
Sentinel介绍
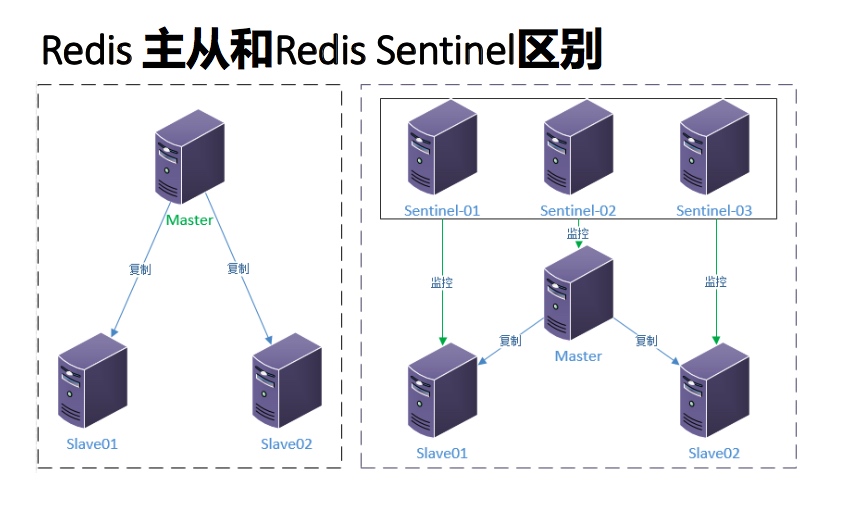
- Redis的主从模式下,主节点一旦发生故障不能提供服务,需要人 工干预,将从节点晋升为主节点,同时还需要修改客户端配置。 对于很多应用场景这种方式无法接受。
- Redis从 2.8发布了一个稳定版本的Redis Sentinel 。当前版本的 Sentinel称为Sentinel 2。它是使用更强大和更简单的预测算法来重 写初始Sentinel实现。(Redis2.6版本提供Sentinel 1版本,但是有 一些问题)
- Sentinel(哨兵)架构解决了redis主从人工干预的问题。
- Redis Sentinel是redis的高可用实现方案,在实际生产环境中,对 提高整个系统可用性是非常有帮助的。
Redis Sentinel
- Redis Sentinel是一个分布式系统,Redis Sentinel为Redis提供高可用性。可以在没有人为干预的情况下 阻止某种类型的故障。
- 可以在一个架构中运行多个 Sentinel 进程(progress), 这些进程使用流言协议(gossip protocols)来 接收关于主服务器是否下线的信息, 并使用投票协议(agreement protocols)来决定是否执行自动故 障迁移, 以及选择哪个从服务器作为新的主服务器。
Redis 的 Sentinel 系统用于管理多个 Redis 服务器(instance) 该系统执行以下三个任务:
- 监控(Monitoring): Sentinel 会不断地定期检查你的主服务器和从服务器是否运作正常。
- 提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automaticfailover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中 一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客 户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主 服务器代替失效服务器
Redis Sentinel 高可用性
- 当主节点出现故障时redis sentinel 能自动完成故障发现和故障转移,并通知客户端从而实现真正的高可用。
- Redis Sentinel是一个分布式架构,其中包含N个Sentinel节点和Redis数 据节点,每个Sentinel节点会对数据节点和其他Sentinel节点进行监控, 当它返现节点不可达时,会对节点做下线标识,如果被标识的是主节 点,它还会和其他Sentinel及诶单进行“协商”,当大多数节点都认为主 节点不可达时,会选举出一个Sentinel节点来完成自动故障转移的工作, 同时会将这个变化实时通知给redis的客户端,整个过程是自动的不需 要人工干预,有效的解决了redis的高可用问题。
- 同时看出,Redis Sentinel包含多个Sentinel节点,这样做带来两个好处:
- 对于节点的故障判断是由多个节点共同完成,这样可以有效的防止误判断
- 多个Sentinel节点出现个别节点不可用,也不会影响客户端的访问
Sentinel的“仲裁会”
前面我们谈到,当一个master被sentinel集群监控时,需要为它指定一个参数,这个参数指定了当需要判决master为不可用,并且进行failover时,所需要的sentinel数量,本文中我们暂时称这个参数为票数
不过,当failover主备切换真正被触发后,failover并不会马上进行,还需要sentinel中的大多数sentinel授权后才可以进行failover。
当ODOWN时,failover被触发。failover一旦被触发,尝试去进行failover的sentinel会去获得“大多数”sentinel的授权(如果票数比大多数还要大的时候,则询问更多的sentinel)
这个区别看起来很微妙,但是很容易理解和使用。例如,集群中有5个sentinel,票数被设置为2,当2个sentinel认为一个master已经不可用了以后,将会触发failover,但是,进行failover的那个sentinel必须先获得至少3个sentinel的授权才可以实行failover。
如果票数被设置为5,要达到ODOWN状态,必须所有5个sentinel都主观认为master为不可用,要进行failover,那么得获得所有5个sentinel的授权。
配置版本号
为什么要先获得大多数sentinel的认可时才能真正去执行failover呢?
