- жµПиІИ: 278975 жђ°
- жАІеИЂ:

- жЭ•иЗ™: жЭ≠еЈЮ
-

жЦЗзЂ†еИЖз±ї
з§ЊеМЇзЙИеЭЧ
- жИСзЪДиµДиЃѓ ( 0)
- жИСзЪДиЃЇеЭЫ ( 0)
- жИСзЪДйЧЃз≠Ф ( 0)
е≠Шж°£еИЖз±ї
- 2020-06 ( 1)
- 2018-04 ( 1)
- 2014-02 ( 1)
- жЫіе§Ъе≠Шж°£...
жЬАжЦ∞иѓДиЃЇ
-
lgh1992314пЉЪ
" target="_blank" ...
springж°ЖжЮґе≠¶дє†зђФиЃ∞пЉИдЇМпЉЙвАФвАФspringзЪДiocдєЛResource -
15533921258пЉЪ
ж•ЉдЄїеЖЩзЪДзЬЯдЄНйФЩеХКпЉМеЊИе§ЪдЇЇзЪДеНЪеЃҐеП™иѓіеЃҐжИЈзЂѓеПСдЄАжђ°иѓЈж±Ве∞±дЉЪзФЯжИРht ...
Servletе≠¶дє†жХізРЖпЉИеЫЫпЉЙвАФвАФ ServletRequestеТМServletResponse -
rc111xпЉЪ
ељУдљ†жЙАжЬЙзЪДдЄЬи•њйГљеЉДе•љдєЛеРО,еЬ®й°єзЫЃйЗМйЭҐеРѓеК®jettyжЬНеК°еЩ®еРОеЗЇзО∞ ...
еИ©зФ®mavenеИЫеїЇwebx3й°єзЫЃвАФвАФеЃЮзО∞зЃАеНХзЪДзХЩи®АжЭњпЉИеЕ≠пЉЙ -
rc111xпЉЪ
rc111x еЖЩйБУL_Griselda еЖЩйБУL_Griseld ...
еИ©зФ®mavenеИЫеїЇwebx3й°єзЫЃвАФвАФеЃЮзО∞зЃАеНХзЪДзХЩи®АжЭњпЉИеЕ≠пЉЙ -
rc111xпЉЪ
L_Griselda еЖЩйБУL_Griselda еЖЩйБУдљ†е•љпЉМжИСжГ≥ ...
еИ©зФ®mavenеИЫеїЇwebx3й°єзЫЃвАФвАФеЃЮзО∞зЃАеНХзЪДзХЩи®АжЭњпЉИеЕ≠пЉЙ
1.еЯЇз°АзЯ•иѓЖ¬†
иЃ°зЃЧжЬЇдЄ≠еВ®е≠ШзЪДдњ°жБѓйГљжШѓзФ®дЇМињЫеИґжХ∞и°®з§ЇзЪДпЉЫиАМжИСдїђеЬ®е±ПеєХдЄКзЬЛеИ∞зЪДиЛ±жЦЗгАБж±Йе≠Чз≠Йе≠Чзђ¶жШѓдЇМињЫеИґжХ∞иљђжНҐдєЛеРОзЪДзїУжЮЬгАВйАЪдњЧзЪДиѓіпЉМжМЙзЕІдљХзІНиІДеИЩе∞Же≠Чзђ¶е≠ШеВ®еЬ®иЃ°зЃЧжЬЇдЄ≠пЉМе¶В'a'зФ®дїАдєИи°®з§ЇпЉМзІ∞дЄЇ"зЉЦз†Б"пЉЫеПНдєЛпЉМе∞Же≠ШеВ®еЬ®иЃ°зЃЧжЬЇдЄ≠зЪДдЇМињЫеИґжХ∞иІ£жЮРжШЊз§ЇеЗЇжЭ•пЉМзІ∞дЄЇ"иІ£з†Б"пЉМе¶ВеРМеѓЖз†Бе≠¶дЄ≠зЪДеК†еѓЖеТМиІ£еѓЖгАВеЬ®иІ£з†БињЗз®ЛдЄ≠пЉМе¶ВжЮЬдљњзФ®дЇЖйФЩиѓѓзЪДиІ£з†БиІДеИЩпЉМеИЩеѓЉиЗі'a'иІ£жЮРжИР'b'жИЦиАЕдє±з†БгАВ¬†
е≠Чзђ¶йЫЖпЉИCharsetпЉЙпЉЪжШѓдЄАдЄ™з≥їзїЯжФѓжМБзЪДжЙАжЬЙжКљи±°е≠Чзђ¶зЪДйЫЖеРИгАВе≠Чзђ¶жШѓеРДзІНжЦЗе≠ЧеТМзђ¶еПЈзЪДжАїзІ∞пЉМеМЕжЛђеРДеЫљеЃґжЦЗе≠ЧгАБж†ЗзВєзђ¶еПЈгАБеی嚥琶еПЈгАБжХ∞е≠Чз≠ЙгАВ¬†
е≠Чзђ¶зЉЦз†БпЉИCharacter EncodingпЉЙпЉЪжШѓдЄАе•Чж≥ХеИЩпЉМдљњзФ®иѓ•ж≥ХеИЩиГље§ЯеѓєиЗ™зДґиѓ≠и®АзЪДе≠Чзђ¶зЪДдЄАдЄ™йЫЖеРИпЉИе¶Ве≠ЧжѓНи°®жИЦйЯ≥иКВи°®пЉЙпЉМдЄОеЕґдїЦдЄЬи•њзЪДдЄАдЄ™йЫЖеРИпЉИе¶ВеПЈз†БжИЦзФµиДЙеЖ≤пЉЙињЫи°МйЕНеѓєгАВеН≥еЬ®зђ¶еПЈйЫЖеРИдЄОжХ∞е≠Чз≥їзїЯдєЛйЧіеїЇзЂЛеѓєеЇФеЕ≥з≥їпЉМеЃГжШѓдњ°жБѓе§ДзРЖзЪДдЄАй°єеЯЇжЬђжКАжЬѓгАВйАЪеЄЄдЇЇдїђзФ®зђ¶еПЈйЫЖеРИпЉИдЄАиИђжГЕеЖµдЄЛе∞±жШѓжЦЗе≠ЧпЉЙжЭ•и°®иЊЊдњ°жБѓгАВиАМдї•иЃ°зЃЧжЬЇдЄЇеЯЇз°АзЪДдњ°жБѓе§ДзРЖз≥їзїЯеИЩжШѓеИ©зФ®еЕГдїґпЉИз°ђдїґпЉЙдЄНеРМзКґжАБзЪДзїДеРИжЭ•е≠ШеВ®еТМе§ДзРЖдњ°жБѓзЪДгАВеЕГдїґдЄНеРМзКґжАБзЪДзїДеРИиГљдї£и°®жХ∞е≠Чз≥їзїЯзЪДжХ∞е≠ЧпЉМеЫ†ж≠§е≠Чзђ¶зЉЦз†Бе∞±жШѓе∞Жзђ¶еПЈиљђжНҐдЄЇиЃ°зЃЧжЬЇеПѓдї•жО•еПЧзЪДжХ∞е≠Чз≥їзїЯзЪДжХ∞пЉМзІ∞дЄЇжХ∞е≠Чдї£з†БгАВ¬†
2.еЄЄзФ®е≠Чзђ¶йЫЖеТМе≠Чзђ¶зЉЦз†Б¬†
еЄЄиІБе≠Чзђ¶йЫЖеРНзІ∞пЉЪASCIIе≠Чзђ¶йЫЖгАБGB2312е≠Чзђ¶йЫЖгАБBIG5е≠Чзђ¶йЫЖгАБGB18030е≠Чзђ¶йЫЖгАБUnicodeе≠Чзђ¶йЫЖз≠ЙгАВиЃ°зЃЧжЬЇи¶БеЗЖз°ЃзЪДе§ДзРЖеРДзІНе≠Чзђ¶йЫЖжЦЗе≠ЧпЉМйЬАи¶БињЫи°Ме≠Чзђ¶зЉЦз†БпЉМдї•дЊњиЃ°зЃЧжЬЇиГље§ЯиѓЖеИЂеТМе≠ШеВ®еРДзІНжЦЗе≠ЧгАВ
2.1. ASCIIе≠Чзђ¶йЫЖ&зЉЦз†Б¬†
ASCIIпЉИAmerican Standard Code for Information InterchangeпЉМзЊОеЫљдњ°жБѓдЇ§жНҐж†ЗеЗЖдї£з†БпЉЙжШѓеЯЇдЇОжЛЙдЄБе≠ЧжѓНзЪДдЄАе•ЧзФµиДСзЉЦз†Бз≥їзїЯгАВеЃГдЄїи¶БзФ®дЇОжШЊз§ЇзО∞дї£иЛ±иѓ≠пЉМиАМеЕґжЙ©е±ХзЙИжЬђEASCIIеИЩеПѓдї•еЛЙеЉЇжШЊз§ЇеЕґдїЦи•њжђІиѓ≠и®АгАВеЃГжШѓзО∞дїКжЬАйАЪзФ®зЪДеНХе≠ЧиКВзЉЦз†Бз≥їзїЯпЉИдљЖжШѓжЬЙ襀UnicodeињљдЄКзЪДињєи±°пЉЙпЉМеєґз≠ЙеРМдЇОеЫљйЩЕж†ЗеЗЖISO/IEC 646гАВ¬†
ASCIIе≠Чзђ¶йЫЖпЉЪдЄїи¶БеМЕжЛђжОІеИґе≠Чзђ¶пЉИеЫЮиљ¶йФЃгАБйААж†ЉгАБжНҐи°МйФЃз≠ЙпЉЙпЉЫеПѓжШЊз§Їе≠Чзђ¶пЉИиЛ±жЦЗе§Іе∞ПеЖЩе≠Чзђ¶гАБйШњжЛЙдЉѓжХ∞е≠ЧеТМи•њжЦЗзђ¶еПЈпЉЙгАВ¬†
ASCIIзЉЦз†БпЉЪе∞ЖASCIIе≠Чзђ¶йЫЖиљђжНҐдЄЇиЃ°зЃЧжЬЇеПѓдї•жО•еПЧзЪДжХ∞е≠Чз≥їзїЯзЪДжХ∞зЪДиІДеИЩгАВдљњзФ®7дљНпЉИbitsпЉЙи°®з§ЇдЄАдЄ™е≠Чзђ¶пЉМеЕ±128е≠Чзђ¶пЉЫдљЖжШѓ7дљНзЉЦз†БзЪДе≠Чзђ¶йЫЖеП™иГљжФѓжМБ128дЄ™е≠Чзђ¶пЉМдЄЇдЇЖи°®з§ЇжЫіе§ЪзЪДжђІжі≤еЄЄзФ®е≠Чзђ¶еѓєASCIIињЫи°МдЇЖжЙ©е±ХпЉМASCIIжЙ©е±Хе≠Чзђ¶йЫЖдљњзФ®8дљНпЉИbitsпЉЙи°®з§ЇдЄАдЄ™е≠Чзђ¶пЉМеЕ±256е≠Чзђ¶гАВASCIIе≠Чзђ¶йЫЖжШ†е∞ДеИ∞жХ∞е≠ЧзЉЦз†БиІДеИЩе¶ВдЄЛеЫЊжЙАз§ЇпЉЪ¬†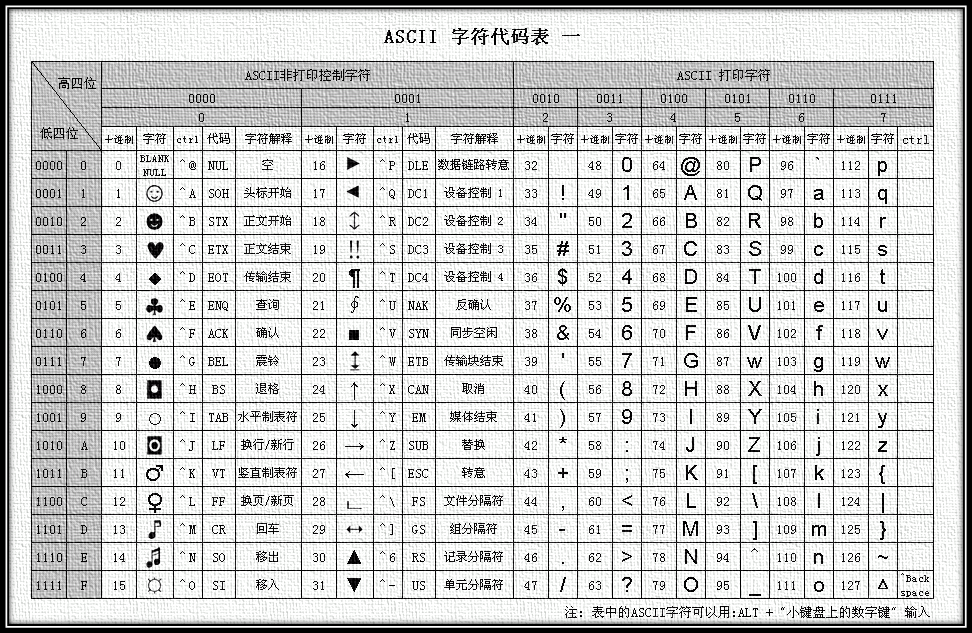
еЫЊ1 ASCIIзЉЦз†Би°®¬†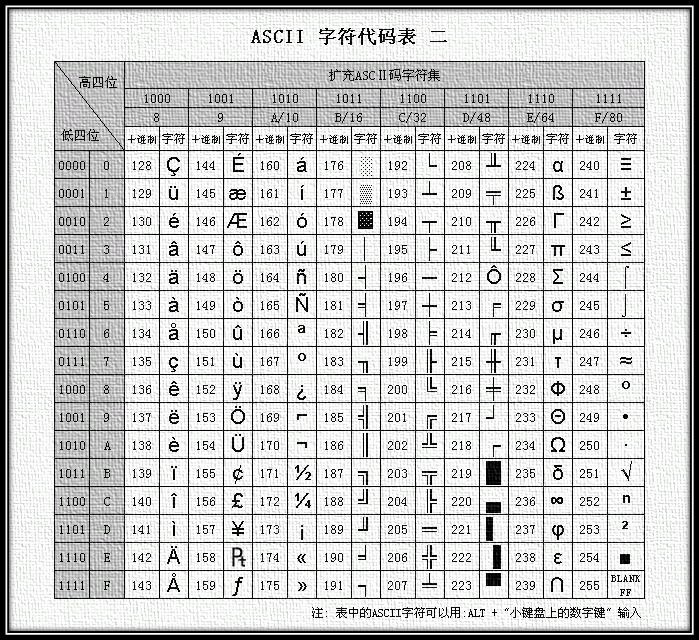
