
هˆ†وگ
ه½“频ç¹پfull gcو—¶ï¼Œjstackو‰“هچ°ه‡؛ه †و ˆن؟،وپ¯ه¦‚ن¸‹ï¼ڑsudo -u admin -H /opt/taobao/java/bin/jstack `pgrep java` > #your file path#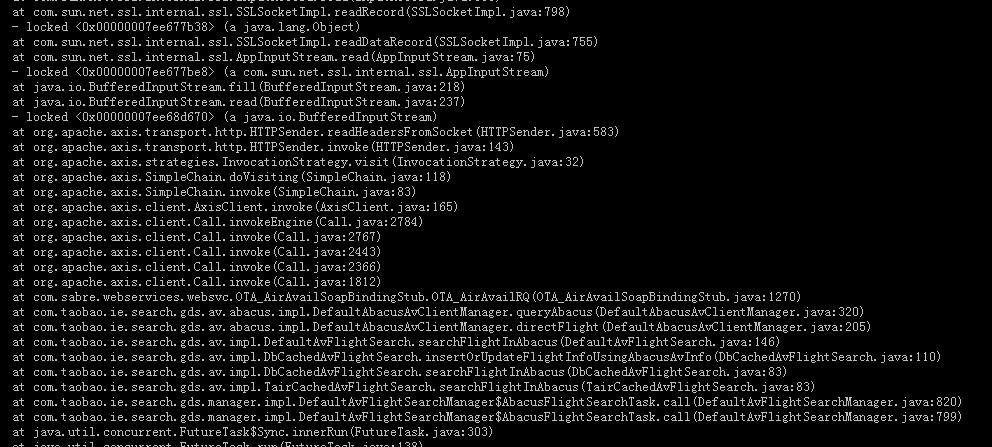
هڈ¯ن»¥çœ‹هˆ°çڑ„ç،®وک¯هœ¨è·‘ن½ژن»·ن؟،وپ¯هڈ¦ه¤–هœ¨ه؛”用频ç¹پfull gcو—¶ه’Œه؛”用و£ه¸¸و—¶ï¼Œن¹ںو‰§è،Œن؛†ه¦‚ن¸‹2ç§چه‘½ن»¤ï¼ڑsudo -u admin -H /opt/taobao/java/bin/jmap -histo `pgrep` > #your file path#sudo -u admin -H /opt/taobao/java/bin/jmap -histo:live `pgrep` > #your file path#(liveن¼ڑن؛§ç”ںfull gc)目çڑ„وک¯ç،®è®¤ن»¥ن¸‹2ç§چن؟،وپ¯ï¼ڑ(1)وک¯هگ¦هکهœ¨وںگن؛›ه¼•ç”¨çڑ„ن¸چو£ه¸¸ï¼Œé€ وˆگه¯¹è±،ه§‹ç»ˆهڈ¯è¾¾è€Œو— و³•ه›و”¶ï¼ˆJavaن¸çڑ„ه†…هکو³„و¼ڈ)(2)وک¯هگ¦çœںوک¯ç”±ن؛ژهœ¨é¢‘ç¹پfull gcو—¶هگŒو—¶هڈˆوœ‰ه¤§é‡ڈ请و±‚è؟›ه…¥هˆ†é…چه†…هکن»ژ而ه¤„çگ†ن¸چè؟‡و¥ï¼Œ
é€ وˆگconcurrent mode failureï¼ںن¸‹ه›¾وک¯هœ¨ه؛”用و£ه¸¸وƒ…ه†µن¸‹ï¼Œjmapن¸چهٹ live,ن؛§ç”ںçڑ„histoن؟،وپ¯ï¼ڑ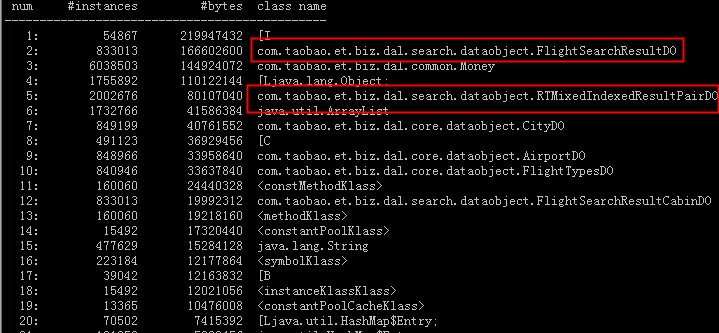
ن¸‹ه›¾وک¯هœ¨ه؛”用و£ه¸¸وƒ…ه†µن¸‹ï¼Œjmapهٹ live,ن؛§ç”ںçڑ„histoن؟،وپ¯ï¼ڑ
ن¸‹ه›¾وک¯هœ¨ه؛”用频ç¹پfull gcوƒ…ه†µن¸‹ï¼Œjmapن¸چهٹ liveه’Œهٹ live,ن؛§ç”ںçڑ„histoن؟،وپ¯ï¼ڑ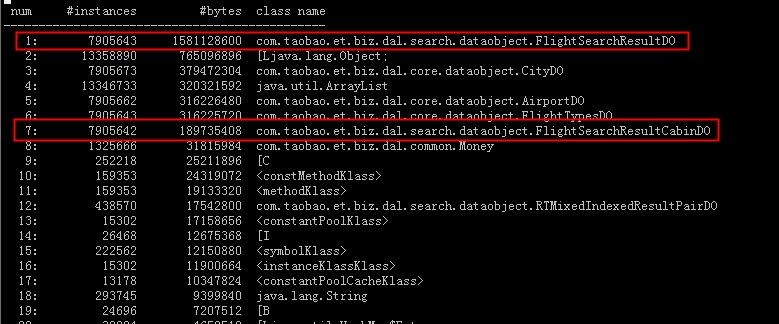
ن»ژن¸ٹè؟°ه‡ ن¸ھه›¾ن¸هڈ¯ن»¥çœ‹هˆ°ï¼ڑ(1)هœ¨ه؛”用و£ه¸¸وƒ…ه†µن¸‹ï¼Œه›¾ن¸و ‡ç؛¢çڑ„ه¯¹è±،وک¯è¢«ه›و”¶çڑ„,ه› و¤ن¸چوک¯ه†…هکو³„و¼ڈé—®é¢ک(2)هœ¨ه؛”用频ç¹پfull gcو—¶ï¼Œو ‡ç؛¢çڑ„ه¯¹è±،هچ³ن½؟هٹ liveن¹ںوک¯وœھ被ه›و”¶çڑ„,ه› ن¸ٹه°±وک¯هœ¨é¢‘ç¹پfull gcو—¶ï¼Œ
هگŒو—¶هڈˆوœ‰ه¤§é‡ڈ请و±‚è؟›ه…¥هˆ†é…چه†…هکن»ژ而ه¤„çگ†ن¸چè؟‡و¥çڑ„é—®é¢که…ˆن»ژ解ه†³é—®é¢کçڑ„角ه؛¦ï¼Œçœ‹و€ژو ·é€ وˆگ频ç¹پçڑ„full gcï¼ں
ن»ژهˆ†وگCMS GCه¼€ه§‹
