
这是ElasticSearch 2.4 版本系列的第三篇:
- ElasticSearch入门 第一篇:Windows下安装ElasticSearch
- ElasticSearch入门 第二篇:集群配置
- ElasticSearch入门 第三篇:索引
- ElasticSearch入门 第四篇:使用C#添加和更新文档
- ElasticSearch入门 第五篇:使用C#查询文档
- ElasticSearch入门 第六篇:复合数据类型——数组,对象和嵌套
- ElasticSearch入门 第七篇:分析器
- ElasticSearch入门 第八篇:存储
- ElasticSearch入门 第九篇:实现正则表达式查询的思路
ElasticSearch是文档型数据库,索引(Index)定义了文档的逻辑存储和字段类型,每个索引可以包含多个文档类型,文档类型是文档的集合,文档以索引定义的逻辑存储模型,比如,指定分片和副本的数量,配置刷新频率,分配分析器等,存储在索引中的海量文档分布式存储在ElasticSearch集群中。
ElasticSearch是基于Lucene框架的全文搜索引擎,将所有文档的信息写入到倒排索引(Inverted Index)的数据结构中,倒排索引建立的是索引中词和文档之间的映射关系,在倒排索引中,数据是面向词(Term)而不是面向文档的。
ElasticSearch的对象模型,跟关系型数据库模型相比:
- 索引(Index):相当于数据库,用于定义文档类型的存储;在同一个索引中,同一个字段只能定义一个数据类型;
- 文档类型(Type):相当于关系表,用于描述文档中的各个字段的定义;不同的文档类型,能够存储不同的字段,服务于不同的查询请求;
-
文档(Document):相当于关系表的数据行,存储数据的载体,包含一个或多个存有数据的字段;
- 字段(Field):文档的一个Key/Value对;
- 词(Term):表示文本中的一个单词;
- 标记(Token):表示在字段中出现的词,由该词的文本、偏移量(开始和结束)以及类型组成;
索引是由段(Segment)组成的,段存储在硬盘(Disk)文件中,段不是实时更新的,这意味着,段在写入磁盘后,就不再被更新。ElasticSearch引擎把被删除的文档的信息存储在一个单独的文件中,在搜索数据时,ElasticSearch引擎首先从段中查询,再从查询结果中过滤被删除的文档,这意味着,段中存储着“被删除”的文档,这使得段中含有”正常文档“的密度降低。多个段可以通过段合并(Segment Merge)操作把“已删除”的文档将从段中物理删除,把未删除的文档合并到一个新段中,新段中没有”已删除文档“,因此,段合并操作能够提高索引的查找速度,但段合并是IO密集型的操作,需要消耗大量的硬盘IO。
一,创建索引
在创建索引之前,首先了解RESTful API的调用风格,在管理和使用ElasticSearch服务时,常用的HTTP动词有下面五个:
-
GET 请求:获取服务器中的对象
- 相当于SQL的Select命令
- GET /blogs:列出所有博客
-
POST 请求:在服务器上更新对象
- 相当于SQL的Update命令
- POST /blogs/ID:更新指定的博客
-
PUT 请求:在服务器上创建对象
- 相当于SQL的Create命令
- PUT /blogs/ID:新建一个博客
- DELETE 请求:删除服务器中的对象
- 相当于SQL的Delete命令
- DELETE /blogs/ID:删除指定的博客
- HEAD 请求:仅仅用于获取对象的基础信息
1,禁用自动创建索引
推荐设置:在全局配置文件 elasticsearch.yml 中,禁用自动创建索引:
action.auto_create_index:false
2,手动创建索引
创建索引的语法是:PUT http://host:port/index_name/ + index_configuration
其中,index_name是创建的索引的名字,indiex_configuration 是向ElasticSearch服务器传递的请求负载的主体,数据格式是json,用于定义索引的配置信息:映射节(mappings)和配置节(settings)。
在创建索引时,需要精心设计索引的映射节(mappings)和配置节(settings),本例创建blog索引和articles文档类型,创建索引的语法是:
PUT http://localhost:9200/blog/
下文详细介绍ElasticSearch索引的映射(Mapping)配置,详细信息请参考《Elasticsearch Reference [2.4] » Mapping》。注意,ElasticSearch引擎是大小写敏感的,强制性要求索引名和文档类型小写,对于字段名,ElasticSearch引擎会将首字母小写,建议在配置索引,文档类型和字段名时,都使用小写字母。
二,索引映射节(mappings)
1,索引结构
索引是由文档类型构成的,在mappings字段中定义索引的文档类型,示例代码中为blog索引定义了三个文档类型:articles,followers和comments

{ "mappings":{ "articles":{ }, "followers":{ }, "comments":{ } } }
2,文档属性
文档属性定义了文档类型的共用属性,适用于文档的所有字段:
- dynamic_date_formats属性:该属性定义可以识别的日期格式列表;
-
dynamic属性:默认值为true,允许动态地向文档类型中加入新的字段。推荐设置为false,禁止向文档中添加字段,这样,文档类型的所有字段必须在索引映射的properties属性中显式定义,在properties字段中未定义的字段都将会ElasticSearch忽略。
- dynamic设置为ture:默认值,新增加的字段被添加到索引映射中;
- dynamic设置为false:新增加的字段会被忽略;
- dynamic设置为strict:当向文档中新增字段时,ElasticSearch引擎抛出异常;
{ "mappings":{ "articles":{ "dynamic":false, "dynamic_date_formats":["yyyy-MM-dd hh:mm:ss", "yyyy-MM-dd" ], "properties":{ "id":{}, "title":{}, "author":{}, "content":{}, "postedat":{} } } } }
三,文档的字段属性
1,字段的数据类型
字段的数据类型由字段的属性type指定,ElasticSearch支持的基础数据类型主要有:
- 字符串类型:string;
- 数值类型:字节(byte)、2字节(short)、4字节(integer)、8字节(long)、float、double;
- 布尔类型:boolean,值是true或false;
- 时间/日期类型:date,用于存储日期和时间;
- 二进制类型:binary;
- IP地址类型:ip,以字符串形式存储IPv4地址;
- 特殊数据类型:token_count,用于存储索引的字数信息
在文档类型的properties属性中,定义字段的type属性,指定字段的数据类型,属性properties 用于定义文档类型的字段属性,或字段对象的属性:
"properties":{
"id":{"type":"long"},
2,字段的公共属性
-
index:该属性控制字段是否编入索引被搜索,该属性共有三个有效值:analyzed、no和not_analyzed:
- analyzed:表示该字段被分析,编入索引,产生的token能被搜索到;
- not_analyzed:表示该字段不会被分析,使用原始值编入索引,在索引中作为单个词;
- no:不编入索引,无法搜索该字段;
- 其中analyzed是分析,分解的意思,默认值是analyzed,表示将该字段编入索引,以供搜索。
- store:指定是否将字段的原始值写入索引,默认值是no,字段值被分析,能够被搜索,但是,字段值不会存储,这意味着,该字段能够被查询,但是不会存储字段的原始值。
- boost:字段级别的助推,默认值是1,定义了字段在文档中的重要性/权重;
- include_in_all:该属性指定当前字段是否包括在_all字段中,默认值是ture,所有的字段都会包含_all字段中;如果index=no,那么属性include_in_all无效,这意味着当前字段无法包含在_all字段中。
- copy_to:该属性指定一个字段名称,ElasticSearch引擎将当前字段的值复制到该属性指定的字段中;
- doc_values:文档值是存储在硬盘上的索引时(indexing time)数据结构,对于not_analyzed字段,默认值是true,analyzed string字段不支持文档值;
- fielddata:字段数据是存储在内存中的查询时(querying time)数据结构,只支持analyzed string字段;
- null_value:该属性指定一个值,当字段的值为NULL时,该字段使用null_value代替NULL值;在ElasticSearch中,NULL 值不能被索引和搜索,当一个字段设置为NULL值,ElasticSearch引擎认为该字段没有任何值,使用该属性为NULL字段设置一个指定的值,使该字段能够被索引和搜索。
3,字符串类型常用的其他属性
- analyzer:该属性定义用于建立索引和搜索的分析器名称,默认值是全局定义的分析器名称,该属性可以引用在配置结点(settings)中自定义的分析器;
- search_analyzer:该属性定义的分析器,用于处理发送到特定字段的查询字符串;
- ignore_above:该属性指定一个整数值,当字符串字段(analyzed string field)的字节数量大于该数值之后,超过长度的部分字符数据将不能被analyzer处理,不能被编入索引;对于 not analyzed string字段,超过长度的部分字符将被忽略,不会被编入索引。默认值是0,禁用该属性;
- position_increment_gap:该属性指定在相同词的位置上增加的gap,默认值是100;
-
index_options:索引选项控制添加到倒排索引(Inverted Index)的信息,这些信息用于搜索(Search)和高亮显示:
- docs:只索引文档编号(Doc Number)
- freqs:索引文档编号和词频率(term frequency)
- positions:索引文档编号,词频率和词位置(序号)
- offsets:索引文档编号,词频率,词偏移量(开始和结束位置)和词位置(序号)
