
一、背景知识
Amoeba(变形虫)项目,专注 分布式数据库 proxy 开发。座落与Client、DB Server(s)之间。对客户端透明。具有负载均衡、高可用性、sql过滤、读写分离、可路由相关的query到目标数据库、可并发请求多台数据库合并结果。
要想搭建Amoeba读写分离,首先需要知道MySQL的主从配置,可参考:Ubuntu下MySQL搭建Master/Slave,更好的情况下是你还需要了解MySQL-Proxy,可参考:Ubuntu下搭建MySQL Proxy读写分离
二、搭建过程
(一) 测试环境
Amoeba for MySQL:192.168.1.147
Master:192.168.1.25
Slave1:192.168.1.30
Slave2:192.168.1.35
数据库为:dba_db,帐号密码统一为:test/123456
(二) 前期准备
1. 验证Amoeba是否安装成功的命令(如下图):/usr/local/amoeba/bin/amoeba
![]()
(图1:安装成功)
2. 启动amoeba:/usr/local/amoeba/bin/amoeba start
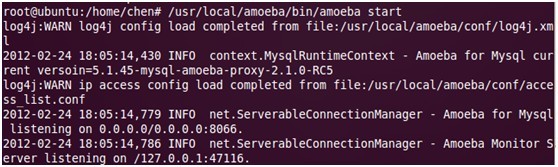
(图2:启动成功)
(三) Amoeba读写分离配置
1. 修改amoeba.xml,设置登陆amoeba的帐号密码。
<property name="user">testuser</property>
<property name="password">password</property>
2. 测试使用上面帐号是否正常登陆,如果出现上面的图2界面说明设置的帐号密码成功。
#mysql -u testuser -p -h 192.168.1.147 -P 8066
3. 修改dbServers.xml,设置数据库、登陆MySQL的帐号和密码。
<property name="schema">dba_db</property>
<property name="user">test</property>
<property name="password">123456</property>
4. 修改dbServers.xml,设置数据库服务器的IP地址和服务器别名。
<dbServer name="Master" parent="abstractServer">
<factoryConfig>
<property name="ipAddress">192.168.1.25</property>
</factoryConfig>
</dbServer>
<dbServer name="Slave1" parent="abstractServer">
<factoryConfig>
<property name="ipAddress">192.168.1.30</property>
</factoryConfig>
</dbServer>
<dbServer name="Slave2" parent="abstractServer">
<factoryConfig>
<property name="ipAddress">192.168.1.35</property>
</factoryConfig>
</dbServer>
5. 修改dbServers.xml,设置ROUNDROBIN(轮询策略);
<dbServer name="virtualSlave" virtual="true">
<poolConfig class="com.meidusa.amoeba.server.MultipleServerPool">
<!-- Load balancing strategy: 1=ROUNDROBIN , 2=WEIGHTBASED , 3=HA-->
<property name="loadbalance">1</property>
<property name="poolNames">Slave1,Slave2,Slave2</property>
</poolConfig>
</dbServer>
6. 修改amoeba.xml,设置读写分离,修改queryRouter标签下的;
<property name="LRUMapSize">1500</property>
<property name="defaultPool">Master</property>
<property name="writePool">Master</property>
<property name="readPool">virtualSlave</property>
<property name="needParse">true</property>
7. 重新启动amoeba,如果出现上面的图2界面说明设置成功;
8. 如果你已经使用终端登陆了amoeba(#mysql -u testuser -p -h 192.168.1.147 -P 8066),那么你需要重启打开终端;如果你使用SQLyog的工具登陆了amoeba,那么你需要关闭链接,再重新链接amoeba。
(四) MySQL的Master/Slave配置
1. Master服务器/etc/mysql/my.cnf目录 [mysqld] 区块中加上:
log-bin=mysql-bin
server-id=1
innodb_flush_log_at_trx_commit=1
sync_binlog=1
binlog_do_db=dba_db
binlog_ignore_db=mysql
2. 登陆Master的MySQL,新建一个用户赋予“REPLICATION SLAVE”的权限。你不需要再赋予其它的权限:(因为是有两个Salve,所以使用了%)
mysql>use mysql;
mysql>create user viajar@'192.168.1.%' identified by '123456';
mysql>grant replication slave on *.* to viajar@'192.168.1.%' identified by '123456';
3. 重启Master的MySQL:
#service mysql restart
4. 获取Master的binlog信息:(mysql-bin.000136,106)
mysql>SHOW MASTER logs;