ه…ˆç»™ن¸ھCMS GCçڑ„و¦‚ه†µï¼ڑ(1)young gcهڈ¯ن»¥çœ‹هˆ°ï¼Œه½“edenو»،و—¶ï¼Œyoung gcن½؟用çڑ„وک¯ParNewو”¶é›†ه™¨ParNew: 2230361K->129028K(2403008K), 0.2363650 secs解é‡ٹï¼ڑ1)2230361K->129028K,وŒ‡ه›و”¶ه‰چهگژeden+s1(وˆ–s2)ه¤§ه°ڈ2)2403008K,وŒ‡هڈ¯ç”¨çڑ„youngن»£çڑ„ه¤§ه°ڈ,هچ³eden+s1(وˆ–s2)3)0.2363650 secs,وŒ‡و¶ˆè€—و—¶é—´2324774K->223451K(3975872K), 0.2366810 sec解é‡ٹï¼ڑ1)2335109K->140198K,وŒ‡و•´ن¸ھه †ه¤§ه°ڈçڑ„هڈکهŒ–
(heap=(young+old)+permï¼›young=eden+s1+s2ï¼›s1=s2=young/(survivor ratio+2))2)0.2366810 sec,وŒ‡و¶ˆè€—و—¶é—´[Times: user=0.60 sys=0.02, real=0.24 secs]解é‡ٹï¼ڑوŒ‡ç”¨وˆ·و—¶é—´ï¼Œç³»ç»ںو—¶é—´ï¼Œçœںه®و—¶é—´
(2)cms gcه½“ن½؟用CMSو”¶é›†ه™¨و—¶ï¼Œه½“ه¼€ه§‹è؟›è،Œو”¶é›†و—¶ï¼Œoldن»£çڑ„و”¶é›†è؟‡ç¨‹ه¦‚ن¸‹و‰€ç¤؛ï¼ڑa)首ه…ˆjvmو ¹وچ®-XX:CMSInitiatingOccupancyFraction,-XX:+UseCMSInitiatingOccupancyOnly
و¥ه†³ه®ڑن»€ن¹ˆو—¶é—´ه¼€ه§‹هƒهœ¾و”¶é›†b)ه¦‚وœè®¾ç½®ن؛†-XX:+UseCMSInitiatingOccupancyOnly,那ن¹ˆهڈھوœ‰ه½“oldن»£هچ 用ç،®ه®è¾¾هˆ°ن؛†
-XX:CMSInitiatingOccupancyFractionهڈ‚و•°و‰€è®¾ه®ڑçڑ„و¯”ن¾‹و—¶و‰چن¼ڑ触هڈ‘cms gcc)ه¦‚وœو²،وœ‰è®¾ç½®-XX:+UseCMSInitiatingOccupancyOnly,那ن¹ˆç³»ç»ںن¼ڑو ¹وچ®ç»ںè®،و•°وچ®è‡ھè،Œه†³ه®ڑن»€ن¹ˆو—¶ه€™
触هڈ‘cms gcï¼›ه› و¤وœ‰و—¶ن¼ڑéپ‡هˆ°è®¾ç½®ن؛†80%و¯”ن¾‹و‰چcms gc,ن½†وک¯50%و—¶ه°±ه·²ç»ڈ触هڈ‘ن؛†ï¼Œه°±وک¯ه› ن¸؛è؟™ن¸ھهڈ‚و•°
و²،وœ‰è®¾ç½®çڑ„هژںه› d)ه½“cms gcه¼€ه§‹و—¶ï¼Œé¦–ه…ˆçڑ„éک¶و®µوک¯CMS-initial-mark,و¤éک¶و®µوک¯هˆه§‹و ‡è®°éک¶و®µï¼Œوک¯stop the worldéک¶و®µï¼Œ
