- жөҸи§Ҳ: 7339470 ж¬Ў
- жҖ§еҲ«:

- жқҘиҮӘ: дёҠжө·
-

ж–Үз« еҲҶзұ»
- е…ЁйғЁеҚҡе®ў (1546)
- дјҒдёҡдёӯй—ҙ件 (236)
- дјҒдёҡеә”з”Ёйқўдёҙзҡ„й—®йўҳ (236)
- е°ҸеёғOracleеӯҰд№ з¬”и®°жұҮжҖ» (36)
- Spring ејҖеҸ‘еә”з”Ё (54)
- IBatisејҖеҸ‘еә”з”Ё (16)
- OracleеҹәзЎҖеӯҰд№ (23)
- struts2.0 (41)
- JVM&ClassLoader&GC (16)
- JQueryзҡ„ејҖеҸ‘еә”з”Ё (17)
- WebServiceзҡ„ејҖеҸ‘еә”з”Ё (21)
- Java&Socket (44)
- ејҖжәҗ组件зҡ„еә”з”Ё (254)
- еёёз”ЁJavascriptзҡ„ејҖеҸ‘еә”з”Ё (28)
- J2EEејҖеҸ‘жҠҖжңҜжҢҮеҚ— (163)
- EJB3ејҖеҸ‘еә”з”Ё (11)
- GIS&Mobile&MAP (36)
- SWT-GEF-RCP (52)
- з®—жі•&ж•°жҚ®з»“жһ„ (6)
- ApacheејҖжәҗз»„д»¶з ”з©¶ (62)
- Hibernate еӯҰд№ еә”з”Ё (57)
- java并еҸ‘зј–зЁӢ (59)
- MySQL&Mongodb&MS/SQL (15)
- Oracleж•°жҚ®еә“е®һйӘҢе®Ө (55)
- жҗңзҙўеј•ж“Һзҡ„ејҖеҸ‘еә”з”Ё (34)
- иҪҜ件е·ҘзЁӢеёҲ笔иҜ•з»Ҹе…ё (14)
- е…¶д»–жқӮйЎ№ (10)
- AndroidPn& MQTT&C2DM&жҺЁжҠҖжңҜ (29)
- ActiveMQеӯҰд№ е’Ңз ”з©¶ (38)
- GoogleжҠҖжңҜеә”з”ЁејҖеҸ‘е’ҢAPIеҲҶжһҗ (11)
- flexзҡ„еӯҰд№ жҖ»з»“ (59)
- йЎ№зӣ®дёӯдёҖзӮ№жҖ»з»“ (20)
- javaз–‘жғ‘ javaйқўеҗ‘еҜ№иұЎзј–зЁӢ (28)
- Android ејҖеҸ‘еӯҰд№ (133)
- linuxе’ҢUNIXзҡ„жҖ»з»“ (37)
- TitaniumеӯҰд№ жҖ»з»“ (20)
- JQueryMobileеӯҰд№ жҖ»з»“ (34)
- PhonegapеӯҰд№ жҖ»з»“ (32)
- HTML5еӯҰд№ жҖ»з»“ (41)
- JeeCMSз ”з©¶е’ҢзҗҶи§ЈеҲҶжһҗ (9)
зӨҫеҢәзүҲеқ—
- жҲ‘зҡ„иө„и®Ҝ ( 0)
- жҲ‘зҡ„и®әеқӣ ( 92)
- жҲ‘зҡ„й—®зӯ” ( 6)
еӯҳжЎЈеҲҶзұ»
- 2014-06 ( 10)
- 2014-01 ( 8)
- 2013-12 ( 16)
- жӣҙеӨҡеӯҳжЎЈ...
жңҖж–°иҜ„и®ә
-
lgh1992314пјҡ
[u][i][b][flash=200,200][url][i ...
зңӢзңӢmybatis жәҗд»Јз Ғ -
е°јеҸӨжӢүж–Ҝ.fwpпјҡ
еӣҫзүҮж №жң¬е°ұдёҚеҮәжқҘеҘҪеҗ§гҖӮгҖӮгҖӮгҖӮгҖӮгҖӮ
Androidж–Ү件еӣҫзүҮдёҠдј зҡ„иҜҰз»Ҷи®Іи§ЈпјҲдёҖпјүHTTP multipart/form-data дёҠдј жҠҘж–Үж јејҸе®һзҺ°жүӢжңәз«ҜдёҠдј -
ln94223пјҡ
第дёҖдёӘеә”иҜҘз”ЁжҺ’е®ғзҪ‘е…іеҗ§ жҖҺд№ҲжҳҜ并иЎҢзҪ‘е…іпјҢ 并иЎҢзҪ‘е…іжҳҜжүҖжңүexe ...
е·ҘдҪңжөҒActivitiзҡ„еӯҰд№ жҖ»з»“пјҲе…«пјүActivitiиҮӘеҠЁжү§иЎҢзҡ„еә”з”Ё -
ZY199266пјҡ
иҺ·еҸ–дёҚеҲ°д»»дҪ•ж¶ҲжҒҜдҝЎжҒҜпјҢиҜ·й—®иҝҷжҳҜд»Җд№ҲеҺҹеӣ е‘ўпјҹ
ActiveMQ йҖҡиҝҮJMXзӣ‘жҺ§ConnectionпјҢQueueпјҢTopicзҡ„дҝЎжҒҜ -
xiaoyaoйң„пјҡ
DestinationSourceMonitor жҠҘй”ҷ еә”иҜҘеҜј ...
