其实大家都知道hadoop为我们提供了一个大的框架,真正的算法还是要程序员自己去实现,所以了解hadoop大概架构之后就要了解一些基本的算法。
mahout--可以理解为hadoop的驾驶员。学习它一定要从《mahout in action》入手,在此我记录下一些学习的笔记仅供参考。
第一节:基于用户的推荐算法
GenericUserBasedRecommender 算法原理
官方解释:
for every other user w
compute a similarity s between u and w
retain the top users, ranked by similarity, as a “neighborhood” n
for every item i that some user in n has a preference for,
but that u has no preference for yet
for every other user v in n that has a preference for i
compute a similarity s between u and v
incorporate v's preference for i, weighted by s, into a running average
一:所有用户与用户U做相似性计算,计算出其邻居集合 n
二:循环所有的商品,计算出邻居集合n有兴趣且用户U没有兴趣的商品集合items
三:循环items和邻居集合n,计算出邻居和用户u 的相似度s集合
四:返回s集合并根据相似度排序。
similarity 几个主要算法
在此只做主要介绍,感兴趣的朋友可以研究下具体公式
1、皮尔逊相关系数
用于度量两个变量X和Y之间的相关(线性相关),其值介于-1与1之间。两个变量相关性越高,则系数趋近于1,两个变量相互独立,则系数为0,两系数对立,则系数趋近于0。我们看下书本上的例子:

从上图可以看出 user1 和 user4的相关性 比 user1 和user5的相关性高,这似乎有一些counterintuitive。
还有user1和user3是没有相关系数的,这是因为算法程序的规则。
还有一种情况下相关性是不计算的,如果一个user 对所有的item 的perference value相同。
书中介绍这种算法不好不坏,仅仅让你理解一下它的工作原理就好了。
2、欧几里德距离算法
该算法是基于两个user之间的distance,想象用户的坐标就是用户的preference values,距离越小,则说明用户相似度越高。该算法返回值为 1/(1+d),所以当算法返回值为1时,表示两用户相似度完全相等。看下书本上的例子

可以看出该算法和皮尔逊系数有相同的问题,users 1 and 4 have a higher similarity than users 1 and 5.
3、余弦测量相似度算法
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。我们需要立即的就是余弦值在-1到1之间,角度越小(相似度越高)越趋近于1。
4、
其余更多算法请参考 http://www.cnblogs.com/shipengzhi/articles/2540382.html
第二节:基于物品的推荐算法
GenericItemBasedRecommender 算法原理
for every item i that u has no preference for yet
for every item j that u has a preference for
compute a similarity s between i and j
add u's preference for j, weighted by s, to a running average
return the top items, ranked by weighted average
一:循环所有用户没有偏好的物品 i
二:循环所有用户有偏好的物品 j
三:计算i和j的相似度 s
四:为物品j赋予 相似度
五:返回所有物品按权重排序
相似度相关算法例如
public Recommender buildRecommender(DataModel model)
throws TasteException {
ItemSimilarity similarity = new PearsonCorrelationSimilarity(model);
return new GenericItemBasedRecommender(model, similarity);
}
可以看到这里PearsonCorrelationSimilarity 仍然可以使用,因为它实现了ItemSimilarity接口,ItemSimilarity接口完全类似UserSimilarity。
GenericItemBasedRecommender构建比GenericUserBasedRecommender简单,它只需要一个数据模型datamodel,一个相似度算法,而不需要ItemNeighborhood,因为在算法的一开始,用户就已经表达了自己的偏好,这就类似于ItemNeighborhood。
在物品较用户少的情况下,基于物品的推荐算法将运行的更快
第三节:Slope-one 推荐算法

