
前言
Mahout是Hadoop家族一员,从血缘就继承了Hadoop程序的特点,支持HDFS访问和MapReduce分步式算法。随着Mahout的发展,从0.7版本开始,Mahout做了重大的升级。移除了部分算法的单机内存计算,只支持基于Hadoop的MapReduce平行计算。
从这点上,我们能看出Mahout走向大数据,坚持并行化的决心!相信在Hadoop的大框架下,Mahout最终能成为一个大数据的明星产品!
目录
- Mahout开发环境介绍
- Mahout基于Hadoop的分步环境介绍
- 用Mahout实现协同过滤ItemCF
- 模板项目上传github
1. Mahout开发环境介绍
在 用Maven构建Mahout项目 文章中,我们已经配置好了基于Maven的Mahout的开发环境,我们将继续完成Mahout的分步式的程序开发。
本文的mahout版本为0.8。
开发环境:
- Win7 64bit
- Java 1.6.0_45
- Maven 3
- Eclipse Juno Service Release 2
- Mahout 0.8
- Hadoop 1.1.2
找到pom.xml,修改mahout版本为0.8
<mahout.version>0.8</mahout.version>然后,下载依赖库。
~ mvn clean install由于 org.conan.mymahout.cluster06.Kmeans.java 类代码,是基于mahout-0.6的,所以会报错。我们可以先注释这个文件。
2. Mahout基于Hadoop的分步环境介绍
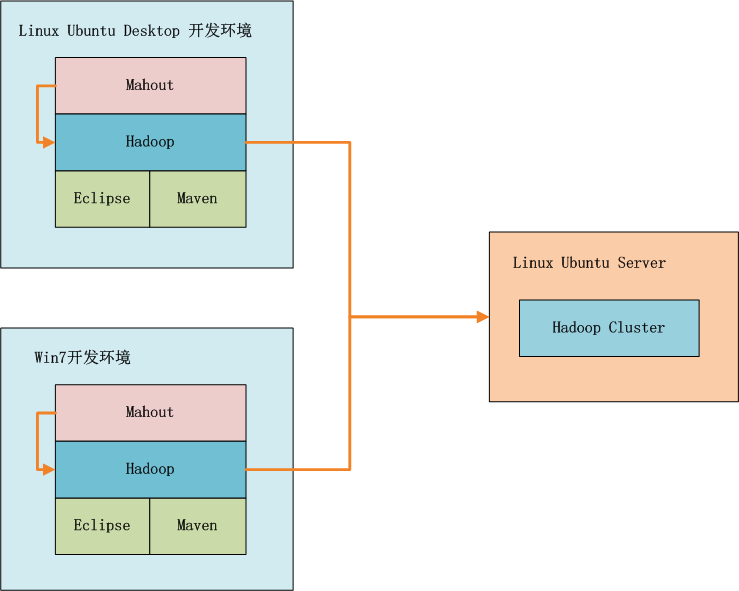
如上图所示,我们可以选择在win7中开发,也可以在linux中开发,开发过程我们可以在本地环境进行调试,标配的工具都是Maven和Eclipse。
Mahout在运行过程中,会把MapReduce的算法程序包,自动发布的Hadoop的集群环境中,这种开发和运行模式,就和真正的生产环境差不多了。
3. 用Mahout实现协同过滤ItemCF
实现步骤:
- 1. 准备数据文件: item.csv
- 2. Java程序:HdfsDAO.java
- 3. Java程序:ItemCFHadoop.java
- 4. 运行程序
- 5. 推荐结果解读
1). 准备数据文件: item.csv
上传测试数据到HDFS,单机内存实验请参考文章:用Maven构建Mahout项目
~ hadoop fs -mkdir /user/hdfs/userCF
~ hadoop fs -copyFromLocal /home/conan/datafiles/item.csv /user/hdfs/userCF
~ hadoop fs -cat /user/hdfs/userCF/item.csv
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0
2). Java程序:HdfsDAO.java
HdfsDAO.java,是一个HDFS操作的工具,用API实现Hadoop的各种HDFS命令,请参考文章:Hadoop编程调用HDFS
我们这里会用到HdfsDAO.java类中的一些方法:
HdfsDAO hdfs = new HdfsDAO(HDFS, conf);
hdfs.rmr(inPath);
hdfs.mkdirs(inPath);
hdfs.copyFile(localFile, inPath);
hdfs.ls(inPath);
hdfs.cat(inFile);
3). Java程序:ItemCFHadoop.java
用Mahout实现分步式算法,我们看到Mahout in Action中的解释。
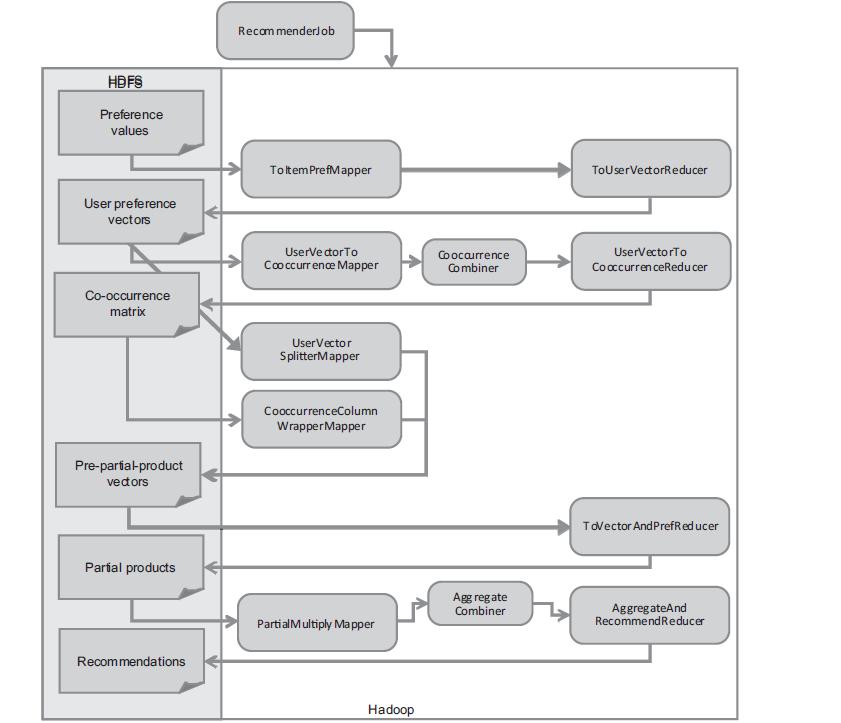
实现程序:
package org.conan.mymahout.recommendation;
import org.apache.hadoop.mapred.JobConf;
import org.apache.mahout.cf.taste.hadoop.item.RecommenderJob;
import org.conan.mymahout.hdfs.HdfsDAO;
public class ItemCFHadoop {
private static final String HDFS = "hdfs://192.168.1.210:9000";
public static void main(String[] args) throws Exception {
String localFile = "datafile/item.csv";
String inPath = HDFS + "/user/hdfs/userCF";
String inFile = inPath + "/item.csv";
String outPath = HDFS + "/user/hdfs/userCF/result/";
String outFile = outPath + "/part-r-00000";
String tmpPath = HDFS + "/tmp/" + System.currentTimeMillis();
JobConf conf = config();
HdfsDAO hdfs = new HdfsDAO(HDFS, conf);
hdfs.rmr(inPath);
hdfs.mkdirs(inPath);
hdfs.copyFile(localFile, inPath);
hdfs.ls(inPath);
hdfs.cat(inFile);
StringBuilder sb = new StringBuilder();
sb.append("--input ").append(inPath);
sb.append(" --output ").append(outPath);
sb.append(" --booleanData true");
sb.append(" --similarityClassname org.apache.mahout.math.hadoop.similarity.cooccurrence.measures.EuclideanDistanceSimilarity");
sb.append(" --tempDir ").append(tmpPath);
args = sb.toString().split(" ");
RecommenderJob job = new RecommenderJob();
job.setConf(conf);
job.run(args);
hdfs.cat(outFile);
}
public static JobConf config() {
JobConf conf = new JobConf(ItemCFHadoop.class);
conf.setJobName("ItemCFHadoop");
conf.addResource("classpath:/hadoop/core-site.xml");
conf.addResource("classpath:/hadoop/hdfs-site.xml");
conf.addResource("classpath:/hadoop/mapred-site.xml");
return conf;
}
}
RecommenderJob.java,实际上就是封装了,上面整个图的分步式并行算法的执行过程!如果没有这层封装,我们需要自己去实现图中8个步骤MapReduce算法。
关于上面算法的深度剖析,请参考文章:R实现MapReduce的协同过滤算法
4). 运行程序
控制台输出:
Delete: hdfs://192.168.1.210:9000/user/hdfs/userCF
Create: hdfs://192.168.1.210:9000/user/hdfs/userCF
copy from: datafile/item.csv to hdfs://192.168.1.210:9000/user/hdfs/userCF
ls: hdfs://192.168.1.210:9000/user/hdfs/userCF
==========================================================
name: hdfs://192.168.1.210:9000/user/hdfs/userCF/item.csv, folder: false, size: 229
==========================================================