当一个sentinel被授权后,它将会获得宕掉的master的一份最新配置版本号,当failover执行结束以后,这个版本号将会被用于最新的配置。因为大多数sentinel都已经知道该版本号已经被要执行failover的sentinel拿走了,所以其他的sentinel都不能再去使用这个版本号。这意味着,每次failover都会附带有一个独一无二的版本号。我们将会看到这样做的重要性。
而且,sentinel集群都遵守一个规则:如果sentinel A推荐sentinel B去执行failover,B会等待一段时间后,自行再次去对同一个master执行failover,这个等待的时间是通过failover-timeout配置项去配置的。从这个规则可以看出,sentinel集群中的sentinel不会再同一时刻并发去failover同一个master,第一个进行failover的sentinel如果失败了,另外一个将会在一定时间内进行重新进行failover,以此类推。
redis sentinel保证了活跃性:如果大多数sentinel能够互相通信,最终将会有一个被授权去进行failover.
redis sentinel也保证了安全性:每个试图去failover同一个master的sentinel都会得到一个独一无二的版本号。
配置传播
一旦一个sentinel成功地对一个master进行了failover,它将会把关于master的最新配置通过广播形式通知其它sentinel,其它的sentinel则更新对应master的配置。
一个faiover要想被成功实行,sentinel必须能够向选为master的slave发送SLAVE OF NO ONE命令,然后能够通过INFO命令看到新master的配置信息。
当将一个slave选举为master并发送SLAVE OF NO ONE`后,即使其它的slave还没针对新master重新配置自己,failover也被认为是成功了的,然后所有sentinels将会发布新的配置信息。
新配在集群中相互传播的方式,就是为什么我们需要当一个sentinel进行failover时必须被授权一个版本号的原因。
每个sentinel使用发布/订阅的方式持续地传播master的配置版本信息,配置传播的发布/订阅管道是:__sentinel__:hello
因为每一个配置都有一个版本号,所以以版本号最大的那个为标准。
举个栗子:假设有一个名为mymaster的地址为192.168.56.11:6379。一开始,集群中所有的sentinel都知道这个地址,于是为mymaster的配置打上版本号1。一段时候后mymaster死了,有一个sentinel被授权用版本号2对其进行failover。如果failover成功了,假设地址改为了192.168.56.12:6279,此时配置的版本号为2,进行failover的sentinel会将新配置广播给其他的sentinel,由于其他sentinel维护的版本号为1,发现新配置的版本号为2时,版本号变大了,说明配置更新了,于是就会采用最新的版本号为2的配置。
这意味着sentinel集群保证了第二种活跃性:一个能够互相通信的sentinel集群最终会采用版本号最高且相同的配置。
SDOWN和ODOWN的更多细节
- 主观下线(Subjectively Down, 简称 SDOWN)指的是单个 Sentinel 实例对服务器做出的下线判断。
- 客观下线(Objectively Down, 简称 ODOWN)指的是多个 Sentinel 实例在对同一个服务器做出 SDOWN 判断, 并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后, 得出的服务器下线判断。 (一个 Sentinel 可以通过向另一个 Sentinel 发送
SENTINEL is-master-down-by-addr命令来询问对方是否认为给定的服务器已下线。)
从sentinel的角度来看,如果发送了PING心跳后,在master-down-after-milliseconds时间内没有收到合法的回复,就达到了SDOWN的条件。
当sentinel发送PING后,以下回复之一都被认为是合法的:
PING replied with +PONG.PING replied with -LOADING error.-
PING replied with -MASTERDOWN error.
其它任何回复(或者根本没有回复)都是不合法的。
从SDOWN切换到ODOWN不需要任何一致性算法,只需要一个gossip协议:如果一个sentinel收到了足够多的sentinel发来消息告诉它某个master已经down掉了,SDOWN状态就会变成ODOWN状态。如果之后master可用了,这个状态就会相应地被清理掉。
正如之前已经解释过了,真正进行failover需要一个授权的过程,但是所有的failover都开始于一个ODOWN状态。
ODOWN状态只适用于master,对于不是master的redis节点sentinel之间不需要任何协商,slaves和sentinel不会有ODOWN状态。
每个 Sentinel 都需要定期执行的任务
- 每个 Sentinel 以每秒钟一次的频率向它所知的主服务器、从服务器以及其他 Sentinel 实例发送一个 PING 命令。
- 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 那么这个实例会被 Sentinel 标记为主观下线。 一个有效回复可以是: +PONG 、 -LOADING 或者 -MASTERDOWN 。
- 如果一个主服务器被标记为主观下线, 那么正在监视这个主服务器的所有 Sentinel 要以每秒一次的频率确认主服务器的确进入了主观下线状态。
- 如果一个主服务器被标记为主观下线, 并且有足够数量的 Sentinel (至少要达到配置文件指定的数量)在指定的时间范围内同意这一判断, 那么这个主服务器被标记为客观下线。
- 在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有主服务器和从服务器发送 INFO 命令。 当一个主服务器被 Sentinel 标记为客观下线时, Sentinel 向下线主服务器的所有从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
- 当没有足够数量的 Sentinel 同意主服务器已经下线, 主服务器的客观下线状态就会被移除。 当主服务器重新向 Sentinel 的 PING 命令返回有效回复时, 主服务器的主管下线状态就会被移除。
Sentinel之间和Slaves之间的自动发现机制
虽然sentinel集群中各个sentinel都互相连接彼此来检查对方的可用性以及互相发送消息。但是你不用在任何一个sentinel配置任何其它的sentinel的节点。因为sentinel利用了master的发布/订阅机制去自动发现其它也监控了统一master的sentinel节点。
