
┬а
тЅЇУеђ
ТюгТќЄТў»Mahoutт«ъуј░ТјеУЇљу│╗у╗ЪуџётЈѕСИђТАѕСЙІ№╝їућеMahoutТъёт╗║тЏЙС╣дТјеУЇљу│╗у╗ЪсђѓСИјС╣ІтЅЇуџёСИцу»ЄТќЄуФа№╝їТђЮУи»СИіжЮбу▒╗С╝╝№╝їСЙДжЄЇуѓ╣тюеС║јтЏЙС╣дуџёт▒ъТђДтдѓСйЋтѕЕућесђѓТюгТќЄуџёТЋ░ТЇ«тюеУЄфС║јAmazonуйЉуФЎ№╝їућ▒уѕгУЎФТіЊтЈќУјитЙЌсђѓ
уЏ«тйЋ
- жА╣уЏ«УЃїТЎ»
- жюђТ▒ѓтѕєТъљ
- ТЋ░ТЇ«У»┤Тўј
- у«ЌТ│ЋТеАтъІ
- уеІт║Јт╝ђтЈЉ
1. жА╣уЏ«УЃїТЎ»
AmazonТў»ТюђТЌЕуџёућхтГљтЋєтіАуйЉуФЎС╣ІСИђ№╝їС╗ЦуйЉСИітЏЙС╣дУхит«Х№╝їТюђтљјтЈЉт▒ЋТѕљСИ║жЪ│тЃЈ№╝їућхтГљТХѕУ┤╣тЊЂ№╝їТИИТѕЈ№╝їућЪТ┤╗ућетЊЂуГЅуџёу╗╝тљѕТђДућхтГљтЋєтіАт╣│тЈ░сђѓAmazonуџёТјеУЇљу│╗у╗Ъ№╝їТў»С║њУЂћуйЉСИіТюђТЌЕуџётЋєтЊЂТјеУЇљу│╗у╗Ъ№╝їт«ЃСИ║AmazonтИдТЮЦС║єУЄ│т░Љ30%уџёТхЂжЄЈ№╝їтњїтЈ»УДѓуџёжћђтћ«тѕЕТХдсђѓ
тдѓС╗іТјеУЇљу│╗у╗Ъти▓у╗ЈТѕљСИ║ућхтГљтЋєтіАуйЉуФЎуџёТаЄжЁЇ№╝їтдѓТъюУ┐ўТ▓АТюЅТјеУЇљу│╗у╗ЪжЃйСИЇтЦйТёЈТђЮ№╝їУ»┤УЄфти▒Тў»тЂџућхтЋєуџёсђѓ
2. жюђТ▒ѓтѕєТъљ
ТјеУЇљу│╗у╗ЪтдѓТГцжЄЇУдЂ№╝їТѕЉС╗гт║ћУ»ЦтдѓТъюуљєУДБ№╝Ъ
ТЅЊт╝ђAmazonуџёMahout In ActionтЏЙС╣джАхжЮб№╝џ
http://www.amazon.com/Mahout-Action-Sean-Owen/dp/1935182684/ref=pd_sim_b_1?ie=UTF8&refRID=0H4H2NSSR8F34R76E2TP
уйЉжАхСИіуџётЁЃу┤а№╝џ
- т╣┐тЉіСйЇ№╝џт╣┐тЉітЋєТіЋТћЙт╣┐тЉіуџёСйЇуй«№╝їуйЉуФЎтЈ»С╗ЦжЮауйЉу╗ют╣┐тЉіУхџжњ▒№╝їСИђУѕгТў»уйЉжАхТюђтЦйуџёСйЇуй«сђѓ
- т╣│тЮЄтѕє№╝џућеТѕит»╣тЏЙС╣дуџёТЅЊтѕє
- тЁ│УЂћУДётѕЎ№╝џжђџУ┐ЄтЁ│УЂћУДётѕЎ№╝їТјеУЇљСйЇ
- тЇЈтљїУ┐ЄТ╗ц№╝џжђџУ┐ЄтЪ║С║јуЅЕтЊЂуџётЇЈтљїУ┐ЄТ╗цу«ЌТ│Ћуџё№╝їТјеУЇљСйЇ
- тЏЙС╣дт▒ъТђД№╝џтїЁТІгжАхТЋ░№╝їтЄ║уЅѕуцЙ№╝їISBN№╝їУ»ГУеђуГЅ
- СйюУђЁС╗Іу╗Ї№╝џТюЅтЁ│СйюУђЁуџёС╗Іу╗Ї№╝їтњїСйюУђЁуџётЁХС╗ќУЉЌСйю
- ућеТѕиУ»ётѕє№╝џућеТѕиУ»ётѕєУАїСИ║
- ућеТѕиУ»ёУ«║№╝џућеТѕиУ»ёУ«║уџётєЁт«╣
тюеуйЉжАхСИі№╝їтЁХС╗ќуџёТјеУЇљСйЇ№╝џ
у╗ЊтљѕСИіжЮб2т╝аТѕфтЏЙ№╝їТѕЉС╗гСИЇжџЙтЈЉуј░№╝їТјеУЇљт»╣С║јAmazonуџёжЄЇУдЂТђДсђѓжЎцС║єТюђТўјТўЙуџёт╣┐тЉіСйЇу╗ЎС║єУЃйуЏ┤ТјЦтИдТЮЦтѕЕТХдуџёт╣┐тЉітЋє№╝їуйЉжАхСИГТюЅ4тцёТјеУЇљСйЇ№╝їтѕєтѕФС╗јСИЇтљїуџёу╗┤т║д№╝їућеСИЇтљїуџёТјеУЇљу«ЌТ│Ћ№╝їуїюућеТѕитќюТгбуџётЋєтЊЂсђѓ
3. ТЋ░ТЇ«У»┤Тўј
2СИфТЋ░ТЇ«ТќЄС╗Х№╝џ
- rating.csv №╝џућеТѕиУ»ётѕєУАїСИ║ТЋ░ТЇ«
- users.csv №╝џућеТѕит▒ъТђДТЋ░ТЇ«
1). book-ratings.csv
- 3тѕЌТЋ░ТЇ«№╝џућеТѕиID№╝їтЏЙС╣дID, ућеТѕит»╣тЏЙС╣дуџёУ»ётѕє
- У«░тйЋТЋ░: 4000ТгАуџётЏЙС╣дУ»ётѕє
- ућеТѕиТЋ░: 200СИф
- тЏЙС╣дТЋ░: 1000СИф
- У»ётѕє№╝џ1-10
ТЋ░ТЇ«уц║СЙІ
1,565,3
1,807,2
1,201,1
1,557,9
1,987,10
1,59,5
1,305,6
1,153,3
1,139,7
1,875,5
1,722,10
2,977,4
2,806,3
2,654,8
2,21,8
2,662,5
2,437,6
2,576,3
2,141,8
2,311,4
2,101,3
2,540,9
2,87,3
2,65,8
2,501,6
2,710,5
2,331,9
2,542,4
2,757,9
2,590,7
2). users.csv
- 3тѕЌТЋ░ТЇ«№╝џућеТѕиID№╝їућеТѕиТђДтѕФ№╝їућеТѕит╣┤жЙё
- ућеТѕиТЋ░: 200СИф
- ућеТѕиТђДтѕФ: MСИ║ућиТђД№╝їFСИ║тЦ│ТђД
- ућеТѕит╣┤жЙё: 11-80т▓ЂС╣ІжЌ┤
ТЋ░ТЇ«уц║СЙІ
1,M,40
2,M,27
3,M,41
4,F,43
5,F,16
6,M,36
7,F,36
8,F,46
9,M,50
10,M,21
11,F,11
12,M,42
13,F,40
14,F,28
15,M,25
16,M,68
17,M,53
18,F,69
19,F,48
20,F,56
21,F,36
4. у«ЌТ│ЋТеАтъІ
ТюгТќЄСИ╗УдЂС╗Іу╗ЇMahoutуџётЪ║С║јуЅЕтЊЂуџётЇЈтљїУ┐ЄТ╗цТеАтъІ№╝їтЁХС╗ќуџёу«ЌТ│ЋТеАтъІт░єСИЇтєЇУ┐ЎжЄїУДБжЄісђѓ
жњѕт»╣СИіжЮбуџёТЋ░ТЇ«№╝їТѕЉт░єуће7уДЇу«ЌТ│Ћу╗ётљѕУ┐ЏУАїТхІУ»Ћ№╝џТюЅтЁ│Mahoutу«ЌТ│Ћу╗ётљѕуџёУ»ду╗єУДБжЄі№╝їУ»итЈѓУђЃТќЄуФа№╝џС╗јТ║љС╗БуаЂтЅќТъљMahoutТјеУЇљт╝ЋТЊј
7уДЇу«ЌТ│Ћу╗ётљѕ
