
在查阅google之后,我发现没有一处对并发算法或是数据结构规定的演进条件(progress condition,注:参考[1],译者认为翻译为演进状态更为合适)做合理的解释。甚至在”The Art of Multiprocessor Programming“中也只有围绕书本的一小段定义,大部分定义是单行的句子,因而造成了我们普通人含义模糊的理解,所以在这里我把我对这些概念的理解整理在一起,并且在每一种概念后面给出相应的例子。
我们先将演进条件分为四个主要类别,阻塞(blocking),无干扰(obstruction-free),无锁(lock-free),和无等待(wait-free)。详细列表如下:
Blocking
1. Blocking
2. Starvation-Free
Obstruction-Free
3. Obstruction-Free
Lock-Free
4. Lock-Free (LF)
Wait-Free
5. Wait-Free (WF)
6. Wait-Free Bounded (WFB)
7. Wait-Free Population Oblivious (WFPO)
在我们开始解释每一个术语的意义之前,让我们先了解一些相关细节。
根据《The Art of Multiprocessor Programming》一书3.6节中的相关描述,我们很难理解有界无等待(wait-free bounded,注:参考[1])和集居数无关无等待(wait-free population oblivious,注:参考[1])的概念是否相关。就我个人而言,我认为一个算法如果满足集居数无关无等待,就意味着这个算法是有限界的,从而这个算法也满足有界无等待。这代表一个方法(或者是一个算法,一个类)可以是无等待,或者有界无等待,或者集居数无关无等待,最后一个条件是所有演进条件中“最好”的。
在这篇文章中我们讨论的例子都是关于某个(一个算法中,或一个类中)的特定方法的演进条件,而不是完整的算法。我们这样做的原因是一个算法中不同的方法可能会采用不同的演进保证(progress guarantees),举个例子:(某个算法)写操作可能是阻塞的,然而读操作是满足集居数无关无等待,这样的情况在你第一次观察某个无锁和无等待数据结构的时候并不是显而易见的。
是的,你的结论是正确的:一个数据结构中可能有某些操作是阻塞的,另外一些操作是无锁的,剩下的甚至是无等待的。另一方面,当我们称某个特定的数据结构是无锁,这代表这个数据结构的所有操作都是无锁,或者更好的状态(无等待或者更好)。
事实上在著作中没有严格对那种状态更好有严格的定义,但是一般而言说是这样的:
无等待>无锁>阻塞
上述说法的理由是:现实中并没有太多无锁或者是无等待的(实用)数据结构,所以通常不会出现关于演进状态合理分类的问题。Andreia和我提出了很多不同种类的并发算法,其中混合了各种演进状态。因此我们需要对这些演进状态合理地命名,并且对他们排序,从而继续对他们的处理,并且发现哪些算法值得研究。
我们提出的顺序就是文章开头描述的列表,表中阻塞是最差的,集居数无关无等待是可能达到的最好状态。
另一个通常会导致困惑的说法是“无等待意味着无锁”(但是不能反过来说)。这意味着一个方法如果满足无等待,那么这个方法有着和一个无锁方法同样的演进保证。下图是一张venn图,可能能够更好的解释我们的意思。
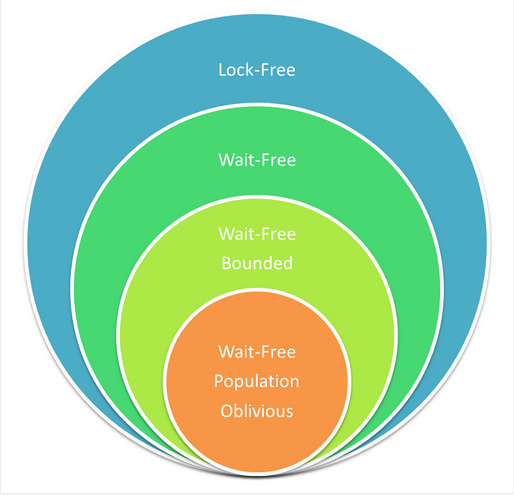
这张图展示了算法的集合,图中无等待的算法也是无锁算法的一部分。
1. 阻塞
阻塞是大家所熟知的。基本所有加锁的算法都可以说是阻塞的。某个线程所引起的意外延迟会阻止其他线程继续运行。在最坏的情况下,某个占有锁的线程可能被睡眠,从而阻止其他等待锁释放的线程进行接下来的任何操作。
定义:
一个方法被称为阻塞的,即这个方法在其演进过程中不能正常运行直到其他(占有锁的)线程释放。
例子:
循环中对拥有两个状态的变量的简单CAS操作
01 |
AtomicInteger lock = new AtomicInteger(0);
|
02 |
03 |
public void funcBlocking() {
|
04 |
05 |
while (!lock.compareAndSet(0, 1)) {
