htmlunit 是一款开源的java 页面分析工具,读取页面后,可以有效的使用htmlunit分析页面上的内容。项目可以模拟浏览器运行,被誉为java浏览器的开源实现。这个没有界面的浏览器,运行速度也是非常迅速的。相关文件下载地址:http://sourceforge.net/projects/htmlunit/files/ (依赖的包略多 )
)
我的需求是使用百度的高级新闻搜索,抓取指定时间段的新闻,手动搜索的设置如图所示:
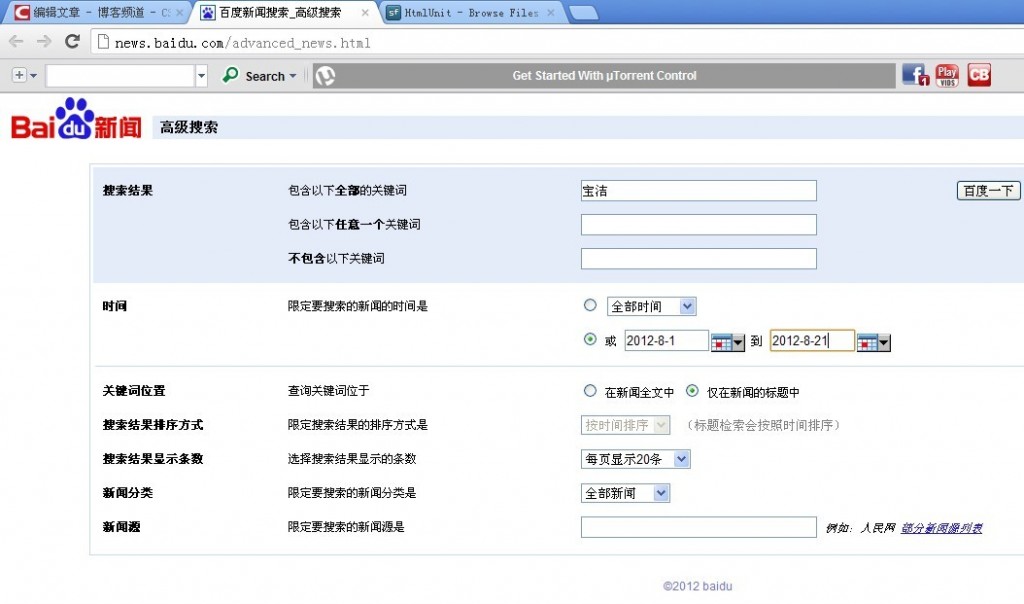
通过htmlunit可以方便地操作网页中的form和各类的input控件,如HtmlSubmitInput,HtmlTextInput,HtmlRadioButtonInput,HtmlHiddenInput等等,可以通过name和value查找对应的DOM结点。一开始遇到的问题是,即使正确地操作了radio Button,也不能得出正确的时间段内的结果,用chrome查看了Http
header后发现,百度在form中隐藏了两个参数,参数名为bt和et,分别代表用户选中的那两个时间begin_date和end_date与1970-1-1之间的间隔时长的时间戳,因此还需要手动添加这两个参数,才能得出对应时间段的结果,代码如下:
final WebClient webclient = new WebClient();
final HtmlPage htmlpage = webclient
.getPage("http://news.baidu.com/advanced_news.html");
webclient.setCssEnabled(false);
webclient.setJavaScriptEnabled(false);
// System.out.println(htmlpage.getTitleText());
final HtmlForm form = htmlpage.getFormByName("f");
final HtmlSubmitInput button = form.getInputByValue("百度一下");
final HtmlTextInput textField = form.getInputByName("q1");
textField.setValueAttribute(word);
final List<HtmlRadioButtonInput> radioButtons = form
.getRadioButtonsByName("s");
radioButtons.get(0).setChecked(false);
radioButtons.get(1).setChecked(true);// 选中限定时间段的radion button
final List<HtmlRadioButtonInput> titleButtons = form
.getRadioButtonsByName("tn");
titleButtons.get(0).setChecked(false);
titleButtons.get(1).setChecked(true); //选中“仅在新闻的标题中”的radion button
HtmlHiddenInput bt = form.getInputByName("bt");
bt.setValueAttribute("1167580800"); //2007-1-1的时间戳
HtmlHiddenInput et = form.getInputByName("et");
et.setValueAttribute("1199116799"); //2007-12-31的时间戳
final HtmlPage page2 = button.click();
String result = page2.asText();
Pattern pattern = Pattern.compile("找到相关新闻 约(.*) 篇");
Matcher matcher = pattern.matcher(result);
webclient.closeAllWindows();
if (matcher.find())
return matcher.group(1);
分享到:





相关推荐
java使用htmlunit工具抓取js中加载的数据.docx
以下是使用HTMLUnit进行此类操作的基本步骤: 1. **导入库**:在Java项目中,你需要添加HTMLUnit的依赖。如果你使用的是Maven,可以在pom.xml文件中添加以下依赖: ```xml <groupId>net.sourceforge.htmlunit</...
