
工具传送门:
- Taskctl商业付费版(付费)
- Taskctl Web商业免费版(永久免费)
- Kettle(开源免费)
- Datastage (付费)
ETL是数据仓库中的非常重要的一环,是承前启后的必要的一步。ETL负责将分布的、异构数据源中的数据如关系数据、平面数据文件等抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或数据集市中,成为联机分析处理、数据挖掘的基础。
下面给大家介绍一下什么是ETL以及ETL常用的三种工具——Datastage,Taskctl,Kettle。
什么是ETL?
ETL,Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。
数据仓库结构
通俗的说法就是从数据源抽取数据出来,进行清洗加工转换,然后加载到定义好的数据仓库模型中去。目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。
ETL是BI项目重要的一个环节,其设计的好坏影响生成数据的质量,直接关系到BI项目的成败。
为什么要用ETL工具?
在数据处理的时候,我们有时会遇到这些问题:
- 当数据来自不同的物理主机,这时候如使用SQL语句去处理的话,就显得比较吃力且开销也更大。
- 数据来源可以是各种不同的数据库或者文件,这时候需要先把他们整理成统一的格式后才可以进行数据的处理,这一过程用代码实现显然有些麻烦。
- 在数据库中我们当然可以使用存储过程去处理数据,但是处理海量数据的时候存储过程显然比较吃力,而且会占用较多数据库的资源,这可能会导致数据资源不足,进而影响数据库的性能。
而上述遇到的问题,我们用ETL工具就可以解决。ETL工具具有以下几点优势:
- 支持多种异构数据源的连接。(部分)
- 图形化的界面操作十分方便。
- 处理海量数据速度快、流程更清晰等。
ETL工具介绍
1.Datastage

IBM公司的商业软件,专业的ETL工具,但同时价格不菲,适合大规模的ETL应用。
使用难度:★★★★
2.Taskctl
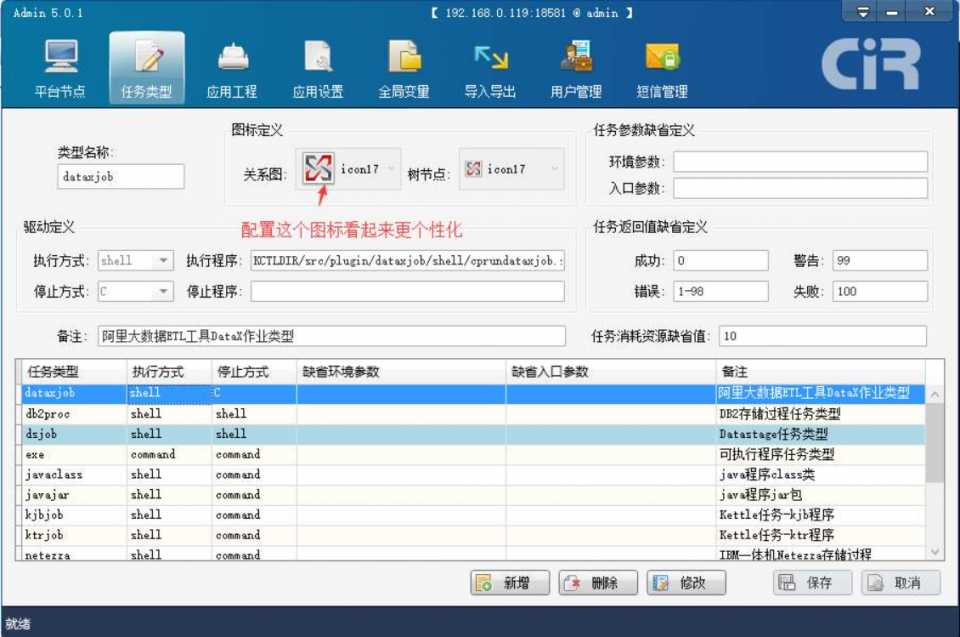
商业软件,国产专业的ETL工具平台。价格上比Datastage便宜很多,适合大规模的ETL应用。
使用难度:★★★
3.Taskctl Web版
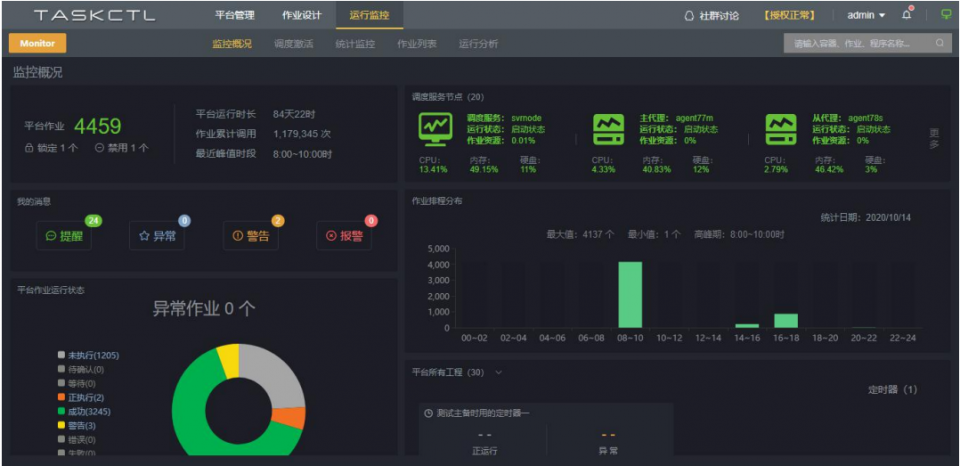
免费,在商业版 Taskctl 6.0 基础上纵向扩展而来,可跨多平台适合中小企业IT自动化类系统建和数据开发人员,如数据系统批量调度自动化、系统运维自动化、企业数据资产监控等等
使用难度:★
4.Kettle
