原文链接:
http://www.eygle.com/special/NLS_CHARACTER_SET_06.htm
原文发表于itpub技术丛书《Oracle数据库DBA专题技术精粹》,未经许可,严禁转载本文.
最后我们来讨论一下乱码的产生。
通常在我们的现实环境中,存在3个字符集设置。
第一: 客户端应用字符集(Client Application Character Set)
第二: 客户端NLS_LANG参数设置
第三: 服务器端,数据库字符集(Character Set)设置
我们说,一个字符在客户端应用(比如SQLPLUS,CMD,NOTEPAD等)中以怎样的字符显示取决于客户端操作系统,客户端能够显示怎样的字符,
我们就可以在应用中录入这些字符,至于这些字符能否在数据库中正常存储,就和另外的两个字符集设置紧密相关了。
在传输过程中,客户端NLS_LANG主要用于进行转换判断
如果NLS_LANG等于数据库字符集,则不进行任何转换直接把字符插入数据库
如果不同则进行转换,转换主要有两个任务
- 如果存在对应关系,则把相应二进制编码经过映射后(这一步映射以后,所代表的字符可能发生转换)传递给数据库
- 如果不存在对应关系,则传递一个替换字符(很多平台就是?)
数据库字符集,在和客户端NLS_LANG不同时,会把经过NLS_LANG转换的字符进行进一步处理
- 对于?(即不存在对应关系的字符)直接以?形式存放入数据库
- 对于其他字符,在NLS_LANG和数据库字符集之间进行转换后存入。
以下我们来看一下最为常见的字符集及乱码的产生:
1.当NLS_LANG字符集与数据库字符集不同,同时NLS_LANG不同于Server端字符集设置
在这种情况下,存在两种可能:
- 客户端输入的字符在NLS_LANG中没有对应的字符,这时无法转换,NLS_LANG使用替换字符替代这些无法映射的字符(这一步转换在TTS中
完成),在很多字符集中这个替代字符就是”?”
- 当客户端的字符在NLS_LANG中对应了不同的字符时,传递给数据库以后发生转换,存储的是字符,但是已经丢失了元数据,数据库中
的字符不再代表客户端的输入。而且这个过程不可逆,这也就是为什么很多时候在客户端输入的是正常的编码,查询之后会得到未知字符的原因。
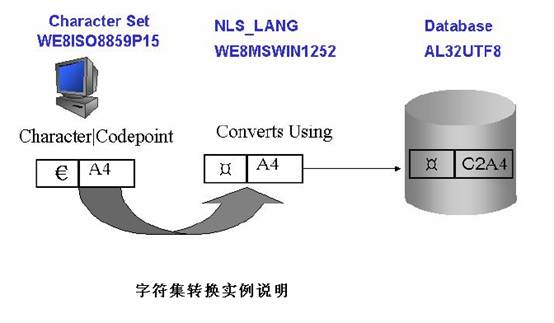
我们通过上图来简单说明一下这个过程,当客户端在WE8ISO8859P15字符集时,输入欧元符号: €,这时客户端NLS_LANG和数据库端字符集不同,
进行第一次转换,客户端€符号编码是A4,在NLS_LANG转换时,A4对应了NLS_LANG中的‘¤’,这一步的转换产生了错误映射。由于数据库字符集不
同于NLS_LANG设置,这时进一步的转换发生了,存入数据库的编码变成了C2A4,虽然同NLS_LANG进行了正确的转换,但是客户端录入的数据已经
损坏或者丢失了。
我们可以用我们熟悉的字符集做一个简单的测试:
测试环境:
客户端应用为中文18030字符集
NLS_LANG设置为US7ASCII字符集
数据库CHARACTER SET为ZHS16GBK
c:\>set NLS_LANG=AMERICAN_AMERICA.US7ASCII
c:\>sqlplus eygle/eygle
SQL*Plus: Release 9.2.0.4.0 - Production on Tue Nov 4 01:19:57 2003
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
Connected to:
Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options
JServer Release 9.2.0.4.0 - Production
SQL> insert into test values('测试');
1 row created.
