- 浏览: 34075 次
- 性别:

- 来自: 北京
-

最新评论
Android SurfaceFlinger中的SharedClient -- 客户端(Surface)和服务端(Layer)之间的显示缓冲区管理
- 博客分类:
- Android
原文地址:http://blog.csdn.net/DroidPhone/article/details/5972568
SurfaceFlinger在系统启动阶段作为系统服务被加载。应用程序中的每个窗口,对应本地代码中的Surface,而Surface又对应于 SurfaceFlinger中的各个Layer,SurfaceFlinger的主要作用是为这些Layer申请内存,根据应用程序的请求管理这些 Layer显示、隐藏、重画等操作,最终由SurfaceFlinger把所有的Layer组合到一起,显示到显示器上。当一个应用程序需要在一个 Surface上进行画图操作时,首先要拿到这个Surface在内存中的起始地址,而这块内存是在SurfaceFlinger中分配的,因为 SurfaceFlinger和应用程序并不是运行在同一个进程中,如何在应用客户端(Surface)和服务端(SurfaceFlinger - Layer)之间传递和同步显示缓冲区?这正是本文要讨论的内容。
Surface的创建过程
我们先看看Android如何创建一个Surface,下面的序列图展示了整个创建过程。
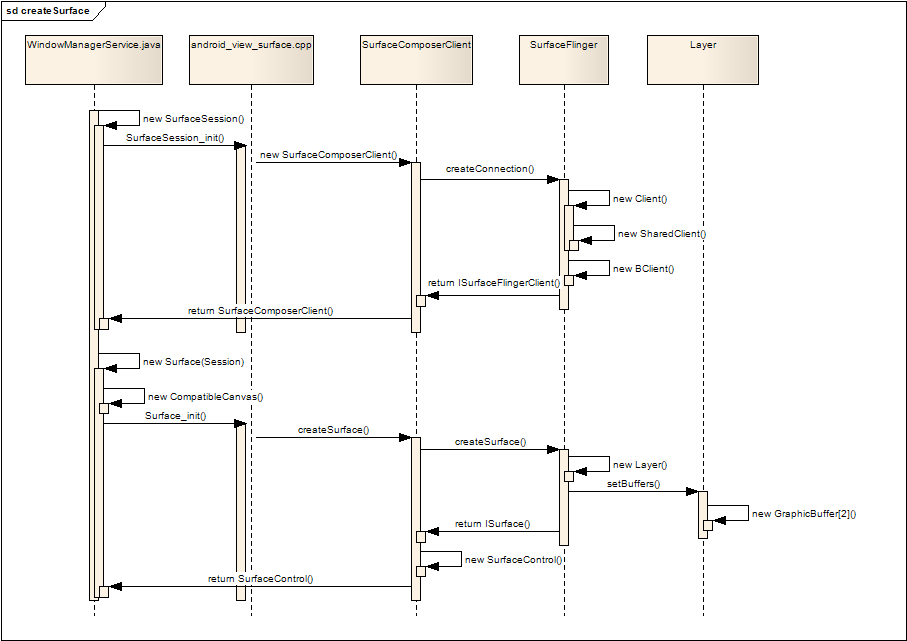
图一 Surface的创建过程
创建Surface的过程基本上分为两步:
1. 建立SurfaceSession
第一步通常只执行一次,目的是创建一个SurfaceComposerClient的实例,JAVA层通过JNI调用本地代码,本地代码创建一个 SurfaceComposerClient的实例,SurfaceComposerClient通过ISurfaceComposer接口调用 SurfaceFlinger的createConnection,SurfaceFlinger返回一个ISurfaceFlingerClient接 口给SurfaceComposerClient,在createConnection的过程中,SurfaceFlinger创建了用于管理缓冲区切换 的SharedClient,关于SharedClient我们下面再介绍,最后,本地层把SurfaceComposerClient的实例返回给 JAVA层,完成SurfaceSession的建立。
2. 利用SurfaceSession创建Surface
JAVA层通过JNI调用本地代码Surface_Init(),本地代码首先取得第一步创建的SurfaceComposerClient实例, 通过SurfaceComposerClient,调用ISurfaceFlingerClient接口的createSurface方法,进入 SurfaceFlinger,SurfaceFlinger根据参数,创建不同类型的Layer,然后调用Layer的setBuffers()方法, 为该Layer创建了两个缓冲区,然后返回该Layer的ISurface接口,SurfaceComposerClient使用这个ISurface接 口创建一个SurfaceControl实例,并把这个SurfaceControl返回给JAVA层。
由此得到以下结果:
- JAVA层的Surface实际上对应于本地层的SurfaceControl对象,以后本地代码可以使用JAVA传入的SurfaceControl对象,通过SurfaceControl的getSurface方法,获得本地Surface对象;
- Android为每个Surface分配了两个图形缓冲区,以便实现Page-Flip的动作;
- 建立SurfaceSession时,SurfaceFlinger创建了用于管理两个图形缓冲区切换的SharedClient对 象,SurfaceComposerClient可以通过ISurfaceFlingerClient接口的getControlBlock()方法获得 这个SharedClient对象,查看SurfaceComposerClient的成员函数_init:
void SurfaceComposerClient::_init(
const sp<ISurfaceComposer>& sm, const sp<ISurfaceFlingerClient>& conn)
{
......