- userCF1: EuclideanSimilarity+ NearestNUserNeighborhood+ GenericUserBasedRecommender
- userCF2: LogLikelihoodSimilarity+ NearestNUserNeighborhood+ GenericUserBasedRecommender
- userCF3: EuclideanSimilarity+ NearestNUserNeighborhood+ GenericBooleanPrefUserBasedRecommender
- itemCF1: EuclideanSimilarity + GenericItemBasedRecommender
- itemCF2: LogLikelihoodSimilarity + GenericItemBasedRecommender
- itemCF3: EuclideanSimilarity + GenericBooleanPrefItemBasedRecommender
- slopeOne№╝џSlopeOneRecommender
т»╣СИіжЮбуџёу«ЌТ│ЋУ┐ЏУАїу«ЌТ│ЋУ»ёС╝░№╝їТюЅтЁ│С║ју«ЌТ│ЋУ»ёС╝░уџёУ»ду╗єУДБжЄі№╝їУ»итЈѓУђЃТќЄуФа№╝џMahoutТјеУЇљу«ЌТ│ЋAPIУ»дУДБ
- ТЪЦтЄєујЄ:
- тЈгтЏъујЄ(ТЪЦтЁеујЄ):
5. уеІт║Јт╝ђтЈЉ
у│╗у╗ЪТъХТъё№╝џMahoutСИГТјеУЇљУ┐ЄТ╗цу«ЌТ│ЋТћ»ТїЂтЇЋТю║у«ЌТ│ЋтњїтѕєТГЦт╝Ју«ЌТ│ЋСИцуДЇсђѓ
- тЇЋТю║у«ЌТ│Ћ: тюетЇЋТю║тєЁтГўУ«Ау«Ќ№╝їТћ»ТїЂтцџуДЇу«ЌТ│ЋТјеУЇљу«ЌТ│Ћ№╝їжЃеуй▓У┐љУАїу«ђтЇЋ№╝їС┐«ТГБтцёуљєТЋ░ТЇ«жЄЈТюЅжЎљ
- тѕєТГЦт╝Ју«ЌТ│Ћ: тЪ║С║јHadoopжЏєуЙцУ┐љУАї№╝їТћ»ТїЂТюЅжЎљуџётЄауДЇТјеУЇљу«ЌТ│Ћ№╝їжЃеуй▓У┐љУАїтцЇТЮѓ№╝їТћ»ТїЂТхижЄЈТЋ░ТЇ«
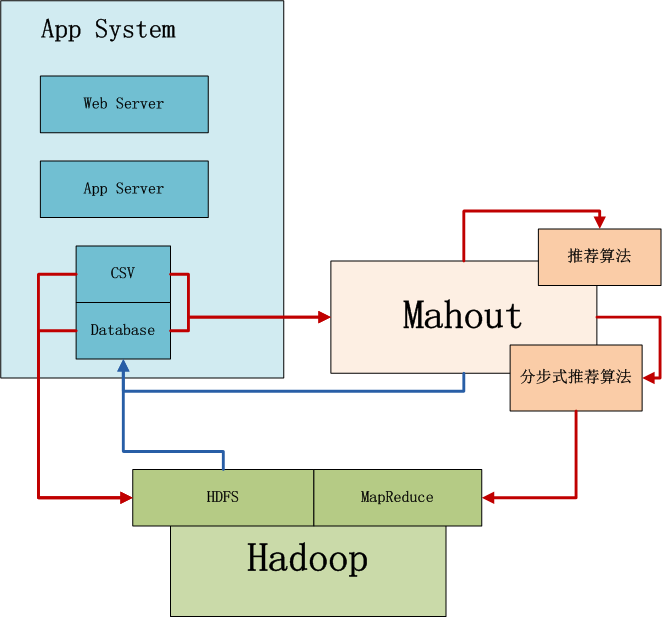
т╝ђтЈЉуј»тбЃ
- Win7 64bit
- Java 1.6.0_45
- Maven3
- Eclipse Juno Service Release 2
- Mahout-0.8
- Hadoop-1.1.2
т╝ђтЈЉуј»тбЃmahoutуЅѕТюгСИ║0.8сђѓ У»итЈѓУђЃТќЄуФа№╝џућеMavenТъёт╗║MahoutжА╣уЏ«
Тќ░т╗║Javaу▒╗№╝џ
- BookEvaluator.java, жђЅтЄ║РђюУ»ёС╝░ТјеУЇљтЎеРђЮжфїУ»ЂтЙЌтѕєУЙЃжФўуџёу«ЌТ│Ћ
- BookResult.java, т»╣ТїЄт«џТЋ░жЄЈуџёу╗ЊТъюС║║тиЦТ»ћУЙЃ
- BookFilterGenderResult.java№╝їтЈфС┐ЮуЋЎућиТђДућеТѕиуџётЏЙС╣дтѕЌУАе
1). BookEvaluator.java, жђЅтЄ║РђюУ»ёС╝░ТјеУЇљтЎеРђЮжфїУ»ЂтЙЌтѕєУЙЃжФўуџёу«ЌТ│Ћ
Т║љС╗БуаЂ
package org.conan.mymahout.recommendation.book;
import java.io.IOException;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.eval.RecommenderBuilder;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood;
import org.apache.mahout.cf.taste.similarity.ItemSimilarity;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
public class BookEvaluator {
final static int NEIGHBORHOOD_NUM = 2;
final static int RECOMMENDER_NUM = 3;
public static void main(String[] args) throws TasteException, IOException {
String file = "datafile/book/rating.csv";
DataModel dataModel = RecommendFactory.buildDataModel(file);
userEuclidean(dataModel);
userLoglikelihood(dataModel);
userEuclideanNoPref(dataModel);
itemEuclidean(dataModel);
itemLoglikelihood(dataModel);
itemEuclideanNoPref(dataModel);
slopeOne(dataModel);
}
public static RecommenderBuilder userEuclidean(DataModel dataModel) throws TasteException, IOException {
System.out.println("userEuclidean");
UserSimilarity userSimilarity = RecommendFactory.userSimilarity(RecommendFactory.SIMILARITY.EUCLIDEAN, dataModel);
UserNeighborhood userNeighborhood = RecommendFactory.userNeighborhood(RecommendFactory.NEIGHBORHOOD.NEAREST, userSimilarity, dataModel, NEIGHBORHOOD_NUM);
RecommenderBuilder recommenderBuilder = RecommendFactory.userRecommender(userSimilarity, userNeighborhood, true);
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
return recommenderBuilder;
}