通过向名为__sentinel__:hello的管道中发送消息来实现。
同样,你也不需要在sentinel中配置某个master的所有slave的地址,sentinel会通过询问master来得到这些slave的地址的。
- 每个 Sentinel 会以每两秒一次的频率, 通过发布与订阅功能, 向被它监视的所有主服务器和从服务器的
__sentinel__:hello频道发送一条信息, 信息中包含了 Sentinel 的 IP 地址、端口号和运行 ID (runid)。 - 每个 Sentinel 都订阅了被它监视的所有主服务器和从服务器的
__sentinel__:hello频道, 查找之前未出现过的 sentinel (looking for unknown sentinels)。 当一个 Sentinel 发现一个新的 Sentinel 时, 它会将新的 Sentinel * 添加到一个列表中, 这个列表保存了 Sentinel 已知的, 监视同一个主服务器的所有其他 Sentinel 。 - Sentinel 发送的信息中还包括完整的主服务器当前配置(configuration)。 如果一个 Sentinel 包含的主服务器配置比另一个 Sentinel 发送的配置要旧, 那么这个 Sentinel 会立即升级到新配置上。
- 在将一个新 Sentinel 添加到监视主服务器的列表上面之前, Sentinel 会先检查列表中是否已经包含了和要添加的 Sentinel 拥有相同运行 ID 或者相同地址(包括 IP 地址和端口号)的 Sentinel , 如果是的话, Sentinel 会先移除列表中已有的那些拥有相同运行 ID 或者相同地址的 Sentinel , 然后再添加新 Sentinel 。
网络隔离时的一致性
redis sentinel集群的配置的一致性模型为最终一致性,集群中每个sentinel最终都会采用最高版本的配置。然而,在实际的应用环境中,有三个不同的角色会与sentinel打交道:
Redis实例.
Sentinel实例.
客户端.
为了考察整个系统的行为我们必须同时考虑到这三个角色。
下面有个简单的例子,有三个主机,每个主机分别运行一个redis和一个sentinel:
+-------------+
| Sentinel 1 | <--- Client A
| Redis 1 (M) |
+-------------+
|
|
+-------------+ | +------------+
| Sentinel 2 |-----+-- / partition / ----| Sentinel 3 | <--- Client B
| Redis 2 (S) | | Redis 3 (M)|
+-------------+ +------------+在这个系统中,初始状态下redis3是master, redis1和redis2是slave。之后redis3所在的主机网络不可用了,sentinel1和sentinel2启动了failover并把redis1选举为master。
Sentinel集群的特性保证了sentinel1和sentinel2得到了关于master的最新配置。但是sentinel3依然持着的是就的配置,因为它与外界隔离了。
当网络恢复以后,我们知道sentinel3将会更新它的配置。但是,如果客户端所连接的master被网络隔离,会发生什么呢?
客户端将依然可以向redis3写数据,但是当网络恢复后,redis3就会变成redis的一个slave,那么,在网络隔离期间,客户端向redis3写的数据将会丢失。
也许你不会希望这个场景发生:
如果你把redis当做缓存来使用,那么你也许能容忍这部分数据的丢失。
但如果你把redis当做一个存储系统来使用,你也许就无法容忍这部分数据的丢失了。
因为redis采用的是异步复制,在这样的场景下,没有办法避免数据的丢失。然而,你可以通过以下配置来配置redis3和redis1,使得数据不会丢失。
min-slaves-to-write 1
min-slaves-max-lag 10通过上面的配置,当一个redis是master时,如果它不能向至少一个slave写数据(上面的min-slaves-to-write指定了slave的数量),它将会拒绝接受客户端的写请求。由于复制是异步的,master无法向slave写数据意味着slave要么断开连接了,要么不在指定时间内向master发送同步数据的请求了(上面的min-slaves-max-lag指定了这个时间)。
故障转移
一次故障转移操作由以下步骤组成:
- 发现主服务器已经进入客观下线状态。
- 对我们的当前纪元进行自增(详情请参考 Raft leader election ), 并尝试在这个纪元中当选。
- 如果当选失败, 那么在设定的故障迁移超时时间的两倍之后, 重新尝试当选。 如果当选成功, 那么执行以下步骤。
- 选出一个从服务器,并将它升级为主服务器。
- 向被选中的从服务器发送 SLAVEOF NO ONE 命令,让它转变为主服务器。
- 通过发布与订阅功能, 将更新后的配置传播给所有其他 Sentinel , 其他 Sentinel 对它们自己的配置进行更新。
- 向已下线主服务器的从服务器发送 SLAVEOF 命令, 让它们去复制新的主服务器。
- 当所有从服务器都已经开始复制新的主服务器时, 领头 Sentinel 终止这次故障迁移操作。
每当一个 Redis 实例被重新配置(reconfigured) —— 无论是被设置成主服务器、从服务器、又或者被设置成其他主服务器的从服务器 —— Sentinel 都会向被重新配置的实例发送一个 CONFIG REWRITE 命令, 从而确保这些配置会持久化在硬盘里。Sentinel 使用以下规则来选择新的主服务器:
- 在失效主服务器属下的从服务器当中, 那些被标记为主观下线、已断线、或者最后一次回复 PING 命令的时间大于五秒钟的从服务器都会被淘汰。
- 在失效主服务器属下的从服务器当中, 那些与失效主服务器连接断开的时长超过 down-after 选项指定的时长十倍的从服务器都会被淘汰。
- 在经历了以上两轮淘汰之后剩下来的从服务器中, 我们选出复制偏移量(replication offset)最大的那个从服务器作为新的主服务器; 如果复制偏移量不可用, 或者从服务器的复制偏移量相同, 那么带有最小运行 ID 的那个从服务器成为新的主服务器。
Sentinel状态持久化
snetinel的状态会被持久化地写入sentinel的配置文件中。每次当收到一个新的配置时,或者新创建一个配置时,配置会被持久化到硬盘中,并带上配置的版本戳。这意味着,可以安全的停止和重启sentinel进程。
安装和部署Redis Sentinel
| Master,sentinel1 | 192.168.56.11 | 6379,26379 |
| Slave 01,sentinel2 | 192.168.56.12 | 6379,26379 |
| Slave 02,sentinel3 | 192.168.56.13 | 6379,26379 |
