
这是我2010年写的hadoop搭建过程,现在重新发出来,当作hadoop学习的开始。
俗话说的好:计划赶不上变化,这几天还真在我身上应验了。原计划4小时完成,结果40小时才...
不写篇日志,简直对不起我的一片苦心。
这周五计划搭建Hadoop环境(在winodws环境下用虚拟机虚拟两个ubuntu系统进行搭建)。
先介绍下准备工作:
1: Hadoop 0.20.2 (官网下载)
2: VMware7 (官网下载)
3: jdk-6u20-linux (官网下载) //我就是没从官网下最后就悲剧了。
4: Ubuntu 10.04 (ISO)
用户 :jackydai(192.168.118.128) jacky(192.168.118.129)
jackydai 对应 namenode/JobTracker jacky datanode/Tasttrack
晚上7点正式开伙。首先装VMware7.01。这个so easy!
因为班上同学有在虚拟机下装过ubuntu,所以安装简单还算简单,同学一手操办了。
附上分区建议:
硬盘15G分区如下:
1、boot 200M
2、swap 2G
3、home 7G
4、root 剩下的全部
结果20分钟安完了,结果同学说要更新,ubuntu更新管理一打开需要下载80多个文件,2个多小时。我忍了,看着10K-15K的速度。两个多小时后,终于完成了。 结果才发现,竟然还要安装一个ubuntu!。我又忍了。这次190K-210K. 总算老天开眼。(谁知后头.....)大概10点才把系统完全安完。
1:开始安装JDK。由于从没用过ubuntu 连安装文件都不会。不过还好班上强人多,马上请帮手,忙乎了半个小时。连JDK都没安好。同学有事先走了。马上再请一个来,结果10分钟后还是没成功。结果大胆猜测JDK文件原本就有错误。同学从官网上下了一个安了,好了。我滴个神.... 都12点了。才把JDK安好。我心都凉了。这件事情告诉我们,软件包要从官网下。当然是建立在免费软件基础上。
命令:
(1):$ chmod 777 ./home/jackydai/jdk-6u20-linux-i586-rpm.bin //添加权限
(2):$ ./home/jackydai/jdk-6u20-linux-i586-rpm.bin //安装JDK
(3):/etc/profile 添加如下代码: //设置环境变量
export JAVA_HOME="/usr/java/jdk1.6.0_20"
export PATH="$PATH : $JAVA_HOME/bin:$JAVA_HOME/jre/bin:"
export CLASSPATH="$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib"
(4):souce /etc/profile //使环境变量生效
(5):which java //测试JDK安装是否成功成功显示 /usr/java/jdk1.6.0_12/bin/java
2: 安装SSH,实现SSH的无密码连接。
命令:
(1):$ sudo apt-get install ssh //安装ssh
(2): ssh -keygen -t dsa //生成密钥 文件如:id_dsa id_dsa.pub
(3) cp id_dsa.pub anthorized_keys //加入受信列表
(4) ssh localhost 或者 ssh jackydai //成功就能无密码访问 这个是进行的本地测试、
这个弄完凌晨3点,悲剧--睡觉。
3:安装Hadoop:
第二天10点半起来,马上开始进行两个系统的无密码访问。一直整起3点无任何进展。期间ubuntu论坛发帖一次,百度知道发贴一次。ubuntu群发问5次。无一直接回答,悲剧--睡觉。 5点过起来,弄了1个小时还是没完成,算了直接安装hadoop。晚上12点结束时,才把Hadoop安装好,进行了伪节点模式的测试。睡觉。 第二天早上10点半开始又整,终于完成SSH无密码连接,但文件的目录又出错。5点解决目录问题,datanode启动又出问题,晚上7点解决全部问题。HOHO~~
命令:
(1):修改 etc/hosts
192.168.118.128 jackydai
