
本文的 重点 是:不要让 Ring 重叠;如何通知消费者;生产者一端的批处理;以及多个生产者如何协同工作。
ProducerBarriers
Disruptor 代码 给 消费者 提供了一些接口和辅助类,但是没有给写入 Ring Buffer 的 生产者 提供接口。这是因为除了你需要知道生产者之外,没有别人需要访问它。尽管如此,Ring Buffer 还是与消费端一样提供了一个 ProducerBarrier 对象,让生产者通过它来写入 Ring Buffer。
写入 Ring Buffer 的过程涉及到两阶段提交 (two-phase commit)。首先,你的生产者需要申请 buffer 里的下一个节点。然后,当生产者向节点写完数据,它将会调用 ProducerBarrier 的 commit 方法。
那么让我们首先来看看第一步。 “给我 Ring Buffer 里的下一个节点”,这句话听起来很简单。的确,从生产者角度来看它很简单:简单地调用 ProducerBarrier 的 nextEntry() 方法,这样会返回给你一个 Entry 对象,这个对象就是 Ring Buffer 的下一个节点。
ProducerBarrier 如何防止 Ring Buffer 重叠
在后台,由 ProducerBarrier 负责所有的交互细节来从 Ring Buffer 中找到下一个节点,然后才允许生产者向它写入数据。
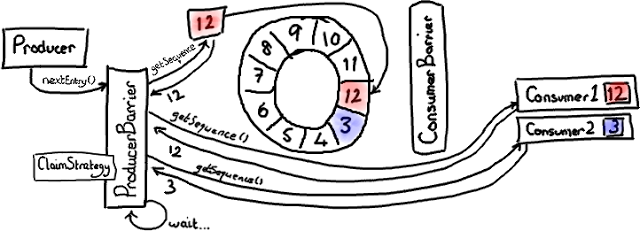
在这幅图中,我们假设只有一个生产者写入 Ring Buffer。过一会儿我们再处理多个生产者的复杂问题。
ConsumerTrackingProducerBarrier 对象拥有所有正在访问 Ring Buffer 的 消费者 列表。这看起来有点儿奇怪-我从没有期望 ProducerBarrier 了解任何有关消费端那边的事情。但是等等,这是有原因的。因为我们不想与队列“混为一谈”(队列需要追踪队列的头和尾,它们有时候会指向相同的位置),Disruptor 由消费者负责通知它们处理到了哪个序列号,而不是 Ring Buffer。所以,如果我们想确定我们没有让 Ring Buffer 重叠,需要检查所有的消费者们都读到了哪里。
在上图中,有一个 消费者 顺利的读到了最大序号 12(用红色/粉色高亮)。第二个消费者 有点儿落后——可能它在做 I/O 操作之类的——它停在序号 3。因此消费者 2 在赶上消费者 1 之前要跑完整个 Ring Buffer 一圈的距离。
现在生产者想要写入 Ring Buffer 中序号 3 占据的节点,因为它是 Ring Buffer 当前游标的下一个节点。但是 ProducerBarrier 明白现在不能写入,因为有一个消费者正在占用它。所以,ProducerBarrier 停下来自旋 (spins),等待,直到那个消费者离开。
申请下一个节点
现在可以想像消费者 2 已经处理完了一批节点,并且向前移动了它的序号。可能它挪到了序号 9(因为消费端的批处理方式,现实中我会预计它到达 12,但那样的话这个例子就不够有趣了)。
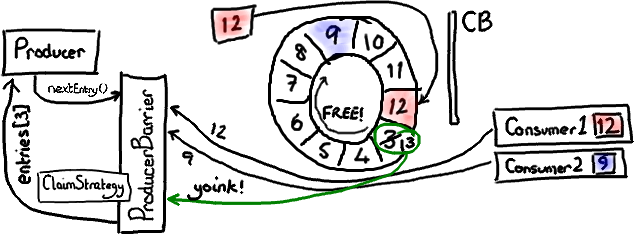
ProducerBarier 会看到下一个节点——序号 3 那个已经可以用了。它会抢占这个节点上的 Entry(我还没有特别介绍 Entry 对象,基本上它是一个放写入到某个序号的 Ring Buffer 数据的桶),把下一个序号(13)更新成 Entry 的序号,然后把 Entry 返回给生产者。生产者可以接着往 Entry 里写入数据。
提交新的数据
两阶段提交的第二步是——对,提交。
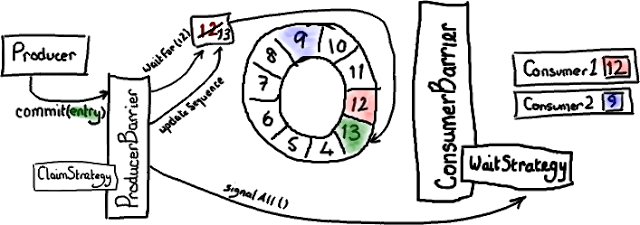
当生产者结束向 Entry 写入数据后,它会要求 ProducerBarrier 提交。
ProducerBarrier 先等待 Ring Buffer 的游标追上当前的位置(对于单生产者这毫无意义-比如,我们已经知道游标到了 12 ,而且没有其他人正在写入 Ring Buffer)。然后 ProducerBarrier 更新 Ring Buffer 的游标到刚才写入的 Entry 序号-在我们这儿是 13。接下来,ProducerBarrier 会让消费者知道 buffer 中有新东西了。它戳一下 ConsumerBarrier 上的 WaitStrategy 对象说-“喂,醒醒!有事情发生了!”(注意-不同的 WaitStrategy 实现以不同的方式来实现提醒,取决于它是否采用阻塞模式。)
