
HBase是什么?
HBase是Apache Hadoop中的一个子项目,Hbase依托于Hadoop的HDFS作为最基本存储基础单元,通过使用hadoop的DFS工具就可以看到这些这些数据 存储文件夹的结构,还可以通过Map/Reduce的框架(算法)对HBase进行操作,如右侧的图所示:
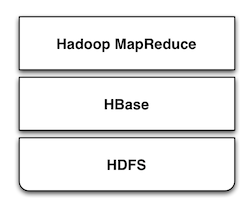
HBase在产品中还包含了Jetty,在HBase启动时采用嵌入式的方式来启动Jetty,因此可以通过web界面对HBase进行管理和查看当前运行的一些状态,非常轻巧。
为什么采用HBase?
HBase 不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库.所谓非结构化数据存储就是说HBase是基于列的而不是基于行的模式,这样方面读写你的大数据内容。
HBase是介于Map Entry(key & value)和DB Row之间的一种数据存储方式。就点有点类似于现在流行的Memcache,但不仅仅是简单的一个key对应一个 value,你很可能需要存储多个属性的数据结构,但没有传统数据库表中那么多的关联关系,这就是所谓的松散数据。
简单来说,你在HBase中的表创建的可以看做是一张很大的表,而这个表的属性可以根据需求去动态增加,在HBase中没有表与表之间关联查询。你只需要 告诉你的数据存储到Hbase的那个column families 就可以了,不需要指定它的具体类型:char,varchar,int,tinyint,text等等。但是你需要注意HBase中不包含事务此类的功 能。
Apache HBase 和Google Bigtable 有非常相似的地方,一个数据行拥有一个可选择的键和任意数量的列。表是疏松的存储的,因此用户可以给行定义各种不同的列,对于这样的功能在大项目中非常实用,可以简化设计和升级的成本。
如何运行HBase?
从 Apache的HBase的镜像网站上下载一个稳定版本的HBase http://mirrors.devlib.org/apache/hbase/stable/hbase-0.20.6.tar.gz, 下载完成后,对其进行解压缩。确定你的机器中已经正确的安装了Java SDK、SSH,否则将无法正常运行。
$ cd /work/hbase
进入此目录
$ vim conf/hbase-env.sh
export JAVA_HOME=/JDK_PATH
编辑 conf/hbase-env.sh 文件,将JAVA_HOME修改为你的JDK安装目录
$ vim conf/regionservers
输入你的所有HBase服务器名,localhost,或者是ip地址
$ bin/start-hbase.sh
启动hbase, 中间需要你输入两次密码,也可以进行设置不需要输入密码,启动成功,如图所示:

$ bin/hbase rest start
启动hbase REST服务后就可以通过对uri: http://localhost:60050/api/ 的通用REST操作(GET/POST/PUT/DELETE)实现对hbase的REST形式数据操作.
也可以输入以下指令进入HQL指令模式
$ bin/hbase shell
$ bin/stop-hbase.sh
关闭HBase服务
启动时存在的问题
由于linux系统的主机名配置不正确,在运行HBase服务器中可能存在的问题,如图所示:
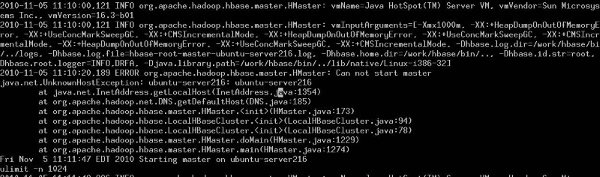
2010-11-05 11:10:20,189 ERROR org.apache.hadoop.hbase.master.HMaster: Can not start master
java.net.UnknownHostException: ubuntu-server216: ubuntu-server216
表示你的主机名不正确,你可以先查看一下 /etc/hosts/中名称是什么,再用 hostname 命令进行修改, hostname you_server_name
查看运行状态
- 如果你需要对HBase的日志进行监控你可以查看 hbase.x.x./logs/下的日志文件,可以使用tail -f 来查看。
- 通过 web方式查看运行在 HBase 下的zookeeper http://localhost:60010/zk.jsp
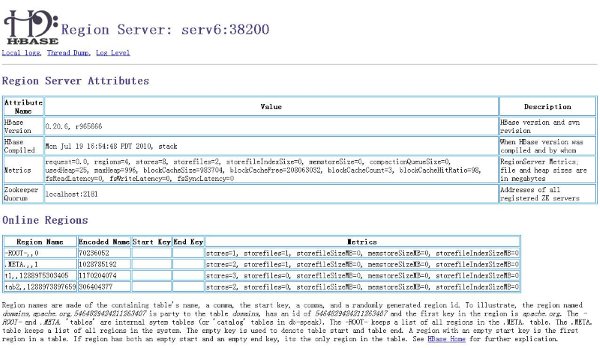
- 如果你需要查看当前的运行状态可以通过web的方式对HBase服务器进行查看,如图所示:
扩展阅读1:
Apach 的 Hadoop的项目中包含了那些产品,如图所示:

Pig 是在MapReduce上构建的查询语言(SQL-like),适用于大量并行计算。
Chukwa 是基于Hadoop集群中监控系统,简单来说就是一个“看门狗” (WatchDog)
Hive 是DataWareHouse 和 Map Reduce交集,适用于ETL方面的工作。
HBase 是一个面向列的分布式数据库。
Map Reduce 是Google提出的一种算法,用于超大型数据集的并行运算。
HDFS 可以支持千万级的大型分布式文件系统。
Zookeeper 提供的功能包括:配置维护、名字服务、分布式同步、组服务等,用于分布式系统的可靠协调系统。
Avro 是一个数据序列化系统,设计用于支持大批量数据交换的应用。
扩展阅读2:
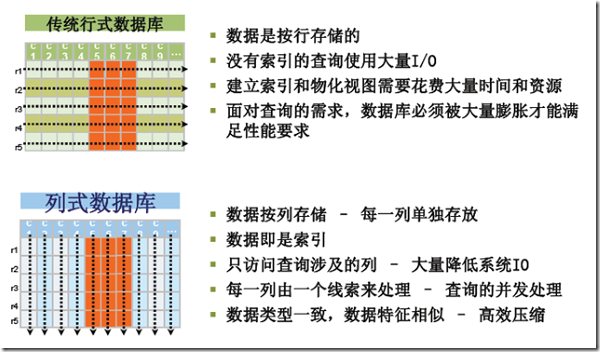
