
Apache Flume是一个分布式的、可靠的、高效的日志数据收集组件;我们通常使用Flume将分散在集群中多个Servers的log文件,汇集到中央式的数据平台中,以解决“从离散的日志文件中查看、统计数据困难”的问题。当然,Flume不仅仅可以收集log文件,它也支持比如TCP、UDP等消息数据的收集;无论如何,我们最终解决的问题就是“将离散的数据进行收集”。我们先描述几个概念:
1、Event:消息,事件,在Flume中数据传输的单位是“event”,Flume将解析的日志数据、接收到的TCP数据等分装成events在内部Flow中传递。
2、Agent:临近数据源(比如logs文件)的、部署在宿主机器上的Flume进程,通常用于收集、过滤、分拣数据,Flume Agent通常需要对源数据进行“修饰”后转发给远端的Collector。
3、Collector:另一种Flume进程(Agent),它用于接收Flume agents发送的消息,相对于Agent,Collector“收集”的消息通常来自多个Server,它的作用就是对消息进行“聚合”、“清洗”、“分类”、“过滤”等,并负责保存和转发给downstream。
4、Source:Flume内部组件之一,用于解析原始数据并封装成event、或者是接收Client端发送的Flume Events;对于Flume进程而言,source是整个数据流(Data Flow)的最前端,用于“产生”events。(读)
5、Channel:Flume内部组件之一,用于“传输”events的通道,Channel通常具备“缓存”数据、“流量控制”等特性;Channel的upstream端是Source,downstream为Sink,如果你熟悉pipeline模式的流数据模型,这个概念应该非常容易理解。
6、Sink:Flume内部组件之一,用于将内部的events通过合适的协议发送给第三方组件,比如Sink可以将events写入本地磁盘文件、基于Avro协议通过TCP方式发给其他Flume,可以发给kafka等其他数据存储平台等;Sink最终将events从内部数据流中移除。(写)
组件内部链接关系:
1、一个Source可以将events传送给一个或者多个Channel,通常一个Source对应一个Channel;如果一个Source将event发给多个Channels时,需要使用“selector”机制(见下文)。
2、Channel作为Flow关联的节点,其upstream为Source,downstream为Sink。一个Channel可以接入多个Sources,即多个Sources可以将events发给一个Channel。同时多个Sinks可以从一个Channel中消费消息,需要使用Sink Processor机制(见下文)。
3、Sink的上游为Channel,一个Sink只能从一个Channel中消费消息。
4、Source将消息传送给Channel,以及Sink从Channel中消费消息,均为在内部的事务中进行。Channel的实现通常为有界的BlockingQueue,如果Channel溢满,那么Source的put操作将会被拒绝且异常返回,稍后重试;如果Channel为空,那么Sink将不能获取消息。
一、架构
1、数据流模型
每个Flume Event由“byte payload”和一组可选的string属性构成;如果你熟悉JMS编程,那么可以认为“byte payload”就是Event的body,由一序列字节数组构成,是消息的内容主体,除此之外,Event还有一些headers构成,K-V结构,用于保存此event的一些属性。
Flume Agent进程(JVM)内部有多个组件构成,可以将源数据解析成event并将其通过特定的Flow从source转发给其他目的地(hop)。
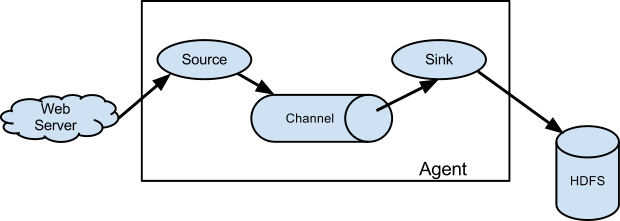
Flume Source用于消费由外部数据源发给它的events;外部数据源将消息发给Flume agent,以Flume Source支持的格式。比如,Flume Avro Source可以用来接收Avro Client或者其他Flume Avro Sink发送的消息。当然,类似的Flume Thrift Source可以接收Thrift Client或者其他Flume Thrift Sink发送的消息。当Flume Source接收到消息以后,它可以将消息保存(store)在一个或者多个Channels中。Channel是一个被动式(passive)存储,用于保存消息直到Flume Sink消费,比如FileChannel,它基于本地的文件系统(将消息保存在本地文件中,append)。对于Sink而言,它从Channel中移除消息,然后将消息发送给第三方(外部)的存储平台,比如HDFS Sink,将消息保存在HDFS系统中;或者将消息转发给下一级Flume Agent(next hop)的Flume Source(多级架构中)。在Agent内部,source和sink均为异步的方式、批量操作Channel中的消息。(稍后基于源码,详解各个组件的工作原理)