本文将深入探讨如何使用HTMLUnit、PhantomJS和JBrowserDriver这三种无头浏览器技术来实现网页抓取。这些工具都基于Java语言,因此适合Java开发者进行网页抓取工作。 首先,HTMLUnit是一个强大的无头Java浏览器,它...
HTMLUnit是一个强大的Java库,它模拟了一个无头Web浏览器,主要用于自动化测试和网页抓取。在版本2.23的zip文件中,我们主要关注HTMLUnit的核心功能和它如何帮助开发者处理HTML内容。 HTMLUnit的核心是基于Jakarta ...
HTMLUnit使用HttpClient来处理网络通信,包括GET和POST请求,设置请求头,处理重定向等。版本4.5.2提供了一套完整的HTTP协议实现,支持HTTPS和各种HTTP特性。 4. **xml-apis-1.4.01.jar**:这是一个XML API的集合,...
常规的AJAX页面抓取: 对于绝大部分诸如jQuery ajax加载的页面,可以直接用protocol-htmlunit插件抓取。 特殊的AJAX请求页面抓取: 诸如淘宝/天猫的页面采用了独特的Kissy Javascript组件, 导致...
**结合使用htmlunit2.8与jsoup1.7** 将这两个库结合起来,可以实现更强大的数据抓取能力。首先,HtmlUnit加载整个网页,执行JavaScript,然后Jsoup解析HtmlUnit得到的HTML内容,提取我们需要的数据。这样做的好处...
HTMLUnit是一个Java库,它提供了一个无头浏览器模拟器,用于自动化Web页面的测试和抓取。这个库的核心功能是能够解析、渲染和执行JavaScript,从而使得开发者可以在没有实际浏览器环境的情况下,对网页进行功能测试...
5. **CSS解析**: 对于CSS的支持,HTMLUnit使用了Cascading Style Sheets (CSS) Object Model (CSOM)来解析和应用CSS规则。 6. **异常处理和模拟**: HTMLUnit还包含了各种模拟浏览器行为的组件,如模拟点击、填写...
将这些JAR文件解压并导入到你的Java项目后,你就可以开始使用HTMLUnit进行网页测试或抓取。例如,你可以创建一个`HtmlPage`对象,加载URL,然后通过这个对象来执行JavaScript、查找元素或提取数据。 8. **示例代码...
使用HTMLUnit,开发者可以编写代码来浏览网页、填写表单、点击链接,甚至执行JavaScript,而无需真正打开一个浏览器。这对于自动化测试、数据抓取和无头爬虫来说非常有用。由于其无头特性,HTMLUnit在服务器端或...
HTMLUnit是一个强大的Java库,主要用于自动化网页浏览和数据抓取任务。它是一个无头浏览器,意味着它可以在没有图形用户界面的情况下运行,这对于自动化测试和Web抓取非常有用。标题中的"htmlunit-2.31.jar"是...
这个“htmlunit-2.19-bin”压缩包包含了HTMLUnit的二进制版本,允许开发者在Java应用程序中进行网页自动化测试和网页抓取。以下是关于HTMLUnit及其2.19版本的一些关键知识点: 1. **HTMLUnit简介**:HTMLUnit是一个...
使用HTMLUnit进行网页抓取时,应遵守网站的robots.txt协议,尊重网站的版权和隐私政策。此外,频繁的抓取可能会被服务器视为攻击,因此需要合理控制请求频率,必要时使用代理IP。 总结来说,"htmlunit爬取数据转储...
HTMLUnit是一款强大的Java库,它模拟了一个无头Web浏览器,主要用于自动化Web测试和网页抓取。这个参考文档是关于HTMLUnit的API详细说明,对于开发者来说是理解和使用HTMLUnit的重要资源。下面,我们将深入探讨...
9. **安全性**:在使用HTMLUnit进行网页抓取时,需要遵循网络伦理和法律法规,尊重网站的robots.txt文件,避免对目标服务器造成过大的负载,防止被识别为恶意爬虫。 10. **学习资源**:要学习和使用HTMLUnit,可以...
值得注意的是,随着Java版本的更新,某些新特性可能无法在HTMLUnit 2.20中使用,但它的稳定性和对Java 7的支持使其在某些场景下仍然很有价值。 HTMLUnit的核心功能包括: 1. **无头浏览器模拟**:HTMLUnit可以在...
3. **错误处理**:在使用HTMLUnit时,由于JavaScript执行和网络请求的复杂性,需要处理可能出现的各种异常。 4. **性能优化**:虽然HTMLUnit是为了快速和自动化测试设计的,但在大规模使用时,仍需考虑性能优化,...
这个"giat-htmlunit_test.rar"压缩包显然包含了与使用HTMLUnit进行JavaScript交互和网页抓取相关的代码示例或测试用例。在本文中,我们将深入探讨HTMLUnit的用途、如何使用它来访问和修改网页上的JavaScript,以及...