
зњїиѓСиЗ™пЉЪhttp://mechanical-sympathy.blogspot.com/2011/07/false-sharing.html
дЉ™еЕ±дЇЂ
еЖЕе≠ШеЬ®зЉУе≠Шз≥їзїЯйЗМжШѓдї•зЉУе≠Ши°МдЄЇеНХдљНе≠ШеВ®зЪДгАВзЉУе≠Ши°МжШѓе§Іе∞ПдЄЇ2зЪДжХіжХ∞еєВзЪДињЮзї≠е≠ЧиКВпЉМеЕЄеЮЛжШѓ32-256е≠ЧиКВгАВжЬАжЩЃйБНзЪДзЉУе≠Ши°Ме§Іе∞ПжШѓ64е≠ЧиКВгАВдЉ™еЕ±дЇЂжШѓ дЄ™жЬѓиѓ≠пЉМзФ®дЇОељУе§ЪдЄ™зЇњз®ЛдЄНзЯ•дЄНиІЙеЬ∞зЫЄдЇТељ±еУНеѓєжЦєзЪДжАІиГљпЉМеЬ®дњЃжФєдљњзФ®зЫЄеРМзЉУе≠Ши°МзЪДдЊЭиµЦеПШйЗПжЧґгАВзЉУе≠Ши°МдЄКзЪДеЖЩеЖ≤з™БжШѓеєґи°МжЙІи°МзЇњз®ЛеЬ®SMPпЉИеѓєзІ∞е§Ъе§ДзРЖеЩ® пЉЙз≥їзїЯдЄКиОЈеЊЧдЉЄзЉ©жАІзЪДеНХдЄАжЬАе§ІеИґзЇ¶еЫ†зі†гАВжИСеЈ≤еРђеИ∞дЉ™еű䯀襀жППињ∞дЄЇжЧ†е£∞зЪДжАІиГљжЭАжЙЛпЉМеЫ†дЄЇеЬ®жЯ•зЬЛдї£з†БжЧґпЉМеЃГйЭЮеЄЄдЄНжШОжШЊгАВ
дЄЇдЇЖиЊЊеИ∞жМЙзЇњз®ЛжХ∞йЗПзЪДзЇњжАІдЉЄзЉ©жАІпЉМжИСдїђењЕй°їз°ЃдњЭж≤°жЬЙдЄ§дЄ™зЇњз®ЛеЖЩеРМдЄАдЄ™еПШйЗПжИЦеРМдЄАдЄ™зЉУе≠Ши°МгАВдЄ§дЄ™зЇњз®ЛеЖЩеРМдЄАдЄ™еПШйЗПеПѓдї•еЬ®дї£з†Бе±ВйЭҐиЈЯиЄ™еИ∞гАВдЄЇдЇЖзЯ•йБУзЛђзЂЛ еПШйЗПжШѓеР¶еЕ±дЇЂеРМдЄАдЄ™зЉУе≠Ши°МпЉМжИСдїђйЬАи¶БзЯ•йБУеЖЕе≠ШеЄГе±АпЉМжИЦиАЕиЃ©еЈ•еЕЈеСКиѓЙжИСдїђгАВ Intel VTuneжШѓињЩж†ЈзЪДдЄАдЄ™еИЖжЮРеЈ•еЕЈгАВеЬ®ињЩзѓЗжЦЗзЂ†пЉМжИСе∞ЖиІ£йЗКJavaеѓєи±°зЪДеЖЕе≠ШеЄГе±АеТМе¶ВдљХйАЪињЗе°ЂеЕЕзЉУе≠Ши°МжЭ•йБњеЕНдЉ™еЕ±дЇЂгАВ
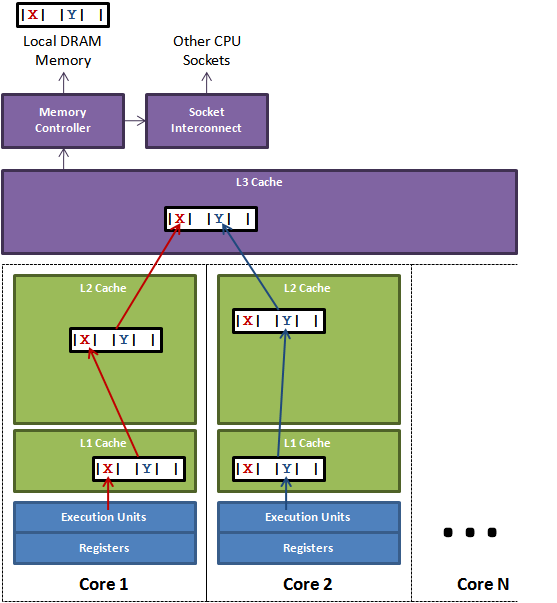
дЄКеЫЊе±Хз§ЇдЇЖдЉ™еЕ±дЇЂзЪДйЧЃйҐШгАВзЇњз®ЛAеЕБиЃЄеЬ®Core 1пЉМжГ≥жЫіжЦ∞еПШйЗПXпЉМињРи°МеЬ®Core 2зЪДзЇњз®ЛжГ≥жЫіжЦ∞еПШйЗПYгАВдЄНеєЄзЪДжШѓињЩдЄ§дЄ™зГ≠йЧ®еПШйЗПе±ЮдЇОеРМдЄАдЄ™зЉУе≠Ши°МгАВжѓПдЄ™зЇњз®Ле∞ЖзЂЮдЇЙзЉУе≠Ши°МзЪДжЙАжЬЙжЭГпЉМињЩж†ЈеЃГдїђеПѓдї•жЫіжЦ∞еЃГгАВе¶ВжЮЬCore 1иОЈеЊЧжЙАжЬЙжЭГпЉМзЉУе≠Ше≠Рз≥їзїЯйЬАи¶БдљЬеЇЯCore 2еѓєеЇФзЪДзЉУе≠Ши°МгАВељУCore 2иОЈеЊЧжЙАжЬЙжЭГеєґжЙІи°МеЃГзЪДжЫіжЦ∞пЉМCore 1 е∞Ж襀еСКиѓЙеОїдљЬеЇЯеЃГзЪДзЉУе≠Ши°МжЛЈиіЭгАВињЩе∞ЖжЭ•жЭ•еЫЮеЫЮеЊАињФиЃ©L3зЉУе≠ШжЮБе§Іељ±еУНжАІиГљгАВе¶ВжЮЬзЂЮдЇЙзЪДCoreе§ДдЇОдЄНеРМзЪДsocketsпЉМйВ£дєИйЬАи¶БйҐЭе§ЦзЪДиЈ®SocketдЇТ ињЮпЉМињЩдЄ™йЧЃйҐШе∞ЖжЫіеК†жБґеМЦгАВ