什么是列存储?列存储不同于传统的关系型数据库,其数据在表中是按行存储的,列方式所带来的重要好处之一就是,由于查询中的选择规则是通过列来定义的,因 此整个数据库是自动索引化的。按列存储每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量,一个字段的数据聚集存储,那就 更容易为这种聚集存储设计更好的压缩/解压算法。这张图讲述了传统的行存储和列存储的区别:
扩展阅读3:
对系统海量的Log4J日志可以存放在一个集中式的机器上,在此机器上安装 splunk 可以方便对所有日志查看,安装方法可以参考:
http://www.splunk.com/base/Documentation/latest/Installation/InstallonLinux
本篇文章讲述用HBase Shell命令 和 HBase Java API 对HBase 服务器 进行操作。在此之前需要对HBase的总体上有个大概的了解。比如说HBase服务器内部由哪些主要部件构成?HBase的内部工作原理是什么?我想学习 任何一项知识、技术的态度不能只是知道如何使用,对产品的内部构建一点都不去关心,那样出了问题,很难让你很快的找到答案,甚至我们希望最后能对该项技术 的领悟出自己的心得,为我所用,借鉴该项技术其中的设计思想创造出自己的解决方案,更灵活的去应对多变的计算场景与架构设计。以我目前的对HBase的了 解还不够深入,将来不断的学习,我会把我所知道的点滴分享到这个Blog上。
先来看一下读取一行记录HBase是如何进行工作的,首先HBase Client端会连接Zookeeper Qurom(从下面的代码也能看出来,例如:HBASE_CONFIG.set("hbase.zookeeper.quorum", "192.168.50.216") )。通过Zookeeper组件Client能获知哪个Server管理-ROOT- Region。那么Client就去访问管理-ROOT-的Server,在META中记录了HBase中所有表信息,(你可以使用 scan '.META.' 命令列出你创建的所有表的详细信息),从而获取Region分布的信息。一旦Client获取了这一行的位置信息,比如这一行属于哪个 Region,Client将会缓存这个信息并直接访问HRegionServer。久而久之Client缓存的信息渐渐增多,即使不访问.META.表 也能知道去访问哪个HRegionServer。HBase中包含两种基本类型的文件,一种用于存储WAL的log,另一种用于存储具体的数据,这些数据 都通过DFS Client和分布式的文件系统HDFS进行交互实现存储。
如图所示:
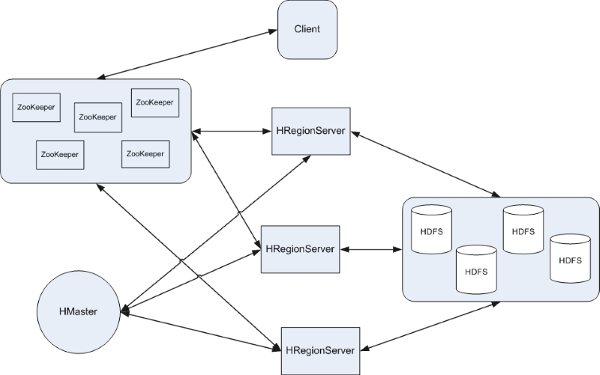
再来看看HBase的一些内存实现原理:
- HMaster— HBase中仅有一个Master server。
- HRegionServer—负责多个HRegion使之能向client端提供服务,在HBase cluster中会存在多个HRegionServer。
- ServerManager—负责管理Region server信息,如每个Region server的HServerInfo(这个对象包含HServerAddress和startCode),已load Region个数,死亡的Region server列表
- RegionManager—负责将region分配到region server的具体工作,还监视root和meta 这2个系统级的region状态。
- RootScanner—定期扫描root region,以发现没有分配的meta region。
- MetaScanner—定期扫描meta region,以发现没有分配的user region。
HBase基本命令
下面我们再看看看HBase的一些基本操作命令,我列出了几个常用的HBase Shell命令,如下:
|
名称
|
命令表达式
|
| 创建表 | create '表名称', '列名称1','列名称2','列名称N' |
| 添加记录 | put '表名称', '行名称', '列名称:', '值' |
| 查看记录 | get '表名称', '行名称' |
| 查看表中的记录总数 | count '表名称' |
| 删除记录 | delete '表名' ,'行名称' , '列名称' |
| 删除一张表 | 先要屏蔽该表,才能对该表进行删除,第一步 disable '表名称' 第二步 drop '表名称' |
| 查看所有记录 | scan "表名称" |
| 查看某个表某个列中所有数据 | scan "表名称" , ['列名称:'] |
| 更新记录 | 就是重写一遍进行覆盖 |
如果你是一个新手队HBase的一些命令还不算非常熟悉的话,你 可以进入 hbase 的shell 模式中你可以输入 help 命令查看到你可以执行的命令和对该命令的说明,例如对scan这个命令,help中不仅仅提到有这个命令,还详细的说明了scan命令中可以使用的参数和 作用,例如,根据列名称查询的方法和带LIMIT 、STARTROW的使用方法:
scan Scan a table; pass table name and optionally a dictionary of scanner specifications.
Scanner specifications may include one or more of the following: LIMIT, STARTROW, STOPROW, TIMESTAMP, or COLUMNS.