mClient = conn;
if (mClient == 0) {
mStatus = NO_INIT;
return;
}
mControlMemory = mClient->getControlBlock();
mSignalServer = sm;
mControl = static_cast<SharedClient *>(mControlMemory->getBase());
}
获得Surface对应的显示缓冲区
虽然在SurfaceFlinger在创建Layer时已经为每个Layer申请了两个缓冲区,但是此时在JAVA层并看不到这两个缓冲 区,JAVA层要想在Surface上进行画图操作,必须要先把其中的一个缓冲区绑定到Canvas中,然后所有对该Canvas的画图操作最后都会画到 该缓冲区内。下图展现了绑定缓冲区的过程:
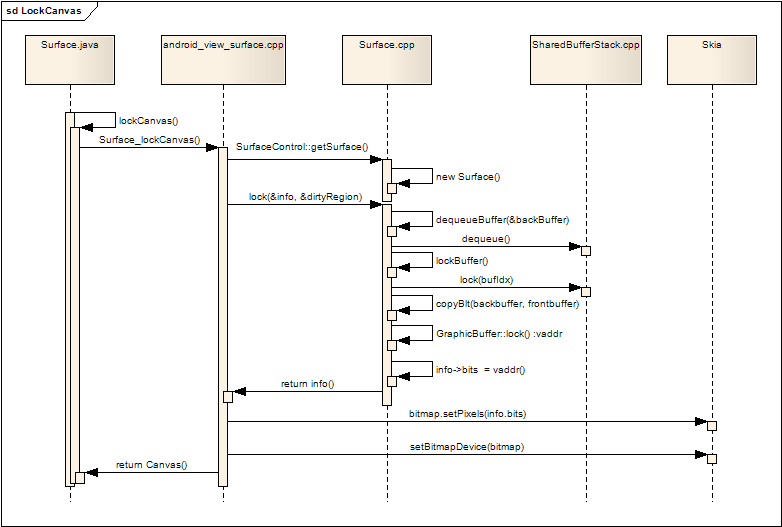
图二 绑定缓冲区的过程
开始在Surface画图前,Surface.java会先调用lockCanvas()来得到要进行画图操作的Canvas,lockCanvas会进 一步调用本地层的Surface_lockCanvas,本地代码利用JAVA层传入的SurfaceControl对象,通过getSurface() 取得本地层的Surface对象,接着调用该Surface对象的lock()方法,lock()返回了改Surface的信息,其中包括了可用缓冲区的 首地址vaddr,该vaddr在Android的2D图形库Skia中,创建了一个bitmap,然后通过Skia库中Canvas的 API:Canvas.setBitmapDevice(bitmap),把该bitmap绑定到Canvas中,最后把这个Canvas返回给JAVA 层,这样JAVA层就可以在该Canvas上进行画图操作,而这些画图操作最终都会画在以vaddr为首地址的缓冲区中。
再看看在Surface的lock()方法中做了什么:
-
dequeueBuffer(&backBuffer)获取backBuffer
- SharedBufferClient->dequeue()获得当前空闲缓冲区的编号
- 通过缓冲区编号获得真正的GraphicBuffer:backBuffer
- 如果还没有对Layer中的buffer进行映射(Mapper),getBufferLocked通过ISurface接口重新重新映射
- 获取frontBuffer
- 根据两个Buffer的更新区域,把frontBuffer的内容拷贝到backBuffer中,这样保证了两个Buffer中显示内容的同步
- backBuffer->lock() 获得backBuffer缓冲区的首地址vaddr
- 通过info参数返回vaddr
释放Surface对应的显示缓冲区
画图完成后,要想把Surface的内容显示到屏幕上,需要把Canvas中绑定的缓冲区释放,并且把该缓冲区从变成可投递(因为默认只有两个 buffer,所以实际上就是变成了frontBuffer),SurfaceFlinger的工作线程会在适当的刷新时刻,把系统中所有的 frontBuffer混合在一起,然后通过OpenGL刷新到屏幕上。下图展现了解除绑定缓冲区的过程:

图三 解除绑定缓冲区的过程
- JAVA层调用unlockCanvasAndPost
- 进入本地代码:Surface_unlockCanvasAndPost
- 本地代码利用JAVA层传入的SurfaceControl对象,通过getSurface()取得本地层的Surface对象
- 绑定一个空的bitmap到Canvas中
-
调用Surface的unlockAndPost方法
- 调用GraphicBuffer的unlock(),解锁缓冲区
- 在queueBuffer()调用了SharedBufferClient的queue(),把该缓冲区更新为可投递状态
SharedClient 和 SharedBufferStack