现在消费者 1 可以读 Entry 13 的数据,消费者 2 可以读 Entry 13 以及前面的所有数据,然后它们都过得很 happy。
ProducerBarrier 上的批处理
有趣的是 Disruptor 可以同时在生产者和 消费者 两端实现批处理。还记得伴随着程序运行,消费者 2 最后达到了序号 9 吗?ProducerBarrier 可以在这里做一件很狡猾的事-它知道 Ring Buffer 的大小,也知道最慢的消费者位置。因此它能够发现当前有哪些节点是可用的。
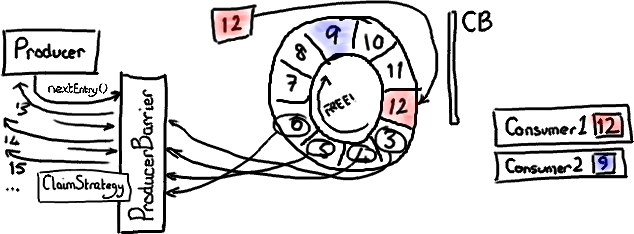
如果 ProducerBarrier 知道 Ring Buffer 的游标指向 12,而最慢的消费者在 9 的位置,它就可以让生产者写入节点 3,4,5,6,7 和 8,中间不需要再次检查消费者的位置。
多个生产者的场景
到这里你也许会以为我讲完了,但其实还有一些细节。
在上面的图中我稍微撒了个谎。我暗示了 ProducerBarrier 拿到的序号直接来自 Ring Buffer 的游标。然而,如果你看过代码的话,你会发现它是通过 ClaimStrategy 获取的。我省略这个对象是为了简化示意图,在单个生产者的情况下它不是很重要。
在多个生产者的场景下,你还需要其他东西来追踪序号。这个序号是指当前可写入的序号。注意这和“向 Ring Buffer 的游标加 1”不一样-如果你有一个以上的生产者同时在向 Ring Buffer 写入,就有可能出现某些 Entry 正在被生产者写入但还没有提交的情况。

让我们复习一下如何申请写入节点。每个生产者都向 ClaimStrategy 申请下一个可用的节点。生产者 1 拿到序号 13,这和上面单个生产者的情况一样。生产者 2 拿到序号 14,尽管 Ring Buffer的当前游标仅仅指向 12。这是因为 ClaimSequence 不但负责分发序号,而且负责跟踪哪些序号已经被分配。
现在每个生产者都拥有自己的写入节点和一个崭新的序号。
我把生产者 1 和它的写入节点涂上绿色,把生产者 2 和它的写入节点涂上可疑的粉色-看起来像紫色。

现在假设生产者 1 还生活在童话里,因为某些原因没有来得及提交数据。生产者 2 已经准备好提交了,并且向 ProducerBarrier 发出了请求。
就像我们先前在 commit 示意图中看到的一样,ProducerBarrier 只有在 Ring Buffer 游标到达准备提交的节点的前一个节点时它才会提交。在当前情况下,游标必须先到达序号 13 我们才能提交节点 14 的数据。但是我们不能这样做,因为生产者 1 正盯着一些闪闪发光的东西,还没来得及提交。因此 ClaimStrategy 就停在那儿自旋 (spins), 直到 Ring Buffer 游标到达它应该在的位置。

现在生产者 1 从迷糊中清醒过来并且申请提交节点 13 的数据(生产者 1 发出的绿色箭头代表这个请求)。ProducerBarrier 让 ClaimStrategy 先等待 Ring Buffer 的游标到达序号 12,当然现在已经到了。因此 Ring Buffer 移动游标到 13,让 ProducerBarrier 戳一下 WaitStrategy 告诉所有人都知道 Ring Buffer 有更新了。现在 ProducerBarrier 可以完成生产者 2 的请求,让 Ring Buffer 移动游标到 14,并且通知所有人都知道。
你会看到,尽管生产者在不同的时间完成数据写入,但是 Ring Buffer 的内容顺序总是会遵循 nextEntry() 的初始调用顺序。也就是说,如果一个生产者在写入 Ring Buffer 的时候暂停了,只有当它解除暂停后,其他等待中的提交才会立即执行。
呼——。我终于设法讲完了这一切的内容并且一次也没有提到内存屏障(Memory Barrier)。



相关推荐
##### 2.3 写入Ring Buffer 生产者通过更新尾指针来写入数据。为了避免数据覆盖,生产者还需要检查Ring Buffer是否已满。如果Ring Buffer已满,则生产者必须等待消费者处理一些数据后再继续写入。 ##### 2.4 解析...