If no columns are specified, all columns will be scanned. To scan all members of a column family, leave the
qualifier empty as in 'col_family:'. Examples:
hbase> scan '.META.'
hbase> scan '.META.', {COLUMNS => 'info:regioninfo'}
hbase> scan 't1', {COLUMNS => ['c1', 'c2'], LIMIT => 10, STARTROW => 'xyz'}
|
使用Java API对HBase服务器进行操作
需要下列jar包
hbase-0.20.6.jar
hadoop-core-0.20.1.jar
commons-logging-1.1.1.jar
zookeeper-3.3.0.jar
log4j-1.2.91.jar
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.BatchUpdate;
@SuppressWarnings("deprecation")
public class HBaseTestCase {
static HBaseConfiguration cfg = null;
static {
Configuration HBASE_CONFIG = new Configuration();
HBASE_CONFIG.set("hbase.zookeeper.quorum", "192.168.50.216");
HBASE_CONFIG.set("hbase.zookeeper.property.clientPort", "2181");
cfg = new HBaseConfiguration(HBASE_CONFIG);
}
/**
* 创建一张表
*/
public static void creatTable(String tablename) throws Exception {
HBaseAdmin admin = new HBaseAdmin(cfg);
if (admin.tableExists(tablename)) {
System.out.println("table Exists!!!");
}
else{
HTableDescriptor tableDesc = new HTableDescriptor(tablename);
tableDesc.addFamily(new HColumnDescriptor("name:"));
admin.createTable(tableDesc);
System.out.println("create table ok .");
}
}
/**
* 添加一条数据
*/
public static void addData (String tablename) throws Exception{
HTable table = new HTable(cfg, tablename);
BatchUpdate update = new BatchUpdate("Huangyi");
update.put("name:java", "http://www.javabloger.com".getBytes());
table.commit(update);
System.out.println("add data ok .");
}
/**
* 显示所有数据
*/
public static void getAllData (String tablename) throws Exception{
HTable table = new HTable(cfg, tablename);
Scan s = new Scan();
ResultScanner ss = table.getScanner(s);
for(Result r:ss){
for(KeyValue kv:r.raw()){
System.out.print(new String(kv.getColumn()));
System.out.println(new String(kv.getValue() ));
}
}
}
public static void main (String [] agrs) {
try {
String tablename="tablename";
HBaseTestCase.creatTable(tablename);
HBaseTestCase.addData(tablename);
HBaseTestCase.getAllData(tablename);
}
catch (Exception e) {
e.printStackTrace();
}
}
}
|
这篇文章浅显的从几个方面谈谈HBase的一些优化技巧,只能作为我学习笔记的一部分,因为学多了怕忘,留给自己以后看看。
1 修改 linux 系统参数
Linux系统最大可打开文件数一般默认的参数值是1024,如果你不进行修改并发量上来的时候会出现“Too Many Open Files”的错误,导致整个HBase不可运行,你可以用ulimit -n 命令进行修改,或者修改/etc/security/limits.conf 和/proc/sys/fs/file-max 的参数,具体如何修改可以去Google 关键字 “linux limits.conf ”
2 JVM 配置
修改 hbase-env.sh 文件中的配置参数,根据你的机器硬件和当前操作系统的JVM(32/64位)配置适当的参数
HBASE_HEAPSIZE 4000 HBase使用的 JVM 堆的大小
HBASE_OPTS "‐server ‐XX:+UseConcMarkSweepGC"JVM GC 选项
HBASE_MANAGES_ZKfalse 是否使用Zookeeper进行分布式管理
3 HBase持久化
重启操作系统后HBase中数据全无,你可以不做任何修改的情况 下,创建一张表,写一条数据进行,然后将机器重启,重启后你再进入HBase的shell中使用 list 命令查看当前所存在的表,一个都没有了。是不是很杯具?没有关系你可以在hbase/conf/hbase-default.xml中设置 hbase.rootdir的值,来设置文件的保存位置指定一个文件夹 ,例如:<value>file:///you/hbase-data/path</value>,你建立的HBase中的表和 数据就直接写到了你的磁盘上,如图所示:
同样你也可以指定你的分布式文件系统HDFS的路径例如: hdfs://NAMENODE_SERVER:PORT/HBASE_ROOTDIR,这样就写到了你的分布式文件系统上了。
4 配置HBase运行参数
