
注:以下内容摘自:http://segmentfault.com/blogs
Spark是基于内存的分布式计算引擎,以处理的高效和稳定著称。然而在实际的应用开发过程中,开发者还是会遇到种种问题,其中一大类就是和性能相关。在本文中,笔者将结合自身实践,谈谈如何尽可能地提高应用程序性能。
分布式计算引擎在调优方面有四个主要关注方向,分别是CPU、内存、网络开销和I/O,其具体调优目标如下:
-
提高CPU利用率。
-
避免OOM。
-
降低网络开销。
-
减少I/O操作。
第1章 数据倾斜
数据倾斜意味着某一个或某几个Partition中的数据量特别的大,这意味着完成针对这几个Partition的计算需要耗费相当长的时间。
如果大量数据集中到某一个Partition,那么这个Partition在计算的时候就会成为瓶颈。图1是Spark应用程序执行并发的示意图,在Spark中,同一个应用程序的不同Stage是串行执行的,而同一Stage中的不同Task可以并发执行,Task数目由Partition数来决定,如果某一个Partition的数据量特别大,则相应的task完成时间会特别长,由此导致接下来的Stage无法开始,整个Job完成的时间就会非常长。
要避免数据倾斜的出现,一种方法就是选择合适的key,或者是自己定义相关的partitioner。在Spark中Block使用了ByteBuffer来存储数据,而ByteBuffer能够存储的最大数据量不超过2GB。如果某一个key有大量的数据,那么在调用cache或persist函数时就会碰到spark-1476这个异常。
下面列出的这些API会导致Shuffle操作,是数据倾斜可能发生的关键点所在
-
groupByKey
-
reduceByKey
-
aggregateByKey
-
sortByKey
-
join
-
cogroup
-
cartesian
-
coalesce
-
repartition
-
repartitionAndSortWithinPartitions

图1: Spark任务并发模型
def rdd: RDD[T]
}
// TODO View bounds are deprecated, should use context bounds
// Might need to change ClassManifest for ClassTag in spark 1.0.0
case class DemoPairRDD[K <% Ordered[K] : ClassManifest, V: ClassManifest](
rdd: RDD[(K, V)]) extends RDDWrapper[(K, V)] {
// Here we use a single Long to try to ensure the sort is balanced,
// but for really large dataset, we may want to consider
// using a tuple of many Longs or even a GUID
def sortByKeyGrouped(numPartitions: Int): RDD[(K, V)] =
rdd.map(kv => ((kv._1, Random.nextLong()), kv._2)).sortByKey()
.grouped(numPartitions).map(t => (t._1._1, t._2))
}
case class DemoRDD[T: ClassManifest](rdd: RDD[T]) extends RDDWrapper[T] {
def grouped(size: Int): RDD[T] = {
// TODO Version where withIndex is cached
val withIndex = rdd.mapPartitions(_.zipWithIndex)
val startValues =
withIndex.mapPartitionsWithIndex((i, iter) =>
Iterator((i, iter.toIterable.last))).toArray().toList
.sortBy(_._1).map(_._2._2.toLong).scan(-1L)(_ + _).map(_ + 1L)
withIndex.mapPartitionsWithIndex((i, iter) => iter.map {
case (value, index) => (startValues(i) + index.toLong, value)
})
.partitionBy(new Partitioner {
def numPartitions: Int = size
def getPartition(key: Any): Int =
(key.asInstanceOf[Long] * numPartitions.toLong / startValues.last).toInt
})
.map(_._2)
}
}
定义隐式的转换
implicit def toDemoRDD[T: ClassManifest](rdd: RDD[T]): DemoRDD[T] =
new DemoRDD[T](rdd)
implicit def toDemoPairRDD[K <% Ordered[K] : ClassManifest, V: ClassManifest](
rdd: RDD[(K, V)]): DemoPairRDD[K, V] = DemoPairRDD(rdd)
implicit def toRDD[T](rdd: RDDWrapper[T]): RDD[T] = rdd.rdd
}