192.168.118.129 jacky
(2):tar -xzvf hadoop-0.20.0.tar.gz //安装hadoop
(3):添加 hadoop-0.20.0/conf 下的 hadoop-env.sh文件 export JAVA_HOME=/usr/java/jdk1.6.0_20
(4):配置master jackydai 配置slaves jacky@jacky
(5): 修 改 core-site.xml
<property>
<name> fs.default.name </name>
<value>hdfs://jackydai:9000</value>
</property>
修改 mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>jackydai:9001</value>
</property>
修改 hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/jackydai/hadoop_tmp_dir/</value>
</property>
(6):bin/hadoop namenode -format //必需初始化 只需要namdnode
(7): bin/start-all.sh //启动 在namenode
PS (这些才让我泪奔的地方):1:slaves 是jacky的ssh连接账户,虽然是jacky账户, 但ssh的连接账户可能不一样。这个今天下午才发现。jacky@jacky
2:ssh的两机连接,有两种办法。从客户端上既jacky 使用 $ scp /home/jacky/.ssh/id_dsa.pub 拷贝。
也可以直接用U盘拷过去,或者使用共享文件夹拷贝。
3: Hadoop 环境只需要 namenode 无密码到 datanode。 所以只需从服务器拷贝客户端
4:三个文件的设置、Hadoop的安装、hosts文件设置在两台电脑上的配置应该一样。
5:两个系统安装Hadoop的文件名应该一样既: /home/jackydai/hadoop-0.20.0 不然启动的时候没相应的目录
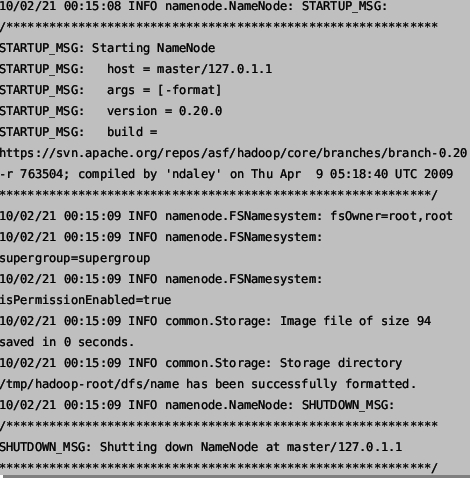
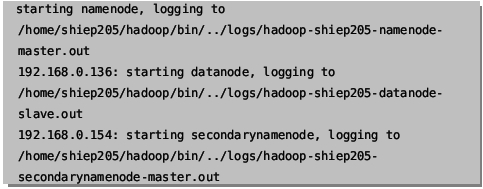
6:附上初始化成功和启动成功的截图(这个是我从资料上截得图)
初始化界面
启动画面
搭建好了,可以通过 http://jackydai :50070 查看namenode 状态
http://jackydai :50030 查看 JobTracke状态
剩下就可以运行Hadoop里自带的例子看看是否成功。
总结:
终于写完了,当个记录,不然过两天又搞忘了。这都是时间换来的经验啊。
搭建个平台没什么,把ubuntu的基本操作命令全记下来了。至少每个都敲了100次+,就可以知道搭建过程多痛苦了。再加上天不时地不利人不和,光荣的战斗了40+个小时--泪奔~~



相关推荐
在本教程中,我们将详细介绍如何在Windows系统下搭建Hadoop环境,内容涉及虚拟机的安装、基础环境配置以及Hadoop集群的具体搭建步骤。适合初学者跟随本教程一步步进行操作。 首先,搭建Hadoop环境需要一台高性能...
在本实验环境中,我们将搭建一个包含一个NameNode和两个DataNode的集群。 为了实现这个环境,我们需要在单个物理主机上使用VMware Workstation创建三个虚拟机,分别用于NameNode、DataNode1和DataNode2。每个虚拟机...
### Hadoop 2.8.0 在 Ubuntu 虚拟机上的搭建步骤及注意事项 #### 一、虚拟机与Ubuntu系统的安装 1. **下载与安装 VMware Workstation** - 下载`VMware-workstation-full-10.0.0-1295980.exe`至本地。 - 按照安装...
2. **资源需求**:在家庭环境中搭建Hadoop集群,通常难以获取多台物理服务器。此时,可以通过在高性能电脑上安装VMware等虚拟机软件,创建多个虚拟机,并配置成内部局域网,以此模拟一个小型Hadoop集群。 3. **...