- 默认情况下,被分析的字符串(analyzed string)字段使用positions,其他字段使用docs;
- docs:只索引文档编号(Doc Number)
分析器(analyzer)把analyzed string 字段的值,转换成标记流(Token stream),例如,字符串"The quick Brown Foxes",可能被分解成的标记(Token)是:quick,brown,fox。这些词(term)是该字段的索引值,这使用对索引文本的查找更有效率。字段的属性 analyzer 用于指定在index-time和search-time时,ElasticSearch引擎分解字段值的分析器名称。
4,数值类型的其他属性
- precision_step:该属性指定为数值字段每个值生成的term数量,值越低,产生的term数量越高,范围查询越快,索引越大,默认值是4;
- ignore_malformed:忽略格式错误的数值,默认值是false,不忽略错误格式,对整个文档不处理,并且抛出异常;
- coerce:默认值是true,尝试将字符串转换为数值,如果字段类型是整数,那么将小数取整;
5,日期类型的其他属性
- format:指定日期的格式,例如:“yyyy-MM-dd hh:mm:ss”
- precision_step:该属性指定数值字段每隔多少数值,生成一个词(term);step值越低,产生的词数量越高,范围查询越快,索引越大,占用存储空间越大;
- ignore_malformed:忽略错误格式,默认值是false,不忽略错误格式;
6,多字段(fields)
在fields属性中定义一个或多个字段,该字段的值和当前字段值相同,可以设置一个字段用于搜索,一个字段用于排序等。
"properties": { "id":{ "type":"long", "fields":{ "id2":{"type":"long","index":"not_analyzed"} } },
7,文档值(doc_values)
默认情况下,多数字段都被一起编入索引,用户使用倒排索引(Inverted Index)可以搜索到相应的词(Term),倒排索引支持在唯一的有序词列表中查找特定词,或检查文档中是否包含某个词,但是,对于排序(Sort),聚合和在脚本中访问特定字段的值(Field value),这三个操作需要执行不同的数据访问模式,即单字段数据访问:在文档中查找特定的字段,检查该字段是否包含指定的词。
文档值(doc_values)属性指定将字段的值写入到硬盘上的列式结构,实现了单个字段的数据访问模式,能够高效执行排序和聚合搜索。使用文档值的字段将有专属的字段数据缓存实例,无需像普通字段一样倒排。是存储在硬盘上的数据结构,在文档索引时创建。文档值数据存在硬盘上,在文档索引时创建,存储的数据和字段存储在_source 字段的数据相同,文档值支持所有的字段类型,除了analyzed string 字段之外。
默认情况下,所有的字段都支持文档值,默认是启用的(enabled),如果不需要在单个字段上执行排序或聚合操作,或者从脚本中访问指定字段的值,那么,可以禁用文档值,字段的值将不会存储在硬盘空间中。
"properties": { "status_code": { "type": "string", "index": "not_analyzed" "doc_values": true }, "session_id": { "type": "string", "index": "not_analyzed", "doc_values": false } }
8,字段数据(Fielddata)
字段数据(Fielddata)是存储在内存中的查询时数据结构,只支持analyzed string字段。该数据结构在字段第一次执行聚合,排序或被脚本访问时创建。创建的过程是:在读取整个倒排索引(Inverted Index)时,ElasticSearch从硬盘上加载倒排索引的每个段(Segment),倒转词(Term)和文档的关系,并将其存储在JVM堆内存中。加载字段数据的过程是非常消耗IO资源的,一旦被加载,就被存储在内存中,直到段的生命周期结束。
对于analyzed string字段,fielddata字段是默认启用的,
"text":{ "type":"string", "fielddata":{ "loading":"lazy" } }
详细信息,请参考Mapping parameters » fielddata
Analyzed strings use a query-time data structure called fielddata. This data structure is built on demand the first time that a field is used for aggregations, sorting, or is accessed in a script. It is built by reading the entire inverted index for each segment from disk, inverting the term ↔︎ document relationship, and storing the result in memory, in the JVM heap.