public static RecommenderBuilder userLoglikelihood(DataModel dataModel) throws TasteException, IOException {
System.out.println("userLoglikelihood");
UserSimilarity userSimilarity = RecommendFactory.userSimilarity(RecommendFactory.SIMILARITY.LOGLIKELIHOOD, dataModel);
UserNeighborhood userNeighborhood = RecommendFactory.userNeighborhood(RecommendFactory.NEIGHBORHOOD.NEAREST, userSimilarity, dataModel, NEIGHBORHOOD_NUM);
RecommenderBuilder recommenderBuilder = RecommendFactory.userRecommender(userSimilarity, userNeighborhood, true);
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
return recommenderBuilder;
}
public static RecommenderBuilder userEuclideanNoPref(DataModel dataModel) throws TasteException, IOException {
System.out.println("userEuclideanNoPref");
UserSimilarity userSimilarity = RecommendFactory.userSimilarity(RecommendFactory.SIMILARITY.EUCLIDEAN, dataModel);
UserNeighborhood userNeighborhood = RecommendFactory.userNeighborhood(RecommendFactory.NEIGHBORHOOD.NEAREST, userSimilarity, dataModel, NEIGHBORHOOD_NUM);
RecommenderBuilder recommenderBuilder = RecommendFactory.userRecommender(userSimilarity, userNeighborhood, false);
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
return recommenderBuilder;
}
public static RecommenderBuilder itemEuclidean(DataModel dataModel) throws TasteException, IOException {
System.out.println("itemEuclidean");
ItemSimilarity itemSimilarity = RecommendFactory.itemSimilarity(RecommendFactory.SIMILARITY.EUCLIDEAN, dataModel);
RecommenderBuilder recommenderBuilder = RecommendFactory.itemRecommender(itemSimilarity, true);
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
return recommenderBuilder;
}
public static RecommenderBuilder itemLoglikelihood(DataModel dataModel) throws TasteException, IOException {
System.out.println("itemLoglikelihood");
ItemSimilarity itemSimilarity = RecommendFactory.itemSimilarity(RecommendFactory.SIMILARITY.LOGLIKELIHOOD, dataModel);
RecommenderBuilder recommenderBuilder = RecommendFactory.itemRecommender(itemSimilarity, true);
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
return recommenderBuilder;
}
public static RecommenderBuilder itemEuclideanNoPref(DataModel dataModel) throws TasteException, IOException {
System.out.println("itemEuclideanNoPref");
ItemSimilarity itemSimilarity = RecommendFactory.itemSimilarity(RecommendFactory.SIMILARITY.EUCLIDEAN, dataModel);
RecommenderBuilder recommenderBuilder = RecommendFactory.itemRecommender(itemSimilarity, false);
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
return recommenderBuilder;
}
public static RecommenderBuilder slopeOne(DataModel dataModel) throws TasteException, IOException {
System.out.println("slopeOne");
RecommenderBuilder recommenderBuilder = RecommendFactory.slopeOneRecommender();
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
return recommenderBuilder;
}
}
ТјДтѕХтЈ░УЙЊтЄ║№╝џ
userEuclidean
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:0.33333325386047363
Recommender IR Evaluator: [Precision:0.3010752688172043,Recall:0.08542713567839195]