еЫЊ2 жЙ©е±ХASCIIзЉЦз†Би°®¬†
ASCIIзЪДжЬАе§ІзЉЇзВєжШѓеП™иГљжШЊз§Ї26дЄ™еЯЇжЬђжЛЙдЄБе≠ЧжѓНгАБйШњжЛЙдЉѓжХ∞зЫЃе≠ЧеТМиЛ±еЉПж†ЗзВєзђ¶еПЈпЉМеЫ†ж≠§еП™иГљзФ®дЇОжШЊз§ЇзО∞дї£зЊОеЫљиЛ±иѓ≠пЉИиАМдЄФеЬ®е§ДзРЖиЛ±иѓ≠ељУдЄ≠зЪДе§ЦжЭ•иѓНе¶Вna√ѓveгАБcaf√©гАБ√©liteз≠Йз≠ЙжЧґпЉМжЙАжЬЙйЗНйЯ≥зђ¶еПЈйГљдЄНеЊЧдЄНеОїжОЙпЉМеН≥дљњињЩж†ЈеБЪдЉЪињЭеПНжЛЉеЖЩиІДеИЩпЉЙгАВиАМEASCIIиЩљзДґиІ£еЖ≥дЇЖйГ®дїљи•њжђІиѓ≠и®АзЪДжШЊз§ЇйЧЃйҐШпЉМдљЖеѓєжЫіе§ЪеЕґдїЦиѓ≠и®АдЊЭзДґжЧ†иГљдЄЇеКЫгАВеЫ†ж≠§зО∞еЬ®зЪДиЛєжЮЬзФµиДСеЈ≤зїПжКЫеЉГASCIIиАМиљђзФ®UnicodeгАВ¬†
2.2. GBXXXXе≠Чзђ¶йЫЖ&зЉЦз†Б¬†
иЃ°зЃЧжЬЇеПСжШОдєЛе§ДеПКеРОйЭҐеЊИйХњдЄАжЃµжЧґйЧіпЉМеП™зФ®еЇФзФ®дЇОзЊОеЫљеПКи•њжЦєдЄАдЇЫеПСиЊЊеЫљеЃґпЉМASCIIиГље§ЯеЊИе•љжї°иґ≥зФ®жИЈзЪДйЬАж±ВгАВдљЖжШѓељУ*****дєЯжЬЙдЇЖиЃ°зЃЧжЬЇдєЛеРОпЉМдЄЇдЇЖжШЊз§ЇдЄ≠жЦЗпЉМењЕй°їиЃЊиЃ°дЄАе•ЧзЉЦз†БиІДеИЩзФ®дЇОе∞Жж±Йе≠ЧиљђжНҐдЄЇиЃ°зЃЧжЬЇеПѓдї•жО•еПЧзЪДжХ∞е≠Чз≥їзїЯзЪДжХ∞гАВ¬†
*****дЄУеЃґжККйВ£дЇЫ127еПЈдєЛеРОзЪДе•ЗеЉВзђ¶еПЈдїђпЉИеН≥EASCIIпЉЙеПЦжґИжОЙпЉМиІДеЃЪпЉЪдЄАдЄ™е∞ПдЇО127зЪДе≠Чзђ¶зЪДжДПдєЙдЄОеОЯжЭ•зЫЄеРМпЉМдљЖдЄ§дЄ™е§ІдЇО127зЪДе≠Чзђ¶ињЮеЬ®дЄАиµЈжЧґпЉМе∞±и°®з§ЇдЄАдЄ™ж±Йе≠ЧпЉМеЙНйЭҐзЪДдЄАдЄ™е≠ЧиКВпЉИдїЦзІ∞дєЛдЄЇйЂШе≠ЧиКВпЉЙдїО0xA1зФ®еИ∞ 0xF7пЉМеРОйЭҐдЄАдЄ™е≠ЧиКВпЉИдљОе≠ЧиКВпЉЙдїО0xA1еИ∞0xFEпЉМињЩж†ЈжИСдїђе∞±еПѓдї•зїДеРИеЗЇе§ІзЇ¶7000е§ЪдЄ™зЃАдљУж±Йе≠ЧдЇЖгАВеЬ®ињЩдЇЫзЉЦз†БйЗМпЉМињШжККжХ∞е≠¶зђ¶еПЈгАБзљЧй©ђеЄМиЕКзЪД е≠ЧжѓНгАБжЧ•жЦЗзЪДеБЗеРНдїђйГљзЉЦињЫеОїдЇЖпЉМињЮеЬ®ASCIIйЗМжЬђжЭ•е∞±жЬЙзЪДжХ∞е≠ЧгАБж†ЗзВєгАБе≠ЧжѓНйГљзїЯзїЯйЗНжЦ∞зЉЦдЇЖдЄ§дЄ™е≠ЧиКВйХњзЪДзЉЦз†БпЉМињЩе∞±жШѓеЄЄиѓізЪД"еЕ®иІТ"е≠Чзђ¶пЉМиАМеОЯжЭ•еЬ®127еПЈдї•дЄЛзЪДйВ£дЇЫе∞±еПЂ"еНКиІТ"е≠Чзђ¶дЇЖгАВ¬†
дЄКињ∞зЉЦз†БиІДеИЩе∞±жШѓGB2312гАВGB2312жИЦGB2312-80жШѓдЄ≠еЫљеЫљеЃґж†ЗеЗЖзЃАдљУдЄ≠жЦЗе≠Чзђ¶йЫЖпЉМеЕ®зІ∞гАКдњ°жБѓдЇ§жНҐзФ®ж±Йе≠ЧзЉЦз†Бе≠Чзђ¶йЫЖ¬ЈеЯЇжЬђйЫЖгАЛпЉМеПИзІ∞GB0пЉМзФ±дЄ≠еЫљеЫљеЃґж†ЗеЗЖжАїе±АеПСеЄГпЉМ1981еєі5жЬИ1жЧ•еЃЮжЦљгАВGB2312зЉЦз†БйАЪи°МдЇОдЄ≠еЫље§ІйЩЖпЉЫжЦ∞еК†еЭ°з≠ЙеЬ∞дєЯйЗЗзФ®ж≠§зЉЦз†БгАВдЄ≠еЫље§ІйЩЖеЗ†дєОжЙАжЬЙзЪДдЄ≠жЦЗз≥їзїЯеТМеЫљйЩЕеМЦзЪДиљѓдїґйГљжФѓжМБGB2312гАВGB2312зЪДеЗЇзО∞пЉМеЯЇжЬђжї°иґ≥дЇЖж±Йе≠ЧзЪДиЃ°зЃЧжЬЇе§ДзРЖйЬАи¶БпЉМеЃГжЙАжФґељХзЪДж±Йе≠ЧеЈ≤зїПи¶ЖзЫЦдЄ≠еЫље§ІйЩЖ99.75%зЪДдљњзФ®йҐСзОЗгАВеѓєдЇОдЇЇеРНгАБеП§ж±Йиѓ≠з≠ЙжЦєйЭҐеЗЇзО∞зЪДзљХзФ®е≠ЧпЉМGB2312дЄНиГље§ДзРЖпЉМињЩеѓЉиЗідЇЖеРОжЭ•GBKеПКGB 18030ж±Йе≠Че≠Чзђ¶йЫЖзЪДеЗЇзО∞гАВдЄЛеЫЊжШѓGB2312зЉЦз†БзЪДеЉАеІЛйГ®еИЖпЉИзФ±дЇОеЕґйЭЮеЄЄеЇЮе§ІпЉМеП™еИЧдЄЊеЉАеІЛйГ®еИЖпЉМеЕЈдљУеПѓжЯ•зЬЛGB2312зЃАдљУдЄ≠жЦЗзЉЦз†Би°®пЉЙпЉЪ¬†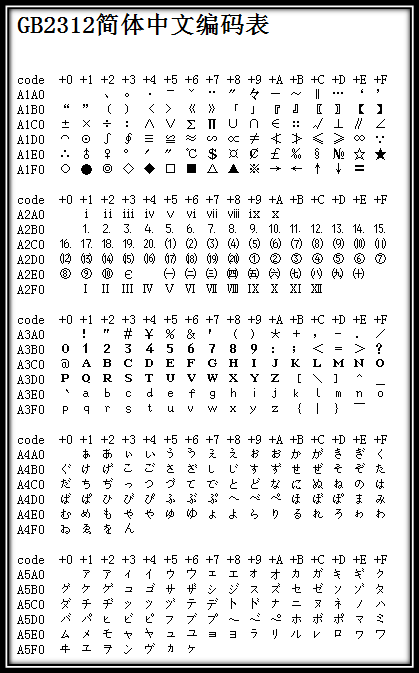
еЫЊ3 GB2312зЉЦз†Би°®зЪДеЉАеІЛйГ®еИЖ¬†
зФ±дЇОGB 2312-80еП™жФґељХ6763дЄ™ж±Йе≠ЧпЉМжЬЙдЄНе∞Сж±Йе≠ЧпЉМе¶ВйГ®еИЖеЬ®GB 2312-80жО®еЗЇдї•еРОжЙНзЃАеМЦзЪДж±Йе≠ЧпЉИе¶В"еХ∞"пЉЙпЉМйГ®еИЖдЇЇеРНзФ®е≠ЧпЉИе¶ВдЄ≠еЫљеЙНжАїзРЖжЬ±йХХеЯЇзЪД"йХХ"е≠ЧпЉЙпЉМеП∞жєЊеПКй¶ЩжЄѓдљњзФ®зЪДзєБдљУе≠ЧпЉМжЧ•иѓ≠еПКжЬЭй≤Ьиѓ≠ж±Йе≠Чз≠ЙпЉМеєґжЬ™жЬЙжФґељХеЬ®еЖЕгАВдЇОжШѓеОВеХЖеЊЃиљѓеИ©зФ®GB 2312-80жЬ™дљњзФ®зЪДзЉЦз†Бз©ЇйЧіпЉМжФґељХGB 13000.1-93еЕ®йГ®е≠Чзђ¶еИґеЃЪдЇЖGBKзЉЦз†БгАВж†єжНЃеЊЃиљѓиµДжЦЩпЉМGBKжШѓеѓєGB2312-80зЪДжЙ©е±ХпЉМдєЯе∞±жШѓCP936е≠Чз†Би°® (Code Page 936)зЪДжЙ©е±ХпЉИдєЛеЙНCP936еТМGB 2312-80дЄАж®°дЄАж†ЈпЉЙпЉМжЬАжЧ©еЃЮзО∞дЇОWindows 95зЃАдљУдЄ≠жЦЗзЙИгАВиЩљзДґGBKжФґељХGB 13000.1-93зЪДеЕ®йГ®е≠Чзђ¶пЉМдљЖзЉЦз†БжЦєеЉПеєґдЄНзЫЄеРМгАВGBKиЗ™иЇЂеєґйЭЮеЫљеЃґж†ЗеЗЖпЉМеП™жШѓжЫЊзФ±еЫљеЃґжКАжЬѓзЫСзЭ£е±Аж†ЗеЗЖеМЦеПЄгАБзФµе≠РеЈ•дЄЪйГ®зІСжКАдЄОиі®йЗПзЫСзЭ£еПЄеЕђеЄГдЄЇ"жКАжЬѓиІДиМГжМЗеѓЉжАІжЦЗдїґ"гАВеОЯеІЛGB13000дЄАзЫіжܙ襀дЄЪзХМйЗЗзФ®пЉМеРОзї≠еЫљеЃґж†ЗеЗЖGB18030жКАжЬѓдЄКеЕЉеЃєGBKиАМйЭЮGB13000гАВ¬†
GB 18030пЉМеЕ®зІ∞пЉЪеЫљеЃґж†ЗеЗЖGB 18030-2005гАКдњ°жБѓжКАжЬѓ дЄ≠жЦЗзЉЦз†Бе≠Чзђ¶йЫЖгАЛпЉМжШѓдЄ≠еНОдЇЇж∞СеЕ±еТМеЫљзО∞жЧґжЬАжЦ∞зЪДеЖЕз†Бе≠ЧйЫЖпЉМжШѓGB 18030-2000гАКдњ°жБѓжКАжЬѓ дњ°жБѓдЇ§жНҐзФ®ж±Йе≠ЧзЉЦз†Бе≠Чзђ¶йЫЖ еЯЇжЬђйЫЖзЪДжЙ©еЕЕгАЛзЪДдњЃиЃҐзЙИгАВдЄОGB 2312-1980еЃМеЕ®еЕЉеЃєпЉМдЄОGBKеЯЇжЬђеЕЉеЃєпЉМжФѓжМБGB 13000еПКUnicodeзЪДеЕ®йГ®зїЯдЄАж±Йе≠ЧпЉМеЕ±жФґељХж±Йе≠Ч70244дЄ™гАВGB 18030дЄїи¶БжЬЙдї•дЄЛзЙєзВєпЉЪ¬†