cat: hdfs://192.168.1.210:9000/user/hdfs/userCF/item.csv
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
2013-10-14 10:26:35 org.apache.hadoop.util.NativeCodeLoader
警告: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2013-10-14 10:26:35 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 10:26:35 org.apache.hadoop.io.compress.snappy.LoadSnappy
警告: Snappy native library not loaded
2013-10-14 10:26:36 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0001
2013-10-14 10:26:36 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:36 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 10:26:36 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 10:26:36 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 10:26:36 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 10:26:36 org.apache.hadoop.io.compress.CodecPool getCompressor
信息: Got brand-new compressor
2013-10-14 10:26:36 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 10:26:36 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0001_m_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:36 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:36 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0001_m_000000_0' done.
2013-10-14 10:26:36 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:36 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:36 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 10:26:36 org.apache.hadoop.io.compress.CodecPool getDecompressor
信息: Got brand-new decompressor
2013-10-14 10:26:36 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 42 bytes
2013-10-14 10:26:36 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:36 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0001_r_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:36 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:36 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0001_r_000000_0 is allowed to commit now
2013-10-14 10:26:36 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0001_r_000000_0' to hdfs://192.168.1.210:9000/tmp/1381717594500/preparePreferenceMatrix/itemIDIndex
2013-10-14 10:26:36 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 10:26:36 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0001_r_000000_0' done.
2013-10-14 10:26:37 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 10:26:37 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0001
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Counters: 19
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=187
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=3287330
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=916
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=3443292
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=645
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=229
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=46
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Map input records=21
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=14
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=84
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=376569856
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=116
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Combine input records=21
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=7
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=7
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Combine output records=7
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=7
2013-10-14 10:26:37 org.apache.hadoop.mapred.Counters log
信息: Map output records=21
2013-10-14 10:26:37 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 10:26:37 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0002
