
1. Kettle的简单介绍
Kettle(现名Data Integration)是一款使用Java编写的功能强大的ETL(Extract Transform and Load)工具,支持关系型数据库(PostgreSQL、MySQL、Oracle等)、非关系型数据库(MongoDB、ElasticSearch等)以及文件之间的大规模数据迁移。
2. 常用组件
Kettle提供了极为丰富的组件库,下面列举的是它的一些常用组件,以及对组件的常用参数进行简单介绍,详细的参数说明可参考Kettle的帮助文档。
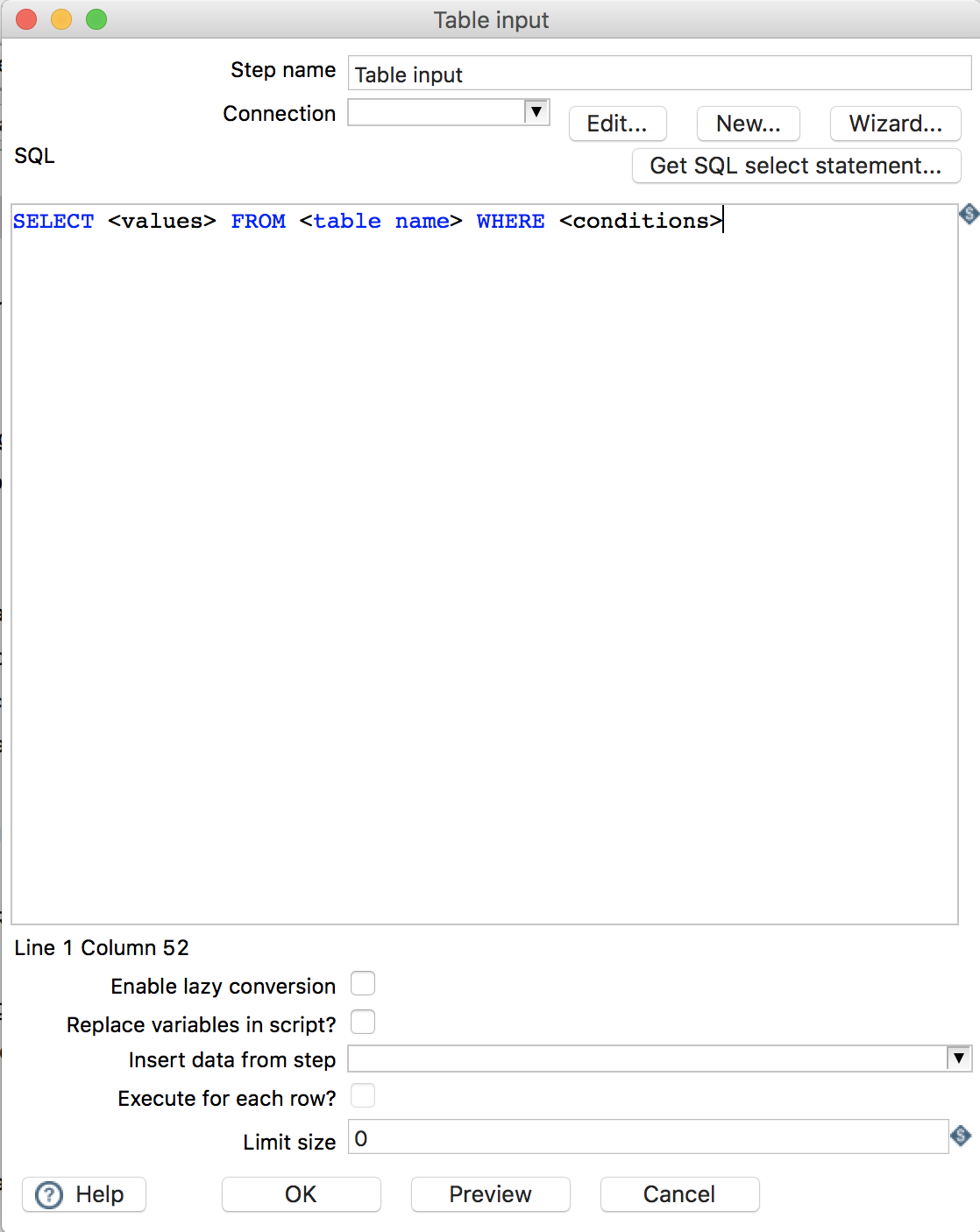
2.1 Table input
指定数据库表作为输入。
-
Step name: 步骤名称,Kettle的每一个组件即一个步骤,可为该步骤取一个别名 -
Connection: 指定数据库连接 -
SQL: 编写SQL,从该数据库表中筛选出符合条件的数据
2.2 Table output
指定数据库表作为输出
-
Step name: 步骤名称 -
Connection: 指定数据库连接 -
Target schema: 输出的数据库表模式 -
Target table: 指定输出的数据库表 -
Use batch update for inserts: 是否使用批处理进行插入 -
Database fields: 配置字段映射关系-
