
第дёҖйғЁеҲҶпјҡTop K з®—жі•иҜҰи§Ј
й—®йўҳжҸҸиҝ°
зҷҫеәҰйқўиҜ•йўҳпјҡ
В В В жҗңзҙўеј•ж“ҺдјҡйҖҡиҝҮж—Ҙеҝ—ж–Ү件жҠҠз”ЁжҲ·жҜҸж¬ЎжЈҖзҙўдҪҝз”Ёзҡ„жүҖжңүжЈҖзҙўдёІйғҪи®°еҪ•дёӢжқҘпјҢжҜҸдёӘжҹҘиҜўдёІзҡ„й•ҝеәҰдёә1-255еӯ—иҠӮгҖӮ
В В В еҒҮи®ҫзӣ®еүҚжңүдёҖеҚғдёҮдёӘи®°еҪ•пјҲиҝҷдәӣжҹҘиҜўдёІзҡ„йҮҚеӨҚеәҰжҜ”иҫғй«ҳпјҢиҷҪ然жҖ»ж•°жҳҜ1еҚғдёҮпјҢдҪҶеҰӮжһңйҷӨеҺ»йҮҚеӨҚеҗҺпјҢдёҚи¶…иҝҮ3зҷҫдёҮдёӘгҖӮдёҖдёӘжҹҘиҜўдёІзҡ„йҮҚеӨҚеәҰи¶Ҡй«ҳпјҢиҜҙжҳҺжҹҘиҜўе®ғзҡ„з”ЁжҲ·и¶ҠеӨҡпјҢд№ҹе°ұжҳҜи¶Ҡзғӯй—ЁгҖӮпјүпјҢиҜ·дҪ з»ҹи®ЎжңҖзғӯй—Ёзҡ„10дёӘжҹҘиҜўдёІпјҢиҰҒжұӮдҪҝз”Ёзҡ„еҶ…еӯҳдёҚиғҪи¶…иҝҮ1GгҖӮ
еҝ…еӨҮзҹҘиҜҶпјҡ
В В В д»Җд№ҲжҳҜе“ҲеёҢиЎЁпјҹ
В В В е“ҲеёҢиЎЁпјҲHash tableпјҢд№ҹеҸ«ж•ЈеҲ—иЎЁпјүпјҢжҳҜж №жҚ®е…ій”®з ҒеҖј(Key value)иҖҢзӣҙжҺҘиҝӣиЎҢи®ҝй—®зҡ„ж•°жҚ®з»“жһ„гҖӮд№ҹе°ұжҳҜиҜҙпјҢе®ғйҖҡиҝҮжҠҠе…ій”®з ҒеҖјжҳ е°„еҲ°иЎЁдёӯдёҖдёӘдҪҚзҪ®жқҘи®ҝй—®и®°еҪ•пјҢд»ҘеҠ еҝ«жҹҘжүҫзҡ„йҖҹеәҰгҖӮиҝҷдёӘжҳ е°„еҮҪж•°еҸ«еҒҡж•ЈеҲ—еҮҪж•°пјҢеӯҳж”ҫи®°еҪ•зҡ„ж•°з»„еҸ«еҒҡж•ЈеҲ—иЎЁгҖӮ
В В В е“ҲеёҢиЎЁзҡ„еҒҡжі•е…¶е®һеҫҲз®ҖеҚ•пјҢе°ұжҳҜжҠҠKeyйҖҡиҝҮдёҖдёӘеӣәе®ҡзҡ„з®—жі•еҮҪж•°ж—ўжүҖи°“зҡ„е“ҲеёҢеҮҪж•°иҪ¬жҚўжҲҗдёҖдёӘж•ҙеһӢж•°еӯ—пјҢ然еҗҺе°ұе°ҶиҜҘж•°еӯ—еҜ№ж•°з»„й•ҝеәҰиҝӣиЎҢеҸ–дҪҷпјҢеҸ–дҪҷз»“жһңе°ұеҪ“дҪңж•°з»„зҡ„дёӢж ҮпјҢе°ҶvalueеӯҳеӮЁеңЁд»ҘиҜҘж•°еӯ—дёәдёӢж Үзҡ„ж•°з»„з©әй—ҙйҮҢгҖӮ
В В В иҖҢеҪ“дҪҝз”Ёе“ҲеёҢиЎЁиҝӣиЎҢжҹҘиҜўзҡ„ж—¶еҖҷпјҢе°ұжҳҜеҶҚж¬ЎдҪҝз”Ёе“ҲеёҢеҮҪж•°е°ҶkeyиҪ¬жҚўдёәеҜ№еә”зҡ„ж•°з»„дёӢж ҮпјҢ并е®ҡдҪҚеҲ°иҜҘз©әй—ҙиҺ·еҸ–valueпјҢеҰӮжӯӨдёҖжқҘпјҢе°ұеҸҜд»Ҙе……еҲҶеҲ©з”ЁеҲ°ж•°з»„зҡ„е®ҡдҪҚжҖ§иғҪиҝӣиЎҢж•°жҚ®е®ҡдҪҚпјҲж–Үз« з¬¬дәҢгҖҒдёүйғЁеҲҶпјҢдјҡй’ҲеҜ№HashиЎЁиҜҰз»Ҷйҳҗиҝ°пјүгҖӮ
й—®йўҳи§Јжһҗпјҡ
В В В иҰҒз»ҹи®ЎжңҖзғӯй—ЁжҹҘиҜўпјҢйҰ–е…Ҳе°ұжҳҜиҰҒз»ҹи®ЎжҜҸдёӘQueryеҮәзҺ°зҡ„ж¬Ўж•°пјҢ然еҗҺж №жҚ®з»ҹи®Ўз»“жһңпјҢжүҫеҮәTop 10гҖӮжүҖд»ҘжҲ‘们еҸҜд»ҘеҹәдәҺиҝҷдёӘжҖқи·ҜеҲҶдёӨжӯҘжқҘи®ҫи®ЎиҜҘз®—жі•гҖӮ
В В В еҚіпјҢжӯӨй—®йўҳзҡ„и§ЈеҶіеҲҶдёәд»ҘдёӢдҝ©дёӘжӯҘйӘӨпјҡ
第дёҖжӯҘпјҡQueryз»ҹи®Ў
В В В Queryз»ҹи®Ўжңүд»ҘдёӢдҝ©дёӘж–№жі•пјҢеҸҜдҫӣйҖүжӢ©пјҡ
В В В 1гҖҒзӣҙжҺҘжҺ’еәҸжі•
В В В йҰ–е…ҲжҲ‘们жңҖе…ҲжғіеҲ°зҡ„зҡ„з®—жі•е°ұжҳҜжҺ’еәҸдәҶпјҢйҰ–е…ҲеҜ№иҝҷдёӘж—Ҙеҝ—йҮҢйқўзҡ„жүҖжңүQueryйғҪиҝӣиЎҢжҺ’еәҸпјҢ然еҗҺеҶҚйҒҚеҺҶжҺ’еҘҪеәҸзҡ„QueryпјҢз»ҹи®ЎжҜҸдёӘQueryеҮәзҺ°зҡ„ж¬Ўж•°дәҶгҖӮ
В В В дҪҶжҳҜйўҳзӣ®дёӯжңүжҳҺзЎ®иҰҒжұӮпјҢйӮЈе°ұжҳҜеҶ…еӯҳдёҚиғҪи¶…иҝҮ1GпјҢдёҖеҚғдёҮжқЎи®°еҪ•пјҢжҜҸжқЎи®°еҪ•жҳҜ255ByteпјҢеҫҲжҳҫ然иҰҒеҚ жҚ®2.375GеҶ…еӯҳпјҢиҝҷдёӘжқЎд»¶е°ұдёҚж»Ўи¶іиҰҒжұӮдәҶгҖӮ
В В В и®©жҲ‘们еӣһеҝҶдёҖдёӢж•°жҚ®з»“жһ„иҜҫзЁӢдёҠзҡ„еҶ…е®№пјҢеҪ“ж•°жҚ®йҮҸжҜ”иҫғеӨ§иҖҢдё”еҶ…еӯҳж— жі•иЈ…дёӢзҡ„ж—¶еҖҷпјҢжҲ‘们еҸҜд»ҘйҮҮз”ЁеӨ–жҺ’еәҸзҡ„ж–№жі•жқҘиҝӣиЎҢжҺ’еәҸпјҢиҝҷйҮҢжҲ‘们еҸҜд»ҘйҮҮз”ЁеҪ’并жҺ’еәҸпјҢеӣ дёәеҪ’并жҺ’еәҸжңүдёҖдёӘжҜ”иҫғеҘҪзҡ„ж—¶й—ҙеӨҚжқӮеәҰO(NlgN)гҖӮ
В В В жҺ’е®ҢеәҸд№ӢеҗҺжҲ‘们еҶҚеҜ№е·Із»ҸжңүеәҸзҡ„Queryж–Ү件иҝӣиЎҢйҒҚеҺҶпјҢз»ҹи®ЎжҜҸдёӘQueryеҮәзҺ°зҡ„ж¬Ўж•°пјҢеҶҚж¬ЎеҶҷе…Ҙж–Ү件дёӯгҖӮ
В В В з»јеҗҲеҲҶжһҗдёҖдёӢпјҢжҺ’еәҸзҡ„ж—¶й—ҙеӨҚжқӮеәҰжҳҜO(NlgN)пјҢиҖҢйҒҚеҺҶзҡ„ж—¶й—ҙеӨҚжқӮеәҰжҳҜO(N)пјҢеӣ жӯӨиҜҘз®—жі•зҡ„жҖ»дҪ“ж—¶й—ҙеӨҚжқӮеәҰе°ұжҳҜO(N+NlgN)=OпјҲNlgNпјүгҖӮ
В В В 2гҖҒHash Tableжі•
В В В еңЁз¬¬1дёӘж–№жі•дёӯпјҢжҲ‘们йҮҮз”ЁдәҶжҺ’еәҸзҡ„еҠһжі•жқҘз»ҹи®ЎжҜҸдёӘQueryеҮәзҺ°зҡ„ж¬Ўж•°пјҢж—¶й—ҙеӨҚжқӮеәҰжҳҜNlgNпјҢйӮЈд№ҲиғҪдёҚиғҪжңүжӣҙеҘҪзҡ„ж–№жі•жқҘеӯҳеӮЁпјҢиҖҢж—¶й—ҙеӨҚжқӮеәҰжӣҙдҪҺе‘ўпјҹ
В В В йўҳзӣ®дёӯиҜҙжҳҺдәҶпјҢиҷҪ然жңүдёҖеҚғдёҮдёӘQueryпјҢдҪҶжҳҜз”ұдәҺйҮҚеӨҚеәҰжҜ”иҫғй«ҳпјҢеӣ жӯӨдәӢе®һдёҠеҸӘжңү300дёҮзҡ„QueryпјҢжҜҸдёӘQuery255ByteпјҢеӣ жӯӨжҲ‘们еҸҜд»ҘиҖғиҷ‘жҠҠ他们йғҪж”ҫиҝӣеҶ…еӯҳдёӯеҺ»пјҢиҖҢзҺ°еңЁеҸӘжҳҜйңҖиҰҒдёҖдёӘеҗҲйҖӮзҡ„ж•°жҚ®з»“жһ„пјҢеңЁиҝҷйҮҢпјҢHash Tableз»қеҜ№жҳҜжҲ‘们дјҳе…Ҳзҡ„йҖүжӢ©пјҢеӣ дёәHash Tableзҡ„жҹҘиҜўйҖҹеәҰйқһеёёзҡ„еҝ«пјҢеҮ д№ҺжҳҜO(1)зҡ„ж—¶й—ҙеӨҚжқӮеәҰгҖӮ
В В В йӮЈд№ҲпјҢжҲ‘们зҡ„з®—жі•е°ұжңүдәҶпјҡз»ҙжҠӨдёҖдёӘKeyдёәQueryеӯ—дёІпјҢValueдёәиҜҘQueryеҮәзҺ°ж¬Ўж•°зҡ„HashTableпјҢжҜҸж¬ЎиҜ»еҸ–дёҖдёӘQueryпјҢеҰӮжһңиҜҘеӯ—дёІдёҚеңЁTableдёӯпјҢйӮЈд№ҲеҠ е…ҘиҜҘеӯ—дёІпјҢ并且е°ҶValueеҖји®ҫдёә1пјӣеҰӮжһңиҜҘеӯ—дёІеңЁTableдёӯпјҢйӮЈд№Ҳе°ҶиҜҘеӯ—дёІзҡ„и®Ўж•°еҠ дёҖеҚіеҸҜгҖӮжңҖз»ҲжҲ‘们еңЁO(N)зҡ„ж—¶й—ҙеӨҚжқӮеәҰеҶ…е®ҢжҲҗдәҶеҜ№иҜҘжө·йҮҸж•°жҚ®зҡ„еӨ„зҗҶгҖӮ