дЄОUTF-8зЫЄеРМпЉМйЗЗзФ®е§Ъе≠ЧиКВзЉЦз†БпЉМжѓПдЄ™е≠ЧеПѓдї•зФ±1дЄ™гАБ2дЄ™жИЦ4дЄ™е≠ЧиКВзїДжИРгАВ¬†
зЉЦз†Бз©ЇйЧіеЇЮе§ІпЉМжЬАе§ЪеПѓеЃЪдєЙ161дЄЗдЄ™е≠Чзђ¶гАВ¬†
жФѓжМБдЄ≠еЫљеЫљеЖЕе∞СжХ∞ж∞СжЧПзЪДжЦЗе≠ЧпЉМдЄНйЬАи¶БеК®зФ®йА†е≠ЧеМЇгАВ¬†
ж±Йе≠ЧжФґељХиМГеЫіеМЕеРЂзєБдљУж±Йе≠Чдї•еПКжЧ•йЯ©ж±Йе≠Ч¬†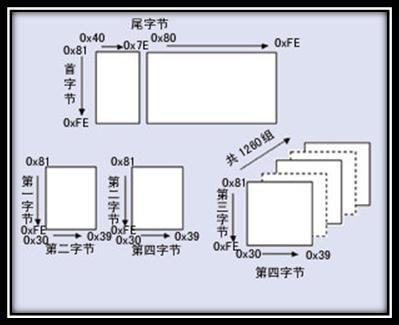
еЫЊ4 GB18030зЉЦз†БжАїдљУзїУжЮД¬†
жЬђиІДж†ЉзЪДеИЭзЙИдљњдЄ≠еНОдЇЇж∞СеЕ±еТМеЫљдњ°жБѓдЇІдЄЪйГ®зФµе≠РеЈ•дЄЪж†ЗеЗЖеМЦз†Фз©ґжЙАиµЈиНЙпЉМзФ±еЫљеЃґиі®йЗПжКАжЬѓзЫСзЭ£е±АдЇО2000еєі3жЬИ17жЧ•еПСеЄГгАВзО∞и°МзЙИжЬђдЄЇеЫљеЃґиі®йЗПзЫСзЭ£ж£Ай™МжАїе±АеТМдЄ≠еЫљеЫљеЃґж†ЗеЗЖеМЦзЃ°зРЖеІФеСШдЉЪдЇО2005еєі11жЬИ8жЧ•еПСеЄГпЉМ2006еєі5жЬИ1жЧ•еЃЮжЦљгАВж≠§иІДж†ЉдЄЇеЬ®дЄ≠еЫљеҐГеЖЕжЙАжЬЙиљѓдїґдЇІеУБжФѓжМБзЪДеЉЇеИґиІДж†ЉгАВ¬†
2.3. BIG5е≠Чзђ¶йЫЖ&зЉЦз†Б¬†
Big5пЉМеПИзІ∞дЄЇе§ІдЇФз†БжИЦдЇФе§Із†БпЉМжШѓдљњзФ®зєБдљУдЄ≠жЦЗпЉИж≠£дљУдЄ≠жЦЗпЉЙз§ЊеМЇдЄ≠жЬАеЄЄзФ®зЪДзФµиДСж±Йе≠Че≠Чзђ¶йЫЖж†ЗеЗЖпЉМеЕ±жФґељХ13,060дЄ™ж±Йе≠ЧгАВдЄ≠жЦЗз†БеИЖдЄЇеЖЕз†БеПКдЇ§жНҐз†БдЄ§з±їпЉМBig5е±ЮдЄ≠жЦЗеЖЕз†БпЉМзЯ•еРНзЪДдЄ≠жЦЗдЇ§жНҐз†БжЬЙCCCIIгАБCNS11643гАВBig5иЩљжЩЃеПКдЇОеП∞жєЊгАБй¶ЩжЄѓдЄОжЊ≥йЧ®з≠ЙзєБдљУдЄ≠жЦЗйАЪи°МеМЇпЉМдљЖйХњжЬЯдї•жЭ•еєґйЭЮељУеЬ∞зЪДеЫљеЃґж†ЗеЗЖпЉМиАМеП™жШѓдЄЪзХМж†ЗеЗЖгАВеАЪ姩дЄ≠жЦЗз≥їзїЯгАБWindowsз≠ЙдЄїи¶Бз≥їзїЯзЪДе≠Чзђ¶йЫЖйГљжШѓдї•Big5дЄЇеЯЇеЗЖпЉМдљЖеОВеХЖеПИеРДиЗ™еҐЮеК†дЄНеРМзЪДйА†е≠ЧдЄОйА†е≠ЧеМЇпЉМжіЊзФЯжИРе§ЪзІНдЄНеРМзЙИжЬђгАВ2003еєіпЉМBig5襀жФґељХеИ∞CNS11643дЄ≠жЦЗж†ЗеЗЖдЇ§жНҐз†БзЪДйЩДељХељУдЄ≠пЉМеПЦеЊЧдЇЖиЊГж≠£еЉПзЪДеЬ∞дљНгАВињЩдЄ™жЬАжЦ∞зЙИжܐ襀зІ∞дЄЇBig5-2003гАВ¬†
Big5з†БжШѓдЄАе•ЧеПМе≠ЧиКВе≠Чзђ¶йЫЖпЉМдљњзФ®дЇЖеПМеЕЂз†Бе≠ШеВ®жЦєж≥ХпЉМдї•дЄ§дЄ™е≠ЧиКВжЭ•еЃЙжФЊдЄАдЄ™е≠ЧгАВзђђдЄАдЄ™е≠ЧиКВзІ∞дЄЇ"йЂШдљНе≠ЧиКВ"пЉМзђђдЇМдЄ™е≠ЧиКВзІ∞дЄЇ"дљОдљНе≠ЧиКВ"гАВ"йЂШдљНе≠ЧиКВ"дљњзФ®дЇЖ0x81-0xFEпЉМ"дљОдљНе≠ЧиКВ"дљњзФ®дЇЖ0x40-0x7EпЉМеПК0xA1-0xFEгАВеЬ®Big5зЪДеИЖеМЇдЄ≠пЉЪ¬†
0x8140-0xA0FE
дњЭзХЩзїЩзФ®жИЈиЗ™еЃЪдєЙе≠Чзђ¶пЉИйА†е≠ЧеМЇпЉЙ
0xA140-0xA3BF
ж†ЗзВєзђ¶еПЈгАБеЄМиЕКе≠ЧжѓНеПКзЙєжЃКзђ¶еПЈпЉМеМЕжЛђеЬ®0xA259-0xA261пЉМеЃЙжФЊдЇЖдєЭдЄ™иЃ°йЗПзФ®ж±Йе≠ЧпЉЪеЕЩеЕЫеЕЮеЕЭеЕ°еЕ£еЧІзУ©з≥ОгАВ
0xA3C0-0xA3FE
дњЭзХЩгАВж≠§еМЇж≤°жЬЙеЉАжФЊдљЬйА†е≠ЧеМЇзФ®гАВ
0xA440-0xC67E
еЄЄзФ®ж±Йе≠ЧпЉМеЕИжМЙзђФеИТеЖНжМЙйГ®й¶ЦжОТеЇПгАВ
0xC6A1-0xC8FE
дњЭзХЩзїЩзФ®жИЈиЗ™еЃЪдєЙе≠Чзђ¶пЉИйА†е≠ЧеМЇпЉЙ
0xC940-0xF9D5
жђ°еЄЄзФ®ж±Йе≠ЧпЉМдЇ¶жШѓеЕИжМЙзђФеИТеЖНжМЙйГ®й¶ЦжОТеЇПгАВ
0xF9D6-0xFEFE
дњЭзХЩзїЩзФ®жИЈиЗ™еЃЪдєЙе≠Чзђ¶пЉИйА†е≠ЧеМЇпЉЙ
Unicodeе≠Чзђ¶йЫЖ&UTFзЉЦз†Б¬†
3.дЉЯе§ІзЪДеИЫжГ≥Unicode¬†
вАФвАФдЄНеЊЧдЄНеНХзЛђиѓіUnicode¬†
еГП*****дЄАж†ЈпЉМељУиЃ°зЃЧжЬЇдЉ†еИ∞дЄЦзХМеРДдЄ™еЫљеЃґжЧґпЉМдЄЇдЇЖйАВеРИељУеЬ∞иѓ≠и®АеТМе≠Чзђ¶пЉМиЃЊиЃ°еТМеЃЮзО∞з±їдЉЉGB232/GBK/GB18030/BIG5зЪДзЉЦз†БжЦєж°ИгАВињЩж†ЈеРДжРЮдЄАе•ЧпЉМеЬ®жЬђеЬ∞дљњзФ®ж≤°жЬЙйЧЃйҐШпЉМдЄАжЧ¶еЗЇзО∞еЬ®зљСзїЬдЄ≠пЉМзФ±дЇОдЄНеЕЉеЃєпЉМдЇТзЫЄиЃњйЧЃе∞±еЗЇзО∞дЇЖдє±з†БзО∞и±°гАВ¬†
дЄЇдЇЖиІ£еЖ≥ињЩдЄ™йЧЃйҐШпЉМдЄАдЄ™дЉЯе§ІзЪДеИЫжГ≥дЇІзФЯдЇЖвАФвАФUnicodeгАВUnicodeзЉЦз†Бз≥їзїЯдЄЇи°®иЊЊдїїжДПиѓ≠и®АзЪДдїїжДПе≠Чзђ¶иАМиЃЊиЃ°гАВеЃГдљњзФ®4е≠ЧиКВзЪДжХ∞е≠ЧжЭ•и°®иЊЊжѓПдЄ™е≠ЧжѓНгАБзђ¶еПЈпЉМжИЦиАЕи°®жДПжЦЗе≠Ч(ideograph)гАВжѓПдЄ™жХ∞е≠Чдї£и°®еФѓдЄАзЪДиЗ≥е∞СеЬ®жЯРзІНиѓ≠и®АдЄ≠дљњзФ®зЪДзђ¶еПЈгАВпЉИеєґдЄНжШѓжЙАжЬЙзЪДжХ∞е≠ЧйГљзФ®дЄКдЇЖпЉМдљЖжШѓжАїжХ∞еЈ≤зїПиґЕињЗдЇЖ65535пЉМжЙАдї•2дЄ™е≠ЧиКВзЪДжХ∞е≠ЧжШѓдЄНе§ЯзФ®зЪДгАВпЉЙ襀еЗ†зІНиѓ≠и®АеЕ±зФ®зЪДе≠Чзђ¶йАЪеЄЄдљњзФ®зЫЄеРМзЪДжХ∞е≠ЧжЭ•зЉЦз†БпЉМйЩ§йЭЮе≠ШеЬ®дЄАдЄ™еЬ®зРЖзЪДиѓ≠жЇРе≠¶(etymological)зРЖзФ±дљњдЄНињЩж†ЈеБЪгАВдЄНиАГиЩСињЩзІНжГЕеЖµзЪДиѓЭпЉМжѓПдЄ™е≠Чзђ¶еѓєеЇФдЄАдЄ™жХ∞е≠ЧпЉМжѓПдЄ™жХ∞е≠ЧеѓєеЇФдЄАдЄ™е≠Чзђ¶гАВеН≥дЄНе≠ШеЬ®дЇМдєЙжАІгАВдЄНеЖНйЬАи¶БиЃ∞ељХ"ж®°еЉП"дЇЖгАВU+0041жАїжШѓдї£и°®'A'пЉМеН≥дљњињЩзІНиѓ≠и®Аж≤°жЬЙ'A'ињЩдЄ™е≠Чзђ¶гАВ¬†