userLoglikelihood
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:2.5245869159698486
Recommender IR Evaluator: [Precision:0.11764705882352945,Recall:0.017587939698492466]
userEuclideanNoPref
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:4.288461538461536
Recommender IR Evaluator: [Precision:0.09045226130653267,Recall:0.09296482412060306]
itemEuclidean
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:1.408880928305655
Recommender IR Evaluator: [Precision:0.0,Recall:0.0]
itemLoglikelihood
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:2.448554412835434
Recommender IR Evaluator: [Precision:0.0,Recall:0.0]
itemEuclideanNoPref
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:2.5665197873957957
Recommender IR Evaluator: [Precision:0.6005025125628134,Recall:0.6055276381909548]
slopeOne
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:2.6893078179405814
Recommender IR Evaluator: [Precision:0.0,Recall:0.0]
тЈ»УДєтїќРђюУ»ёС╝░ТјеУЇљтЎеРђЮУЙЊтЄ║№╝џ
ТјеУЇљуџёу╗ЊТъюуџёт╣│тЮЄУиЮуд╗
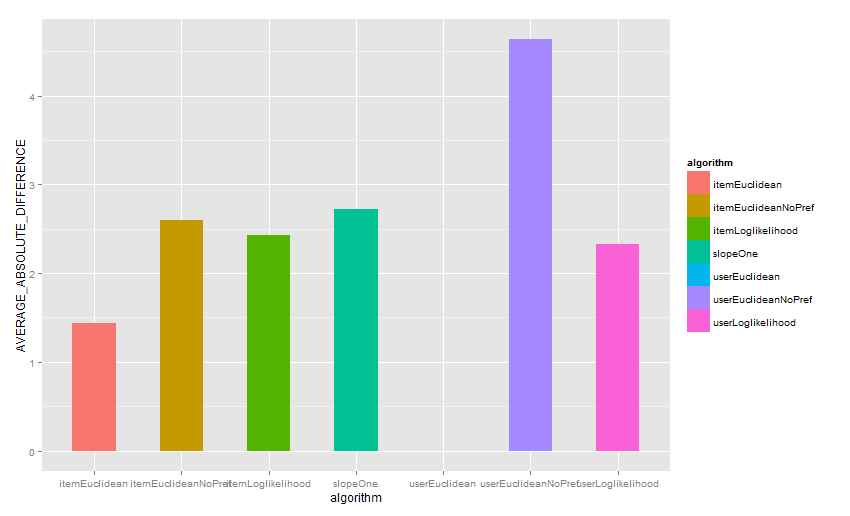
ТјеУЇљтЎеуџёУ»ётѕє
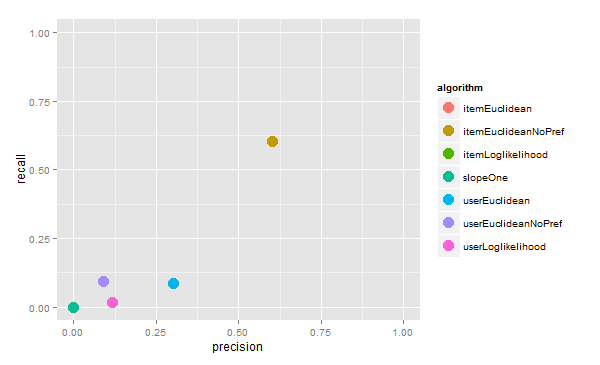
тЈфТюЅitemEuclideanNoPrefу«ЌТ│ЋУ»ёС╝░уџёу╗ЊТъюТў»жЮътИИтЦйуџё№╝їтЁХС╗ќу«ЌТ│Ћуџёу╗ЊТъюжЃйСИЇтцфтЦйсђѓ
2). BookResult.java, т»╣ТїЄт«џТЋ░жЄЈуџёу╗ЊТъюС║║тиЦТ»ћУЙЃ
СИ║тЙЌтѕ░ти«т╝ѓтїќу╗ЊТъю№╝їТѕЉС╗гтѕєтѕФтЈќ4СИфу«ЌТ│Ћ№╝џuserEuclidean,itemEuclidean№╝їuserEuclideanNoPref№╝їitemEuclideanNoPref№╝їт»╣ТјеУЇљу╗ЊТъюС║║тиЦТ»ћУЙЃсђѓ
Т║љС╗БуаЂ
package org.conan.mymahout.recommendation.book;
import java.io.IOException;
import java.util.List;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.eval.RecommenderBuilder;
import org.apache.mahout.cf.taste.impl.common.LongPrimitiveIterator;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
public class BookResult {
final static int NEIGHBORHOOD_NUM = 2;
final static int RECOMMENDER_NUM = 3;
public static void main(String[] args) throws TasteException, IOException {
String file = "datafile/book/rating.csv";
DataModel dataModel = RecommendFactory.buildDataModel(file);
RecommenderBuilder rb1 = BookEvaluator.userEuclidean(dataModel);
RecommenderBuilder rb2 = BookEvaluator.itemEuclidean(dataModel);
RecommenderBuilder rb3 = BookEvaluator.userEuclideanNoPref(dataModel);
RecommenderBuilder rb4 = BookEvaluator.itemEuclideanNoPref(dataModel);
LongPrimitiveIterator iter = dataModel.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
System.out.print("userEuclidean =>");
result(uid, rb1, dataModel);
System.out.print("itemEuclidean =>");
result(uid, rb2, dataModel);
System.out.print("userEuclideanNoPref =>");
result(uid, rb3, dataModel);
System.out.print("itemEuclideanNoPref =>");
result(uid, rb4, dataModel);
}
}
public static void result(long uid, RecommenderBuilder recommenderBuilder, DataModel dataModel) throws TasteException {
List list = recommenderBuilder.buildRecommender(dataModel).recommend(uid, RECOMMENDER_NUM);
RecommendFactory.showItems(uid, list, false);
}
}
ТјДтѕХтЈ░УЙЊтЄ║№╝џтЈфТѕфтЈќжЃетѕєу╗ЊТъю
...