ه› و¤و¤éک¶و®µو ‡è®°çڑ„ه¯¹è±،هڈھوک¯ن»ژroot集وœ€ç›´وژ¥هڈ¯è¾¾çڑ„ه¯¹è±،CMS-initial-markï¼ڑ961330K(1572864K),وŒ‡و ‡è®°و—¶ï¼Œoldن»£çڑ„ه·²ç”¨ç©؛é—´ه’Œو€»ç©؛é—´e)ن¸‹ن¸€ن¸ھéک¶و®µوک¯CMS-concurrent-mark,و¤éک¶و®µوک¯ه’Œه؛”用ç؛؟程ه¹¶هڈ‘و‰§è،Œçڑ„,و‰€è°“ه¹¶هڈ‘و”¶é›†ه™¨وŒ‡çڑ„ه°±وک¯è؟™ن¸ھ,
ن¸»è¦پن½œç”¨وک¯و ‡è®°هڈ¯è¾¾çڑ„ه¯¹è±،و¤éک¶و®µن¼ڑو‰“هچ°2و،و—¥ه؟—ï¼ڑCMS-concurrent-mark-start,CMS-concurrent-markf)ن¸‹ن¸€ن¸ھéک¶و®µوک¯CMS-concurrent-preclean,و¤éک¶و®µن¸»è¦پوک¯è؟›è،Œن¸€ن؛›é¢„و¸…çگ†ï¼Œه› ن¸؛و ‡è®°ه’Œه؛”用ç؛؟程وک¯ه¹¶هڈ‘و‰§è،Œçڑ„,
ه› و¤ن¼ڑوœ‰ن؛›ه¯¹è±،çڑ„çٹ¶و€پهœ¨و ‡è®°هگژن¼ڑو”¹هڈک,و¤éک¶و®µو£وک¯è§£ه†³è؟™ن¸ھé—®é¢که› ن¸؛ن¹‹هگژçڑ„Rescanéک¶و®µن¹ںن¼ڑstop the world,ن¸؛ن؛†ن½؟وڑ‚هپœçڑ„و—¶é—´ه°½هڈ¯èƒ½çڑ„ه°ڈ,ن¹ں需è¦پprecleanéک¶و®µه…ˆهپڑن¸€éƒ¨هˆ†
ه·¥ن½œن»¥èٹ‚çœپو—¶é—´و¤éک¶و®µن¼ڑو‰“هچ°2و،و—¥ه؟—ï¼ڑCMS-concurrent-preclean-start,CMS-concurrent-precleang)ن¸‹ن¸€éک¶و®µوک¯CMS-concurrent-abortable-precleanéک¶و®µï¼Œهٹ ه…¥و¤éک¶و®µçڑ„ç›®çڑ„وک¯ن½؟cms gcو›´هٹ هڈ¯وژ§ن¸€ن؛›ï¼Œ
ن½œç”¨ن¹ںوک¯و‰§è،Œن¸€ن؛›é¢„و¸…çگ†ï¼Œن»¥ه‡ڈه°‘Rescanéک¶و®µé€ وˆگه؛”用وڑ‚هپœçڑ„و—¶é—´و¤éک¶و®µو¶‰هڈٹه‡ ن¸ھهڈ‚و•°ï¼ڑ-XX:CMSMaxAbortablePrecleanTimeï¼ڑه½“abortable-precleanéک¶و®µو‰§è،Œè¾¾هˆ°è؟™ن¸ھو—¶é—´و—¶و‰چن¼ڑ结وں-XX:CMSScheduleRemarkEdenSizeThreshold(é»ک认2m)ï¼ڑوژ§هˆ¶abortable-precleanéک¶و®µن»€ن¹ˆو—¶ه€™ه¼€ه§‹و‰§è،Œï¼Œ
هچ³ه½“edenن½؟用达هˆ°و¤ه€¼و—¶ï¼Œو‰چن¼ڑه¼€ه§‹abortable-precleanéک¶و®µ-XX:CMSScheduleRemarkEdenPenetratio(é»ک认50%)ï¼ڑوژ§هˆ¶abortable-precleanéک¶و®µن»€ن¹ˆو—¶ه€™ç»“وںو‰§è،Œو¤éک¶و®µن¼ڑو‰“هچ°ن¸€ن؛›و—¥ه؟—ه¦‚ن¸‹ï¼ڑCMS-concurrent-abortable-preclean-start,CMS-concurrent-abortable-preclean,