2013-10-14 10:26:37 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 10:26:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 10:26:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 10:26:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 10:26:37 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 10:26:37 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0002_m_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:37 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:37 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0002_m_000000_0' done.
2013-10-14 10:26:37 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:37 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:37 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 10:26:37 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 68 bytes
2013-10-14 10:26:37 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:37 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0002_r_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:37 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:37 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0002_r_000000_0 is allowed to commit now
2013-10-14 10:26:37 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0002_r_000000_0' to hdfs://192.168.1.210:9000/tmp/1381717594500/preparePreferenceMatrix/userVectors
2013-10-14 10:26:37 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 10:26:37 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0002_r_000000_0' done.
2013-10-14 10:26:38 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 10:26:38 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0002
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Counters: 20
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: org.apache.mahout.cf.taste.hadoop.item.ToUserVectorsReducer$Counters
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: USERS=5
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=288
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=6574274
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=1374
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=6887592
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=1120
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=229
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=72
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Map input records=21
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=42
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=63
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=575930368
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=116
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Combine input records=0
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=21
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=5
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Combine output records=0
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=5
2013-10-14 10:26:38 org.apache.hadoop.mapred.Counters log
信息: Map output records=21
2013-10-14 10:26:38 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 10:26:38 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0003
2013-10-14 10:26:38 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:38 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 10:26:38 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 10:26:38 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 10:26:38 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 10:26:38 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 10:26:38 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0003_m_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:38 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:38 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0003_m_000000_0' done.