userEuclidean =>uid:63,
itemEuclidean =>uid:63,(984,9.000000)(690,9.000000)(943,8.875000)
userEuclideanNoPref =>uid:63,(4,1.000000)(723,1.000000)(300,1.000000)
itemEuclideanNoPref =>uid:63,(867,3.791667)(947,3.083333)(28,2.750000)
userEuclidean =>uid:64,
itemEuclidean =>uid:64,(368,8.615385)(714,8.200000)(290,8.142858)
userEuclideanNoPref =>uid:64,(860,1.000000)(490,1.000000)(64,1.000000)
itemEuclideanNoPref =>uid:64,(409,3.950000)(715,3.830627)(901,3.444048)
userEuclidean =>uid:65,(939,7.000000)
itemEuclidean =>uid:65,(550,9.000000)(334,9.000000)(469,9.000000)
userEuclideanNoPref =>uid:65,(939,2.000000)(185,1.000000)(736,1.000000)
itemEuclideanNoPref =>uid:65,(666,4.166667)(96,3.093931)(345,2.958333)
userEuclidean =>uid:66,
itemEuclidean =>uid:66,(971,9.900000)(656,9.600000)(918,9.577709)
userEuclideanNoPref =>uid:66,(6,1.000000)(492,1.000000)(676,1.000000)
itemEuclideanNoPref =>uid:66,(185,3.650000)(533,3.617307)(172,3.500000)
userEuclidean =>uid:67,
itemEuclidean =>uid:67,(663,9.700000)(987,9.625000)(486,9.600000)
userEuclideanNoPref =>uid:67,(732,1.000000)(828,1.000000)(113,1.000000)
itemEuclideanNoPref =>uid:67,(724,3.000000)(279,2.950000)(890,2.750000)
...
ТѕЉС╗гТЪЦуюІuid=65уџёућеТѕиТјеУЇљС┐АТЂ»№╝џ
ТЪЦуюІuser.csvТЋ░ТЇ«жЏє
> user[65,]
userid gender age
65 65 M 14
ућеТѕи65№╝їућиТђД№╝ї14т▓Ђсђѓ
С╗ЦitemEuclideanNoPrefуџёу«ЌТ│ЋуџёТјеУЇљу╗ЊТъю№╝їТЪЦуюІbookid=666уџётЏЙС╣дУ»ётѕєТЃЁтєх
> rating[which(rating$bookid==666),]
userid bookid pref
646 44 666 10
1327 89 666 7
2470 165 666 3
2697 179 666 7
тЈЉуј░ТюЅ4СИфућеТѕит»╣666уџётЏЙС╣дУ»ётѕє№╝їТЪЦуюІУ┐Ў4СИфућеТѕиуџёт▒ъТђДТЋ░ТЇ«
> user[c(44,89,165,179),]
userid gender age
44 44 F 76
89 89 M 40
165 165 F 59
179 179 F 68
У┐Ў4СИфућеТѕи№╝ї3тЦ│1ућисђѓ
ТѕЉС╗гтЂЄУ«ЙућиТђДтњїућиТђДТюЅуЏИтљїуџётЏЙС╣дтЁ┤УХБ№╝їтЦ│ТђДтњїтЦ│ТђДТюЅуЏИтљїуџётЏЙС╣дтЂЈтЦйсђѓтЏаСИ║ућеТѕи65Тў»ућиТђД№╝їТЅђС╗ЦТѕЉС╗гТјЦСИІТЮЦТјњжЎцтЦ│ТђДуџёУ»ётѕєУђЁ№╝їтЈфС┐ЮуЋЎућиТђДУ»ётѕєУђЁуџёУ»ётѕєУ«░тйЋсђѓ
3). BookFilterGenderResult.java№╝їтЈфС┐ЮуЋЎућиТђДућеТѕиуџётЏЙС╣дтѕЌУАе
Т║љС╗БуаЂ
package org.conan.mymahout.recommendation.book;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.eval.RecommenderBuilder;
import org.apache.mahout.cf.taste.impl.common.LongPrimitiveIterator;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.recommender.IDRescorer;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
public class BookFilterGenderResult {
final static int NEIGHBORHOOD_NUM = 2;
final static int RECOMMENDER_NUM = 3;
public static void main(String[] args) throws TasteException, IOException {
String file = "datafile/book/rating.csv";
DataModel dataModel = RecommendFactory.buildDataModel(file);
RecommenderBuilder rb1 = BookEvaluator.userEuclidean(dataModel);
RecommenderBuilder rb2 = BookEvaluator.itemEuclidean(dataModel);
RecommenderBuilder rb3 = BookEvaluator.userEuclideanNoPref(dataModel);
RecommenderBuilder rb4 = BookEvaluator.itemEuclideanNoPref(dataModel);
long uid = 65;
System.out.print("userEuclidean =>");
filterGender(uid, rb1, dataModel);
System.out.print("itemEuclidean =>");
filterGender(uid, rb2, dataModel);
System.out.print("userEuclideanNoPref =>");
filterGender(uid, rb3, dataModel);
System.out.print("itemEuclideanNoPref =>");
filterGender(uid, rb4, dataModel);
}
/**
* т»╣ућеТѕиТђДтѕФУ┐ЏУАїУ┐ЄТ╗ц
*/
public static void filterGender(long uid, RecommenderBuilder recommenderBuilder, DataModel dataModel) throws TasteException, IOException {
Set userids = getMale("datafile/book/user.csv");
//У«Ау«ЌућиТђДућеТѕиТЅЊтѕєУ┐ЄуџётЏЙС╣д
Set bookids = new HashSet();