从前面的讨论可以看到,Canvas绑定缓冲区时,要通过SharedBufferClient的dequeue方法取得空闲的缓冲区,而解除绑定 并提交缓冲区投递时,最后也要调用SharedBufferClient的queue方法通知SurfaceFlinger的工作线程。实际上,在 SurfaceFlinger里,每个Layer也会关联一个SharedBufferServer,SurfaceFlinger的工作线程通过 SharedBufferServer管理着Layer的缓冲区,在SurfaceComposerClient建立连接的阶 段,SurfaceFlinger就已经为该连接创建了一个SharedClient 对象,SharedClient 对象中包含了一个SharedBufferStack数组,数组的大小是31,每当创建一个Surface,就会占用数组中的一个 SharedBufferStack,然后SurfaceComposerClient端的Surface会创建一个 SharedBufferClient和该SharedBufferStack关联,而SurfaceFlinger端的Layer也会创建 SharedBufferServer和SharedBufferStack关联,实际上每对 SharedBufferClient/SharedBufferServer是控制着同一个SharedBufferStack对象,通过 SharedBufferStack,保证了负责对Surface的画图操作的应用端和负责刷新屏幕的服务端(SurfaceFlinger)可以使用不 同的缓冲区,并且让他们之间知道对方何时锁定/释放缓冲区。
SharedClient和SharedBufferStack的代码和头文件分别位于:
/frameworks/base/libs/surfaceflinger_client/SharedBufferStack.cpp
/frameworks/base/include/private/surfaceflinger/SharedBufferStack.h
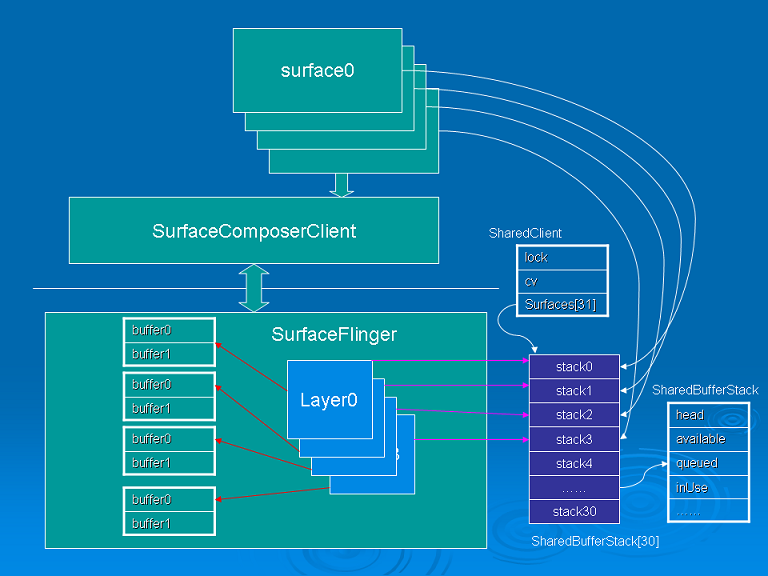
图四 客户端和服务端缓冲区管理
继续研究SharedClient、SharedBufferStack、SharedBufferClient、SharedBufferServer的诞生过程。
1. SharedClient
- 在createConnection阶段,SurfaceFlinger创建Client对象:
sp<ISurfaceFlingerClient> SurfaceFlinger::createConnection()
{
Mutex::Autolock _l(mStateLock);
uint32_t token = mTokens.acquire();
sp<Client> client = new Client(token, this);
if (client->ctrlblk == 0) {
mTokens.release(token);
return 0;
}
status_t err = mClientsMap.add(token, client);
if (err < 0) {
mTokens.release(token);
return 0;
}
sp<BClient> bclient =
new BClient(this, token, client->getControlBlockMemory());
return bclient;
}
Client::Client(ClientID clientID, const sp<SurfaceFlinger>& flinger)
: ctrlblk(0), cid(clientID), mPid(0), mBitmap(0), mFlinger(flinger)
{
const int pgsize = getpagesize();
const int cblksize = ((sizeof(SharedClient)+(pgsize-1))&~(pgsize-1));
mCblkHeap = new MemoryHeapBase(cblksize, 0,
"SurfaceFlinger Client control-block");
ctrlblk = static_cast<SharedClient *>(mCblkHeap->getBase());
if (ctrlblk) { // construct the shared structure in-place.
new(ctrlblk) SharedClient;
}
}
- 回到createConnection中,通过Client的getControlBlockMemory()方法获得共享内存块的 IMemoryHeap接口,接着创建ISurfaceFlingerClient的子类BClient,BClient的成员变量mCblk保存了 IMemoryHeap接口指针;