В В В жң¬ж–№жі•зӣёжҜ”з®—жі•1пјҡеңЁж—¶й—ҙеӨҚжқӮеәҰдёҠжҸҗй«ҳдәҶдёҖдёӘж•°йҮҸзә§пјҢдёәOпјҲNпјүпјҢдҪҶдёҚд»…д»…жҳҜж—¶й—ҙеӨҚжқӮеәҰдёҠзҡ„дјҳеҢ–пјҢиҜҘж–№жі•еҸӘйңҖиҰҒIOж•°жҚ®ж–Ү件дёҖж¬ЎпјҢиҖҢз®—жі•1зҡ„IOж¬Ўж•°иҫғеӨҡзҡ„пјҢеӣ жӯӨиҜҘз®—жі•2жҜ”з®—жі•1еңЁе·ҘзЁӢдёҠжңүжӣҙеҘҪзҡ„еҸҜж“ҚдҪңжҖ§гҖӮ
第дәҢжӯҘпјҡжүҫеҮәTop 10
В В В В з®—жі•дёҖпјҡжҷ®йҖҡжҺ’еәҸ
В В В жҲ‘жғіеҜ№дәҺжҺ’еәҸз®—жі•еӨ§е®¶йғҪе·Із»ҸдёҚйҷҢз”ҹдәҶпјҢиҝҷйҮҢдёҚеңЁиөҳиҝ°пјҢжҲ‘们иҰҒжіЁж„Ҹзҡ„жҳҜжҺ’еәҸз®—жі•зҡ„ж—¶й—ҙеӨҚжқӮеәҰжҳҜNlgNпјҢеңЁжң¬йўҳзӣ®дёӯпјҢдёүзҷҫдёҮжқЎи®°еҪ•пјҢз”Ё1GеҶ…еӯҳжҳҜеҸҜд»ҘеӯҳдёӢзҡ„гҖӮ
В В В з®—жі•дәҢпјҡйғЁеҲҶжҺ’еәҸ
В В В йўҳзӣ®иҰҒжұӮжҳҜжұӮеҮәTop 10пјҢеӣ жӯӨжҲ‘们没жңүеҝ…иҰҒеҜ№жүҖжңүзҡ„QueryйғҪиҝӣиЎҢжҺ’еәҸпјҢжҲ‘们еҸӘйңҖиҰҒз»ҙжҠӨдёҖдёӘ10дёӘеӨ§е°Ҹзҡ„ж•°з»„пјҢеҲқе§ӢеҢ–ж”ҫе…Ҙ10дёӘQueryпјҢжҢүз…§жҜҸдёӘQueryзҡ„з»ҹи®Ўж¬Ўж•°з”ұеӨ§еҲ°е°ҸжҺ’еәҸпјҢ然еҗҺйҒҚеҺҶиҝҷ300дёҮжқЎи®°еҪ•пјҢжҜҸиҜ»дёҖжқЎи®°еҪ•е°ұе’Ңж•°з»„жңҖеҗҺдёҖдёӘQueryеҜ№жҜ”пјҢеҰӮжһңе°ҸдәҺиҝҷдёӘQueryпјҢйӮЈд№Ҳ继з»ӯйҒҚеҺҶпјҢеҗҰеҲҷпјҢе°Ҷж•°з»„дёӯжңҖеҗҺдёҖжқЎж•°жҚ®ж·ҳжұ°пјҢеҠ е…ҘеҪ“еүҚзҡ„QueryгҖӮжңҖеҗҺеҪ“жүҖжңүзҡ„ж•°жҚ®йғҪйҒҚеҺҶе®ҢжҜ•д№ӢеҗҺпјҢйӮЈд№ҲиҝҷдёӘж•°з»„дёӯзҡ„10дёӘQueryдҫҝжҳҜжҲ‘们иҰҒжүҫзҡ„Top10дәҶгҖӮ
В В В дёҚйҡҫеҲҶжһҗеҮәпјҢиҝҷж ·пјҢз®—жі•зҡ„жңҖеқҸж—¶й—ҙеӨҚжқӮеәҰжҳҜN*KпјҢ е…¶дёӯKжҳҜжҢҮtopеӨҡе°‘гҖӮ
В В В з®—жі•дёүпјҡе Ҷ
В В В еңЁз®—жі•дәҢдёӯпјҢжҲ‘们已з»Ҹе°Ҷж—¶й—ҙеӨҚжқӮеәҰз”ұNlogNдјҳеҢ–еҲ°NKпјҢдёҚеҫ—дёҚиҜҙиҝҷжҳҜдёҖдёӘжҜ”иҫғеӨ§зҡ„ж”№иҝӣдәҶпјҢеҸҜжҳҜжңүжІЎжңүжӣҙеҘҪзҡ„еҠһжі•е‘ўпјҹ
В В В еҲҶжһҗдёҖдёӢпјҢеңЁз®—жі•дәҢдёӯпјҢжҜҸж¬ЎжҜ”иҫғе®ҢжҲҗд№ӢеҗҺпјҢйңҖиҰҒзҡ„ж“ҚдҪңеӨҚжқӮеәҰйғҪжҳҜKпјҢеӣ дёәиҰҒжҠҠе…ғзҙ жҸ’е…ҘеҲ°дёҖдёӘзәҝжҖ§иЎЁд№ӢдёӯпјҢиҖҢдё”йҮҮз”Ёзҡ„жҳҜйЎәеәҸжҜ”иҫғгҖӮиҝҷйҮҢжҲ‘们注ж„ҸдёҖдёӢпјҢиҜҘж•°з»„жҳҜжңүеәҸзҡ„пјҢдёҖж¬ЎжҲ‘们жҜҸж¬ЎжҹҘжүҫзҡ„ж—¶еҖҷеҸҜд»ҘйҮҮз”ЁдәҢеҲҶзҡ„ж–№жі•жҹҘжүҫпјҢиҝҷж ·ж“ҚдҪңзҡ„еӨҚжқӮеәҰе°ұйҷҚеҲ°дәҶlogKпјҢеҸҜжҳҜпјҢйҡҸд№ӢиҖҢжқҘзҡ„й—®йўҳе°ұжҳҜж•°жҚ®з§»еҠЁпјҢеӣ дёә移еҠЁж•°жҚ®ж¬Ўж•°еўһеӨҡдәҶгҖӮдёҚиҝҮпјҢиҝҷдёӘз®—жі•иҝҳжҳҜжҜ”з®—жі•дәҢжңүдәҶж”№иҝӣгҖӮ
В В В еҹәдәҺд»ҘдёҠзҡ„еҲҶжһҗпјҢжҲ‘们жғіжғіпјҢжңүжІЎжңүдёҖз§Қж—ўиғҪеҝ«йҖҹжҹҘжүҫпјҢеҸҲиғҪеҝ«йҖҹ移еҠЁе…ғзҙ зҡ„ж•°жҚ®з»“жһ„е‘ўпјҹеӣһзӯ”жҳҜиӮҜе®ҡзҡ„пјҢйӮЈе°ұжҳҜе ҶгҖӮ
В В В еҖҹеҠ©е Ҷз»“жһ„пјҢжҲ‘们еҸҜд»ҘеңЁlogйҮҸзә§зҡ„ж—¶й—ҙеҶ…жҹҘжүҫе’Ңи°ғж•ҙ/移еҠЁгҖӮеӣ жӯӨеҲ°иҝҷйҮҢпјҢжҲ‘们зҡ„з®—жі•еҸҜд»Ҙж”№иҝӣдёәиҝҷж ·пјҢз»ҙжҠӨдёҖдёӘK(иҜҘйўҳзӣ®дёӯжҳҜ10)еӨ§е°Ҹзҡ„е°Ҹж №е ҶпјҢ然еҗҺйҒҚеҺҶ300дёҮзҡ„QueryпјҢеҲҶеҲ«е’Ңж №е…ғзҙ иҝӣиЎҢеҜ№жҜ”гҖӮ
В В В В жҖқжғідёҺдёҠиҝ°з®—жі•дәҢдёҖиҮҙпјҢеҸӘжҳҜз®—жі•еңЁз®—жі•дёүпјҢжҲ‘们йҮҮз”ЁдәҶжңҖе°Ҹе Ҷиҝҷз§Қж•°жҚ®з»“жһ„д»Јжӣҝж•°з»„пјҢжҠҠжҹҘжүҫзӣ®ж Үе…ғзҙ зҡ„ж—¶й—ҙеӨҚжқӮеәҰжңүOпјҲKпјүйҷҚеҲ°дәҶOпјҲlogKпјүгҖӮ
В В В йӮЈд№Ҳиҝҷж ·пјҢйҮҮз”Ёе Ҷж•°жҚ®з»“жһ„пјҢз®—жі•дёүпјҢжңҖз»Ҳзҡ„ж—¶й—ҙеӨҚжқӮеәҰе°ұйҷҚеҲ°дәҶNвҖҳlogKпјҢе’Ңз®—жі•дәҢзӣёжҜ”пјҢеҸҲжңүдәҶжҜ”иҫғеӨ§зҡ„ж”№иҝӣгҖӮ
В
жҖ»з»“пјҡ
В В В иҮіжӯӨпјҢз®—жі•е°ұе®Ңе…Ёз»“жқҹдәҶпјҢз»ҸиҝҮдёҠиҝ°з¬¬дёҖжӯҘгҖҒе…Ҳз”ЁHashиЎЁз»ҹи®ЎжҜҸдёӘQueryеҮәзҺ°зҡ„ж¬Ўж•°пјҢOпјҲNпјүпјӣ然еҗҺ第дәҢжӯҘгҖҒйҮҮз”Ёе Ҷж•°жҚ®з»“жһ„жүҫеҮәTop 10пјҢN*OпјҲlogKпјүгҖӮжүҖд»ҘпјҢжҲ‘们жңҖз»Ҳзҡ„ж—¶й—ҙеӨҚжқӮеәҰжҳҜпјҡOпјҲNпјү + N'*OпјҲlogKпјүгҖӮпјҲNдёә1000дёҮпјҢNвҖҷдёә300дёҮпјүгҖӮеҰӮжһңеҗ„дҪҚжңүд»Җд№ҲжӣҙеҘҪзҡ„з®—жі•пјҢж¬ўиҝҺз•ҷиЁҖиҜ„и®әгҖӮ第дёҖйғЁеҲҶпјҢе®ҢгҖӮ
В
第дәҢйғЁеҲҶгҖҒHashиЎЁ з®—жі•зҡ„иҜҰз»Ҷи§Јжһҗ
д»Җд№ҲжҳҜHash
В В В В HashпјҢдёҖиҲ¬зҝ»иҜ‘еҒҡвҖңж•ЈеҲ—вҖқпјҢд№ҹжңүзӣҙжҺҘйҹіиҜ‘дёәвҖңе“ҲеёҢвҖқзҡ„пјҢе°ұжҳҜжҠҠд»»ж„Ҹй•ҝеәҰзҡ„иҫ“е…ҘпјҲеҸҲеҸ«еҒҡйў„жҳ е°„пјҢ pre-imageпјүпјҢйҖҡиҝҮж•ЈеҲ—з®—жі•пјҢеҸҳжҚўжҲҗеӣәе®ҡй•ҝеәҰзҡ„иҫ“еҮәпјҢиҜҘиҫ“еҮәе°ұжҳҜж•ЈеҲ—еҖјгҖӮиҝҷз§ҚиҪ¬жҚўжҳҜдёҖз§ҚеҺӢзј©жҳ е°„пјҢд№ҹе°ұжҳҜпјҢж•ЈеҲ—еҖјзҡ„з©әй—ҙйҖҡеёёиҝңе°ҸдәҺиҫ“е…Ҙзҡ„з©әй—ҙпјҢдёҚеҗҢзҡ„иҫ“е…ҘеҸҜиғҪдјҡж•ЈеҲ—жҲҗзӣёеҗҢзҡ„иҫ“еҮәпјҢиҖҢдёҚеҸҜиғҪд»Һж•ЈеҲ—еҖјжқҘе”ҜдёҖзҡ„зЎ®е®ҡиҫ“е…ҘеҖјгҖӮз®ҖеҚ•зҡ„иҜҙе°ұжҳҜдёҖз§Қе°Ҷд»»ж„Ҹй•ҝеәҰзҡ„ж¶ҲжҒҜеҺӢзј©еҲ°жҹҗдёҖеӣәе®ҡй•ҝеәҰзҡ„ж¶ҲжҒҜж‘ҳиҰҒзҡ„еҮҪж•°гҖӮ
В В В HASHдё»иҰҒз”ЁдәҺдҝЎжҒҜе®үе…ЁйўҶеҹҹдёӯеҠ еҜҶз®—жі•пјҢе®ғжҠҠдёҖдәӣдёҚеҗҢй•ҝеәҰзҡ„дҝЎжҒҜиҪ¬еҢ–жҲҗжқӮд№ұзҡ„128дҪҚзҡ„зј–з Ғ,иҝҷдәӣзј–з ҒеҖјеҸ«еҒҡHASHеҖј. д№ҹеҸҜд»ҘиҜҙпјҢhashе°ұжҳҜжүҫеҲ°дёҖз§Қж•°жҚ®еҶ…е®№е’Ңж•°жҚ®еӯҳж”ҫең°еқҖд№Ӣй—ҙзҡ„жҳ е°„е…ізі»гҖӮ