配置 redis 集群
cat redis_6379.conf
protected-mode yes
bind 192.168.56.12
port 6379
daemonize yes
supervised no
pidfile "/var/run/redis_6379.pid"
loglevel notice
logfile "/data/app/redis/logs/redis_6379.log"
databases 16
dbfilename "dump_6379.rdb"
dir "/data/db/redis_6379"配置redis实例cd /data/app/redis/conf
启动: /data/app/redis/bin/redis-server redis_6379.conf
检查是否启动: /data/app/redis/bin/redis-cli -h 192.168.56.11 -p 6379 ping
配置主从:
/data/app/redis/bin/redis-cli -h 192.168.56.12 -p 6379
/data/app/redis/bin/redis-cli -h 192.168.56.13 -p 6379
>SLAVEOF 192.168.56.11 6379
>CONFIG REWRITE #写入配置文件 Master确认主从: /home/mdb/redis/src/redis-cli -h 192.168.56.11 -p 6379
role:master
connected_slaves:2
slave0:ip=192.168.56.12,port=6379,state=online,offset=239,lag=1 slave1:ip=192.168.56.13,port=6379,state=online,offset=239,lag=1
master_repl_offset:239配置 Sentinel
sentinel 节点启动有两种方式:
- 使用
redis-sentinel sentinel_6379.conf - 使用
redis-server sentinel_6379.conf --sentinel
port 26379
daemonize no
bind 192.168.56.11
logfile "/data/app/redis/logs/sentinel_26379.log"
dir "/data/db/sentinel_26379"
sentinel monitor mymaster 192.168.56.11 6379 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000接下来我们将一行一行地解释上面的配置项:
sentinel monitor mymaster 192.168.56.11 6379 2这一行代表sentinel监控的master的名字叫做mymaster,地址为192.168.56.11:6379,行尾最后的一个2代表什么意思呢?我们知道,网络是不可靠的,有时候一个sentinel会因为网络堵塞而误以为一个master redis已经死掉了,当sentinel集群式,解决这个问题的方法就变得很简单,只需要多个sentinel互相沟通来确认某个master是否真的死了,这个2代表,当集群中有2个sentinel认为master死了时,才能真正认为该master已经不可用了。(sentinel集群中各个sentinel也有互相通信,通过gossip协议)。
除了第一行配置,我们发现剩下的配置都有一个统一的格式:
sentinel <option_name> <master_name> <option_value>接下来我们根据上面格式中的option_name一个一个来解释这些配置项:
down-after-millisecondssentinel会向master发送心跳PING来确认master是否存活,如果master在“一定时间范围”内不回应PONG 或者是回复了一个错误消息,那么这个sentinel会主观地(单方面地)认为这个master已经不可用了(subjectively down, 也简称为SDOWN)。而这个down-after-milliseconds就是用来指定这个“一定时间范围”的,单位是毫秒。
不过需要注意的是,这个时候sentinel并不会马上进行failover主备切换,这个sentinel还需要参考sentinel集群中其他sentinel的意见,如果超过某个数量的sentinel也主观地认为该master死了,那么这个master就会被客观地(注意哦,这次不是主观,是客观,与刚才的subjectively down相对,这次是objectively down,简称为ODOWN)认为已经死了。需要一起做出决定的sentinel数量在上一条配置中进行配置。
parallel-syncs在发生failover主备切换时,这个选项指定了最多可以有多少个slave同时对新的master进行同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave处于不能处理命令请求的状态。
其他配置项在sentinel.conf中都有很详细的解释。
所有的配置都可以在运行时用命令SENTINEL SET command动态修改。
启动: /data/app/redis/bin/redis-sentinel /data/app/redis/conf/sentinel_26379.conf
cat ../logs/sentinel_26379.log
99344:X 16 Oct 16:20:59.156 # Sentinel ID is f16a463d7387bf71f5ebce0c969d01d5bd802ac4
99344:X 16 Oct 16:20:59.156 # +monitor master mymaster 192.168.56.11 6379 quorum 2
99344:X 16 Oct 16:20:59.156 * +slave slave 192.168.56.12:6379 192.168.56.12 6379 @ mymaster 192.168.56.11 6379
99344:X 16 Oct 16:20:59.157 * +slave slave 192.168.56.13:6379 192.168.56.13 6379 @ mymaster 192.168.56.11 6379
99344:X 16 Oct 16:21:01.087 * +sentinel sentinel eb2582f3d12d8ed7710a94e6555a858047a91d2e 192.168.56.12 26379 @ mymaster 192.168.56.11 6379