2013-10-14 10:26:38 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:38 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:38 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 10:26:38 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 89 bytes
2013-10-14 10:26:38 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:38 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0003_r_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:38 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:38 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0003_r_000000_0 is allowed to commit now
2013-10-14 10:26:38 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0003_r_000000_0' to hdfs://192.168.1.210:9000/tmp/1381717594500/preparePreferenceMatrix/ratingMatrix
2013-10-14 10:26:38 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 10:26:38 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0003_r_000000_0' done.
2013-10-14 10:26:39 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 10:26:39 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0003
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Counters: 21
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=335
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: org.apache.mahout.cf.taste.hadoop.preparation.ToItemVectorsMapper$Elements
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: USER_RATINGS_NEGLECTED=0
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: USER_RATINGS_USED=21
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=9861349
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=1950
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=10331958
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=1751
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=288
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=93
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Map input records=5
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=14
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=336
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=775290880
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=157
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Combine input records=21
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=7
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=7
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Combine output records=7
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=7
2013-10-14 10:26:39 org.apache.hadoop.mapred.Counters log
信息: Map output records=21
2013-10-14 10:26:39 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 10:26:39 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0004
2013-10-14 10:26:39 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:39 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 10:26:39 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 10:26:39 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 10:26:39 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 10:26:39 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 10:26:39 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0004_m_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:39 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:39 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0004_m_000000_0' done.
2013-10-14 10:26:39 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:39 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:39 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 10:26:39 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 118 bytes
2013-10-14 10:26:39 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:39 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0004_r_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:39 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:39 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0004_r_000000_0 is allowed to commit now
2013-10-14 10:26:39 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0004_r_000000_0' to hdfs://192.168.1.210:9000/tmp/1381717594500/weights
2013-10-14 10:26:39 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 10:26:39 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0004_r_000000_0' done.
2013-10-14 10:26:40 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 10:26:40 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0004
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Counters: 20
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=381
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=13148476
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=2628
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=13780408
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=2551
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=335
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: org.apache.mahout.math.hadoop.similarity.cooccurrence.RowSimilarityJob$Counters
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: ROWS=7
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=122
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Map input records=7
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=16
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=516
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=974651392
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=158
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Combine input records=24
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=8
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=8
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Combine output records=8
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=5
2013-10-14 10:26:40 org.apache.hadoop.mapred.Counters log
信息: Map output records=24
2013-10-14 10:26:40 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 10:26:40 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0005
2013-10-14 10:26:40 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:40 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 10:26:40 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 10:26:40 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 10:26:40 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 10:26:40 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 10:26:40 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0005_m_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:40 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:40 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0005_m_000000_0' done.
2013-10-14 10:26:40 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:40 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:40 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 10:26:40 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 121 bytes
2013-10-14 10:26:40 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:40 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0005_r_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:40 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:40 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0005_r_000000_0 is allowed to commit now
2013-10-14 10:26:40 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0005_r_000000_0' to hdfs://192.168.1.210:9000/tmp/1381717594500/pairwiseSimilarity
2013-10-14 10:26:40 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 10:26:40 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0005_r_000000_0' done.
2013-10-14 10:26:41 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 10:26:41 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0005
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Counters: 21
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=392
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=16435577
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=3488
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=17230010
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=3408
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=381
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: org.apache.mahout.math.hadoop.similarity.cooccurrence.RowSimilarityJob$Counters
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: PRUNED_COOCCURRENCES=0
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: COOCCURRENCES=57
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=125
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Map input records=5
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=14
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=744
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=1174011904
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=129
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Combine input records=21
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=7
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=7
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Combine output records=7
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=7
2013-10-14 10:26:41 org.apache.hadoop.mapred.Counters log
信息: Map output records=21
2013-10-14 10:26:41 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 10:26:41 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0006
2013-10-14 10:26:41 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:41 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 10:26:41 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 10:26:41 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 10:26:41 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 10:26:41 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 10:26:41 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0006_m_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:41 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:41 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0006_m_000000_0' done.