for (long uids : userids) {
LongPrimitiveIterator iter = dataModel.getItemIDsFromUser(uids).iterator();
while (iter.hasNext()) {
long bookid = iter.next();
bookids.add(bookid);
}
}
IDRescorer rescorer = new FilterRescorer(bookids);
List list = recommenderBuilder.buildRecommender(dataModel).recommend(uid, RECOMMENDER_NUM, rescorer);
RecommendFactory.showItems(uid, list, false);
}
/**
* УјитЙЌућиТђДућеТѕиID
*/
public static Set getMale(String file) throws IOException {
BufferedReader br = new BufferedReader(new FileReader(new File(file)));
Set userids = new HashSet();
String s = null;
while ((s = br.readLine()) != null) {
String[] cols = s.split(",");
if (cols[1].equals("M")) {// тѕцТќГућиТђДућеТѕи
userids.add(Long.parseLong(cols[0]));
}
}
br.close();
return userids;
}
}
/**
* т»╣у╗ЊТъюжЄЇУ«Ау«Ќ
*/
class FilterRescorer implements IDRescorer {
final private Set userids;
public FilterRescorer(Set userids) {
this.userids = userids;
}
@Override
public double rescore(long id, double originalScore) {
return isFiltered(id) ? Double.NaN : originalScore;
}
@Override
public boolean isFiltered(long id) {
return userids.contains(id);
}
}
ТјДтѕХтЈ░УЙЊтЄ║:
userEuclidean =>uid:65,
itemEuclidean =>uid:65,(784,8.090909)(276,8.000000)(476,7.666667)
userEuclideanNoPref =>uid:65,
itemEuclideanNoPref =>uid:65,(887,2.250000)(356,2.166667)(430,1.866667)
ТѕЉС╗гтЈЉуј░№╝їућ▒С║јтЈфС┐ЮуЋЎућиТђДуџёУ»ётѕєУ«░тйЋ№╝їТЋ░ТЇ«жЄЈт░▒тЈўтЙЌТ»ћУЙЃт░ЉС║є№╝їтЪ║С║јућеТѕиуџётЇЈтљїУ┐ЄТ╗цу«ЌТ│Ћ№╝їти▓у╗ЈТ▓АТюЅУЙЊтЄ║уџёу╗ЊТъюС║єсђѓтЪ║С║јуЅЕтЊЂуџётЇЈтљїУ┐ЄТ╗цу«ЌТ│Ћ№╝їу╗ЊТъюжЏєС╣ЪТюЅТЅђтЈўтїќсђѓ
т»╣С║јitemEuclideanNoPrefу«ЌТ│Ћ№╝їУЙЊтЄ║ТјњтљЇуггСИђТЮАСИ║IDСИ║887уџётЏЙС╣дсђѓ
ТѕЉтєЇУ┐ЏСИђТГЦтљЉСИІУ┐йУИф№╝џТЪЦУ»бтЊфС║ЏућеТѕит»╣тЏЙС╣д887У┐ЏУАїС║єТЅЊтѕєсђѓ
> rating[which(rating$bookid==887),]
userid bookid pref
1280 85 887 2
1743 119 887 8
2757 184 887 4
2791 186 887 5
ТюЅ4СИфућеТѕит»╣тЏЙС╣д887У»ётѕє№╝їтєЇтѕєтѕФТЪЦуюІУ┐ЎСИфућеТѕиуџёт▒ъТђД
> user[c(85,119,184,186),]
userid gender age
85 85 F 31
119 119 F 49
184 184 M 27
186 186 M 35
тЁХСИГ2ући№╝ї2тЦ│сђѓућ▒С║јТѕЉС╗гуџёу«ЌТ│Ћ№╝їти▓у╗ЈТјњжЎцС║єтЦ│ТђДуџёУ»ётѕє№╝їТѕЉС╗гтЈ»С╗ЦТјеТќГтЏЙС╣д887уџёТјеУЇљт║ћУ»ЦТЮЦУЄфС║ј2СИфућиТђДуџёУ»ётѕєУђЁуџёТјеУЇљсђѓ
тѕєтѕФУ«Ау«ЌућеТѕи65№╝їСИјућеТѕи184тњїућеТѕи186уџёУ»ётѕєуџётЏЙС╣дС║цжЏєсђѓ
rat65<-rating[which(rating$userid==65),]
rat184<-rating[which(rating$userid==184),]
rat186<-rating[which(rating$userid==186),]
> intersect(rat65$bookid ,rat184$bookid)
integer(0)
> intersect(rat65$bookid ,rat186$bookid)
[1] 65 375
ТюђтљјтЈЉуј░№╝їућеТѕи65СИјућеТѕи186жЃйу╗ЎтЏЙС╣д65тњїтЏЙС╣д375ТЅЊУ┐ЄтѕєсђѓТѕЉС╗гтєЇТЅЊтѕєтЄ║ућеТѕи186уџёУ»ётѕєУ«░тйЋсђѓ
> rat186
userid bookid pref
2790 186 65 7
2791 186 887 5
2792 186 529 3
2793 186 375 6
2794 186 566 7
2795 186 169 4
2796 186 907 1
2797 186 821 2
2798 186 720 5
2799 186 642 5
2800 186 137 3
2801 186 744 1
2802 186 896 2
2803 186 156 6
2804 186 392 3
2805 186 386 3
2806 186 901 7
2807 186 69 6
2808 186 845 6
2809 186 998 3
ућеТѕи186№╝їУ┐ўу╗ЎтЏЙС╣д887ТЅЊУ┐Єтѕє№╝їТЅђС╗Цт»╣С║ју╗Ў65ућеТѕиТјеУЇљтЏЙС╣д887№╝їТў»тљѕуљєуџёсђѓ
ТѕЉС╗гжђџУ┐ЄСИђСИфт«ъжЎЁуџётЏЙС╣дТјеУЇљуџёТАѕСЙІ№╝їТЏ┤У┐ЏСИђТГЦтю░С║єУДБС║єтдѓСйЋућеMahoutТъёт╗║ТјеУЇљу│╗у╗Ъсђѓ
УйгУййУ»иТ│еТўјтЄ║тцё№╝џ
http://blog.fens.me/hadoop-mahout-recommend-book/



уЏИтЁ│ТјеУЇљ
У┐ЎжЄїТѕЉС╗гтЁ│Т│еуџёТў»СИђСИфтЪ║С║јApache Mahoutт«ъуј░уџётЏЙС╣дТјеУЇљу│╗у╗ЪсђѓMahoutТў»СИђСИфТхЂУАїуџёт╝ђТ║љТю║тЎетГдС╣ат║Њ№╝їуЅ╣тѕФжђѓућеС║јТъёт╗║тцДУДёТеАуџёТјеУЇљу│╗у╗Ъсђѓ ждќтЁѕ№╝їТѕЉС╗гжюђУдЂС║єУДБтЇЈтљїУ┐ЄТ╗цуџётЪ║ТюгТдѓт┐хсђѓтЇЈтљїУ┐ЄТ╗цТў»СИђуДЇТјеУЇљу│╗у╗ЪуџёТќ╣Т│Ћ№╝їт«ЃСИ╗УдЂ...