Table field: 输出的数据库表字段 -
Stream field: 流字段(流入该组件的数据字段)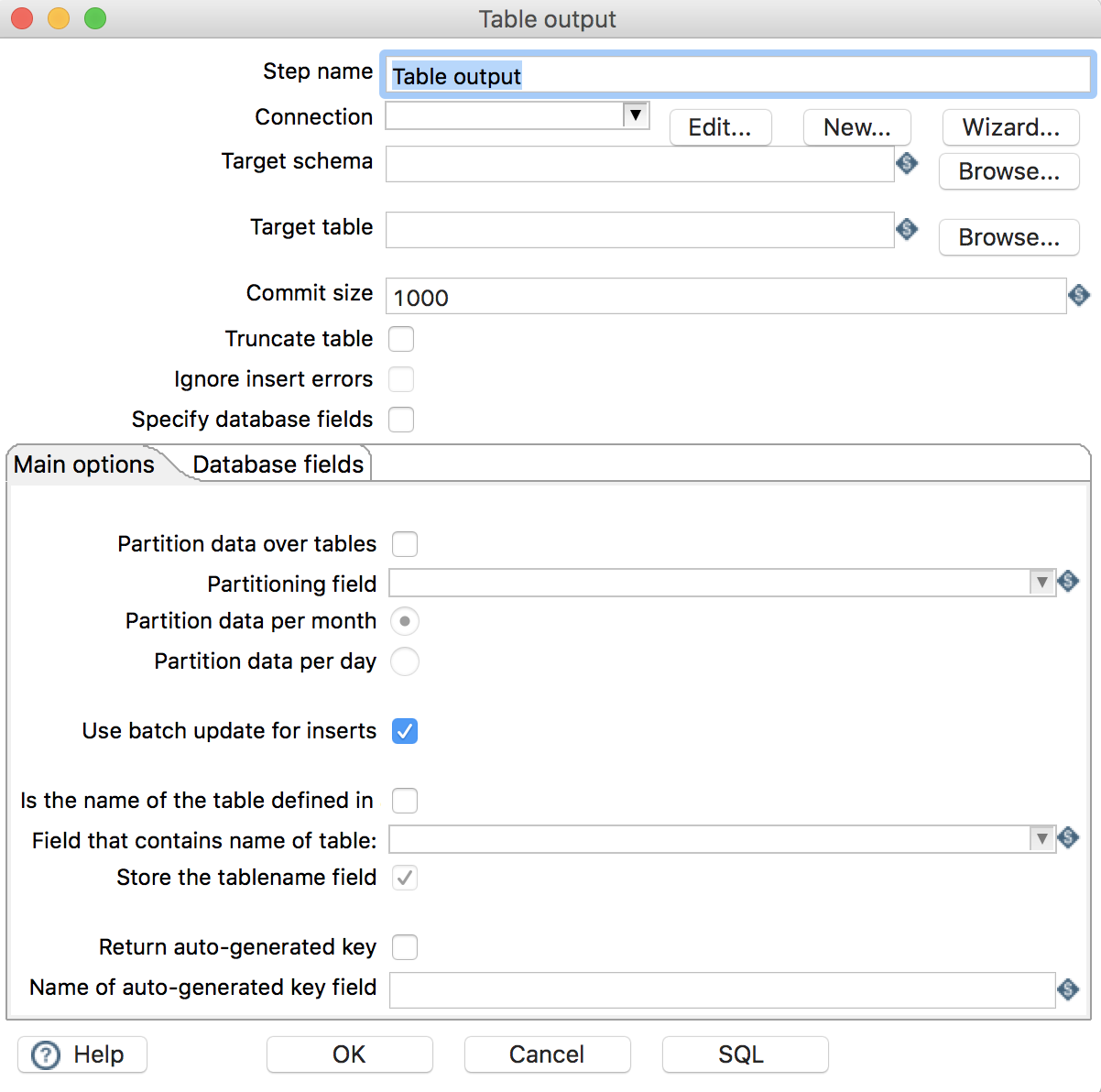
-
2.3 Sort rows
按照某字段进行排序
-
Step name: 步骤名称 -
Fields:-
Fieldname: 排序的字段名 -
Ascending: 排序方式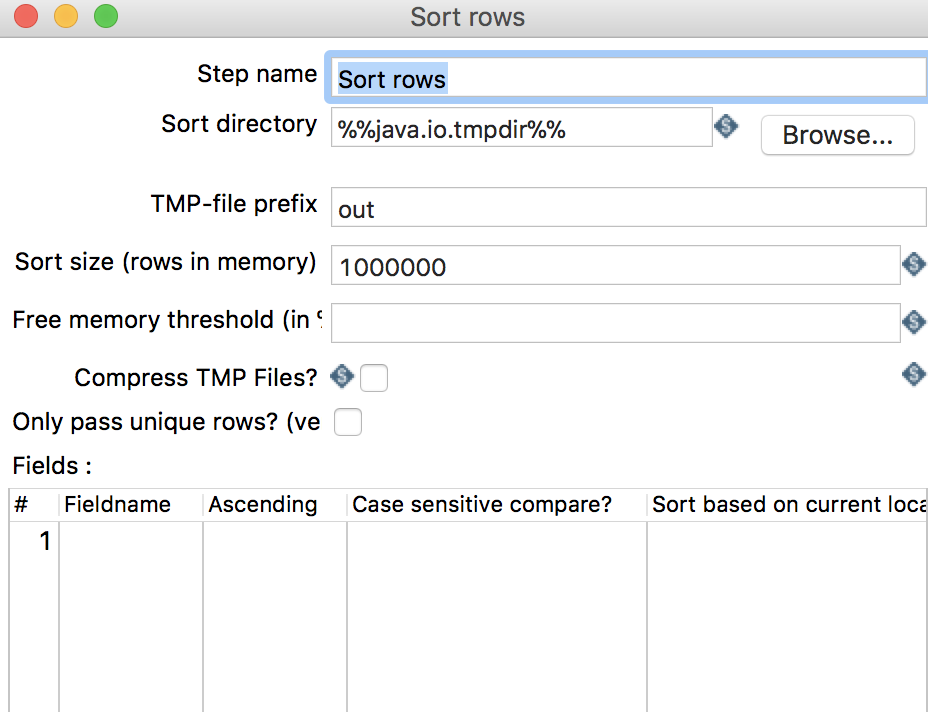
-
2.4 Merge join
将不同来源数据进行融合,类似于
SQL中的join,注意: 该组件接收的数据必须按照join字段按照相同规则进行排序,否则join后的数据会有丢失。
-
Step name: 步骤名称 -
First Step: 需要融合的一组数据 -
Second Step: 需要融合的另一组数据 -
Join Type: 融合的类型 -
Keys for 1st step:First Step中进行融合的字段 -
Keys for 2nd step:Second Step中进行融合的字段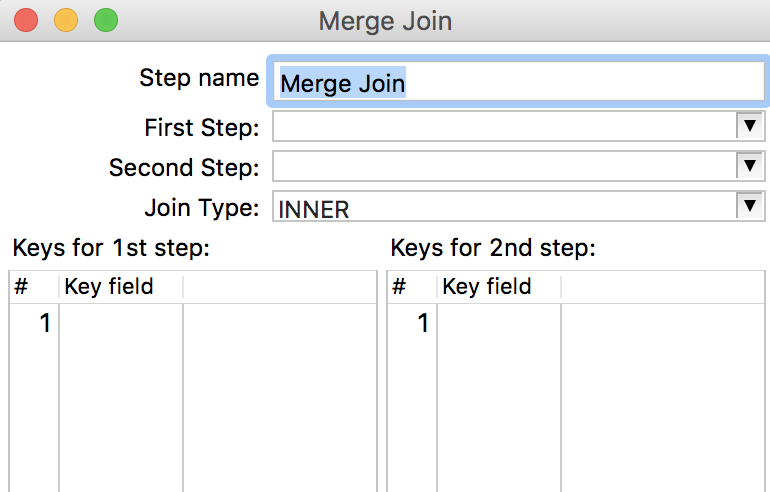
2.5 Add sequence
读取指定的序列值
-
Step name: 步骤名称 -
Name of value: 序列值别名 -
Use DB to get sequence: 是否使用数据库序列 -
Connnection: 数据库连接 -