2013-10-14 10:26:41 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:41 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:41 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 10:26:41 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 158 bytes
2013-10-14 10:26:41 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:41 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0006_r_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:41 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:41 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0006_r_000000_0 is allowed to commit now
2013-10-14 10:26:41 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0006_r_000000_0' to hdfs://192.168.1.210:9000/tmp/1381717594500/similarityMatrix
2013-10-14 10:26:41 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 10:26:41 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0006_r_000000_0' done.
2013-10-14 10:26:42 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 10:26:42 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0006
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Counters: 19
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=554
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=19722740
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=4342
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=20674772
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=4354
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=392
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=162
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Map input records=7
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=14
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=599
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=1373372416
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=140
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Combine input records=25
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=7
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=7
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Combine output records=7
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=7
2013-10-14 10:26:42 org.apache.hadoop.mapred.Counters log
信息: Map output records=25
2013-10-14 10:26:42 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 10:26:42 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 10:26:42 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0007
2013-10-14 10:26:42 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 10:26:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 10:26:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 10:26:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 10:26:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 10:26:42 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0007_m_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:42 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:42 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0007_m_000000_0' done.
2013-10-14 10:26:42 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 10:26:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 10:26:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 10:26:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 10:26:42 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 10:26:42 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0007_m_000001_0 is done. And is in the process of commiting
2013-10-14 10:26:42 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:42 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0007_m_000001_0' done.
2013-10-14 10:26:42 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:42 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:42 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 2 sorted segments
2013-10-14 10:26:42 org.apache.hadoop.io.compress.CodecPool getDecompressor
信息: Got brand-new decompressor
2013-10-14 10:26:42 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 2 segments left of total size: 233 bytes
2013-10-14 10:26:42 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:42 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0007_r_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:42 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:42 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0007_r_000000_0 is allowed to commit now
2013-10-14 10:26:42 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0007_r_000000_0' to hdfs://192.168.1.210:9000/tmp/1381717594500/partialMultiply
2013-10-14 10:26:42 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 10:26:42 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0007_r_000000_0' done.
2013-10-14 10:26:43 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 10:26:43 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0007
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Counters: 19
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=572
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=34517913
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=8751
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=36182630
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=7934
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=0
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=241
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Map input records=12
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=56
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=453
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=2558459904
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=665
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Combine input records=0
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=28
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=7
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Combine output records=0
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=7
2013-10-14 10:26:43 org.apache.hadoop.mapred.Counters log
信息: Map output records=28
2013-10-14 10:26:43 org.apache.hadoop.mapreduce.lib.input.FileInputFormat listStatus
信息: Total input paths to process : 1
2013-10-14 10:26:43 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Running job: job_local_0008
2013-10-14 10:26:43 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:43 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: io.sort.mb = 100
2013-10-14 10:26:43 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: data buffer = 79691776/99614720
2013-10-14 10:26:43 org.apache.hadoop.mapred.MapTask$MapOutputBuffer
信息: record buffer = 262144/327680
2013-10-14 10:26:43 org.apache.hadoop.mapred.MapTask$MapOutputBuffer flush
信息: Starting flush of map output
2013-10-14 10:26:43 org.apache.hadoop.mapred.MapTask$MapOutputBuffer sortAndSpill
信息: Finished spill 0
2013-10-14 10:26:43 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0008_m_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:43 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:43 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0008_m_000000_0' done.
2013-10-14 10:26:43 org.apache.hadoop.mapred.Task initialize
信息: Using ResourceCalculatorPlugin : null
2013-10-14 10:26:43 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:43 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Merging 1 sorted segments
2013-10-14 10:26:43 org.apache.hadoop.mapred.Merger$MergeQueue merge
信息: Down to the last merge-pass, with 1 segments left of total size: 206 bytes
2013-10-14 10:26:43 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:43 org.apache.hadoop.mapred.Task done
信息: Task:attempt_local_0008_r_000000_0 is done. And is in the process of commiting
2013-10-14 10:26:43 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息:
2013-10-14 10:26:43 org.apache.hadoop.mapred.Task commit
信息: Task attempt_local_0008_r_000000_0 is allowed to commit now
2013-10-14 10:26:43 org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter commitTask
信息: Saved output of task 'attempt_local_0008_r_000000_0' to hdfs://192.168.1.210:9000/user/hdfs/userCF/result
2013-10-14 10:26:43 org.apache.hadoop.mapred.LocalJobRunner$Job statusUpdate
信息: reduce > reduce
2013-10-14 10:26:43 org.apache.hadoop.mapred.Task sendDone
信息: Task 'attempt_local_0008_r_000000_0' done.
