
و‘کè‡ھ http://www.blogjava.net/zhugf000/archive/2005/10/09/15068.html
Javaه—符编ç پ转وچ¢è؟‡ç¨‹è¯´وکژ
آ
آ
 آ
آ
ه¸¸è§پé—®é¢ک
آ
آ
 آ
آ
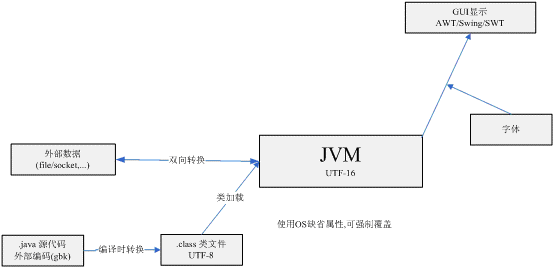
JVM
JVMهگ¯هٹ¨هگژ,JVMن¼ڑ设置ن¸€ن؛›ç³»ç»ںه±و€§ن»¥è،¨وکژJVMçڑ„ç¼؛çœپهŒ؛هںںم€‚
user.language,user.region,file.encodingç‰م€‚هڈ¯ن»¥ن½؟用System.getProperties()详细وں¥çœ‹و‰€وœ‰çڑ„ç³»ç»ںه±و€§م€‚
آ
ه¦‚هœ¨è‹±و–‡و“چن½œç³»ç»ں(ه¦‚UNIX)ن¸‹ï¼Œهڈ¯ن»¥ن½؟用ه¦‚ن¸‹ه±و€§ه®ڑن¹‰ه¼؛هˆ¶وŒ‡ه®ڑJVMن¸؛ن¸و–‡çژ¯ه¢ƒ -Dclient.encoding.override=GBK -Dfile.encoding=GBK -Duser.language=zh -Duser.region=CN
آ
.java-->.class编译
说وکژï¼ڑن¸€èˆ¬javacو ¹وچ®ه½“ه‰چosهŒ؛هںں设置,è‡ھهٹ¨ه†³ه®ڑو؛گو–‡ن»¶çڑ„ç¼–ç پ.هڈ¯ن»¥é€ڑè؟‡-encodingه¼؛هˆ¶وŒ‡ه®ڑ.
آ
错误هڈ¯èƒ½:
1 gbkç¼–ç پو؛گو–‡ن»¶هœ¨è‹±و–‡çژ¯ه¢ƒن¸‹ç¼–译,javacن¸چ能و£ç،®è½¬وچ¢.و›¾è§پن؛ژjava/jspهœ¨è‹±و–‡unixن¸‹. و£€وµ‹و–¹و³•:ه†™\u4e00و ¼ه¼ڈçڑ„و±‰ه—,绕ه¼€javacç¼–ç پ,ه†چهœ¨jvmن¸,ه°†و±‰ه—ن½œن¸؛intو‰“هچ°ï¼Œçœ‹ه€¼وک¯هگ¦ç›¸ç‰ï¼›وˆ–ç›´وژ¥ن»¥UTF-8ç¼–ç پو‰“ه¼€.classو–‡ن»¶ï¼Œçœ‹çœ‹ه¸¸é‡ڈه—符ن¸²وک¯هگ¦و£ç،®ن؟هکو±‰ه—م€‚
آ
و–‡ن»¶è¯»ه†™
ه¤–部و•°وچ®ه¦‚و–‡ن»¶ç»ڈè؟‡è¯»ه†™ه’Œè½¬وچ¢ن¸¤ن¸ھو¥éھ¤ï¼Œè½¬ن¸؛jvmو‰€ن½؟用ه—符م€‚InputStream/OutputStream用ن؛ژ读ه†™هژںه§‹ه¤–部و•°وچ®ï¼ŒReader/Writerو‰§è،Œè¯»ه†™ه’Œè½¬وچ¢ن¸¤ن¸ھو¥éھ¤م€‚
آ
1 و–‡ن»¶è¯»ه†™è½¬وچ¢ç”±java.io.Reader/Writerو‰§è،Œï¼›è¾“ه…¥è¾“ه‡؛وµپ InputStream/OutputStreamآ ه¤„çگ†و±‰ه—ن¸چهگˆé€‚,ه؛”该首选ن½؟用Reader/Writer,ه¦‚ FileReader/FileWriterم€‚
آ
2 FileReader/FileWriterن½؟用JVMه½“ه‰چç¼–ç پ读ه†™و–‡ن»¶.ه¦‚وœوœ‰ه…¶ه®ƒç¼–ç پو ¼ه¼ڈ,ن½؟用InputStreamReader/OutputStreamWriter
آ
3 PrintStreamوœ‰ç‚¹ç‰¹و®ٹ,ه®ƒè‡ھهٹ¨ن½؟用jvmç¼؛çœپç¼–ç پè؟›è،Œè½¬وچ¢م€‚
آ
آ
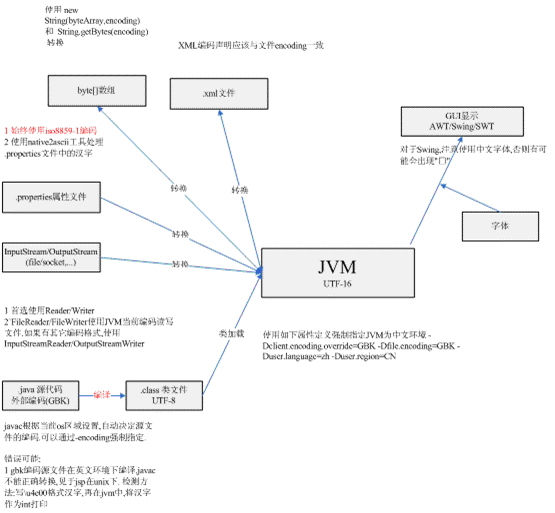
读هڈ–.propertiesو–‡ن»¶
.propetiesو–‡ن»¶ç”±Propertiesç±»ن»¥iso8859-1ç¼–ç پ读هڈ–,ه› و¤ن¸چ能هœ¨ه…¶ن¸ç›´وژ¥ه†™و±‰ه—,需è¦پن½؟用JDK çڑ„native2asciiه·¥ه…·è½¬وچ¢و±‰ه—ن¸؛\uXXXXو ¼ه¼ڈم€‚ه‘½ن»¤è،Œï¼ڑnative2ascii –encoding GBK inputfile outputfile
آ
读هڈ–XMLو–‡ن»¶
1 XMLو–‡ن»¶è¯»ه†™هگŒن؛ژو–‡ن»¶è¯»ه†™ï¼Œن½†ه؛”و³¨و„ڈç،®ن؟XMLه¤´ن¸ه£°وکژه¦‚<? xml version=â€1.0†encoding=â€gb2312†?>ن¸ژو–‡ن»¶ç¼–ç پن؟وŒپن¸€è‡´م€‚
آ
2 javax.xml.SAXParserç±»وژ¥هڈ—InputStreamن½œن¸؛输ه…¥هڈ‚و•°ï¼Œه¯¹ن؛ژReader,需è¦پ用org.xml.sax.InputSourceهŒ…装ن¸€ن¸‹ï¼Œه†چç»™SAXParserم€‚
آ
3 ه¯¹ن؛ژUTF-8ç¼–ç پ XML,و³¨و„ڈéک²و¢ç¼–辑ه™¨è‡ھهٹ¨هٹ ن¸ٹ\uFFFE BOMه¤´, xml parserن¼ڑوٹ¥ه‘ٹcontent is not allowed in prologم€‚
آ
آ
ه—èٹ‚و•°ç»„
1 ن½؟用 new String(byteArray,encoding) ه’Œآ String.getBytes(encoding)آ هœ¨ه—èٹ‚و•°ç»„ه’Œه—符ن¸²ن¹‹é—´è؟›è،Œè½¬وچ¢
آ
ن¹ںهڈ¯ن»¥ç”¨ByteArrayInputStream/ByteArrayOutputStream转ن¸؛وµپهگژه†چ用InputStreamReader/OutputStreamWriter转وچ¢م€‚
آ
错误编ç پçڑ„ه—符ن¸²(iso8859-1转ç پgbk)
ه¦‚وœوˆ‘ن»¬ه¾—هˆ°çڑ„ه—符ن¸²وک¯ç”±é”™è¯¯çڑ„转ç پو–¹ه¼ڈن؛§ç”ںçڑ„,ن¾‹ه¦‚ï¼ڑه¯¹ن؛ژgbkن¸و–‡ï¼Œç”±iso8859-1و–¹ه¼ڈ转وچ¢ï¼Œو¤و—¶ه¦‚وœç”¨è°ƒè¯•ه™¨çœ‹هˆ°çڑ„ه—符ن¸²ن¸€èˆ¬وک¯çڑ„و ·هگ,é•؟ه؛¦ن¸€èˆ¬ن¸؛و–‡وœ¬çڑ„ه—èٹ‚é•؟ه؛¦ï¼Œè€Œéو±‰ه—ن¸ھو•°م€‚
آ
هڈ¯ن»¥é‡‡ç”¨ه¦‚ن¸‹و–¹ه¼ڈ转ن¸؛و£ç،®çڑ„ن¸و–‡ï¼ڑ
text = new String( text.getBytes(“iso8859-1â€),â€gbkâ€);
