
š┐╗Ŕ»ĹŔ笴╝ÜMartin Thompson ÔÇô Memory Barriers/Fences
ňťĘŔ┐Öš»çŠľçšźáÚçî´╝Ĺň░ćŔ«ĘŔ«║ň╣ÂňĆĹš╝ľšĘőÚçÇňč║šíÇšÜäŠŐÇŠť»ÔÇôń╗ąňćůňşśňů│ňŹíŠłľŠáůŠáĆŔĹŚšž░´╝îÚéúŔ«ęŔ┐ŤšĘőňćůšÜäňćůňşśšŐŠÇüň»╣ňůÂń╗ľŔ┐ŤšĘőňĆ»ŔžüŃÇé
CPU ńŻ┐šöĘń║ćňżłňĄÜŠŐÇŠť»ňÄ╗ň░ŁŔ»ĽňĺîÚÇéň║öŔ┐ÖŠáĚšÜäń║őň«×´╝ÜCPU ŠëžŔíîňŹĽňůâšÜäŠÇžŔâŻňĚ▓Ŕ┐ťŔ┐ťŔÂůňç║ńŞ╗ňćůňşśŠÇžŔâŻŃÇéňťĘŠłĹšÜäÔÇťWriting CombiningÔÇŁŠľçšźá´╝ĹňƬŠś»Ŕ░łňĆŐňůÂńŞşńŞÇšžŹŠŐÇŠť»ŃÇéCPU ńŻ┐šöĘšÜäšöĘŠŁąÚÜÉŔŚĆňćůňşśň╗ÂŔ┐čšÜ䊝NJ֫ÚÇÜŠŐÇŠť»Šś»š«íš║┐ňîçń╗Ą´╝îšäÂňÉÄń╗śňç║ňĚĘňĄžňŐ¬ňŐŤňĺîŔÁäŠ║ÉňÄ╗ň░ŁŔ»ĽÚ珊Äĺň║ĆŔ┐Öń║Ťš«íš║┐ŠŁąŠťÇň░Ćňîľš╝ôňşśńŞŹňĹŻńŞşšÜ䊝ëňů│Šőľň╗ÂŃÇé
ňŻôńŞÇńެšĘőň║ĆŠëžŔíîšÜ䊌ÂňÇÖ´╝îň«âńŞŹňťĘń╣Ä´╝îňŽéŠ×ťÚ珊Äĺň║ĆňÉÄšÜäŠîçń╗ĄŠĆÉńżŤń║ćńŞÇŠáĚšÜ䊝ǚ╗łš╗ôŠ×ťŃÇéńżőňŽé´╝îňťĘńŞÇńެňż¬šÄ»ňćů´╝îňŽéŠ×ťňż¬šÄ»ňćůŠ▓튝ëŠôŹńŻťńŻ┐šöĘňż¬šÄ»Ŕ«íš«ŚňÖĘ´╝îňż¬šÄ»Ŕ«íŠĽ░ňÖĘń╗Ç ń╣łŠŚÂňÇÖŠŤ┤Šľ░Šś»ńŞŹňťĘń╣ÄšÜäŃÇéš╝ľŔ»ĹňÖĘňĺî CPU Ŕ笚ö▒ňť░Ú珊Äĺň║ĆŠîçń╗ĄŠŁąŠťÇňĄžňîľňť░ňłęšöĘ CPU´╝┤ňł░ńŞőńŞÇŠČíŔ┐şń╗úňŹ│ň░ćň╝ÇňžőŠŚÂŠëŹŠŤ┤Šľ░ň«â´╝łňż¬šÄ»Ŕ«íŠĽ░ňÖĘ´╝ëŃÇéń╣čňĆ»Ŕ⯴╝îňťĘńŞÇńެňż¬šÄ»šÜäŠëžŔíîŔ┐çšĘőńŞş´╝îŔ┐ÖńެňĆśÚçĆňĆ»ŔâŻňşśňéĘňťĘńŞÇńެň»äňşśňÖĘÚçî´╝îŠ░ŞŔ┐ťńŞŹń╝ÜŠÄĘňł░š╝ôňşśŠłľńŞ╗ňćů ňşś´╝îňŤáŠşĄ´╝îň«âň»╣ňůÂň«â CPU Š░ŞŔ┐ťńŞŹňĆ»ŔžüŃÇé
CPU ŠáŞňîůňÉźňĄÜńެŠëžŔíîňŹĽňůâŃÇéńżőňŽé´╝îńŞÇńެšÄ░ń╗úšÜäIntel CPU ňîůňÉź6ńެŠëžŔíîňŹĽňůâ´╝îňĆ»ń╗ąňüÜńŞÇš╗䊼░ňşŽ´╝íń╗ÂÚÇ╗ŔżĹňĺîňćůňşśŠôŹńŻťšÜäš╗äňÉłŃÇ銻ĆńެŠëžŔíîňŹĽňůâňĆ»ń╗ąňüÜŔ┐Öń║Ťń╗╗ňŐíšÜäš╗äňÉłŃÇéŔ┐Öń║ŤŠëžŔíîňŹĽňůâň╣ÂŔíîňť░ŠôŹńŻť´╝îňůüŔ«ŞŠîçń╗Ąň╣ÂŔíîňť░ŠëžŔíîŃÇéňŽéŠ×ťń╗Ä ňůÂň«â CPU ŠŁąŔžéň»č´╝îŔ┐Öň╝Ľňůąń║ćšĘőň║ĆÚí║ň║ĆšÜäňĆŽńŞÇň▒éńŞŹší«ň«ÜŠÇžŃÇé
