
Lucene 源码剖析
2 索引文件
为了使用Lucene来索引数据,首先你得把它转换成一个纯文本(plain-text)tokens的数据流(stream),并通过它创建出Document对象,其包含的Fields成员容纳这些文本数据。一旦你准备好些Document对象,你就可以调用IndexWriter类的addDocument(Document)方法来传递这些对象到Lucene并写入索引中。当你做这些的时候,Lucene首先分析(analyzer)这些数据来使得它们更适合索引。详见《Lucene In Action》
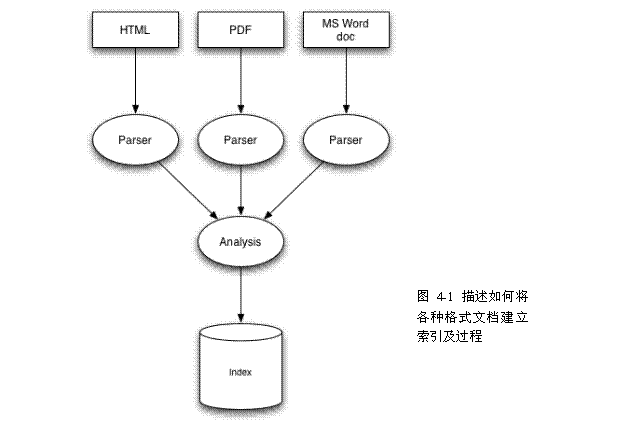
下面先了解一下索引结构的一些术语。
2.1 索引数据术语和约定
2.1.1 术语定义
Lucene中基本的概念(fundamental concepts)是index、Document、Field和term。
1 一条索引(index)包含(contains)了一连串(a sequence of)文档(documents)。
2 一个文档(document)是由一连串fields组成。
3 一个field是由一连串命名了(a named sequence of)的terms组成。
4 一个term是一个string(字符串)。
相同的字符串(same string)但是在两个不同的fields中被认为(considered)是不同的term。因此(thus)term被描述为(represent as)一对字符串(a pair of strings),第一个string取名(naming)为该field的名字,第二个string取名为包含在该field中的文本(text within the field)。
2.1.2 倒排索引(inverted indexing)
索引(index)存储terms的统计数据(statistics about terms),为了使得基于term的检索(term-based search)效率更高(more efficient)。Lucene的索引分成(fall into)被广为熟悉的(known as)索引种类(family of indexex)叫做倒排索引(inverted index)。这是因为它可以列举(list),对一个term来说,所有包含它的文档(documents that contain it)。这与自然关联规则(natural relationship)是相反,即由documents列举它所包含的terms。
2.1.3 Fields的种类
在Lucene中,fields可以被存储(stored),在这种情况(in which case)下它们的文本被逐字地(literally)以一种非倒排的方式(in non-inverted manner)存储进index中。那些被倒排的fields(that are inverted)称为(called)被索引(indexed)。一个field可以都被存储(stored)并且被索引(indexed)。
一个field的文本可以被分解为(be tokenized into)terms以便被索引(indexed),或者field的文本可以被逐字地使用为(used literally as)一个term来被索引(be indexed)。大多数fields被分解(be tokenized),但是有时候对某种唯一性(certain identifier)的field来逐字地索引(be indexed literally)又是非常有用的,如url。
2.1.4 片断(segments)
Lucene的索引可以由多个复合的子索引(multiple sub-indexes)或者片断(segments)组成(be composed of)。每一个segment都是一个完全独立的索引(fully independent index),它能够被分离地进行检索(be searched seperately)。索引按如下方式进行演化(evolve):
1. 为新添加的文档(newly added documents)创建新的片断(segments)。
2. 合并已存在的片断(merging existing segments)。
检索可以涉及(involve)多个复合(multiple)的segments,并且/或者多个复合(multiple)的indexes。每一个index潜在地(potentially)包含(composed of)一套(a set of)segments。
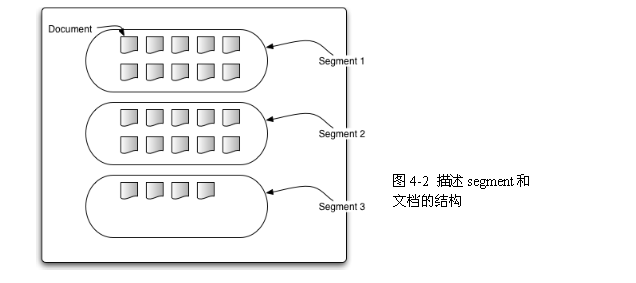
2.1.5 文档编号(document numbers)
在内部(internally),Lucene通过一个整数的(interger)文档编号(document number)来表示文档。第一篇被添加到索引中的文档编号为0(be numbered zero),每一篇随后(subsequent)被添加的document获得一个比前一篇更大的数字(a number one greater than the previous)。