В В В ж•°з»„зҡ„зү№зӮ№жҳҜпјҡеҜ»еқҖе®№жҳ“пјҢжҸ’е…Ҙе’ҢеҲ йҷӨеӣ°йҡҫпјӣиҖҢй“ҫиЎЁзҡ„зү№зӮ№жҳҜпјҡеҜ»еқҖеӣ°йҡҫпјҢжҸ’е…Ҙе’ҢеҲ йҷӨе®№жҳ“гҖӮйӮЈд№ҲжҲ‘们иғҪдёҚиғҪз»јеҗҲдёӨиҖ…зҡ„зү№жҖ§пјҢеҒҡеҮәдёҖз§ҚеҜ»еқҖе®№жҳ“пјҢжҸ’е…ҘеҲ йҷӨд№ҹе®№жҳ“зҡ„ж•°жҚ®з»“жһ„пјҹзӯ”жЎҲжҳҜиӮҜе®ҡзҡ„пјҢиҝҷе°ұжҳҜжҲ‘们иҰҒжҸҗиө·зҡ„е“ҲеёҢиЎЁпјҢе“ҲеёҢиЎЁжңүеӨҡз§ҚдёҚеҗҢзҡ„е®һзҺ°ж–№жі•пјҢжҲ‘жҺҘдёӢжқҘи§ЈйҮҠзҡ„жҳҜжңҖеёёз”Ёзҡ„дёҖз§Қж–№жі•вҖ”вҖ”жӢүй“ҫжі•пјҢжҲ‘们еҸҜд»ҘзҗҶи§ЈдёәвҖңй“ҫиЎЁзҡ„ж•°з»„вҖқпјҢеҰӮеӣҫпјҡ
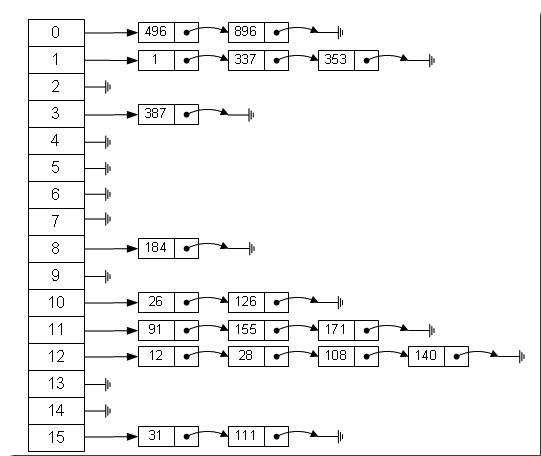
В В В е·Ұиҫ№еҫҲжҳҺжҳҫжҳҜдёӘж•°з»„пјҢж•°з»„зҡ„жҜҸдёӘжҲҗе‘ҳеҢ…жӢ¬дёҖдёӘжҢҮй’ҲпјҢжҢҮеҗ‘дёҖдёӘй“ҫиЎЁзҡ„еӨҙпјҢеҪ“然иҝҷдёӘй“ҫиЎЁеҸҜиғҪдёәз©әпјҢд№ҹеҸҜиғҪе…ғзҙ еҫҲеӨҡгҖӮжҲ‘д»¬ж №жҚ®е…ғзҙ зҡ„дёҖдәӣзү№еҫҒжҠҠе…ғзҙ еҲҶй…ҚеҲ°дёҚеҗҢзҡ„й“ҫиЎЁдёӯеҺ»пјҢд№ҹжҳҜж №жҚ®иҝҷдәӣзү№еҫҒпјҢжүҫеҲ°жӯЈзЎ®зҡ„й“ҫиЎЁпјҢеҶҚд»Һй“ҫиЎЁдёӯжүҫеҮәиҝҷдёӘе…ғзҙ гҖӮ
В В В е…ғзҙ зү№еҫҒиҪ¬еҸҳдёәж•°з»„дёӢж Үзҡ„ж–№жі•е°ұжҳҜж•ЈеҲ—жі•гҖӮж•ЈеҲ—жі•еҪ“然дёҚжӯўдёҖз§ҚпјҢдёӢйқўеҲ—еҮәдёүз§ҚжҜ”иҫғеёёз”Ёзҡ„пјҡ
1пјҢйҷӨжі•ж•ЈеҲ—жі•В
жңҖзӣҙи§Ӯзҡ„дёҖз§ҚпјҢдёҠеӣҫдҪҝз”Ёзҡ„е°ұжҳҜиҝҷз§Қж•ЈеҲ—жі•пјҢе…¬ејҸпјҡВ
В В В В В index = value % 16В
еӯҰиҝҮжұҮзј–зҡ„йғҪзҹҘйҒ“пјҢжұӮжЁЎж•°е…¶е®һжҳҜйҖҡиҝҮдёҖдёӘйҷӨжі•иҝҗз®—еҫ—еҲ°зҡ„пјҢжүҖд»ҘеҸ«вҖңйҷӨжі•ж•ЈеҲ—жі•вҖқгҖӮ
2пјҢе№іж–№ж•ЈеҲ—жі•В
жұӮindexжҳҜйқһеёёйў‘з№Ғзҡ„ж“ҚдҪңпјҢиҖҢд№ҳжі•зҡ„иҝҗз®—иҰҒжҜ”йҷӨжі•жқҘеҫ—зңҒж—¶пјҲеҜ№зҺ°еңЁзҡ„CPUжқҘиҜҙпјҢдј°и®ЎжҲ‘们ж„ҹи§үдёҚеҮәжқҘпјүпјҢжүҖд»ҘжҲ‘们иҖғиҷ‘жҠҠйҷӨжі•жҚўжҲҗд№ҳжі•е’ҢдёҖдёӘдҪҚ移ж“ҚдҪңгҖӮе…¬ејҸпјҡВ
В В В В В index = (value * value) >> 28В В В пјҲеҸіз§»пјҢйҷӨд»Ҙ2^28гҖӮи®°жі•пјҡе·Ұ移еҸҳеӨ§пјҢжҳҜд№ҳгҖӮеҸіз§»еҸҳе°ҸпјҢжҳҜйҷӨгҖӮпјү
еҰӮжһңж•°еҖјеҲҶй…ҚжҜ”иҫғеқҮеҢҖзҡ„иҜқиҝҷз§Қж–№жі•иғҪеҫ—еҲ°дёҚй”ҷзҡ„з»“жһңпјҢдҪҶжҲ‘дёҠйқўз”»зҡ„йӮЈдёӘеӣҫзҡ„еҗ„дёӘе…ғзҙ зҡ„еҖјз®—еҮәжқҘзҡ„indexйғҪжҳҜ0вҖ”вҖ”йқһеёёеӨұиҙҘгҖӮд№ҹи®ёдҪ иҝҳжңүдёӘй—®йўҳпјҢvalueеҰӮжһңеҫҲеӨ§пјҢvalue * valueдёҚдјҡжәўеҮәеҗ—пјҹзӯ”жЎҲжҳҜдјҡзҡ„пјҢдҪҶжҲ‘们иҝҷдёӘд№ҳжі•дёҚе…іеҝғжәўеҮәпјҢеӣ дёәжҲ‘д»¬ж №жң¬дёҚжҳҜдёәдәҶиҺ·еҸ–зӣёд№ҳз»“жһңпјҢиҖҢжҳҜдёәдәҶиҺ·еҸ–indexгҖӮ
3пјҢж–җжіўйӮЈеҘ‘пјҲFibonacciпјүж•ЈеҲ—жі•
е№іж–№ж•ЈеҲ—жі•зҡ„зјәзӮ№жҳҜжҳҫиҖҢжҳ“и§Ғзҡ„пјҢжүҖд»ҘжҲ‘们иғҪдёҚиғҪжүҫеҮәдёҖдёӘзҗҶжғізҡ„д№ҳж•°пјҢиҖҢдёҚжҳҜжӢҝvalueжң¬иә«еҪ“дҪңд№ҳж•°е‘ўпјҹзӯ”жЎҲжҳҜиӮҜе®ҡзҡ„гҖӮ
1пјҢеҜ№дәҺ16дҪҚж•ҙж•°иҖҢиЁҖпјҢиҝҷдёӘд№ҳж•°жҳҜ40503В
2пјҢеҜ№дәҺ32дҪҚж•ҙж•°иҖҢиЁҖпјҢиҝҷдёӘд№ҳж•°жҳҜ2654435769В
3пјҢеҜ№дәҺ64дҪҚж•ҙж•°иҖҢиЁҖпјҢиҝҷдёӘд№ҳж•°жҳҜ11400714819323198485
В В В иҝҷеҮ дёӘвҖңзҗҶжғід№ҳж•°вҖқжҳҜеҰӮдҪ•еҫ—еҮәжқҘзҡ„е‘ўпјҹиҝҷи·ҹдёҖдёӘжі•еҲҷжңүе…іпјҢеҸ«й»„йҮ‘еҲҶеүІжі•еҲҷпјҢиҖҢжҸҸиҝ°й»„йҮ‘еҲҶеүІжі•еҲҷзҡ„жңҖз»Ҹе…ёиЎЁиҫҫејҸж— з–‘е°ұжҳҜи‘—еҗҚзҡ„ж–җжіўйӮЈеҘ‘ж•°еҲ—пјҢеҚіеҰӮжӯӨеҪўејҸзҡ„еәҸеҲ—пјҡ0,В 1,В 1,В 2,В 3,В 5,В 8,В 13,В 21,В 34,В 55,В 89,В 144,233,В 377,В 610пјҢ 987, 1597, 2584, 4181, 6765, 10946пјҢвҖҰгҖӮеҸҰеӨ–пјҢж–җжіўйӮЈеҘ‘ж•°еҲ—зҡ„еҖје’ҢеӨӘйҳізі»е…«еӨ§иЎҢжҳҹзҡ„иҪЁйҒ“еҚҠеҫ„зҡ„жҜ”дҫӢеҮәеҘҮеҗ»еҗҲгҖӮ
В В В еҜ№жҲ‘们常и§Ғзҡ„32дҪҚж•ҙж•°иҖҢиЁҖпјҢе…¬ејҸпјҡВ
В В В В В В В В В В В index = (value * 2654435769) >> 28
В В В еҰӮжһңз”Ёиҝҷз§Қж–җжіўйӮЈеҘ‘ж•ЈеҲ—жі•зҡ„иҜқпјҢйӮЈдёҠйқўзҡ„еӣҫе°ұеҸҳжҲҗиҝҷж ·дәҶпјҡ
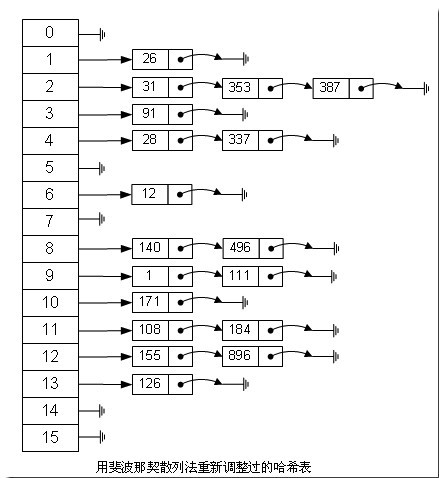
еҫҲжҳҺжҳҫпјҢз”Ёж–җжіўйӮЈеҘ‘ж•ЈеҲ—жі•и°ғж•ҙд№ӢеҗҺиҰҒжҜ”еҺҹжқҘзҡ„еҸ–ж‘ёж•ЈеҲ—жі•еҘҪеҫҲеӨҡгҖӮВ
йҖӮз”ЁиҢғеӣҙ
В В В еҝ«йҖҹжҹҘжүҫпјҢеҲ йҷӨзҡ„еҹәжң¬ж•°жҚ®з»“жһ„пјҢйҖҡеёёйңҖиҰҒжҖ»ж•°жҚ®йҮҸеҸҜд»Ҙж”ҫе…ҘеҶ…еӯҳгҖӮ
еҹәжң¬еҺҹзҗҶеҸҠиҰҒзӮ№
В В В hashеҮҪж•°йҖүжӢ©пјҢй’ҲеҜ№еӯ—з¬ҰдёІпјҢж•ҙж•°пјҢжҺ’еҲ—пјҢе…·дҪ“зӣёеә”зҡ„hashж–№жі•гҖӮВ
зў°ж’һеӨ„зҗҶпјҢдёҖз§ҚжҳҜopen hashingпјҢд№ҹз§°дёәжӢүй“ҫжі•пјӣеҸҰдёҖз§Қе°ұжҳҜclosed hashingпјҢд№ҹз§°ејҖең°еқҖжі•пјҢopened addressingгҖӮ
жү©еұ•В
