- µĄÅĶ¦ł: 587526 µ¼Ī
- µĆ¦Õł½:

- µØźĶć¬: Õ╣┐ÕĘ×
-

µ¢ćń½ĀÕłåń▒╗
- Õģ©ķā©ÕŹÜÕ«ó (188)
- java (14)
- web (14)
- web service (3)
- µØéĶ░ł (14)
- Version Control (13)
- software test (30)
- linux (17)
- database (3)
- distributed storage and computing (1)
- ejb (7)
- project building (46)
- spring & IOC (2)
- Thread (2)
- xml (2)
- tool software (0)
- [ńĮæń½ÖÕłåń▒╗]1.ńĮæń½Öķ”¢ķĪĄÕÄ¤ÕłøJavaµŖƵ£»Õī║(Õ»╣ķ”¢ķĪĄµ¢ćń½ĀńÜäĶ”üµ▒é: ÕÄ¤ÕłøŃĆüķ½śĶ┤©ķćÅŃĆüń╗ÅĶ┐ćĶ«żń£¤µĆØĶĆāÕ╣Čń▓ŠÕ┐āÕåÖõĮ£ŃĆéBlogJavań«ĪńÉåÕøóķś¤õ╝ÜÕ»╣ķ”¢ķĪĄńÜäµ¢ćń½ĀĶ┐øĶĪīń«ĪńÉåŃĆé) (0)
- project manager (9)
- OSGI (1)
- nosql (3)
ńżŠÕī║ńēłÕØŚ
- µłæńÜäĶĄäĶ«» ( 0)
- µłæńÜäĶ«║ÕØø ( 483)
- µłæńÜäķŚ«ńŁö ( 6)
ÕŁśµĪŻÕłåń▒╗
- 2014-04 ( 1)
- 2013-02 ( 1)
- 2013-01 ( 1)
- µø┤ÕżÜÕŁśµĪŻ...
µ£Ćµ¢░Ķ»äĶ«║
-
sp42’╝Ü
ÕźĮµÉ×ń¼æ┬Ā
õĮĀµćéõĖŹµćéxml! (2) -
cherishmmo2004’╝Ü
µä¤Ķ¦ēõĮĀõ╗¼ķāĮÕŠłńēøµÄ░’╝īµłæõ╗¼ÕüÜńÜäõĖĆõĖ¬Ķ┐Éń╗┤Õ╣│ÕÅ░õ╣¤µś»ńö©karafńÜä’╝īńö©k ...
Õ¤║õ║ÄosgiÕ╝ĆÕÅæÕż¦Õ×ŗńÜäõ╝üõĖÜÕ║öńö© -
liubey’╝Ü
ŌĆ£Ķć¬õĮ£Ķü¬µśÄŌĆØńÜäõĮ┐ńö©õ║åĶ»╗ÕåÖķöü’╝īÕģČÕ«×ÕŬõĮ┐ńö©ReentrantLoc ...
ń╝¢ńĀüµ£ĆõĮ│Õ«×ĶĘĄ(4)--Õ░ÅÕ┐āLinkedHashMapńÜäget()µ¢╣µ│Ģ -
liubey’╝Ü
õĮĀĶ┐ÖõĖ¬õ╗ŻńĀüµś»sublistÕÉÄõ╗ŹńäČõĖĆńø┤µīüµ£ēĶ┐ÖõĖ¬subńÜäÕ╝Ģńö©’╝īõĖĆĶł¼ ...
ń╝¢ńĀüµ£ĆõĮ│Õ«×ĶĘĄ(5)--Õ░ÅÕ┐ā’╝üĶ┐ÖÕŬµś»Õå░Õ▒▒õĖĆĶ¦Æ -
xiegqooo’╝Ü
┬Ā┬Ā┬Ā
ÕłØÕŁ”maven(5)-õĮ┐ńö©assembly pluginÕ«×ńÄ░Ķć¬Õ«Üõ╣ēµēōÕīģ
õĮ┐ńö©AIOÕÆīSEDAµ©ĪÕ×ŗµØźµ×äÕ╗║ÕÅ»õ╝Ėń╝®ńÜäõ╝üõĖÜÕ║öńö©
- ÕŹÜÕ«óÕłåń▒╗’╝Ü
- Thread
Õżćµ│©’╝Üń┐╗Ķ»æĶć¬theserverside.comńÜäõĖĆń»ćµ¢ćń½Ā’╝īÕĤµ¢ćÕ£░ÕØĆĶ»ĘĶ¦ühttp://www.theserverside.com/tt/articles/article.tss?l=IOandSEDAModelŃĆéĶŗ▒µ¢ćĶāĮÕŖøõĖĆĶł¼’╝īń┐╗Ķ»æĶ┤©ķćÅõĖŹµś»ńē╣Õł½ńÉåµā│’╝īÕż¦Õ«ČÕ░åÕ░▒ńé╣ń£ŗÕɦŃĆéՔ鵣ēķöÖĶ»»Ķ»ĘÕĖ«Õ┐Öµī浣ŻŃĆé
µŁŻµ¢ćÕ”éõĖŗ’╝Ü
Ķ«©Ķ«║
┬Ā┬Ā┬Ā Ķ┐Öń»ćµ¢ćń½ĀÕ▒Ģńż║õĖĆõĖ¬Ķ¦ŻÕå│µ¢╣µĪł’╝īńö©µØźĶ¦ŻÕå│õ╝üõĖÜÕ║öńö©õĖŁńÜäÕÅ»õ╝Ėń╝®µĆ¦ķŚ«ķóś,Ķ┐Öõ║øÕ║öńö©Õ┐ģķĪ╗µö»µīüÕŹ│Ķ”üµ▒éÕ┐½ķƤÕōŹÕ║öĶĆīÕÅłķĢ┐µŚČķŚ┤Ķ┐ÉĶĪīńÜäõĖÜÕŖĪń©ŗÕ║Å’╝īÕÉ×ÕÉÉķćŵł¢Õż¦µł¢Õ░ÅŃĆé
┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā Ķ«®µłæõ╗¼Õ«Üõ╣ēõĖĆõĖ¬ń«ĆÕŹĢńÜäńż║õŠŗÕ£║µÖ»µØźµ©Īµŗ¤Ķ┐Öń¦ŹµāģÕåĄŃĆ鵳æõ╗¼µ£ēõĖĆõĖ¬ÕēŹń½»webÕ║öńö©ń©ŗÕ║Å’╝īķĆÜĶ┐ćhttpµÄźµöČĶ»Ęµ▒é’╝īńäČÕÉĵŖŖĶ»Ęµ▒éÕÅæķĆüń╗ÖõĖŹÕÉīńÜäweb serviceÕÉÄń½»ŃĆéweb serviceĶ»Ęµ▒éńÜäÕÉÄń½»Õ╣│ÕÅ░õĖŁµ£ēõĖĆõĖ¬ÕōŹÕ║öÕŠłµģóŃĆéń╗ōµ×£Õ»╝Ķć┤µłæõ╗¼Õ░åĶÄĘÕŠŚõĖĆõĖ¬ÕŠłõĮÄńÜäÕÉ×ÕÉÉķćÅ.ÕøĀõĖ║Ķ┐ÖõĖ¬ÕōŹÕ║öÕŠłµģóńÜäµ£ŹÕŖĪõĮ┐ÕŠŚwebµ£ŹÕŖĪÕÖ©ńÜäń║┐ń©ŗµ▒ĀõĖŁńÜäõĖĆõĖ¬ÕĘźõĮ£ń║┐ń©ŗÕ¦ŗń╗łõ┐صīüń╣üÕ┐Ö’╝īÕģČõ╗¢Ķ»Ęµ▒鵌Āµ│ĢÕŠŚÕł░ÕżäńÉåŃĆé
┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā Ķ┐Öķćīµ£ēõĖĆõĖ¬Ķ¦ŻÕå│Ķ┐Öń¦ŹµāģÕåĄńÜäµ¢╣µĪł’╝īĶÖĮńäČńÄ░Õ£©Ķ┐śµ▓Īµ£ēµĀćÕćåÕī¢’╝īõĮåÕĘ▓ń╗ÅĶó½ÕćĀõ╣ĵēƵ£ēservletÕ«╣ÕÖ©õ╗źĶ┐ÖµĀʵł¢ĶĆģķ鯵ĀĘńÜäµ¢╣µ│ĢÕ«×ńÄ░’╝ÜJetty, Apache Jakarta Tomcat, and Weblogic. Ķ┐ÖÕ░▒µś»Õ╝鵣źIO(asynchronous IO,or AIO).
┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā õĖŖķØóµÅÉÕł░ńÜäĶ¦ŻÕå│µ¢╣µĪłõĖŁõĮ┐ńö©Õł░ńÜäÕģ│ķö«µ×ȵ×äń╗äõ╗ČÕ”éõĖŗ’╝Ü
┬Ā┬Ā┬Ā ┬Ā┬Ā┬Ā 1. Õ£©servletÕ«╣ÕÖ©õĖŁõĮ┐ńö©Õ╝鵣źIO
┬Ā┬Ā┬Ā ┬Ā┬Ā┬Ā 2. ķśČµ«ĄÕī¢õ║ŗõ╗Čķ®▒ÕŖ©µ×ȵ×䵩ĪÕ×ŗ(SEDA)
┬Ā┬Ā┬Ā ┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā Õ£©servletÕ«╣ÕÖ©õĖŁõĮ┐ńö©Õ╝鵣źIO
┬Ā┬Ā┬Ā servletÕ«╣ÕÖ©µŁŻµłÉõĖ║Õ£©java nioÕ║ōõ╣ŗõĖŖÕ«×ńÄ░ķ½śÕÅ»õ╝Ėń╝®µĆ¦Õ║öńö©ńÜäĶē»ÕźĮµ£║õ╝ÜŌĆöŌĆönioń▒╗Õ║ōń╗Öõ║łõ╗ĵ»ÅĶ┐׵ğõĖĆń║┐ń©ŗĶĮ¼ÕÅśõĖ║µ»ÅĶ»Ęµ▒éõĖĆń║┐ń©ŗńÜäĶāĮÕŖøŃĆé
┬Ā┬Ā┬Ā ÕĮōńäČĶ┐Öõ║øĶ┐śõĖŹÕż¤’╝īÕ£©Õ«×ńÄ░Reverse Ajax-basedńÜäÕ║öńö©µŚČõ╝ÜÕÅæńö¤ķŚ«ķóśŃĆéńø«ÕēŹµ▓Īµ£ēµ£║ÕłČµÅÉõŠøservlet APIµØźÕ«╣Ķ«ĖÕ╝鵣źÕÅæķĆüµĢ░µŹ«ń╗ÖÕ«óµłĘń½»ŃĆéńø«ÕēŹReverse Ajaxµ£ēõĖēń¦ŹÕ«×ńÄ░µ¢╣Õ╝Å’╝Ü
┬Ā┬Ā┬Ā * polling
┬Ā┬Ā┬Ā * piggy back
┬Ā┬Ā┬Ā * Comet
┬Ā┬Ā┬Ā ÕĮōÕēŹÕ¤║õ║ÄCommetńÜäÕ«×ńÄ░µś»õ┐صīüÕÆīÕ«óµłĘń½»ńÜäõĖĆõĖ¬µēōÕ╝ĆńÜäķĆÜķüō’╝īÕ¤║õ║ĵ¤Éõ║øõ║ŗõ╗ČÕÅæÕø×µĢ░µŹ«ŃĆéõĮåµś»Ķ┐ÖµēōńĀ┤õ║åµ»ÅĶ»Ęµ▒éõĖĆń║┐ń©ŗµ©ĪÕ×ŗ’╝īÕ£©µ£ŹÕŖĪÕÖ©ń½»Ķć│Õ░æķ£ĆĶ”üÕłåµ┤ŠõĖĆõĖ¬ÕĘźõĮ£ń║┐ń©ŗŃĆé
┬Ā┬Ā┬Ā Õ£©servletÕ«╣ÕÖ©õĖŁńø«ÕēŹµ£ēõĖżń¦ŹÕ«×ńÄ░µ¢╣Õ╝Å’╝Ü
┬Ā┬Ā┬Ā 1.Õ╝鵣źIO(Apache Tomcat, Bea Weblogic)ŌĆöŌĆöÕ«╣Ķ«ĖservletÕ╝鵣źÕżäńÉåµĢ░µŹ«
┬Ā┬Ā┬Ā 2.continuations (Õ╗Čń╗Ł?)(Jetty)ŌĆöŌĆöÕ£©Jetty6õ╗ŗń╗ŹńÜäķØ×ÕĖĖµ£ēĶČŻńÜäńē╣µĆ¦’╝īÕ«╣Ķ«ĖµīéĶĄĘÕĮōÕēŹĶ»Ęµ▒éÕ╣ČķćŖµöŠÕĮōÕēŹń║┐ń©ŗŃĆé
┬Ā┬Ā┬Ā µēƵ£ēĶ┐Öõ║øÕ«×ńÄ░ķāĮµ£ēõ╝śńé╣ÕÆīń╝║ńé╣’╝īĶĆīµ£ĆÕźĮńÜäÕ«×ńÄ░Õ░åµś»µēƵ£ēĶ┐Öõ║øÕ«×ńÄ░ńÜäń╗äÕÉłŃĆé
┬Ā┬Ā┬Ā µłæńÜäõŠŗÕŁÉÕ¤║õ║ÄApache Jakarta TomcatńÜäÕ«×ńÄ░’╝īń¦░õĖ║CometProcessorŃĆéĶ┐Öń¦ŹÕ«×ńÄ░Õ░åĶ»Ęµ▒éÕÆīÕ║öńŁöõ╗ÄÕĘźõĮ£ń║┐ń©ŗõĖŁĶ¦ŻĶĆ”’╝īõ╗ÄĶĆīÕ«╣Ķ«ĖÕĘźõĮ£ń║┐ń©ŗń©ŹÕÉÄÕåŹÕ«īµłÉÕ║öńŁöŃĆé
┬Ā┬Ā┬Ā Staged event-driven architecture (SEDA) model
┬Ā┬Ā┬Ā SEDAµ©ĪÕ×ŗµś»õ╝»ÕģŗÕł®Õż¦ÕŁ”ńÜäMatt Welsh, David CullerÕÆīEric BrewerµÄ©ĶŹÉńÜäõĖĆõĖ¬µ×ȵ×äĶ«ŠĶ«ĪŃĆéSEDAÕ░åÕ║öńö©ÕłåĶ¦ŻõĖ║ńö▒ÕŖ©µĆüĶĄäµ║ÉµÄ¦ÕłČÕÖ©Õłåń”╗ńÜäõĖŹÕÉīķśČµ«Ą’╝īõ╗ÄĶĆīÕ«╣Ķ«ĖÕ║öńö©ń©ŗÕ║ÅÕŖ©µĆüĶ░āµĢ┤µØźµö╣ÕÅśĶ┤¤ĶĮĮŃĆé
┬Ā┬Ā┬Ā õĖŗķØóõĮĀÕ░åń£ŗÕł░Õ¤║õ║ÄSEDAńÜäHTTPµ£ŹÕŖĪÕÖ©’╝Ü
┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā 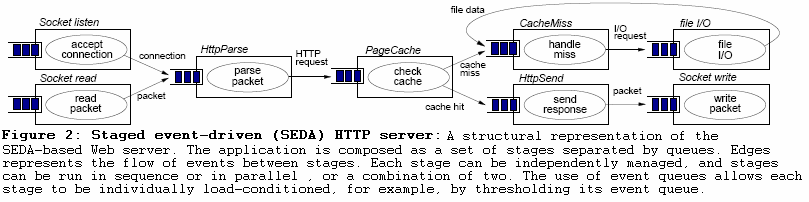
┬Ā┬Ā┬Ā ÕøŠńēć2’╝Ü SEDA HTTPµ£ŹÕŖĪÕÖ©’╝Ü Õ¤║õ║ÄSEDAńÜäHTTPµ£ŹÕŖĪÕÖ©ńÜäµ×ȵ×äĶĪ©Ķ┐░ŃĆéÕ║öńö©ńö▒Ķó½ķś¤ÕłŚÕłåń”╗ńÜäÕżÜõĖ¬ķśČµ«ĄńÜäķøåÕÉłń╗䵳ÉŃĆéń«ŁÕż┤ĶĪ©Ķ┐░õ║åķśČµ«Ąõ╣ŗķŚ┤ńÜäõ║ŗõ╗ȵĄüń©ŗŃĆéµ»ÅõĖ¬ķśČµ«ĄÕÅ»õ╗źĶó½ńŗ¼ń½ŗń«ĪńÉå’╝īÕ╣ČõĖöķśČµ«ĄÕÅ»õ╗źµīēķĪ║Õ║ÅõŠØµ¼ĪĶ┐ÉĶĪīµł¢Õ╣ČÕÅæĶ┐ÉĶĪī’╝īµł¢ĶĆģµś»õĖżĶĆģńÜäń╗äÕÉłŃĆ鵌ČķŚ┤ķś¤ÕłŚńÜäõĮ┐ńö©Õ«╣Ķ«Ėµ»ÅõĖ¬ķśČµ«ĄÕłåÕł½load-conditioned’╝łĶ┤¤ĶĮĮĶ░āĶŖé?).õŠŗÕ”é’╝īĶ«ŠńĮ«õ║ŗõ╗Čķś¤ÕłŚńÜäķśĆÕĆ╝ŃĆé
┬Ā┬Ā┬Ā µ£ēÕģ│Ķ┐ÖõĖ¬µ×ȵ×äńÜäµø┤ÕżÜÕåģÕ«╣ÕÅ»õ╗źÕ£©Ķ┐ÖõĖ¬ķĪĄķØóµēŠÕł░’╝ÜSEDA: An Architecture for Well-Conditioned, Scalable Internet Services.
┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā Ķ«®µłæõ╗¼õĖĆĶĄĘµØźń£ŗ’╝īµłæõ╗¼ńÜäń«ĆÕī¢Õ£║µÖ»µś»Õ”éõĮĢµśĀÕ░äÕł░Ķ┐ÖõĖ¬SEDAµ×ȵ×äńÜäŃĆé
┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā Õ¤║õ║ÄSEDAńÜäÕ║öńö©Õ░åńö▒õĖāõĖ¬ķśČµ«Ąń╗䵳ÉŃĆéÕĮōõĖĆõĖ¬ńē╣Õ«Üń▒╗Õ×ŗńÜäĶ»Ęµ▒éÕł░ĶŠŠµŚČ’╝īÕ«āÕ░åĶó½ĶĘ»ńö▒Õł░µŁŻńĪ«ńÜäķś¤ÕłŚõĖŁŃĆéÕ»╣Õ║öńÜäķśČµ«ĄÕ░åÕżäńÉåĶ┐ÖõĖ¬µČłµü»’╝īńäČÕÉÄÕ░åÕ║öńŁöµöŠÕł░Õ║öńŁöķś¤ÕłŚõĖŁŃĆéµ£ĆÕÉĵĢ░µŹ«Õ░åĶó½ÕÅæķĆüń╗ÖÕ«óµłĘń½»ŃĆéķĆÜĶ┐ćĶ┐Öń¦Źµ¢╣µ│Ģµłæõ╗¼ÕÅ»õ╗źĶ¦ŻÕå│ÕĮōĶ»Ęµ▒éĶó½ĶĘ»ńö▒Õł░Õ║öńŁöń╝ōµģóńÜäµ£ŹÕŖĪµŚČķś╗ÕĪ×ÕģČõ╗¢Ķ»Ęµ▒éÕżäńÉåĶĆīÕĖ”µØźńÜäµē®Õ▒ĢµĆ¦ķŚ«ķóśŃĆé
┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā Ķ«®µłæõ╗¼õĖĆĶĄĘµØźń£ŗń£ŗµĆÄõ╣łńö©MuleµØźÕ«×ńÄ░Ķ┐Öń¦Źµ×ȵ×äŃĆé
┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā Muleµś»õĖĆń¦ŹÕ╝Ƶ║ÉEnterprise Message Bus (ESB)’╝īÕ«āńÜ䵩ĪÕ×ŗµ”éÕ┐Ąµś»Õ¤║õ║ÄSEDAµ©ĪÕ×ŗŃĆéMuleõ╣¤µö»µīüÕģČõ╗¢õ┐Īµü»µ©ĪÕ×ŗ’╝īõĮåķ╗śĶ«żµś»SEDAµ©ĪÕ×ŗŃĆéÕ£©Ķ┐Öń¦Źµ©ĪÕ╝ÅõĖŗ’╝īMuleÕ░åµ»ÅõĖ¬ń╗äõ╗ČÕĮōµłÉõĖĆõĖ¬ķśČµ«Ą’╝īõĮ┐ńö©Ķć¬ÕĘ▒ńÜäń║┐ń©ŗÕÆīÕĘźõĮ£ķś¤ÕłŚŃĆé
┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā Õ£©SEDAµ©ĪÕ×ŗõĖŁńÜäÕģ│ķö«ń╗äõ╗ČŌĆöŌĆöIncoming Event Queue(ĶŠōÕģźõ║ŗõ╗Čķś¤ÕłŚ), Admission Controller(Ķ«ĖÕÅ»µÄ¦ÕłČÕÖ©), Dynamically sized Thread Pool(ÕŖ©µĆüń║┐ń©ŗµ▒Ā), Event Handler(õ║ŗõ╗ČÕżäńÉåÕÖ©)ÕÆīResource Controller(ĶĄäµ║ÉµÄ¦ÕłČÕÖ©)ŌĆöŌĆöĶó½µśĀÕ░äÕł░MuleńÜäµ£ŹÕŖĪń╗äõ╗ČŃĆé
┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā Õ£©MuleõĖŁ’╝īIncoming Event Queue(ĶŠōÕģźõ║ŗõ╗Čķś¤ÕłŚ)µś»õĮ£õĖ║õĖĆõĖ¬inbound’╝łÕåģķā©’╝¤’╝ēńÜäĶĘ»ńö▒ÕÖ©µł¢ĶĆģń╗łń½»µÅÉõŠø’╝īĶĆīEvent Handler(õ║ŗõ╗ČÕżäńÉåÕÖ©)Ķć¬Ķ║½Õ░▒µś»õĮ£õĖ║õĖĆõĖ¬ń╗äõ╗ČŃĆéThus we're short of an Admission Controller, Resource Controller and a Dynamically sized Thread Pool. ’╝łbe short of ?µĆÄõ╣łń┐╗Ķ»æ’╝īsorry’╝ē
┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā Admission Controller(Ķ«ĖÕÅ»µÄ¦ÕłČÕÖ©)õĮ£õĖ║SEDAķśČµ«ĄÕÆīIncoming Event Queue(ĶŠōÕģźõ║ŗõ╗Čķś¤ÕłŚ)Ķ┐׵ğ’╝īńö©MuleńÜäµ£»Ķ»ŁĶ»┤µś»ń╗äõ╗ČŃĆéÕ«×ńÄ░Ķ┐Öń¦Źµ¢╣Õ╝ÅńÜäµ£Ćńø┤µÄźńÜäµ¢╣µ│Ģµś»õĮ£õĖ║õĖĆõĖ¬InboundĶĘ»ńö▒ÕÖ©’╝īńö©õ║ÄµÄ¦ÕłČĶó½µ│©ÕåīÕł░ķĆÜķüōõĖŖńÜäń╗äõ╗ȵğÕÅŚńÜäõ║ŗõ╗Č’╝īÕō¬õ║øĶ»źĶó½ÕżäńÉåÕÆīĶ»źÕ”éõĮĢÕżäńÉåŃĆé
┬Ā┬Ā┬Ā µłæõ╗¼Õ£║µÖ»ńÜäķĆ╗ĶŠæµĄüń©ŗ’╝īÕ░åÕ£©õĖŗķØóńÜäÕøŠõĖŁÕ▒Ģńż║Õ”éõĮĢĶó½µśĀÕ░äÕł░Muleµ©ĪÕ×ŗŃĆéÕøŠõĖŁÕłŚõĖŠńÜ䵣źķ¬żÕ”éõĖŗ’╝Ü
┬Ā┬Ā┬Ā 1. Õ«óµłĘń½»ķĆÜĶ┐ćhttpĶ»Ęµ▒éõĖŗõĖĆõĖ¬Ķ«óÕŹĢ
┬Ā┬Ā┬Ā 2. Ķ»Ęµ▒éĶó½httpµ£ŹÕŖĪÕÖ©ÕżäńÉå’╝īÕ£©µłæõ╗¼ńÜäµĪłõŠŗõĖŁµś»Apache Jakarta TomcatŃĆéÕ¤║õ║ÄhttpĶ»Ęµ▒éµÅÉõŠøńÜäÕÅéµĢ░’╝īÕēŹń½»Õ║öńö©ń©ŗÕ║Åń╗äÕÉłõĖĆõĖ¬Ķ»Ęµ▒éÕ»╣Ķ▒ĪŃĆéÕ£©µłæõ╗¼ńÜäÕ£║µÖ»õĖŁ’╝īµłæõ╗¼µ£ēõĖżõĖ¬Õ»╣Ķ▒Īń▒╗Õ×ŗ’╝īPriceOrderRequestÕÆīStockOrderRequestŃĆéµ»ÅõĖ¬Ķ»Ęµ▒éõ╝ÜĶć¬ÕŖ©ńö¤µłÉõĖĆõĖ¬Õģ│Ķüöid’╝īÕ╣ČĶó½µśĀÕ░äÕł░Õģ│ĶüöĶ┐ÖõĖ¬Ķ»Ęµ▒éńÜäÕ║öńŁöÕ»╣Ķ▒ĪõĖŁŃĆ鵳æõ╗¼Õ░åÕ£©ń©ŹÕÉÄń£ŗÕł░Ķ┐ÖõĖ¬Õģ│ĶüöidÕ░åĶó½Õ”éõĮĢńö©õ║ÄÕī╣ķģŹõ╗ÄMuleÕ«╣ÕÖ©Õł░ÕĤզŗÕ«óµłĘń½»Ķ»Ęµ▒éńÜäÕ║öńŁöŃĆéõ╗ÄńÄ░Õ£©Õ╝ĆÕ¦ŗ’╝īĶ»Ęµ▒éÕ»╣Ķ▒ĪÕ░åÕīģÕɽĶ┐ÖõĖ¬Õģ│Ķüöid’╝īÕ╣ČÕ░åÕ£©ÕēŹń½»Õ║öńö©ń©ŗÕ║ÅńÜäµēƵ£ēÕ▒éõ╣ŗķŚ┤õ╝ĀķĆÆ’╝īÕĮōńäČõ╣¤õ╝Üń®┐ķĆÅMuleńÜäń╗äõ╗ČŃĆéĶ┐ÖõĖ¬Ķ»Ęµ▒éĶ«óÕŹĢ’╝īõĖŹń«Īµś»PriceOrderRequestĶ┐śµś»StockOrderRequest’╝īÕ░åĶó½ÕÅæķĆüÕł░accessÕ▒éŃĆéÕ£©accessÕ▒éÕ░åµ£ēõĖĆõĖ¬ÕćåÕżćÕźĮńÜäJMSńö¤õ║¦ĶĆģńö©õ║ÄÕ░åĶ┐ÖõĖ¬õ┐Īµü»ÕŖĀÕģźÕł░Ķ»Ęµ▒éķś¤ÕłŚŃĆéńÄ░Õ£©Ķ»Ęµ▒éĶ«óÕŹĢÕ░åĶó½Muleń╗äõ╗ČÕżäńÉåŃĆéĶó½webµ£ŹÕŖĪÕÖ©ÕłåķģŹńö©µØźµ£ŹÕŖĪõ║ĵłæõ╗¼httpĶ»Ęµ▒éńÜäÕĘźõĮ£ń║┐ń©ŗńÄ░Õ£©Ķó½ķćŖµöŠÕÅ»õ╗źńö©õ║ĵ£ŹÕŖĪÕģČõ╗¢Ķ»Ęµ▒é’╝īÕ«āõĖŹķ£ĆĶ”üńŁēÕŠģµłæõ╗¼ńÜäõĖÜÕŖĪÕżäńÉåń╗ōµØ¤ŃĆé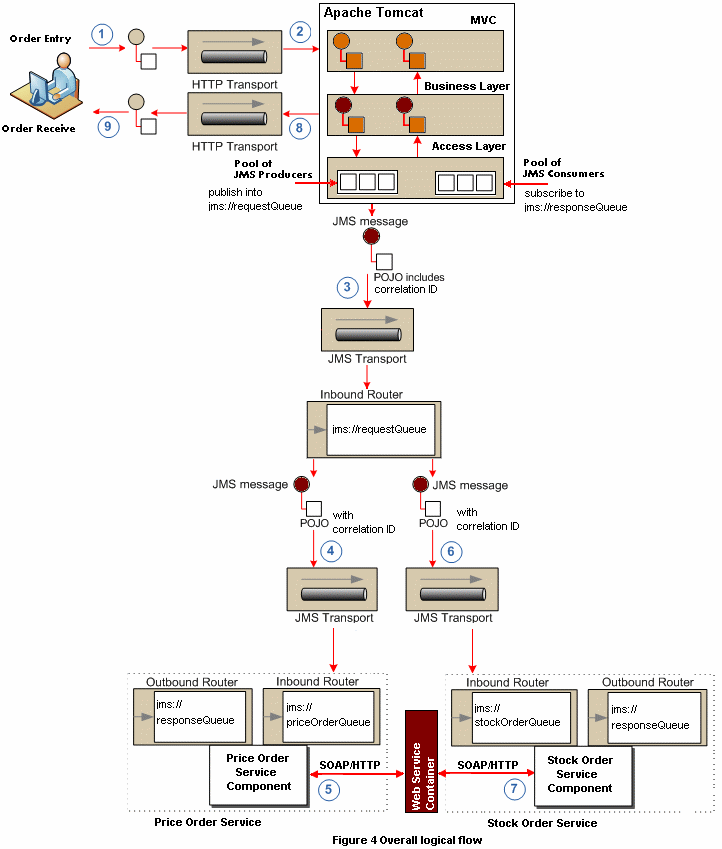
┬Ā┬Ā┬Ā 3. µłæõ╗¼ńÜäĶ»Ęµ▒éĶ«óÕŹĢńÄ░Õ£©Õ£©jmsńÜäķś¤ÕłŚõĖŁ’╝īÕ£░ÕØƵś»jms://requestQueueŃĆéńÄ░Õ£©ÕżäńÉåĶó½ĶĮ¼ń¦╗Õł░MuleõĖŁŃĆé
┬Ā┬Ā┬Ā 4. Õ¤║õ║ÄÕ»╣Ķ▒Īń▒╗Õ×ŗ’╝īĶ«óÕŹĢÕ░åĶó½ĶĘ»ńö▒Õł░õĖŹÕÉīńÜäķś¤ÕłŚŃĆéÕ£©µłæõ╗¼ńÜäµĪłõŠŗõĖŁ’╝īµłæõ╗¼µ£ēõĖĆõĖ¬PriceOrderRequest’╝īµēĆõ╗źõ┐Īµü»Ķó½ĶĘ»ńö▒Õł░jms://priceOrderQueueŃĆé
┬Ā┬Ā┬Ā 5. ķĆÜĶ┐ćõĮ┐ńö©Apache CXF’╝īõĖĆõĖ¬SOAPĶ»Ęµ▒éĶó½ńö¤µłÉÕ╣ČÕÅæķĆüÕł░web serviceÕ«╣ÕÖ©ŃĆéÕ║öńŁöÕ░åĶó½ÕÅæķĆüÕł░jms://responseQueue.