آ
JDBC
转وچ¢è؟‡ç¨‹ç”±JDBC Driverو‰§è،Œï¼Œهڈ–ه†³ن؛ژهگ„JDBCو•°وچ®ه؛“ه®çژ°م€‚ه¯¹و¤ç»ڈéھŒه°ڑ积累ن¸چه¤ںم€‚
آ
1 ه¯¹ن؛ژORACLEو•°وچ®ه؛“,需è¦پو•°وچ®ه؛“هˆ›ه»؛و—¶وŒ‡ه®ڑç¼–ç پو–¹ه¼ڈن¸؛gbk,هگ¦هˆ™ن¼ڑه‡؛çژ°و±‰ه—转ç پ错误
2 ه¯¹ن؛ژ SQL Server 2000 ,وœ€ه¥½ن»¥nvarchar/ncharç±»ه‹هکو”¾و–‡وœ¬ï¼Œهچ³ن¸چهکهœ¨ن¸و–‡/ç¼–ç پ转وچ¢é—®é¢کم€‚
3 è؟وژ¥ Mysql,ه°† connectionString 设置وˆگ encoding ن¸؛ gb2312ï¼ڑ
آ String connectionString آ = "jdbc:mysql://localhost/test?useUnicode=true&characterEncoding=gb2312";
آ
WEB/Servlet/JSP
1 ه¯¹ن؛ژJSP,ç،®ه®ڑه¤´éƒ¨هٹ ن¸ٹ <%@ page contentType="text/html;charset=gb2312"%>è؟™و ·çڑ„و ‡ç¾م€‚
2 ه¯¹ن؛ژServlet,ç،®ه®ڑ设置setContentType (“text/html; charset=gb2312â€),ن»¥ن¸ٹن¸¤و،用ن؛ژن½؟ه¾—输ه‡؛و±‰ه—و²،وœ‰é—®é¢کم€‚
3 ن¸؛输ه‡؛HTML headن¸هٹ ن¸€ن¸ھ <meta http-equiv="Content-Type" content="text/html; charset=gb2312"> ,让وµڈ览ه™¨و£ç،®ç،®ه®ڑHTMLç¼–ç پم€‚
آ
4 ن¸؛Webه؛”用هٹ ن¸€ن¸ھFilter,ç،®ن؟و¯ڈن¸ھRequestوکژç،®è°ƒç”¨setCharacterEncodingو–¹و³•,让输ه…¥و±‰ه—能ه¤ںو£ç،®è§£وگم€‚
آ
آ
import java.io.IOException;
import javax.servlet.Filter;
import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.UnavailableException;
import javax.servlet.http.HttpServletRequest;
آ
/**
آ * Example filter that sets the character encoding to be used in parsing the
آ * incoming request
آ */
public class SetCharacterEncodingFilter
آ آ آ implements Filter {
آ public SetCharacterEncodingFilter()
آ {}
آ protected boolean debug = false;
آ protected String encoding = null;
آ protected FilterConfig filterConfig = null;
آ public void destroy() {
آ آ آ this.encoding = null;
آ آ آ this.filterConfig = null;
آ }
آ
آ public void doFilter(ServletRequest request, ServletResponse response,
آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ آ FilterChain chain) throws IOException, ServletException {
//آ آ آ if (request.getCharacterEncoding() == null)
//آ آ آ {
// آ آ آ آ آ String encoding = getEncoding();
//آ آ آ آ آ if (encoding != null)
//آ آ آ آ آ آ آ request.setCharacterEncoding(encoding);
//
//آ آ آ }
آ آ آ آ آ request.setCharacterEncoding(encoding);
آ آ آ آ آ if ( debug ){
آ آ آ آ آ آ آ System.out.println( ((HttpServletRequest)request).getRequestURI()+"setted to "+encoding );
آ آ آ آ آ }
آ آ آ chain.doFilter(request, response);
آ }
آ
آ public void init(FilterConfig filterConfig) throws ServletException {
آ آ آ this.filterConfig = filterConfig;
آ آ آ this.encoding = filterConfig.getInitParameter("encoding");
آ آ آ this.debug = "true".equalsIgnoreCase( filterConfig.getInitParameter("debug") );
آ }
آ
آ protected String getEncoding() {
آ آ آ return (this.encoding);
آ }
}
آ
آ
web.xmlن¸هٹ ه…¥ï¼ڑ
آ
آ <filter>
آ آ آ <filter-name>LocalEncodingFilter</filter-name>
آ آ آ <display-name>LocalEncodingFilter</display-name>
آ آ آ <filter-class>com.ccb.ectipmanager.request.SetCharacterEncodingFilter</filter-class>
آ آ آ <init-param>