SQL> select name,dump(name) from test;
NAME DUMP(NAME)
--------------------------------------------------
2bJT Typ=1 Len=4: 50,98,74,84
这时候我们发现,查询出来的是混乱的字符,我们把这些字符转换为2进制就是
110010 1100010 1001010 1010100
补全8位就是 00110010 01100010 01001010 01010100
我们把首位换成1 10110010 11100010 11001010 11010100
我们来看正确的存储:
c:\>set nls_lang=AMERICAN_AMERICA.ZHS16GBK
c:\>sqlplus eygle/eygle
SQL*Plus: Release 9.2.0.4.0 - Production on Tue Nov 4 01:40:18 2003
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
Connected to:
Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options
JServer Release 9.2.0.4.0 - Production
SQL> insert into test values('测试');
1 row created.
SQL> col dump(name) for a30
SQL> select name,dump(name) from test;
NAME DUMP(NAME)
---------- ------------------------------
测试 Typ=1 Len=4: 178,226,202,212
1 row selected.
我们把这个结果转换为2进制表示
10110010 11100010 11001010 11010100
这个结果正是我们前面乱码首位补全1后的结果。
这个测试说明在US7ASCII转换中文的时候除去了首位的 1,这样就丢失了元数据,导致乱码出现,NLS_LANG的转换作用由此可加一斑!
|
3. NLS_LANG和数据库字符集相同时
在这种情况下,数据库端对客户端传递过来的编码不进行任何转换(这样可以提高性能),直接存储进入数据库,那么这时候就存在和上面同样的问题,
如果客户端传递过来的字符集在数据库中有正确的对应就可以正确存储,如果没有,就会被替换字符置换成?,乱码就这样产生了。
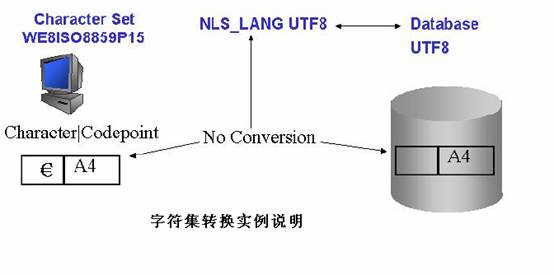
如上图所示,当NLS_LANG和数据库字符集设置相同都为UTF8时,客户端的欧元符号的编码A4就不会经过任何转换就插入到数据库中,而在UTF8的数
据库中,A4代表的是一个非法字符。
我们来看一个简单的测试
测试环境:
客户端字符集应用为中文GB18030
客户端NLS_LANG为US7ASCII
数据库字符集为US7ASCII
我们知道这个时候,存入的数据,数据库不进行任何转换,在以下的测试中,我们看到中文在US7ASCII字符集下得以正确显示。
c:\>set nls_lang=AMERICAN_AMERICA.US7ASCII
c:\>sqlplus eygle/eygle
SQL*Plus: Release 9.2.0.4.0 - Production on Tue Nov 4 01:02:04 2003
Copyright (c) 1982, 2002, Oracle Corporation. All rights reserved.
Connected to:
Oracle9i Enterprise Edition Release 9.2.0.4.0 - Production
With the Partitioning, Oracle Label Security, OLAP and Oracle Data Mining options
JServer Release 9.2.0.4.0 - Production
SQL> insert into test values('测试');
1 row created.
SQL> commit;
Commit complete.
SQL> select * from test;
NAME
----------
测试
1 row selected.
SQL> col dump(name) for a30
SQL> select name,dump(name) from test;
NAME DUMP(NAME)
---------- ------------------------------
测试 Typ=1 Len=4: 178,226,202,212
1 row selected.
SQL> select * from nls_database_parameters;
PARAMETER VALUE
------------------------------ ----------------------------------------
NLS_LANGUAGE AMERICAN
NLS_TERRITORY AMERICA
NLS_CURRENCY $
NLS_ISO_CURRENCY AMERICA
NLS_NUMERIC_CHARACTERS .,
NLS_CHARACTERSET US7ASCII
NLS_CALENDAR GREGORIAN
NLS_DATE_FORMAT DD-MON-RR
NLS_DATE_LANGUAGE AMERICAN
NLS_SORT BINARY
NLS_TIME_FORMAT HH.MI.SSXFF AM
PARAMETER VALUE
------------------------------ ----------------------------------------
NLS_TIMESTAMP_FORMAT DD-MON-RR HH.MI.SSXFF AM
NLS_TIME_TZ_FORMAT HH.MI.SSXFF AM TZR
NLS_TIMESTAMP_TZ_FORMAT DD-MON-RR HH.MI.SSXFF AM TZR
NLS_DUAL_CURRENCY $
NLS_COMP BINARY
NLS_LENGTH_SEMANTICS BYTE
NLS_NCHAR_CONV_EXCP FALSE
NLS_NCHAR_CHARACTERSET AL16UTF16
NLS_RDBMS_VERSION 9.2.0.4.0
20 rows selected.