2013-10-14 10:26:44 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: map 100% reduce 100%
2013-10-14 10:26:44 org.apache.hadoop.mapred.JobClient monitorAndPrintJob
信息: Job complete: job_local_0008
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Counters: 19
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: File Output Format Counters
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Bytes Written=217
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: FileSystemCounters
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_READ=26299802
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_READ=7357
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: FILE_BYTES_WRITTEN=27566408
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: HDFS_BYTES_WRITTEN=6269
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: File Input Format Counters
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Bytes Read=572
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Map-Reduce Framework
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Map output materialized bytes=210
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Map input records=7
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Reduce shuffle bytes=0
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Spilled Records=42
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Map output bytes=927
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Total committed heap usage (bytes)=1971453952
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: SPLIT_RAW_BYTES=137
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Combine input records=0
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Reduce input records=21
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Reduce input groups=5
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Combine output records=0
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Reduce output records=5
2013-10-14 10:26:44 org.apache.hadoop.mapred.Counters log
信息: Map output records=21
cat: hdfs://192.168.1.210:9000/user/hdfs/userCF/result//part-r-00000
1 [104:1.280239,106:1.1462644,105:1.0653841,107:0.33333334]
2 [106:1.560478,105:1.4795978,107:0.69935876]
3 [103:1.2475469,106:1.1944525,102:1.1462644]
4 [102:1.6462644,105:1.5277859,107:0.69935876]
5 [107:1.1993587]
5). 推荐结果解读
我们可以把上面的日志分解析成3个部分解读
- a. 初始化环境
- b. 算法执行
- c. 打印推荐结果
a. 初始化环境
出初HDFS的数据目录和工作目录,并上传数据文件。
Delete: hdfs://192.168.1.210:9000/user/hdfs/userCF
Create: hdfs://192.168.1.210:9000/user/hdfs/userCF
copy from: datafile/item.csv to hdfs://192.168.1.210:9000/user/hdfs/userCF
ls: hdfs://192.168.1.210:9000/user/hdfs/userCF
==========================================================
name: hdfs://192.168.1.210:9000/user/hdfs/userCF/item.csv, folder: false, size: 229
==========================================================
cat: hdfs://192.168.1.210:9000/user/hdfs/userCF/item.csv
b. 算法执行
分别执行,上图中对应的8种MapReduce算法。
Job complete: job_local_0001
Job complete: job_local_0002
Job complete: job_local_0003
Job complete: job_local_0004
Job complete: job_local_0005
Job complete: job_local_0006
Job complete: job_local_0007
Job complete: job_local_0008
c. 打印推荐结果
方便我们看到计算后的推荐结果
cat: hdfs://192.168.1.210:9000/user/hdfs/userCF/result//part-r-00000
1 [104:1.280239,106:1.1462644,105:1.0653841,107:0.33333334]
2 [106:1.560478,105:1.4795978,107:0.69935876]
3 [103:1.2475469,106:1.1944525,102:1.1462644]
4 [102:1.6462644,105:1.5277859,107:0.69935876]
5 [107:1.1993587]
4. 模板项目上传github
https://github.com/bsspirit/maven_mahout_template/tree/mahout-0.8
大家可以下载这个项目,做为开发的起点。
~ git clone https://github.com/bsspirit/maven_mahout_template
~ git checkout mahout-0.8
我们完成了基于物品的协同过滤分步式算法实现,下面将继续介绍Mahout的Kmeans的分步式算法实现,请参考文章:Mahout分步式程序开发 聚类Kmeans



相关推荐
Mahout中的分布式协同过滤推荐算法主要有两种实现方式:用户(User-Based)协同过滤和物品(Item-Based)协同过滤。用户协同过滤通过找到与目标用户行为相似的其他用户,利用这些用户的行为来预测目标用户可能喜欢的...