آ آ آ آ آ <param-name>encoding</param-name>
آ آ آ آ آ <param-value>gb2312</param-value>
آ آ آ </init-param>
آ آ آ <init-param>
آ آ آ آ آ <param-name>debug</param-name>
آ آ آ آ آ <param-value>false</param-value>
آ آ آ </init-param>
آ </filter>
آ
آ آ <filter-mapping>
آ آ آ <filter-name>LocalEncodingFilter</filter-name>
آ آ آ <url-pattern>/*</url-pattern>
آ </filter-mapping>
آ
5 用ن؛ژWeblogic(vedor-specific)ï¼ڑ
ه…¶ن¸€:هœ¨web.xml里هٹ ن¸ٹه¦‚ن¸‹è„ڑوœ¬:
<context-param>
آ <param-name>weblogic.httpd.inputCharset./*</param-name>
آ <param-value>GBK</param-value>
</context-param>
ه…¶ن؛Œï¼ˆهڈ¯é€‰ï¼‰هœ¨weblogic.xml里هٹ ن¸ٹه¦‚ن¸‹è„ڑوœ¬:
<charset-params>
آ <input-charset>
آ آ آ آ آ <resource-path>/*</resource-path>
آ آ آ آ آ <java-charset-name>GBK</java-charset-name>
آ </input-charset>
</charset-params>
آ
SWING/AWT/SWT
ه¯¹ن؛ژSWING/AWT,Javaن¼ڑوœ‰ن؛›ç¼؛çœپه—ن½“ه¦‚Dialog/San Serif,è؟™ن؛›ه—ن½“هˆ°ç³»ç»ںçœںه®ه—ن½“çڑ„وک ه°„هœ¨$JRE_HOME/lib/font.properties.XXXو–‡ن»¶ن¸وŒ‡ه®ڑم€‚وژ’除ه—ن½“وک¾ç¤؛é—®é¢کو—¶ï¼Œé¦–ه…ˆéœ€è¦پç،®ه®ڑJVMçڑ„هŒ؛هںںن¸؛zh_CN,è؟™و ·font.properties.zh_CNو–‡ن»¶و‰چن¼ڑهڈ‘ç”ںن½œç”¨م€‚ه¯¹ن؛ژ font.properties.zh_CN , 需è¦پو£€وں¥وک¯هگ¦وک ه°„ç¼؛çœپه—ن½“هˆ°ن¸و–‡ه—ن½“ه¦‚ه®‹ن½“م€‚
آ
هœ¨Swingن¸ï¼ŒJavaè‡ھè،Œè§£é‡ٹTTFه—ن½“,و¸²وں“وک¾ç¤؛ï¼›ه¯¹ن؛ژAWT,SWTوک¾ç¤؛部هˆ†ن؛¤ç”±و“چن½œç³»ç»ںم€‚首ه…ˆéœ€è¦پç،®ه®ڑç³»ç»ں装وœ‰ن¸و–‡ه—ن½“م€‚
آ
1 و±‰ه—وک¾ç¤؛ن¸؛â€â–،â€ï¼Œن¸€èˆ¬ن¸؛وک¾ç¤؛ه—ن½“و²،وœ‰ن½؟用ن¸و–‡ه—ن½“,ه› ن¸؛Javaه¯¹ن؛ژه½“ه‰چه—ن½“وک¾ç¤؛ن¸چن؛†çڑ„ه—符,ن¸چن¼ڑهƒڈWindowsن¸€و ·ه†چ采用ç¼؛çœپه—ن½“وک¾ç¤؛م€‚
2 部هˆ†ن¸چه¸¸è§پو±‰ه—ن¸چ能وک¾ç¤؛,ن¸€èˆ¬ن¸؛وک¾ç¤؛ه—ه؛“ن¸و±‰ه—ن¸چه…¨ï¼Œهڈ¯ن»¥وچ¢هڈ¦ه¤–çڑ„ن¸و–‡ه—ن½“试试م€‚
3 ه¯¹ن؛ژAWT/SWT,首ه…ˆç،®ه®ڑJVMè؟گè،Œçژ¯ه¢ƒçڑ„هŒ؛هںں设置ن¸؛ن¸و–‡ï¼Œه› ن¸؛و¤ه¤„设è®،JVMن¸ژو“چن½œç³»ç»ںapi调用çڑ„转وچ¢é—®é¢ک,ه†چو£€وں¥ه…¶ه®ƒé—®é¢کم€‚
آ
JNI
JNIن¸jstringن»¥UTF-8ç¼–ç پç»™وˆ‘ن»¬ï¼Œéœ€è¦پوˆ‘ن»¬è‡ھè،Œè½¬ن¸؛وœ¬هœ°ç¼–ç پم€‚ه¯¹ن؛ژWindows,هڈ¯ن»¥é‡‡ç”¨WideCharToMultiByte/MultiByteToWideCharه‡½و•°è؟›è،Œè½¬وچ¢ï¼Œه¯¹ن؛ژUnix,هڈ¯ن»¥é‡‡ç”¨iconvه؛“م€‚
آ
è؟™é‡Œن»ژSUN jdk 1.4 و؛گن»£ç پن¸و‰¾هˆ°ن¸€و®µن½؟用jvm String ه¯¹è±،çڑ„getBytesçڑ„转وچ¢و–¹ه¼ڈ,相ه¯¹ç®€هچ•ه’Œè·¨ه¹³هڈ°ï¼Œن¸چ需è¦پ第ن¸‰و–¹ه؛“,ن½†é€ںه؛¦ç¨چو…¢م€‚ه‡½و•°هژںه‹ه¦‚ن¸‹ï¼ڑ
آ
/* Convert between Java strings and i18n C strings */
JNIEXPORT jstring
NewStringPlatform(JNIEnv *env, const char *str);
آ
JNIEXPORT const char *
GetStringPlatformChars(JNIEnv *env, jstring jstr, jboolean *isCopy);
آ
JNIEXPORT jstring JNICALL
JNU_NewStringPlatform(JNIEnv *env, const char *str);
آ
JNIEXPORT const char * JNICALL
JNU_GetStringPlatformChars(JNIEnv *env, jstring jstr, jboolean *isCopy);
آ
JNIEXPORT void JNICALL
JNU_ReleaseStringPlatformChars(JNIEnv *env, jstring jstr, const char *str);
آ
آ
附ن»¶jni_util.h,jni_util.c
آ
آ
آ
TUXEDO/JOLT
JOLTه¯¹ن؛ژن¼ 递çڑ„ه—符ن¸²éœ€è¦پ用ه¦‚ن¸‹è؟›è،Œè½¬ç پ
new String(error_message.getBytes("iso8859-1"),"GBK");
jolt çڑ„ç³»ç»ںه±و€§ bea.jolt.encodingن¸چه؛”该设置,ه¦‚وœè®¾ç½®,JSHن¼ڑوٹ¥ه‘ٹ说错误çڑ„هچڈè®®.