еЬ®иЃ°зЃЧжЬЇзІСе≠¶йҐЖеЯЯдЄ≠пЉМUnicodeпЉИзїЯдЄАз†БгАБдЄЗеЫљз†БгАБеНХдЄАз†БгАБж†ЗеЗЖдЄЗеЫљз†БпЉЙжШѓдЄЪзХМзЪДдЄАзІНж†ЗеЗЖпЉМеЃГеПѓдї•дљњзФµиДСеЊЧдї•дљУзО∞дЄЦзХМдЄКжХ∞еНБзІНжЦЗе≠ЧзЪДз≥їзїЯгАВUnicode жШѓеЯЇдЇОйАЪзФ®е≠Чзђ¶йЫЖпЉИUniversal Character SetпЉЙзЪДж†ЗеЗЖжЭ•еПСе±ХпЉМеєґдЄФеРМжЧґдєЯдї•дє¶жЬђзЪД嚥еЉП[1]еѓєе§ЦеПСи°®гАВUnicode ињШдЄНжЦ≠еЬ®жЙ©еҐЮпЉМ жѓПдЄ™жЦ∞зЙИжЬђжПТеЕ•жЫіе§ЪжЦ∞зЪДе≠Чзђ¶гАВзЫіиЗ≥зЫЃеЙНдЄЇж≠ҐзЪДзђђеЕ≠зЙИпЉМUnicode е∞±еЈ≤зїПеМЕеРЂдЇЖиґЕињЗеНБдЄЗдЄ™е≠Чзђ¶пЉИеЬ®2005еєіпЉМUnicode зЪДзђђеНБдЄЗдЄ™е≠Ч琶襀йЗЗзЇ≥дЄФиЃ§еПѓжИРдЄЇж†ЗеЗЖдєЛдЄАпЉЙгАБдЄАзїДеПѓзФ®дї•дљЬдЄЇиІЖиІЙеПВиАГзЪДдї£з†БеЫЊи°®гАБдЄАе•ЧзЉЦз†БжЦєж≥ХдЄОдЄАзїДж†ЗеЗЖе≠Чзђ¶зЉЦз†БгАБдЄАе•ЧеМЕеРЂдЇЖдЄКж†Зе≠ЧгАБдЄЛж†Зе≠Чз≠Йе≠Чзђ¶зЙєжАІзЪДжЮЪдЄЊз≠ЙгАВUnicode зїДзїЗпЉИThe Unicode ConsortiumпЉЙжШѓзФ±дЄАдЄ™йЭЮиР•еИ©жАІзЪДжЬЇжЮДжЙАињРдљЬпЉМеєґдЄїеѓЉ Unicode зЪДеРОзї≠еПСе±ХпЉМеЕґзЫЃж†ЗеЬ®дЇОпЉЪе∞ЖжЧҐжЬЙзЪДе≠Чзђ¶зЉЦз†БжЦєж°Идї•Unicode зЉЦз†БжЦєж°ИжЭ•еК†дї•еПЦдї£пЉМзЙєеИЂжШѓжЧҐжЬЙзЪДжЦєж°ИеЬ®е§Ъиѓ≠зОѓеҐГдЄЛпЉМзЪЖдїЕжЬЙжЬЙйЩРзЪДз©ЇйЧідї•еПКдЄНеЕЉеЃєзЪДйЧЃйҐШгАВ¬†
пЉИеПѓдї•ињЩж†ЈзРЖиІ£пЉЪUnicodeжШѓе≠Чзђ¶йЫЖпЉМUTF-32/ UTF-16/ UTF-8жШѓдЄЙзІНе≠Чзђ¶зЉЦз†БжЦєж°ИгАВпЉЙ¬†
3.1.UCS & UNICODE 
йАЪзФ®е≠Чзђ¶йЫЖпЉИUniversal Character SetпЉМUCSпЉЙжШѓзФ±ISOеИґеЃЪзЪДISO 10646пЉИжИЦзІ∞ISO/IEC 10646пЉЙж†ЗеЗЖжЙАеЃЪдєЙзЪДж†ЗеЗЖе≠Чзђ¶йЫЖгАВеОЖеП≤дЄКе≠ШеЬ®дЄ§дЄ™зЛђзЂЛзЪДе∞ЭиѓХеИЫзЂЛеНХдЄАе≠Чзђ¶йЫЖзЪДзїДзїЗпЉМеН≥еЫљйЩЕж†ЗеЗЖеМЦзїДзїЗпЉИISOпЉЙеТМе§Ъиѓ≠и®АиљѓдїґеИґйА†еХЖзїДжИРзЪДзїЯдЄАз†БиБФзЫЯгАВеЙНиАЕеЉАеПСзЪД ISO/IEC 10646 й°єзЫЃпЉМеРОиАЕеЉАеПСзЪДзїЯдЄАз†Бй°єзЫЃгАВеЫ†ж≠§жЬАеИЭеИґеЃЪдЇЖдЄНеРМзЪДж†ЗеЗЖгАВ¬†
1991еєіеЙНеРОпЉМдЄ§дЄ™й°єзЫЃзЪДеПВдЄОиАЕйГљиЃ§иѓЖеИ∞пЉМдЄЦзХМдЄНйЬАи¶БдЄ§дЄ™дЄНеЕЉеЃєзЪДе≠Чзђ¶йЫЖгАВдЇОжШѓпЉМеЃГдїђеЉАеІЛеРИеєґеПМжЦєзЪДеЈ•дљЬжИРжЮЬпЉМеєґдЄЇеИЫзЂЛдЄАдЄ™еНХдЄАзЉЦз†Би°®иАМеНПеРМеЈ•дљЬгАВдїОUnicode 2.0еЉАеІЛпЉМUnicodeйЗЗзФ®дЇЖдЄОISO 10646-1зЫЄеРМзЪДе≠ЧеЇУеТМе≠Чз†БпЉЫISOдєЯжЙњиѓЇпЉМISO 10646е∞ЖдЄНдЉЪжЫњиґЕеЗЇU+10FFFFзЪДUCS-4зЉЦз†БиµЛеАЉпЉМдї•дљњеЊЧдЄ§иАЕдњЭжМБдЄАиЗігАВдЄ§дЄ™й°єзЫЃдїНйГље≠ШеЬ®пЉМеєґзЛђзЂЛеЬ∞еЕђеЄГеРДиЗ™зЪДж†ЗеЗЖгАВдљЖзїЯдЄАз†БиБФзЫЯеТМISO/IEC JTC1/SC2йГљеРМжДПдњЭжМБдЄ§иАЕж†ЗеЗЖзЪДз†Би°®еЕЉеЃєпЉМеєґзіІеѓЖеЬ∞еЕ±еРМи∞ГжХідїїдљХжЬ™жЭ•зЪДжЙ©е±ХгАВеЬ®еПСеЄГзЪДжЧґеАЩпЉМUnicodeдЄАиИђйГљдЉЪйЗЗзФ®жЬЙеЕ≥е≠Чз†БжЬАеЄЄиІБзЪДе≠ЧеЮЛпЉМдљЖISO 10646дЄАиИђйГље∞љеПѓиГљйЗЗзФ®Centuryе≠ЧеЮЛгАВ¬†
3.2.UTF-32 
дЄКињ∞дљњзФ®4е≠ЧиКВзЪДжХ∞е≠ЧжЭ•и°®иЊЊжѓПдЄ™е≠ЧжѓНгАБзђ¶еПЈпЉМжИЦиАЕи°®жДПжЦЗе≠Ч(ideograph)пЉМжѓПдЄ™жХ∞е≠Чдї£и°®еФѓдЄАзЪДиЗ≥е∞СеЬ®жЯРзІНиѓ≠и®АдЄ≠дљњзФ®зЪДзђ¶еПЈзЪДзЉЦз†БжЦєж°ИпЉМзІ∞дЄЇUTF-32гАВUTF-32еПИзІ∞UCS-4жШѓдЄАзІНе∞ЖUnicodeе≠Чзђ¶зЉЦз†БзЪДеНПеЃЪпЉМеѓєжѓПдЄ™е≠Чзђ¶йГљдљњзФ®4е≠ЧиКВгАВе∞±з©ЇйЧіиАМи®АпЉМжШѓйЭЮеЄЄж≤°жЬЙжХИзОЗзЪДгАВ¬†
ињЩзІНжЦєж≥ХжЬЙеЕґдЉШзВєпЉМжЬАйЗНи¶БзЪДдЄАзВєе∞±жШѓеПѓдї•еЬ®еЄЄжХ∞жЧґйЧіеЖЕеЃЪдљНе≠Чзђ¶дЄ≤йЗМзЪДзђђNдЄ™е≠Чзђ¶пЉМеЫ†дЄЇзђђNдЄ™е≠Чзђ¶дїОзђђ4√ЧNthдЄ™е≠ЧиКВеЉАеІЛгАВиЩљзДґжѓПдЄАдЄ™з†БдљНдљњзФ®еЫЇеЃЪйХњеЃЪзЪДе≠ЧиКВзЬЛдЉЉжЦєдЊњпЉМеЃГеєґдЄНе¶ВеЕґеЃГUnicodeзЉЦз†БдљњзФ®еЊЧеєњж≥ЫгАВ¬†
3.3.UTF-16 
е∞љзЃ°жЬЙUnicodeе≠Чзђ¶йЭЮеЄЄе§ЪпЉМдљЖжШѓеЃЮйЩЕдЄКе§Іе§ЪжХ∞дЇЇдЄНдЉЪзФ®еИ∞иґЕињЗеЙН65535дЄ™дї•е§ЦзЪДе≠Чзђ¶гАВеЫ†ж≠§пЉМе∞±жЬЙдЇЖеП¶е§ЦдЄАзІНUnicodeзЉЦз†БжЦєеЉПпЉМеПЂеБЪUTF-16(еЫ†дЄЇ16дљН = 2е≠ЧиКВ)гАВUTF-16е∞Ж0вАУ65535иМГеЫіеЖЕзЪДе≠Чзђ¶зЉЦз†БжИР2дЄ™е≠ЧиКВпЉМе¶ВжЮЬзЬЯзЪДйЬАи¶Би°®иЊЊйВ£дЇЫеЊИе∞СдљњзФ®зЪД"жШЯиКТе±В(astral plane)"еЖЕиґЕињЗињЩ65535иМГеЫізЪДUnicodeе≠Чзђ¶пЉМеИЩйЬАи¶БдљњзФ®дЄАдЇЫиѓ°еЉВзЪДжКАеЈІжЭ•еЃЮзО∞гАВUTF-16зЉЦз†БжЬАжШОжШЊзЪДдЉШзВєжШѓеЃГеЬ®з©ЇйЧіжХИзОЗдЄКжѓФUTF-32йЂШдЄ§еАНпЉМеЫ†дЄЇжѓПдЄ™е≠Чзђ¶еП™йЬАи¶Б2дЄ™е≠ЧиКВжЭ•е≠ШеВ®пЉИйЩ§еОї65535иМГеЫідї•е§ЦзЪДпЉЙпЉМиАМдЄНжШѓUTF-32дЄ≠зЪД4дЄ™е≠ЧиКВгАВеєґдЄФпЉМе¶ВжЮЬжИСдїђеБЗиЃЊжЯРдЄ™е≠Чзђ¶дЄ≤дЄНеМЕеРЂдїїдљХжШЯиКТе±ВдЄ≠зЪДе≠Чзђ¶пЉМйВ£дєИжИСдїђдЊЭзДґеПѓдї•еЬ®еЄЄжХ∞жЧґйЧіеЖЕжЙЊеИ∞еЕґдЄ≠зЪДзђђNдЄ™е≠Чзђ¶пЉМзЫіеИ∞еЃГдЄНжИРзЂЛдЄЇж≠ҐињЩжАїжШѓдЄАдЄ™дЄНйФЩзЪДжО®жЦ≠гАВеЕґзЉЦз†БжЦєж≥ХжШѓпЉЪ¬†
е¶ВжЮЬе≠Чзђ¶зЉЦз†БUе∞ПдЇО0x10000пЉМдєЯе∞±жШѓеНБињЫеИґзЪД0еИ∞65535дєЛеЖЕпЉМеИЩзЫіжО•дљњзФ®дЄ§е≠ЧиКВи°®з§ЇпЉЫ¬†