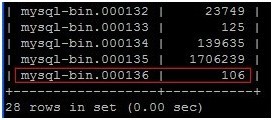
(图3)
5. Slave1服务器/etc/mysql/my.cnf目录 [mysqld] 区块中加上:
server-id=2
6. 重启Slave1的MySQL:
#service mysql restart
7. 登陆Slave1的MySQL,执行命令:
mysql> change master to master_host='192.168.1.25', master_user='viajar', master_password='123456', master_log_file='mysql-bin.000136', master_log_pos=106;
8. 启动Slave1的Slave:
mysql>START SLAVE;
9. 检查Slave1的Slave是否正常:
mysql>show slave status\G;
10. 以同样的方式配置Slave2,唯一有不同的就是第5步的设置:server-id=3
(五) 验证读写分离
1. 登陆到amoeba(147),插入下面的测试数据
INSERT INTO label(Id,NAME,Description,AddOn)
VALUES (1,'viajar','我的博客',NOW());
INSERT INTO label(Id,NAME,Description,AddOn)
VALUES (2,'viajar','我的博客',NOW());
INSERT INTO label(Id,NAME,Description,AddOn)
VALUES (3,'viajar','我的博客',NOW());
INSERT INTO label(Id,NAME,Description,AddOn)
VALUES (4,'viajar','我的博客',NOW());
2. 登陆Master、Slave1、Slave2、amoeba分别验证数据的分布,四个地方看到数据都如下图所示:
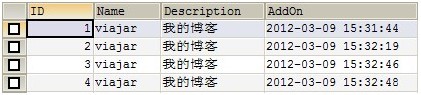
(图4)
四个地方的数据都如图4的意思是搭建的replication成功了;Amoeba作为透明的代理已经基本成功,程序只需要知道Amoeba的地址就可以,完全不需要理会后台的处理;接下来我们验证Amoeba读写是否是分离的。
3. 停止Slave1上的Slave,删除id为3的记录:
mysql>stop slave;
mysql>DELETE FROM label WHERE id =3;

(图5:Slave1)
4. 停止Slave2上的Slave,添加一条新的记录:
mysql>stop slave;

(图6:Slave2)
5. 到Amoeba上执行多次查询,查询返回的结果集:
mysql>SELECT * FROM label;
发现Slave1,Slave2,Slave2这样的配置会返回:图5出现1次,图6出现2次的规律进行返回的。
到此Amoeba的读写分离已经测试完毕。
三、注意事项
1. 在做Master/Slave的时候,当删除了master的帐号,如果想要看到slave的效果,那就需要重启master的数据库服务再去看slave的status;(但是当salve从不可用到master可用了,不用重启master的数据库服务,slave也能看到效果)
2. 在做Master/Slave的时候,我们有两台Salve,而且是内网的机器,所以使用了“192.168.1.%”这样的方式来创建用户,在一定的程度上保障帐号的安全性,又方便管理,使用“*”是错误的;
3. 对于多Slave的帐号问题,还可以有其它方式来创建帐号的,就是在Master为每个Slave创建独立的帐号和密码;
4. 修改log4j.xml 取消日志文件生成(太大了,磁盘很容易满),<param name="file" value="${amoeba.home}/logs/project.log"/>改成:<param name="file" value="<![CDATA[${amoeba.home}/logs/project.log>/dev/null]]>"/>
5. 性能优化,打开bin/amoeba,DEFAULT_OPTS="-server -Xms256m -Xmx256m -Xss128k"改成:DEFAULT_OPTS="-server -Xms512m -Xmx512m -Xmn100m -Xss1204k"
6. loadbalance元素设置了loadbalance策略的选项,这里选择第一个“ROUNDROBIN”轮询策略,该配置提供负载均衡、failOver、故障恢复功能。poolNames定义了其中的数据库节点配置(当然也可以是虚拟的节点)。此外对于轮询策略,poolNames还定义了其轮询规则,比如设置成“Slave1,Slave1,Slave2”那么Amoeba将会以两次Slave1,一次Slave2的顺序循环对这些数据库节点转发请求。
四、疑问
1. 修改dbServers.xml的时候,设置virtualSlave 为ROUNDROBIN(轮询策略):<property name="poolNames">Slave1,Slave2</property>,删除Slave1(30)一条数据,插入Slave2(35)一条数据,如图所示,到amoeba(147)执行多次Select,但是却没有出现负载均衡的效果,一直显示为Slave1的数据:(图5、图6)
Slave1,Slave2或者Slave1,Slave2,Slave1,Slave2这样的模式是无法达到轮询Slave1和Slave2的目的。当设置为Slave1,Slave1,Slave2或者Slave1,Slave2,Slave1或者Slave1,Slave2,Slave2就生效了。为什么呢?Amoeba for mysql读写分离
五、参考文献
Amoeba新版本MYSQL读写分离配置(log4j.xml设置)
Amoeba for mysql读写分离(比较多的测试)



相关推荐
MySQL 搭建 Amoeba 读写分离 在本文中,我们将详细介绍如何使用 Amoeba 实现 MySQL 读写分离的配置过程。Amoeba 是一个基于 MySQL 的 proxy,能够集中地响应应用的请求,并根据用户事先设置的规则,将 SQL 请求发送...