Schema name: 数据库模式名称 -
Sequence name: 序列名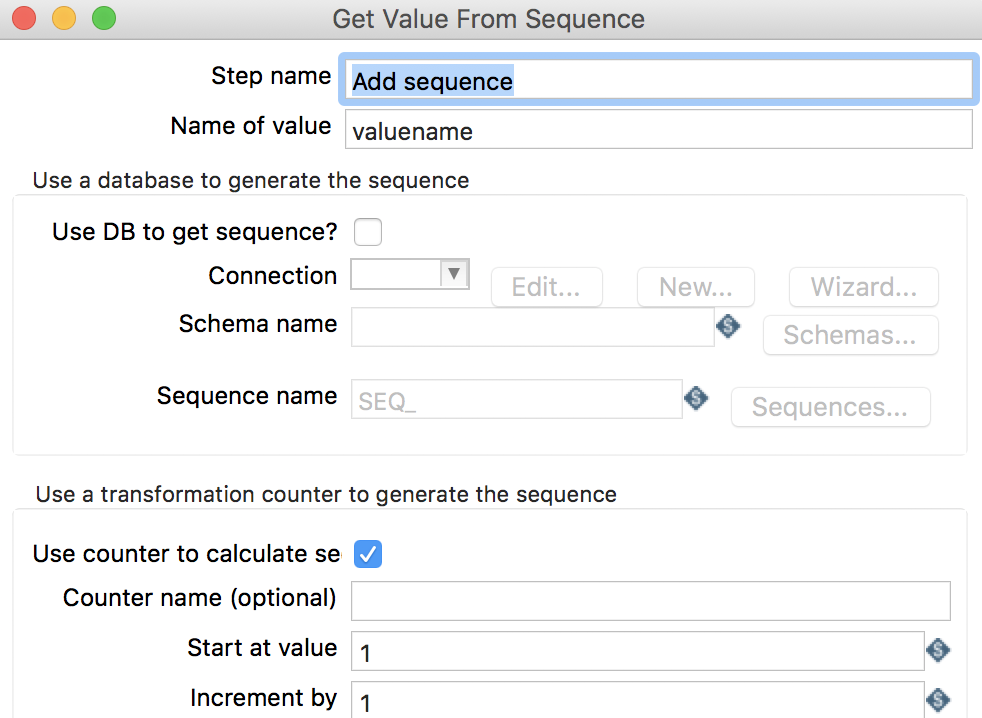
2.6 Modified Java Script Value
支持编写
JavaScript脚本,用于实现必要的业务逻辑
-
Step name: 步骤名称 -
Java script functions: 提供了一些JavaScript函数 -
Java script: 脚本编辑窗口 -
Fields: 可将脚本中的定义的变量映射出去
3. 在实际场景中的应用
在软件开发中,经常会遇到这样的场景: 新开发的系统即将替换老系统,而老系统庞大的数据需迁移到新系统中,但数据结构与新系统不完全兼容,下面通过一个简单的例子来介绍
Kettle是如何处理这些老数据,完成数据迁移任务的。
3.1 老数据结构
-
company公司表:
-
district区域表:
该表存储了省市区,通过parent_id进行关联
-
company_district公司区域表:
-
employee员工表:
-
employee_company员工公司表:
3.2 新数据结构
-
company公司表: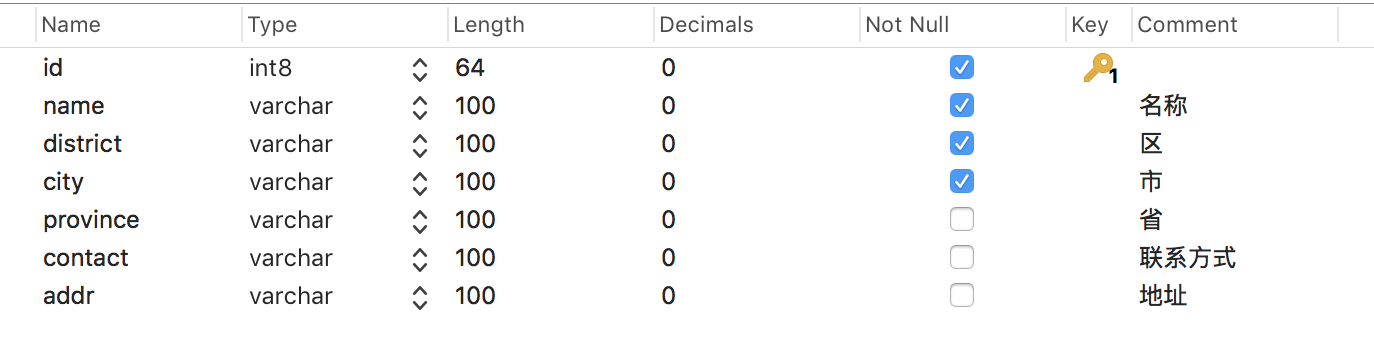
对比老数据