е¶ВжЮЬе≠Чзђ¶зЉЦз†БUе§ІдЇО0x10000пЉМзФ±дЇОUNICODEзЉЦз†БиМГеЫіжЬАе§ІдЄЇ0x10FFFFпЉМдїО0x10000еИ∞0x10FFFFдєЛйЧі еЕ±жЬЙ0xFFFFFдЄ™зЉЦз†БпЉМдєЯе∞±жШѓйЬАи¶Б20дЄ™bitе∞±еПѓдї•ж†Зз§ЇињЩдЇЫзЉЦз†БгАВзФ®U'и°®з§ЇдїО0-0xFFFFFдєЛйЧізЪДеАЉпЉМе∞ЖеЕґеЙН 10 bitдљЬдЄЇйЂШдљНеТМ16 bitзЪДжХ∞еАЉ0xD800ињЫи°М йАїиЊСor жУНдљЬпЉМе∞ЖеРО10 bitдљЬдЄЇдљОдљНеТМ0xDC00еБЪ йАїиЊСor жУНдљЬпЉМињЩж†ЈзїДжИРзЪД 4дЄ™byteе∞±жЮДжИРдЇЖUзЪДзЉЦз†БгАВ¬†
еѓєдЇОUTF-32еТМUTF-16зЉЦз†БжЦєеЉПињШжЬЙдЄАдЇЫеЕґдїЦдЄНжШОжШЊзЪДзЉЇзВєгАВдЄНеРМзЪДиЃ°зЃЧжЬЇз≥їзїЯдЉЪдї•дЄНеРМзЪДй°ЇеЇПдњЭе≠Ше≠ЧиКВгАВињЩжДПеС≥зЭАе≠Чзђ¶U+4E2DеЬ®UTF-16зЉЦз†БжЦєеЉПдЄЛеПѓиÚ襀дњЭе≠ШдЄЇ4E 2DжИЦиАЕ2D 4EпЉМињЩеПЦеЖ≥дЇОиѓ•з≥їзїЯдљњзФ®зЪДжШѓе§Іе∞ЊзЂѓ(big-endian)ињШжШѓе∞Пе∞ЊзЂѓ(little-endian)гАВпЉИеѓєдЇОUTF-32зЉЦз†БжЦєеЉПпЉМеИЩжЬЙжЫіе§ЪзІНеПѓиГљзЪДе≠ЧиКВжОТеИЧгАВпЉЙеП™и¶БжЦЗж°£ж≤°жЬЙз¶їеЉАдљ†зЪДиЃ°зЃЧжЬЇпЉМеЃГињШжШѓеЃЙеЕ®зЪДвАФвАФеРМдЄАеП∞зФµиДСдЄКзЪДдЄНеРМз®ЛеЇПдљњзФ®зЫЄеРМзЪДе≠ЧиКВй°ЇеЇП(byte order)гАВдљЖжШѓељУжИСдїђйЬАи¶БеЬ®з≥їзїЯдєЛйЧідЉ†иЊУињЩдЄ™жЦЗж°£зЪДжЧґеАЩпЉМдєЯиЃЄеЬ®дЄЗзїізљСдЄ≠пЉМжИСдїђе∞±йЬАи¶БдЄАзІНжЦєж≥ХжЭ•жМЗз§ЇељУеЙНжИСдїђзЪДе≠ЧиКВжШѓжАОж†Је≠ШеВ®зЪДгАВдЄНзДґзЪДиѓЭпЉМжО•жФґжЦЗж°£зЪДиЃ°зЃЧжЬЇе∞±жЧ†ж≥ХзЯ•йБУињЩдЄ§дЄ™е≠ЧиКВ4E 2Dи°®иЊЊзЪДеИ∞еЇХжШѓU+4E2DињШжШѓU+2D4EгАВ
дЄЇдЇЖиІ£еЖ≥ињЩдЄ™йЧЃйҐШпЉМе§Ъе≠ЧиКВзЪДUnicodeзЉЦз†БжЦєеЉПеЃЪдєЙдЇЖдЄАдЄ™"е≠ЧиКВй°ЇеЇПж†ЗиЃ∞(Byte Order Mark)"пЉМеЃГжШѓдЄАдЄ™зЙєжЃКзЪДйЭЮжЙУеН∞е≠Чзђ¶пЉМдљ†еПѓдї•жККеЃГеМЕеРЂеЬ®жЦЗж°£зЪДеЉАе§іжЭ•жМЗз§Їдљ†жЙАдљњзФ®зЪДе≠ЧиКВй°ЇеЇПгАВеѓєдЇОUTF-16пЉМе≠ЧиКВй°ЇеЇПж†ЗиЃ∞жШѓU+FEFFгАВе¶ВжЮЬжФґеИ∞дЄАдЄ™дї•е≠ЧиКВFF FEеЉАе§ізЪДUTF-16зЉЦз†БзЪДжЦЗж°£пЉМдљ†е∞±иГљз°ЃеЃЪеЃГзЪДе≠ЧиКВй°ЇеЇПжШѓеНХеРСзЪД(one way)зЪДдЇЖпЉЫе¶ВжЮЬеЃГдї•FE FFеЉАе§іпЉМеИЩеПѓдї•з°ЃеЃЪе≠ЧиКВй°ЇеЇПеПНеРСдЇЖгАВ¬†
3.4.UTF-8 
UTF-8пЉИ8-bit Unicode Transformation FormatпЉЙжШѓдЄАзІНйТИеѓєUnicodeзЪДеПѓеПШйХњеЇ¶е≠Чзђ¶зЉЦз†БпЉИеЃЪйХњз†БпЉЙпЉМдєЯжШѓдЄАзІНеЙНзЉАз†БгАВеЃГеПѓдї•зФ®жЭ•и°®з§ЇUnicodeж†ЗеЗЖдЄ≠зЪДдїїдљХе≠Чзђ¶пЉМдЄФеЕґзЉЦз†БдЄ≠зЪДзђђдЄАдЄ™е≠ЧиКВдїНдЄОASCIIеЕЉеЃєпЉМињЩдљњеЊЧеОЯжЭ•е§ДзРЖASCIIе≠Чзђ¶зЪДиљѓдїґжЧ†й°їжИЦеП™й°їеБЪе∞СйГ®дїљдњЃжФєпЉМеН≥еПѓзїІзї≠дљњзФ®гАВеЫ†ж≠§пЉМеЃГйАРжЄРжИРдЄЇзФµе≠РйВЃдїґгАБзљСй°µеПКеЕґдїЦе≠ШеВ®жИЦдЉ†йАБжЦЗе≠ЧзЪДеЇФзФ®дЄ≠пЉМдЉШеЕИйЗЗзФ®зЪДзЉЦз†БгАВдЇТиБФзљСеЈ•з®ЛеЈ•дљЬе∞ПзїДпЉИIETFпЉЙи¶Бж±ВжЙАжЬЙдЇТиБФзљСеНПиЃЃйГљењЕй°їжФѓжМБUTF-8зЉЦз†БгАВ¬†
UTF-8дљњзФ®дЄАиЗ≥еЫЫдЄ™е≠ЧиКВдЄЇжѓПдЄ™е≠Чзђ¶зЉЦз†БпЉЪ¬†
128дЄ™US-ASCIIе≠Чзђ¶еП™йЬАдЄАдЄ™е≠ЧиКВзЉЦз†БпЉИUnicodeиМГеЫізФ±U+0000иЗ≥U+007FпЉЙгАВ¬†
еЄ¶жЬЙйЩДеК†зђ¶еПЈзЪДжЛЙдЄБжЦЗгАБеЄМиЕКжЦЗгАБи•њйЗМе∞Фе≠ЧжѓНгАБдЇЪзЊОе∞ЉдЇЪиѓ≠гАБеЄМдЉѓжЭ•жЦЗгАБйШњжЛЙдЉѓжЦЗгАБеПЩеИ©дЇЪжЦЗеПКеЃГжЛње≠ЧжѓНеИЩйЬАи¶БдЇМдЄ™е≠ЧиКВзЉЦз†БпЉИUnicodeиМГеЫізФ±U+0080иЗ≥U+07FFпЉЙгАВ¬†
еЕґдїЦеЯЇжЬђе§ЪжЦЗзІНеє≥йЭҐпЉИBMPпЉЙдЄ≠зЪДе≠Чзђ¶пЉИињЩеМЕеРЂдЇЖе§ІйГ®еИЖеЄЄзФ®е≠ЧпЉЙдљњзФ®дЄЙдЄ™е≠ЧиКВзЉЦз†БгАВ¬†
еЕґдїЦжЮБе∞СдљњзФ®зЪДUnicodeиЊЕеК©еє≥йЭҐзЪДе≠Чзђ¶дљњзФ®еЫЫе≠ЧиКВзЉЦз†БгАВ¬†
еЬ®е§ДзРЖзїПеЄЄдЉЪзФ®еИ∞зЪДASCIIе≠Чзђ¶жЦєйЭҐйЭЮеЄЄжЬЙжХИгАВеЬ®е§ДзРЖжЙ©е±ХзЪДжЛЙдЄБе≠Чзђ¶йЫЖжЦєйЭҐдєЯдЄНжѓФUTF-16еЈЃгАВеѓєдЇОдЄ≠жЦЗе≠Чзђ¶жЭ•иѓіпЉМжѓФUTF-32и¶Бе•љгАВеРМжЧґпЉМпЉИеЬ®ињЩдЄАжЭ°дЄКдљ†еЊЧзЫЄдњ°жИСпЉМеЫ†дЄЇжИСдЄНжЙУзЃЧзїЩдљ†е±Хз§ЇеЃГзЪДжХ∞е≠¶еОЯзРЖгАВпЉЙзФ±дљНжУНдљЬзЪД姩жАІдљњзДґпЉМдљњзФ®UTF-8дЄНеЖНе≠ШеЬ®е≠ЧиКВй°ЇеЇПзЪДйЧЃйҐШдЇЖгАВдЄАдїљдї•utf-8зЉЦз†БзЪДжЦЗж°£еЬ®дЄНеРМзЪДиЃ°зЃЧжЬЇдєЛйЧіжШѓдЄАж†ЈзЪДжѓФзЙєжµБгАВ¬†
жАїдљУжЭ•иѓіпЉМеЬ®Unicodeе≠Чзђ¶дЄ≤дЄ≠дЄНеПѓиГљзФ±з†БзВєжХ∞йЗПеЖ≥еЃЪжШЊз§ЇеЃГжЙАйЬАи¶БзЪДйХњеЇ¶пЉМжИЦиАЕжШЊз§Їе≠Чзђ¶дЄ≤дєЛеРОеЬ®жЦЗжЬђзЉУеЖ≤еМЇдЄ≠еЕЙж†ЗеЇФиѓ•жФЊзљЃзЪДдљНзљЃпЉЫзїДеРИе≠Чзђ¶гАБеПШеЃље≠ЧдљУгАБдЄНеПѓжЙУеН∞е≠Чзђ¶еТМдїОеП≥иЗ≥еЈ¶зЪДжЦЗе≠ЧйГљжШѓеЕґељТеЫ†гАВжЙАдї•е∞љзЃ°еЬ®UTF-8е≠Чзђ¶дЄ≤дЄ≠е≠Чзђ¶жХ∞йЗПдЄОз†БзВєжХ∞йЗПзЪДеЕ≥з≥їжѓФUTF-32жЫідЄЇе§НжЭВпЉМеЬ®еЃЮйЩЕдЄ≠еЊИе∞СдЉЪйБЗеИ∞жЬЙдЄНеРМзЪДжГЕ嚥гАВ¬†
дЉШзВє¬†
UTF-8жШѓASCIIзЪДдЄАдЄ™иґЕйЫЖгАВеЫ†дЄЇдЄАдЄ™зЇѓASCIIе≠Чзђ¶дЄ≤дєЯжШѓдЄАдЄ™еРИж≥ХзЪДUTF-8е≠Чзђ¶дЄ≤пЉМжЙАдї•зО∞е≠ШзЪДASCIIжЦЗжЬђдЄНйЬАи¶БиљђжНҐгАВдЄЇдЉ†зїЯзЪДжЙ©е±ХASCIIе≠Чзђ¶йЫЖиЃЊиЃ°зЪДиљѓдїґйАЪеЄЄеПѓдї•дЄНзїПдњЃжФєжИЦеЊИе∞СдњЃжФєе∞±иГљдЄОUTF-8дЄАиµЈдљњзФ®гАВ¬†