ŠťÇš╗ł´╝îńŻćš╝ôňşśńŞŹňĹŻńŞşňĆĹšö芌´╝îšÄ░ń╗ú CPU ňĆ»ń╗ąŠá╣ŠŹ«ňćůňşśňŐáŔŻŻšÜäš╗ôŠ×ťňüÜńŞÇńެňüçŔ«ż´╝îšäÂňÉÄňč║ń║ÄŔ┐ÖńެňüçŔ«żš╗žš╗şŠëžŔí┤Ŕç│ň«×ÚÖůŠĽ░ŠŹ«šÜäňŐáŔŻŻň«îŠłÉŃÇé
ŠĆÉńżŤÔÇťšĘőň║ĆÚí║ň║ĆÔÇŁń┐ŁšĽÖń║ć CPU ňĺîš╝ľŔ»ĹňÖĘŔ笚ö▒ňť░ňüÜň«âń╗ČŔ«ĄńŞ║ňĆ»ń╗ąŠĆÉňŹçŠÇžŔ⯚Üäń║őŠâůŃÇé
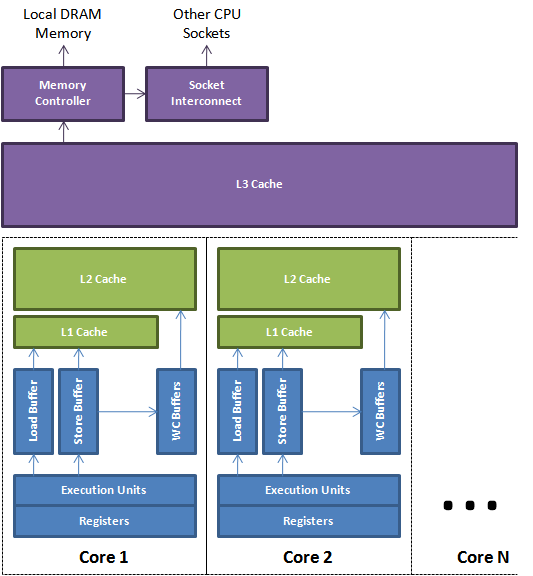
ňŐáŔŻŻ´╝łload´╝ëňĺîňşśňéĘ´╝łstore´╝ëňł░š╝ôňşśňĺîńŞ╗ňćůňşśŠś»Ŕóźš╝ôňć▓ňĺîÚ珊Äĺň║ĆšÜä´╝îńŻ┐šöĘňŐáŔŻŻ´╝łload´╝ë´╝îňşśňéĘ´╝łstore´╝ë´╝îňĺîňćÖš╗äňÉł´╝łwriting- combining´╝ëš╝ôňşśŃÇéŔ┐Öń║Ťš╝ôňşśŠś»ňů│ŔüöšÜäÚśčňłŚ´╝îňůüŔ«Şň┐źÚÇčŠčąŠëżŃÇéŔ┐ÖšžŹŠčąŠëżŠś»ň┐ůÚí╗šÜä´╝îňŻôńŞÇńެšĘŹňÉÄšÜäňŐáŔŻŻÚťÇŔŽüŔ»╗ňĆľńŞÇńެń╣őňëŹňşśňéĘšÜäŃÇüŔ┐śŠ▓튝ëňł░Ŕżżš╝ôňşśšÜäňÇ╝ŠŚÂŃÇéńŞŐ ňŤżŠĆĆš╗śń║ćšÄ░ń╗úňĄÜŠáŞ CPU šÜäš«ÇňîľŔžćňŤżŃÇéň«âŠśżšĄ║ń║ćŠëžŔíîňŹĽňůâňŽéńŻĽńŻ┐šöĘŠťČňť░ň»äňşśňÖĘňĺîš╝ôňşśŠŁąš«íšÉćňćůňşś´╝îńŞÄš╝ôňşśňşÉš│╗š╗芣ąňŤ×ń╝áÚÇüŃÇé
ňťĘňĄÜš║┐šĘőšÄ»ňóâńŞő´╝îÚťÇŔŽüÚççšöĘńŞÇń║ŤŠŐÇŠť»ŠŁąŔ«ęšĘőň║Ćš╗ôŠ×ťňĆŐŠŚÂňĆ»ŔžüŃÇ銳ĹńŞŹń╝ÜňťĘŔ┐Öš»çŠľçšźáÚçîŠÂëňĆŐš╝ôňşśńŞÇŔç┤ŠÇžŃÇéń╗ůń╗ůňüçŔ«żńŞÇŠŚŽňćůňşśŔóźŠÄĘňł░š╝ôňşś´╝îšäÂňÉÄŠťëńŞÇńެňŹĆŔ««ŠÂłŠü»ň░ćňĆĹšöč´╝îń╗ąší«ń┐ŁŠëÇŠťëňů▒ń║źŠĽ░ŠŹ«šÜäš╝ôňşśŠś»ńŞÇŔç┤šÜäŃÇéŔ┐ÖšžŹńŻ┐ňćůňşśň»╣ňĄäšÉćňÖĘŠáŞňĆ»ŔžüšÜäŠŐÇŠť»Ŕóźšž░ńŞ║ňćůňşśňů│ňŹíŠłľŠáůŠáĆŃÇé
ňćůňşśňů│ňŹíŠĆÉńżŤń║ćńŞĄšžŹň▒׊ǞŃÇéÚŽľňůł´╝îň«âń╗Čń┐ŁšĽÖń║ćňĄľÚâĘňĆ»ŔžüšÜäšĘőň║ĆÚí║ň║Ć´╝îÚÇÜŔ┐çší«ń┐ŁŠëÇŠťëšÜäŃÇüňů│ňŹíńŞĄńżžšÜäŠîçń╗ĄŔíĘšÄ░ňç║Šşúší«šÜäšĘőň║ĆÚí║ň║Ć´╝îňŽéŠ×ťń╗ÄňůÂń╗ľCPUŔžéň»čŃÇéšČČń║î´╝îň«âń╗ČńŻ┐ňćůňşśňĆ»Ŕžü´╝îÚÇÜŔ┐çší«ń┐ŁŠĽ░ŠŹ«ń╝áŠĺşňł░š╝ôňşśňşÉš│╗š╗čŃÇé