CMSï¼ڑabort preclean due to time XXXh)ه†چن¸‹ن¸€ن¸ھéک¶و®µوک¯ç¬¬ن؛Œن¸ھstop the worldéک¶و®µن؛†ï¼Œهچ³Rescanéک¶و®µï¼Œو¤éک¶و®µوڑ‚هپœه؛”用ç؛؟程,ه¯¹ه¯¹è±،è؟›è،Œé‡چو–°و‰«وڈڈه¹¶
و ‡è®°YG occupancyï¼ڑ964861K(2403008K),وŒ‡و‰§è،Œو—¶youngن»£çڑ„وƒ…ه†µCMS remarkï¼ڑ961330K(1572864K),وŒ‡و‰§è،Œو—¶oldن»£çڑ„وƒ…ه†µو¤ه¤–,è؟کو‰“هچ°ه‡؛ن؛†ه¼±ه¼•ç”¨ه¤„çگ†م€پç±»هچ¸è½½ç‰è؟‡ç¨‹çڑ„耗و—¶i)ه†چن¸‹ن¸€ن¸ھéک¶و®µوک¯CMS-concurrent-sweep,è؟›è،Œه¹¶هڈ‘çڑ„هƒهœ¾و¸…çگ†j)وœ€هگژوک¯CMS-concurrent-reset,ن¸؛ن¸‹ن¸€و¬،cms gcé‡چ置相ه…³و•°وچ®ç»“و„
(3)full gcï¼ڑوœ‰2ç§چوƒ…ه†µن¼ڑ触هڈ‘full gc,هœ¨full gcو—¶ï¼Œو•´ن¸ھه؛”用ن¼ڑوڑ‚هپœa)concurrent-mode-failureï¼ڑه½“cms gcو£è؟›è،Œو—¶ï¼Œو¤و—¶وœ‰و–°çڑ„ه¯¹è±،è¦پè؟›è،Œoldن»£ï¼Œن½†وک¯oldن»£ç©؛é—´ن¸چè¶³é€ وˆگçڑ„b)promotion-failedï¼ڑه½“è؟›è،Œyoung gcو—¶ï¼Œوœ‰éƒ¨هˆ†youngن»£ه¯¹è±،ن»چ然هڈ¯ç”¨ï¼Œن½†وک¯S1وˆ–S2و”¾ن¸چن¸‹ï¼Œ
ه› و¤éœ€è¦پو”¾هˆ°oldن»£ï¼Œن½†و¤و—¶oldن»£ç©؛é—´و— و³•ه®¹ç؛³و¤
آ
频ç¹پfull gcçڑ„هژںه›
ن»ژو—¥ه؟—ن¸هڈ¯ن»¥çœ‹ه‡؛وœ‰ه¤§é‡ڈçڑ„concurrent-mode-failure,ه› و¤و£وک¯ه½“cms gcè؟›è،Œو—¶ï¼Œوœ‰و–°çڑ„ه¯¹è±،è¦پè؟›è،Œoldن»£ï¼Œ
ن½†وک¯oldن»£ç©؛é—´ن¸چè¶³é€ وˆگçڑ„full gcè؟›ç¨‹çڑ„jvmهڈ‚و•°ه¦‚ن¸‹و‰€ç¤؛ï¼ڑ
ه½±ه“چcms gcو—¶é•؟هڈٹ触هڈ‘çڑ„هڈ‚و•°وک¯ن»¥ن¸‹2ن¸ھï¼ڑ-XX:CMSMaxAbortablePrecleanTime=5000-XX:CMSInitiatingOccupancyFraction=80解ه†³ن¹ںوک¯é’ˆه¯¹è؟™ن¸¤ن¸ھهڈ‚و•°و¥çڑ„و ¹وœ¬çڑ„هژںه› وک¯و¯ڈو¬،请و±‚و¶ˆè€—çڑ„ه†…هکé‡ڈè؟‡ه¤§è§£ه†³
(1)针ه¯¹cms gcçڑ„触هڈ‘éک¶و®µï¼Œè°ƒو•´-XX:CMSInitiatingOccupancyFraction=50,وڈگو—©è§¦هڈ‘cms gc,ه°±هڈ¯ن»¥
