
Sql语句优化
Sql语句优化工具
·慢日志
如果发现系统慢了,又说不清楚是哪里慢,那么就该用这个工具了。只需要为mysql配置参数,mysql会自己记录下来慢的sql语句。配置很简单,参数文件里配置:
slow_query_log=d:/slow.txt
long_query_time = 2
就可以在d:/slow.txt里找到执行时间超过2秒的语句了,根据这个文件定位问题吧。
·mysqldumpslow.pl
慢日志文件可能会很大,让人去看是很难受的事。这时候我们可以通过mysql自带的工具来分析。这个工具可以格式化慢日志文件,对于只是参数不同的语句会归类类并,比如有两个语句select * from a where id=1 和select * from a where id=2,经过这个工具整理后就只剩下select * from a where id=N,这样读起来就舒服多了。而且这个工具可以实现简单的排序,让我们有的放矢。下面介绍下用法。因为这是个perl脚本,先要安装perl环境。脚本在mysql自带的脚本目录里,我的是在D:\mysql-5.1.30-win32\scripts
先mysqldumpslow –help以下,俺主要用的是
-s ORDER what to sort by (t, at, l, al, r, ar etc), ‘at’ is default
-t NUM just show the top n queries
-g PATTERN grep: only consider stmts that include this string
-s,是order的顺序,说明写的不够详细,俺用下来,包括看了代码,主要有
c,t,l,r和ac,at,al,ar,分别是按照query次数,时间,lock的时间和返回的记录数来排序,前面加了a的时倒叙
-t,是top n的意思,即为返回前面多少条的数据
-g,后边可以写一个正则匹配模式,大小写不敏感的
mysqldumpslow -s c -t 20 slow.txt
mysqldumpslow -s r -t 20 slow.txt
上述命令可以看出访问次数最多的20个sql语句和返回记录集最多的20个sql。
mysqldumpslow -t 10 -s t -g “left join” slow.txt
这个是按照时间返回前10条里面含有左连接的sql语句。
Explain
现在我们已经知道是哪个语句慢了,那么它为什么慢呢?看看mysql是怎么执行的吧,用explain可以看到mysql执行计划,下面的用法来源于手册
EXPLAIN语法(获取SELECT相关信息)
EXPLAIN [EXTENDED] SELECT select_options
EXPLAIN语句可以用作DESCRIBE的一个同义词,或获得关于MySQL如何执行SELECT语句的信息:
· EXPLAIN tbl_name是DESCRIBE tbl_name或SHOW COLUMNS FROM tbl_name的一个同义词。
· 如果在SELECT语句前放上关键词EXPLAIN,MySQL将解释它如何处理SELECT,提供有关表如何联接和联接的次序。
该节解释EXPLAIN的第2个用法。
借助于EXPLAIN,可以知道什么时候必须为表加入索引以得到一个使用索引来寻找记录的更快的SELECT。
如果由于使用不正确的索引出现了问题,应运行ANALYZE TABLE更新表的统计(例如关键字集的势),这样会影响优化器进行的选择。
还可以知道优化器是否以一个最佳次序联接表。为了强制优化器让一个SELECT语句按照表命名顺序的联接次序,语句应以STRAIGHT_JOIN而不只是SELECT开头。
EXPLAIN为用于SELECT语句中的每个表返回一行信息。表以它们在处理查询过程中将被MySQL读入的顺序被列出。MySQL用一遍扫描多次联接(single-sweep multi-join)的方式解决所有联接。这意味着MySQL从第一个表中读一行,然后找到在第二个表中的一个匹配行,然后在第3个表中等等。当所有的表处理完后,它输出选中的列并且返回表清单直到找到一个有更多的匹配行的表。从该表读入下一行并继续处理下一个表。
当使用EXTENDED关键字时,EXPLAIN产生附加信息,可以用SHOW WARNINGS浏览。该信息显示优化器限定SELECT语句中的表和列名,重写并且执行优化规则后SELECT语句是什么样子,并且还可能包括优化过程的其它注解。
const用于用常数值比较PRIMARY KEY或UNIQUE索引的所有部分时。在下面的查询中,tbl_name可以用于const表:
SELECT * from tbl_name WHERE primary_key=1;
SELECT * from tbl_name
WHERE primary_key_part1=1和 primary_key_part2=2;
⊙eq_ref