Disruptor的工作原理基于环形缓冲区(Ring Buffer)的设计,它将生产者和消费者之间的数据传递过程转换为顺序写入和读取,避免了传统并发模型中的锁竞争和上下文切换,从而实现了极高的消息传递效率。在SpringBoot中...
3. 环形缓冲区(RingBuffer):存储数据的容器,采用循环数组实现,确保空间利用率。 4. 事件处理器(EventHandler):消费者处理数据的逻辑封装,每个消费者可以注册多个事件处理器。 5. 事件处理器组...
5. **启动Disruptor**:获取RingBuffer实例,并通过它来生产数据。 6. **处理数据**:数据被自动发布到RingBuffer,并由相应的消费者进行处理。 通过以上步骤,我们就可以构建一个基于Disruptor的高性能并发处理...
`src`目录包含了Disruptor的源代码,包括`com.lmax.disruptor`包下的各种类,如`RingBuffer`、`EventProcessor`和`SequenceBarrier`等,它们是理解Disruptor工作原理的关键。 5. **应用实例** `lib`目录可能包含了...
Disruptor的核心是一个环形缓冲区(Ring Buffer),它采用了无锁算法来实现线程间的通信,避免了传统的锁机制带来的性能开销。无锁队列是Disruptor中的关键数据结构,通过使用CAS(Compare and Swap)操作,能够在不...
Disruptor框架是LMAX交易所开源的一个高性能、低延迟的消息队列实现,它采用无锁化编程技术,利用环形缓冲区(Ring Buffer)来实现高效的多生产者多消费者模型。本文将深入分析Disruptor的代码,特别聚焦于`...
Disruptor的工作原理大致如下:它使用环形缓冲区(Ring Buffer)作为基础数据结构,将生产者和消费者的操作解耦,并通过序列号(Sequence)来确保数据的一致性。生产者可以连续写入而不必等待消费者的读取,而消费者...
Disruptor-3.2.1是由LMAX公司开发并开源的一款高性能的并发框架,其核心是一个环形缓冲区(Ring Buffer)。这个框架的设计理念是消除多线程之间的锁竞争,从而大幅度提高系统的处理速度。在3.2.1版本中,Disruptor...
在这个例子中,`EventProducer`是生产者的实现,它使用Disruptor提供的`ringBuffer.next()`和`ringBuffer.publish()`方法来发布事件。`next()`方法返回一个可用于写入事件的序列号,而`publish()`方法则确认事件已经...
Disruptor 框架使用 RingBuffer 数据结构来实现高效的并发处理。 六、Go 语言中的 Context Go 语言中的 Context 是一个高级的并发编程概念,使用 Context 可以实现高效的并发处理。Context 通过使用原子操作和锁...
1. **环形缓冲区(Ring Buffer)**:Disruptor的核心是环形缓冲区,它是一个固定大小的数组,用于存储待处理的事件。这个设计避免了在内存中频繁分配和释放空间,从而减少了垃圾回收的压力。环形缓冲区的索引使用模...
Disruptor不仅仅是一个简单的循环队列,它还引入了更高级的并发控制策略,如使用了环形缓冲区(Ring Buffer)。环形缓冲区是一种特殊的循环队列,其大小固定,通过预分配内存空间和利用位运算优化索引访问,进一步提高...
Disruptor的核心是其环形缓冲区(Ring Buffer)设计,这是一个固定大小的数组,生产者和消费者通过序列号进行同步,而无需锁或其他同步机制。这种设计消除了传统队列中的锁和条件变量,极大地提高了并发性能。 总结...
Disruptor模式的核心思想是消除线程间的共享数据,通过一个环形缓冲区(Ring Buffer)来传递消息,从而避免了锁和条件变量带来的性能开销。在传统的并发编程中,线程间通信通常涉及到内存同步,这可能导致阻塞和上...
Buffer的设计灵感来源于LMAX Disruptor,这是一个高性能的多线程间通信库,其核心就是高效的环形缓冲区(Ring Buffer)。 1. **环形缓冲区(Ring Buffer)**: - 环形缓冲区是一种内存数据结构,用于存储固定数量...
Disruptor的环形缓冲区(Ring Buffer)设计能够减少数据在内存中的复制,进一步提升了处理速度。同时,其多生产者模型允许来自不同源头的数据并行写入,而单消费者模型则可以高效地顺序处理这些事件,确保了游戏逻辑...
10. **无锁并发**:使用无锁并发机制,如Disruptor框架中的Ringbuffer,提高系统的并发性能。 #### 五、业务逻辑设计 1. **加解密**:保护用户数据安全,对敏感信息进行加密处理。 2. **数据采集**:从各个渠道...