ňćůňşśňů│ňŹíŠś»ńŞÇńެňĄŹŠŁéšÜäńŞ╗ÚóśŃÇéň«âń╗ČňťĘńŞŹňÉîšÜä CPU Š×Š×äńŞŐšÜäň«×šÄ░Šś»ÚŁ×ňŞŞńŞŹňÉîšÜäŃÇéIntel CPU ŠťëńŞÇńެňů│ŔüöšÜäň╝║ňćůňşśŠĘíň×őŃÇ銝Ț»çň░ćń╗ą x86 CPU ńŞ║ňč║šíÇŔ«▓ŔžúŃÇé
ňşśňéĘňů│ňŹí´╝łstore barrier´╝ë
ňşśňéĘňů│ňŹí´╝îňťĘx86 ńŞŐŠś»ÔÇŁsfenceÔÇŁŠîçń╗Ą´╝îň╝║Ŕ┐źŠëÇŠťëšÜäŃÇüňťĘňů│ňŹíŠîçń╗Ąń╣őň돚Üä ňşśňéĘŠîçń╗ĄňťĘňů│ňŹíń╗ąňëŹňĆĹšöč´╝îň╣ÂńŞöŔ«ę store buffers ňłĚŠľ░ňł░ňĆĹňŞâŔ┐ÖńެŠîçń╗ĄšÜä CPU cacheŃÇéŔ┐Öň░ćńŻ┐šĘőň║ĆšŐŠÇüň»╣ňůÂń╗ľ CPU ňĆ»Ŕžü´╝îŔ┐ÖŠáĚ´╝îňŽéŠ×ťÚťÇŔŽüň«âń╗ČňĆ»ń╗ąň»╣ň«âňüÜňç║ňôŹň║öŃÇéńŞÇńެň«×ÚÖůšÜäňąŻńżőňşÉŠś»ńŞőÚŁóšÜäŃÇüš«ÇňîľšÜäŃÇüŠŁąŔç¬DisruptoršÜäš▒╗BatchEventProcessorŃÇéňŻôsequenceŔ󟊍┤Šľ░ňÉÄ´╝îňůÂń╗ľŠÂłŔ┤╣ŔÇůňĺîšöčń║žŔÇůščąÚüôŔ┐ÖńެŠÂłŔ┤╣ŔÇůšÜäŔ┐Ťň▒Ľ´╝îň╣ÂŔ┐ŤŔíîÚÇéňŻôšÜäňôŹň║öŃÇéŠëÇŠťëňťĘňů│ňŹíń╣őňëŹň»╣ňćůňşśšÜ䊍┤Šľ░šÄ░ňťĘÚâŻňĆ»Ŕžüń║ćŃÇé
private volatile long sequence = RingBuffer.INITIAL_CURSOR_VALUE;
// from inside the run() method
T event = null;
long nextSequence = sequence.get() + 1L;
while (running)
{
try
{
// Ŕ»ĹŠ│Ę´╝Übarrier ń╝ÜŔ»╗ňĆľňůÂń╗ľsequence šÜäňÇ╝´╝îŠëÇń╗ąŔ┐ÖÚçîÚŁóŠťëńެ load barrier Šîçń╗ĄŃÇé
final long availableSequence = barrier.waitFor(nextSequence);
while (nextSequence <= availableSequence)
{
event = ringBuffer.get(nextSequence);
boolean endOfBatch = nextSequence == availableSequence;
eventHandler.onEvent(event, nextSequence, endOfBatch);
nextSequence++;
}
sequence.set(nextSequence - 1L);
// store barrier ŠĆĺňůąňł░Ŕ┐ÖÚçî !!!