其次就需要对hbase/conf/hbase-default.xml 文件进行配置,以下是我认为比较重要的配置参数
hbase.client.write.buffer
描述:这个参数可以设置写入数据缓冲区的大小,当客户端和服务器端传输数据,服务器为了提高系统运行性能开辟一个写的缓冲区来处理它, 这个参数设置如果设置的大了,将会对系统的内存有一定的要求,直接影响系统的性能。
hbase.master.meta.thread.rescanfrequency
描述:多长时间 HMaster对系统表 root 和 meta 扫描一次,这个参数可以设置的长一些,降低系统的能耗。
hbase.regionserver.handler.count
描述:由于HBase/Hadoop的Server是采用 Multiplexed, non-blocking I/O方式而设计的,所以它可以透过一个Thread来完成处理,但是由于处理Client端所呼叫的方法是Blocking I/O,所以它的设计会将Client所传递过来的物件先放置在Queue,并在启动Server时就先产生一堆Handler(Thread),该 Handler会透过Polling的方式来取得该物件并执行对应的方法,默认为25,根据实际场景可以设置大一些。
hbase.regionserver.thread.splitcompactcheckfrequency
描述:这个参数是表示多久去RegionServer服务器运行 一次split/compaction的时间间隔,当然split之前会先进行一个compact操作.这个compact操作可能是minor compact也可能是major compact.compact后,会从所有的Store下的所有StoreFile文件最大的那个取midkey.这个midkey可能并不处于全部数 据的mid中.一个row-key的下面的数据可能会跨不同的HRegion。
hbase.hregion.max.filesize
描述:HRegion中的HStoreFile最大值,任何表中的列族一旦超过这个大小将会被切分,而HStroeFile的默认大小是256M。
hfile.block.cache.size
描述:指定 HFile/StoreFile 缓存在JVM堆中分配的百分比,默认值是0.2,意思就是20%,而如果你设置成0,就表示对该选项屏蔽。
hbase.zookeeper.property.maxClientCnxns
描述: 这项配置的选项就是从zookeeper中来的,表示ZooKeeper客户端同时访问的并发连接数,ZooKeeper对于HBase来说就是一个入口这个参数的值可以适当放大些。
hbase.regionserver.global.memstore.upperLimit
描述:在Region Server中所有memstores占用堆的大小参数配置,默认值是0.4,表示40%,如果设置为0,就是对选项进行屏蔽。
hbase.hregion.memstore.flush.size
描述:Memstore中缓存的内容超过配置的范围后将会写到磁 盘上,例如:删除操作是先写入MemStore里做个标记,指示那个value, column 或 family等下是要删除的,HBase会定期对存储文件做一个major compaction,在那时HBase会把MemStore刷入一个新的HFile存储文件中。如果在一定时间范围内没有做major compaction,而Memstore中超出的范围就写入磁盘上了。
5 HBase中log4j的日志
HBase中日志输出等级默认状态下是把debug、 info 级别的日志打开的,可以根据自己的需要调整log级别,HBase的log4j日志配置文件在 hbase\conf\log4j.properties 目录下。
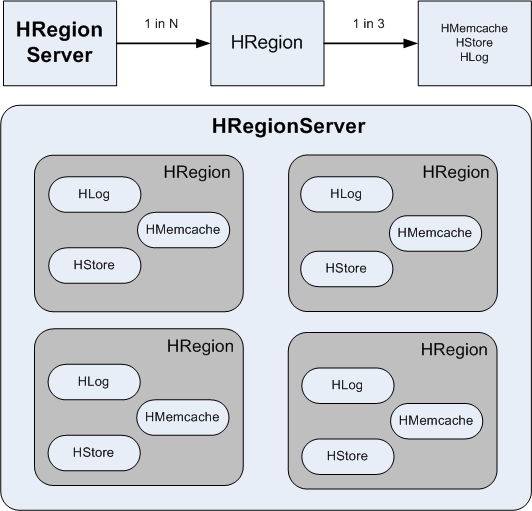
在HBase中创建的一张表可以分布在多个Hregion,也就说一张表可以被拆分成多块,每一块称我们呼为一个Hregion。每个Hregion会保 存一个表里面某段连续的数据,用户创建的那个大表中的每个Hregion块是由Hregion服务器提供维护,访问Hregion块是要通过 Hregion服务器,而一个Hregion块对应一个Hregion服务器,一张完整的表可以保存在多个Hregion 上。HRegion Server 与Region的对应关系是一对多的关系。每一个HRegion在物理上会被分为三个部分:Hmemcache(缓存)、Hlog(日志)、HStore(持久层)。
上述这些关系在我脑海中的样子,如图所示:
1.HRegionServer、HRegion、Hmemcache、Hlog、HStore之间的关系,如图所示:
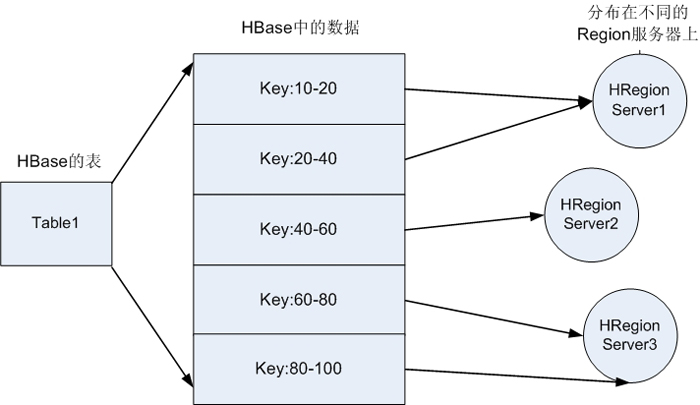
2.HBase表中的数据与HRegionServer的分布关系,如图所示:
HBase读数据
HBase读取数据优先读取HMemcache中的内容,如果未取到再去读取Hstore中的数据,提高数据读取的性能。
HBase写数据
HBase写入数据会写到HMemcache和Hlog中,HMemcache建立缓存,Hlog同步Hmemcache和Hstore的事务日志,发起Flush Cache时,数据持久化到Hstore中,并清空HMemecache。
客户端访问这些数据的时候通过Hmaster ,每个 Hregion 服务器都会和Hmaster 服务器保持一个长连接,Hmaster 是HBase分布式系统中的管理者,他的主要任务就是要告诉每个Hregion 服务器它要维护哪些Hregion。用户的这些都数据可以保存在Hadoop 分布式文件系统上。 如果主服务器Hmaster死机,那么整个系统都会无效。下面我会考虑如何解决Hmaster的SPFO的问题,这个问题有点类似Hadoop的SPFO 问题一样只有一个NameNode维护全局的DataNode,HDFS一旦死机全部挂了,也有人说采用Heartbeat来解决这个问题,但我总想找出 其他的解决方案,多点时间,总有办法的。
昨天在hadoop-0.21.0、hbase-0.20.6的环境中折腾了很久,一直报错,错误信息如下:
Exception in thread "main" java.io.IOException: Call to localhost/serv6:9000 failed on local exception:
java.io.EOFException
10/11/10 15:34:34 ERROR master.HMaster: Can not start master