- 把BClient返回给SurfaceComposerClient,SurfaceComposerClient通过 ISurfaceFlingerClient接口的getControlBlock()方法获得IMemoryHeap接口指针,同时保存在 SurfaceComposerClient的成员变量mControlMemory中;
- 继续通过IMemoryHeap接口的getBase ()方法获取共享内存的首地址,转换为SharedClient指针后保存在SurfaceComposerClient的成员变量mControl中;
- 至此,SurfaceComposerClient的成员变量mControl和SurfaceFlinger::Client.ctrlblk指向了同一个内存块,该内存块上就是SharedClient对象。
2. SharedBufferStack、SharedBufferServer、SharedBufferClient
SharedClient对象中有一个SharedBufferStack数组:
SharedBufferStack surfaces[ NUM_LAYERS_MAX ];
NUM_LAYERS_MAX 被定义为31,这样保证了SharedClient对象的大小正好满足4KB的要求。创建一个新的Surface时,进入SurfaceFlinger的 createSurface函数后,先取在createConnection阶段创建的Client对象,通过Client在 0--NUM_LAYERS_MAX 之间取得一个尚未被使用的编号,这个编号实际上就是SharedBufferStack数组的索引:
int32_t id = client->generateId(pid);
layer = createNormalSurfaceLocked(client, d, id,
w, h, flags, format);
sp<Layer> layer = new Layer(this, display, client, id);
LayerBaseClient::LayerBaseClient(SurfaceFlinger* flinger, DisplayID display,
const sp<Client>& client, int32_t i)
: LayerBase(flinger, display), lcblk(NULL), client(client), mIndex(i),
mIdentity(uint32_t(android_atomic_inc(&sIdentity)))
{
lcblk = new SharedBufferServer(
client->ctrlblk, i, NUM_BUFFERS,
mIdentity);
}
自此,Layer通过lcblk成员变量(SharedBufferServer)和SharedClient共享内存区建立了关联,并且每个Layer对应于SharedBufferStack 数组中的一项。
回到SurfaceFlinger的客户端Surface.cpp中,Surface的构造函数如下:
Surface::Surface(const sp<SurfaceControl>& surface)
: mClient(surface->mClient), mSurface(surface->mSurface),
mToken(surface->mToken), mIdentity(surface->mIdentity),
mFormat(surface->mFormat), mFlags(surface->mFlags),
mBufferMapper(GraphicBufferMapper::get()), mSharedBufferClient(NULL),
mWidth(surface->mWidth), mHeight(surface->mHeight)
{
mSharedBufferClient = new SharedBufferClient(
mClient->mControl, mToken, 2, mIdentity);
init();
}
SharedBufferClient构造参数mClient->mControl就是共享内存块中的SharedClient对象,mToken就是SharedBufferStack 数组索引值。