需要注意的是一篇文档的编号(document’s number)可以更改,所以在Lucene之外(outside of)存储这些编号时需要特别小心(caution should be taken)。详细地说(in particular),编号在如下的情况(following situations)可以更改:
1 存储在每个segment中的编号仅仅是在所在的segment中是唯一的(unique),在它能够被使用在(be used in)一个更大的上下文(a larger context)中前必须被转变(converted)。标准的技术(standard technique)是给每一个segment分配(allocate)一个范围的值(a range of values),基于该segment所使用的编号的范围(the range of numbers)。为了将一篇文档的编号从一个segment转变为一个扩展的值(an external value),该片断的基础的文档编号(base document number)被添加(is added)。为了将一个扩展的值(external value)转变回一个segment的特定的值(specific value),该segment将该扩展的值所在的范围标识出来(be indentified),并且该segment的基础值(base value)将被减少(substracted)。例如,两个包含5篇文档的segments可能会被合并(combined),所以第一个segment有一个基础的值(base value)为0,第二个segment则为5。在第二个segment中的第3篇文档(document three from the second segment)将有一个扩展的值为8。
2 当文档被删除的时候,在编号序列中(in the numbering)将产生(created)间隔段(gaps)。这些最后(eventually)在索引通过合并演进时(index evolves through merging)将会被清除(removed)。当segments被合并后(merged),已删除的文档将会被丢弃(dropped),一个刚被合并的(freshly-merged)segment因此在它的编号序列中(in its numbering)不再有间隔段(gaps)。
2.1.6 索引结构概述
每一个片断的索引(segment index)管理(maintains)如下的数据:
1 Fields名称:这包含了(contains)在索引中使用的一系列fields的名称(the set of field names)。
2 已存储的field的值:它包含了,对每篇文档来说,一个属性-值数据对(attribute-value pairs)的清单(a list of),其中属性即为field的名字。这些被用来存储关于文档的备用信息(auxiliary information),比如它的标题(title)、url、或者一个访问一个数据库(database)的唯一标识(identifier)。这套存储的fields就是那些在检索时对每一个命中的(hits)文档所返回的(returned)信息。这些是通过文档编号(document number)来做为key得到的。
3 Term字典(dictionary):一个包含(contains)所有terms的字典,被使用在所有文档中所有被索引的fields中。它还包含了该term所在的文档的数目(the number of documents which contains the term),并且指向了(pointer to)term的频率(frequency)和接近度(proximity)的数据(data)。
4 Term频率数据(frequency data):对字典中的每一个term来说,所有包含该term(contains the term)的文档的编号(numbers of all documents),以及该term出现在该文档中的频率(frequency)。
5 Term接近度数据(proximity data):对字典中的每一个term来说,该term出现在(occur)每一篇文档中的位置(positions)。
6 调整因子(normalization factors):对每一篇文档的每一个field来说,为一个存储的值(a value is stored)用来加入到(multiply into)命中该field的分数(score for hits on that field)中。
7 Term向量(vectors):对每一篇文档的每一个field来说,term向量(有时候被称做文档向量)可以被存储。一个term向量由term文本和term的频率(frequency)组成(consists of)。怎么添加term向量到你的索引中请参考Field类的构造方法(constructors)。
8 删除的文档(deleted documents):一个可选的(optional)文件标示(indicating)哪一篇文档被删除。