|
06 |
07 |
hread.yield();
|
08 |
09 |
}
|
10 |
11 |
} |
2. 无饥饿
(无饥饿)有的时候也被称为无闭锁。这是一个独立的性质,只有当底层平台/系统提供了明确的保障以后讨论这个性质才有意义。
定义:
只要有一个线程在互斥区中,那么一些希望进入互斥区域的线程最终都能够进入互斥区域(即使之前在互斥区中的线程意外停止了)。
例子:
一个严格公平的互斥锁通常是无饥饿的。
在JDK 8中的StampedLock有这样的性质,因为它创建了一个线程队列(链表)等待获取锁。这个队列的插入操作是无锁的,但是在插入之后,每个线程都会自旋或者让步从而被当前占有锁的线程锁阻塞。释放锁的线程采用unsafe.park()/unpark()机制,够唤醒下一个在队列中等待的线程,从而执行了严格的优先级。这个机制的意义是,如果给予其他线程(占有锁的线程)足够的时间去完成他们的操作,那么当前线程可以确保最终获取锁,然后完成自己的操作。
有关StampedLock的源码详见这里:
3. 无干扰
这是一个非阻塞性质。关于无干扰和无饥饿的更多细节可以查看《The Art of Multiprocessor Programming》(revised edition)的第60页。
定义:
如果一个方法满足无干扰性质,那么这个方法从任意一点开始它的执行都是隔离的,并且能够在有限步内完成。
例子:
我所知道的唯一例子就是Maurice Herlihy,Mark Moir和Victor Luchangco所提出的Double-ended Queue。
http://cs.brown.edu/~mph/HerlihyLM03/main.pdf
4. 无锁
无锁的性质保证了至少有一个线程在正常运行。在理论上这代表了一个方法可能需要无限的操作才能完成,但是在实践中只需要消耗很短的时间,否则这个性质就没有什么价值了。
定义:
如果一个方法是lock-free的,它保证线程无限次调用这个方法都能够在有限步内完成。
例子:
一个调用CAS操作的循环增加原子整形变量。
01 |
AtomicInteger atomicVar = new AtomicInteger(0);
|
02 |
03 |
public void funcLockFree() {
|
04 |
05 |
int localVar = atomicVar.get();
|
06 |
07 |
while (!atomicVar.compareAndSet(localVar, localVar+1)) {
|
08 |
09 |
localVar = atomicVar.get();
|
10 |
11 |
}
|
12 |
13 |
} |
另外一个比较著名的例子是java.util.concurrent中的ConcurrentLinkedQueue,其中add()和remove()操作是无锁的。
5. 无等待
无等待性质保证了任何一个时间片内的线程可以运行,并且最后完成。这个性质保证步骤是有限的,但是在实践中,这个数字可能是极大的,并且依赖活动的线程数目,因此目前没有很多实用的无等待数据结构。
定义:
假如一个方法是无等待的,那么它保证了每一次调用都可以在有限的步骤内结束。
例子:
这篇论文给出了一个无等待(有界无等待)算法的例子。
http://www.cs.technion.ac.il/~moran/r/PS/bm94.ps
6. 有界无等待
任何一个有界无等待的算法,也是无等待的(但并不一定是集居数无关无等待的)。
定义:
如果一个方法是有界无等待的,那么这个方法保证每次调用都能够在有限,并且有界的步骤内完成。这个界限可能依赖于线程的数量。
例子:
一个扫描/写入到长度和线程数目相关的数组的方法。如果数组中每个条目的操作数是常量,那么显然这个方法是有界无等待的,并且不是集居数无关无等待,因为数组的长度和线程的数目有关。
01 |
AtomicIntegerArray intArray = new AtomicIntegerArray(MAX_THREADS);
|
02 |
03 |
public void funcWaitFreeBounded() {
|
04 |