дљњзФ®ж†ЗеЗЖзЪДйЭҐеРСе≠ЧиКВзЪДжОТеЇПдЊЛз®ЛеѓєUTF-8жОТеЇПе∞ЖдЇІзФЯдЄОеЯЇдЇОUnicodeдї£з†БзВєжОТеЇПзЫЄеРМзЪДзїУжЮЬгАВпЉИе∞љзЃ°ињЩеП™жЬЙжЬЙйЩРзЪДжЬЙзФ®жАІпЉМеЫ†дЄЇеЬ®дїїдљХзЙєеЃЪиѓ≠и®АжИЦжЦЗеМЦдЄЛйГљдЄН姙еПѓиГљжЬЙдїНеПѓжО•еПЧзЪДжЦЗе≠ЧжОТеИЧй°ЇеЇПгАВпЉЙ¬†
UTF-8еТМUTF-16йГљжШѓеПѓжЙ©е±Хж†ЗиЃ∞иѓ≠и®АжЦЗж°£зЪДж†ЗеЗЖзЉЦз†БгАВжЙАжЬЙеЕґеЃГзЉЦз†БйГљењЕй°їйАЪињЗжШЊеЉПжИЦжЦЗжЬђе£∞жШОжЭ•жМЗеЃЪгАВ¬†
дїїдљХйЭҐеРСе≠ЧиКВзЪДе≠Чзђ¶дЄ≤жРЬ糥зЃЧж≥ХйГљеПѓдї•зФ®дЇОUTF-8зЪДжХ∞жНЃпЉИеП™и¶БиЊУеЕ•дїЕзФ±еЃМжХізЪДUTF-8е≠Чзђ¶зїДжИРпЉЙгАВдљЖжШѓпЉМеѓєдЇОеМЕеРЂе≠Чзђ¶иЃ∞жХ∞зЪДж≠£еИЩи°®иЊЊеЉПжИЦеЕґеЃГзїУжЮДењЕй°їе∞ПењГгАВ¬†
UTF-8е≠Чзђ¶дЄ≤еПѓдї•зФ±дЄАдЄ™зЃАеНХзЪДзЃЧж≥ХеПѓйЭ†еЬ∞иѓЖеИЂеЗЇжЭ•гАВе∞±жШѓпЉМдЄАдЄ™е≠Чзђ¶дЄ≤еЬ®дїїдљХеЕґеЃГзЉЦз†БдЄ≠и°®зО∞дЄЇеРИж≥ХзЪДUTF-8зЪДеПѓиГљжАІеЊИдљОпЉМеєґйЪПе≠Чзђ¶дЄ≤йХњеЇ¶еҐЮйХњиАМеЗПе∞ПгАВдЄЊдЊЛиѓіпЉМе≠Чзђ¶еАЉC0,C1,F5иЗ≥FFдїОжЭ•ж≤°жЬЙеЗЇзО∞гАВдЄЇдЇЖжЫіе•љзЪДеПѓйЭ†жАІпЉМеПѓдї•дљњзФ®ж≠£еИЩи°®иЊЊеЉПжЭ•зїЯиЃ°йЭЮж≥ХињЗйХњеТМжЫњдї£еАЉпЉИеПѓдї•жЯ•зЬЛW3 FAQ: Multilingual FormsдЄКзЪДй™МиѓБUTF-8е≠Чзђ¶дЄ≤зЪДж≠£еИЩи°®иЊЊеЉПпЉЙгАВ¬†
зЉЇзВє¬†
еЫ†дЄЇжѓПдЄ™е≠Чзђ¶дљњзФ®дЄНеРМжХ∞йЗПзЪДе≠ЧиКВзЉЦз†БпЉМжЙАдї•еѓїжЙЊдЄ≤дЄ≠зђђNдЄ™е≠Чзђ¶жШѓдЄАдЄ™O(N)е§НжЭВеЇ¶зЪДжУНдљЬ вАФ еН≥пЉМдЄ≤иґКйХњпЉМеИЩйЬАи¶БжЫіе§ЪзЪДжЧґйЧіжЭ•еЃЪдљНзЙєеЃЪзЪДе≠Чзђ¶гАВеРМжЧґпЉМињШйЬАи¶БдљНеПШжНҐжЭ•жККе≠Чзђ¶зЉЦз†БжИРе≠ЧиКВпЉМжККе≠ЧиКВиІ£з†БжИРе≠Чзђ¶гАВ¬†
4.Accept-Charset/Accept-Encoding/Accept-Language/Content-Type/Content-Encoding/Content-Language 
еЬ®HTTPдЄ≠пЉМдЄОе≠Чзђ¶йЫЖеТМе≠Чзђ¶зЉЦз†БзЫЄеЕ≥зЪДжґИжБѓе§іжШѓAccept-Charset/Content-TypeпЉМеП¶е§ЦдЄїеМЇеМЇеИЖAccept-Charset/Accept-Encoding/Accept-Language/Content-Type/Content-Encoding/Content-LanguageпЉЪ¬†
Accept-CharsetпЉЪжµПиІИеЩ®зФ≥жШОиЗ™еЈ±жО•жФґзЪДе≠Чзђ¶йЫЖпЉМињЩе∞±жШѓжЬђжЦЗеЙНйЭҐдїЛзїНзЪДеРДзІНе≠Чзђ¶йЫЖеТМе≠Чзђ¶зЉЦз†БпЉМе¶Вgb2312пЉМutf-8пЉИйАЪеЄЄжИСдїђиѓіCharsetеМЕжЛђдЇЖзЫЄеЇФзЪДе≠Чзђ¶зЉЦз†БжЦєж°ИпЉЙпЉЫ¬†
Accept-EncodingпЉЪжµПиІИеЩ®зФ≥жШОиЗ™еЈ±жО•жФґзЪДзЉЦз†БжЦєж≥ХпЉМйАЪеЄЄжМЗеЃЪеОЛзЉ©жЦєж≥ХпЉМжШѓеР¶жФѓжМБеОЛзЉ©пЉМжФѓжМБдїАдєИеОЛзЉ©жЦєж≥ХпЉИgzipпЉМdeflateпЉЙпЉМпЉИж≥®жДПпЉЪињЩдЄНжШѓеП™е≠Чзђ¶зЉЦз†БпЉЙпЉЫ¬†
Accept-LanguageпЉЪжµПиІИеЩ®зФ≥жШОиЗ™еЈ±жО•жФґзЪДиѓ≠и®АгАВиѓ≠и®АиЈЯе≠Чзђ¶йЫЖзЪДеМЇеИЂпЉЪдЄ≠жЦЗжШѓиѓ≠и®АпЉМдЄ≠жЦЗжЬЙе§ЪзІНе≠Чзђ¶йЫЖпЉМжѓФе¶Вbig5пЉМgb2312пЉМgbkз≠Йз≠ЙпЉЫ¬†
Content-TypeпЉЪWEBжЬНеК°еЩ®еСКиѓЙжµПиІИеЩ®иЗ™еЈ±еУНеЇФзЪДеѓєи±°зЪДз±їеЮЛеТМе≠Чзђ¶йЫЖгАВдЊЛе¶ВпЉЪContent-Type: text/html; charset='gb2312'¬†
Content-EncodingпЉЪWEBжЬНеК°еЩ®и°®жШОиЗ™еЈ±дљњзФ®дЇЖдїАдєИеОЛзЉ©жЦєж≥ХпЉИgzipпЉМdeflateпЉЙеОЛзЉ©еУНеЇФдЄ≠зЪДеѓєи±°гАВдЊЛе¶ВпЉЪContent-EncodingпЉЪgzip¬†
Content-LanguageпЉЪWEBжЬНеК°еЩ®еСКиѓЙжµПиІИеЩ®иЗ™еЈ±еУНеЇФзЪДеѓєи±°зЪДиѓ≠и®АгАВ¬†
еПВиАГжЦЗзМЃ&ињЫдЄАж≠•йШЕиѓї¬†
зЩЊеЇ¶зЩЊзІС. е≠Чзђ¶йЫЖ.¬†http://baike.baidu.com/view/51987.htm, 2010-12-28¬†
зїіеЯЇзЩЊзІС. е≠Чзђ¶зЉЦз†Б.¬†http://zh.wikipedia.org/wiki/%E5%AD%97%E7%AC%A6%E7%BC%96%E7%A0%81, 2011-1-5¬†
зїіеЯЇзЩЊзІС. ASCII.¬†http://zh.wikipedia.org/wiki/ASCII, 2011-4-5¬†
зїіеЯЇзЩЊзІС. GB2312.¬†http://zh.wikipedia.org/wiki/GB_2312, 2011-3-17¬†
зїіеЯЇзЩЊзІС. GB18030.¬†http://zh.wikipedia.org/wiki/GB_18030, 2010-3-10¬†
зїіеЯЇзЩЊзІС. GBK.¬†http://zh.wikipedia.org/wiki/GBK, 2011-3-7¬†
зїіеЯЇзЩЊзІС. Unicode.¬†http://zh.wikipedia.org/wiki/Unicode, 2011-4-30¬†
Laruence. е≠Чзђ¶зЉЦз†Биѓ¶иІ£(еЯЇз°А).¬†http://www.laruence.com/2009/08/22/1059.html, 2009-8-22¬†
Jan Hunt. Character Sets and Encoding for Web Designers - UCS/UNICODE. http://www.uninetnews.com/other_standards/charset.php 
дљЬиАЕпЉЪеРізІ¶
еЗЇе§ДпЉЪhttp://www.cnblogs.com/skynet/
жЬђжЦЗеЯЇдЇОзљ≤еРН 2.5 дЄ≠еЫље§ІйЩЖиЃЄеПѓеНПиЃЃеПСеЄГпЉМ搥ињОиљђиљљпЉМжЉФзїОжИЦзФ®дЇОеХЖдЄЪзЫЃзЪДпЉМдљЖжШѓењЕй°їдњЭзХЩжЬђжЦЗзЪДзљ≤еРНеРізІ¶пЉИеМЕеРЂйУЊжО•пЉЙ.