对于上面的数据,首先计算每个item之间的相似性,形成item-item之间的相似度关系。相似度的计算过程不是采用余弦相似度公式等方法,而是根据用户中共同评分的item的差值进行计算的。
相似度计算
例如,item 1与item 2的相似度为 (2+(-1))/2=0.5。但是item 2与item 1之间的相似度为-0.5,整个相似度矩阵不是对称矩阵。而是反对称矩阵。为了后续更新方便,可以将分子与分母分别存储,用的时候再计算相似度。同样的方法,可以计算item1与item 3之间的相似度3。
预测评分
预测的时候,简单的加权是对两个item共同评分的数量,例如item1与item2有2个user共同评分了,则权重是2,同样的item1与item3的权重是1。
Lucy对item 1的预测评分公式如下:
((2+0.5)*2+(3+5)*1)/(2+1)=4.33
在mahout中有这个方法的实现。
第三节:协同过滤之同现矩阵
测试数据集:small.csv
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.0
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0
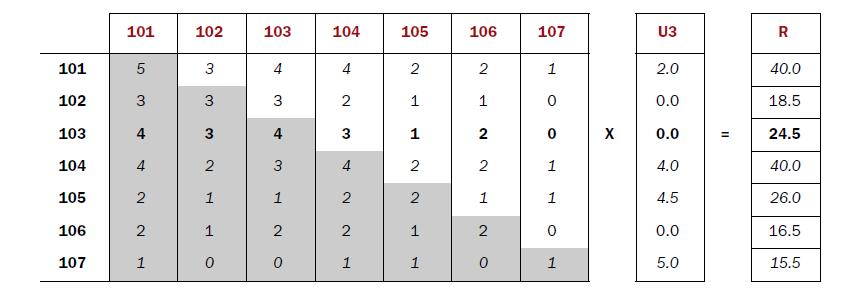
1). 建立物品的同现矩阵
按用户分组,找到每个用户所选的物品,单独出现计数及两两一组计数。
[101] [102] [103] [104] [105] [106] [107]
[101] 5 3 4 4 2 2 1
[102] 3 3 3 2 1 1 0
[103] 4 3 4 3 1 2 0
[104] 4 2 3 4 2 2 1
[105] 2 1 1 2 2 1 1
[106] 2 1 2 2 1 2 0
[107] 1 0 0 1 1 0 1
2). 建立用户对物品的评分矩阵
按用户分组,找到每个用户所选的物品及评分
U3
[101] 2.0
[102] 0.0
[103] 0.0
[104] 4.0
[105] 4.5
[106] 0.0
[107] 5.0
3). 矩阵计算推荐结果
同现矩阵*评分矩阵=推荐结果

- 大小: 15.1 KB

- 大小: 17 KB

- 大小: 23.8 KB
分享到:




相关推荐
Mahout 0.8版本是一个重要的里程碑,包含了丰富的机器学习算法,如协同过滤推荐算法、K-means聚类算法、随机森林分类算法等。这些算法都是经过优化的,能够高效地运行在大规模数据集上,尤其适合处理大数据的场景。 ...
总结来说,Hadoop-Mahout是处理大规模数据挖掘和机器学习任务的理想工具。它不仅提供了推荐系统、聚类和分类等核心功能,还与Hadoop紧密集成,借助Java的灵活性,为开发者提供了强大的平台来探索和理解大数据中的...
- Mahout作为基于Hadoop的机器学习库,提供了丰富的数据挖掘算法实现推荐系统的推荐算法层。 - 分布式推荐引擎的架构设计需要考虑如何将推荐算法高效地部署在分布式环境中,确保推荐过程的稳定性和可扩展性。 3. ...
1. **Mahout核心功能**: Mahout提供了多种机器学习算法,包括推荐系统、聚类和分类。推荐系统如协同过滤,用于个性化推荐;聚类算法如K-means,用于将数据分成多个相似的组;分类算法如随机森林,用于预测目标变量...
本项目名为“Recommendation-with-mahout”,它结合了Maven、Hadoop和Apache Mahout这三个强大的工具,旨在实现高效的推荐算法。以下是对这些技术及其整合应用的详细说明。 **Apache Mahout** Apache Mahout是一个...
Apache Mahout是一个基于Hadoop的大规模数据集上实现的机器学习库,它的主要目标是提供简单易用的算法,用于构建智能应用。在标题中提到的"apache-mahout-distribution-0.12.2.tar.gz"是Mahout的一个发行版本,版本...
Apache Mahout起源于2008年,由Apache Software Foundation发起,旨在提供可扩展的、用户友好的机器学习算法实现,支持大数据平台如Hadoop。它的核心目标是让数据科学家和开发者能够轻松地构建推荐系统、分类和聚类...
Mahout的协同过滤算法是其核心功能之一,它通过分析用户的历史行为来预测他们可能感兴趣的新内容。这种算法分为两种类型:用户-用户协同过滤和物品-物品协同过滤。用户-用户协同过滤基于“有相似历史行为的用户可能...
1. **机器学习算法**:Mahout的核心在于它提供了多种机器学习算法,包括分类(如决策树、随机森林)、聚类(如K-Means、Fuzzy K-Means)、协同过滤(用于推荐系统)等。这些算法可以处理大规模数据,并且利用Hadoop...
- **Mahout**:一个机器学习库,提供了许多用于推荐引擎、聚类、分类等功能的算法。 **高可用 CDH4:Namenode HA + HA 自动切换** 为了提高系统的可用性和可靠性,CDH4 提供了 Namenode HA 功能。这通常涉及以下...
本文探讨了基于Hadoop与Mahout的云数据挖掘推荐系统,旨在通过并行化的架构和算法处理和分析大数据集,解决传统数据管理难以深度挖掘云端数据的问题,并将云数据转化为有用的资讯和知识,以期在特定领域实现其价值。...
Apache Mahout是一个基于Hadoop的数据挖掘库,它提供了大规模机器学习算法的实现,包括推荐引擎、分类、聚类和关联规则挖掘。Mahout 0.9版本是该库的一个重要里程碑,尤其因为它是第一个全面支持Hadoop 2的版本。在...
Mahout的设计目的是为了在大规模数据集上进行机器学习任务,其核心算法都是基于Apache Hadoop实现的,因此能够很好地利用分布式计算的优势。 #### 二、环境准备 在进行Mahout 0.9的安装与配置之前,我们需要确保...
二、核心算法 1. **协同过滤(Collaborative Filtering)**:Mahout 提供了基于用户的协同过滤(User-Based Collaborative Filtering)和基于物品的协同过滤(Item-Based Collaborative Filtering)算法,用于推荐...
#### Mahout的核心特性 Mahout的主要特性包括但不限于: - **算法多样性**:支持多种机器学习算法,如K-Means聚类、协同过滤推荐系统、逻辑回归等。 - **高度可扩展性**:借助Hadoop的MapReduce框架,Mahout能够在...
总结来说,Mahout 0.9-jar包是一个包含所有必要组件的二进制发行版,旨在简化将机器学习功能集成到Java项目中的过程,特别适合那些希望利用推荐系统、聚类和分类算法的开发者。通过理解和运用这些工具,开发者可以...
其核心算法包括协同过滤、聚类分析及分类算法,广泛应用于电子商务、社交网络等多个领域。 #### 推荐算法评判标准 在Mahout推荐算法中,评估推荐系统性能的标准通常包括**召回率**与**准确率**两个关键指标: - *...
Apache Mahout是一个基于Hadoop的机器学习库,它提供了多种推荐算法,旨在帮助开发者构建大规模的数据挖掘和机器学习系统。这本书的目标是通过实际案例来指导读者理解并应用Mahout的推荐算法。 推荐算法是现代数据...
1. **分布式计算**:Mahout充分利用了Hadoop的分布式计算框架,能够处理大规模的数据集,使得机器学习算法能够在分布式环境中高效运行。 2. **算法库**:Mahout包含了大量的机器学习算法,如聚类、分类、推荐系统等...
Mahout是机器学习和数据挖掘的一个分布式框架,它是基于Hadoop上的,用MapReduce实现了部分数据挖掘算法,解决了并行挖掘的问题。 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,主要是用来解决...