99344:X 16 Oct 16:21:01.119 * +sentinel sentinel 2a716b1f6e6e9ab6688a99160e7a6616b913336b 192.168.56.13 26379 @ mymaster 192.168.56.11 6379当所有节点启动以后,配置文件发生了变化,sentinel发现了从节点和其余的 sentinel 节点 去掉了默认的故障转移,复制参数,
port 26379
daemonize no
bind 192.168.56.12
logfile "/data/app/redis/logs/sentinel_26379.log"
dir "/data/db/sentinel_26379"
sentinel myid eb2582f3d12d8ed7710a94e6555a858047a91d2e
sentinel monitor mymaster 192.168.56.13 6379 2
sentinel config-epoch mymaster 1
sentinel leader-epoch mymaster 1
# Generated by CONFIG REWRITE
sentinel known-slave mymaster 192.168.56.12 6379
sentinel known-slave mymaster 192.168.56.11 6379
sentinel known-sentinel mymaster 192.168.56.11 26379 f16a463d7387bf71f5ebce0c969d01d5bd802ac4
sentinel known-sentinel mymaster 192.168.56.13 26379 2a716b1f6e6e9ab6688a99160e7a6616b913336b
sentinel current-epoch 1模拟故障转移
/data/app/redis/bin/redis-cli -h 192.168.56.12 -p 26379
192.168.56.12:26379> info
master0:name=mymaster,status=ok,address=192.168.56.11:6379,slaves=2,sentinels=3
192.168.56.12:26379> sentinel failover mymaster
OK
192.168.56.12:26379> info
master0:name=mymaster,status=ok,address=192.168.56.13:6379,slaves=2,sentinels=3查看 sentinel 日志:
21808:X 16 Oct 16:24:54.045 # Executing user requested FAILOVER of 'mymaster'
21808:X 16 Oct 16:24:54.045 # +new-epoch 1
21808:X 16 Oct 16:24:54.045 # +try-failover master mymaster 192.168.56.11 6379
21808:X 16 Oct 16:24:54.084 # +vote-for-leader eb2582f3d12d8ed7710a94e6555a858047a91d2e 1
21808:X 16 Oct 16:24:54.084 # +elected-leader master mymaster 192.168.56.11 6379
21808:X 16 Oct 16:24:54.084 # +failover-state-select-slave master mymaster 192.168.56.11 6379
21808:X 16 Oct 16:24:54.137 # +selected-slave slave 192.168.56.13:6379 192.168.56.13 6379 @ mymaster 192.168.56.11 6379
21808:X 16 Oct 16:24:54.137 * +failover-state-send-slaveof-noone slave 192.168.56.13:6379 192.168.56.13 6379 @ mymaster 192.168.56.11 63
79
21808:X 16 Oct 16:24:54.214 * +failover-state-wait-promotion slave 192.168.56.13:6379 192.168.56.13 6379 @ mymaster 192.168.56.11 6379
21808:X 16 Oct 16:24:55.177 # +promoted-slave slave 192.168.56.13:6379 192.168.56.13 6379 @ mymaster 192.168.56.11 6379
21808:X 16 Oct 16:24:55.177 # +failover-state-reconf-slaves master mymaster 192.168.56.11 6379
21808:X 16 Oct 16:24:55.243 * +slave-reconf-sent slave 192.168.56.12:6379 192.168.56.12 6379 @ mymaster 192.168.56.11 6379
21808:X 16 Oct 16:24:56.215 * +slave-reconf-inprog slave 192.168.56.12:6379 192.168.56.12 6379 @ mymaster 192.168.56.11 6379
21808:X 16 Oct 16:24:56.215 * +slave-reconf-done slave 192.168.56.12:6379 192.168.56.12 6379 @ mymaster 192.168.56.11 6379
21808:X 16 Oct 16:24:56.317 # +failover-end master mymaster 192.168.56.11 6379
21808:X 16 Oct 16:24:56.317 # +switch-master mymaster 192.168.56.11 6379 192.168.56.13 6379
21808:X 16 Oct 16:24:56.318 * +slave slave 192.168.56.12:6379 192.168.56.12 6379 @ mymaster 192.168.56.13 6379
21808:X 16 Oct 16:24:56.318 * +slave slave 192.168.56.11:6379 192.168.56.11 6379 @ mymaster 192.168.56.13 6379模拟故障转移
查看 sentinel 配置文件更新变化和 redis 主节点变化
sentinel monitor mymaster 192.168.56.13 6379 2
sentinel config-epoch mymaster 1