В В В d-left hashingдёӯзҡ„dжҳҜеӨҡдёӘзҡ„ж„ҸжҖқпјҢжҲ‘们е…Ҳз®ҖеҢ–иҝҷдёӘй—®йўҳпјҢзңӢдёҖзңӢ2-left hashingгҖӮ2-left hashingжҢҮзҡ„жҳҜе°ҶдёҖдёӘе“ҲеёҢиЎЁеҲҶжҲҗй•ҝеәҰзӣёзӯүзҡ„дёӨеҚҠпјҢеҲҶеҲ«еҸ«еҒҡT1е’ҢT2пјҢз»ҷT1е’ҢT2еҲҶеҲ«й…ҚеӨҮдёҖдёӘе“ҲеёҢеҮҪж•°пјҢh1е’Ңh2гҖӮеңЁеӯҳеӮЁдёҖдёӘж–°зҡ„keyж—¶пјҢеҗҢ ж—¶з”ЁдёӨдёӘе“ҲеёҢеҮҪж•°иҝӣиЎҢи®Ўз®—пјҢеҫ—еҮәдёӨдёӘең°еқҖh1[key]е’Ңh2[key]гҖӮиҝҷж—¶йңҖиҰҒжЈҖжҹҘT1дёӯзҡ„h1[key]дҪҚзҪ®е’ҢT2дёӯзҡ„h2[key]дҪҚзҪ®пјҢе“ӘдёҖдёӘ дҪҚзҪ®е·Із»ҸеӯҳеӮЁзҡ„пјҲжңүзў°ж’һзҡ„пјүkeyжҜ”иҫғеӨҡпјҢ然еҗҺе°Ҷж–°keyеӯҳеӮЁеңЁиҙҹиҪҪе°‘зҡ„дҪҚзҪ®гҖӮеҰӮжһңдёӨиҫ№дёҖж ·еӨҡпјҢжҜ”еҰӮдёӨдёӘдҪҚзҪ®йғҪдёәз©әжҲ–иҖ…йғҪеӯҳеӮЁдәҶдёҖдёӘkeyпјҢе°ұжҠҠж–°key еӯҳеӮЁеңЁе·Ұиҫ№зҡ„T1еӯҗиЎЁдёӯпјҢ2-leftд№ҹз”ұжӯӨиҖҢжқҘгҖӮеңЁжҹҘжүҫдёҖдёӘkeyж—¶пјҢеҝ…йЎ»иҝӣиЎҢдёӨж¬ЎhashпјҢеҗҢж—¶жҹҘжүҫдёӨдёӘдҪҚзҪ®гҖӮ
й—®йўҳе®һдҫӢпјҲжө·йҮҸж•°жҚ®еӨ„зҗҶпјүВ
В В В жҲ‘们зҹҘйҒ“hash иЎЁеңЁжө·йҮҸж•°жҚ®еӨ„зҗҶдёӯжңүзқҖе№ҝжіӣзҡ„еә”з”ЁпјҢдёӢйқўпјҢиҜ·зңӢеҸҰдёҖйҒ“зҷҫеәҰйқўиҜ•йўҳпјҡ
йўҳзӣ®пјҡжө·йҮҸж—Ҙеҝ—ж•°жҚ®пјҢжҸҗеҸ–еҮәжҹҗж—Ҙи®ҝй—®зҷҫеәҰж¬Ўж•°жңҖеӨҡзҡ„йӮЈдёӘIPгҖӮ
ж–№жЎҲпјҡIPзҡ„ж•°зӣ®иҝҳжҳҜжңүйҷҗзҡ„пјҢжңҖеӨҡ2^32дёӘпјҢжүҖд»ҘеҸҜд»ҘиҖғиҷ‘дҪҝз”Ёhashе°ҶipзӣҙжҺҘеӯҳе…ҘеҶ…еӯҳпјҢ然еҗҺиҝӣиЎҢз»ҹи®ЎгҖӮ
В
第дёүйғЁеҲҶгҖҒжңҖеҝ«зҡ„HashиЎЁз®—жі•
В В В В жҺҘдёӢжқҘпјҢе’ұ们жқҘе…·дҪ“еҲҶжһҗдёҖдёӢдёҖдёӘжңҖеҝ«зҡ„HasbиЎЁз®—жі•гҖӮ
В В В жҲ‘们з”ұдёҖдёӘз®ҖеҚ•зҡ„й—®йўҳйҖҗжӯҘе…ҘжүӢпјҡжңүдёҖдёӘеәһеӨ§зҡ„еӯ—з¬ҰдёІж•°з»„пјҢ然еҗҺз»ҷдҪ дёҖдёӘеҚ•зӢ¬зҡ„еӯ—з¬ҰдёІпјҢи®©дҪ д»ҺиҝҷдёӘж•°з»„дёӯжҹҘжүҫжҳҜеҗҰжңүиҝҷдёӘеӯ—з¬Ұ串并жүҫеҲ°е®ғпјҢдҪ дјҡжҖҺд№ҲеҒҡпјҹжңүдёҖдёӘж–№жі•жңҖз®ҖеҚ•пјҢиҖҒиҖҒе®һе®һд»ҺеӨҙжҹҘеҲ°е°ҫпјҢдёҖдёӘдёҖдёӘжҜ”иҫғпјҢзӣҙеҲ°жүҫеҲ°дёәжӯўпјҢжҲ‘жғіеҸӘиҰҒеӯҰиҝҮзЁӢеәҸи®ҫи®Ўзҡ„дәәйғҪиғҪжҠҠиҝҷж ·дёҖдёӘзЁӢеәҸдҪңеҮәжқҘпјҢдҪҶиҰҒжҳҜжңүзЁӢеәҸе‘ҳжҠҠиҝҷж ·зҡ„зЁӢеәҸдәӨз»ҷз”ЁжҲ·пјҢжҲ‘еҸӘиғҪз”Ёж— иҜӯжқҘиҜ„д»·пјҢжҲ–и®ёе®ғзңҹзҡ„иғҪе·ҘдҪңпјҢдҪҶ...д№ҹеҸӘиғҪеҰӮжӯӨдәҶгҖӮ
В В В жңҖеҗҲйҖӮзҡ„з®—жі•иҮӘ然жҳҜдҪҝз”ЁHashTableпјҲе“ҲеёҢиЎЁпјүпјҢе…Ҳд»Ӣз»Қд»Ӣз»Қе…¶дёӯзҡ„еҹәжң¬зҹҘиҜҶпјҢжүҖи°“HashпјҢдёҖиҲ¬жҳҜдёҖдёӘж•ҙж•°пјҢйҖҡиҝҮжҹҗз§Қз®—жі•пјҢеҸҜд»ҘжҠҠдёҖдёӘеӯ—з¬ҰдёІ"еҺӢзј©" жҲҗдёҖдёӘж•ҙж•°гҖӮеҪ“然пјҢж— и®әеҰӮдҪ•пјҢдёҖдёӘ32дҪҚж•ҙж•°жҳҜж— жі•еҜ№еә”еӣһдёҖдёӘеӯ—з¬ҰдёІзҡ„пјҢдҪҶеңЁзЁӢеәҸдёӯпјҢдёӨдёӘеӯ—з¬ҰдёІи®Ўз®—еҮәзҡ„HashеҖјзӣёзӯүзҡ„еҸҜиғҪйқһеёёе°ҸпјҢдёӢйқўзңӢзңӢеңЁMPQдёӯзҡ„Hashз®—жі•пјҡ
еҮҪж•°дёҖгҖҒд»ҘдёӢзҡ„еҮҪж•°з”ҹжҲҗдёҖдёӘй•ҝеәҰдёә0x500пјҲеҗҲ10иҝӣеҲ¶ж•°пјҡ1280пјүзҡ„cryptTable[0x500]
void prepareCryptTable()
{В
В В В unsigned long seed = 0x00100001, index1 = 0, index2 = 0, i;
В
В В В for( index1 = 0; index1 < 0x100; index1++ )
В В В {В
В В В В В В В for( index2 = index1, i = 0; i < 5; i++, index2 += 0x100 )
В В В В В В В {В
В В В В В В В В В В В unsigned long temp1, temp2;
В
В В В В В В В В В В В seed = (seed * 125 + 3) % 0x2AAAAB;
В В В В В В В В В В В temp1 = (seed & 0xFFFF) << 0x10;
В
В В В В В В В В В В В seed = (seed * 125 + 3) % 0x2AAAAB;
В В В В В В В В В В В temp2 = (seed & 0xFFFF);
В
В В В В В В В В В В В cryptTable[index2] = ( temp1 | temp2 );В
В В В В В В }В
В В }В
}В
еҮҪж•°дәҢгҖҒд»ҘдёӢеҮҪж•°и®Ўз®—lpszFileName еӯ—з¬ҰдёІзҡ„hashеҖјпјҢе…¶дёӯdwHashType дёәhashзҡ„зұ»еһӢпјҢеңЁдёӢйқўзҡ„еҮҪж•°дёүгҖҒGetHashTablePosеҮҪж•°дёӯи°ғз”ЁжӯӨеҮҪж•°дәҢпјҢе…¶еҸҜд»ҘеҸ–зҡ„еҖјдёә0гҖҒ1гҖҒ2пјӣиҜҘеҮҪж•°иҝ”еӣһlpszFileName еӯ—з¬ҰдёІзҡ„hashеҖјпјҡВ
unsigned longВ HashString( char *lpszFileName, unsigned long dwHashType )
{В
В В В unsigned char *keyВ = (unsigned char *)lpszFileName;
unsigned long seed1 = 0x7FED7FED;
unsigned long seed2 = 0xEEEEEEEE;
В В В int ch;
В
В В В while( *key != 0 )
В В В {В
В В В В В В В ch = toupper(*key++);
В
В В В В В В В seed1 = cryptTable[(dwHashType << 8) + ch] ^ (seed1 + seed2);
В В В В В В В seed2 = ch + seed1 + seed2 + (seed2 << 5) + 3;В
В В В }
В В В return seed1;В
}
В В В Blizzardзҡ„иҝҷдёӘз®—жі•жҳҜйқһеёёй«ҳж•Ҳзҡ„пјҢиў«з§°дёә"One-Way Hash"( A one-way hash is a an algorithm that is constructed in such a way that deriving the original string (set of strings, actually) is virtually impossible)гҖӮдёҫдёӘдҫӢеӯҗпјҢеӯ—з¬ҰдёІ"unitneutralacritter.grp"йҖҡиҝҮиҝҷдёӘз®—жі•еҫ—еҲ°зҡ„з»“жһңжҳҜ0xA26067F3гҖӮ