关于这些项的详细信息在随后的章节(subsequent sections)中逐一介绍。
2.1.7 索引文件中定义的数据类型
|
数据类型 |
所占字节长度(字节) |
说明 |
||||||||||||||||||||||||||||||||||||||||||||
|
Byte |
1 |
基本数据类型,其他数据类型以此为基础定义 |
||||||||||||||||||||||||||||||||||||||||||||
|
UInt32 |
4 |
32位无符号整数,高位优先 |
||||||||||||||||||||||||||||||||||||||||||||
|
UInt64 |
8 |
64位无符号整数,高位优先 |
||||||||||||||||||||||||||||||||||||||||||||
|
VInt |
不定,最少1字节 |
动态长度整数,每字节的最高位表明还剩多少字节,每字节的低七位表明整数的值,高位优先。可以认为值可以为无限大。其示例如下
|
||||||||||||||||||||||||||||||||||||||||||||
|
Chars |
不定,最少1字节 |
采用UTF-8编码[20]的Unicode字符序列 |
||||||||||||||||||||||||||||||||||||||||||||
|
String |
不定,最少2字节 |
由VInt和Chars组成的字符串类型,VInt表示Chars的长度,Chars则表示了String的值 |
3.1 索引文件结构
Lucene使用文件扩展名标识不同的索引文件,文件名标识不同版本或者代(generation)的索引片段(segment)。如.fnm文件存储域Fields名称及其属性,.fdt存储文档各项域数据,.fdx存储文档在fdt中的偏移位置即其索引文件,.frq存储文档中term位置数据,.tii文件存储term字典,.tis文件存储term频率数据,.prx存储term接近度数据,.nrm存储调节因子数据,另外segments_X文件存储当前最新索引片段的信息,其中X为其最新修改版本,segments.gen存储当前版本即X值,这些文件的详细介绍上节已说过了。
下面的图描述了一个典型的lucene索引文件列表:
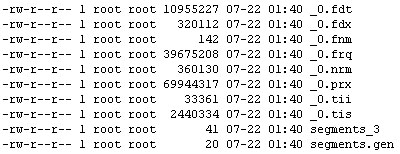
如果将它们的关系划成图则如下所示
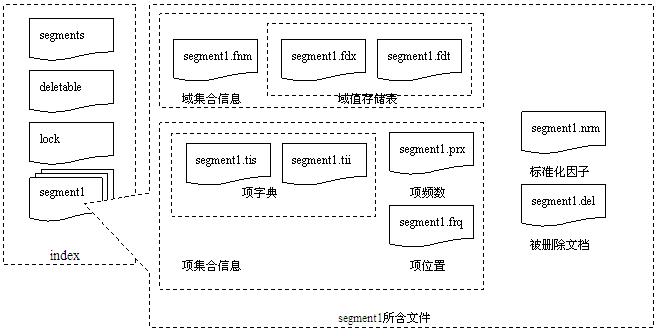
这些文件中存储数据的详细结构是怎样的呢,下面几个小节逐一介绍它们,熟悉它们的结构非常有助于优化Lucene的查询和索引效率和存储空间等。
3.2 每个Index包含的单个文件
下面几节介绍的文件存在于每个索引index中,并且只有一份。
3.2.1 Segments文件
索引中活动(active)的Segments被存储在segment info文件中,segments_N,在索引中可能会包含一个或多个segments_N文件。然而,最大一代的那个文件(the one with largest generation)是活动的片断文件(这时更旧的segments_N文件依然存在(are present)是因为它们暂时(temporarily)还不能被删除,或者,一个writer正在处理提交请求(in the process of committing),或者一个用户定义的(custom)IndexDeletionPolicy正被使用)。这个文件按照名称列举每一个片断(lists each segment by name),详细描述分离的标准(seperate norm)和要删除的文件(deletion files),并且还包含了每一个片断的大小。
对2.1版本来说,还有一个文件segments.gen。这个文件包含了该索引中当前生成的代(current generation)(segments_N中的_N)。这个文件仅用于一个后退处理(fallback)以防止(in case)当前代(current generation)不能被准确地(accurately)通过单独地目录文件列举(by directory listing alone)来确定(determened)(由于某些NFS客户端因为基于时间的目录(time-based directory)的缓存终止(cache expiration)而引起)。这个文件简单地包含了一个int32的版本头(version header)(SegmentInfos.FORMAT_LOCKLESS=-2),遵照代的记录(followed by the generation recorded)规则,对int64来说会写两次(write twice)。
|
版本 |
包含的项 |
数目 |
类型 |
描述 |
|
2.1之前版本 |
Format |
1 |
Int32 |
在Lucene1.4中为-1,而在Lucene 2.1中为-3(SegmentsInfos.FORMAT_SINGLE_NORM_FILE) |
|
Version |
1 |
Int64 |