sentinel leader-epoch mymaster 1
# Generated by CONFIG REWRITE
sentinel known-slave mymaster 192.168.56.12 6379
sentinel known-slave mymaster 192.168.56.11 6379
sentinel known-sentinel mymaster 192.168.56.11 26379 f16a463d7387bf71f5ebce0c969d01d5bd802ac4
sentinel known-sentinel mymaster 192.168.56.13 26379 2a716b1f6e6e9ab6688a99160e7a6616b913336b
sentinel current-epoch 1注意事项
- sentinel 节点不要部署在同一台机器
- 至少不是三个且奇数个的 sentinel 节点,增加选举的准确性因为领导者选举需要至少一半加1个节点
- sentinel节点集合可以只监控一个主节点,也可以监控多个主节点, 尽量使用一套sentinel监控一个主节点。
- sentinel的数据节点与普通的 redis 数据节点没有区别
- 客户端初始化连接的是 Sentinel节点集合,不再是具体的 redis 节 点,但是Sentinel 是配置中心不是代理。
Sentinel日常运维
Sentinel常用命令
以下列出的是Sentinel接受的命令:
-
PING:返回PONG。 -
SENTINEL master <master name>:用于查看监控的某个Redis Master信息,包括配置和状态等。 -
SENTINEL slaves <master name>:列出给定主服务器的所有从服务器,以及这些从服务器的当前状态。 -
SENTINEL sentinels <master name>:查看给定主服务器的Sentinel实例列表及其状态。 -
SENTINEL get-master-addr-by-name <master name>:返回给定名字的主服务器的IP地址和端口号。 如果这个主服务器正在执行故障转移操作,或者针对这个主服务器的故障转移操作已经完成,那么这个命令返回新的主服务器的IP地址和端口号。 -
SENTINEL reset <pattern>:重置所有名字和给定模式pattern相匹配的主服务器。pattern 参数是一个Glob风格的模式。重置操作清除主服务器目前的所有状态,包括正在执行中的故障转移,并移除目前已经发现和关联的,主服务器的所有从服务器和Sentinel。 -
SENTINEL failover <master name>:当主服务器失效时, 在不询问其他Sentinel意见的情况下, 强制开始一次自动故障迁移(不过发起故障转移的Sentinel会向其他Sentinel发送一个新的配置,其他Sentinel会根据这个配置进行相应的更新)。 -
SENTINEL reset <pattern>:强制重设所有监控的Master状态,清除已知的Slave和Sentinel实例信息,重新获取并生成配置文件。 -
SENTINEL failover <master name>:强制发起一次某个Master的failover,如果该Master不可访问的话。 -
SENTINEL ckquorum <master name>:检测Sentinel配置是否合理,failover的条件是否可能满足,主要用来检测你的Sentinel配置是否正常。 -
SENTINEL flushconfig:强制Sentinel重写所有配置信息到配置文件。 -
SENTINEL is-master-down-by-addr <ip> <port>:一个Sentinel可以通过向另一个Sentinel发送SENTINEL is-master-down-by-addr命令来询问对方是否认为给定的服务器已下线。
动态修改Sentinel配置
以下是一些修改sentinel配置的命令:
-
SENTINEL MONITOR <name> <ip> <port> <quorum>这个命令告诉sentinel去监听一个新的master -
SENTINEL REMOVE <name>命令sentinel放弃对某个master的监听 -
SENTINEL SET <name> <option> <value>这个命令很像Redis的CONFIG SET命令,用来改变指定master的配置。支持多个
增加和移除Sentinel
增加新的Sentinel实例非常简单,修改好配置文件,启动即可,其他Sentinel会自动发现该实例并加入集群。如果要批量启动一批Sentinel节点,最好以30秒的间隔一个一个启动为好,这样能确保整个 Sentinel集群的大多数能够及时感知到新节点,满足当时可能发生的选举条件。
移除一个Sentinel实例会相对麻烦一些,因为Sentinel不会忘记已经感知到的Sentinel实例,所以最好按照下列步骤来处理:
停止将要移除的sentinel进程。
给其余的sentinel进程发送SENTINEL RESET *命令来重置状态,忘记将要移除的sentinel,每个进程之间间隔30秒。
确保所有sentinel对于当前存货的sentinel数量达成一致,可以通过SENTINEL MASTER <mastername>命令来观察,或者查看配置文件。
删除旧master或者不可达slave
sentinel永远会记录好一个Master的slaves,即使slave已经与组织失联好久了。这是很有用的,因为sentinel集群必须有能力把一个恢复可用的slave进行重新配置。
并且,failover后,失效的master将会被标记为新master的一个slave,这样的话,当它变得可用时,就会从新master上复制数据。
然后,有时候你想要永久地删除掉一个slave(有可能它曾经是个master),你只需要发送一个SENTINEL RESET master命令给所有的sentinels,它们将会更新列表里能够正确地复制master数据的slave。
发布/订阅
客户端可以向一个sentinel发送订阅某个频道的事件的命令,当有特定的事件发生时,sentinel会通知所有订阅的客户端。需要注意的是客户端只能订阅,不能发布。
订阅频道的名字与事件的名字一致。例如,频道名为sdown 将会发布所有与SDOWN相关的消息给订阅者。
如果想要订阅所有消息,只需简单地使用PSUBSCRIBE *
以下是所有你可以收到的消息的消息格式,如果你订阅了所有消息的话。第一个单词是频道的名字,其它是数据的格式。
注意:以下的instance details的格式是:
<instance-type> <name> <ip> <port> @ <master-name> <master-ip> <master-port>
如果这个redis实例是一个master,那么@之后的消息就不会显示。
+reset-master <instance details> -- 当master被重置时.