┬Ā┬Ā┬Ā 6. ÕÉīµĀĘńÜäń▒╗õ╝╝µŁźķ¬ż4ńÜäÕ£║µÖ»ÕÅæńö¤Õ£©StockOrderRequestńÜäµĪłõŠŗõĖŁŃĆé
┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā 7. ń▒╗õ╝╝µŁźķ¬ż5.
┬Ā┬Ā┬Ā 8. JMSńÜäµČłĶ┤╣ĶĆģµ▒ĀńøæÕɼthe jms://responseQueue. Ķ┐ÖõĖ¬ķś¤ÕłŚÕīģÕɽõĖÜÕŖĪĶ»Ęµ▒éńÜäÕ║öńŁöõ┐Īµü»ŃĆéĶ┐ÖõĖ¬µČłµü»ÕīģÕɽգ©µŁźķ¬ż2õĖŁńö¤µłÉńÜäÕģ│ĶüöidÕģāµĢ░µŹ«’╝īĶ┐ÖÕ░åÕ«╣Ķ«Ėµłæõ╗¼Ķ»åÕł½Ķ»Ęµ▒éńÜäÕÅæĶĄĘĶĆģŃĆé
┬Ā┬Ā┬Ā 9. õĖƵŚ”httpÕ║öńŁöÕ»╣Ķ▒ĪĶó½Ķ»åÕł½’╝īµłæõ╗¼ÕÅ»õ╗źÕÅæķĆüÕ║öńŁöń╗ÖÕ«óµłĘń½»ŃĆé
┬Ā┬Ā┬Ā õĖŖķØóµĄüń©ŗńÜäMuleķģŹńĮ«õ┐Īµü»Õ▒Ģńż║Õ”éõĖŗ’╝Ü
< model┬Ā name ="Sample" >
┬Ā┬Ā┬Ā┬Ā < service┬Ā name ="Order┬ĀService" ┬Ā > ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < inbound >
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < jms:inbound-endpoint┬Ā queue ="requestQueue" /> ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā </ inbound > ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < component┬Ā class ="org.mule.example.Logger" />
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < outbound >
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < filtering-router >
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < jms:outbound-endpoint┬Ā queue ="priceOrderQueue" ┬Ā />
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < payload-type-filter┬Ā expectedType ="org.mule.model.PriceOrderRequest" />
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā </ filtering-router > ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < filtering-router > ┬Ā┬Ā┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < jms:outbound-endpoint┬Ā queue ="stockOrderQueue" ┬Ā /> ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < payload-type-filter┬Ā expectedType ="org.mule.model.StockOrderRequest" ┬Ā />
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā </ filtering-router >
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā </ outbound > ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā┬Ā </ service >
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā┬Ā < service┬Ā name ="stockService" >
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < inbound >
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < jms:inbound-endpoint┬Ā queue ="stockOrderQueue" ┬Ātransformer-refs ="JMSToObject┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀStockOrderRequestToServiceRequest" ┬Ā />
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā </ inbound > ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < outbound >
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < chaining-router >
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < cxf:outbound-endpoint┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā address ="http://localhost:8080/axis2/services/getStock"
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀclientClass ="org.axis2.service.stock.GetStock_Service" ┬Ā┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀwsdlPort ="getStockHttpSoap12Endpoint" ┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀwsdlLocation ="classpath:/Stock.wsdl" ┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āoperation ="getStock" ┬Ā />
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < jms:outbound-endpoint┬Ā queue ="responseQueue" ┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ātransformer-refs ="ServiceResponseToStockOrderResponse┬ĀObjectToJMS" />
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā </ chaining-router > ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā </ outbound >
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < default-service-exception-strategy >
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < jms:outbound-endpoint┬Ā queue ="responseQueue" ┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ātransformer-refs ="ExceptionToResponse┬ĀObjectToJMS" />