company表,新的company表中新增了district、city、province字段,他们可以从老数据company_district表和district表中取得;contact字段对应tel字段;addr对应address。 -
employee员工表: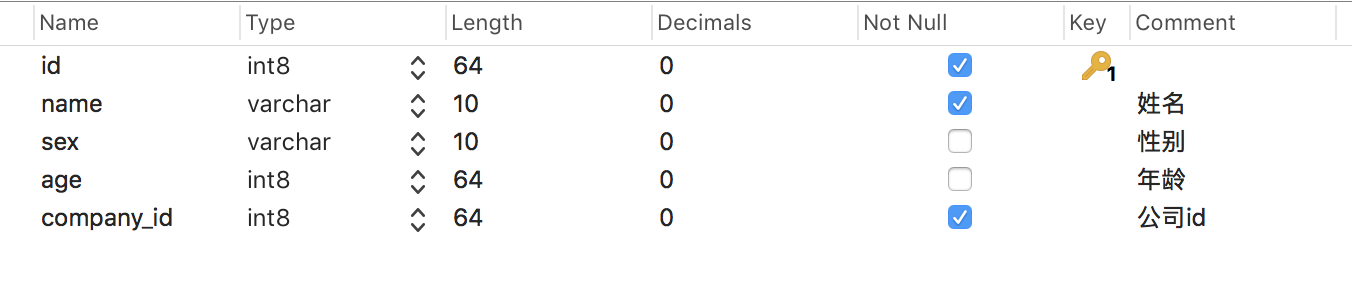
对比老数据
employee表,新的employee表中新增company_id字段且有外键约束;sex字段由原来的1、2变更为男、女
3.3 数据迁移
由于
employee有外键关联company,因此先迁移company表数据,新的company表需新增old_id字段来保存老的company表的id,用于员工关联公司。
3.3.1 company表
数据迁移前的分析:
company表数据来源于三张表:company、company_district、district,因此需要三个Table input组件。company和company_district需进行join,join的结果还需和district进行join,因此需要两个Merge Join组件。- 使用
Merge join组件之前需进行排序,因此需要三个Sort rows组件- 新的
company表的id来源于自增长序列,因此需要一个Add sequence组件。- 最后将结果导入新的
company表,因此需要一个Table output组件。
- 打开
Kettle,点击File->new->Transformation,新建一个转换流程 - 点击左侧