ActiveMQ йҖҡиҝҮJMXзӣ‘жҺ§ConnectionпјҢQueueпјҢTopicзҡ„дҝЎжҒҜ
HadoopеӯҰд№ з¬”и®°дёҖ з®ҖиҰҒд»Ӣз»Қ
- еҚҡе®ўеҲҶзұ»пјҡ
- жҗңзҙўеј•ж“Һзҡ„ејҖеҸ‘еә”з”Ё
иҝҷйҮҢе…ҲеӨ§иҮҙд»Ӣз»ҚдёҖдёӢHadoop.
В В В жң¬ж–ҮеӨ§йғЁеҲҶеҶ…е®№йғҪжҳҜд»Һе®ҳзҪ‘HadoopдёҠжқҘзҡ„гҖӮе…¶дёӯжңүдёҖзҜҮд»Ӣз»ҚHDFSзҡ„pdfж–ҮжЎЈпјҢйҮҢйқўеҜ№Hadoopд»Ӣз»Қзҡ„жҜ”иҫғе…ЁйқўдәҶгҖӮжҲ‘зҡ„иҝҷдёҖдёӘзі»еҲ—зҡ„HadoopеӯҰд№ з¬”и®°д№ҹжҳҜд»ҺиҝҷйҮҢдёҖжӯҘдёҖжӯҘиҝӣиЎҢдёӢжқҘзҡ„пјҢеҗҢж—¶еҸҲеҸӮиҖғдәҶзҪ‘дёҠзҡ„еҫҲеӨҡж–Үз« пјҢеҜ№еӯҰд№ HadoopдёӯйҒҮеҲ°зҡ„й—®йўҳиҝӣиЎҢдәҶеҪ’зәіжҖ»з»“гҖӮ
В В В иЁҖеҪ’жӯЈдј пјҢе…ҲиҜҙдёҖдёӢHadoopзҡ„жқҘйҫҷеҺ»и„үгҖӮи°ҲеҲ°Hadoopе°ұдёҚеҫ—дёҚжҸҗеҲ°Luceneе’ҢNutchгҖӮйҰ–е…ҲпјҢLucene并дёҚжҳҜдёҖдёӘеә”з”ЁзЁӢеәҸпјҢиҖҢжҳҜжҸҗдҫӣдәҶдёҖдёӘзәҜJavaзҡ„й«ҳжҖ§иғҪе…Ёж–Үзҙўеј•еј•ж“Һе·Ҙе…·еҢ…пјҢе®ғеҸҜд»Ҙж–№дҫҝзҡ„еөҢе…ҘеҲ°еҗ„з§Қе®һйҷ…еә”з”Ёдёӯе®һзҺ°е…Ёж–Үжҗңзҙў/зҙўеј•еҠҹиғҪгҖӮNutchжҳҜдёҖдёӘеә”з”ЁзЁӢеәҸпјҢжҳҜдёҖдёӘд»ҘLuceneдёәеҹәзЎҖе®һзҺ°зҡ„жҗңзҙўеј•ж“Һеә”з”ЁпјҢLuceneдёәNutchжҸҗдҫӣдәҶж–Үжң¬жҗңзҙўе’Ңзҙўеј•зҡ„APIпјҢNutchдёҚе…үжңүжҗңзҙўзҡ„еҠҹиғҪпјҢиҝҳжңүж•°жҚ®жҠ“еҸ–зҡ„еҠҹиғҪгҖӮеңЁnutch0.8.0зүҲжң¬д№ӢеүҚпјҢHadoopиҝҳеұһдәҺNutchзҡ„дёҖйғЁеҲҶпјҢиҖҢд»Һnutch0.8.0ејҖе§ӢпјҢе°Ҷе…¶дёӯе®һзҺ°зҡ„NDFSе’ҢMapReduceеүҘзҰ»еҮәжқҘжҲҗз«ӢдёҖдёӘж–°зҡ„ејҖжәҗйЎ№зӣ®пјҢиҝҷе°ұжҳҜHadoopпјҢиҖҢnutch0.8.0зүҲжң¬иҫғд№Ӣд»ҘеүҚзҡ„NutchеңЁжһ¶жһ„дёҠжңүдәҶж №жң¬жҖ§зҡ„еҸҳеҢ–пјҢйӮЈе°ұжҳҜе®Ңе…Ёжһ„е»әеңЁHadoopзҡ„еҹәзЎҖд№ӢдёҠдәҶгҖӮеңЁHadoopдёӯе®һзҺ°дәҶGoogleзҡ„GFSе’ҢMapReduceз®—жі•пјҢдҪҝHadoopжҲҗдёәдәҶдёҖдёӘеҲҶеёғејҸзҡ„и®Ўз®—е№іеҸ°гҖӮ
В В В е…¶е®һпјҢHadoop并дёҚд»…д»…жҳҜдёҖдёӘз”ЁдәҺеӯҳеӮЁзҡ„еҲҶеёғејҸж–Ү件系з»ҹпјҢиҖҢжҳҜи®ҫи®Ўз”ЁжқҘеңЁз”ұйҖҡз”Ёи®Ўз®—и®ҫеӨҮз»„жҲҗзҡ„еӨ§еһӢйӣҶзҫӨдёҠжү§иЎҢеҲҶеёғејҸеә”з”Ёзҡ„жЎҶжһ¶гҖӮ