}
catch (final Exception ex)
{
exceptionHandler.handle(ex, nextSequence, event);
sequence.set(nextSequence);
// store barrier ŠĆĺňůąňł░Ŕ┐ÖÚçî !!!
nextSequence++;
}
}
ňŐáŔŻŻňů│ňŹí´╝łload barrier´╝ë
ňŐáŔŻŻňů│ňŹí´╝îňťĘx86 ńŞŐŠś»ÔÇŁlfenceÔÇŁŠîçń╗Ą´╝îň╝║Ŕ┐źŠëÇŠťëšÜäŃÇüňŐáŔŻŻŠîçń╗Ąń╣őňÉÄšÜäŠîçń╗ĄňťĘňů│ňŹíń╣őňÉÄňĆĹšöč´╝îšäÂňÉÄšşëňżůÚéúńެ CPU šÜä load buffer ŠÄĺšę║ŃÇéŔ┐ÖńŻ┐ňůÂň«â CPU ŠÜ┤Úť▓ňç║ŠŁąšÜäšĘőň║ĆšŐŠÇüň»╣Ŕ┐Öńެ CPU ňĆ»Ŕžü´╝îňťĘňüÜňç║ŠŤ┤ňĄÜŔ┐Ťň▒Ľń╣őňëŹŃÇéŔ┐ÖńެšÜäńŞÇńެňąŻńżőňşÉŠś»ňëŹÚŁóň╝ĽšöĘšÜä BatchEventProcessor šÜä sequence ŔóźňůÂň«âšöčń║žŔÇůŠłľŠÂłŔ┤╣ŔÇůŔ»╗ňĆľŠŚÂ´╝îDisruptor Úç뚺ëń╗ĚšÜäŠîçń╗ĄŃÇé
Full Barrier
Full Barrier´╝îňťĘx86 ńŞŐŠś»ÔÇŁmfenceÔÇŁŠîçń╗Ą´╝îňťĘ CPU ńŞŐŠś»ňŐáŔŻŻňĺîňşśňéĘňů│ňŹíšÜäš╗äňÉłŃÇé
Java ňşśňéĘŠĘíň×ő´╝łJava Memory Model´╝ë
ňťĘJava ňşśňéĘŠĘíň×őÚçî´╝îvolatile ňşŚŠ«ÁňťĘňćÖňůąňÉÄŠĆĺňůąńŞÇńެňşśňéĘňů│ňŹí´╝îňťĘŔ»╗ňĆľň돊ĆĺňůąňŐáŔŻŻňů│ňŹíŃÇéš▒╗ÚçîÚŁóń┐«Úą░ńŞ║ final šÜäňşŚŠ«ÁňťĘň«âń╗ČŔóźňłŁňžőňîľňÉÄŠĆĺňůąńŞÇńެňşśňéĘŠîçń╗Ą´╝îń╗ąší«Ŕ┐Öń║ŤňşŚŠ«ÁňťĘŠ×äÚÇáň篊Ľ░ň«îŠłÉŃÇüŠťëňĆ»šöĘň╝ĽšöĘňł░Ŕ┐Öńެň»╣Ŕ▒튌Šś»ňĆ»ŔžüšÜäŃÇé
ňÄčňşÉŠîçń╗ĄňĺîŔŻ»ń╗ÂÚöü´╝łAtomic Instructions and Software Locks´╝ë
ňÄčňşÉŠîçń╗Ą´╝îňŽéx86ÚçîšÜä ÔÇťlock ÔÇŽÔÇŁ Šîçń╗Ą´╝»ÚźśŠĽłšÜä full barrier´╝îň«âń╗ČÚöüńŻĆňşśňéĘňşÉš│╗š╗芣ąŠëžŔíîŠôŹńŻť´╝ëňĆŚń┐ŁŔ»üšÜäňůĘň║Ćňů│š│╗´╝łtotal order´╝ë´╝îňŹ│ńŻ┐ŔĚĘ CPUŃÇéŔŻ»ń╗ÂÚöüÚÇÜňŞŞńŻ┐šöĘňşśňéĘňů│ňŹí´╝ľňÄčňşÉŠîçń╗ĄŠŁąŔżżňł░ňĆ»ŔžćŠÇžňĺîń┐ŁšĽÖšĘőň║ĆÚí║ň║ĆŃÇé