DesignTab页,将Table input组件拖拽至右侧转换流程窗口,在组件上右键点击edit,弹出该组件的编辑窗口,设置步骤名称、数据库连接和SQL语句,如下图所示: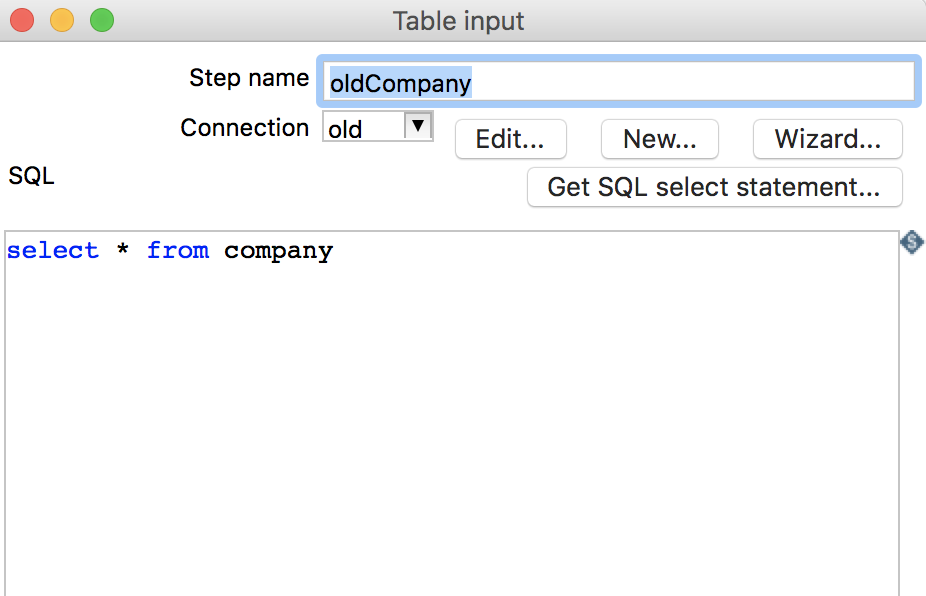
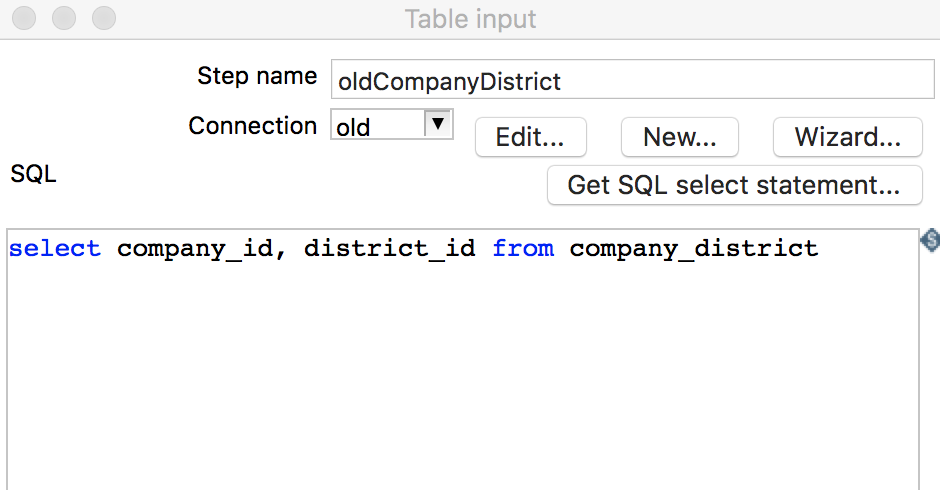

-
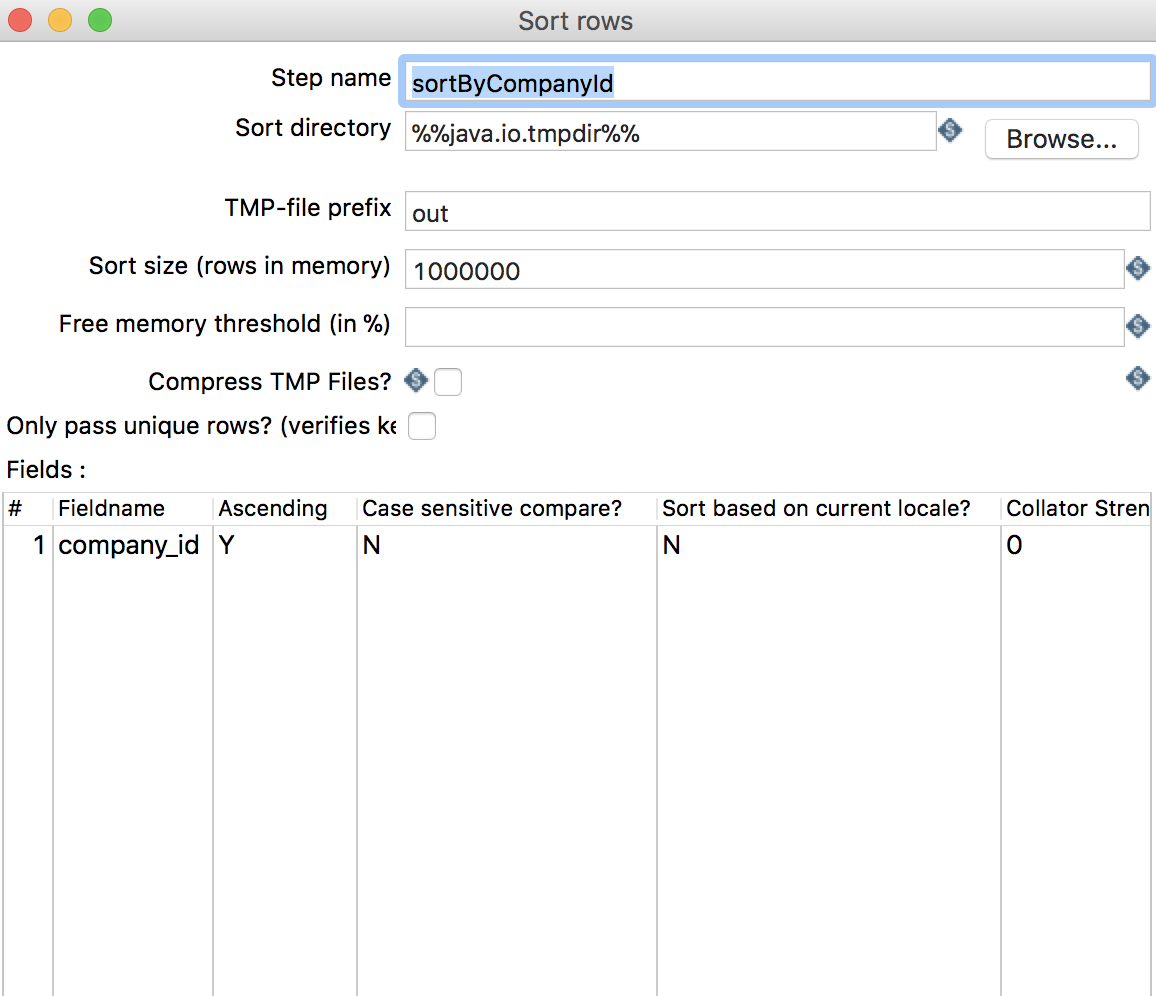
将
company和company_district数据进行left join,join之前需按照join字段排序,将Sort rows组件拖拽至右侧转换流程窗口,并进行编辑,如下图所示: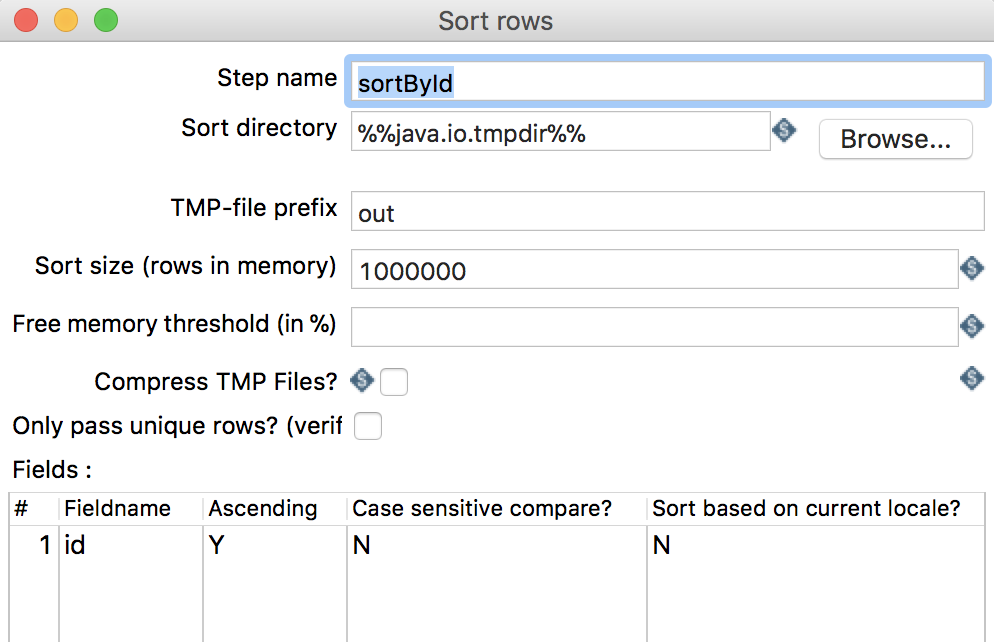
-
将
Merge Join组件拖拽至右侧,并进行编辑,如下图所示: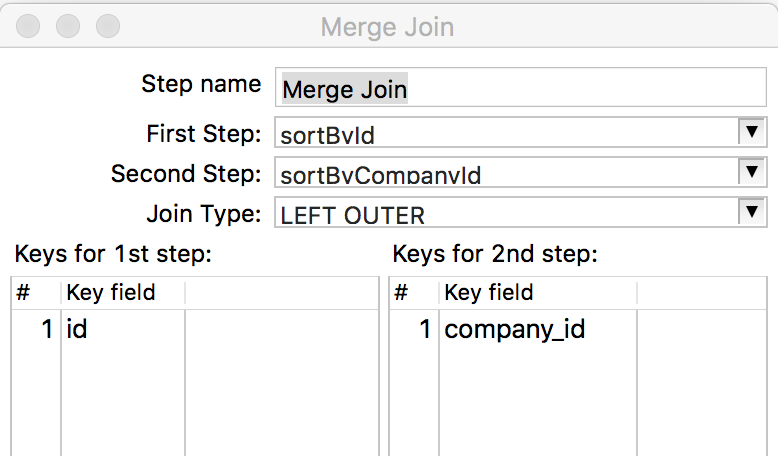
-
将
company和company_districtMerge Join的结果和district数据分别进行排序,同上面步骤 -
将两者进行
join,同上面步骤 -
添加
Add sequence组件,并进行编辑,如下图所示: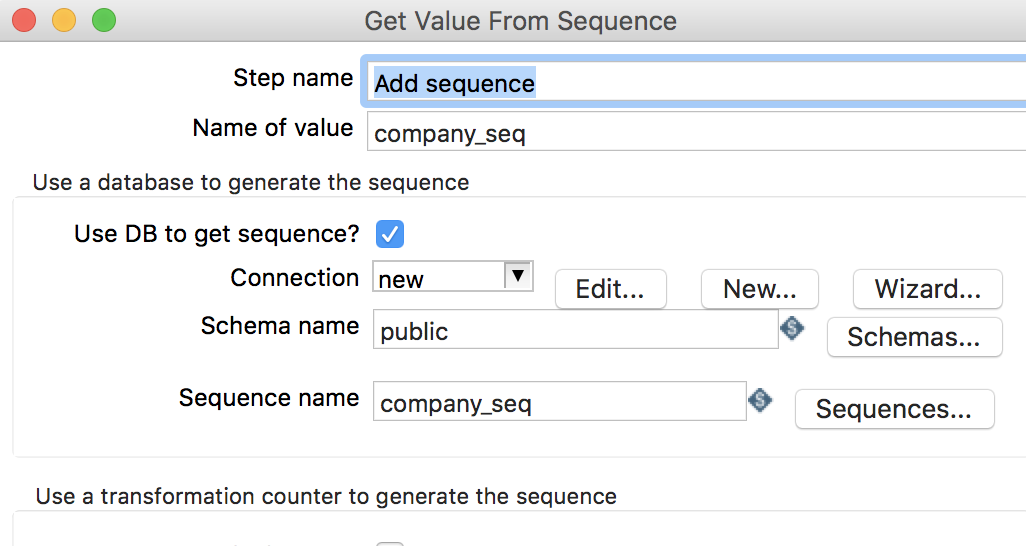
-
添加