В В В HadoopеҢ…еҗ«дёӨдёӘйғЁеҲҶпјҡ
В В В 1гҖҒHDFS
В В В В В В еҚіHadoop Distributed File System (HadoopеҲҶеёғејҸж–Ү件系з»ҹ)
В В В В В В HDFSе…·жңүй«ҳе®№й”ҷжҖ§пјҢ并且еҸҜд»Ҙиў«йғЁзҪІеңЁдҪҺд»·зҡ„硬件и®ҫеӨҮд№ӢдёҠгҖӮHDFSеҫҲйҖӮеҗҲйӮЈдәӣжңүеӨ§ж•°жҚ®йӣҶзҡ„еә”з”ЁпјҢ并且жҸҗдҫӣдәҶеҜ№ж•°жҚ®иҜ»еҶҷзҡ„й«ҳеҗһеҗҗзҺҮгҖӮHDFSжҳҜдёҖдёӘmaster/slaveзҡ„з»“жһ„пјҢе°ұйҖҡеёёзҡ„йғЁзҪІжқҘиҜҙпјҢеңЁmasterдёҠеҸӘиҝҗиЎҢдёҖдёӘNamenodeпјҢиҖҢеңЁжҜҸдёҖдёӘslaveдёҠиҝҗиЎҢдёҖдёӘDatanodeгҖӮ
В В В В В В HDFSж”ҜжҢҒдј з»ҹзҡ„еұӮж¬Ўж–Ү件组з»Үз»“жһ„пјҢеҗҢзҺ°жңүзҡ„дёҖдәӣж–Ү件系з»ҹеңЁж“ҚдҪңдёҠеҫҲзұ»дјјпјҢжҜ”еҰӮдҪ еҸҜд»ҘеҲӣе»әе’ҢеҲ йҷӨдёҖдёӘж–Ү件пјҢжҠҠдёҖдёӘж–Ү件д»ҺдёҖдёӘзӣ®еҪ•з§»еҲ°еҸҰдёҖдёӘзӣ®еҪ•пјҢйҮҚе‘ҪеҗҚзӯүзӯүж“ҚдҪңгҖӮNamenodeз®ЎзҗҶзқҖж•ҙдёӘеҲҶеёғејҸж–Ү件系з»ҹпјҢеҜ№ж–Ү件系з»ҹзҡ„ж“ҚдҪңпјҲеҰӮе»әз«ӢгҖҒеҲ йҷӨж–Ү件е’Ңж–Ү件еӨ№пјүйғҪжҳҜйҖҡиҝҮNamenodeжқҘжҺ§еҲ¶гҖӮВ
В В В В В дёӢйқўжҳҜHDFSзҡ„з»“жһ„пјҡ
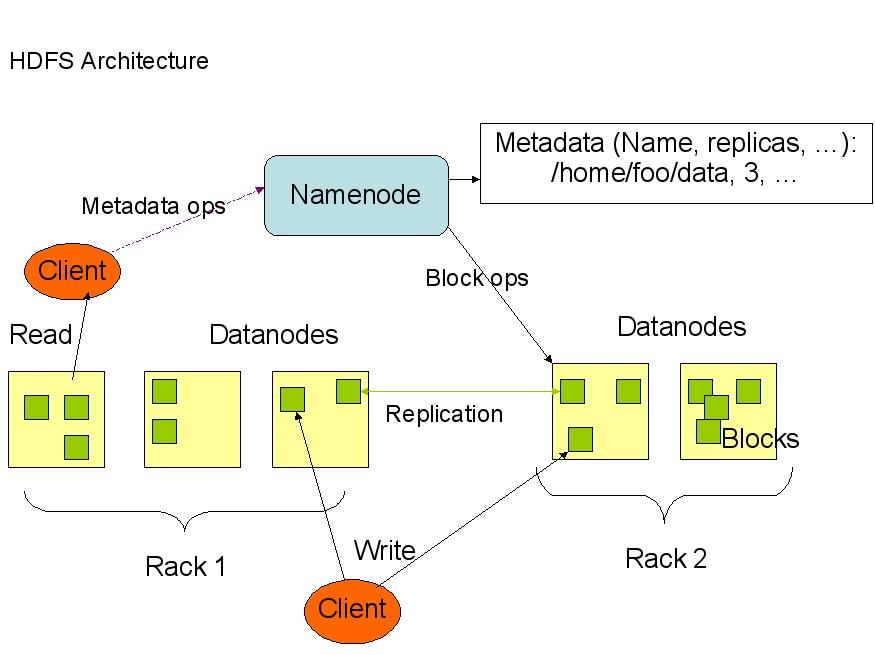
В В В В В В д»ҺдёҠйқўзҡ„еӣҫдёӯеҸҜд»ҘзңӢеҮәпјҢNamenodeпјҢDatanodeпјҢClientд№Ӣй—ҙзҡ„йҖҡдҝЎйғҪжҳҜе»әз«ӢеңЁTCP/IPзҡ„еҹәзЎҖд№ӢдёҠзҡ„гҖӮеҪ“ClientиҰҒжү§иЎҢдёҖдёӘеҶҷе…Ҙзҡ„ж“ҚдҪңзҡ„ж—¶еҖҷпјҢе‘Ҫд»ӨдёҚжҳҜ马дёҠе°ұеҸ‘йҖҒеҲ°NamenodeпјҢClientйҰ–е…ҲеңЁжң¬жңәдёҠдёҙж—¶ж–Ү件еӨ№дёӯзј“еӯҳиҝҷдәӣж•°жҚ®пјҢеҪ“дёҙж—¶ж–Ү件еӨ№дёӯзҡ„ж•°жҚ®еқ—иҫҫеҲ°дәҶи®ҫе®ҡзҡ„Blockзҡ„еҖјпјҲй»ҳи®ӨжҳҜ64Mпјүж—¶пјҢClientдҫҝдјҡйҖҡзҹҘNamenodeпјҢNamenodeдҫҝе“Қеә”Clientзҡ„RPCиҜ·жұӮпјҢе°Ҷж–Ү件еҗҚжҸ’е…Ҙж–Ү件系з»ҹеұӮж¬Ўдёӯ并且еңЁDatanodeдёӯжүҫеҲ°дёҖеқ—еӯҳж”ҫиҜҘж•°жҚ®зҡ„blockпјҢеҗҢж—¶е°ҶиҜҘDatanodeеҸҠеҜ№еә”зҡ„ж•°жҚ®еқ—дҝЎжҒҜе‘ҠиҜүClientпјҢClientдҫҝиҝҷдәӣжң¬ең°дёҙж—¶ж–Ү件еӨ№дёӯзҡ„ж•°жҚ®еқ—еҶҷе…ҘжҢҮе®ҡзҡ„ж•°жҚ®иҠӮзӮ№гҖӮ