ňşśňéĘňů│ňŹíň»╣ŠÇžŔ⯚ÜäňŻ▒ňôŹ´╝łPerformance Impact of Memory Barriers´╝ë
ňşśňéĘňů│ňŹíÚś╗Šşóń║ć CPU ŠëžŔíîňżłňĄÜÚÜÉŔŚĆňćůňşśň╗ÂŔ┐čšÜäŠŐÇŠť»´╝îňŤáŠşĄŠťëň«âń╗ČŠťëŠśżŔĹŚšÜäŠÇžŔâŻň╝ÇÚöÇ´╝îň┐ůÚí╗ŔÇâŔÖĹŃÇéńŞ║ń║ćŔżżňł░ŠťÇňĄžŠÇžŔ⯴╝ÇňąŻň»╣ÚŚ«Úóśň╗║ŠĘí´╝îŔ┐ÖŠáĚňĄäšÉćňÖĘňĆ»ń╗ąňüÜňĚąńŻťňŹĽňůâ´╝îšäÂňÉÄŔ«ęŠëÇŠťëň┐ůÚí╗šÜäňşś ňéĘňů│ňŹíňťĘňĚąńŻťňŹĽňůâšÜäŔż╣šĽîńŞŐňĆĹšöčŃÇéÚççšöĘŔ┐ÖšžŹŠľ╣Š│ĽňůüŔ«ŞňĄäšÉćňÖĘńŞŹňĆŚÚÖÉňłÂňť░ń╝śňîľňĚąńŻťňŹĽňůâŃÇéŠŐŐň┐ůÚí╗šÜäňşśňéĘňů│ňŹíňłćš╗䊜»ŠťëšŤŐšÜä´╝îÚéúŠáĚ´╝îňťĘšČČńŞÇńެń╣őňÉÄšÜä buffer ňłĚŠľ░šÜäň╝ÇÚöÇń╝Üň░Ćšé╣´╝îňŤáńŞ║Š▓튝ëňĚąńŻťÚťÇŔŽüŔ┐ŤŔíîÚ珊ľ░ňíźňůůň«âŃÇé
Ŕ»ĹŠ│Ę´╝Üňů│ń║ÄDisruptorňĆ»ń╗ąšťőŠłĹń╣őň돚ÜäŔ┐Öš»çŠľçšźá´╝Ühttp://coderbee.net/index.php/open-source/20130812/400



šŤŞňů│ŠÄĘŔŹÉ
ŠľçšźáŠĚ▒ňůąŠÄóŔ«Ęń║ćňćůňşśň▒ĆÚÜť´╝łMemory Barriers´╝ëšÜ䊎éň┐ÁňĆŐňůÂňťĘšÄ░ń╗úňĄÜňĄäšÉćňÖĘš│╗š╗čńŞşšÜäńŻťšöĘ´╝îň╣ÂŔžúÚçŐń║ćńŞ║ń╗Çń╣łCPUŔ«żŔ«íŔÇůÚťÇŔŽüň░ćňćůňşśň▒ĆÚÜťň╝║ňŐáš╗ÖSMP´╝łň»╣šž░ňĄÜňĄäšÉćňÖĘ´╝ëŔŻ»ń╗ÂŔ«żŔ«íňŞłŃÇé #### ň╣ÂňĆĹňÉąńŞÄňćůňşśň▒ĆÚÜť ňćůňşśň▒ĆÚÜťŠś»šöĘń║Äší«ń┐Ł...
ňćůňşśň▒ĆÚÜťŠś»ńŞÇšžŹňťĘňĄÜňĄäšÉćňÖĘš│╗š╗čńŞşŔóźň╣┐Š│ŤńŻ┐šöĘšÜäňÉąŠť║ňłÂ´╝îň«âší«ń┐Łń║ćňćůňşśŠôŹńŻťšÜäÚí║ň║ĆŠÇž´╝îň»╣ń║Äń┐ŁŔ»üňĄÜŠáŞňĄäšÉćňÖʚĻňóâńŞőŔŻ»ń╗šÜ䊺úší«Ŕ┐ÉŔíîŔç│ňů│ÚçŹŔŽüŃÇéńŞ║ń║抍┤ňąŻňť░šÉćŔžúňćůňşśň▒ĆÚÜťšÜäńŻťšöĘňĺîň«âňťĘšíČń╗Âň▒éÚŁóšÜäŔíĘšÄ░´╝Ĺń╗ČŠťëň┐ůŔŽüňůłń║ćŔžúCPUš╝ôňşś...