05 |
for (int i = 0; i < MAX_THREADS ; i++) {
|
06 |
07 |
intArray.set(i, 1);
|
08 |
09 |
}
|
10 |
11 |
} |
7. 集居数无关无等待
这个性质用来描述这些在一定数量步骤内完成一些指令,并且指令数目与活动线程数目无关的方法。任何一个集居数无关无等待的方法都是有界无等待的。
定义:
一个无等待的方法,如果其性能和活动线程数目无关,那么被称为集居数无关无等待的。
例子:
最简单的例子是使用fetch-and-add原语(在X86 CPU上是XADD指令)增加一个原子变量。这个操作可以用C11/C++11中的fetch_add()原子方法完成。
1 |
atomic counter; |
2 |
3 |
void funcWaitFreeBoundedPopulationOblivious() {
|
4 |
5 |
counter.fetch_add(1);
|
6 |
7 |
} |
结论
上述的这些并不是问题的全部。我们忽略了两个了解全貌需要掌握的知识点:
第一点,如果你的方法需要分配内存,那么这个方法可以提供的演进保证在实际中受到内存分配机制的演进条件所限制。我认为,我们需要针对方法是否需要分配内存进行不同的分类。你可以在这篇文章中了解更多的细节,但是基本的思想是创造一个集居数无关无等待的,并且一直需要用阻塞机制分配内存的方法没有太大的意义。
第二点,关于演进条件的完整概念是用于将算法和方法按照时间保证分类,但是这些定义却是基于操作数目。这基于一个操作的完成时间与活动线程数目无关这个假设的,这些假设在单线程代码中是正确的,但是在多线程程序中将会失效。
CPU缓存一致性的工作机制,将会导致多线程/多核访问(原子)变量的竞争,从而使得一个操作/指令在一定情况下(因为cache-miss)需要相对更长的时间才能完成。如果你不相信我的话,可以看一看这篇文章,这就是为什么许多wait-free数据结构的实现要比lock-free的相同数据结构更慢的主要的原因(或者说主要原因之一),尽管他们对执行的操作总次数有更强的保证,每一个操作因为竞争的因素却可能要用很长的时间去完成……还可能是他们平均执行的操作次数更多。
总的来说,对于倾向于数学的读者,这里有我提出的定义:
设F为一个函数方法
设L为同时调用F的并发线程数目
设N为一个与L无关的变量
设OpsF()代表一个指定线程完成F需要进行的操作数目。
设C(n,L)为一个依赖N和L的函数
当任何有限值L满足以下条件时,F方法是对应的进行状态:
Lock-free:
如果至少有一个L线程在有限步骤内完成操作;OpsF() < C(N,L)
Wait-free:
如果所有的L个线程在有限的步骤内完成操作:OpsF() < C(N,L)
Wait-free bounded:
如果所有的L个线程消耗C(N,L)或者更少的时间完成操作:OpsF() < C(N,L)
Wait-free population oblivious:
如果所有的L个线程在有限操作内完成F,并且和L无关:OpsF() < C(N)
在实践中,“无等待”和“有界无等待”的区别很小,这篇论文中有很好的解释:
http://www.cs.technion.ac.il/~moran/r/PS/bm94.ps
另一个细节是,并没有“集居数无关无等待”(的数据结构,注:准确的话说是没有一个所有方法都是集居数无关无等待的数据结构),因为达到集居数无关的状态意味着,F方法有一个使其运行结束所需的最坏操作数目上限。
希望这篇文章可以帮助你理解lock-free和wait-free的区别。
参考
[1] 多处理器编程的艺术,http://book.douban.com/subject/3901836/
转自:http://ifeve.com/lock-free-and-wait-free/?utm_source=tuicool



相关推荐
- **无阻塞同步**:包括无等待、无锁和无阻碍三种类型。其中: - 无等待(Wait-Free):所有操作在有限的时间内完成。 - 无锁(Lock-Free):至少有一个进程可以在有限时间内完成其操作。 - 无阻碍(Obstruction-...