+slave <instance details> -- 当检测到一个slave并添加进slave列表时.
+failover-state-reconf-slaves <instance details> -- Failover状态变为reconf-slaves状态时
+failover-detected <instance details> -- 当failover发生时
+slave-reconf-sent <instance details> -- sentinel发送SLAVEOF命令把它重新配置时
+slave-reconf-inprog <instance details> -- slave被重新配置为另外一个master的slave,但数据复制还未发生时。
+slave-reconf-done <instance details> -- slave被重新配置为另外一个master的slave并且数据复制已经与master同步时。
-dup-sentinel <instance details> -- 删除指定master上的冗余sentinel时 (当一个sentinel重新启动时,可能会发生这个事件).
+sentinel <instance details> -- 当master增加了一个sentinel时。
+sdown <instance details> -- 进入SDOWN状态时;
-sdown <instance details> -- 离开SDOWN状态时。
+odown <instance details> -- 进入ODOWN状态时。
-odown <instance details> -- 离开ODOWN状态时。
+new-epoch <instance details> -- 当前配置版本被更新时。
+try-failover <instance details> -- 达到failover条件,正等待其他sentinel的选举。
+elected-leader <instance details> -- 被选举为去执行failover的时候。
+failover-state-select-slave <instance details> -- 开始要选择一个slave当选新master时。
no-good-slave <instance details> -- 没有合适的slave来担当新master
selected-slave <instance details> -- 找到了一个适合的slave来担当新master
failover-state-send-slaveof-noone <instance details> -- 当把选择为新master的slave的身份进行切换的时候。
failover-end-for-timeout <instance details> -- failover由于超时而失败时。
failover-end <instance details> -- failover成功完成时。
switch-master <master name> <oldip> <oldport> <newip> <newport> -- 当master的地址发生变化时。通常这是客户端最感兴趣的消息了。
+tilt -- 进入Tilt模式。
-tilt -- 退出Tilt模式。TILT 模式
redis sentinel非常依赖系统时间,例如它会使用系统时间来判断一个PING回复用了多久的时间。
然而,假如系统时间被修改了,或者是系统十分繁忙,或者是进程堵塞了,sentinel可能会出现运行不正常的情况。
当系统的稳定性下降时,TILT模式是sentinel可以进入的一种的保护模式。当进入TILT模式时,sentinel会继续监控工作,但是它不会有任何其他动作,它也不会去回应is-master-down-by-addr这样的命令了,因为它在TILT模式下,检测失效节点的能力已经变得让人不可信任了。
如果系统恢复正常,持续30秒钟,sentinel就会退出TITL模式。
-BUSY状态
注意:该功能还未实现。当一个脚本的运行时间超过配置的运行时间时,sentinel会返回一个-BUSY 错误信号。如果这件事发生在触发一个failover之前,sentinel将会发送一个SCRIPT KILL命令,如果script是只读的话,就能成功执行。
生产环境推荐
对于一个最小集群,Redis应该是一个Master带上两个Slave,并且开启下列选项:
min-slaves-to-write 1
min-slaves-max-lag 10这样能保证写入Master的同时至少写入一个Slave,如果出现网络分区阻隔并发生failover的时候,可以保证写入的数据最终一致而不是丢失,写入老的Master会直接失败。
Slave可以适当设置优先级,除了0之外(0表示永远不提升为Master),越小的优先级,越有可能被提示为Master。如果Slave分布在多个机房,可以考虑将和Master同一个机房的Slave的优先级设置的更低以提升他被选为新的Master的可能性。
考虑到可用性和选举的需要,Sentinel进程至少为3个,推荐为5个。如果有网络分区,应当适当分布(比如2个在A机房, 2个在B机房,一个在C机房)等。
客户端实现
客户端从过去直接连接Redis ,变成:
先连接一个Sentinel实例
使用 SENTINEL get-master-addr-by-name master-name 获取Redis地址信息。
连接返回的Redis地址信息,通过ROLE命令查询是否是Master。如果是,连接进入正常的服务环节。否则应该断开重新查询。
(可选)客户端可以通过SENTINEL sentinels 来更新自己的Sentinel实例列表。
当Sentinel发起failover后,切换了新的Master,Sentinel会发送 CLIENT KILL TYPE normal命令给客户端,客户端需要主动断开对老的Master的链接,然后重新查询新的Master地址,再重复走上面的流程。这样的方式仍然相对不够实时,可以通过Sentinel提供的Pub/Sub来更快地监听到failover事件,加快重连。
如果需要实现读写分离,读走Slave,那可以走SENTINEL slaves 来查询Slave列表并连接。
其他
由于Redis是异步复制,所以Sentinel其实无法达到强一致性,它承诺的是最终一致性:最后一次failover的Redis Master赢者通吃,其他Slave的数据将被丢弃,重新从新的Master复制数据。此外还有前面提到的分区带来的一致性问题。
其次,Sentinel的选举算法依赖时间,因此要确保所有机器的时间同步,如果发现时间不一致,Sentinel实现了一个TITL模式来保护系统的可用性。
from redis.sentinel import Sentinel
sentinel = Sentinel([('localhost', 26379)], socket_timeout=0.1)
print(sentinel.discover_master('mymaster'))
print(sentinel.discover_slaves('mymaster'))
master = sentinel.master_for('mymaster', socket_timeout=0.1)
master.set('foo', 'bar')
slave = sentinel.slave_for('mymaster', socket_timeout=0.1)
slave.get('foo')
'bar'


相关推荐
标题中的“redissentinel基于phpredis扩展的redissentinel客户端”指的是一个使用PHP语言开发的Redis Sentinel客户端,它依赖于phpredis扩展来实现与Redis Sentinel服务的交互。Redis Sentinel是Redis集群的一个重要...