ń╗ąň돊łĹń╗ČŔ»┤Ŕ┐çňťĘńŞÇń║Ťš«ÇňŹĽšÜäńżőňşÉńŞş´╝öňŽéńŞ║ńŞÇńެňşŚŠ«ÁŔÁőňÇ╝ŠłľÚÇĺňó×Ŕ»ąňşŚŠ«Á´╝Ĺń╗ČÚťÇŔŽüň»╣...Memory Barriers and Volatility (ňćůňşśŠáůŠáĆňĺôňĄ▒ňşŚŠ«Á )ŔÇâŔÖĹńŞőńŞőÚŁóšÜäń╗úšáü´╝Ü ń╗úšáüňŽéńŞő:int _answer;┬ábool _complete;┬ávoid A()┬á{┬á
ňćůňşśň▒ĆÚÜťŠś»Ŕ«íš«ŚŠť║šžĹňşŽńŞşšÜäńŞÇńެŠŽéň┐Á´╝îńŞ╗ŔŽüšöĘń║ÄňĄÜŠáŞňĄäšÉćňÖĘŠłľňĄÜňĄäšÉćňÖʚĻňóâńŞş´╝îší«ń┐ŁŠĽ░ŠŹ«šÜäňĆ»ŔžüŠÇžňĺîńŞÇŔç┤ŠÇžŃÇéňťĘLinuxňćůŠáŞńŞş´╝îňćůňşśň▒ĆÚÜťŠś»šöĘŠŁąŠÄžňłÂŠîçń╗ĄŠëžŔíîÚí║ň║ĆšÜ䊝║ňłÂ´╝îń╗ąń┐ŁŔ»üńŞŹňÉîňĄäšÉćňÖĘŠłľńŞŹňÉîšíČń╗ÂÚŚ┤šÜäńŞÇŔç┤ŠÇžŠôŹńŻťŃÇéňćůňşśň▒ĆÚÜť...
Ŕ«░ň┐ćň▒ĆÚÜť´╝łMemory Barrier´╝ë´╝늌Âń╣čŔóźšž░ńŞ║ňćůňşśň▒ĆÚÜťŠłľŠáůŠáĆ´╝łFence´╝ë´╝»ńŞÇšžŹňÉąŠť║ňłÂ´╝îšöĘń║ÄŠÄžňłÂš│╗š╗čńŞşńŞŹňÉîňĄäšÉćňÖĘŠłľňĄäšÉćňÖĘŠáŞň┐âń╣őÚŚ┤šÜäňćůňşśŔ«┐ÚŚ«Úí║ň║ĆŃÇéňťĘňĄÜš║┐šĘőŠłľňĄÜňĄäšÉćňÖĘšÜäšÄ»ňóâńŞş´╝îńŞ║ń║ćń╝śňǞŔ⯴╝îš╝ľŔ»ĹňÖĘňĺîňĄäšÉćňÖĘÚâŻňĆ»ŔâŻ...
ňćůňşśň▒ĆÚÜť´╝łMemory Barriers´╝늜»šÄ░ń╗úŔ«íš«ŚŠť║š│╗š╗čńŞşńŞÇńެňů│Úö«ŠŽéň┐Á´╝îň░ĄňůÂňťĘňĄÜňĄäšÉćňÖĘš│╗š╗č´╝łSMP´╝ëšÄ»ňóâńŞő´╝îň»╣ń║Äší«ń┐ŁŠĽ░ŠŹ«ńŞÇŔç┤ŠÇžŔç│ňů│ÚçŹŔŽüŃÇ銝Ȋľçň░ćŠĚ▒ňůąŠÄóŔ«Ęňćůňşśň▒ĆÚÜťšÜäňč║ŠťČňÄčšÉćŃÇüńŻťšöĘŠť║ňłÂń╗ąňĆŐň«âń╗ČňťĘšíČń╗Âň▒éÚŁóňŽéńŻĽŠö»ŠîüŔŻ»ń╗ÂŔ«żŔ«íŃÇé ...
ńŞ║ń║ćŔžúňć│Ŕ┐ÖńŞ¬ÚŚ«Úóś´╝îLinuxšĄżňî║ňťĘŔ┐çňÄ╗ńżŁŔÁľń║ÄŠľçŠíúŃÇŐDocumentation/memory-barriers.txtŃÇőń╗ąňĆŐńŞÇń║ŤńŞôň«ÂšÜäń╗úšáüň«íŠčą´╝îňŽéPaul MckenneyŃÇüPeter ZijlstraňĺîWill Deaconšşëń║║ŃÇéÚÜĆšŁÇŠŚÂÚŚ┤šÜäŠÄĘšž╗´╝îň░ĄňůŠś»ňťĘ2014ň╣┤ňł░2015ň╣┤ŠťčÚŚ┤´╝î...
LinuxňćůŠáŞÚÇÜŔ┐çńŞÇš│╗ňłŚŠť║ňłÂší«ń┐Łń║ćňćůňşśŠôŹńŻťšÜäÚí║ň║ĆŠÇžňĺîńŞÇŔç┤ŠÇž´╝îňůÂńŞşŠťÇÚçŹŔŽüšÜ䊝║ňłÂń╣őńŞÇńż┐Šś»ňćůňşśň▒ĆÚÜť´╝łmemory barriers´╝ëŃÇé ÚŽľňůł´╝îń╗őš╗ŹLinuxš│╗š╗čňćůňşśńŞÇŔç┤ŠÇžŠĘíň×őŃÇéňťĘňĄÜŠáŞš│╗š╗čńŞş´╝ĆńެCPUŠáŞň┐âÚ⯊ťëŔç¬ňĚ▒šÜäš╝ôňşś´╝îŔ┐Öń║Ťš╝ôňşśń╣őÚŚ┤šÜä...