java.lang.reflect.InvocationTargetException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:39)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:27)
at java.lang.reflect.Constructor.newInstance(Constructor.java:513)
at org.apache.hadoop.hbase.master.HMaster.doMain(HMaster.java:1233)
at org.apache.hadoop.hbase.master.HMaster.main(HMaster.java:1274)
|
死活连接不上HDFS,也无法连接HMaster,郁闷啊。
我想想啊,慢慢想,我眼前一亮 java.io.EOFException 这个异常,是不是有可能是RPC 协定格式不一致导致的?也就是说服务器端和客户端的版本不一致的问题?换了一个HDFS的服务器端以后,一切都好了,果然是版本的问题,最后采用 hadoop-0.20.2 搭配hbase-0.20.6 比较稳当。
最后的效果如图所示:
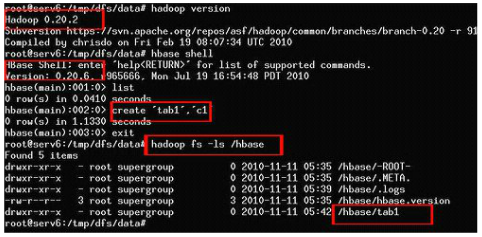
上图的一些文字说明:
- hadoop版本是0.20.2 ,
- hbase版本是0.20.6,
- 在hbase中创建了一张表 tab1,退出hbase shell环境,
- 用hadoop命令查看,文件系统中的文件果然多了一个刚刚创建的tab1目录,以上这张图片说明HBase在分布式文件系统Apache HDFS中运行了。
在上一篇关于HBase的文章中曾经讲述过HBase在分布式中的架构,这篇文章将会讲述HBase在分布式环境中是如何排除单点故障的(SPFO),做一个小实验讲述HBase在分布式环境中的高可用性,亲眼看到一些现象,延伸一些思考的话题。
先来回顾一下HBase主要部件:
- HBaseMaster
- HRegionServer
- HBase Client
- HBase Thrift Server
- HBase REST Server
HBaseMaster
HMaster 负责给HRegionServer分配区域,并且负责对集群环境中的HReginServer进行负载均衡,HMaster还负责监控集群环境中的 HReginServer的运行状况,如果某一台HReginServer down机,HBaseMaster将会把不可用的HReginServer来提供服务的HLog和表进行重新分配转交给其他HReginServer来 提供,HBaseMaster还负责对数据和表进行管理,处理表结构和表中数据的变更,因为在 META 系统表中存储了所有的相关表信息。并且HMaster实现了ZooKeeper的Watcher接口可以和zookeeper集群交互。
HRegionServer
HReginServer负责处理用户的读和写的操作。 HReginServer通过与HBaseMaster通信获取自己需要服务的数据表,并向HMaster反馈自己的运行状况。当一个写的请求到来的时 候,它首先会写到一个叫做HLog的write-ahead log中。HLog被缓存在内存中,称为Memcache,每一个HStore只能有一个Memcache。当Memcache到达配置的大小以后,将会 创建一个MapFile,将其写到磁盘中去。这将减少HReginServer的内存压力。当一起读取的请求到来的时候,HReginServer会先在 Memcache中寻找该数据,当找不到的时候,才会去在MapFiles 中寻找。
HBase Client
HBase Client负责寻找提供需求数据的HReginServer。在这个过程中,HBase Client将首先与HMaster通信,找到ROOT区域。这个操作是Client和Master之间仅有的通信操作。一旦ROOT区域被找到以 后,Client就可以通过扫描ROOT区域找到相应的META区域去定位实际提供数据的HReginServer。当定位到提供数据的 HReginServer以后,Client就可以通过这个HReginServer找到需要的数据了。这些信息将会被Client缓存起来,当下次请求 的时候,就不需要走上面的这个流程了。
HBase服务接口
HBase Thrift Server和HBase REST Server是通过非Java程序对HBase进行访问的一种途径。
进入正题
先来看一个HBase集群的模拟环境,此环境中一共有4台机器,分别包含 zookeeper、HBaseMaster、HReginServer、HDSF 4个服务,为了展示失效转发的效果HBaseMaster、HReginServer各有2台,只是在一台机器上即运行了HBaseMaster,也运行了HReginServer。
注意,HBase的集群环境中HBaseMaster只有失效转发没有压力分载的功能,而HReginServer即提供失效转发也提供压力分载。
服务器清单如下:
- zookeeper 192.168.20.214
- HBaseMaster 192.168.20.213/192.168.20.215
- HReginServer 192.168.20.213/192.168.20.215
- HDSF 192.168.20.212
整个模拟环境的架构如图所示:
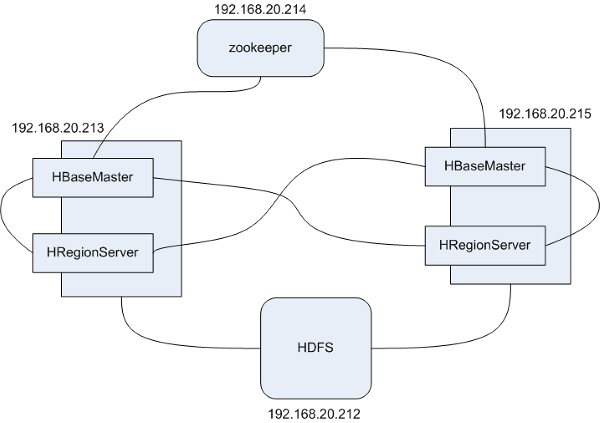
注意,这里只是做了一个模拟环境,因为这个环境的重点是HBase,所以zookeeper和HDFS服务都是单台。
虽然说在整个HBase的集群环境中只能有一个HMaster, 可是在集群环境中HMaster可以启动多个,但真正使用到的HMaster Server只有一个,他不down掉的时候,其他启动的HMaster Server并不会工作,直到与ZooKeeper服务器判断与当前运行的HMaster通讯超时,认为这个正在运行的HMaster服务器down掉 了,Zookeeper才会去连接下一台HMaster Server。
简单来说,如果运行中HMaster服务器down掉了,那么zookeeper会从列表中选择下一个HMaster 服务器进行访问,让他接管down掉的HMaster任务,换而言之,用Java客户端对HBase进行操作是通过ZooKeeper的,也就是说如果zookeeper集群中的节点全挂了 那么HBase的集群也挂了。本身HBase并不存储中的任何数据 真正的数据是保存在HDFS上,所以HBase的数据是一致的,但是HDFS文件系统挂了,HBase的集群也挂。
在一台HMaster失败后,客户端对HBase集群环境访问时,客户端先会通过zookeeper识别到HMaster运行异常,直到确认多次后,才连接到下一个HMaster,此时,备份的HMaster服务才生效,在IDE环境中的效果,如图所示:
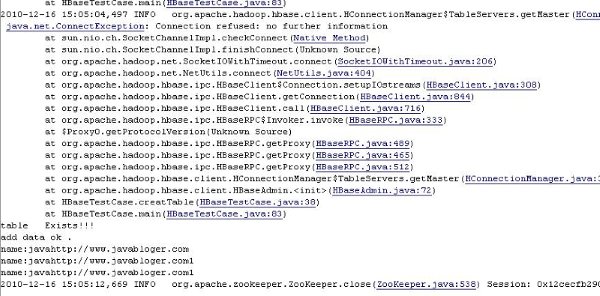
上图中能看见抛出的一些异常和name:javahttp://www.javabloger.com和name:javahttp: //www.javabloger.com1的结果集,因为我在serv215机器上用killall java命令把 HMaster和HReginServer都关掉,并且立刻用Java客户端对HBase的集群环境进行访问有异常抛出,但是retry到一定次数后查询 出结果,前面已经说了访问HBase是通过zookeeper再和真正的数据打交道,也就是说zookeeper接管了一个standby 的 HMaster,让原先Standby的HMaster接替了失效的HMaster任务,而被接管的HBaseMaster再对HReginServer 的任务进行分配,当 HReginServer失败后zookeeper会通知 HMaster对HReginServer的任务进行分配。这样充分的说明了HBase做到了实效转发的功能。
如图所示:

口水:
1、HBase的失效转发的效率比较慢了,不指望能在1-2秒切换和恢复完毕,也许是我暂时没有发现有什么参数可以提高失效转发和恢复过程的速度,将来会继续关注这个问题。
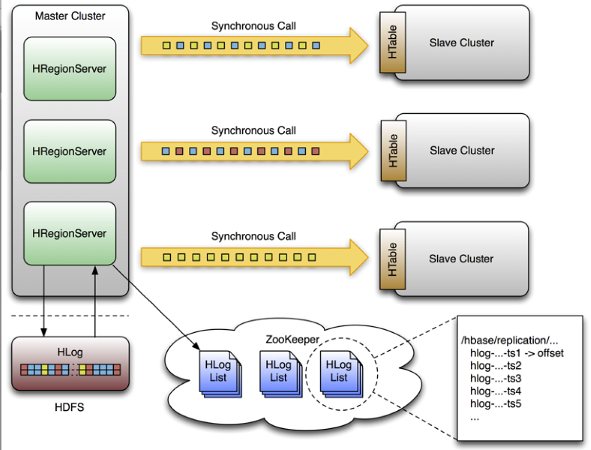
2、在官方网站上看见HBase0.89.20100924的版 本有篇讲述关于数据同步的文章,我尝试了一下在一台机器上可以运行所谓的HBase虚拟集群环境,但是切换到多台机器的分布式环境中,单点失效转发的速度 很慢比HBase0.20.6还要慢,我又检查了是否存在网络的问题,目前尚未找到正确的答案,对与HBase0.89.20100924 新版中的数据同步的原理,如图所示:(更多信息)
我的废话1:
任何一项新技术并非救命稻草,一抹一擦立马药到病除的百宝箱,并非使用Spring或者NOSQL的产品就神乎其神+五光十色,如果那样基本是扯淡。同类 型产品中不管那种技术最终要达到的目的是一样的,通过新的技术手段你往往可能避讳了当前你所需要面对的问题,但过后新的问题又来了。也许回过头来看看还不 如在原来的基础上多动动脑筋 想想办法 做些改良可以得到更高的回报。
传统数据库是以数据块来存储数据,简单来说,你的表字段越多,占 用的数据空间就越多,那么查询有可能就要跨数据块,将会导致查询的速度变慢。在大型系统中一张表上百个字段,并且表中的数据上亿条这是完全是有可能的。因 此会带来数据库查询的瓶颈。我们都知道一个常识数据库中表记录的多少对查询的性能有非常大的影响,此时你很有可能想到分表、分库的做法来分载数据库运算的 压力,那么又会带来新的问题,例如:分布式事务、全局唯一ID的生成、跨数据库查询 等,依旧会让你面对棘手的问题。如果打破这种按照行存储的模式,采用一种基于列存储的模式,对于大规模数据场景这样情况有可能发生一些好转。由于查询中的 选择规则是通过列来定义的,因此整个数据库是自动索引化的。按列存储每个字段的数据聚集存储, 可以动态增加,并且列为空就不存储数据,节省存储空间。 每个字段的数据按照聚集存储,能大大减少读取的数据量,查询时指哪打哪,来的更直接。无需考虑分库、分表 Hbase将对存储的数据自动切分数据,并支持高并发读写操作,使得海量数据存储自动具有更强的扩展性。
Java中的HashMap是Key/Value的结构,你也可以把HBase的数据结构看做是一个Key/Value的体系,话说HBase的区域由表 名和行界定的。在HBase区域每一个"列族"都由一个名为HStore的对象管理。每个HStore由一个或多个MapFiles(Hadoop中的一 个文件类型)组成。MapFiles的概念类似于Google的SSTable。 在Hbase里面有以下两个主要的概念,Row key 和 Column Family,其次是Cell qualifier和Timestamp tuple,Column family我们通常称之为“列族”,访问控制、磁盘和内存的使用统计都是在列族层面进行的。列族Column family是之前预先定义好的数据模型,每一个Column Family都可以根据“限定符”有多个column。在HBase每个cell存储单元对同一份数据有多个版本,根据唯一的时间戳来区分每个版本之间的 差异,最新的数据版本排在最前面 。
口水:Hbase将table水平划分成N个Region,region按column family划分成Store,每个store包括内存中的memstore和持久化到disk上的HFile。
上述可能我表达的还不够到位,下面来看一个实践中的场景,将原来是存放在MySQL中Blog中的数据迁移到HBase中的过程:
MySQL中现有的表结构:
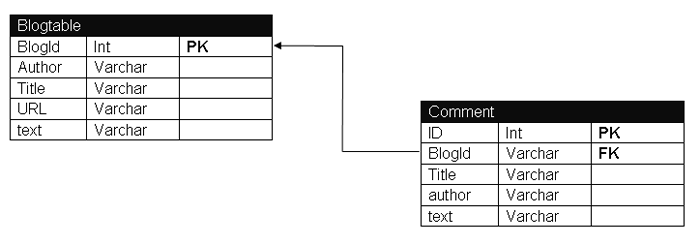
迁移HBase中的表结构:
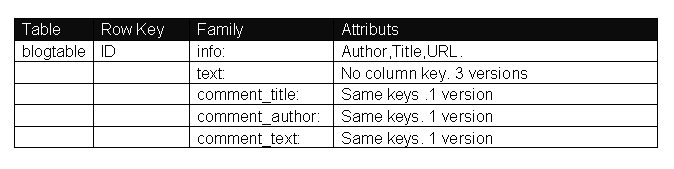
原来系统中有2张表blogtable和comment表,采用HBase后只有一张blogtable表,如果按照传统的RDBMS的话,blogtable表中的列是固定的,比如schema 定义了Author,Title,URL,text等属性,上线后表字段是不能动态增加的。但是如果采用列存储系统,比如Hbase,那么我们可以定义blogtable表,然后定义info 列族,User的数据可以分为:info:title ,info:author ,info:url 等,如果后来你又想增加另外的属性,这样很方便只需要 info:xxx 就可以了。
对于Row key你可以理解row key为传统RDBMS中的某一个行的主键,Hbase是不支持条件查询以及Order by等查询,因此Row key的设计就要根据你系统的查询需求来设计了额。 Hbase中的记录是按照rowkey来排序的,这样就使得查询变得非常快。
具体操作过程如下:
============================创建blogtable表========================= create 'blogtable', 'info','text','comment_title','comment_author','comment_text' ============================插入概要信息========================= put 'blogtable', '1', 'info:title', 'this is doc title' put 'blogtable', '1', 'info:author', 'javabloger' put 'blogtable', '1', 'info:url', 'http://www.javabloger.com/index.php' put 'blogtable', '2', 'info:title', 'this is doc title2' put 'blogtable', '2', 'info:author', 'H.E.' put 'blogtable', '2', 'info:url', 'http://www.javabloger.com/index.html' ============================插入正文信息========================= put 'blogtable', '1', 'text:', 'what is this doc context ?' put 'blogtable', '2', 'text:', 'what is this doc context2?' ==========================插入评论信息=============================== put 'blogtable', '1', 'comment_title:', 'this is doc comment_title ' put 'blogtable', '1', 'comment_author:', 'javabloger' put 'blogtable', '1', 'comment_text:', 'this is nice doc' put 'blogtable', '2', 'comment_title:', 'this is blog comment_title ' put 'blogtable', '2', 'comment_author:', 'H.E.' put 'blogtable', '2', 'comment_text:', 'this is nice blog' |
HBase的数据查询\读取,可以通过单个row key访问,row key的range和全表扫描,大致如下:
注意:HBase不能支持where条件、Order by 查询,只支持按照Row key来查询,但是可以通过HBase提供的API进行条件过滤。
例如:http://hbase.apache.org/apidocs/org/apache/hadoop/hbase/filter/ColumnPrefixFilter.html
scan 'blogtable' ,{COLUMNS => ['text:','info:title'] } —> 列出 文章的内容和标题
scan 'blogtable' , {COLUMNS => 'info:url' , STARTROW => '2'} —> 根据范围列出 文章的内容和标题
get 'blogtable','1' —> 列出 文章id 等于1的数据
get 'blogtable','1', {COLUMN => 'info'} —> 列出 文章id 等于1 的 info 的头(Head)内容
get 'blogtable','1', {COLUMN => 'text'} —> 列出 文章id 等于1 的 text 的具体(Body)内容
get 'blogtable','1', {COLUMN => ['text','info:author']} —> 列出 文章id 等于1 的内容和作者(Body/Author)内容
我的废话2:
有人会问Java Web服务器中是Tomcat快还是GlassFish快?小型数据库中是MySQL效率高还是MS-SQL效率高?我看是关键用在什么场景和怎么使用这 个产品(技术),所以我渐渐的认为是需要对产品、技术本身深入的了解,而并非一项新的技术就是绝佳的选择。试问:Tomcat的默认的运行参数能和我们线 上正在使用的GlassFish性能相提并论吗?我不相信GlassFishv2和GlassFishv3在默认的配置参数下有显著的差别。我们需要对产 品本身做到深入的了解才能发挥他最高的性能,而并非感观听从厂家的广告和自己的感性认识 迷信哪个产品的优越性。
我的废话3:
对于NOSQL这样的新技术,的的确确是可以解决过去我们所需要面对的问题,但也并非适合每个应用场景,所以在使用新产品的同时需要切合当前的产品需要, 是需求在引导新技术的投入,而并非为了赶时髦去使用他。你的产品是否过硬不是你使用了什么新技术,用户关心的是速度和稳定性,不会关心你是否使用了 NOSQL。相反Google有着超大的数据量,能给全世界用户带来了惊人的速度和准确性,大家才会回过头来好奇Google到底是怎么做到的。所以根据 自己的需要千万别太勉强自己使用了某项新技术。
我的废话4:
总之一句话,用什么不是最关键,最关键是怎么去使用!
我的废话:
大年三十夜,看春晚实在是太无聊了,整个《新闻联播》的电视剧版本,还不如上上网,看看资料,喝喝老酒,写点东西来的快活。
近2年来云计算的话题到目前为止风风火火从来没有平静过,一直是大家嘴边讨论的热门话题,人们期望运用云计算提供可靠、稳定、高速的计算,在云计算中 Google是目前最大的云计算供应商,例如:Google GAE(Google App Engine)和Google的Docs在线文章服务,这些SaaS上线产品的数据存储(datastore)是由BigTable提供存储服务的,在次 之前我提到过Yahoo贡献给Apache的那些山寨版本(Google与Yahoo的那些利器),其中Apache的HBase就是山寨了Google 的BigTable。
我们知道在云计算的技术话题中Apache的Hadoop项目是一块基石,利用Hadoop项目中的产品可以建立云计算平台和超大型的计算。不知道你是否 有想过如果将HBase作为Google GAE上的数据存储(datastore),那么每个用户之间的数据访问权限怎么办?如果使用HBase提供对大客户提供“私有云”(private cloud)或者另一种可能一个公司内部的集群上运行HBase,公司的内部可能有几个部门,某几个部门之间的数据都是独立分离但又运行在一个平台上,那 么你就会发现HBase不具备这样的功能,貌似目前HBase的最高版本0.90.0还没有这样的功能对用户的表、Row、Cell的访问权限。但是我们 知道Google的GAE上每个用户访问的数据肯定是有权限划分的,不然我只要有权限登录GEA就能看见所有用户存放的数据了。这样的问题你有可能没有想 过,但趋势公司的工程师们却为此想到了这点,并且把他们的设想和设计提交了HBase项目组,并且提出了以下主要的设计思想:
- Client access to HBase is authenticated
- User data is private unless access has been granted
- Access to data can be granted at a table or per column family basis.