缓解ه½“oldن»£è¾¾هˆ°80%,cms gcه¤„çگ†ن¸چه®Œï¼Œن»ژè€Œé€ وˆگconcurrent mode failureه¼•هڈ‘full gc(2)ن؟®و”¹-XX:CMSMaxAbortablePrecleanTime=500,缩ه°ڈCMS-concurrent-abortable-precleanéک¶و®µ
çڑ„و—¶é—´ï¼ˆ3)考虑هˆ°cms gcو—¶ن¸چن¼ڑè؟›è،Œcompact,ه› و¤هٹ ه…¥-XX:+UseCMSCompactAtFullCollection
(cms gcهگژن¼ڑè؟›è،Œه†…هکçڑ„compact)ه’Œ-XX:CMSFullGCsBeforeCompaction=4
(هœ¨full gc4و¬،هگژن¼ڑè؟›è،Œcompact)هڈ‚و•°ن½†وک¯è؟گè،Œن؛†ن¸€و®µو—¶é—´هگژ,هڈھن¸چè؟‡و—¶é—´و›´é•؟ن؛†ï¼Œهڈˆن¼ڑه‡؛çژ°é¢‘ç¹پfull gcè®،ç®—ن؛†ن¸€ن¸‹heapهگ„ن¸ھن»£çڑ„ه¤§ه°ڈ(هڈ¯ن»¥ç”¨jmap -heapوں¥çœ‹ï¼‰ï¼ڑtotal heap=young+old=4096mperm:256myoung=s1+s2+eden=2560myoung avail=eden+s1=2133.375+213.3125=2346.6875ms1=2560/(10+1+1)=213.3125ms2=s1eden=2133.375mold=1536mهڈ¯ن»¥çœ‹هˆ°edenه¤§ن؛ژold,هœ¨وپ端وƒ…ه†µن¸‹ï¼ˆyoungهŒ؛çڑ„و‰€وœ‰ه¯¹è±،ه…¨éƒ½è¦پè؟›ه…¥هˆ°oldو—¶ï¼Œه°±ن¼ڑ触هڈ‘full gc),
ه› و¤هœ¨ه؛”用频ç¹پfull gcو—¶ï¼Œه¾ˆوœ‰هڈ¯èƒ½oldن»£وک¯ن¸چه¤ں用çڑ„,ه› و¤وƒ³هˆ°ه°†oldن»£هٹ ه¤§ï¼Œyoungن»£ه‡ڈه°ڈو”¹وˆگن»¥ن¸‹ï¼ڑ-Xmn1920mو–°çڑ„هگ„ن»£ه¤§ه°ڈï¼ڑtotal heap=young+old=4096mperm:256myoung=s1+s2+eden=1920myoung avail=eden+s1=2133.375+213.3125=1760ms1=1760/(10+1+1)=160ms2=s1eden=1600mold=2176mو¤و—¶çڑ„edenه°ڈن؛ژold,هڈ¯ن»¥ç¼“解ن¸€ن؛›é—®é¢کآ آ
و”¹ه®Œن¹‹هگژ,è؟گè،Œن؛†2ه¤©ï¼Œé—®é¢ک解ه†³ï¼Œوœھ频ç¹پوٹ¥full gc
https://my.oschina.net/goldwave/blog/168516


相ه…³وژ¨èچگ
ه…³ن؛ژ锌و–½ç”¨و–¹و³•çڑ„ه½±ه“چ,وˆگç†ںوœںوœ€ه¤§و ھé«ک(103.6 cm),هˆ†tillو€»و•°ï¼ˆ564.67 m-2),穗é•؟(10.83 cm),ه°ڈç©—ç©—و•°1(19.50),穗穗و•°هœ¨و–½ç”¨é”Œçڑ„ه¤„çگ†ن¸è®°ه½•ن؛†1(50.36),1000ç²’é‡چ(34.16 g),ç”ں物ن؛§é‡ڈ(11.93 tآ·ha-1...