- 2011-11-18 09:35
- жµПиІИ 1087
- иѓДиЃЇ(0)
- еИЖз±ї:зЉЦз®Лиѓ≠и®А
- жЯ•зЬЛжЫіе§Ъ
еПСи°®иѓДиЃЇ

-
жО•еП£зЪДеєВз≠ЙжАІ
2018-06-07 16:04 0жО•еП£зЪДеєВз≠ЙжАІ -
javaдЄ≠зЪДjava.util.MapжО•еП£еПКеЕґеЃЮзО∞
2013-11-18 18:04 4150javaдЄЇжХ∞жНЃзїУжЮДдЄ≠зЪДжШ†е ... -
javaдЄ≠class.forName()зЪДеРЂдєЙеТМдљЬзФ®
2013-11-07 10:38 1650еРЂдєЙ ¬† ¬† ¬† ¬† ¬† ¬†Class.forName ... -
javaдљЬдЄЪи∞ГеЇ¶гАБеЃЪжЧґдїїеК°еЃЮиЈµ
2013-05-26 16:13 9319жЬАињСй°єзЫЃдЄ≠зФ®еИ∞дЇЖеЃЪжЧґдїїеК°пЉМдї•еЙНж≤°жЬЙжО•иІ¶ињЗпЉМеЬ®ж≠§еѓєjavaдЄ≠ ... -
javaеЖЕе≠ШжЇҐеЗЇеТМеЖЕе≠Шж≥ДйЬ≤
2013-04-07 15:29 22662¬† иЩљзДґjvmеПѓдї•йАЪињЗGCиЗ™еК®еЫЮжФґжЧ†зФ®зЪДеЖЕе≠ШпЉМдљЖжШѓдї£з†БдЄН ... -
JDKеТМJREгАБpahtеТМclasspath
2013-03-24 16:38 1855е≠¶дє†javaињЩдєИдєЕдЇЖпЉМз™БзДґеПСзО∞иЗ™еЈ±еѓєJDKеТМJREињШж≤°жЬЙдЄА ... -
еѓєjava IOжµБзЪДзРЖиІ£
2013-04-07 15:37 701гАБjavaдЄ≠зЪДвАЬжµБвАЭ ¬† дЄЇдїАдєИи¶БеЕИиЃ®иЃЇвАЬжµБвАЭеСҐпЉМеЫ† ... -
JavaзЪДJARеМЕпЉМ EARеМЕ пЉМWARеМЕеЖЕйГ®зїУжЮД
2012-12-08 21:53 6124JARеМЕ JAR жЦЗдїґж†ЉеЉПдї•жµБи°МзЪД ZIP жЦЗдїґж†ЉеЉПдЄЇеЯЇз°АпЉЫ ... -
ж≠£еИЩи°®иЊЊеЉП
2012-02-26 22:29 1140¬† дЄАгАБеЯЇжЬђж¶Вењµ ж≠£еИЩи°®иЊЊеЉПпЉЪ¬† ¬† ¬† ¬† вАЬ ... -
гАРиљђгАСжЙЛеЈ•жЮДеїЇJAVAеЈ•з®ЛдєЛjavaжЙУеМЕи°Аж≥™еП≤
2012-02-02 09:56 1083¬† ¬†дїК姩жЙУзЃЧе≠¶дє†дЄЛеЈ•з®ЛжЮДеїЇеЈ•еЕЈantпЉМзЬЛзЪДдє¶жШѓгАКйЫґеЯЇз°Ае≠¶J ... -
log4jзЃАдїЛеПКдљњзФ®дЄЊдЊЛ
2011-12-17 19:28 1217зЃАдїЛ еЬ®еЉЇи∞ГеПѓйЗНзФ®зїДдїґеЉАеПСзЪДдїК姩пЉМйЩ§дЇЖиЗ™еЈ±дїОе§іеИ∞е∞ЊеЉАеПСдЄАдЄ™ ... -
Java еЉВеЄЄе§ДзРЖ
2011-11-25 14:25 1193¬† Java еЉВеЄЄе§ДзРЖеЉХеЗЇ еБ ... -
Properties
2011-11-18 09:43 0з±їProperties extends Hashtab ... -
гАРиљђгАСjava Reference
2011-12-12 17:49 1059¬† JavaеЯЇжЬђеКЯвАФвАФReferenceReferen ... -
sessionеТМcookie
2011-11-14 21:19 1104¬† ¬† ¬† ¬† cookie ¬† ¬† ¬† й ... -
иІ£иА¶дЄОеЇПеИЧеМЦгАБжМБдєЕеМЦгАРиљђгАС
2011-11-09 18:43 1430http://kongtong2004.blog.163.co ... -
DataеТМDataFormat
2011-11-14 21:19 12402¬† ¬†1пЉЙSystem.currentTimeMillis ... -
abstract classеТМinterfaceзЪДеМЇеИЂгАРиљђгАС
2011-11-08 15:24 1324¬† ¬† abstract classеТМinterfa ... -
finallyжЈ±еЕ•дЇЖиІ£
2011-11-08 15:20 1069¬† ¬† ¬† ¬†дї•еЙНеП™зЯ•йБУдЄНзЃ° try иѓ≠еП•еЭЧж≠£еЄЄзїУжЭЯињШжШѓеЉВеЄЄ ... -
гАРиљђгАСfinal
2011-11-08 15:12 1044finalжШѓжМЗињЩдЄ™еПШйЗПдЄНеП ...
зЫЄеЕ≥жО®иНР
зЫЄдњ°е§ІеЃґдЄАеЃЪзҐ∞еИ∞ињЗпЉМжЙУеЉАжЯРдЄ™зљСй°µпЉМеНіжШЊз§ЇдЄАе†ЖеГПдє±з†БпЉМе¶В"–±&#...ињШиЃ∞еЊЧHTTPдЄ≠зЪДAccept-CharsetгАБAccept-EncodingгАБAccept-LanguageгАБContent-EncodingгАБContent-Languageз≠ЙжґИжБѓе§іе≠ЧжЃµпЉЯињЩдЇЫе∞±жШѓжО•дЄЛжЭ•жИСдїђи¶БжОҐиЃ®зЪД
жЬђжЦЗе∞ЖеЫізїХвАЬJavaе≠Чзђ¶йЫЖзЉЦз†БзЃАиЃ∞вАЭињЩдЄАдЄїйҐШпЉМжЈ±еЕ•жОҐиЃ®зЫЄеЕ≥зЯ•иѓЖзВєпЉМеєґзїУеРИж†Зз≠ЊвАЬжЇРз†БвАЭеТМвАЬеЈ•еЕЈвАЭпЉМжОҐиЃ®еЬ®еЃЮйЩЕеЉАеПСдЄ≠е¶ВдљХињРзФ®еТМе§ДзРЖе≠Чзђ¶зЉЦз†БйЧЃйҐШгАВ й¶ЦеЕИпЉМжИСдїђйЬАи¶БзРЖиІ£е≠Чзђ¶йЫЖзЪДж¶ВењµгАВе≠Чзђ¶йЫЖжШѓдЄАз≥їеИЧзђ¶еПЈзЪДйЫЖеРИпЉМдЊЛе¶В...
еЬ®еЃЮйЩЕеЉАеПСдЄ≠пЉМеЇФж†єжНЃеЕЈдљУйЬАж±ВйАЙжЛ©еРИйАВзЪДе≠Чзђ¶йЫЖзЉЦз†БпЉМеєґж≥®жДПеЬ®дЄНеРМзОѓиКВдњЭжМБе≠Чзђ¶йЫЖзЉЦз†БзЪДдЄАиЗіжАІпЉМдї•йБњеЕНдє±з†БеТМеЕґдїЦжљЬеЬ®йЧЃйҐШгАВйАЪињЗдЄКињ∞еѓєJAVAеПКзЫЄеЕ≥е≠Чзђ¶йЫЖзЉЦз†БйЧЃйҐШзЪДжЈ±еЕ•жОҐиЃ®пЉМеЄМжЬЫиГљеЄЃеК©еЉАеПСиАЕдїђжЫіе•љеЬ∞зРЖиІ£еТМеЇФеѓєињЩдЄА...
ж†ЗйҐШдЄ≠зЪДвАЬе≠Чзђ¶йЫЖзЉЦз†БзЪДиѓЖеИЂвАЭжШѓдЄАдЄ™еЕ≥дЇОиЃ°зЃЧжЬЇзІСе≠¶еТМзЉЦз®ЛзЪДйЗНи¶БдЄїйҐШпЉМдЄїи¶БжґЙеПКжЦЗжЬђжХ∞жНЃеЬ®иЃ°зЃЧжЬЇеЖЕйГ®зЪДи°®з§ЇжЦєеЉПгАВе≠Чзђ¶йЫЖзЉЦз†БжШѓе∞Же≠Чзђ¶дЄОдЇМињЫеИґжХ∞е≠ЧдєЛйЧіеїЇзЂЛжШ†е∞ДеЕ≥з≥їзЪДдЄАзІНжЦєж≥ХпЉМдљњеЊЧиЃ°зЃЧжЬЇиГље§ЯзРЖиІ£еТМе§ДзРЖеРДзІНиѓ≠и®АзЪД...
Oracle е≠Чзђ¶йЫЖеСљеРНйБµеЊ™дї•дЄЛиІДеИЩпЉЪ`<Language><bitsize><encoding>`пЉМеН≥ `<иѓ≠и®А><жѓФзЙєдљНжХ∞><зЉЦз†Б>`гАВдЊЛе¶ВпЉМZHS16GBK и°®з§Ї 16 дљНзЃАдљУдЄ≠жЦЗ GBK е≠Чзђ¶йЫЖгАВ **3.3 е≠Чзђ¶зЉЦз†БжЦєж°И** - **еНХе≠ЧиКВзЉЦз†Б**: - еНХе≠ЧиКВ 7 дљНе≠Чзђ¶...
е≠Чзђ¶йЫЖеТМдє±з†БиІ£еЖ≥жЦєж°И е≠Чзђ¶йЫЖжШѓиЃ°зЃЧжЬЇдЄ≠зФ®дЇОи°®з§ЇжЦЗжЬђзЪДзЉЦз†БжЦєеЉПпЉМе≠Чзђ¶йЫЖзЪДдЄНеРМеПѓиГљдЉЪеѓЉиЗідє±з†БйЧЃйҐШгАВеЬ®JavaдЄ≠пЉМдє±з†БйЧЃйҐШжШѓеЄЄиІБзЪДйЧЃйҐШдєЛдЄАпЉМжЬђжЦЗе∞ЖиЃ®иЃЇе≠Чзђ¶йЫЖеТМдє±з†БиІ£еЖ≥жЦєж°ИпЉМеЄЃеК©еЉАеПСиАЕиІ£еЖ≥дє±з†БйЧЃйҐШгАВ е≠Чзђ¶йЫЖзЃАдїЛ ...