9,存储(store)
存储(store)属性指定是否将字段的原始值写入索引,默认值是no,字段值被分析,能够被搜索,但是,字段的原始值不会存储,这意味着,该字段能够被查询,但是无法获取字段的原始值。默认情况下,该字段的值会被存储到_source字段中,如果想要获取单个或多个字段的值,而不是整个_source字段,可以使用 source filtering 来实现;但是在特定的条件下,只存储一个字段的值是有意义的(make sense),例如,一个article文档包含:title,postdate和content字段,从文档中只获取title和postdate字段,并且使_source 字段包含content字段,必须通过store属性来控制:
"mappings": { "my_type": { "properties": { "title": { "type": "string", "store": true }, "date": { "type": "date", "store": true }, "content": { "type": "string",
"store": false } } } }
10,位置增加间隔(position_increment_gap)
对于analyzed string字段,都会考虑把词的位置信息,用于支持位置和短语匹配查询(proximity or phrase queries),例如,有一个字符串字段,该字段中存在多个词“fake”,ElasticSearch引擎会在每个值之间增加一个gap,以防止短语匹配或位置匹配查询出现跨越多个词的异常,这个gap的值就是属性position_increment_gap,默认值是100;
四,元字段
在索引的映射中,元字段(Meta-field)是以下划线开头的字段,部分元字段可以配置,部分元字段不可配置,只能用于返回信息。
1,_all 字段,可以配置
ElasticSearch使用_all字段存储其他字段的数据以便搜索,默认情况下,_all字段是启用的,包含了索引中所有字段的数据,然而这一字段使索引变大,如果不需要,请禁用该字段,或排除某些字段。为了在_all字段中不包括某个特定字段,在字段中设置“include_in_all”属性为false。
禁用_all字段,需要修改映射配置:
{ "articles":{ "_all":{ "enabled":false } } }
2,_source 字段,可以配置
_source字段表示在生成索引的过程中,存储发送到ElasticSearch的原始JSON文档,默认情况下,该字段会被启用,因为索引的局部更新功能依赖该字段。
{ "articles":{ "_source":{ "enabled":true } } } { "articles":{ "_source":{ "excludes":["Content","Comments"], "includes":["author"] } } }
3,_routing 字段,可以配置
路由字段,将一个文档值进行哈希映射,并将该文档路由到指定的分片,路由的公式是:
shard_num = hash(_routing) % num_primary_shards
在ElasticSearch 2.4 版本中,path参数被废弃,使用的默认字段是_id,设置required为true,表示路由字段在进行索引的CRUD操作时必需显式赋值。
{ "articles":{ "_routing":{ "required":true } } }
在put 命令中,使用自定义的路由字段,以下示例使用 user1字段作为路由字段更新和查询文档:
PUT my_index/my_type/1?routing=user1 { "title": "This is a document" } GET my_index/my_type/1?routing=user1
4,不可配置的元字段
- _index:返回文档所属的索引
- _uid:返回文档的type和id
- _type:返回文档类型(type)
- _id:返回文档的ID;
- _size:返回文档的_source字段中函数的字节数量;
- _field_names:返回文档中不包含null值的字段名称;
详细信息,请参考:Mapping » Meta-Fields
五,索引配置节(settings)
1,配置索引的分片和副本数量
ElasticSearch索引是有一个或多个分片组成的,每个分片是索引的一个水平分区,包含了文档数据的一部分;每个分片有0,1或多个副本,分片的副本和分片存储相同的数据。
示例代码,为索引创建5个分片,分片没有副本:
"settings":{ "number_of_shards":5, "number_of_replicas":0,
2,配置分析器(analyzer)
在配置结点的analysis属性中配置分析器,参考官方文档了解更多,
分词器(tokenizer)是系统预定义的,常用的分词器是:
- standard:默认值,用于大多数欧洲语言的标准分词器
- simple:基于非字母字符来分词,并将其转化为小写形式
- whitespace:基于空格来分词
- stop:除了simple的所有功能,还能基于停用词(stop words)过滤数据;
- pattern:使用正则表达式分词;
- snowball:除了standard提供的分词功能之外,还提供词干提取功能;
过滤器是系统预定义的,常用的过滤器是:
- asciifolding
- lowercase
- kstem
在配置结点中,自定义分析器(analyzer)示例代码:
 View Code
View Code
六,删除索引
删除索引的语法是: DELETE http://localhost:9200/blog
七,更新索引
索引的更新分为逐个文档的更新和批量文档更新:
1,单个文档(Individual Document)的更新
单个文档更新的语法是:POST http://localhost:9200/blog/articles/1 +文档对象的JSON数据
POST http://localhost:9200/blog/articles/1
文档对象的JSON数据示例如下:
{ "id":1, "title":"Elasticsearch index", "Author":"悦光阴", "content":"xxxxxxxxxxx", "postedat":"2017-03-14" }
2,批量文档的更新(Bluk)
批量文档更新的语法是:POST http://localhost:9200/_bulk + 批量文档对象的JSON数据,在_bulk 端进行批量更新操作。
在传递的请求主体中,每一个请求分为两个JSON数据,第一个JSON数据包含操作说明的描述信息,第二个JSON数据包含文档对象:
View Code
八,搜索索引
在_search端对索引数据进行搜索,ES查询的语法非常复杂,总体来说,ElasticSearch支持聚合查询和简单查询。
1,按照路由搜索
路由可以控制文档和查询转发的目的分片,ElasticSearch计算路由字段的哈希值,对于相同的路由值,将产生相同的哈希值,分配到特定的分片上;如果在查询时,指定路由值,那么只需要搜索单个分片而不是整个索引,就能获取查询结果。
路由字段由文档类型的_routing属性定义,在查询时,使用routing参数来查找特定路由的文档:
GET http://localhost:9200/blog/_search?routing=1235&q=article_id=100
2,聚合和简单查询
请阅读《ElasticSearch查询 第一篇:搜索API》
附:索引的配置文档
View Code
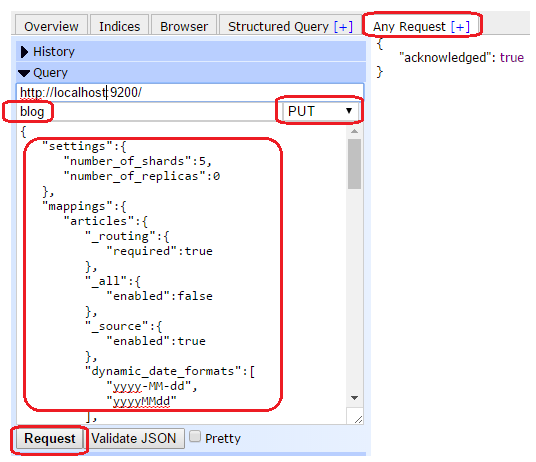
在head插件中,打开"Any Request"窗体,输入索引名称:blog;在操作列表中选择PUT,并将配置文档作为请求body,点击下方的“Request”按钮,向Elasticsearch引擎发起请求,当右边面板中出现"acknowledged":true 时,说明索引blog创建成功。
在测试阶段,可以禁用路由(_routing)和_all字段,启用源(_source)字段,以便更好的观察索引的行为。
当启用dynamic属性时,推荐所有字段的名称都使用小写,
参考文档:
Elasticsearch Reference [2.4] » Mapping » Mapping parameters
Elasticsearch Reference [2.4] » Index Modules
Elasticsearch Reference [2.4] » Mapping



相关推荐
版本 2.4 是 Elasticsearch 的一个稳定版本,提供了强大的搜索性能和丰富的分析功能。 **IK 分词器** IK 分词器(Intelligent Chinese Analyzer for Elasticsearch)是针对 Elasticsearch 设计的一款中文分词插件...
在使用 Elasticsearch 2.4 之前,需要确保系统至少安装了 JDK 1.7,因为这是该版本 Elasticsearch 的最低Java运行时环境要求。 ### 1. 分布式架构 Elasticsearch 的核心特性之一是其分布式架构。它能够自动将数据...
- 2.4.1版本继续支持基于HTTP的RESTful API,这使得与Elasticsearch的交互变得简单直观,可以使用各种编程语言轻松进行集成。 4. **查询与分析**: - 提供了丰富的查询语法,包括全文搜索、短语匹配、范围查询、...
版本 2.4.6 是 Elasticsearch 的一个重要里程碑,提供了稳定性和性能的优化。 **1. 安装与配置** 在 Linux 系统上安装 Elasticsearch 2.4.6,首先需要下载提供的 `elasticsearch-2.4.6` 压缩包。解压后,将文件移动...