Java еЖЕе≠ШеЄГе±А
еѓєдЇОHotSpot JVMпЉМжЙАжЬЙеѓєи±°йГљжЬЙдЄАдЄ™2-е≠ЧпЉИworldпЉЙзЪДе§ігАВзђђдЄАдЄ™жШѓвАЬж†ЗиЃ∞пЉИmarkпЉЙвАЭе≠ЧпЉМжЬЙ24жѓФзЙєдљНзФ®дЇОеУИеЄМз†БеТМ8жѓФзЙєдљНзФ®дЇОж†ЗиЃ∞пЉМдЊЛе¶ВйФБзКґжАБпЉМжИЦдЇ§жНҐзФ® дЇОйФБеѓєи±°гАВзђђдЇМдЄ™е≠ЧжШѓжМЗеРСеѓєи±°жЙАе±Юз±їзЪДеЉХзФ®гАВжХ∞зїДжЬЙйҐЭе§ЦзЪДе≠ЧзФ®дЇОжХ∞зїДзЪДе§Іе∞ПгАВжѓПдЄ™еѓєи±°еѓєйљРеИ∞8е≠ЧиКВзЪДз≤ТеЇ¶иЊєзХМпЉМдЄЇдЇЖжАІиГљгАВеЫ†иАМдЄЇдЇЖжЫійЂШжХИе°ЂеЕЕпЉМеѓєи±°зЪДе≠ЧжЃµ е∞Ж襀йЗНжОТеЇПпЉМдїОе£∞жШОзЪДй°ЇеЇПеИ∞дЄЛйЭҐзЪДеЯЇдЇОе≠ЧиКВе§Іе∞ПзЪДй°ЇеЇПпЉЪ
- doubles (8) and longs (8)
- ints (4) and floats (4)
- shorts (2) and chars (2)
- booleans (1) and bytes (1)
- references (4/8)
- <repeat for sub-class fields>
пЉИиѓСж≥®пЉЪдЄКйЭҐе∞ПжЛђеПЈйЗМзЪДжХ∞е≠Чи°®з§ЇеН†зФ®зЪДе≠ЧиКВжХ∞гАВпЉЙ
жЬЙдЇЖињЩдЇЫзЯ•иѓЖпЉМжИСдїђеПѓдї•зФ®7дЄ™longеЬ®дїїжДПе≠ЧжЃµдєЛйЧіе°ЂеЕЕзЉУе≠Ши°МгАВеЬ®DisruptorйЗМпЉМжИСдїђеЬ®RingBufferжЄЄж†ЗеТМBatchEventProcessorеЇПеПЈеЩ®еС®еЫіе°ЂеЕЕзЉУе≠Ши°МгАВ
дЄЇдЇЖе±Хз§ЇжАІиГљељ±еУНпЉМиЃ©жИСдїђзФ®дЄАдЇЫзЇњз®ЛеРДиЗ™жЫіжЦ∞иЗ™еЈ±зЛђзЂЛзЪДиЃ°жХ∞еЩ®гАВињЩдЇЫиЃ°жХ∞еЩ®е∞ЖжШѓvolatileдњЃй•∞зЪДlongпЉМињЩж†Је∞ЖеПѓдї•зЬЛеИ∞дїЦдїђзЪДињЫе±ХгАВ
public final class FalseSharing
implements Runnable
{
public final static int NUM_THREADS = 4; // change
public final static long ITERATIONS = 500L * 1000L * 1000L;
private final int arrayIndex;
private static VolatileLong[] longs = new VolatileLong[NUM_THREADS];
static
{
for (int i = 0; i < longs.length; i++)
{
longs[i] = new VolatileLong();
}
}