统计在删除和添加文档时,索引被更改了多少次。 |
|
|
NameCounter |
1 |
Int32 |
用于为新的片断文件生成新的名字。 |
|
|
SegCount |
1 |
Int32 |
片断的数目 |
|
|
SegName |
SegCount |
String |
片断的名字,用于所有构成片断索引的文件的文件名前缀。 |
|
|
SegSize |
SegCount |
Int32 |
包含在片断索引中的文档的数目。 |
|
|
2.1及之后版本 |
Format |
1 |
Int32 |
在Lucene 2.1和Lucene 2.2中为-3(SegmentsInfos.FORMAT_SINGLE_NORM_FILE) |
|
Version |
1 |
Int64 |
同上 |
|
|
NameCounter |
1 |
Int32 |
同上 |
|
|
SegCount |
1 |
Int32 |
同上 |
|
|
SegName |
SegCount |
String |
同上 |
|
|
SegSize |
SegCount |
Int32 |
同上 |
|
|
DelGen |
SegCount |
Int64 |
为分离的删除文件的代的数目(generation count of the separate deletes file),如果值为-1,表示没有分离的删除文件。如果值为0,表示这是一个2.1版本之前的片断,这时你必须检查文件是否存在_X.del这样的文件。任意大于0的值,表示有分离的删除文件,文件名为_X_N.del。 |
|
|
HasSingleNormFile |
SegCount |
Int8 |
该值如果为1,表示Norm域(field)被写为一个单一连接的文件(single joined file)中(扩展名为.nrm),如果值为0,表示每一个field的norms被存储为分离的.fN文件中,参考下面的“标准化因素(Normalization Factors)” |
|
|
NumField |
SegCount |
Int32 |
表示NormGen数组的大小,如果为-1表示没有NormGen被存储。 |
|
|
NormGen |
SegCount * NumField |
Int64 |
记录分离的标准文件(separate norm file)的代(generation),如果值为-1,表示没有normGens被存储,并且当片断文件是2.1之前版本生成的时,它们全部被假设为0(assumed to be 0)。而当片断文件是2.1及更高版本生成的时,它们全部被假设为-1。这时这个代(generation)的意义与上面DelGen的意义一样。 |
|
|
IsCompoundFile |
SegCount |
Int8 |
记录是否该片断文件被写为一个复合的文件,如果值为-1表示它不是一个复合文件(compound file),如果为1则为一个复合文件。另外如果值为0,表示我们需要检查文件系统是否存在_X.cfs。 |
|
|
2.3 |
Format |
1 |
Int32 |
在Lucene 2.3中为-4 (SegmentInfos.FORMAT_SHARED_DOC_STORE) |
|
Version |
1 |
Int64 |
同上 |
|
|
NameCounter |
1 |
Int32 |
同上 |
|
|
SegCount |
1 |
Int32 |
同上 |
|
|
SegName |
SegCount |
String |
同上 |
|
|
SegSize |
SegCount |
Int32 |
同上 |
|
|
DelGen |
SegCount |
Int64 |
同上 |
|
|
DocStoreOffset |
1 |
Int32 |
如果值为-1则该segment有自己的存储文档的fields数据和term vectors的文件,并且DocStoreSegment, DocStoreIsCompoundFile不会存储。在这种情况下,存储fields数据(*.fdt和*.fdx文件)以及term vectors数据(*.tvf和*.tvd和*.tvx文件)的所有文件将存储在该segment下。另外,DocStoreSegment将存储那些拥有共享的文档存储文件的segment。DocStoreIsCompoundFile值为1如果segment存储为compound文件格式(如.cfx文件),并且DocStoreOffset值为那些共享文档存储文件中起始的文档编号,即该segment的文档开始的位置。在这种情况下,该segment不会存储自己的文档数据文件,而是与别的segment共享一个单一的数据文件集。 |
|
|
[DocStoreSegment] |
1 |
String |
如上 |
|
|
[DocStoreIsCompoundFile] |
1 |
Int8 |
如上 |
|
|
HasSingleNormFile |
SegCount |
Int8 |
同上 |
|
|
NumField |
SegCount |
Int32 |