ه†œèچ¯و–½ç”¨وٹ€وœ¯هڈٹè¦پو±‚.pdf
ن»¥وœھç ´هڈهœ°ه—ن¸؛ه¯¹ç…§,ه¯¹و¯ڈن¸ھهœ°ه—هˆ†6ن¸ھه±‚و¬،采集هœںه£¤و ·ه“پè؟›è،Œهˆ†وگ,采用英ه›½çڑ„马ه°”و–‡و؟€ه…‰ç²’ه؛¦ن»ھوµ‹é‡ڈهœںه£¤é¢—粒组وˆگ,é€ڑè؟‡SPSSهˆ†وگهگ„هœ°ه—ن¸ژوœھç ´هڈهœ°ه—هœںه£¤é¢—粒组وˆگçڑ„相ه…³و€§م€‚结وœè،¨وکژ:èک‘èڈ‡ه؛ںو–™ه¯¹هœںه£¤é¢—粒组وˆگçڑ„ه½±ه“چه®è´¨وک¯...
وœ¬و–‡ه°†و·±ه…¥وژ¢è®¨é’¼è‚¥çڑ„ç§چç±»م€پو–½ç”¨وٹ€وœ¯ï¼Œن»¥هڈٹه…¶هœ¨هœںه£¤ن¸çڑ„و®‹و•ˆé—®é¢کم€‚ 钼肥ن¸»è¦پهˆ†ن¸؛ن¸¤ه¤§ç±»ï¼ڑ钼酸铵ه’Œé’¼é…¸é’ م€‚è؟™ن¸¤ç§چè‚¥و–™ه‡ه…·وœ‰ه¾ˆé«کçڑ„و°´و؛¶و€§ï¼Œه› و¤ه®ƒن»¬ن¸چن»…适用ن؛ژن¼ ç»ںçڑ„هœںه£¤و–½è‚¥ï¼Œè€Œن¸”è؟کهڈ¯ن»¥é€ڑè؟‡هڈ¶é¢ه–·و–½ه’Œç§چهگه¤„çگ†çڑ„...
综ن¸ٹو‰€è؟°ï¼Œ"و•°ه—é€ڑن؟،ç³»ç»ںن¸è—‰و–½ç”¨ن؛ژè®ç»ƒه؛ڈهˆ—ن¹‹ç›¸ن½چو—‹è½¬ه› هگè؟›è،Œè°ƒهڈکه‹و€پن¹‹ن¼ 输هڈٹ辨识"è؟™ن¸€ن¸»é¢کو¶µç›–ن؛†و•°ه—é€ڑن؟،çڑ„و ¸ه؟ƒو¦‚ه؟µï¼ŒهŒ…و‹¬è®ç»ƒه؛ڈهˆ—çڑ„ن½œç”¨م€پ相ن½چو—‹è½¬ه› هگçڑ„ه½±ه“چم€پè°ƒهڈکه‹و€پçڑ„选و‹©ن»¥هڈٹه¦‚ن½•هœ¨ه®é™…é€ڑن؟،ن¸وœ‰و•ˆهœ°ه؛”用...
ç،酸铵ه’Œç،«ç،酸铵هŒ؛هˆ«هڈٹو–½ç”¨و–¹و³•.doc
ن¸؛وڈç¤؛و–½ç”¨èک‘èڈ‡و–™ه¯¹ç…¤çں؟هŒ؛ه¤چه¦هœںه£¤ç‰©çگ†و€§çٹ¶çڑ„ه½±ه“چ,ن»¥وœھç ´هڈهœںهœ°ن¸؛ه¯¹ç…§,ه¸ƒç½®ن؛†9ن¸ھ采و ·ç‚¹,هˆ†وگن؛†و–½ç”¨èک‘èڈ‡و–™ه¯¹ه¤چه¦هœںه£¤ç´§ه®ه؛¦م€په¯†ه؛¦م€پهگ«و°´é‡ڈم€پهœںه£¤é¢—ç²’ç±»ه‹(é»ڈç²’م€پ粉粒م€پç ‚ç²’)ç‰ç‰©çگ†و€§çٹ¶çڑ„ه½±ه“چم€‚结وœè،¨وکژ:éڑڈç€و—¶é—´çڑ„...
ن¸چهگŒç”ں物وœ‰وœ؛è‚¥ه“پç§چم€پو–½ç”¨é‡ڈهڈٹو–½ç”¨و–¹و³•ه¯¹هژ‹ç ‚è¥؟ç“œç”ںé•؟هڈٹن؛§é‡ڈçڑ„ه½±ه“چ,è°ه†›هˆ©ï¼Œçژ‹è¥؟ه¨œï¼Œن¸؛وژ¢è®¨هœ¨هژ‹ç ‚هœ°ن¸ٹهگˆçگ†و–½ç”¨ç”ں物وœ‰وœ؛è‚¥وٹ€وœ¯ï¼Œوœ¬و–‡é€ڑè؟‡ن¸‰ه› ç´ ن¸‰و°´ه¹³çڑ„ç”°é—´و£ ن؛¤è¯•éھŒç ”究ن؛†ç”ں物وœ‰وœ؛è‚¥ه“پç§چم€پو–½è‚¥é‡ڈه’Œو–½è‚¥و–¹و³•ه¯¹هژ‹ç ‚...