到这里我们终于知道,Surface中的mSharedBufferClient成 员和Layer中的lcblk成员(SharedBufferServer),通过SharedClient中的同一个 SharedBufferStack,共同管理着Surface(Layer)中的两个缓冲区。


发表评论

-
Android核心分析(21)----Android应用框架之AndroidApplication
2012-02-13 14:34 799原文地址:http://blog.csdn ... -
Android核心分析(20)----Android应用程序框架之无边界设计意图
2012-02-13 14:31 922原文地址:http://blog.csdn ... -
Android核心分析(19)----电话系统之GSMCallTacker
2012-02-13 14:25 834原文地址:http://blog.csdn ... -
Android核心分析(18)-----Android电话系统之RIL-Java
2012-02-13 14:10 1176原文地址:http://blog.csdn.net/maxle ... -
Android核心分析(17) ------电话系统之rilD
2012-02-13 14:02 698原文地址:http://blog.csdn.net/maxle ... -
Android核心分析(16)-----Android电话系统-概述篇
2012-01-31 14:39 920原文地址:http://blog.csdn.net/m ... -
Android核心分析(15)--------Android输入系统之输入路径详解
2012-01-31 14:22 859原文地址:http://blog.csdn.net/maxle ... -
Android核心分析(14)------ Android GWES之输入系统
2012-01-31 10:47 969原文地址:http://blog.csdn ... -
Android 核心分析(13) -----Android GWES之Android窗口管理
2012-01-31 10:44 844原文地址:http://blog.csdn ... -
Android 核心分析(12) -----Android GEWS窗口管理之基本架构原理
2012-01-31 10:27 1059原文地址:http://blog.csdn.net/maxle ... -
Android核心分析 之十一-------Android GWES之消息系统
2012-01-10 14:09 700原文地址:http://blog.csdn.net/maxle ... -
Android核心分析 之十-------Android GWES之基本原理篇
2011-12-30 15:08 751原文地址:http://blog.csdn ... -
Android核心分析 之九-------Zygote Service
2011-12-30 15:02 777原文地址:http://blog.csdn.net/maxle ... -
Android 核心分析 之八------Android 启动过程详解
2011-12-30 14:56 649原文地址:http://blog.csdn.net/maxle ... -
Android 核心分析 之七------Service深入分析
2011-12-30 14:48 1152原文地址:http://blog.csdn.net/maxle ... -
Android 核心分析 之六 -----IPC框架分析 Binder,Service,Service manager
2011-12-30 14:41 954原文地址:http://blog.csdn.net/maxle ... -
Android 核心分析 之五 -----基本空间划分
2011-12-29 11:13 675原文地址:http://blog.csdn.net/maxle ... -
Android核心分析之四 ---手机的软件形态
2011-12-29 11:09 680原文地址:http://blog.csdn.net/maxle ... -
Android是什么 之三-------手机之硬件形态
2011-12-29 11:07 657原文地址:http://blog.csdn.net/maxle ... -
Android核心分析 之二 -------方法论探讨之概念空间篇
2011-12-29 11:03 606原文地址:http://blog.csdn.net/maxle ...
