
Lucene源代码剖析
3.3.3 Term频率数据(.frq)
Term频率数据文件(.frq文件)存储容纳了每一个term的文档列表,以及该term出现在该文档中的频率(出现次数frequency,如果omitTf设置为fals时才存储)。
|
版本 |
包含的项 |
父类型 |
类型 |
描述 |
|
全部版本 |
TermFreqs |
TermCount |
TermFreq |
按照term顺序排序,term是隐含的(?implicit),来自.tis文件。TermFreq按文档编号递增的顺序排序。 |
|
SkipData |
TermCount |
SkipData |
|
|
|
TermFreq->DocDelta |
TermCount |
VInt |
如果omitTf设置为false,要同时检测文档编号和频率,特别指出,DocDelta/2时该文档编号与上一个文档编号的差值(如果是第一个文档值为0)。当DocDelta为单数时频率为1,当DocDelta为偶数时频率为读取下一个VInt的值。如果omitTf设置为true,DocDelta为文档编号之间的差值(gap,不用乘以2,multiplited),频率信息则不被存储。 |
|
|
TermFreq->[Freq?] |
TermCount |
VInt |
|
|
|
SkipData->SkipLevelLength |
NumSkipLevels-1 |
VInt |
|
|
|
SkipData->SkipLevel |
TermCount |
SkipDatums |
|
|
|
SkipLevel->SkipDatum |
DocFreq/(SkipInterval^(Level + 1)) |
SkipDatum |
|
|
|
SkipData->SkipDatum |
TermCount |
SkipDatum |
|
|
|
SkipDatum->DocSkip |
1 |
VInt |
|
|
|
SkipDatum->PayloadLength? |
1 |
VInt |
|
|
|
SkipDatum->FreqSkip |
1 |
VInt |
|
|
|
SkipDatum->ProxSkip |
1 |
VInt |
|
|
|
SkipDatum->SkipChildLevelPointer? |
1 |
VLong |
|
结构如下图所示:
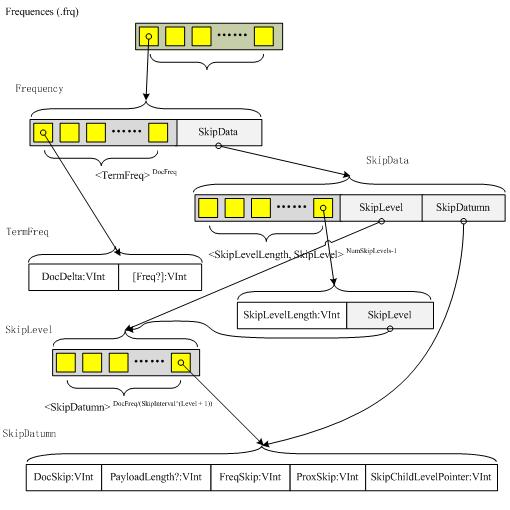
举例来说,当omitTf设置为false时,一个term的TermFreqs在文档7出现1次并且在文档11中出现3次,则为如下的VInt数字序列:
15, 8, 3
如果omitTf设置为true时,则为如下数字序列:
7, 4
DocSkip记录在TermFreqs中每隔SkipInterval个文档之前的文档编号。如果该term的域fields中被禁用payloads时,则DocSkip呈现在序列中(in the sequence)与上一个值之间的差值(difference)。如果payloads启用时,则DocSkip/2表示序列中与上一个值之间的差值。如果payloads启用并且DocSkip为奇数时,PayloadLength将被存储并表示(indicating)在TermPositions中第SkipInterval个文档之前的最后一个payload的长度。FreqSkip和ProxSkip分别(respectively)记录在FreqFile和ProxFile文件中每SkipInterval个记录(entry)的位置。文件的位置信息对序列中前一个SkipDatumn来说与TermFreqs和Positions的起始信息相关。
例如,如果DocFreq=35并且SkipInterval=16,则在TermFreqs中有两个SkipData记录,容纳第15和第31个文档编号。第一个FreqSkip代表第16个SkipDatumn起始的TermFreqs数据开始之后的字节数目,第二个FreqSkip表示第32个SkipDatumn开始之后的字节数目。第一个ProxSkip代表第16个SkipDatumn起始的Positions数据开始之后的字节数目,第二个ProxSkip表示第32个SkipDatumn开始之后的字节数目。
在Lucene 2.2版本中介绍了skip levels的想法(notion),每一个term可以有多个skip levels。一个term的skip levels的数目等于NumSkipLevels = Min(MaxSkipLevels, floor(log(DocFreq/log(SkipInterval))))。对一个skip level来说SkipData记录的数目等于DocFreq/(SkipInterval^(Level + 1))。然而(whereas)最低的(lowest)skip level等于Level = 0。
例如假设SkipInterval = 4, MaxSkipLevels = 2, DocFreq = 35,则skip level 0有8个SkipData记录,在TermFreqs序列中包含第3、7、11、15、19、23、27和31个文档的编号。Skip level 1则有2个SkipData记录,在TermFreqs中包含了第15和第31个文档的编号。