гҖҖгҖҖжҳҜдёҚжҳҜжҠҠ第дёҖдёӘз®—жі•ж”№иҝӣдёҖдёӢпјҢж”№жҲҗйҖҗдёӘжҜ”иҫғеӯ—з¬ҰдёІзҡ„HashеҖје°ұеҸҜд»ҘдәҶе‘ўпјҢзӯ”жЎҲжҳҜпјҢиҝңиҝңдёҚеӨҹпјҢиҰҒжғіеҫ—еҲ°жңҖеҝ«зҡ„з®—жі•пјҢе°ұдёҚиғҪиҝӣиЎҢйҖҗдёӘзҡ„жҜ”иҫғпјҢйҖҡеёёжҳҜжһ„йҖ дёҖдёӘе“ҲеёҢиЎЁ(Hash Table)жқҘи§ЈеҶій—®йўҳпјҢе“ҲеёҢиЎЁжҳҜдёҖдёӘеӨ§ж•°з»„пјҢиҝҷдёӘж•°з»„зҡ„е®№йҮҸж №жҚ®зЁӢеәҸзҡ„иҰҒжұӮжқҘе®ҡд№үпјҢдҫӢеҰӮ1024пјҢжҜҸдёҖдёӘHashеҖјйҖҡиҝҮеҸ–жЁЎиҝҗз®— (mod) еҜ№еә”еҲ°ж•°з»„дёӯзҡ„дёҖдёӘдҪҚзҪ®пјҢиҝҷж ·пјҢеҸӘиҰҒжҜ”иҫғиҝҷдёӘеӯ—з¬ҰдёІзҡ„е“ҲеёҢеҖјеҜ№еә”зҡ„дҪҚзҪ®жңүжІЎжңүиў«еҚ з”ЁпјҢе°ұеҸҜд»Ҙеҫ—еҲ°жңҖеҗҺзҡ„з»“жһңдәҶпјҢжғіжғіиҝҷжҳҜд»Җд№ҲйҖҹеәҰпјҹжҳҜзҡ„пјҢжҳҜжңҖеҝ«зҡ„O(1)пјҢзҺ°еңЁд»”з»ҶзңӢзңӢиҝҷдёӘз®—жі•еҗ§пјҡ
typedef struct
{
В В В int nHashA;
В В В int nHashB;
В В В char bExists;
В В ......
} SOMESTRUCTRUE;
дёҖз§ҚеҸҜиғҪзҡ„з»“жһ„дҪ“е®ҡд№үпјҹ
еҮҪж•°дёүгҖҒдёӢиҝ°еҮҪж•°дёәеңЁHashиЎЁдёӯжҹҘжүҫжҳҜеҗҰеӯҳеңЁзӣ®ж Үеӯ—з¬ҰдёІпјҢжңүеҲҷиҝ”еӣһиҰҒжҹҘжүҫеӯ—з¬ҰдёІзҡ„HashеҖјпјҢж— еҲҷпјҢreturn -1.
intВ GetHashTablePos( har *lpszString, SOMESTRUCTURE *lpTable )В
//lpszStringиҰҒеңЁHashиЎЁдёӯжҹҘжүҫзҡ„еӯ—з¬ҰдёІпјҢlpTableдёәеӯҳеӮЁеӯ—з¬ҰдёІHashеҖјзҡ„HashиЎЁгҖӮ
{В
В В В int nHash = HashString(lpszString);В В //и°ғз”ЁдёҠиҝ°еҮҪж•°дәҢпјҢиҝ”еӣһиҰҒжҹҘжүҫеӯ—з¬ҰдёІlpszStringзҡ„HashеҖјгҖӮ
В В В int nHashPos = nHash % nTableSize;
В
В В В if ( lpTable[nHashPos].bExistsВ &&В !strcmp( lpTable[nHashPos].pString, lpszString ) )В
В В В {В В //еҰӮжһңжүҫеҲ°зҡ„HashеҖјеңЁиЎЁдёӯеӯҳеңЁпјҢдё”иҰҒжҹҘжүҫзҡ„еӯ—з¬ҰдёІдёҺиЎЁдёӯеҜ№еә”дҪҚзҪ®зҡ„еӯ—з¬ҰдёІзӣёеҗҢпјҢ
В В В В В В В return nHashPos;В В В В //еҲҷиҝ”еӣһдёҠиҝ°и°ғз”ЁеҮҪж•°дәҢеҗҺпјҢжүҫеҲ°зҡ„HashеҖј
В В В }В
В В В else
В В В {
В В В В В В В return -1;В В
В В В }В
}
В
В В В зңӢеҲ°жӯӨпјҢжҲ‘жғіеӨ§е®¶йғҪеңЁжғідёҖдёӘеҫҲдёҘйҮҚзҡ„й—®йўҳпјҡвҖңеҰӮжһңдёӨдёӘеӯ—з¬ҰдёІеңЁе“ҲеёҢиЎЁдёӯеҜ№еә”зҡ„дҪҚзҪ®зӣёеҗҢжҖҺд№ҲеҠһпјҹвҖқ,жҜ•з«ҹдёҖдёӘж•°з»„е®№йҮҸжҳҜжңүйҷҗзҡ„пјҢиҝҷз§ҚеҸҜиғҪжҖ§еҫҲеӨ§гҖӮи§ЈеҶіиҜҘй—®йўҳзҡ„ж–№жі•еҫҲеӨҡпјҢжҲ‘йҰ–е…ҲжғіеҲ°зҡ„е°ұжҳҜз”ЁвҖңй“ҫиЎЁвҖқ,ж„ҹи°ўеӨ§еӯҰйҮҢеӯҰзҡ„ж•°жҚ®з»“жһ„ж•ҷдјҡдәҶиҝҷдёӘзҷҫиҜ•зҷҫзҒөзҡ„жі•е®қпјҢжҲ‘йҒҮеҲ°зҡ„еҫҲеӨҡз®—жі•йғҪеҸҜд»ҘиҪ¬еҢ–жҲҗй“ҫиЎЁжқҘи§ЈеҶіпјҢеҸӘиҰҒеңЁе“ҲеёҢиЎЁзҡ„жҜҸдёӘе…ҘеҸЈжҢӮдёҖдёӘй“ҫиЎЁпјҢдҝқеӯҳжүҖжңүеҜ№еә”зҡ„еӯ—з¬ҰдёІе°ұOKдәҶгҖӮдәӢжғ…еҲ°жӯӨдјјд№ҺжңүдәҶе®ҢзҫҺзҡ„з»“еұҖпјҢеҰӮжһңжҳҜжҠҠй—®йўҳзӢ¬иҮӘдәӨз»ҷжҲ‘и§ЈеҶіпјҢжӯӨж—¶жҲ‘еҸҜиғҪе°ұиҰҒејҖе§Ӣе®ҡд№үж•°жҚ®з»“жһ„然еҗҺеҶҷд»Јз ҒдәҶгҖӮ
   然иҖҢBlizzardзҡ„зЁӢеәҸе‘ҳдҪҝз”Ёзҡ„ж–№жі•еҲҷжҳҜжӣҙзІҫеҰҷзҡ„ж–№жі•гҖӮеҹәжң¬еҺҹзҗҶе°ұжҳҜпјҡ他们еңЁе“ҲеёҢиЎЁдёӯдёҚжҳҜз”ЁдёҖдёӘе“ҲеёҢеҖјиҖҢжҳҜз”ЁдёүдёӘе“ҲеёҢеҖјжқҘж ЎйӘҢеӯ—з¬ҰдёІгҖӮ
В
В В В MPQдҪҝз”Ёж–Ү件еҗҚе“ҲеёҢиЎЁжқҘи·ҹиёӘеҶ…йғЁзҡ„жүҖжңүж–Ү件гҖӮдҪҶжҳҜиҝҷдёӘиЎЁзҡ„ж јејҸдёҺжӯЈеёёзҡ„е“ҲеёҢиЎЁжңүдёҖдәӣдёҚеҗҢгҖӮйҰ–е…ҲпјҢе®ғжІЎжңүдҪҝз”Ёе“ҲеёҢдҪңдёәдёӢж ҮпјҢжҠҠе®һйҷ…зҡ„ж–Ү件еҗҚеӯҳеӮЁеңЁиЎЁдёӯз”ЁдәҺйӘҢиҜҒпјҢе®һйҷ…дёҠе®ғж №жң¬е°ұжІЎжңүеӯҳеӮЁж–Ү件еҗҚгҖӮиҖҢжҳҜдҪҝз”ЁдәҶ3з§ҚдёҚеҗҢзҡ„е“ҲеёҢпјҡдёҖдёӘз”ЁдәҺе“ҲеёҢиЎЁзҡ„дёӢж ҮпјҢдёӨдёӘз”ЁдәҺйӘҢиҜҒгҖӮиҝҷдёӨдёӘйӘҢиҜҒе“ҲеёҢжӣҝд»ЈдәҶе®һйҷ…ж–Ү件еҗҚгҖӮ
В В В еҪ“然дәҶпјҢиҝҷж ·д»Қ然дјҡеҮәзҺ°2дёӘдёҚеҗҢзҡ„ж–Ү件еҗҚе“ҲеёҢеҲ°3дёӘеҗҢж ·зҡ„е“ҲеёҢгҖӮдҪҶжҳҜиҝҷз§Қжғ…еҶөеҸ‘з”ҹзҡ„жҰӮзҺҮе№іеқҮжҳҜпјҡ1:18889465931478580854784пјҢиҝҷдёӘжҰӮзҺҮеҜ№дәҺд»»дҪ•дәәжқҘиҜҙеә”иҜҘйғҪжҳҜи¶іеӨҹе°Ҹзҡ„гҖӮзҺ°еңЁеҶҚеӣһеҲ°ж•°жҚ®з»“жһ„дёҠпјҢBlizzardдҪҝз”Ёзҡ„е“ҲеёҢиЎЁжІЎжңүдҪҝз”Ёй“ҫиЎЁпјҢиҖҢйҮҮз”Ё"йЎә延"зҡ„ж–№ејҸжқҘи§ЈеҶій—®йўҳпјҢзңӢзңӢиҝҷдёӘз®—жі•пјҡ
еҮҪж•°еӣӣгҖҒlpszString дёәиҰҒеңЁhashиЎЁдёӯжҹҘжүҫзҡ„еӯ—з¬ҰдёІпјӣlpTable дёәеӯҳеӮЁеӯ—з¬ҰдёІhashеҖјзҡ„hashиЎЁпјӣnTableSize дёәhashиЎЁзҡ„й•ҝеәҰпјҡВ
intВ GetHashTablePos( char *lpszString, MPQHASHTABLE *lpTable, int nTableSize )
{
В В В const intВ HASH_OFFSET = 0, HASH_A = 1, HASH_B = 2;
В
В В В intВ nHash = HashString( lpszString, HASH_OFFSET );
В В В intВ nHashA = HashString( lpszString, HASH_A );
В В В intВ nHashB = HashString( lpszString, HASH_B );
В В В intВ nHashStart = nHash % nTableSize;
В В В intВ nHashPos = nHashStart;
В
В В В while ( lpTable[nHashPos].bExists )
В В {
В В В В /*еҰӮжһңд»…д»…жҳҜеҲӨж–ӯеңЁиҜҘиЎЁдёӯж—¶еҖҷеӯҳеңЁиҝҷдёӘеӯ—з¬ҰдёІпјҢе°ұжҜ”иҫғиҝҷдёӨдёӘhashеҖје°ұеҸҜд»ҘдәҶпјҢдёҚз”ЁеҜ№