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā </ default-service-exception-strategy >
┬Ā┬Ā┬Ā </ service > ┬Ā┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā < service┬Ā name ="priceService" >
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < inbound >
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < jms:inbound-endpoint┬Ā queue ="priceOrderQueue" ┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ātransformer-refs ="JMSToObject┬ĀPriceOrderRequestToServiceRequest" />
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā </ inbound > ┬Ā┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < outbound >
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < chaining-router >
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < cxf:outbound-endpoint┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā address ="http://localhost:8080/axis2/services/getPrice"
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀclientClass ="org.axis2.service.price.GetPrice_Service" ┬Ā┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀwsdlPort ="getPriceHttpSoap12Endpoint" ┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀwsdlLocation ="classpath:/Price.wsdl" ┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Āoperation ="getPrice" ┬Ā />
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < jms:outbound-endpoint┬Ā queue ="responseQueue" ┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ātransformer-refs ="ServiceResponseToPriceOrderResponse┬ĀObjectToJMS" />
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā </ chaining-router > ┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā </ outbound >
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā < default-service-exception-strategy >
┬Ā┬Ā┬Ā Ķ┐ÖõĖ¬õ║ŗõ╗Čķ®▒ÕŖ©ńÜäµ×ȵ×䵩ĪÕ×ŗµ£ēõĖĆõĖ¬µīæµłśµĆ¦ńÜäķŚ«ķóś’╝īÕ”éõĮĢÕ░åÕ║öńŁöÕÆīĶ»Ęµ▒éÕģ│Ķüö’╝¤Ķ»Ęµ▒éĶó½ńö¤µłÉ’╝īõĖÜÕŖĪÕ»╣Ķ▒ĪĶó½ÕłøÕ╗║’╝īÕ╣ČĶó½õĮ£õĖ║jsmÕ»╣Ķ▒Īõ┐Īµü»ńÜäĶ┤¤ĶĮĮÕ£©Muleń®║ķŚ┤õĖŁķĆÜĶ┐ćÕżÜõĖ¬jmsķś¤ÕłŚõ╝ĀĶŠōŃĆéĶ┐ÖõĖ¬õ┐Īµü»Ķó½õ╗ÄõĖĆõĖ¬ķś¤ÕłŚĶĘ»ńö▒Õł░ÕÅ”õĖĆõĖ¬’╝īķĆÜÕĖĖĶó½ńö©µØźõĮ£õĖ║Õł░web serviceĶ»Ęµ▒éńÜäĶŠōÕģźŃĆé
┬Ā┬Ā┬Ā Õ«╣Ķ«Ėµłæõ╗¼µīüń╗ŁĶ┐ĮĶĖ¬õ┐Īµü»ńÜäÕģ│ķö«õ┐Īµü»µś»µØźĶć¬jmsĶ¦äĶīāńÜäÕģ│ĶüöidŃĆéÕÅ»õ╗źķĆÜĶ┐ćõĮ┐ńö©message.setJMSCorrelationID()µØźĶ«ŠńĮ«ŃĆéńäČĶĆīÕ”éµ×£õĮĀÕ£©jmsķś¤ÕłŚõĖŁÕÅæÕĖāĶ«ŠńĮ«õ║åĶ┐ÖõĖ¬Õ▒׵ƦńÜäõ┐Īµü»’╝īMuleõ╝╝õ╣Äõ╝ÜĶ”åńø¢Ķ┐ÖõĖ¬õ┐Īµü»Õ╣ČõĖ║µČłµü»ÕłøÕ╗║õĖĆõĖ¬Õ░åĶ┤»ń®┐µĢ┤õĖ¬µĄüń©ŗńÜäµ¢░ńÜäÕģ│ĶüöidŃĆéÕ╣ĖÕźĮĶ┐śµ£ēõĖĆõĖ¬Õåģķā©ńÜäÕÉŹõĖ║MULE_CORRELATION_IDńÜäMuleµČłµü»Õ▒׵ƦŃĆéÕ”éµ×£MuleÕÅæńÄ░µČłµü»ńÜäĶ┐ÖõĖ¬Õ▒׵ƦĶó½Ķ«ŠńĮ«’╝īÕ«āÕ░åĶó½ńö©õ║Äń®┐ĶČŖµĄüń©ŗõĖŁµēƵ£ēńÜäń╗äõ╗Č’╝īÕÅ”Õż¢Õ”éµ×£Õģ│Ķüöidµ▓Īµ£ēĶó½Ķ«ŠńĮ«’╝īMULE_CORRELATION_IDÕ▒׵ƦńÜäÕĆ╝Ķ┐śÕ░åĶó½õĮ£õĖ║Õģ│ĶüöidńÜäÕĆ╝õĮ┐ńö©ŃĆé
conn = getConnection();
session = conn.createSession( false ,┬ĀSession.AUTO_ACKNOWLEDGE);
producer = ┬Āsession.createProducer(getDestination(Constants.JMS_DESTINATION_REQUEST_QUEUE));
jmsMessage = session.createObjectMessage();
jmsMessage.setObject(request);
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀjmsMessage.setStringProperty(Constants.PROPS_MULE_CORRELATION_ID,┬Ārequest.getCorrelationID());
producer.send(jmsMessage);
┬Ā┬Ā┬Ā µēĆõ╗źµ»ÅõĖ¬Ķ»Ęµ▒éÕ┐ģķĪ╗Õ£©Õ»╣Õ║öńÜäõĖÜÕŖĪÕ»╣Ķ▒ĪĶó½ÕÅæķĆüÕł░MuleÕģźÕÅŻ(õĖĆõĖ¬jmsÕ»╣Ķ▒Ī)ÕēŹńö¤µłÉõĖĆõĖ¬Õö»õĖĆńÜäÕģ│ĶüöidŃĆé
┬Ā┬Ā┬Ā õĖĆõĖ¬ÕÅ»ĶĪīńÜäµ¢╣µ│Ģµś»ńö¤µłÉõĖĆõĖ¬UUIDńö©ÕüÜÕģ│Ķüöid’╝īÕÉīµĀĘÕ░åUUIDµśĀÕ░äÕł░CometProcessorµÄźÕÅŻõĖŁńÜäõ║ŗõ╗ȵ¢╣µ│ĢµÅÉõŠøńÜäĶó½ÕīģĶŻ╣õĖ║CometEventÕ»╣Ķ▒ĪńÜäHttpServletResponseÕ»╣Ķ▒ĪŃĆé
*┬Āgenerate┬Āthe┬ĀUUID┬Āfor┬Āthe┬ĀCORRELATION┬ĀID┬Āand┬Āmap┬Āto┬Āthe┬ĀHttpServletResponse┬Ā
*/
public ┬Ā class ┬ĀIdentityCreator┬Ā extends ┬ĀMethodInterceptorAspect{
┬Ā┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā┬Ā protected ┬Ā void ┬ĀbeforeInvoke(MethodInvocation┬Āmethod){┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀObject[]┬Āargs = method.getArguments();