相关推荐
这篇文章深入探讨了SurfaceFlinger与应用程序之间如何共享和管理显示缓冲区的核心机制。特别关注了其中的关键概念如surface、layer、buffer以及它们之间的关联,尤其是C++类之间的相互作用。 #### Surface、Layer与...
Alibaba_Java_Coding_Guidelines-2.2.3.0x
【ABB机器人】-IRB460机器人维护信息V1.pdf
内容概要:本文详细介绍了新能源汽车VCU(车辆控制单元)控制器的开源项目,涵盖从应用层代码到底层代码、原理图、PCB设计、通信协议及控制策略等多个方面。应用层代码展示了如何根据电池电量调整车辆行驶模式,底层代码涉及硬件驱动如GPIO控制和ADC采样配置。硬件设计部分包括详细的原理图和PCB布局,确保系统的稳定性和可靠性。通信协议采用CAN网络,确保数据可靠传输,控制策略则涵盖了能量回收、扭矩控制等关键技术。丰富的文档资料和测试用例为开发人员提供了宝贵的学习和开发资源。 适合人群:新能源汽车开发人员、硬件工程师、嵌入式软件工程师、学生及研究人员。 使用场景及目标:帮助开发人员深入了解新能源汽车VCU控制器的工作原理和技术细节,加速项目开发进程,降低开发难度。无论是初学者还是有经验的专业人士,都可以从中受益。 其他说明:该项目不仅提供了完整的源代码和硬件设计文件,还包括详细的测试用例和故障处理方案,使得VCU开发变得更加透明和可复现。
详解DeepSeek的十个安全问题.pdf
《网络传播技术与实务》第10章-握在手中的网络——移动通信与无线网络技术.ppt
《计算机专业英语》chapter9-Communication-by-Avatars.ppt
性能测试工具Xrunner的使用手册
内容概要:本文深入探讨了基于自抗扰控制(ADRC)的永磁同步电机(PMSM)矢量控制调速系统的仿真方法及其优势。首先介绍了模型搭建,包括DC直流电压源、三相逆变器、永磁同步电机、采样模块、Clark、Park、Ipark以及SVPWM等关键组件。接着详细解析了ADRC在电流环和转速环中的应用,展示了其通过扩张状态观测器(ESO)实现的高精度扰动观测与补偿机制。文中还提供了部分MATLAB代码示例,如SVPWM模块和ADRC控制器的具体实现。仿真结果显示,ADRC相比传统PI控制器,在突加负载时表现出更好的稳定性和更快的响应速度,且不存在积分饱和问题。此外,文章讨论了一些实际应用中的注意事项和技术挑战。 适合人群:从事电机控制领域的研究人员、工程师及高校相关专业师生。 使用场景及目标:适用于希望深入了解和掌握现代先进电机控制技术的研究人员和工程师。目标是通过仿真平台验证ADRC的有效性,并为实际工程项目提供理论支持和技术指导。 其他说明:尽管ADRC具有诸多优点,但在实际应用中仍需注意参数选择和硬件条件限制等问题。
《网络设备安装与调试(锐捷版)》项目1-配置交换机设备-优化网络传输.pptx