В В В В В В HDFSйҮҮеҸ–дәҶеүҜжң¬зӯ–з•ҘпјҢе…¶зӣ®зҡ„жҳҜдёәдәҶжҸҗй«ҳзі»з»ҹзҡ„еҸҜйқ жҖ§пјҢеҸҜз”ЁжҖ§гҖӮHDFSзҡ„еүҜжң¬ж”ҫзҪ®зӯ–з•ҘжҳҜдёүдёӘеүҜжң¬пјҢдёҖдёӘж”ҫеңЁжң¬иҠӮзӮ№дёҠпјҢдёҖдёӘж”ҫеңЁеҗҢдёҖжңәжһ¶дёӯзҡ„еҸҰдёҖдёӘиҠӮзӮ№дёҠпјҢиҝҳжңүдёҖдёӘеүҜжң¬ж”ҫеңЁеҸҰдёҖдёӘдёҚеҗҢзҡ„жңәжһ¶дёӯзҡ„дёҖдёӘиҠӮзӮ№дёҠгҖӮеҪ“еүҚзүҲжң¬зҡ„hadoop0.12.0дёӯиҝҳжІЎжңүе®һзҺ°пјҢдҪҶжҳҜжӯЈеңЁиҝӣиЎҢдёӯпјҢзӣёдҝЎдёҚд№…е°ұеҸҜд»ҘеҮәжқҘдәҶгҖӮ
В В В 2гҖҒMapReduceзҡ„е®һзҺ°
В В В В В В MapReduceжҳҜGoogle зҡ„дёҖйЎ№йҮҚиҰҒжҠҖжңҜпјҢе®ғжҳҜдёҖдёӘзј–зЁӢжЁЎеһӢпјҢз”Ёд»ҘиҝӣиЎҢеӨ§ж•°жҚ®йҮҸзҡ„и®Ўз®—гҖӮеҜ№дәҺеӨ§ж•°жҚ®йҮҸзҡ„и®Ўз®—пјҢйҖҡеёёйҮҮз”Ёзҡ„еӨ„зҗҶжүӢжі•е°ұжҳҜ并иЎҢи®Ўз®—гҖӮиҮіе°‘зҺ°йҳ¶ж®өиҖҢиЁҖпјҢеҜ№и®ёеӨҡејҖеҸ‘дәәе‘ҳжқҘиҜҙпјҢ并иЎҢи®Ўз®—иҝҳжҳҜдёҖдёӘжҜ”иҫғйҒҘиҝңзҡ„дёңиҘҝгҖӮMapReduceе°ұжҳҜдёҖз§Қз®ҖеҢ–并иЎҢи®Ўз®—зҡ„зј–зЁӢжЁЎеһӢпјҢе®ғи®©йӮЈдәӣжІЎжңүеӨҡ少并иЎҢи®Ўз®—з»ҸйӘҢзҡ„ејҖеҸ‘дәәе‘ҳд№ҹеҸҜд»ҘејҖеҸ‘并иЎҢеә”з”ЁгҖӮ
В В В В В В MapReduceзҡ„еҗҚеӯ—жәҗдәҺиҝҷдёӘжЁЎеһӢдёӯзҡ„дёӨйЎ№ж ёеҝғж“ҚдҪңпјҡMapе’Ң ReduceгҖӮд№ҹи®ёзҶҹжӮүFunctional ProgrammingпјҲеҮҪж•°ејҸзј–зЁӢпјүзҡ„дәәи§ҒеҲ°иҝҷдёӨдёӘиҜҚдјҡеҖҚж„ҹдәІеҲҮгҖӮз®ҖеҚ•зҡ„иҜҙжқҘпјҢMapжҳҜжҠҠдёҖз»„ж•°жҚ®дёҖеҜ№дёҖзҡ„жҳ е°„дёәеҸҰеӨ–зҡ„дёҖз»„ж•°жҚ®пјҢе…¶жҳ е°„зҡ„规еҲҷз”ұдёҖдёӘеҮҪж•°жқҘжҢҮе®ҡпјҢжҜ”еҰӮеҜ№[1, 2, 3, 4]иҝӣиЎҢд№ҳ2зҡ„жҳ е°„е°ұеҸҳжҲҗдәҶ[2, 4, 6, 8]гҖӮReduceжҳҜеҜ№дёҖз»„ж•°жҚ®иҝӣиЎҢеҪ’зәҰпјҢиҝҷдёӘеҪ’зәҰзҡ„规еҲҷз”ұдёҖдёӘеҮҪж•°жҢҮе®ҡпјҢжҜ”еҰӮеҜ№[1, 2, 3, 4]иҝӣиЎҢжұӮе’Ңзҡ„еҪ’зәҰеҫ—еҲ°з»“жһңжҳҜ10пјҢиҖҢеҜ№е®ғиҝӣиЎҢжұӮз§Ҝзҡ„еҪ’зәҰз»“жһңжҳҜ24гҖӮ
В В В В В В е…ідәҺMapReduceзҡ„еҶ…е®№пјҢе»әи®®зңӢзңӢеӯҹеІ©зҡ„иҝҷзҜҮMapReduce:The Free Lunch Is Not Over!
