 1. **وڈ’ه…¥وژ’ه؛ڈ**ï¼ڑ وڈ’ه…¥وژ’ه؛ڈوک¯ن¸€ç§چ...
è؟™é‡Œوˆ‘ن»¬ه°†و·±ه…¥وژ¢è®¨ه››ç§چه¸¸è§پçڑ„وژ’ه؛ڈç®—و³•ï¼ڑهں؛و•°وژ’ه؛ڈم€په †وژ’ه؛ڈم€په¸Œه°”وژ’ه؛ڈه’Œç›´وژ¥وڈ’ه…¥وژ’ه؛ڈم€‚ 首ه…ˆï¼Œهں؛و•°وژ’ه؛ڈوک¯ن¸€ç§چéو¯”较ه‹و•´و•°وژ’ه؛ڈç®—و³•ï¼Œه®ƒçڑ„هں؛وœ¬و€وƒ³وک¯ه°†و•´و•°وŒ‰ن½چو•°هˆ‡ه‰²وˆگن¸چهگŒçڑ„و•°ه—,然هگژوŒ‰و¯ڈن¸ھن½چو•°هˆ†هˆ«و¯”较م€‚هں؛و•°وژ’ه؛ڈ...
ه¸Œه°”وژ’ه؛ڈ(Shell Sort)وک¯ن¸€ç§چهں؛ن؛ژوڈ’ه…¥وژ’ه؛ڈçڑ„ه؟«é€ںوژ’ه؛ڈç®—و³•ï¼Œç”±Donald Shellن؛ژ1959ه¹´وڈگه‡؛م€‚ه®ƒçڑ„ن¸»è¦پو€وƒ³وک¯ه°†ه¾…وژ’ه؛ڈçڑ„و•°وچ®وŒ‰ç…§ن¸€ن¸ھه¢é‡ڈه؛ڈهˆ—هˆ†وˆگè‹¥ه¹²ن¸ھهگه؛ڈهˆ—,然هگژه¯¹و¯ڈن¸ھهگه؛ڈهˆ—è؟›è،Œوڈ’ه…¥وژ’ه؛ڈ,وœ€هگژه‡ڈه°ڈه¢é‡ڈ,é‡چه¤چè؟™ن¸ھ...
### ه¸Œه°”وژ’ه؛ڈهژںçگ†ن¸ژه®çژ° #### ن¸€م€په¸Œه°”وژ’ه؛ڈ简ن»‹ ه¸Œه°”وژ’ه؛ڈ(Shell Sort)وک¯ن¸€ç§چهں؛ن؛ژوڈ’ه…¥وژ’ه؛ڈçڑ„é«کو•ˆç®—و³•م€‚ه®ƒé€ڑè؟‡ه°†هژںه§‹و•°ç»„هˆ†ه‰²وˆگه¤ڑن¸ھهگه؛ڈهˆ—و¥è؟›è،Œوژ’ه؛ڈ,ن»ژ而وڈگé«کن؛†وڈ’ه…¥وژ’ه؛ڈçڑ„و•ˆçژ‡م€‚ه¸Œه°”وژ’ه؛ڈçڑ„و ¸ه؟ƒو€وƒ³وک¯é€ڑè؟‡ه°†ç›¸éڑ”...
وœ¬èµ„و؛گوڈگن¾›ن؛†ن¸ƒه¤§ç»ڈه…¸وژ’ه؛ڈç®—و³•çڑ„ه®çژ°ç¨‹ه؛ڈ,هŒ…و‹¬ه؟«é€ںوژ’ه؛ڈم€په†’و³،وژ’ه؛ڈم€پ选و‹©وژ’ه؛ڈم€په½’ه¹¶وژ’ه؛ڈم€پوڈ’ه…¥وژ’ه؛ڈم€په¸Œه°”وژ’ه؛ڈه’Œه †وژ’ه؛ڈم€‚ن¸‹é¢ه°†é€گن¸€è¯¦ç»†ن»‹ç»چè؟™ن؛›وژ’ه؛ڈç®—و³•هڈٹه…¶هژںçگ†م€‚ 1. ه؟«é€ںوژ’ه؛ڈï¼ڑç”±C.A.R. Hoareوڈگه‡؛,وک¯ن¸€ç§چ采用...