2、复合流(Complex Flows)
Flume允许开发者构建多级(multi-hop)的Flows模型,消息在到达最终目的地之前可以经过多个Flume Agents;它也允许构建比如fan-in(扇入)、fan-out(扇出)结构的Flows,以及上下文路由、Failover模式的模型。
3、可靠性(Reliability)
消息(批量)通过每个Agent的channel,然后发送给下一个Agent或者最终的存储平台。只有当下一个agent或者最终的存储平台接收并保存后,才会从Channel中移除。这也是Flume(单跳,single-hop)传送语义中如何提供端对端的数据流可靠性的。
Flume使用事务方式来保证消息传输的可靠性(这一点非常重要)。Sources和Sinks在存储、检索的操作都会分别分装在由Channel提供的事务中,这可以确保一组消息在Flow内部点对点传递的可靠性(source->channel->sink)。即使在多级Flows模式中,上一级的sink和下一级的source之间的数据传输也运行在各自的事务中,以确保数据可以安全的被存储在下一级的channel中。
4、恢复能力
Flume支持持久类型的FileChannel,即Channel的消息可以被保存在本地的文件系统中,这种Channel支持数据恢复。此外,还支持MemoryChannel,它是基于内存的队列,效率很高但是当Agent进程失效后,那些遗留在Channel中的消息将会丢失(而无法恢复)。
二、安装与使用
1、Flume是JAVA开发,所以需要在宿主机器上首先安装JDK,建议1.7+版本;安装Flume本身并不复杂,只需要准备一个flume配置文件即可;配置文件中声明,source、channel、sink等各自的属性,以及它们之间的Flow关联。
2、Flow中的每个组件(source、channel、sink)都有name、type,以及一组特定的配置选项。比如Avro source需要指定绑定的hostname以及本地的端口,memory channel需要指定容量的大小,HDFS Sink需要声明HDFS URI和文件的path等。
3、组件关系
最终,Agent需要知道各个组件之间的关系,以构建Flow模型。在我们声明sources、channels、sinks的各个组件的配置特性之后,然后为channels指定sinks和sources的连接关系,即sources将使用哪些channels保存消息,以及sinks将从哪些channels中获取消息。
4、启动Agent
在bin目录下有一个flume-ng脚本,可以用来启动agent,不过在启动flume之前,我们通常会调整JVM的相关参数,可以通过在flume-env.sh中增加相关配置,比如:
xport JAVA_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=5445 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -verbose:gc -server -Xms512M -Xmx512M -XX:NewRatio=3 -XX:SurvivorRatio=8 -XX:MaxMetaspaceSize=128M -XX:+UseConcMarkSweepGC -XX:CompressedClassSpaceSize=128M -XX:MaxTenuringThreshold=5 -XX:CMSInitiatingOccupancyFraction=70 -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/opt/flume/logs/server-gc.log.$(date +%Y%m%d%H%M) -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=1 -XX:GCLogFileSize=64M"
此后,我们在conf目录下创建一个flume-conf.properties文件,用于声明flume组件,示例如下:
agent.channels=ch-spooling agent.sources=src-spooling agent.sinks=sink-avro-spooling ##spooling agent.channels.ch-spooling.type=file agent.channels.ch-spooling.checkpointDir=/opt/flume/.flume/file-channel/ch-spooling/checkpoint agent.channels.ch-spooling.dataDirs=/opt/flume/.flume/file-channel/ch-spooling/data agent.channels.ch-spooling.capacity=1000000 agent.channels.ch-spooling.transactionCapacity=10000 agent.sources.src-spooling.type=spooldir agent.sources.src-spooling.channels=ch-spooling agent.sources.src-spooling.spoolDir=/opt/deploy/tomcat/order-center/logs agent.sources.src-spooling.deletePolicy=immediate #agent.sources.src-spooling.deletePolicy=never agent.sources.src-spooling.includePattern=((access)|(order-center)).*\.log.+ agent.sources.src-spooling.ignorePattern=^.*\.gz$ agent.sources.src-spooling.consumeOrder=oldest agent.sources.src-spooling.recursiveDirectorySearch=false agent.sources.src-spooling.batchSize=1000 agent.sources.src-spooling.inputCharset=UTF-8 agent.sources.src-spooling.decodeErrorPolicy=IGNORE agent.sinks.sink-avro-spooling.channel=ch-spooling agent.sinks.sink-avro-spooling.type=avro agent.sinks.sink-avro-spooling.hostname=10.0.1.100 agent.sinks.sink-avro-spooling.port=9011 agent.sinks.sink-avro-spooling.batch-size=1000 agent.sinks.sink-avro-spooling.compression-type=deflate
然后我们可以通过如下方式启动flume:
bin/flume-ng agent --conf /opt/flume/conf --conf-file /opf/flume/conf/flume-conf.properties --name agent -Dflume.root.logger=INFO,LOGFILE -Dorg.apache.flume.log.printconfig=true -Dorg.apache.flume.log.rawdata=true
上述配置文件,声明了agent名称为“agent”,即所有配置型的前缀需要以agent名称开头,用于限定配置的“命名空间”,一个配置文件中可以声明多个agent。此配置文件中,分别声明一个source、channel和sink。
我们在启动时,通过“--conf-file”来指定配置文件的路径,通过“--name”来指定需要加载的agent的名称。
5、在log中输出原始数据
很多时候,特别是在开发测试期间,我们通常需要检测Flume中数据的信息:
1)通过指定“-Dorg.apache.flume.log.printconfig=true”,可以在启动日志中查看flume的配置信息。
2)通过“-Dorg.apache.flume.log.rawdata=true”,可以查看flume中消息的原始数据,包括headers和body内容。
3)通过“-Dflume.root.logger=DEBUG,console”(一般生产环境为INFO,LOGFILE),可以声明logger的级别以及打印的输出终端。
6、基于zookeeper配置管理:
通常情况下,flume的配置文件保存在agent本地,如果你的flume集群比较庞大,当需要调整配置时将比较麻烦,我们可以将flume的配置保存在zookeeper上,那么在启动flume时指定zookeeper地址和path即可:
bin/flume-ng agent -conf /opt/flume/conf -z zk1:2181,zk2:2181 -p /flume -name agent
我个人认为,用zookeeper保存Flume配置增加了管理的复杂度,毕竟操作zookeeper也需要一定的技术门槛;我们可以基于“jenkins + 配置中控”方式来解决此问题,即将flume配置放在配置中控机上,使用jenkins统一部署flume,在部署启动flume之前,将配置文件通过ssh的方式同步到flume agent机器上,然后再启动。(目前本人采用的就是此方式)
7、第三方插件或者依赖库