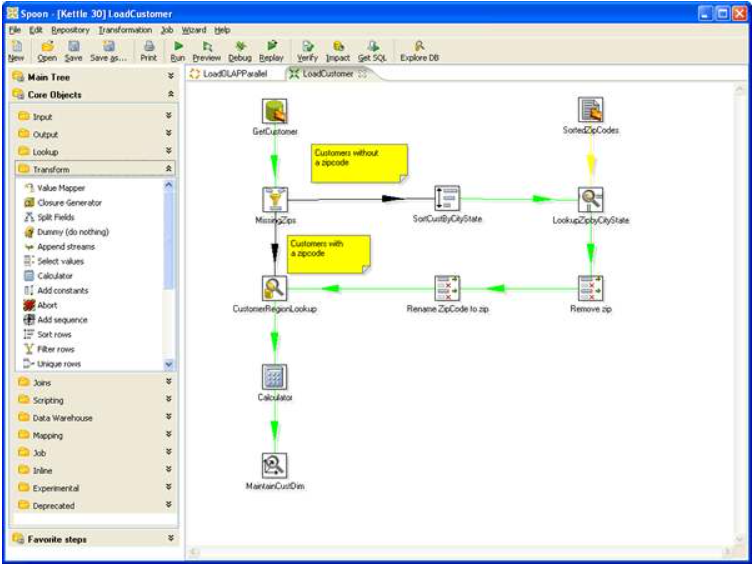
免费,最著名的开源产品,是用纯java编写的ETL工具,只需要JVM环境即可部署,可跨平台,扩展性好。
使用难度:★★
三种ETL工具的对比
Datastage、Taskctl、Kettle三个ETL工具的特点和差异介绍:
1.操作
这三种ETL工具都是属于比较简单易用的,主要看开发人员对于工具的熟练程度。
2.部署
Kettle只需要JVM环境,Taskctl 需要服务器和客户端安装,而 Datastage 的部署比较耗费时间,有一点难度。
3.数据处理的速度
大数据量下 Taskctl 与 Datastage 的处理速度是比较快的,比较稳定。Kettle的处理速度相比之下稍慢。
4.服务
Taskctl 与 Datastage 有很好的商业化的技术支持,而 Kettle 则没有。商业软件的售后服务上会比免费的开源软件好很多。
5.风险
风险与成本成反比,也与技术能力成正比。
6.扩展
Kettle的扩展性无疑是最好,因为是开源代码,可以自己开发拓展它的功能,而 Taskctl 和Datastage 由于是商业软件,基本上不支持。
7.Job的监控
三者都有监控和日志工具。
在数据的监控上,个人觉得 Taskctl 的实时监控做的更加好,可以直观看到数据抽取的情况,运行到哪一个控件上。这对于调优来说,我们可以更快的定位到处理速度太慢的控件并进行处理,而 Datastage 也有相应的功能,但是并不直观,需要通过两个界面的对比才可以定位到处理速度缓慢的控件。有时候还需要通过一些方法去查找。
8.网上的技术服务支持
Kettle< Datastage < Taskctl 相对来说,Kettle 在遇到问题去网上快速找到解决方法的概率比较低,只有通过网上翻阅技术文档和加入社群询问,效率比较低;而相比 Datastage 和 Taskctl 则比较完善、由于是商业软件,网上不仅有完善的技术文档,24小时线上还有技术远程支持答疑人员。
项目经验分享
在项目中,很多时候我们都需要同步生产库的表到数据仓库中。一百多张表同步、重复的操作,对开发人员来说是细心和耐心的考验。在这种情况下,开发人员最喜欢的工具无疑是 kettle,多个表的同步都可以用同一个程序运行,不必每一张表的同步都建一个程序,而 Taskctl 虽然有提供工具去批量设计,但还是需要生成多个程序进行一一配置,而 datastage 在这方面就显得比较笨拙。
在做增量表的时候,每次运行后都需要把将最新的一条数据操作时间存到数据库中,下次运行我们就取大于这个时间的数据。Kettle 和 Taskctl 有控件可以直接读取数据库中的这个时间置为变量。
有一句话说的好:世上没有最好的,只有适合的!