Javaе≠Чзђ¶йЫЖдЄОзЉЦз†БйЧЃйҐШеЬ®зЉЦз®ЛеЃЮиЈµдЄ≠зїПеЄЄйБЗеИ∞пЉМе∞§еЕґжШѓеЬ®е§ДзРЖдЄ≠жЦЗе≠Чзђ¶жЧґгАВJavaз≥їзїЯеЖЕйГ®дї•UTF-8зЉЦз†БињЫи°Ме≠Чзђ¶дЄ≤ињРзЃЧпЉМдљЖе≠Чзђ¶дЄ≤зЪДеИЭеІЛзЉЦз†БеИЩеПЦеЖ≥дЇОжУНдљЬз≥їзїЯзЪДйїШиЃ§зЉЦз†БгАВињЩжДПеС≥зЭАпЉМе¶ВжЮЬJavaз®ЛеЇПзЪДиЊУеЕ•гАБиЊУеЗЇдї•еПКжУНдљЬз≥їзїЯдЄЙ...
йЪПзЭАеЕ®зРГеМЦзЪДеПСе±Хдї•еПКдЇТиБФзљСжКАжЬѓзЪДињЫж≠•пЉМе§ДзРЖдЄНеРМиѓ≠и®АеТМе≠Чзђ¶йЫЖзЪДйЬАж±ВеПШеЊЧиґКжЭ•иґКжЩЃйБНгАВеЫ†ж≠§пЉМжЈ±еЕ•зРЖиІ£е≠Чзђ¶зЉЦз†БзЪДж¶ВењµгАБз±їеЮЛеПКеЕґеЇФзФ®еѓєдЇОз°ЃдњЭиљѓдїґдЇІеУБзЪДеЕЉеЃєжАІеТМеЫљйЩЕеМЦиЗ≥еЕ≥йЗНи¶БгАВ #### еЯЇз°Аж¶Вењµ **е≠Чзђ¶**пЉЪжМЗзЪДжШѓ...
SQLite C# е§Ъе≠Чзђ¶йЫЖжФѓжМБз§ЇдЊЛз®ЛеЇПгАВ ињСжЬЯжЬЙдЄ™й°єзЫЃи¶БеѓєжО•жµЈеЇЈйБУйЧЄиЃЊе§ЗпЉМжµЈеЇЈзФ®sqliteдљЬдЄЇжХ∞жНЃеЇУе≠ШеВ®гАВ жµЈеЇЈеВ®е≠ШжЦЗжЬђжШѓc++зФ®gb2312е≠ШеВ®зЪДпЉМиАМsqliteйїШиЃ§жШѓдї•utf8зЉЦз†Бе≠ШеВ®зЪДпЉМSystem.Data.SQLiteйїШиЃ§дєЯжШѓдї•utf8ињЫи°Ме≠ШеПЦ...
WebеЉАеПСдЄ≠зЪДе≠Чзђ¶йЫЖеТМе≠Чзђ¶зЉЦз†БжШѓз°ЃдњЭж≠£з°ЃжШЊз§ЇеТМе§ДзРЖжЦЗжЬђжХ∞жНЃзЪДеЕ≥йФЃеЫ†зі†пЉМзЙєеИЂжШѓеЬ®жґЙеПКе§Ъиѓ≠и®АеТМзЙєжЃКе≠Чзђ¶жЧґгАВ...еЬ®еЃЮйЩЕеЈ•дљЬдЄ≠пЉМи¶БжЧґеИїеЕ≥ж≥®зЉЦз†БеЕЉеЃєжАІпЉМе∞§еЕґжШѓеЬ®е§Ъиѓ≠и®АзОѓеҐГдЄЛпЉМйАЙжЛ©еРИйАВзЪДе≠Чзђ¶йЫЖеТМзЉЦз†БжЦєеЉПиЗ≥еЕ≥йЗНи¶БгАВ
"charset"пЉМдЄ≠жЦЗеРНдЄЇе≠Чзђ¶йЫЖжИЦе≠Чзђ¶зЉЦз†БпЉМжШѓзФ®жЭ•еЃЪдєЙдЄНеРМиѓ≠и®АжЦЗе≠ЧзЪДзЉЦз†БжЦєеЉПпЉМз°ЃдњЭжµПиІИеЩ®иГље§ЯеЗЖз°ЃеЬ∞иІ£жЮРеєґжШЊз§ЇзљСй°µдЄКзЪДжЦЗжЬђгАВеЬ®и∞Јж≠МжµПиІИеЩ®пЉИGoogle ChromeпЉЙдЄ≠пЉМиЃЊзљЃж≠£з°ЃзЪДе≠Чзђ¶зЉЦз†БеѓєдЇОйШЕиѓїйЭЮж†ЗеЗЖжИЦзЙєжЃКиѓ≠и®АзЪДзљСй°µе∞§еЕґ...
еЬ®иЃ°зЃЧжЬЇзІСе≠¶дЄ≠пЉМе≠Чзђ¶йЫЖзЉЦз†БпЉИCharacter Set EncodingпЉЙжШѓе∞Же≠Чзђ¶жШ†е∞ДеИ∞е≠ЧиКВеЇПеИЧзЪДдЄАзІНжЦєеЉПпЉМзФ®дЇОе≠ШеВ®еТМдЉ†иЊУжЦЗжЬђжХ∞жНЃгАВдЄНеРМзЪДзЉЦз†Бз≥їзїЯжЬЙдЄНеРМзЪДиІДеИЩеТМиМГеЫіпЉМеЄЄиІБзЪДеМЕжЛђASCIIгАБISO 8859-1гАБGB2312гАБGBKгАБUTF-8еТМUnicode...
2. GBKзЉЦз†БпЉЪGBKжШѓдЄ≠еЫље§ІйЩЖеєњж≥ЫдљњзФ®зЪДе§Ъе≠ЧиКВе≠Чзђ¶йЫЖпЉМеЃГжШѓGB2312зЪДжЙ©е±ХпЉМеЕЉеЃєASCIIпЉМеєґеҐЮеК†дЇЖеѓєдЄ≠жЦЗгАБжЧ•жЦЗгАБйЯ©жЦЗз≠Йе≠Чзђ¶зЪДжФѓжМБпЉМе§ІзЇ¶еМЕеРЂ20902дЄ™ж±Йе≠ЧеТМеЕґдїЦзђ¶еПЈгАВ 3. UTF-8зЉЦз†БпЉЪUTF-8жШѓUnicode Transformation ...
жЬђжЦЗдЄїи¶БжОҐиЃ®дЇЖе≠Чзђ¶зЉЦз†БзЪДеЯЇжЬђж¶Вењµдї•еПКJavaзЉЦз®Лиѓ≠и®Ае¶ВдљХе§ДзРЖдЄНеРМе≠Чзђ¶йЫЖгАВйЪПзЭАдњ°жБѓжКАжЬѓзЪДеПСе±ХпЉМе≠Чзђ¶зЉЦз†БжКАжЬѓдєЯеЬ®дЄНжЦ≠жЉФињЫпЉМдї•жФѓжМБеЕ®зРГиМГеЫіеЖЕеРДзІНиѓ≠и®АзЪДжЦЗжЬђи°®з§ЇйЬАж±ВгАВжЦЗзЂ†йАЪињЗвАЬдЄ≠жЦЗвАЭдЇМе≠ЧдљЬдЄЇз§ЇдЊЛпЉМдїЛзїНдЇЖеЗ†зІНеЄЄиІБзЪД...
`getBytes()`дЉЪж†єжНЃйїШиЃ§е≠Чзђ¶йЫЖзЉЦз†Бе≠Чзђ¶дЄ≤дЄЇе≠ЧиКВжХ∞зїДпЉМиАМ`new String(byte[], charset)`еИЩеПѓдї•жМЗеЃЪе≠Чзђ¶йЫЖиІ£з†Бе≠ЧиКВжХ∞зїДпЉЪ ```java String str = "дљ†е•љпЉМдЄЦзХМ"; byte[] bytes = str.getBytes("UTF-8"); // зЉЦз†Б String...
зЙєеИЂжШѓеЬ®е§Ъиѓ≠и®АзОѓеҐГдЄЛпЉМUTF-8зЉЦз†БзФ±дЇОеЕґеєњж≥ЫжФѓжМБеРДзІНе≠Чзђ¶йЫЖпЉМйАЪ媪襀жО®иНРдЄЇй¶ЦйАЙзЉЦз†БгАВ 2. **SetCharacterEncodingFilterиѓ¶иІ£** `SetCharacterEncodingFilter`жШѓдЄАдЄ™Java Servlet FilterпЉМеЃГзЪДдЄїи¶БдљЬзФ®жШѓеЬ®HTTPиѓЈж±В...
JavaдЄ≠пЉМ`Charset`з±їзФ®дЇОе§ДзРЖе≠Чзђ¶йЫЖеТМзЉЦз†БиљђжНҐгАВ 2. **JavaдЄ≠зЪДе≠Чзђ¶зЉЦз†Б** Javaж†ЗеЗЖеЇУжПРдЊЫдЇЖеєњж≥ЫзЪДе≠Чзђ¶йЫЖжФѓжМБпЉМйАЪињЗ`java.nio.charset.Charset`з±їеПѓдї•иЃњйЧЃеТМжУНдљЬеЃГдїђгАВеЬ®JavaдЄ≠пЉМе≠Чзђ¶дЄ≤йїШиЃ§дљњзФ®UnicodeпЉИUTF-16пЉЙ...
Javaе≠Чзђ¶йЫЖжШѓJavaзЉЦз®Лиѓ≠и®АдЄ≠е§ДзРЖе≠Чзђ¶зЉЦз†БзЪДеЯЇз°Аж¶ВењµпЉМеЃГеѓєдЇОзРЖиІ£е¶ВдљХеЬ®з®ЛеЇПдЄ≠ж≠£з°ЃеЬ∞е≠ШеВ®гАБе§ДзРЖеТМдЉ†иЊУжЦЗжЬђиЗ≥еЕ≥йЗНи¶БгАВеЬ®JavaдЄ≠пЉМе≠Чзђ¶йЫЖдЄїи¶БжМЗзЪДжШѓUnicodeе≠Чзђ¶йЫЖпЉМзЙєеИЂжШѓеЕґе≠РйЫЖUTF-8пЉМеЃГжШѓJavaйїШиЃ§дљњзФ®зЪДе≠Чзђ¶зЉЦз†БгАВJava...
HTMLпЉИиґЕжЦЗжЬђж†ЗиЃ∞иѓ≠и®АпЉЙжШѓзФ®дЇОеИЫеїЇзљСй°µзЪДж†ЗеЗЖж†ЗиЃ∞иѓ≠и®АпЉМиАМе≠Чзђ¶йЫЖзЪДе£∞жШОеЬ®HTMLжЦЗж°£зЪДйГ®еИЖзЪДж†Зз≠ЊдЄ≠еЃЪдєЙпЉМдЊЛе¶ВдљњзФ®charsetжМЗеЃЪзЉЦз†БжЦєеЉПдЄЇgb2312жИЦbig5з≠ЙпЉМдї•з°ЃдњЭзљСй°µеЬ®дЄНеРМжµПиІИеЩ®еТМжУНдљЬз≥їзїЯдЄКзЪДж≠£з°ЃжШЊз§ЇгАВ XMLпЉИеПѓжЙ©е±Х...
### SSH+MySQLеЉАеПСдЄ≠зЪДе≠Чзђ¶йЫЖйЧЃйҐШиѓ¶иІ£ ...йЗНи¶БзЪДжШѓи¶Бз°ЃдњЭеЬ®жХ∞жНЃеЇУгАБж°ЖжЮґдї•еПКеЇФзФ®еРДдЄ™е±ВйЭҐйГљдљњзФ®зЫЄеРМзЪДе≠Чзђ¶йЫЖиЃЊзљЃпЉМињЩж†ЈжЙНиГљдњЭиѓБжХ∞жНЃзЪДдЄАиЗіжАІеТМеЗЖз°ЃжАІгАВеЄМжЬЫжЬђжЦЗиГље§ЯеЄЃеК©еИ∞ж≠£еЬ®йЭҐдЄізЫЄеРМйЧЃйҐШзЪДеЉАеПСиАЕдїђгАВ