在spark-shell中就可以使用了
import RDDConversions._
yourRdd.grouped(5)
第2章 减少网络通信开销
Spark的Shuffle过程非常消耗资源,Shuffle过程意味着在相应的计算节点,要先将计算结果存储到磁盘,后续的Stage需要将上一个Stage的结果再次读入。数据的写入和读取意味着Disk I/O操作,与内存操作相比,Disk I/O操作是非常低效的。
使用iostat来查看disk i/o的使用情况,disk i/o操作频繁一般会伴随着cpu load很高。
如果数据和计算节点都在同一台机器上,那么可以避免网络开销,否则还要加上相应的网络开销。 使用iftop来查看网络带宽使用情况,看哪几个节点之间有大量的网络传输。
图2是Spark节点间数据传输的示意图,Spark Task的计算函数是通过Akka通道由Driver发送到Executor上,而Shuffle的数据则是通过Netty网络接口来实现。由于Akka通道中参数spark.akka.framesize决定了能够传输消息的最大值,所以应该避免在Spark Task中引入超大的局部变量。
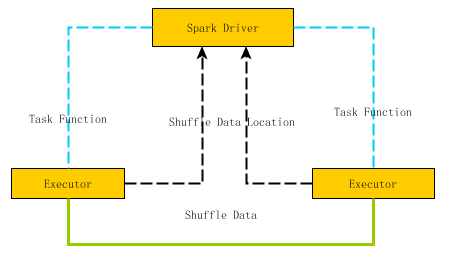
图2: Spark节点间的数据传输
第1节 选择合适的并发数
为了提高Spark应用程序的效率,尽可能的提升CPU的利用率。并发数应该是可用CPU物理核数的两倍。在这里,并发数过低,CPU得不到充分的利用,并发数过大,由于spark是每一个task都要分发到计算结点,所以任务启动的开销会上升。
并发数的修改,通过配置参数来改变spark.default.parallelism,如果是sql的话,可能通过修改spark.sql.shuffle.partitions来修改。
第1项 Repartition vs. Coalesce
repartition和coalesce都能实现数据分区的动态调整,但需要注意的是repartition会导致shuffle操作,而coalesce不会。
第2节 reduceByKey vs. groupBy
groupBy操作应该尽可能的避免,第一是有可能造成大量的网络开销,第二是可能导致OOM。以WordCount为例来演示reduceByKey和groupBy的差异
reduceByKey
sc.textFile(“README.md”).map(l=>l.split(“,”)).map(w=>(w,1)).reduceByKey(_ + _)
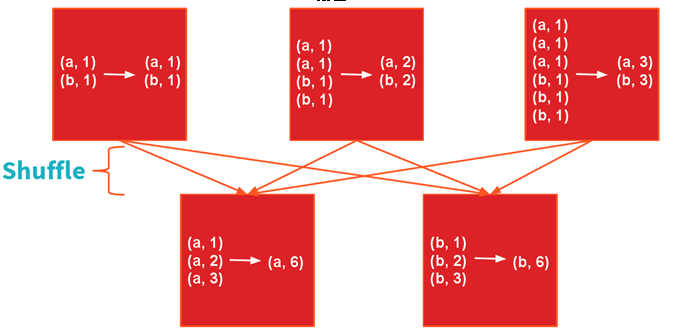
图3:reduceByKey的Shuffle过程
Shuffle过程如图2所示
groupByKey
sc.textFile(“README.md”).map(l=>l.split(“,”)).map(w=>(w,1)).groupByKey.map(r=>(r._1,r._2.sum))
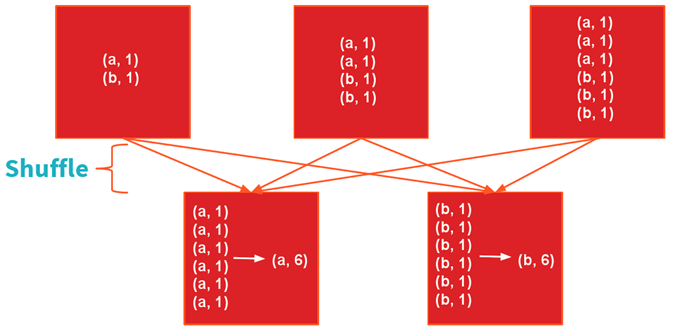
图4:groupByKey的Shuffle过程
建议: 尽可能使用reduceByKey, aggregateByKey, foldByKey和combineByKey
假设有一RDD如下所示,求每个key的均值
val data = sc.parallelize( List((0, 2.), (0, 4.), (1, 0.), (1, 10.), (1, 20.)) )
方法一:reduceByKey
data.map(r=>(r._1, (r.2,1))).reduceByKey((a,b)=>(a._1 + b._1, a._2 + b._2)).map(r=>(r._1,(r._2._1/r._2._2)).foreach(println)
方法二:combineByKey
data.combineByKey(value=>(value,1),
(x:(Double, Int), value:Double)=> (x._1+value, x._2 + 1), (x:(Double,Int), y:(Double, Int))=>(x._1 + y._1, x._2 + y._2))
第3节 BroadcastHashJoin vs. ShuffleHashJoin
在Join过程中,经常会遇到大表和小表的join. 为了提高效率可以使用BroadcastHashJoin, 预先将小表的内容广播到各个Executor, 这样将避免针对小表的Shuffle过程,从而极大的提高运行效率。
其实BroadCastHashJoin核心就是利用了BroadCast函数,如果理解清楚broadcast的优点,就能比较好的明白BroadcastHashJoin的优势所在。
以下是一个简单使用broadcast的示例程序。
val lst = 1 to 100 toList
val exampleRDD = sc.makeRDD(1 to 20 toSeq, 2)
val broadcastLst = sc.broadcast(lst)
exampleRDD.filter(i=>broadcastLst.valuecontains(i)).collect.foreach(println)
第4节 map vs. mapPartitions
有时需要将计算结果存储到外部数据库,势必会建立到外部数据库的连接。应该尽可能的让更多的元素共享同一个数据连接而不是每一个元素的处理时都去建立数据库连接。
在这种情况下,mapPartitions和foreachPartitons将比map操作高效的多。
第5节 数据就地读取
移动计算的开销远远低于移动数据的开销。
Spark中每个Task都需要相应的输入数据,因此输入数据的位置对于Task的性能变得很重要。按照数据获取的速度来区分,由快到慢分别是:
-
PROCESS_LOCAL
-
NODE_LOCAL
-
RACK_LOCAL
Spark在Task执行的时候会尽优先考虑最快的数据获取方式,如果想尽可能的在更多的机器上启动Task,那么可以通过调低spark.locality.wait的值来实现, 默认值是3s。
除了HDFS,Spark能够支持的数据源越来越多,如Cassandra, HBase,MongoDB等知名的NoSQL数据库,随着Elasticsearch的日渐兴起,spark和elasticsearch组合起来提供高速的查询解决方案也成为一种有益的尝试。
上述提到的外部数据源面临的一个相同问题就是如何让spark快速读取其中的数据, 尽可能的将计算结点和数据结点部署在一起是达到该目标的基本方法,比如在部署Hadoop集群的时候,可以将HDFS的DataNode和Spark Worker共享一台机器。
以cassandra为例,如果Spark的部署和Cassandra的机器有部分重叠,那么在读取Cassandra中数据的时候,通过调低spark.locality.wait就可以在没有部署Cassandra的机器上启动Spark Task。
对于Cassandra, 可以在部署Cassandra的机器上部署Spark Worker,需要注意的是Cassandra的compaction操作会极大的消耗CPU,因此在为Spark Worker配置CPU核数时,需要将这些因素综合在一起进行考虑。
这一部分的代码逻辑可以参考源码TaskSetManager::addPendingTask
private def addPendingTask(index: Int, readding: Boolean = false) {
// Utility method that adds `index` to a list only if readding=false or it's not already there
def addTo(list: ArrayBuffer[Int]) {
if (!readding || !list.contains(index)) {
list += index
}
}
for (loc <- tasks(index).preferredLocations) {
loc match {
case e: ExecutorCacheTaskLocation =>
addTo(pendingTasksForExecutor.getOrElseUpdate(e.executorId, new ArrayBuffer))
case e: HDFSCacheTaskLocation => {
val exe = sched.getExecutorsAliveOnHost(loc.host)
exe match {
case Some(set) => {
for (e <- set) {
addTo(pendingTasksForExecutor.getOrElseUpdate(e, new ArrayBuffer))
}
logInfo(s"Pending task $index has a cached location at ${e.host} " +
", where there are executors " + set.mkString(","))
}
case None => logDebug(s"Pending task $index has a cached location at ${e.host} " +
", but there are no executors alive there.")
}
}
case _ => Unit
}
addTo(pendingTasksForHost.getOrElseUpdate(loc.host, new ArrayBuffer))
for (rack <- sched.getRackForHost(loc.host)) {
addTo(pendingTasksForRack.getOrElseUpdate(rack, new ArrayBuffer))
}
}
if (tasks(index).preferredLocations == Nil) {
addTo(pendingTasksWithNoPrefs)
}
if (!readding) {
allPendingTasks += index // No point scanning this whole list to find the old task there
}
}
如果准备让spark支持新的存储源,进而开发相应的RDD,与位置相关的部分就是自定义getPreferredLocations函数,以elasticsearch-hadoop中的EsRDD为例,其代码实现如下。
override def getPreferredLocations(split: Partition): Seq[String] = {
val esSplit = split.asInstanceOf[EsPartition]
val ip = esSplit.esPartition.nodeIp
if (ip != null) Seq(ip) else Nil
}
第6节 序列化
使用好的序列化算法能够提高运行速度,同时能够减少内存的使用。
Spark在Shuffle的时候要将数据先存储到磁盘中,存储的内容是经过序列化的。序列化的过程牵涉到两大基本考虑的因素,一是序列化的速度,二是序列化后内容所占用的大小。
kryoSerializer与默认的javaSerializer相比,在序列化速度和序列化结果的大小方面都具有极大的优势。所以建议在应用程序配置中使用KryoSerializer.