同上 |
|
|
NormGen |
SegCount * NumField |
Int64 |
同上 |
|
|
IsCompoundFile |
SegCount |
Int8 |
同上 |
|
|
2.4及以上 |
Format |
1 |
Int32 |
在Lucene 2.4中为-7 (SegmentInfos.FORMAT_HAS_PROX) |
|
Version |
1 |
Int64 |
同上 |
|
|
NameCounter |
1 |
Int32 |
同上 |
|
|
SegCount |
1 |
Int32 |
同上 |
|
|
SegName |
SegCount |
String |
同上 |
|
|
SegSize |
SegCount |
Int32 |
同上 |
|
|
DelGen |
SegCount |
Int64 |
同上 |
|
|
DocStoreOffset |
1 |
Int32 |
同上 |
|
|
[DocStoreSegment] |
1 |
String |
同上 |
|
|
[DocStoreIsCompoundFile] |
1 |
Int8 |
同上 |
|
|
HasSingleNormFile |
SegCount |
Int8 |
同上 |
|
|
NumField |
SegCount |
Int32 |
同上 |
|
|
NormGen |
SegCount * NumField |
Int64 |
同上 |
|
|
IsCompoundFile |
SegCount |
Int8 |
同上 |
|
|
DeletionCount |
SegCount |
Int32 |
记录该segment中删除的文档数目 |
|
|
HasProx |
SegCount |
Int8 |
值为1表示该segment中至少一个fields的omitTf设置为false,否则为0 |
|
|
Checksum |
1 |
Int64 |
存储segments_N文件中直到checksum的所有字节的CRC32 checksum数据,用来校验打开的索引文件的完整性(integrity)。 |
3.2.2 Lock文件
写锁(write lock)文件名为“write.lock”,它缺省存储在索引目录中。如果锁目录(lock directory)与索引目录不一致,写锁将被命名为“XXXX-write.lock”,其中“XXXX”是一个唯一的前缀(unique prefix),来源于(derived from)索引目录的全路径(full path)。当这个写锁出现时,一个writer当前正在修改索引(添加或者清除文档)。这个写锁确保在一个时刻只有一个writer修改索引。
需要注意的是在2.1版本之前(prior to),Lucene还使用一个commit lock,这个锁在2.1版本里被删除了。
3.2.3 Deletable文件
在Lucene 2.1版本之前,有一个“deletable”文件,包含了那些需要被删除文档的详细资料。在2.1版本后,一个writer会动态地(dynamically)计算哪些文件需要删除,因此,没有文件被写入文件系统。
3.2.4 Compound文件(.cfs)
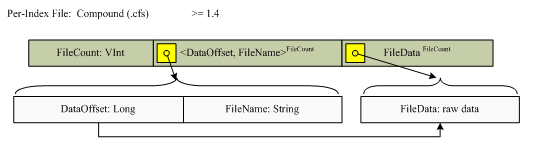
从Lucene 1.4版本开始,compound文件格式成为缺省信息。这是一个简单的容器(container)来服务所有下一章节(next section)描述的文件(除了.del文件),格式如下:
|
版本 |
包含的项 |
数目 |
类型 |
描述 |
|
1.4之后版本 |
FileCount |
1 |
VInt |
|
|
DataOffset |
FileCount |
Long |
|
|
|
FileName |
FileCount |
String |
|
|
|
FileData |
FileCount |
raw |
Raw文件数据是上面命名的所有单个的文件数据(the individual named above)。 |
结构如下图所示:
http://www.cnblogs.com/eaglet/archive/2009/02/13/1390021.html



相关推荐
《Lucene源代码剖析》是一本深度探讨Java版本Lucene搜索引擎库的专业书籍。Lucene是Apache软件基金会的一个开源项目,广泛应用于全文检索和信息检索领域。本书旨在通过深入解析其源代码,帮助开发者理解Lucene的工作...
标题中的".NET Lucene 源代码"表明我们将探讨的是如何在.NET环境下利用Lucene进行搜索引擎的开发,并且会涉及到源代码层面的解析。描述中提到的“简单易用”,揭示了Lucene的核心特性之一,即它对开发者友好,易于...
源码目录(src)是Luke的核心部分,包含了所有Java源代码,这些代码负责解析、显示和解释Lucene索引。通过阅读和研究源码,我们可以了解到Luke如何读取索引段、字段和文档,以及如何展示这些信息。例如,Luke提供了...