public FalseSharing(final int arrayIndex)
{
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception
{
final long start = System.nanoTime();
runTest();
System.out.println("duration = " + (System.nanoTime() - start));
}
private static void runTest() throws InterruptedException
{
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++)
{
threads[i] = new Thread(new FalseSharing(i));
}
for (Thread t : threads)
{
t.start();
}
for (Thread t : threads)
{
t.join();
}
}
public void run()
{
long i = ITERATIONS + 1;
while (0 != --i)
{
longs[arrayIndex].value = i;
}
}
public final static class VolatileLong
{
public volatile long value = 0L;
public long p1, p2, p3, p4, p5, p6; // comment out
}
}
зїУжЮЬ
ињРи°МдЄКйЭҐзЪДдї£з†БпЉМйАРжЄРеҐЮеК†зЇњз®ЛжХ∞йЗПеТМжЈїеК†/зІїйЩ§зЉУе≠Ши°Ме°ЂеЕЕпЉМжИСеЊЧеИ∞зЪДзїУжЮЬе¶ВдЄЛеЫЊжЙАз§ЇгАВињЩжШѓи°°йЗПињРи°МеЬ®жИСзЪД4ж†Є Nehalem дЄКзЪДжµЛиѓХжМБзї≠жЧґйЧігАВ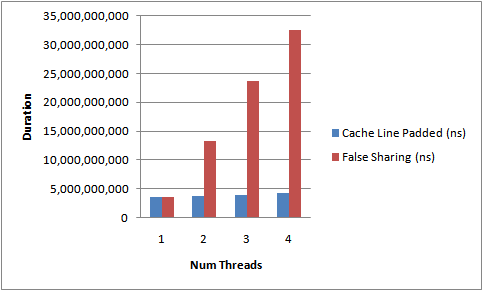
дЉ™еЕ±дЇЂзЪДељ±еУНжШѓжЄЕжЩ∞еПѓиІБзЪДпЉМйАЪињЗеЃМжИРжµЛиѓХйЬАи¶БзЪДжЧґйЧізЪДеҐЮеК†гАВж≤°жЬЙзЉУе≠Ши°МзЂЮдЇЙпЉМжИСдїђеПѓдї•иЊЊеИ∞жО•ињСжМЙзЇњз®ЛзЇњжАІзЪДжЙ©е±ХгАВ
ињЩдЄНжШѓдЄАдЄ™еЃМзЊОз≠ЙжµЛиѓХпЉМеЫ†дЄЇжИСдїђдЄНиГљз°ЃеЃЪVolatileLongsе∞ЖеЄГе±АеИ∞еЖЕе≠ШзЪДеУ™йЗМгАВдїЦдїђжШѓзЛђзЂЛзЪДеПШйЗПгАВзДґиАМпЉМзїПй™МжШЊз§ЇеРМжЧґеИЖйЕНзЪДеѓєи±°еАЊеРСдЇОеРМеЬ∞еНПдљЬпЉИco-locatedпЉЙгАВ
зО∞еЬ®дљ†зЯ•йБУпЉМдЉ™еЕ±дЇЂжШѓжЧ†е£∞зЪДжАІиГљжЭАжЙЛдЇЖгАВ
еП¶дЄАдЄ™жµЛиѓХдЊЛе≠Р
ињЩжШѓжЭ•иЗ™дљЬиАЕзЪДеП¶дЄАзѓЗжЦЗзЂ†пЉЪhttp://mechanical-sympathy.blogspot.com/2011/08/false-sharing-java-7.htmlпЉМзФ±дЇОзЫЄеЕ≥пЉМе∞±жФЊдЄАиµЈдЇЖгАВ