В В В В *з»“жһ„дҪ“дёӯзҡ„еӯ—з¬ҰдёІиҝӣиЎҢжҜ”иҫғгҖӮиҝҷж ·дјҡеҠ еҝ«иҝҗиЎҢзҡ„йҖҹеәҰпјҹеҮҸе°‘hashиЎЁеҚ з”Ёзҡ„з©әй—ҙпјҹиҝҷз§Қ
В В В В В *ж–№жі•дёҖиҲ¬еә”з”ЁеңЁд»Җд№ҲеңәеҗҲпјҹ*/
В В В В В В В if ( гҖҖ lpTable[nHashPos].nHashA == nHashA
В В В В В В В &&В lpTable[nHashPos].nHashB == nHashB )
В В В В В В {
В В В В В В В В В В В return nHashPos;
В В В В В В В }
В В В В В В В else
В В В В В В {
В В В В В В В В В В В В nHashPos = (nHashPos + 1) % nTableSize;
В В В В В В В }
В
В В В В В В В В if (nHashPos == nHashStart)
В В В В В В В В В В В В В break;
В В В }
В В В В return -1;
}
дёҠиҝ°зЁӢеәҸи§ЈйҮҠпјҡ
1.и®Ўз®—еҮәеӯ—з¬ҰдёІзҡ„дёүдёӘе“ҲеёҢеҖјпјҲдёҖдёӘз”ЁжқҘзЎ®е®ҡдҪҚзҪ®пјҢеҸҰеӨ–дёӨдёӘз”ЁжқҘж ЎйӘҢ)
2. еҜҹзңӢе“ҲеёҢиЎЁдёӯзҡ„иҝҷдёӘдҪҚзҪ®
3. е“ҲеёҢиЎЁдёӯиҝҷдёӘдҪҚзҪ®дёәз©әеҗ—пјҹеҰӮжһңдёәз©әпјҢеҲҷиӮҜе®ҡиҜҘеӯ—з¬ҰдёІдёҚеӯҳеңЁпјҢиҝ”еӣһ-1гҖӮ
4. еҰӮжһңеӯҳеңЁпјҢеҲҷжЈҖжҹҘе…¶д»–дёӨдёӘе“ҲеёҢеҖјжҳҜеҗҰд№ҹеҢ№й…ҚпјҢеҰӮжһңеҢ№й…ҚпјҢеҲҷиЎЁзӨәжүҫеҲ°дәҶиҜҘеӯ—з¬ҰдёІпјҢиҝ”еӣһе…¶HashеҖјгҖӮ
5. 移еҲ°дёӢдёҖдёӘдҪҚзҪ®пјҢеҰӮжһңе·Із»Ҹ移еҲ°дәҶиЎЁзҡ„жң«е°ҫпјҢеҲҷеҸҚз»•еҲ°иЎЁзҡ„ејҖе§ӢдҪҚзҪ®иө·з»§з»ӯжҹҘиҜўгҖҖ
6. зңӢзңӢжҳҜдёҚжҳҜеҸҲеӣһеҲ°дәҶеҺҹжқҘзҡ„дҪҚзҪ®пјҢеҰӮжһңжҳҜпјҢеҲҷиҝ”еӣһжІЎжүҫеҲ°
7. еӣһеҲ°3
okпјҢиҝҷе°ұжҳҜжң¬ж–ҮдёӯжүҖиҜҙзҡ„жңҖеҝ«зҡ„HashиЎЁз®—жі•гҖӮд»Җд№Ҳ?дёҚеӨҹеҝ«?:DгҖӮж¬ўиҝҺпјҢеҗ„дҪҚжү№иҜ„жҢҮжӯЈгҖӮ
--------------------------------------------
иЎҘе……1гҖҒдёҖдёӘз®ҖеҚ•зҡ„hashеҮҪж•°пјҡ
/*keyдёәдёҖдёӘеӯ—з¬ҰдёІпјҢnTableLengthдёәе“ҲеёҢиЎЁзҡ„й•ҝеәҰ
*иҜҘеҮҪж•°еҫ—еҲ°зҡ„hashеҖјеҲҶеёғжҜ”иҫғеқҮеҢҖ*/
unsigned long getHashIndex( const char *key, int nTableLength )
{
В В В unsigned long nHash = 0;
В В В
В В В while (*key)
В В В {
В В В В В В В nHash = (nHash<<5) + nHash + *key++;
В В В }
В В В В В В В В
В В В return ( nHash % nTableLength );
}
В
иЎҘе……2гҖҒдёҖдёӘе®Ңж•ҙжөӢиҜ•зЁӢеәҸпјҡВ В
В В В е“ҲеёҢиЎЁзҡ„ж•°з»„жҳҜе®ҡй•ҝзҡ„пјҢеҰӮжһңеӨӘеӨ§пјҢеҲҷжөӘиҙ№пјҢеҰӮжһңеӨӘе°ҸпјҢдҪ“зҺ°дёҚеҮәж•ҲзҺҮгҖӮеҗҲйҖӮзҡ„ж•°з»„еӨ§е°ҸжҳҜе“ҲеёҢиЎЁзҡ„жҖ§иғҪзҡ„е…ій”®гҖӮе“ҲеёҢиЎЁзҡ„е°әеҜёжңҖеҘҪжҳҜдёҖдёӘиҙЁж•°гҖӮеҪ“然пјҢж №жҚ®дёҚеҗҢзҡ„ж•°жҚ®йҮҸпјҢдјҡжңүдёҚеҗҢзҡ„е“ҲеёҢиЎЁзҡ„еӨ§е°ҸгҖӮеҜ№дәҺж•°жҚ®йҮҸж—¶еӨҡж—¶е°‘зҡ„еә”з”ЁпјҢжңҖеҘҪзҡ„и®ҫи®ЎжҳҜдҪҝз”ЁеҠЁжҖҒеҸҜеҸҳе°әеҜёзҡ„е“ҲеёҢиЎЁпјҢйӮЈд№ҲеҰӮжһңдҪ еҸ‘зҺ°е“ҲеёҢиЎЁе°әеҜёеӨӘе°ҸдәҶпјҢжҜ”еҰӮе…¶дёӯзҡ„е…ғзҙ жҳҜе“ҲеёҢиЎЁе°әеҜёзҡ„2еҖҚж—¶пјҢжҲ‘们е°ұйңҖиҰҒжү©еӨ§е“ҲеёҢиЎЁе°әеҜёпјҢдёҖиҲ¬жҳҜжү©еӨ§дёҖеҖҚгҖӮ
В В В дёӢйқўжҳҜе“ҲеёҢиЎЁе°әеҜёеӨ§е°Ҹзҡ„еҸҜиғҪеҸ–еҖјпјҡ
В В В В 17,В В В В В В В В В В В 37,В В В В В В В В В 79,В В В В В В В 163,В В В В В В В В В 331,В В
В В В 673,В В В В В В В В В В 1361,В В В В В В В 2729,В В В В В В 5471,В В В В В В В В 10949,В В В В В В В В
В В 21911,В В В В В В В В В 43853,В В В В В 87719,В В В В В 175447,В В В В В 350899,
В 701819,В В В В В В В В 1403641,В В В 2807303,В В В В 5614657,В В В В 11229331,В В В
В 22458671,В В В В В В 44917381,В В В 89834777,В В В 179669557,В В 359339171,В В
718678369,В В В В В 1437356741,В 2147483647
В
д»ҘдёӢдёәиҜҘзЁӢеәҸзҡ„е®Ңж•ҙжәҗз ҒпјҢе·ІеңЁlinuxдёӢжөӢиҜ•йҖҡиҝҮпјҡ
- #includeВ <stdio.h>В В
- #includeВ <ctype.h>В В В В В //еӨҡи°ўcityloveжҢҮжӯЈгҖӮВ В
- //crytTable[]йҮҢйқўдҝқеӯҳзҡ„жҳҜHashStringеҮҪж•°йҮҢйқўе°Ҷдјҡз”ЁеҲ°зҡ„дёҖдәӣж•°жҚ®пјҢеңЁprepareCryptTableВ В
- //еҮҪж•°йҮҢйқўеҲқе§ӢеҢ–В В
- unsignedВ longВ cryptTable[0x500];В В
- В В
- //д»ҘдёӢзҡ„еҮҪж•°з”ҹжҲҗдёҖдёӘй•ҝеәҰдёә0x500пјҲеҗҲ10иҝӣеҲ¶ж•°пјҡ1280пјүзҡ„cryptTable[0x500]В В
- voidВ prepareCryptTable()В В
- {В В В
- В В В В unsignedВ longВ seedВ =В 0x00100001,В index1В =В 0,В index2В =В 0,В i;В В
- В В
- В В В В for(В index1В =В 0;В index1В <В 0x100;В index1++В )В В
- В В В В {В В В
- В В В В В В В В for(В index2В =В index1,В iВ =В 0;В iВ <В 5;В i++,В index2В +=В 0x100В )В В
- В В В В В В В В {В В В
- В В В В В В В В В В В В unsignedВ longВ temp1,В temp2;В В
- В В
- В В В В В В В В В В В В seedВ =В (seedВ *В 125В +В 3)В %В 0x2AAAAB;В В
- В В В В В В В В В В В В temp1В =В (seedВ &В 0xFFFF)В <<В 0x10;В В
- В В