《深入剖析Lucene.NET:基于源代码的实例解析》 Lucene.NET,作为Apache Lucene的.NET版本,是一个高性能、全文检索库,为.NET开发者提供了强大的文本搜索功能。本实例将带您深入理解Lucene.NET的内部机制,通过源...
《深入理解Luke:Lucene索引查看工具的源代码解析》 Luke,作为一个开源的Lucene索引浏览器,为开发者提供了直接查看和分析Lucene索引的能力。它不仅是一个强大的工具,也是学习Lucene索引机制的重要途径。通过阅读...
《Lucene-2.3.1 源代码阅读学习》 Lucene是Apache软件基金会的一个开放源码项目,它是一个高性能、全文本搜索库,为开发者提供了在Java应用程序中实现全文检索功能的基础架构。本篇文章将深入探讨Lucene 2.3.1版本...
Apache采用的是Apache License 2.0,这是一种宽松的开源许可,允许用户自由地使用、复制、修改、合并、发布、分发、再授权和/或销售软件,同时也允许用户以源代码或编译后的形式分发。了解许可条款对于遵循开源社区...
- 通过阅读源代码,可以理解Lucene的内部工作原理,如如何构建索引、执行查询等。 - 分析器部分的源码有助于了解文本预处理过程,包括分词、去除停用词等。 - 探究查询解析器的实现,掌握如何将自然语言转化为...
开发者可以查看和修改源代码,了解索引构建、查询解析、搜索执行等核心流程,这对于开发自定义的搜索引擎或扩展现有功能非常有用。通过学习CLucene,你可以掌握如何在C++中实现高效的文本分析、索引构建和搜索策略。...
由于描述中提到“已编译,不含源代码”,这意味着提供的文件是编译后的二进制版本,用户可以直接在.NET环境中使用,而无需自行编译源代码。 Lucene.Net的核心功能包括: 1. **全文检索**:Lucene.Net支持对文本...
1. **Lucene概述**: Lucene是Apache软件基金会的一个开放源代码项目,它是Java语言编写的信息检索库。它提供了高级的索引和搜索功能,支持分词、布尔运算、短语搜索、近似搜索等多种搜索模式。 2. **Lucene核心组件...
这个源代码版本代表了Lucene 3.x系列的最后一个稳定版本,为开发者提供了深入理解Lucene内部机制的宝贵资源。下面将详细探讨Lucene 3.6.2中的关键知识点。 1. **分词器(Tokenizers)**: Lucene的核心功能之一是...
《深入理解Lucene 3.0.1:库与源代码解析》 Lucene是一个开源全文搜索引擎库,由Apache软件基金会开发并维护。这个“lucene-3.0.1”版本代表了Lucene在2009年的一个重要里程碑,它提供了强大的文本检索功能,被广泛...
Lucene是Apache软件基金会的一个开放源代码项目,它是一个全文搜索引擎库,提供了文本分析、索引和搜索的基本功能。 1. **Lucene简介** Lucene是一个高性能、全文本检索库,可集成到各种系统中,用于构建强大的...
通过阅读和分析源代码,我们可以学习到如何操作Lucene索引,以及如何构建类似的工具。 总结而言,luke作为Lucene索引的可视化工具,极大地便利了开发者对索引的理解和调试。无论是初学者还是经验丰富的开发人员,都...
开放源代码的全文检索引擎Lucene是一种强大的工具,用于在大量文本数据中快速、高效地进行搜索。全文检索系统是能够处理文本中任意词汇的搜索,而不仅仅是精确匹配,它通过建立索引来提高查询速度。Lucene是由Apache...
Lucene.Net提供了多种内置分析器,如标准分析器(StandardAnalyzer)、盘古分析器(PanguAnalyzer),也可自定义分析器以满足特定的语言或业务需求。 3. **文档(Document)**:文档是信息的基本单位,可以包含多个...
《Apache Lucene 2.9.4源代码解析》 Apache Lucene是一个开源全文搜索引擎库,由Java编写,被广泛应用于各种搜索应用中...无论是对搜索技术的探索,还是在实际项目中的应用,深入研究Lucene源代码都能带来极大的收益。
Apache License 2.0是一个开放源代码许可,允许商业和非商业用途,但通常需要保留版权和许可信息。 3. **README.txt**:一般提供关于如何安装、配置和使用软件的基本指南,有时也会包含一些开发团队的信息和项目...