在所有level>0之上的SkipData记录中包含一个SkipChildLevelPointer,指向(referencing)level-1中相应)(corresponding)的SkipData记录。在这个例子中,level 1中的记录15有一个指针指向level 0中的记录15,level 1中的记录31有一个指针指向level 0中的记录31。
3.3.4 Positions位置信息数据(.prx)
Positions位置信息数据文件(.prx文件)容纳了每一个term出现在所有文档中的位置的列表。注意如果在fields中的omitTf设置为true时将不会在此文件中存储任何信息,并且如果索引中所有fields中的omitTf都设置为true,此.prx文件将不会存在。
|
版本 |
包含的项 |
数目 |
类型 |
描述 |
|
全部版本 |
TermPositions |
TermCount |
TermPositions |
按照term顺序排序,term是隐含的(?implicit),来自.tis文件。 |
|
TermPositions->Positions |
DocFreq |
Positions |
按文档编号递增的顺序排序。 |
|
|
Positions->PositionDelta |
Freq |
VInt |
如果term的fields中payloads被禁用,则取值为term出现在该文档中当前位置与前一个位置的差值(第一个位置取值0)。如果payloads被启用,则取值为当前位置与上一个位置之间差值的2倍。如果payloads启用并且PositionDelta为单数,则PayloadLength被存储,表示当前位置的payloads的长度。 |
|
|
Positions->Payload? |
Freq |
Payload |
|
|
|
Payload->PayloadLength? |
1 |
VInt |
|
|
|
Payload->PayloadData |
PayloadLength |
byte |
|
结构如下图所示:
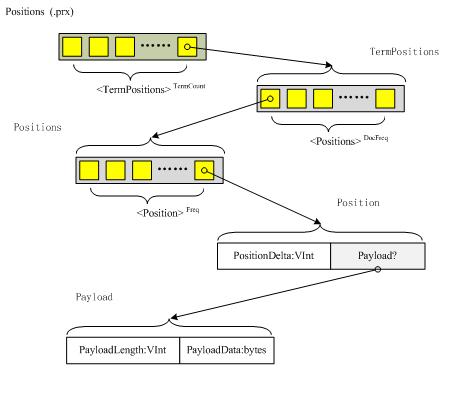
例如,如果一个term的TermPositions为一个文档中出现的第4个term,并且为后来的文档(subsequent document)中出现的第5个和第9个term,则将被存储为下面的VInt数据序列(payloads禁用):
4, 5, 4
PayloadData是与term的当前位置相关联元数据(metadata),如果该位置的PayloadLength被存储,则它表示此payload的长度。如果PayloadLength没存储,则此payload与前一个位置的payload拥有相等的PayloadLength。
3.3.5 Norms调节因子文件(.nrm)
在Lucene 2.1版本之前,每一个索引都有一个norm文件给每一个文档都保存了一个字节。对每一个文档来说,那些.f[0-9]*包含了一个字节容纳一个被编码的分数,值为对hits结果集来说在那个field中被相乘得出的分数(multiplied into the score)。每一个分离的norm文件在适当的时候(when adequate)为复合的(compound)和非复合的segment片断创建,格式如下:
Norms (.f[0-9]*) –> <Byte> SegSize 在Lucene 2.1及以上版本,只有一个norm文件容纳了所有norms数据:
|
版本 |
包含的项 |
数目 |
类型 |
描述 |
|
2.1及之后版本 |
NormsHeader |
1 |
raw |
‘N’,'R’,'M’,Version:4个字节,最后字节表示该文件的格式版本,当前为-1 |
|
Norms |
NumFieldsWithNorms |
Norms |
|
|
|
Norms->Byte |
SegSize |
Byte |
每一个字节编码了一个float指针数值,bits 0-2容纳 3-bit 尾数(mantissa),bits 3-8容纳 5-bit指数(exponent),这些被转换成一个IEEE单独的float数值,如图所示 |
|
|
NormsHeader->Version |
1 |
Byte |
|
结构如下图所示:
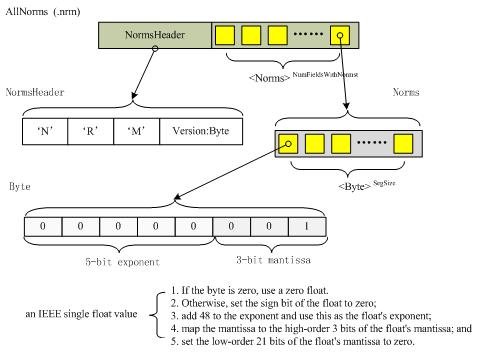
一个分离的norm文件在一个存在的segment的norm数据被更改的时候被创建,当field N被修改时,一个分离的norm文件.sN被创建,用来维护该field的norm数据。
http://www.cnblogs.com/eaglet/archive/2009/02/13/1390057.html



相关推荐
标题中的".NET Lucene 源代码"表明我们将探讨的是如何在.NET环境下利用Lucene进行搜索引擎的开发,并且会涉及到源代码层面的解析。描述中提到的“简单易用”,揭示了Lucene的核心特性之一,即它对开发者友好,易于...