Table output组件,并进行编辑,如下图所示: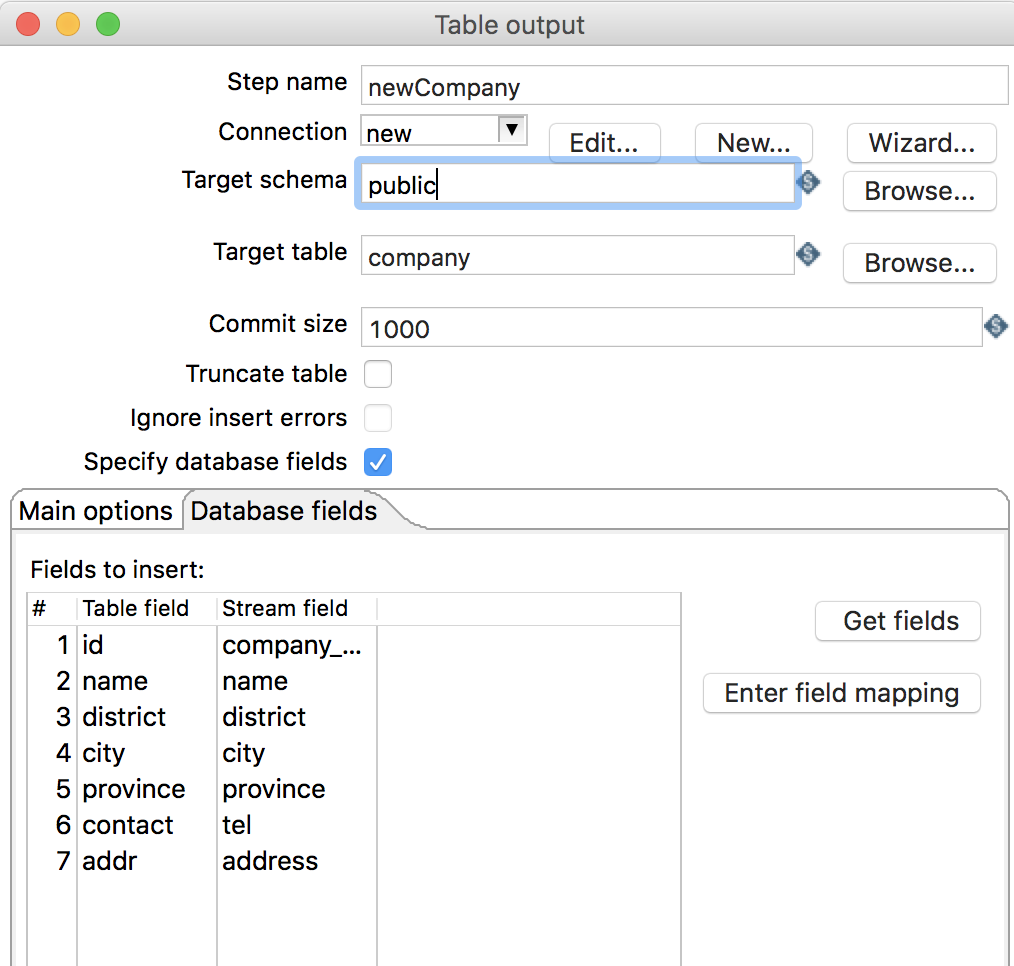
-
整体流程如下图所示:
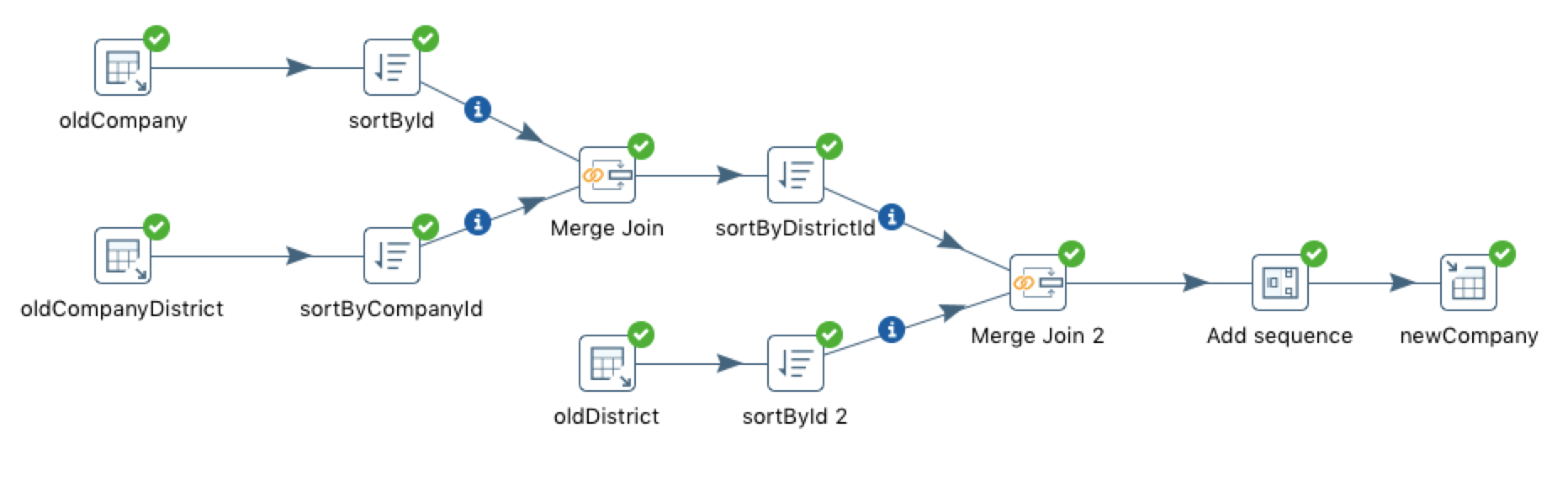
-
点击启动按钮执行整个流程,直至所有步骤右上角出现绿色的箭头,
company表便完成了迁移。
3.3.2 employee表
数据迁移前的分析:
employee表数据来源三张表: 老的employee、老的employee_company和新的company,因此需要三个Table input组件- 老的
employee和employee_company需进行join,join的结果还需和新的company进行join,因此需要两个Merge join组件和三个Sort rows组件。- 新的
employee表的id来源于自增长序列,因此需要一个Add sequence组件。- 新的
employee表的sex字段存储的是'男/女',而不是'1/2',因此需要一个Modified Java Script Value组件进行简单处理。- 最后将结果导入新的
employee表,因此需要一个Table output组件。
- 与
company的数据迁移类似,添加三个Table input组件,并进行编辑 - 分别将
employee和employee_company按照join字段进行统一排序 - 将排序的结果进行
join - 分别将新的