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀHttpServletRequest┬ĀhttpRequest = ((CometEvent)args[ 0 ]).getHttpServletRequest();
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀString┬Āuuid = UuidFactory.getUuid();
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀhttpRequest.setAttribute(Constants.PROPS_MULE_CORRELATION_ID,┬Āuuid);
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀHttpResponseManager.getInstance().saveResponse(uuid,┬Ā((CometEvent)args[ 0 ]).getHttpServletResponse());
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā┬Ā}
┬Ā┬Ā┬Ā┬Ā protected ┬Ā void ┬ĀafterInvoke(MethodInvocation┬Āmethod){
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā return ;
┬Ā┬Ā┬Ā┬Ā}
┬Ā┬Ā┬Ā┬Ā@Override
┬Ā┬Ā┬Ā┬Ā public ┬Ā void ┬ĀafterExceptionInvoke(MethodInvocation┬Āmethod)┬Ā throws ┬ĀThrowable┬Ā{┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀObject[]┬Āargs = method.getArguments();
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀHttpServletRequest┬ĀhttpRequest = ((CometEvent)args[ 0 ]).getHttpServletRequest();
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀString┬Āuuid = (String)httpRequest.getAttribute(Constants.PROPS_MULE_CORRELATION_ID);
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā if ┬Ā(uuid != null )┬ĀHttpResponseManager.getInstance().removeResponse(uuid);┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā┬Ā}
}
┬Ā┬Ā┬Ā
┬Ā┬Ā┬Ā ÕĮōÕ║öńŁöµČłµü»Ķ┐öÕø×µŚČ’╝īµłæõ╗¼µēĆķ£ĆĶ”üÕüÜńÜäÕŬµś»õ╗ÄjmsµČłµü»Õ▒׵ƦõĖŁĶÄĘÕÅ¢Õģ│ĶüöÕ»╣Ķ▒ĪńÜäÕĆ╝’╝īµ¤źµēŠÕ»╣Ķ▒ĪńÜäHttpServletResponseÕ»╣Ķ▒Ī’╝īńäČÕÉÄÕÅæķĆüÕ║öńŁöń╗ÖÕ«óµłĘń½»ŃĆé
┬Ā┬Ā┬Ā µĄŗĶ»Ģ
┬Ā┬Ā┬Ā õĖĆõ║øµĄŗĶ»ĢÕÅ»õ╗źµÅÉõŠøµłæõ╗¼Ķ┐ÖõĖ¬µ×ȵ×äõ╝śńé╣ńÜäµĖģµÖ░Ķ¦üĶ¦ŻŃĆéõĮ┐ńö©Apache JMeter’╝īµ»ÅõĖ¬µĪłõŠŗķāĮµē¦ĶĪīõĖĆõĖ¬µĄŗĶ»Ģ’╝īõĖĆõĖ¬µ×ȵ×äõĮ┐ńö©Õ╝鵣źservletÕÆīSEDAµ©ĪÕ×ŗ’╝īÕÅ”õĖĆõĖ¬µ×ȵ×äõĖŹõĮ┐ńö©Ķ┐ÖõĖ¬µ©ĪÕ×ŗŃĆ鵥ŗĶ»ĢĶ┐ÉĶĪīõ║å1õĖ¬Õ░ŵŚČ’╝īµ»Åń¦Æ10õĖ¬ń║┐ń©ŗ’╝īõĖżń¦Źń▒╗Õ×ŗńÜäĶ»Ęµ▒éõ║żõ║ÆõĮ┐ńö©ŃĆéõĖ║õ║åĶ┐Öõ║øµĄŗĶ»Ģ’╝īµłæõ╗¼ÕłåķģŹõ║åµĆ╗Õģ▒6õĖ¬ÕĘźõĮ£ń║┐ń©ŗŃĆéÕ£©µ▓Īµ£ēµē®Õ▒ĢµĆ¦µÅÉÕŹćńÜäµĪłõŠŗõĖŁ’╝īµēƵ£ē6õĖ¬ń║┐ń©ŗķāĮĶó½TomcatńÜäń║┐ń©ŗµ▒ĀÕŹĀńö©ŃĆé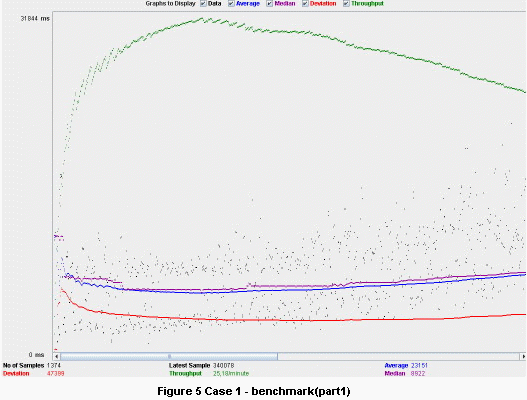
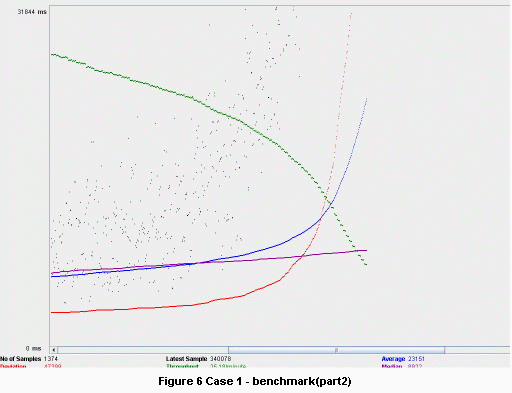
┬Ā┬Ā┬Ā ÕÅ»õ╗źķØ×ÕĖĖµĖģµźÜńÜäń£ŗÕł░’╝īÕÉ×ÕÉÉķćÅ’╝łń╗┐ń║┐’╝ēµś»Õ”éõĮĢõĖŗķÖŹÕł░Õż¦µ”é 23 Ķ»Ęµ▒éµ»ÅÕłåķƤńÜäŃĆé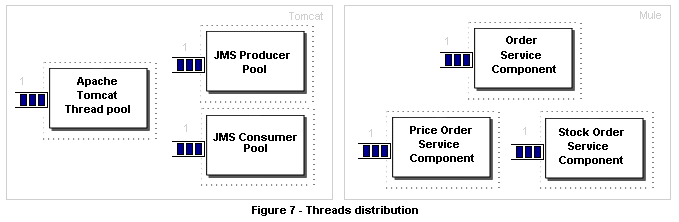
┬Ā┬Ā┬Ā ńÄ░Õ£©Ķ«®µłæõ╗¼Õ£©µłæõ╗¼ńÜäń╗äõ╗ČõĖŁÕłåķģŹĶ┐Ö6õĖ¬ń║┐ń©ŗŃĆéµ»ÅõĖ¬ń╗äõ╗ČÕłåķģŹõĖĆõĖ¬ÕŹĢõĖĆń║┐ń©ŗŃĆé
┬Ā┬Ā┬Ā Õ£©Jakarta TomcatõĖŁ’╝īserver.xmlķģŹńĮ«µ¢ćõ╗ČõĖŁńÜäõĖŗķØóĶ┐Öõ║øĶĪīķ£ĆĶ”üõ┐«µö╣’╝Ü
┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬Ā┬ĀmaxThreads ="1" ┬ĀminSpareThreads ="0" />
┬Ā┬Ā┬Ā Õ£©MuleńÜäµĪłõŠŗõĖŁ’╝īķ£ĆĶ”üÕ£©MuleķģŹńĮ«µ¢ćõ╗ČõĖŁõĖ║µ»ÅõĖ¬µ£ŹÕŖĪń╗äõ╗ČÕ£©serviceµĀćńŁŠõĖŁÕó×ÕŖĀõ╗źõĖŗĶĪī’╝Ü
┬Ā┬Ā┬Ā┬Ā maxThreadsActive ="1" ┬ĀmaxThreadsIdle ="0" ┬ĀpoolExhaustedAction ="RUN" ┬Ā
┬Ā┬Ā┬Ā┬ĀmaxBufferSize ="20" ┬ĀthreadWaitTimeout ="300" />
┬Ā┬Ā┬Ā Õ╝鵣źÕÆīSEDAµ©ĪÕ×ŗµ×ȵ×äńÜ䵥ŗĶ»ĢÕ£©õĖŗķØóÕÅ»õ╗źń£ŗÕł░ŃĆéÕÉ×ÕÉÉķćÅÕ£©23Ķ»Ęµ▒éµ»ÅÕłåķƤõ┐صīüõĖŹÕÅśŃĆé
┬Ā┬Ā┬Ā Õ”éµ×£µłæõ╗¼Ķ┐ÉĶĪīµĆ¦ĶāĮµĄŗĶ»ĢĶČģĶ┐ć1Õ░ŵŚČ’╝īń¼¼õĖĆõĖ¬µĪłõŠŗńÜäÕÉ×ÕÉÉķćÅĶ┐śÕ░åń╗¦ń╗ŁõĖŗķÖŹ’╝īõĮåµś»ń¼¼õ║īõĖ¬µĪłõŠŗõŠØńäČÕ░åõ┐صīüÕÉīµĀĘńÜäÕĆ╝ŃĆé


- 2008-09-04 22:58
- µĄÅĶ¦ł 2519
- Ķ»äĶ«║(1)
- µ¤źń£ŗµø┤ÕżÜ
Ķ»äĶ«║
ń╝║ŃĆüń╝║Õ░æ
ŌĆ£Thus we're short of an Admission Controller, Resource Controller and a Dynamically sized Thread Pool. ŌĆØ ŌĆöŌĆö µłæõ╗¼Ķ┐śń╝║Ķ«ĖÕÅ»µÄ¦ÕłČÕÖ©ŃĆüĶĄäµ║ÉµÄ¦ÕłČÕÖ©ÕÆīÕŖ©µĆüń║┐ń©ŗµ▒ĀŃĆé
ÕÅæĶĪ©Ķ»äĶ«║

ńøĖÕģ│µÄ©ĶŹÉ
JavaõĮ£õĖ║õĖĆķŚ©Õ╣┐µ│øõĮ┐ńö©ńÜäÕ╝ĆÕÅæĶ»ŁĶ©Ć’╝īµÅÉõŠøõ║åÕżÜń¦ŹI/O’╝łInput/Output’╝ēķĆÜõ┐Īµ©ĪÕ×ŗ’╝īÕīģµŗ¼õ╝Āń╗¤ńÜäķś╗ÕĪ×I/O’╝łBIO’╝ēŃĆüķØ×ķś╗ÕĪ×I/O’╝łNIO’╝ēõ╗źÕÅŖÕ╝鵣źI/O’╝łAIO’╝ēŃĆéĶ┐Öõ║øķĆÜõ┐Īµ©ĪÕ×ŗÕ£©õĖŹÕÉīńÜäÕ£║µÖ»õĖŗµ£ēńØĆÕÉäĶć¬ńÜäõ╝śÕŖ┐’╝īńÉåĶ¦ŻÕÆīµÄīµÅĪÕ«āõ╗¼Õ»╣õ║Äõ╝śÕī¢...