ТюгжА╣уЏ«СИ╗УдЂТјбУ«еС║єтдѓСйЋтѕЕућеJavaу╝ќуеІУ»ГУеђС╗ЦтЈіApache MahoutТАєТъХТЮЦТъёт╗║СИђСИфтЏЙС╣дТјеУЇљу│╗у╗Ъ№╝їУ»Цу│╗у╗ЪУ┐љућеС║єтЇЈтљїУ┐ЄТ╗цТјеУЇљу«ЌТ│Ћ№╝їТЌетюеСИ║ућеТѕиТЈљСЙЏСИфТђДтїќуџётЏЙС╣дТјеУЇљТюЇтіАсђѓтЇЈтљїУ┐ЄТ╗цТў»СИђуДЇт╣┐Т│Џт║ћућеС║јТјеУЇљу│╗у╗ЪСИГуџёТю║тЎетГдС╣ау«ЌТ│Ћ№╝їтЁХ...
сђљТаЄжбўсђЉСИГуџёРђютЪ║С║јhadoopт«ъуј░уџётЏЙС╣дТјеУЇљу│╗у╗ЪРђЮТїЄуџёТў»Сй┐ућеHadoopУ┐ЎСИђт╝ђТ║љтцДТЋ░ТЇ«тцёуљєТАєТъХТЮЦТъёт╗║СИђСИфУЃйтцЪСИ║ућеТѕиТјеУЇљтЏЙС╣дуџёу│╗у╗ЪсђѓHadoopТў»ApacheУй»С╗ХтЪ║жЄЉС╝џт╝ђтЈЉуџётѕєтИЃт╝ЈтГўтѓетњїУ«Ау«Ќт╣│тЈ░№╝їт«ЃтЁЂУ«ИжФўТЋѕтю░тцёуљєТхижЄЈТЋ░ТЇ«№╝їт░цтЁХ...
ТюгжА╣уЏ«С╗ЦJavaТіђТю»ТаѕСИ║тЪ║уАђ№╝їу╗ЊтљѕSpringBootТАєТъХтњїSSM№╝ѕSpringсђЂSpringMVCсђЂMyBatis№╝ЅТъХТъё№╝їТъёт╗║С║єСИђСИфтЪ║С║јSSMтЇЈтљїУ┐ЄТ╗цу«ЌТ│ЋуџётЏЙС╣дТјеУЇљу│╗у╗Ъсђѓ 1. **SSMТъХТъёУ»дУДБ** SSMТў»Java Webт╝ђтЈЉСИГуџёСИ╗ТхЂТАєТъХу╗ётљѕ№╝їућ▒SpringТАєТъХ...
сђіMahout in ActionсђІСИГТќЄуЅѕТў»СИђжЃеУ»ду╗єС╗Іу╗ЇApache Mahoutуџёт«ъУихТђДтЏЙС╣д№╝їТЌетюетИ«тіЕУ»╗УђЁуљєУДБтњїт║ћућеУ┐ЎСИфт╝║тцДуџёТю║тЎетГдС╣ат║ЊсђѓApache MahoutТў»СИђСИфт╝ђТ║љжА╣уЏ«№╝їСИЊТ│еС║јТю║тЎетГдС╣ау«ЌТ│Ћуџёт«ъуј░№╝їт░цтЁХтюетЇЈтљїУ┐ЄТ╗цсђЂУЂџу▒╗тњїтѕєу▒╗Тќ╣жЮбсђѓУ┐Ў...
тЇЈтљїУ┐ЄТ╗цТјеУЇљу«ЌТ│ЋТў»СИђуДЇт╣┐Т│Џт║ћућеС║јСИфТђДтїќТјеУЇљу│╗у╗ЪСИГуџёТќ╣Т│Ћ№╝їт░цтЁХтюежЪ│С╣љсђЂућхтй▒тњїтЏЙС╣дуГЅжбєтЪЪТЋѕТъюТўЙУЉЌсђѓУ»Цу«ЌТ│ЋтЪ║С║јућеТѕиуџётјєтЈ▓УАїСИ║№╝їтдѓУ»ётѕєсђЂТћХУЌЈуГЅ№╝їТЮЦжбёТхІС╗ќС╗гтЈ»УЃйт»╣ТюфТјЦУДдУ┐ЄуџётєЁт«╣уџётЁ┤УХБсђѓС╗ЦСИІТў»т»╣У»Цу«ЌТ│ЋтЈітЁХС╗БуаЂт«ъуј░...
1. тиЦтЁиС╣д№╝џтїЁТІгDockerсђЂZookeeperсђЂSparkсђЂHadoopтњїMahoutуГЅуЏИтЁ│С╣ду▒Ї№╝їТЈљСЙЏуљєУ«║ТїЄт»╝сђѓ 2. т«ъжфїуј»тбЃ№╝џжЁЇтцЄт┐ЁУдЂуџёуАгС╗ХУ«ЙтцЄ№╝їтдѓУБЁТюЅJDK1.7сђЂeclipseсђЂTomcat7.0сђЂCentosсђЂCDHуџёУ«Ау«ЌТю║сђѓ 3. УхёТ║љУјитЈќ№╝џтѕЕућеуйЉу╗ютњїтЏЙС╣д...