内容概要:本文详细介绍了如何使用Fortran语言在ABAQUS中开发UMAT(用户材料子程序)和VUMAT(显式用户材料子程序),以实现材料损伤断裂弹塑性的自定义建模。文章首先阐述了材料损伤断裂弹塑性的重要性和应用场景,强调了自定义材料子程序在处理复杂材料行为方面的优势。接着,分别展示了UMAT和VUMAT的基本代码结构及其核心计算步骤,如材料参数读取、弹性刚度矩阵初始化、塑性应变增量计算以及应力更新等。此外,还讨论了DISP模型的应用,提供了具体的损伤演化和应力折减方法,并分享了一些实用的调试技巧和注意事项。 适合人群:具备一定ABAQUS使用经验和Fortran编程基础的研究人员和技术人员,尤其是从事材料力学、结构工程等领域的工作人士。 使用场景及目标:适用于需要对特定材料进行精确建模的工程项目,如航空航天、土木建筑等。通过自定义UMAT和VUMAT子程序,能够更好地模拟材料在复杂载荷条件下的损伤演化与断裂过程,提高结构安全性和可靠性评估的准确性。 其他说明:文中不仅提供了详细的代码示例,还分享了许多实践经验,帮助开发者避免常见错误并优化性能。同时提醒读者关注材料参数的正确配置、雅可比矩阵的对称性等问题,确保计算稳定可靠。
V1_3_example.ipynb
安川机器人DX100操作要领书 通用-搬运用途-E.0.pdf
这个是完整源码 SpringBoot + vue 实现 【java毕业设计】SpringBoot+Vue图书馆(图书借阅)管理系统 源码+sql脚本+论文 完整版 数据库是mysql 随着社会的发展,计算机的优势和普及使得阿博图书馆管理系统的开发成为必需。阿博图书馆管理系统主要是借助计算机,通过对图书借阅等信息进行管理。减少管理员的工作,作,同时也方便广大用户对所需图书借阅信息的及时查询以及管理。 阿博图书馆管理系统的开发过程中,采用B / S架构,主要使用Java技术进行开发,结合最新流行的springboot框架。使用Mysql数据库和Eclipse开发环境。该阿博图书馆馆管理系统的开发过程中,采用B / S架构,主要使用Java技术进行开发,结合最新流行的spri管理系统包括用户和管理员。其主要功能包括管理员:首页、个人中心、用户管理、图书分类管理、图书信息管理、图书借阅管理、图书归还管理、缴纳罚金管理、留言板管理、系同时也方便广大用户对所需图书借阅信息的及时查询以及管理。 阿博图书馆管理系统的开发过程中,采用B / S架构,主要使用Java技术进行开发,结合最新流行的springboot框架。使用Mysql数据库和Eclipse开发环境。该阿博图书馆管理系统包括用户和管理员。其主要功能包括管理员:首页、个人中心、用户管理、图书分类管理、图书信息管理、图书借阅管理、图书归还管理、缴纳罚金管理、留言板管理、系统管理,用户:首页、个人中心、图书借阅管理、图书归还管理、缴纳罚金管理、我的收藏管理,前台首页;首页、图书信息、公告信息、留言反馈、个人中心、后台管理等功能。 本论文对阿博图书馆管理系统的发展背景进行详细的介绍,并且对系统开发技术进行介绍,然后对系统进行需求分析,对阿博图书馆管理系统业务流程、系统结构以及数据都进行详细说明。用户可根据关键字进行查找自己想要的信息等。