Õ║öńö©ń©ŗÕ║ÅÕÅ»õ╗źõĮ┐ńö©`aio_error`µŻĆµ¤źµōŹõĮ£ńŖȵĆü’╝ī`aio_return`ĶÄĘÕÅ¢µōŹõĮ£ń╗ōµ×£’╝īĶĆī`aio_notify`ÕÆīõ┐ĪÕÅʵ£║ÕłČÕłÖńö©õ║ÄķĆÜń¤źI/OÕ«īµłÉŃĆ鵣żÕż¢’╝īĶ┐śÕÅ»õ╗źõĮ┐ńö©ń║┐ń©ŗµ▒ĀÕÆīÕø×Ķ░āÕćĮµĢ░µØźÕżäńÉåÕ«īµłÉńÜäI/Oõ║ŗõ╗Č’╝īĶ┐øõĖƵŁźµÅÉÕŹćÕ╣ČÕÅæµĆ¦ŃĆé AIOńÜäõ╝śÕŖ┐Õ£©õ║Ä’╝īÕ«ā...
µĆ╗õ╣ŗ’╝īķĆÜĶ┐ćĶ┐ÖõĖ¬õĮ┐ńö©AIOÕ«×ńÄ░ńÜäķØ×ķś╗ÕĪ×socketķĆÜõ┐ĪķĪ╣ńø«’╝īµłæõ╗¼ÕÅ»õ╗źÕŁ”õ╣ĀÕł░Õ”éõĮĢÕł®ńö©Java AIOĶ┐øĶĪīķ½śµĢłńÜäńĮæń╗£ń╝¢ń©ŗ’╝īńÉåĶ¦ŻÕÆīÕ«×ĶĘĄÕ╝鵣źI/Oµ©ĪÕ×ŗ’╝īĶ┐ÖÕ»╣õ║ĵ×äÕ╗║ķ½śµĆ¦ĶāĮŃĆüķ½śÕ╣ČÕÅæńÜäńĮæń╗£Õ║öńö©Ķć│Õģ│ķćŹĶ”üŃĆéķĆÜĶ┐ćÕ«×ķÖģµōŹõĮ£’╝īõĮĀÕÅ»õ╗źµø┤ÕźĮÕ£░ńÉåĶ¦ŻķØ×...
BIOŃĆüNIOÕÆīAIOÕÉäµ£ēõ╝śń╝║ńé╣’╝īķĆēµŗ®Õō¬ń¦Źµ©ĪÕ×ŗÕÅ¢Õå│õ║ÄÕģĘõĮōńÜäÕ║öńö©ķ£Ćµ▒éŃĆéÕ»╣õ║ÄÕ░ÅĶ¦äµ©ĪŃĆüÕø║Õ«ÜĶ┐׵ğµĢ░ńÜäń«ĆÕŹĢÕ║öńö©’╝īBIOÕÅ»ĶāĮµś»µ£ĆõĮ│ķĆēµŗ®’╝īÕøĀõĖ║ÕģČń╝¢ń©ŗń«ĆÕŹĢŃĆéÕ»╣õ║Äķ£ĆĶ”üÕżäńÉåÕż¦ķćÅÕ╣ČÕÅæĶ┐׵ğńÜäķ½śµĆ¦ĶāĮµ£ŹÕŖĪÕÖ©’╝īNIOµÅÉõŠøõ║åµø┤ÕźĮńÜäµĆ¦ĶāĮÕÆīĶĄäµ║ÉÕł®ńö©ńÄć...
Õ£©µ¢ćõ╗Čõ╝ĀĶŠōĶ┐ćń©ŗõĖŁ’╝īÕÅ»õ╗źõĮ┐ńö©`asyncio.StreamReader`ÕÆī`asyncio.StreamWriter`Õ»╣Ķ▒ĪµØźĶ»╗ÕÅ¢ÕÆīÕåÖÕģźµ¢ćõ╗ȵĢ░µŹ«’╝īÕ«āõ╗¼µÅÉõŠøõ║åķØ×ķś╗ÕĪ×ńÜäĶ»╗ÕåֵğÕÅŻ’╝īķØ×ÕĖĖķĆéÕÉłõ║ÄaioÕ£║µÖ»ŃĆé µŁżÕż¢’╝īõĖ║õ║åńĪ«õ┐ص¢ćõ╗Čõ╝ĀĶŠōńÜäÕ«īµĢ┤µĆ¦ÕÆīÕÅ»ķØĀµĆ¦’╝īķĆÜÕĖĖõ╝Üķććńö©TCP...
õĖ║õ║åÕżäńÉåõĖÄÕż¢ķā©õĖ¢ńĢīńÜäõ║żõ║Æ’╝īJavaµÅÉõŠøõ║åõĖēń¦ŹõĖŹÕÉīńÜäI/Oµ©ĪÕ×ŗ’╝ÜBIO’╝ł Blocking I/O’╝ēŃĆüNIO’╝łNon-blocking I/O’╝ēÕÆīAIO’╝łAsynchronous I/O’╝ēŃĆéĶ┐Öõ║øµ©ĪÕ×ŗÕÉäµ£ēõ╝śń╝║ńé╣’╝īķĆéńö©õ║ÄõĖŹÕÉīÕ£║µÖ»ŃĆéõĖŗķØóµłæõ╗¼Õ░åµĘ▒ÕģźµÄóĶ«©Ķ┐ÖõĖēń¦ŹI/Oµ©ĪÕ×ŗ’╝īÕ╣Č...
ķĆÜĶ┐ćķśģĶ»╗õ╗ŻńĀüÕÆīµ¢ćµĪŻ’╝īõĮĀÕ░åĶāĮÕż¤µø┤ÕźĮÕ£░ńÉåĶ¦ŻĶ┐ÖõĖżń¦ŹAIOÕ«×ńÄ░ńÜäÕī║Õł½ÕÆīÕ║öńö©Õ£║µÖ»ŃĆé µĆ╗ńÜäµØźĶ»┤’╝īAIOÕ£©ÕżäńÉåÕż¦ķćÅÕ╣ČÕÅæI/OµōŹõĮ£µŚČĶāĮÕĖ”µØźµśŠĶæŚńÜäµĆ¦ĶāĮµÅÉÕŹć’╝īÕ░żÕģČķĆéńö©õ║ÄńĮæń╗£µ£ŹÕŖĪÕÖ©ŃĆüµĢ░µŹ«Õ║ōń│╗ń╗¤ńŁēÕ£║µÖ»ŃĆéķĆÜĶ┐ćµĘ▒ÕģźÕŁ”õ╣ĀÕÆīÕ«×ĶĘĄ’╝īõĮĀÕÅ»õ╗źÕł®ńö©...
Õ£©NettyõĖŁ’╝īõĮ┐ńö©NIOµł¢AIOÕ«×ńÄ░ńÜäTCPĶ┐׵ğ’╝īÕÅ»õ╗źń╗ōÕÉłÕģČń║┐ń©ŗµ©ĪÕ×ŗ’╝īÕ”éEventLoopGroup’╝łõ║ŗõ╗ČÕŠ¬ńÄ»ń╗ä’╝ēÕÆīChannelHandler’╝łķĆÜķüōÕżäńÉåÕÖ©’╝ēńŁēń╗äõ╗Č’╝īÕ«×ńÄ░ķ½śµĢłŃĆüÕÅ»µē®Õ▒ĢńÜäńĮæń╗£ķĆÜõ┐ĪŃĆéõŠŗÕ”é’╝īBossGroupÕżäńÉåµ¢░ńÜäĶ┐׵ğĶ»Ęµ▒é’╝īWorkerGroup...
**Netty5 AIO µĘ▒Õ║”Ķ¦Żµ×É** Netty µś»õĖĆõĖ¬ķ½śµĆ¦ĶāĮŃĆüÕ╝鵣źõ║ŗõ╗Čķ®▒ÕŖ©ńÜäńĮæń╗£Õ║öńö©ń©ŗÕ║ŵĪåµ×Č’╝īńö©õ║ÄÕ┐½ķƤÕ╝ĆÕÅæÕÅ»ń╗┤µŖżńÜäķ½śµĆ¦ĶāĮÕŹÅĶ««µ£ŹÕŖĪÕÖ©ÕÆīÕ«óµłĘń½»...Õ»╣õ║ĵā│Ķ”üµĘ▒ÕģźńÉåĶ¦ŻńĮæń╗£ń╝¢ń©ŗÕÆīJavaÕ╣ČÕÅæńÜäÕ╝ĆÕÅæĶĆģµØźĶ»┤’╝īNetty5 AIOµś»õĖŹÕÅ»µł¢ń╝║ńÜäń¤źĶ»åńé╣ŃĆé
"www.pudn.com.txt"ÕÅ»ĶāĮµś»õĖĆõĖ¬µ¢ćµ£¼µ¢ćõ╗Č’╝īÕīģÕɽõ║åµø┤ÕżÜÕģ│õ║ÄĶ»źõĖ╗ķóśńÜäķōŠµÄźµł¢ĶĆģÕ╝Ģńö©õ┐Īµü»’╝īĶĆī"AIO"ÕÅ»ĶāĮµś»õĖ╗µ¢ćµĪŻ’╝īĶ»”ń╗åķśÉĶ┐░õ║åAIOÕ£©uC/OS IIõĖŁńÜäÕ«×ńÄ░ÕÆīÕ║öńö©ŃĆéÕ£©Ķ┐ÖõĖ¬µ¢ćµĪŻõĖŁ’╝īµłæõ╗¼ÕÅ»ĶāĮõ╝Üń£ŗÕł░õ╗źõĖŗń¤źĶ»åńé╣’╝Ü 1. AIOńÜäµ”éÕ┐ĄÕÆīÕĤńÉå’╝Ü...