ńŞ║ń║ćŠúÇŠÁőňćůňşśÚöÖŔ»»´╝îLinuxňćůŠáŞŔ┐śň╝Ľňůąń║ćňćůňşśň▒ĆÚÜť´╝łMemory Barriers´╝ëňĺîÚöüŠť║ňłÂ´╝îń╗ąń┐ŁŔ»üňćůňşśŠôŹńŻťšÜäÚí║ň║ĆŠÇžňĺîńŞÇŔç┤ŠÇžŃÇ銺ĄňĄľ´╝îŔ┐śŠťëňćůňşśŔ░âŔ»ĽňĚąňůĚňŽéKMemleak´╝îň«âňĆ»ń╗ąŠúÇŠÁőňł░Šť¬ÚçŐŠöżšÜäňćůňşś´╝îňŞ«ňŐęň╝ÇňĆĹŔÇůň«ÜńŻŹňćůňşśŠ│äŠ╝ĆÚŚ«ÚóśŃÇé ňĆŽňĄľ´╝î...
ÚÜĆšŁÇŠĚ▒ňůąšáöšę´╝îŔ┐śń╝ÜŠÂëňĆŐňł░ňćůňşśňłćÚůŹňÖĘ´╝łňŽéslabňĺîń╝Öń╝┤š│╗š╗č´╝ëŃÇüňćůňşśň▒ĆÚÜť´╝łMemory Barriers´╝ëń╗ąňĆŐňćůňşśň»╣ÚŻÉ´╝łMemory Alignment´╝ëšşëÚŚ«Úóś´╝îŔ┐Öń║ŤÚ⯊ś»ňćůňşśš«íšÉćńŞşńŞŹňĆ»Šłľš╝║šÜäÚâĘňłćŃÇé ŠťÇňÉÄ´╝îšÉćŔžúLinuxňćůňşśš«íšÉćň»╣ń║Äš│╗š╗čň╝ÇňĆĹŔÇůŃÇü...
ńżőňŽé´╝îňŽéŠ×ťŠ▓튝ëÚÇéňŻôšÜäňćůňşśň▒ĆÚÜť(memory barriers)´╝îš╝ľŔ»ĹňÖĘňĆ»ŔâŻń╝ÜÚ珊ľ░ŠÄĺňłŚŠîçń╗ĄÚí║ň║Ć´╝îň»╝Ŕç┤ńŞÇńެš║┐šĘőšťőňł░šÜ䊼░ŠŹ«ńŞÄÚó䊝čńŞŹšČŽŃÇé #### ňŤŤŃÇüC++09ňćůňşśŠĘíň×őšÜäšë╣šé╣ ńŞ║ń║ćň║öň»╣Ŕ┐Öń║ŤÚŚ«Úóś´╝îC++09ň╝Ľňůąń║ćńŞÇńެňůĘŠľ░šÜäňćůňşśŠĘíň×ő´╝îŔ»ąŠĘíň×ő...
JavaňćůňşśŠĘíň×őŠś»JavaŔÖÜŠő芝║ŔžäŔîâńŞşň«Üń╣ëšÜäńŞÇÚâĘňłć´╝îň«âŔžäň«Üń║ćJavašĘőň║ĆńŞşňĆśÚçĆšÜäŔ»╗ňćÖŔíîńŞ║´╝îń╗ąňĆŐš║┐šĘőń╣őÚŚ┤šÜäń║Ąń║ĺŔžäňłÖŃÇéšÉćŔžúJavaňćůňşśŠĘíň×őň»╣ń║Äš╝ľňćÖŠşúší«ŃÇüÚźśŠĽłšÜäňĄÜš║┐šĘőšĘőň║ĆŔç│ňů│ÚçŹŔŽüŃÇéňťĘJava 5ń╣őň돴╝îJavaňćůňşśŠĘíň×őšÜäŠĆĆŔ┐░Š»öŔżâŠĘíš│Ő´╝î...
ŃÇŐńŻ┐šöĘOpenMP´╝Üńż┐ŠÉ║ň╝Ćňů▒ń║źňćůňşśň╣ÂŔíîš╝ľšĘőŃÇőŠś»ńŞÇŠťČŠĚ▒ňůąŠÄóŔ«ĘOpenMPŠŐÇŠť»šÜäń╣Žš▒Ź´╝îňç║šëłń║Ä2007ň╣┤ŃÇéOpenMPŠś»ň╣ÂŔíîŔ«íš«ŚÚóćňččň╣┐Š│Ťň║öšöĘšÜäńŞÇšžŹŠÄąňĆúŠáçňçć´╝îň«âńŞ║šĘőň║ĆňĹśŠĆÉńżŤń║ćńŞÇšžŹš«ÇňŹĽšÜ䊾╣ň╝ĆŠŁąš╝ľňćÖňĄÜš║┐šĘőšĘőň║Ć´╝îńŻ┐ňżŚń╗úšáüňťĘŠö»Šîüňů▒ń║źňćůňşś...