В В В еҘҪдәҶпјҢдҪңдёәиҝҷдёӘзі»еҲ—зҡ„第дёҖзҜҮе°ұеҶҷиҝҷд№ҲеӨҡдәҶпјҢжҲ‘д№ҹжҳҜеҲҡејҖе§ӢжҺҘи§ҰHadoopпјҢдёӢдёҖзҜҮе°ұжҳҜи®ІHadoopзҡ„йғЁзҪІпјҢи°Ҳи°ҲжҲ‘еңЁйғЁзҪІHadoopж—¶йҒҮеҲ°зҡ„й—®йўҳпјҢд№ҹз»ҷеӨ§е®¶дёҖдёӘеҸӮиҖғпјҢе°‘иө°зӮ№ејҜи·ҜгҖӮ


- 2009-03-17 15:40
- жөҸи§Ҳ 1774
- иҜ„и®ә(0)
- жҹҘзңӢжӣҙеӨҡ
еҸ‘иЎЁиҜ„и®ә

-
Luceneе…Ёж–ҮжҗңзҙўжЎҶжһ¶
2009-11-09 17:16 36161 luceneз®Җд»Ӣ 1.1 д»Җд№ҲжҳҜluc ... -
пҪғпҪҸпҪҚпҪҗпҪҒпҪ“пҪ“зҡ„ејҖеҸ‘жҮүз”ЁпјӘпј°пјЎ+пјЈпҪҸпҪҚпҪҗпҪҒпҪ“пҪ“ж•ҙеҗҲ
2009-10-10 17:21 2505жҹҘиҜўз»“жһңзҡ„й«ҳдә®жҳҫзӨә: В йҮҮз”Ёзҡ„жҳҜJPAзҡ„жіЁи§Јж–№ејҸпјҢ йҰ– ... -
Compass еҜҰз”Ёдёӯжү©еұ•жҮүз”Ё
2009-10-10 14:12 2929пј‘В В Compassдёӯзҡ„ж“ҚдҪңйҖҡиҝҮCompassSessionжҲ‘ ... -
Spring ,JPA,CompassдҪҝз”ЁжіЁи§ЈејҖеҸ‘зҡ„еҚҡе®ўз«ҷеҶ…жҗңзҙў
2009-10-10 12:54 3922В В В В В В В В еҪ“дёҖдёӘзҪ‘з« ... -
Webжҗңзҙўеј•ж“ҺжҠҖжңҜ
2009-09-25 13:38 2661дёҖгҖҒWebжҗңзҙўеј•ж“ҺжҠҖжңҜз»ји ... -
жҗңзҙўеј•ж“ҺжҠҖжңҜеҺҹзҗҶ
2009-09-25 13:37 2639дёҖгҖҒжҗңзҙўеј•ж“Һзҡ„еҲҶзұ» иҺ ... -
жҗңзҙўи®Ўз®—зҡ„规еҲҷ
2009-05-15 10:28 2190йқўеҗ‘Webеә”з”Ёзҡ„зҪ‘йЎөйў„еӨ„зҗҶ2003е№ҙ12жңҲ3ж—Ҙ(и®ІзЁҝз”ұеј еҝ—еҲҡеҚҸ ... -
з”Ё Lucene еҠ йҖҹ Web жҗңзҙўеә”з”ЁзЁӢеәҸзҡ„ејҖеҸ‘
2009-05-02 09:18 20372006 е№ҙ 9 жңҲ 06 ж—Ҙ Lucene жҳҜеҹәдәҺ Jav ... -
з”Ё Lucene еҠ йҖҹ Web жҗңзҙўеә”з”ЁзЁӢеәҸзҡ„ејҖеҸ‘
2009-05-02 09:17 18332006 е№ҙ 9 жңҲ 06 ж—Ҙ Lucene жҳҜеҹәдәҺ Jav ... -
жҗңзҙўеј•ж“Һеҹәжң¬е·ҘдҪңеҺҹзҗҶ
2009-05-02 07:48 2055жҗңзҙўеј•ж“Һеҹәжң¬е·ҘдҪңеҺҹзҗҶ дәҶи§Јжҗңзҙўеј•ж“Һзҡ„е·ҘдҪңеҺҹзҗҶеҜ№жҲ‘们 ... -
жҗңзҙўеј•ж“Һиңҳиӣӣе·ҘдҪңеҺҹзҗҶ
2009-05-02 07:46 2586зҪ‘з«ҷиғҪеңЁжҗңзҙўеј•ж“Һиў«жҗңе ... -
luenceеӯҰд№ зҡ„жҢҮеҚ—ж–ҮжЎЈпјҲдә”пјү
2009-03-17 17:00 2668пј–.жҗңзҙўеј•ж“Һзҡ„жҖ§иғҪиҖғиҷ‘дҝЎжҒҜпјҡ В В зҙўеј•ж•°еӯ—пјҡй’ҲеҜ№ж•°еӯ—зҡ„жЈҖзҙў ... -
luenceеӯҰд№ зҡ„жҢҮеҚ—ж–ҮжЎЈпјҲдёүпјү
2009-03-17 16:58 22713.В дҪҝз”ЁеңәеҗҲпјҡеӨҡдёӘжҗңзҙўеј•ж“ҺжҹҘиҜўзҡ„ж•°жҚ®з»“жһңзҡ„еҗҲ并дҝЎжҒҜж“ҚдҪңпјҡж·» ... -
luenceеӯҰд№ зҡ„жҢҮеҚ—ж–ҮжЎЈ