зЬЛиµЈжЭ•Java 7еПШеЊЧжЫіиБ™жШОдЇЖпЉМдЉЪжґИйЩ§жИЦйЗНжОТеЇПжЬ™дљњзФ®зЪДе≠ЧжЃµпЉМињЩйЗНжЦ∞еЉХеЕ•дЉ™еЕ±дЇЂгАВдљЬиАЕиЃ§дЄЇдЄЛйЭҐзЪДдї£з†БжШѓжЬАеПѓйЭ†зЪДпЉЪ
import java.util.concurrent.atomic.AtomicLong;
public final class FalseSharing
implements Runnable
{
public final static int NUM_THREADS = 4; // change
public final static long ITERATIONS = 500L * 1000L * 1000L;
private final int arrayIndex;
private static PaddedAtomicLong[] longs = new PaddedAtomicLong[NUM_THREADS];
static
{
for (int i = 0; i < longs.length; i++)
{
longs[i] = new PaddedAtomicLong();
}
}
public FalseSharing(final int arrayIndex)
{
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception
{
final long start = System.nanoTime();
runTest();
System.out.println("duration = " + (System.nanoTime() - start));
}
private static void runTest() throws InterruptedException
{
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++)
{
threads[i] = new Thread(new FalseSharing(i));
}
for (Thread t : threads)
{
t.start();
}
for (Thread t : threads)
{
t.join();
}
}
public void run()
{
long i = ITERATIONS + 1;
while (0 != --i)
{
longs[arrayIndex].set(i);
}
}
public static long sumPaddingToPreventOptimisation(final int index)
{
PaddedAtomicLong v = longs[index];
return v.p1 + v.p2 + v.p3 + v.p4 + v.p5 + v.p6;
}
public static class PaddedAtomicLong extends AtomicLong
{
public volatile long p1, p2, p3, p4, p5, p6 = 7L;
}
}



зЫЄеЕ≥жО®иНР
1.2 зЉУе≠Ши°МзЪДж¶Вењµ1.3 дЉ™еЕ±дЇЂпЉИFalse SharingпЉЙзЪДж¶Вењµ + еЕґеПѓиГљеЉХеПСзЪДжАІиГљйЧЃйҐШ2 е¶ВдљХйБњеЕНдЉ™еЕ±дЇЂ вАФ жХ∞жНЃе°ЂеЕЕ2.1 дЄНдљњзФ®жХ∞жНЃе°ЂеЕЕжЧґзЪДжХИзОЗй™МиѓБ2.2 жЙЛеК®ињЫи°МжХ∞жНЃе°ЂеЕЕзЪДжХИзОЗй™МиѓБ2.3 йАЪињЗjava8жЦ∞зЙєжАІ@sun.misc.Contended...