Flume本身已经支持了比较丰富的组件,但是我们在很多情况下,或许需要扩展它的特性,比如自主开发Flume的拦截器、Sink等,此后我们需要将自己的jar放在Flume的CLASSPATH中。在flume的“plugins.d”目录下,可以根据你的组件特性创建子目录,每个子目录下需要具备如下三个子目录,比如:plugins.d/my-ext/:
1)lib:此插件的jar。
2)libext:此插件依赖的jar。
3)native:此插件依赖的本地库,比如“.so”文件。
三、复杂设计
1、Multi-agent

为了实现消息可以通过多个agents或者hops,前一个agent的sink和当前agent的source需要使用avro RPC,两者之间需要协定hostname(IP)和port。
2、数据合并(Consolidation)
一个比较通用的场景是:多个产生日志的Clients发送数据给几个关联到存储系统的agents,比如agents从数百个web servers上收集日志,然后发给几个agents并有它们写入HDFS集群。
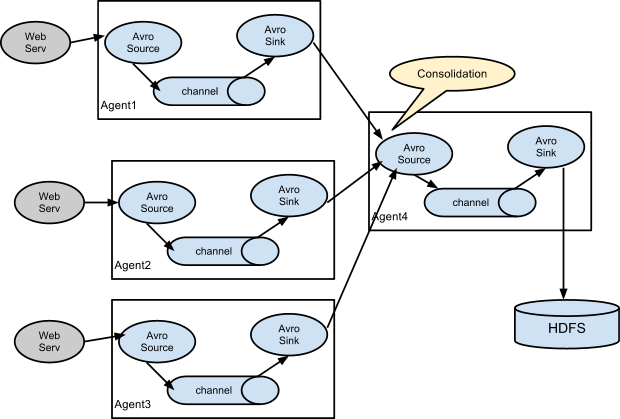
这种多层(multi-tier)的架构中,第一层的Flume Agents使用Avro sink,并都指向远端的一个agent的Avro source(目前版本中,你多个agents之间也可以使用Thrift sink + Thrift source)。第二层Agent的sourc可以将收到的多个agents的消息合并到一个channel中,然后此channel可以被当前agent的sink消费并写入目标存储平台。(我们为什么采用多级架构,而不是每个agent直接写入目标存储?请回答!)
3、Multiplexing the flow(多路复用流)
Flume支持将消息流复制到一个或者多个目的地,可以通过声明Flow 复用器为replicate、或者是选择性将消息路由到一个或者多个channels中。
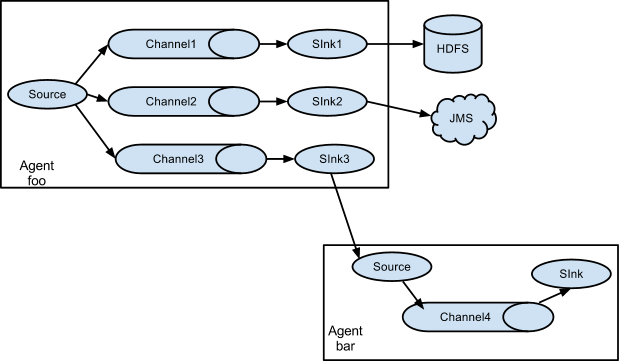
上述例子中,agent “foo”的source将消息流“扇出”到三个不同的channels中,这种扇出可以为“replicating”、“multiplexing”。在replicating情况下,每个event都会被发给三个channels。对于multiplexing,任何event将会根据配置中的匹配方式和结果,被传送给可用channels中的一个子集;比如event有个属性为“txnType” ,当值为“customer”时它应该到”channel1“和“channel3”,当值为“vendor”时应该到“channel2”,否则其他值时应该到“channel3”;这种值匹配的映射关系可以配置文件中指定。
四、配置(简述)
从上述例子中我们已经知道,配置文件中需要声明“source”、“channel”、“sink”三种组件的特性,每个组件都需要以agent 名称作为前缀,比如“agent”。
<agent-name>.sources=<source1> <source2> ##多个值之间以空格间隔 <agent-name>.channels=<channel1> <channel2> <agent-name>.sinks=<sink1> <sink2> ##逐个声明组件的属性 <agent-name>.sources.<source-name>.type=<type> ... ##声明组件的Flow连接关系 <agent-name>.sources.<source-name>.channels=<channel1> <channel2> ... <agent-name>.sinks.<sink-name>.channel=<channel> ##需要特别强调,每个sink只能接入一个channel ##每个sources可以根据“复用”情况,传输到多个channels
关于“扇出”流:
如上所述,Flume支持将消息流从source中扇出到多个channels。有2种扇出的模型:replicating、multiplexing;“replicating”模式下,消息将会发给所有的指定的channels(复制);在multiplexing模式下,根据匹配和映射关系,消息仅会发给符合要求的channels。为了实现扇出,需要在source中指定channels的列表和扇出的策略。可以通过在channel中指定“selector”属性为“replicating”或者“multiplexing”,然后再指定选择器的规则。默认情况下,“selector”类型为“replicating”:
<agent-name>.sources.<source1>.channels=<channel1> <channel2> <agent-name>.sources.<source1>.selector.type=replicating ##multiplexing <agent-name>.sinks.<sink1>.channel=<channel1> ...