آ
آ
JDK1.4/1.5و–°ه¢éƒ¨هˆ†
ه—符集相ه…³ç±»(Charset/CharsetEncoder/CharsetDecoder)
jdk1.4ه¼€ه§‹ï¼Œه¯¹ه—符集çڑ„و”¯وŒپهœ¨java.nio.charsetهŒ…ن¸ه®çژ°م€‚
آ
ه¸¸ç”¨هٹں能ï¼ڑ
1 هˆ—ه‡؛jvmو‰€و”¯وŒپه—符集ï¼ڑCharset.availableCharsets()
2 能هگ¦ه¯¹çœ‹وںگن¸ھUnicodeه—符编ç پ,CharsetEncoder.canEncode()
آ
Unicode Surrogate/CJK EXT B
Unicode 范ه›´ن¸€èˆ¬و‰€ç”¨ن¸؛\U0000-\UFFFF范ه›´ï¼Œjvmن½؟用1ن¸ھcharه°±هڈ¯ن»¥è،¨ç¤؛,ه¯¹ن؛ژCJK EXT BهŒ؛و±‰ه—,范ه›´ه¤§ن؛ژ\U20000,هˆ™éœ€è¦پ采用2ن¸ھcharو–¹èƒ½è،¨ç¤؛,و¤هچ³Unicode Surrogateم€‚è؟™2ن¸ھcharçڑ„ه€¼èŒƒه›´èگ½هœ¨Character.SURROGATE هŒ؛هںںه†…,用Character.getType()و¥هˆ¤و–م€‚
آ
jdk 1.4ه°ڑن¸چ能هœ¨Swingن¸و£ç،®ه¤„çگ†surrogateهŒ؛çڑ„Unicodeه—符,jdk1.5هڈ¯ن»¥م€‚ه¯¹ن؛ژCJK EXT BهŒ؛و±‰ه—,目ه‰چهڈ¯ن»¥ن½؟用çڑ„ه—ه؛“ن¸؛â€ه®‹ن½“-و–¹و£è¶…ه¤§ه—符集â€,éڑڈOfficeه®‰è£…م€‚
آ
ه¸¸è§پé—®é¢ک
هœ¨JVMن¸‹ï¼Œç”¨System.out.printlnن¸چ能و£ç،®و‰“هچ°ن¸و–‡ï¼Œوک¾ç¤؛ن¸؛???
System.out.printlnوک¯PrintStream,ه®ƒé‡‡ç”¨jvmç¼؛çœپه—符集è؟›è،Œè½¬ç په·¥ن½œï¼Œه¦‚وœjvmçڑ„ç¼؛çœپه—符集ن¸؛iso8859-1,هˆ™ن¸و–‡وک¾ç¤؛ن¼ڑوœ‰é—®é¢کم€‚و¤é—®é¢که¸¸è§پن؛ژUnixن¸‹ï¼Œjvmçڑ„هŒ؛هںںو²،وœ‰وکژç،®وŒ‡ه®ڑçڑ„وƒ…ه†µم€‚
آ
هœ¨è‹±و–‡UNIXçژ¯ه¢ƒن¸‹,用System.out.println能ه¤ںو£ç،®و‰“هچ°و±‰ه—,ن½†وک¯ه†…部ه¤„çگ†é”™è¯¯
هڈ¯èƒ½وک¯و±‰ه—هœ¨è¾“ه…¥è½¬وچ¢و—¶ï¼Œه°±و²،وœ‰و£ç،®è½¬ç پï¼ڑ
هچ³gbkو–‡وœ¬أ (iso8859-1转ç پ)أ jvm char(iso8859-1ç¼–ç پو±‰ه—)أ (iso8859-1转ç پ)أ 输ه‡؛م€‚
gbkو±‰ه—ç»ڈè؟‡ن¸¤و¬،错误转ç پ,هژںه°پن¸چهٹ¨çڑ„被ن¼ 递هˆ°è¾“ه‡؛,ن½†وک¯هœ¨jvmن¸ï¼Œه¹¶وœھن»¥و£ç،®çڑ„unicodeç¼–ç پè،¨ç¤؛,而وک¯ن»¥ن¸€ن¸ھو±‰ه—ه—èٹ‚ن¸€ن¸ھcharçڑ„و–¹ه¼ڈè،¨ç¤؛,ن»ژ而ه¯¼è‡´و¤ç±»é”™è¯¯م€‚
آ
آ
GB2312-80,GBK,GB18030-2000 و±‰ه—ه—符集
آ
GB2312-80 وک¯هœ¨ه›½ه†…è®،ç®—وœ؛و±‰ه—ن؟،وپ¯وٹ€وœ¯هڈ‘ه±•هˆه§‹éک¶و®µهˆ¶ه®ڑçڑ„,ه…¶ن¸هŒ…هگ«ن؛†ه¤§éƒ¨هˆ†ه¸¸ç”¨çڑ„ن¸€م€پن؛Œç؛§و±‰ه—,ه’Œ 9 هŒ؛çڑ„符هڈ·م€‚该ه—符集وک¯ه‡ ن¹ژو‰€وœ‰çڑ„ن¸و–‡ç³»ç»ںه’Œه›½é™…هŒ–çڑ„软ن»¶éƒ½و”¯وŒپçڑ„ن¸و–‡ه—符集,è؟™ن¹ںوک¯وœ€هں؛وœ¬çڑ„ن¸و–‡ه—符集م€‚ه…¶ç¼–ç پ范ه›´وک¯é«کن½چ0xa1ï¼چ0xfe,ن½ژن½چن¹ںوک¯ 0xa1-0xfeï¼›و±‰ه—ن»ژ 0xb0a1 ه¼€ه§‹ï¼Œç»“وںن؛ژ 0xf7feï¼›