дЉ™еЕ±дЇЂ(False Sharing)жШѓеЬ®е§ЪзЇњз®ЛзОѓеҐГдЄ≠еЗЇзО∞зЪДдЄАзІНзО∞и±°пЉМзЙєеИЂжШѓеЬ®жґЙеПКе§Ъж†Єе§ДзРЖеЩ®зЪДжГЕеЖµдЄЛжЫідЄЇжШЊиСЧгАВеЬ®зО∞дї£иЃ°зЃЧжЬЇдљУз≥їзїУжЮДдЄ≠пЉМCPUзЉУе≠Шз≥їзїЯжШѓдї•зЉУе≠Ши°М(Cache Line)дЄЇеНХдљНињЫи°Ме≠ШеВ®зЪДгАВйАЪеЄЄжГЕеЖµдЄЛпЉМдЄїжµБCPUзЪДзЉУе≠Ши°Ме§Іе∞П...
windowsиЃњйЧЃubuntuеЊИзЃАеНХпЉМ еЕИеЬ®ubuntuдЄКиЃЊзљЃеЕ±дЇЂзЫЃељХеН≥еПѓпЉМ йЉ†ж†ЗеП≥йФЃзВєзЫЃељХпЉМйАЙжЛ©sharing options, е§ЯйАЙshare this folderпЉМйЬАи¶БзЪДиѓЭдєЯеПѓдї•е§ЯйАЙдЄЛйЭҐзЪДallow write ињЩжЧґеЬ®windowsзЪДзљСзїЬйВїе±ЕдЄ≠зЪДзљСзїЬдЄ≠жЯ•жЙЊе∞±иГљжЙЊеИ∞...
гАКEasy File Sharing Web Server 7.2пЉЪдЊњжНЈзЪДжЦЗдїґеЕ±дЇЂиІ£еЖ≥жЦєж°ИгАЛ Easy File Sharing Web Server 7.2 жШѓдЄАжђЊйЂШжХИдЄФжШУзФ®зЪДжЦЗдїґеЕ±дЇЂиљѓдїґпЉМеЃГдЄУдЄЇеЄМжЬЫйАЪињЗзљСзїЬиљїжЭЊињЫи°МжЦЗдїґдЄКдЉ†дЄОдЄЛиљљзЪДзФ®жИЈиЃЊиЃ°гАВињЩжђЊз≥їзїЯдљњеЊЧеЬ®дЇТиБФзљС...
ж†ЗйҐШдЄ≠зЪД"DesktopSharing"жМЗзЪДжШѓдЄАдЄ™еЯЇдЇОWindowsж°МйЭҐеЕ±дЇЂAPIеЉАеПСзЪДеЇФзФ®з®ЛеЇПпЉМеЃГеЕБиЃЄзФ®жИЈеИЖдЇЂдїЦдїђзЪДж°МйЭҐеЖЕеЃєзїЩеЕґдїЦдЇЇгАВеЬ®жЬђжЦЗдЄ≠пЉМжИСдїђе∞ЖжЈ±еЕ•жОҐиЃ®Windowsж°МйЭҐеЕ±дЇЂAPIзЪДеОЯзРЖгАБдљњзФ®C#зЉЦз®Лиѓ≠и®АеЃЮзО∞ж°МйЭҐеЕ±дЇЂзЪДжЦєж≥ХпЉМдї•еПК...
гАРж†ЗйҐШиІ£жЮРгАСпЉЪвАЬеЕЂеєізЇІиЛ±иѓ≠дљЬжЦЗеЕ±дЇЂеНХиљ¶Bike-sharingвАЭињЩзѓЗж†ЗйҐШи°®жШОдЇЖињЩжШѓдЄАзѓЗйТИеѓєеИЭдЄ≠зФЯзЪДиЛ±иѓ≠еЖЩдљЬпЉМдЄїйҐШжШѓеЕ≥дЇОеЕ±дЇЂеНХиљ¶пЉИBike-sharingпЉЙзЪДзО∞и±°еПКеЕґељ±еУНпЉМжЧ®еЬ®йФїзВЉе≠¶зФЯзЪДиЛ±иѓ≠и°®иЊЊиГљеКЫеТМеѓєз§ЊдЉЪзО∞и±°зЪДзРЖиІ£гАВ...