对于每个来自于前面的表的行组合,从该表中读取一行。这可能是最好的联接类型,除了const类型。它用在一个索引的所有部分被联接使用并且索引是UNIQUE或PRIMARY KEY。
eq_ref可以用于使用= 操作符比较的带索引的列。比较值可以为常量或一个使用在该表前面所读取的表的列的表达式。
在下面的例子中,MySQL可以使用eq_ref联接来处理ref_tables:
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column_part1=other_table.column
AND ref_table.key_column_part2=1;
⊙ref
对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取。如果联接只使用键的最左边的前缀,或如果键不是UNIQUE或PRIMARY KEY(换句话说,如果联接不能基于关键字选择单个行的话),则使用ref。如果使用的键仅仅匹配少量行,该联接类型是不错的。
ref可以用于使用=或<=>操作符的带索引的列。
在下面的例子中,MySQL可以使用ref联接来处理ref_tables:
SELECT * FROM ref_table WHERE key_column=expr;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column_part1=other_table.column
AND ref_table.key_column_part2=1;
⊙ref_or_null
该联接类型如同ref,但是添加了MySQL可以专门搜索包含NULL值的行。在解决子查询中经常使用该联接类型的优化。
在下面的例子中,MySQL可以使用ref_or_null联接来处理ref_tables:
SELECT * FROM ref_table
WHERE key_column=expr OR key_column IS NULL;
⊙ index_merge
该联接类型表示使用了索引合并优化方法。在这种情况下,key列包含了使用的索引的清单,key_len包含了使用的索引的最长的关键元素。
⊙ unique_subquery
该类型替换了下面形式的IN子查询的ref:
value IN (SELECT primary_key FROM single_table WHERE some_expr)
unique_subquery是一个索引查找函数,可以完全替换子查询,效率更高。
⊙ index_subquery
该联接类型类似于unique_subquery。可以替换IN子查询,但只适合下列形式的子查询中的非唯一索引:
value IN (SELECT key_column FROM single_table WHERE some_expr)
⊙ range
只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引。key_len包含所使用索引的最长关键元素。在该类型中ref列为NULL。
当使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或者IN操作符,用常量比较关键字列时,可以使用range:
SELECT * FROM tbl_name
WHERE key_column = 10;
SELECT * FROM tbl_name
WHERE key_column BETWEEN 10 and 20;
SELECT * FROM tbl_name
WHERE key_column IN (10,20,30);
SELECT * FROM tbl_name
WHERE key_part1= 10 AND key_part2 IN (10,20,30);
⊙ index
该联接类型与ALL相同,除了只有索引树被扫描。这通常比ALL快,因为索引文件通常比数据文件小。
当查询只使用作为单索引一部分的列时,MySQL可以使用该联接类型。
⊙ALL
对于每个来自于先前的表的行组合,进行完整的表扫描。如果表是第一个没标记const的表,这通常不好,并且通常在它情况下很差。通常可以增加更多的索引而不要使用ALL,使得行能基于前面的表中的常数值或列值被检索出。
· possible_keys
possible_keys列指出MySQL能使用哪个索引在该表中找到行。注意,该列完全独立于EXPLAIN输出所示的表的次序。这意味着在possible_keys中的某些键实际上不能按生成的表次序使用。
如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查WHERE子句看是否它引用某些列或适合索引的列来提高你的查询性能。如果是这样,创造一个适当的索引并且再次用EXPLAIN检查查询。
为了看清一张表有什么索引,使用SHOW INDEX FROM tbl_name。
· key