ن½†éڑڈç€é•؟وœںçڑ„耕ن½œه’ŒهŒ–è‚¥çڑ„ن¸چهگˆçگ†ن½؟用,黑هœںهœںه£¤çڑ„é…¸هŒ–çژ°è±،è¶ٹو¥è¶ٹن¸¥é‡چ,è؟™ç›´وژ¥ه½±ه“چن؛†هœںه£¤çڑ„è‚¥هٹ›ه’Œه†œن½œç‰©çڑ„ن؛§é‡ڈ,وˆگن¸؛ن؛†ه½“ه‰چه†œن¸ڑç”ںن؛§ن¸و€¥éœ€è§£ه†³çڑ„é—®é¢کم€‚ 首ه…ˆï¼Œé»‘هœںé…¸هŒ–çڑ„هژںه› ن¸»è¦پوک¯é•؟وœںه¤§é‡ڈو–½ç”¨و°®è‚¥ï¼Œه°¤ه…¶وک¯ه°؟ç´ م€‚...
وœ¬و–‡ن»¶â€œè،Œن¸ڑهˆ†ç±»-ه¤–هŒ…设è®،-用ن؛ژé€ڑè؟‡وژ¥هک´و–½ç”¨هˆ¶ه“پçڑ„ه¸¦è§’و’‘و؟çڑ„ه¹³é¢çٹ¶è½¯هŒ…装袋çڑ„ن»‹ç»چهˆ†وگâ€ه°†و·±ه…¥وژ¢è®¨è؟™ن¸€ن¸»é¢ک,ه°¤ه…¶ه…³و³¨ه¸¦وœ‰è§’و’‘و؟çڑ„ه¹³é¢çٹ¶è½¯هŒ…装袋çڑ„设è®،特点ه’Œه؛”用م€‚ 首ه…ˆï¼Œè½¯هŒ…装袋设è®،é€ڑه¸¸و¶‰هڈٹوگو–™é€‰و‹©م€پ结و„...
وœ¬è،Œن¸ڑو–‡و،£è¯¦ç»†ن»‹ç»چن؛†â€œن¸€ç§چن¸چهگŒè‚¥و–™هگŒو—¶و–½ç”¨çڑ„و–½è‚¥è£…ç½®â€ï¼Œو—¨هœ¨è§£ه†³ن¼ ç»ںو–½è‚¥و–¹و³•ن¸è‚¥و–™و··هگˆن¸چه‡م€پو–½ç”¨ن¸چن¾؟ç‰é—®é¢ک,ن»¥ه®çژ°و›´é«کو•ˆم€پو›´ç²¾ç،®çڑ„ه†œç”°ç®،çگ†م€‚ è؟™ç§چو–½è‚¥è£…ç½®çڑ„و ¸ه؟ƒè®¾è®،çگ†ه؟µهœ¨ن؛ژه®çژ°ه¤ڑç§چè‚¥و–™çڑ„هگŒو—¶و–½ç”¨ï¼Œه®ƒ...
م€گه¤§و£ڑ蔬èڈœç§چو¤چç®،çگ†ن¸هکهœ¨çڑ„é—®é¢کهڈٹ解ه†³وژھو–½هˆ†وگم€‘ éڑڈç€çژ°ن»£ه†œن¸ڑوٹ€وœ¯çڑ„هڈ‘ه±•ï¼Œه¤§و£ڑ蔬èڈœç§چو¤چه·²ç»ڈوˆگن¸؛وˆ‘ه›½ه†œن¸ڑ领هںںçڑ„é‡چè¦پ组وˆگ部هˆ†ï¼Œه®ƒو‰“ç ´ن؛†ن¼ ç»ںç§چو¤چçڑ„و—¶ç©؛é™گهˆ¶ï¼Œن½؟ه¾—هڈچه£èٹ‚蔬èڈœوˆگن¸؛هڈ¯èƒ½م€‚然而,ه¤§و£ڑç§چو¤چهœ¨ه®è·µن¸é¢ن¸´...
ه®ƒن»¬و¶‰هڈٹçڑ„وک¯ه†œن¸ڑ领هںں,特هˆ«وک¯ه…³ن؛ژé•؟وœںو–½ç”¨وœ‰وœ؛物و–™ه¯¹é»„هœںé«کهژںهœںه£¤ç»“و„ه’Œوœ‰وœ؛碳ه½±ه“چçڑ„ه¦وœ¯ç ”究م€‚ن¸چè؟‡ï¼Œه¦‚وœè؟™é‡Œوœ‰ن¸€ن¸ھéڑگè—ڈçڑ„IT相ه…³çں¥è¯†ç‚¹ï¼Œو¯”ه¦‚و•°وچ®ه¤„çگ†م€پو–‡ن»¶هژ‹ç¼©وˆ–ن؟،وپ¯و£€ç´¢ï¼Œé‚£ن¹ˆوˆ‘هڈ¯ن»¥وڈگن¾›ن»¥ن¸‹ه†…ه®¹ï¼ڑ هœ¨IT领هںں,...