2009-03-17 16:56 29762пјҺд»Јз ҒдҪҝз”ЁеңәеҗҲпјҡеңЁжҗңзҙўеј•ж“ҺжЈҖзҙўзҙўеј•зӣ®еҪ•зҡ„дёӯзҡ„дҝЎжҒҜ /** ... -
luenceеӯҰд№ зҡ„жҢҮеҚ—ж–ҮжЎЈ
2009-03-17 16:54 2225жҗңзҙўеј•ж“ҺеӯҰд№ жҖ»з»“пјҲе®һжҲҳе’ҢдҪҝз”ЁеңәеҗҲпјү еӨҮжіЁд»ҘдёӢд»Јз ҒдҪҝз”Ёзҡ„зҺҜеўғдёә ... -
жҸӯејҖзҘһз§ҳйқўзәұ,жҗңзҙўеј•ж“ҺеҺҹзҗҶжө…жһҗ
2009-03-17 16:10 1926еңЁжө©еҰӮзғҹжө·зҡ„InternetдёҠпјҢзү№еҲ«жҳҜе…¶дёҠзҡ„WebпјҲWorld ... -
luceneе…Ёж–ҮжЈҖзҙўеә”з”ЁзӨәдҫӢеҸҠд»Јз Ғз®Җжһҗ
2009-03-17 16:02 2141В LuceneжҳҜapacheиҪҜ件еҹәйҮ‘дјҡВ jakartaйЎ№зӣ®з»„ ... -
е…ідәҺluceneзҡ„еӯҰд№ з¬”и®°liui :иҪ¬е…ідәҺluncene еҶ…еұӮзҡ„з ”з©¶
2009-03-17 15:59 2422зҺ°еңЁе·Із»ҸдёҚз”ЁеҺ»з ”究йӮЈдәӣд»Јз ҒпјҢдҪҶиҝҳжҳҜеҲҶдә«еҮәжқҘз»ҷеӨ§е®¶д»Ҙеё®еҠ©гҖӮи°ўи°ў1 ... -
luceneеӨ§ж•°жҚ®йҮҸзҡ„еҠЁжҖҒжӣҙж–°й—®йўҳи§ЈеҶіж–№ејҸ. з”ЁеҶ…еӯҳ
2009-03-17 15:55 4680й—®йўҳ: зӣ®еүҚзҙўеј•йҮҢйқўе·Із»Ҹжңү1000еӨҡдёҮзҡ„ж•°жҚ®дәҶпјҢзҺ°еңЁйңҖиҰҒжҜҸеҮ еҲҶ ... -
lucene иҮӘе®ҡд№үSORT
2009-03-17 15:54 3237еҰӮж¬ІиҪ¬иҪҪпјҢиҜ·жіЁжҳҺдҪңиҖ…п ...
зӣёе…іжҺЁиҚҗ
HadoopеӯҰд№ з¬”и®°пјҢиҮӘе·ұжҖ»з»“зҡ„дёҖдәӣHadoopеӯҰд№ з¬”и®°пјҢжҜ”иҫғз®ҖеҚ•гҖӮ
гҖҗHADOOPеӯҰд№ з¬”и®°гҖ‘ HadoopжҳҜApacheеҹәйҮ‘дјҡејҖеҸ‘зҡ„дёҖдёӘејҖжәҗеҲҶеёғејҸи®Ўз®—жЎҶжһ¶пјҢжҳҜдә‘и®Ўз®—йўҶеҹҹзҡ„йҮҚиҰҒз»„жҲҗйғЁеҲҶпјҢе°Өе…¶еңЁеӨ§ж•°жҚ®еӨ„зҗҶж–№йқўжңүзқҖе№ҝжіӣзҡ„еә”з”ЁгҖӮжң¬еӯҰд№ з¬”и®°е°Ҷж·ұе…ҘжҺўи®ЁHadoopзҡ„ж ёеҝғ组件гҖҒжһ¶жһ„д»ҘеҸҠеҰӮдҪ•жҗӯе»әдә‘и®Ўз®—е№іеҸ°гҖӮ...
HadoopжҳҜдёҖз§ҚејҖжәҗзҡ„еҲҶеёғејҸеӯҳеӮЁе’Ңи®Ўз®—зі»з»ҹпјҢе®ғз”ұApacheиҪҜ件еҹәйҮ‘дјҡејҖеҸ‘гҖӮеңЁеҲқеӯҰиҖ…зҡ„и§’еәҰпјҢзҗҶи§ЈHadoopзҡ„з»„жҲҗйғЁеҲҶд»ҘеҸҠе…¶жһ¶жһ„и®ҫи®ЎжҳҜеӯҰд№ Hadoopзҡ„еҹәзЎҖгҖӮ йҰ–е…ҲпјҢHadoopзҡ„еҲҶеёғејҸж–Ү件系з»ҹпјҲHDFSпјүжҳҜе…¶ж ёеҝғ组件д№ӢдёҖпјҢе®ғе…·жңүй«ҳ...
### HadoopеӯҰд№ з¬”и®°зҹҘиҜҶзӮ№жўізҗҶ #### дёҖгҖҒHadoopз®Җд»Ӣ - **е®ҡд№ү**: HadoopжҳҜдёҖдёӘејҖжәҗзҡ„еҲҶеёғејҸи®Ўз®—жЎҶжһ¶пјҢиғҪеӨҹж”ҜжҢҒеӨ§и§„жЁЎж•°жҚ®йӣҶзҡ„еӨ„зҗҶгҖӮе®ғжңҖеҲқз”ұApacheиҪҜ件еҹәйҮ‘дјҡејҖеҸ‘пјҢж—ЁеңЁжҸҗдҫӣдёҖз§Қз®ҖеҚ•й«ҳж•Ҳзҡ„еҲҶеёғејҸи®Ўз®—и§ЈеҶіж–№жЎҲгҖӮ - ...