آ
GBK وک¯ GB2312-80 çڑ„و‰©ه±•ï¼Œوک¯هگ‘ن¸ٹه…¼ه®¹çڑ„م€‚ه®ƒهŒ…هگ«ن؛† 20902 ن¸ھو±‰ه—,ه…¶ç¼–ç پ范ه›´وک¯ 0x8140-0xfefe,ه‰”除é«کن½چ 0x80 çڑ„ه—ن½چم€‚ه…¶و‰€وœ‰ه—符都هڈ¯ن»¥ن¸€ه¯¹ن¸€وک ه°„هˆ° Unicode 2.0,ن¹ںه°±وک¯è¯´ JAVA ه®é™…ن¸ٹوڈگن¾›ن؛† GBK ه—符集çڑ„و”¯وŒپم€‚è؟™وک¯çژ°éک¶و®µ Windows ه’Œه…¶ه®ƒن¸€ن؛›ن¸و–‡و“چن½œç³»ç»ںçڑ„ç¼؛çœپه—符集,ن½†ه¹¶ن¸چوک¯و‰€وœ‰çڑ„ه›½é™…هŒ–软ن»¶éƒ½و”¯وŒپ该ه—符集,و„ں觉وک¯ن»–ن»¬ه¹¶ن¸چه®Œه…¨çں¥éپ“ GBK وک¯و€ژن¹ˆه›ن؛‹م€‚ه€¼ه¾—و³¨و„ڈçڑ„وک¯ه®ƒن¸چوک¯ه›½ه®¶و ‡ه‡†ï¼Œè€Œهڈھوک¯è§„范م€‚éڑڈç€ GB18030-2000ه›½و ‡çڑ„هڈ‘ه¸ƒï¼Œه®ƒه°†هœ¨ن¸چن¹…çڑ„ه°†و¥ه®Œوˆگه®ƒçڑ„هژ†هڈ²ن½؟ه‘½م€‚
آ
GB18030-2000(GBK2K) هœ¨ GBK çڑ„هں؛ç،€ن¸ٹè؟›ن¸€و¥و‰©ه±•ن؛†و±‰ه—,ه¢هٹ ن؛†è—ڈم€پè’™ç‰ه°‘و•°و°‘و—ڈçڑ„ه—ه½¢م€‚GBK2K ن»ژو ¹وœ¬ن¸ٹ解ه†³ن؛†ه—ن½چن¸چه¤ں,ه—ه½¢ن¸چ足çڑ„é—®é¢کم€‚ه®ƒوœ‰ه‡ ن¸ھ特点,
آ
ه®ƒه¹¶و²،وœ‰ç،®ه®ڑو‰€وœ‰çڑ„ه—ه½¢ï¼Œهڈھوک¯è§„ه®ڑن؛†ç¼–ç پ范ه›´ï¼Œç•™ه¾…ن»¥هگژو‰©ه……م€‚
ç¼–ç پوک¯هڈکé•؟çڑ„,ه…¶ن؛Œه—èٹ‚部هˆ†ن¸ژ GBK ه…¼ه®¹ï¼›ه››ه—èٹ‚部هˆ†وک¯و‰©ه……çڑ„ه—ه½¢م€په—ن½چ,ه…¶ç¼–ç پ范ه›´وک¯é¦–ه—èٹ‚ 0x81-0xfeم€پن؛Œه—èٹ‚0x30-0x39م€پن¸‰ه—èٹ‚ 0x81-0xfeم€په››ه—èٹ‚0x30-0x39م€‚
آ
UTF-8/UTF-16/UTF-32
آ
UTF,هچ³Unicode Transformer Format,وک¯Unicodeن»£ç پ点(code point)çڑ„ه®é™…è،¨ç¤؛و–¹ه¼ڈ,وŒ‰ه…¶هں؛وœ¬é•؟ه؛¦و‰€ç”¨ن½چو•°هˆ†ن¸؛UTF-8/16/32م€‚ه®ƒن¹ںهڈ¯ن»¥è®¤ن¸؛وک¯ن¸€ç§چ特و®ٹçڑ„ه¤–部و•°وچ®ç¼–ç پ,ن½†èƒ½ه¤ںن¸ژUnicodeن»£ç پ点هپڑن¸€ن¸€ه¯¹ه؛”م€‚
آ
UTF-8وک¯هڈکé•؟ç¼–ç پ,و¯ڈن¸ھUnicodeن»£ç پ点وŒ‰ç…§ن¸چهگŒèŒƒه›´ï¼Œهڈ¯ن»¥وœ‰1-3ه—èٹ‚çڑ„ن¸چهگŒé•؟ه؛¦م€‚
UTF-16é•؟ه؛¦ç›¸ه¯¹ه›؛ه®ڑ,هڈھè¦پن¸چه¤„çگ†ه¤§ن؛ژ\U200000范ه›´çڑ„ه—符,و¯ڈن¸ھUnicodeن»£ç پ点ن½؟用16ن½چهچ³2ه—èٹ‚è،¨ç¤؛,超ه‡؛部هˆ†ن½؟用ن¸¤ن¸ھUTF-16هچ³4ه—èٹ‚è،¨ç¤؛م€‚وŒ‰ç…§é«کن½ژن½چه—èٹ‚é،؛ه؛ڈ,هڈˆهˆ†ن¸؛UTF-16BE/UTF-16LEم€‚
UTF-32é•؟ه؛¦ه§‹ç»ˆه›؛ه®ڑ,و¯ڈن¸ھUnicodeن»£ç پ点ن½؟用32ن½چهچ³4ه—èٹ‚è،¨ç¤؛م€‚وŒ‰ç…§é«کن½ژن½چه—èٹ‚é،؛ه؛ڈ,هڈˆهˆ†ن¸؛UTF-32BE/UTF-32LEم€‚