key列显示MySQL实际决定使用的键(索引)。如果没有选择索引,键是NULL。要想强制MySQL使用或忽视possible_keys列中的索引,在查询中使用FORCE INDEX、USE INDEX或者IGNORE INDEX。
对于MyISAM和BDB表,运行ANALYZE TABLE可以帮助优化器选择更好的索引。对于MyISAM表,可以使用myisamchk --analyze。
· key_len
key_len列显示MySQL决定使用的键长度。如果键是NULL,则长度为NULL。注意通过key_len值我们可以确定MySQL将实际使用一个多部关键字的几个部分。
· ref
ref列显示使用哪个列或常数与key一起从表中选择行。
· rows
rows列显示MySQL认为它执行查询时必须检查的行数。
· Extra
该列包含MySQL解决查询的详细信息。下面解释了该列可以显示的不同的文本字符串:
⊙Distinct
MySQL发现第1个匹配行后,停止为当前的行组合搜索更多的行。
⊙Not exists
MySQL能够对查询进行LEFT JOIN优化,发现1个匹配LEFT JOIN标准的行后,不再为前面的的行组合在该表内检查更多的行。
下面是一个可以这样优化的查询类型的例子:
SELECT * 从t1 LEFT JOIN t2 ON t1.id=t2.id
WHERE t2.id IS NULL;
假定t2.id定义为NOT NULL。在这种情况下,MySQL使用t1.id的值扫描t1并查找t2中的行。如果MySQL在t2中发现一个匹配的行,它知道t2.id绝不会为NULL,并且不再扫描t2内有相同的id值的行。换句话说,对于t1的每个行,MySQL只需要在t2中查找一次,无论t2内实际有多少匹配的行。
⊙ range checked for each record (index map: #)
MySQL没有发现好的可以使用的索引,但发现如果来自前面的表的列值已知,可能部分索引可以使用。对前面的表的每个行组合,MySQL检查是否可以使用range或index_merge访问方法来索取行。
这并不很快,但比执行没有索引的联接要快得多。
⊙Using filesort
MySQL需要额外的一次传递,以找出如何按排序顺序检索行。通过根据联接类型浏览所有行并为所有匹配WHERE子句的行保存排序关键字和行的指针来完成排序。然后关键字被排序,并按排序顺序检索行。
⊙Using index
从只使用索引树中的信息而不需要进一步搜索读取实际的行来检索表中的列信息。当查询只使用作为单一索引一部分的列时,可以使用该策略。
⊙Using temporary
为了解决查询,MySQL需要创建一个临时表来容纳结果。典型情况如查询包含可以按不同情况列出列的GROUP BY和ORDER BY子句时。
⊙Using where
WHERE子句用于限制哪一个行匹配下一个表或发送到客户。除非你专门从表中索取或检查所有行,如果Extra值不为Using where并且表联接类型为ALL或index,查询可能会有一些错误。
如果想要使查询尽可能快,应找出Using filesort 和Using temporary的Extra值。
⊙Using sort_union(...), Using union(...), Using intersect(...)
这些函数说明如何为index_merge联接类型合并索引扫描。详细信息参见
⊙Using index for group-by
类似于访问表的Using index方式,Using index for group-by表示MySQL发现了一个索引,可以用来查询GROUP BY或DISTINCT查询的所有列,而不要额外搜索硬盘访问实际的表。并且,按最有效的方式使用索引,以便对于每个组,只读取少量索引条目。
通过相乘EXPLAIN输出的rows列的所有值,你能得到一个关于一个联接如何的提示。这应该粗略地告诉你MySQL必须检查多少行以执行查询。当你使用max_join_size变量限制查询时,也用这个乘积来确定执行哪个多表SELECT语句。
下列例子显示出一个多表JOIN如何能使用EXPLAIN提供的信息逐步被优化。
假定你有下面所示的SELECT语句,计划使用EXPLAIN来检查它:
EXPLAIN SELECT tt.TicketNumber, tt.TimeIn,
tt.ProjectReference, tt.EstimatedShipDate,
tt.ActualShipDate, tt.ClientID,
tt.ServiceCodes, tt.RepetitiveID,
tt.CurrentProcess, tt.CurrentDPPerson,
tt.RecordVolume, tt.DPPrinted, et.COUNTRY,
et_1.COUNTRY, do.CUSTNAME
FROM tt, et, et AS et_1, do
WHERE tt.SubmitTime IS NULL
AND tt.ActualPC = et.EMPLOYID