- **ТјеУЇљу│╗у╗Ъ**№╝џу╗ЊтљѕHadoopСИјMahout№╝їт«ъуј░тЪ║С║јућеТѕиУАїСИ║уџёТјеУЇљу«ЌТ│Ћ№╝їтГдС╣атЇЈтљїУ┐ЄТ╗цтњїтЁ│УЂћУДётѕЎТїќТјўсђѓ 4. **уД╗тіет╝ђтЈЉ** - **Androidт║ћућет╝ђтЈЉ**№╝џт╝ђтЈЉу«ђтЇЋуџёAndroidт║ћуће№╝їтдѓтцЕТ░ћТЪЦУ»бсђЂТќ░жЌ╗жўЁУ»╗№╝їТјїТЈАAndroid SDKтњї...
тюеУ┐ЎСИфжА╣уЏ«СИГ№╝їСйат░єтГдС╣атдѓСйЋт«ъуј░тЪ║С║јJavaуџётЏЙС╣дТЋ░ТЇ«т║Њу│╗у╗Ъ№╝їС╗ЦтЈітдѓСйЋУ«ЙУ«АтЈІтЦйуџёућеТѕиуЋїжЮбсђѓ 8. **AppJXC**№╝џУ┐ЎтЈ»УЃйТў»СИђСИфУ┐ЏжћђтГўу│╗у╗Ъ№╝їућеС║ју«АуљєтЋєтЊЂуџёжЄЄУ┤ГсђЂжћђтћ«тњїт║ЊтГўсђѓжА╣уЏ«т░єТХЅтЈіт║ЊтГўу«АуљєсђЂУ«бтЇЋтцёуљєсђЂТіЦУАеућЪТѕљуГЅ№╝ї...
ТЋЎТЮљжђЅућеУЄфу╝ќуџёсђіHadoopтцДТЋ░ТЇ«ТіђТю»СИјт║ћућесђІ№╝їт╣ХТјеУЇљС║єTom WhiteуџёсђіHadoopТЮЃтеЂТїЄтЇЌсђІтњїТъЌтГљжЏеуџёсђітцДТЋ░ТЇ«ТіђТю»тјЪуљєСИјт║ћућесђІСйюСИ║тЈѓУђЃС╣дсђѓжђџУ┐ЄУ┐ЎжЌеУ»ЙуеІ№╝їтГдућЪт░єтЁежЮбС║єУДБтњїТјїТЈАHadoopтцДТЋ░ТЇ«тцёуљєуџёТаИт┐ЃТіђТю»тњїт║ћућесђѓ
У»ЙуеІуџёуЪЦУ»єуЏ«ТаЄтїЁТІгТјїТЈАHadoopТАєТъХ№╝їУЃйуІгуФІТљГт╗║Hadoopуј»тбЃ№╝їуљєУДБHDFSтњїMapReduceуџётиЦСйютјЪуљє№╝їуєЪТѓЅHadoopућЪТђЂу│╗у╗ЪСИГуџётЁ│жћ«у╗ёС╗ХтдѓYARNсђЂHBaseсђЂHiveсђЂPigсђЂFlumeсђЂSqoopсђЂAmbariсђЂZookeeperтњїMahoutсђѓТГцтцќ№╝їтГдућЪт║ћтЁитцЄ...
- **ТаИт┐Ѓу╗ёС╗Х**№╝џтїЁТІгСйєСИЇжЎљС║јMahoutТю║тЎетГдС╣асђЂRУ»ГУеђсђЂHadoopућЪТђЂу│╗у╗ЪуџётљёСИфу╗ёС╗ХуГЅсђѓ - **тіЪУЃй**№╝џТћ»ТїЂС╗јТЋ░ТЇ«жЄЄжЏєтѕ░Тюђу╗ѕт║ћућеуџётЁеТхЂуеІТЊЇСйю№╝їт«ъуј░жФўТЋѕуџёТЋ░ТЇ«тѕєТъљтњїу«Ауљєсђѓ #### С║ћсђЂТаАтЏГу«АуљєжЮбСИ┤уџёТїЉТѕўтЈіУДБтє│Тќ╣ТАѕС╗итђ╝ ...
- **ТАѕСЙІуаћуЕХ**№╝џУ«Итцџт╝ђТ║љжА╣уЏ«тњїтЋєСИџС║ДтЊЂ№╝їтдѓApache Nutch№╝ѕуйЉу╗юуѕгУЎФ№╝ЅсђЂApache Mahout№╝ѕТю║тЎетГдС╣ат║Њ№╝ЅуГЅ№╝їжЃйСЙЮУхќLuceneТЮЦт«ъуј░тЁХТљюу┤бтіЪУЃйсђѓ Тђ╗уџёТЮЦУ»┤№╝їLuceneТў»СИђСИфт╝║тцДСИћуЂхТ┤╗уџётЁеТќЄТБђу┤бтиЦтЁи№╝їт«ЃуџёТаИт┐ЃтюеС║јтдѓСйЋжФўТЋѕ...
ТаЄжбўСИГуџёРђюThesis:СИђуДЇТю║тЎетГдС╣аТќ╣Т│Ћ№╝їућеС║јжбёТхІТюфТЮЦуџётГдућЪТў»тљдС╝џТјЦтЈЌтйЋтЈќжђџуЪЦС╣дРђЮТїЄтЄ║У┐ЎТў»СИђСИфуаћуЕХжА╣уЏ«№╝їСИ╗УдЂтЁ│Т│етѕЕућеТю║тЎетГдС╣аТіђТю»ТЮЦжбёТхІтГдућЪуџётйЋтЈќтє│уГќсђѓтюеТЈЈУ┐░СИГ№╝їТѕЉС╗гС║єУДБтѕ░У┐ЎТў»СИђСИфтїЁтљФУ«║ТќЄсђЂУй»С╗ХТќЄТАБтњїТ║љС╗БуаЂуџё...