对于“multiplexing”还需要其他的配置项,event属性与channel的映射关系是必须配置的。selector会检测event headers中配置的属性,如果值匹配,则会将此消息发给相应的channels中,否则将会发送到配置中指定的default的channel:
<agent-name>.sources.<source1>.selector.type=multiplexing <agent-name>.sources.<source1>.selector.header=<someHeader> <agent-name>.sources.<source1>.selector.mapping.<value1>=<channel1> ##当someHeader的值为value1时,消息发给channel1 <agent-name>.sources.<source1>.selector.mapping.<value2>=<channel2> <channel3> <agent-name>.sources.<source1>.selector.mapping.default=<channel1> ##如果没有匹配成功,则使用default指定的channel。 ##需要特别注意:event中必须包含此header,且值不能为null,否则会导致无法匹配任何channel。
五、Flume Sources(简述)
Source组件可以接收来自TCP连接的数据、或者解析本地文件的日志条目,然后将数据封装成events,并将events传送给内部的channels;Source是Flume agent中数据流的最前端。目前Flume内置的比较常用的source类型有:
1)Avro Source:基于TCP、Avro数据协议,此source作为Avro RPC的server端,用于接收Client发送的Avro数据。
2)Thrift Source:基于TPC、Thrift数据协议,此source作为Thrift RPC的server端,用于接收Client 发送的Thrift数据。
3)Spooling Directory Source:检测本地文件目录中文件,并将现有(或新增)文件解析成events。这种source通常用来收集“历史日志文件”,比如每天新增的日志文件等。
4)Taildir Source:类似于“tail”指令,检测指定文件是否有新增(append)的数据,将新增的数据封装成events,每次操作都会记录当前文件已经处理的position,下一次操作将从position处继续进行。这对我们收集“实时日志”非常有用。
5)kafka source:作为kafka的consumer,指定kafka的Topics列表,从kafka中消费消息。
6)还有其他的sources,比如:Syslog、NetCat、HTTP等。
六、Flume Sinks(简述)
1)HDFS Sink:将消息写入到HDFS文件系统中,支持path自动创建、文件切分等特性。
2)Avro Sink:最常用Sink之一,将消息通过Avro RPC方式传送给远端Server。通常用在multi-tier架构中,是Flume 推荐的Sink。
3)Thrift Sink:同上。
4)File Roll Sink:将消息写入本地文件系统,支持按照时间切分,支持自定义的path管理。(很多时候我们需要扩展它)
5)Null Sink:有些场景非常有用,直接丢弃消息。
6)Kafka Sink:将消息写入Kafka,最常用的Sink之一,此Sink作为kafka的producer端。
七、Flume Channels(简述)
1)Memory Channel:将Events保存在内存中,一个BlockqingQueue,这是数据可靠性较弱、但是效率最高的Channel。通常适用于实时数据传输。
2)File Channel:将Events保存在本地的File中,数据可靠性较高、但是效率较低的Channel,通常用于传输那些可靠性要求较高的数据。
3)其他:比如JDBC Channel、kafka Channel,还有实验性的Spillable Memory Channel(基于Memory和File)
八、Flume Selectors(选择器)
在上文中我们已经提到Selector的机制,即用于Source中消息的路由,通过一定的条件将一个Source中的events传送给相应的Channel。目前支持两种selector:replicating和multiplexing,默认为“replicating”。
1、replicating:复制,即每个event都将以“复制”的方式传送给多个channels。
agent.sources=s1 agent.channels=c1 c2 c3 agent.sources.s1.selector.type=replicating agent.sources.s1.channels=c1 c2 c3 agent.sources.s1.selector.optional=c3