通过 docker-compose 使用 redis sentinel 构建 Redis 集群redis-cluster-带 sentinel使用 Docker Compose 进行 Redis 集群集群中有以下服务,master主 Redis 服务器从属从属 Redis 服务器sentinel哨兵服务器哨兵...
示例:$sentinel = new \Jenner\RedisSentinel\Sentinel(); $sentinel->connect('127.0.0.1', 6379); $address = $sentinel->getMasterAddrByName('mymaster'); $redis = new Redis(); $redis->connect($...
Redis Sentinel是Redis的一个高可用性解决方案,它提供了监控、故障检测和自动故障转移等功能,确保在主Redis服务器出现故障时,系统能够无缝地切换到备份节点,从而保持服务的连续性和稳定性。SpringBoot是一个轻量...
Sentinel是Redis的一个高可用性解决方案,它可以监控Redis实例,并在主节点出现问题时自动进行故障转移,确保服务的连续性。 在这个"spring + redis + sentinel"配置中,我们将探讨如何整合这三个组件以创建一个...
当使用Redis做Master-slave的高可用方案时,假如master宕机了,Redis本身(包括它的很多客户端)都没有实现自动进行主备切换,而Redis-Sentinel本身也是一个独立运行的进程,它能监控多个master-slave集群,发现...
本文详细介绍了 Redis Sentinel 模式的原理和应用,讨论了高可用性服务的定义、异常类型、设计思想和解决方案,并提供了搭建高可用 Redis 服务的步骤和 Redis Sentinel 在高可用服务设计中的应用。
重新快乐 提供高可用性 Redis 服务的一种方法是使用Redis Sentinel进行部署。Redis Sentinel 监控您的 Redis 集群,并在检测到故障时将某个从属节点提升为新的主节点。RedisHappy 提供了一个守护进程来监控此提升并...
redis搭建sentinel高可用方法
Redis Sentinel 主从部署 使用Python脚本获取Redis主从节点信息
Windos系统的Redis sentinel集群。 启动命令:D:\redis-2.8.18.rar\redis-2.8.18>redis-server.exe sentinel.conf --sentinel
Redis Sentinel是Redis数据库系统中的高可用性解决方案,用于监控、通知和自动故障转移。在Windows环境下搭建Redis Sentinel集群,你需要了解以下几个关键知识点: 1. **Redis Sentinel系统**:Redis Sentinel是一...
另一种使用内置 redis sentinel 的 ruby redis 自动主/从故障转移解决方案(已弃用)Redis::Sentinel(已弃用)redis gem从 3.2 版本开始支持 sentinel,如果你使用的是 Redis 2.8.x 或更高版本,则不需要 redis...
Predixy中文版Predixy是 redis sentinel 和 redis cluster 的高性能、功能齐全的代理特征高性能且重量轻。多线程支持。适用于 Linux、OSX、BSD、Windows(Cygwin)。支持Redis Sentinel,单/多Redis组。支持Redis...
Redis Sentinel是Redis的高可用性解决方案,当主节点发生故障时,可以自动进行故障转移。部署Redis Sentinel主要涉及以下几个关键点: 1. Redis Sentinel的作用与优点 Redis Sentinel的主要功能是监控Redis主从...
Redis Sentinel是一个高可用性(HA)解决方案,它的主要任务是监控、提醒和自动故障转移。在 Sentinel 系统中,多个Sentinel节点会监控主Redis服务器和其对应的从服务器。当主服务器出现故障时,Sentinel节点会进行...
redis-operator概述Redis 操作员在 Kubernetes 上使用 Sentinel构建高可用性 Redis 集群。使用此操作员,您可以创建一个无需人工干预即可抵御某些类型故障的 Redis 部署。操作符本身是用操作符框架构建的。它受到...
本项目"spring+springmvc+mybatis+redisSentinel"结合了Spring、SpringMVC、MyBatis以及Redis Sentinel,构建了一个高可用的Web应用程序,同时利用了Redis作为缓存系统提升性能。以下将详细讲解这些技术及其整合过程...
Redis Sentinel 是 Redis 为了实现高可用性(High Availability, HA)而设计的一种分布式监控和故障转移系统。它能够监控主从结构的 Redis 集群,并在主节点出现故障时,自动将一个从节点提升为主节点,从而确保服务...
Redis Sentinel集群和双机热备是 Redis 高可用性(High Availability, HA)的重要组成部分,它们确保了在主节点故障时能够快速切换到备份节点,从而维持服务的连续性。以下将详细介绍这两个概念以及相关配置和操作。...