company和join之后的结果按照join字段进行统一排序 - 将排序的结果进行
join - 编写脚本,转换
sex字段
- 读取新的
employee序列值 - 输出到新的
employee表中 -
整体流程如下图所示:
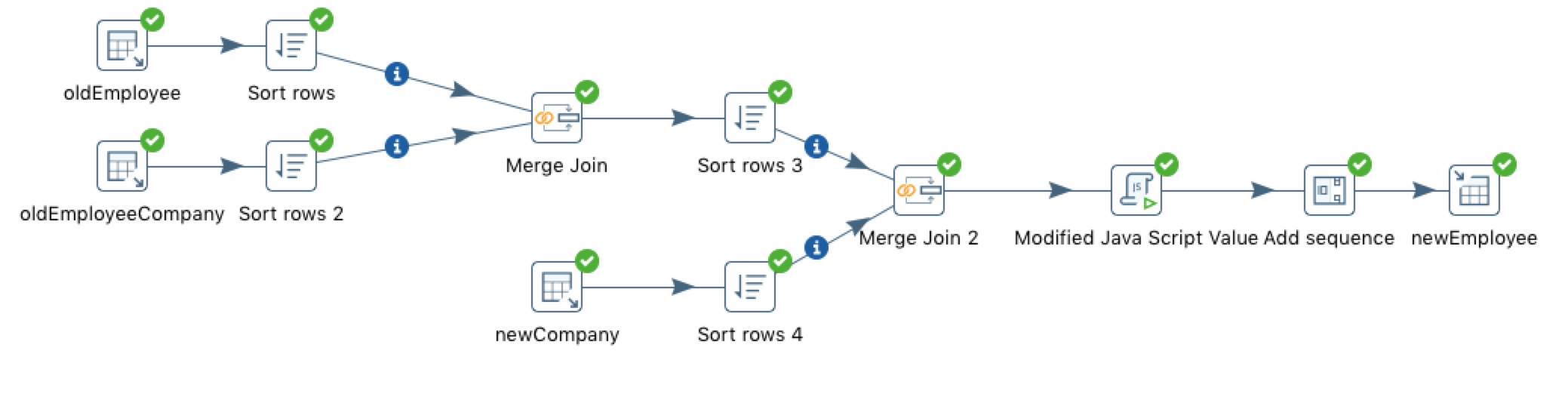
-
点击启动按钮执行整个流程,直至所有步骤右上角出现绿色的箭头,
employee表便完成了迁移。
3.4 结果
-
company表
-
employee表
至此,便完成了老数据的迁移。
4. 遇到的问题
在
Kettle使用过程中会发现,当需要进行迁移的数据量较为庞大时(千万级),常常会出现内存溢出的问题,解决方法是将Kettle内存调高些: 打开spoon.sh文件,找到PENTAHO_DI_JAVA_OPTIONS="-Xms1024m -Xmx2048m -XX:MaxPermSize=256m",将其修改为PENTAHO_DI_JAVA_OPTIONS="-Xms16384m -Xmx32768m -XX:MaxPermSize=16384m",重启即可。



相关推荐
本文主要探讨如何在Kettle 7.0环境下实现数据库迁移,特别是从Oracle到MySQL的迁移,同时也涵盖了对其他数据库类型的迁移支持。 Kettle,又称Pentaho Data Integration (PDI),是一款强大的ETL(提取、转换、加载)...