Amoeba MySQL 读写分离部署说明 Amoeba 是一款专为 MySQL 设计的中间件,用于实现数据库的读写分离和负载均衡。它的主要功能是接收应用程序的 SQL 请求,根据预设规则将这些请求转发到合适的 MySQL 实例上执行,...
在Linux环境下,MySQL数据库的读写分离和数据同步是提高数据库性能和可用性的关键策略。MySQL的主从复制(Master-Slave Replication)和读写分离(Read-Write Separation)是实现这一目标的常用方法。这里我们将探讨...
通过以上步骤,我们可以在Windows平台上搭建Amoeba与MySQL相结合的读写分离环境。需要注意的是,在实施过程中可能会遇到各种配置问题和异常情况,比如网络延迟、主从同步延迟、主从服务器间的复制冲突等。因此,在...
mysql读写分离 中间件amoeba配置文件配置号的改几个参数就可以直接用https://blog.csdn.net/z13615480737/article/details/79951505 参考这个改2个文件就可直接用
标题中的"amoeba-aladdin-0.5.zip_Amoeba for Aladdin_MYSQL_aladdin_amoeba"揭示了这是一个关于Amoeba与Aladdin在MySQL集群环境中的整合应用。Amoeba是一个分布式数据库中间件,它能将一个单一的MySQL数据库实例...
配合docker_mn.sh 主从复制和jdk1.8.sh jdk安装脚本 可以搭建mysql数据库的读写分离
这里我们主要探讨的是如何使用Amoeba与MySQL实现读写分离,以及如何利用Keepalived来构建MySQL的高可用集群。这两部分内容对于保障数据库服务的稳定性和效率至关重要。 **Amoeba+MySQL 读写分离** Amoeba 是一个...
总之,Amoeba作为一款Java环境下的MySQL读写分离解决方案,通过智能的分片策略和高可用性设计,能够有效提升系统的读取性能和容错能力。但在实际应用中,需要结合业务需求和技术限制,合理选择和配置,才能发挥其...
### Amoeba 读写分离配置详解 #### 一、配置前的准备工作 为了实现数据库的读写分离,首先需要确保所有的服务器均处于同一局域网内,并且完成以下准备工作: 1. **主机A(Amoeba服务器)**: - 安装 Java SE 1.6 ...
具有负载均衡、高可用性、SQL 过滤、读写分离、可路由相关的到目标数据库、可并发请求多台数据库合并结果。 通过Amoeba能够完成多数据源的高可用、负载均衡、数据切片的功能,目前Amoeba已在很多企业的生产线上面...
amoeba是一款开源的读写分离中间件,适用于MySQL数据库。 ```bash wget http://amoeba.googlecode.com/files/amoeba-3.0.5.tar.gz tar -zxvf amoeba-3.0.5.tar.gz cd amoeba-3.0.5/ ``` ##### 2、修改配置文件 ...
### 使用mysql-proxy实现MySQL读写分离 随着业务规模的不断扩大,数据库系统往往成为整个系统中的瓶颈之一。为了提高系统的响应速度以及数据处理能力,一种常用的技术手段就是采用**读写分离**的方式。读写分离的...
在搭建MySQL读写分离环境中,首先需要创建一个Master-Slave复制环境,这样可以从Master节点实时同步数据到Slave节点,从而实现数据的冗余备份,并为后续的读写分离打下基础。 **2.1.1 配置Master** 1. **安装MySQL...
MySQL的主从复制和读写分离是数据库高可用性和负载均衡的重要策略,它们在大型分布式系统中尤为关键。本文将详细解析这两个概念及其实施过程。 首先,MySQL的主从复制是指在一个MySQL集群中,数据的变化(写操作)...
使用amoeba实现mysql读写分离.md
这是针对amoeba for mysql的一个具体案例,实现水平切分和读写分离
综上所述,"Amoeba_website_" 的压缩包很可能是为了提供一系列具有现代设计感、响应式布局、良好用户体验的免费网站模板,帮助初学者或开发者快速搭建自己的网站。这些模板可能涉及到HTML、CSS、JavaScript代码,...
Mysql安装手则 ..................................... 3 一、 下载Mysql软件 .......................................... 3 二、 安装Mysql软件 .......................................... 4 三、 Mysql设置 ....
Amoeba搞定mysql主从读写分离.pdf