- В В В В В В В В В В В В seedВ =В (seedВ *В 125В +В 3)В %В 0x2AAAAB;В В
- В В В В В В В В В В В В temp2В =В (seedВ &В 0xFFFF);В В
- В В
- В В В В В В В В В В В В cryptTable[index2]В =В (В temp1В |В temp2В );В В В
- В В В В В В В }В В В
- В В В }В В В
- }В В
- В В
- //д»ҘдёӢеҮҪж•°и®Ўз®—lpszFileNameВ еӯ—з¬ҰдёІзҡ„hashеҖјпјҢе…¶дёӯdwHashTypeВ дёәhashзҡ„зұ»еһӢпјҢВ В
- //еңЁдёӢйқўGetHashTablePosеҮҪж•°йҮҢйқўи°ғз”Ёжң¬еҮҪж•°пјҢе…¶еҸҜд»ҘеҸ–зҡ„еҖјдёә0гҖҒ1гҖҒ2пјӣиҜҘеҮҪж•°В В
- //иҝ”еӣһlpszFileNameВ еӯ—з¬ҰдёІзҡ„hashеҖјпјӣВ В
- unsignedВ longВ HashString(В charВ *lpszFileName,В unsignedВ longВ dwHashTypeВ )В В
- {В В В
- В В В В unsignedВ charВ *keyВ В =В (unsignedВ charВ *)lpszFileName;В В
- unsignedВ longВ seed1В =В 0x7FED7FED;В В
- unsignedВ longВ seed2В =В 0xEEEEEEEE;В В
- В В В В intВ ch;В В
- В В
- В В В В while(В *keyВ !=В 0В )В В
- В В В В {В В В
- В В В В В В В В chВ =В toupper(*key++);В В
- В В
- В В В В В В В В seed1В =В cryptTable[(dwHashTypeВ <<В 8)В +В ch]В ^В (seed1В +В seed2);В В
- В В В В В В В В seed2В =В chВ +В seed1В +В seed2В +В (seed2В <<В 5)В +В 3;В В В
- В В В В }В В
- В В В В returnВ seed1;В В В
- }В В
- В В
- //еңЁmainдёӯжөӢиҜ•argv[1]зҡ„дёүдёӘhashеҖјпјҡВ В
- //./hashВ В "arr/units.dat"В В
- //./hashВ В "unit/neutral/acritter.grp"В В
- intВ main(В intВ argc,В charВ **argvВ )В В
- {В В
- В В В В unsignedВ longВ ulHashValue;В В
- В В В В intВ iВ =В 0;В В
- В В
- В В В В ifВ (В argcВ !=В 2В )В В
- В В В В {В В
- В В В В В В В В printf("pleaseВ inputВ twoВ arguments/n");В В
- В В В В В В В В returnВ -1;В В
- В В В В }В В
- В В
- В В В В В /*еҲқе§ӢеҢ–ж•°з»„пјҡcrytTable[0x500]*/В В
- В В В В В prepareCryptTable();В В
- В В
- В В В В В /*жү“еҚ°ж•°з»„crytTable[0x500]йҮҢйқўзҡ„еҖј*/В В
- В В В В В forВ (В ;В iВ <В 0x500;В i++В )В В
- В В В В В {В В
- В В В В В В В В В ifВ (В iВ %В 10В ==В 0В )В В
- В В В В В В В В В {В В
- В В В В В В В В В В В В В printf("/n");В В
- В В В В В В В В В }В В
- В В
- В В В В В В В В В printf("%-12X",В cryptTable[i]В );В В
- В В В В В }В В
- В В
- В В В В В ulHashValueВ =В HashString(В argv[1],В 0В );В В
- В В В В В printf("/n----%XВ ----/n",В ulHashValueВ );В В
- В В
- В В В В В ulHashValueВ =В HashString(В argv[1],В 1В );В В
- В В В В В printf("----%XВ ----/n",В ulHashValueВ );В В
- В В
- В В В В В ulHashValueВ =В HashString(В argv[1],В 2В );В В
- В В В В В printf("----%XВ ----/n",В ulHashValueВ );В В
- В В
- В В В В В returnВ 0;В В
- } В



зӣёе…іжҺЁиҚҗ
### д»ҺеӨҙеҲ°е°ҫеҪ»еә•и§ЈжһҗHashиЎЁз®—жі• #### 第дёҖйғЁеҲҶпјҡTop Kз®—жі•иҜҰи§Ј ##### й—®йўҳиғҢжҷҜдёҺжҸҸиҝ° жң¬йғЁеҲҶжҺўи®ЁдәҶдёҖйҒ“е…ёеһӢзҡ„зҷҫеәҰйқўиҜ•йўҳпјҢж—ЁеңЁеҜ»жүҫжңҖзғӯй—Ёзҡ„10дёӘжҹҘиҜўдёІгҖӮиҝҷдёӘй—®йўҳи®ҫе®ҡеңЁдёҖдёӘжӢҘжңү1еҚғдёҮжқЎи®°еҪ•зҡ„ж—Ҙеҝ—ж–Ү件зҺҜеўғдёӯпјҢ...
MurmurHashз®—жі•з”ұAustin ApplebyеҲӣе»әдәҺ2008е№ҙпјҢзҺ°е·Іеә”з”ЁеҲ°HadoopгҖҒlibstdc гҖҒnginxгҖҒlibmemcached,RedisпјҢMemcachedпјҢCassandraпјҢHBaseпјҢLuceneзӯүејҖжәҗзі»з»ҹгҖӮ2011е№ҙApplebyиў«GoogleйӣҮдҪЈпјҢйҡҸеҗҺGoogleжҺЁеҮәе…¶еҸҳз§Қзҡ„...
еңЁи®Ўз®—жңә科еӯҰдёӯпјҢе“ҲеёҢпјҲHashпјүз®—жі•жҳҜдёҖз§Қз”ЁдәҺе°Ҷд»»ж„Ҹй•ҝеәҰзҡ„ж•°жҚ®жҳ е°„дёәеӣәе®ҡй•ҝеәҰиҫ“еҮәзҡ„еҮҪж•°гҖӮиҝҷз§Қиҫ“еҮәйҖҡеёёз§°дёәе“ҲеёҢеҖјжҲ–ж¶ҲжҒҜж‘ҳиҰҒгҖӮеңЁJavaзј–зЁӢиҜӯиЁҖдёӯпјҢе®һзҺ°е“ҲеёҢз®—жі•еҸҜд»Ҙж–№дҫҝең°з”ЁдәҺж•°жҚ®йӘҢиҜҒгҖҒжҹҘжүҫиЎЁд»ҘеҸҠеҜҶз ҒеӯҳеӮЁзӯүеӨҡз§Қз”ЁйҖ”...
еңЁITйўҶеҹҹпјҢе“ҲеёҢз®—жі•пјҲHash AlgorithmпјүжҳҜдёҖз§Қз”ЁдәҺе°Ҷд»»ж„Ҹй•ҝеәҰзҡ„ж•°жҚ®иҪ¬еҢ–дёәеӣәе®ҡй•ҝеәҰиҫ“еҮәзҡ„з®—жі•гҖӮиҝҷдёӘиҝҮзЁӢйҖҡеёёз§°дёәе“ҲеёҢжҲ–ж•ЈеҲ—гҖӮе“ҲеёҢз®—жі•еңЁдҝЎжҒҜе®үе…ЁгҖҒж•°жҚ®е®Ңж•ҙжҖ§йӘҢиҜҒгҖҒеҜҶз ҒеӯҰзӯүеӨҡдёӘж–№йқўйғҪжңүзқҖе№ҝжіӣзҡ„еә”з”ЁгҖӮжң¬йЎ№зӣ®жҳҜз”Ё...
Hash Join з®—жі•жҳҜдёҖз§Қй«ҳж•Ҳзҡ„ж•°жҚ®еә“иҝһжҺҘж“ҚдҪңпјҢе°Өе…¶еңЁеӨ„зҗҶеӨ§ж•°жҚ®йҮҸзҡ„зӣёзӯүиҝһжҺҘж—¶иЎЁзҺ°дјҳи¶ҠгҖӮе®ғеңЁOracle 7.3зүҲжң¬еј•е…ҘпјҢеҸӘйҖӮз”ЁдәҺзӣёзӯүиҝһжҺҘпјҢ并且еҝ…йЎ»еңЁCost-Based Optimizer (CBO)жЁЎејҸдёӢиҝҗиЎҢгҖӮдёҚеҗҢдәҺNested Loop JoinпјҢHash...