ńżőňŽé´╝îńŻ┐šöĘňÄčňşÉŠôŹńŻť´╝łatomic operations´╝늳ľňćůňşśň▒ĆÚÜť´╝łmemory barriers´╝ëňĆ»ń╗ąÚü┐ňůŹŠĽ░ŠŹ«šź×ń║ë´╝łdata races´╝ëŃÇé 9. **ŔÁäŠ║Éš«íšÉć**´╝Üňů▒ń║źňćůňşśŠ«ÁňťĘňłŤň╗║ňÉÄÚťÇŔŽüňŽąňľäš«íšÉć´╝îňîůŠőČŠŞůšÉćńŞŹňćŹńŻ┐šöĘšÜäňćůňşśŠ«Á´╝łńŻ┐šöĘ`shmctl`šÜäIPC_RMID...
CUDAŠĆÉńżŤń║ćńŞŹňÉîš║žňłźšÜäňÉąŠť║ňłÂ´╝îňîůŠőČňćůňşśŠáůŠáĆ´╝łMemory Barriers´╝ëňĺîňÄčňşÉŠôŹńŻť´╝łAtomic Operations´╝ëŃÇéŔ»ĽÚóśňĆ»ŔâŻń╝ÜŔÇâň»čňŽéńŻĽńŻ┐šöĘŔ┐Öń║ŤňÉąňĚąňůĚŠŁąŔžúňć│ŠĽ░ŠŹ«šź×ń║ëňĺîší«ń┐ŁňćůňşśńŞÇŔç┤ŠÇžšÜäÚŚ«ÚóśŃÇé 5. ň╣ÂŔíîš«ŚŠ│ĽŔ«żŔ«í´╝Üň╣ÂŔíîš«ŚŠ│ĽŔ«żŔ«íŠś»...
Ŕ┐ÖňîůŠőČCUDAš╝ľšĘőŔ»şŔĘÇšÜäňč║ŠťČňůâš┤á´╝îňŽéňćůŠáŞň篊Ľ░´╝łKernel Functions´╝ëŃÇüňůĘň▒Çňćůňşś´╝łGlobal Memory´╝ëŃÇüňů▒ń║źňćůňşś´╝łShared Memory´╝ëŃÇüňŞŞÚçĆňćůňşś´╝łConstant Memory´╝ëňĺîš║╣šÉćňćůňşś´╝łTexture Memory´╝ëšşëŃÇéšÉćŔžúŔ┐Öń║Ťňćůňşśň▒éŠČíňĺîň«âń╗ČšÜä...
### šÄ»ňóâňÖ¬ňú░ň▒ĆÚÜť´╝Üňú░ňşŽńŞÄŔžćŔžëŔ«żŔ«íŠîçňŹŚ #### ščąŔ»ćšé╣ńŞÇ´╝ܚĻňóâňÖ¬ňú░ň▒ĆÚÜťŠŽéŔ┐░ - **ň«Üń╣ë**´╝ܚĻňóâňÖ¬ňú░ň▒ĆÚÜťŠś»ŠîçšöĘń║ÄňçĆň░Ĺń║ĄÚÇÜŠłľňůÂń╗ľŠŁąŠ║Éń║žšöčšÜäňÖ¬ňú░ň»╣ňĹĘňŤ┤šÄ»ňóâňŻ▒ňôŹšÜäńŞÇšžŹš╗ôŠ×䊳ľŔ«żŠľŻŃÇé - **ÚçŹŔŽüŠÇž**´╝ÜÚÜĆšŁÇňčÄňŞéňîľŔ┐ŤšĘőšÜäňŐáň┐ź´╝î...
ÚŽľňůł´╝îŃÇÉŠáçÚóśŃÇĹńŞşŠĆÉňł░šÜäÔÇťBreaking the wireless barriers to mobilize 5G NR mmWave.pdfÔÇŁŔíĘŠśÄŔ┐Öń╗ŻŠľçń╗ÂňĆ»Ŕ⯊ÂëňĆŐňŽéńŻĽÚÇÜŔ┐çŔžúňć│ŠŚáš║┐ÚÇÜń┐íńŞşšÜäÚÜżÚ󜊣ąŠÄĘŔ┐Ť5G NR´╝łNew Radio´╝░ŠŚáš║┐´╝ëšÜ䊻źš▒│Š│óŠŐÇŠť»ŃÇ銻źš▒│Š│óŠś»5GŠŐÇŠť»šÜäňů│Úö«...