1.3 准备Hadoop源代码
在Hadoop的官方网站(http://hadoop.apache.org/)中,可以找到Hadoop项目相关的信息,如图1-14所示。
1.3.1 下载Hadoop
前面在介绍Hadoop生态系统的时候,已经了解到Hadoop发展初期的系统中包括Common(开始使用的名称是Core)、HDFS和MapReduce三部分,现在这些子系统都已经独立,成为Apache的子项目。但在Hadoop 1.0的发行包中,Common、HDFS和MapReduce还是打包在一起,我们只需要下载一个hadoop-1.0.0.tar.gz包即可。注意,Hadoop官方也提供Subversion(SVN)方式的代码下载,SVN地址为http://svn.apache.org/repos/asf/hadoop/common/tags/release-0.1.0/。
熟悉Subversion的读者,也可以通过该地址下载Hadoop1.0版本代码,该Tag也包含了上述三部分的代码。
Apache提供了大量镜像网站,供大家下载它的软件和源码,上面提到的hadoop-1.0.0.tar.gz的一个下载地址为http://apache.etoak.com/hadoop/common/hadoop-1.0.0,如图1-15所示。
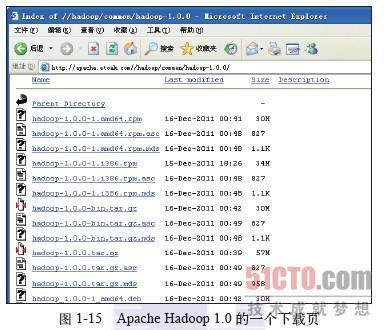
该地址包含了Hadoop 1.0的多种发行方式,如64位系统上的hadoop-1.0.0-1.adm64.rpm、不包含源代码的发行包hadoop-1.0.0.bin.tar.gz等。下载的hadoop-1.0.0.tar.gz是包括源代码的Hadoop发行包。
1.3.2 创建Eclipse项目
解压下载的hadoop-1.0.0.tar.gz包,假设解压后Hadoop的根目录是E:\hadoop-1.0.0,启动Cygwin,进入项目的根目录,我们开始将代码导入Eclipse。Hadoop的Ant配置文件build.xml中提供了eclipse任务,该任务可以为Hadoop代码生成Eclipse项目文件,免去创建Eclipse项目所需的大量配置工作。只需在Cygwin下简单地执行“ant eclipse”命令即可,如图1-16所示。

在Ubutu环境下注意安装:ant、libtool。

注意 该过程需要使用UNIX的在线编辑器sed,所以一定要在Cygwin环境里执行上述命令,否则会出错。
命令运行结束后,就可以在Eclipse中创建项目了。打开Eclipse的File→New→Java Project,创建一个新的Java项目,选择项目的位置为Hadoop的根目录,即E:\hadoop-1.0.0,然后单击“Finish”按钮,就完成了Eclipse项目的创建,如图1-17所示。

完成上述工作以后,Eclipse提示一个错误:“Unbound classpath variable: 'ANT_HOME/lib/ant.jar' in project 'hadoop-1.0.0'”。
显然,我们需要设置系统的ANT_HOME变量,让Eclipse能够找到编译源码需要的Ant库,选中项目,然后打开Eclipse的Project→Properties→Java Build Path,在Libraries页编辑(单击“Edit”按钮)出错的项:ANT_HOME/lib/ant.jar,创建变量ANT_HOME(在接下来第一个对话框里单击“Varliable”,第二个对话框里单击“New”按钮),其值为Ant的安装目录,如图1-18所示。
由于本书只分析Common和HDFS两个模块,在Project→Properties→Java Build Path的Source页只保留两个目录,分别是core和hdfs,如图1-19所示。
完成上述操作以后,创建Eclipse项目的任务就完成了。

1.3.3 Hadoop源代码组织
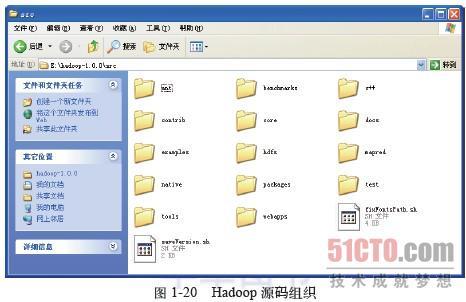
打开已经解压的Hadoop 1.0源代码,进入src目录,该目录包含了Hadoop中所有的代码,如图1-20所示。
前面已经提到过,Hadoop 1.0的发行包中,Common、HDFS和MapReduce三个模块还是打包在一起的,它们的实现分别位于core、hdfs和mapred子目录下。源代码目录src下还有若干值得关注的子目录,具体如下。
tools:包含Hadoop的一些实用工具的实现,如存档文件har、分布式拷贝工具distcp、MapReduce执行情况分析工具rumen等。
benchmarks:包含对Hadoop进行性能测试的两个工具gridmix和gridmix2,通过这些工具,可以测试Hadoop集群的一些性能指标。
c++:需要提及的是libhdfs,它通过Java的C语言库界面,实现了一套访问HDFS的C接口。
examples:为开发人员提供了一些使用Hadoop的例子,不过这些例子只涉及MapReduce的API,本书中不会讨论这部分内容。
contrib:是contribution的缩写,包含大量Hadoop辅助模块的实现,如在亚马逊弹性计算云上部署、运行Hadoop所需的脚本就在contrib\ec2目录下。
test:包含项目的单元测试用例,在该目录中能找到Common、HDFS和MapReduce等模块的单元测试代码。
分享到:




相关推荐
“Hadoop技术内幕”共两册,分别从源代码的角度对“Common+HDFS”和“MapReduce的架构...1.3 搭建hadoop源代码阅读环境/ 8 1.3.1 创建hadoop工程/ 8 1.3.2 hadoop源代码阅读技巧/ 9 1.4 hadoop源代码组织结构/ 10
在深入分析Hadoop中HDFS的源代码之前,我们首先需要理解Hadoop系统的基础知识。 ### 一、Hadoop系统基础 #### 1.1 Hadoop简介 Hadoop是一个开源框架,由Apache软件基金会开发,主要用于处理和存储大量数据。它设计...
描述中提到的同样是"hadoop-3.1.3.tar.gz.gz",这通常意味着这是一个压缩过的tar文件,可能包含了Hadoop的源代码或者二进制分发版。".tar"文件是Linux/Unix系统中常用的归档格式,用于将多个文件和目录打包成一个...
3. 下载Nutch1.3源代码:从Apache Nutch官网获取Nutch1.3的源代码压缩包,并解压到本地目录。 接下来,我们按照以下步骤在MyEclipse中部署Nutch1.3源代码: 步骤1:创建新项目 - 打开MyEclipse,选择"File" -> ...
Hadoop YARN Server ResourceManager 和 Elasticsearch Dataformat 插件都是遵循开放源代码许可的项目,这意味着它们的源代码可供开发者研究、学习和改进。这样的开放性促进了技术社区的协作和创新,使得全球的...
本文档详细介绍了如何从零开始搭建一个适合编译Hadoop的开发环境,包括Maven的安装配置、必要软件的安装、protobuf的安装以及Hadoop源代码的下载、编译和验证。通过遵循这些步骤,开发者能够顺利地完成Hadoop的本地...
这个源码包 "apache-nutch-1.3-src.tar.gz" 和 "nutch-1.3.tar.gz" 包含了 Nutch 1.3 的源代码和编译后的二进制文件,对于开发者和研究者来说是非常有价值的资源。 **Nutch 概述** Nutch 是基于 Java 开发的,遵循 ...
8.3 关联spring源代码87 8.4 小结89 第9章 创建Spring MVC之器90 9.1 整体结构介绍90 9.2 HttpServletBean93 9.3 FrameworkServlet95 9.4 DispatcherServlet100 9.5 小结107 第10章 Spring MVC之用108 10.1...
CentOS是一种免费的Linux发行版,基于Red Hat Enterprise Linux (RHEL) 的源代码构建而成。它的主要特点是长期支持周期、稳定的版本发布以及对企业级应用的高度兼容性。 - **长期支持**:每个版本的CentOS都将获得...
1.3 下载Dr-Elephant源代码 从GitHub上下载Dr-Elephant的源代码,例如,版本2.1.7。 1.4 编译与安装 进入下载的源代码目录,执行以下命令进行编译和安装: ``` mvn clean package -DskipTests sudo cp -r ...
- **社区**: Hadoop项目是一个开放源代码的项目,拥有庞大的开发者社区。 - **生态系统**: Hadoop不仅仅是一个单一的工具,而是一个包含众多组件的生态系统,如HDFS、MapReduce、YARN等。 #### 二、MapReduce简介 ...
- **编译**: 使用Maven或Ant等构建工具编译源代码。 - **运行**: 通过命令行方式运行编译后的程序,例如 `bin/hadoop jar hadoop-mapreduce-examples-*.jar testdfsio`。 ##### 2.5 样例: TeraSort Benchmark Suite...
ProxyTerminator-1.3.tar.gz这个压缩包包含了ProxyTerminator库的1.3版本源代码。在Python开发中,开发者通常会将代码打包成.tar.gz格式的文件,以便于分发和安装。这个压缩包可能包含README文件,该文件会提供关于...
【标签】"开源项目"表明这两个压缩包中的内容都是开放源代码的,这意味着任何人都可以查看、使用、修改并分发这些代码,这遵循了开源软件的许可证规定。开源项目通常会促进社区协作和创新,因为开发者可以从彼此的...
SatNOGS是一个开放源代码的全球网络,致力于监测和记录卫星过境,提供了一个开源的、分布式的卫星地面站网络。 首先,我们来了解一下数据库API客户端。在软件开发中,API(Application Programming Interface)是让...
1.3 本章小结 第2 部分 数据逻辑. 2 将数据导入导出Hadoop. 2.1 导入导出的关键要素 2.2 将数据导入Hadoop . 2.2.1 将日志文件导入Hadoop 技术点1 使用Flume 将系统日志文件导入HDFS 2.2.2 导入...
Hadoop是开放源代码软件实用程序的集合,这些实用程序可帮助使用许多计算机组成的网络来解决涉及大量数据和计算的问题。 它提供了使用MapReduce编程模型进行大数据的分布式存储和处理的软件框架。 最初是为使用商品...
1. 使用Git克隆Nutch 1.2的源代码库: ``` git clone https://github.com/apache/nutch.git -b branch-1.2 ``` **构建Nutch** 1. 进入Nutch源代码目录: ``` cd nutch ``` 2. 使用Maven构建Nutch: ``` mvn...
访问上述链接,用户可以克隆或下载项目源代码,进行查看、学习或者在原有基础上进行二次开发。 1.1.2 开源项目 该项目是开源的,这意味着它的源代码对公众开放,鼓励社区参与改进和扩展,遵循开源软件的许可证规定...
压缩包arvados-cwl-runner-1.3.0.20181130210406内通常包含源代码、文档、配置文件以及必要的依赖信息。解压后,用户可以查看项目的具体结构,了解其模块划分、脚本和配置文件,以便于理解和定制arvados-cwl-runner...