ж†ЗйҐШ "P2P_file_sharing_code.rar_Find Files_VB жЦЗдїґеЕ±дЇЂ_sharing files" жПРдЊЫдЇЖжИСдїђиЃ®иЃЇзЪДеЕ≥йФЃзВєпЉЪињЩжШѓдЄАдЄ™еЯЇдЇОVBпЉИVisual BasicпЉЙзЉЦз®Лиѓ≠и®АеЃЮзО∞зЪДP2PпЉИзВєеѓєзВєпЉЙжЦЗдїґеЕ±дЇЂеЃҐжИЈзЂѓпЉМеЃГзЪДдЄїи¶БеКЯиГљжШѓиЃ©зФ®жИЈиГље§ЯжРЬ糥庴...
жХ∞жНЃжЭ•иЗ™KaggleзЪДBikeSharing DemandйҐДжµЛй°єзЫЃпЉМжПРдЊЫдЇЖеНОзЫЫй°њзЙєеМЇ2011еєі1жЬИ1жЧ•иЗ≥2012еєі12жЬИ31жЧ•зЪДеЕ±дЇЂеНХиљ¶зІЯиµБжХ∞жНЃгАВжХ∞жНЃйЫЖеИЖдЄЇtrain.csvеТМtest.csvпЉМtrain.csvеМЕеРЂдЇЖдЄ§еєіеЖЕжѓПжЬИ1жЧ•иЗ≥19жЧ•зЪДзІЯиµБжХ∞жНЃпЉМtest.csvеМЕеРЂдЇЖ...
ChatGPT Plus еЕ±дЇЂжЦєж°ИгАВChatGPT Plus _ OpenAI API sharing solution.zip
1. **Sharing-aware Block Devices**пЉЪељУжХ∞жНЃињЫеЕ•еЖЕе≠ШжЧґпЉМз≥їзїЯдЉЪеЬ®й°µзЉУе≠ШдЄ≠зЂЛеН≥ж£АжЯ•еЕ±дЇЂжЬЇдЉЪпЉМдїОиАМеЃЮзО∞еЃЮжЧґзЪДеЕ±дЇЂж£АжµЛгАВ 2. **Repayment FIFO**пЉЪе¶ВжЮЬеű䯀姱賕пЉМз≥їзїЯдЉЪе∞Жй°µйЭҐињФеЫЮзїЩGuestпЉМз°ЃдњЭиµДжЇРзЪДжЬЙжХИеИЖйЕНгАВ ...
гАРж†ЗйҐШгАС"kaggleеє≥еП∞bike-sharingзЂЮиµЫжХ∞жНЃйЫЖ"жШѓдЄАдЄ™иСЧеРНзЪДжХ∞жНЃеИЖжЮРжѓФиµЫпЉМжЧ®еЬ®йҐДжµЛеЕ±дЇЂеНХиљ¶зЪДдљњзФ®йЬАж±ВгАВињЩдЄ™жХ∞жНЃйЫЖеЬ®KaggleдЄКеєњж≥Ы襀жХ∞жНЃзІСе≠¶еЃґеТМжЬЇеЩ®е≠¶дє†зИ±е•љиАЕзФ®жЭ•зїГдє†еТМе±Хз§ЇдїЦдїђзЪДжКАиГљгАВKaggleжШѓGoogleдЄїеКЮзЪДдЄАдЄ™...
еЯЇдЇОVueзЪДCampus-Cloud-Sharingж†°еЫ≠еЄИзФЯиµДжЦЩеЕ±дЇЂз≥їзїЯдЊњжШѓеЬ®ињЩж†ЈзЪДиГМжЩѓдЄЛеЇФињРиАМзФЯзЪДдЄАдЄ™й°єзЫЃгАВ иѓ•й°єзЫЃзЪДж†ЄењГеЉАеПСж°ЖжЮґйАЙжЛ©дЇЖVue.jsпЉМињЩжШѓдЄАдЄ™жЄРињЫеЉПJavaScriptж°ЖжЮґпЉМзФ®дЇОжЮДеїЇзФ®жИЈзХМйЭҐгАВVueзЪДеПМеРСжХ∞жНЃзїСеЃЪгАБзїДдїґеМЦзїУжЮД...