对HBase中的表和数据划分权限等级和身份验证后,操作权限被分为3大类,每类中包含的操作权限如下所示:
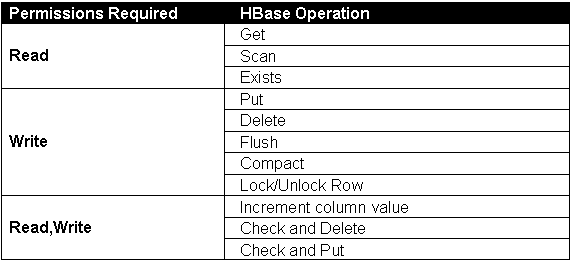
对于方案中涉及到存储的权限的是指整个表或表中的列族,也就是说只考虑在表这个级别的权限,表与表之间的所属关系是存放在 .META. 系统表中,以regioninfo:owner 的格式进行存放,例如:系统中table1这个表是有权限的,这个表权限的存根保存在3个地方 :
- The row in .META. for the first region of table1
- The node /hbase/acl/table1 of Zookeeper
- The in-memory Permissions Mirror of every regionserver that serves table1
如图所示,图中的箭头表示了数据流向的顺序:
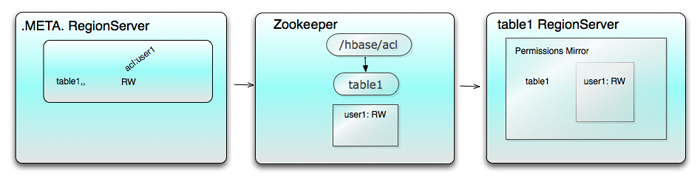
方案中HBase在分布式、集群环境下,而权限一致性的问题交给了Zookeeper来处理,在多个regionservers中,每个服务器的 HRegion中存放着多个表,并且实现了(implement)ZKPermissionWatcher接口的nodeCreated() 和 nodeChanged() 方法,这2个方法对Zookeeper 的节点进行监控, 节点的状态发生相应的变化时会ZooKeeper刷新镜像中的权限。
如图所示:

HBase的这一关于权限的功能正在设计和研讨当中,让我们继续对他保持关注,看看今后将会发生的变化能给我们带来什么样的效果,非常期待这个功能早日正式发布。



相关推荐
HBase是Apache Hadoop中的一个子项目,Hbase依托于Hadoop的HDFS作为最基本存储基础单元,通过使用hadoop的DFS工具就可以看到这些这些数据 存储文件夹的结构,还可以通过Map/Reduce的框架(算法)对HBase进行操作.
本人总结的hbase入门+提高培训ppt,对于对初级人员进行hbase培训,讲解思路在我的一篇博文中:http://blog.csdn.net/kirayuan/article/details/6321966#reply
- **HDFS+MapReduce+Hive十分钟快速入门.doc**:这篇文档可能提供了一个快速了解Hadoop生态系统的概览,包括HDFS的基本操作、MapReduce的工作原理以及Hive的简单查询示例。 - **hive函数大全.doc**:这可能是一份...
MongoDB入门篇1主要介绍了数据的基本概念,数据库管理系统(DBMS)的定义,常见的数据库管理系统,以及NoSQL数据库的相关知识。 1. 数据:数据是未经处理的原始记录,描述事物存在的符号,通常需要通过组织和分类...
本篇文章将围绕"基于Hadoop、HBase的WordCount代码"进行详细讲解,旨在帮助读者理解如何在Hadoop上实现基础的数据统计,并利用HBase存储和查询结果。 首先,让我们来了解一下Hadoop的WordCount程序。WordCount是...
可见,无论使用多少堆外内存,对JVM内存的使用终究是绕不过去,既然绕不过去...本文就将会介绍HBase应用场景下CMS GC策略的调优技巧,后续还会针对另一业界开始使用的GC策略-G1GC策略在HBase应用场景下进行调优介绍。
kafka 详解和实战案例09.S图表框架HighCharts介绍10.HBase快速入门11.基于HBase的Dao基类和实现类开发一12.基于HBase的Dao基类和实现类开发二13.项目1-地区销售额-需求分析和架构设计14.项目1-地区销售额-Spout融合...
2. 从外部存储系统中创建:支持HDFS、Cassandra、HBase等,直接读取数据创建RDD。 3. 从其他RDD转换:通过一系列的转换操作算子,如map、filter等,生成新的RDD。 Spark的编程模型基于Driver和Worker。Driver程序...
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、...
4. **大数据工程师篇2017转取.pdf** - 大数据工程师需要掌握大数据处理框架如Hadoop、Spark,数据存储系统如HDFS、HBase,以及数据清洗、分析和可视化工具。此图谱可能还包括ETL流程、MapReduce编程模型等内容。 5....
Hadoop的发展历史与Google的三篇论文(GFS、MapReduce、BigTable)密切相关,这三篇论文奠定了大数据处理的理论基础。Hadoop的创始人Doug Cutting在借鉴这些论文的基础上,开发出了Hadoop。其发展过程中的一个重要...
### Hadoop快速入门知识点梳理 #### 一、Hadoop概览与背景介绍 **1.1 何为Hadoop** - **定义**:Hadoop是一个由Apache基金会支持的开源软件框架,旨在通过集群中的普通商用硬件来处理大量数据集。 - **核心功能**...
Hadoop的诞生可以追溯到Google公开的三篇核心论文,分别介绍了GFS(Google File System)、MapReduce算法和BigTable。这三篇论文揭示了Google处理海量数据的技术机制,对Hadoop的发展起到了关键作用。 Hadoop的生态...
本篇文章将详细介绍MySQL的基础知识点,内容包含其在淘宝的应用概况、常见操作、数据类型、SQL优化方法以及InnoDB索引等方面。了解这些知识对初学者来说,有助于快速掌握MySQL的基本使用与优化技巧。 一、淘宝MySQL...
它可以与Hadoop生态系统无缝集成,使用YARN或Mesos作为资源管理和调度器,处理Hadoop支持的所有数据源,如HDFS和HBase。这样,用户无需迁移数据即可利用Spark的能力。 Spark集群由Master和Worker组成,Master作为...
### NoSQL数据库详细介绍入门经典 #### 序言 随着互联网技术的发展及大数据时代的到来,传统的关系型数据库在处理海量数据时逐渐显露出不足。NoSQL(Not Only SQL)数据库应运而生,以其灵活的数据模型、高扩展性...