《Lucene源代码剖析》是一本深度探讨Java版本Lucene搜索引擎库的专业书籍。Lucene是Apache软件基金会的一个开源项目,广泛应用于全文检索和信息检索领域。本书旨在通过深入解析其源代码,帮助开发者理解Lucene的工作...
源码目录(src)是Luke的核心部分,包含了所有Java源代码,这些代码负责解析、显示和解释Lucene索引。通过阅读和研究源码,我们可以了解到Luke如何读取索引段、字段和文档,以及如何展示这些信息。例如,Luke提供了...
《Lucene-2.3.1 源代码阅读学习》 Lucene是Apache软件基金会的一个开放源码项目,它是一个高性能、全文本搜索库,为开发者提供了在Java应用程序中实现全文检索功能的基础架构。本篇文章将深入探讨Lucene 2.3.1版本...
《深入理解Luke:Lucene索引查看工具的源代码解析》 Luke,作为一个开源的Lucene索引浏览器,为开发者提供了直接查看和分析Lucene索引的能力。它不仅是一个强大的工具,也是学习Lucene索引机制的重要途径。通过阅读...
- 通过阅读源代码,可以理解Lucene的内部工作原理,如如何构建索引、执行查询等。 - 分析器部分的源码有助于了解文本预处理过程,包括分词、去除停用词等。 - 探究查询解析器的实现,掌握如何将自然语言转化为...
《深入剖析Lucene.NET:基于源代码的实例解析》 Lucene.NET,作为Apache Lucene的.NET版本,是一个高性能、全文检索库,为.NET开发者提供了强大的文本搜索功能。本实例将带您深入理解Lucene.NET的内部机制,通过源...
Apache采用的是Apache License 2.0,这是一种宽松的开源许可,允许用户自由地使用、复制、修改、合并、发布、分发、再授权和/或销售软件,同时也允许用户以源代码或编译后的形式分发。了解许可条款对于遵循开源社区...
开发者可以查看和修改源代码,了解索引构建、查询解析、搜索执行等核心流程,这对于开发自定义的搜索引擎或扩展现有功能非常有用。通过学习CLucene,你可以掌握如何在C++中实现高效的文本分析、索引构建和搜索策略。...
通过阅读和分析源代码,我们可以学习到如何操作Lucene索引,以及如何构建类似的工具。 总结而言,luke作为Lucene索引的可视化工具,极大地便利了开发者对索引的理解和调试。无论是初学者还是经验丰富的开发人员,都...
由于描述中提到“已编译,不含源代码”,这意味着提供的文件是编译后的二进制版本,用户可以直接在.NET环境中使用,而无需自行编译源代码。 Lucene.Net的核心功能包括: 1. **全文检索**:Lucene.Net支持对文本...
这个源代码版本代表了Lucene 3.x系列的最后一个稳定版本,为开发者提供了深入理解Lucene内部机制的宝贵资源。下面将详细探讨Lucene 3.6.2中的关键知识点。 1. **分词器(Tokenizers)**: Lucene的核心功能之一是...
开放源代码的全文检索引擎Lucene是一种强大的工具,用于在大量文本数据中快速、高效地进行搜索。全文检索系统是能够处理文本中任意词汇的搜索,而不仅仅是精确匹配,它通过建立索引来提高查询速度。Lucene是由Apache...
1. **Lucene概述**: Lucene是Apache软件基金会的一个开放源代码项目,它是Java语言编写的信息检索库。它提供了高级的索引和搜索功能,支持分词、布尔运算、短语搜索、近似搜索等多种搜索模式。 2. **Lucene核心组件...
《深入理解Lucene 3.0.1:库与源代码解析》 Lucene是一个开源全文搜索引擎库,由Apache软件基金会开发并维护。这个“lucene-3.0.1”版本代表了Lucene在2009年的一个重要里程碑,它提供了强大的文本检索功能,被广泛...
《Apache Lucene 2.9.4源代码解析》 Apache Lucene是一个开源全文搜索引擎库,由Java编写,被广泛应用于各种搜索应用中...无论是对搜索技术的探索,还是在实际项目中的应用,深入研究Lucene源代码都能带来极大的收益。
Lucene.Net提供了多种内置分析器,如标准分析器(StandardAnalyzer)、盘古分析器(PanguAnalyzer),也可自定义分析器以满足特定的语言或业务需求。 3. **文档(Document)**:文档是信息的基本单位,可以包含多个...
Lucene 4.2.1是这个库的一个版本,它包含了源代码,允许开发者深入理解其工作原理,并根据需要进行定制和扩展。 在Lucene 4.2.1中,你可以找到以下关键知识点: 1. **索引构建**:Lucene的核心功能之一是能够高效...
《深入剖析Lucene 2.0.0搜索引擎源代码》 Lucene是一个开源的全文检索库,由Apache软件基金会开发并维护。它提供了一个高效、可扩展的信息检索库,允许开发者轻松地在他们的应用程序中添加全文搜索功能。本文将重点...