ه¸Œه°”وژ’ه؛ڈ,هڈˆç§°ه¸Œه°”و–¯وژ’ه؛ڈ,وک¯ç”±ç¾ژه›½è®،ç®—وœ؛科ه¦ه®¶Donald Shellن؛ژ1959ه¹´وڈگه‡؛çڑ„ن¸€ç§چهں؛ن؛ژوڈ’ه…¥وژ’ه؛ڈçڑ„ه؟«é€ںوژ’ه؛ڈç®—و³•م€‚è؟™ç§چوژ’ه؛ڈو–¹و³•é€ڑè؟‡è®¾ç½®ن¸€ن¸ھه¢é‡ڈه؛ڈهˆ—,ه°†ه¾…وژ’ه؛ڈو•°ç»„هˆ†ه‰²وˆگè‹¥ه¹²ن¸ھهگه؛ڈهˆ—,然هگژه¯¹و¯ڈن¸ھهگه؛ڈهˆ—è؟›è،Œوڈ’ه…¥وژ’ه؛ڈم€‚...
ه¸Œه°”وژ’ه؛ڈوک¯ن¸€ç§چهں؛ن؛ژوڈ’ه…¥وژ’ه؛ڈçڑ„ه؟«é€ںوژ’ه؛ڈç®—و³•ï¼Œç”±Donald Shellهœ¨1959ه¹´وڈگه‡؛م€‚ه®ƒçڑ„ن¸»è¦پ特点وک¯é€ڑè؟‡ه°†ه¾…وژ’ه؛ڈçڑ„و•°ç»„ه…ƒç´ وŒ‰ç…§ن¸€ه®ڑçڑ„é—´éڑ”هˆ†ç»„,然هگژه¯¹و¯ڈ组è؟›è،Œوڈ’ه…¥وژ’ه؛ڈ,éڑڈç€é—´éڑ”é€گو¸گه‡ڈه°ڈ,直هˆ°é—´éڑ”ن¸؛1و—¶ï¼Œو•´ن¸ھو•°ç»„وˆگن¸؛ن¸€ن¸ھ...
### ه¸Œه°”وژ’ه؛ڈç®—و³•è¯¦è§£ #### ç®—و³•و¦‚è؟° ه¸Œه°”وژ’ه؛ڈ(Shell Sort),هڈˆç§°ن¸؛缩ه°ڈه¢é‡ڈوژ’ه؛ڈ,وک¯وڈ’ه…¥وژ’ه؛ڈçڑ„ن¸€ç§چو›´é«کو•ˆçڑ„و”¹è؟›ç‰ˆوœ¬م€‚ه®ƒç”±Donald Shellهœ¨1959ه¹´وڈگه‡؛م€‚ه¸Œه°”وژ’ه؛ڈçڑ„هں؛وœ¬و€وƒ³وک¯ï¼ڑه°†ه¾…وژ’ه؛ڈهˆ—هˆ†ه‰²وˆگè‹¥ه¹²هگه؛ڈهˆ—هˆ†هˆ«...
ه¸Œه°”وژ’ه؛ڈوک¯ن¸€ç§چهں؛ن؛ژوڈ’ه…¥وژ’ه؛ڈçڑ„ه؟«é€ںوژ’ه؛ڈç®—و³•ï¼Œç”±Donald Shellهœ¨1959ه¹´وڈگه‡؛م€‚ه®ƒé€ڑè؟‡è®¾ç½®ن¸€ن¸ھé—´éڑ”ه؛ڈهˆ—,ه°†ه¾…وژ’ه؛ڈçڑ„و•°ç»„هˆ†ن¸؛è‹¥ه¹²ن¸ھهگه؛ڈهˆ—,然هگژه¯¹و¯ڈن¸ھهگه؛ڈهˆ—è؟›è،Œوڈ’ه…¥وژ’ه؛ڈ,éڑڈç€é—´éڑ”ه؛ڈهˆ—é€گو¸گه‡ڈه°ڈ,وœ€ç»ˆه®Œوˆگو•´ن¸ھو•°ç»„çڑ„وژ’ه؛ڈ...