SQL>
|
结语:
对于DBA来说,有一个很重要的原则就是:不要把你的数据库置于危险的境地!
这就要求我们,在进行任何可能对数据库结构发生改变的操作之前,先做有效的备份,很多DBA没有备份的操作中得到了惨痛的教训。
分享到:





相关推荐
最后,"修改props$中字符集的恢复 - fengjin821的个人空间 - ITPUB个人空间 - powered by X-Space_files"和"字符集问题的初步探讨(三)-字符集的更改 - Oracle Life_files"可能是原始网页的资源文件夹,包含了图片、...
- 比如,在支持中文、英文等多种语言的应用程序中,使用Unicode字符集(如UTF8)可以避免乱码问题。 **3. 性能优化:** - 不同的字符集可能会对数据库性能产生影响,特别是在处理大量文本数据时。 - 选择合适的...
这样可以避免因不同环节采用不同字符集而导致的乱码问题。 2. **配置JSP页面**:在JSP页面头部明确声明字符集,例如`;charset=UTF-8" %>`。 3. **数据库配置**:根据实际情况调整数据库的字符集设置,确保与前端页面...
- **Form乱码解决**:解决字符编码问题导致的乱码现象。 - **利用TEMPLATE.fmb模板来开发Form**:基于模板快速开发Form。 - **注册表单FORM**:将开发的Form注册到EBS系统中。 - **注册请求**:创建并配置请求...
总结以上内容,FCKeditor 2.6出现乱码的问题通常是由于编辑器文件编码和声明的字符集不一致所导致的。解决该问题,需要将编辑器文件保存为UTF-8格式,并确保在页面中的编码声明正确。同时,也要注意服务器端的配置和...
- 解决因字符集不匹配导致的乱码问题。 **3. TEMPLATE.fmb模板开发** - TEMPLATE.fmb是用于创建表单模板的文件,可以在此基础上进行定制开发。 **4. 注册表单FORM** - 在EBS中注册自定义的FORM,使其成为系统的一...
解决方法包括确保请求体和响应体的字符集统一,如设置Content-Type为'application/x-www-form-urlencoded; charset=UTF-8',并在服务器端正确处理请求的编码。 3. **jQuery Ui IE67 下 radio选择的怪异问题.txt** -...
它能够识别多种常见的字符集,如ASCII、UTF-8、GBK等,对于处理跨平台或跨语言的数据传输尤为有用。`cpdetector`通过分析文件内容的字节模式来判断其可能的编码方式,帮助开发者避免因为编码问题导致的乱码问题。 `...
首先,Java中的`Charset`类是处理字符编码的基础,它提供了识别和转换字符集的方法。然而,Java标准库并没有提供一种直接的自动检测文件编码的方法。通常,开发者需要借助第三方库或者自定义算法来实现这个功能。 ...
由于不同的终端和服务器可能使用不同的字符集,不匹配的编码可能导致显示乱码。这份文档可能详细解释了如何识别和设置正确的字符编码,以便在telnet会话中正确地显示文本。 最后,HTTP协议(RFC2616)中文版.pdf是...
123456,并设置为英文字符集避免乱码。 2. 加入管理员组:将test用户添加到本地管理员组,赋予高级权限。 3. 开启RDP服务:通过命令行修改注册表项,打开3389端口以允许远程桌面连接。 4. 远程登录主机:使用...
如果遇到乱码问题,可以尝试使用`"utf-8"`或其他编码。 2. **`header`**:布尔值,指示文件的第一行是否包含列名。默认为`TRUE`。 3. **`sep`**:字符向量,指定字段分隔符。默认为逗号`","`。对于制表符分隔的文件...
如果需要,我们可以将上述知识点进一步细化,探讨它们在具体计算机系统设计中的应用,例如讨论在设计处理器时如何平衡指令集的复杂性和处理速度,或者在设计存储系统时如何兼顾成本和性能。 另外,需要注意的是,在...