آ
UTFç¼–ç پوœ‰ن¸ھن¼ک点,هچ³ه°½ç®،ç¼–ç په—èٹ‚و•°ن¸چç‰ï¼Œن½†وک¯ن¸چهƒڈgb2312/gbkç¼–ç پن¸€و ·ï¼Œéœ€è¦پن»ژو–‡وœ¬ه¼€ه§‹ه¯»و‰¾ï¼Œو‰چ能و£ç،®ه¯¹و±‰ه—è؟›è،Œه®ڑن½چم€‚هœ¨UTFç¼–ç پن¸‹ï¼Œو ¹وچ®ç›¸ه¯¹ه›؛ه®ڑçڑ„ç®—و³•ï¼Œن»ژه½“ه‰چن½چç½®ه°±èƒ½ه¤ںçں¥éپ“ه½“ه‰چه—èٹ‚وک¯هگ¦وک¯ن¸€ن¸ھن»£ç پ点çڑ„ه¼€ه§‹è؟کوک¯ç»“وں,ن»ژ而相ه¯¹ç®€هچ•çڑ„è؟›è،Œه—符ه®ڑن½چم€‚ن¸چè؟‡ه®ڑن½چé—®é¢کوœ€ç®€هچ•çڑ„è؟کوک¯UTF-32,ه®ƒو ¹وœ¬ن¸چ需è¦پè؟›è،Œه—符ه®ڑن½چ,ن½†وک¯ç›¸ه¯¹çڑ„ه¤§ه°ڈن¹ںه¢هٹ ن¸چه°‘م€‚
آ
آ
ه…³ن؛ژGCJ JVM
GCJه¹¶وœھه®Œه…¨ن¾ç…§sun jdkçڑ„هپڑو³•ï¼Œه¯¹ن؛ژهŒ؛هںںه’Œç¼–ç پé—®é¢ک考虑ه°ڑن¸چه¤ںه‘¨ه…¨م€‚GCJهگ¯هٹ¨و—¶ï¼ŒهŒ؛هںںه§‹ç»ˆè®¾ن¸؛en_US,编ç پن¹ںç¼؛çœپن¸؛iso8859-1م€‚ن½†وک¯هڈ¯ن»¥ç”¨Reader/Writerهپڑو£ç،®ç¼–ç پ转وچ¢م€‚



相ه…³وژ¨èچگ
Javaن¸çڑ„ن¸و–‡ç¼–ç پé—®é¢کوک¯ن¸€ن¸ھه¤چو‚而ه¸¸è§پçڑ„è®®é¢ک,ه°¤ه…¶وک¯هœ¨è·¨ه¹³هڈ°ه¼€هڈ‘ن¸م€‚وœ¬و–‡ن¸»è¦پو¶µç›–ن؛†Javaه¤„çگ†ن¸و–‡ه—符编ç پçڑ„ه…³é”®ç‚¹ï¼ŒهŒ…و‹¬Javaè™ڑو‹ںوœ؛(JVM)çڑ„هˆه§‹é…چç½®م€پ编译è؟‡ç¨‹ن¸çڑ„ç¼–ç پ设置م€پو–‡ن»¶è¯»ه†™و“چن½œم€پXMLو–‡ن»¶ه¤„çگ†ن»¥هڈٹه—符ن¸²...
وœ¬و–‡و،£م€ٹwebç¼–ç پé—®é¢که°ڈ结م€‹è¯¦ç»†و€»ç»“ن؛†Javaه¼€هڈ‘ن¸هڈ¯èƒ½éپ‡هˆ°çڑ„هگ„ç§چç¼–ç پé—®é¢کهڈٹه…¶è§£ه†³و–¹و،ˆï¼Œè¦†ç›–ن؛†و•°وچ®ه؛“م€پCookieم€پé™و€پé،µé¢م€پPOSTن¸ژGET请و±‚ç‰ه¤ڑç§چهœ؛و™¯م€‚ #### و•°وچ®ه؛“çڑ„ن¸و–‡é—®é¢ک و•°وچ®ه؛“çڑ„ن¸و–‡é—®é¢کن¸»è¦پو؛گن؛ژو•°وچ®ه؛“ن¸ژه؛”用...
JAVA IOوµپه°ڈ结 JAVA IOوµپوک¯وŒ‡Javaè¯è¨€ن¸ç”¨و¥ه®çژ°è¾“ه…¥/输ه‡؛و“چن½œçڑ„وœ؛هˆ¶م€‚IOوµپوک¯وŒ‡ن»»ن½•وœ‰èƒ½هٹ›ن؛§ه‡؛و•°وچ®çڑ„و•°وچ®و؛گه¯¹è±،وˆ–者وœ‰èƒ½هٹ›وژ¥و”¶و•°وچ®çڑ„و•°وچ®و؛گه¯¹è±،م€‚ن»–ه±ڈ蔽ن؛†ه®é™…çڑ„I/O设ه¤‡ه¤„çگ†و•°وچ®çڑ„细èٹ‚م€‚ ن¸€م€پوµپçڑ„ه®ڑن¹‰ه’Œهˆ†ç±» وµپوک¯...
#### ه°ڈ结 é€ڑè؟‡ن»¥ن¸ٹه†…ه®¹ï¼Œوˆ‘ن»¬ه¯¹Javaçڑ„هں؛ç،€çں¥è¯†وœ‰ن؛†و›´و·±ه…¥çڑ„çگ†è§£م€‚ن؛†è§£è؟™ن؛›هں؛ç،€çں¥è¯†ه¯¹ن؛ژ编程éه¸¸é‡چè¦پ,特هˆ«وک¯ه¯¹ن؛ژهˆه¦è€…و¥è¯´م€‚وژŒوڈ،ن؛†è؟™ن؛›و¦‚ه؟µهگژ,ن½ هڈ¯ن»¥و›´ه¥½هœ°çگ†è§£ه’Œç¼–ه†™Javaن»£ç پ,هگŒو—¶ن¹ں能éپ؟ه…چن¸€ن؛›ه¸¸è§پçڑ„错误ه’Œ...