4. Õ«ēĶŻģÕÆīķģŹńĮ«’╝ܵÅÉõŠøĶ»”ń╗åµŁźķ¬żµØźµīćÕ»╝ńö©µłĘÕ”éõĮĢÕ«ēĶŻģÕÆīķģŹńĮ«Ķüöµā│ĶČģĶ׏ÕÉłAIO H1000ń│╗ń╗¤’╝īõ╗źÕÅŖÕ”éõĮĢĶ┐øĶĪīńĮæń╗£Ķ«ŠńĮ«ÕÆīĶĮ»õ╗ČÕ«ēĶŻģŃĆé 5. ÕģźķŚ©µīćÕ»╝’╝ÜõĖ║µ¢░ńö©µłĘµÅÉõŠøÕ┐½ķƤõĖŖµēŗµīćÕŹŚ’╝īÕĖ«ÕŖ®õ╗¢õ╗¼õ║åĶ¦Żõ║¦ÕōüńÜäÕ¤║µ£¼µōŹõĮ£’╝īÕīģµŗ¼ńö©µłĘńĢīķØóõ╗ŗń╗ŹŃĆüÕ”éõĮĢ...
**JDK1.7 AIO µĘ▒Õ║”Ķ¦Żµ×É** AIO’╝łAsynchronous Input/Output’╝īÕ╝鵣źĶŠōÕģźĶŠōÕć║’╝ēµś»Java 7Õ╝ĢÕģźńÜäõĖĆń¦Źµ¢░ńÜäI/Oµ©ĪÕ×ŗ’╝īÕ«ā...Õ»╣õ║ÄÕż¦Õ×ŗŃĆüķ½śµĆ¦ĶāĮńÜäÕ║öńö©µØźĶ»┤’╝īµŖĢÕģźÕŁ”õ╣ĀAIOµś»ÕĆ╝ÕŠŚńÜä’╝īÕøĀõĖ║Õ«āĶāĮÕĖ”µØźµśŠĶæŚńÜäµĆ¦ĶāĮµÅÉÕŹćÕÆīµø┤ÕźĮńÜäĶĄäµ║ÉÕł®ńö©ŃĆé
µĆ╗ń╗ō’╝īńÉåĶ¦ŻÕÆīńå¤ń╗āµÄīµÅĪJavaõĖŁńÜäõĖēń¦ŹķĆÜĶ«»µ©ĪÕ×ŗ’╝īµ£ēÕŖ®õ║ĵłæõ╗¼µ×äÕ╗║µø┤ÕŖĀķ½śµĢłŃĆüń©│Õ«ÜńÜäµ£ŹÕŖĪń½»Õ║öńö©’╝īµÅÉķ½śń│╗ń╗¤ńÜäÕ╣ČÕÅæÕżäńÉåĶāĮÕŖøÕÆīÕōŹÕ║öķƤÕ║”ŃĆéÕ£©ķĪ╣ńø«Õ«×ĶĘĄõĖŁ’╝īń╗ōÕÉłÕģĘõĮōÕ£║µÖ»ķĆēµŗ®ÕÉłķĆéńÜäķĆÜĶ«»µ©ĪÕ×ŗ’╝īµś»õ╝śÕī¢ń│╗ń╗¤µĆ¦ĶāĮńÜäÕģ│ķö«ŃĆé
4. **µĪłõŠŗńĀöń®ČÕÆīÕ«×õŠŗ**’╝ܵ¢░ńēłµĢÖµØÉÕŠĆÕŠĆõ╝ܵ£ēµø┤ÕżÜńÜäÕ«×ķÖģµĪłõŠŗńĀöń®ČÕÆīÕ║öńö©Õ£║µÖ»’╝īõ╗źÕĖ«ÕŖ®ĶĆāńö¤µø┤ÕźĮÕ£░ńÉåĶ¦ŻńÉåĶ«║ń¤źĶ»å’╝īÕ╣ČÕ░åÕģČÕ║öńö©õ║ÄÕ«×ķÖģÕĘźõĮ£õĖŁŃĆéAIO5ÕÅ»ĶāĮõ╝ÜÕīģÕɽµø┤ÕżÜÕÅŹµśĀÕĮōÕēŹÕ«ēÕģ©µīæµłśÕÆīĶ¦ŻÕå│µ¢╣µĪłńÜäÕ«×õŠŗŃĆé 5. **ń╗āõ╣ĀķóśõĖĵ©Īµŗ¤µĄŗĶ»Ģ**...
Õ£©µ×äÕ╗║ķ½śµĆ¦ĶāĮńÜäÕż¦Õ×ŗÕłåÕĖāÕ╝ÅJavaÕ║öńö©µŚČ’╝īµłæõ╗¼ķØóõĖ┤ńÜ䵜»ÕżŹµØéńÜäµŖƵ£»µīæµłśÕÆīõ╝śÕī¢ńø«µĀćŃĆéĶ”üÕ«×ńÄ░Ķ┐ÖµĀĘńÜäń│╗ń╗¤’╝īµłæõ╗¼ķ£ĆĶ”üµĘ▒Õģźõ║åĶ¦ŻJavaÕ╣│ÕÅ░ńÜäńē╣ńé╣’╝īõ╗źÕÅŖÕ”éõĮĢÕł®ńö©ÕģČõ╝śÕŖ┐µØźÕżäńÉåÕż¦Ķ¦äµ©ĪµĢ░µŹ«ÕÆīķ½śÕ╣ČÕÅæĶ»Ęµ▒éŃĆéõ╗źõĖŗµś»õĖĆõ║øÕģ│ķö«ńÜäń¤źĶ»åńé╣’╝Ü 1....
µĀćķóś "Õ¤║õ║ÄAIOńÜäĶČģĶĮ╗ķćÅHTTPµ£ŹÕŖĪÕÖ©Õ«×ńÄ░" µīćńÜ䵜»õĮ┐ńö©Õ╝鵣źI/O’╝łAsynchronous Input/Output’╝īń«Ćń¦░AIO’╝ēµ©ĪÕ×ŗµ×äÕ╗║õĖĆõĖ¬ĶĮ╗ķćÅń║¦ńÜäHTTPµ£ŹÕŖĪÕÖ©ŃĆéAIOÕ£©JavaõĖŁķĆÜÕĖĖµīćńÜ䵜»NIO.2’╝łNew I/O 2’╝ē’╝īÕ«āµÅÉõŠøõ║åķØ×ķś╗ÕĪ×I/OµōŹõĮ£’╝īĶāĮÕż¤µø┤µ£ēµĢłÕ£░...
JavaõĖŁIOµ©ĪÕ×ŗµ£ēõĖēń¦Ź’╝ÜBIOŃĆüNIOÕÆīAIO’╝īõĖŗķØóµłæõ╗¼µØźĶ»”ń╗åõ╗ŗń╗ŹÕ«āõ╗¼ńÜäÕī║Õł½ÕÆīÕ║öńö©Õ£║µÖ»ŃĆé BIO’╝łBlocking I/O’╝ē BIOµś»JavaõĖŁµ£ĆÕÅżĶĆüńÜäIOµ©ĪÕ×ŗ’╝īÕ«āµś»ÕÉīµŁźÕ╣Čķś╗ÕĪ×ńÜäŃĆéµ£ŹÕŖĪÕÖ©ńÜäÕ«×ńÄ░µ©ĪÕ╝ŵś»õĖĆõĖ¬Ķ┐׵ğõĖĆõĖ¬ń║┐ń©ŗ’╝īĶ┐ÖµĀĘńÜ䵩ĪÕ╝ÅÕŠłµśÄµśŠńÜäõĖĆ...
Cordovaµś»õĖĆń¦ŹµĄüĶĪīńÜäÕ╝Ƶ║ɵĪåµ×Č’╝īÕ«āÕģüĶ«ĖÕ╝ĆÕÅæĶĆģõĮ┐ńö©HTMLŃĆüCSSÕÆīJavaScriptµØźµ×äÕ╗║ÕĤńö¤ńÜäń¦╗ÕŖ©Õ║öńö©ń©ŗÕ║ÅŃĆéķĆÜĶ┐ćWebViewµŖƵ£»’╝īCordovaÕ░åWebÕ║öńö©ÕīģĶŻģµłÉÕĤńö¤ńÜäń¦╗ÕŖ©Õ║öńö©’╝īõĮ┐ÕŠŚÕ╝ĆÕÅæĶĆģÕÅ»õ╗źÕł®ńö©ń夵éēńÜäWebÕ╝ĆÕÅæµŖƵ£»’╝īÕÉīµŚČõ║½ÕÅŚń¦╗ÕŖ©Õ╣│ÕÅ░...