在本教程中,使用VMWare来创建运行Ubuntu系统的虚拟机,这是因为Ubuntu是一个流行的Linux发行版,它被广泛应用于Hadoop集群环境中。 搭建Hadoop集群的过程中,首先需要准备至少两台机器(节点),一台作为主节点...
本文档详细介绍了如何在Ubuntu11.10操作系统上搭建Hadoop1.0.2双机集群的过程,并通过WordCount示例验证了集群的正确性和可用性。该文档对于希望在类Ubuntu环境中部署Hadoop集群的用户具有较高的参考价值。 #### 二...
- **VMware Workstation 8:** 一款功能强大的桌面虚拟计算机软件,可以模拟出完整的网络环境,便于搭建Hadoop集群。 - **Ubuntu 10.04 LTS:** 长期支持版操作系统,稳定性较高,适合用于服务器部署环境。 **2. ...
总的来说,搭建Hadoop云计算平台是一个涉及虚拟化、操作系统安装、分布式系统配置和故障排除的复杂过程。这个平台不仅可以处理大量数据,还可以通过MapReduce和HBase等工具进行数据挖掘和实时查询,为企业带来数据...
本次实验的主要目的是让学生在虚拟机环境下安装并配置Hadoop单机模式,并在此基础上实现一个简单的WordCount程序。具体包括两个核心任务: 1. **在虚拟机Ubuntu上安装Hadoop单机模式**:通过该步骤使学生熟悉Hadoop...
本文将指导初学者如何在虚拟机上搭建Hadoop集群,尽管使用的是虚拟环境,但搭建过程同样适用于实际的物理服务器。 首先,对于硬件配置,至少需要一台具有足够资源的计算机。在虚拟机环境下,作者使用的配置是Intel...
本文主要讲述了如何在虚拟机上安装Linux系统,配置网络,设置语言,并安装软件,特别是针对云计算平台的搭建,包括JDK、SSH服务的安装以及Hadoop的安装过程。以下是详细的知识点解析: 1. **虚拟机与Linux系统安装*...
本实验主要涵盖了云计算的基础知识,包括Linux系统、KVM虚拟化技术以及Hadoop分布式计算框架的使用。实验目的是通过实际操作加深对这些技术的理解,并运用到具体的WordCount程序中,体验云计算的初步应用。 1. **...
1. **隔离性**:通过虚拟机,可以在不影响主机操作系统的情况下搭建Hadoop集群。 2. **灵活性**:可以轻松地在不同的环境中复制和迁移虚拟机,便于测试和部署。 3. **资源控制**:虚拟机允许用户精确地分配硬件资源...
在HDFS文件系统下创建两个测试文本文件`file01`和`file02`,并使用`hdfs dfs -put <source> <destination>`命令上传至HDFS指定目录。 #### 六、编写并运行MapReduce程序 1. **创建Map/Reduce项目**: - 在MyEclipse...
- **主要设计思路:** 在Ubuntu操作系统环境下,完成必要的软件安装和环境搭建,使用Eclipse进行程序编码,最终实现大数据统计功能。本实验以统计软件代理系统中操作员的操作记录为例,具体而言就是统计每位操作员...
2. **在虚拟机上安装Linux操作系统**:尽管Hadoop可以在Windows系统上运行,但为了保持稳定性和减少错误发生概率,推荐在Linux环境下进行安装。常见的Linux发行版包括Ubuntu、CentOS、Red Hat、Fedora等,本文以...
在搭建Hadoop环境时,首先需要创建虚拟机并安装操作系统,如Ubuntu。然后,配置虚拟机的网络设置,使本地主机能通过SSH连接到虚拟机。接着,安装Java环境,确保版本为Java 8或以上,因为Hadoop需要Java支持。最后,...
首先,我们强调了安装软件的重要性,包括VMware Workstation 8和Ubuntu 10.04 LTS,因为它们是搭建Hadoop环境的基础。选择10.04作为操作系统是因为它是一个长期支持版本,可以提供长期的技术维护。 在安装过程中,...