该资源是在Eclipse平台里,使用Mahout库的API,实现基于用户的协同过滤算法,从而进行商品推荐。 软件环境是:win7 64位 +Eclipse4.4 + jdk1.6, 用到了7个.jar包, 分别为:commons-logging-1.2.jar, commons-...
基于物品的协同过滤推荐算法是推荐系统中一种广泛使用的策略,它主要依赖于用户对物品的评价或行为历史来预测用户可能对未评价物品的兴趣。在这个场景中,我们讨论的是如何利用MapReduce框架,通常是Hadoop,来实现...
基于Mahout协同过滤实现图书推荐系统_书籍推荐系统源码+项目说明.zip 基于协同过滤的书籍推荐系统,图书推荐系统 最新版本,在原先手动计算皮尔逊相似度和评分矩阵的基础上添加了Mahout实现的协同过滤推荐算法. ...
基于Java+Mahout的协同过滤推荐算法图书推荐系统源码+项目说明.zip 基于协同过滤的书籍推荐系统,图书推荐系统 最新版本,在原先手动计算皮尔逊相似度和评分矩阵的基础上添加了Mahout实现的协同过滤推荐算法。 ...
本项目"基于Mahout实现协同过滤推荐算法的电影推荐系统"旨在利用Apache Mahout这一开源机器学习库,构建一个能够为用户推荐个性化电影的系统。以下将详细介绍该系统的相关知识点: 1. **协同过滤推荐算法**: 协同...
它分为基于用户(User-Based)和基于物品(Item-Based)两种过滤方式。 在基于用户的协同过滤中,系统首先会计算用户之间的相似度,这通常通过用户对共同观看过的电影的评分来实现。一种常见的相似度计算方法是...
协同过滤算法主要基于两个原则:用户-用户协同过滤和物品-物品协同过滤。 在Spring Boot中构建基于协同过滤算法的商品推荐系统可以遵循以下步骤: 数据收集:收集用户行为数据,包括用户对商品的评分、点击、购买...
本项目重点介绍了Mahout中的User-Based Collaborative Filtering(用户基协同过滤,UserCF)、Item-Based Collaborative Filtering(物品基协同过滤,ItemCF)以及Slope One算法的实现。 1. **User-Based ...
协同过滤(Collaborative Filtering,简称CF)是一种基于用户行为的推荐方法,主要分为两种类型:用户-用户协同过滤和物品-物品协同过滤。前者通过找到与目标用户兴趣相似的其他用户,然后推荐他们喜欢的物品;后者...
本设计源码提供了一个基于Mahout的协同过滤电影推荐系统...该项目是基于Mahout实现的协同过滤推荐算法的电影推荐系统,适合用于学习和实践Java、JavaScript技术,以及开发基于Mahout的协同过滤电影推荐系统相关的系统。
在这个“基于Mahout协同过滤实现图书推荐系统”中,开发者可能利用了这些工具来处理用户-用户或物品-物品的相似度计算,并生成推荐列表。 源码通常包含以下几个关键部分: 1. 数据预处理:导入用户-书籍评分数据,...
开发语言:Java 框架:springboot JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7(一定要5.7版本) 数据库工具:Navicat11 开发软件:eclipse/myeclipse/idea Maven包:Maven3.3.9 浏览器:谷歌浏览器 Java...
**基于 Mahout 实现协同过滤推荐算法的电影推荐系统** 是一套完整的学习和开发资源,旨在帮助用户使用 Apache Mahout 构建一个功能完善的电影推荐系统。Mahout 是一个高效的机器学习库,专注于大规模数据的推荐、...
协同过滤分为基于用户的协同过滤和基于物品的协同过滤两种主要类型。 1. 基于用户的协同过滤:这种算法假设具有相似行为历史的用户在未来也会有相似的兴趣。首先,计算用户之间的相似度(常用余弦相似度或皮尔逊...
项目名称:MovieRecommender - 基于Mahout的协同过滤电影推荐系统 项目概述: MovieRecommender是一个基于Apache Mahout的协同过滤算法实现的电影推荐系统。该系统主要以Java语言开发,同时整合了JavaScript以提供...