selector有两个属性“type”和“optional”,其中type用于指定选择器的类型,必须为“replicating”。其中“optional”表示可选的channel,即channles中声明的“c1 c2 c3”,其中消息在“c1 c2”写入失败时将会导致事务操作失败,因为c3为optional,那么写入c3失败的消息将会被忽略。
2、multiplexing:复用,即消息根据一定的策略,发给Channels列表中某个channel;events复用这些Channels。
agent.sources=s1 agent.channels=c1 c2 c3 c4 agent.sources.s1.selector.type=multiplexing agent.sources.s1.selector.header=state agent.sources.s1.selector.mapping.CZ=c1 agent.sources.s1.selector.mapping.US=c2 c3 agent.sources.s1.selector.default=c4
此种类型的selector对消息的路由,需要声明mapping。通过“header”指定需要匹配的header,如果header的值与mapping列表中匹配,消息将会传送给mapping对应的channel,如果均无匹配,则传送给“default”指定的channel。在此需要注意,event中必须存在此heeader,且值不能为null,否则将导致消息无法传送。
九、Flume Sink Processors(处理器)
高级特性,Sink groups可以将多个sinks作为一个整体,对一个group中的多个sinks实现比如“load balancing”或者“failover”特性。目前支持两种processors:load_balance、failover。
agent.sinkgroups=g1 agent.sinkgroups.g1.sinks=sink1 sink2 agent.sinkgroups.g1.processor.type=load_balance
1) Failover Sink Processor
在group中声明多个sinks,只要有一个sink有效,消息都将被处理和传送。它的原理比较简单,当一个sink消息发送出现异常后,此sink将被标记为“fail”并将其添加到failSinks列表中,并从aliveSinks列表中选择一个priority值最高的sink来接管,并负责此后的消息发送,直到它出现异常为止。那些标记为fail的sink,将会间歇性的检测它们的状态,遍历failSinks列表,逐个让它们尝试发送消息,如果发送成功则将此sink添加到aliveSinks中。(稍后将基于源码解释内部原理)
在任何时刻,sinks列表中只有一个sink负责消息传送,其他sinks只做“backup”,这符合failover的语义。
agent.sinkgroups=g1 agent.sinkgroups.g1.sinks=sink1 sink2 agent.sinkgroups.g1.processor.type=failover agent.sinkgroups.g1.processor.priority.sink1=5 agent.sinkgroups.g1.processor.priority.sink2=10 ##对于failed sinks,backoff的最长时间(毫秒),超时后将会 ##尝试让它们发送消息,以验证活性。 agent.sinkgroups.g1.processor.maxpenalty=10000
2)Load balanceing Sink Processor
支持在多个Sinks之间负载均衡,sink的选择机制分为“random”和“round_robin”,默认为“round_robin”。在处理消息时,选择器根据配置的选择机制,从sinks列表中选择一个sink,并使用此sink消费消息(从Channel中获取消息);如果此sink无法传送消息,选择器将会重新选择sink,如果所有的sinks都无法传送,那么最终将抛出异常。
如果开启了backoff,那些failedSink将被添加到“黑名单”中,并“保留”一段时间;超时后,此failed Sink可以被重新添加到选择列表中(或许此时它仍然不可用,如果再次不可用,它的timeout时间将会增长,最长为maxTimeout)。选择器在每次选择sink时,那些在“黑名单”中的sink将不参与。
agent.singroups=g1 agent.sinkgroups.g1.sinks=s1 s2 ##必须为load_balance agent.sinkgroups.g1.processor.type=load_balance ##开启backoff agent.sinkgroups.g1.processor.backoff=true ##选择机制:random、round_robin agent.sinkgroups.g1.processor.selector=random ##backoff最长时间,毫秒 agent.sinkgroups.g1.processor.selector.maxTimeout=30000