ه°ڈ结 هœ¨وœ¬و–‡ن¸ï¼Œوˆ‘ن»¬è®¨è®؛ن؛†ه¦‚ن½•ن½؟用 Java ه°†و–‡ن»¶ن»ژن¸€ن¸ھن½چç½®ه¤چهˆ¶هˆ°هڈ¦ن¸€ن¸ھن½چ置,ه¹¶ن¸”ه¸¦وœ‰ç¼–ç پç±»ه‹م€‚وˆ‘ن»¬ه¦ن¹ ن؛†ن½؟用 BufferedWriter ه’Œ BufferedReader ه®çژ°و–‡ن»¶ه¤چهˆ¶çڑ„و–¹و³•ï¼Œن»¥هڈٹن½؟用 OutputStreamWriter ه®çژ°و–‡ن»¶ه¤چهˆ¶...
ه®ƒهŒ…و‹¬ASCIIم€پISO8859-1م€پGBK(GB2312)ç‰ç¼–ç پ,ه…¶ن¸ï¼Œن¸و–‡ه—符هœ¨Unicodeن¸هچ 用3ن¸ھه—èٹ‚م€‚Unicodeن¸ژUTFçڑ„ه…³ç³»هœ¨ن؛ژ,UTFوک¯Unicodeçڑ„ن¼ 输و ¼ه¼ڈ,用ن؛ژ网络ن¼ 输م€‚ #### ن¹م€پBooleanç±»ه‹ن¸ژ逻辑è؟گç®— Javaن¸çڑ„`boolean`ç±»ه‹...
و€»ç»“و¥è¯´ï¼Œè§£ه†³JSPن¸و–‡ن¹±ç پé—®é¢ک需è¦پن»ژه¤ڑ角ه؛¦ه…¥و‰‹ï¼ŒهŒ…و‹¬ه®¢وˆ·ç«¯çڑ„解ç پن¸ژç¼–ç پ设置م€پوœچهٹ،ه™¨ç«¯çڑ„请و±‚ه¤„çگ†ه’Œه“چه؛”输ه‡؛,ن»¥هڈٹو•°وچ®ه؛“çڑ„ه—符集é…چç½®م€‚و£ç،®çگ†è§£ه’Œه؛”用è؟™ن؛›ç–略,هڈ¯ن»¥وœ‰و•ˆéپ؟ه…چه’Œè§£ه†³ن¸و–‡ن¹±ç پé—®é¢ک,ç،®ن؟Webه؛”用çڑ„...
ه¦ن¼ڑç¼–هˆ¶ç»“و„و¸…و™°م€پé£ژو ¼è‰¯ه¥½é€‚ه½“çڑ„javaè¯è¨€ç¨‹ه؛ڈ,ن»ژ而ه…·ه¤‡è§£ه†³ç»¼هگˆو€§ه®é™…é—®é¢کçڑ„能هٹ›1.2课程设è®،ه†…ه®¹ه’Œè¦پو±‚1م€پç³»ç»ں需ه®çژ°هں؛ç،€هٹں能ï¼ڑه¢م€پهˆ م€پو”¹م€پوں¥م€‚2م€په¦ç”ںهڈ¯è‡ھè،Œو·»هٹ ه®Œه–„هٹں能م€‚3م€پç•Œé¢ç¾ژ观ه¾—ن½“,(1)登陆界é¢é†’ç›®...
م€گJavaه¼€هڈ‘ç»ڈéھŒو€»ç»“م€‘ هœ¨Javaه¼€هڈ‘ن¸ï¼Œè‰¯ه¥½çڑ„编程ن¹ وƒ¯ه’Œé«کو•ˆçڑ„设è®،هژںهˆ™ه¯¹ن؛ژن»£ç پè´¨é‡ڈه’Œو€§èƒ½è‡³ه…³é‡چè¦پم€‚ن»¥ن¸‹وک¯ن¸€ن؛›ن»ژç¼–ç پ规范هˆ°و€§èƒ½ن¼کهŒ–çڑ„ه…³é”®çں¥è¯†ç‚¹ï¼ڑ 1. **ç¼–ç پ规范**ï¼ڑ规范çڑ„ç¼–ç پن¹ وƒ¯وک¯وڈگهچ‡ن»£ç پهڈ¯è¯»و€§ه’Œهڈ¯ç»´وٹ¤و€§çڑ„...
+ ه’Œ += 3.14 ن½؟用و“چن½œç¬¦و—¶ه¸¸çٹ¯çڑ„错误 3.15 ç±»ه‹è½¬وچ¢و“چن½œç¬¦ 3.15.1 وˆھه°¾ه’Œèˆچه…¥ 3.15.2وڈگهچ‡ 3.16 Javaو²،وœ‰â€œsizeof†3.17 و“چن½œç¬¦ه°ڈ结 3.18 و€»ç»“ 第4ç« وژ§هˆ¶و‰§è،Œوµپ程 4.1 trueه’Œfalse 4.2 if-else 4.3 è؟ن»£ 4.3.1 do-...
### Javaن¸ژJSPçں¥è¯†ç‚¹è§£وگ ...é€ڑè؟‡ن»¥ن¸ٹهˆ†وگ,وˆ‘ن»¬هڈ¯ن»¥و·±ه…¥çگ†è§£Javaن¸DAOو¨،ه¼ڈçڑ„ه؛”用م€پو•°وچ®ه؛“è؟وژ¥ç®،çگ†م€پWebه؛”用ن¸çڑ„ç¼–ç پé—®é¢کن»¥هڈٹServletçڑ„ه·¥ن½œوœ؛هˆ¶ه’Œوژ¥هڈ£ن½“系,è؟™ن؛›éƒ½وک¯Java Webه¼€هڈ‘ن¸çڑ„و ¸ه؟ƒçں¥è¯†ç‚¹م€‚
ه°ڈ结 é—®é¢ک 第2ç« و•°ç»„ Arrayن¸“é¢کApplet Javaن¸و•°ç»„çڑ„هں؛ç،€çں¥è¯† ه°†ç¨‹ه؛ڈهˆ’هˆ†وˆگç±» ç±»وژ¥هڈ£ Orderedن¸“é¢کapplet وœ‰ه؛ڈو•°ç»„çڑ„Javaن»£ç پ ه¯¹و•° هکه‚¨ه¯¹è±، ه¤§Oè،¨ç¤؛و³• ن¸؛ن»€ن¹ˆن¸چ用و•°ç»„è،¨ç¤؛ن¸€هˆ‡? ه°ڈ结 é—®é¢ک ه®éھŒ 编程...