еєґиБФзФµжЇРзЪДиіЯиљљеЕ±дЇЂ load sharingпЉМиЃЊиЃ°дЄОдїЛзїНпЉМе§ЪзФ®еЬ®е§НжЭВйАЪдњ°гАБеЈ•дЄЪиЃЊе§ЗиЃЊиЃ°еЇФзФ®жЧґпЉМзФµжЇРзЪДе§ЗдїљпЉМзФµжЇРдљњзФ®жХИзОЗдЉШеМЦиЃЊиЃ°
иЩЪеБЗеЕ±дЇЂеїЇйА†mvn clean packagedocker build -t false-sharing .иЈСdocker run false-sharing
secret-sharing, дЄАдЄ™зІШеѓЖеИЖи£ВзІШеѓЖзІШеѓЖзІШеѓЖзІШеѓЖеЕ±дЇЂжЦєж°ИзЪДз≥їзїЯ зІШеѓЖеЕ±дЇЂ дЄАзІНзФ®дЇОеИЖеИЖеТМеЕ±дЇЂеѓЖйТ•( е∞±еГПжѓФзЙєжѓФзЙє private еѓЖйТ•)зЪДеЫЊдє¶й¶ЖпЉМдљњзФ®iframeеЕ±дЇЂжЦєж°ИгАВеЃЙи£Е>>> pip install secretsharingз§ЇдЊЛзФ®
жШУжНЈжЦЗдїґеЕ±дЇЂWebжЬНеК°еЩ®3.0з†іиІ£зЙИ,еЃЮзФ®зЪДеЕ±дЇЂжЬНеК°еЩ®иљѓдїґ
androidжЙЛжЬЇusbиЩЪжЛЯзљСеН°й©±еК®вАФжЙЛжЬЇиЩЪжЛЯзљСеН°вАФвАФRemote_NDIS_based_Internet_Sharing_Device жЬђжЦЗдїґдЄЇXPз≥їзїЯзФµиДСињЮжО•жЙЛжЬЇеРОе∞ЖжЙЛжЬЇзЪДдЄКзљСиµДжЇРеИЖдЇЂзїЩзФµиДСдљњзФ®гАВ tips:дљњзФ®жЙЛжЬЇжµБйЗПзїЩзФµиДСдЄКзљСеПѓдї•е§ІйЗПжґИиАЧдљ†зЪДжЙЛжЬЇжµБйЗП...
Easy File Sharing Web ServerеЕБиЃЄзФ®жИЈдЄНйЬАи¶БдїїдљХйЩДеК†зЪДиљѓдїґжИЦжЬНеК°е∞±еПѓдї•жЮґиЃЊдЄАдЄ™еЃЙеЕ®зЪДгАБеЯЇдЇОзљСй°µзЪДP2PжЦЗдїґеИЖдЇЂгАБдЉ†иЊУз≥їзїЯгАВ йЩ§дЇЖHTMLзљСй°µзХМйЭҐиЃЊиЃ°пЉМEasy File Sharing Web ServerињШеПѓдї•иЃ©дљ†зЫіжО•еЬ®иЗ™еЈ±зЪДPCдЄКењЂйАЯ...
еЬ®Androidз≥їзїЯдЄ≠пЉМ"Remote NDIS based Internet Sharing Device"жШѓдЄАзІНжКАжЬѓпЉМеЃГеЕБиЃЄжЙЛжЬЇйАЪињЗUSBињЮжО•еИ∞иЃ°зЃЧжЬЇпЉМеєґе∞ЖжЙЛжЬЇдљЬдЄЇдЄАдЄ™зљСзїЬжО•еП£иЃЊе§ЗпЉИзљСеН°пЉЙжЭ•еЕ±дЇЂзІїеК®жХ∞жНЃињЮжО•гАВињЩдЄ™еКЯиГљдљњеЊЧзФ®жИЈиГље§ЯеИ©зФ®жЩЇиГљжЙЛжЬЇзЪД3GгАБ4G...