内容概要:本文详细介绍了一个基于YALMIP和MATLAB的微电网优化调度模型,旨在帮助新手理解和应用微电网优化调度的基本概念和技术。模型综合考虑了蓄电池管理、市场购电售电约束以及功率平衡等因素,以实现系统总费用最低为目标。文中提供了详细的MATLAB代码示例,涵盖变量定义、约束条件建立、目标函数设定及优化求解过程,并附带了调试建议和可视化方法。此外,还讨论了一些常见的错误及其解决办法,如充放电互斥约束、功率平衡约束等。 适合人群:对微电网优化调度感兴趣的初学者,尤其是有一定MATLAB基础的学生或研究人员。 使用场景及目标:适用于希望快速掌握微电网优化调度基本原理的学习者,通过动手实践加深对相关理论的理解。具体应用场景包括但不限于:学术研究、课程作业、个人兴趣项目等。 其他说明:该模型不仅有助于理解微电网的工作机制,还可以为进一步探索复杂的微电网优化问题奠定坚实的基础。
内容概要:本文详细介绍了如何利用MATLAB搭建卷积神经网络(CNN),用于处理具有10个输入特征和3个输出变量的数据预测任务。首先进行数据预处理,包括数据读取、归一化以及训练集和测试集的划分。接着设计了一个包含多个卷积层、批量归一化层、ReLU激活函数层和全连接层的网络架构,确保能够有效提取特征并完成多输出预测。训练过程中采用Adam优化算法,并设置了合理的超参数如最大迭代次数、批次大小和初始学习率等。最终通过预测和反归一化步骤得到模型性能评价指标MAE和R²,展示了良好的预测效果。 适合人群:具有一定MATLAB编程基础和技术背景的研究人员或工程师,尤其是那些从事数据分析、机器学习领域的专业人士。 使用场景及目标:适用于需要解决多输入多输出预测问题的实际项目中,比如工业生产过程监控、设备故障诊断等领域。目的是帮助用户掌握使用MATLAB实现CNN的方法论,从而提高工作效率和解决问题的能力。 其他说明:文中提供了完整的代码片段供读者参考实践,同时针对可能出现的问题给出了实用性的建议,如调整批量大小、降低学习率等方法来应对训练不稳定的情况。此外还提到了一些改进方向,例如改变卷积核尺寸或者引入空洞卷积以增强模型表现。
机器人概要(外形图、目录的阅读方法)20120428.ppt
《计算机程序设计(C语言)》第7章-第2节-函数的定义.ppt
《网络工程设计与项目实训》02-交换机及其基本配置.ppt
内容概要:本文档详细介绍了将服务迁移到Nacos注册与配置中心的具体步骤,包括pom文件中依赖包的更新、启动类注解的添加以及详细的nacos客户端和服务配置文件设置。在pom文件中,需要移除旧的服务发现工具(如Eureka)相关依赖并引入特定版本的nacos-client及相关starter组件,确保springboot版本不低于2.2.3。启动类需添加`@EnableDiscoveryClient`注解以启用服务发现功能。配置文件中,明确指定了服务的基本信息(如端口、应用名称)、nacos服务器地址、命名空间、分组等关键参数,并强调了配置文件格式为YAML的重要性。对于已存在的服务,仅需完成前三个步骤,而对于新的服务,则还需进行配置文件的导入工作。 适合人群:对微服务架构有一定了解,特别是正在考虑或已经决定从其他服务发现工具迁移至Nacos的企业级开发者或运维人员。 使用场景及目标:①帮助团队将现有基于其他服务发现机制的应用程序平滑迁移到Nacos平台;②确保新开发的服务能够正确地注册到Nacos并使用其提供的配置管理功能;③通过合理的配置减少服务间的耦合度,提高系统的可维护性和扩展性。 阅读建议:由于涉及到具体的版本号和配置细节,在实际操作过程中应严格按照文档指导执行,同时关注官方最新动态,确保所使用的版本是最稳定且符合项目需求的。此外,建议在非生产环境中先行测试,验证配置无误后再推广到生产环境。