十、Event Serializers(消息序列化)
序列化,即在sink将Event传送时如何序列化Event。序列化与反序列化对应,所以当前sink的序列化应该与remote端的反序列化互相对应。
1、Body Text Serializer
别名(简写):text,直接将Event body以流的方式写入,event的headers部分将会被忽略。
agent.sinks=s1 agent.sinks.s1.type=file_roll ##将event写入本地磁盘 agent.sinks.s1.directory=/logs/flume agent.sinks.s1.serializer=text agent.sinks.s1.serializer.appendNewline=true
此序列化只有一个属性“appendNewline”,即是否在body数据写入完毕之后追加一个“换行符”。
2、Avro Event Serializer
对于AvroSink,或者将event 写入Avro序列化文件时,可以使用此序列化方式。
十一、Flume Interceptors(拦截器)
非常重要的特性,我们可以使用拦截器实现对events的修改和丢弃(modify/drop),flume支持链式的拦截器,即多个拦截器将根据其在配置中声明的顺序依次执行,events(通常是批量)将依次经过每个拦截器。我们在拦截器中,可以修改event的headers甚至body;如果拦截器决定丢弃某个event,只需要在返回的events列表中不包含它即可,如果想放弃所有,只需要返回空的list即可。
agent.sources=s1 agent.channels=c1 agent.sources.s1.interceptors=i1 i2 agent.sources.s1.interceptors.i1.type=host agent.sources.s1.interceptors.i2=timestamp
注意,只有source组件支持拦截器,即events在传送给channel之前,允许使用拦截器对events进行调整。对于自定义的拦截器,需要在“type”属性中声明类的全名(比如:com.test.flume.interceptors.MyInterceptor$Builder),自定义的interceptor需要实现“org.apache.flume.interceptor.Interceptor”接口,需要注意“Builder”需要在interceptor中声明。
1、Timstamp 拦截器
在event的headers中添加一个header,其值为event被处理的时间戳。如果event中已经存在此header(比如上一级agent已经在headers中添加了),可以通过“preserveExisting”来决定是否保留原值。此拦截器的简写为:timestamp。
2、Host拦截器
在event的headers中添加一个header,其值为agent所在机器的hostname或者IP;此拦截器简写为:host
3、Static拦截器
在headers中添加一个常量;简写为:static。
agent.sources.s1.interceptors.i1.type=static agent.sources.s1.interceptors.i1.key=project agent.sources.s1.interceptors.i1.value=order_center
4、UUID拦截器:为event添加一个全局唯一的UUID header;简写为:UUID。
5、Regex过滤拦截器:通过正则表达式匹配body内容,可以根据匹配结果来决定是否包含或者丢弃此event。



相关推荐
flume1.7的taildir支持windows,flume1.7的taildir支持windows
### Windows 下 Flume 1.7 的使用指南 #### Apache Flume 概述 Apache Flume 是一个分布式的、可靠的且高可用的系统,用于从不同的数据源收集、汇总和传输大量的日志数据到集中式的数据存储中心。Flume 的设计目的...
Apache Flume 是一个分布式、可靠且可用于有效收集、聚合和移动大量日志数据的系统。它具有高可用性、容错性和可扩展性,广泛应用于大数据处理领域。Flume 1.7.0 是该软件的一个版本,包含了完整的源代码,便于...
### Apache Flume 1.7 用户指南核心知识点 #### 一、引言与概述 - **Apache Flume** 是一个分布式、可靠且可用的系统,主要用于高效地收集、聚合并移动大量的日志数据,这些数据来自不同的源并最终存储到集中式...
#### 1.2 Flume特性 - **可靠性**:Flume确保数据传输过程中数据的完整性,即使在网络不稳定的情况下也能最小化数据丢失的风险。 - **可扩展性**:随着数据源数量的增加,Flume可以通过添加更多的节点来轻松扩展其...