HashеҮҪж•°йӣҶеҗҲпјҢеҢ…еҗ«дё»жөҒзҡ„hashеҮҪж•°: nginx_hashз®—жі•пјҢOpenSSL_hashз®—жі•пјҢRSHashпјҢJSHashпјҢPJWHashпјҢELFHashпјҢBKDRHashпјҢDJBHashпјҢDEKHashпјҢAPHashзӯүзӯү!
еңЁITйўҶеҹҹпјҢHashз®—жі•жҳҜдёҖз§Қе№ҝжіӣеә”з”ЁдәҺж•°жҚ®йӘҢиҜҒгҖҒеӯҳеӮЁе’ҢжҜ”иҫғзҡ„жҠҖжңҜгҖӮе®ғе°Ҷд»»ж„Ҹй•ҝеәҰзҡ„ж•°жҚ®иҪ¬жҚўжҲҗеӣәе®ҡй•ҝеәҰзҡ„иҫ“еҮәпјҢйҖҡеёёз§°дёәHashеҖјжҲ–жҢҮзә№гҖӮеңЁиҝҷдёӘеҺӢзј©еҢ…дёӯпјҢжҲ‘们йҮҚзӮ№е…іжіЁзҡ„жҳҜеӣҫеғҸзҡ„зӣёдјјеәҰHashз®—жі•пјҢзү№еҲ«жҳҜе№іеқҮе“ҲеёҢз®—жі•(a...
дёҖгҖҒA*жҗңзҙўз®—жі• дёҖпјҲз»ӯпјүгҖҒA*пјҢDijkstraпјҢBFS з®—жі•жҖ§иғҪжҜ”иҫғеҸҠA*з®—жі•зҡ„еә”з”Ё ...еҚҒдёҖгҖҒд»ҺеӨҙеҲ°е°ҫеҪ»еә•и§ЈжһҗHash иЎЁз®—жі• еҚҒдәҢгҖҒеҝ«йҖҹжҺ’еәҸз®—жі•д№ӢжүҖжңүзүҲжң¬зҡ„c/c++е®һзҺ° еҚҒдёүгҖҒйҖҡиҝҮжөҷеӨ§дёҠжңәеӨҚиҜ•иҜ•йўҳеӯҰSPFA з®—жі•
Javaе®һзҺ°GeoHashз®—жі•жҳҜдёҖз§ҚеңЁITйўҶеҹҹдёӯз”ЁдәҺең°зҗҶдҪҚзҪ®ж•°жҚ®еӯҳеӮЁе’ҢжЈҖзҙўзҡ„жҠҖжңҜгҖӮGeoHashе°Ҷз»Ҹзә¬еәҰеқҗж ҮиҪ¬жҚўдёәеӯ—з¬ҰдёІпјҢдҪҝеҫ—ең°зҗҶдҪҚзҪ®еҸҜд»Ҙиў«й«ҳж•Ҳең°зҙўеј•е’ҢжҹҘиҜўгҖӮиҝҷз§Қз®—жі•еҲ©з”ЁдәҶз©әй—ҙеҲҶеүІе’Ңзј–з Ғзӯ–з•ҘпјҢдҪҝеҫ—зӣёйӮ»зҡ„дҪҚзҪ®еңЁзј–з ҒеҗҺе…·жңү...
дёҖдёӘhashз®—жі•зҡ„е·Ҙе…·зұ»пјҢйҮҢйқўеҢ…еҗ«дәҶдёҖдәӣеёёз”Ёзҡ„hashз®—жі•
еңЁи§Јжһҗз®—жі•е’Ңе®һзҺ°жҠҖжңҜд№ӢеӨ–пјҢжң¬ж–ҮиҝҳжҸҗеҲ°дәҶеҜ№дәҺHashеҮҪж•°е’ҢHashиЎЁз®—жі•зҡ„е®һйҷ…жөӢиҜ•пјҢеҲҶжһҗдәҶдёҚеҗҢзҡ„HashеҮҪж•°з®—жі•зҡ„иЎЁзҺ°еҸҠе…¶дјҳеҠЈпјҢиҝҷе°ҶжңүеҠ©дәҺжҲ‘们йҖүжӢ©жңҖйҖӮеҗҲзү№е®ҡеә”з”ЁеңәжҷҜзҡ„HashеҮҪж•°гҖӮиҖҢиҝҷдәӣзҹҘиҜҶзӮ№зҡ„и®Іи§Је’ҢжөӢиҜ•з»“жһңпјҢеҜ№дәҺеёҢжңӣ...
### Hashз®—жі•зӣёе…ід»Ӣз»Қ еңЁи®Ўз®—жңә科еӯҰйўҶеҹҹпјҢе“ҲеёҢпјҲHashпјүжҳҜдёҖз§Қе°Ҷд»»ж„Ҹй•ҝеәҰзҡ„ж•°жҚ®жҳ е°„дёәеӣәе®ҡй•ҝеәҰж•°жҚ®зҡ„жҠҖжңҜгҖӮе“ҲеёҢз®—жі•е№ҝжіӣеә”з”ЁдәҺеӨҡз§ҚеңәжҷҜдёӯпјҢеҢ…жӢ¬дҪҶдёҚйҷҗдәҺж•°жҚ®е®Ңж•ҙжҖ§йӘҢиҜҒгҖҒеҜҶз ҒеӯҳеӮЁгҖҒеҝ«йҖҹжҹҘжүҫзӯүгҖӮжң¬ж–Үдё»иҰҒд»Ӣз»ҚдәҶеҮ з§Қ...
### Hashз®—жі•ж·ұеәҰи§Јжһҗ #### ж•ЈеҲ—ж–№жі•жҰӮи§Ҳ Hashз®—жі•пјҢдҪңдёәдёҖз§Қй«ҳж•Ҳзҡ„ж•°жҚ®еӨ„зҗҶжңәеҲ¶пјҢеңЁи®Ўз®—жңә科еӯҰйўҶеҹҹжү®жј”зқҖдёҫи¶іиҪ»йҮҚзҡ„и§’иүІгҖӮдёҚеҗҢдәҺдј з»ҹзҡ„жҗңзҙўж–№ејҸпјҢеҰӮйЎәеәҸжҹҘжүҫгҖҒдәҢеҲҶжҹҘжүҫд»ҘеҸҠеҹәдәҺж ‘з»“жһ„зҡ„жҹҘжүҫж–№жі•пјҢHashз®—жі•зҡ„ж ёеҝғ...
Hash Join з®—жі•зҡ„еҹәжң¬жҖқжғіжҳҜж №жҚ®е°Ҹзҡ„ row sourcesпјҲз§°дҪң build inputпјүе»әз«ӢдёҖдёӘеҸҜд»ҘеӯҳеңЁдәҺ Hash Area еҶ…еӯҳдёӯзҡ„ Hash иЎЁпјҢ然еҗҺз”ЁеӨ§зҡ„ row sourcesпјҲз§°дҪң probe inputпјүжқҘжҺўжөӢеүҚйқўжүҖе»әзҡ„ Hash иЎЁгҖӮеҰӮжһң Hash Area еҶ…еӯҳ...
GeoHashз®—жі•жҳҜдёҖз§ҚеҹәдәҺең°зҗҶеқҗж Үзҡ„еҲҶеёғејҸз©әй—ҙзҙўеј•жҠҖжңҜпјҢе®ғйҖҡиҝҮе°Ҷең°зҗғиЎЁйқўзҡ„з»Ҹзә¬еәҰеқҗж ҮиҪ¬еҢ–дёәеҸҜжҜ”иҫғзҡ„еӯ—з¬ҰдёІпјҢдҪҝеҫ—жҲ‘们еҸҜд»Ҙй«ҳж•Ҳең°иҝӣиЎҢең°зҗҶдҪҚзҪ®зҡ„жҗңзҙўгҖҒиҢғеӣҙжҹҘиҜўд»ҘеҸҠйӮ»еұ…жҹҘжүҫзӯүж“ҚдҪңгҖӮиҝҷз§Қз®—жі•е°Өе…¶йҖӮз”ЁдәҺеӨ§ж•°жҚ®е’ҢеҲҶеёғејҸ...
"Hashз®—жі•MD5е®һйӘҢжҠҘе‘Ҡжқҗж–ҷ" жң¬е®һйӘҢжҠҘе‘Ҡдё»иҰҒд»Ӣз»ҚдәҶHashз®—жі•MD5зҡ„е®һйӘҢжҠҘе‘ҠпјҢж—ЁеңЁйҖҡиҝҮе®һйҷ…зј–зЁӢжқҘдәҶи§ЈMD5з®—жі•зҡ„еҠ еҜҶе’Ңи§ЈеҜҶиҝҮзЁӢпјҢ并еҠ ж·ұеҜ№Hashз®—жі•зҡ„и®ӨиҜҶгҖӮ дёҖгҖҒHashз®—жі•зҡ„е®ҡд№ү Hashз®—жі•жҳҜдёҖз§Қе°Ҷиҫ“е…Ҙж•°жҚ®иҪ¬жҚўдёәеӣәе®ҡ...
### еёёи§Ғзҡ„HASHз®—жі•и§Јжһҗ еңЁи®Ўз®—жңә科еӯҰйўҶеҹҹпјҢе“ҲеёҢз®—жі•пјҲHASHз®—жі•пјүжҳҜдёҖз§Қе°Ҷд»»ж„Ҹй•ҝеәҰзҡ„ж•°жҚ®жҳ е°„еҲ°еӣәе®ҡй•ҝеәҰж•°жҚ®зҡ„з®—жі•пјҢйҖҡеёёз”ЁдәҺж•°жҚ®жҹҘжүҫгҖҒеҜҶз ҒеӯҳеӮЁгҖҒж¶ҲжҒҜе®Ңж•ҙжҖ§йӘҢиҜҒзӯүеӨҡз§ҚеңәжҷҜгҖӮжң¬ж–Үе°ҶиҜҰз»Ҷд»Ӣз»ҚеҮ з§Қеёёи§Ғзҡ„е“ҲеёҢз®—жі•пјҢ...
е“ҲеёҢпјҲHashпјүз®—жі•еңЁи®Ўз®—жңә科еӯҰдёӯжү®жј”зқҖйҮҚиҰҒзҡ„и§’иүІпјҢзү№еҲ«жҳҜеңЁж•°жҚ®еӯҳеӮЁгҖҒж–Үд»¶ж ЎйӘҢгҖҒдҝЎжҒҜе®үе…ЁзӯүйўҶеҹҹгҖӮжң¬ж–Үе°Ҷж·ұе…ҘжҺўи®Ёе“ҲеёҢз®—жі•зҡ„еҺҹзҗҶпјҢ并жҸҗдҫӣдёҖдёӘз®ҖеҚ•зҡ„CиҜӯиЁҖе®һзҺ°зӨәдҫӢгҖӮ е“ҲеёҢз®—жі•пјҢеҸҲз§°дёәж•ЈеҲ—еҮҪж•°пјҢжҳҜдёҖз§Қе°Ҷд»»ж„Ҹй•ҝеәҰзҡ„...
Geohashз®—жі•е®һзҺ°пјҢз»Ҹзә¬еәҰеҲ°geohashзј–з Ғзҡ„е®һзҺ°