spark.serializer org.apache.spark.serializer.KryoSerializer
默认的cache没有对缓存的对象进行序列化,使用的StorageLevel是MEMORY_ONLY,这意味着要占用比较大的内存。可以通过指定persist中的参数来对缓存内容进行序列化。
exampleRDD.persist(MEMORY_ONLY_SER)
需要特别指出的是persist函数是等到job执行的时候才会将数据缓存起来,属于延迟执行; 而unpersist函数则是立即执行,缓存会被立即清除。



相关推荐
我们谈大数据性能调优,到底在谈什么,它的本质是什么,以及 Spark 在性能调优部份的要点,这两点让在进入性能调优之前都是一个至关重要的问题,它的本质限制了我们调优到底要达到一个什么样的目标或者说我们是从...
Spark性能调优是提高大数据处理效率的关键步骤,尤其在处理大规模数据时,高效的资源配置和并行度设置至关重要。本文将详细解析如何通过分配更多资源和提高并行度来优化Spark作业的性能。 **1. 分配更多的资源** ...
课程内容涵盖了Spark性能调优的各个方面,包括内存管理、并行度设置、数据倾斜处理、Shuffle调优、资源配置等关键技术和策略。学员将通过实际案例的演示和分析,掌握解决Spark应用性能问题的方法和技巧,从而提升...
《Spark性能调优与故障处理》 Spark作为一个强大的分布式计算框架,其性能调优和故障处理是提升系统效率和稳定性的重要环节。本文主要探讨Spark的性能优化策略,包括常规性能调优、算子调优、shuffle调优、JVM调优...
### Spark性能调优的核心原则详解 #### 一、引言 在大数据处理领域,Apache Spark因其高效、易用的特点成为了主流工具之一。然而,随着业务规模的不断扩大和技术需求的日益复杂,Spark作业的性能问题逐渐凸显。...
该xmind文件介绍了spark性能调优时涉及到的各个方面。
spark性能调优,共包含了调优的最佳方法,以及JVM调优,troubleshooting,数据倾斜的使用方法。 为了更好的搭配该性能调优方案,顾把项目也分享给大家。 并且,代码有了一份scala 编写的spark SQL我会分享到github上...
### Spark性能调优和数据倾斜解决方案 #### 一、引言 随着大数据处理需求的日益增长,Apache Spark作为主流的大数据分析引擎之一,其性能优化变得至关重要。本文将深入探讨Spark性能调优的关键技术和方法,特别是在...
在Spark中,性能调优的参数非常丰富,其中Shuffle操作是影响Spark性能的一个重要因素。Shuffle操作涉及到排序、磁盘IO、网络IO等多种CPU或IO密集型操作。为了更好地管理和优化Shuffle操作,Spark设计了一个可插拔的...
### Spark性能调优详解 #### 一、引言 随着大数据技术的发展,Apache Spark作为一款通用的大数据分析引擎,因其高效的数据处理能力而受到广泛青睐。然而,在实际应用中,为了充分发挥Spark的优势,对其进行合理的...
Spark性能受多种因素影响,包括数据大小、数据分布、计算任务类型、硬件配置、网络延迟和并行度设置等。数据量越大,处理时间越长,不均匀的数据分布会引发节点负载不均,影响整体性能。硬件配置(CPU、内存、磁盘...
Spark性能调优的核心在于合理分配资源,这涉及到Executor的数量、Driver内存、Executor内存以及Executor的CPU核心数。增加资源分配通常能带来性能的提升,但需注意不能超过系统可用资源的范围。在Spark Standalone...
### Spark性能优化指南 #### 一、基础篇:开发调优与资源调优 ##### 1. 开发调优 **1.1 调优概述** 开发阶段的调优至关重要,它涉及到如何构建Spark应用的基本框架。在开发Spark应用程序时,有几个基本原则需要...
Spark内核深度剖析 Spark调优 SparkSQL精讲 SparkStreaming精讲 Spark2新特性
### Spark性能优化指南—高级篇 #### 数据倾斜调优 数据倾斜是Spark处理大数据时最常见的问题之一,它严重影响了任务的执行效率。本章节重点探讨数据倾斜现象的原因、识别方式及解决方案。 ##### 调优概述 数据...
以下将详细阐述Spark性能调优的主要方面,包括资源分配、代码优化、数据处理策略以及应对数据倾斜的策略。 1. **资源分配**: - `num-executors`:设置executor的数量,这决定了并行处理任务的能力。合理分配能...
Spark SQL不仅是Spark用于处理结构化数据的一个模块,它还提供了一种高效的数据交互方式,并且在性能调优方面占有了较大比重。Spark SQL性能优化的关键在于对其执行计划的理解和分析,只有明确了执行计划的各个阶段...