гҖҗж ҮйўҳгҖ‘"Hadoopд№ӢHBaseеӯҰд№ з¬”и®°"дё»иҰҒиҒҡз„ҰдәҺHadoopз”ҹжҖҒдёӯзҡ„еҲҶеёғејҸж•°жҚ®еә“HBaseгҖӮHBaseжҳҜдёҖдёӘеҹәдәҺGoogle BigtableзҗҶеҝөи®ҫи®Ўзҡ„ејҖжәҗNoSQLж•°жҚ®еә“пјҢе®ғиҝҗиЎҢеңЁHadoopд№ӢдёҠпјҢжҸҗдҫӣй«ҳжҖ§иғҪгҖҒй«ҳеҸҜйқ жҖ§д»ҘеҸҠеҸҜж°ҙе№іжү©еұ•зҡ„ж•°жҚ®еӯҳеӮЁиғҪеҠӣ...
ж №жҚ®2017еӨ§ж•°жҚ®еҸ‘еұ•и¶ӢеҠҝпјҢз»“еҗҲеӣҪеҶ…еӣҪеӨ–зҡ„еӨ§ж•°жҚ®еҸ‘еұ•зҺ°зҠ¶пјҢд»ҘеҸҠж”ҝзӯ–зәІиҰҒпјҢжө…еұӮж¬Ўзҡ„д»Ӣз»ҚдәҶеӨ§ж•°жҚ®еҸ‘еұ•зҡ„и¶ӢеҠҝпјҢд»ҘеҸҠз®ҖеҚ•зҡ„еӨ§ж•°жҚ®жһ¶жһ„гҖӮж–Үз« жүҖиҝ°д»…д»ЈиЎЁдёӘдәәи§ӮзӮ№пјҢдёҚи¶ід№ӢеӨ„иҝҳиҜ·жҢҮжӯЈгҖӮж–ҮжЎЈд»…йҷҗеӯҰд№ жүҖз”ЁпјҢзҰҒжӯўд»…йҷҗе•ҶдёҡиҪ¬ж’ӯгҖӮ...
- **е‘ҪеҗҚз”ұжқҘ**пјҡHadoopиҝҷдёӘеҗҚеӯ—жқҘжәҗдәҺCuttingзҡ„еӯ©еӯҗз»ҷдёҖеӨҙзҺ©е…·еӨ§иұЎиө·зҡ„еҗҚеӯ—пјҢе®ғжҳҜдёҖдёӘйқһжӯЈејҸзҡ„еҗҚз§°пјҢз®ҖеҚ•жҳ“и®°пјҢжІЎжңүзү№ж®Ҡеҗ«д№үгҖӮ - **еҸ‘еұ•еҺҶзЁӢ**пјҡ - **2004е№ҙ**пјҡCuttingе’ҢCafarellaејҖе§ӢејҖеҸ‘NutchйЎ№зӣ®пјҢиҝҷжҳҜдёҖдёӘ...
### Hadoopи®Ід№үеҹәзЎҖзҜҮзҹҘиҜҶзӮ№жҰӮиҝ° #### еҝ…еӯҰеҝ…дјҡзҡ„Shellе‘Ҫд»Ө Shellе‘Ҫд»ӨжҳҜиҝӣиЎҢзі»з»ҹз®ЎзҗҶе’Ң...йҖҡиҝҮеҜ№д»ҘдёҠзҹҘиҜҶзӮ№зҡ„еӯҰд№ пјҢжҲ‘们еҸҜд»ҘжӣҙеҘҪең°зҗҶи§Је’ҢжҺҢжҸЎHadoopзӣёе…ізҡ„еҹәзЎҖзҹҘиҜҶе’ҢжҠҖжңҜж ҲпјҢдёәиҝӣдёҖжӯҘж·ұе…ҘеӯҰд№ Hadoopжү“дёӢеқҡе®һзҡ„еҹәзЎҖгҖӮ
### Hadoop е®үиЈ…еҸҠиҜҰз»ҶеӯҰд№ з¬”и®° #### Hadoop жҰӮиҝ° Hadoop жҳҜдёҖдёӘиғҪеӨҹеҜ№еӨ§йҮҸж•°жҚ®иҝӣиЎҢеҲҶеёғејҸеӨ„зҗҶзҡ„иҪҜ件жЎҶжһ¶пјҢе®ғж—ЁеңЁжҸҗдҫӣй«ҳжү©еұ•жҖ§гҖҒеҸҜйқ жҖ§е’Ңй«ҳж•ҲжҖ§пјҢйҖӮз”ЁдәҺеӨ„зҗҶPBзә§еҲ«зҡ„ж•°жҚ®йӣҶгҖӮHadoop зҡ„ж ёеҝғ组件еҢ…жӢ¬ HDFSпјҲHadoop ...