AND tt.AssignedPC = et_1.EMPLOYID
AND tt.ClientID = do.CUSTNMBR;
对于这个例子,假定:
· 被比较的列声明如下:
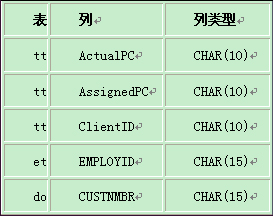
· 表有下面的索引:

· tt.ActualPC值不是均匀分布的。
开始,在进行优化前,EXPLAIN语句产生下列信息:
table type possible_keys key key_len ref rows Extra
et ALL PRIMARY NULL NULL NULL 74
do ALL PRIMARY NULL NULL NULL 2135
et_1 ALL PRIMARY NULL NULL NULL 74
tt ALL AssignedPC, NULL NULL NULL 3872
ClientID,
ActualPC
range checked for each record (key map: 35)
因为type对每张表是ALL,这个输出显示MySQL正在对所有表产生一个笛卡尔乘积;即每一个行的组合!这将花相当长的时间,因为必须检查每张表的行数的乘积!对于一个实例,这是74 * 2135 * 74 * 3872 = 45,268,558,720行。如果表更大,你只能想象它将花多长时间……
这里的一个问题是MySQL能更高效地在声明具有相同类型和尺寸的列上使用索引。在本文中,VARCHAR和CHAR是相同的,除非它们声明为不同的长度。因为tt.ActualPC被声明为CHAR(10)并且et.EMPLOYID被声明为CHAR(15),长度不匹配。
为了修正在列长度上的不同,使用ALTER TABLE将ActualPC的长度从10个字符变为15个字符:
mysql> ALTER TABLE tt MODIFY ActualPC VARCHAR(15);
现在tt.ActualPC和et.EMPLOYID都是VARCHAR(15),再执行EXPLAIN语句产生这个结果:
table type possible_keys key key_len ref rows Extra
tt ALL AssignedPC, NULL NULL NULL 3872 Using
ClientID, where
ActualPC
do ALL PRIMARY NULL NULL NULL 2135
range checked for each record (key map: 1)
et_1 ALL PRIMARY NULL NULL NULL 74
range checked for each record (key map: 1)
et eq_ref PRIMARY PRIMARY 15 tt.ActualPC 1
这不是完美的,但是好一些了:rows值的乘积少了一个因子74。这个版本在几秒内执行完。
第2种方法能消除tt.AssignedPC = et_1.EMPLOYID和tt.ClientID = do.CUSTNMBR比较的列的长度失配问题:
mysql> ALTER TABLE tt MODIFY AssignedPC VARCHAR(15),
-> MODIFY ClientID VARCHAR(15);
EXPLAIN产生的输出显示在下面:
table type possible_keys key key_len ref rows Extra
et ALL PRIMARY NULL NULL NULL 74
tt ref AssignedPC, ActualPC 15 et.EMPLOYID 52 Using
ClientID, where
ActualPC


发表评论

-
MySQL 优化总结 (五)
2009-05-31 14:52 818Join Vs select 结果集作列 ... -
MySQL 优化总结 (四)
2009-05-31 14:47 767减少不必要的表关联 有时候一个查询需要很 ... -
MySQL 优化总结 (三)
2009-05-31 14:43 866range checked for each rec ... -
堆排序算法原理以及实例代码
2009-02-17 21:11 29741、 堆排序定义 n个关键 ... -
MyEclipse 6.5 最新下载、注册、汉化
2008-11-11 14:36 12811因最近发现网上很多转� ... -
SCJP 310-055 资料汇总 (不断更新中……)
2008-11-05 17:05 1049SCJP在线练习 http://www.java3z.com ...
相关推荐
MySQL性能优化总结.pdf
MySQL性能优化是一个涵盖广泛的主题,涉及数据库设计、SQL查询优化、索引策略等多个方面。以下是对标题和描述中提到的一些关键知识点的详细说明: 1. **表的优化**: - **定长与变长字段的分离**:将定长字段(如...