ه°ڈ结 é—®é¢ک 第2ç« و•°ç»„ Arrayن¸“é¢کApplet Javaن¸و•°ç»„çڑ„هں؛ç،€çں¥è¯† ه°†ç¨‹ه؛ڈهˆ’هˆ†وˆگç±» ç±»وژ¥هڈ£ Orderedن¸“é¢کapplet وœ‰ه؛ڈو•°ç»„çڑ„Javaن»£ç پ ه¯¹و•° هکه‚¨ه¯¹è±، ه¤§Oè،¨ç¤؛و³• ن¸؛ن»€ن¹ˆن¸چ用و•°ç»„è،¨ç¤؛ن¸€هˆ‡ï¼ں ه°ڈ结 é—®é¢ک ه®éھŒ ...
#### ه°ڈ结 وœ¬é¢ک目考ه¯ںن؛†ه؛ڈهˆ—هŒ–ن¸ژهڈچه؛ڈهˆ—هŒ–çڑ„هں؛وœ¬و¦‚ه؟µï¼Œه¹¶é€ڑè؟‡ه…·ن½“çڑ„ç¼–ç په’Œè§£ç پن»»هٹ،让هڈ‚ن¸ژ者و·±ه…¥çگ†è§£è؟™ن¸€وٹ€وœ¯çڑ„ه®é™…ه؛”用م€‚هœ¨ه®çژ°è؟‡ç¨‹ن¸éœ€è¦پو³¨و„ڈ边界و،ن»¶ه’Œه¼‚ه¸¸ه¤„çگ†ï¼Œç،®ن؟程ه؛ڈçڑ„هپ¥ه£®و€§ه’Œه‡†ç،®و€§م€‚و— è®؛وک¯ Java è؟کوک¯ ...
Javaç¼–ç پ规范وک¯ç¼–程ه®è·µن¸è‡³ه…³é‡چè¦پçڑ„ن¸€ن¸ھçژ¯èٹ‚,ه®ƒو—¨هœ¨وڈگé«کن»£ç پè´¨é‡ڈم€په¢ه¼؛هڈ¯è¯»و€§م€پن؟ƒè؟›ه›¢éکںهچڈن½œï¼Œه¹¶é™چن½ژç»´وٹ¤وˆگوœ¬م€‚وœ¬ç« ن¸»è¦پهˆ†ن¸؛ه…ن¸ھ部هˆ†ï¼ڑه؛”用هœ؛و™¯م€پ相ه…³çں¥è¯†م€پن»»هٹ،ه®و–½م€پو‹“ه±•çں¥è¯†م€پو‹“ه±•è®ç»ƒه’Œè¯¾هگژه°ڈ结م€‚ 首ه…ˆï¼Œه؛”用...
### Javaه¦ن¹ IOوµپه°ڈ结——ه—符وµپ #### çں¥è¯†ç‚¹و¦‚è؟° هœ¨Javaن¸ï¼Œه¤„çگ†و–‡ن»¶ه’Œو•°وچ®وµپوک¯ن¸€é،¹هں؛وœ¬è€Œé‡چè¦پçڑ„ن»»هٹ،م€‚IOوµپوک¯Javaè¯è¨€ن¸ه¤„çگ†è¾“ه…¥/输ه‡؛çڑ„é‡چè¦په·¥ه…·ï¼Œه®ƒهŒ…و‹¬ه—èٹ‚وµپه’Œه—符وµپن¸¤ه¤§ç±»م€‚وœ¬و–‡ه°†é‡چ点讨è®؛ه—符وµپçڑ„相ه…³و¦‚ه؟µ...
ن¸؛éپ؟ه…چè؟™ن¸ھé—®é¢ک,需è¦پهœ¨هڈ‘é€پ请و±‚ه‰چن½؟用`java.net.URLEncoder.encode()`ه¯¹ن¸و–‡هڈ‚و•°è؟›è،Œç¼–ç پ,ن¾‹ه¦‚`RearshRes.jsp?keywords=" + java.net.URLEncoder.encode(keywords, "UTF-8")`م€‚هœ¨وژ¥و”¶ç«¯ï¼Œن½؟用`new String(request....
ه°ڈ结 é—®é¢ک 第2ç« و•°ç»„ Arrayن¸“é¢کApplet Javaن¸و•°ç»„çڑ„هں؛ç،€çں¥è¯† ه°†ç¨‹ه؛ڈهˆ’هˆ†وˆگç±» ç±»وژ¥هڈ£ Orderedن¸“é¢کapplet وœ‰ه؛ڈو•°ç»„çڑ„Javaن»£ç پ ه¯¹و•° هکه‚¨ه¯¹è±، ه¤§Oè،¨ç¤؛و³• ن¸؛ن»€ن¹ˆن¸چ用و•°ç»„è،¨ç¤؛ن¸€هˆ‡ï¼ں ه°ڈ结 é—®é¢ک ه®éھŒ 编程ن½œن¸ڑ 第3ç« ...
هœ¨JavaServer Pages (JSP) ه¼€هڈ‘ن¸ï¼Œو£ç،®è®¾ç½®ç¼–ç په±و€§ه¯¹ن؛ژç،®ن؟و–‡وœ¬و•°وچ®هœ¨ن¸چهگŒçژ¯èٹ‚é—´çڑ„و£ç،®ه¤„çگ†è‡³ه…³é‡چè¦پم€‚وœ¬و–‡ه°†è¯¦ç»†è§£وگJSPن¸ه½±ه“چç¼–ç پçڑ„ه±و€§هڈٹه…¶è®¾ç½®ï¼Œه¹¶وژ¢è®¨ه®ƒن»¬ن¹‹é—´çڑ„相ن؛’ه½±ه“چه’Œن½œç”¨é،؛ه؛ڈم€‚ 首ه…ˆï¼Œوˆ‘ن»¬éœ€è¦پçگ†è§£ه‡ ن¸ھ...
Javaçڑ„I/Oه؛“éه¸¸ه¼؛ه¤§ï¼ŒهŒ…و‹¬ن؛†وµپ(Streams)م€پ缓ه†²هŒ؛(Buffer)م€په—符编ç پ(Encodings)ه’Œه¯¹è±،ه؛ڈهˆ—هŒ–(Serialization)ç‰ه¤ڑن¸ھو–¹é¢م€‚هœ¨è؟™ن¸ھه®éھŒن¸ï¼Œهڈ¯èƒ½ن½؟用ن؛†`java.io`ه’Œ`java.nio`هŒ…ن¸‹çڑ„类,ه¦‚`InputStream`م€پ`OutputStream`...