Kettle实现数据库迁移的过程可以分为以下几个关键步骤: 1. **项目初始化**:首先,我们需要在Kettle环境中创建一个新的转换或工作,这是所有数据处理任务的基础。在这个阶段,我们可以定义源数据库和目标数据库的...
有了这些驱动,Kettle可以识别并连接到指定的数据库,执行SQL查询,读取或写入数据,从而实现数据集成的目标。 总的来说,"Kettle所有数据库数据库连接驱动Jar"是一个宝贵的资源,它提供了与多种数据库系统连接的...
该实例主要完成sqlserver数据库表信息到Oracle数据库表的一次数据迁移,用kettle工具(简称水壶)编写好转换文件后保存,最后执行转化,即可完成数据库表的数据迁移。运行该实例你需下载kettle工具,并对实例中的...
因此,该插件的出现弥补了这一空白,使得用户能够充分利用Kettle的强大功能处理神通数据库中的数据。 神通数据库,又称为OSCAR数据库,是一种面向对象的关系型数据库管理系统,特别适合于管理复杂数据结构和大数据...
在这个“Kettle的一套流程完成对整个数据库迁移”的压缩包中,包含了完成数据库迁移所需的所有步骤。数据库迁移通常涉及从一个数据库系统迁移到另一个系统,确保数据的完整性和一致性。 首先,理解Kettle的工作原理...
总结来说,"Kettle常用的数据库驱动脚本"这个资源包提供了Kettle连接四大主流数据库所必需的驱动文件,使得数据工程师可以方便地进行跨数据库的数据迁移、转换和分析。理解并掌握这些驱动的使用,对于提升Kettle在...
使用kettle重复的画着:表输入-表输出、创建表,很烦恼。 实现了一套通用的数据库迁移流程。 做一个批量抽取的job
通过以上步骤,你可以利用Kettle实现数据库之间的数据同步。理解这些核心概念和操作,不仅可以解决本例中的问题,也能为其他复杂的数据集成任务提供基础。在实际应用中,还需要根据具体需求和环境进行调整,以达到...
在IT行业中,数据库是数据管理和存储的核心工具,而Kettle(又称Pentaho Data Integration,简称PDI)是一款强大的ETL(Extract, Transform, Load)工具,用于在不同数据源之间进行数据迁移、清洗和转换。Kettle支持...
将Kettle与Clickhouse结合,可以实现对大数据的高效处理和分析。 在Kettle中连接ClickHouse数据库,首先需要确保你已经安装了Kettle(也称为Pentaho Data Integration或PDI)以及对应的ClickHouse JDBC驱动。以下是...
Kettle,也称为Pentaho Data Integration(PDI),是一款强大的ETL(Extract, Transform, Load)工具,常用于数据整合、数据清洗和数据库迁移等任务。本示例将详细介绍如何利用Kettle来实现整套数据库的迁移操作。 ...
kettle-达梦数据库jar包
1. 数据库连接的核心:数据库连接驱动包是Kettle与各种数据库进行通信的桥梁,它负责解析和执行SQL语句,实现数据的读取、写入和更新。如果没有匹配的驱动包,Kettle将无法识别和连接到特定的数据库系统,导致操作...
通过在Kettle作业或转换中配置正确的数据库连接,用户可以执行数据提取、清洗、转换和加载任务,实现数据的高效管理和分析。在实际使用中,选择合适的驱动版本取决于目标数据库的版本,以确保最佳的兼容性和性能。
kettle连接达梦8数据库所需Jar包
数据库迁移工具方法是实现数据库迁移的重要手段。本文总结了三种适用于 MySQL 和 Oracle 数据库迁移的工具方法: * 使用 DB Convert Studio 工具进行数据库迁移 * 使用 ETL-Kettle 工具进行数据库迁移 * 在数据库...
标题中的“Kettle学习资料分享,附大神用Kettle的一套流程完成对整个数据库迁移方法”揭示了本文将深入探讨Kettle这一ETL(Extract, Transform, Load)工具在数据库迁移过程中的应用。Kettle,又称为Pentaho Data ...
标题中的“kettle连接clickhouse数据库插件”指的是在Pentaho Kettle(也称为Spoon)这款数据集成工具中,使用特定的插件来连接和操作ClickHouse数据库。ClickHouse是一个高性能的列式数据库管理系统(Column-...
在“ETL工具实现不同数据库迁移”的主题中,我们主要关注如何利用Kettle进行数据库之间的数据迁移。首先,我们需要理解Kettle的工作原理。它基于Job和Transformation两种核心元素。Job负责整体流程的调度和控制,而...