每一款ETL工具都有它的优缺点,我们需要根据实际项目,权衡利弊选择适合的ETL工具,合适的就是最好的。当下越来越多公司及其客户更重视最新的数据(实时数据)展现,传统的ETL工具可能满足不了这样的需求,而实时流数据处理和云计算技术更符合。所以我们也需要与时俱进,学习大数据时代下的ETL工具。



相关推荐
这一步骤通常涉及优化数据加载策略,以减少对数据仓库性能的影响,如使用批量加载工具、分区加载等技术。 ### ETL工具与实践 随着技术的发展,市场上出现了多种ETL工具,如IBM DB2 DataStage、Informatica Power...
TASKCTL是ETL调度领域专业的调度产品,适用于各行业的企业级、项目级ETL调度平台建设。此版是在C/S桌面客户端的基础上,TASKCTL 重新构建了一套基于web浏览器的B/S版本; 其中 TASKCTL 基础版的设计核心是以开发...
Oracle Warehouse Builder这样的工具,虽然在此文档中没有详细讨论,但在实际ETL流程中扮演着调度、监控和维护的角色,确保整个过程的顺利进行。 总结来说,Oracle 9i的ETL处理不仅提升了数据仓库的性能和效率,还...
ETL(Extract, Transform, Load)是数据仓库和大数据处理领域中的关键概念,它涉及到从各种数据源抽取数据(Extract)、对数据进行清洗和转换(Transform)、然后将处理后的数据加载到目标系统(Load)的过程。这个...
此外,基于SOA的批量处理作业调度逻辑,实现跨平台、面向数据的高效并发调度,保证了作业流程的可控性和稳定性。 ETL技术在平台中扮演关键角色,它负责从各种来源抽取数据,进行清洗、转换,并加载到目标系统,如...
根据提供的文档信息,本文将对《Oracle_10g数据仓库实践(最全面)》这一资料中的关键知识点进行深入解析,旨在为读者提供一个全面、系统的学习指南。 ### 一、Oracle 10g 数据仓库简介 #### 1.1 数据仓库概念与...
大数据平台是现代企业数据分析...以上功能设计是构建一个强大且灵活的大数据平台的基础,旨在满足业务分析、决策支持以及更高级的数据挖掘和预测需求。通过这样的平台,企业可以充分利用数据资产,驱动业务创新和增长。
- **作业调度和监控**: 确保ETL作业按时完成,并能及时发现并解决问题。 - **元数据管理**: 记录数据来源、转换规则等元数据信息。 - **ETL模块设计**: 包括数据抽取模块、数据清洗模块、数据加载模块等。 - **ETL...
数据挖掘则依赖于各种算法,如MLLib(机器学习库)、Graphx(图计算)以及各种预测和分析算法,如关联分析、评估算法、深度学习、增强学习、推荐算法、时序分析和回归算法。 5. **数据流结构**:数据流结构包括结构...
这里提到了Kafka、Storm、Flume以及传统的ETL工具,它们用于实时或批量地抽取数据。 - **数据存储**:数据仓库需要能够处理大量数据的存储解决方案。本方案采用Hdfs(分布式文件系统)、Hbase(分布式NoSQL数据库)...
京东金融可能使用日志服务、API接口、ETL工具(如Kettle或Informatica)来实现数据的实时或批量导入。 2. 数据存储:大数据平台通常采用分布式存储系统,如Hadoop HDFS,用于存储海量非结构化和半结构化数据。同时...
5. **数据挖掘**:通过机器学习等技术发现数据中的潜在模式。 6. **数据治理**:确保数据的质量、安全和合规性。 **数据采集与预处理** 数据采集包括ETL(抽取-转换-加载)、互联网爬虫和流处理。ETL主要处理批量...
BI(Business Intelligence)是商业智能技术的简称,以数据仓库、在线分析和数据挖掘为核心技术,同时融合了关系数据库和在线事务处理技术。 数据抽取是BI系统中一个重要的步骤,涉及互连、复制、增量、转换、调度...
数据应用方面,有赞提供了多种工具支持即席查询、BI系统以及数据挖掘等功能,以满足不同场景下的数据分析需求。 #### 二、有赞元数据系统发展历程 元数据系统的建设对于数据仓库而言至关重要,它能够帮助管理者更...
在应用场景上,大数据离线计算主要用于数据分析和数据挖掘,尤其是商业智能(BI)系统,这些系统利用数据仓库、OLAP工具和数据挖掘技术来支持业务决策。传统的BI系统虽然在结构化数据处理方面表现出色,但面对非结构...
1. 数据采集层:通过ETL(Extract, Transform, Load)工具,实时或批量地从各种数据源抽取数据,进行预处理和转换。 2. 数据存储层:使用分布式数据库和数据仓库,如Hadoop HDFS、HBase、Hive等,提供海量数据的...
数据源可以分为内部数据和外部数据,结构上分为结构化数据和非结构化数据,从可变性角度分为不可变可添加数据和可修改删除数据,以及按规模分为大量数据和小量数据。内部数据通常采用主动写入技术,外部数据可能需要...
- **企业级ETL平台**:负责数据的采集、加工、汇总、分发,实现数据的标准化和集中化处理,支持非实时和实时数据处理,提供数据抽取、转换、加载、汇总、分发和挖掘功能。 - **存储与计算中心**:建立统一数据模型...