作为具体例子,文档展示了无锁的双栈(dual stacks)和双队列(dual queues),并实验性地将它们的性能与基于锁和非阻塞的替代方案进行了比较。 线性化是一种用于推断并发对象正确性的标准方法,其理念是提供一种...
开发者通常会定义一个函数作为新线程的入口点,然后使用`CreateThread()`来启动这个函数在一个新的线程上执行。 2. "StdAfx.cpp" 和 "StdAfx.h":这两个文件是预编译头文件,用于提高编译速度。"StdAfx.h"包含了...
事件处理器是用户定义的业务逻辑,它们在Disruptor提供的无锁、低延迟环境中运行。此外,Disruptor还支持多个消费者并行消费,通过顺序屏障(Barrier)确保事件的正确顺序。 Disruptor的应用实例通常包括以下几个...
- **等待/通知机制:** `wait()`和`notify()`方法可用于实现线程间的等待和唤醒。 - **`join`方法:** 一个线程可以调用另一个线程的`join()`方法来等待该线程的结束。 - **屏障(Barriers):** `CyclicBarrier`和`...
《Java并发编程艺术》是Java开发者深入理解并发编程的一本经典著作。这本书涵盖了Java多线程和并发库的广泛主题,旨在帮助开发者有效地...书中的例子和源码将有助于你理解和实践这些理论,从而提升你的并发编程能力。
在并发编程中,Disruptor的优势在于它的无锁设计和高效的事件处理流程。通过消除锁和最小化内存屏障,Disruptor能够实现极低的延迟和高吞吐量。这使得Disruptor成为金融交易、实时分析和其他对性能要求苛刻的领域的...
为了解决这个问题,可以考虑使用条件变量(`std::condition_variable`)或者无锁数据结构(如`std::atomic`),来优化日志队列的实现。当线程尝试写入日志时,它们可以先将日志条目添加到队列中,然后等待通知,只有...
- **Sync**:抽象同步器,继承自`AbstractQueuedSynchronizer`,负责管理锁的状态和排队等待的线程。 - **Condition**:条件变量,支持更复杂的线程间协作。 - **主要方法**: - **lock()**:获取锁。 - **...
ExecutorService接口是核心,它定义了执行任务的方法,如`execute()`。ThreadPoolExecutor是常用的实现,可以配置线程池的大小、队列类型等参数。 2. **Future和Callable**:Future接口代表异步计算的结果,可以...
内存顺序是描述线程间操作顺序的规则,C++标准定义了三种关系和六种内存顺序。三种关系包括:先发生(happens-before)、后发生(happens-after)和无序(unordered)。六种内存顺序则分为从弱到强的六个级别:无序...
在这个例子中,`increment_counter`函数内部使用了`std::lock_guard`,它自动管理互斥量的锁定和解锁过程。即使在异常情况下,`lock_guard`也会确保互斥量最终会被正确解锁,避免了死锁的风险。 四、互斥量与其他...
Java提供了多种线程安全的类,如ArrayList(非线程安全)与CopyOnWriteArrayList(线程安全)的区别就是一个很好的例子。 以上只是Java多线程、锁和内存模型的一部分核心概念,深入理解这些知识点对于编写高效、...
- **内存模型**:Java内存模型定义了线程之间的内存可见性和有序性规则,确保了数据的一致性和线程之间的正确交互。 - **垃圾回收器**:现代JVM支持并发垃圾收集器,能够在应用程序运行时清理不再使用的对象,减少对...
- **3.3.1 队列Queue与BlockingQueue**:`Queue`接口定义了一个先进先出(FIFO)的队列,而`BlockingQueue`是一个特殊类型的队列,它提供额外的方法来阻塞线程直到队列中有空间可用或有元素可用。 - **3.3.2 使用...
为了克服这些困难,作者们在第一章中探讨了多种解决方案和技术,比如使用同步机制、锁优化策略以及无锁编程技术等。通过详细介绍这些问题的本质原因及其解决方案,帮助读者建立扎实的基础,以便更好地理解后续章节的...