### Hadoop еӯҰд№ иө„жәҗжҰӮи§Ҳ #### дёҖгҖҒHadoop е®ҳж–№ж–ҮжЎЈ ...д»ҘдёҠиө„жәҗиҰҶзӣ–дәҶHadoopеӯҰд№ зҡ„еҗ„дёӘж–№йқўпјҢд»ҺзҗҶи®әеҲ°е®һи·өпјҢд»ҺеҹәзЎҖеҲ°й«ҳзә§пјҢж—ЁеңЁеё®еҠ©еҲқеӯҰиҖ…зі»з»ҹең°жҺҢжҸЎHadoopеҸҠе…¶зӣёе…іжҠҖжңҜгҖӮеёҢжңӣиҝҷдәӣиө„жәҗиғҪеӨҹеҜ№дҪ жңүжүҖеё®еҠ©пјҒ
иҝҷдёӘвҖңhadoop笔记вҖқеҸҜиғҪеҢ…еҗ«дәҶе…ідәҺHadoopз”ҹжҖҒзі»з»ҹгҖҒHadoopеҲҶеёғејҸж–Ү件系з»ҹпјҲHDFSпјүгҖҒMapReduceзј–зЁӢжЁЎеһӢгҖҒYARNиө„жәҗз®ЎзҗҶеҷЁд»ҘеҸҠзӣёе…іе·Ҙе…·зҡ„иҜҰз»ҶеӯҰд№ и®°еҪ•гҖӮзҺ°еңЁпјҢи®©жҲ‘们ж·ұе…ҘжҺўи®ЁдёҖдёӢиҝҷдәӣе…ій”®зҹҘиҜҶзӮ№гҖӮ 1. Hadoopз”ҹжҖҒзі»з»ҹпјҡ...
### VMwareдёӢе®Ңе…ЁеҲҶеёғејҸHadoopйӣҶзҫӨе®ү装笔记 #### дёҖгҖҒеҮҶеӨҮе·ҘдҪңдёҺзҺҜеўғжҗӯе»ә **1. е®үиЈ…VMware** еңЁејҖе§Ӣд№ӢеүҚпјҢйҰ–е…ҲйңҖиҰҒдёҖдёӘиҷҡжӢҹеҢ–е№іеҸ°жқҘжЁЎжӢҹеӨҡеҸ°и®Ўз®—жңәд№Ӣй—ҙзҡ„дәӨдә’пјҢиҝҷйҮҢйҖүжӢ©зҡ„жҳҜVMwareгҖӮж №жҚ®жӮЁзҡ„ж“ҚдҪңзі»з»ҹйҖүжӢ©еҗҲйҖӮзҡ„...
иҝҷд»ҪвҖңJavaеӯҰд№ з¬”и®°(еҝ…зңӢз»Ҹе…ё).docвҖқж–ҮжЎЈе°Ҷж¶өзӣ–Javaзҡ„ж ёеҝғжҰӮеҝөе’ҢйҮҚиҰҒзҹҘиҜҶзӮ№пјҢеҜ№дәҺеҲқеӯҰиҖ…е’Ңжңүз»ҸйӘҢзҡ„ејҖеҸ‘иҖ…жқҘиҜҙйғҪжҳҜе®қиҙөзҡ„еҸӮиҖғиө„ж–ҷгҖӮ йҰ–е…ҲпјҢJavaзҡ„еҹәзЎҖйғЁеҲҶйҖҡеёёеҢ…жӢ¬д»ҘдёӢеҮ дёӘж–№йқўпјҡ 1. **JavaиҜӯжі•еҹәзЎҖ**пјҡиҝҷжҳҜжүҖжңү...
### еӨ§ж•°жҚ®еӯҰд№ з¬”и®°зҹҘиҜҶзӮ№жҰӮи§Ҳ #### 第дёҖйғЁеҲҶпјҡSparkеӯҰд№ ##### 第1з« пјҡSparkд»Ӣз»Қ - **1.1 Sparkз®Җд»ӢдёҺеҸ‘еұ•** - **иғҢжҷҜ**пјҡйҡҸзқҖеӨ§ж•°жҚ®еӨ„зҗҶйңҖжұӮзҡ„еўһй•ҝпјҢдј з»ҹзҡ„Hadoop MapReduceжЎҶжһ¶иҷҪ然жҸҗдҫӣдәҶејәеӨ§зҡ„и®Ўз®—иғҪеҠӣпјҢдҪҶ...
RPCпјҲRemote Procedure CallпјүиҝңзЁӢиҝҮзЁӢи°ғз”ЁжҳҜдёҖз§ҚзҪ‘з»ңйҖҡдҝЎеҚҸи®®пјҢе…Ғи®ёдёҖеҸ°и®Ўз®—жңәдёҠзҡ„зЁӢеәҸи°ғз”ЁеҸҰдёҖеҸ°и®Ўз®—жңәдёҠзҡ„зЁӢеәҸпјҢе°ұеғҸи°ғз”Ёжң¬ең°еҮҪж•°дёҖж ·з®ҖеҚ•гҖӮеңЁеҲҶеёғејҸзі»з»ҹдёӯпјҢRPCжү®жј”зқҖж ёеҝғи§’иүІпјҢдҪҝеҫ—еҗ„жңҚеҠЎд№Ӣй—ҙиғҪеӨҹж–№дҫҝең°иҝӣиЎҢ...
### PigеӯҰд№ з¬”и®°зІҫиҰҒ **Pig** жҳҜдёҖдёӘеңЁ **Hadoop** е№іеҸ°дёҠз”ЁдәҺж•°жҚ®еҲҶжһҗзҡ„й«ҳзә§е·Ҙе…·пјҢе®ғжҸҗдҫӣдәҶдёҖз§ҚйқһзЁӢеәҸеҢ–зҡ„ж•°жҚ®жөҒиҜӯиЁҖпјҢз§°дёә **Pig Latin** пјҢжқҘеӨ„зҗҶеӨ§и§„жЁЎзҡ„ж•°жҚ®йӣҶгҖӮPig зҡ„и®ҫи®Ўзӣ®зҡ„жҳҜдёәдәҶз®ҖеҢ– **MapReduce** зҡ„...