1. **事件(Event)**:事件是Flume数据处理的基本单位,包含一个字节数组的有效负载(payload)和可选的header(字符串属性)。事件从源(Source)产生,通过通道(Channel)传递,最终由水槽(Sink)处理。 2. **源...
如果你的环境是基于JDK 1.7的,你需要寻找Flume的1.7版本,这也是描述中提到的。 描述中指出,由于Flume官网的下载速度可能较慢,提供了一个备用的下载链接,方便用户获取Apache Flume 1.8.0的版本。此外,资源中还...
Flume基本理论与实践 Flume是一个高可用的、分布式的海量日志采集、聚合和传输的系统,由Cloudera提供。它基于流式架构,灵活简单。Flume主要由Agent、Source、Channel、Sink四个组件组成,每个组件都扮演着重要的...
总结,Flume是一个强大且灵活的日志管理系统,它的分布式特性、可定制的数据源和存储以及高可用性设计使其在大数据环境中广受欢迎。通过阅读和理解官方文档,结合实际的配置和运行经验,我们可以充分利用Flume解决大...
1. **Flume基本架构**:Flume由Source、Channel和Sink三部分组成。Source负责接收数据,Channel作为临时存储,Sink负责将数据发送到目的地,如Elasticsearch。 2. **Flume配置**:为了将Flume连接到Elasticsearch,...
Flume Agent是Flume的基本工作单位,它是一个独立的Java虚拟机进程,负责执行数据流处理。Agent内部包含了Source、Channel和Sink三个组件,它们各自承担不同的职责: 1. Source:Source是数据的入口,负责从各种...
- **系统要求:** 安装JDK1.7及以上版本,Flume版本推荐使用1.5.2。 - **集群部署:** 建议按照官方文档的推荐结构,即使用Source-Client/Channel-Client/Sink-Client以及Source-Server/Channel-Server/Sink-Server...
本文将指导您完成 Flume-NG 的安装和基本配置。 安装 Flume-NG 1. 先决条件:Java JDK 安装 在安装 Flume-NG 之前,需要先安装 Java JDK。您可以按照 JDK 的安装指南进行安装。 2. 下载 Flume-NG 使用 wget 命令...
在大数据实时处理领域,Flume、Kafka 和 Spark Streaming 是常用的数据采集、传输与处理工具。本实验报告详细阐述了如何将这三个组件结合使用,构建一个高效的数据流处理系统。 一、Flume 与 Spark Streaming 的...
Agent 是一个 JVM 进程,它以事件的形式将数据从源头送至目的地,是 Flume 数据传输的基本单元。Agent 主要有 3 个部分组成,Source、Channel 和 Sink。 1.2.2 Source Source 是负责接收数据到 Flume Agent 的组件...
/opt/flume1.7/bin/flume-ng agent --conf /opt/flume1.7/conf/ --name a1 --conf-file /opt/flume1.7/job/flume-netcat-test01.conf -Dflume.root.logger=INFO,console ``` 使用netcat工具向55555端口发送数据: `...
6. **Flume的高级特性**: - **多级处理**:Flume支持多级数据处理,你可以创建多个源、通道和接收器的组合来实现复杂的流程。 - **容错性**:Flume使用持久化通道(如文件通道)来确保在故障时不会丢失数据。 ...
2. **Event**:Flume传输的基本单位,由Header和Body组成。Header包含元数据信息,Body则是实际的数据内容。 3. **Agent**:Flume的核心组件,由Source、Channel和Sink等构成,负责将Event从一个地方传输到另一个...
Flume 是 Apache Hadoop 生态系统中的一个分布式、...理解 Flume 的基本概念、配置以及各种组件的使用,是充分利用 Flume 功能的关键。在实际应用中,可以根据具体需求调整配置,以适应不同的数据源和数据处理任务。
Flume-ng 在 Windows 环境搭建并测试 + Log4j 日志通过 Flume 输出到 HDFS Flume-ng 是一个高可用、可靠、分布式的日志聚合系统,可以实时地从各种数据源(如日志文件、网络 socket、数据库等)中收集数据,并将其...