此插件的版本为2.4.3.0,提供了与传统关系型数据库相似的交互方式,使那些熟悉SQL语法的用户能够更便捷地在Elasticsearch中进行数据管理。 Elasticsearch本身是一个分布式的、实时的搜索和分析引擎,它以JSON文档为...
这个插件的版本是2.4.5.0,它提供了一种熟悉的方式来访问Elasticsearch的数据,特别是对于那些习惯于传统数据库系统的人来说,这是一个非常方便的功能。 首先,让我们深入了解一下Elasticsearch。Elasticsearch是一...
Elasticsearch 使用 JSON(JavaScript Object Notation)作为数据交换格式,使得数据的导入和查询更加方便,同时也与现代Web服务和NoSQL数据库紧密集成。 ### 4. RESTful API Elasticsearch 采用 RESTful 风格的 ...
本pdfjs版本2.4.456,截至上传时间,当前的稳定版,官方的下载超级慢,好不容易下载了,分享出来。 说明:里面有两套压缩包文件,分别是Prebuilt 和Prebuilt (ES5-compatible),后者是对ES5做了兼容。 其中build...
Elasticsearch(简称ES)是一个强大的分布式全文搜索引擎,而Elasticsearch-SQL插件则使得我们能够通过熟悉的SQL语法来查询ES中的数据,极大地降低了使用门槛,尤其对熟悉关系型数据库的开发者而言。下面我们将详细...
这个压缩包“pdfjs-2.4.456-dist”包含了该库的最新稳定版本,允许用户在各种现代浏览器环境中查看PDF文件。让我们深入探讨一下PDF.js的关键特性、工作原理以及如何使用它。 PDF.js的核心功能在于其能够解析PDF文件...
### Elasticsearch数据库的下载、配置与使用案例 #### 一、Elasticsearch数据库的下载与安装 **1.1 下载与解压** - **下载Elasticsearch:** - **官方网站下载:** 访问Elasticsearch官方网站...
"elasticsearch-analysis-ik-1.10.1.zip"是该插件的1.10.1版本压缩包,经过解压后即可在ES 2.4版本上直接使用。这个版本的IK分词插件经过了长时间的优化和迭代,稳定性较高,与ES 2.4的兼容性也得到了充分的验证。 ...
标题“es2.4.4添加ik分词插件”涉及到的是在Elasticsearch(ES)2.4.4版本中安装IK分词插件的过程。这个过程是为了解决中文文本的索引和搜索问题,因为Elasticsearch默认的分词器主要针对英文,对中文的支持不够理想...
**Elasticsearch Head 插件详解** Elasticsearch Head 是一个非常实用的开源插件,专为 Elasticsearch 设计,提供了一个直观的用户界面,让用户能够方便地管理和监控 Elasticsearch 集群。它以其轻量级、易安装和即...
标题“es2.4.1客户端连接修正”指的是在Elasticsearch 2.4.1版本中遇到的客户端连接问题的修复。Elasticsearch(简称ES)是一个分布式、开源的全文搜索引擎,广泛应用于数据存储、搜索和分析。在这个特定的案例中,...
总结,ESManager是Elasticsearch 2.4版本中的得力助手,通过其丰富的功能,我们可以高效地管理和维护ES集群,提升工作效率。在实际应用中,结合官方文档和社区资源,不断探索和实践,才能更好地驾驭Elasticsearch,...
Elasticsearch(ES)是一款强大的开源搜索引擎,其核心功能是全文检索,而分词器则是实现全文检索的关键组件。在ES 2.4.0版本中,IK分词器(IK Analyzer)作为中文分词工具,扮演着至关重要的角色。IK分词器是由国人...
### ElasticSearch搜索引擎使用 #### 一、ElasticSearch概述 **ElasticSearch**是一个高度分布式的、基于**Lucene**的全文搜索引擎。它为用户提供了一种简单的方式来进行大规模的数据搜索和分析工作。Elastic...
在jdk为1.7当中,不支持elasticSearch2.4以上,这里的资源为elasticSearch2.3.5加上对应elasticSearch版本的ik分词器,和gson的jar包,可以处理json到实体类,map,list的转换。在项目中会使用到
### Elasticsearch 5.4.1 安装与配置详解 #### 一、Elasticsearch简介 Elasticsearch是一个基于Lucene的开源搜索和分析引擎,适用于各种类型的数据,包括文本、数字、地理空间数据等。它能够提供快速的全文搜索能力...