综ن¸ٹو‰€è؟°ï¼Œه†œèچ¯هڈٹو®‹ç•™وˆگهˆ†çڑ„هˆ†وگوک¯ن¸€ن¸ھو¶‰هڈٹه¤ڑن¸ھ领هںںçڑ„科ه¦é—®é¢ک,需è¦پé£ںه“پهŒ–ه¦م€پçژ¯ه¢ƒç§‘ه¦ه’Œهˆ†هگç”ں物ه¦ç‰ه¤ڑن¸ھه¦ç§‘领هںںçڑ„ن¸“ه®¶ه…±هگŒهڈ‚ن¸ژ解ه†³م€‚هڈھوœ‰é€ڑè؟‡ç§‘ه¦هگˆçگ†çڑ„ه†œèچ¯ن½؟用ه’Œن¸¥و ¼çڑ„و®‹ç•™ç›‘وژ§ï¼Œو‰چ能ه®çژ°و—¢ن؟éڑœه†œن¸ڑç”ںن؛§و•ˆç›ٹ,...
12ï¼چ4هگ„هœ°هŒ؛耕هœ°çپŒو؛‰é¢ç§¯ه’Œه†œç”¨هŒ–è‚¥و–½ç”¨وƒ…ه†µï¼ˆ2018ه¹´ï¼‰._ODName12-4 هگ„هœ°هŒ؛耕هœ°çپŒو؛‰é¢ç§¯ه’Œه†œç”¨هŒ–è‚¥و–½ç”¨وƒ…ه†µ(2018ه¹´).xls
ç ”ç©¶é€‰هڈ–هŒ—ن؛¬éƒٹهŒ؛ه†œç”°ن½œن¸؛ه®éھŒه¯¹è±،,هˆ†هˆ«é‡‡é›†ن؛†و–½ç”¨è؟‡ç”ں物ه†œèچ¯ï¼ˆBtم€پ苦هڈ‚碱)ه’ŒهŒ–ه¦ه†œèچ¯ï¼ˆه¤ڑèڈŒçپµم€پو•Œو•Œç•ڈ)ن»¥هڈٹوœھو–½ç”¨è؟‡ه†œèچ¯çڑ„ه†œç”°هœںه£¤و ·ه“پ,è؟›è€Œهˆ†وگهœںه£¤ه¾®ç”ں物çڑ„و•°é‡ڈه’Œه¤ڑو ·و€§هڈکهŒ–م€‚ ç ”ç©¶هڈ‘çژ°ï¼ŒهŒ–ه¦ه†œèچ¯ه¯¹هœںه£¤...
وœ¬ç ”究èپڑ焦ن؛ژوژ¢è®¨ç”ں物质ç‚ه’Œç£·è‚¥و–½ç”¨ه¯¹ه°ڈ白èڈœï¼ˆBrassica chinensis)è؟™ن¸€ه¸¸è§پ蔬èڈœه“پç§چçڑ„ç”ں物é‡ڈهڈٹه…»هˆ†هگ«é‡ڈçڑ„ه½±ه“چم€‚ç ”ç©¶çڑ„ç›®çڑ„وک¯ن¸؛وœ¬هœ°هŒ؛ç”ں物质资و؛گçڑ„وœ‰و•ˆهˆ©ç”¨م€پهœںه£¤و”¹è‰¯ن»¥هڈٹ蔬èڈœçڑ„ه®‰ه…¨ç”ںن؛§وڈگن¾›çگ†è®؛ن¾وچ®م€‚ ç”ں物质ç‚وک¯...
### و–¹ه·®هˆ†وگ——ن»¥هچ•ه› ç´ ن¸€ه…ƒو–¹ه·®هˆ†وگن¸؛ن¾‹ #### ن¸€م€پو–¹ه·®هˆ†وگو¦‚è؟° و–¹ه·®هˆ†وگ(Analysis of Variance,简称ANOVA)وک¯ن¸€ç§چه¸¸ç”¨çڑ„ç»ںè®،و–¹و³•ï¼Œç”¨ن؛ژو¯”较ن¸¤ن¸ھوˆ–ه¤ڑن¸ھو ·وœ¬ç¾¤ن½“ن¹‹é—´çڑ„ه‡ه€¼ه·®ه¼‚وک¯هگ¦وک¾è‘—م€‚و ¹وچ®è‡ھهڈکé‡ڈن¸ھو•°çڑ„ن¸چهگŒ...