MySQL 性能优化总结 MySQL 性能优化是数据库管理和开发人员需要掌握的重要技能。性能优化的目标是让查询更快,减少查询所消耗的时间。为了达到这个目标,我们需要从每一个环节入手,包括连接、配置优化、索引优化、...
### MySQL优化技巧总结 #### 一、MySQL慢查询日志(Slow Query Log)与mysqldumpslow工具 **慢查询日志**是MySQL提供的一种非常实用的功能,它能够帮助我们记录并分析那些执行时间较长的SQL语句,进而找出性能瓶颈并...
Mysql基础性能优化思维导向图 (其中包括:mysql基础、mysql性能优化、mysql锁机制和主从复制) 文件名称:MySQL基础与性能优化总结.xmind
课程内容进行了精华的浓缩,有四大内容主旨,MySQL架构与执行流程,MySQL索引原理详解,MySQL事务原理与事务并发,MySQL性能优化总结与MySQL配置优化。课程安排的学习的教程与对应的学习课件,详细的学习笔以及课程...
MySQL优化 MySQL优化是数据库管理中的一个重要...总结而言,MySQL优化是一个涉及多个层面的复杂过程,需要综合考虑配置、索引、查询语句、服务器状态等多方面因素,通过合理配置和优化,以达到提升数据库性能的目的。
### MySQL优化知识点详解 #### 一、MySQL简介 MySQL是一款由MySQL AB公司开发的开源数据库管理系统,后来该公司被Sun Microsystems收购。MySQL因其简单、高效、可靠的特点,在IT行业中迅速崭露头角,成为最受欢迎...
以下是对MySQL优化的详细总结,供您参考学习。 一、查询优化 1. **索引优化**:索引能显著提高查询速度。应为经常用于搜索的列创建索引,特别是主键和外键。复合索引在多条件查询时特别有用,但要注意避免冗余和...
MySQL 5.6 性能优化总结 MySQL 5.6 是一个高性能的关系型数据库管理系统,然而随着数据库规模的增长和复杂度的增加,性能问题开始浮现。因此,性能优化成为 MySQL 数据库管理员和开发者的首要任务。本文将总结 ...
### MySQL优化实战视频课程知识点概览 #### 一、MySQL优化基础 ##### 1.1 数据库优化的重要性 - **背景介绍**:随着互联网技术的发展,数据量呈指数级增长,对数据库系统的性能要求越来越高。 - **核心价值**:...
MySQL优化是数据库管理中至关重要的环节,它关系到系统性能和响应速度。下面将详细介绍MySQL自带的慢查询日志分析工具mysqldumpslow及其使用方法,以及如何使用EXPLAIN来分析SQL查询。 首先,MySQL的慢查询日志...
Mysql数据库优化总结-飞鸿无痕-ChinaUnix博客................................................................................................................
第4课 查询优化技术理论与MySQL实践(二)------子查询的优化(二) 从理论看,子查询包括的内容和范围,建立清晰的概念 从实践看,MySQL的子查询优化技术的内容和范围,明确掌握子查询优化手段 预计时间2小时,每...
总结,MySQL性能优化与架构设计涵盖了许多方面,包括查询优化、索引策略、数据库设计、缓存利用、并行处理、架构设计、数据分布以及监控与调优工具的使用。理解和掌握这些知识点,能够帮助我们构建高效、稳定的...
#### 一、什么是MySQL优化? MySQL优化是指通过合理安排资源和调整系统参数,使得MySQL运行得更快、更节省资源的过程。优化的目的在于减少系统瓶颈,降低资源消耗,提升系统的响应速度。 #### 二、优化的主要方面 ...
### 2G内存的MySQL数据库服务器优化 在IT行业中,对于资源有限的环境进行数据库优化是一项挑战性工作,尤其是在仅有2GB内存的情况下对MySQL数据库服务器进行优化。这种优化旨在提高性能的同时确保系统的稳定运行。 ...
### MySQL 5.6 性能优化 #### 一、优化概述 在现代数据库管理中,MySQL作为一种广泛使用的开源关系型数据库管理系统,在诸多业务场景下扮演着重要角色。随着业务需求的增长和技术的发展,如何有效提升MySQL数据库...